Spatial Patterns of Childhood Obesity Prevalence in Relation to Socioeconomic Factors across England




Abstract
1. Introduction
2. Methods
2.1. Research Data
2.2. Exploring Spatial Patterns of Childhood Obesity Prevalence
2.3. Investigating Spatial Associations of Childhood Obesity Prevalence and Socioeconomic Factors
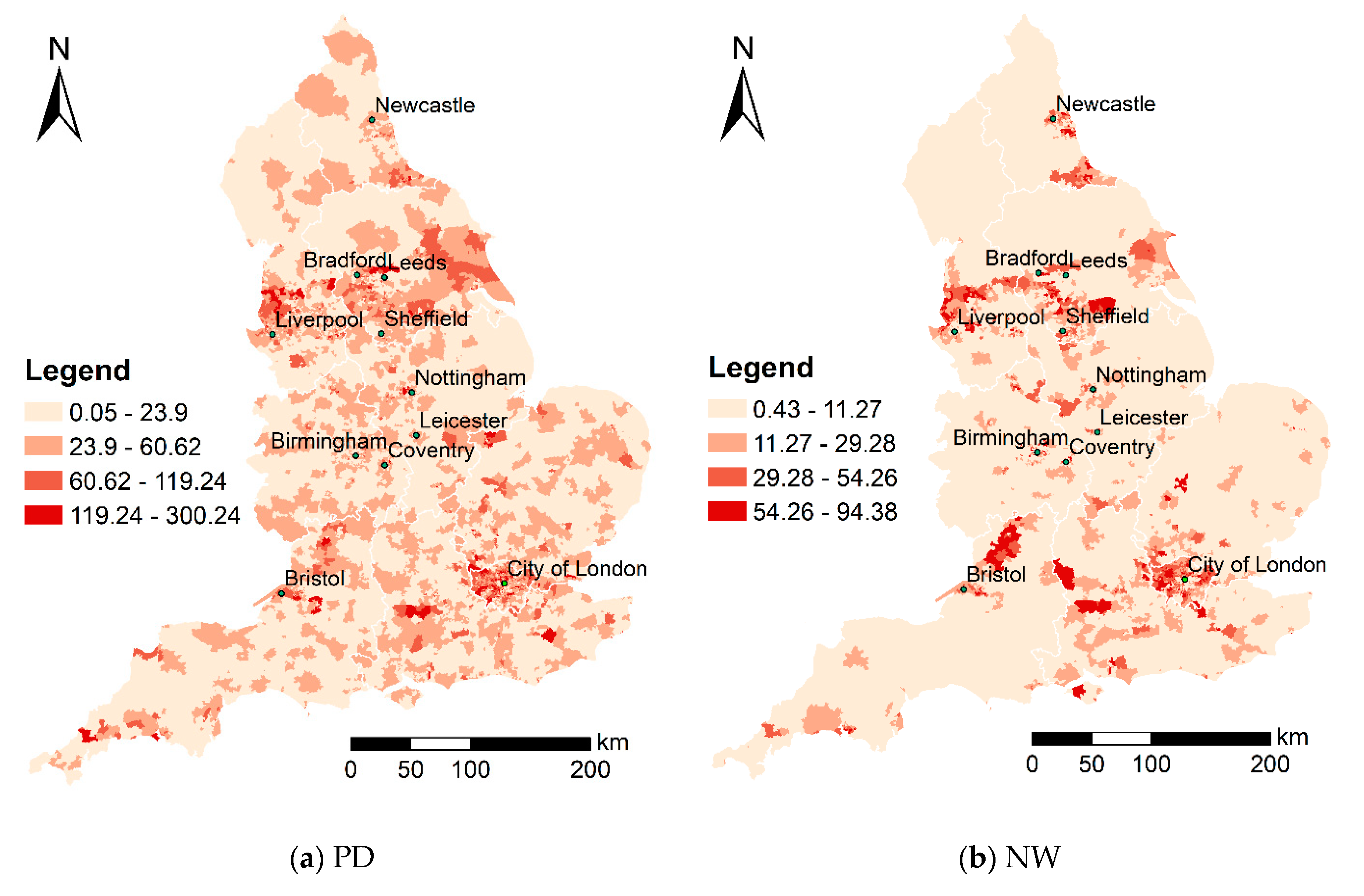
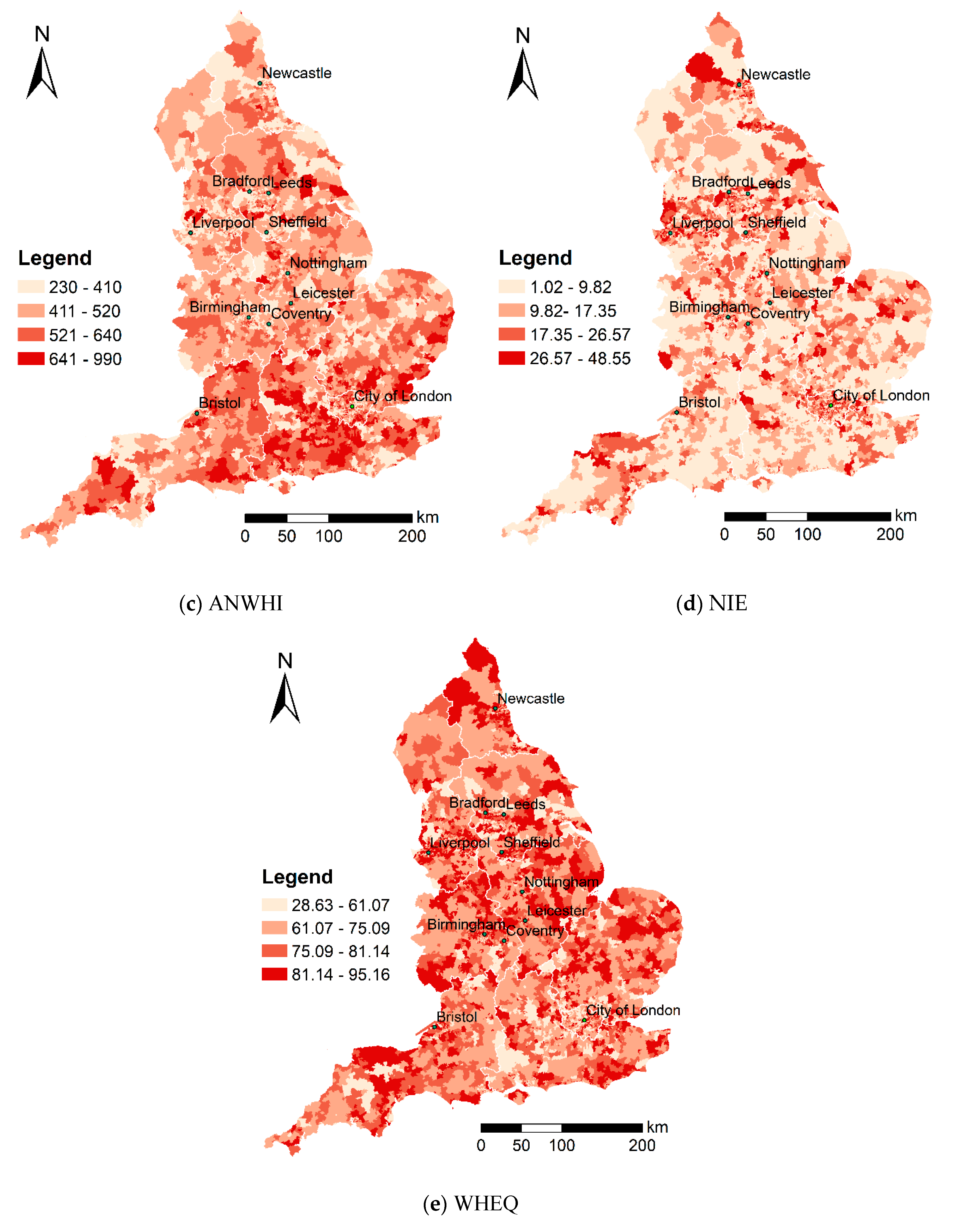
2.3.1. Socioeconomic Factors
2.3.2. Model Selection and Estimation
3. Results
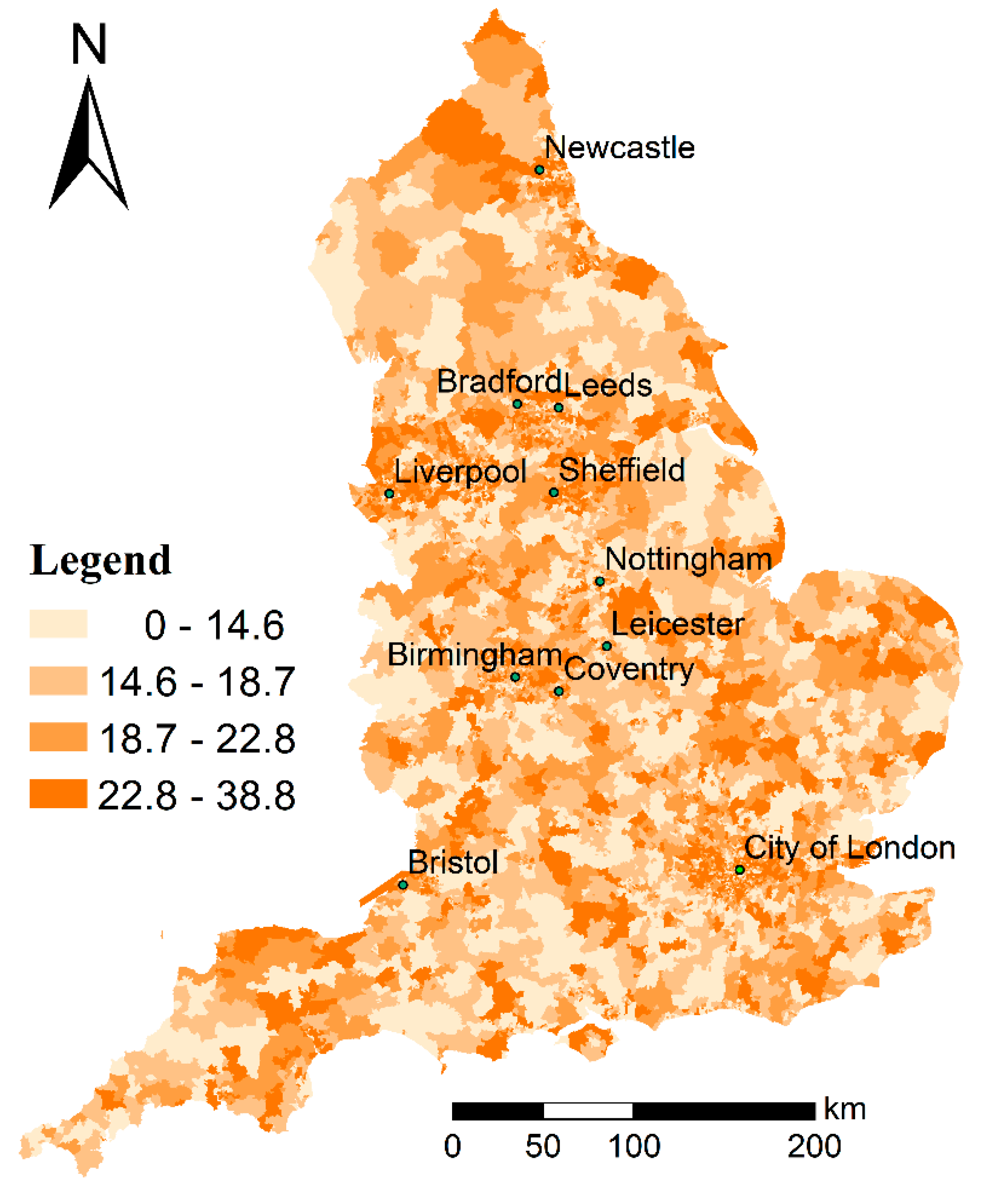
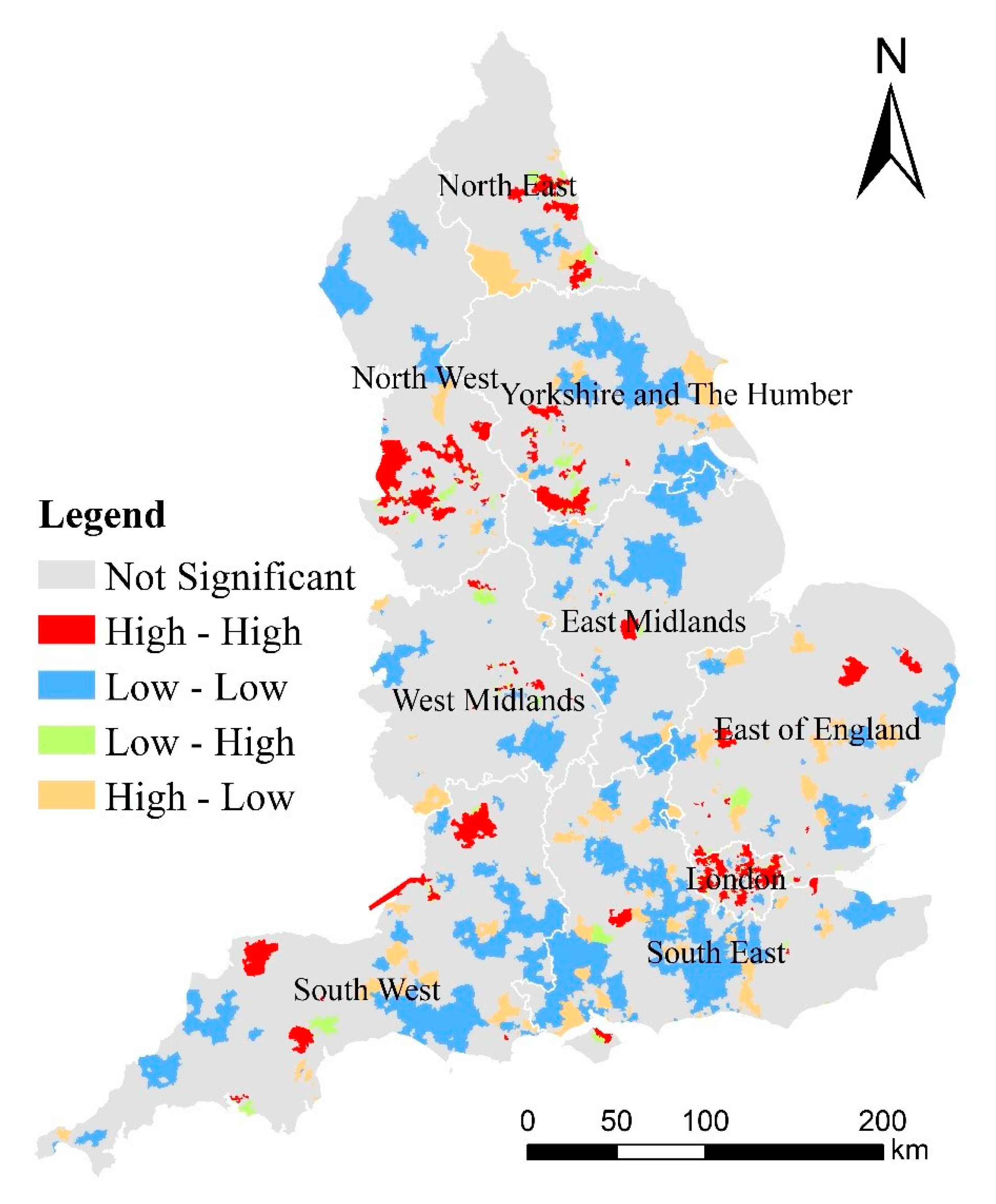
3.1. Spatial Patterns of Childhood Obesity Prevalence
3.2. Spatial Associations of Childhood Obesity Prevalence and Socioeconomic Factors
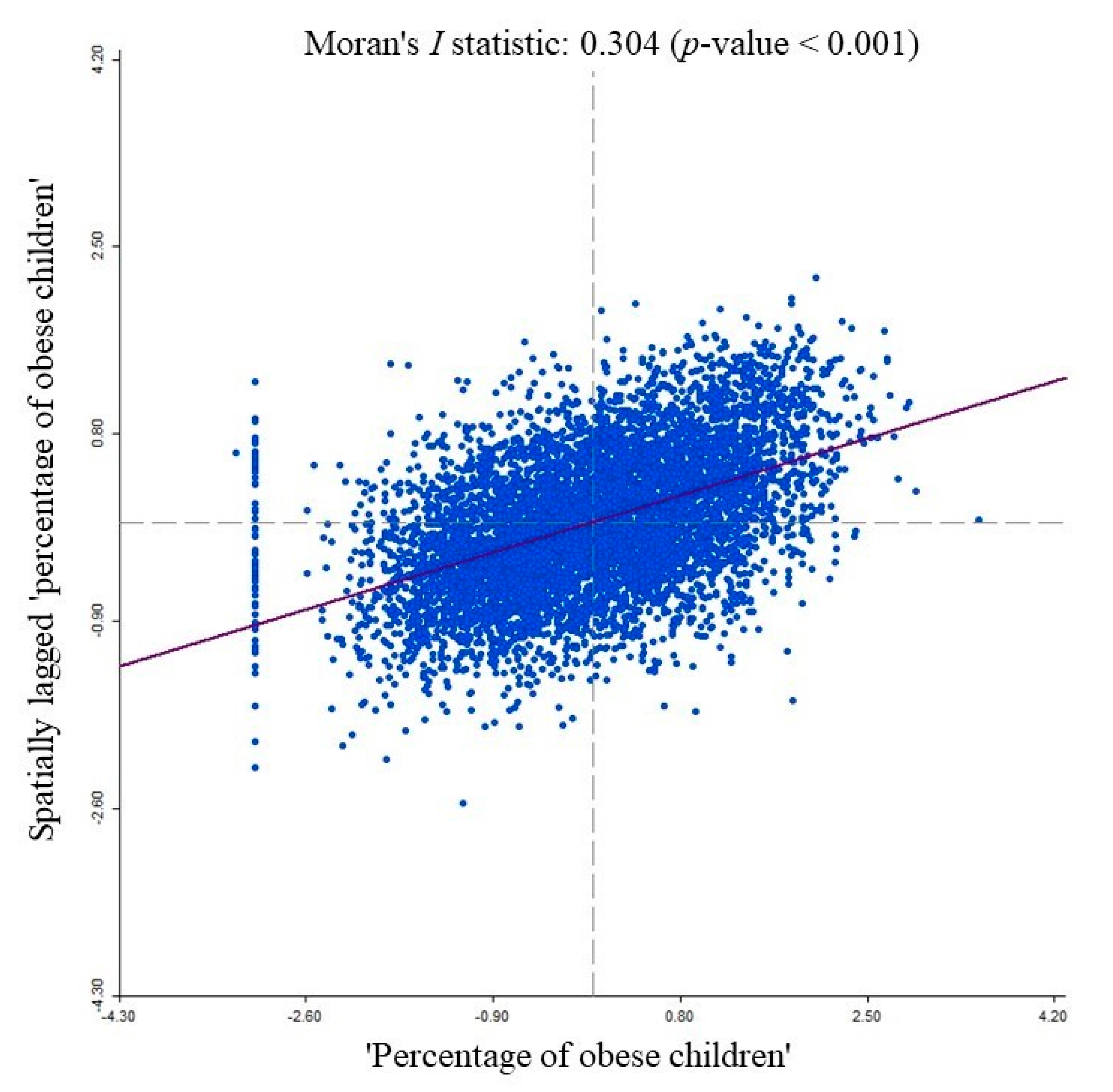
3.2.1. Test Results for the Presence of Spatial Autocorrelation in the Residuals of an OLS Model
3.2.2. Model Selection and Estimation
4. Discussion and Policy Implications
5. Conclusions
6. Limitations and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- World Health Organization. Taking Action on Childhood Obesity; World Health Organization: Geneva, Switzerland, 2018; pp. 1–7. [Google Scholar]
- Singh, G.K.; Siahpush, M.; Kogan, M.D. Rising social inequalities in US childhood obesity, 2003–2007. Ann. Epidemiol. 2010, 20, 40–52. [Google Scholar] [CrossRef]
- Wang, Y.; Lim, H. The global childhood obesity epidemic and the association between socio-economic status and childhood obesity. Int. Rev. Psychiatry 2012, 24, 176–188. [Google Scholar] [CrossRef] [PubMed]
