A Distributed Storage and Access Approach for Massive Remote Sensing Data in MongoDB

 ,
, 
 ,
,
Abstract
:1. Introduction
2. Background
2.1. NoSQL and MongoDB
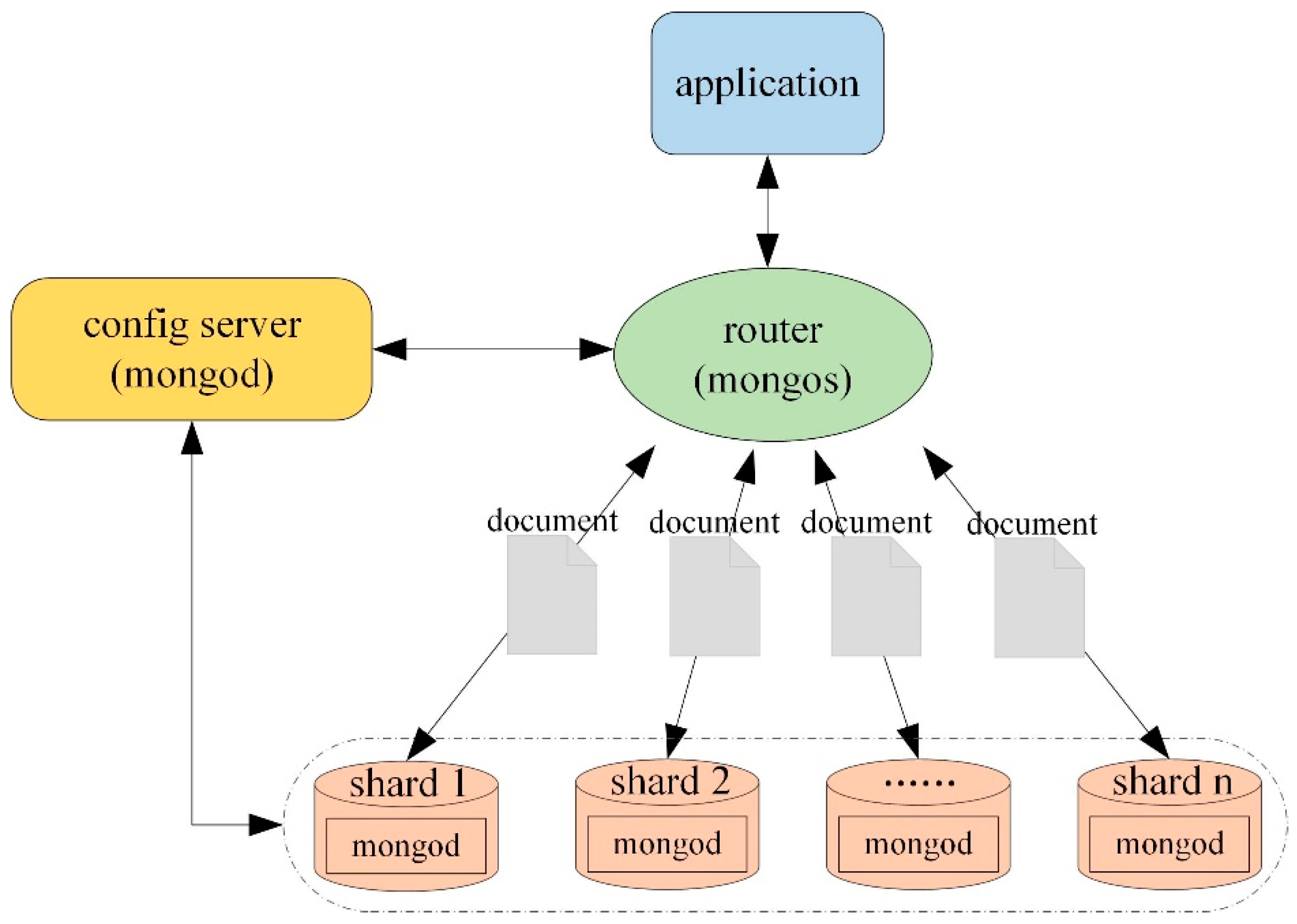
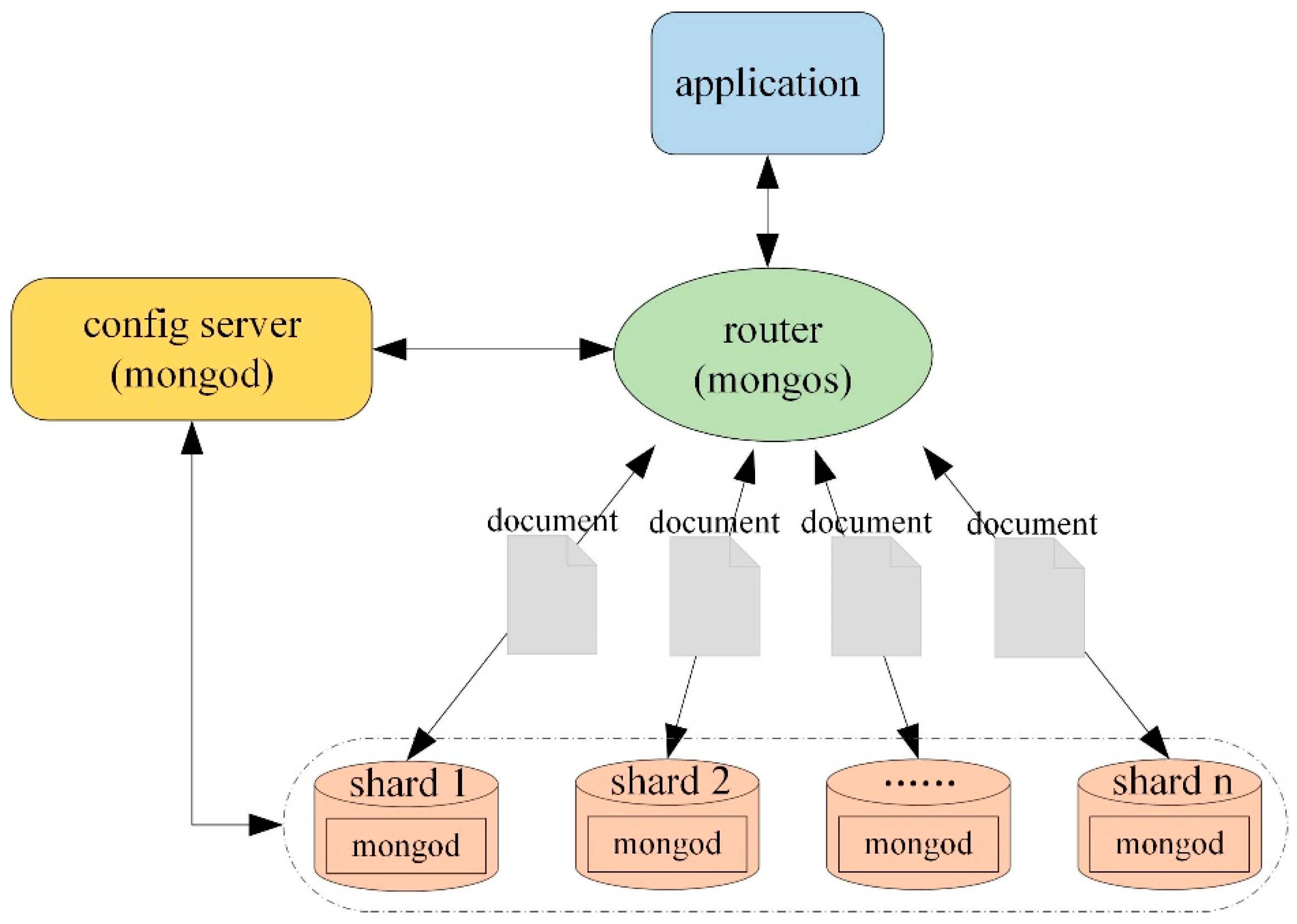
2.2. Sharding Technology
2.3. GridFS Mechanism
3. Storage and Access of Remote Sensing Data in MongoDB
