Deep Learning-Based Named Entity Recognition and Knowledge Graph Construction for Geological Hazards



Abstract
:1. Introduction
- To the best of our knowledge, this is the first work to apply the NER technique to extract named entities and build a knowledge graph for geological hazards literature.
- This paper proposed a deep learning-based NER model that combines a multi-branch BiGRU layer and a CRF model for geological hazard NER. The model uses a multi-branch structure; each branch contains a BiGRU layer of different depths to extract different levels of features, and then further enhances the preliminary features using the attention mechanism and the residual structure.
- This paper proposed a pattern-based method to build a large-scale geological hazard literature NER corpus with little manual costs.
2. Related Work
3. Preliminaries
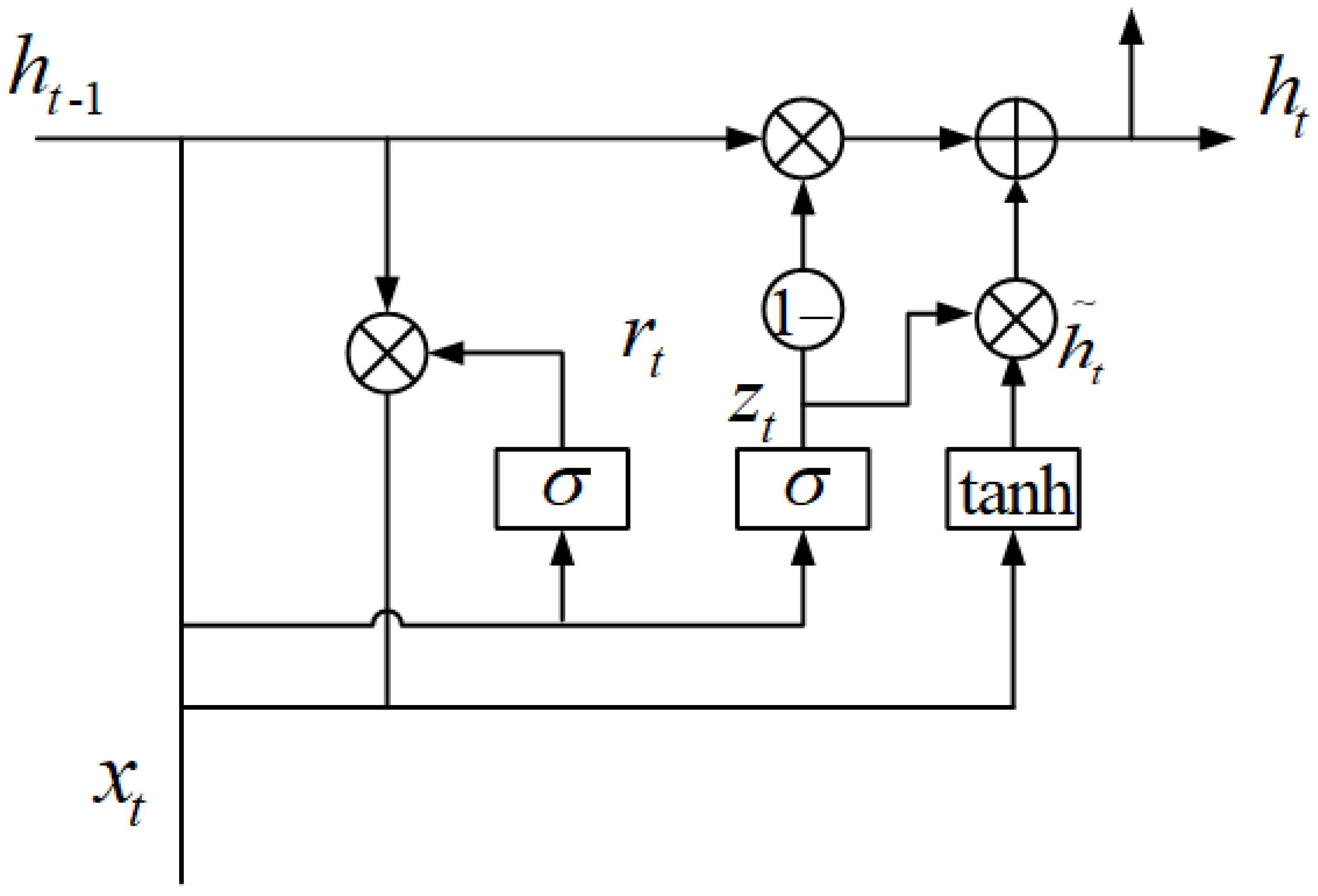
3.1. GRU
3.2. CRF
Linear Chain-CRFs
4. The Proposed Methods
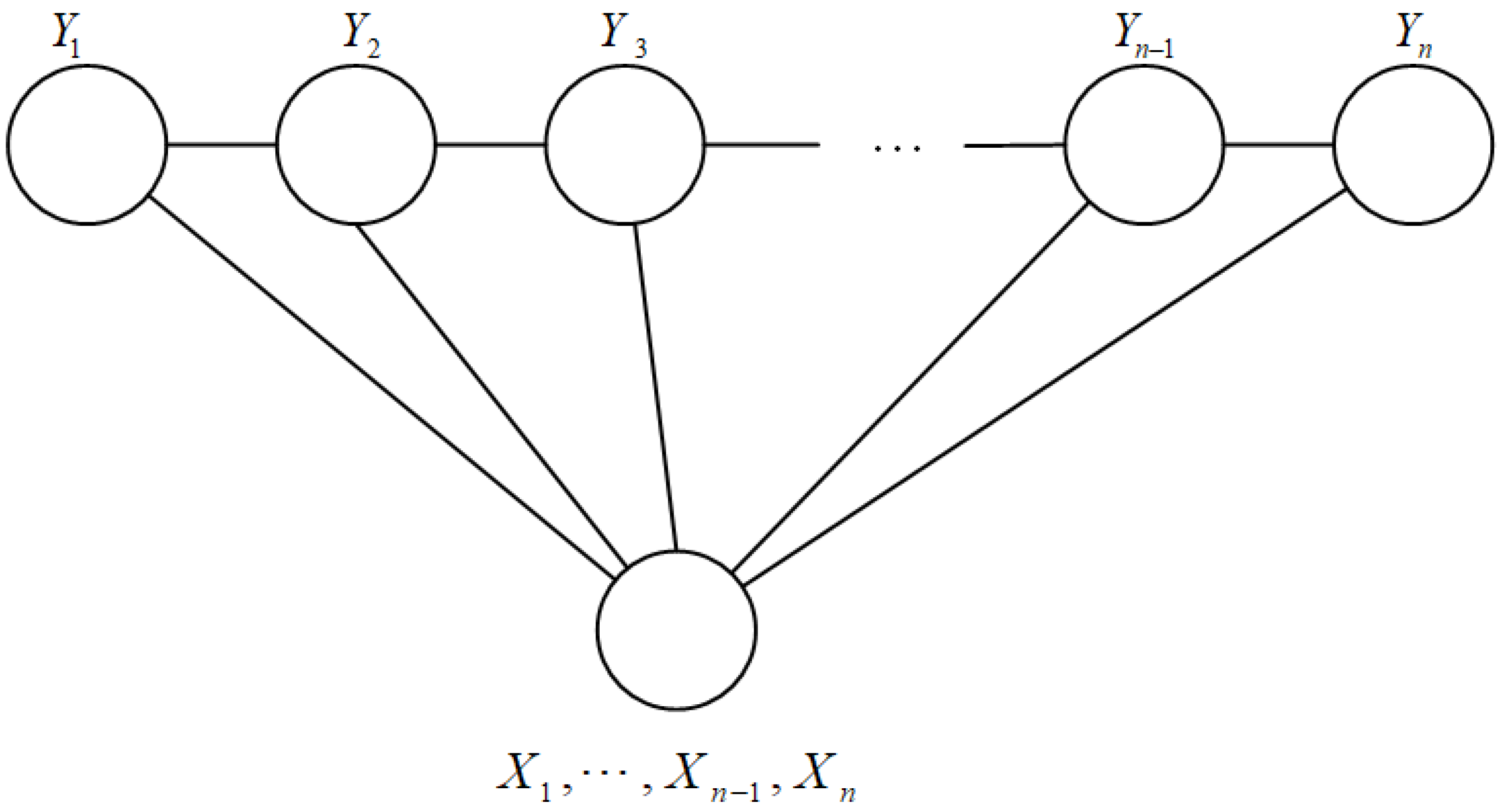
- Pattern-based corpus construction. Given literature documents where is the n-th document and where , , are patterns for , , and , respectively. The pattern-based corpus construction method aims to construct a named entity corpus C.