- Chung, A.; Backholer, K.; Wong, E.; Palermo, C.; Keating, C.; Peeters, A. Trends in child and adolescent obesity prevalence in economically advanced countries according to socioeconomic position: A systematic review. Obes. Rev. 2016, 17, 276–295. [Google Scholar] [CrossRef] [PubMed]
- Lobstein, T.; Baur, L.; Uauy, R. Obesity in children and young people: A crisis in public health. Obes. Rev. 2004, 5, 4–85. [Google Scholar] [CrossRef] [PubMed]
- McLaren, L. Socioeconomic status and obesity. Epidemiol. Rev. 2007, 29, 29–48. [Google Scholar] [CrossRef]
- Department of Health Public Health Research Consortium; Law, C.; Power, C.; Graham, H.; Merrick, D. Obesity and health inequalities. Obes. Rev. 2007, 8, 19–22. [Google Scholar] [CrossRef]
- Peeters, A.; Backholer, K. Prioritising and tackling socio-economic inequalities in obesity. BMC Obes. 2014, 1, 16. [Google Scholar] [CrossRef]
- Chi, G.; Zhu, J. Spatial regression models for demographic analysis. Popul. Res. Policy Rev. 2008, 27, 17–42. [Google Scholar] [CrossRef]
- Anselin, L. Spatial Econometrics: Methods and Models; Springer Science & Business Media: New York, NY, USA, 2013; Volume 4. [Google Scholar]
- LeSage, J.P.; Pace, R.K. Introduction to Spatial Econometrics; CRC Press: Boca Raton, FL, USA, 2009; Chapter 9. [Google Scholar]
- Drewnowski, A.; Rehm, C.D.; Arterburn, D. The geographic distribution of obesity by census tract among 59 767 insured adults in King County, WA. Int. J. Obes. 2014, 38, 833–839. [Google Scholar] [CrossRef]
- Chalkias, C.; Papadopoulos, A.G.; Kalogeropoulos, K.; Tambalis, K.; Psarra, G.; Sidossis, L. Geographical heterogeneity of the relationship between childhood obesity and socio-environmental status: Empirical evidence from Athens, Greece. Appl. Geogr. 2013, 37, 34–43. [Google Scholar] [CrossRef]
