Towards Deriving Freight Traffic Measures from Truck Movement Data for State Road Planning: A Proposed System Framework

 ,
,
Abstract
1. Introduction
- How can the DRD’s requirements (traffic measures) be gathered effectively during the development phase of the database system?
- What are the different types of raw freight data that are required to enable the processing system to satisfy the DRD’s requirements?
- What are the procedures and systems to collect and analyze the shared freight data and ensure data privacy?
- How much data is required to provide statistically significant freight data analyses?
“Public Organizations”, “Department of Transportation”, “Transport Policy”, “Public Sector”; “Origin–Destination”, “Logistics”, “Freight”, “Lorries”, “GPS”, “Trucks”, “Data”.
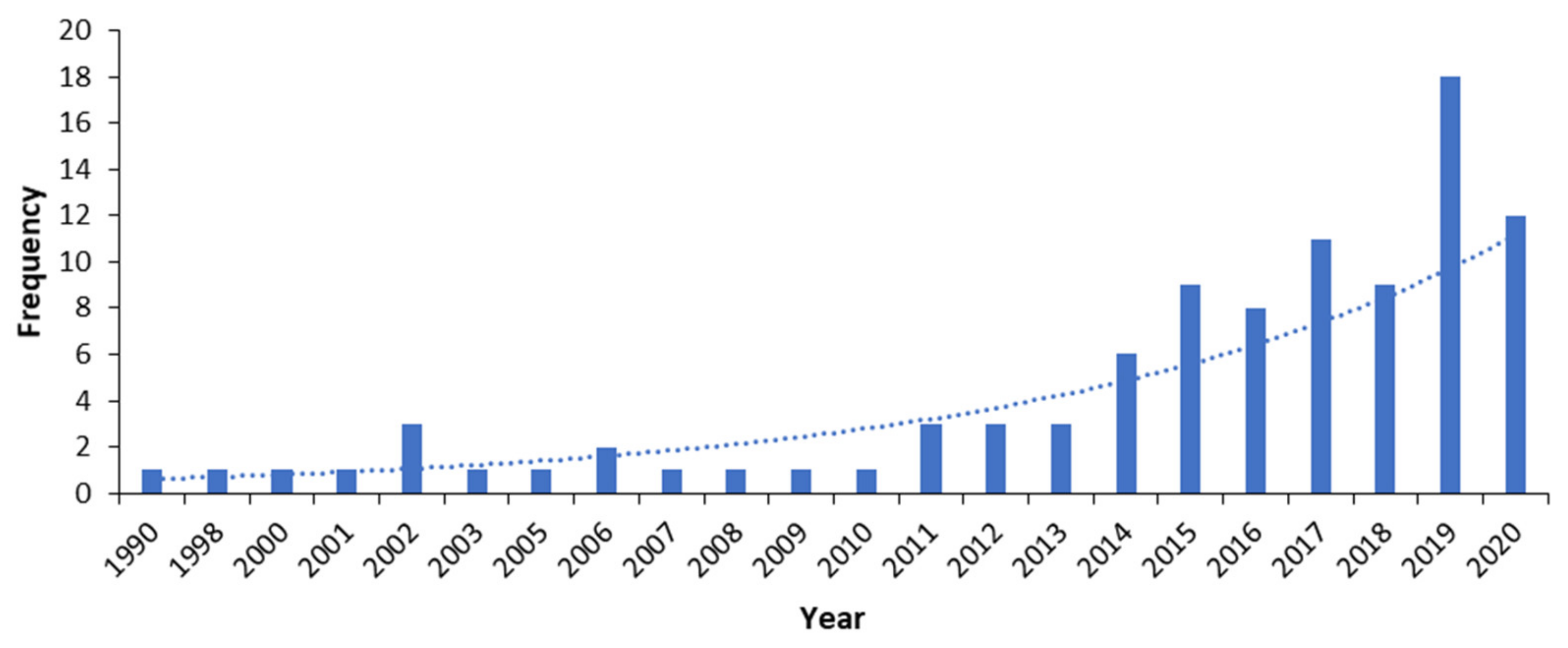
2. Identifying the Most Important Traffic Measures from Final Users’ Perspectives
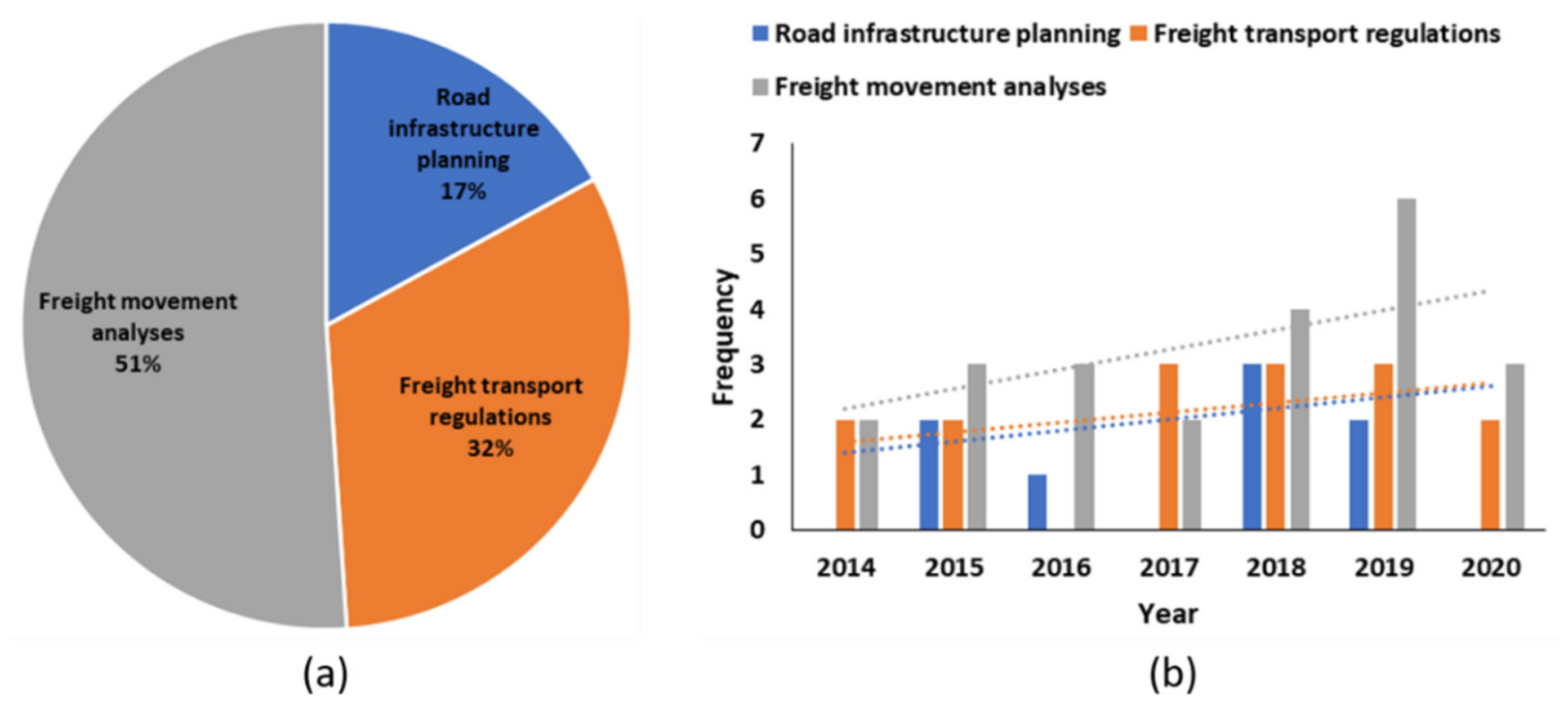
- Road infrastructure planning: this category includes studies that used the freight data to validate or investigate the impact of new roads, parking areas for trucks, and potentials for toll roads.
- Freight transport regulations: this category includes studies of how the freight data can be used to suggest and validate freight traffic policies.
- Freight movement analyses: this category includes studies that analysed the freight data in order to form a better understanding of how road networks are used by freight trucks.
