1. Introduction
Recent studies have found that China is one of the fastest growing countries in the world [
1]. However, rapid urbanization has introduced great challenges with respect to the sustainable development of Chinese cities. By using remote sensing data and GIS (geographic information system) technology, Han et al. [
2] found that the growth scale of construction land outside the planning boundary is larger than that within the planning boundary in Beijing. Tian et al. [
3] and Xu et al. [
4] found that Guangzhou and Shanghai also have significant urban developments that are located outside the planning boundary. Thus, since 2000, the planning community has gradually changed its previous practice—which concentrated on compiling information about urban planning but neglected its practical implementation—and has instead begun to focus on implementing urban planning designs and conducting postimplementation evaluations. For instance, researchers have studied the criteria and approaches used to evaluate urban planning implementations [
5,
6,
7,
8] by conducting empirical studies to assess urban spatial pattern development [
9,
10,
11] and the dynamic effects of each master plan [
12,
13]. Determining the consistency between urban spatial layout and planning is the main goal of assessing implemented construction. Scholars often adopt urban, commercial central districts as an important research object when studying urban spatial layouts [
14,
15,
16]. Therefore, it is necessary to identify the current commercial central district, compare it with the planning designs to grasp the reality of the current commercial district development, and then effectively guide the further sustainable development of the city.
Urban, commercial central districts, as a concept of urban geography, have been studied in various contexts. In the literature, urban, commercial central districts are described as having two main characteristics: (1) a dense distribution of commercial facilities and (2) a high density of road networks. McColl [
17] defined that the central business district (CBD) as an area that contains the main concentration of commercial land use. Drozdz and Appert [
18] described the CBD as a unique area with a massive concentration of activities and a focal point for the polarization of capital and economic and financial activities in a city. Yan et al. [
19] pointed out that a remarkable characteristic of a CBD is the high aggregation of commercial functions. Murphey and Vance [
20] proposed using the indices of central business height (CBHI) and intensity (CBII) to identify the CBD. Taubenböck [
21] and Wurm [
22] suggested using the parameter of building density to define urban centers. Borruso [
23,
24,
25] delineated the CBD by using a simple index of road network density. Combining the three centrality indices of closeness, betweenness, and straightness, Wang et al. [
26] indicated that land use density is highly correlated with street centrality. Porta et al. [
27,
28] used the multiple centrality assessment (MCA) model to explain commercial densities. Therefore, we define the urban commercial central district as an area with an obvious concentration of commercial facilities and a high density of road networks in the city.
The methods for recognizing urban commercial centers are commonly divided into two main approaches: (1) questionnaire-based methods and (2) geographic data-based methods. The results of the first method are obtained from the citizens’ perceptions of the city. Lynch [
29] proposed the concept of a “mental map” to address the fact that the boundary of a city center is fuzzy. Le et al. [
30] asserted that citizens could sense the function of a city center. Borruso and Porceddu [
31] defined the city center from the pedestrians’ perception. Lüscher and Weibel [
32] created an index to represent the typical composition of a city center by asking participants to classify facilities into three types. However, it was difficult to verify the representativeness of the interview groups and the validity of the experimental results. In contrast, identifying urban commercial centers by the geographic data-based approach is more objective and more practicable. Taubenboeck et al. [
33] used physical and morphological parameters to define the CBD from remotely sensed data. Kangmin et al. [
34] identified the boundaries of urban commercial centers by using open data source points of interest (POIs). Zhu and Sun [
14] built an urban spatial structure to identify the city center from land use data. Sun et al. [
35] adopted three different clustering methods (local Getis–Ord Gi*, DBSCAN, and Grivan–Newman) to identify the city center from location-based social networks data. Thurstain and Unwin [
36] combined the kernel density estimation (KDE) method and the index of town centeredness to define urban central areas from unit post codes. The increasing use of location-based services, as well as the growing ubiquity of location/activity-sensing technologies have led to an increasing availability of location-based data [
37]. POI data are a key type of data in location-based services (LBS). Compared with traditional geographic data, POI data are more current and accurate and can be shared more easily and classified in multiple ways. Such data not only reduce the cost of research, but also provide researchers with more value [
38,
39,
40]. Although POI data offer a wealth of information on individual objects, POI data rarely represent the higher order geographic phenomena that are only vaguely defined and that have uncertainties [
32], such as urban, commercial central districts. Therefore, how to analyze the location and contextual information of POIs to model the higher order geographic phenomena has attracted the interest of many scholars in the fields of knowledge discovery and data mining. Studies have found that the dense distribution of commercial facilities in the urban, commercial central district could be reflected by the high concentration of commercial POIs. According to the spatial distribution of commercial POIs, scholars have devised a variety of spatial analyses to identify urban commercial centers [
34,
41].
Kernel density estimation, a spatial density analysis method, has been widely used in POI data analysis and is often used to detect spatial “hot spots”, such as accident hotspots [
42], the density of retail areas and services [
28], and crime hotspots [
43,
44]. Conventional planar KDE assumes that geospatial space is homogeneous and isotropic by using Euclidean distance to detect commercial centers. However, studies have indicated that the layout of commercial centers is influenced by certain social and economic factors, and the road network, which is a bridge to connect the commercial center and consumer demand, plays an important role in urban social and economic activities [
45,
46]. Therefore, scholars have proposed using network kernel density estimation (network KDE) instead of planar KDE to calculate the density value of the points in a network. Yu et al. [
47] proposed using network KDE to identify the CBD from POIs. Yu and Ai [
48] analyzed the distribution characteristic of services using network KDE. Okabe et al. [
49] and Mohaymany et al. [
50] used the network KDE method to analyze traffic accidents. However, whether planar KDE or network KDE is used, only the similarity measurement method between commercial POIs is changed. Planar KDE adopts a Euclidean distance measurement, while network KDE adopts a network distance measurement. In addition, Borruso [
24] found that the density decreases locally in a region with a high road network density. Therefore, the two methods only affect the density distribution of commercial POIs, but neither of them takes into account the characteristics of the road network density in a commercial central district.
Accordingly, we propose a commercial-intersection kernel density estimation method. First, according to the non-uniform probability distribution of commercial POIs to road intersections, each commercial POI is mapped to the road intersections in its neighborhood, so that every road intersection has the attribute of commercial density. Then, the road intersection kernel density surface with commercial density is constructed (commercial-intersection kernel density surface). Because the spatial distribution of road intersections and road networks is approximate [
23], the characteristics of dense road networks in a commercial central district can be replaced by a high density of road intersections. The “hot spot” of commercial-intersection kernel density surface is the commercial central district with a high density of commercial POIs and road intersections. Our experiment shows that we can effectively identify current urban commercial central districts from POI data and road networks. Furthermore, the feasibility of the proposed method illustrates the viewpoint proposed by Huang et al. [
37], suggesting that we can model a city’s higher order geographic phenomena and mine a city’s dynamics and semantics (urban commercial central districts, in this paper) by integrating LBS-generated data and other multi-source data, so that people can better understand the city’s development.
The remainder of this paper is organized as follows. In
Section 2, we describe the study area and the commercial-intersection KDE method, its algorithm, and the selection of appropriate thresholds. In
Section 3, we present the case study experiment conducted in Nanjing.
Section 4 discusses the experimental results.
Section 5 presents our conclusions on the experimental results and proposes future work.
2. Materials and Methods
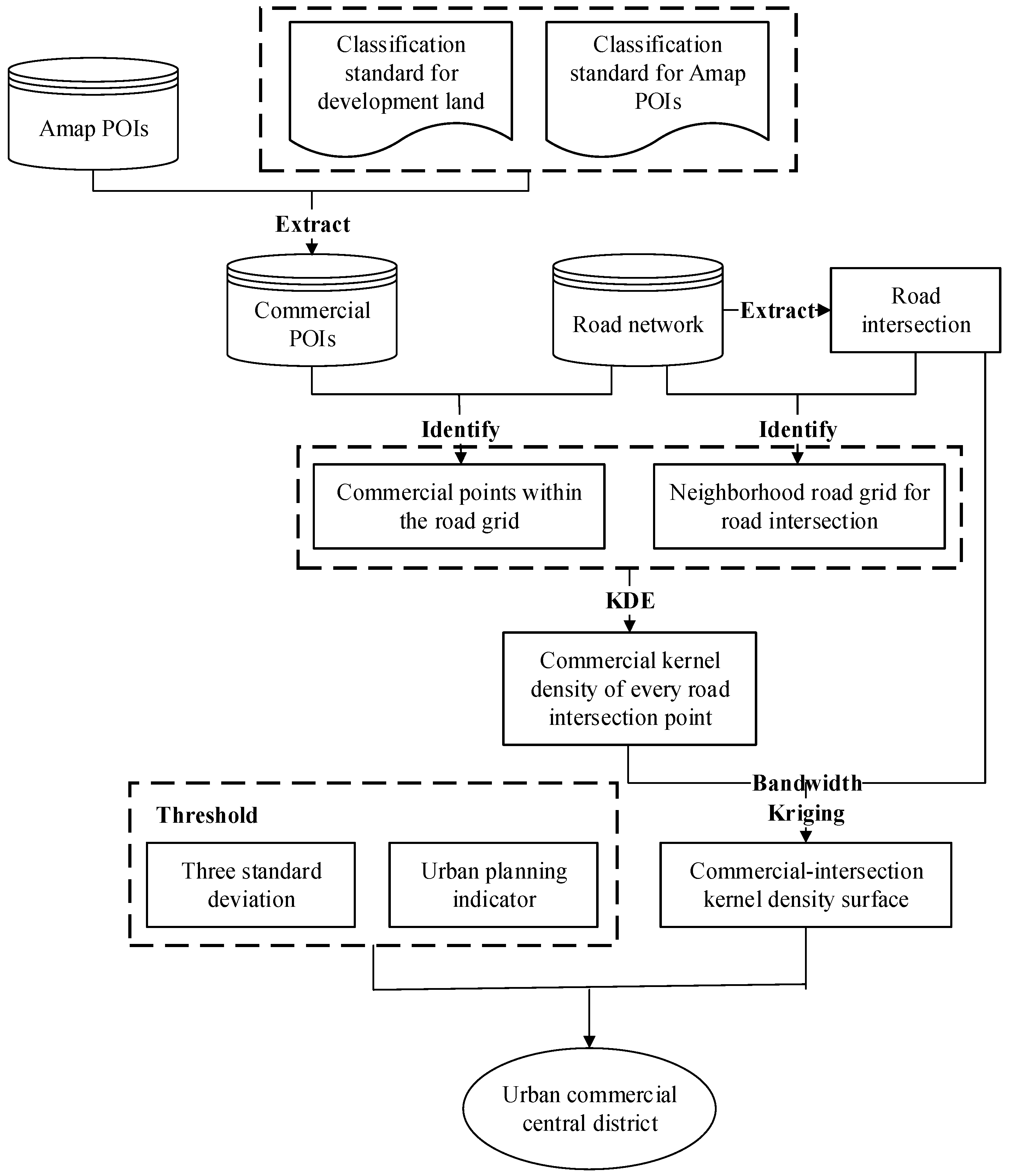
Figure 1 shows an overview of the proposed methodology for delineating urban, commercial central districts. Amap is a prevalent navigation electronic map in China, which is very similar to Google Maps. Every POI in the Amap represents an entity in the geographical space. The methodology uses Amap POIs and road networks as input data and delimits the central districts through three steps. The first step is identifying commercial POIs (see
Section 2.2). This task consists of data preparation by extracting the commercial POIs defined in the classification standard for urban development land from Amap and collecting the road intersections from the road network. The second step is constructing the kernel density surface (see
Section 2.3). In this step, we calculate the commercial kernel density of every road intersection point and input the values into a kernel function to obtain the commercial-intersection kernel density values. Then, by combining the commercial-intersection kernel density values and the kriging interpolation method, we construct a commercial-intersection kernel density surface. The third step is detecting the commercial central districts (see
Section 2.4). When constructing a commercial-intersection kernel density surface, we set the suitable bandwidth and use a natural breaks (Jenks) classification technique to divide the density values into different classes. In addition, we select the three standard deviations method and the commercial center area indicator, which is specified in the text of the urban commercial network planning as concentration and area threshold to detect commercial central districts from the kernel density surface.