- Carroll-Scott, A.; Gilstad-Hayden, K.; Rosenthal, L.; Peters, S.M.; McCaslin, C.; Joyce, R.; Ickovics, J.R. Disentangling neighborhood contextual associations with child body mass index, diet, and physical activity: The role of built, socioeconomic, and social environments. Soc. Sci. Med. 2013, 95, 106–114. [Google Scholar] [CrossRef] [PubMed]
- GOV.UK. Child Obesity and Excess Weight: Small Area Level Data. 2019. Available online: https://www.gov.uk/government/statistics/child-obesity-and-excess-weight-small-area-level-data (accessed on 27 March 2019).
- Office for National Statistics. Small Area Model-Based Income Estimates, England and Wales: Financial Year Ending 2014. 2016. Available online: https://www.ons.gov.uk/peoplepopulationandcommunity/personalandhouseholdfinances/incomeandwealth/bulletins/smallareamodelbasedincomeestimates/financialyearending2014 (accessed on 16 December 2016).
- Williams, A.S.; Ge, B.; Petroski, G.; Kruse, R.L.; McElroy, J.A.; Koopman, R.J. Socioeconomic status and other factors associated with childhood obesity. J. Am. Board Fam. Med. 2018, 31, 514–521. [Google Scholar] [CrossRef]
- Oddo, V.M.; Nicholas, L.H.; Bleich, S.N.; Jones-Smith, J.C. The impact of changing economic conditions on overweight risk among children in California from 2008 to 2012. J. Epidemiol. Community Health 2016, 70, 874–880. [Google Scholar] [CrossRef] [PubMed]
- Evans, G.W.; Jones-Rounds, M.L.; Belojevic, G.; Vermeylen, F. Family income and childhood obesity in eight European cities: The mediating roles of neighborhood characteristics and physical activity. Soc. Sci. Med. 2012, 75, 477–481. [Google Scholar] [CrossRef] [PubMed]