2.1. OD-Matrices
2.2. Driving Patterns among Zones
2.3. Parking Pattern Analyses
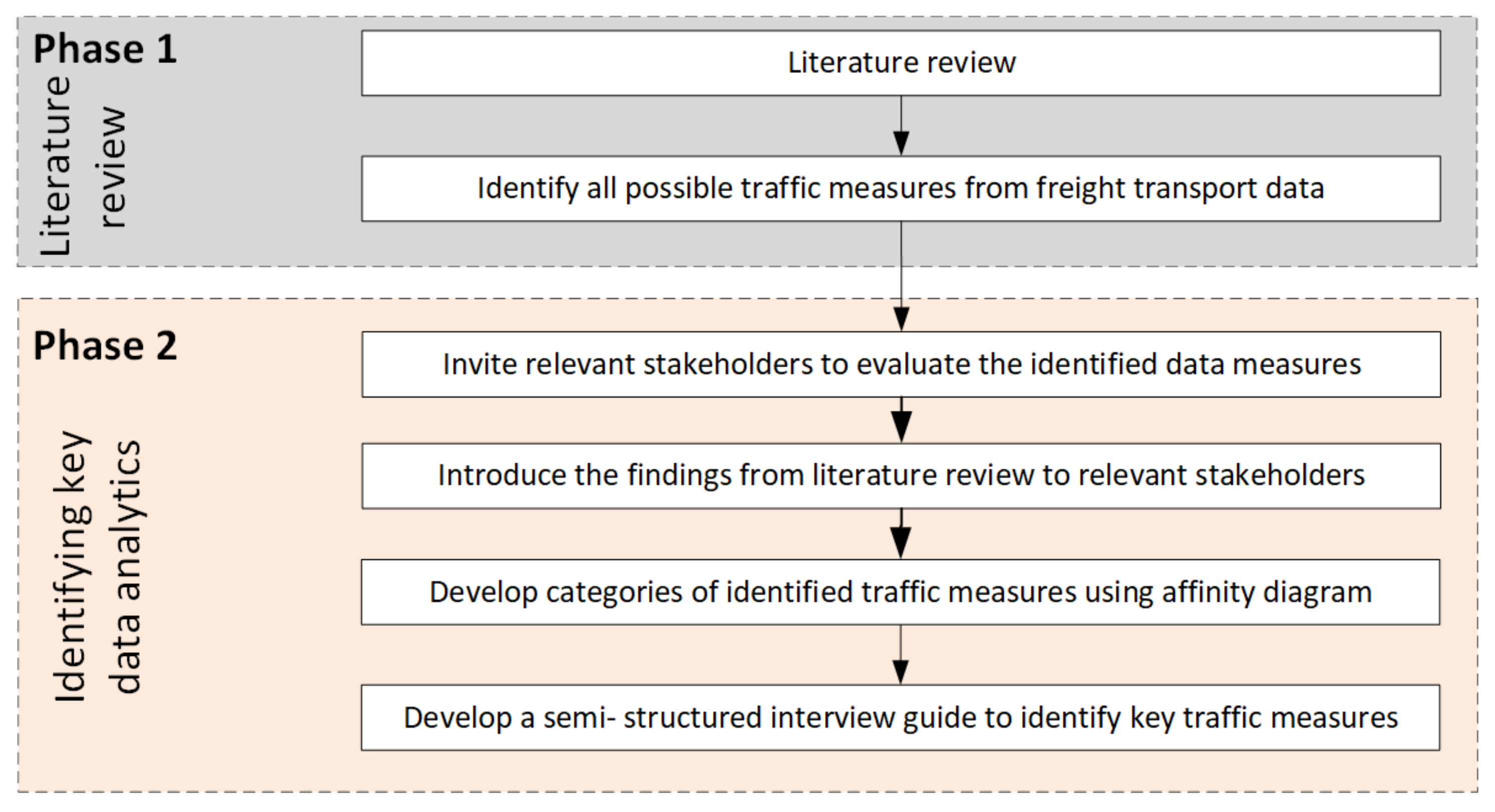
3. Identifying Input Data Requirements
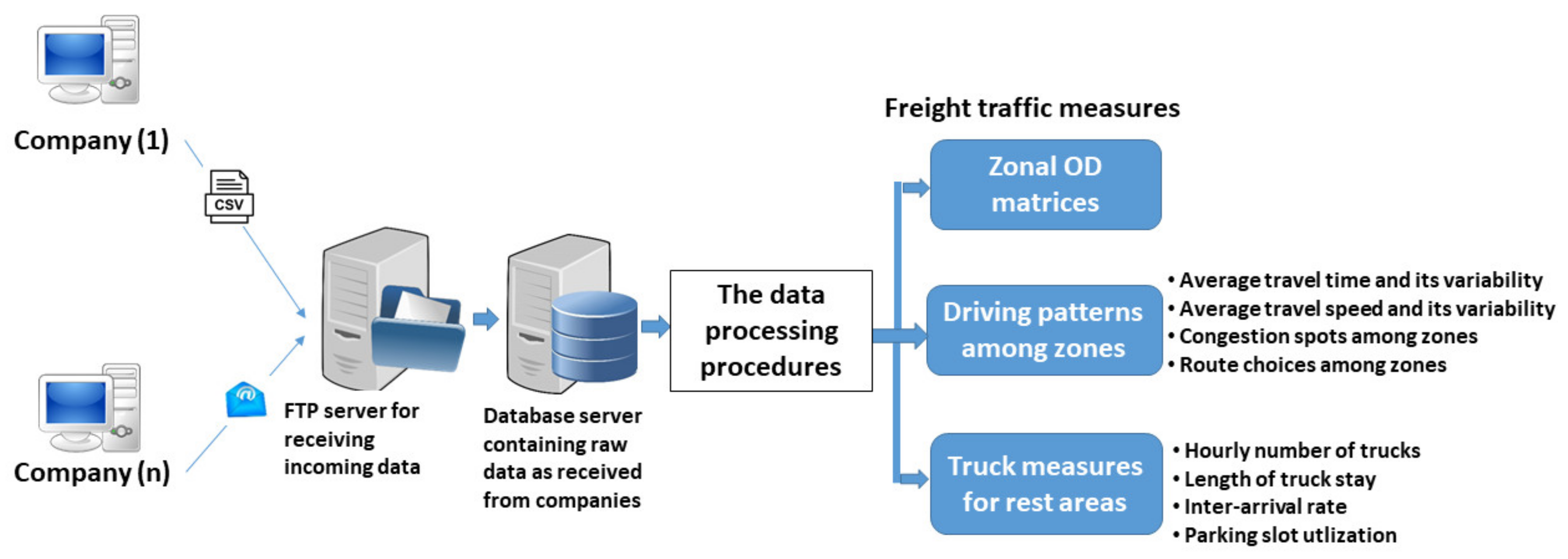
4. Procedures and System for Developing Freight Traffic Measures
- (a)
- Raw data acquisition and analysis.
- (b)
- Data storage and database development.
- (c)
- Raw data processing;
- -
- Data filtration procedure;
- -
- Sample size determination procedure;
- -
- Freight transportation analyses procedure.
- (d)
- Validation of the freight transportation analyses.
4.1. Raw Data Acquisition and Analysis
4.2. Data Storage and Database Development
4.3. Data Processing Procedures
4.3.1. Data Filtration and Correction
- GPS signals may be lost when effective communication between GPS devices and GPS satellites has signal loss. Such blockage may negatively affect identification of the OD data. In response to this signal loss problem, the GPS records reported before and after the signal loss can be used to assume the lost GPS records. For example, if the average of the travel speeds for the GPS records before and after the signal loss is below a threshold speed limit, i.e., 8 km/h, it is reasonable to assume that a trip had ended in the area of signal loss. On the contrary, if the average travel speed for the GPS records before and after the signal loss is above this threshold, the truck is assumed to continue travelling constantly with a speed equal to the average travel speed in the area of the signal loss.
- In some cases, the GPS records of the same truck indicate that the truck suddenly left the route and returned, for example it sometimes occurs that one GPS point is recorded far away from the route, but the preceding and following GPS points are on the same route. Such GPS points are not considered in the analysis.
4.3.2. Sample Size Determination and Data Sufficiency Analysis
- n is the sample size, expressed in number of trucks equipped with GPS probes.
- = is the tabulated z-value corresponding to 100 × , for example a confidence level of 95% means that there is a probability of 95% that the population speed estimates will fall within the specified range of speed values identified based on the sample.
- σ = Standard Deviation.
- SE = Sampling Error, which is user-selected allowable relative error in the estimate of the average speed.
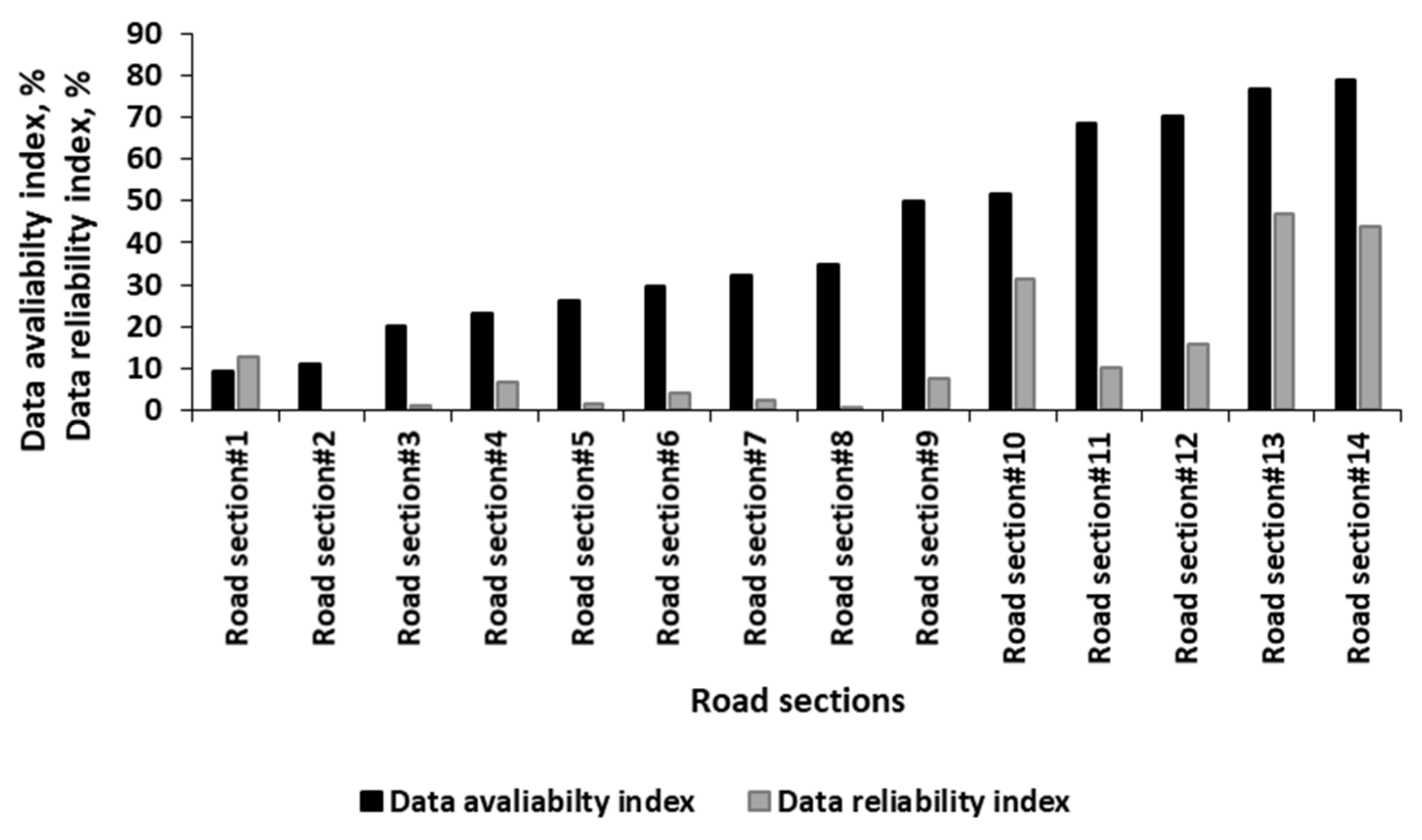
- Data availability index (u), which indicates the percentage (%) of daily hours at which at least one GPS truck is available. u can be calculated as follows:where l is the number of hours at which at least one truck is available. l is calculated from the available GPS data. For example, if u for a specific road segment is 100%, this means that at least one GPS-data record is available at each hour for this segment.
