Visualisation of Spatial Data Uncertainty. A Case Study of a Database of Topographic Objects

Abstract
1. Introduction
2. Materials and Methods
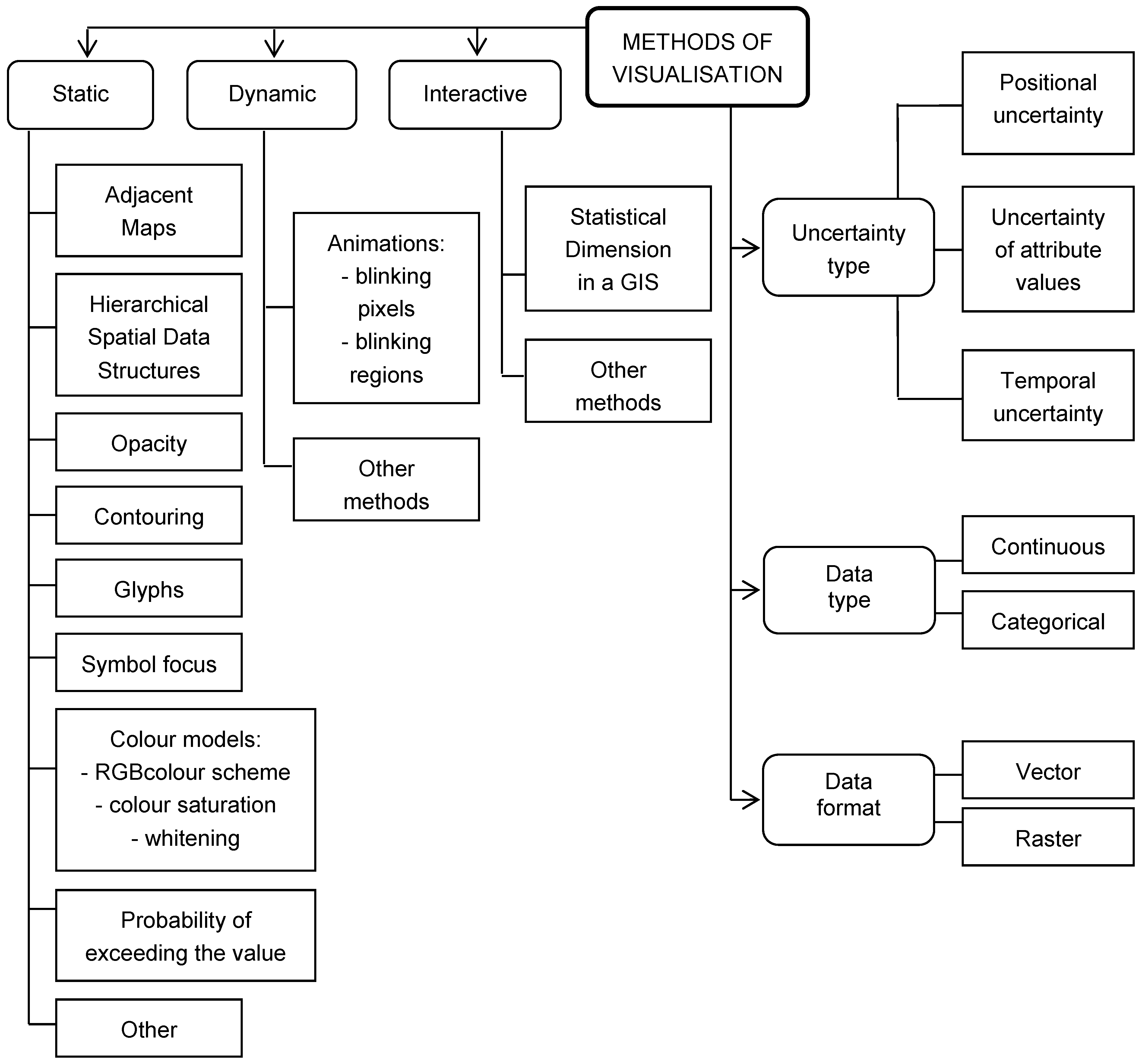
2.1. Spatial Data Uncertainty Visualisation Methods
