1. Introduction
People are the main body of geographical environment and social activities, and their distribution pattern is an important subject in many research fields such as sociology, geography, environmental studies, and so on [
1,
2]. Common population data mainly include two forms: demographic data and spatialized data. Currently, using demographic data based on administrative units is the main way to obtain population distribution information. Although the census data have the advantages of being comprehensive, accurate, and authoritative [
3,
4], they have the disadvantages of low spatial resolution, excessively long statistical period, and low update frequency. Therefore, the low spatial and temporal resolution of census data is not conducive to effective urban governance. Compared with demographic data, spatialized population data can express the true population distribution more intuitively and on multiple scales, thereby effectively overcome the shortcomings of demographic data.
In recent years, the emergence of multi-source data such as point of interest (POI for short), location check-in data, sharing-bikes’ trajectories, floating car GPS, and night light remote sensing data provide time-efficient, fine-grained, and reliable data source for gridded population distribution estimation, while machine learning technologies provide advanced methods for simulating gridded population distribution. Hence, with the progress of data sources and research methods, it is possible to accurately understand the urban population distribution in multiple scales and recognize spatiotemporal patterns [
5,
6,
7]. Guangzhou is one of the core cities of Guangdong-Hong Kong-Macao Greater Bay Area. Due to the fast urbanization process, it is facing several threats, such as large population, high population density, traffic congestion, and irrational allocation of resources. To solve the above problems, detailed population distribution information is essential basic information.
Research on the population distribution map can be traced back to 1930. American social geographer Wright J.K. proposed the dasymetric method, which combined population distribution with land use types to generate a population distribution map of Cape Cod, Massachusetts [
8]. Based on the literature review, approaches used to map populations differ in techniques (disaggregation or aggregation), mapping unit (e.g., administrative units, enumeration units, geographical units, regular grid), ancillary data used (e.g., topographic maps, land use/land cover vector data-sets, cadastral data, satellite images, LIDAR data, etc.), and visualization methods (e.g., choropleth map, isolines, dasymetric map, 3D visualization) [
9]. In this paper, we focus on the disaggregation mapping technique in grid unit. Regarding the gridded population distribution data research, existing studies can be divided into different scales such as global, country, city, and commune. In the 1990s, many global population datasets were developed, such as the Gridded Population of the World (GPW), the Gridded Rural Urban Mapping Project (GRUMP), LandScan, Worldpop, and so on. These global population datasets employed different ancillary datasets with various approaches. In spite of these, datasets are important for the data-poor regions; their accuracies in city or commune scale are still worth noting. The authors developed an automatic and powerful method to improve the mapping accuracy of GPW dataset, by detecting and mitigating major discrepancies and anomalies occurring in geospatial census data [
10]. Their work illustrates the value and possible contribution of detailed, updated, and independent remote sensing data to complement and improve conventional sources of fundamental population statistics. In their work, global and consistent remote sensing-derived data reporting on built-up presence was used to revise census units deemed as ‘unpopulated’ and to harmonize population distribution along coastlines. The results show that the targeted anomalies were significantly mitigated and that the baseline census database has improved, potentially benefitting other uses of the same statistical base. There are also some scholars who tried to conduct high-resolution population research at the national level [
11,
12,
13]. However, there are relatively few detailed studies on small-scale areas such as cities, due to the various urban fabric patterns and city complexity. As the basic unit of China’s economic activities and social management, cities urgently need precise and accurate population distribution information to improve the level of urban governance.
In summary, gridded population distribution is usually simulated in four different ways, including spatial interpolation method, land use inversion method, night lighting modeling method, and multi-source data fusion method. Each method has its advantages and drawbacks. The spatial interpolation method uses interpolation algorithm to obtain gridded population distribution data by taking census data as model input [
14,
15,
16] and has been widely applied for the spatial decomposition of census data [
17,
18,
19]. The gridded population data can be interpolated directly, or based on the information provided by other auxiliary data, thus it is divided into regional interpolation without auxiliary data and regional interpolation with auxiliary data. Commonly used spatial interpolation methods include point interpolation and area weight interpolation. The implementation steps of the point interpolation method are as follows. First, control points in the study area are selected and the density of the center point are used to symbolize the population density of each source area. Then, an appropriate interpolation algorithm (such as Inverse distance weighted (IDW), Kriging, etc.) is selected to generate population density raster map. Finally, the gridded population map is obtained by overlaying population density raster map and the administrative boundary. This method is relatively easy to implement, but it has severe limitations. First, the spatial resolution of model outputs is generally coarse, mostly at tens of kilometers. Second, the model’s error is difficult to quantify. Third, regional interpolation is affected by the error of the original region aggregation or decomposition operation, and its accuracy largely depends on how to define the original region and the target region, the degree of generalization during the interpolation process, and the characteristics of the partition surface [
20]. Therefore, the ability of spatial interpolation method to describe the real population distribution is weak.