- Data reliability index (d) indicates the percentage (%) of daily hours at which the available GPS data satisfies the minimum sample size requirement. d can be calculated by this equation:where v is the number of hours at which GPS data satisfies the minimum sample size requirement. For example, if d is 54.2%, this means that around 54.2% of the 24 h have sufficient GPS data to provide statistically significant speed measures.
4.3.3. Freight Transportation Analysis Procedure
- Identifying truck stops:The DBSCAN method includes two main steps: (1) identify clusters of GPS points, and (2) implement a time constraint to ensure stops are not detected based on GPS points with a large temporal gap [95].
- Identifying the purpose of truck stops:Publicly available land use data will be used to identify the purposes of stops: rest stops, loading/unloading stops, and fuelling stops [71].
- Determining the origins and destinations for trip generation:Origin and destination stops will be those stops that are not rest, fuel, nor traffic stops.
- Calculating zonal OD-matrix:The zonal OD-matrix will determine the amount of unique trips between each zone [19].
- Determining diversity of route choice between zones:Analysis of route choice describes amount of trips on the individual routes among zones and identifies the main routes of travel between zones as the route with the largest amount of trips [15].
- Determining travel time and speed between zones:The travel time and speed will be calculated using trips’ information among origins and destinations, following the procedures introduced in [67].
- Identifying stops at resting areas:As stated before, the DBSCAN method will be used to identify all possible stops of trucks. Parking analyses will consider only stops made by trucks at the different rest areas in Denmark.
- Determining arrival and staying times:Since each stop is a cluster of GPS records, for each stop, its GPS records are sorted according to the timestamp. Then, the arrival and leaving times of each individual truck will be considered as the first and last timestamps at the rest area. This can allow for analyses on the total staying times on each parking area [96]. This can be considered per hour, day, week or month, depending on the identified needs of the DRD.
- Calculating utilization of parking slots:With information on the arrival and leaving times of trucks, the parking slot’s average utilization can be estimated as the proportion of the number of trucks parked simultaneously to the maximum capacity of the rest area.
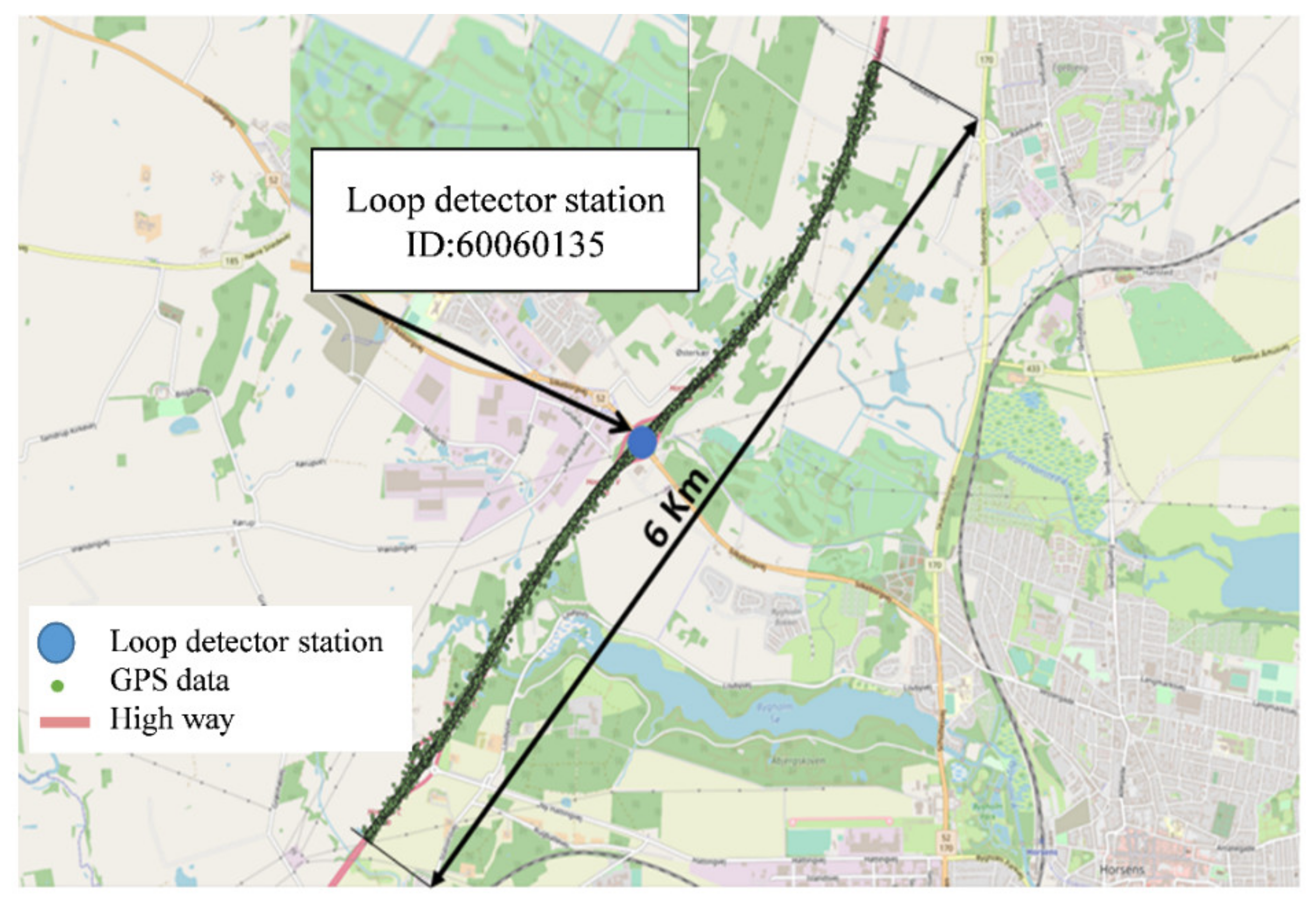
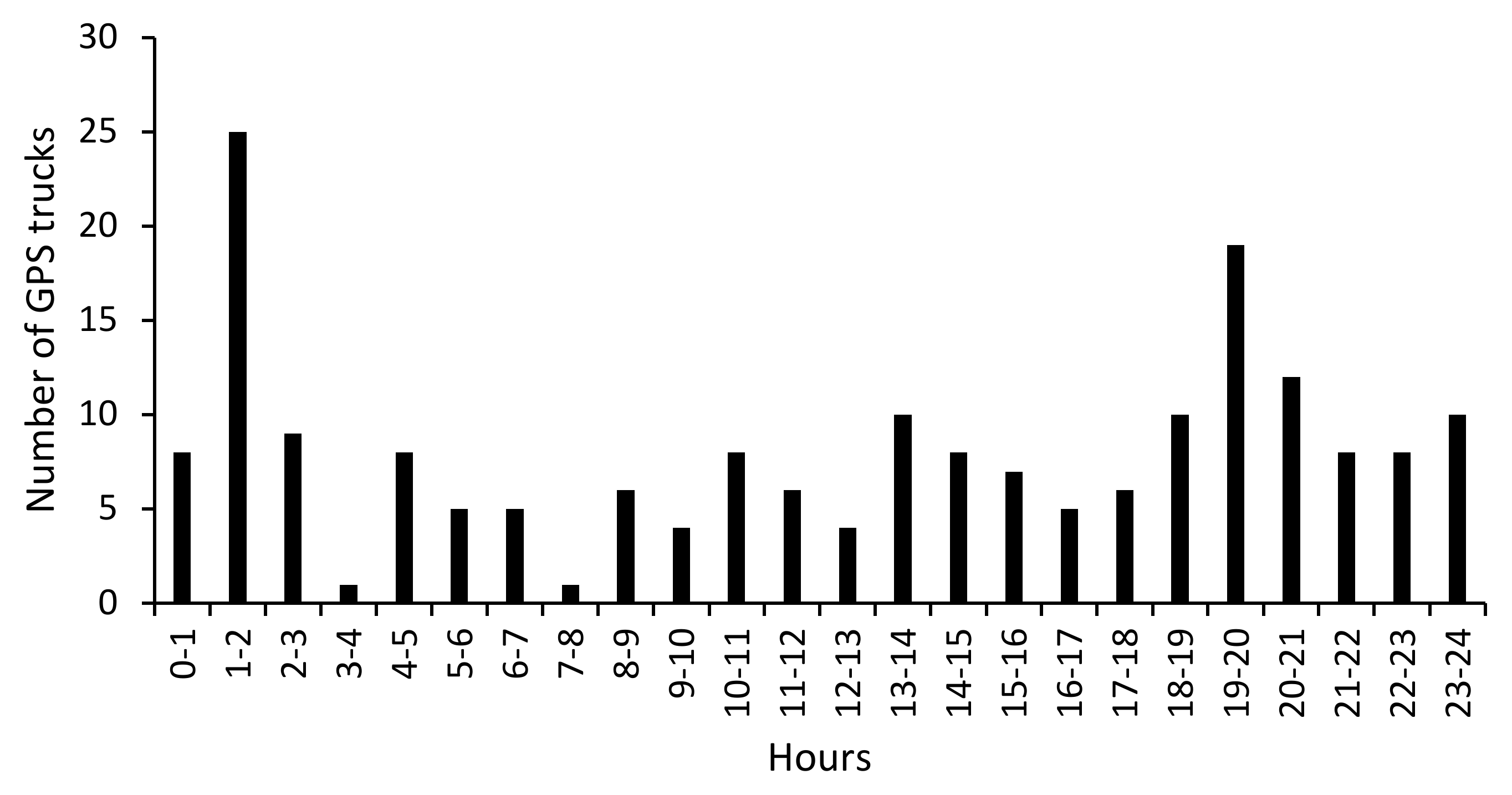
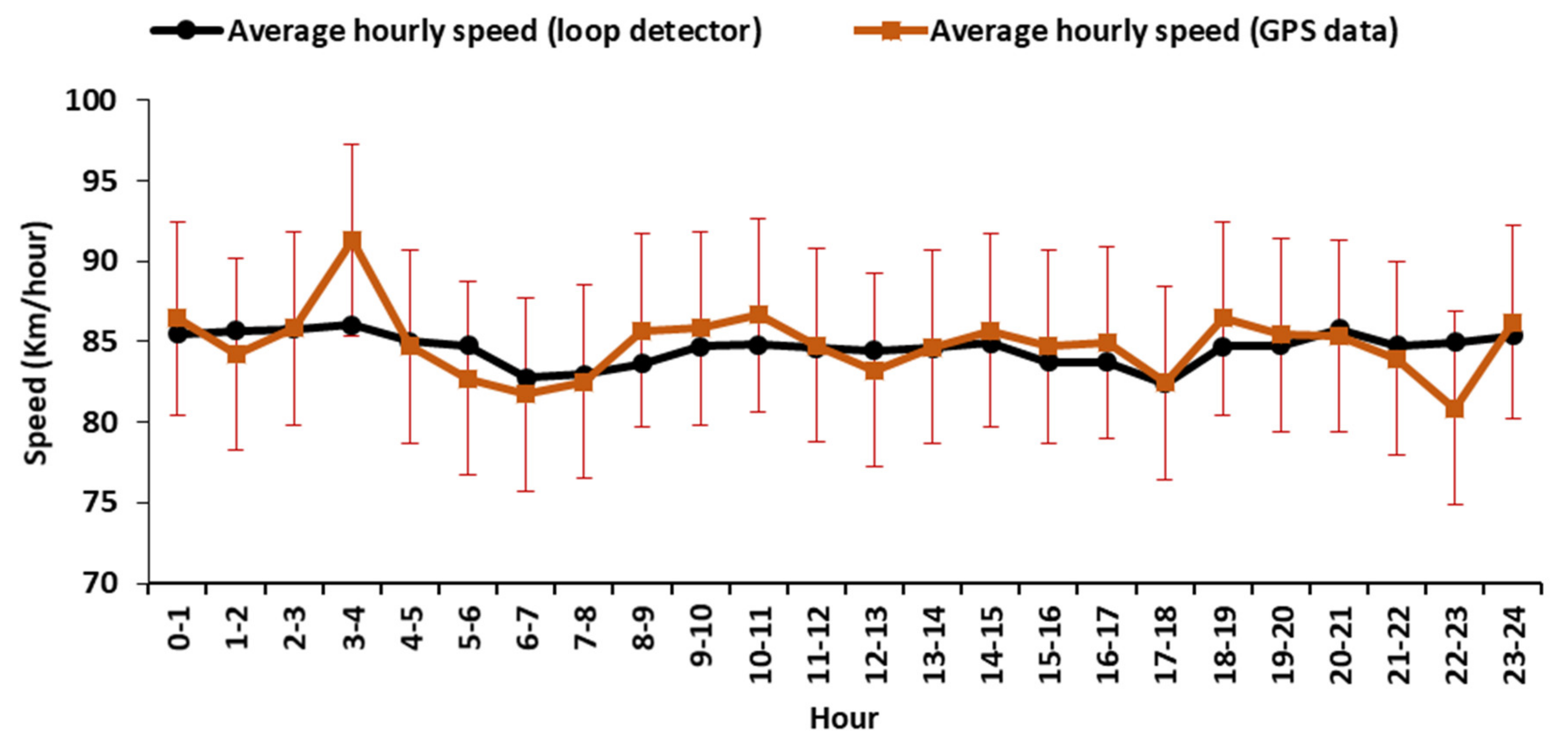
4.4. Validation of the Freight Transportation Analyses
5. An Application Case
6. Conclusions and Future Research
- Future Transport demand: Using data to analyse changes that can affect the demand for freight transport in the future and reveal possibilities to shape the next generation of transport policies. This includes analysing changes in traditional shopping patterns towards more web-based shopping, shifts in travel patterns, policy restrictions on GHG emissions in cities or a shift to electric vehicles, requiring considerations on charging infrastructure and electricity grid distribution.
- Decreasing congestion: An interesting question that can be addressed in future research is “Can time-differentiated toll charges shift delivery times, and thereby affect the congestion rates, by shifting truck driving times away from rush periods?”. In addition, the factors influencing this need to be examined further, e.g., transport price and consumer acceptance of variable delivery time. Analyses of route choices may show which road sections are vulnerable in case of heavy truck traffic, or lack of alternate routes. Using this knowledge can possibly reveal opportunities for expanding roads or building new roads.