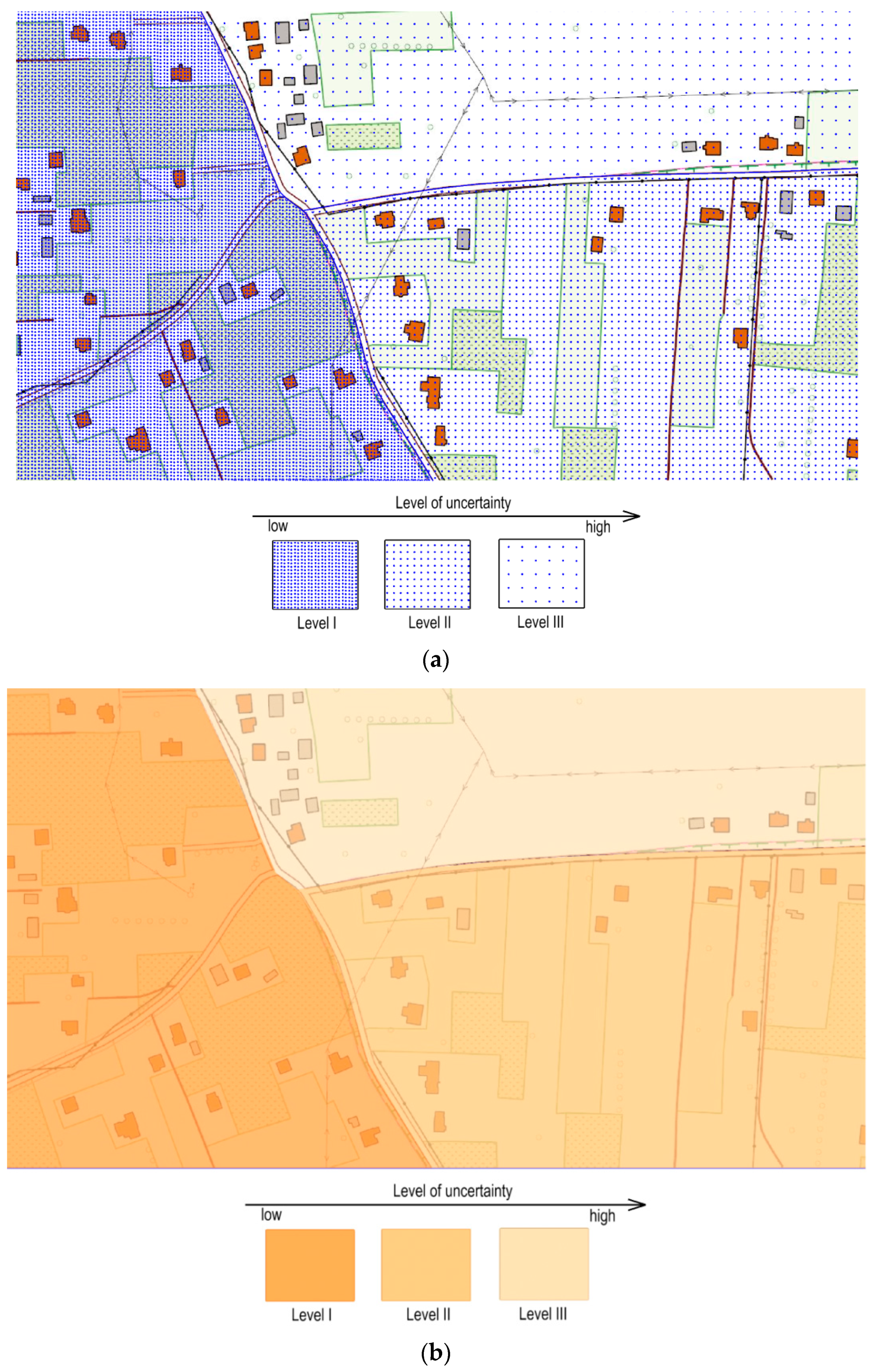
2.2. Data Uncertainty Visualisation in the Database of Topographic Objects (DTO)
2.3. Research Methodology
- How many spatial data uncertainty classes can be identified for each presented visualisation method?
