1. Introduction
Social media such as Twitter enables user communication and the sharing of their state of mind, behavior or activities. In addition, there is also the possibility to provide a current position or location of each tweet. From a geographical aspect, Twitter conveniently provides real time geo-data directly from the users, unlike the official data collections with postponed availability. Various spatial analyses may be performed with collected geographical data, such as identifying trends within the data to obtain information on locations with most Twitter users or analyzing their movement. Crowdsourced (geographic) data are data that are data that are voluntary and involuntary provided by citizens [
1,
2]. Furthermore, [
1] among others refer to the fact that any data from social media are regarded as crowdsourced data In this research crowdsourced geographic data [
1,
2], from the platform Twitter, are collected to analyze the tourist flows in Styria, a state in the country of Austria. In this particular paper, we regard the influx of tourists as “flow” and subsequently try to analyze the spatio-temporal distribution of this tourist influx. As such, in contrast to many publications focusing on a greater scale [
3,
4], this study focuses on the reliability of Twitter data on a regional scale. The investigation of obtained data focused on the recognition of tourist spatial and temporal patterns as well as the evaluation of geo-tagged Twitter data reliability and adequacy in contrast to the public data of the statistical bureau of Austria.
The paper elaborates on the development of a methodology for spatial and semantic analysis that is applied in the test area—the Province of Styria in Austria. The plausibility and accuracy of results obtained with Twitter data are evaluated against official statistics on tourism [
2,
3]. The results and evaluations are interpreted in the form of maps, graphs and statistical evaluations. The detailed research questions of the paper are as follows:
- -
Do crowdsourced data on a regional scale accurately represent the touristic behavior of users?
- -
Are touristic-relevant crowdsourced data correlated to the official tourism statistics?
- -
Are touristic-relevant Twitter data on a regional level sufficient to draw conclusions on the topics covered and concerning the sentiment?
The paper is organized as follows.
Section 2 discusses the relevant literature, and
Section 3 elaborates on the methodology applied to the test data collected. The experiment conducted is described in
Section 4 and the results obtained are listed in
Section 5. A discussion of the results and conclusion is given in
Section 6.
2. Relevant Literature
Literature in the field social sensing for tourism purposes has been published in different scientific fields. Most notably the advances in Geographic Information Science have most impact on the paper. In particular, publications dealing with Volunteered Geographic Information, social sensing, and Geospatial Artificial Intelligence are of particular interest.
The term social sensing combines machine learning approaches and artificial intelligence in general [
5,
6,
7]. According to [
8] it is defined as the usage of user-generated data to understand human dynamics. The methodologies can be utilized to understand human mobility patterns, social network patterns, or even support urban planning [
3,
9,
10]. Hawelka et al. [
11] have investigated the global mobility patterns of different countries in comparison to the Twitter market penetration. An evaluation of their results with the help of tourism statistics revealed that there is a correlation between the number of Twitter users, economic prosperity and mobility behavior of a country. Hence, Twitter is regarded as proxy for global mobility patterns.
The articles [
12,
13] report on migration patterns based on Twitter data. [
12] analyzes migration patterns from Middle East and North Africa to Europe. The authors use spatial and semantic analyses (topic clusters along migration routes), utilizing the OPTICS method. The authors in [
13] developed an estimator for migration patterns based on Twitter data. Other movement patterns involve the detection of trajectories using hot spot analysis and subsequently characterizing them via drift analysis [
14]. The paper is using hot spot cluster analysis and Kernel Density Estimation to derive spatial trajectories. The methodology has been applied to the detection of a concert route of a pop singer.
User-generated data have been used in emergency situations as well. In literature, the Boston marathon bombing is used as an example where social media messages may be a tool for an early recognition of emergency situations [
15]. In [
16], the authors developed an application for earthquake detection and notification, based on social media. The study uses Kalman and particle filtering for location estimation and a semantic analysis based on keywords, number of words and their context, respectively.
Spatial analysis for tourism purposes has been covered in [
17], whereas methodologies for semantic text analysis have been published in [
18]. In [
19] Flickr is used as basis for spatial mobility patterns. Of particular interest for this paper are the works [
20], a geo-location prediction based on Twitter data [
21], as well as [
22] dealing with mobility patterns in cities located in Australia. More recent papers deal with the development of travel planning tools based on user-generated content [
23], digital footprints of crowdsourced data for the management of protected areas [
24], or an analysis of patterns of user-generated content with a focus on Flickr and Panoramio [
25]. The papers [
26,
27,
28] elaborate on data from Location-based social networks (Twitter, Flickr, etc.) to research on urban phenomena, and human activities in general and recreation patterns. On a more general side [
29] looked into the role of Big Data for open innovation strategies in SMEs and large companies, which could be valuable for tourism as well. In particular, [
30] elaborate on the future challenges and action for innovation research in the tourism industry. Social media usage of luxury hospitality facilities in Turkey is analyzed by [
31]. In order to trigger the engagement of users for touristic events and destinations [
32] the authors evaluated two events and their social media outreach different platforms. A contemporary research agenda for Tourism Geographies and Big Data in Tourism Geography has been provided in [
33,
34].
3. Methodology
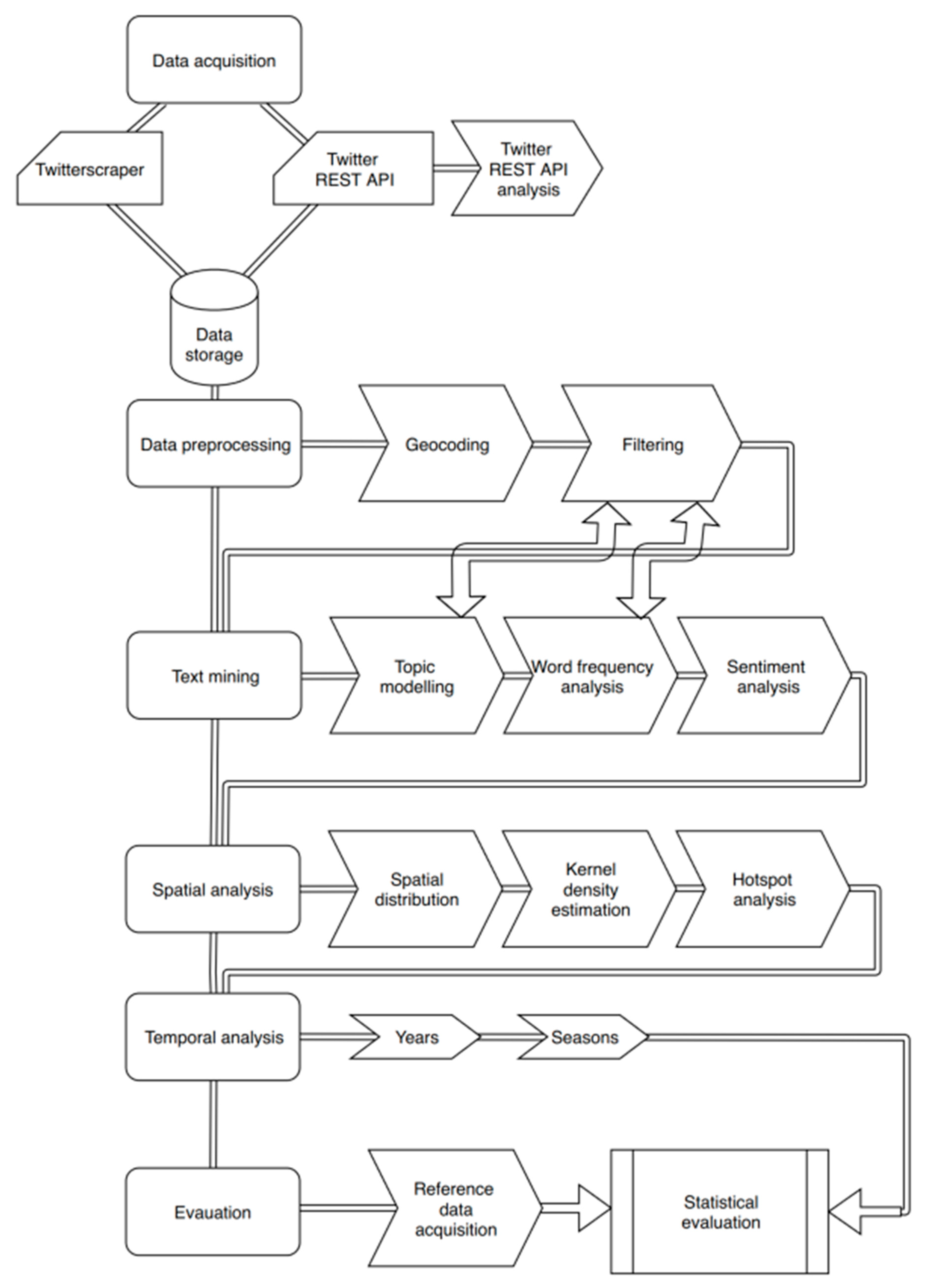
The research did not follow any existent predetermined methodological workflow. Based on the existing literature we selected the most appropriate methods to perform the spatio-temporal and semantic analysis. The developed methodology and workflow in this paper includes methods for data acquisition, processing and filtering, followed by methods for spatial and semantic analysis as well as for visualization, interpretation and evaluation. The methodology is based on six pillars that are depicted in
Figure 1, consisting of data acquisition, data processing and filtering, spatial analysis, semantic text analysis, visualization & interpretation and evaluation.