- The deep, multi-branch BiGRU-CRF model for NER. Given literature documents where is the nth document and the named entity corpus C, the proposed deep, multi-branch BiGRU-CRF model aims to extract , and entities from F and constructs a knowledge graph G.
4.1. Pattern-Based Corpus Construction
4.1.1. Definition of Named Entities in Geological Hazard Literature
4.1.2. Pattern-Based Seed Acquisition
4.1.3. MFM for Corpus Construction
- (1)
- Sort the elements in the entity seed collections , and separately in decreasing order according to length.
- (2)
- Initialize the corpus set C to an empty set.
- (3)
- For each sentence in , look up seeds in the seed sets M, L, and D. If there is a seed that is contained by and is unlabeled, then label the words containing the seed in with the corresponding entity tags.
- (4)
- After traversing all the seed sets M, L, and D, the remaining unlabeled words in are labeled as “O”.
- (5)
- Add the label to the corpus set C.
- (6)
- When there is no unlabeled in S, the program ends and returns the corpus set C.
| Algorithm 1 MFM |
| Input:, , , Output: C
|
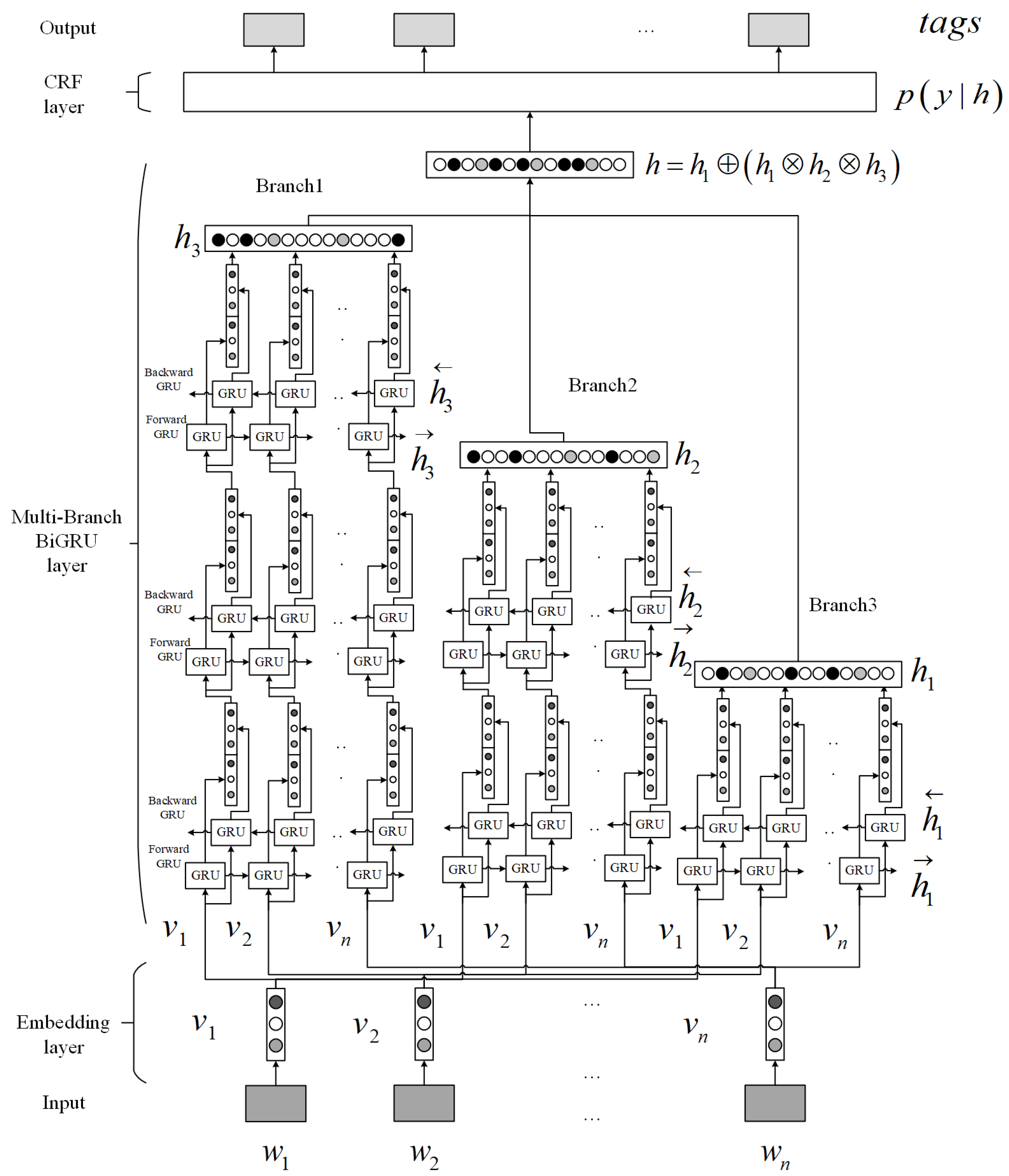
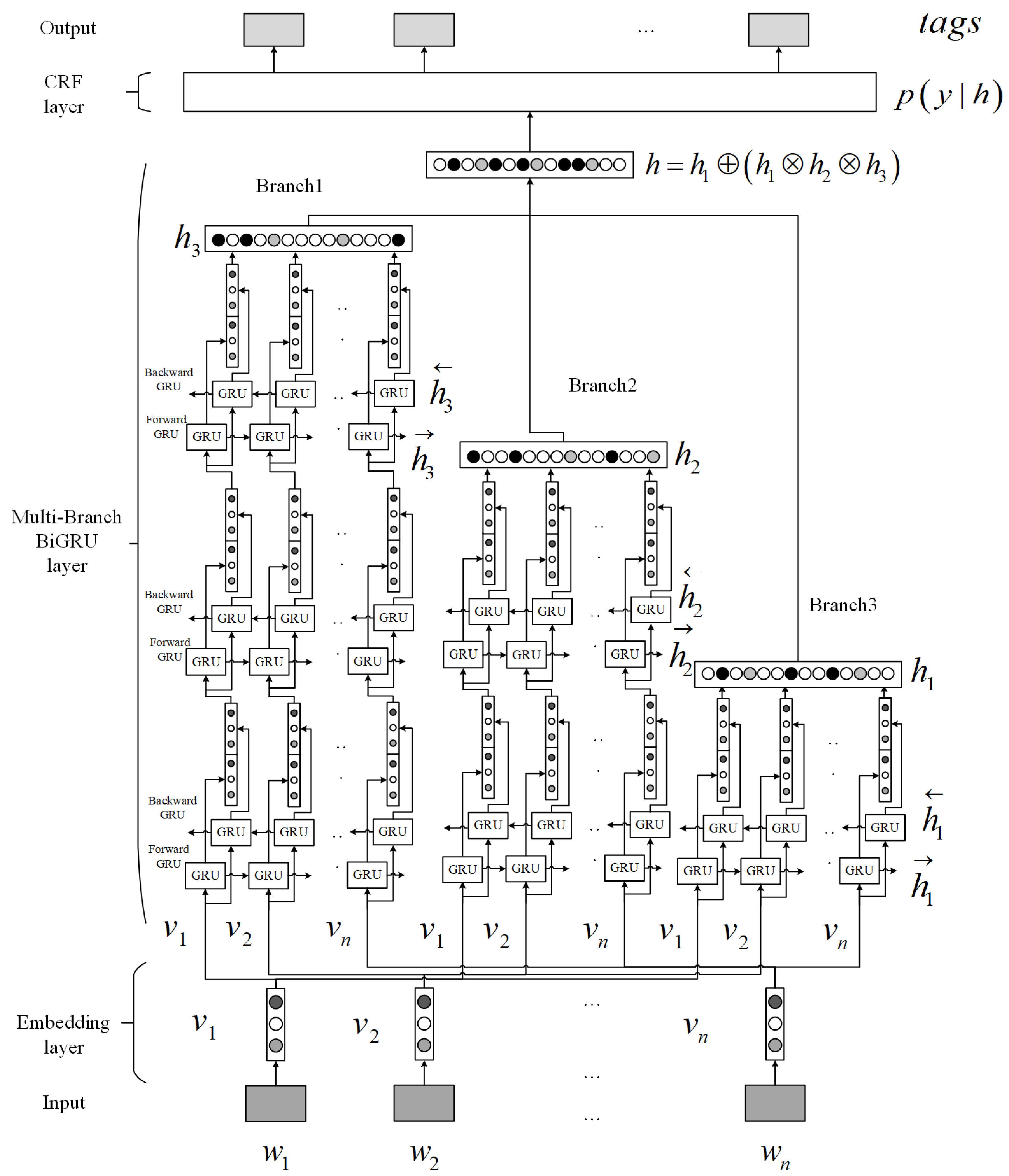
4.2. The Deep Multi-Branch BiGRU-CRF Model
4.2.1. Embedding Layer
4.2.2. Multi-Branch BiGRU Layer
4.2.3. CRF Layer
5. Implementation
6. Experimental Results
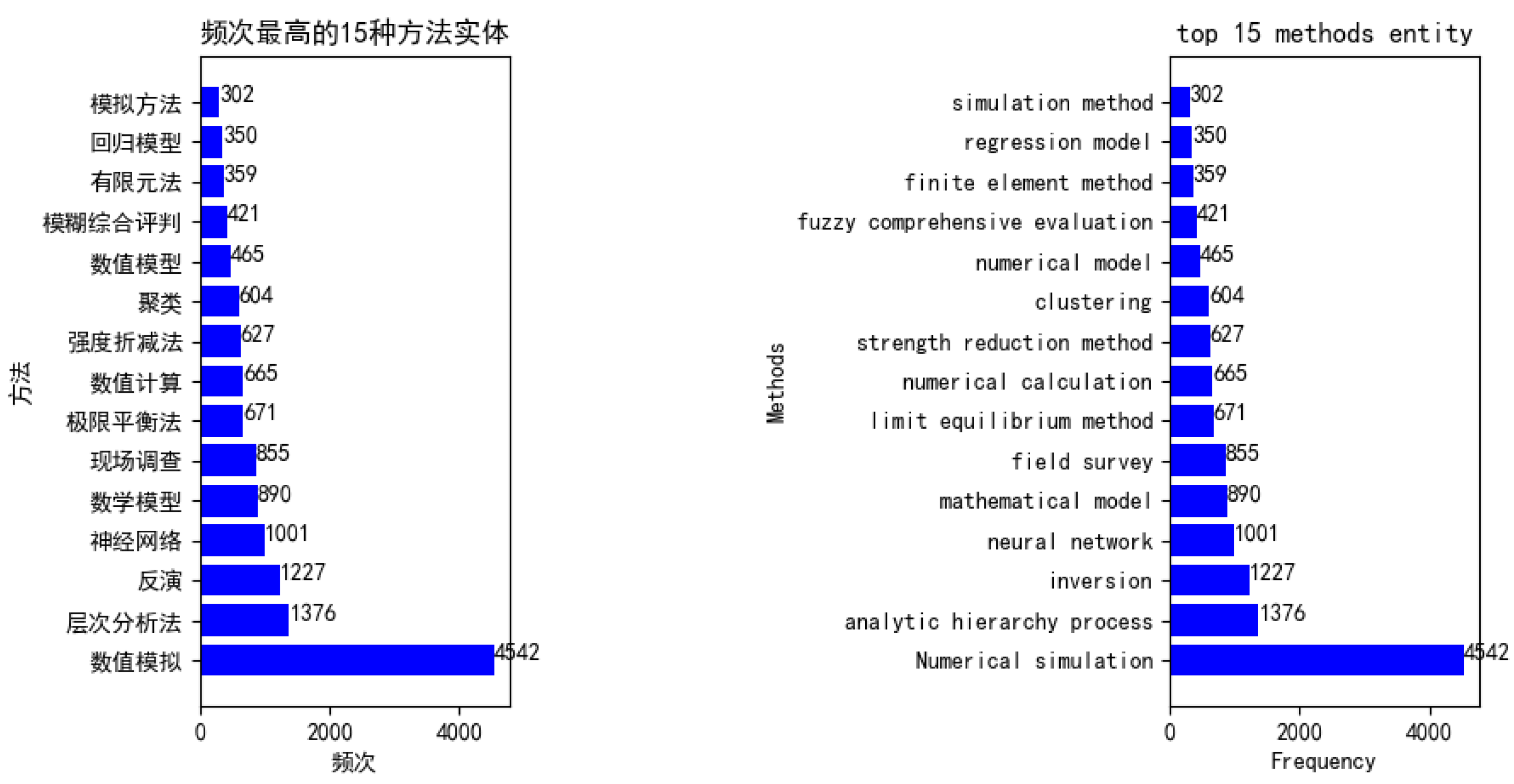
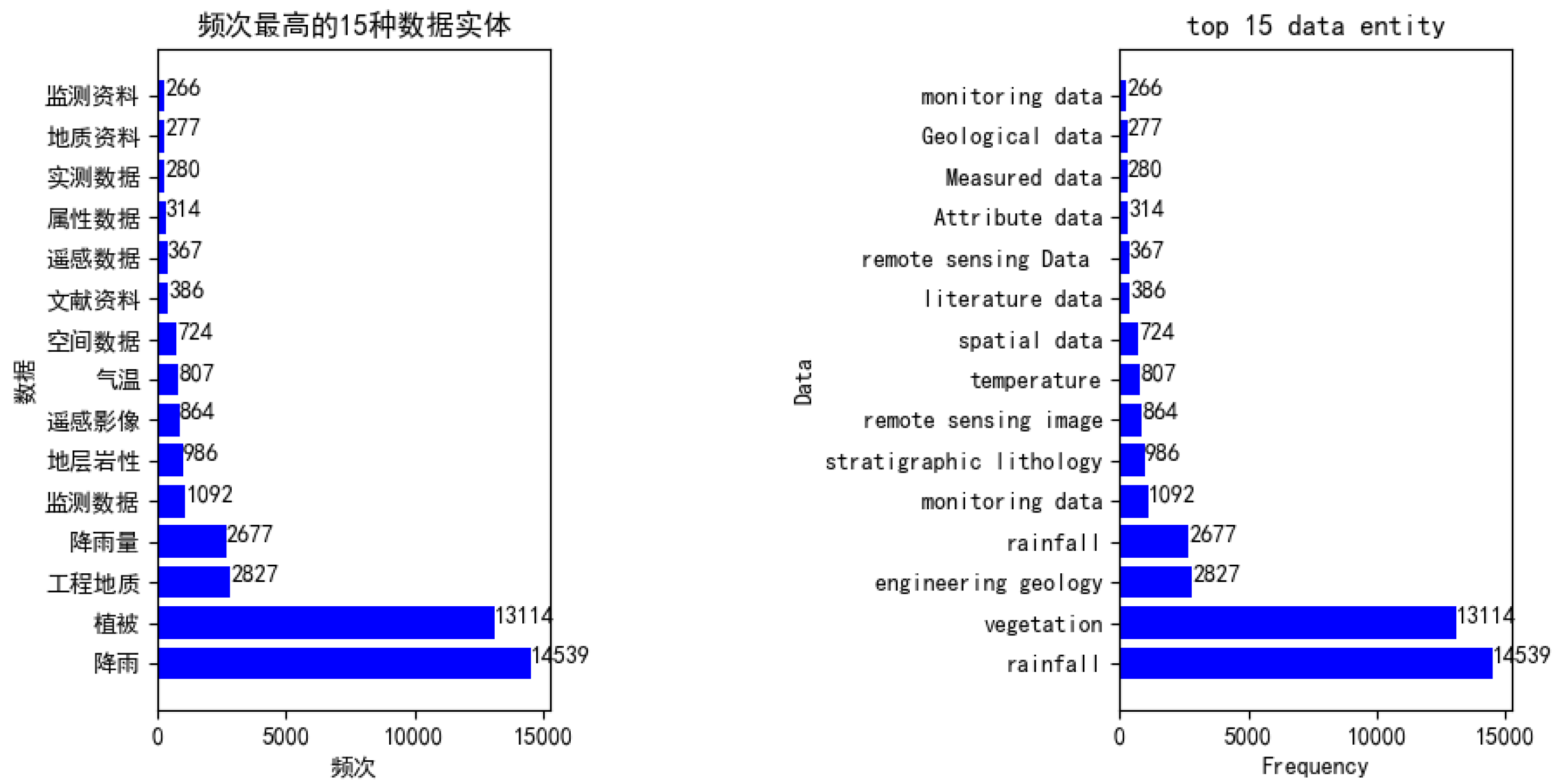
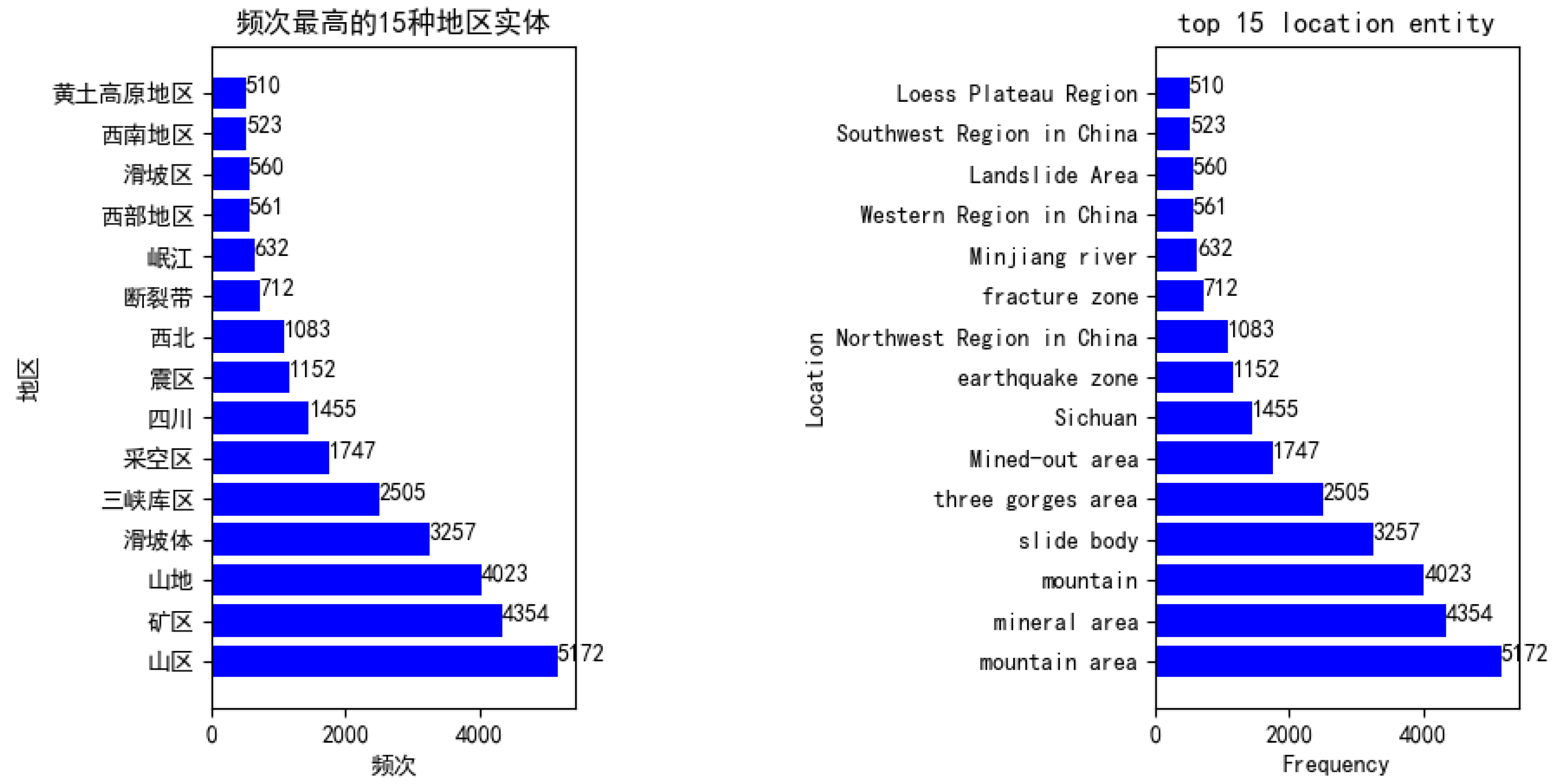
6.1. Corpus Constructed
6.2. Training
6.3. Results
- The CRF model is the model proposed by Sobhana et al. [38], using CRF for NER in geosciences. We used the CRF method as our benchmark. As can be seen in the Table 6, the CRF model could initially identify these geological hazard named entities, achieving an average precision of 0.8210, a recall rate of 0.7765, and an F1 score of 79.81.
- The BiLSTM-CRF model is the state-of-the-art model in current NER tasks [31]. It has one bidirectional LSTM layer and one CRF layer on top. As can be seen in the Table 6, the BiLSTM-CRF model has a significant lead on all indicators compared to the CRF model, with an average precision of 0.9205, an average recall rate of 0.9419, and an average F1 score of 93.10. It fully demonstrated that the BiLSTM-CRF model has more efficient feature extraction and more accurate discriminating ability after adding one bidirectional LSTM layer before the CRF layer.
- The deep, multi-branch BiGRU-CRF model was the proposed model with a three-branch BiGRU layer, which consisted of three branches of stacked BiGRU layers with depths of 1, 2, and 3, respectively, and one CRF layer on top. As can be seen in the Table 6, the deep, multi-branch BiGRU-CRF model had a significant lead on almost all indicators (except the recall rate of methods) compared to the CRF model and BiLSTM-CRF model above, with an average precision of 0.9413, an average recall rate of 0.9425, and an average F1 score of 94.19. It fully demonstrated that the proposed model has more efficient feature extraction and more accurate discriminating ability after adding three branches of BiGRUs with depths of 1, 2, and 3, respectively.