- Describe the preferred hierarchy of importance—from the most accurate objects to objects defined inaccurately.
- Order the methods of visualisation, according to your preferences, for each technique from the most beneficial to the least beneficial one.
- Will the information about data uncertainty represented with the evaluated visualisation techniques be useful when making decisions based on spatial datasets (yes/no)?
3. Results
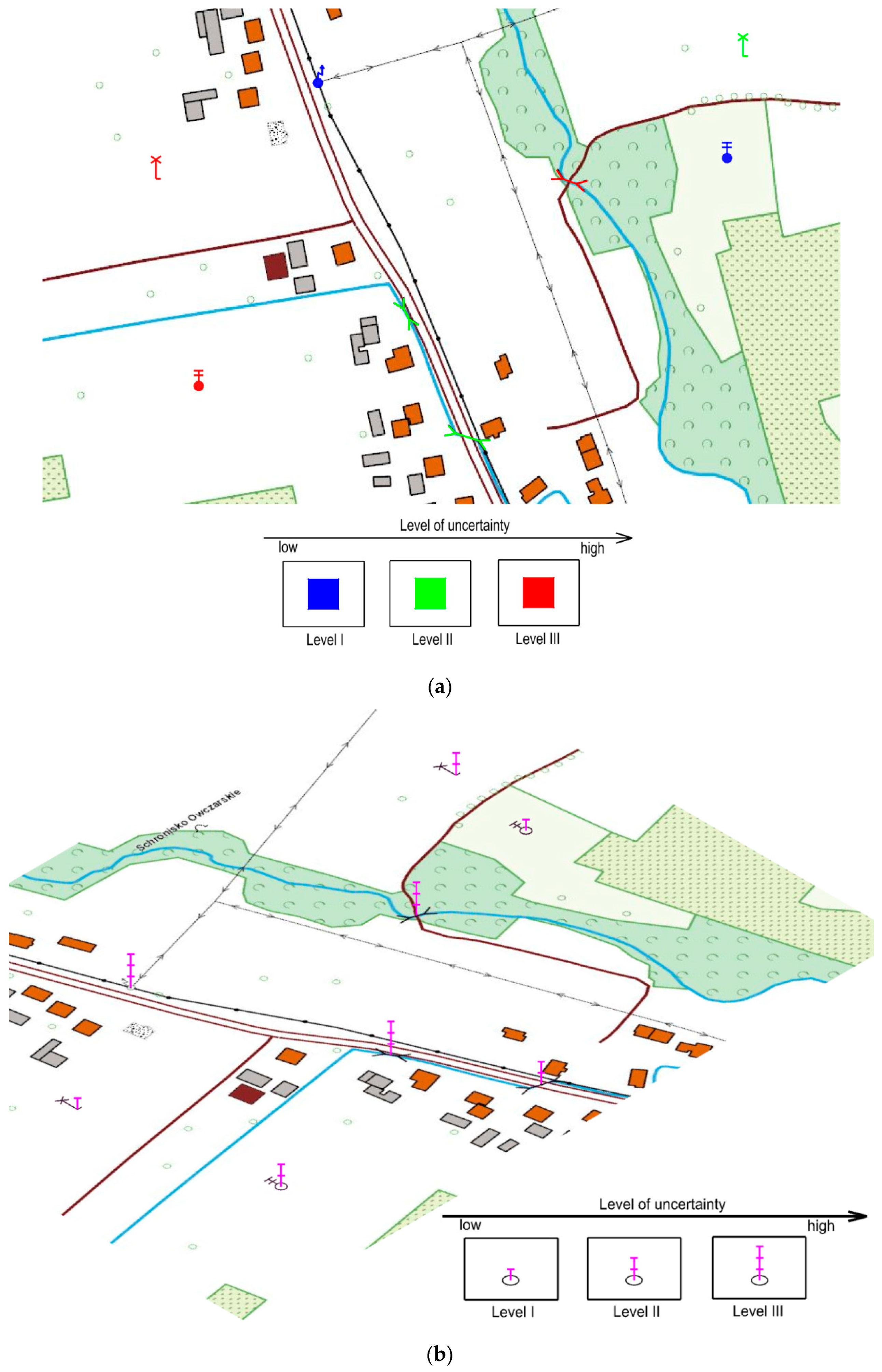
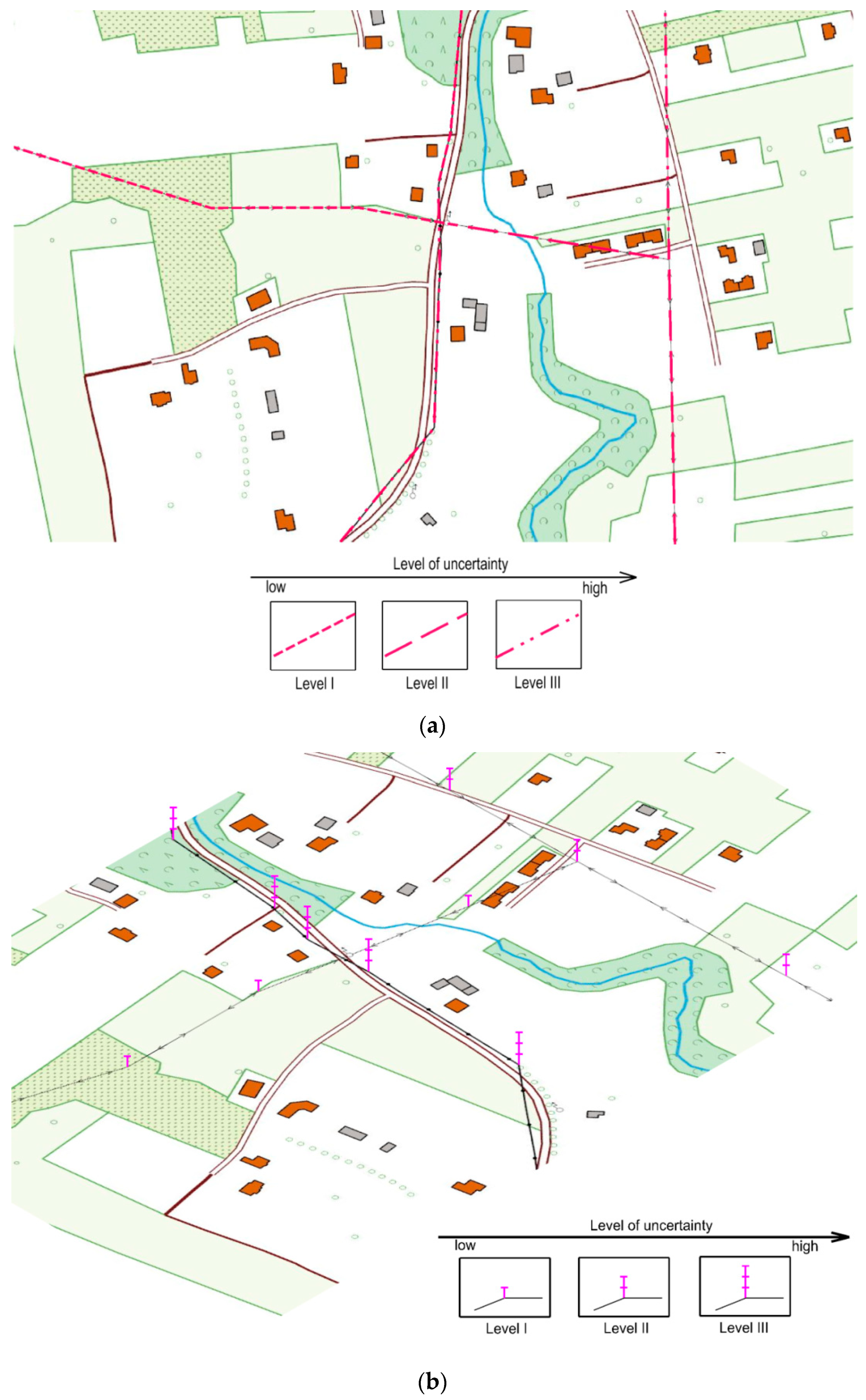
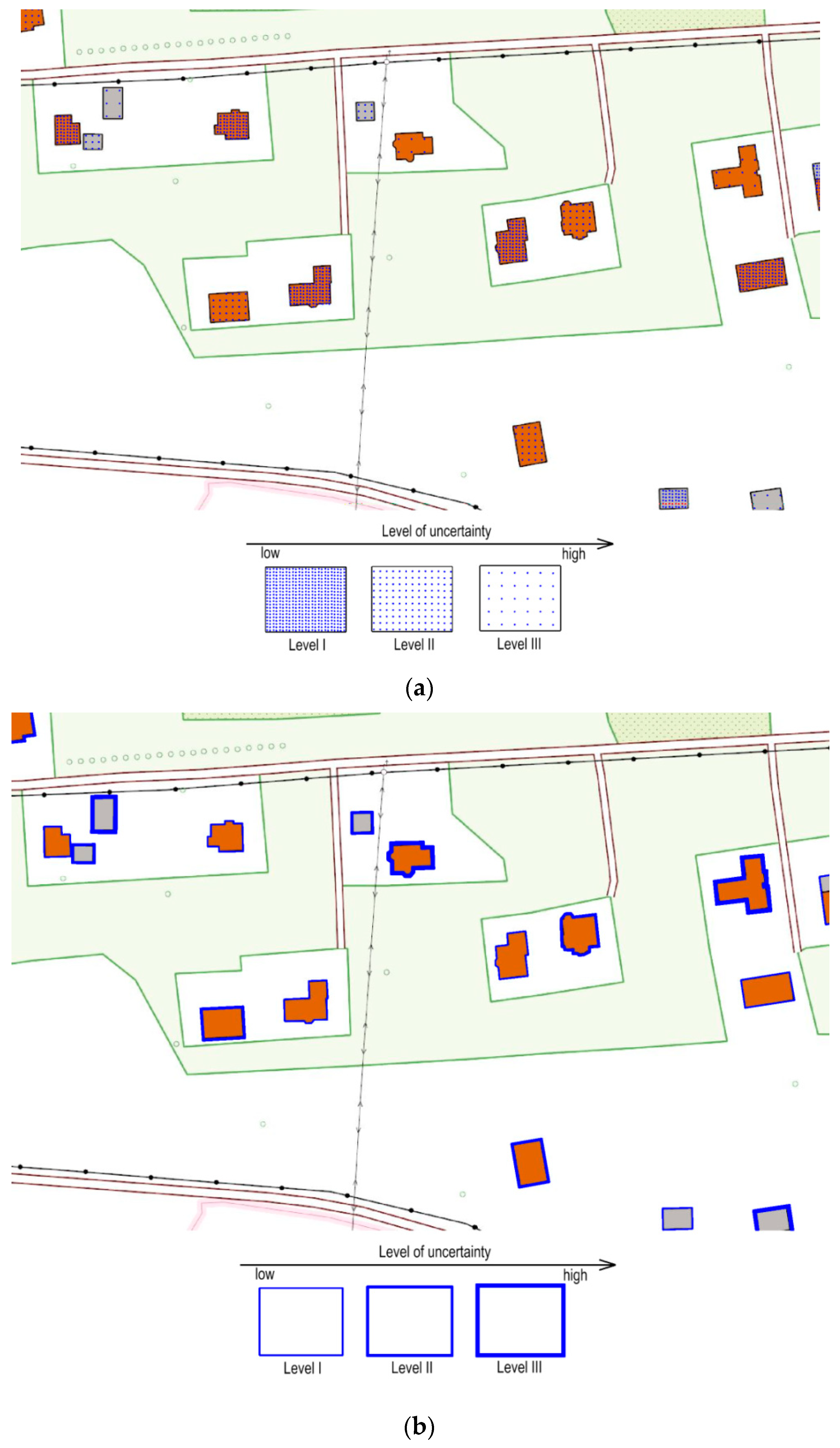
3.1. Data Uncertainty Visualisation Methods for Data in the DTO
3.2. Assessment of the Proposed Methods of Data Uncertainty Visualisation
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Fisher, P.; Comber, A.; Wadsworth, R. Approaches to uncertainty in spatial data. In Fundamentals of Spatial Data Quality; ISTE: London, UK, 2006. [Google Scholar]
- Hunter, G.J.; Goodchild, M.F. Modeling the uncertainty in slope and aspect estimates derived from spatial databases. Geogr. Anal. 1997, 29, 35–49. [Google Scholar] [CrossRef]
- Foodie, G.M.; Atkinson, P.M. Uncertainty in Remote Sensing and GIS; John Wiley and Sons: New York, NY, USA, 2003; p. 326. [Google Scholar]
- Fisher, P.F.; Comber, A.J.; Wadsworth, R. Land use and land cover: Contradiction or complement? In Re-Presenting GIS; Fisher, P.F., Ed.; John Wiley and Sons: London, UK, 2005. [Google Scholar]
- Frank, A.U. Metamodels for Data Quality Description. In Data Quality in Geographic Information: From Error to Uncertainty; Hermès: Paris, France, 1998; pp. 15–29. [Google Scholar]
- Chilès, J.-P.; Delfiner, P. Geostatistics: Modeling Spatial Uncertainty. Series in Probability and Statistics; John Wiley and Sons: New York, NY, USA, 1999. [Google Scholar]