The principle of land use inversion method is to give different weights to each land use type according to the differences of population density between different land use types [
18,
21,
22,
23]. However, the land use inversion method fails to reflect the population distribution difference in the same type of land parcels, and ignores the randomness of population distribution. Since the launch of the DMSP/OLS satellite in 1970s, the night light modeling method has become one of the mainstream methods for simulation of gridded population distribution [
24,
25,
26]. However, the application of DMSP/OLS data is relatively rare, because the sensor stopped working in 2013 and the spatial resolution is too low(1KM). The emergence of Suomi National Polar-Orbiting Partnership Visible Infrared Imaging Radiometer Suite (NPP-VIIRS) data effectively overcomes the shortcomings of DMSP-OLS data in spatio-temporal resolution [
27], and such data are more suitable for the study of human social and economic activities [
28,
29]. Sutton K. et al. used DMSP/OLS night light data to estimate the global population based on a global scale, and found that the global population is about 6.3 billion [
30]. However, spatial resolution of DMSP/OLS and NPP/VIIRS night light data sources are still to coarse for population modelling in local scale. Nowadays, the world’s first professional luminous remote sensing satellite designed by Wuhan University (Wuhan, China), Luojia 1-01 (LJ 1-01), was successfully launched in June 2018. Compared to NPP-VIIRS data, LJ 1-01 data have a significant improvement in spatial resolution and quantitative level, which provide a more refined data source for small-scale population distribution simulations [
31,
32,
33]. In essence, the night light modeling method simulates the gridded population distribution in the study area by establishing a linear relationship between the night light intensity and population density. However, the problems in the night light data seriously affect the accuracy of the model outputs, such as pixel saturation, overflow, and low accuracy of population retrieval in weak light areas. In order to improve the simulation accuracy, some scholars have tried to combine night lighting data with land use data for research [
34,
35,
36]. However, the improvement in accuracy was not significant. Then, some scholars attempted to improve the simulation accuracy by combining the night lights data, land use data, Point of interest (POI) data, and other types of data [
37,
38,
39]. With the continuous enrichment of social sensing data, some scholars attempt to depict the dynamics of population distribution by using these data, such as taxi GPS data [
40], mobile phone data [
41], tencent location service data [
42], baidu heat map data [
43], and so on. The multi-source data fusion method has become one of the most popular method. Due to the limitations of these data, including poor data availability, data heterogeneity, and so on, the conditions for producing gridded population distribution dataset at a large-scale are not yet mature.
Essentially, the spatial decomposition of census data to grid unit is a regression process. Several regression models have been proposed to create the weight layer, such as linear regression (LR), geographically weighted regression (GWR), random forest regression, and so on [
23,
44]. In particular, the random forest (RF for short), one machine learning method which was first systematically proposed by Breiman [
45], is becoming more and more popular in the study of models to produce the weighting layer of population data, as it has several advantages including suitable for collinearity, avoiding over-fitting, high calculation speed, and so on. The idea of RF algorithm is to use the bootstrap resampling method to extract multiple samples from the original sample, model the decision tree for each bootstrap sample, and then combine the results of multiple decision trees to obtain the final regression result by voting. For the first time, scholars obtained 100 m grid population mapping results in three undeveloped countries [
46]. Due to the ease of training and interpretation, the random forest method has received increasing attention in the population mapping research [
42,
47,
48]. In the process of random forest modeling, it is necessary to optimize several parameters for improving the performance and effect of learning, such as the max number of features and the max depth of trees, and so on [
49,
50]. In general, to avoid the impact of the initial data partition on the results, cross validation (CV) and grid search were usually performed to reduce the occasionality and ensure the validity and accuracy of the model training [
51].
The uncertainty of modeling is also an important issue in the study of population distribution mapping, which includes ecological fallacy, modifiable areal unit problem (MAUP), and so on. The MAUP is a classic problem in the Geographical Information Sciences, which has been long acknowledged and explored. For any spatial resolution, as any set of boundaries, MAUP may seriously hamper the strength of statistical results [
52]. Sensitivity Analysis is a useful method to explore the uncertainty of modelling. The authors tested the effect of different geometrical data aggregation schemas—administrative regions and hexagonal surface tessellation—on global spatial autocorrelation statistics, by using several datasets for two study-areas including Continental Portugal (mixed urban-rural) and the Lisbon municipality (urban), and raised an important point, i.e., inferences based on spatial analysis of areal data depend greatly on the method used to quantify the degree of proximity between spatial units [
52].