2.1. Study Area and Data Source
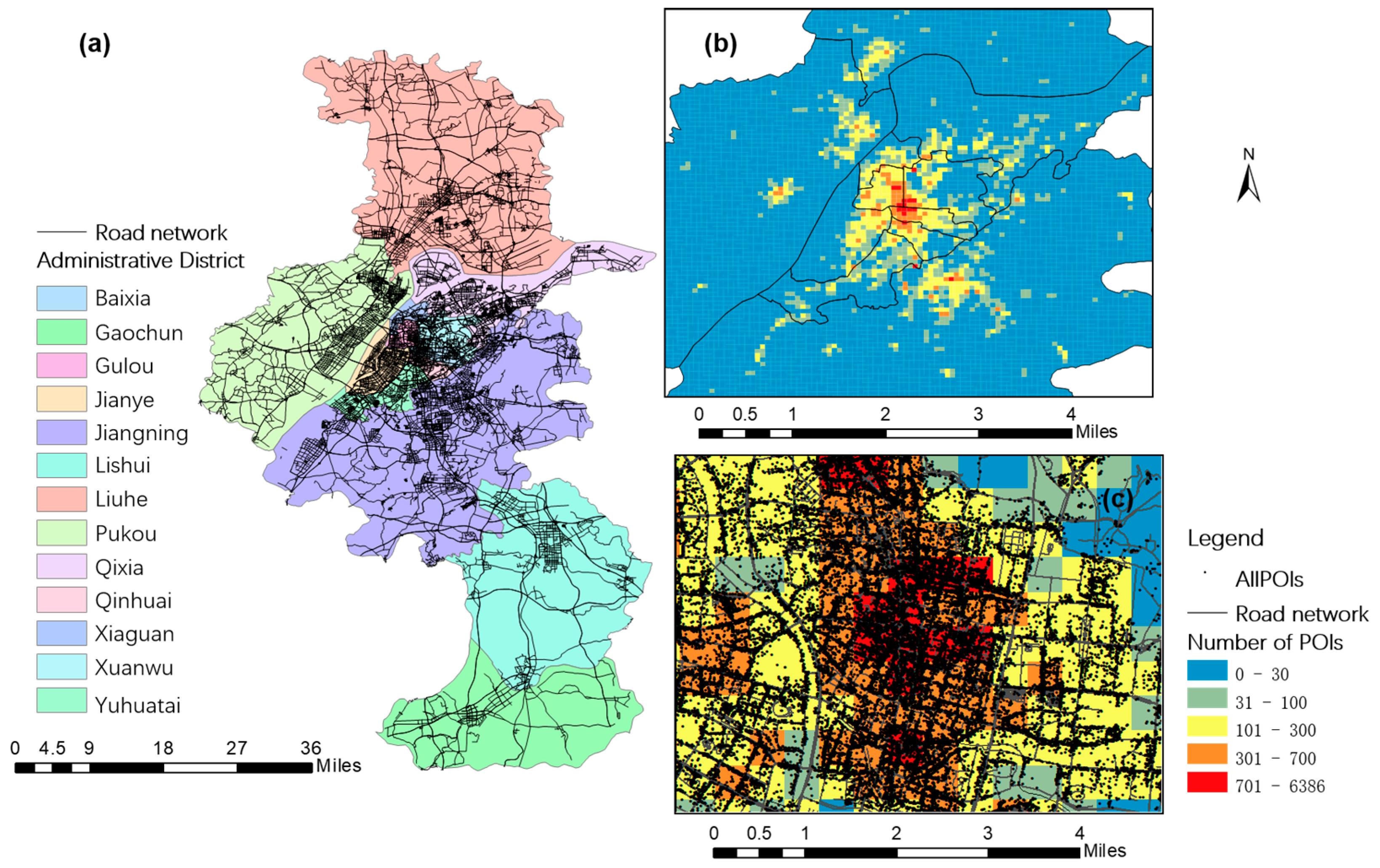
Nanjing, referred to as “Ning”, is the capital of Jiangsu, the second largest city in the Yangtze River Delta region. It is also one of the famous “four ancient capitals”, with great historical and cultural significance in China. Nanjing is located in the middle and lower reaches of the Yangtze River. Its geographical coordinates are 31°14′–32°37′ N, 118°22′–119°14′ E, the administrative area of the city is 6587.02 square kilometers, and the metropolitan area is 4388 square kilometers. The main city covers an area of 243 square kilometers.
From a high-altitude viewpoint, Nanjing is bisected by the Yangtze River, which divides the city into Jiangbei and Jiangnan. Jiangnan consists of 8 districts: Xiaguan District, Qixia District, Xuanwu District, Baixia District, Gulou District, Jianye District, Qinhuai District, and Yuhuatai District; of those, Xiaguan District, Xuanwu District, Baixia District, Gulou District, Jianye District, and Qinhuai District belong to the downtown area. Jiangbei includes Pukou District and Liuhe District. In addition to the above 10 metropolitan areas, 2 other districts in the Nanjing region are Lishui District and Gaochun District.
Furthermore, the commercial centers are divided into 4 grades (municipal, district, town, and village center) in the Nanjing city commercial network planning and construction management measures. It is specified that the municipal commercial central area (commercial center area indicator) should be larger than 300,000 square meters, and the district commercial central area should be larger than 200,000 square meters.