Data acquisition seeks to collect data from the social medial platform Twitter using the Twitterscraper [
35] python package. A basic comparison with the existing Twitter REST API shows that the Twitter REST API has certain limitations in terms of data acquisition quantity (only 180 requests per 15 min, and a maximum of 100 tweets per request are returned) [
36]. Hence, we use Twitterscraper to gather tweets published between 16 February 2008 and 22 August 2018.
Data preprocessing took place in a non-relational (NoSQL) document database. Before the data are entered in the database, a geocoding procedure takes place, where tweets not having a precise location (i.e., coordinates) associated, were analyzed regarding their municipality—and the name and centroid of the municipality are added as object to each data set. The filtering process is intended to do the following:
sort out tweets of organizations
filter out tweets with non-tourism keywords
filter out tweets published several times by the same user and by/for same municipality
This filtering process is intended to sort the remaining tweets into three categories:
documents (i.e., tweets) with a strong relevance to tourism (with the help of defined keywords)
documents (i.e., tweets) that reveal the location of the author—similar to “I am at …” or “I am in …”.
documents (i.e., tweets) that do not fit the categories 1 or 2.
Text analysis is closely related to the filtering process of tweets, mentioned above. In order to perform topic modeling and word frequency analysis, the data have to be preprocessed. The preprocessing step involves a tokenization of the tweets, which breaks text into smaller units (but we preserved hashtags, emoticons or other symbols). In addition, we eliminated English and German stopwords, punctuation and brackets from the data. After the data preprocessing step, we erased all personal information (i.e., username) of the data set in order not to reveal any personal data.
Topic modeling is intended to determine groups of topics in accordance with the words used in the text of the tweets [
37]. We used Latent Semantic Indexing and Latent Dirichlet Allocation [
38,
39,
40] for this purpose. Frequency analysis serves the purpose to identify tourism-related keywords, that can be used for filtering. The frequency analysis implemented in R programming language [
41]. The tourism related keywords are based on existing vocabularies [
42,
43,
44]. The sentiment analysis reveals sentiment orientation, which classifies tweets into polarity classes, such as negative, positive or neutral [
45]. In order to detect the sentiment of the tweets we utilized the VADER algorithm [
46,
47]. VADER is a valence-based approach for sentiment analysis, taking into account both the sentiment itself and its intensity. It the table below examples of words and the degree of intensity of their sentiment ranking are displayed. More positive words have higher and more negative words have lower ratings. As a result, Vader provides three metrics annotating the proportion of the text, that falls into the positive, neutral and negative categories. The fourth metric, called the compound score, is the sum of all of the lexicon ratings standardized between −1 and 1 [
47]. The closer to 1, the more positive the sentiment is and the closer to −1 more negative the sentiment is. A score of 0 represents a completely neutral text. The approach has proven to be a good fit to social media data since it includes a selection of social media related terms or informal writing such as emotions, acronyms or multiple punctuation marks. Even acronyms “omg” (oh my god), or “smh” (shaking my head) are included in the lexicon. Acronyms help to determine the intensity of positivity and negativity. The paper [
46] shows that Vader even outperforms human individual assessors.
The spatial and temporal analysis of the obtained data focuses on the evaluation of spatial distribution and temporal patterns within test region. Our objectives are to statistically analyze the growth of the tweets in our dataset through the years and to compare them with regard to touristic seasons. All tweets that are related to a single municipality have exactly the same coordinates—the municipality’s centroid. To be able to perform further spatial analyses at both municipality and state level, we randomly distribute the tweets within each corresponding municipality. Based on this spatial distribution, further cluster-related analyses are performed. The tweets’ distribution accuracy within the municipality is therefore not absolutely correct, but this approach is an appropriate solution for visualizing the tweets and obtaining answers of relative distribution within the whole state of Styria through further spatial analyses. Hot Spot analysis is a method of cluster identification and visualization that we took advantage of within our research. Hot Spot indicates statistically significant spatial clusters of high values as hot spots and of low values as cold spots. It is based on Getis-Ord Gi* statistic and optionally also on a set of weighted features [
48,
49]. Using Hot Spot analysis for area measurement purposes, an area of high quantity or intensity of observed feature values can be identified [
50,
51]. An alternative to Hot Spot analysis with manual settings, is the Optimized Hot Spot Analysis. With the use of Optimized Hot Spot Analysis, the characteristics of the input data are evaluated automatically, in order to extract the parameters that are needed for an optimal result. After aggregation of the incident data into weighted features an appropriate scale of analysis is determined. The statistically significant values of the end result are adjusted multiple times. Adjustment of the values is performed according to the testing and spatial dependency with the help of the False Discovery Rate (FDR) correction method [
52]. The Hot Spot analysis is implemented with the tool Optimized Hot Spot Analysis within the desktop GIS “ArcGIS”. Kernel Density Estimation (KDE) of Twitter data is a promising technique of density estimation, as it belongs to a non-parametric analysis with no fixed structure and depends on the point data [
3]. With KDE, a magnitude-per-unit area is calculated from point features, hence in this Study from Twitter point data—meaning from positions of the Tweets. By calculating the density, we are spreading the input values over a raster cell. With KDE method in turn, the known quantity value (e.g., a population field) of a feature is spread out from the point location based on a quadratic kernel function [
53] originally described by [
54]. Results of the KDE can be visualized by a heat map. Heat map refers to feature concentration from a geographic, namely spatial, perspective. From point or line data an interpolated surface is created in order to indicate the density of occurrence. It is a way of visualizing a density surface by colored gradient in order to easily identify locations of higher densities or clusters of geographic features [
55].
A temporal analysis is done with respect to the annual and seasonal tweet variability. In addition, the authors investigate the temporal pattern of tweet activity on a district level.
The evaluation seeks to underpin the results revealed from the social media data. Hence, a comparison between the tweets extracted through the Twitterscraper package and reference data is carried out. The reference data originates from official authorities for statistics—e.g., federal Statistical Office of Austria, and the statistics of the Province of Styria. The evaluation approach was based on correlation analysis between twitter data and official data, representing two scale variables. Although graphs may visually demonstrate the relationship between social media and the reference data, the correlation coefficient needs to be determined to confirm whether the correlation is statistically significant or insignificant. We used the Pearson’s coefficient to determine the level of correlation of social media and reference data from 2008 till 2017, at both a province and district level. The seasonal aspect is also taken into consideration. Hence, the Pearson’s coefficient concerning for twitter and reference data for summer and winter season, for each district is calculated as well.
4. Experiment
The experiment is, according to the research questions, carried out using a geographically small test area with a low number of tweets (compared to other touristic hotspots—like London or New York). Hence, our test area is the Province of Styria, Austria. The experiment follows the methodology described in
Section 3, and analyzes tweets published between 16 February 2008 and 22 August 2018.
4.1. Data Acquisition
The processes started with the data acquisition with the help of Twitterscraper Python package [
35]. The data query was performed with the help of the municipality names, exploiting geographic nearness, and used 12 tourism related keywords (see
Table 1) based on [
42,
43,
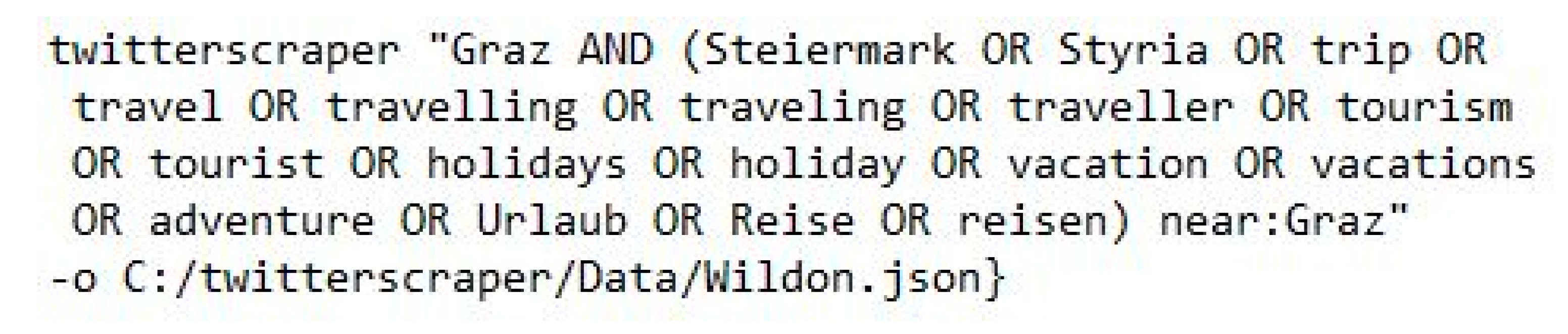
44]. We queried each community name separately—which resulted in 287 queries in total. The query blueprint used to acquire the data is shown in
Figure 2. In
Figure 2 the Twitterscraper query for the city of Graz is depicted.