- Policy support: “Can freight data support public authorities in other areas than transportation planning or support transport professionals in private sectors?” is an interesting question that can be addressed by future research. The data collected primarily focuses on developing freight transport, and related policies, it may be useful in supporting policies for developing, e.g., urban areas, areas where modal shifts occur, etc. By accommodating freight transport in other policy areas, the effects of GHG emissions, noise and access roads may be ameliorated and improved.
- Next generation data: A relevant question is “What are the next technology advances that will provide a further dimension to the available data and allow a step–change in the understanding of policy developments?”. The use of private data in public organisations has a direct effect on private companies gathering more data. This naturalistic sampling enables public organisations to obtain cheap data, without the need for installations of expensive equipment. It does come with shortcomings, e.g., the data is not gathered for a specific purpose. Future research should focus on how to develop new methods, or adjust existing methods.
- Data-gathering methodologies: Consider means to gather knowledge on stop-types and stop-causes, to improve future freight models. Research into which types of data gathering methodologies are best is an important aspect of several studies. As the necessary data required to create OD-matrices is still debated, it is of importance to consider what data is required, and which methods can best support this data, especially considering cost and time to gather the necessary data.
- Metadata analysis: Considering the OD-matrix and driving patterns analyses, understanding the required spread of data is of relevance. To ascertain an unbiased route choice set for OD-pairs, it is necessary to further analyse the temporal spread of data, or to set up analyses of data to conclude how many trips are sufficient [63].
- Model calibration: Calibrating models with OD-matrices, using ground truth data or simulated data, requires further data input types. Which types of data to use for calibration, and how to use these data, is a subject that requires further investigation.
Author Contributions
Funding
Conflicts of Interest
References
- Lavee, D.; Beniad, G.; Solomon, C. The Effect of Investment in Transportation Infrastructure on the Debt-to-GDP Ratio. Transp. Rev. 2011, 1647. [Google Scholar] [CrossRef]
- Danmarks Statistik Number of Enterprises in the Transport Sector in Denmark by Mode. Available online: https://www.statista.com/statistics/448383/number-of-enterprises-in-the-transport-sector-in-denmark-by-mode/ (accessed on 10 October 2019).
- Danmarks Statistik Number of Employees in the Transport Sector in Denmark by Mode. Available online: https://www.statista.com/statistics/448130/number-of-employees-in-the-transport-sector-in-denmark-by-mode/ (accessed on 10 October 2019).
- Danmarks Statistik Denmark Turnover Volume in the Transport Sector by mode. Available online: https://www.statista.com/statistics/448688/denmark-turnover-volume-in-the-transport-sector-by-mode/ (accessed on 10 October 2019).
- Danmarks Statistik Freight Transport by Road Revenue in Denmark. Available online: https://www.statista.com/forecasts/390721/freight-transport-by-road-revenue-in-denmark (accessed on 10 October 2019).
- Kveiborg, O.; Fosgerau, M. Decomposing the decoupling of Danish road freight traffic growth and economic growth. Transp. Policy 2007, 14, 39–48. [Google Scholar] [CrossRef]
- Hwang, T.S. Freight Demand Modeling and Logistics Planning for Assessment of Freight Systems’ Environmental Impacts. Ph.D. Thesis, University of Illinois at Urbana-Champaign, Urbana, IL, USA, 2014. [Google Scholar]
- Vejdirektoratet Statsvejnettet. 2019. Available online: https://www.vejdirektoratet.dk/api/drupal/sites/default/files/2019-07/WEB_Statsvejnettet%202019.pdf (accessed on 10 July 2019).