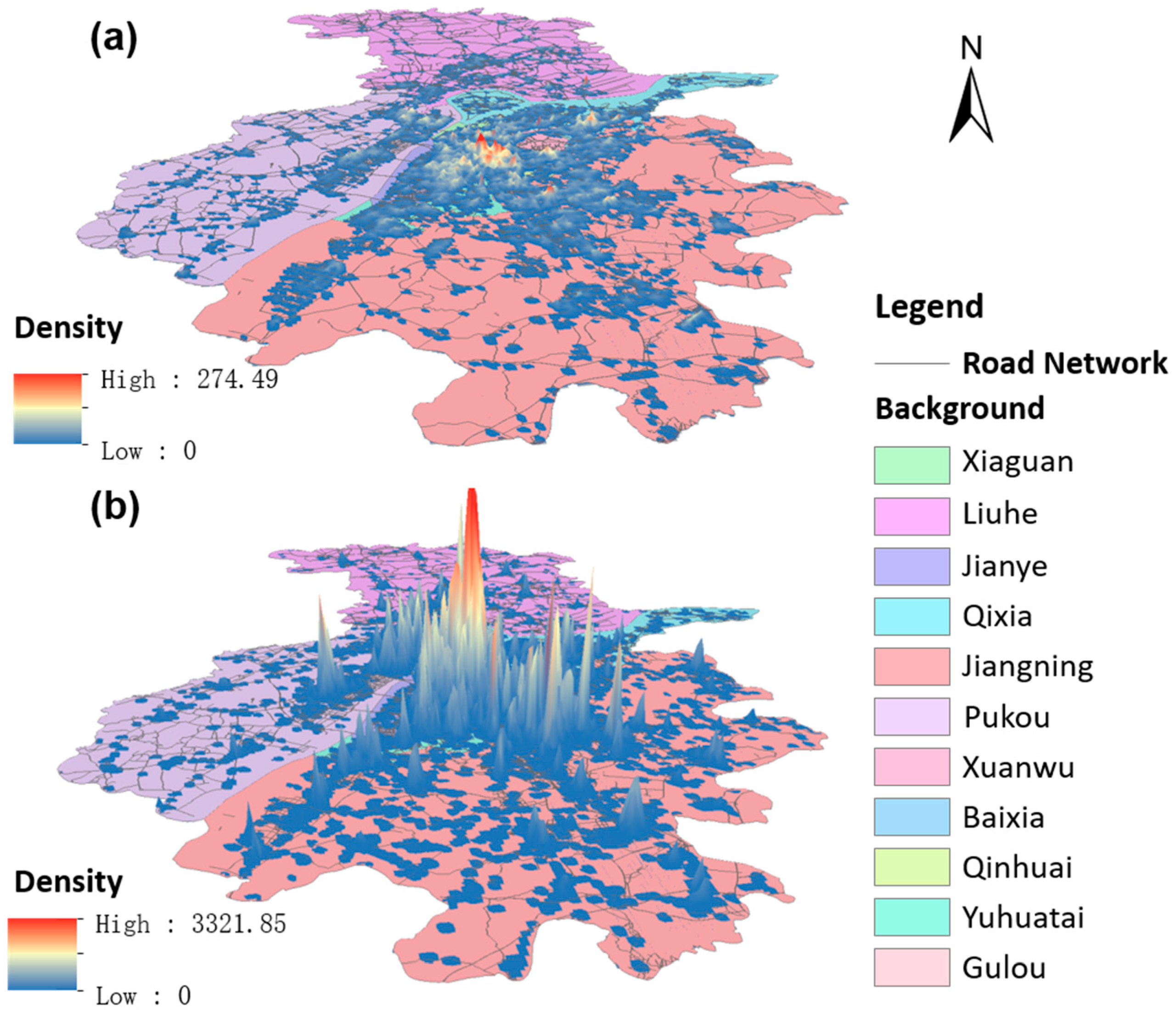
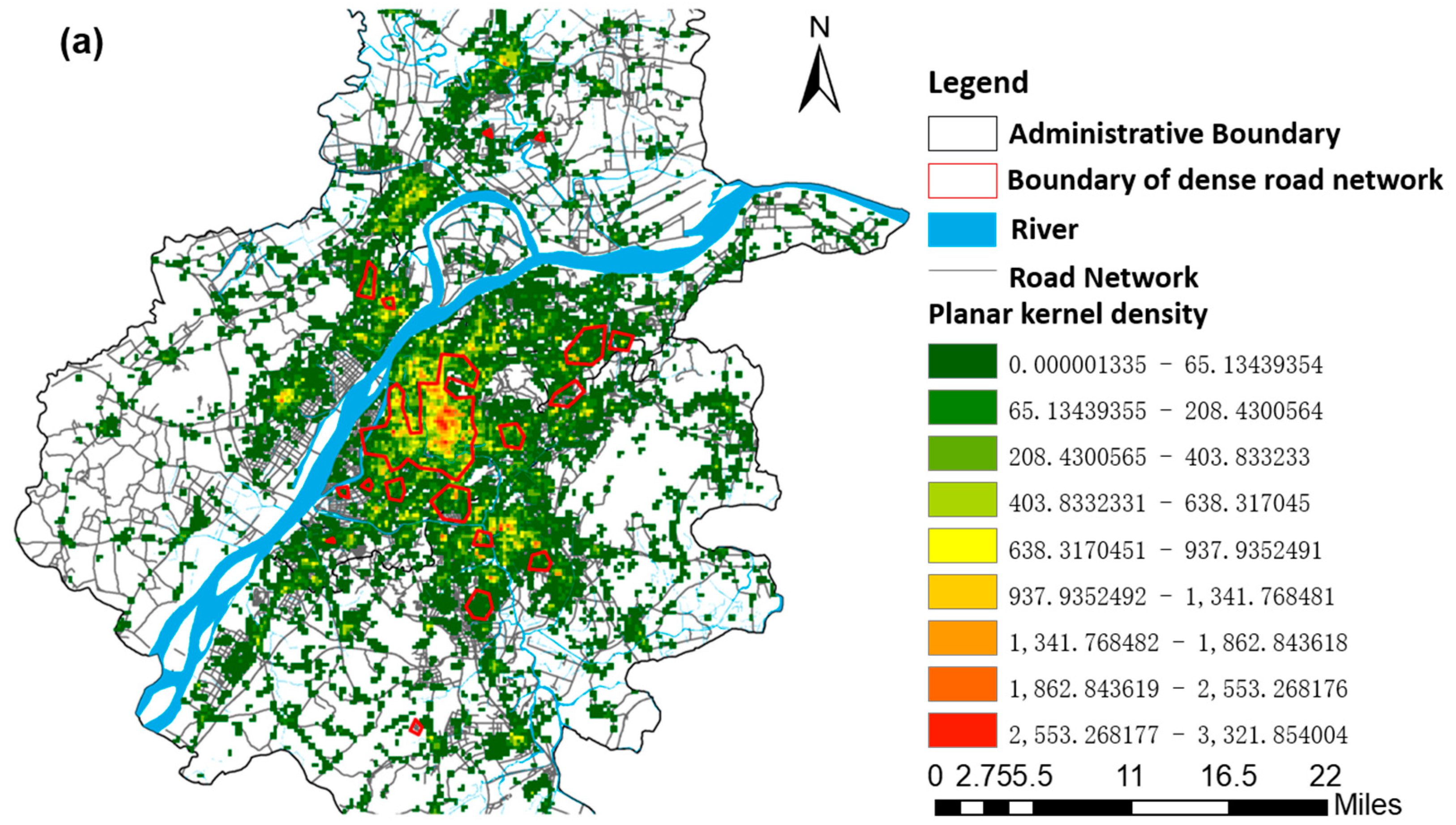
In this experiment, 215,391 Nanjing Amap POIs in 2017 were obtained from Amap API (Application Programming Interface) by using GeoSharpCollector software, which provides free, open, and multi-source geographic data collection [
51]. The spatial distribution of the overall POIs and road network in Nanjing is shown in
Figure 2.
2.2. Identifying Commercial POIs Based on the Classification Standard for Urban Development Land
In Chinese city planning, urban development land is divided into 8 main classes (
Table 1), and geographical entities are represented by different geometric figures (points, lines, and surfaces) to reflect different land use categories.
POI data show geographic entities in point form. As Amap serves the public, its classifications reflect public interests. A survey found that the public is largely interested in catering, attractions, hotels, leisure and entertainment, living facilities, hospitals, schools, shopping, banking, car services, and other services [
52]. The Amap API includes a POI category comparison table that is primarily concerned with public service classifications. Thus, categories for the same type of entity can differ between city planning and Amap. Because a commercial central district is an element of city planning, it is necessary to reclassify the POI data to extract a commercial central district from POIs. By comparing the classification standard for urban development land and the Amap POI categories, we found two relationships between the commercial POI classes in Amap and the commercial and business facilities (B) category, as shown below.
“Containment relation”: A certain class of POI data belongs to the commercial and business facilities (B) category (
Table 2). Thus, this POI class can be directly regarded as commercial points. The set is suitable for use in any city.
“Betweenness relation”: Part of a certain class of POI data belongs to the commercial and business facilities (B) category but part does not (
Table 3). The betweenness relation mainly occurs between the categories of administration and public services (A) and commercial and business facilities (B).
a. According to different investment subjects, China’s talent market can be divided into the state-owned talent market, private talent market, foreign talent market, and so on [
53]. The state-owned talent market belongs to the category of administration and public services (A), while the private talent market and foreign talent market belong to commercial and business facilities of category (B).
b. Libraries can be divided by sponsor into public, school, and enterprise libraries. The public library belongs to the library and exhibition facilities category (A), and school libraries belong to the education and scientific research facilities aspect of category (A). However, the purpose of an enterprise library is to make profit; therefore, these belong to the retail commercial facilities of category (B).
c. Scientific research institutions can be hosted by either enterprises or the government. Recently, most scientific research institutions in China have been converted into enterprises in category (B), but some still exist as institutions in category (A);
d. Similarly, cemeteries, clinics, and animal health facilities can be classified into commercial use in category (B) and public use in category (A).
e. In addition, commercial and residential dual-use housing are comprehensive land types that can be regarded as either residential land in category I or commercial facilities in category (B).
f. In city planning, planners divide driving school training grounds into transport facilities in category (S) and training schools into commercial facilities in category (B).
g. City planners divide the branch offices, service stations, and headquarters of post offices into public facilities in category (U), while post offices and other office sites are classified as commercial facilities in category (B).
Compiling a set of betweenness relations requires a specific analysis of each individual city. The collection of commercial POIs is ultimately made up of the set of containment relations and the commercial POIs (B) in the set of betweenness relations.
2.3. Constructing Kernel Density Surface Based on Commercial-Intersection KDE
The purpose of our method is to identify the urban, commercial central districts with a high density of commercial POIs and road intersections from the commercial-intersection kernel density surfaces. Therefore, calculating the commercial-intersection kernel density is the critical aspect of the commercial-intersection KDE. The basic principles are as follows.
