Review of Big Data and Processing Frameworks for Disaster Response Applications


Abstract
1. Introduction
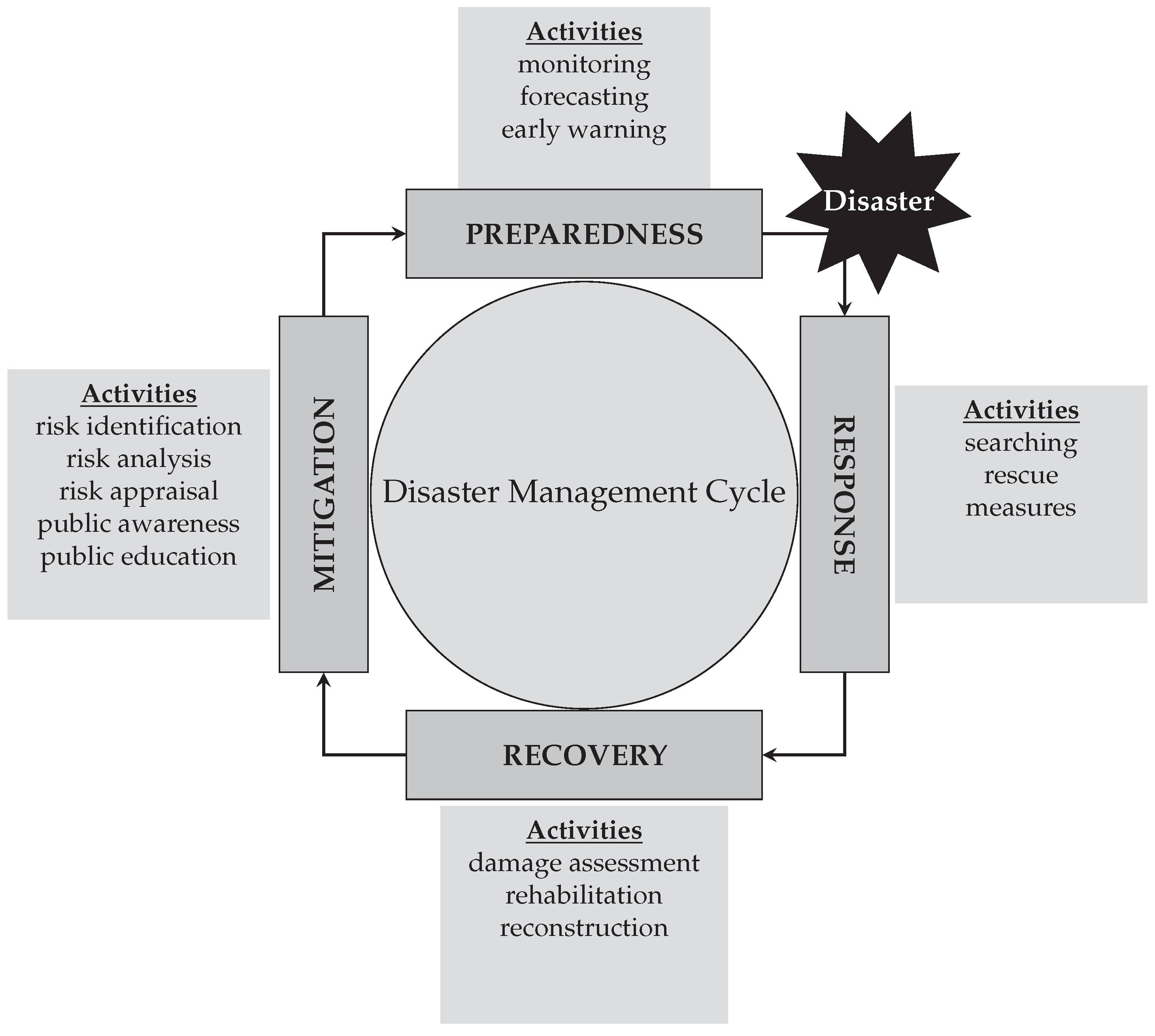
- mitigation (e.g., risk identification, analysis, public awareness and education, etc.);
- preparedness (e.g., emergency planning, training, early warning systems, etc.);
- response (e.g., searching, rescue operations, etc.); and
- recovery (e.g., rehabilitation and reconstruction).