We acquired 35,234 tweets in total, from 287 municipalities for the time span 2 February 2008 until 22 August 2018. From the 287 queries, 80 queries returned no tweets at all, whereas we received tweets for 207 municipalities of Styria.
4.2. Data Preprocessing & Filtering
The acquired data is stored in a MongoDB database where each document (each tweet) gets geocoded—i.e., it was updated with the coordinates of corresponding municipality—in the coordinate reference system WGS84. The filtering process results in 3 different groups of tweets:
documents (i.e., tweets) with a strong relevance to tourism (with the help of defined keywords)
documents (i.e., tweets) that reveal the location of the author—similar to “I am at …” or “I am in …”.
documents (i.e., tweets) that do not fit the categories 1 or 2.
Based on the methodology described in
Section 3, we applied term frequency analysis to determine the most frequent terms in conjunction with tourism contained in the tweets. This is implemented in the package R. For this purpose, the texts were transformed to lowercase letters, punctuation removed, extra whitespaces removed, numbers and stopwords (English & German) removed. Finally, URLs and ASCII signs are eliminated as well. This dataset is the basis for the document-term matrix that is used for word frequency determination. As a result, we obtained 229 words which were used for filtering purposes—i.e., to assign tweets to the groups 1, 2 or 3.
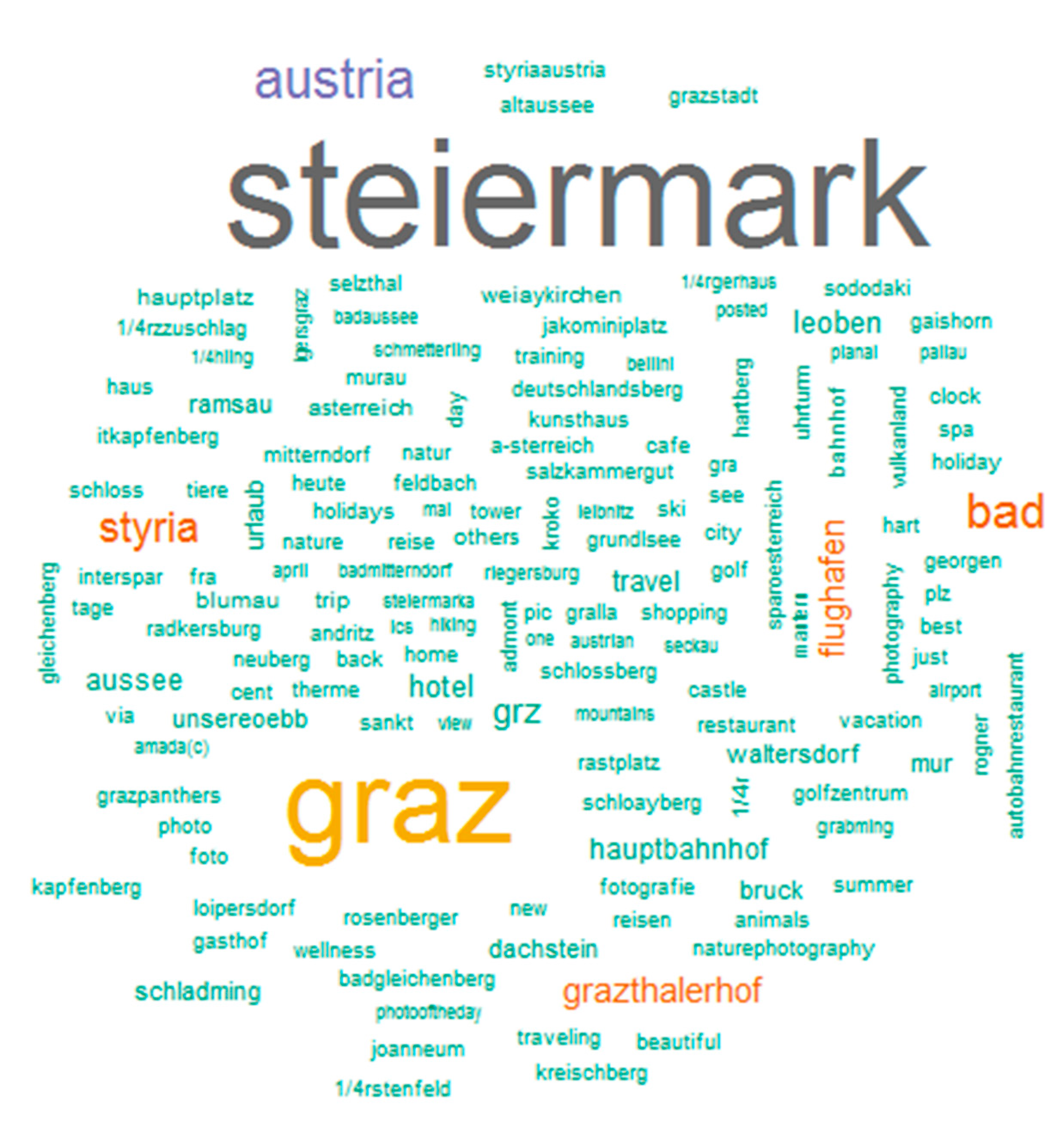
The word cloud of the first 150 most frequent words is depicted in
Figure 3. During filtering we applied text mining in order to choose the final selection of tourism relevant words and then returned to filtering in order to extract the final dataset of our tweets. In the final dataset 6,953 documents/tweets are present. The quantity of tweets and their according groups (1–3) are depicted in
Table 2.
4.3. Sentiment Analysis
A sentiment analysis and topic modelling analysis were performed utilizing Orange Data Mining software [
38,
56]. Orange Data Mining software is an open-source software. To create the sentiment analysis, we applied the VADER algorithm. Sentiment was categorized according to the compound analysis result with more than 0 and up till 1 classified as positive, 0 as neutral and between less than 0 and −1 as negative sentiment. Any spatial analyses and geographical visualizations of the results are performed in ArcGIS.
4.4. Kernel Density Estimation & Hot Spot Analysis
The Hot Spot analysis is implemented using the Optimized Hot Spot Analysis tool provided by ArcGIS. For aggregation purposes a fishnet cell size of 1 km. Kernel Density Estimation was applied with a search radius of 5 km and a cell size of 500 m. Such search radius and output cell size were determined after analyzing results of different settings ranging from a 1 to 10 km search radius and a 100 up to 5000 m output cell size. Selected values were determined as suitable because these settings enable the creation of a convincing visualization with meaningful values. Due to big differences in resulting densities, we used a Jenks Natural Breaks classification method, which arranges values into different classes, minimizing the difference within a class and maximizing it between classes.
4.5. Temporal Analysis & Evaluation
The temporal analysis in the experiment considers classical annual variations as well as seasonal changes. Similar to the reference data, we used the summer and winter tourism season. Tweets from 1 May till 31 October are assigned to the summer season, while tweets from 1 November till 30 April of the following year to the winter season. For evaluation purposes we used the software SPSS in order to perform a correlation analysis between twitter data and reference data.
5. Results
This section contains the results achieved with the experiment and methodology described in the prior sections. The results section covers the evaluation of the results as well.