- Reinke, K.J.; Hunter, G.J. A theory for communicating uncertainty in spatial databases. In Spatial Data Quality; Fisher, P.F., Ed.; Taylor & Francis: London, UK, 2002; pp. 77–101. [Google Scholar]
- Goodchild, M.F.; Jeansoulin, R. Data Quality in Geographic Information: From Error to Uncertainty; Hermès Science Publications: Paris, France, 1998. [Google Scholar]
- Zhang, J.; Goodchild, M.F. Uncertainty in Geographical Information; Taylor & Francis: London, UK, 2002. [Google Scholar]
- Gottsegen, J.; Montello, D.; Goodchild, M.F. A comprehensive model of uncertainty in spatial data. In Spatial Accuracy Assessment Land Information Uncertainty in Natural Resources; Ann Arbor Press: Chelssea, MI, USA, 1999; pp. 175–182. [Google Scholar]
- Comber, A.J.; Law, A.N.R.; Lishman, J.R. A comparison of Bayes’, Dempster-Shafer and endorsement theories for managing knowledge uncertainty in the context of land cover monitoring, Computers. Environ. Urban Syst. 2004, 28, 311–327. [Google Scholar] [CrossRef]
- Devillers, R.; Beard, K. Communication and Use of Spatial Data Quality Information in GIS. In Fundamentals of Spatial Data Quality; ISTE: London, UK, 2006. [Google Scholar]
- Goodchild, M.F.; Clarke, K. Data quality in massive datasets. In Handbook of Massive Datasets; Abello, J., Pardalos, P.M., Resende, M.G.C., Eds.; Kluwer Academic Publishers: Norwell, MA, USA, 2002; pp. 643–659. [Google Scholar]
- Drecki, I. Visualisation of Uncertainty in Geographic Data; Shi, W., Fisher, P., Goodchild, M.F., Eds.; Spatial Data Quality; Taylor & Francis: London, UK, 2002; pp. 140–159. [Google Scholar]
- MacEachren, A.M. Visualizing uncertain information. Cartogr. Perspect. 1992, 13, 10–19. [Google Scholar] [CrossRef]
- Bertin, J. Graphics and Graphic Information Processing; Walter de Gruyter: Berlin, Germany; New York, NY, USA, 1981. [Google Scholar]