2. Big Data for Disaster Management
2.1. Disaster Management
2.2. Disaster Response
2.3. Big Data and Disaster Response
2.3.1. Satellite Imagery
2.3.2. Wireless Sensor Web and Internet of Things (IoT)
2.3.3. Crowdsourcing and Social Media
2.3.4. GPS Traces and Mobile Call Detail Record (CDRs)
2.3.5. Simulation
2.3.6. Unnamed Aerial Vehicles (UAVs), Drones and LiDAR
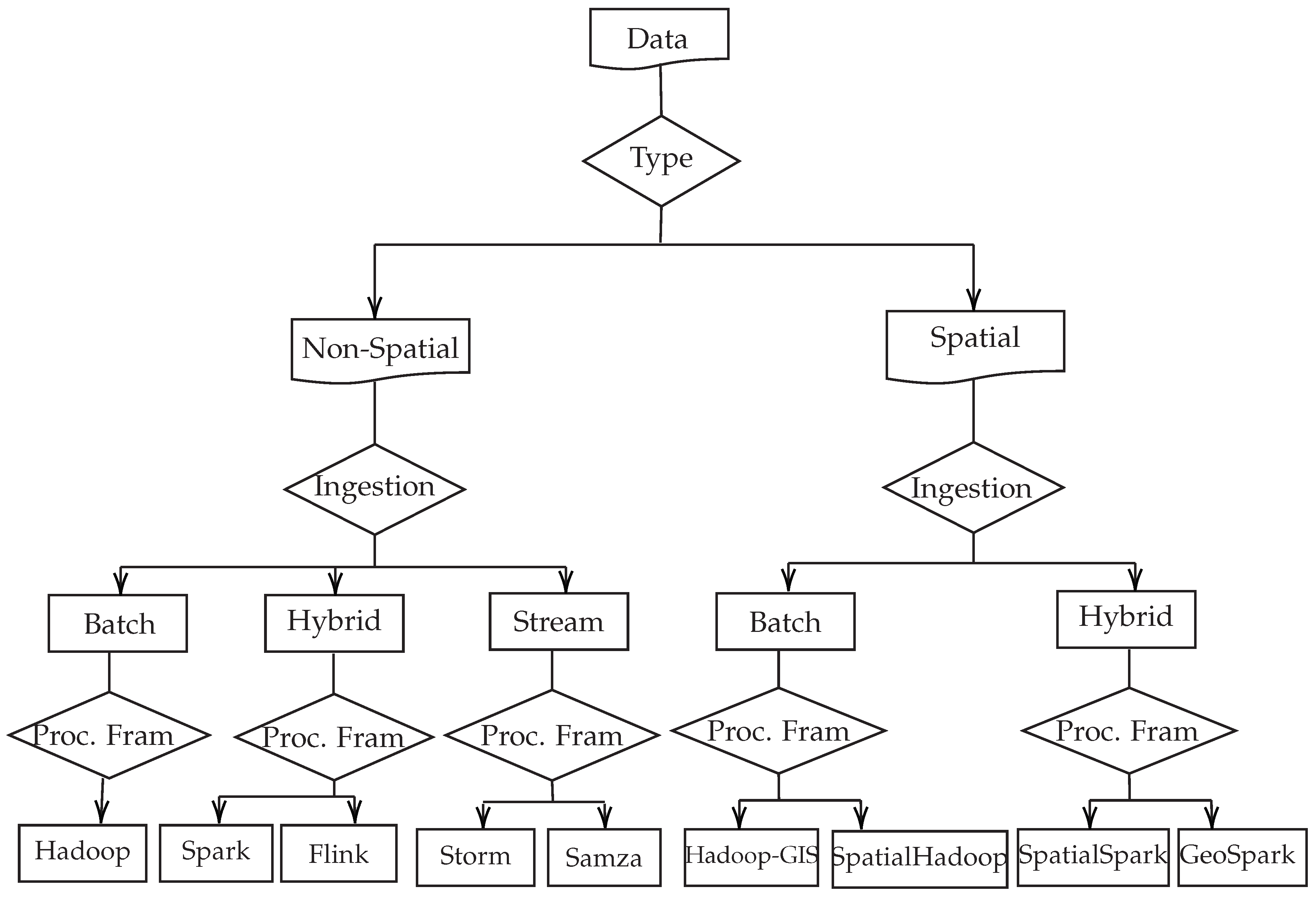
3. Big Data Processing Frameworks
3.1. Popular Big Data Processing Frameworks
3.1.1. Batch Processing Frameworks
3.1.2. Stream Processing Frameworks
Apache Storm
Apache Samza
Comparative Analysis between Storm, Storm Trident and Samza: Main Differences and Similarities
Computing Cluster Architecture
Data Flow
Data Processing
Fault-Tolerance
Latency
Scalability
Back-pressure Mechanism
Programming Languages
Support for Machine Learning
3.1.3. Hybrid Processing Frameworks
Apache Spark
Apache Flink
Comparative Analysis between Spark and Flink: Main Differences and Similarities
Computing Cluster Architecture
Data Flow
Data Processing Model
Fault-Tolerance