- Pan, Q.S. Freight data assembling and modeling: Methodologies and practice. Transp. Plan. Technol. 2006, 29, 43–74. [Google Scholar] [CrossRef]
- McCormack, E.; Hallenbeck, M.E. ITS devices used to collect truck data for performance benchmarks. Natl. State Freight Data Issues Asset Manag. 2006, 1957, 43–50. [Google Scholar] [CrossRef]
- Greaves, S.P.; Figliozzi, M.A. Collecting Commercial Vehicle Tour Data with Passive Global Positioning System Technology: Issues and Potential Applications. Transp. Res. Rec. J. Transp. Res. Board 2008, 2049, 158–166. [Google Scholar] [CrossRef]
- Azab, A.; Karam, A.; Eltawil, A. A simulation-based optimization approach for external trucks appointment scheduling in container terminals. Int. J. Model. Simul. 2020, 40, 321–338. [Google Scholar] [CrossRef]
- Chankaew, N.; Sumalee, A.; Siripirote, T.; Threepak, T.; Ho, H.W.; Lam, W.H.K. Freight Traffic Analytics from National Truck GPS Data in Thailand. Transp. Res. Procedia 2018, 34, 123–130. [Google Scholar] [CrossRef]
- Waller, M.A.; Fawcett, S.E. Click Here for a Data Scientist: Big Data, Predictive Analytics, and Theory Development in the Era of a Maker Movement Supply Chain. J. Bus. Logist. 2013, 34, 249–252. [Google Scholar] [CrossRef]
- Kamali, M.; Ermagun, A.; Viswanathan, K.; Pinjari, A.R. Deriving Truck Route Choice from Large GPS Data Streams. Transp. Res. Rec. J. Transp. Res. Board 2016, 2563, 62–70. [Google Scholar] [CrossRef]
- Zanjani, A.B.; Pinjari, A.R.; Kamali, M.; Thakur, A.; Short, J.; Mysore, V.; Tabatabaee, S.F. Estimation of Statewide Origin-Destination Truck Flows from Large Streams of GPS Data Application for Florida Statewide Model. Transp. Res. Rec. 2015, 87–96. [Google Scholar] [CrossRef]
- Hyun, K.; Ritchie, S.G. Sensor location decision model for truck flow measurement. Transp. Res. Rec. J. Transp. Res. Board 2017, 2644, 1–10. [Google Scholar] [CrossRef]
- Liao, C.-F. Generating reliable freight performance measures with truck GPS data. Transp. Res. Rec. 2014, 2410, 21–30. [Google Scholar] [CrossRef]
- Ma, X.; Mccormack, E.D.; Wang, Y. Processing Commercial Global Positioning System Data to Develop a Web-Based Truck Performance Measures Program. Transp. Res. Rec. J. Transp. Res. Board 2011, 2246, 92–100. [Google Scholar] [CrossRef]
- Parker, C. An approach to requirements analysis for decision support systems. Int. J. Hum. Comput. Stud. 2001, 55, 423–433. [Google Scholar] [CrossRef]
- Illemann, T.M.; Karam, A.; Reinau, K.H. Towards sharing data of private freight companies with public policy makers: A proposed framework for identifying uses of the shared data. In Proceedings of the 2020th IEEE 7th International Conference on Industrial Engineering and Applications (ICIEA), Bangkok, Thailand, 16–21 April 2020. [Google Scholar]
- Chen, M.; Chien, S.I.J. Determining the Number of Probe Vehicles for Freeway Travel Time Estimation by Microscopic Simulation. Transp. Res. Rec. J. Transp. Res. Board 2000, 1719, 61–68. [Google Scholar] [CrossRef]
- Cheu, R.; Xie, C.; Lee, D. Probe Vehicle Population and Sample Size for Arterial Speed Estimation. Comput. Civ. Infrastruct. Eng. 2002, 17, 53–60. [Google Scholar] [CrossRef]
- Li, S.; Zhu, K.; Van Gelder, B.H.W.; Nagle, J.; Tuttle, C. Reconsideration of Sample Size Requirements for Field Traffic Data Collection with Global Positioning System Devices. Transp. Res. Rec. 2002, 1804, 17–22. [Google Scholar] [CrossRef]
- Hsiao, C.T.; Chou, F.C.C.; Hsieh, C.C.; Chang, L.C.; Hsu, C.M. Developing a Competency-Based Learning and Assessment System for Residency Training: Analysis Study of User Requirements and Acceptance. J. Med. Internet Res. 2020, 22, e15655. [Google Scholar] [CrossRef]
- Nicholson, F.; Laursen, R.K.; Cassidy, R.; Farrow, L.; Tendler, L.; Williams, J.; Surdyk, N.; Velthof, G. How can decision support tools help reduce nitrate and pesticide pollution from agriculture? A literature review and practical insights from the EU FAIRWAY project. Water 2020, 12, 768. [Google Scholar] [CrossRef]
- Saeeda, H.; Dong, J.; Wang, Y.; Abid, M.A. A proposed framework for improved software requirements elicitation process in SCRUM: Implementation by a real-life Norway-based IT project. J. Softw. Evol. Process 2020, 32, 1–24. [Google Scholar] [CrossRef]
- Awasthi, A.; Chauhan, S.S. A hybrid approach integrating Affinity Diagram, AHP and fuzzy TOPSIS for sustainable city logistics planning. Appl. Math. Model. 2012, 36, 573–584. [Google Scholar] [CrossRef]
- Cho, S.; Koo, Y. The Proposal of a Smart Car’s User Interface Scenario based on Contextual Inquiry Methodology. Arch. Des. Res. 2020, 33, 113–133. [Google Scholar] [CrossRef]
- Islam, M.N.; Karim, M.; Inan, T.T.; Islam, A.K.M.N. Investigating usability of mobile health applications in Bangladesh. BMC Med. Inform. Decis. Mak. 2020, 20, 19. [Google Scholar] [CrossRef]
- Babbar, S.; Behara, R.; White, E. Mapping product usability. Int. J. Oper. Prod. Manag. 2002, 22, 19. [Google Scholar] [CrossRef]
- Paffumi, E.; De Gennaro, M.; Martini, G. European-wide study on big data for supporting road transport policy. Case Stud. Transp. Policy 2018, 6, 785–802. [Google Scholar] [CrossRef]
- Perez, B.O. Delineating and Justifying Performance Parking Zones Data-Driven Criterion Approach in Washington, D.C. Transp. Res. Rec. 2015, 2537, 148–157. [Google Scholar] [CrossRef]
- Melo, S.; Macedo, J.; Baptista, P. Capacity-sharing in logistics solutions: A new pathway towards sustainability. Transp. Policy 2019, 73, 143–151. [Google Scholar] [CrossRef]
- Alho, A.R.; You, L.; Lu, F.; Cheah, L.; Zhao, F.; Ben-Akiva, M. Next-generation freight vehicle surveys: Supplementing truck GPS tracking with a driver activity survey. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018. [Google Scholar]
- Vegelien, A.G.J.; Dugundji, E.R. A Revealed Preference Time of Day Model for Departure Time of Delivery Trucks in the Netherlands. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018. [Google Scholar]
- Gomez, J.; Vassallo, J.M.M. Evolution over time of Heavy Vehicle Volume in Toll Roads: A Dynamic Panel Data to Identify key Explanatory Variables in Spain. Transp. Res. Part A Policy Pr. 2015, 74, 282–297. [Google Scholar] [CrossRef]
- Bochner, B.S.; Currans, K.M.; Dock, S.P.; Clifton, K.J.; Gibson, P.A.; Hardy, D.K.; Hooper, K.G.; Kim, L.-J.; McCourt, R.S.; Samdahl, D.R.; et al. Advances in urban trip generation estimation. ITE J. 2016, 86, 17–19. [Google Scholar]
- Melander, L.; Dubois, A.; Hedvall, K.; Lind, F. Future goods transport in Sweden 2050: Using a Delphi-based scenario analysis. Technol. Forecast. Soc. Chang. 2019, 138, 178–189. [Google Scholar] [CrossRef]
- Dutta, N.; Boateng, R.A.; Fontaine, M.D. Safety and operational effects of the interstate 66 active traffic management system. J. Transp. Eng. Part A Syst. 2019, 145. [Google Scholar] [CrossRef]
- Grant-Muller, S.; Hodgson, F.; Malleson, N.; Snowball, R. Enhancing Energy, Health and Security Policy by Extracting, Enriching and Interfacing Next Generation Data in the Transport Domain (A Study on the Use of Big Data in Cross-Sectoral Policy Development). In Proceedings of the 2017 IEEE 6th International Congress on Big Data, Honolulu, HI, USA, 25–30 June 2017. [Google Scholar]
- Hadavi, S.; Verlinde, S.; Verbeke, W.; Macharis, C.; Guns, T. Monitoring Urban-Freight Transport Based on GPS Trajectories of Heavy-Goods Vehicles. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3747–3758. [Google Scholar] [CrossRef]
- Lindholm, M.E.E.; Blinge, M. Assessing knowledge and awareness of the sustainable urban freight transport among Swedish local authority policy planners. Transp. Policy 2014, 32, 124–131. [Google Scholar] [CrossRef]
- Minnice, P.; Biernbaum, L.; Mortensen, S. Transit light rail incident response before and after ICM deployment: Strategies and constraints. In Proceedings of the 21st World Congress on Intelligent Transport Systems: Reinventing Transportation in Our Connected World (ITSWC 2014), Detroit, MI, USA, 7–11 September 2014; Intelligent Transportation Society of America: Washington, DC, USA, 2014. [Google Scholar]
- Buldeo Rai, H.; van Lier, T.; Meers, D.; Macharis, C. Improving urban freight transport sustainability: Policy assessment framework and case study. Res. Transp. Econ. 2017, 64, 26–35. [Google Scholar] [CrossRef]
- Sanchez-Diaz, I. Modeling Urban Freight Generation: A Study of Commercial Establishments’ Freight Needs. Transp. Res. Part A Policy Pr. 2017, 102, 3–17. [Google Scholar] [CrossRef]