2.3.1. Calculation of Commercial Kernel Density of Road Intersections
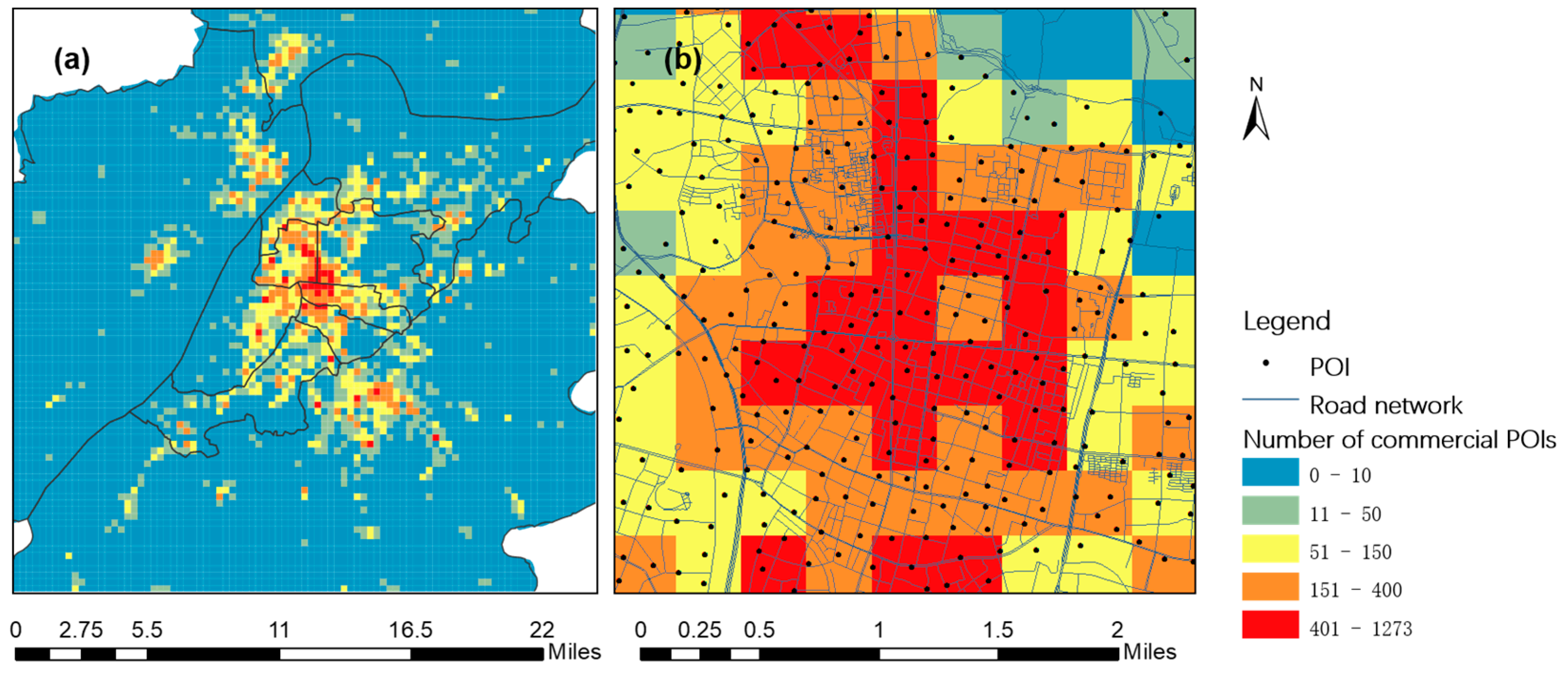
Commercial kernel density is a value used to evaluate spatial commercial density, and it is influenced by neighborhood division. Generally, the neighborhood of traditional planar KDE is determined by the bandwidth. Here, we considered the road grids adjacent to the road intersection to be the neighborhood of that intersection (the area within a thick boundary). The commercial kernel density of each road intersection is affected by the commercial POI distribution within its neighborhood; the more commercial POIs that are located close to a road intersection, the higher the commercial kernel density of that road intersection. As
Figure 3a shows, the road intersection point is the kernel center
, the commercial POI points in the neighbourhood of the road network are the sample points
, and the longest distance from the road intersection to the surrounding commercial POI is the bandwidth
. Then, the commercial kernel density
of each road intersection point is calculated by Equations (1) and (2).
Previous studies have shown that different kernel functions have less influence on kernel density estimation than dose bandwidth selection [
54]. Therefore, this paper uses the common Gauss kernel function:
where
is the longest distance from a road intersection to the surrounding commercial POIs (bandwidth),
is the distance between sample point
and the kernel center
, and
is the Gaussian kernel function.
The Gauss kernel function can be used to calculate the Rosenblatt–Parzen kernel density estimation:
where
is the commercial kernel density (the estimated value of the probability density) of the
-th road intersection point and
is the number of sample points within the neighborhood. A large
value indicates that more commercial POIs are clustered around the road intersection, i.e., the commercial density is high near the road intersection.
2.3.2. Calculation of Commercial-Intersection KDE Value
While
is a value used to describe commercial density, it is based on road intersections. In this study, we planned to identify the commercial central district not only from commercial density values, but also from the road network density, which is considered to be a constraint. Therefore, we took the
value to be an important parameter for calculating the commercial kernel density of a road intersection (
).
is a comprehensive index that indicates both road intersection aggregation and commercial POI aggregation. As
Figure 3b shows, we chose a road intersection as the kernel center
and set the bandwidth to
, and the intersection points within the bandwidth formed the sample points
. Then, the kernel density estimate for road intersection
was calculated by using Equations (3) and (4):
where
is the experimentally selected bandwidth,
is the distance between sample point
and the kernel center
,
is the commercial kernel density of kernel center
,
is the number of intersection points within the bandwidth, and
is the kernel density of the road intersection with the commercial density.
accords with the law of distance attenuation: when the sample points are closer to the kernel center, the kernel density of the road intersection is lager. In addition,
is also directly proportional to
.
2.3.3. Construction of Commercial-Intersection Kernel Density Surface
is an indicator bounded by both the commercial kernel density and the road intersection kernel density. Here, we defined it as the “commercial-intersection kernel density”. In this study, the kriging interpolation method was utilized to construct the commercial-intersection kernel density surface [
55]. Previous studies [
36] found that central activities are affected by regions and present spatial aggregation in local regions, whereas local universal kriging can capture the complexity and retain details [
56]. Thus, we adopted local universal kriging with a linear semivariogram model as the kriging model to predict the unknown commercial-intersection density value.
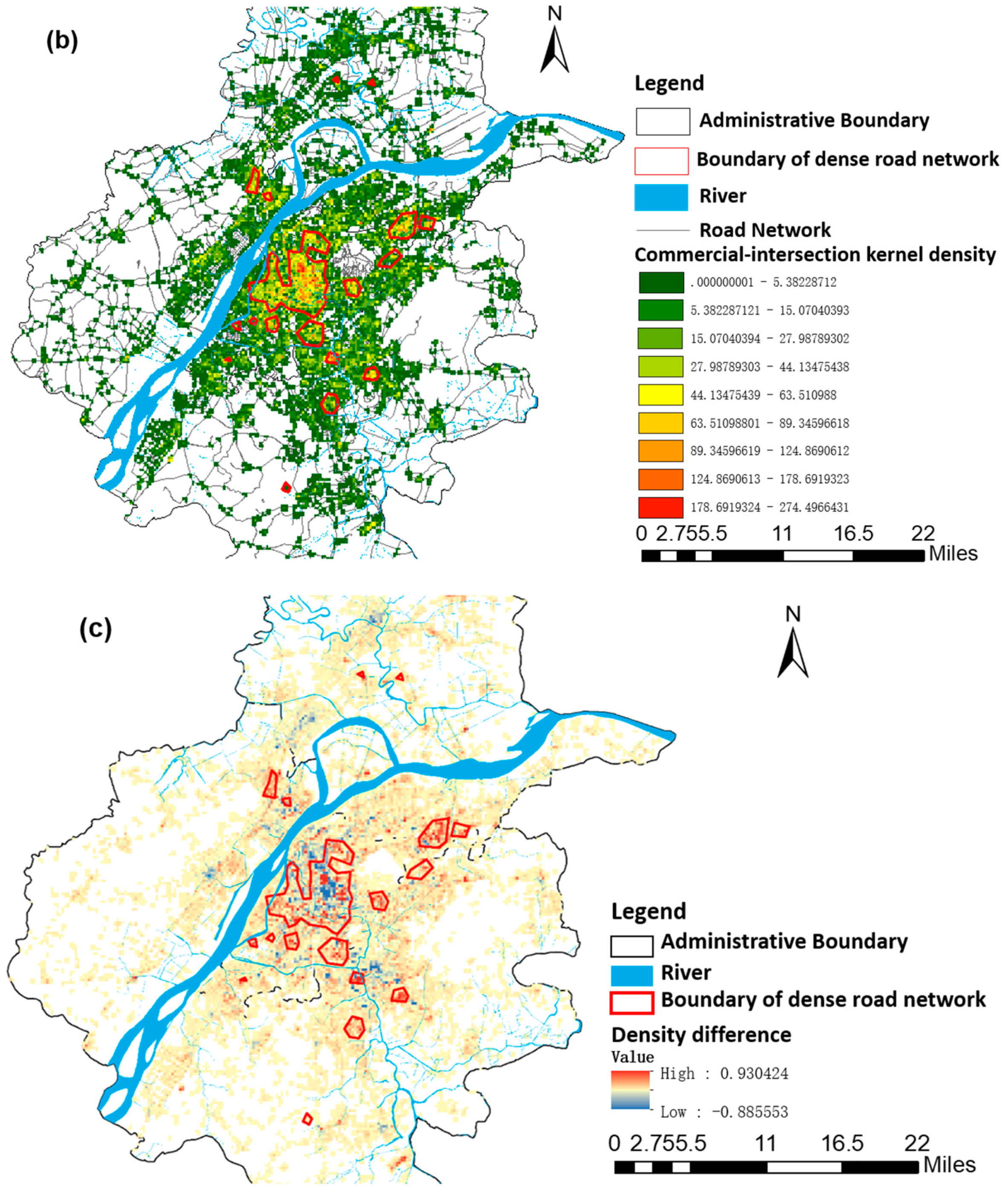
In order to compare the commercial-intersection KDE method with the planar KDE method, the density difference between the commercial-intersection kernel density map and the planar kernel density map were obtained by normalizing the two density maps and grid calculating the difference.
2.3.4. Basic Design of the Algorithm
Because of MATLAB’s efficient numerical calculation and analysis functions, in this study, the algorithm was implemented in MATLAB.