Latency
Scalability
Back-Pressure Mechanism
Programming Languages
Machine Learning
3.2. Big Spatial Data Processing Frameworks
3.2.1. Popular Hadoop-Based Spatial Processing Frameworks
Hadoop-GIS
SpatialHadoop
3.2.2. Popular Hadoop-based Spatial Processing Frameworks
SpatialSpark
GeoSpark
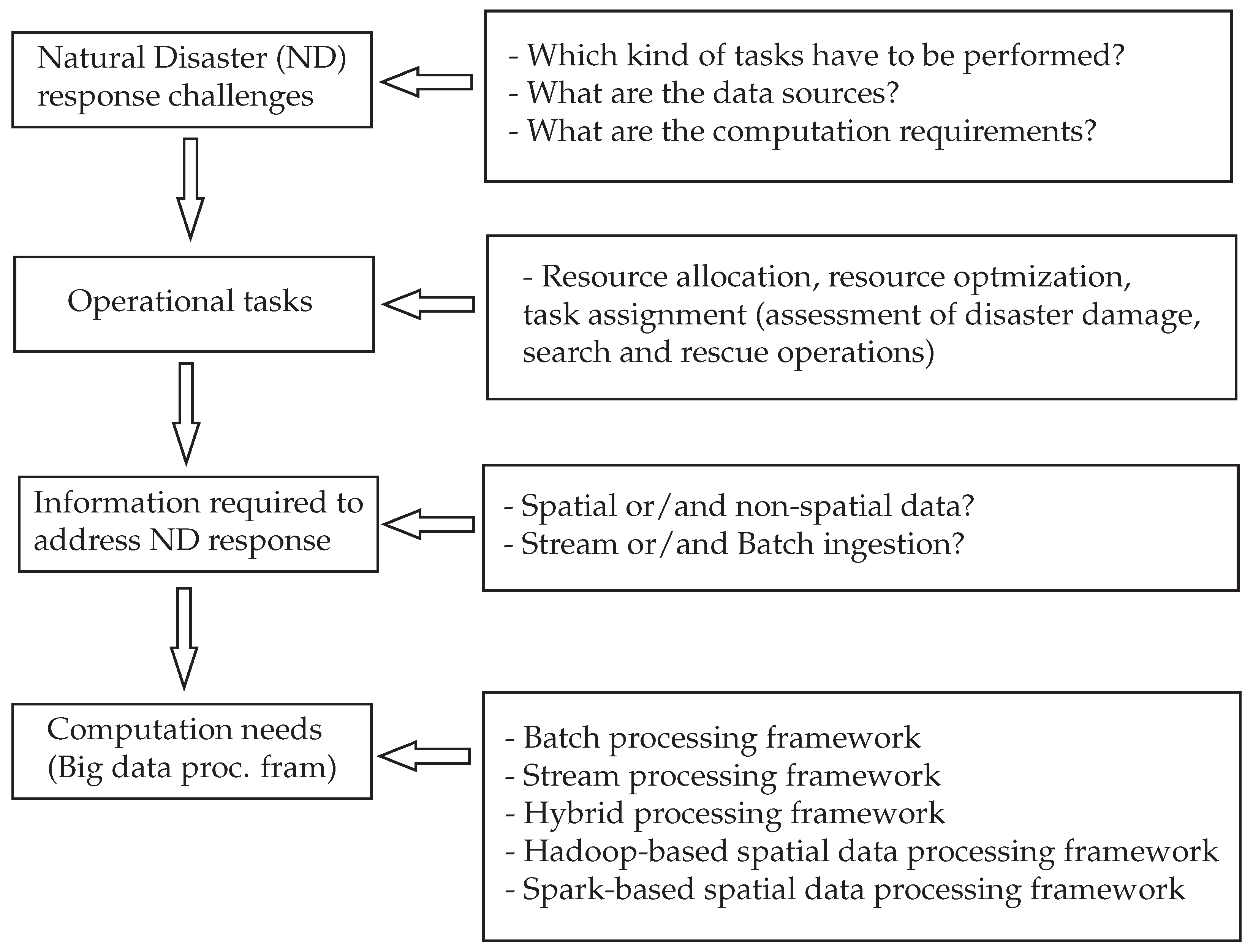
4. Big Data and Processing Frameworks for Disaster Response
4.1. Link between Big Data and Processing Frameworks for Disaster Response
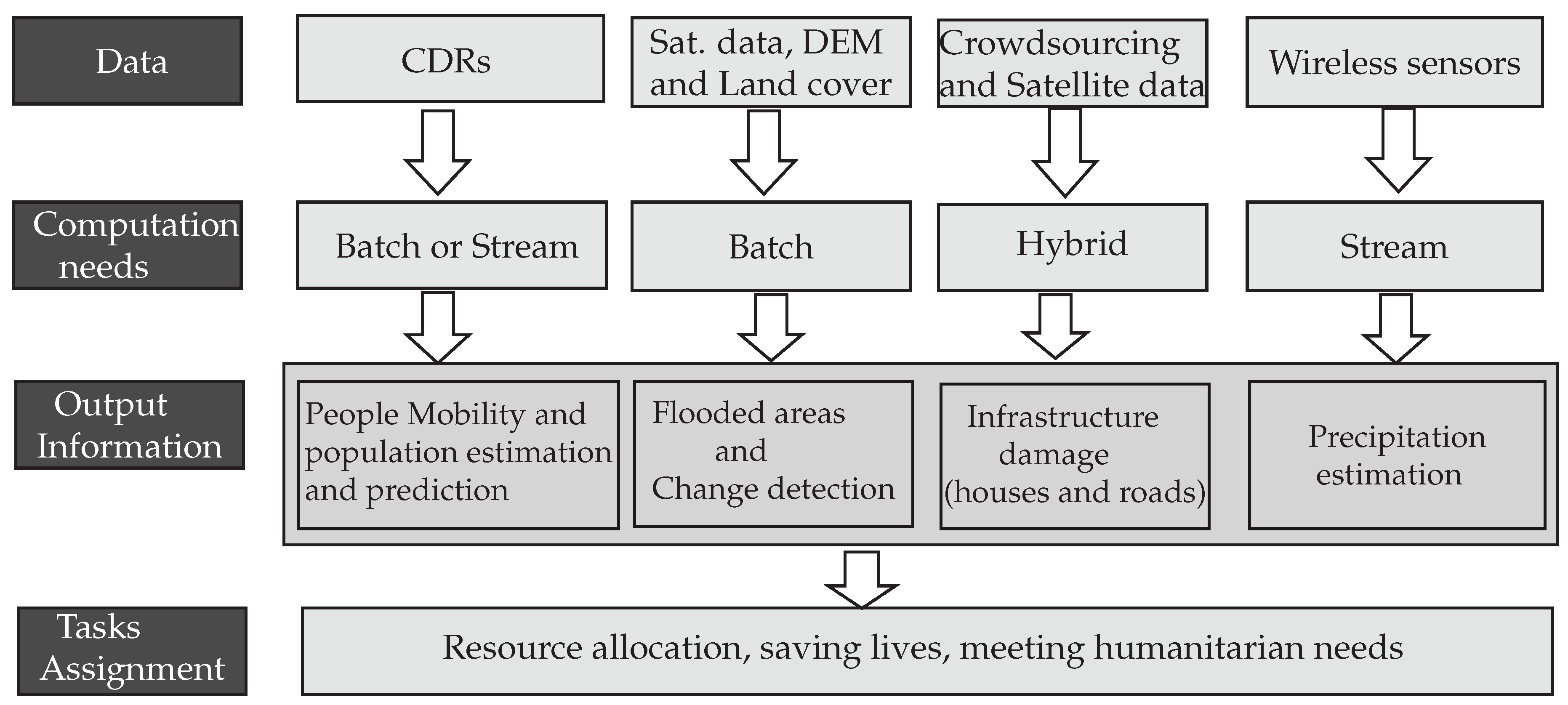
4.2. Use Case—Big Data and Processing Framework for Flooding Response
5. Conclusions and Future Directions of Research
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Olivier, J.G.; Schure, K.; Peters, J. Trends in Global CO2 and Total Greenhouse Gas Emissions; PBL Netherlands Environmental Assessment Agency: The Hague, The Netherlands, 2017; p. 5. [Google Scholar]
- Radford, T. Human Carbon Emissions to Rise in 2019. 2019. Available online: https://climatenewsnetwork.net/human-carbon-emissions-to-rise-in-2019/ (accessed on 3 July 2019).