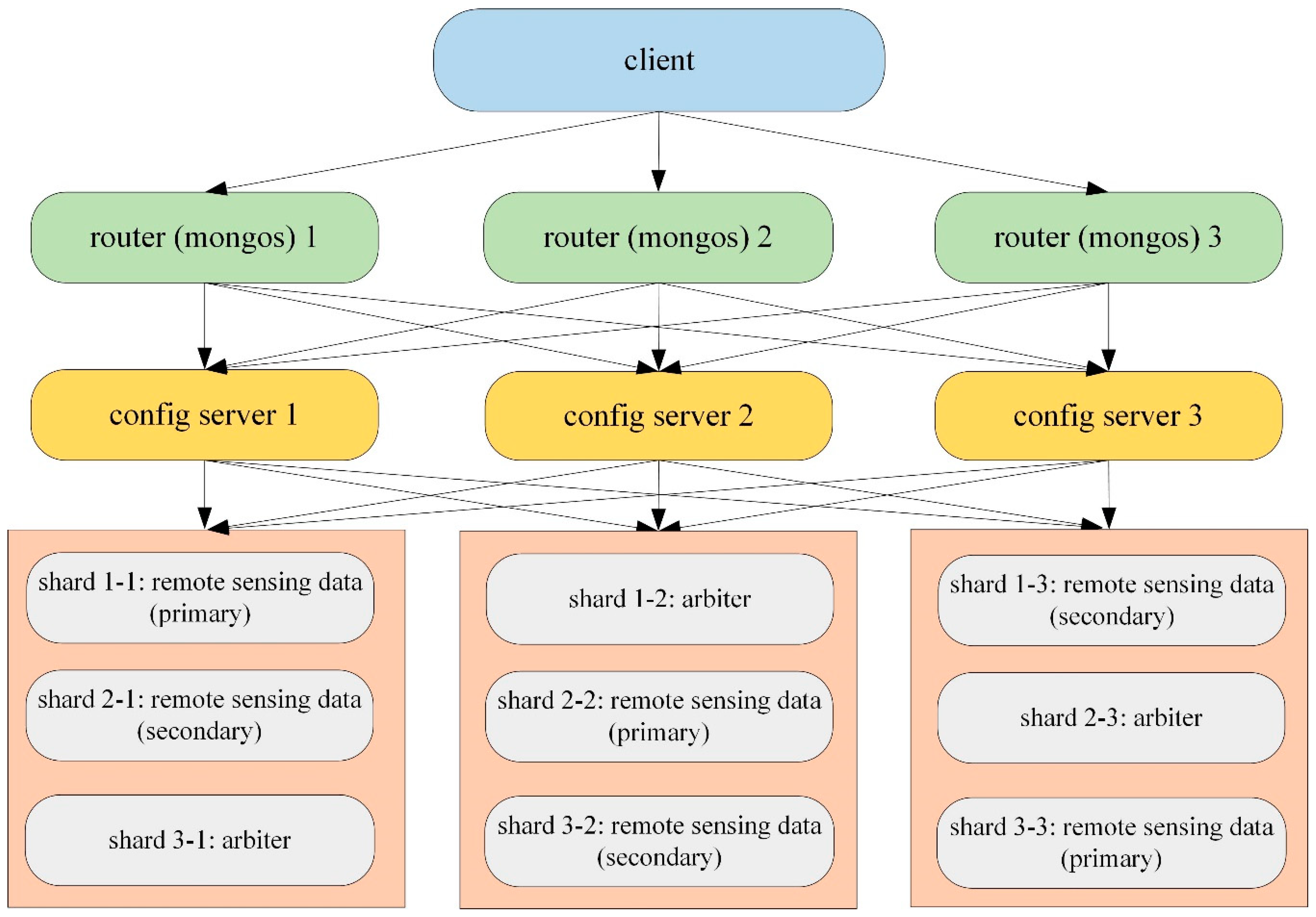
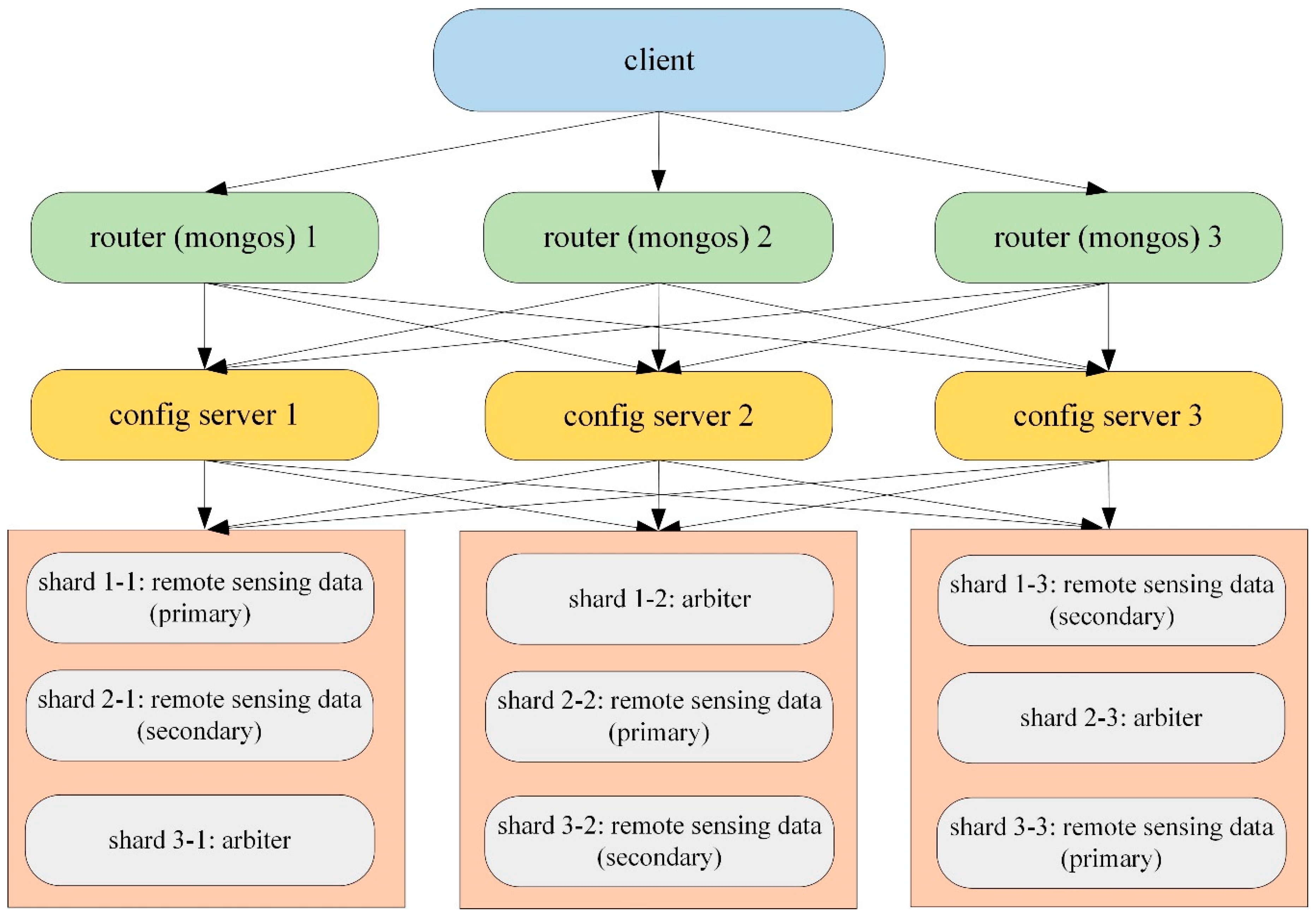
3.1. The Distributed Cluster Architecture
3.2. Archiving Model for Metadata
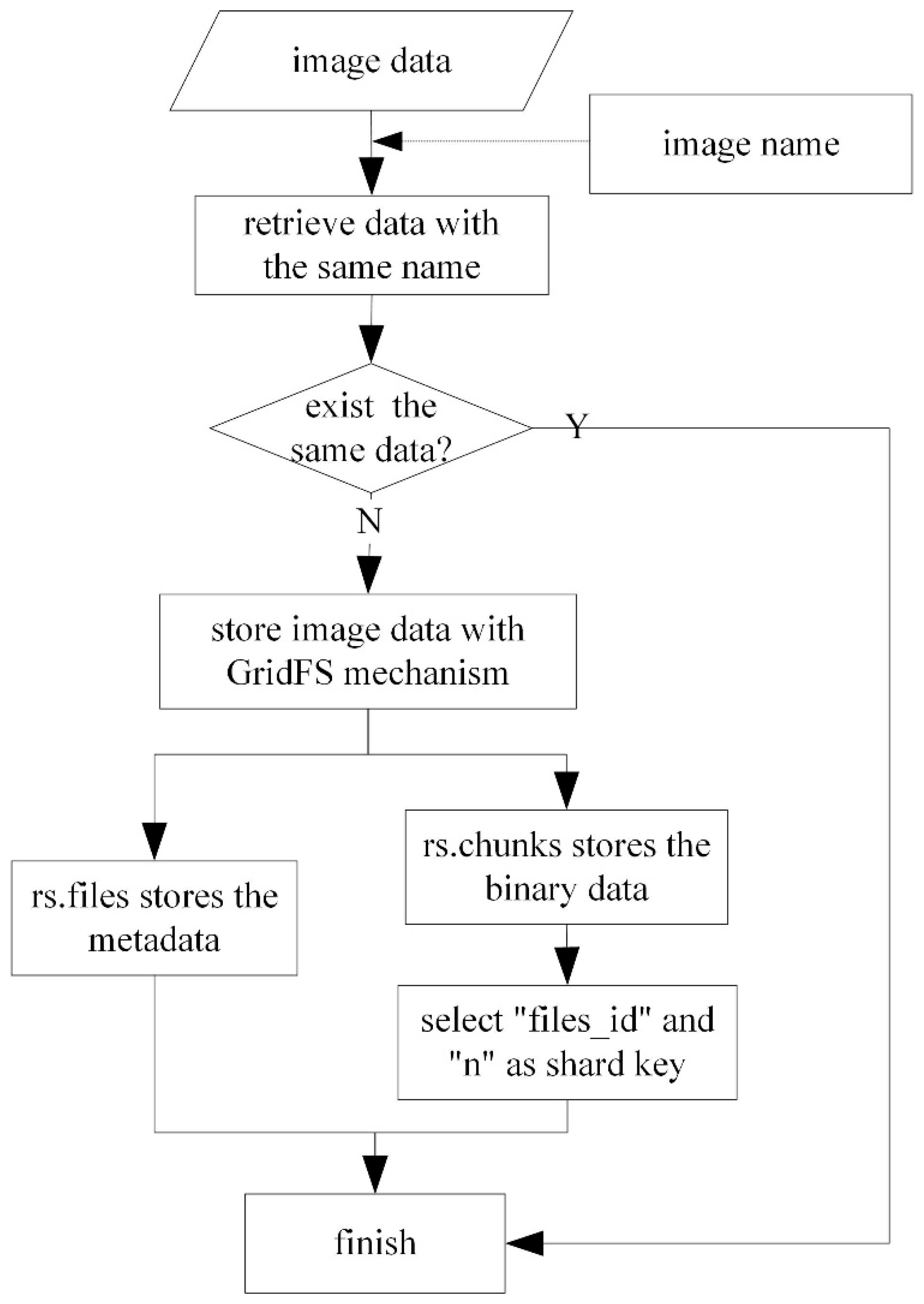
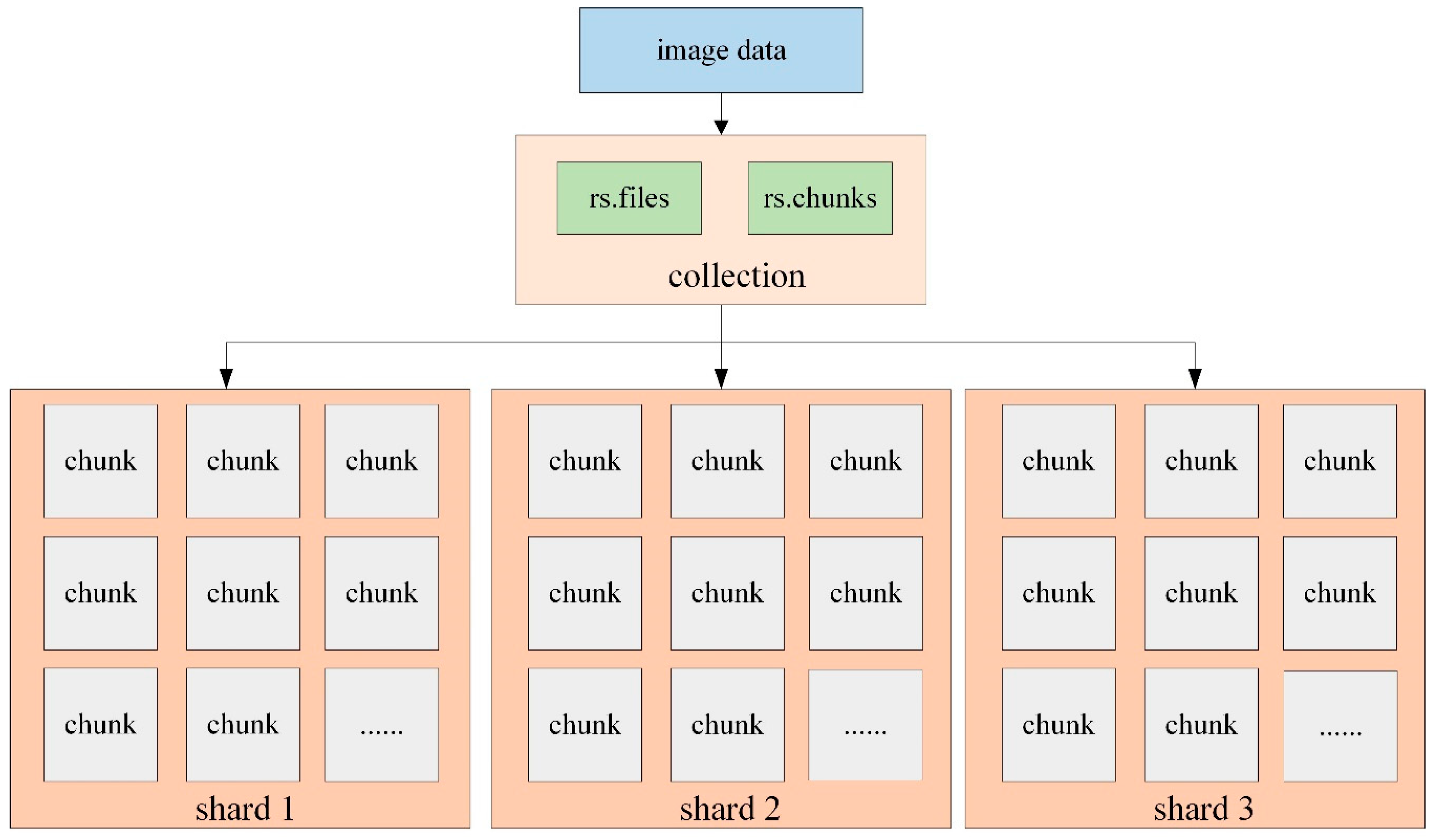
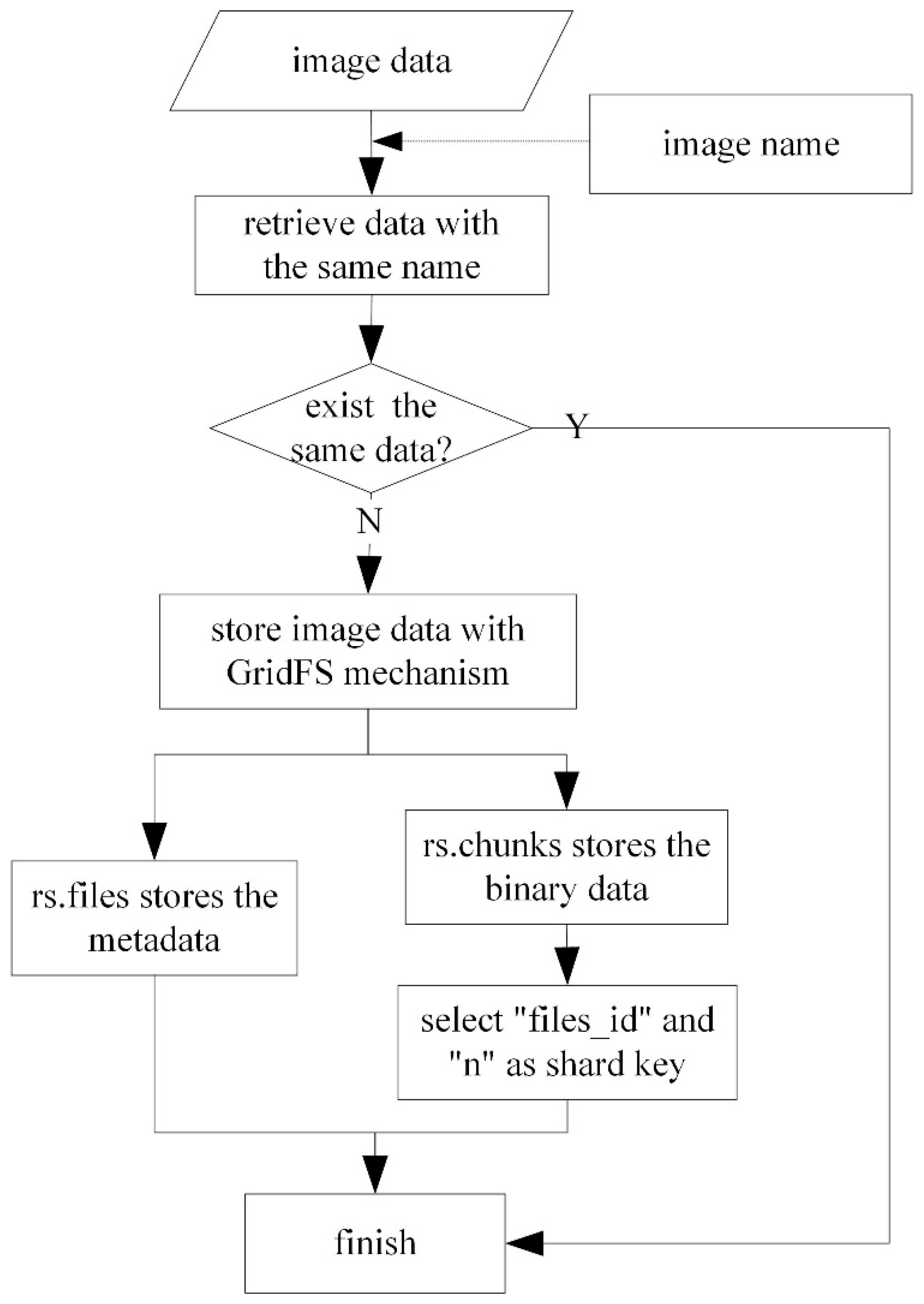
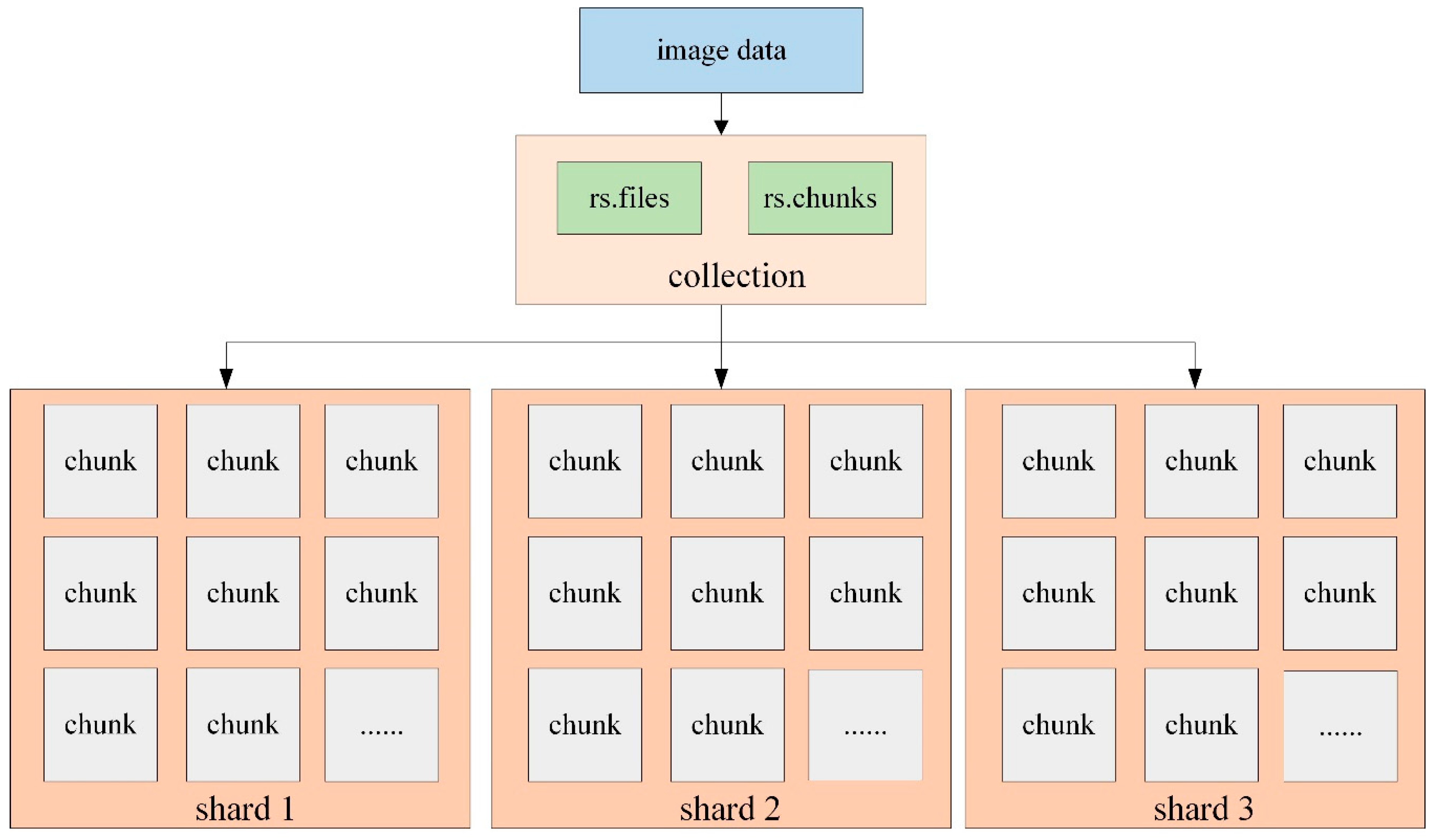
3.3. Storage and Access of Image Data Based on GridFS
- Retrieve the image data waiting to be stored according to the specified image name. If the data with the same name exists, then finish the operation; if not, start to store the data with the GridFS mechanism.
- Store the data in two collections: rs.files and rs.chunks. The “rs.files” collection stores the metadata of each image, while “rs.chunks” collection stores the binary data of each image.
- The data in the “rs.files” collection usually does not need to be split because its data volume is small, while “files_id” and “n” are selected as a combined shard key to divide the data into different shard nodes.
- When accessing the image data, the data is retrieved in the “rs.files” collection with the specified query terms, and then the value of “_id” is obtained. Owing to the equal relationship between “_id” in rs.files and “files_id” in rs.chunks, “files_id” is also determined accordingly. Then the image data can be read sequentially through the value of “n”.
