Recommendation of Heterogeneous Cultural Heritage Objects for the Promotion of Tourism

 ,
,  , , ,
, , ,
Abstract
1. Introduction
2. Related Work
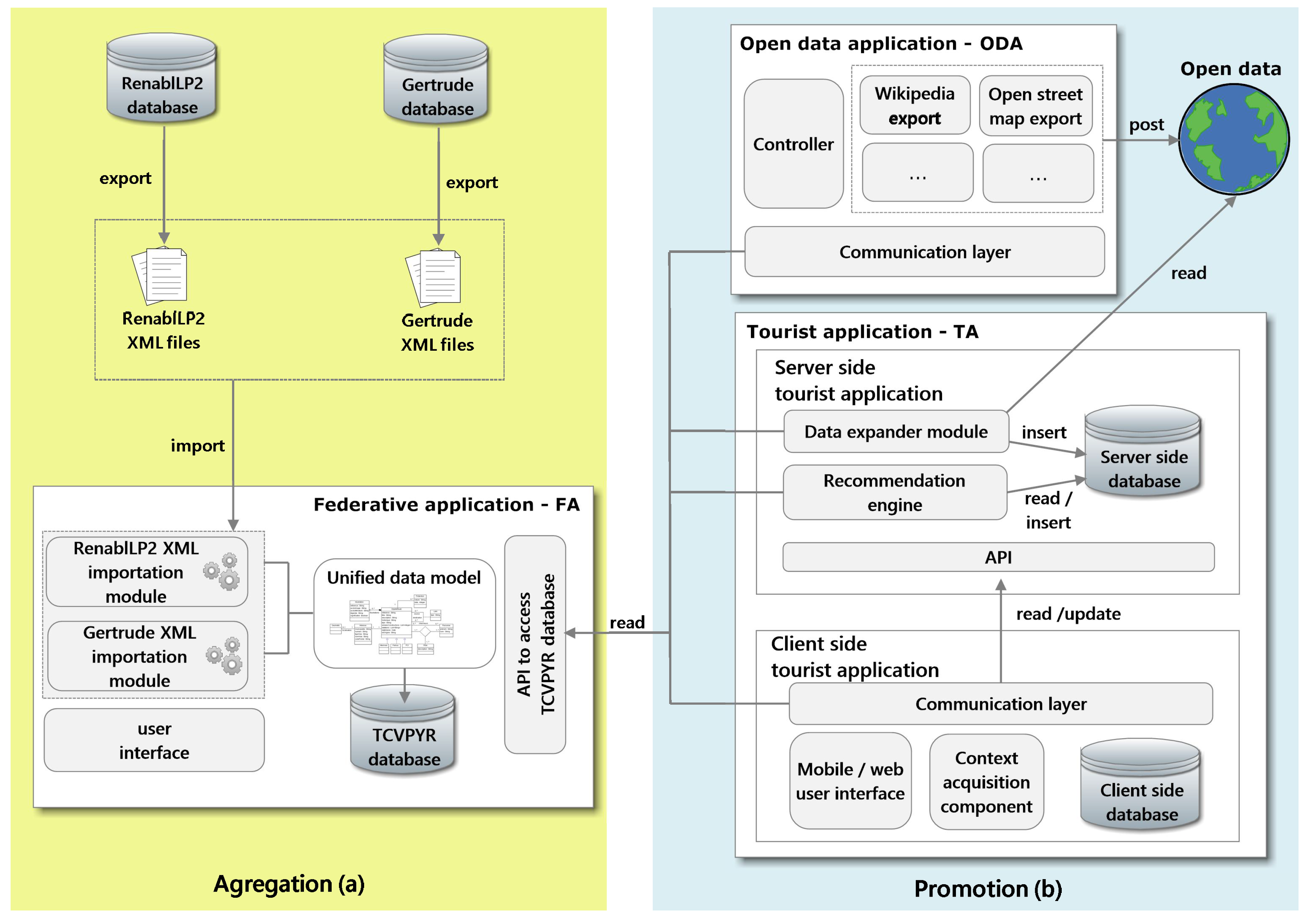
3. Handling Heterogeneous Cultural Heritage Data
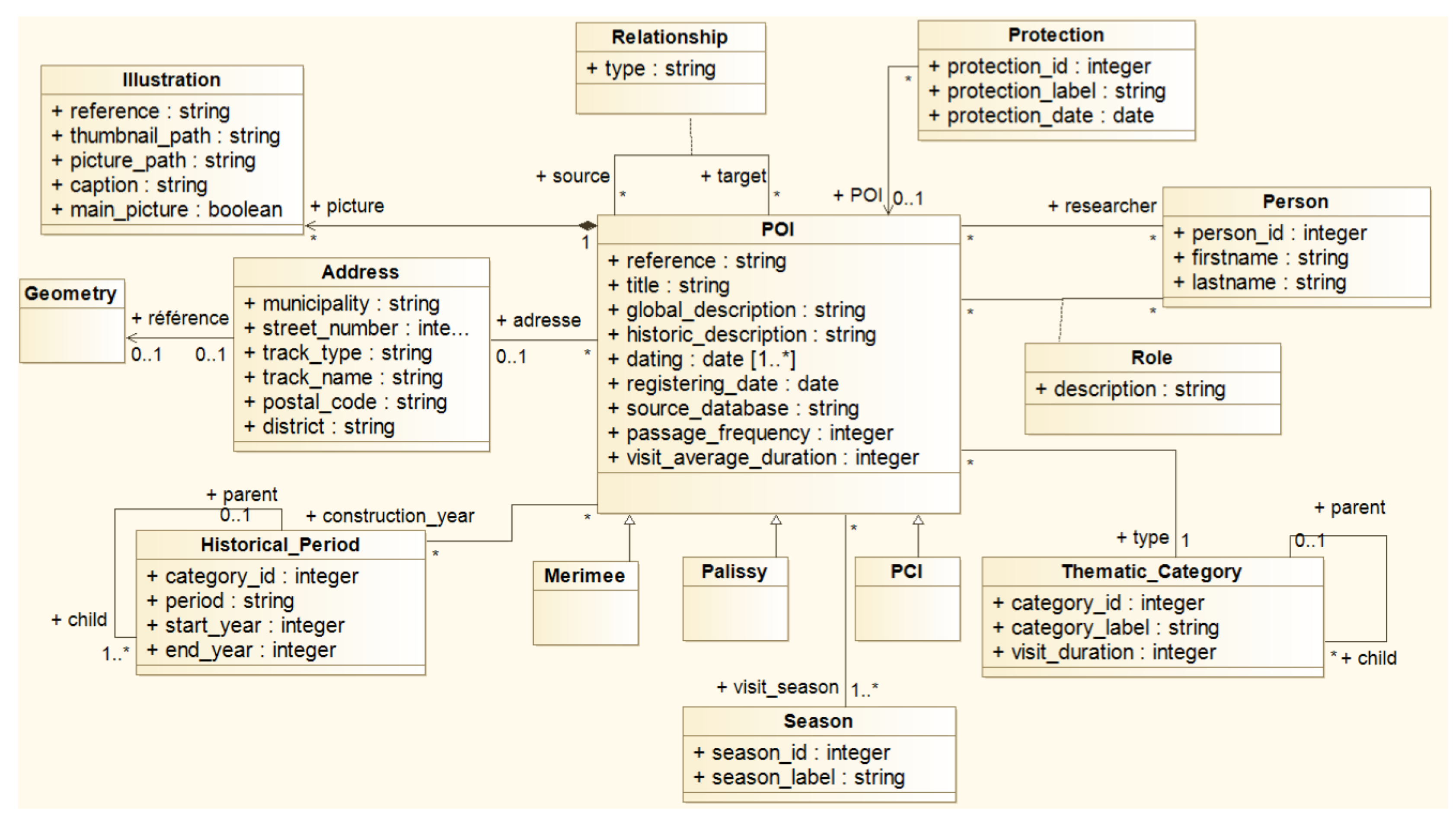
3.1. A Unified Model for Cultural Heritage Data
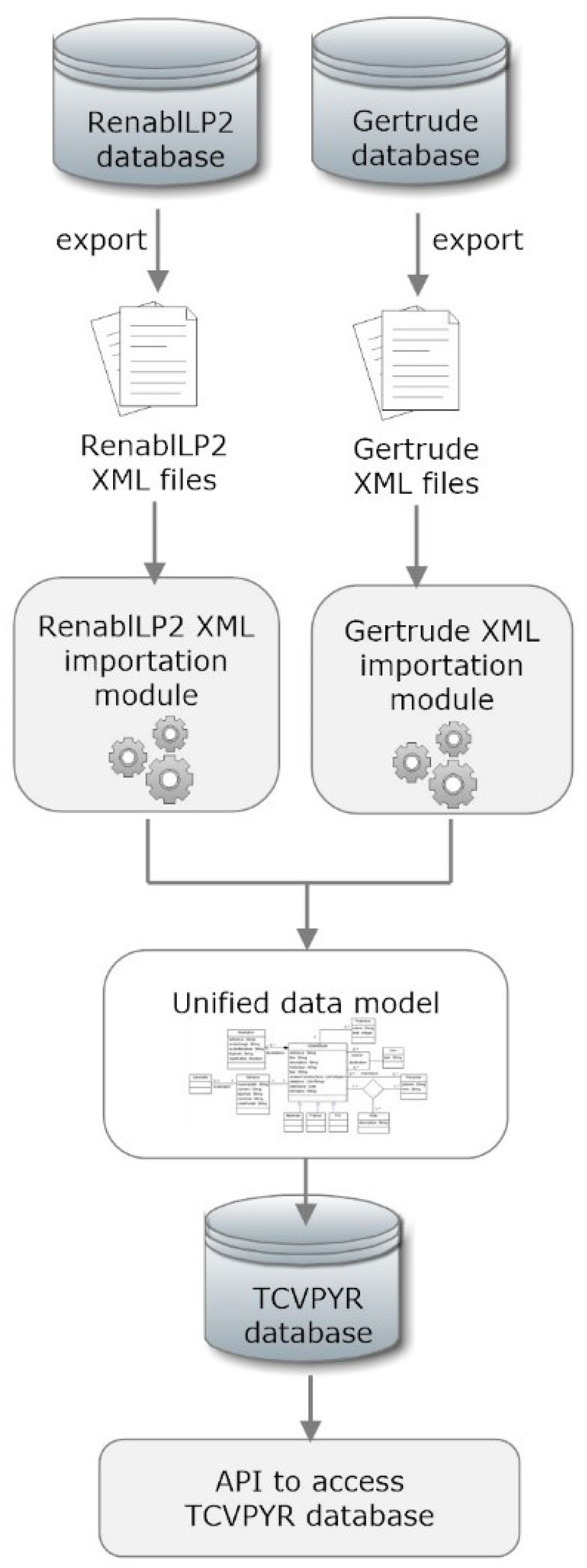
3.2. Importing Heterogeneous Data
4. Leveraging Cultural Heritage Data