- Blaikie, P.; Cannon, T.; Davis, I.; Wisner, B. At Risk: Natural Hazards, People’s Vulnerability and Disasters; Routledge: New York, NY, USA, 2005. [Google Scholar]
- Bank, W.; Nations, U. Natural Hazards, Unnatural Disasters: The Economics of Effective Prevention; The World Bank: Washington, DC, USA, 2010. [Google Scholar]
- IFRC. Resilience: Saving Lives Today, Investing for Tomorrow; World Disasters Report; International Federation of Red Cross and Red Crescent Societies: Geneva, Switzerland, 2016. [Google Scholar]
- USAID. SOUTHERN AFRICA—TROPICAL CYCLONE IDAI. 2019. Available online: https://www.usaid.gov/sites/default/files/documents/1866/04.25.19_-_USAID-DCHA_Southern_Africa_Tropical_Cyclone_Idai_Fact_Sheet_9.pdf (accessed on 20 May 2019).
- Celik, S.; Corbacioglu, S. Role of information in collective action in dynamic disaster environments. Disasters 2010, 34, 137–154. [Google Scholar] [CrossRef] [PubMed]
- Sutanta, H.; Bishop, I.; Rajabifard, A. Integrating Spatial Planning and Disaster Risk Reduction at the Local Level in the Context of Spatially Enabled Government; Leuven University Press: Leuven, Belgium, 2010. [Google Scholar]
- Habiba, M.; Akhter, S. A cloud based natural disaster management system. In International Conference on Grid and Pervasive Computing; Springer: Berlin/Heidelberg, Germany, 2013; pp. 152–161. [Google Scholar]
- Voss, P. Choosing the Right Big Data Execution Framework: Why One Size Doesn’t Fit All. 2015. Available online: https://venturebeat.com/2015/01/27/choosing-the-right-big-data-execution-framework-why-one-size-doesnt-fit-all/ (accessed on 12 May 2019).
- Selamat, N.S. An Overview of Big Data Usage in Disaster Management. J. Inf. Syst. Res. Innov. 2017, 11, 35–40. [Google Scholar]
- Arslan, M.; Roxin, A.M.; Cruz, C.; Ginhac, D. A Review on Applications of Big Data for Disaster Management. In Proceedings of the 2017 13th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Jaipur, India, 4–7 December 2017; pp. 370–375. [Google Scholar]
- Yu, M.; Yang, C.; Li, Y. Big data in natural disaster management: A review. Geosciences 2018, 8, 165. [Google Scholar] [CrossRef]
- Norris, A.C.; Martinez, S.; Labaka, L.; Madanian, S.; Gonzalez, J.J.; Parry, D. Disaster E-Health: A New Paradigm for Collaborative Healthcare in Disasters. In Proceedings of the ISCRAM 2015, Kristiansand, Norway, 24–27 May 2015. [Google Scholar]
- Modh, S. Introduction to Disaster Management; Macmillan: Mumbai, India, 2009. [Google Scholar]
- Poser, K.; Dransch, D. Volunteered geographic information for disaster management with application to rapid flood damage estimation. Geomatica 2010, 64, 89–98. [Google Scholar]
- Taylor-Sakyi, K. Big Data: Understanding Big Data. arXiv, 2016; arXiv:abs/1601.04602. [Google Scholar]
- Kozak, M.; LaClair, V. LiDAR The “I” in Big Data. 2012. Available online: https://eijournal.com/print/articles/lidar-the-i-in-big-data (accessed on 15 July 2019).