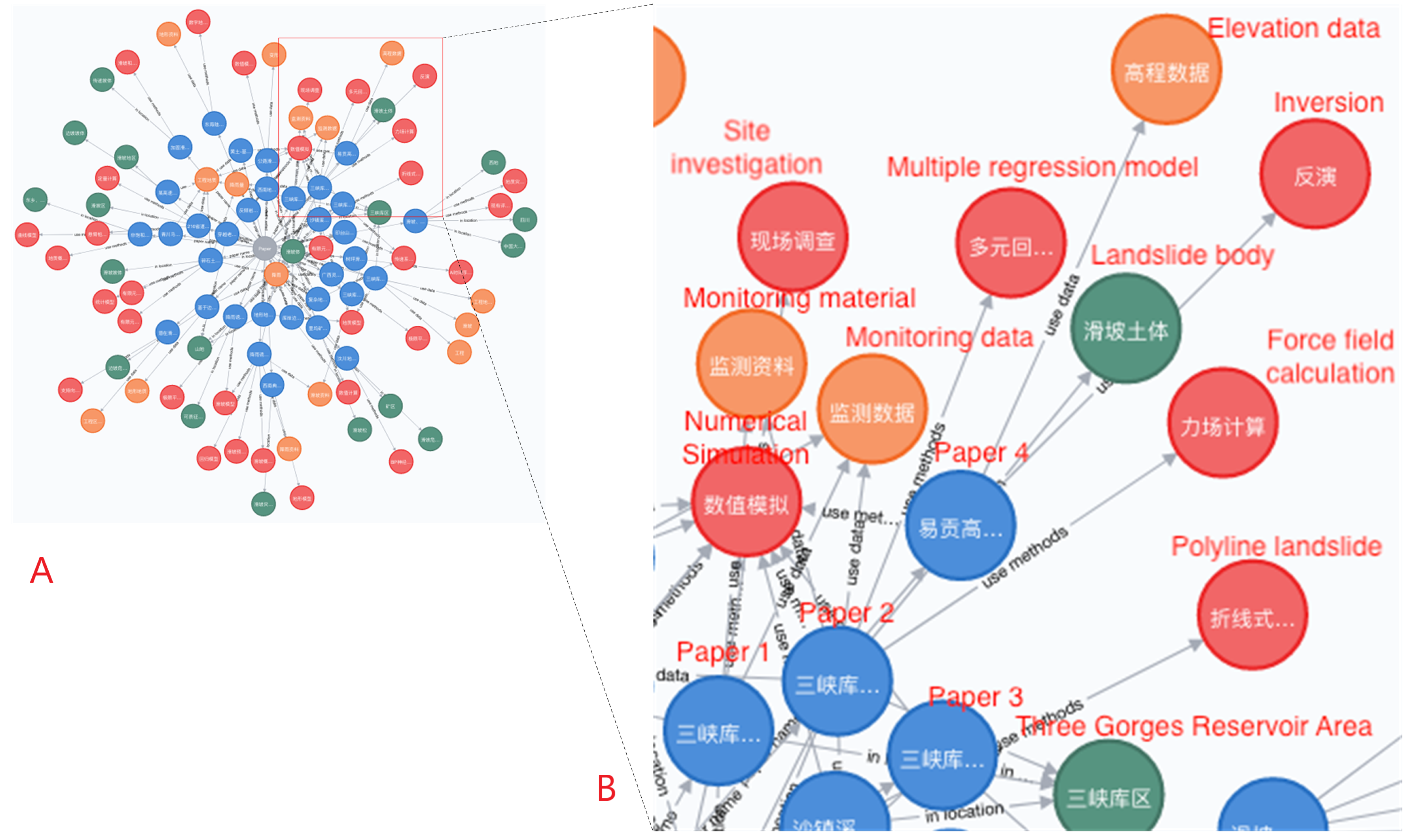
6.4. Knowledge Graph Construction
7. Discussion
7.1. Discussions of Generalizability
- Paper structure. In our practice, we crawled the abstract parts of the articles named entity recognition. Therefore, our method has no special requirements for the structure of the article, so long as the article contains a complete summary section.
- Paper language. In terms of language (in English, for example), the model needs to be adjusted as follows: Firstly, Chinese is based on characters, while English is based on words. Therefore, to extend our method to English papers, we need to rebuild the seed acquisition patterns (in Section 4.1.2) to build a training corpus for the model. Secondly, when doing NER tasks in Chinese, one character corresponds to one tag, but in English, one word corresponds to one tag. Therefore, to extend our method to English papers, we need to change the Chinese character vectors to the English word vectors in the embedding layer (in Section 4.2.1) of the deep, multi-branch BiGRU-CRF Model.
7.2. Discussions of Extensibility
- The flexibility to accommodate new instances. When a new paper is added to the Wanfang database, the newly added papers can be processed into nodes and edges the following three steps. The first step: crawling the abstract part of the new papers from the Wanfang database through web crawler technology; the second step: using the deep, multi-branch BiGRU-CRF model to identify the method, data, and location entities; the third step: the entity acts as a node, and the connections between the entities and the papers act as edges to the knowledge graph.
- The extensibility of the types of entity. At the same time, we also discussed what adjustments our methods need to be made if new entity types (e.g., theory) are added. If a new entity type is added, the deep, multi-branch BiGRU-CRF model needs to be adjusted as follows: First, we need to manually design the seed acquisition patterns (such as A) and build the training corpus using the methods mentioned in Section 4.1.2. Second, due to the addition of new entity types, the probability value of the softmax output of the last layer of our model needs to be changed from 7 (“O,” “I-LDS,” “I-MED,” “B-LDS,” “I-DAT,” “B-MED,” and “B-DAT”) to 9 (“O,” “I-LDS,” “I-MED,” “B-LDS,” “I-DAT,” “B-MED,” “B-DAT,” “B-THE,” and “I-THE”) in which “THE” represents the theory entity.
7.3. Discussions of Limitations and Future Work
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Entity Type | Patterns (Regular Expressions) |
|---|---|
| Location | ‘.*(地处∣位于∣在∣形成∣处于)(了)([]+)(的)(地区∣区域∣山区∣流域∣区).*’ |
| Methods | ‘.*(提供∣使用∣改进∣利用∣运用∣提出∣设计∣发明∣建立∣构造∣实现∣根据∣以 ∣基于∣构建∣结合∣采取∣采用∣推广∣通过) (了∣的∣于∣对应的∣出)(及)([]+)(的)(法∣模型).*’ |
| Data | ‘.*(提供∣使用∣利用∣运用∣提出∣设计∣发明∣建立∣构造 ∣根据∣以∣基于∣构建∣制作∣结合∣采取∣采用∣通过∣构建∣收集) (了∣的∣于∣对∣及)([]+)(的)(数据∣资料∣数据集).*’ |
| Entity Type | Patterns (Regular Expressions) |
|---|---|
| Location | ‘.*(located in∣located in∣in∣form∣located in)(of) ([]+)(of)(area∣region∣mountain area∣river basin∣zone).*’ |
| Methods | ‘.*(provide∣apply∣improve∣utilize∣using∣put forward∣design∣invente∣set up ∣construct∣achieve ∣according to∣take ∣base on∣construct ∣produce∣combine ∣adopt ∣adopt∣by∣construct)(of∣of∣of∣corresponding∣of) (and)([]+)(of) (method∣model).*’ |
| Data | ‘.*(provide∣apply∣utilize∣using∣put forward∣design∣invente∣set up ∣construct∣according to ∣take∣base on∣construct∣produce∣combine∣adopt∣adopt ∣by∣construct∣collect) (of∣of∣of∣corresponding∣and) ([]+)(of)(data∣material∣data set).*’ |
Appendix B
| Paper Name | Location Entities | Methods Entities | Data Entities |
|---|---|---|---|
| 典型人类活动对边坡变形及稳定性的影响研究 | 西南地区 边坡区 采空区 | 现场调查 数值模拟 数值计算 拉格朗日差分法 | 地层岩性 降雨 |
| 降雨诱发滑坡预测模型研究 | 重庆地区 | 滑坡预测模型 概率预测模型 回归模型 滑坡发生概率模型 滑坡模型 正预报模型 | 降雨 降雨资料 滑坡资料 降雨量 |
| 面向对象的程潮铁矿矿山地质环境信息提取方法研究 | 山地 | 模糊分类方法 模糊分类 层次网络 | 遥感数据 遥感影像 遥感 影像数据 |
| Paper Name | Location Entities | Methods Entities | Data Entities |
|---|---|---|---|
| Study on the Influence of Typical Human Activities on Slope Deformation and Stability | Southwestern China Slope area Goaf | Site survey Numerical simulation Numerical calculation Lagrangian difference method | Stratigraphic lithology Rainfall |
| Research on rainfall induced landslide prediction model | Chongqing area | Landslide prediction model Probabilistic prediction model Regression model Landslide probability model Landslide model Positive forecasting model | Rainfall Rainfall data Landslide data Rainfall |
| Research on Object-Oriented Methods for Extracting Geological Environment Information of Chengchao Iron Mine | Mountain | Fuzzy classification method Fuzzy classification Hierarchical network | Remote sensing data Remote sensing images Remote sensing Image data |
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Chowdhury, G.G. Natural language processing. Annu. Rev. Inf. Sci. Technol. 2003, 37, 51–89. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Y.; Zhou, W.; Xu, Y.; Liu, J.; Tan, Y. Intelligent learning for knowledge graph towards geological data. Sci. Program. 2017, 2017, 5072427:1–5072427:13. [Google Scholar] [CrossRef]
- Bauer, F.; Kaltenböck, M. Linked Open Data: The Essentials; Ed. Mono/Monochrom: Vienna, Austria, 2011. [Google Scholar]