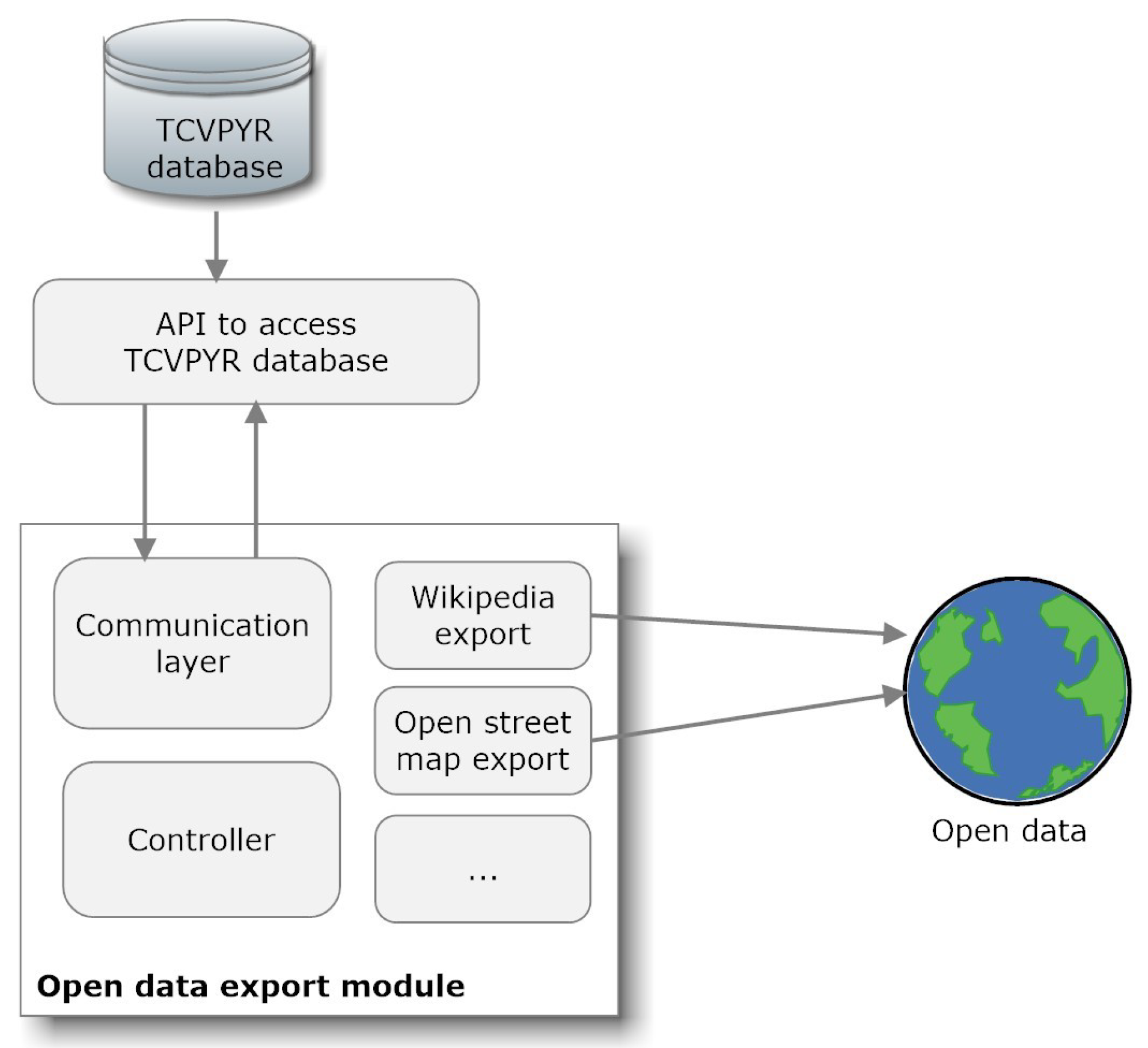
4.1. Cultural Heritage Open Data Publication
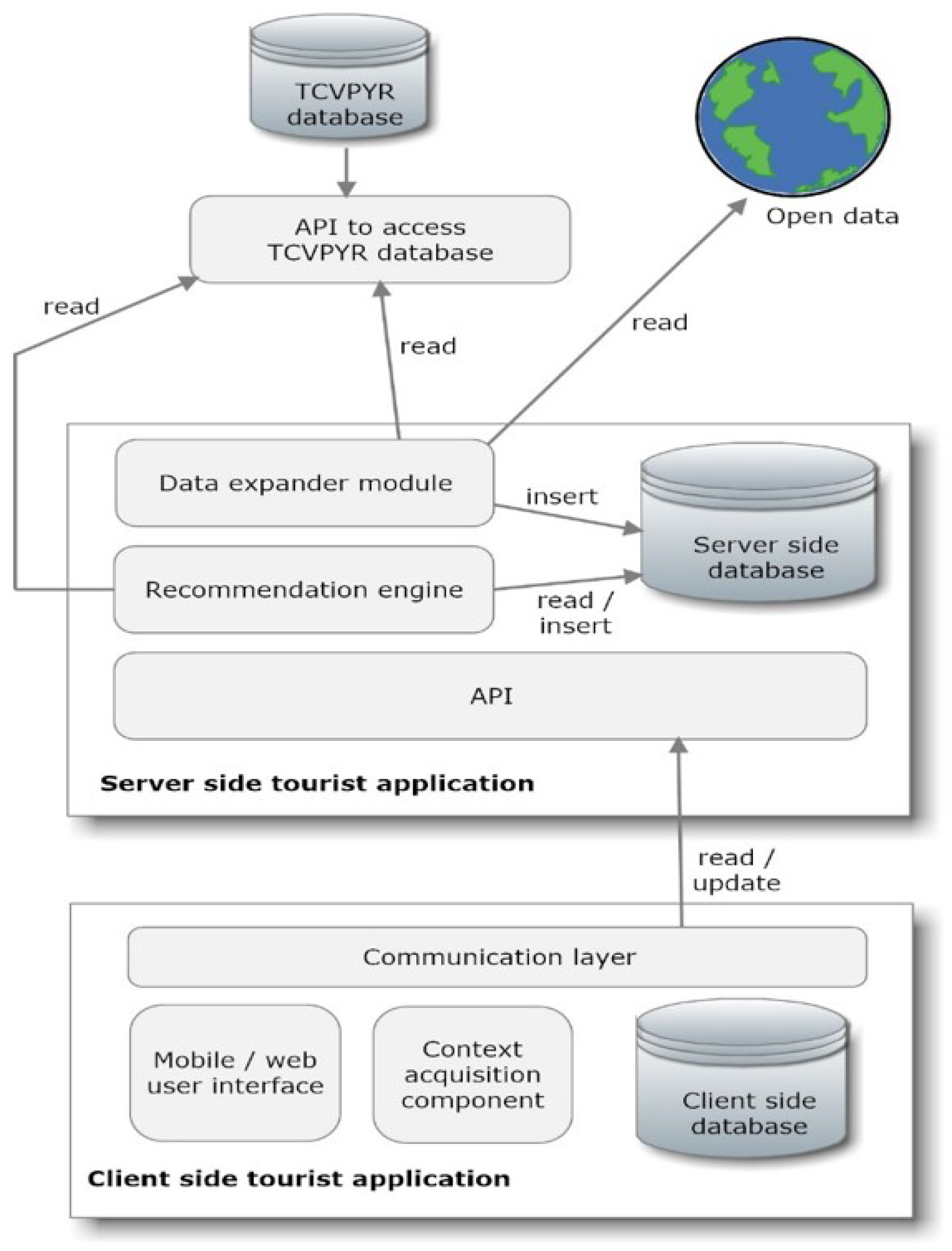
4.2. The Tourist Application and Its Recommendation Mechanism
4.3. Models
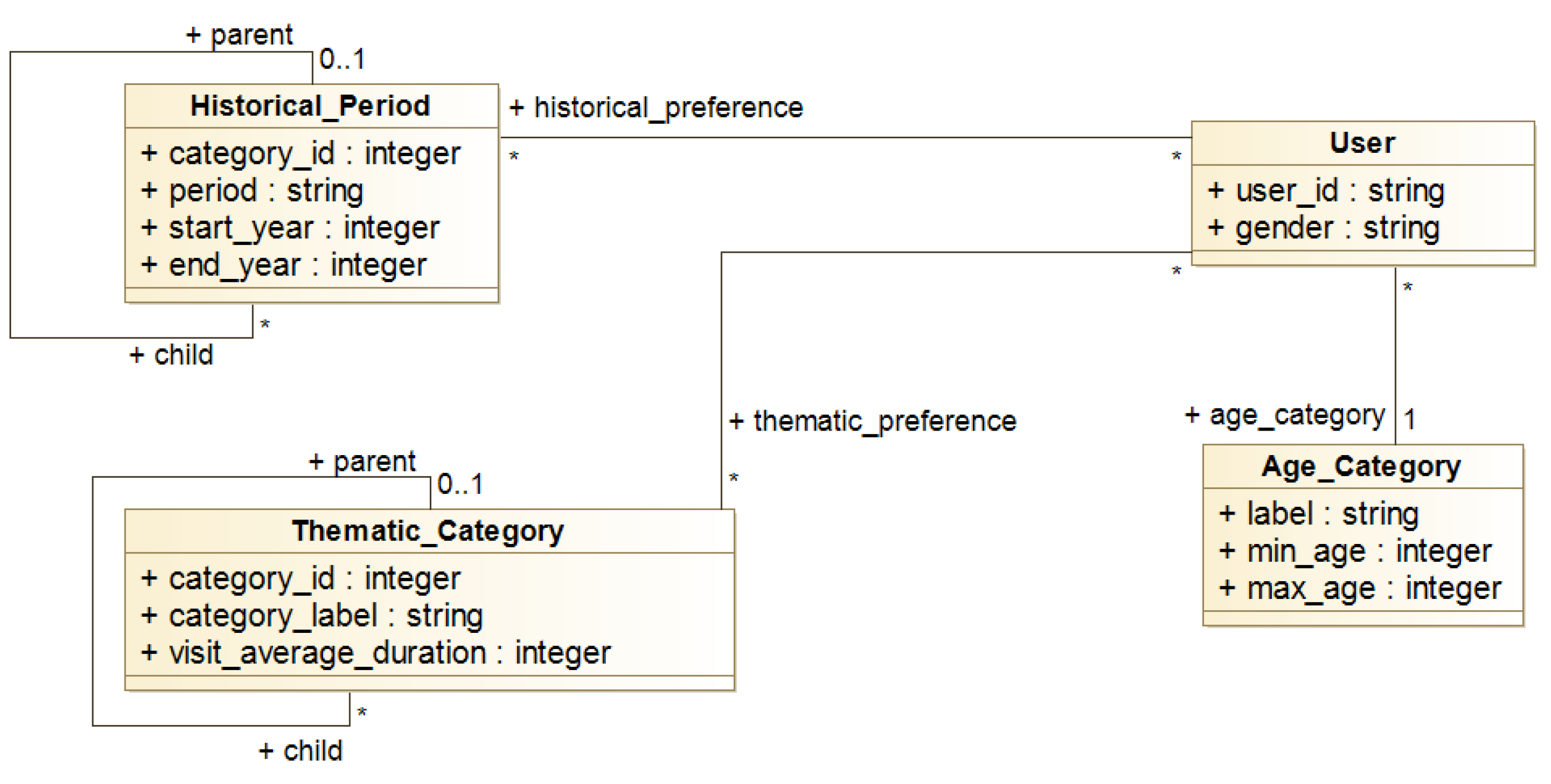
4.3.1. User Model
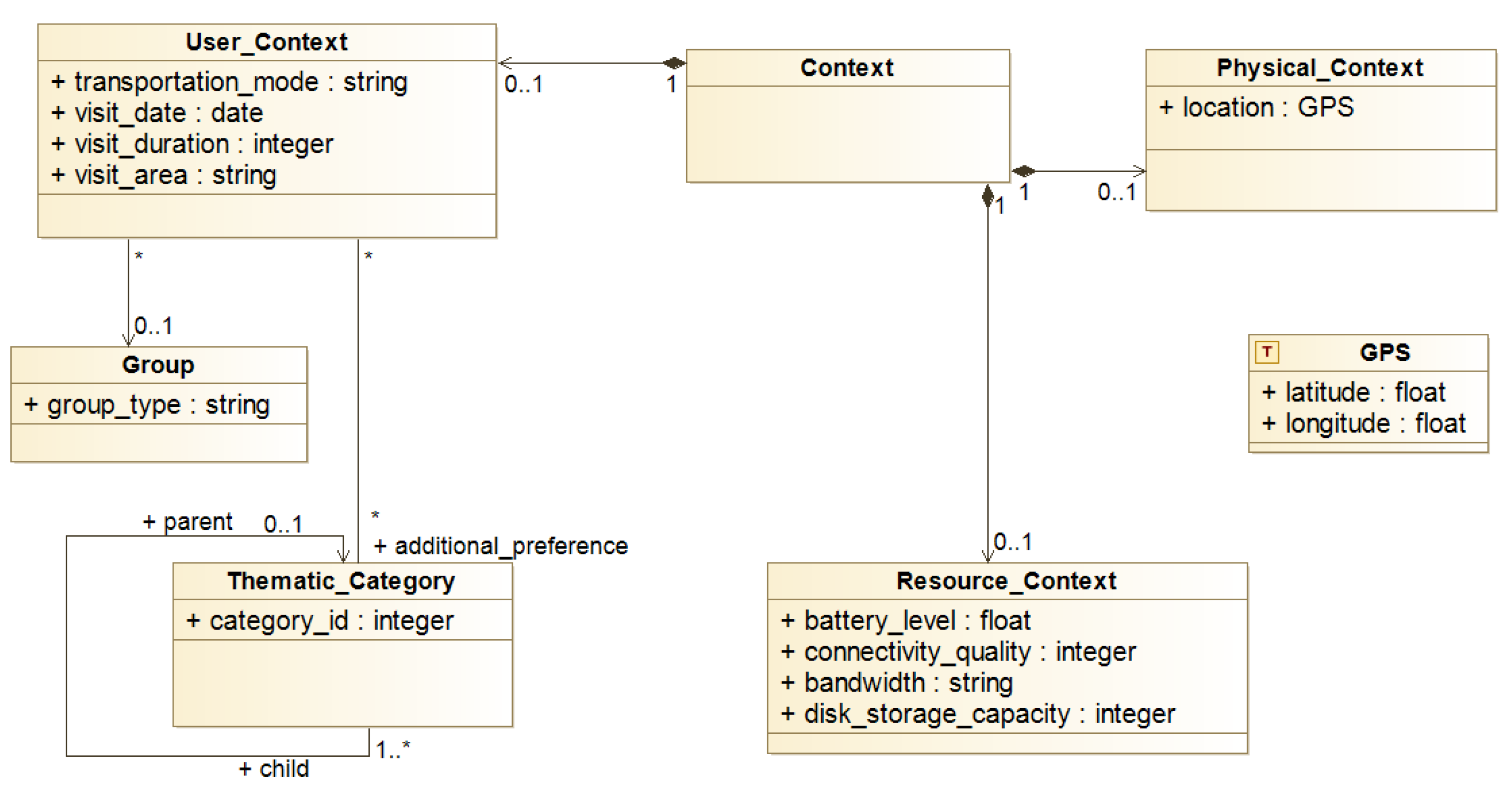
4.3.2. Context Model
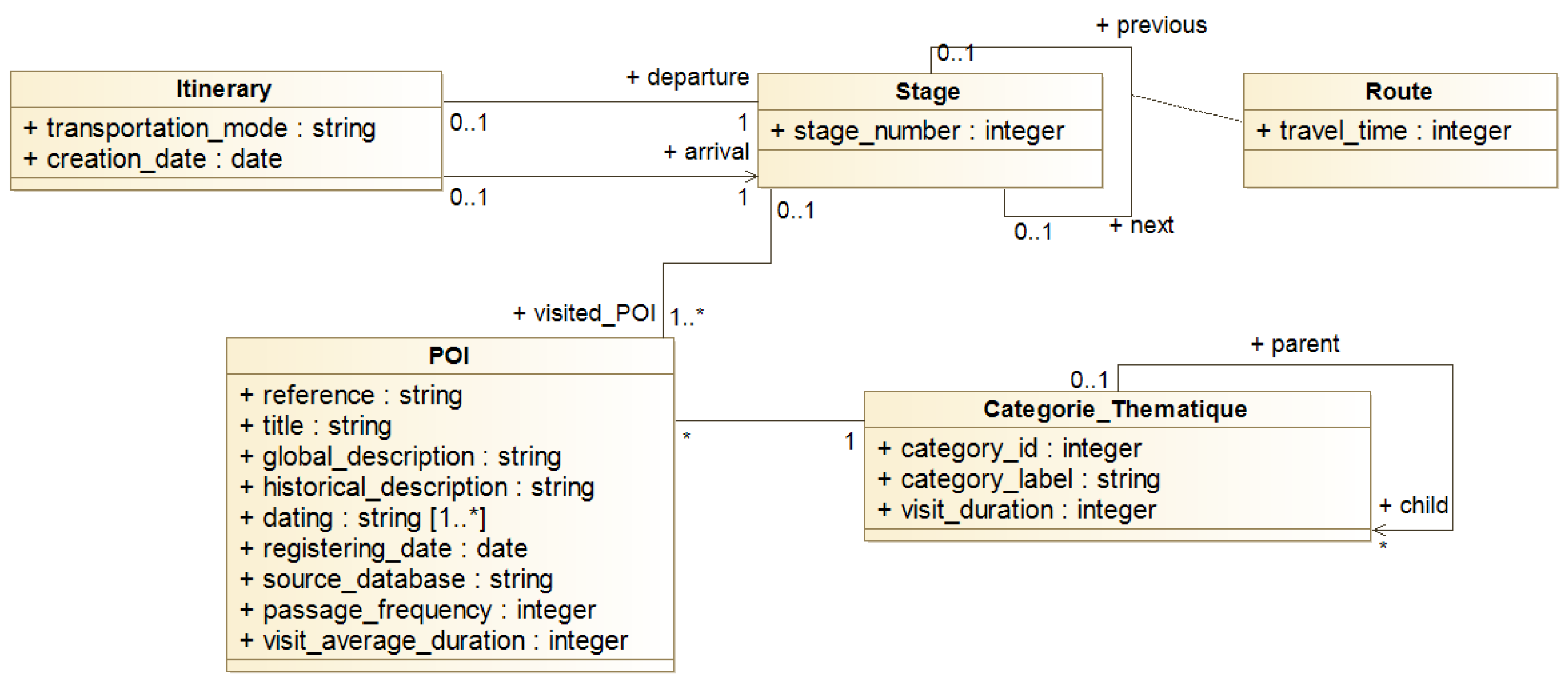
4.3.3. Itinerary Model
4.4. A Recommendation Algorithm for Itineraries
| Algorithm 1: Itinerary recommendation—pseudocode |