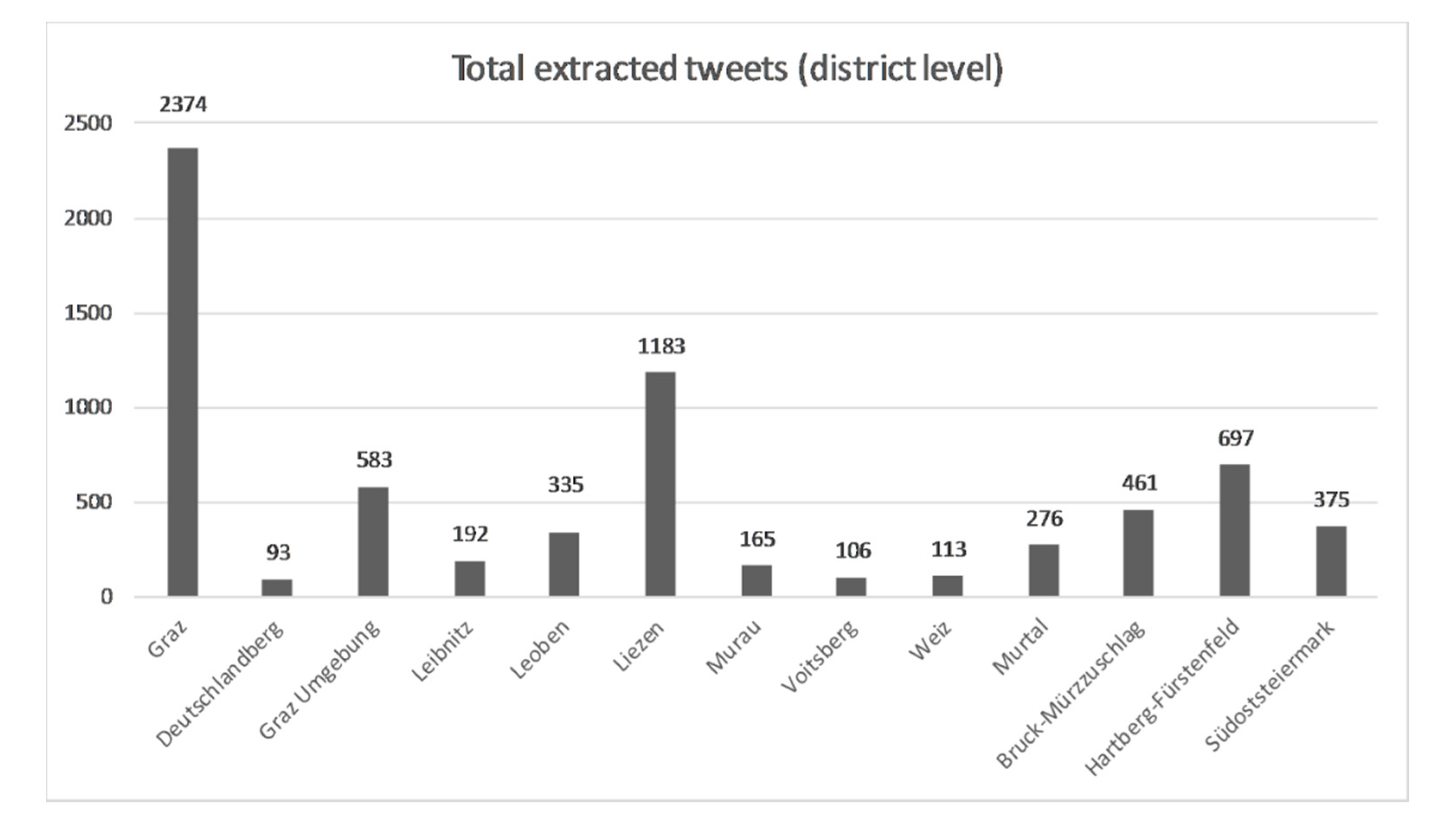
Basically, the resulting set of tourism-related tweets selected from all tweets in the time period between 16 February 2008 and 22 August 2018 contains 6953 tweets. The number of the tourist-related tweets at a district level is given in
Figure 4. Obviously, the city of Graz—as capital of Styria—has most tweets followed by the district of Liezen and Hartberg/Fürstenfeld. In
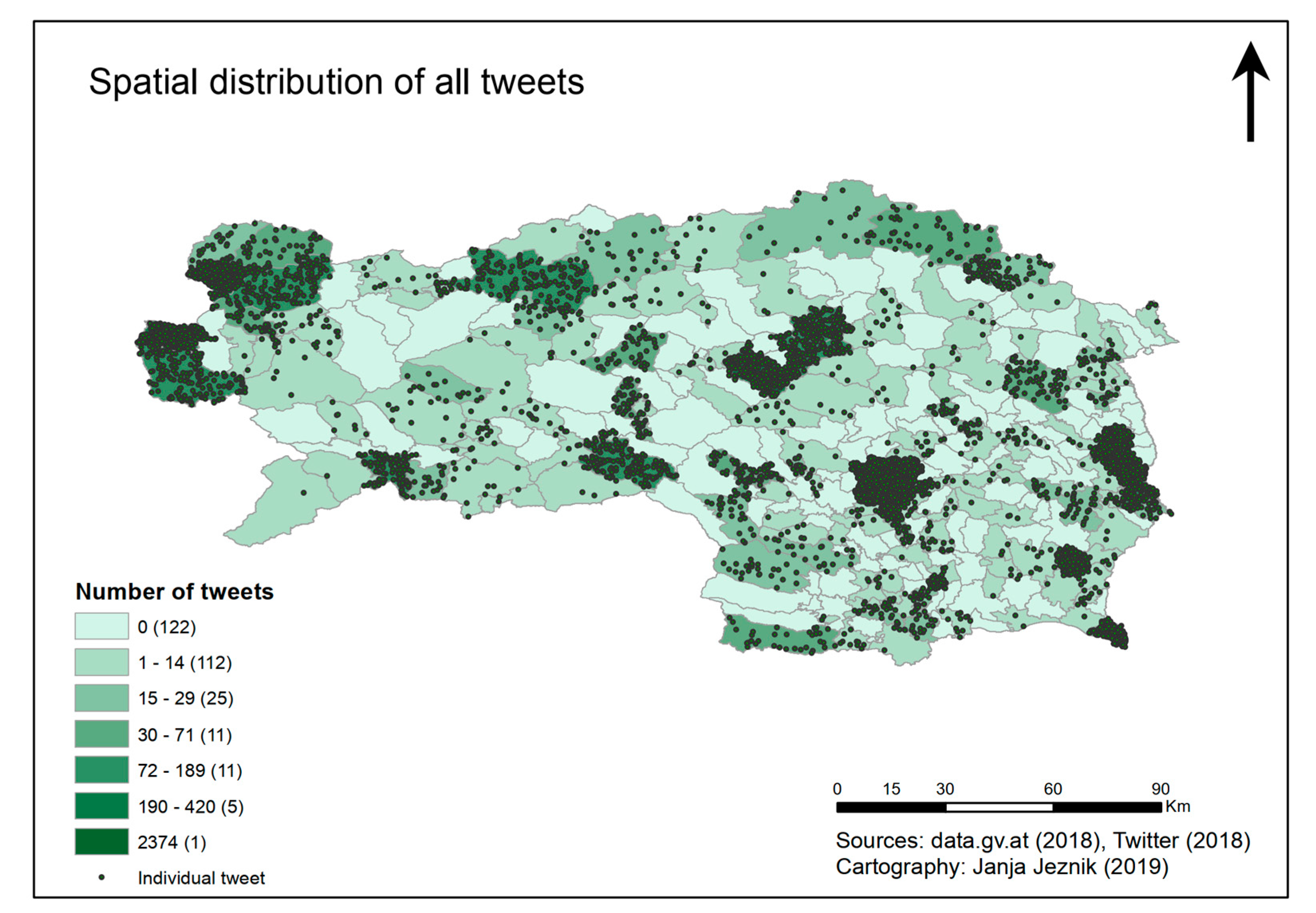
Figure 5 we depict the spatial distribution of the tourism-related tweets according to the districts of the Province of Styria.
