Capturing and Characterizing Human Activities Using Building Locations in America



Abstract
:1. Introduction
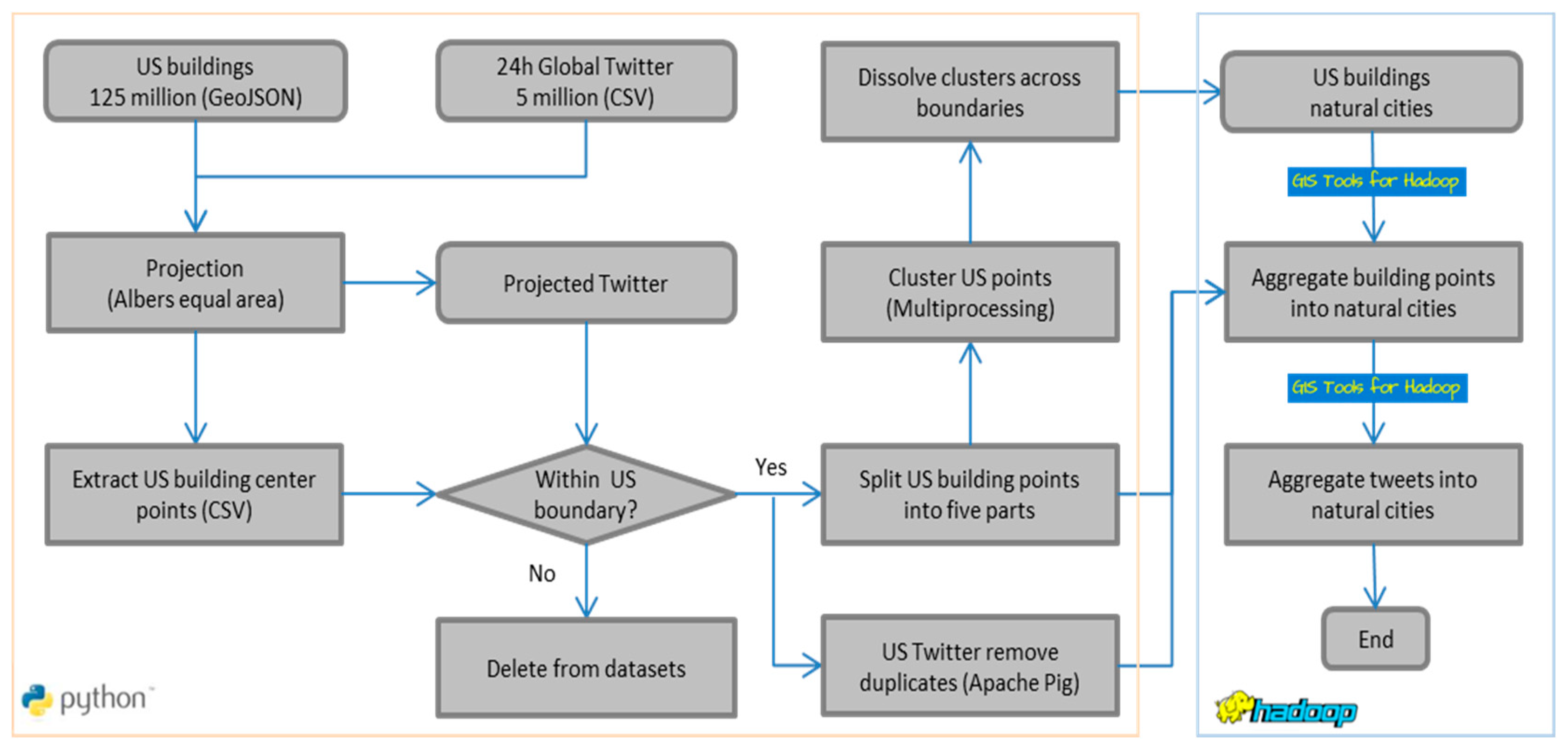
2. Data and Data Preprocessing
3. Methods
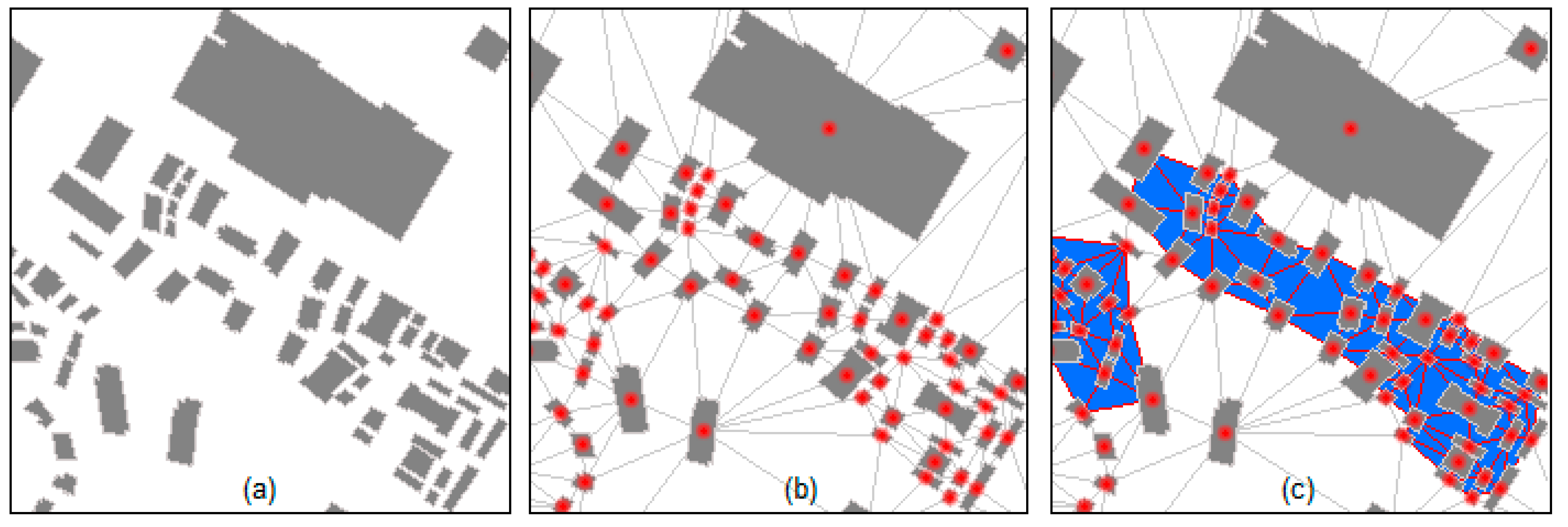
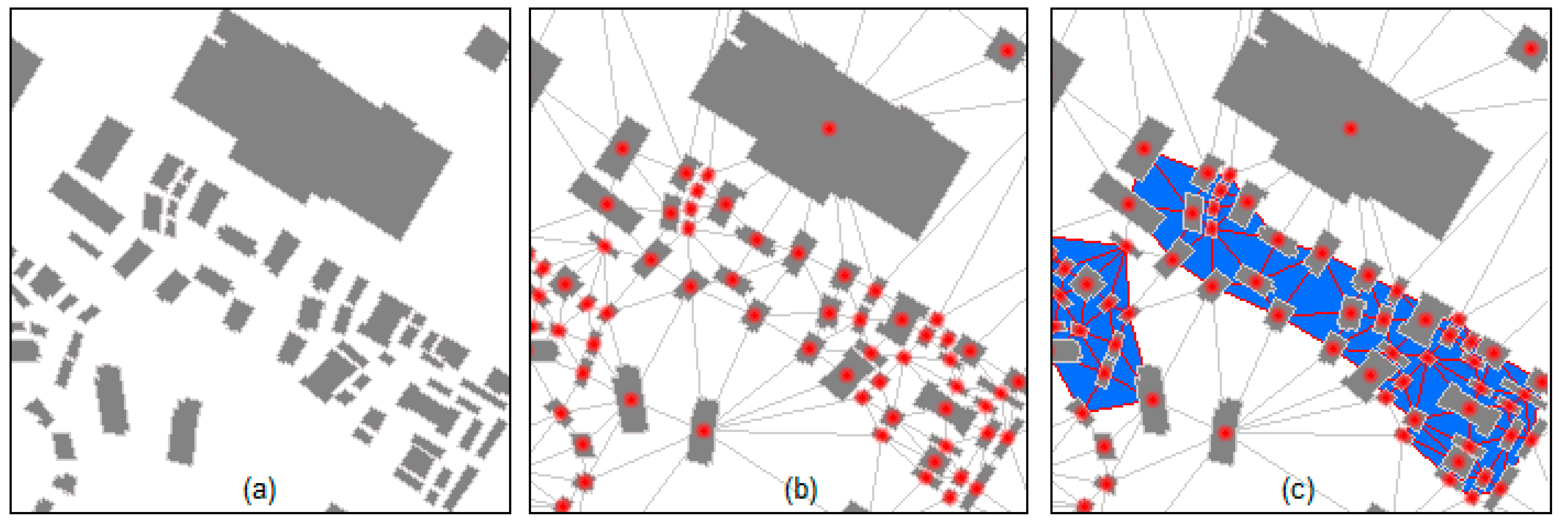
3.1. Spatial Clustering on Big Data
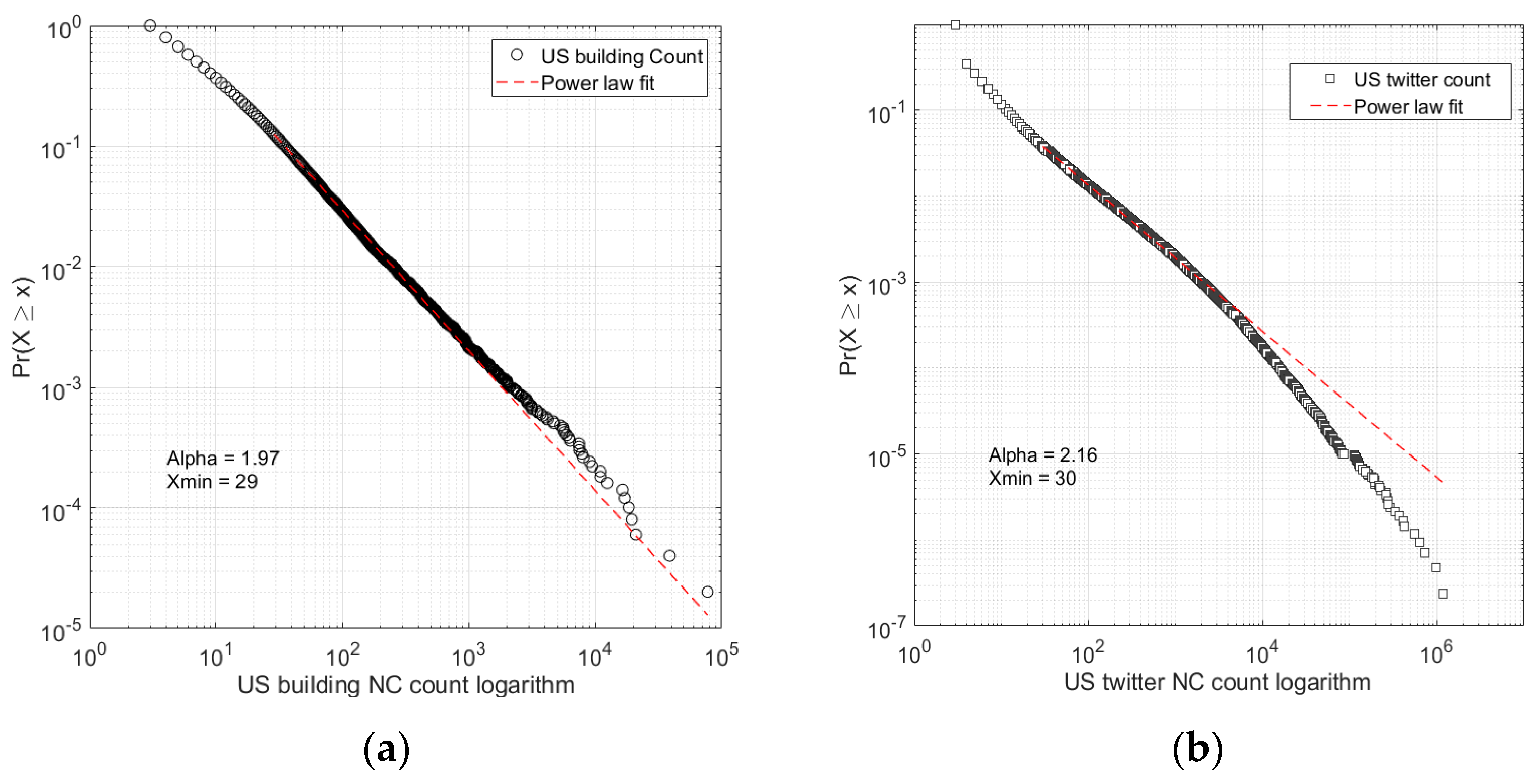
3.2. Power Law Statistics and HT-Index to Quantify the Big Data Hierarchy