4. Experimental Design
4.1. Experimental Data
4.2. Experimental Environment
4.3. Experimental Principle
5. Results and Analysis
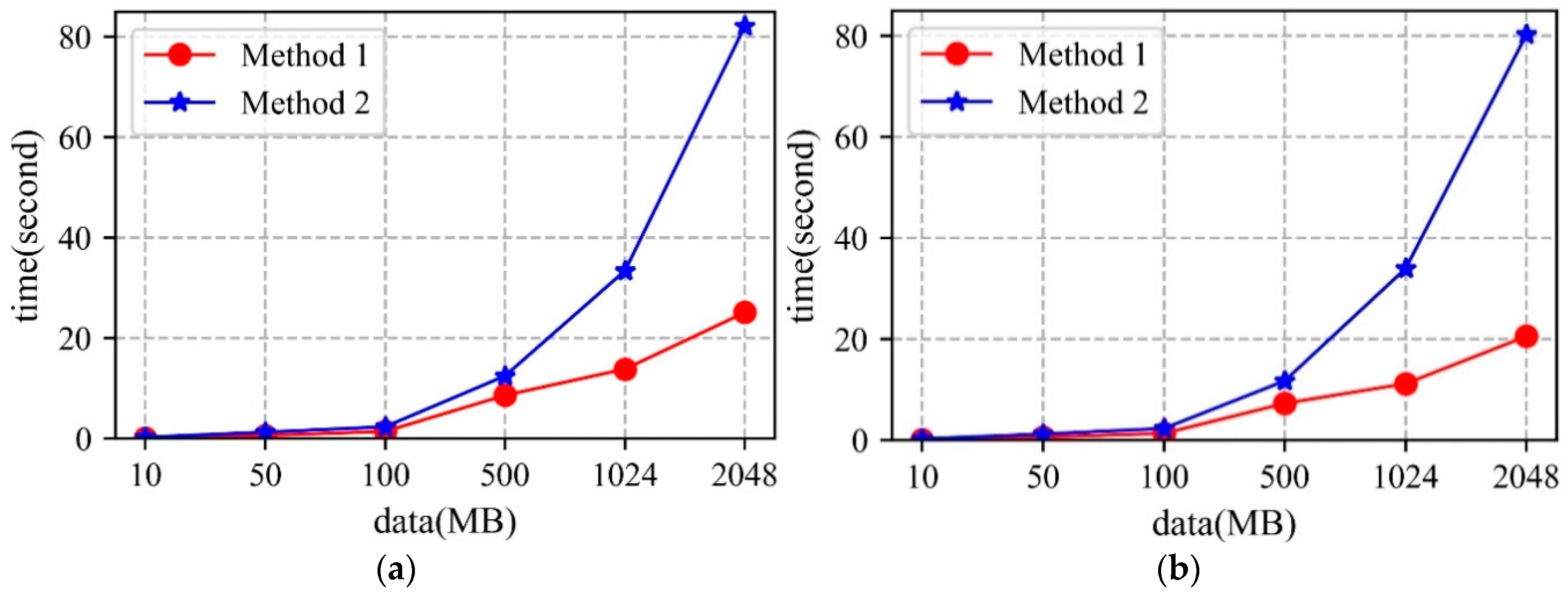
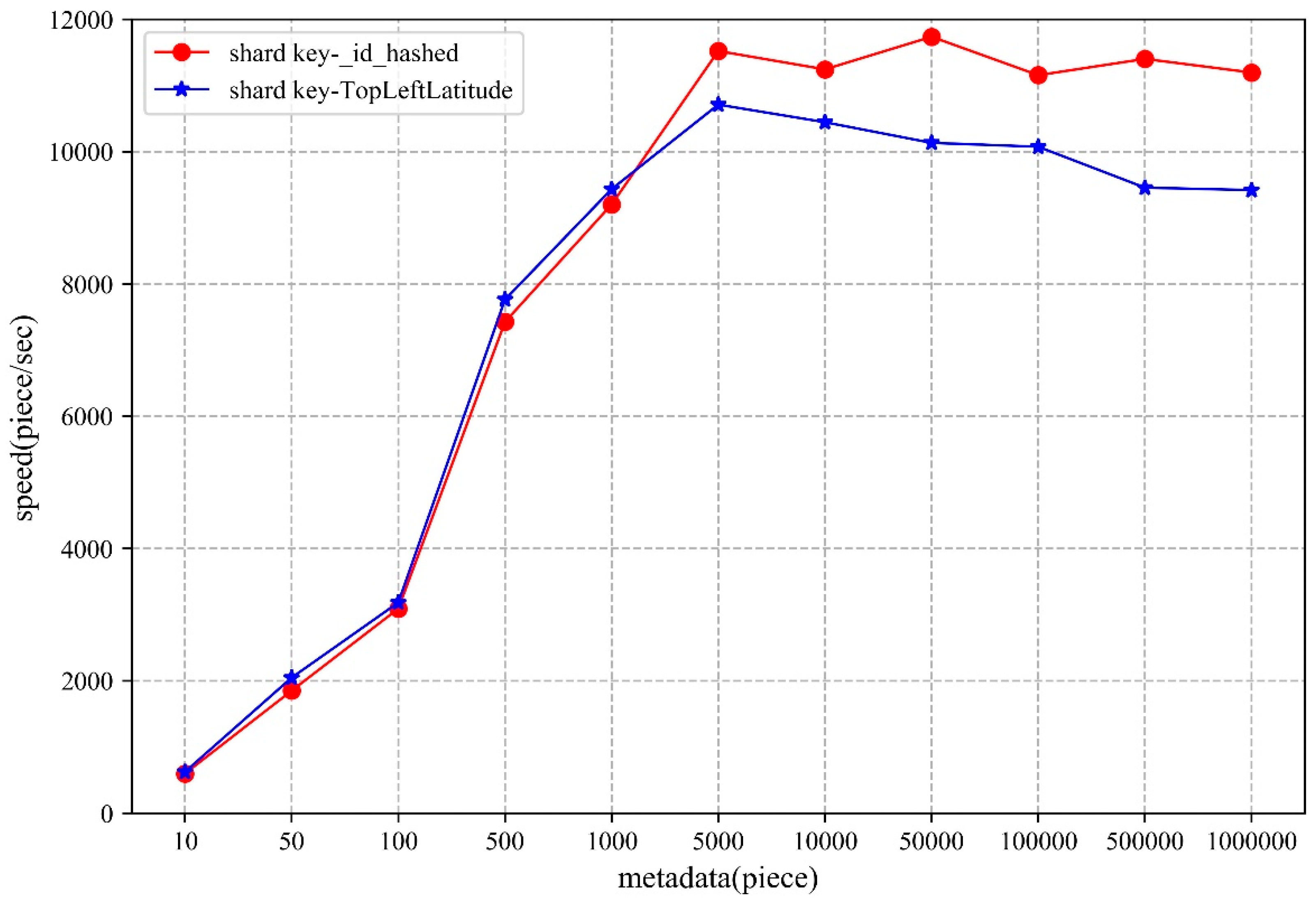
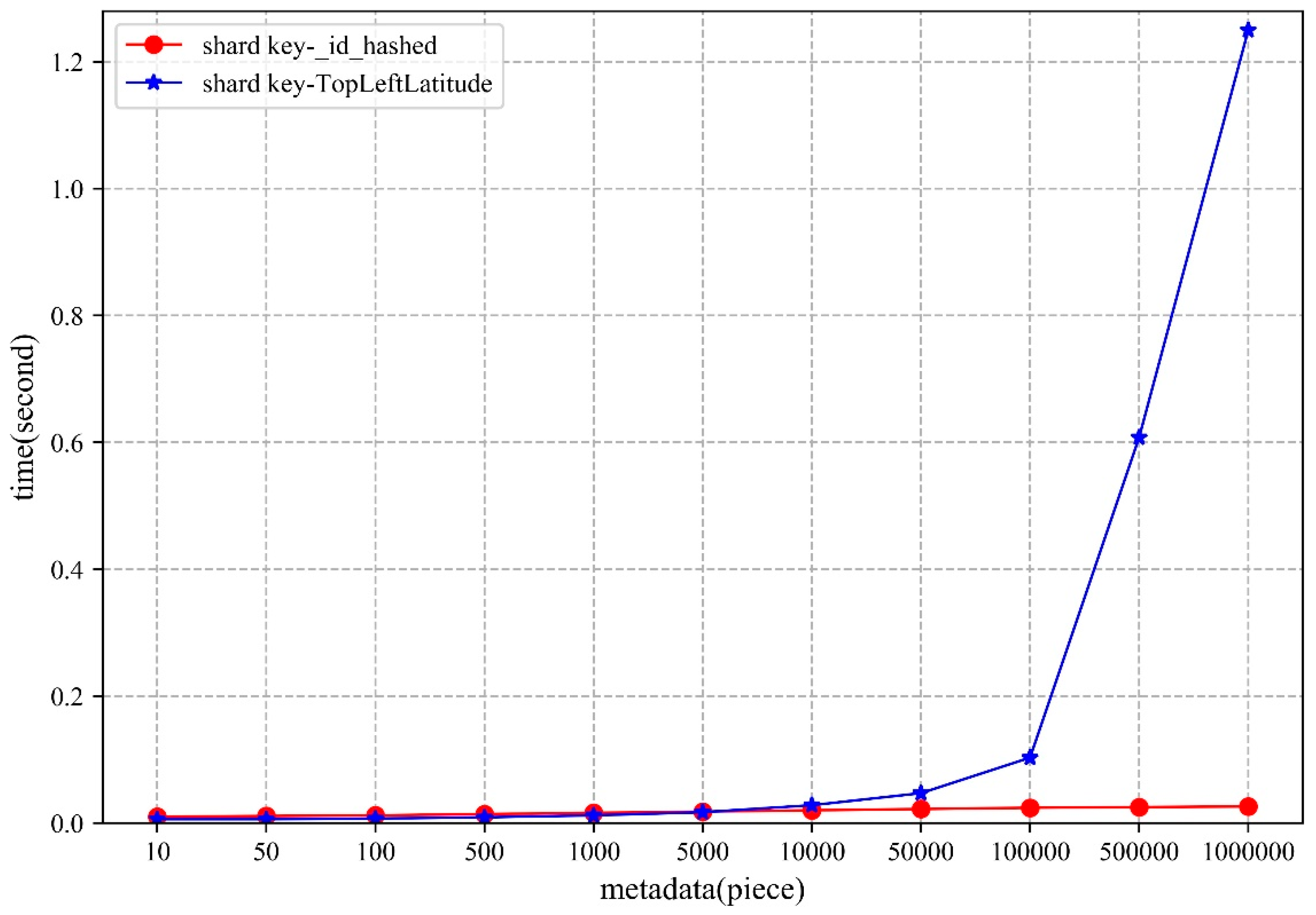
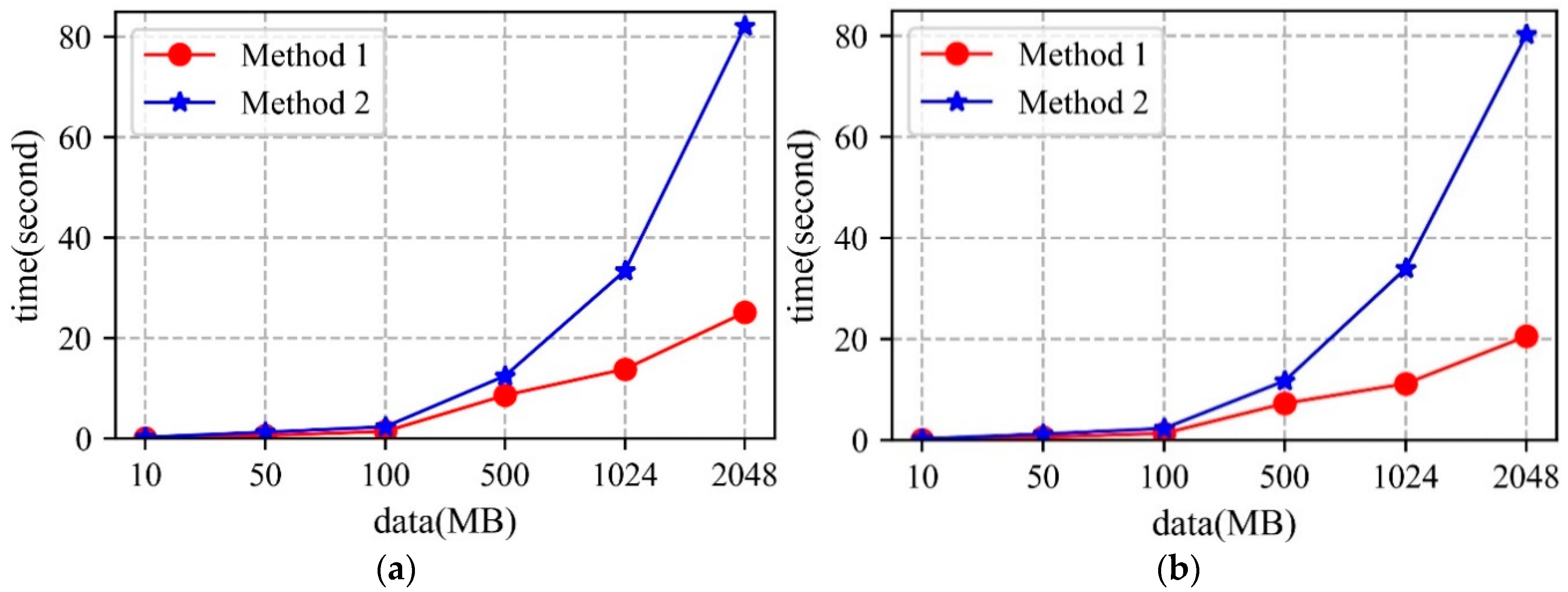