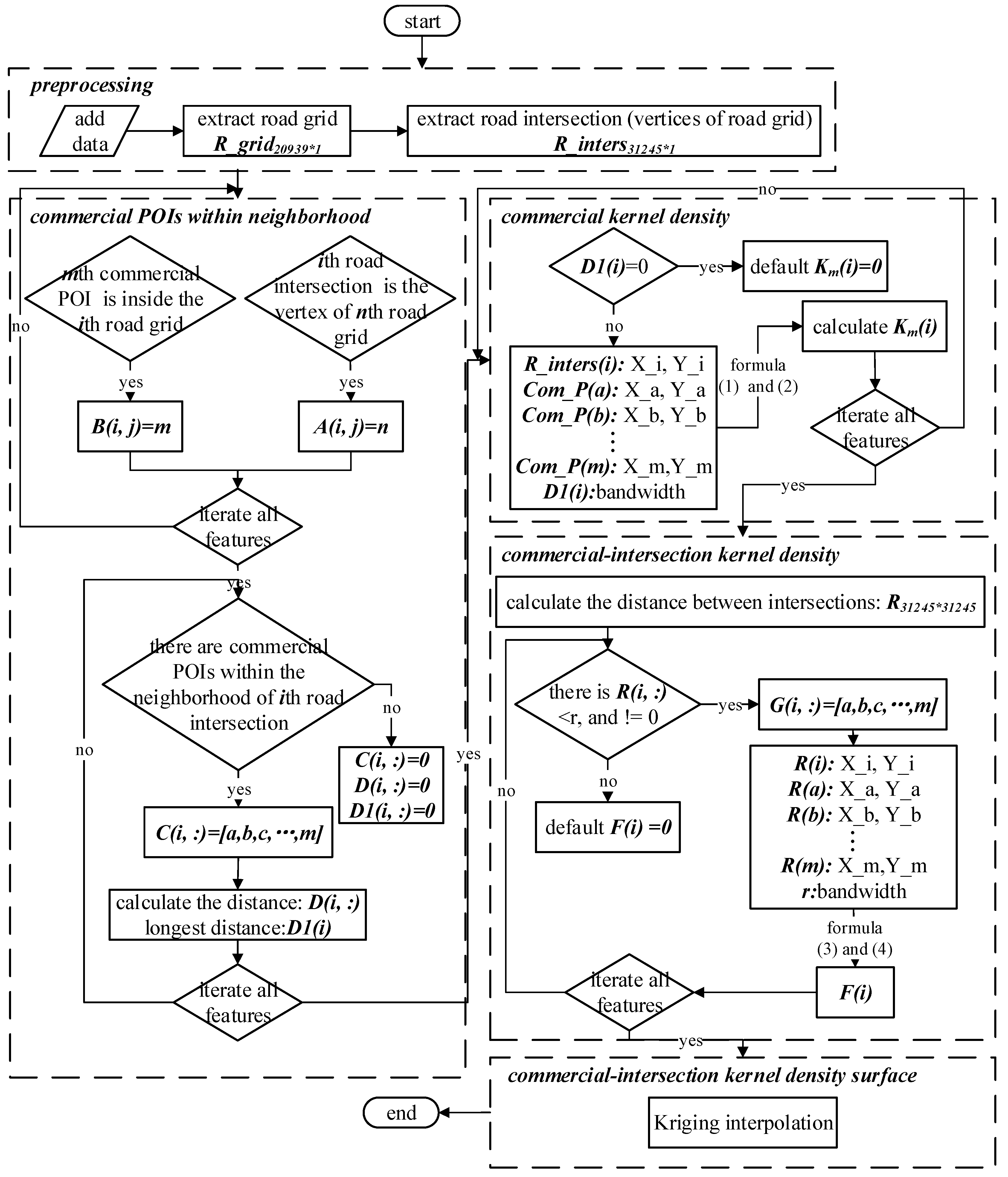
Figure 4 shows the main steps of the commercial-intersection KDE algorithm; the basic algorithm involves 5 distinct stages.
Step 1. Preprocess data. This step is implemented by the following operations:
- ①
Convert the road network data into road grid data and establish a matrix, . Each row of the matrix corresponds to a grid ID (grid unique code). The first column stores geometric type (polygon), the second column and the third column respectively store the X and Y coordinates of the vertices of the polygon. In addition, the storage order of the vertices is clockwise from the first vertex in the upper left corner.
- ②
Extract the road intersections. The intersections also form the vertices of the road grid and establish a matrix, , in which each row corresponds to the road intersection ID, and each column corresponds to the attributes of the intersection.
Step 2. Identify the commercial POIs within the road intersection neighborhoods. This step can be implemented using the following operations:
- ①
Identify the vertices of the different grids and establish a two-dimensional matrix . For example, “” means that the road intersection with ID is a vertex of the road grid with ID n and is the th road grid.
- ②
Identify all the commercial POIs in the different grids and establish a two-dimensional matrix, B. For example, “” means that the commercial POI with ID is inside the road grid with ID , and it is the th commercial POI within this road grid.
- ③
Determine whether commercial POIs exist in the neighborhood of the road intersection, calculate the distance between those commercial POIs and the road intersection, and store them in matrix D1.
Step 3. Calculate the commercial kernel density of the road intersection.
When no commercial POIs exist in the road intersection () neighborhood, set the commercial kernel density of road intersection to 0 ( = 0), which is the default. When commercial POIs do exist in the road intersection () neighborhood, retrieve the coordinates of the road intersections and commercial POIs from the above the matrices and calculate the commercial kernel density of road intersection () using Equations (1) and (2).
Step 4. Calculate the commercial-intersection kernel density. This step can be implemented using the following operations:
- ①
Calculate the distances between the road intersections and save the values in matrix .