4. Capture Human Activities Using Buildings and Twitter Data
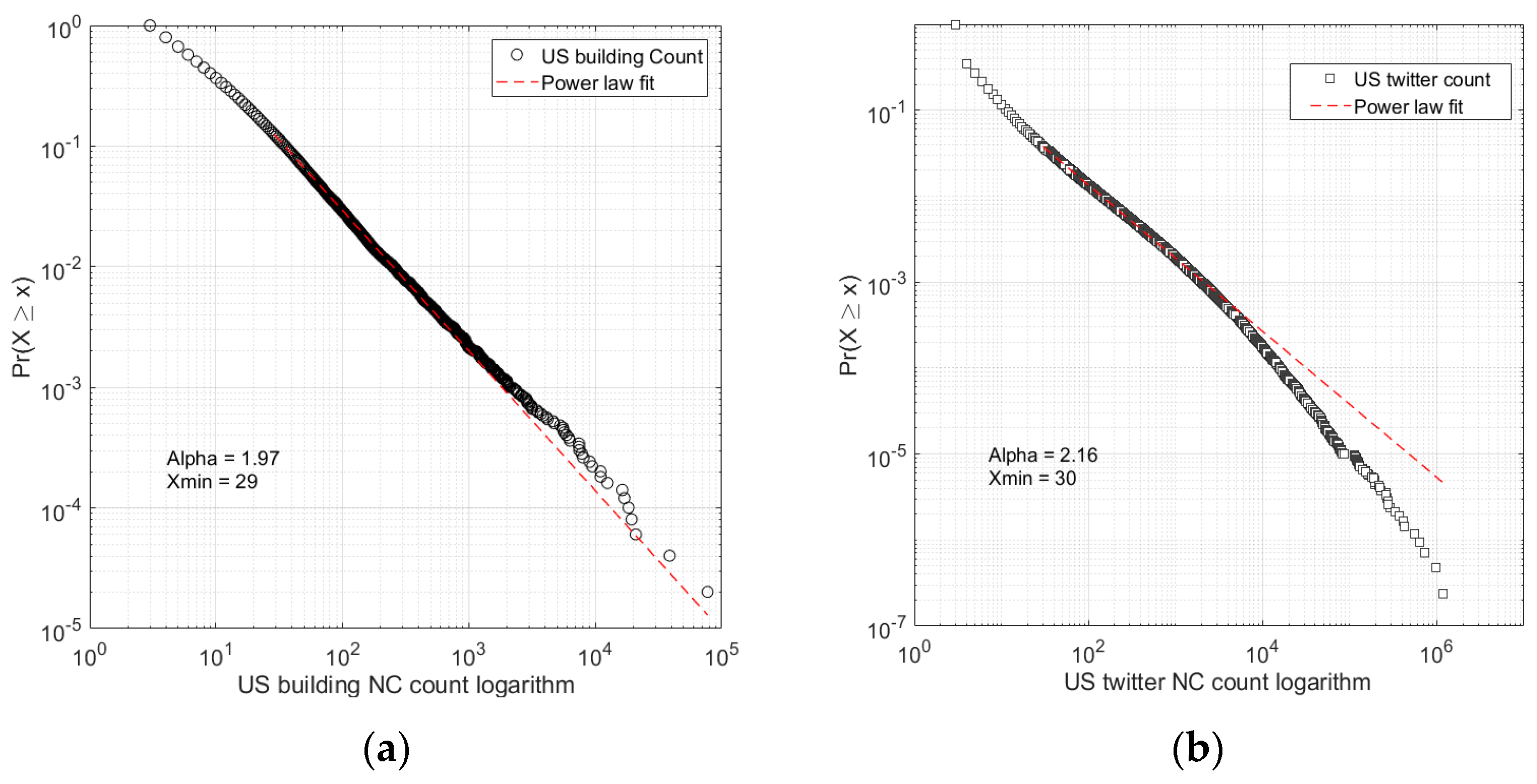
4.1. Capturing Human Activities at the Country Level
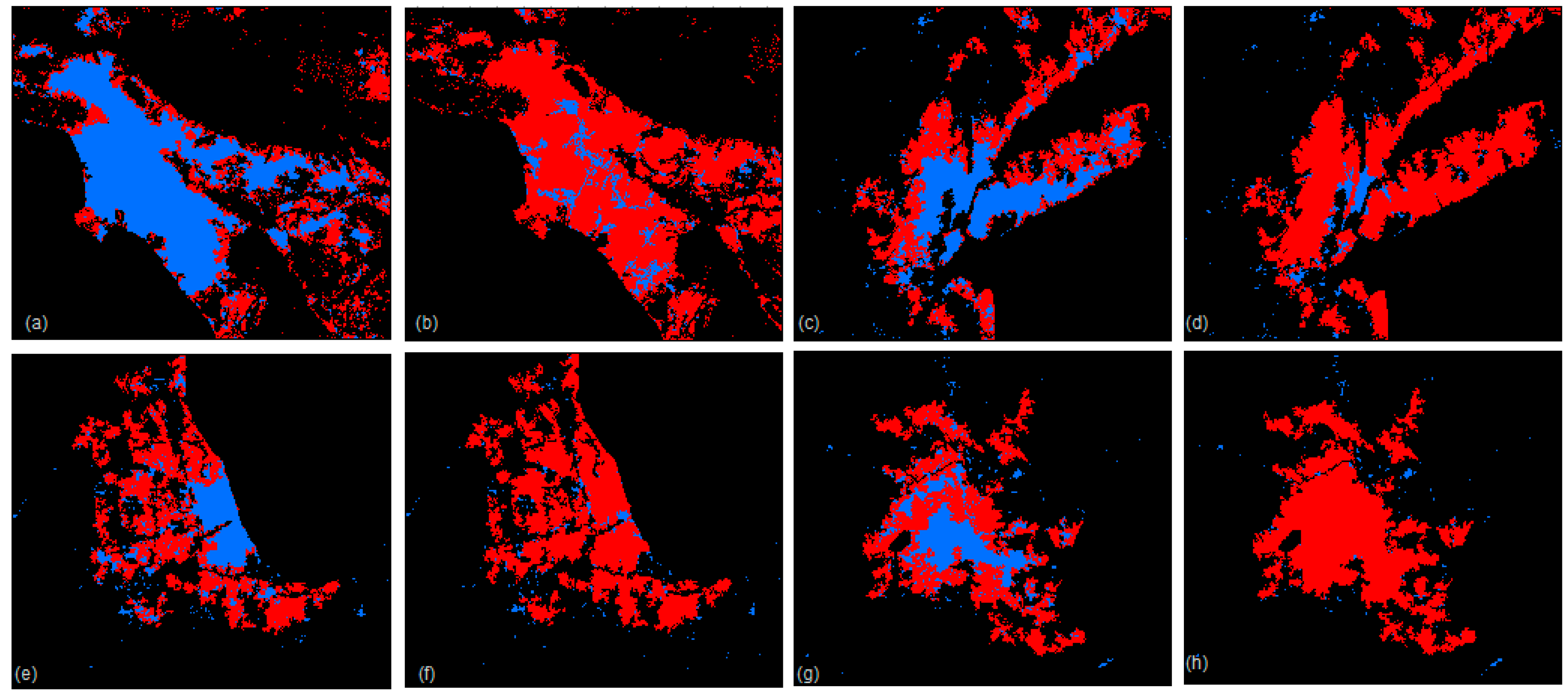
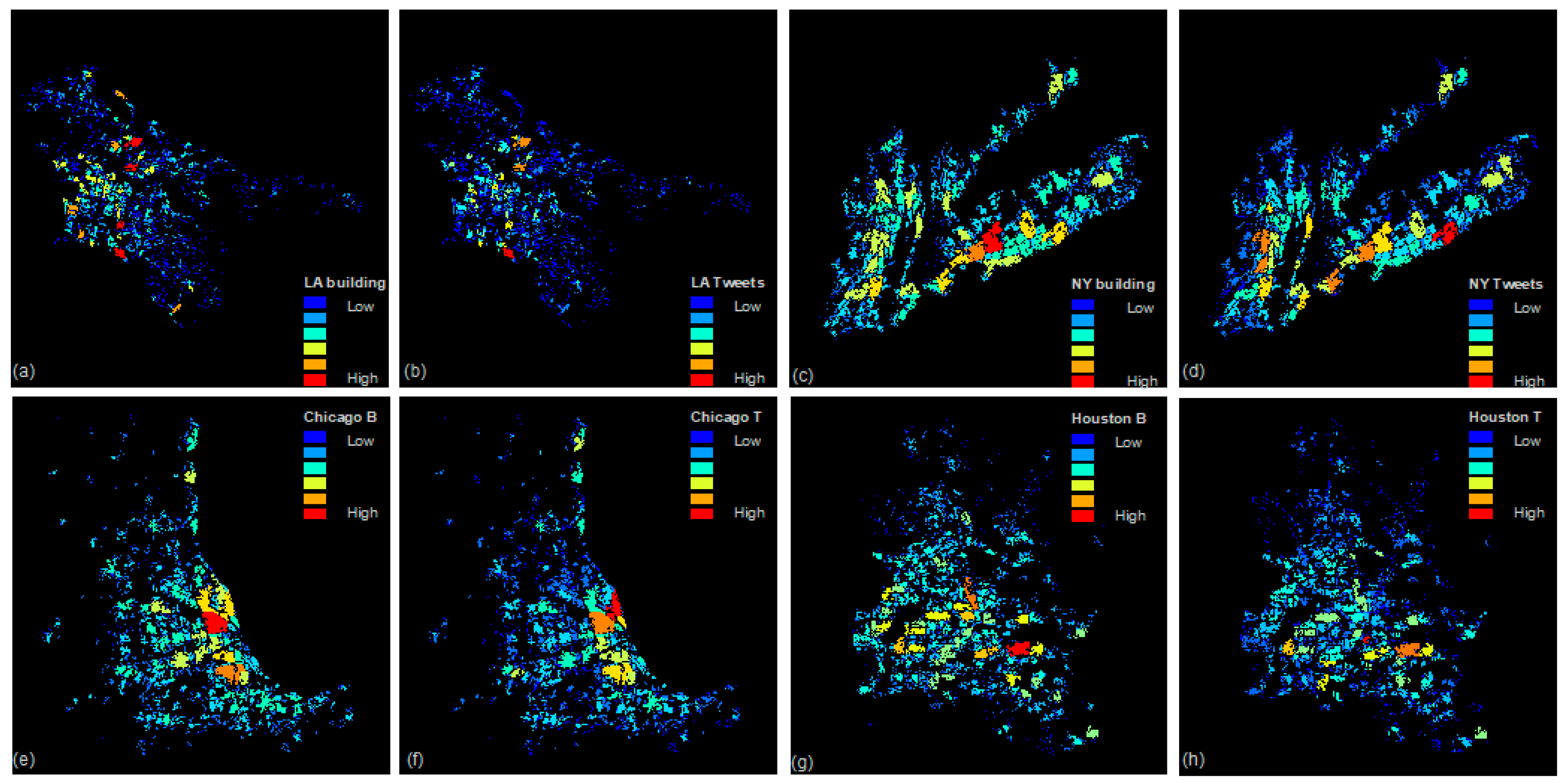
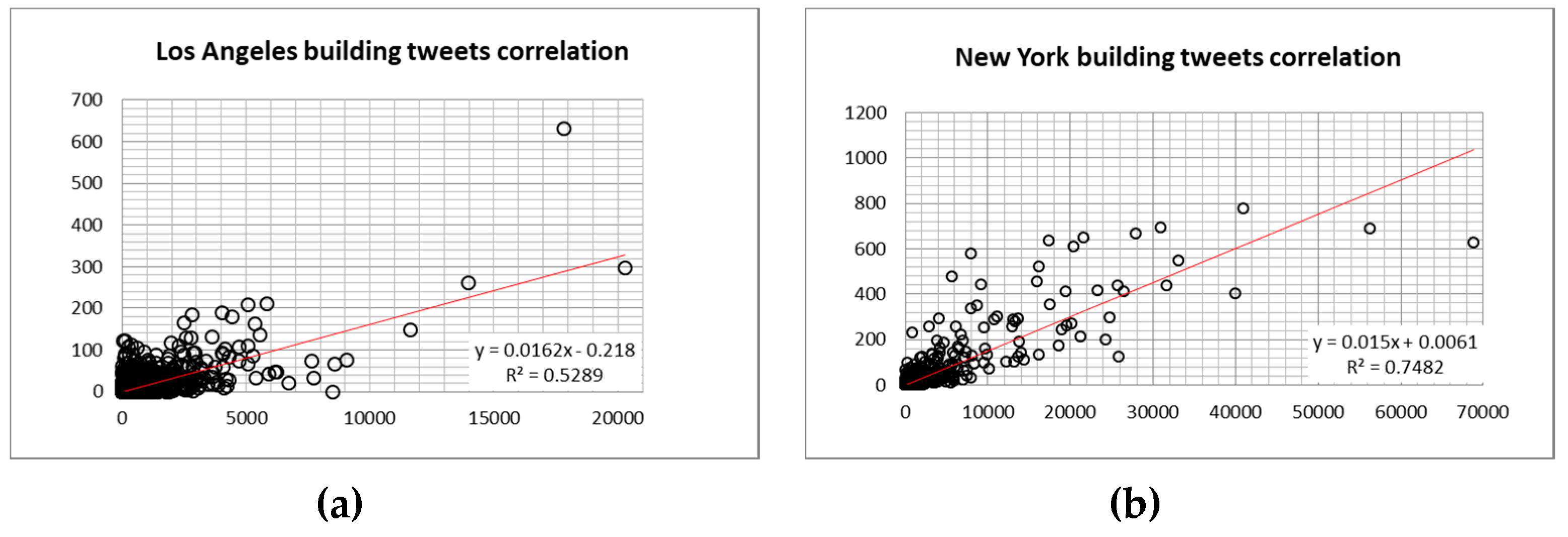
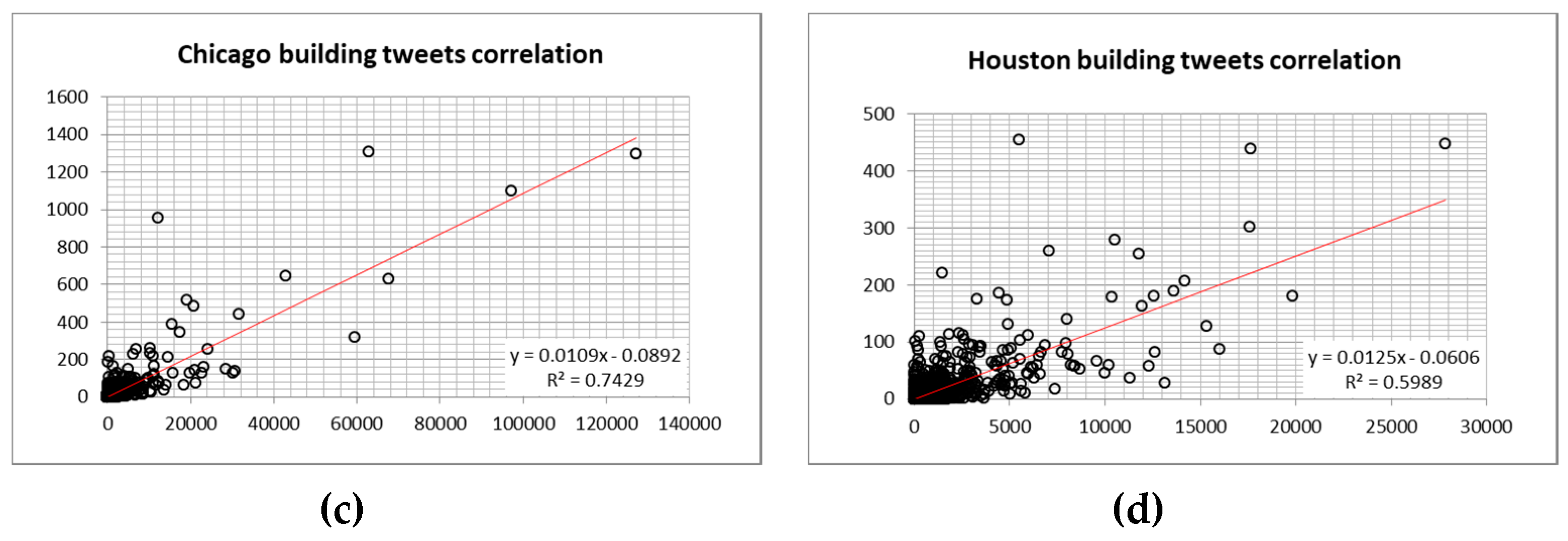
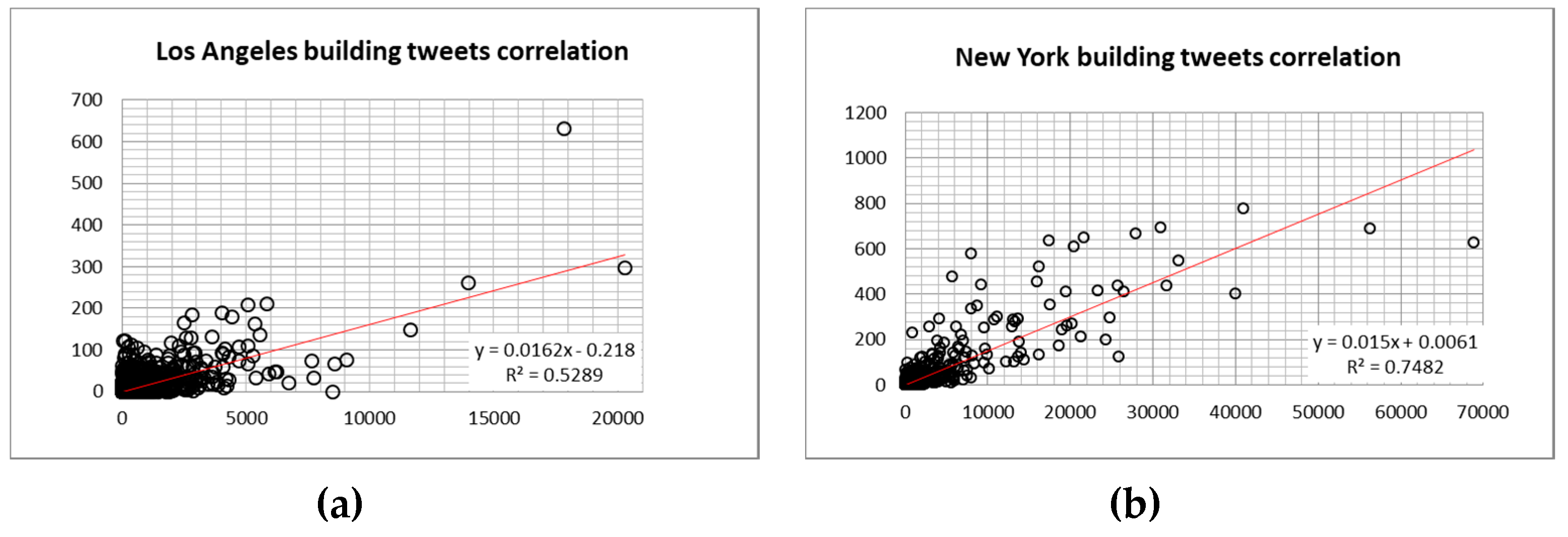
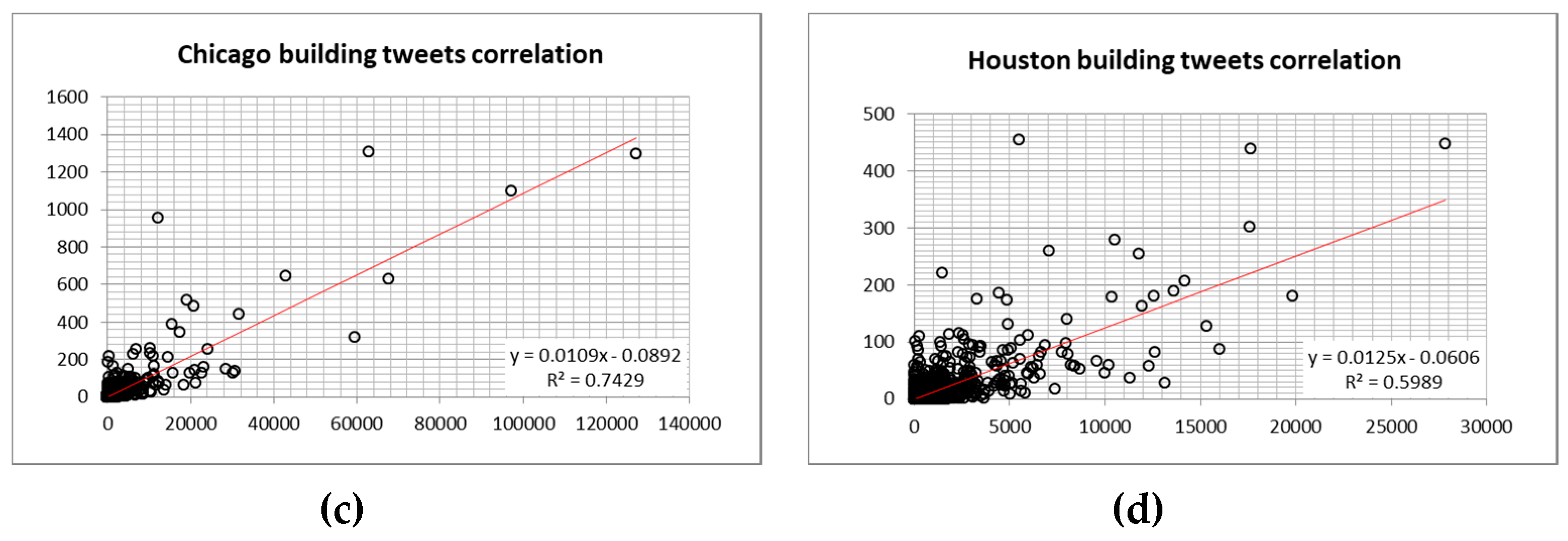
4.2. Predicting of Human Activities in the Hotspots of Four Largest Cities