- Ismail, A.; Intan Suhana, M.R.; Masri, K.A.; Rapar, N.H. Exploration on Pavement Surface Conditions Attributed to Mineral Freight and Logistics Operations on Kuantan Road Network. In IOP Conference Series: Materials Science and Engineering; IOP Publishing Ltd.: Bristol, UK, 2020; Volume 712. [Google Scholar]
- Hernandez, S.; Hyun, K. Fusion of weigh-in-motion and global positioning system data to estimate truck weight distributions at traffic count sites. J. Intell. Transp. Syst. Technol. Plan. Oper. 2020, 24, 201–215. [Google Scholar] [CrossRef]
- Moghimi, B.; Kamga, C.; Zamanipour, M. Look-Ahead Transit Signal Priority Control with Self-Organizing Logic. J. Transp. Eng. Part A Syst. 2020, 146. [Google Scholar] [CrossRef]
- Topilin, I.V.; Volodina, M.V. The traffic simulation of regulated road network using navigation systems. Mater. Sci. Forum 2018, 931, 661–666. [Google Scholar] [CrossRef]
- Adu-Gyamfi, Y.O.; Sharma, A.; Knickerbocker, S.; Hawkins, N.; Jackson, M. Framework for Evaluating the Reliability of Wide-Area Probe Data. Transp. Res. Rec. J. Transp. Res. Board 2017, 2643, 93–104. [Google Scholar] [CrossRef]
- Sharma, S.; Snelder, M.; Lint, H.V. Deriving on-Trip route choices of truck drivers by utilizing Bluetooth data, loop detector data and variable message sign data. In Proceedings of the 6th International Conference on Models and Technologies for Intelligent Transportation System (MT-ITS 2019), Krakow, Poland, 5–7 June 2019. [Google Scholar]
- Katrakazas, C.; Antoniou, C.; Vazquez, N.S.; Trochidis, I.; Arampatzis, S. Big data and emerging transportation challenges: Findings from the noesis project. In Proceedings of the 6th International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS 2019), Krakow, Poland, 5–7 June 2019. [Google Scholar]
- De Gennaro, M.; Paffumi, E.; Martini, G. Big Data for Supporting Low-Carbon Road Transport Policies in Europe: Applications, Challenges and Opportunities. Big Data Res. 2016, 6, 11–25. [Google Scholar] [CrossRef]
- Fridell, E.; Bäckström, S.; Stripple, H. Considering infrastructure when calculating emissions for freight transportation. Transp. Res. Part D Transp. Environ. 2019, 69, 346–363. [Google Scholar] [CrossRef]
- Göçmen, E.; Erol, R. The problem of sustainable intermodal transportation: A case study of an international logistics company, Turkey. Sustainability 2018, 10, 4268. [Google Scholar] [CrossRef]
- Haque, K.; Mishra, S.; Paleti, R.; Golias, M.M.; Sarker, A.A.; Pujats, K. Truck Parking utilization analysis using GPS data. J. Transp. Eng. Part A Syst. 2017, 143, 1–12. [Google Scholar] [CrossRef]
- Paz, A.; Veeramisti, N.; Fuente-Mella, H.D.L.D.L. Forecasting Performance Measures for Traffic Safety Using Deterministic and Stochastic Models. In Proceedings of the 18th IEEE International Conference on Intelligent Transportation Systems (ITSC 2015), Las Palmas, Spain, 15–18 September 2015. [Google Scholar]
- Chance Scott, M.; Sen Roy, S.; Prasad, S. Spatial patterns of off-the-system traffic crashes in Miami–Dade County, Florida, during 2005–2010. Traffic Inj. Prev. 2016, 17, 729–735. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Duan, L. Predicting Crash Rate Using Logistic Quantile Regression with Bounded Outcomes. IEEE Access 2017, 5, 27036–27042. [Google Scholar] [CrossRef]
- Siripirote, T.; Sumalee, A.; Ho, H.W. Statistical estimation of freight activity analytics from Global Positioning System data of trucks. Transp. Res. Part E Logist. Transp. Rev. 2020, 140. [Google Scholar] [CrossRef]
- Zhang, S.; Liu, X.; Tang, J.; Cheng, S.; Qi, Y.; Wang, Y. Spatio-temporal modeling of destination choice behavior through the Bayesian hierarchical approach. Phys. A Stat. Mech. Its Appl. 2018, 512, 537–551. [Google Scholar] [CrossRef]
- Tahlyan, D.; Pinjari, A.R. Performance evaluation of choice set generation algorithms for analyzing truck route choice: Insights from spatial aggregation for the breadth first search link elimination (BFS-LE) algorithm. Transp. A Transp. Sci. 2020, 16, 1030–1061. [Google Scholar] [CrossRef]
- Guler, H. An Empirical Modelling Framework for Forecasting Freight Transportation. Transport 2014, 29, 185–194. [Google Scholar] [CrossRef][Green Version]
- Joubert, J.W.; Meintjes, S. Repeatability & reproducibility: Implications of using GPS data for freight activity chains. Transp. Res. Part B Methodol. 2015, 76, 81–92. [Google Scholar] [CrossRef]
- Ben-Akiva, M.E.; Toledo, T.; Santos, J.; Cox, N.; Zhao, F.; Lee, Y.J.; Marzano, V. Freight data collection using GPS and web-based surveys: Insights from US truck drivers’ survey and perspectives for urban freight. Case Stud. Transp. Policy 2016, 4, 38–44. [Google Scholar] [CrossRef]
- Luong, T.D.; Tahlyan, D.; Pinjari, A.R. Comprehensive Exploratory Analysis of Truck Route Choice Diversity in Florida. Transp. Res. Rec. 2018, 2672, 152–163. [Google Scholar] [CrossRef]
- Momtaz, S.U.; Eluru, N.; Anowar, S.; Keya, N.; Dey, B.K.; Pinjari, A.; Tabatabaee, S.F. Fusing Freight Analysis Framework and Transearch Data: Econometric Data Fusion Approach with Application to Florida. J. Transp. Eng. Part A Syst. 2020, 146. [Google Scholar] [CrossRef]
- Krishnakumari, P.; van Lint, H.; Djukic, T.; Cats, O. A data driven method for OD matrix estimation. Transp. Res. Part C Emerg. Technol. 2019, 1–19. [Google Scholar] [CrossRef]
- Hansen, C.O. Dokumentation af Godsmodel. Available online: http://www.landstrafikmodellen.dk/-/media/Sites/Landstrafikmodellen/Dokumentation-1-1/Notat-Godstrafikmodel.ashx?la=da&hash=A02446304C683ABB573CC76AA5207E60D54BAD91 (accessed on 5 August 2019).
- Taghavi, M.; Irannezhad, E.; Prato, C.G. Identifying Truck Stops from a Large Stream of GPS Data via a Hidden Markov Chain Model. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 2265–2271. [Google Scholar]
- Sambo, F.; Salti, S.; Bravi, L.; Simoncini, M.; Taccari, L.; Lori, A. Integration of GPS and satellite images for detection and classification of fleet hotspots. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017. [Google Scholar] [CrossRef]
- Ashbrook, D.; Starner, T. Using GPS to learn significant locations and predict movement across multiple users. Pers. Ubiquit. Comput. 2003, 7, 275–286. [Google Scholar] [CrossRef]
- Holguín-Veras, J.; Encarnación, T.; Pérez-Guzmán, S.; Yang, X. Mechanistic Identification of Freight Activity Stops from Global Positioning System Data. Transp. Res. Rec. 2020, 2674, 235–246. [Google Scholar] [CrossRef]
- Bernardin, V.L.; Trevino, S.; Short, J.A. Expanding truck gps-based passive origin-destination data in Iowa and Tennessee. In Proceedings of the Transportation Research Board 94th Annual Meeting, Washington DC, USA, 11–15 January 2015. [Google Scholar]
- Bohte, W.; Maat, K. Deriving and Validating Trip Purposes and Travel Modes for Multi-Day GPS-Based Travel Surveys: A Large-Scale Application in the Netherlands. Transp. Res. Part C Emerg. Technol. 2009, 17, 285–297. [Google Scholar] [CrossRef]
- McCormack, E.; Bassok, A. Evaluating two low-cost methods of collecting truck generation data using grocery stores. ITE J. 2011, 81, 34–38. [Google Scholar]
- Muñuzuri, J.; Cortés, P.; Onieva, L.; Guadix, J. Estimation of Daily Vehicle Flows for Urban Freight Deliveries. J. Urban Plan. Dev. 2012, 138, 43–52. [Google Scholar] [CrossRef]
- Mesa-Arango, R.; Ukkusuri, S.; Sarmiento, I. Network Flow Methodology for Estimating Empty Trips in Freight Transportation Models. Transp. Res. Rec. J. Transp. Res. Board 2013, 2378, 110–119. [Google Scholar] [CrossRef]
- Patire, A.D.; Wright, M.; Prodhomme, B.; Bayen, A.M. How much GPS data do we need? Transp. Res. Part C Emerg. Technol. 2015, 58, 325–342. [Google Scholar] [CrossRef]
- Graham, A.; Rogers, J. Evaluation of Freight Transportation Productivity Data Collection Methods and Reliability. In Proceedings of the 2012 Industrial Engineering Research Conference, Orlando, FL, USA, 19–23 May 2012. [Google Scholar]
- Ibarra-Espinosa, S.; Ynoue, R.; Giannotti, M.; Ropkins, K.; de Freitas, E.D. Generating traffic flow and speed regional model data using internet GPS vehicle records. MethodsX 2019, 6, 2065–2075. [Google Scholar] [CrossRef] [PubMed]
- Shen, L.; Stopher, P.R. Review of GPS Travel Survey and GPS Data-Processing Methods. Transp. Rev. 2014, 34, 316–334. [Google Scholar] [CrossRef]
- Danmarks Statistik Bestanden af køretøjer pr 1. januar efter køretøjstype, tid og område. Available online: https://www.dst.dk/da/Statistik/emner/erhvervslivets-sektorer/transport/transportmidler (accessed on 5 October 2019).