- Furht, B.; Villanustre, F. Introduction to big data. In Big Data Technologies and Applications; Springer: Cham, Switzerland, 2016; pp. 3–11. [Google Scholar]
- Sharma, S.; Mangat, V. Technology and trends to handle big data: Survey. In Proceedings of the 2015 Fifth International Conference on Advanced Computing & Communication Technologies (ACCT), Haryana, India, 21–22 February 2015; pp. 266–271. [Google Scholar]
- Fredriksson, C.; Mubarak, F.; Tuohimaa, M.; Zhan, M. Big data in the public sector: A systematic literature review. Scand. J. Public Adm. 2017, 21, 39–62. [Google Scholar]
- De Mauro, A.; Greco, M.; Grimaldi, M. What is big data? A consensual definition and a review of key research topics. AIP Conf. Proc. 2015, 1644, 97–104. [Google Scholar]
- Pradhan, B.; Tehrany, M.S.; Jebur, M.N. A new semiautomated detection mapping of flood extent from TerraSAR-X satellite image using rule-based classification and taguchi optimization techniques. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4331–4342. [Google Scholar] [CrossRef]
- Raspini, F.; Bardi, F.; Bianchini, S.; Ciampalini, A.; Del Ventisette, C.; Farina, P.; Ferrigno, F.; Solari, L.; Casagli, N. The contribution of satellite SAR-derived displacement measurements in landslide risk management practices. Nat. Hazards 2017, 86, 327–351. [Google Scholar] [CrossRef]
- Pesaresi, M.; Ehrlich, D.; Ferri, S.; Florczyk, A.; Freire, S.; Haag, F.; Halkia, M.; Julea, A.; Kemper, T.; Soille, P. Global human settlement analysis for disaster risk reduction. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 40, 837–843. [Google Scholar] [CrossRef]
- McCallum, I.; Liu, W.; See, L.; Mechler, R.; Keating, A.; Hochrainer-Stigler, S.; Mochizuki, J.; Fritz, S.; Dugar, S.; Arestegui, M.; et al. Technologies to support community flood disaster risk reduction. Int. J. Dis. Risk Sci. 2016, 7, 198–204. [Google Scholar] [CrossRef]
- Chen, D.; Liu, Z.; Wang, L.; Dou, M.; Chen, J.; Li, H. Natural disaster monitoring with wireless sensor networks: A case study of data-intensive applications upon low-cost scalable systems. Mobile Netw. Appl. 2013, 18, 651–663. [Google Scholar] [CrossRef]
- Khalil, I.M.; Khreishah, A.; Ahmed, F.; Shuaib, K. Dependable wireless sensor networks for reliable and secure humanitarian relief applications. Ad Hoc Netw. 2014, 13, 94–106. [Google Scholar] [CrossRef]
- Sakhardande, P.; Hanagal, S.; Kulkarni, S. Design of disaster management system using IoT based interconnected network with smart city monitoring. In Proceedings of the International Conference on Internet of Things and Applications (IOTA), Pune, India, 22–24 January 2016; pp. 185–190. [Google Scholar]
- Ray, P.P.; Mukherjee, M.; Shu, L. Internet of things for disaster management: State-of-the-art and prospects. IEEE Access 2017, 5, 18818–18835. [Google Scholar] [CrossRef]
- Stefanidis, A.; Crooks, A.; Radzikowski, J. Harvesting ambient geospatial information from social media feeds. GeoJournal 2013, 78, 319–338. [Google Scholar] [CrossRef]
- Kafi, K.M.; Gibril, M.B.A. GPS Application in Disaster Management: A Review. Asian J. Appl. Sci. 2016, 4, 63–67. [Google Scholar]
- Song, X.; Zhang, Q.; Sekimoto, Y.; Shibasaki, R. Prediction of human emergency behavior and their mobility following large-scale disaster. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 5–14. [Google Scholar]
- Pastor-Escuredo, D.; Morales-Guzmán, A.; Torres-Fernández, Y.; Bauer, J.M.; Wadhwa, A.; Castro-Correa, C.; Romanoff, L.; Lee, J.G.; Rutherford, A.; Frias-Martinez, V.; et al. Flooding through the lens of mobile phone activity. arXiv, 2014; arXiv:1411.6574. [Google Scholar]
- Wilson, R.; zu Erbach-Schoenberg, E.; Albert, M.; Power, D.; Tudge, S.; Gonzalez, M.; Guthrie, S.; Chamberlain, H.; Brooks, C.; Hughes, C.; et al. Rapid and near real-time assessments of population displacement using mobile phone data following disasters: The 2015 Nepal Earthquake. PLoS Curr. 2016, 8. [Google Scholar] [CrossRef]
- Jain, S.; McLean, C. Simulation for emergency response: A framework for modeling and simulation for emergency response. In Proceedings of the 35th Conference on Winter Simulation: Driving Innovation, Winter Simulation Conference, New Orleans, LA, USA, 7–10 December 2003; pp. 1068–1076. [Google Scholar]
- Massaguer, D.; Balasubramanian, V.; Mehrotra, S.; Venkatasubramanian, N. Multi-agent simulation of disaster response. In Proceedings of the First International Workshop on Agent Technology for Disaster Management, Hakodate, Japan, 8–12 May 2006; pp. 124–130. [Google Scholar]
- Dou, M.; Chen, J.; Chen, D.; Chen, X.; Deng, Z.; Zhang, X.; Xu, K.; Wang, J. Modeling and simulation for natural disaster contingency planning driven by high-resolution remote sensing images. Future Gener. Comput. Syst. 2014, 37, 367–377. [Google Scholar] [CrossRef]
- Restas, A. Drone applications for supporting disaster management. World J. Eng. Technol. 2015, 3, 316–321. [Google Scholar] [CrossRef]
- Nonami, K.; Kendoul, F.; Suzuki, S.; Wang, W.; Nakazawa, D. Introduction. In Autonomous Flying Robots; Springer: Tokyo, Japan, 2010; pp. 1–29. [Google Scholar]
- Trinder, J.; Salah, M. Airborne Lidar as a Tool for Disaster Monitoring and Management. In Proceedings of the GeoInformation for Disaster Management, Antalya, Turkey, 3–8 May 2011. [Google Scholar]
- Chandarana, P.; Vijayalakshmi, M. Big data analytics frameworks. In Proceedings of the 2014 International Conference on Circuits, Systems, Communication and Information Technology Applications (CSCITA), Mumbai, India, 4–5 April 2014; pp. 430–434. [Google Scholar]
- Inoubli, W.; Aridhi, S.; Mezni, H.; Jung, A. Big Data Frameworks: A Comparative Study. arXiv, 2016; arXiv:abs/1610.09962. [Google Scholar]
- García-Gil, D.; Ramírez-Gallego, S.; García, S.; Herrera, F. A comparison on scalability for batch big data processing on Apache Spark and Apache Flink. Big Data Anal. 2017, 2, 1. [Google Scholar] [CrossRef]
- Alkatheri, S.; Abbas, S.; Siddiqui, M. A Comparative Study of Big Data Frameworks. Int. J. Comput. Sci. Inf. Secur. 2019, 17, 66–73. [Google Scholar]
- Gurusamy, V.; Kannan, S.; Nandhini, K. The Real Time Big Data Processing Framework: Advantages and Limitations. Int. J. Comput. Sci. Eng. 2017, 5, 305–312. [Google Scholar] [CrossRef]
- Balkenende, M. The Big Data Debate: Batch Versus Stream Processing. 2018. Available online: https://thenewstack.io/the-big-data-debate-batch-processing-vs-streaming-processing/ (accessed on 10 July 2019).