5. Discussion and Implications
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Allen, C.; Tsou, M.-H.; Aslam, A.; Nagel, A.; Gawron, J.-M. Applying GIS and Machine Learning Methods to Twitter Data for Multiscale Surveillance of Influenza. PLOS ONE 2016, 11, e0157734. [Google Scholar] [CrossRef] [PubMed]
- Burton, S.H.; Tanner, K.W.; Giraud, C.G.; West, J.H.; Barnes, M.D. “Right time, right place” health communication on Twitter: Value and accuracy of location information. J. Med. Internet Res. 2012, 14, e156. [Google Scholar] [CrossRef] [PubMed]
- Jiang, B.; Yin, J.; Zhao, S. Characterizing human mobility patterns in a large street network. Phys. Rev. E 2009, 80, 021136. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Zhao, K.; Khan, S.; Cameron, M.; Jurak, R. Multi-scale population and mobility estimation with geo-tagged tweets. In Proceedings of the 2015 31st IEEE International Conference on Data Engineering Workshops, Seoul, Korea, 13–17 April 2015. [Google Scholar]
- Sui, X.; Chen, Z.; Guo, L.; Wu, K.; Ma, J.; Wang, G. Social media as sensor in the real world: Movement trajectory detection in microblog. Soft Comput. 2017, 21, 765–779. [Google Scholar] [CrossRef]
- Klepeis, N.E.; Nelson, W.C.; Ott, W.R.; Robinson, J.P.; Tsang, A.M.; Switzer, P.; Behar, J.V.; Hern, S.C.; Engelmann, W.H. The National Human Activity Pattern Survey (NHAPS): A resource for assessing exposure to environmental pollutants. J. Expo. Sci. Environ. Epidemiol. 2001, 11, 231. [Google Scholar] [CrossRef] [PubMed]
- Jiang, B.; Miao, Y. The evolution of natural cities from the perspective of location-based social media. Prof. Geogr. 2015, 67, 295–306. [Google Scholar] [CrossRef]
- Jiang, B.; Yin, J.; Liu, Q. Zipf’s law for all the natural cities around the world. Int. J. Geogr. Inf. Sci. 2015, 29, 498–522. [Google Scholar] [CrossRef]
- Jiang, B. Big Data Is a New Paradigm 2015. Available online: https://www.researchgate.net/publication/283017967_Big_Data_Is_a_New_Paradigm (accessed on 20 November 2018).
- White, T. Hadoop: The Definitive Guide, 3rd ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2012. [Google Scholar]
- Microsoft 2018. Available online: https://github.com/Microsoft/USBuildingFootprints (accessed on 12 October 2018).