 |
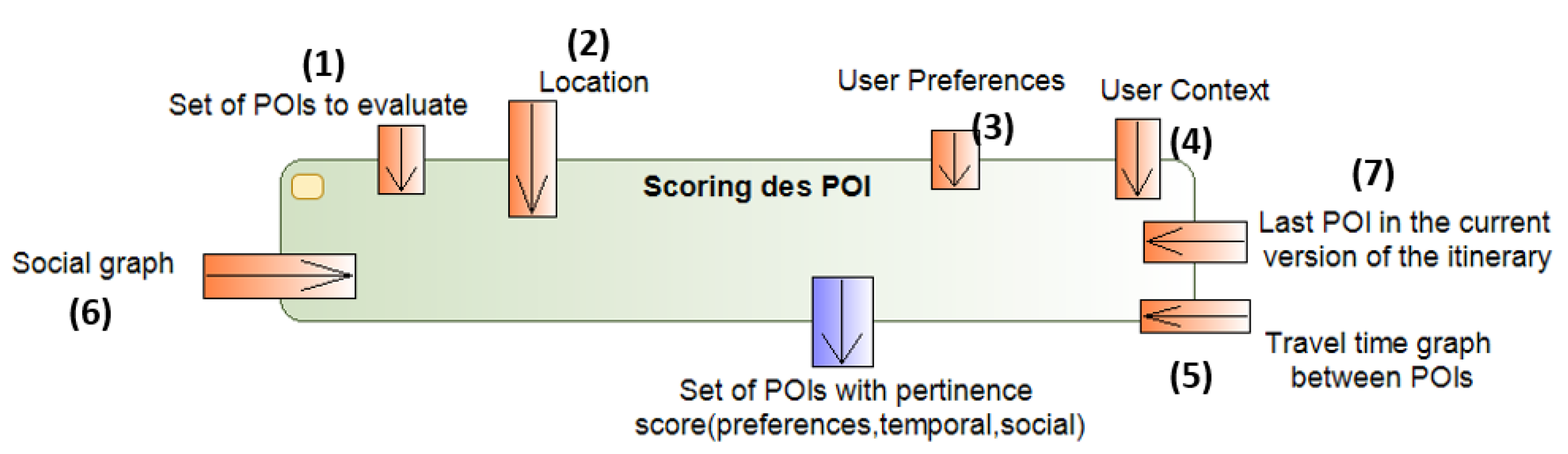
4.4.1. The Scoring Function
- Set of POIs to evaluate (input no. 1)The scoring functions should, of course, receive a list of POIs to be evaluated. Each POI is represented according to the model described in Section 3.2.
- Location (input no. 2)The location is a geographical coordinate corresponding to the position of the last POI added to the itinerary being constructed. It is defined as part of the physical context (Section 4.3.2).
- User preferences (input no. 3)The preferences of the user are composed of thematic and historical preferences. They are described in Section 4.3.1.
- User context (input no. 4)The user context defines the mode of transportation (e.g., driving, cycling), a date, the estimated visit duration, and the group (alone, with kids, with adults, etc.). These elements are described in Section 4.3.2.