- ②
Identify all the road intersection points for which the distances between those road intersections and central road intersections are below (e.g., ()), query the coordinates of those road intersections from the above matrices, and calculate the commercial-intersection kernel density () using Equations (3) and (4). When no road intersection point has a distance of less than , set the commercial-intersection kernel density () to the default value of 0.
Step 5. Construct the commercial-intersection kernel density surface.
Based on the values of the road intersections, use the kriging interpolation method to construct the commercial-intersection kernel density surface.
2.4. Detecting Urban Commercial Central District
Commercial-intersection KDE is a method for constructing the kernel density surface of a study area based on the distribution of the commercial POIs and road intersections. However, the urban commercial central district is an irregular surface formed by commercial POIs and road intersections that reach a certain degree of aggregation. Therefore, we need to set several thresholds and indicators to identify the commercial central district from the overall commercial kernel density surface.
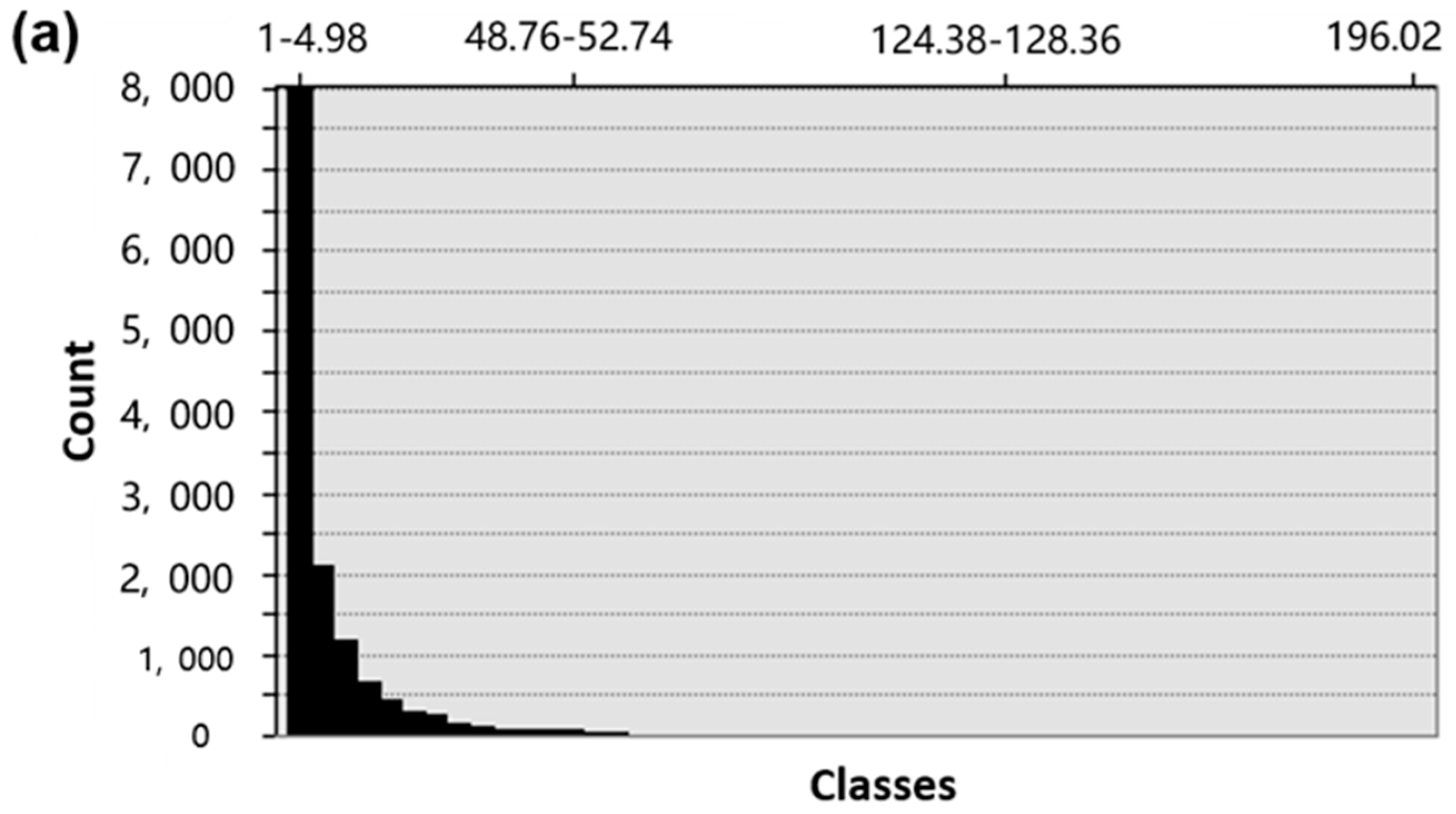
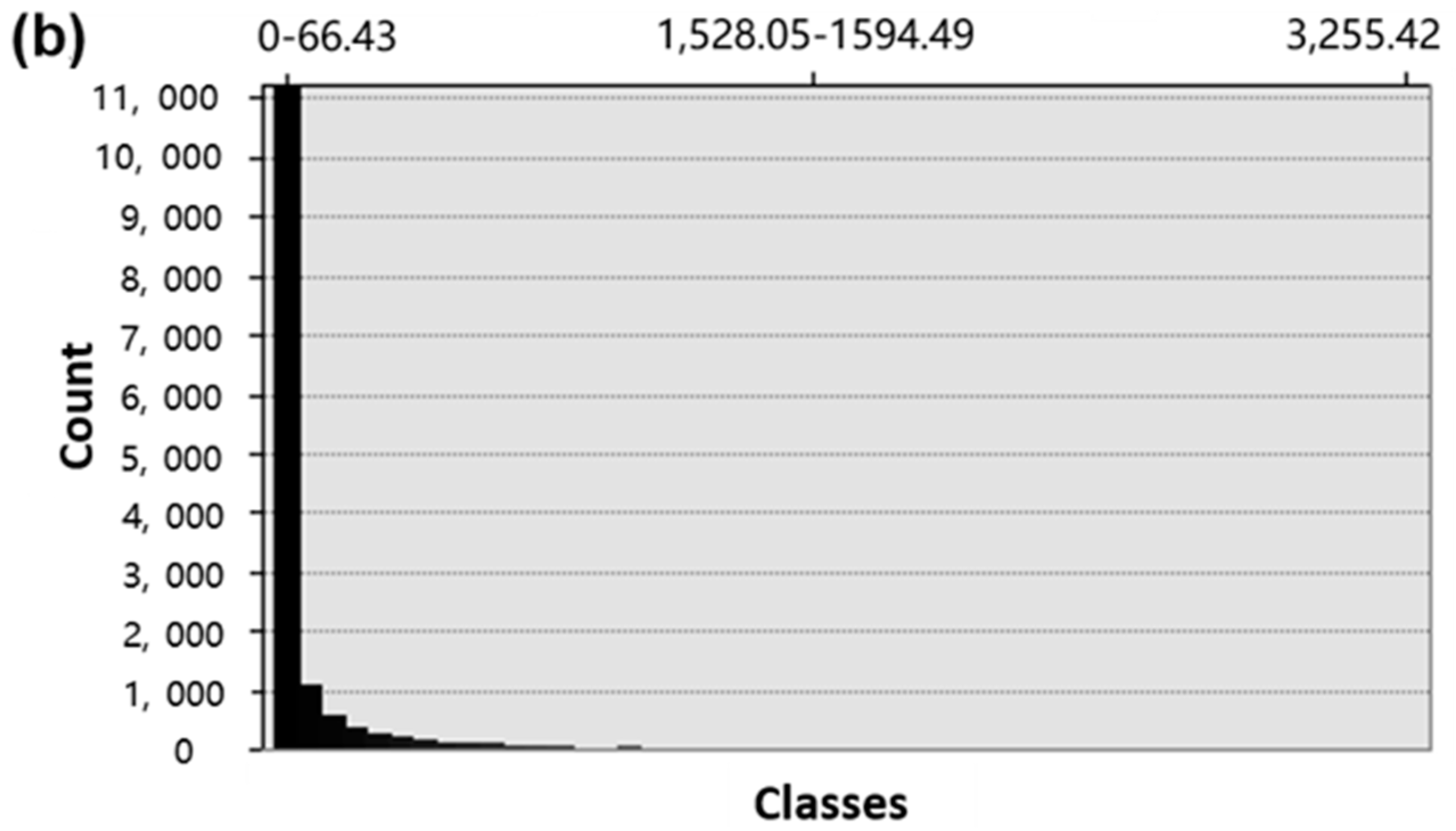
2.4.1. Selection of Classification Methods and Numbers
Because the threshold calculation is based on isolines, and the extraction of isolines is affected by the classes of classification, the choice of a visual classification method and numbers are very important. In view of the literature, equal-interval classification and “Jenks” classification are the two most common classification methods [
47,
57]. In this experiment, we chose the optimal classification method from the two classification methods by analyzing the characteristics of the experimental data.
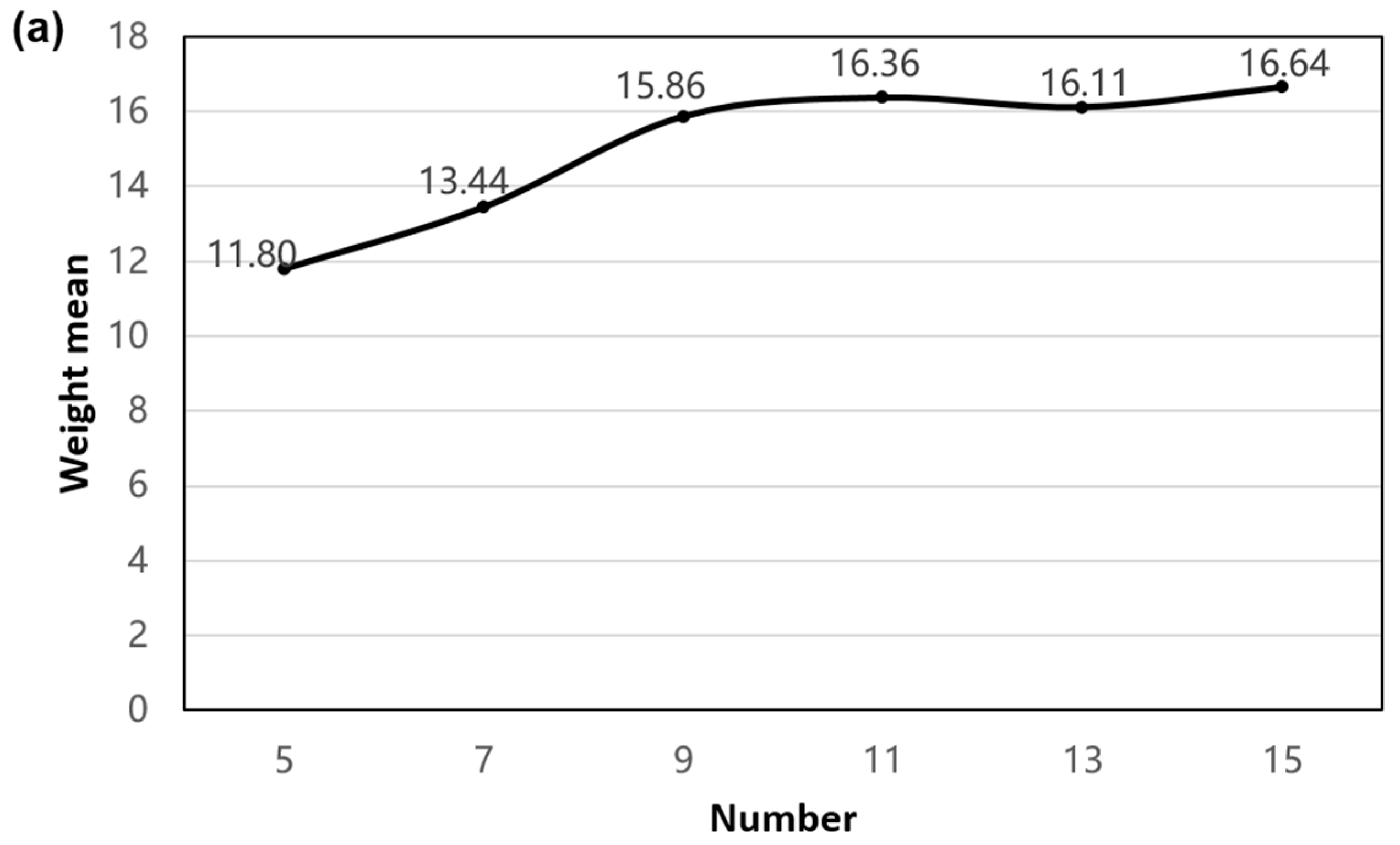
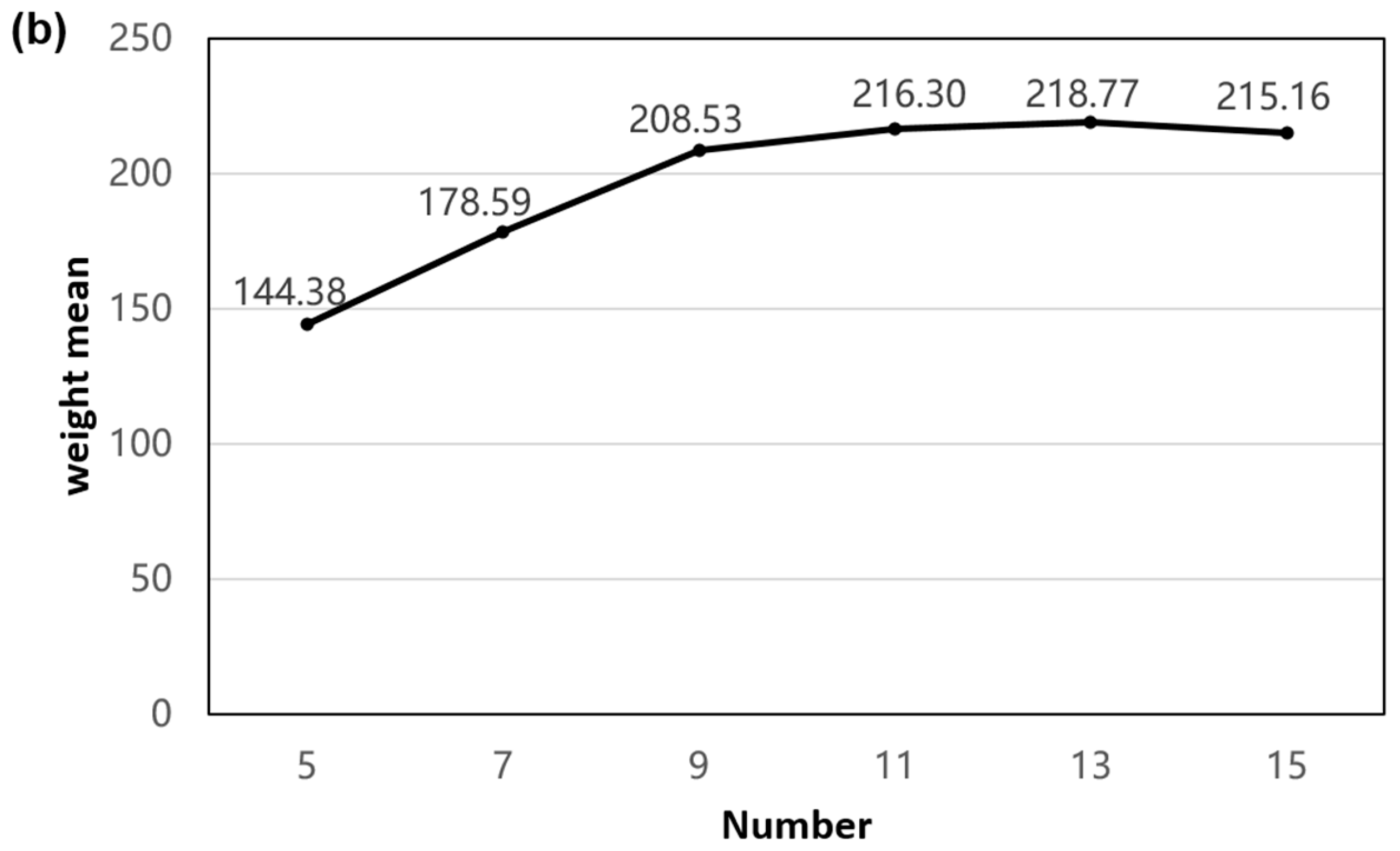
Because the weight mean is an index reflecting the overall characteristics of the data, we used the iterative method to extract the isolines of different classification numbers and then calculated those weight means of the isolines. When the weight mean tends to be stable, the weight mean at this time can best reflect the characteristics of the original data, and the classification number is optimal.