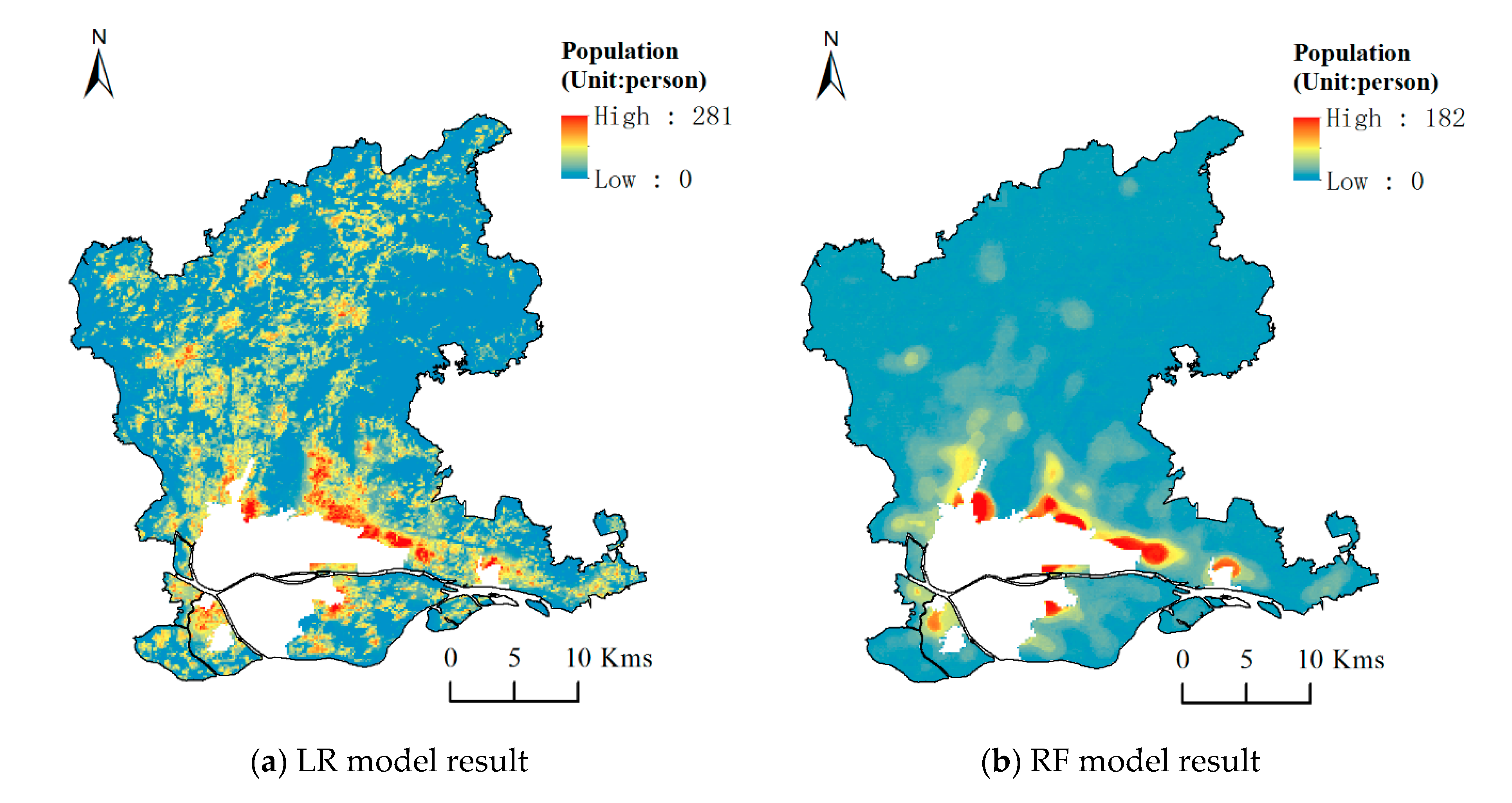
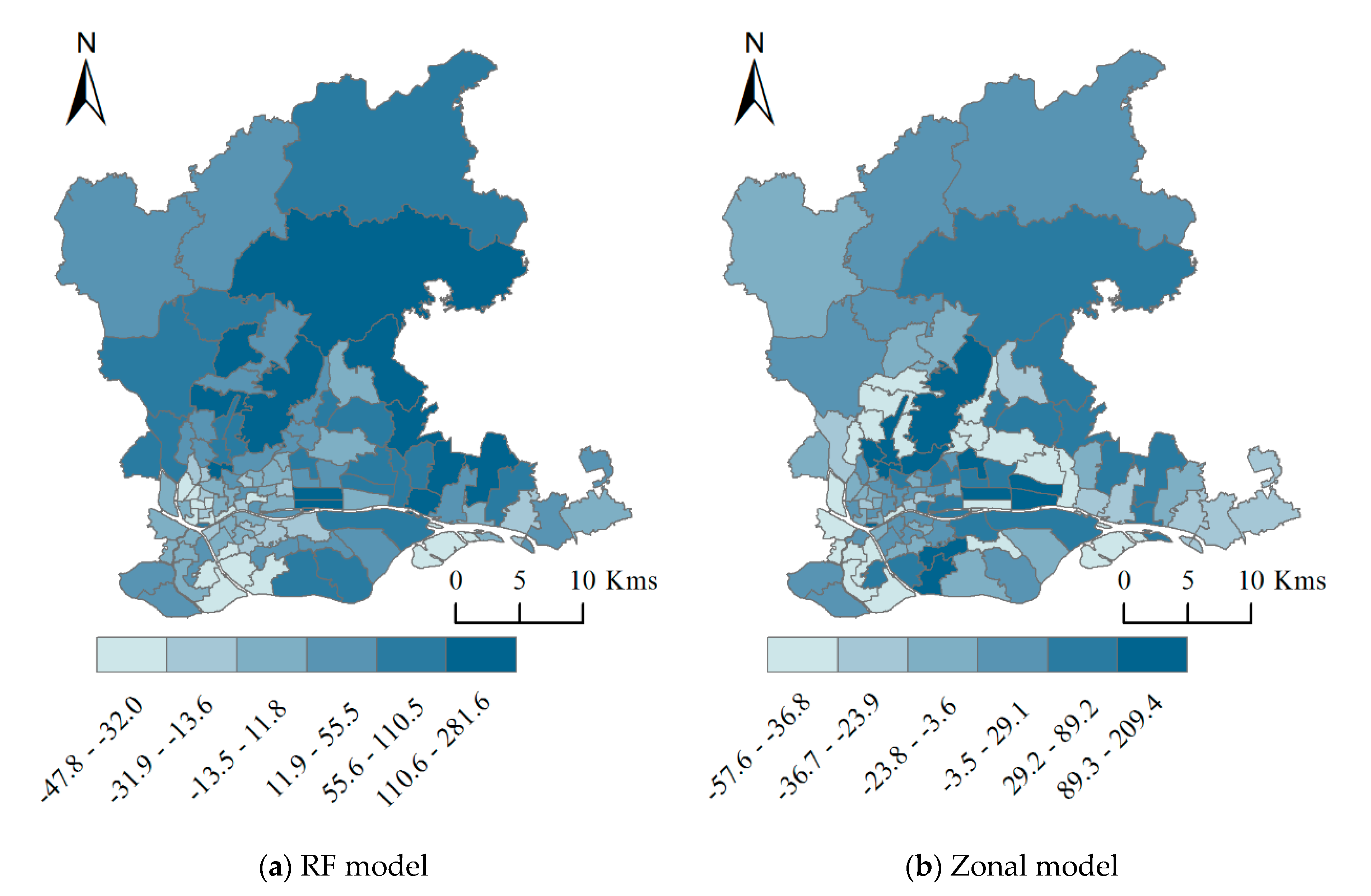
As we know, the relationship between population distribution and influencing factors is an extremely complex nonlinear relationship. A variety of machine learning algorithms, including random forests, neural network, and so on, can handle nonlinear relationship fitting well, while a geographic detector model can handle the spatial heterogeneity of influencing factors. However, most existing studies use a single model to the whole area. For regions with large population density differences, a single or global model cannot accurately explain the mechanism of the spatial distribution of internal population. The zonal strategy can effectively solve the shortcomings of the single model, because it can perform secondary partition modeling on the study area according to the characteristics. To this end, this article intends to illustrated the population map of Guangzhou city based on the idea of zoning modeling and machine learning methods, by using multi-source spatial data such as land use, POI, night lights, and so on. This article attempts to improve the study of mapping population distribution, and provide important basic information for urban management.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}