- Rogers, R.; Eagle, T.F.; Sheetz, A.; Woodward, A.; Leibowitz, R.; Song, M.; Sylvester, R.; Corriveau, N.; Kline-Rogers, E.; Jiang, Q.; et al. The relationship between childhood obesity, low socioeconomic status, and race/ethnicity: Lessons from Massachusetts. Child. Obes. 2015, 11, 691–695. [Google Scholar] [CrossRef]
- Eagle, T.F.; Sheetz, A.; Gurm, R.; Woodward, A.C.; Kline-Rogers, E.; Leibowitz, R.; DuRussel-Weston, J.; Palma-Davis, L.; Aaronson, S.; Fitzgerald, C.M.; et al. Understanding childhood obesity in America: Linkages between household income, community resources, and children’s behaviors. Am. Heart. J. 2012, 163, 836–843. [Google Scholar] [CrossRef] [PubMed]
- Singh, G.K.; Kogan, M.D.; Van Dyck, P.C. Changes in state-specific childhood obesity and overweight prevalence in the United States from 2003 to 2007. Arch. Pediatr. Adolesc. Med. 2010, 164, 598–607. [Google Scholar] [CrossRef]
- Padez, C.; Mourao, I.; Moreira, P.; Rosado, V. Long sleep duration and childhood overweight/obesity and body fat. Am. J. Hum. Biol. 2009, 21, 371–376. [Google Scholar] [CrossRef]
- LeSage, J.P.; Pace, R.K. A matrix exponential specification. J. Econom. 2007, 140, 190–214. [Google Scholar] [CrossRef]
- Murakami, D.; Griffith, D.A. Eigenvector spatial filtering for large data sets: Fixed and random effects approaches. Geogr. Anal. 2019, 51, 23–49. [Google Scholar] [CrossRef]
- Murakami, D.; Griffith, D.A. Random effects specifications in eigenvector spatial filtering: A simulation study. J. Geogr. Syst. 2015, 17, 311–331. [Google Scholar] [CrossRef]