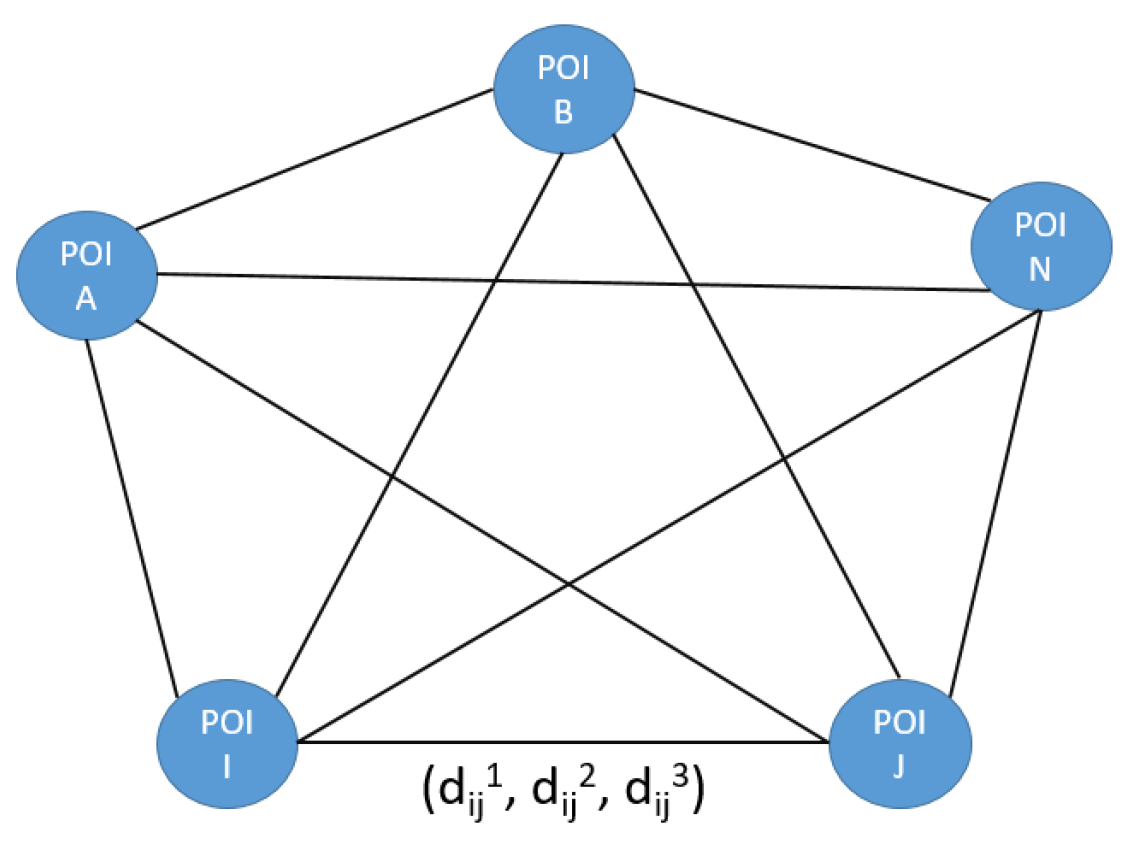
- Travel time graph: (input no. 5)The graph contains information about the time required to travel between POIs. It is defined as , where V is a set of POIs and E is a set of paths (edges) linking two POIs. In our model, we consider that each pair of POIs is linked (i.e., this is a complete graph). The values composing these edges are calculated only once, except if a new edge is inserted in the graph. Since we consider three transportation modes in this paper (on foot, cycling, and driving), each edge contains three values.Figure 12 illustrates the travel time graph between POIs. Each edge contains a triplet of values (, , ) where represents on foot travel time between and , represents cycling travel time between and , and represents driving travel time between and .
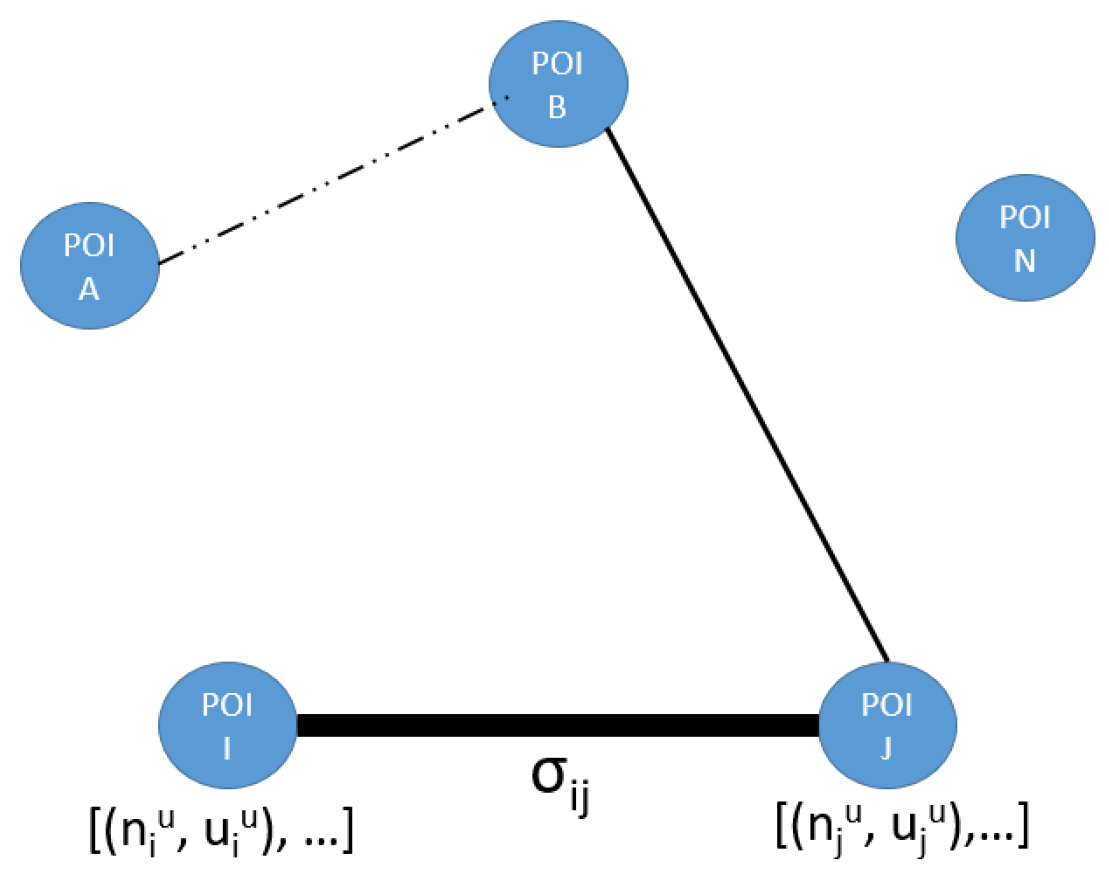
- Social graph: (input no. 6)The graph models the relevance of POIs according to the whole set of users and the relevance of a particular sequence of POIs (pheromone trails). This graph is defined as , where V is the set of POIs and E is the set of edges linking two POIs.Figure 13 illustrates the information about the pheromone trails. Each vertex (POI) has a list of values defining its score for each user. That is, this list is composed of a tuple (score of for user u) and (identity of user u who visited ).Each edge has a value representing the intensity of the link between two POIs. This intensity is defined in terms of past interactions with the set of users of the system and the two POIs. We adopt the hypothesis that if two POIs are frequently visited successively, there is a strong link between them (according to the users’ preferences). This modelling choice inserts characteristics of collaborative filtering algorithms in our approach. Moreover, we also increase the score of a POI for a user if other users like it. This hypothesis is implemented through the incorporation of an ant colony algorithm in our solution. We consider that each user is an ant and that every time an ant passes from one POI to another, a specific quantity of pheromone is left in the path. Whenever the amount of pheromone reaches a certain amount, it means a strong link between two POIs exist. Figure 13 presents the pheromone in terms of edges. The bolder these edges are, the stronger is the pheromone trail left between the two edges.Here, one of the main advantages of using ant colony algorithms is that they take into account not only the links (i.e., passages) existing between vertices but also their absence during a long period. Thus, if a particular path (sequence) is not followed after some time, the pheromone left there will “evaporate”.
- Last POI in the current itinerary (input no. 7)The last POI in current version of the itinerary (under construction) is also used to evaluate the score of candidate POIs. In fact, the pheromone (sequence pertinence) can only be assessed when two POIs are being analysed (the last one in the sequence and the new one to be added).
- User preference pertinence ()We adopt the hypothesis that if the user is interested in a thematic category or historical period, then he is also interested in other semantically similar categories. For example, if the user likes visiting churches, he might enjoy visiting a monastery too. These are two semantically close concepts. In this sense, the function that calculates the pertinence of a POI according to the user’s preference actually measures the semantic similarity between categories that the user is interested in and categories of the POI.and model the semantic similarity between a POI and the thematic and historical categories liked by a user. This similarity function adopted was initially proposed by Wu and Palmer [52]. It takes into consideration the distance between concepts according to a thesaurus and the depth of their first common concept (Least Common Subsummer).
- Temporal pertinence ()The temporal pertinence is defined according to the travel time () between the last POI added to the itinerary and the candidate POI . It also takes into consideration the remaining available time for the trip.Formula (3) formally defines the temporal pertinence of a POI.where i is the transportation mode of the user, is the commuting time between and , and is the remaining time at instant t.In this model, the shorter the time to reach the candidate POI, the greater its score (closer to 1).