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Olston, C.; Reed, B.; Srivastava, U.; Kumar, R.; Tomkins, A. Pig Latin: A not-so-foreign language for data processing. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; pp. 1099–1110. [Google Scholar]
- Jiang, B. Head/Tail Breaks: A New Classification Scheme for Data with a Heavy-Tailed Distribution. Prof. Geogr. 2013, 65, 482–494. [Google Scholar] [CrossRef]
- Jiang, B. Head/tail breaks for visualization of city structure and dynamics. Cities 2015, 43, 69–77. [Google Scholar] [CrossRef]
- Jiang, B. Natural cities generated from all building locations in America. DATA 2019, 4, 59. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96), Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Mai, G.; Janowicz, K.; Hu, Y.; Gao, S. Adcn: An anisotropic density-based clustering algorithm. In Proceedings of the 24th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ACM SIGSPATIAL 2016), San Francisco, CA, USA, 31 October–3 November 2016; p. 58. [Google Scholar]
- Johnson, S.C. Hierarchical clustering schemes. Psychometrika 1967, 32, 241–254. [Google Scholar] [CrossRef] [PubMed]
- Samet, H. Foundations of Multidimensional and Metric Data Structures; Morgan Kaufmann: San Francisco, CA, USA, 2006. [Google Scholar]
- Guttman, A. R-trees: A dynamic index structure for spatial searching. In Proceedings of the 1984 ACM SIGMOD International Conference on Management of Data ACM SIGMOD, Boston, MA, USA, 18–21 June 1984; pp. 47–57. [Google Scholar]
- Zipf, G.K. Human Behavior and the Principles of Least Effort; Addison Wesley: Menlo Park, MA, USA, 1949. [Google Scholar]
- Clauset, A.; Shalizi, C.R.; Newman, M.E.J. Power-law distributions in empirical data. SIAM Rev. 2009, 51, 661–703. [Google Scholar] [CrossRef]
- Jiang, B.; Jia, T. Zipf’s law for all the natural cities in the United States: A geospatial perspective. Int. J. Geogr. Inf. Sci. 2011, 25, 1269–1281. [Google Scholar] [CrossRef]
- Batty, M.; Longley, P. Fractal Cities: A Geometry of Form and Function; Academic Press: London, UK, 1994. [Google Scholar]
- Batty, M. The New Science of Cities; The MIT Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Batty, M. Scale, power laws, and rank size in spatial analysis. In Geocomputation: A Practical Primer; Brunsdon, C., Singleton, A., Eds.; Sage: London, UK, 2015. [Google Scholar]
- Alexander, C. The Nature of Order: An Essay on the Art of Building and the Nature of the Universe; Center for Environmental Structure: Berkeley, CA, USA, 2003–2004. [Google Scholar]
- Kudyba, S. Big Data, Mining, and Analytics: Components of Strategic Decision Making; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Mayer-Schonberger, V.; Cukier, K. Big Data: A Revolution that Will Transform How We Live, Work, and Think; Eamon Dolan/Houghton Mifflin Harcourt: New York, NY, USA, 2013. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | US Building | US Tweets |
|---|---|---|
| Original format | GeoJSON | CSV |
| Original geometry | Polygon | Point |
| Original number | 125,192,184 | 5,427,861 |
| Cleaned number | 124,828,548 | 1,480,522 |
| Datasets | Point# | States# | NC# |
|---|---|---|---|
| West | 21,167,190 | 7 | 122,949 |
| Middle | 20,181,387 | 10 | 532,066 |
| Northeast I | 31,905,414 | 9 | 772,001 |
| Northeast II | 23,530,657 | 14 | 251,107 |
| Southeast | 28,043,904 | 9 | 2,115,482 |
| Datasets | US building | US Twitter |
|---|---|---|
| Data # | 124,828,548 | 1,480,522 |
| Cluster # | 4,237,639 | 49,713 |
| Ht-index | 11 | 8 |
| Chunks | Point# | Alpha (Count) | Xmin | p | Alpha (Area) | Xmin | p |
|---|---|---|---|---|---|---|---|
| Middle | 20,181,387 | 1.95 | 1560 | 0.37 | 2.03 | 2,820,500 | 0.02 |
| West | 21,167,190 | 1.79 | 2764 | 0.50 | 1.87 | 4,361,000 | 0.38 |
| Southeast | 28,043,904 | 1.87 | 921 | 0.33 | 1.98 | 3,840,900 | 0.31 |
| Northeast I | 23,530,657 | 1.92 | 1070 | 0.38 | 1.99 | 3,732,800 | 0.16 |
| Northeast II | 31,905,414 | 1.96 | 1195 | 0.00 | 2.07 | 4,133,400 | 0.36 |
| Total | 124,828,552 | 1.97 | 1602 | 0.25 | 2.00 | 4,096,200 | 0.25 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, Z.; Jiang, B.; Seipel, S. Capturing and Characterizing Human Activities Using Building Locations in America. ISPRS Int. J. Geo-Inf. 2019, 8, 200. https://doi.org/10.3390/ijgi8050200
Ren Z, Jiang B, Seipel S. Capturing and Characterizing Human Activities Using Building Locations in America. ISPRS International Journal of Geo-Information. 2019; 8(5):200. https://doi.org/10.3390/ijgi8050200
Chicago/Turabian StyleRen, Zheng, Bin Jiang, and Stefan Seipel. 2019. "Capturing and Characterizing Human Activities Using Building Locations in America" ISPRS International Journal of Geo-Information 8, no. 5: 200. https://doi.org/10.3390/ijgi8050200
APA StyleRen, Z., Jiang, B., & Seipel, S. (2019). Capturing and Characterizing Human Activities Using Building Locations in America. ISPRS International Journal of Geo-Information, 8(5), 200. https://doi.org/10.3390/ijgi8050200