- Neelon, S.E.; Burgoine, T.; Gallis, J.A.; Monsivais, P. Spatial analysis of food insecurity and obesity by area-level deprivation in children in early years settings in England. Spat. Spatio-Temporal Epidemiol. 2017, 23, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Nackers, L.M.; Appelhans, B.M. Food insecurity is linked to a food environment promoting obesity in households with children. J. Nutr. Educ. Behav. 2013, 45, 780–784. [Google Scholar] [CrossRef] [PubMed]
- Miao, J.; Wu, X. Urbanization, socioeconomic status and health disparity in China. Health Place 2016, 42, 87–95. [Google Scholar] [CrossRef]
- Stein, R.E. Neighborhood Scale and Collective Efficacy: Does Size Matter? Sociol. Compass 2014, 8, 119–128. [Google Scholar] [CrossRef]
- Vandecasteele, L.; Fasang, A.E. Neighbourhoods, networks and unemployment: The role of neighbourhood disadvantage and local networks in taking up work. Urban Stud. 2020, 24, 0042098020925374. [Google Scholar] [CrossRef]
- Grow, H.M.; Cook, A.J.; Arterburn, D.E.; Saelens, B.E.; Drewnowski, A.; Lozano, P. Child obesity associated with social disadvantage of children’s neighborhoods. Soc. Sci. 2010, 71, 584–591. [Google Scholar]
- Wood, S.L.; Demougin, P.R.; Higgins, S.; Husk, K.; Wheeler, B.W.; White, M. Exploring the relationship between childhood obesity and proximity to the coast: A rural/urban perspective. Health Place 2016, 40, 129–136. [Google Scholar] [CrossRef]
- Kim, Y.; Cubbin, C.; Oh, S. A systematic review of neighbourhood economic context on child obesity and obesity-related behaviours. Obes. Rev. 2019, 20, 420–431. [Google Scholar] [CrossRef]