- Moore, A.M. Innovative scenarios for modeling intra-city freight delivery. Transp. Res. Interdiscip. Perspect. 2019, 3. [Google Scholar] [CrossRef]
- Pirra, M.; Carboni, A.; Deflorio, F. Monitoring urban accessibility for freight delivery services from vehicles traces and network modelling. Transp. Res. Procedia 2019, 41, 410–413. [Google Scholar] [CrossRef]
- Gan, M.; Liu, X.; Chen, S.; Yan, Y.; Li, D. The identification of truck-related greenhouse gas emissions and critical impact factors in an urban logistics network. J. Clean. Prod. 2018, 178, 561–571. [Google Scholar] [CrossRef]
- Camargo, P.; Hong, S.; Livshits, V. Expanding the Uses of Truck GPS Data in Freight Modeling and Planning Activities. Transp. Res. Rec. 2017, 2646, 68–76. [Google Scholar] [CrossRef]
- Gingerich, K.; Maoh, H.; Anderson, W. Classifying the Purpose of Stopped Truck Events: An Application of Entropy to GPS Data. Transp. Res. Part C Emerg. Technol. 2016, 64, 17–27. [Google Scholar] [CrossRef]
- Joubert, J.W.; Meintjes, S. Freight activity chain generation using complex networks of connectivity. Transp. Res. Procedia 2016, 12, 425–435. [Google Scholar] [CrossRef][Green Version]
- Sanchez-Diaz, I.; Holguin-Veras, J.; Ban, X. A time-dependent freight tour synthesis model. Transp. Res. Part B Methodol. 2015, 78, 144–168. [Google Scholar] [CrossRef]
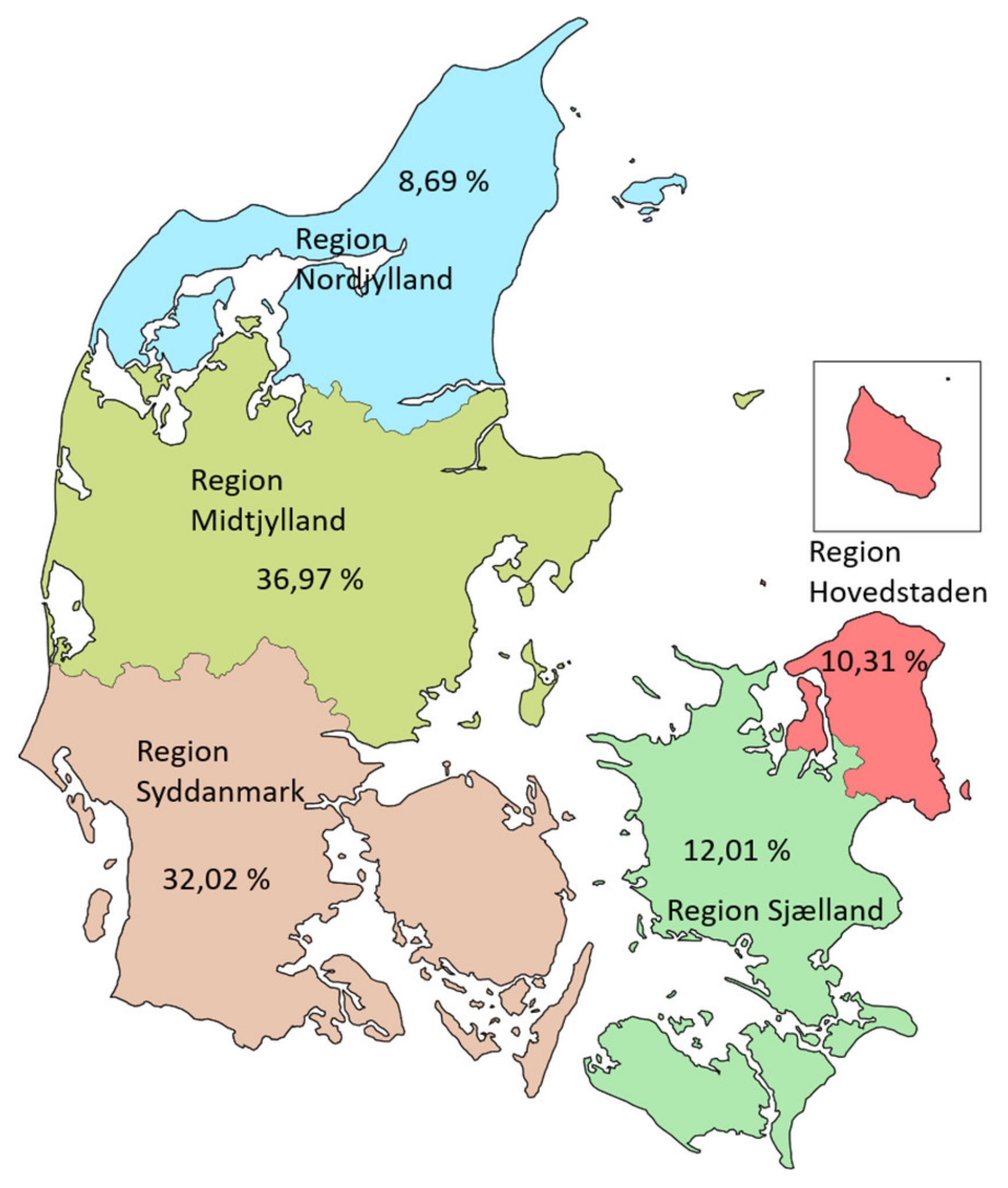
- Denmark Regions. Available online: https://commons.wikimedia.org/wiki/File:Denmark_regions.svg (accessed on 24 October 2019).
- Bekhor, S.; Lotan, T.; Gitelman, V.; Morik, S. Free-Flow Travel Speed Analysis and Monitoring at the National Level Using Global Positioning System Measurements. J. Transp. Eng. 2013, 139, 1235–1243. [Google Scholar] [CrossRef]
- Zheng, J.; Wang, Y.; Nihan, N.L. Quantitative Evaluation of GPS Performance under Forest Canopies. In Proceedings of the 2005 IEEE Networking, Sensing and Control, Tucson, AZ, USA, 19–22 March 2005; pp. 777–782. [Google Scholar]
- Gong, L.; Sato, H.; Yamamoto, T.; Miwa, T.; Morikawa, T. Identification of activity stop locations in GPS trajectories by density-based clustering method combined with support vector machines. J. Mod. Transp. 2015, 23, 202–213. [Google Scholar] [CrossRef]
- U.S. Department of Transportation. Federal Highway Administration Jason’s Law Truck Parking Survey Results and Comparative Analysis. Available online: https://ops.fhwa.dot.gov/freight/infrastructure/truck_parking/jasons_law/truckparkingsurvey/index.htm (accessed on 25 June 2020).
- Han, J.; Polak, J.W.; Barria, J.; Krishnan, R. On the estimation of space-mean-speed from inductive loop detector data. Transp. Plan. Technol. 2010, 33, 91–104. [Google Scholar] [CrossRef]
- Turner, S.M.; Eisele, W.L.; Benz, R.J.; Holdener, D.J. Travel Time Data Collection Handbook; United States Federal Highway Administration: Washington, DC, USA, 1998.