- Dittrich, J.; Quiané-Ruiz, J.A. Efficient big data processing in Hadoop MapReduce. Proc. VLDB Endow. 2012, 5, 2014–2015. [Google Scholar] [CrossRef]
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The hadoop distributed file system. In Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Lake Tahoe, NV, USA, 3–7 May 2010; pp. 1–10. [Google Scholar]
- Kulkarni, A.P.; Khandewal, M. Survey on Hadoop and Introduction to YARN. Int. J. Emerg. Technol. Adv. Eng. 2014, 4, 82–87. [Google Scholar]
- Abadi, D.J.; Ahmad, Y.; Balazinska, M.; Cetintemel, U.; Cherniack, M.; Hwang, J.H.; Lindner, W.; Maskey, A.; Rasin, A.; Ryvkina, E.; et al. The design of the borealis stream processing engine. CIDR 2005, 5, 277–289. [Google Scholar]
- Akidau, T.; Balikov, A.; Bekiroğlu, K.; Chernyak, S.; Haberman, J.; Lax, R.; McVeety, S.; Mills, D.; Nordstrom, P.; Whittle, S. MillWheel: Fault-tolerant stream processing at internet scale. Proc. VLDB Endow. 2013, 6, 1033–1044. [Google Scholar] [CrossRef]
- Ananthanarayanan, R.; Basker, V.; Das, S.; Gupta, A.; Jiang, H.; Qiu, T.; Reznichenko, A.; Ryabkov, D.; Singh, M.; Venkataraman, S. Photon: Fault-tolerant and scalable joining of continuous data streams. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22–27 June 2013; pp. 577–588. [Google Scholar]
- Toshniwal, A.; Taneja, S.; Shukla, A.; Ramasamy, K.; Patel, J.M.; Kulkarni, S.; Jackson, J.; Gade, K.; Fu, M.; Donham, J.; et al. Storm@ twitter. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; pp. 147–156. [Google Scholar]
- Kamburugamuve, S.; Fox, G.; Leake, D.; Qiu, J. Survey of distributed stream processing for large stream sources. Grids Ucs Indiana Edu. 2013, 2, 1–16. [Google Scholar]
- Inoubli, W.; Aridhi, S.; Mezni, H.; Maddouri, M.; Nguifo, E. A Comparative Study on Streaming Frameworks for Big Data. In Proceedings of the VLDB 2018-44th International Conference on Very Large Data Bases: Workshop LADaS-Latin American Data Science, Rio de Janeiro, Brazil, 27 August 2018; pp. 1–8. [Google Scholar]
- Wingerath, W.; Gessert, F.; Friedrich, S.; Ritter, N. Real-time stream processing for Big Data. Inf. Technol. 2016, 58, 186–194. [Google Scholar] [CrossRef]
- Noghabi, S.A.; Paramasivam, K.; Pan, Y.; Ramesh, N.; Bringhurst, J.; Gupta, I.; Campbell, R.H. Samza: Stateful scalable stream processing at LinkedIn. Proc. VLDB Endow. 2017, 10, 1634–1645. [Google Scholar] [CrossRef]
- Grover, M.; Malaska, T.; Seidman, J.; Shapira, G. Hadoop Application Architectures: Designing Real-World Big Data Applications; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2015. [Google Scholar]
- Ericsson. Trident—Benchmarking performance. 2014. Available online: https://www.ericsson.com/research-blog/trident-benchmarking-performance/ (accessed on 7 April 2019).
- Nalya, A.; Jain, A. Using Trident-ML. 2018. Available online: https://www.oreilly.com/library/view/learning-storm/9781783981328/ch09s02.html (accessed on 15 July 2019).