- Edwards, K.L.; Clarke, G.P.; Ransley, J.K.; Cade, J. The neighbourhood matters: Studying exposures relevant to childhood obesity and the policy implications in Leeds, UK. J. Epidemiol. Community Health 2010, 64, 194–201. [Google Scholar] [CrossRef]
- Burgoine, T.; Mackenbach, J.D.; Lakerveld, J.; Forouhi, N.G.; Griffin, S.J.; Brage, S.; Wareham, N.J.; Monsivais, P. Interplay of socioeconomic status and supermarket distance is associated with excess obesity risk: A UK cross-sectional study. Int. J. Environ. Res. Public Health. 2017, 14, 1290. [Google Scholar] [CrossRef] [PubMed]
- Ludwig, D.S.; Peterson, K.E.; Gortmaker, S.L. Relation between consumption of sugar-sweetened drinks and childhood obesity: A prospective, observational analysis. Lancet 2001, 357, 505–508. [Google Scholar] [CrossRef]
- James, J.; Thomas, P.; Cavan, D.; Kerr, D. Preventing childhood obesity by reducing consumption of carbonated drinks: Cluster randomised controlled trial. BMJ 2004, 328, 1237. [Google Scholar] [CrossRef] [PubMed]
- Epstein, L.H.; Gordy, C.C.; Raynor, H.A.; Beddome, M.; Kilanowski, C.K.; Paluch, R. Increasing fruit and vegetable intake and decreasing fat and sugar intake in families at risk for childhood obesity. Obes. Res. 2001, 9, 171–178. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Beydoun, M.A.; Wang, Y. Is sleep duration associated with childhood obesity? A systematic review and meta-analysis. Obesity 2008, 16, 265–274. [Google Scholar] [CrossRef] [PubMed]