- May, A.D. Traffic Flow Fundamentals; Prentice Hall: Englewood Cliffs, NJ, USA, 1990; ISBN 0-13-926072-2. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Usages | Description | Reference |
|---|---|---|---|
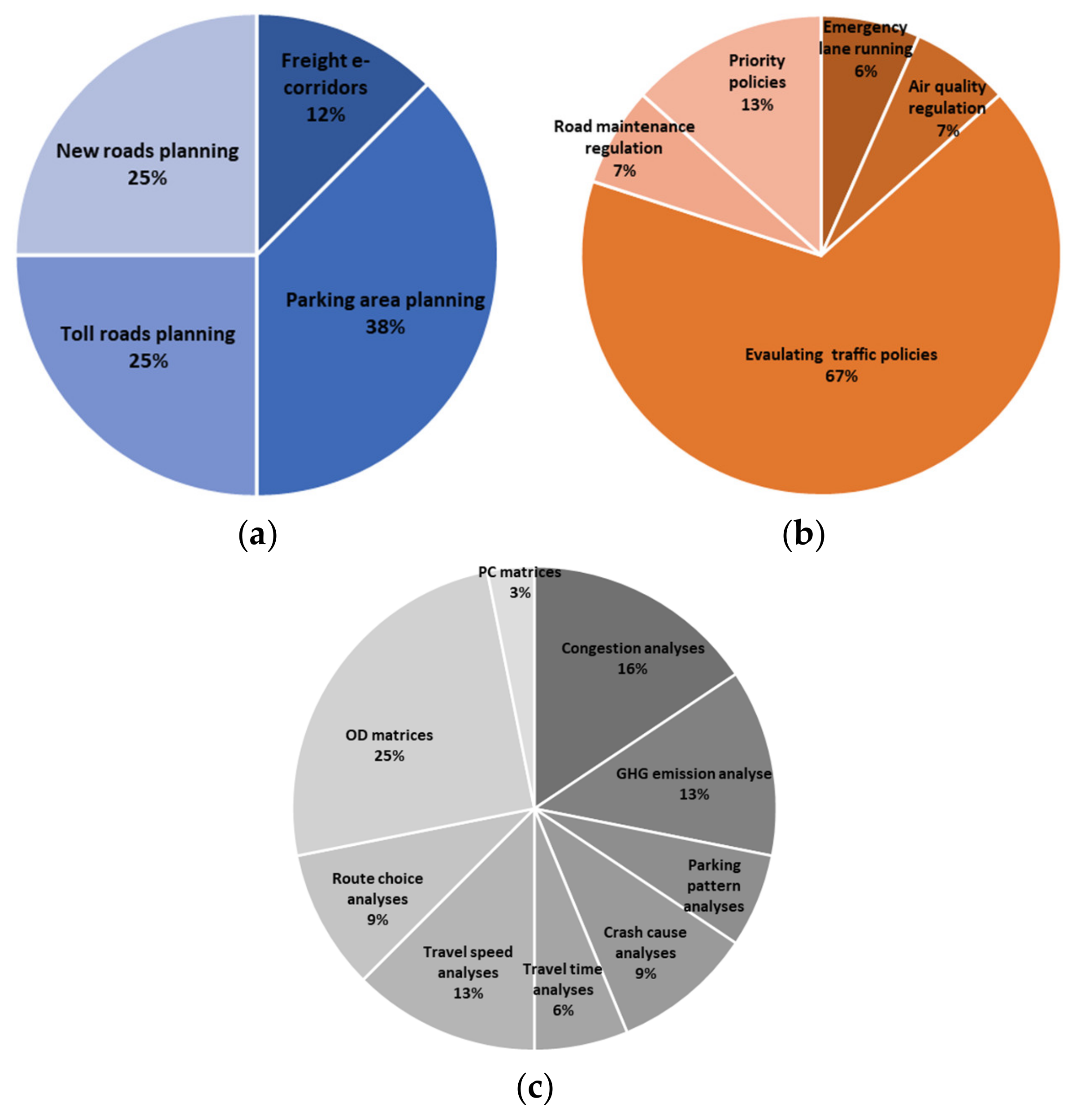
| Road infrastructure planning | Freight e-corridors | Travel data supports deployment of e-corridor for trucks | [32] |
| Parking area planning | Freight data allows for justification of parking zones and rationalisation of areas where new parking may be suggested | [33,34,35] | |
| Toll road planning | Data can be used to identify potentials for toll roads, as well as spreading out freight transport through the day by using time differentiated toll charges | [36,37] | |
| New road planning | Trip data can support development of new roads, by considering route choices, allowing for shorter trips | [38,39] | |
| Freight transport regulations | Emergency lane running | Allowing hard shoulder running, based on analyses of data from former congestions, etc., could reduce travel time during peak hours | [40] |
| Air quality regulation | Combining traffic flow data with air quality sensors allows for the regulation of air quality by traffic policy | [41] | |
| Evaluating traffic policies | A data-based approach allows for the objective and effective proposal of programmes and policies to decision makers, and makes it possible to simulate effects of policy suggestions | [18,32,33,36,39,42,43,44,45,46] | |
| Road maintenance regulation | Maintenance schemes and prediction is possible through analyses of road use by freight data and Weigh-in-Motion (WIM) data | [11,47,48] | |
| Priority policies | Priority measures for freight vehicles can reduce driving time. Use freight data to analyse the impact of priority policies. | [49,50] | |
| Freight movement analyses | Congestion analyses | Use of data from private freight companies allows for identification of congestion spots | [18,42,51,52,53] |
| Greenhouse Gas (GHG) emission analyses | Using freight company data to evaluate and determine high-emission zones through emission modelling | [42,54,55,56] | |
| Parking pattern analyses | Determining truck stopping locations, and analyses of staying times, parking area utilization and parking demand | [34,42,57] | |
| Crash cause analyses | Data can be used for crash analysis in relation to location, speed, weather conditions, etc. | [58,59,60] | |
| Travel time analyses | Freight transport analysis over time allows for better understanding of travel time patterns and driving patterns, as well as peak periods of freight transport | [36,42] | |
| Travel speed analyses | Analysing speed of trucks and providing analyses on travel speed | [11,16,39,61] | |
| Route choice analyses | Better understanding of route choice can assist traffic management and resource allocation | [52,62,63] | |
| OD-Matrix analyses | Freight GPS-data enables automatic creation of OD-matrices | [11,15,18,63,64,65,66,67] | |
| Production–Consumption (PC) matrix analyses | Combination of GPS-data and other data types allows for the creation of PC-matrices | [68] |
| Authors | Data Source | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GPS | Traffic Count | Transport Survey | Freight Transactions | Loop Detector | Traffic Flow Observations | Land Use | Web-Based Survey | Expert Interviews | Weigh-In-Motion | Electronic Truck Tag | No. of Data Sources Used | |
| [63] | X | 1 | ||||||||||
| [85] | X | X | 2 | |||||||||
| [86] | X | 1 | ||||||||||
| [67] | X | 1 | ||||||||||
| [87] | X | 1 | ||||||||||
| [13] | X | X | 2 | |||||||||
| [17] | X | 1 | ||||||||||
| [88] | X | 1 | ||||||||||
| [66] | X | X | 2 | |||||||||
| [15] | X | 1 | ||||||||||
| [89] | X | 1 | ||||||||||
| [90] | X | 1 | ||||||||||
| [65] | X | 1 | ||||||||||
| [91] | X | X | X | X | X | 5 | ||||||
| [16] | X | X | X | X | 4 | |||||||
| [18] | X | X | 2 | |||||||||
| [19] | X | 1 | ||||||||||
| [11] | X | X | 2 | |||||||||
| [10] | X | X | 2 | |||||||||
| Frequency | 19 | 2 | 1 | 1 | 1 | 1 | 2 | 1 | 1 | 2 | 1 | |
| Data Types | Description and Purpose of Usage |
|---|---|
| GPS data | The GPS data describes the trip trajectories of the freight truck while it is moving or stationary. All private logistics companies participating in the project have to provide their GPS truck data. This data will be used as input to the stop identification method to determine OD matrices, analysis of travel time among zones, and parking pattern analyses. The following items have to be available in the GPS data set provided by each company:
|
| Loop detector data | Loop detectors are widely used sensors for data collection about the instantaneous traffic conditions at specific locations. The state roads in Denmark have approximately 110,000 loop detectors, which can report traffic flow (number of vehicles) and point speed, and a select few can report types of vehicles. The loop detector data describes point speed as well as number of trucks passing through specific segments at the motor ways. The data from the Danish loop detectors is available online at (mastra.vd.dk), and access is controlled and granted through permission from DRD. This data can be used to validate the GPS-based speed measurements, as have been done in [18,93]. |
| Observational studies or transport surveys | The observational studies conducted by the DRD at specific rest areas will be used as a reference measure to validate the derived GPS-measures for truck parking. The observations are conducted at specific rest areas and the results of these observations are not publicly available. |
| Shipment data | The shipment data describes the characteristics of loads on the trucks such as weight, volume, type, delivery and pickup dates, origin and destination of each shipment. The shipment data may not be provided by all logistics companies because such data may be very sensitive and hard to be provided by all logistics companies. The shipment data can be used for two purposes. The first purpose is to validate the derived OD matrices, while the second purpose is to estimate GHG emissions. The following items have to be available in the shipment data set provided by each company:
|
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karam, A.; Illemann, T.M.; Reinau, K.H.; Vuk, G.; Hansen, C.O. Towards Deriving Freight Traffic Measures from Truck Movement Data for State Road Planning: A Proposed System Framework. ISPRS Int. J. Geo-Inf. 2020, 9, 606. https://doi.org/10.3390/ijgi9100606
Karam A, Illemann TM, Reinau KH, Vuk G, Hansen CO. Towards Deriving Freight Traffic Measures from Truck Movement Data for State Road Planning: A Proposed System Framework. ISPRS International Journal of Geo-Information. 2020; 9(10):606. https://doi.org/10.3390/ijgi9100606
Chicago/Turabian StyleKaram, Ahmed, Thorbjørn M. Illemann, Kristian Hegner Reinau, Goran Vuk, and Christian O. Hansen. 2020. "Towards Deriving Freight Traffic Measures from Truck Movement Data for State Road Planning: A Proposed System Framework" ISPRS International Journal of Geo-Information 9, no. 10: 606. https://doi.org/10.3390/ijgi9100606
APA StyleKaram, A., Illemann, T. M., Reinau, K. H., Vuk, G., & Hansen, C. O. (2020). Towards Deriving Freight Traffic Measures from Truck Movement Data for State Road Planning: A Proposed System Framework. ISPRS International Journal of Geo-Information, 9(10), 606. https://doi.org/10.3390/ijgi9100606