- Meng, X.; Bradley, J.; Yavuz, B.; Sparks, E.; Venkataraman, S.; Liu, D.; Freeman, J.; Tsai, D.; Amde, M.; Owen, S.; et al. MLlib: Machine Learning in Apache Spark. J. Mach. Learn. Res. 2016, 17, 1–7. [Google Scholar]
- Zaharia, M.; Das, T.; Li, H.; Hunter, T.; Shenker, S.; Stoica, I. Discretized streams: Fault-tolerant streaming computation at scale. In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles, Farmington, PA, USA, 3–6 November 2013; pp. 423–438. [Google Scholar]
- Armbrust, M.; Xin, R.S.; Lian, C.; Huai, Y.; Liu, D.; Bradley, J.K.; Meng, X.; Kaftan, T.; Franklin, M.J.; Ghodsi, A.; et al. Spark sql: Relational data processing in spark. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Melbourne, Victoria, Australia, 31 May–4 June 2015; pp. 1383–1394. [Google Scholar]
- Xin, R.S.; Gonzalez, J.E.; Franklin, M.J.; Stoica, I. Graphx: A resilient distributed graph system on spark. In Proceedings of the First International Workshop on Graph Data Management Experiences and Systems, New York, NY, USA, 23 June 2013; p. 2. [Google Scholar]
- Carbone, P.; Katsifodimos, A.; Ewen, S.; Markl, V.; Haridi, S.; Tzoumas, K. Apache flink: Stream and batch processing in a single engine. Bull. IEEE Comput. Soc. Tech. Community Data Eng. 2015, 36, 28–38. [Google Scholar]
- Kanchana, R.; Shashikumar, D. A Survey on Big Data Stream Processing Technological; International Journal of Engineering Development and Research: Karnataka, India, 2017. [Google Scholar]
- Aridhi, S.; Nguifo, E.M. Big graph mining: Frameworks and techniques. Big Data Res. 2016, 6, 1–10. [Google Scholar] [CrossRef][Green Version]
- Venkataraman, S.; Panda, A.; Ousterhout, K. Low Latency Execution For Apache Spark. 2016. Available online: https://databricks.com/session/low-latency-execution-for-apache-spark (accessed on 10 April 2019).
- Tzoumas, K. High-throughput, low-latency, and exactly-once stream processing with Apache Flink. 2015. Available online: https://data-artisans.com/blog/high-throughput-low-latency-and-exactly-once-stream-processing-with-apache-flink (accessed on 10 April 2019).
- Jiang, L. Enable Back Pressure To Make Your Spark Streaming Application Production Ready. 2017. Available online: https://www.linkedin.com/pulse/enable-back-pressure-make-your-spark-streaming-production-lan-jiang (accessed on 10 April 2019).
- Celebi, U. Enable Back Pressure To Make Your Spark Streaming Application Production Ready. 2015. Available online: https://data-artisans.com/blog/how-flink-handles-backpressure (accessed on 10 April 2019).
- NZGO. What Is Geospatial Information? 2015. Available online: https://www.linz.govt.nz/about-linz/our-vision-purpose-and-values/our-location-strategy/what-geospatial-information (accessed on 7 July 2019).
- Lu, J.; Güting, R.H. Parallel secondo: Boosting database engines with hadoop. In Proceedings of the 2012 IEEE 18th International Conference on Parallel and Distributed Systems, Singapore, 17–19 December 2012; pp. 738–743. [Google Scholar]
- Aji, A.; Wang, F.; Vo, H.; Lee, R.; Liu, Q.; Zhang, X.; Saltz, J. Hadoop gis: A high performance spatial data warehousing system over mapreduce. Proc. VLDB Endow. 2013, 6, 1009–1020. [Google Scholar] [CrossRef]
- Eldawy, A.; Mokbel, M.F. Spatialhadoop: A mapreduce framework for spatial data. In Proceedings of the 2015 IEEE 31st international conference on Data Engineering, Seoul, Korea, 13–17 April 2015; pp. 1352–1363. [Google Scholar]
- Sriharsha, R. Magellan: Geospatial Analytics on Spark. 2015. Available online: https://github.com/harsha2010/magellan (accessed on 9 July 2019).
- You, S.; Zhang, J.; Gruenwald, L. Large-scale spatial join query processing in cloud. In Proceedings of the 2015 31st IEEE International Conference on Data Engineering Workshops, Seoul, Korea, 13–17 April 2015; pp. 34–41. [Google Scholar]
- Hughes, J.N.; Annex, A.; Eichelberger, C.N.; Fox, A.; Hulbert, A.; Ronquest, M. Geomesa: A distributed architecture for spatio-temporal fusion. Proc. SPIE 2015, 9473, 94730F. [Google Scholar]
- Yu, J.; Wu, J.; Sarwat, M. Geospark: A cluster computing framework for processing large-scale spatial data. In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2015; p. 70. [Google Scholar]
- Xie, D.; Li, F.; Yao, B.; Li, G.; Zhou, L.; Guo, M. Simba: Efficient in-memory spatial analytics. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; pp. 1071–1085. [Google Scholar]
- Hagedorn, S.; Räth, T. Efficient Spatio-Temporal Event Processing with STARK. In Proceedings of the 20th International Conference on Extending Database Technology (EDBT), Venice, Italy, 21–24 March 2017. [Google Scholar]
- Chen, X.; Vo, H.; Aji, A.; Wang, F. High performance integrated spatial big data analytics. In Proceedings of the 3rd ACM SIGSPATIAL International Workshop on Analytics for Big Geospatial Data, Dallas, TX, USA, 4 November 2014; pp. 11–14. [Google Scholar]
- Eldawy, A.; Mokbel, M.F. Analyze Your Spatial Data Efficiently Data Efficiently. 2017. Available online: http://spatialhadoop.cs.umn.edu/ (accessed on 13 May 2019).