- Sekine, M.; Yamagami, T.; Handa, K.; Saito, T.; Nanri, S.; Kawaminami, K.; Tokui, N.; Yoshida, K.; Kagamimori, S. A dose–response relationship between short sleeping hours and childhood obesity: Results of the Toyama Birth Cohort Study. Child Care Health Dev. 2002, 28, 163–170. [Google Scholar] [CrossRef] [PubMed]
- Arenz, S.; Rückerl, R.; Koletzko, B.; von Kries, R. Breast-feeding and childhood obesity—A systematic review. Int. J. Obes. 2004, 28, 1247. [Google Scholar] [CrossRef] [PubMed]
- Armstrong, J.; Reilly, J.J. Breastfeeding and lowering the risk of childhood obesity. Lancet 2002, 359, 2003–2004. [Google Scholar] [CrossRef]
- Von Kries, R.; Toschke, A.M.; Koletzko, B.; Slikker, W., Jr. Maternal smoking during pregnancy and childhood obesity. Am. J. Epidemiol. 2002, 156, 954–961. [Google Scholar] [CrossRef]
- Toschke, A.; Koletzko, B.; Slikker, W.; Hermann, M.; von Kries, R. Childhood obesity is associated with maternal smoking in pregnancy. Eur. J. Pediatr. 2002, 161, 445–448. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Full Names | Year |
|---|---|---|
| PD | Population density (persons/hectare) | 2014 |
| NW | Non-white population percentage | 2014 |
| ANWHI | Average net weekly household income after housing costs (£) | 2014 |
| NIE | Percentage of households with dependent children not in employment | 2011 |
| WHEQ | Percent of adults without higher education qualifications | 2011 |
| Variables | Mean | SD |
|---|---|---|
| Prevalence of childhood obesity | 18.62 | 5.75 |
| PD | 33.22 | 34.74 |
| NW | 13.66 | 18 |
| ANWHI | 496.22 | 113.14 |
| NIE | 13.83 | 8.62 |
| WHEQ | 72.91 | 11.42 |
| Observed Moran’s I | P-Value |
|---|---|