- MacEachren, A.M.; Brewer, C.A.; Pickle, L.W. Visualizing Georeferenced Data: Representing Reliability of Health Statistics. Environ. Plan. 1998, 30, 1547–1561. [Google Scholar] [CrossRef]
- Kardos, J.; Benwell, G.; Moore, A. The Visualisation of Uncertainty for Spatially Referenced Census Data Using Hierarchical Tessellations. Trans. GIS 2005, 9, 19–34. [Google Scholar] [CrossRef]
- MacEachren, A.M.; Robinson, A.; Hopper, S.; Gardner, S.; Murray, R.; Gahegan, M.; Hetzler, E. Visualizing Geospatial Information Uncertainty: What We Know and What We Need to Know. Cartogr. Geogr. Inf. Sci. 2005, 32, 139–160. [Google Scholar] [CrossRef]
- Pang, A. Visualizing Uncertainty in Geo-spatial Data. In Proceedings of the Workshop on the Intersections between Geospatial Information and Information Technology, Santa Cruz, CA, USA, 20 September 2001. [Google Scholar]
- Brodlie, K.; Osorio, R.A.; Lopes, A.A. Review of Uncertainty in Data Visualization. In Expanding the Frontiers of Visual Analytics and Visualization; Wong, P.C., Ed.; Springer: London, UK, 2012; pp. 81–109. [Google Scholar]
- Prassni, J.; Ropinski, T.; Hinrichs, K. Uncertainty-aware guided volume segmentation. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1358–1365. [Google Scholar] [CrossRef] [PubMed]
- Ehlschlaeger, C.R.; Shortridge, A.M.; Goodchild, M.F. Visualising Spatial Data Uncertainty Using Animation. Comput. Geosci. 1997, 23, 387–395. [Google Scholar] [CrossRef]
- Kardos, J.; Moore, A.; Benwell, G. Expressing Attribute Uncertainty in Spatial Data Using Blinking Regions. In Proceedings of the 7th International Symposium on Spatial Accuracy Assessment in Natural Resources and Environmental Sciences, Lisbon, Portugal, 5–7 July 2006; pp. 814–824. [Google Scholar]