- Mihalcea, R.; Tarau, P. Textrank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004. [Google Scholar]
- Wang, C.; Ma, X.; Chen, J.; Chen, J. Information extraction and knowledge graph construction from geoscience literature. Comput. Geosci. 2018, 112, 112–120. [Google Scholar] [CrossRef]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the Eighteenth International Conference on Machine Learning (ICML 2001), Williamstown, MA, USA, 28 June–1 July 2001; pp. 282–289. [Google Scholar]
- Powers, D.M. Applications and explanations of Zipf’s law. In Proceedings of the Joint Conferences on New Methods in Language Processing and Computational Natural Language Learning, Sydney, Australia, 11–17 January 1998; Association for Computational Linguistics: Stroudsburg, PA, USA, 1998; pp. 151–160. [Google Scholar]
- Ramos, J. Using tf-idf to determine word relevance in document queries. In Proceedings of the First Instructional Conference on Machine Learning, Piscataway, NJ, USA, 3–8 December 2003; Volume 242, pp. 133–142. [Google Scholar]
- Shi, L.; Jianping, C.; Jie, X. Prospecting Information Extraction by Text Mining Based on Convolutional Neural Networks—A case study of the Lala Copper Deposit, China. IEEE Access 2018, 6, 52286–52297. [Google Scholar] [CrossRef]
- Chinchor, N.; Robinson, P. MUC-7 named entity task definition. In Proceedings of the 7th Conference on Message Understanding, Frascati, Italy, 16 July 1997; Volume 29. [Google Scholar]
- Yates, A.; Cafarella, M.; Banko, M.; Etzioni, O.; Broadhead, M.; Soderland, S. Textrunner: Open information extraction on the web. In Proceedings of the Human Language Technologies: The Annual Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations, New York, NY, USA, 23–25 April 2007; Association for Computational Linguistics: Stroudsburg, PA, USA, 2007; pp. 25–26. [Google Scholar]
- Agichtein, E.; Gravano, L.; Pavel, J.; Sokolova, V.; Voskoboynik, A. Snowball: A prototype system for extracting relations from large text collections. In Proceedings of the International Conference on Digital Libraries, Kyoto, Japan, 13–16 November 2000. [Google Scholar]
- Friburger, N.; Maurel, D. Finite-state transducer cascades to extract named entities in texts. Theor. Comput. Sci. 2004, 313, 93–104. [Google Scholar] [CrossRef] [Green Version]
- Sundheim, B.M. Overview of results of the MUC-6 evaluation. In Proceedings of the 6th Conference on Message Understanding, Columbia, MD, USA, 6–8 November 1995; Association for Computational Linguistics: Stroudsburg, PA, USA, 1995; pp. 13–31. [Google Scholar]
- Chinchor, N. Overview of MUC-7. In Proceedings of the Seventh Message Understanding Conference (MUC-7), Fairfax, VA, USA, 29 April–1 May 1998. [Google Scholar]
- Chieu, H.L.; Ng, H.T. Named entity recognition: A maximum entropy approach using global information. In Proceedings of the 19th International Conference on Computational Linguistics, Taipei, Taiwan, 24 August–1 September 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; Volume 1, pp. 1–7. [Google Scholar]
- Borthwick, A.; Grishman, R. A Maximum Entropy Approach to Named Entity Recognition. Ph.D. Thesis, New York University, New York, NY, USA, 1999. [Google Scholar]
- Curran, J.R.; Clark, S. Language independent NER using a maximum entropy tagger. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, Edmonton, AB, Canada, 31 May–1 June 2003; Association for Computational Linguistics: Stroudsburg, PA, USA, 2003; Volume 4, pp. 164–167. [Google Scholar]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef] [Green Version]
- Isozaki, H.; Kazawa, H. Efficient support vector classifiers for named entity recognition. In Proceedings of the 19th International Conference on Computational Linguistics, Taipei, Taiwan, 24 August–1 September 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; Volume 1, pp. 1–7. [Google Scholar]
- Kazama, J.; Makino, T.; Ohta, Y.; Tsujii, J. Tuning support vector machines for biomedical named entity recognition. In Proceedings of the ACL-02 Workshop on Natural Language Processing in the Biomedical Domain, Phildadelphia, PA, USA, 11 July 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; Volume 3, pp. 1–8. [Google Scholar]
- Ekbal, A.; Bandyopadhyay, S. Named entity recognition using support vector machine: A language independent approach. Int. J. Electr. Comput. Syst. Eng. 2010, 4, 155–170. [Google Scholar]
- Zhou, G.; Su, J. Named entity recognition using an HMM-based chunk tagger. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; pp. 473–480. [Google Scholar]
- Zhao, S. Named entity recognition in biomedical texts using an HMM model. In Proceedings of the International Joint Workshop on Natural Language Processing in Biomedicine and its Applications. Association for Computational Linguistics, Geneva, Switzerland, 28–29 August 2004; pp. 84–87. [Google Scholar]
- Zhang, J.; Shen, D.; Zhou, G.; Su, J.; Tan, C.L. Enhancing HMM-based biomedical named entity recognition by studying special phenomena. J. Biomed. Inform. 2004, 37, 411–422. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McCallum, A.; Li, W. Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, Edmonton, AB, Canada, 31 May–1 June 2003; Association for Computational Linguistics: Stroudsburg, PA, USA, 2003; Volume 4, pp. 188–191. [Google Scholar]