| 0.125 | <0.001 |
| Coefficient | OLS | MESS-SAR (Matrix Exponential Spatial Specification of Spatial Autoregressive) | FRES-ESF (Fast Random Effects Specification of Eigenvector Spatial Filtering) |
|---|---|---|---|
| Intercept | 5.271 *** | 1.695 * | 6.205 *** |
| PD | 0.021 *** | 0.019 *** | 0.02 *** |
| NW | 0.077 *** | 0.067 *** | 0.072 *** |
| ANWHI | −0.007 *** | −0.005 *** | −0.008 *** |
| NIE | 0.172 *** | 0.167 *** | 0.150 *** |
| WHEQ | 0.172 *** | 0.169 *** | 0.174 *** |
| Adjusted R2 | 0.579 | 0.551 | 0.665 |
| Akaike information criterion (AIC) | 37,039 | 36,930 | 36,947 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Hu, X.; Huang, Y.; On Chan, T. Spatial Patterns of Childhood Obesity Prevalence in Relation to Socioeconomic Factors across England. ISPRS Int. J. Geo-Inf. 2020, 9, 599. https://doi.org/10.3390/ijgi9100599
Sun Y, Hu X, Huang Y, On Chan T. Spatial Patterns of Childhood Obesity Prevalence in Relation to Socioeconomic Factors across England. ISPRS International Journal of Geo-Information. 2020; 9(10):599. https://doi.org/10.3390/ijgi9100599
Chicago/Turabian StyleSun, Yeran, Xuke Hu, Ying Huang, and Ting On Chan. 2020. "Spatial Patterns of Childhood Obesity Prevalence in Relation to Socioeconomic Factors across England" ISPRS International Journal of Geo-Information 9, no. 10: 599. https://doi.org/10.3390/ijgi9100599
APA StyleSun, Y., Hu, X., Huang, Y., & On Chan, T. (2020). Spatial Patterns of Childhood Obesity Prevalence in Relation to Socioeconomic Factors across England. ISPRS International Journal of Geo-Information, 9(10), 599. https://doi.org/10.3390/ijgi9100599