2.4.2. Delimitation Criteria
How to use spatial statistical technology to quantify the evaluation has become the key aspect of delimiting urban commercial centers. The urban commercial center is a location with an obvious concentration of commercial POIs. Consequently, from one point of view, we can consider the urban commercial central district to be an abnormal value. There are many ways to eliminate abnormal values; here, we use the common three standard deviations method. For example, suppose that we have set of observations
, whose mean and three standard deviations are as follows:
By default, we assume that the values within the range of
are normal and that values exceeding the range are abnormal. In this experiment, we determined the threshold by extracting the isolines from the kernel density surfaces, recording the isolines’ value, and calculating those isolines’ three standard deviations to delimit the urban commercial central areas. As introduced in
Section 2.1, the area of municipal commercial central area should be larger than 300,000 square meters in Nanjing. Therefore, blocks with areas of less than 300,000 square meters were removed.
2.4.3. Precision Evaluation
Then, we used the anastomosis degree
index to evaluate the accuracy of the results. The more consistent with the prior range, the higher
value, and the extraction accuracy of the extracted commercial central district is as follows:
where
is the range of the urban commercial central district identified by the proposed method,
is the prior range that was delimitated by the city planning bureau in the city planning text, and
is the overlapping area between the two ranges.
4. Discussion
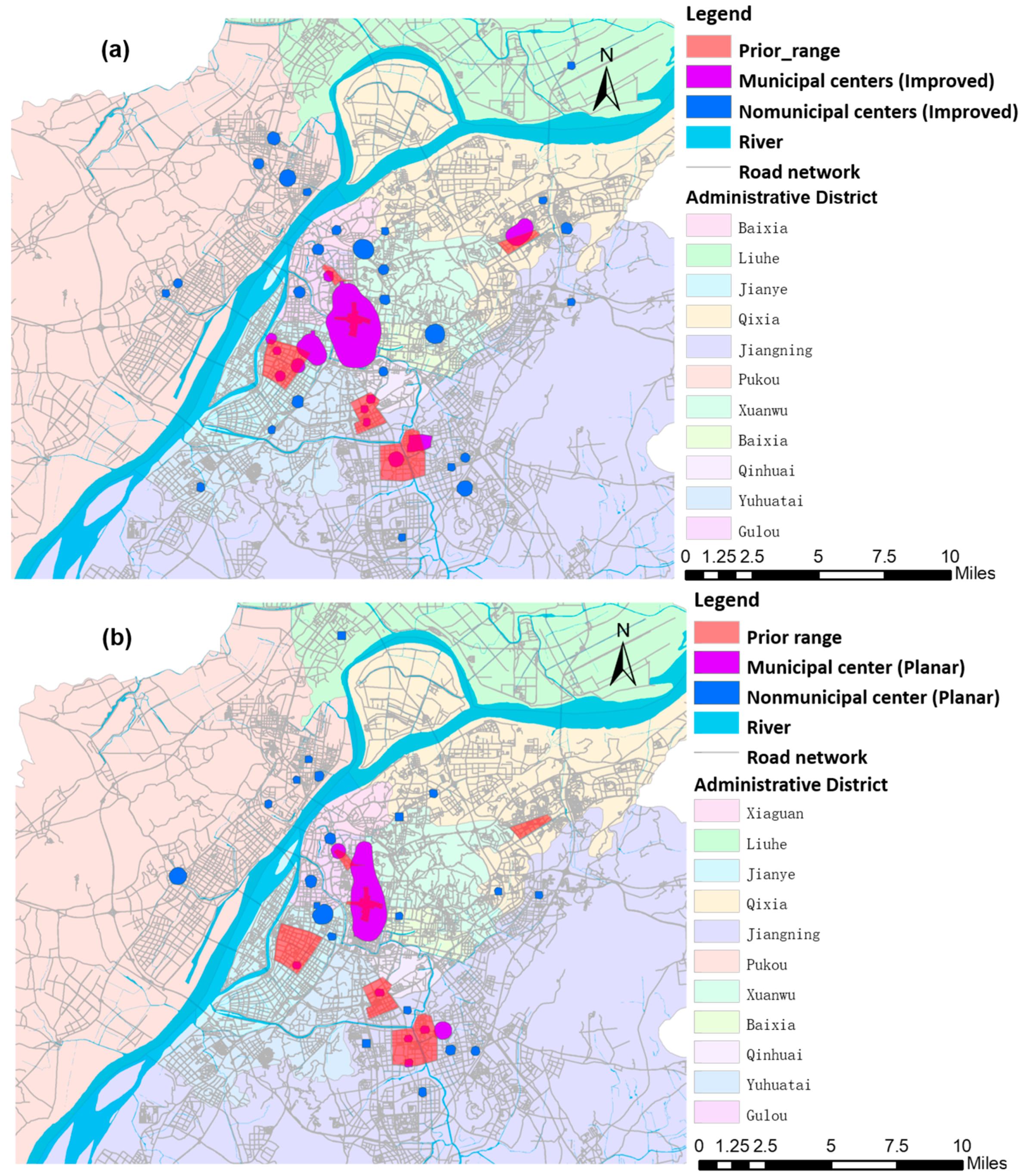
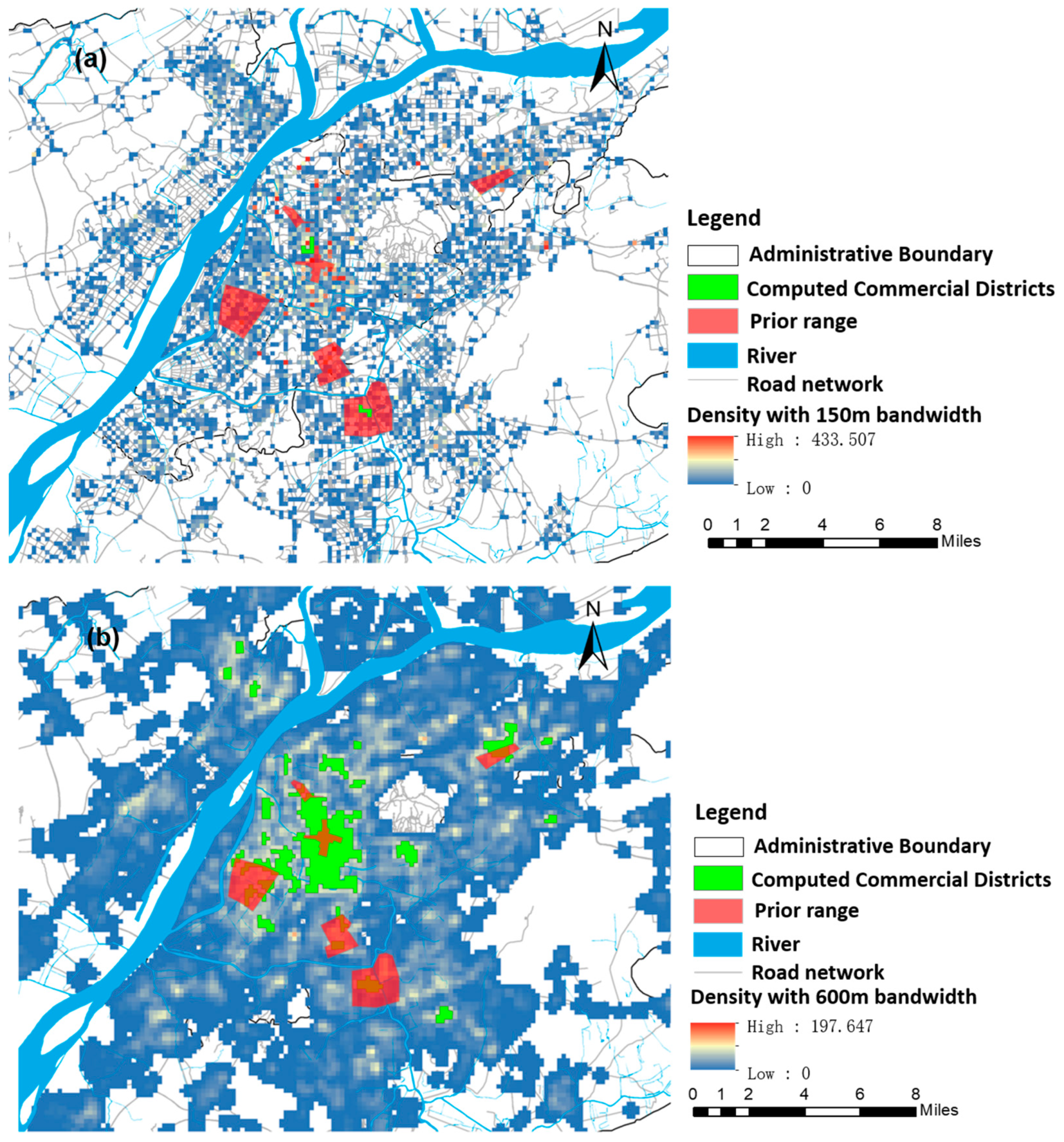
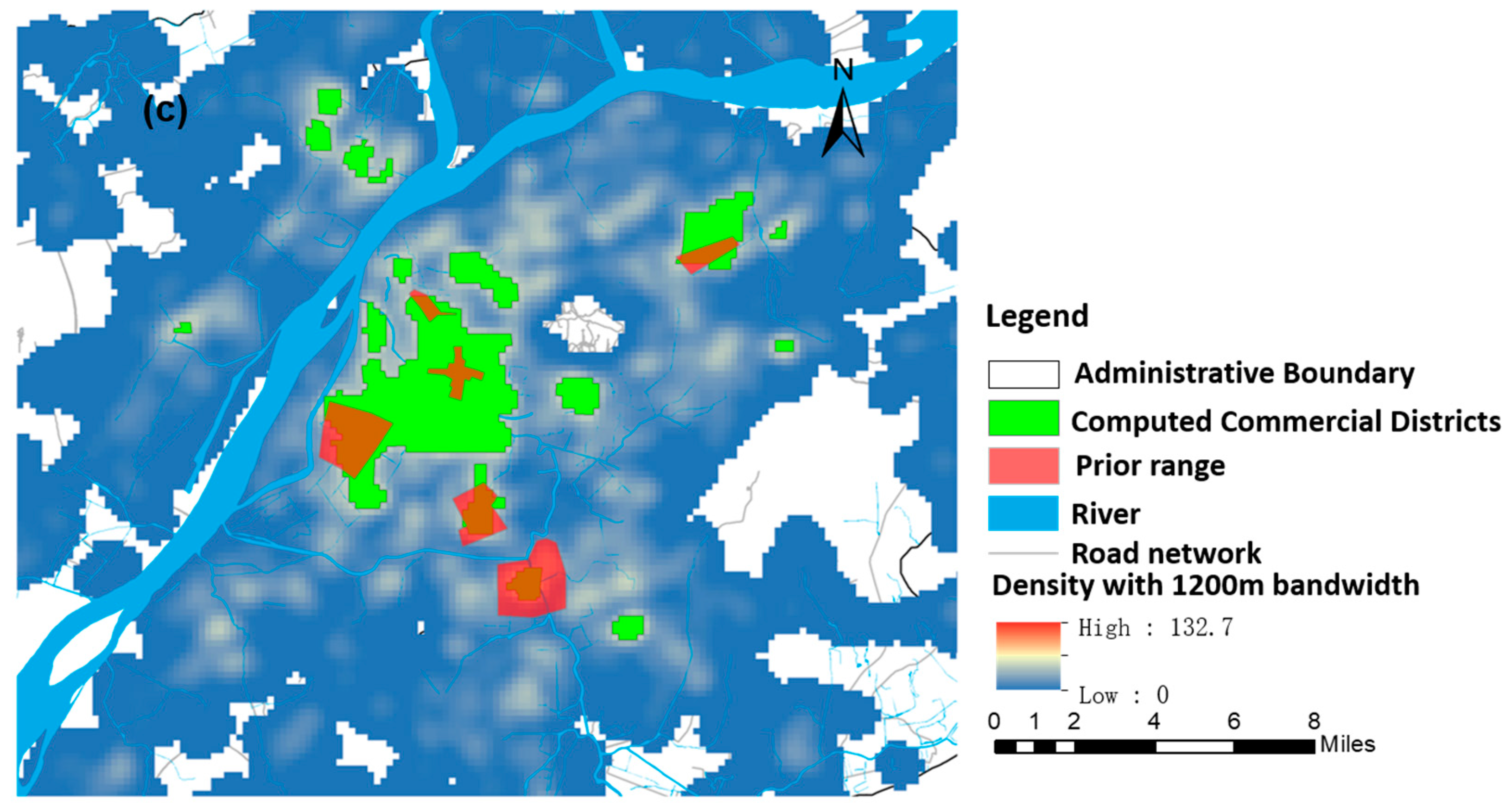
To further prove that 300 m is the optimal bandwidth for identifying commercial central districts, here we extracted commercial central districts with other different bandwidths (150, 600, and 1200 m) and compared the extracted results with the above identified results.
Figure 11a and
Figure 12 display the influence of different bandwidths on the overall density pattern. It appears that the density pattern was bumpy with a narrow bandwidth (
Figure 12a), there were few “hot spots” with an area greater than 300,000 square meters, and only two commercial central districts were identified with 150-m bandwidth. In addition, the density pattern became smoother with the increasing bandwidth. Local “hot spots” were gradually integrated with their neighbors, part of Hunan-Shanxi commercial districts was identified as Xinjiekou commercial district in
Figure 12b, and Xinjiekou, Hunan-Shanxi, and Hexi commercial central districts were clustered together in