- Social PertinenceSocial pertinence is defined by the number of users at instant t who recently went from the last POI added to the itinerary to the candidate POI. This pertinence also takes into account the popularity of the candidate POI at instant t of the evaluation. To define the social pertinence of a POI, we use the graph.Formula (4) defines the social pertinence of a POI formally.with ,where is the last POI added to the itinerary, is the popularity of at instant t, and is represented by the frequency with which tourists travelled from to at instant t.The popularity of a POI is defined in terms of the frequency at which users travelled from the last POI to the POI being analysed and by the score given by other users evaluating the POI. The popularity takes into account the neighbourhood context: indeed, it is normalised by the score and the visit frequency of neighbouring POIs. Note that a set of neighbour POIs is determined by a POI and a geographic neighbourhood radius, which is defined as parameter.Thus, the popularity of a POI is defined by Formula (5):withwhere V is a list of POIs, neighbours of , ranked by their overall assessment ratings. Thus, is a function that computes the position of within the list V according to the average of ratings associated with . In the same way, is a list of POIs, neighbours of , ranked in terms of the frequency with which they have been visited from their neighbouring POIs. The function is a function that computes the position of within the list .Thus, the closer the rank of a POI is to the first position, the higher is its popularity score.The intensity of a link between two POIs and is defined as follows:where t is the instant of the intensity calculation.and are explained in detail below.According to the “ant colony” approach incorporated in our algorithm, a user is represented by an ant. For this reason, when a user visits a POI and then a POI , he deposits pheromones on the path between and (see Section 4.4.1, Figure 13). For each passage on the path - , a quantity Q (predefined) of pheromones is accumulated on the corresponding edge in the graph. corresponds to the total amount (quantity) of pheromones that is accumulated between and at instant t. Finally, corresponds to the maximal value of in the graph (, where each is the quantity of the accumulated pheromones on the paths between POIs of a given city. is dynamic and evolves over time.Thus, when the amount of pheromones on the path – is high (close to ) due to many users taking this path, a visitor should be invited to take the path – when he visits the POI or vice versa.Note that is stored in the graph. This total amount of pheromones is updated every time a user takes this path. Thus, the reinforcement principle of pheromones between and is defined bywith .Moreover, the total amount of pheromone on a path (noted ) decreases progressively if nobody follows this path for a certain period of time.The evaporation principle of pheromones is defined by formula (8):with ,where is the evaporation rate.
4.5. Experiments
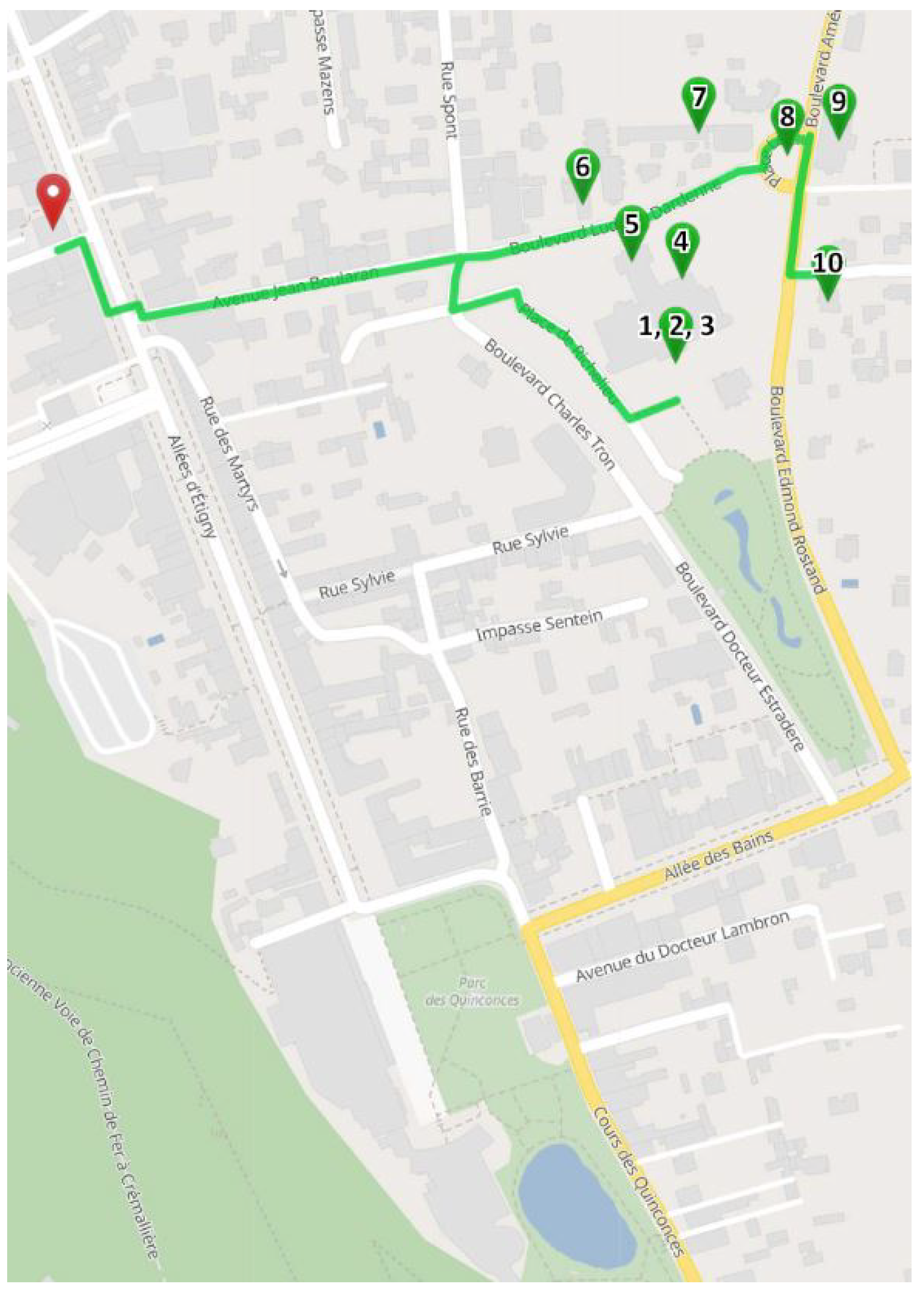
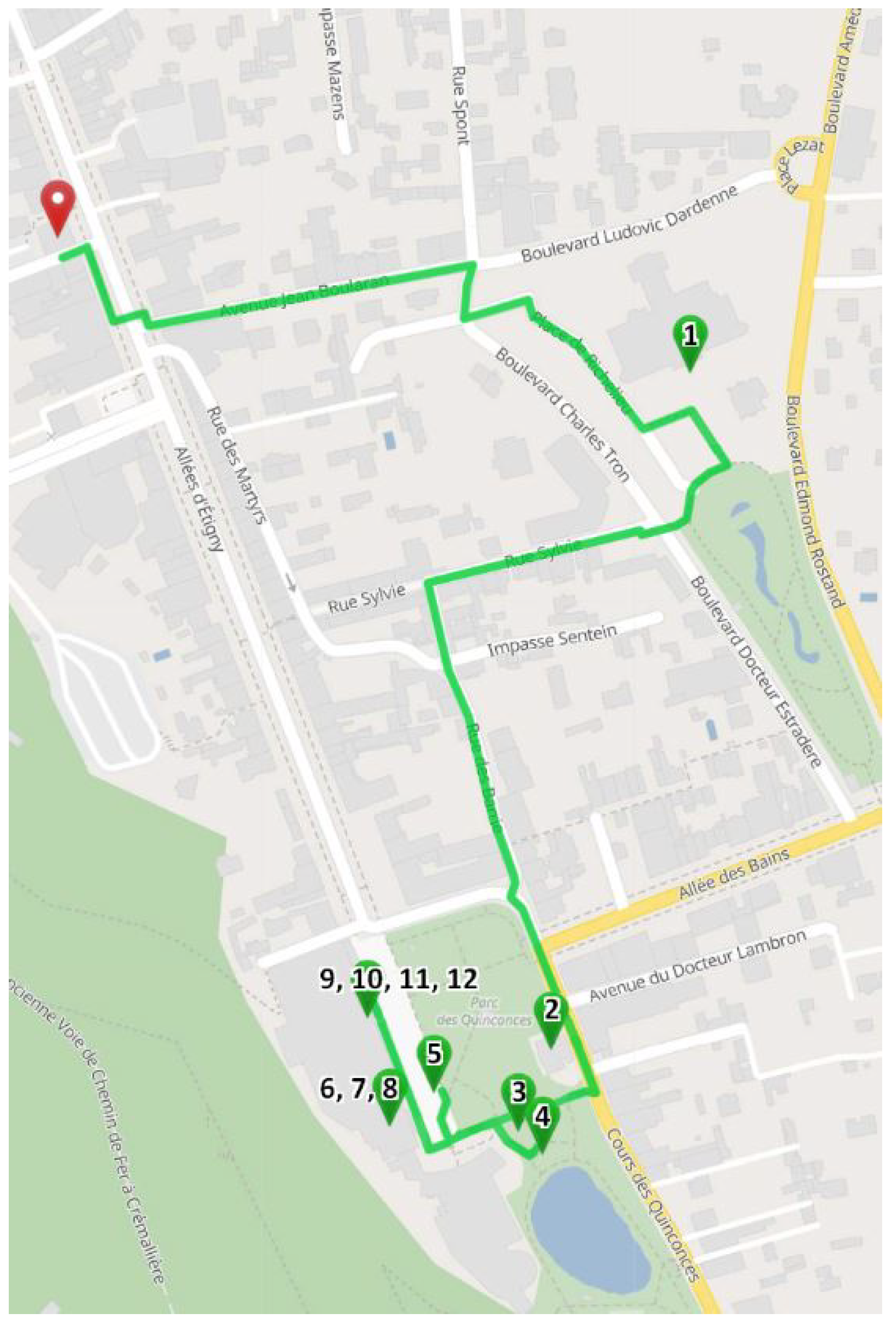
4.5.1. Experimentation of Our Itinerary Generation Approach
4.5.2. Comparison to Similar Approaches
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kucera, J.; Chlapek, D.; Klímek, J.; Necaskỳ, M. Methodologies and Best Practices for Open Data Publication. In DATESO, MATFYZPRESS, Czech Republic. Available online: https://pdfs.semanticscholar.org/de74/2866db8eafa9e2022fad269bf32e328ea8aa.pdf (accessed on 2 April 2019).