- Fisher, P. Visualizing Uncertainty in Soil Maps by Animation. Cartographica 1993, 30, 20–27. [Google Scholar] [CrossRef]
- Pebesma, E.J.; de Jong, K.; Briggs, D. Interactive Visualization of Uncertain Spatial and Spatio-temporal Data Under Different Scenarios: An Air Quality Example. Int. J. Geogr. Inf. Sci. 2007, 21, 515–527. [Google Scholar] [CrossRef]
- Fisher, P.F. Models of Uncertainty in Spatial Data. In Geographical Information Systems: Principles, Techniques, Management and Applications; Rhind, D., Ed.; John Wiley and Sons: New York, NY, USA, 1999; Volume 1, pp. 191–205. [Google Scholar]
- Evans, B.J. Dynamic display of spatial data reliability: Does it benefit the user? Comput. Geosci. 1997, 23, 409–422. [Google Scholar] [CrossRef]
- Cliburn, D.C.; Feddema, J.J.; Miller, J.R.; Slocum, T.A. Design and evaluation of a decision support system in a water balance application. Comput. Graph. 2002, 26, 931–949. [Google Scholar] [CrossRef]
- Senarante, H.; Gerharz, L.; Pebesma, E.J.; Schwering, A. Usability of spatio-temporal uncertainty visualisation methods. Bridging the Geographic Information Sciences. In Lecture Notes in Geoinformation and Cartography; Springer: Berlin/Heidelberg, Germany, 2012; pp. 3–23. [Google Scholar]
- Kalogeropoulos, K.; Stathopoulos, N.; Tsatsaris, A.; Chalkias, C. A survey of the Geoinformatics use for census purposes and the INSPIRE maturity within Statistical Institutes of EU and EFTA countries. Ann. GIS 2019, 25, 167–178. [Google Scholar]
- Bartha, G.; Kocsis, S. Standardization of Geographic Data: The European Inspire Directive. Eur. J. Geogr. 2011, 2, 79–89. [Google Scholar]
- Gallego, F.J. Validation of GIS Layers in the EU: Getting Adapted to Available Reference Data. Int. J. Digit. Earth 2011, 4, 42–57. [Google Scholar] [CrossRef]