- Eldawy, A.; Mokbel, M.F.; Jonathan, C. HadoopViz: A MapReduce framework for extensible visualization of big spatial data. In Proceedings of the 2016 IEEE 32nd International Conference on Data Engineering (ICDE), Helsinki, Finland, 16–20 May 2016; pp. 601–612. [Google Scholar]
- Lenka, R.K.; Barik, R.K.; Gupta, N.; Ali, S.M.; Rath, A.; Dubey, H. Comparative analysis of SpatialHadoop and GeoSpark for geospatial big data analytics. In Proceedings of the 2016 2nd International Conference on Contemporary Computing and Informatics (IC3I), Greater Noida, India, 14–17 December 2016; pp. 484–488. [Google Scholar]
- Yu, J.; Zhang, Z.; Sarwat, M. Spatial data management in apache spark: The GeoSpark perspective and beyond. GeoInformatica 2018. [Google Scholar] [CrossRef]
- You, S.; Zhang, J.; Gruenwald, L. Spatial join query processing in cloud: Analyzing design choices and performance comparisons. In Proceedings of the 2015 44th International Conference on Parallel Processing Workshops (ICPPW), Beijing, China, 1–4 September 2015; pp. 90–97. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Disaster Management Sub-Phase | Data Source | Application Fields |
|---|---|---|
| Damage Assessment | Satellite imagery, UAV and drones, social media, Wireless Sensor Web (WSW) and IoT, crowdsourcing | Earthquake, flood, typhoon, hurricane |
| Post-Disaster Coordination and Response | Social media, satellite imagery, WSW and IoT, UAV, crowdsourcing, simulation, LiDAR, GPS and CDRs, and combination of various data types | General natural disaster, flood and earthquake |
| Framework | Storm | Trident | Samza |
|---|---|---|---|
| Computing cluster architecture | Nimbus | Nimbus | Hadoop YARN and Kafka |
| Data Flow | cyclic graph (stream - spout - bolt - bolt ... output) | directed acyclic graphs (DAGs) | Kafka - Kafka job - Kafka |
| Data Processing Model | at-least-once | exactly-once | at-least-once |
| Fault-Tolerance | Yes | Yes | Yes |
| Latency | several milliseconds | several milliseconds for small batches | several milliseconds |
| Scalability | Yes | User defined parallel processing | Yes |
| Back-pressure mechanism | Yes | Yes | No (uses buffering) |
| Programming Languages | Java API with adapters for Python, Ruby and Perl | Java API with adapters for Python, Ruby and Perl | Mostly uses Java |
| Support for Machine Learning | compatible with SAMOA API | Trident-ML | compatible with SAMOA API |
| Framework | Spark | Flink |
|---|---|---|
| Computing cluster architecture | Hadoop YARN and Apache Mesos | Hadoop YARN and Kafka |
| Data Flow | simple queue of RDDs called DStream processed one-at-a-time using micro-batching cluster | stream system (operators) sinks |
| Data Processing Model | exactly-once | exactly-once |
| Fault-Tolerance | Yes (using lineage) | Yes (generating snapshots) |
| Latency | high | low |
| Scalability | Yes (on user demand) | Yes (parallelize the tasks that can be done in parallel) |
| Back-pressure mechanism | Yes | Yes |
| Programming Languages | API for Scala, Java and Python | Java and Scala |
| Support for Machine Learning | Yes (SparkMLlib) | Yes (FlinkML) |
| Feature | Hadoop-GIS | SpatialHadoop |
|---|---|---|
| DataFrame API | ✗ | ✗ |
| In-memory processing | ✗ | ✗ |
| Spatial Partitioning | SATO | Multiple |
| Spatial Indexing | R-Tree | R-/Quad-Tree |
| KNN query | ✓ | ✓ |
| Query optimizer | ✗ | ✗ |
| Distance query | ✓ | ✓ |
| Distance join | ✓ | ✓ |
| Filter (Contains) | ✓ | ✓ |
| Filter (ContainedBy) | ✓ | ✓ |
| Filter (Intersects) | ✓ | ✓ |
| Filter (WithinDistance) | ✓ | ✓ |
| Feature | SpatialSpark | GeoSpark |
|---|---|---|
| DataFrame API | ✗ | ✓ |
| In-memory processing | ✓ | ✓ |
| Spatial Partitioning | Multiple | Multiple |
| Spatial Indexing | R-Tree | R-/Quad-Tree |
| KNN query | ✗ | ✓ |
| Query optimizer | ✗ | ✓ |
| Distance query | ✓ | ✓ |
| Distance join | ✓ | ✓ |
| Filter (Contains) | ✓ | ✓ |
| Filter (ContainedBy) | ✓ | ✗ |
| Filter (Intersects) | ✓ | ✓ |
| Filter (WithinDistance) | ✓ | ✗ |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cumbane, S.P.; Gidófalvi, G. Review of Big Data and Processing Frameworks for Disaster Response Applications. ISPRS Int. J. Geo-Inf. 2019, 8, 387. https://doi.org/10.3390/ijgi8090387
Cumbane SP, Gidófalvi G. Review of Big Data and Processing Frameworks for Disaster Response Applications. ISPRS International Journal of Geo-Information. 2019; 8(9):387. https://doi.org/10.3390/ijgi8090387
Chicago/Turabian StyleCumbane, Silvino Pedro, and Győző Gidófalvi. 2019. "Review of Big Data and Processing Frameworks for Disaster Response Applications" ISPRS International Journal of Geo-Information 8, no. 9: 387. https://doi.org/10.3390/ijgi8090387
APA StyleCumbane, S. P., & Gidófalvi, G. (2019). Review of Big Data and Processing Frameworks for Disaster Response Applications. ISPRS International Journal of Geo-Information, 8(9), 387. https://doi.org/10.3390/ijgi8090387