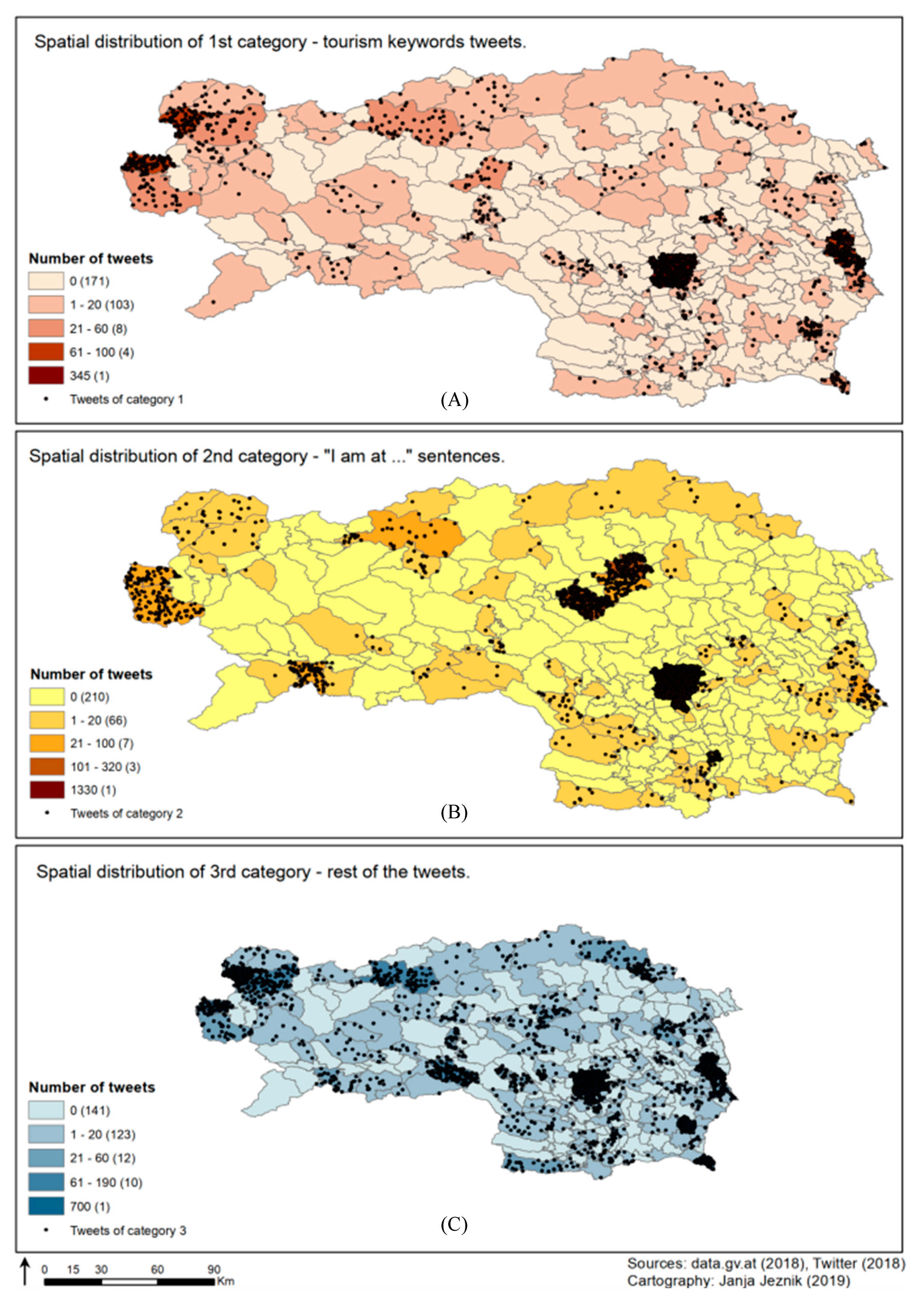
Figure 6 shows the distribution of tweets according to the three categories, described in
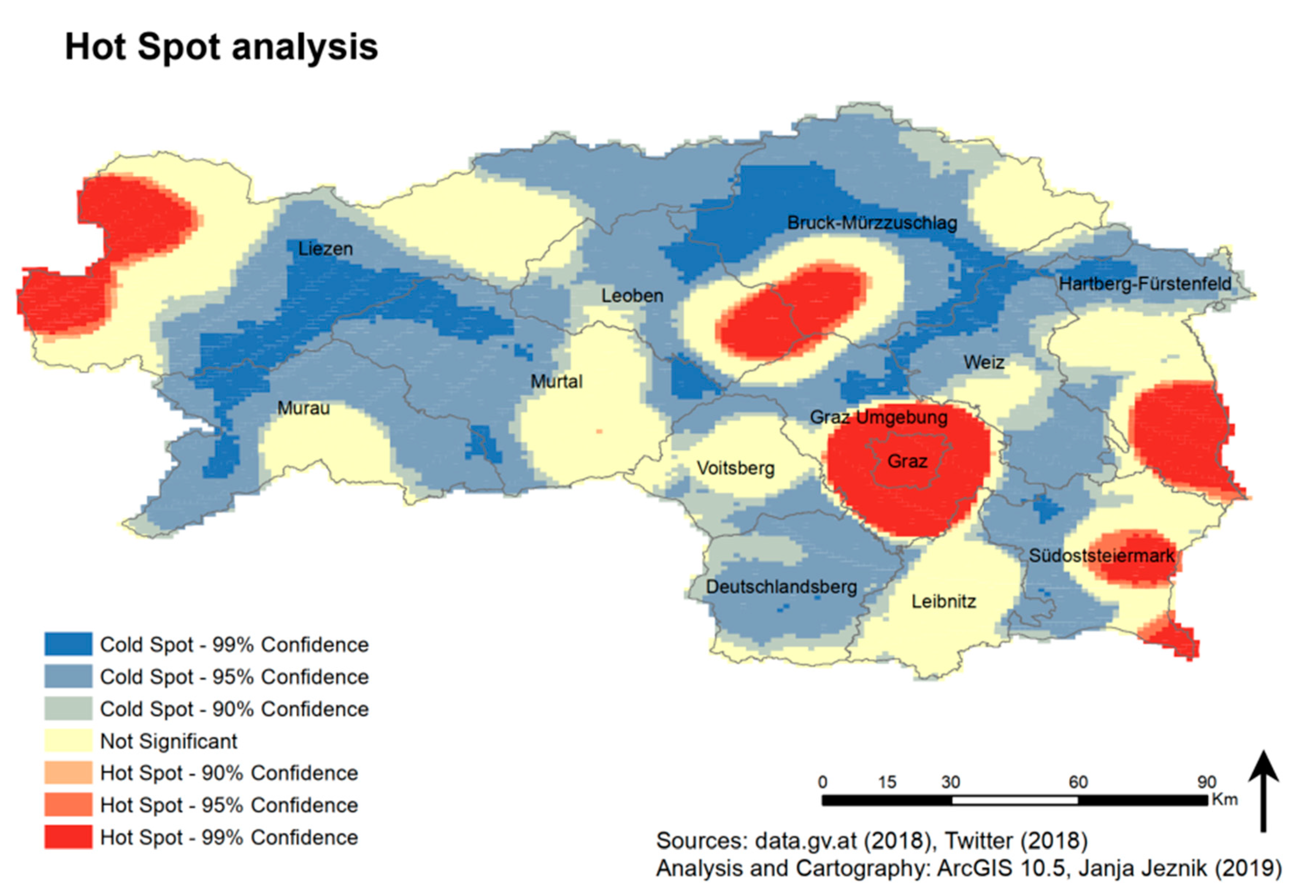
Section 4.2. In addition, the hot spot analysis (see
Figure 7) in conjunction with
Figure 6 shows six clear and evident hot spots with a confidence of 99%. As an obvious and expected result we can observe a hot spot of the state’s capital city of Graz and its surroundings in a central part of southeastern Styria. Further city tourism-related hot spot is the urban agglomeration of the municipalities of Leoben, Bruck an der Mur and Kapfenberg. A hot spot in the shape of a semicircle in the northwest belongs to the tourism intensive municipalities of Bad Aussee and Ramsau am Dachstein, offering a selection of nature- and mountains-related tourism activities, e.g., hiking, skiing or bathing in natural lakes. The last three significant hot spots with 99% confidence belong to the municipalities of health and beauty thermal tourism, namely Bad Radkersburg in the extreme south-east, Bad Gleichenberg further north and Loipersdorf bei Fürstenfeld in the east. Statistically significant cold spots represent areas confronting low tourist visits and are, with the exception of the whole district of Deutschlandsberg located on the edges of more populated areas such as in the mountains or in the countryside. Cold spot clusters with 99% confidence are located in the western and northern mountainous parts of the state, mostly in the districts of Liezen and Bruck-Mürzzuschlag. However, significant cold spots are located also on the peripheral edges of all other districts (except Leibnitz).
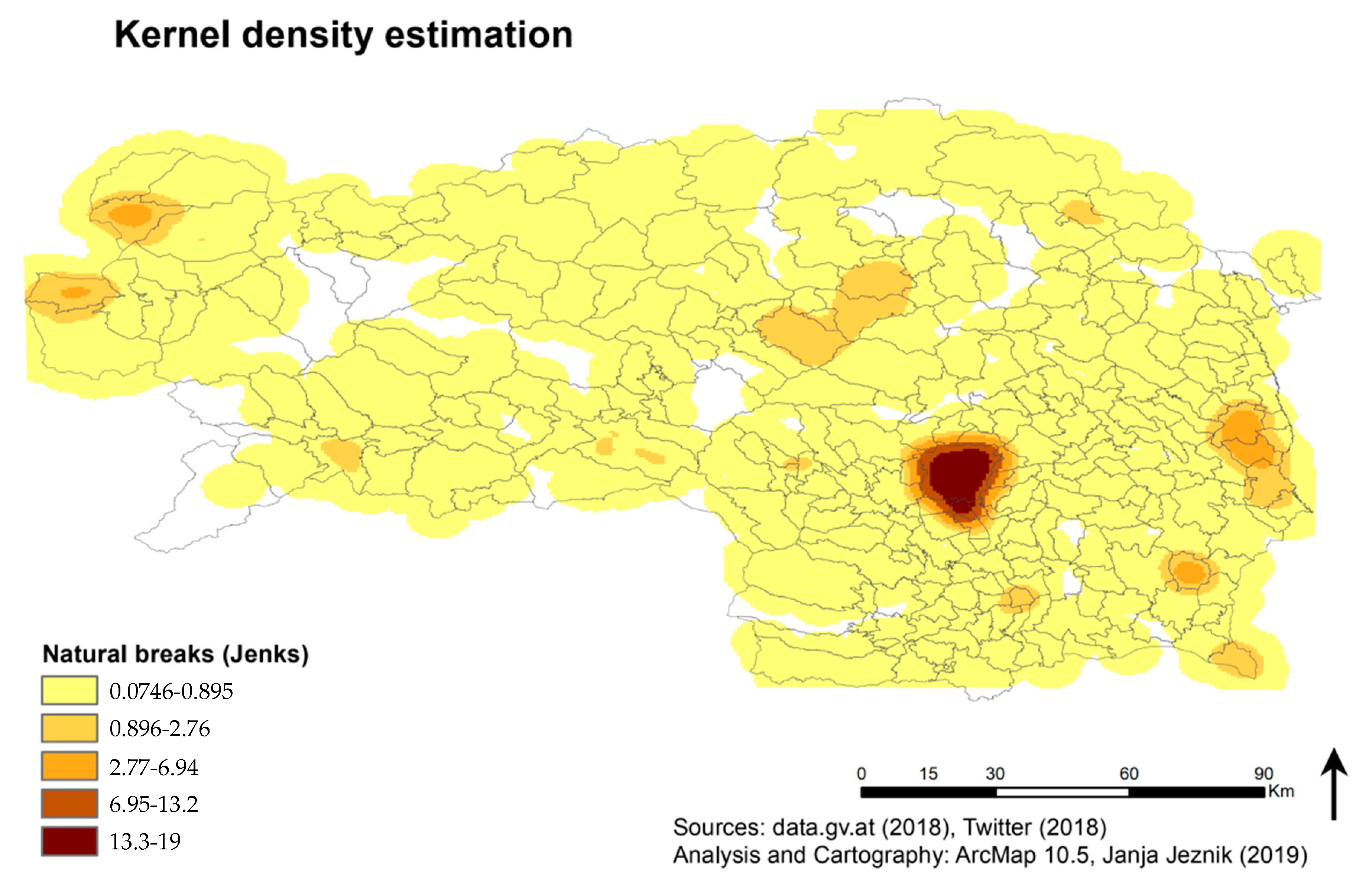
The Kernel Density Estimation results confirm significant changes in values, especially between the state’s capital Graz and other, more rural, areas, as mentioned above (see
Figure 8). Most of the study area corresponds to a density of less than 1 Tweet per search radius. White values are locations with the kernel density of 0 and were excluded from the visualization in order to stress the difference to other areas.