Figure 12c.
Comparing
Table 7 and
Table 8, we found that the identified numbers and accuracy of commercial central districts with 150-m bandwidth were both smaller than that with 300-m bandwidth. The identified numbers with the 300-m, 600-m, and 1200-m bandwidths were the same, except that the identified accuracy of the Nanzhan commercial central districts with 1200-m bandwidth was higher than that with 300-m bandwidth. The identification accuracy of other commercial central districts was relatively smaller than that with 300-m bandwidth. Hence, it is reasonable and feasible to study the urban commercial center with 300-m bandwidth.
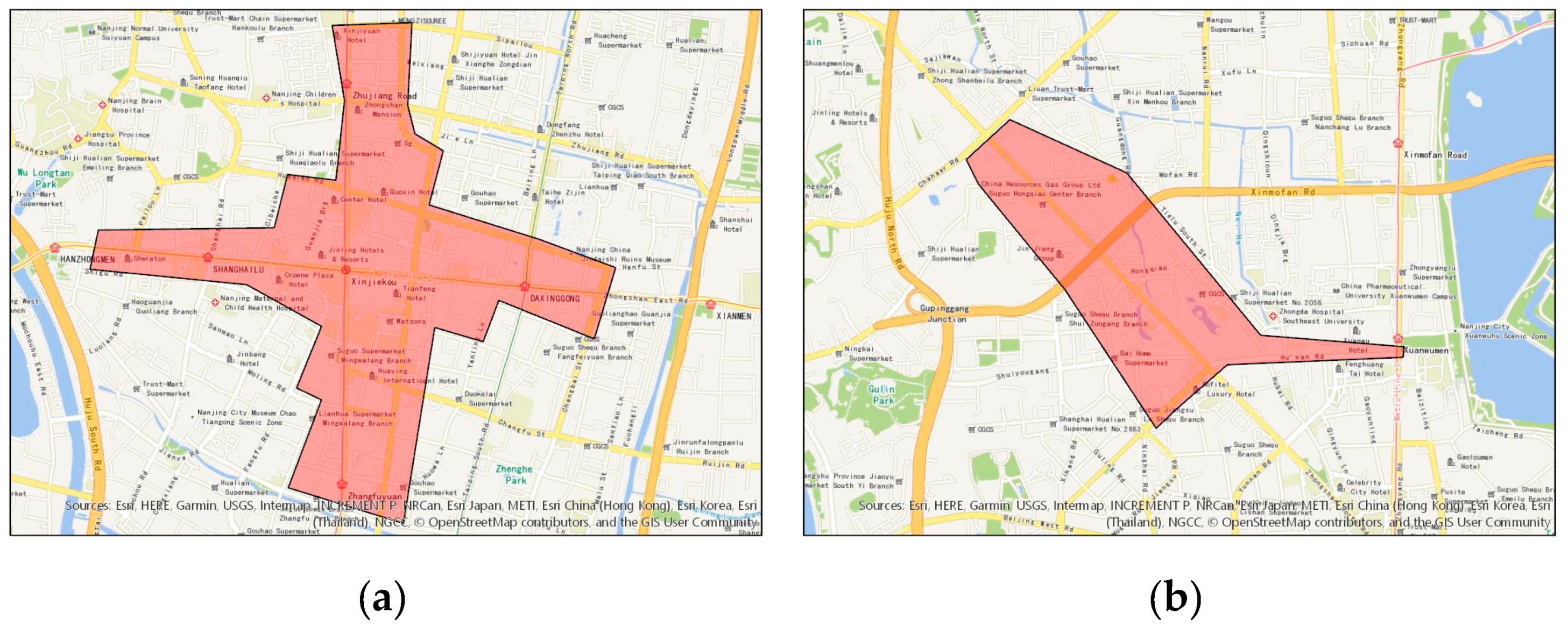
Through the analysis of
Table 8, it was found that the identified accuracy of the commercial-intersection KDE method is slightly lower than that of the planar KDE method with respect to Xinjiekou and Hunan Road commercial central districts. This is because there are two types of distribution patterns of urban commercial centers: (1) banded commercial streets, which form along both sides of the streets and (2) areal commercial centers, which develop around intersections. Xinjiekou and Hunan Road commercial central districts belong to the first distribution pattern—banded commercial streets. As shown in
Figure 13, the commercial district of Xinjiekou is mainly distributed on both sides of two perpendicular roads (Hanzhong Road–Zhongshan East Road and Zhongshan Road–Zhongshan South Road), and the commercial district of Hunan Road is distributed along two intersecting roads (Zhongshan North Road and Hunan Road). This limitation may be due to the fact that this algorithm does not take into account the distribution characteristics of the commercial POIs in the network space. When the commercial POIs are distributed along the street, their kernel center should be the road segment; when the commercial POIs are distributed around the road intersection, their kernel center should be the road intersection.
The proposed method sets the road intersection as the kernel center and does not select the kernel center based on the spatial distribution characteristics of the commercial POIs. However, the characteristics can be obtained by the methods of previous studies [
59,
60], and our algorithm can select the appropriate kernel center according to the distribution type of the commercial POIs.
Hence, the proposed method can be used to delineate current areal commercial centers, compare those centers with the urban planning design, and find deviations in the practical implementation of such designs in order to put forward suggestions for scientific adjustments.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}