- Garcia, A.; Arbelaitz, O.; Linaza, M.T.; Vansteenwegen, P.; Souffriau, W. Personalized tourist route generation. In International Conference on Web Engineering; Springer: Berlin/Heidelberg, Germany, 2010; pp. 486–497. [Google Scholar]
- Ayala, V.A.A.; Gülsen, K.C.; Alzogbi, A.; Färber, M.; Muñiz, M.; Lausen, G. A Delay-Robust Touristic Plan Recommendation Using Real-World Public Transportation Information. In Proceedings of the 2nd Workshop on Recommenders in Tourism Co-Located with 11th ACM Conference on Recommender Systems (RecSys 2017), Como, Italy, 27 August 2017; pp. 9–17. [Google Scholar]
- Dorigo, M.; Bonabeau, E.; Theraulaz, G. Ant algorithms and stigmergy. Future Gen. Comput. Syst. 2000, 16, 851–871. [Google Scholar] [CrossRef]
- Lu, Q.; Guo, F. A novel e-commerce customer continuous purchase recommendation model research based on colony clustering. Int. J. Wirel. Mob. Comput. 2016, 11, 309–317. [Google Scholar] [CrossRef]
- Zhang, X.; Pang, X. Analysis on the Mobile Electronic Commerce Recommendation Model based on the Ant Colony Algorithm. In Proceedings of the 2015 International Conference on Industrial Technology and Management Science, Tianjin, China, 27–28 March 2015. [Google Scholar]
- Minjing, P.; Xinglin, L.; Ximing, L.; Mingliang, Z.; Xianyong, Z.; Xiangming, D.; Mingfen, W. Recognizing intentions of E-commerce consumers based on ant colony optimization simulation. J. Intell. Fuzzy Syst. 2017, 33, 2687–2697. [Google Scholar] [CrossRef]
- Abbassi, Z.; Amer-Yahia, S.; Lakshmanan, L.V.; Vassilvitskii, S.; Yu, C. Getting recommender systems to think outside the box. In Proceedings of the Third ACM Conference on Recommender Systems, New York, NY, USA, 23–25 October 2009; pp. 285–288. [Google Scholar]
- Herlocker, J.L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating collaborative filtering recommender systems. ACM Trans. Inf. Syst. (TOIS) 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Vetrò, A.; Canova, L.; Torchiano, M.; Minotas, C.O.; Iemma, R.; Morando, F. Open data quality measurement framework: Definition and application to Open Government Data. Gov. Inf. Q. 2016, 33, 325–337. [Google Scholar] [CrossRef]
- Abella, A.; Ortiz-de Urbina-Criado, M.; De Pablos-Heredero, C. The process of open data publication and reuse. J. Assoc. Inf. Sci. Technol. 2019, 70, 296–300. [Google Scholar] [CrossRef]
- Castéret, J.J.; Larché, M. Le projet << PCILAB >> pour la valorisation numérique de l’inventaire français du PCI. Les Cahiers du CFPCI 2018, 5, 102–112. [Google Scholar]
- Daquino, M.; Mambelli, F.; Peroni, S.; Tomasi, F.; Vitali, F. Enhancing semantic expressivity in the cultural heritage domain: exposing the Zeri Photo Archive as Linked Open Data. J. Comput. Cult. Herit. (JOCCH) 2017, 10, 21. [Google Scholar] [CrossRef]
- Candela, G.; Escobar, P.; Carrasco, R.C.; Marco-Such, M. A linked open data framework to enhance the discoverability and impact of culture heritage. J. Inf. Sci. 2018. [Google Scholar] [CrossRef]
- Kesorn, K.; Juraphanthong, W.; Salaiwarakul, A. Personalized attraction recommendation system for tourists through check-in data. IEEE Access 2017, 5, 26703–26721. [Google Scholar] [CrossRef]
- Aliannejadi, M.; Mele, I.; Crestani, F. User model enrichment for venue recommendation. In Asia Information Retrieval Symposium; Springer: Cham, Switzerland, 2016; pp. 212–223. [Google Scholar]
- Logesh, R.; Subramaniyaswamy, V.; Vijayakumar, V.; Li, X. Efficient User Profiling Based Intelligent Travel Recommender System for Individual and Group of Users. Mobile Netw. Appl. 2018, 1–16. [Google Scholar] [CrossRef]
- Tsiligirides, T. Heuristic methods applied to orienteering. J. Oper. Res. Soc. 1984, 35, 797–809. [Google Scholar] [CrossRef]
- Bahramian, Z.; Ali Abbaspour, R.; Claramunt, C. A context-aware tourism recommender system based on spreading activation method. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, XLII-4/W4, 333–339. [Google Scholar] [CrossRef]
- Costa, H.; Furtado, B.; Pires, D.; Macedo, L.; Cardoso, A. Context and intention-awareness in pois recommender systems. In Proceedings of the 6th ACM Conferences on Recommender Systems, 4th Workshop on Context-Aware Recommender Systems, RecSys, Dublin, Ireland, 9–13 September 2012. [Google Scholar]
- Bahramian, Z.; Abbaspour, R.; Claramunt, C. A Cold Start Context-Aware Recommender System for Tour Planning Using Artificial Neural Network and Case Based Reasoning. Mob. Inf. Syst. 2017, 2017, 9364903. [Google Scholar] [CrossRef]
- Kłopotek, M.A. Approaches to “Cold-Start” in recommender systems. Stud. Inf. Syst. Inf. Technol. 2009, 1, 47–54. [Google Scholar]
- Wang, J.; Lin, K.; Li, J. A collaborative filtering recommendation algorithm based on user clustering and Slope One scheme. In Proceedings of the 2013 8th International Conference on Computer Science & Education, Colombo, Sri Lanka, 26–28 April 2013; pp. 1473–1476. [Google Scholar]
- Dennouni, N.; Peter, Y.; Lancieri, L.; Slama, Z. Towards an Incremental Recommendation of POIs for Mobile Tourists without Profiles. Int. J. Intell. Syst. Appl. 2018, 10, 42–52. [Google Scholar] [CrossRef]
- Bartolini, I.; Moscato, V.; Pensa, R.G.; Penta, A.; Picariello, A.; Sansone, C.; Sapino, M.L. Recommending multimedia visiting paths in cultural heritage applications. Multimed. Tools Appl. 2016, 75, 3813–3842. [Google Scholar] [CrossRef]
- De Pessemier, T.; Dhondt, J.; Vanhecke, K.; Martens, L. TravelWithFriends: A hybrid group recommender system for travel destinations. In Proceedings of the Workshop on Tourism Recommender Systems (TouRS15), in Conjunction with the 9th ACM Conference on Recommender Systems (RecSys 2015), Vienna, Austria, 16–20 September 2015; pp. 51–60. [Google Scholar]
- Schmidt, A.; Beigl, M.; Gellersen, H. There is more to context than location. Comput. Graph. 1999, 23, 893–901. [Google Scholar] [CrossRef]
- Borràs, J.; Moreno, A.; Valls, A. Intelligent tourism recommender systems: A survey. Expert Syst. Appl. 2014, 41, 7370–7389. [Google Scholar] [CrossRef]
- Lim, K.H.; Chan, J.; Karunasekera, S.; Leckie, C. Tour recommendation and trip planning using location-based social media: A survey. Knowl. Inf. Syst. 2018, 1–29. [Google Scholar] [CrossRef]
- Batet, M.; Moreno, A.; Sánchez, D.; Isern, D.; Valls, A. Turist@: Agent-based personalised recommendation of tourist activities. Expert Syst. Appl. 2012, 39, 7319–7329. [Google Scholar] [CrossRef]
- Ceccaroni, L.; Codina, V.; Palau, M.; Pous, M. PaTac: Urban, ubiquitous, personalized services for citizens and tourists. In Proceedings of the 2009 Third International Conference on Digital Society, Cancun, Mexico, 1–7 February 2009; pp. 7–12. [Google Scholar]