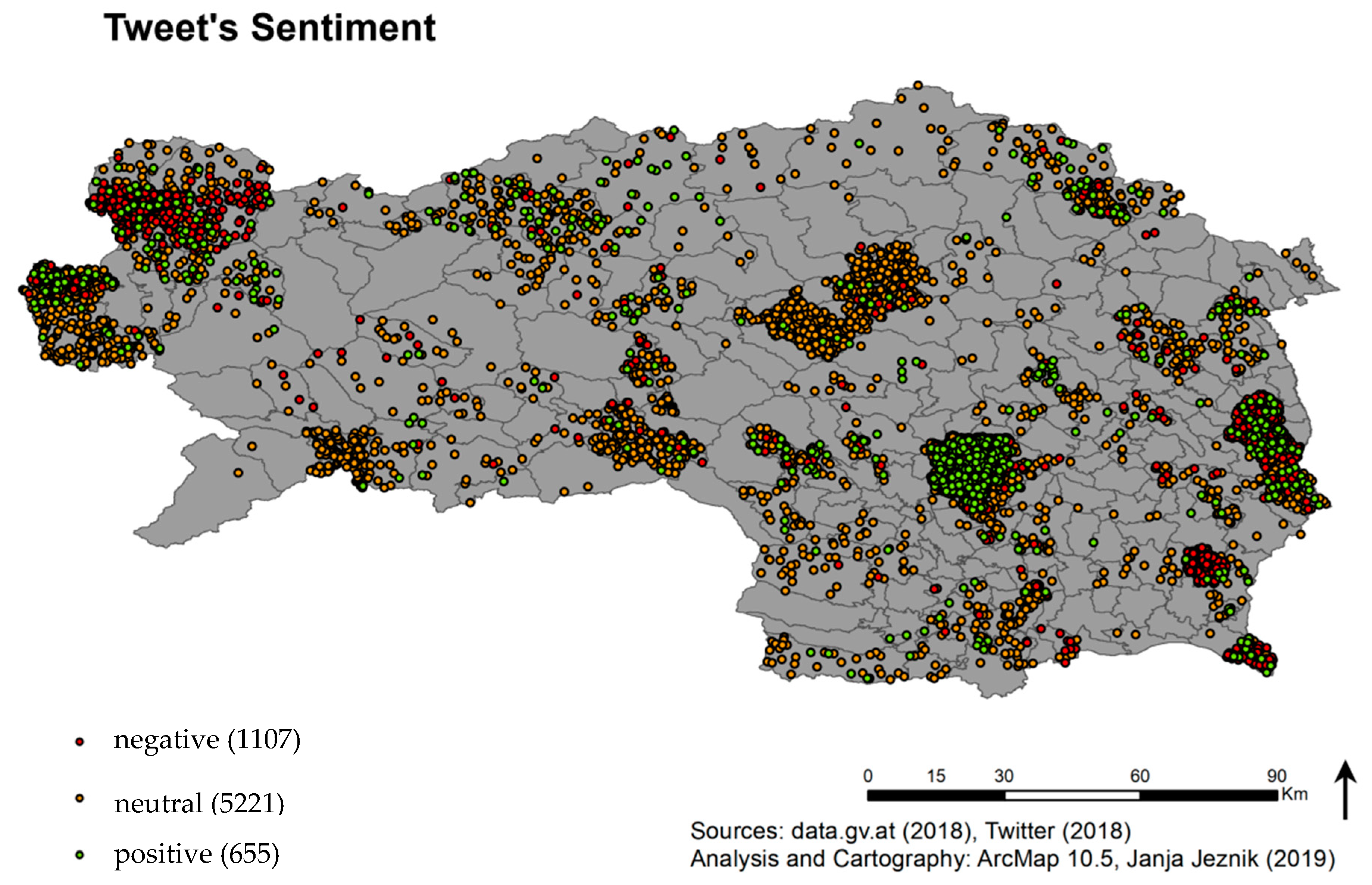
Spatial patterns of positive, negative and neutral sentiments are represented in the map in
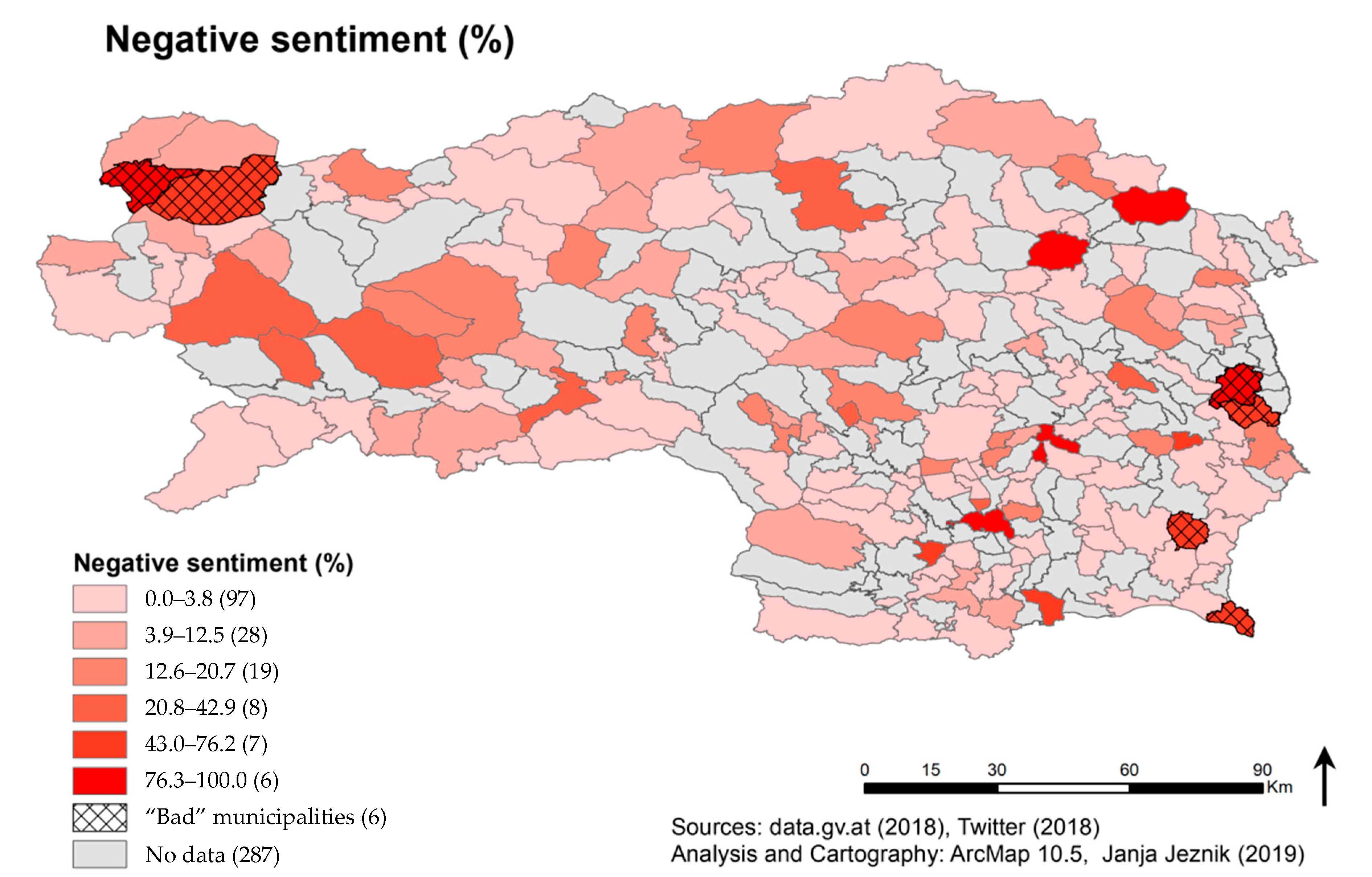
Figure 9. However, it is important to take a notice, that there are some municipalities with the word “Bad” in their name, such as Bad Radkersburg or Bad Aussee. In these cases, although the user was referring to the name of the municipality, the tweet was categorized as negative due to the word “Bad” which refers to thermal or swimming areas in German, but is understood by the algorithm as the English word referring to something negative. As in
Figure 10, six municipalities are marked with a cross hatch pattern, in order to point out their irrelevance to the category of very high negative sentiment percentage.