- Settles, B. Biomedical named entity recognition using conditional random fields and rich feature sets. In Proceedings of the International Joint Workshop on Natural Language Processing in Biomedicine and Its Applications, Geneva, Switzerland, 28–29 August 2004; Association for Computational Linguistics: Stroudsburg, PA, USA, 2004; pp. 104–107. [Google Scholar]
- Li, D.; Kipper-Schuler, K.; Savova, G. Conditional random fields and support vector machines for disorder named entity recognition in clinical texts. In Proceedings of the Workshop on Current Trends in Biomedical Natural Language Processing, Columbus, OH, USA, 19 June 2008; Association for Computational Linguistics: Stroudsburg, PA, USA, 2008; pp. 94–95. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. arXiv 2016, arXiv:1603.01360. [Google Scholar]
- Chiu, J.P.; Nichols, E. Named entity recognition with bidirectional LSTM-CNNs. arXiv 2015, arXiv:1511.08308. [Google Scholar] [CrossRef]
- Hammerton, J. Named entity recognition with long short-term memory. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, Edmonton, AB, Canada, 27 May–1 June 2003; Association for Computational Linguistics: Stroudsburg, PA, USA, 2003; Volume 4, pp. 172–175. [Google Scholar]
- Ma, X.; Hovy, E. End-to-end sequence labeling via bi-directional lstm-cnns-crf. arXiv 2016, arXiv:1603.01354. [Google Scholar]
- Xu, M.; Jiang, H.; Watcharawittayakul, S. A local detection approach for named entity recognition and mention detection. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 1237–1247. [Google Scholar]
- Zhao, D.; Huang, J.; Luo, Y.; Jia, Y. A Joint Decoding Algorithm for Named Entity Recognition. In Proceedings of the 2018 IEEE Third International Conference on Data Science in Cyberspace (DSC), Guangzhou, China, 18–21 June 2018; pp. 705–709. [Google Scholar]
- Nguyen, T.V.T.; Moschitti, A.; Riccardi, G. Kernel-based reranking for named-entity extraction. In Proceedings of the 23rd International Conference on Computational Linguistics: Posters, Beijing, China, 23–27 August 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 901–909. [Google Scholar]
- Sobhana, N.; Mitra, P.; Ghosh, S. Conditional random field based named entity recognition in geological text. Int. J. Comput. Appl. 2010, 1, 143–147. [Google Scholar] [CrossRef]
- Mikolov, T.; Karafiát, M.; Burget, L.; Černockỳ, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association, Makuhari, Chiba, Japan, 26–30 September 2010. [Google Scholar]
- Mikolov, T.; Kombrink, S.; Burget, L.; Černockỳ, J.; Khudanpur, S. Extensions of recurrent neural network language model. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 5528–5531. [Google Scholar]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. In Proceedings of the 9th International Conference on Artificial Neural Networks: ICANN’99, Edinburgh, UK, 7–10 September 1999. [Google Scholar]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory recurrent neural network architectures for large scale acoustic modeling. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Sundermeyer, M.; Schlüter, R.; Ney, H. LSTM neural networks for language modeling. In Proceedings of the Thirteenth Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Gated feedback recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2067–2075. [Google Scholar]
- Dwibedi, D.; Sermanet, P.; Tompson, J.; Diba, A.; Fayyaz, M.; Sharma, V.; Hossein Karami, A.; Mahdi Arzani, M.; Yousefzadeh, R.; Van Gool, L.; et al. Temporal Reasoning in Videos using Convolutional Gated Recurrent Units. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1111–1116. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Hecht-Nielsen, R. Theory of the backpropagation neural network. In Neural Networks for Perception; Elsevier: Amsterdam, The Netherlands, 1992; pp. 65–93. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1310–1318. [Google Scholar]
- Ratnaparkhi, A. A maximum entropy model for part-of-speech tagging. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Philadelphia, PA, USA, 17–18 May 1996. [Google Scholar]
- Baum, L.E.; Petrie, T. Statistical inference for probabilistic functions of finite state Markov chains. Ann. Math. Stat. 1966, 37, 1554–1563. [Google Scholar] [CrossRef]
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P.H. Conditional random fields as recurrent neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1529–1537. [Google Scholar]
- Christ, P.F.; Elshaer, M.E.A.; Ettlinger, F.; Tatavarty, S.; Bickel, M.; Bilic, P.; Rempfler, M.; Armbruster, M.; Hofmann, F.; D’Anastasi, M.; et al. Automatic liver and lesion segmentation in CT using cascaded fully convolutional neural networks and 3D conditional random fields. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens, Greece, 17–21 October2016; pp. 415–423. [Google Scholar]
- Hoberg, T.; Rottensteiner, F.; Feitosa, R.Q.; Heipke, C. Conditional random fields for multitemporal and multiscale classification of optical satellite imagery. IEEE Trans. Geosci. Remote. Sens. 2015, 53, 659–673. [Google Scholar] [CrossRef]