- Lorenzi, F.; Loh, S.; Abel, M. PersonalTour: A recommender system for travel packages. In Proceedings of the 2011 IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology, Lyon, France, 22–27 August 2011; Volume 2, pp. 333–336. [Google Scholar]
- Lee, C.S.; Chang, Y.C.; Wang, M.H. Ontological recommendation multi-agent for Tainan City travel. Expert Syst. Appl. 2009, 36, 6740–6753. [Google Scholar] [CrossRef]
- Kurata, Y.; Hara, T. CT-planner4: Toward a more user-friendly interactive day-tour planner. In Information and Communication Technologies in Tourism 2014; Springer: Cham, Switzerland, 2013; pp. 73–86. [Google Scholar]
- Garcia, A.; Vansteenwegen, P.; Arbelaitz, O.; Souffriau, W.; Linaza, M.T. Integrating public transportation in personalised electronic tourist guides. Comput. Oper. Res. 2013, 40, 758–774. [Google Scholar] [CrossRef]
- Souffriau, W.; Vansteenwegen, P.; Berghe, G.V.; Van Oudheusden, D. The planning of cycle trips in the province of East Flanders. Omega 2011, 39, 209–213. [Google Scholar] [CrossRef]
- Martinez, L.; Rodriguez, R.M.; Espinilla, M. Reja: A georeferenced hybrid recommender system for restaurants. In Proceedings of the 2009 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology, Washington, DC, USA, 15–18 September 2009; pp. 187–190. [Google Scholar]
- Noguera, J.M.; Barranco, M.J.; Segura, R.J.; MartíNez, L. A mobile 3D-GIS hybrid recommender system for tourism. Inf. Sci. 2012, 215, 37–52. [Google Scholar] [CrossRef]
- Gavalas, D.; Kenteris, M. A web-based pervasive recommendation system for mobile tourist guides. Pers. Ubiquit. Comput. 2011, 15, 759–770. [Google Scholar] [CrossRef]
- Pinho, J.; da Silva, B.; Moreno, M.; de Almeida, A.; Martins, C.L. Applying recommender methodologies in tourism sector, highlights in practical applications of agents and multiagent systems. Adv. Intell. Soft Comput. 2011, 89, 101–108. [Google Scholar]
- Fenza, G.; Fischetti, E.; Furno, D.; Loia, V. A hybrid context aware system for tourist guidance based on collaborative filtering. In Proceedings of the 2011 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE 2011), Taipei, Taiwan, 27–30 June 2011; pp. 131–138. [Google Scholar]
- Hsu, F.M.; Lin, Y.T.; Ho, T.K. Design and implementation of an intelligent recommendation system for tourist attractions: The integration of EBM model, Bayesian network and Google Maps. Expert Syst. Appl. 2012, 39, 3257–3264. [Google Scholar] [CrossRef]
- Huang, Y.; Bian, L. A Bayesian network and analytic hierarchy process based personalized recommendations for tourist attractions over the Internet. Expert Syst. Appl. 2009, 36, 933–943. [Google Scholar] [CrossRef]
- Lamsfus, C.; Alzua-Sorzabal, A.; Martín, D.; Salvador, Z.; Usandizaga, A. Human-centric Ontology-based Context Modelling in Tourism. In KEOD; Springer: Berlin/Heidelberg, Germany, 2009; pp. 424–434. [Google Scholar]
- Sánchez, D.; Moreno, A. Pattern-based automatic taxonomy learning from the Web. Ai Commun. 2008, 21, 27–48. [Google Scholar]
- Sánchez, D.; Moreno, A. Learning non-taxonomic relationships from web documents for domain ontology construction. Data Knowl. Eng. 2008, 64, 600–623. [Google Scholar] [CrossRef]
- Wang, W.; Zeng, G.; Tang, D. Bayesian intelligent semantic mashup for tourism. Concurr. Comput. Pract. Exp. 2011, 23, 850–862. [Google Scholar] [CrossRef]
- Ardissono, L.; Kuflik, T.; Petrelli, D. Personalization in cultural heritage: The road travelled and the one ahead. User Model. User-Adapted Interact. 2012, 22, 73–99. [Google Scholar] [CrossRef]
- Hong, M.; Jung, J.J.; Piccialli, F.; Chianese, A. Social recommendation service for cultural heritage. Pers. Ubiquitous Comput. 2017, 21, 191–201. [Google Scholar] [CrossRef]
- Wang, X.; Leckie, C.; Chan, J.; Lim, K.H.; Vaithianathan, T. Improving Personalized Trip Recommendation by Avoiding Crowds. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; ACM: New York, NY, USA, 2016; pp. 25–34. [Google Scholar]
- Hamon, F. Grands ensembles, demande de patrimonialisation et base Mérimée. Hist. Urbaine 2007, 125–132. [Google Scholar] [CrossRef]
- Wu, Z.; Palmer, M. Verbs semantics and lexical selection. In Proceedings of the ACL ’94 32nd Annual Meeting on Association for Computational Linguistics, Las Cruces, New Mexico, 27–30 June 1994; pp. 133–138. [Google Scholar]
- Anagnostopoulos, A.; Atassi, R.; Becchetti, L.; Fazzone, A.; Silvestri, F. Tour recommendation for groups. Data Min. Knowl. Discov. 2017, 31, 1157–1188. [Google Scholar] [CrossRef]
- Sriphaew, K.; Sombatsricharoen, K. Food tour recommendation using modified ant colony algorithm. In Proceedings of the 5th International Conference on Computing and Informatics, ICOCI 2015, Istanbul, Turkey, 11–13 August 2015. [Google Scholar]
- Brilhante, I.; Macedo, J.A.; Nardini, F.M.; Perego, R.; Renso, C. Tripbuilder: A tool for recommending sightseeing tours. In European Conference on Information Retrieval; Springer: Cham, Switzerland, 2014; pp. 771–774. [Google Scholar]
- Moreno, A.; Valls, A.; Isern, D.; Marin, L.; Borràs, J. Sigtur/e-destination: ontology-based personalized recommendation of tourism and leisure activities. Eng. Appl. Artif. Intell. 2013, 26, 633–651. [Google Scholar] [CrossRef]
- Cohen, R.; Katzir, L. The generalized maximum coverage problem. Inf. Process. Lett. 2008, 108, 15–22. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rajaonarivo, L.; Fonteles, A.; Sallaberry, C.; Bessagnet, M.-N.; Roose, P.; Etcheverry, P.; Marquesuzaà, C.; Lacayrelle, A.L.P.; Cayèré, C.; Coudert, Q. Recommendation of Heterogeneous Cultural Heritage Objects for the Promotion of Tourism. ISPRS Int. J. Geo-Inf. 2019, 8, 230. https://doi.org/10.3390/ijgi8050230
Rajaonarivo L, Fonteles A, Sallaberry C, Bessagnet M-N, Roose P, Etcheverry P, Marquesuzaà C, Lacayrelle ALP, Cayèré C, Coudert Q. Recommendation of Heterogeneous Cultural Heritage Objects for the Promotion of Tourism. ISPRS International Journal of Geo-Information. 2019; 8(5):230. https://doi.org/10.3390/ijgi8050230
Chicago/Turabian StyleRajaonarivo, Landy, André Fonteles, Christian Sallaberry, Marie-Noëlle Bessagnet, Philippe Roose, Patrick Etcheverry, Christophe Marquesuzaà, Annig Le Parc Lacayrelle, Cécile Cayèré, and Quentin Coudert. 2019. "Recommendation of Heterogeneous Cultural Heritage Objects for the Promotion of Tourism" ISPRS International Journal of Geo-Information 8, no. 5: 230. https://doi.org/10.3390/ijgi8050230
APA StyleRajaonarivo, L., Fonteles, A., Sallaberry, C., Bessagnet, M.-N., Roose, P., Etcheverry, P., Marquesuzaà, C., Lacayrelle, A. L. P., Cayèré, C., & Coudert, Q. (2019). Recommendation of Heterogeneous Cultural Heritage Objects for the Promotion of Tourism. ISPRS International Journal of Geo-Information, 8(5), 230. https://doi.org/10.3390/ijgi8050230