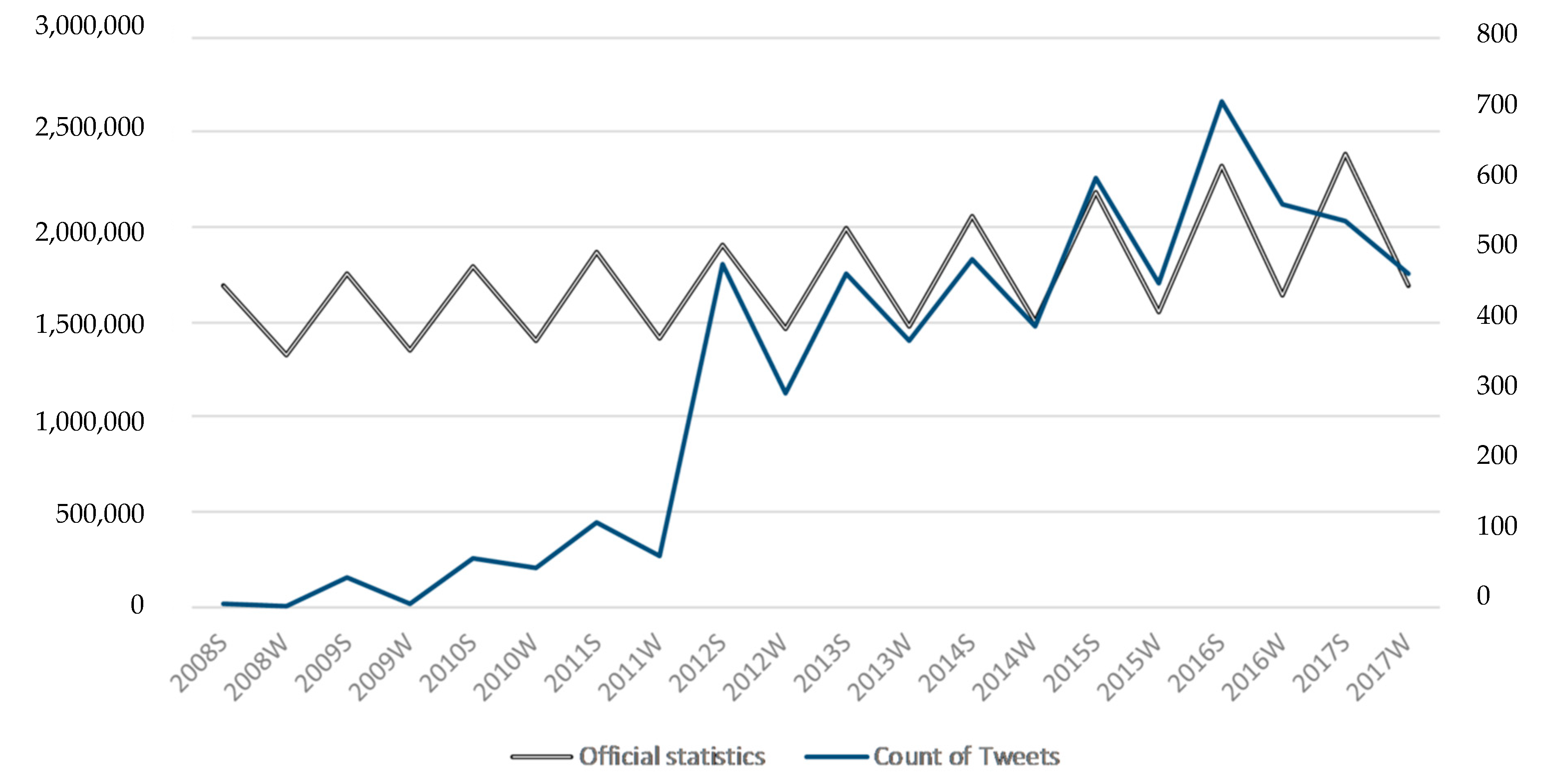
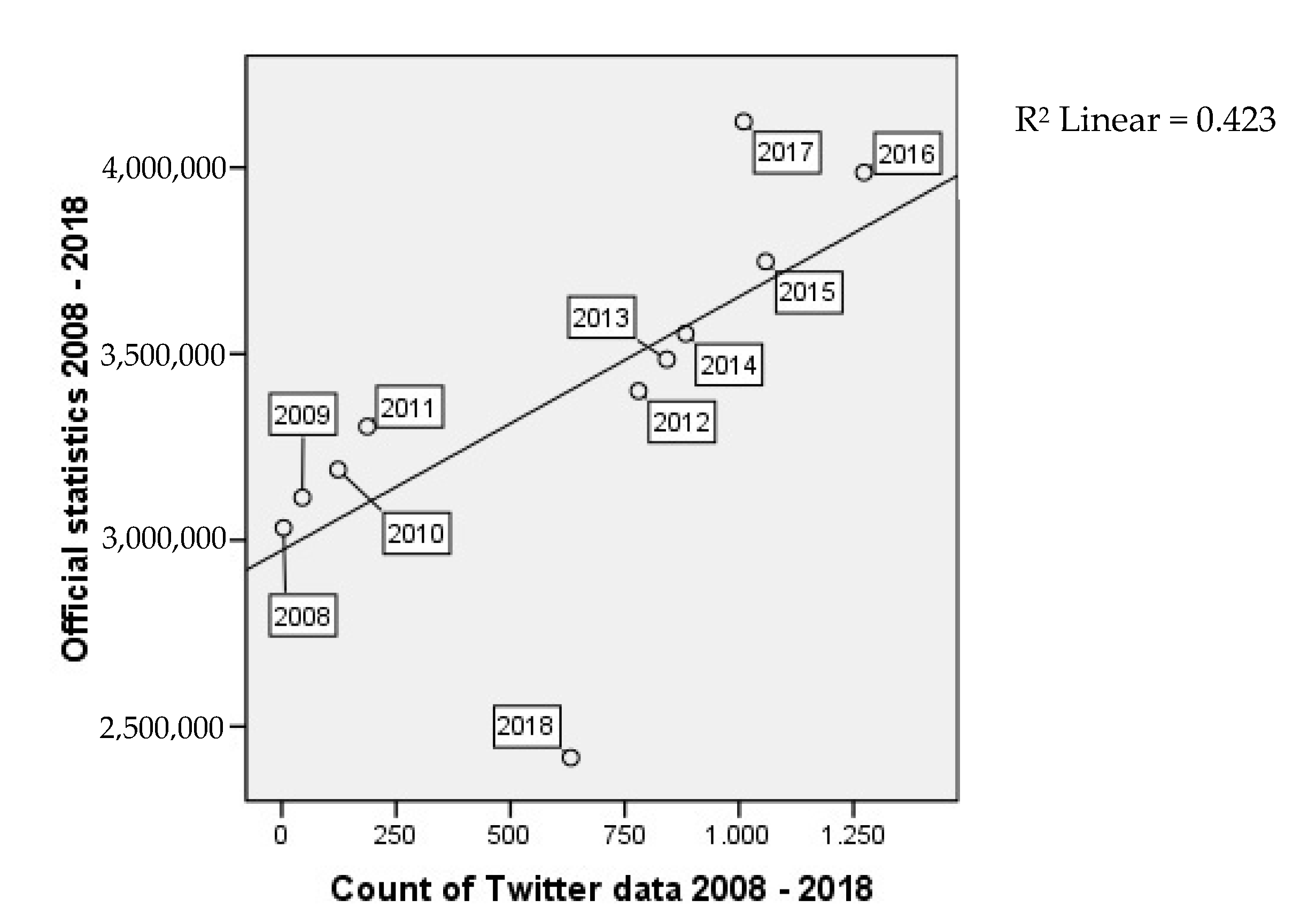
As can be seen in
Figure 11, there is a strong relationship between the crowdsourced data and reference data from 2011 onwards. In order to achieve relevant results, we applied correlation analysis to two separate datasets—one to the whole dataset from 2008 till 2018 (see
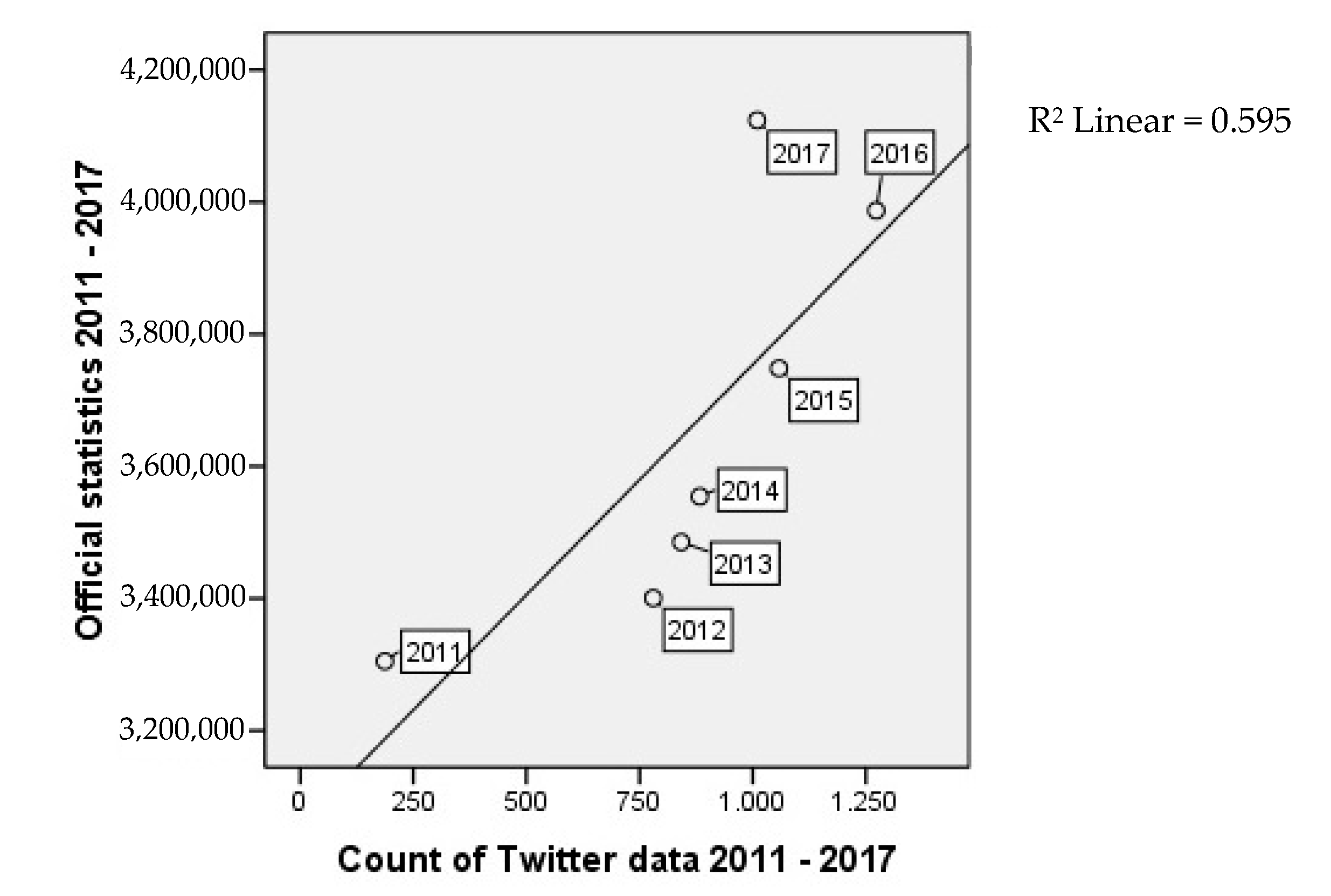
Figure 12), whereas in 2018 only the data of the first half year (and also only first half year of reference data) was used. There is a significant correlation at the 0.05 level with Pearson’s coefficient of 0.650. The Sig(2-tailed) value under 0.05 confirms statistical significance of the correlation. On the other hand, considering only the full years between 2011 and 2017 (see
Figure 13), the Pearson’s coefficient increases to 0.772, which, according to the definitions in our theoretical section, is already a strong correlation. The correlation for years between 2011 and 2017 is also significant at the 0.05 level.
Further correlations were also determined at the district level for the time period from 2011–2017, since we believe that the low count of tweets in the years 2008, 2009 and 2010 does not reflect such low tourist visitors but rather the low number of Twitter users in general. As can be seen in
Table 3, there are 5 districts with positive correlation over 0.8 and are statistically significant at the 0.001 level. Murau, Liezen and Graz Umgebung have a strong correlation over 0.85 and Graz and Südoststeiermark even a very strong correlation over 0.9. With 0.694 there is also Leoben with significant correlation on 0.001 level. However, at half of the districts there is no significant correlation between our and reference data. One district, Voitsberg, even confronts negative correlation at 0.005 significance level. In addition,
Table 3 shows the Pearson’s coefficients for the summer and winter seasons. Districts are arranged according to the correlation strength in the summer season. It can be seen that correlations are, in general, higher in the summer compared to the winter. Graz, Südoststeiermark, Graz Umgebung and Liezen are on the top with the highest values for both seasons. The other districts fluctuate—for instance in Murau there is a significant positive correlation in summer but a very weak negative relationship with no significant correlation in winter. In Bruck-Mürzzuschlag, Deutschlandberg, Hartberg-Fürstenfeld and Voitsberg there are positive relationships in one season and negative relationships in another season.
6. Discussion and Conclusions
The paper evaluates crowdsourced data of the platform Twitter in several “dimensions” in order to analyze the suitability to act as proxy for tourist related questions and tourist flows. In particular, we are interested in the validity of the results gained from small crowdsourced data sets—at a regional level. Therefore, we developed a methodology to analyze the tweets in a spatio-temporal and semantic dimension and tried to evaluate the findings with the help of official tourism data. The methodology was applied to the province of Styria in Austria, for the time period from 2008 until 2018.