- UN DESA. Handbook on Geospatial Infrastructure in Support of Census Activities. In Studies in Methods (Ser. F); European Commission: Brussels, Belgium, 2013. [Google Scholar]
- Gawronek, P.; Makuch, M. TLS Measurement during Static Load Testing of a Railway Bridge. Int. J. Geo-Inf. 2019, 8, 44. [Google Scholar] [CrossRef]
- Gawronek, P.; Makuch, M.; Mitka, B.; Gargula, T. Measurements of the Vertical Displacements of a Railway Bridge Using TLS Technology in the Context of the Upgrade of the Polish Railway Transport. Sensors 2019, 19, 4275. [Google Scholar] [CrossRef] [PubMed]
- Ślusarski, M. BDOT500 Database of Physical Topographic Objects−Basic qualitative analysis. Geomat. Landmanag. Landsc. 2015, 1, 69–75. [Google Scholar] [CrossRef]
- Ślusarski, M. Analysis of underground utility networks damage risk in the context of spatial data quality. Int. Multidiscip. Sci. GeoConf. 2016, 3, 35–42. [Google Scholar]
- Ślusarski, M.; Siejka, M. Model of quality of data collected in the topographic database. Int. Multidiscip. Sci. GeoConf. 2017, 17, 595–603. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name of the Visualisation Method | Assessment of the Number of Data Uncertainty Classes | Preferred Hierarchy of Importance | Preferred Method of Visualisation | Total Score (I+II+III) | |||
|---|---|---|---|---|---|---|---|
| R | Score I | R | Score II | Mean Value | Score III | ||
| Fill hue colours and lightness | 0.90 | 1 | 0.89 | 1 | 1.4 | 1 | 3 |
| Glyphs | 0.92 | 2 | 0.92 | 2 | 1.6 | 2 | 6 |
| Name of the Visualisation Method | Assessment of the Number of Data Uncertainty Classes | Preferred Hierarchy of Importance | Preferred Method of Visualisation | Total Score (I+II+III) | |||
|---|---|---|---|---|---|---|---|
| R | Score I | R | Score II | Mean Value | Score III | ||
| Contouring of linear objects | 0.86 | 1 | 0.92 | 2 | 1.6 | 2 | 5 |