- Li, K.; Ai, W.; Tang, Z.; Zhang, F.; Jiang, L.; Li, K.; Hwang, K. Hadoop recognition of biomedical named entity using conditional random fields. IEEE Trans. Parallel Distrib. Syst. 2015, 26, 3040–3051. [Google Scholar] [CrossRef]
- Sutton, C.; McCallum, A. An introduction to conditional random fields. Found. Trends® Mach. Learn. 2012, 4, 267–373. [Google Scholar] [CrossRef]
- Marsh, E.; Perzanowski, D. MUC-7 evaluation of IE technology: Overview of results. In Proceedings of the Seventh Message Understanding Conference (MUC-7), Fairfax, Virginia, 29 April–1 May 1998. [Google Scholar]
- Kudo, T. CRF++: Yet Another CRF Toolkit. Available online: http://crfpp.sourceforge.net/ (accessed on 22 December 2019).
- Elkan, C. Log-linear models and conditional random fields. Tutor. Notes CIKM 2008, 8, 1–12. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Nadeau, D.; Sekine, S. A survey of named entity recognition and classification. Lingvisticae Investig. 2007, 30, 3–26. [Google Scholar]



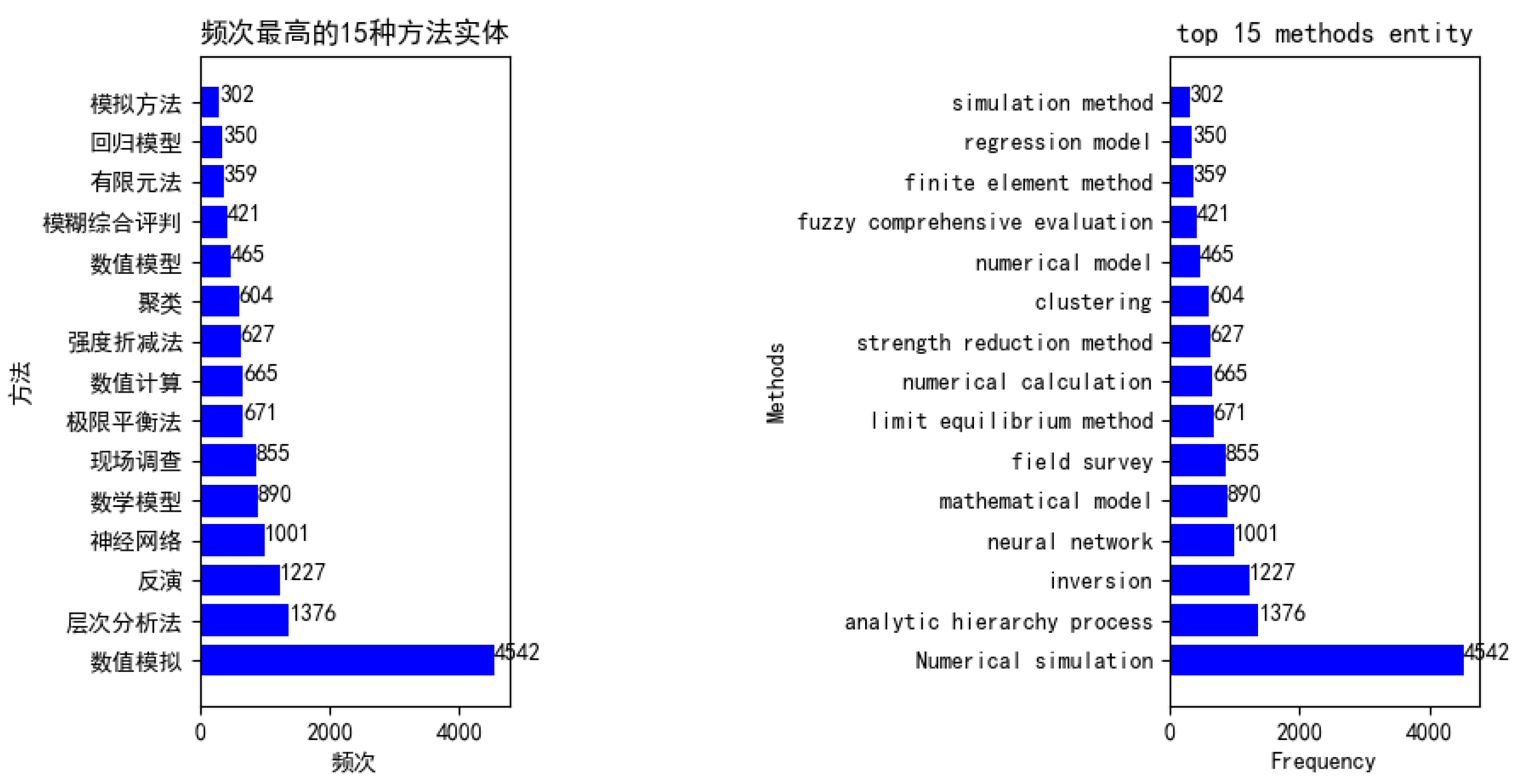
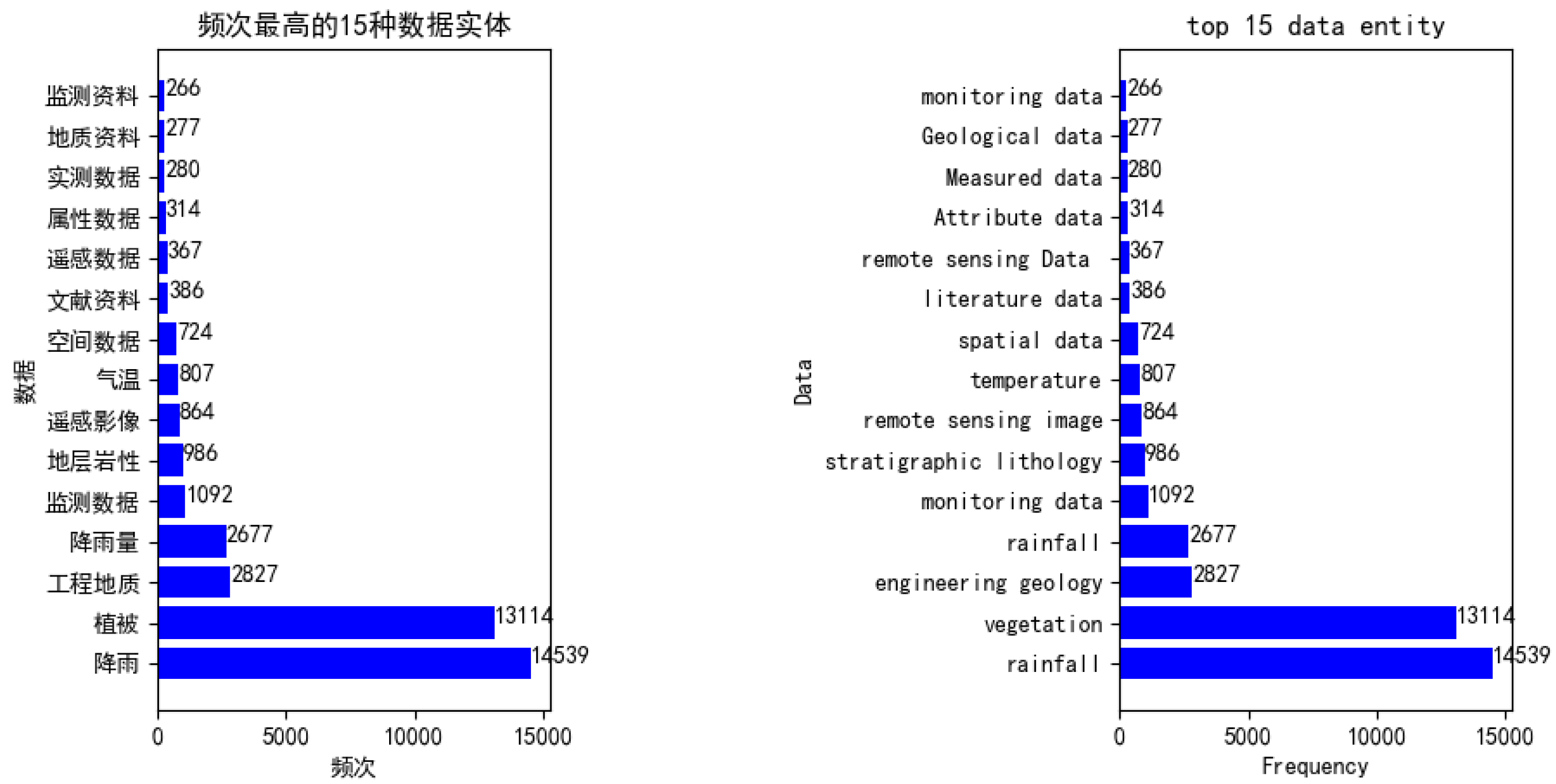

| Entity Type | Description | Tags |
|---|---|---|
| Location | descriptions of regions and location | B-LDS, I-LDS |
| Methods | methods, techniques and models | B-MED, I-MED |
| Data | data used | B-DAT, I-DAT |
| Not an entity | Not a entity | O |
| Entity Type | Patterns (Regular Expressions) |
|---|---|
| Location | ‘.*(located in∣located in∣in∣form∣located in)(of) ([]+)(of)(area∣region∣mountain area∣river basin∣zone).*’ |
| Methods | ‘.*(provide∣apply∣improve∣utilize∣using∣put forward∣design∣invente∣set up ∣construct∣achieve ∣according to∣take ∣base on∣construct ∣produce∣combine ∣adopt ∣adopt∣by∣construct)(of∣of∣of∣corresponding∣of) (and)([]+)(of) (method∣model).*’ |
| Data | ‘.*(provide∣apply∣utilize∣using∣put forward∣design∣invente∣set up ∣construct∣according to ∣take∣base on∣construct∣produce∣combine∣adopt∣adopt ∣by∣construct∣collect) (of∣of∣of∣corresponding∣and) ([]+)(of)(data∣material∣data set).*’ |
| Entity Type | Correct | All | Accuracy |
|---|---|---|---|
| Location | 1179 | 2000 | 0.5895 |
| Methods | 1467 | 2000 | 0.7335 |
| Data | 1305 | 2000 | 0.6525 |
| Tags | O O B-MED I-MED I-MED |
|---|---|
| Translation | Build a numerical analysis model |
| Tags | “O” | “B-MED” | “I-MED” | “B-DAT” | “I-DAT” | “B-LDS” | “I-LDS” |
|---|---|---|---|---|---|---|---|
| The number of the tags | 493,643 | 4230 | 13,682 | 1872 | 4550 | 6133 | 12,316 |
| Model | Evaluate | DAT | LDS | MED | Avg. |
|---|---|---|---|---|---|
| CRF | P | 0.8697 | 0.8662 | 0.7259 | 0.8210 |
| R | 0.7973 | 0.8486 | 0.6648 | 0.7765 | |
| F | 83.00 | 85.73 | 69.40 | 79.81 | |
| BiLSTM-CRF | P | 0.9220 | 0.9450 | 0.8858 | 0.9205 |
| R | 0.9510 | 0.9527 | 0.9215 | 0.9419 | |
| F | 93.63 | 94.89 | 90.33 | 93.10 | |
| Deep Multi-branch BiGRU-CRF model | P | 0.9645 | 0.9519 | 0.9135 | 0.9413 |
| R | 0.9510 | 0.9622 | 0.9100 | 0.9425 | |
| F | 95.77 | 95.70 | 91.17 | 94.19 |
| Paper Name | Location Entities | Methods Entities | Data Entities |
|---|---|---|---|
| Study on the Influence of Typical Human Activities on Slope Deformation and Stability | Southwestern China Slope area Goaf | Site survey Numerical simulation Numerical calculation Lagrangian difference method | Stratigraphic lithology Rainfall |
| Research on rainfall induced landslide prediction model | Chongqing area | Landslide prediction model Probabilistic prediction model Regression model Landslide probability model Landslide model Positive forecasting model | Rainfall Rainfall data Landslide data Rainfall |
| Research on Object-Oriented Methods for Extracting Geological Environment Information of Chengchao Iron Mine | Mountain | Fuzzy classification method Fuzzy classification Hierarchical network | Remote sensing data Remote sensing images Remote sensing Image data |
| Entities Type | Methods | Location | Data | Paper |
|---|---|---|---|---|
| The number of the entities | 8530 | 9123 | 2173 | 14,630 |
| Tags | In Location | Use Methods | Use Data | Paper Name |
|---|---|---|---|---|
| The number of the relations | 24,934 | 25,364 | 19,633 | 14,630 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, R.; Wang, L.; Yan, J.; Song, W.; Zhu, Y.; Chen, X. Deep Learning-Based Named Entity Recognition and Knowledge Graph Construction for Geological Hazards. ISPRS Int. J. Geo-Inf. 2020, 9, 15. https://doi.org/10.3390/ijgi9010015
Fan R, Wang L, Yan J, Song W, Zhu Y, Chen X. Deep Learning-Based Named Entity Recognition and Knowledge Graph Construction for Geological Hazards. ISPRS International Journal of Geo-Information. 2020; 9(1):15. https://doi.org/10.3390/ijgi9010015
Chicago/Turabian StyleFan, Runyu, Lizhe Wang, Jining Yan, Weijing Song, Yingqian Zhu, and Xiaodao Chen. 2020. "Deep Learning-Based Named Entity Recognition and Knowledge Graph Construction for Geological Hazards" ISPRS International Journal of Geo-Information 9, no. 1: 15. https://doi.org/10.3390/ijgi9010015
APA StyleFan, R., Wang, L., Yan, J., Song, W., Zhu, Y., & Chen, X. (2020). Deep Learning-Based Named Entity Recognition and Knowledge Graph Construction for Geological Hazards. ISPRS International Journal of Geo-Information, 9(1), 15. https://doi.org/10.3390/ijgi9010015