First, the absolute annual number of tourist related Tweets is of interest in order to quantify the size of the user basis. From 2008 until 2010 the absolute number is far below 100 for each winter and summer season. Hence, any statistical evaluation of such a low number is questionable due to the low sample size. Thus, we decided to have a detailed look at the years 2011 until 2018—as there are several hundred tourist related Tweets to be analyzed for each season. Comparing the crowdsourced dataset with the official tourism statistic with the help of Pearson’s correlation coefficient, results in half of the districts being significantly correlated. The same applies to the seasonal evaluation, where half of the districts relate better to the reference data in summer than in winter. This reveals that the spatial scale of a state is still an adequate one, while results at a district level must be critically reviewed.
Despite the small size of the crowdsourced tourism-related data set, it is visible that the spatial and temporal distribution of the Tweets is similar to the official tourism data. Spatial clusters of crowdsourced data coincide with the municipalities that have a strong tourism industry (i.e., high number of overnight stays). These touristic regions are located in the North-West (e.g., Bad Aussee, Ramsau am Dachstein) and in the thermal region in the South-East (e.g., Bad Radkersburg, Bad Gleichenberg, Loipersdorf) and the central region (Graz, Bruck/Mur, Leoben). The topic modeling for such a small data set using Latent Ditrichlet Allocation results in topics that are useless, whereas the term frequency analysis resulted in an accurate word cloud that represents touristic subjects in Styria. Text mining approaches for sentiment analysis applied to Twitter data are of great importance, as text in social media is specific and written without any general rules—mostly in an everyday language including abbreviations, typing mistakes, hashtags and emotion tags. Due to multilingual datasets, mistakes may happen during translation steps. In the paper, we highlighted the example of municipalities with the name “Bad” in it. These social media data are regarded to having a negative sentiment, due to the translation of the place name “Bad”. Hence, improvements in analyses with multilingual data could help to improve the accuracy of the results.
In addition, data filtering is crucial for this kind of analysis—as only clean datasets lead to clear and objective results and information. The approach taken in this paper is a combination of an automatic and manual determination of tourism-related tweets—which is based on their content. We strongly believe that a machine learning approach could increase the quality of the filtering approach and could thus be one of the next steps in this research topic. Text mining approaches and sentiment analysis of crowdsourced datasets can help to determine and track user’s opinions. Hence, these data can be a valuable proxy for the opinion of tourists. In particular, in our paper the Tweets—especially from 2011—2018)—can be used as proxy to determine the demand and occupancy in the tourism industry.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}