| Glyphs | 0.90 | 2 | 0.91 | 1 | 1.4 | 1 | 4 |
| Name of the Visualisation Method | Assessment of the Number of Data Uncertainty Classes | Preferred Hierarchy of Importance | Preferred Method of Visualisation | Total Score (I+II+III) | |||
|---|---|---|---|---|---|---|---|
| R | Score I | R | Score II | Mean Value | Score III | ||
| Fill grain density | 0.92 | 2 | 0.89 | 2 | 1.7 | 2 | 6 |
| Contour crispness | 0.86 | 1 | 0.87 | 1 | 1.3 | 1 | 3 |
| Name of the Visualisation Method | Assessment of the Number of Data Uncertainty Classes | Preferred Hierarchy of Importance | Preferred Method of Visualisation | Total Score (I+II+III) | |||
|---|---|---|---|---|---|---|---|
| R | Score I | R | Score II | Mean Value | Score III | ||
| Fill grain density | 0.91 | 1 | 0.90 | 1 | 1.2 | 1 | 3 |
| Fill colour value | 0.92 | 2 | 0.92 | 2 | 1.8 | 2 | 6 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ślusarski, M.; Jurkiewicz, M. Visualisation of Spatial Data Uncertainty. A Case Study of a Database of Topographic Objects. ISPRS Int. J. Geo-Inf. 2020, 9, 16. https://doi.org/10.3390/ijgi9010016
Ślusarski M, Jurkiewicz M. Visualisation of Spatial Data Uncertainty. A Case Study of a Database of Topographic Objects. ISPRS International Journal of Geo-Information. 2020; 9(1):16. https://doi.org/10.3390/ijgi9010016
Chicago/Turabian StyleŚlusarski, Marek, and Magdalena Jurkiewicz. 2020. "Visualisation of Spatial Data Uncertainty. A Case Study of a Database of Topographic Objects" ISPRS International Journal of Geo-Information 9, no. 1: 16. https://doi.org/10.3390/ijgi9010016
APA StyleŚlusarski, M., & Jurkiewicz, M. (2020). Visualisation of Spatial Data Uncertainty. A Case Study of a Database of Topographic Objects. ISPRS International Journal of Geo-Information, 9(1), 16. https://doi.org/10.3390/ijgi9010016