5.1. Metadata
5.1.1. Storage
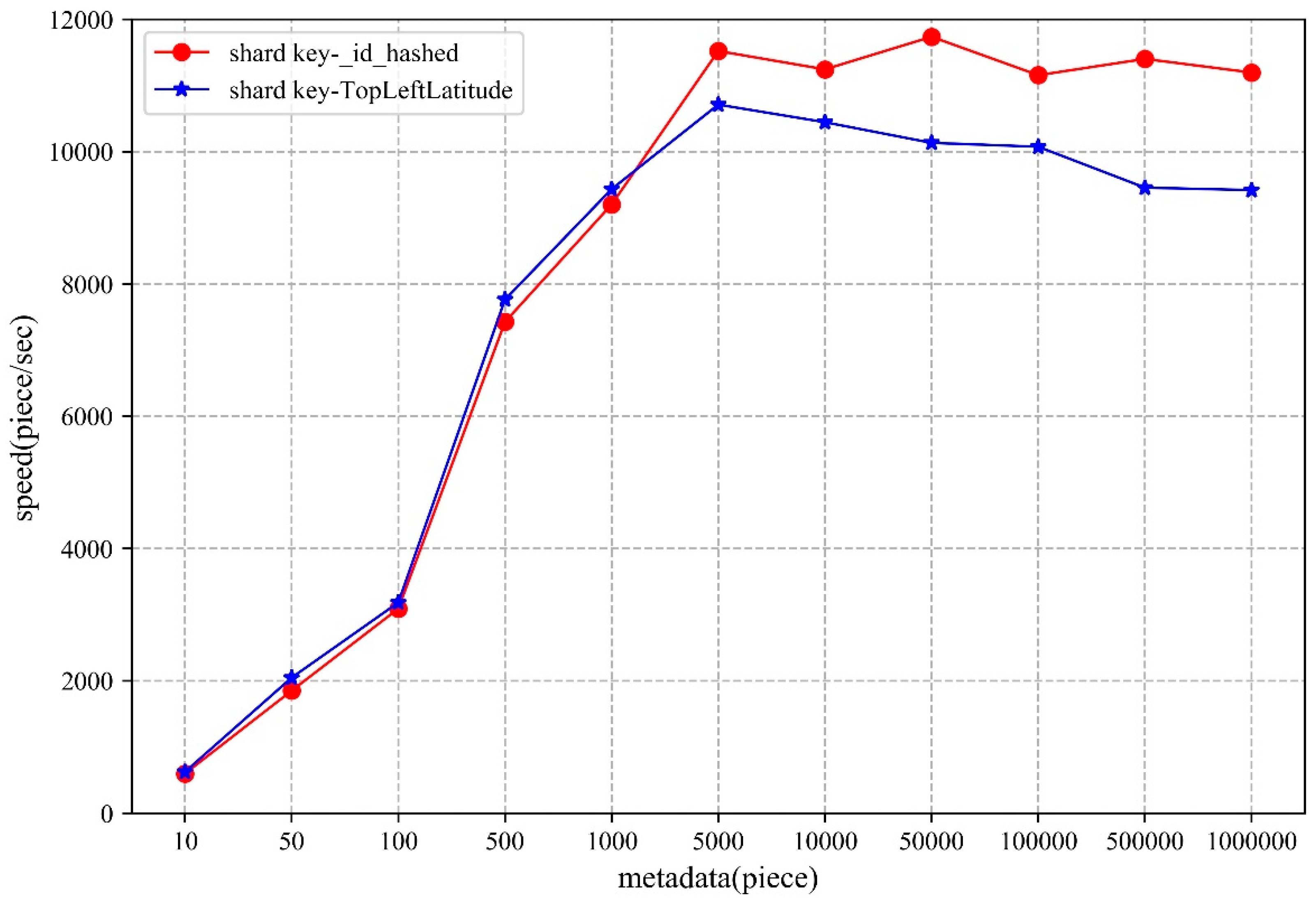
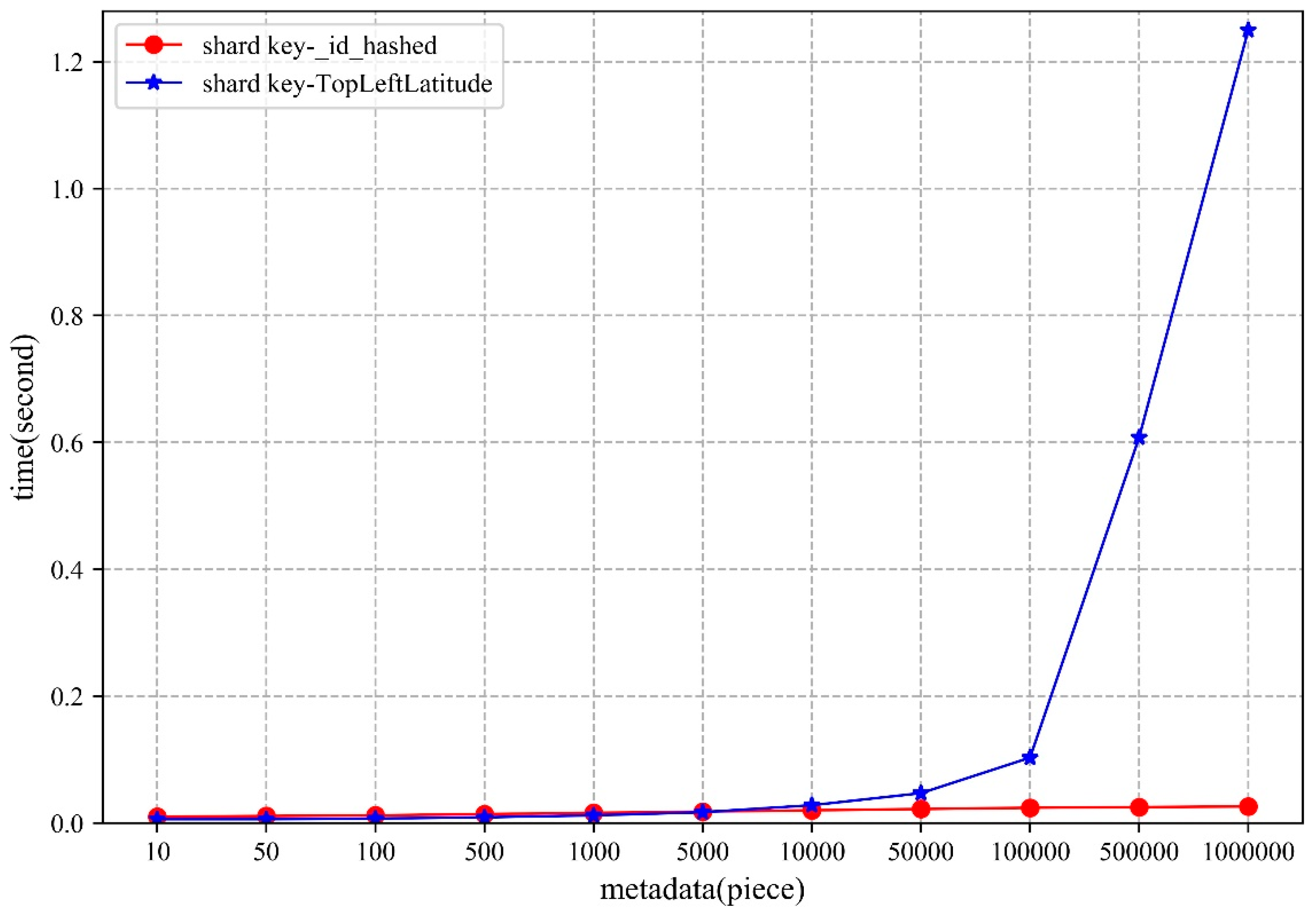
5.1.2. Access
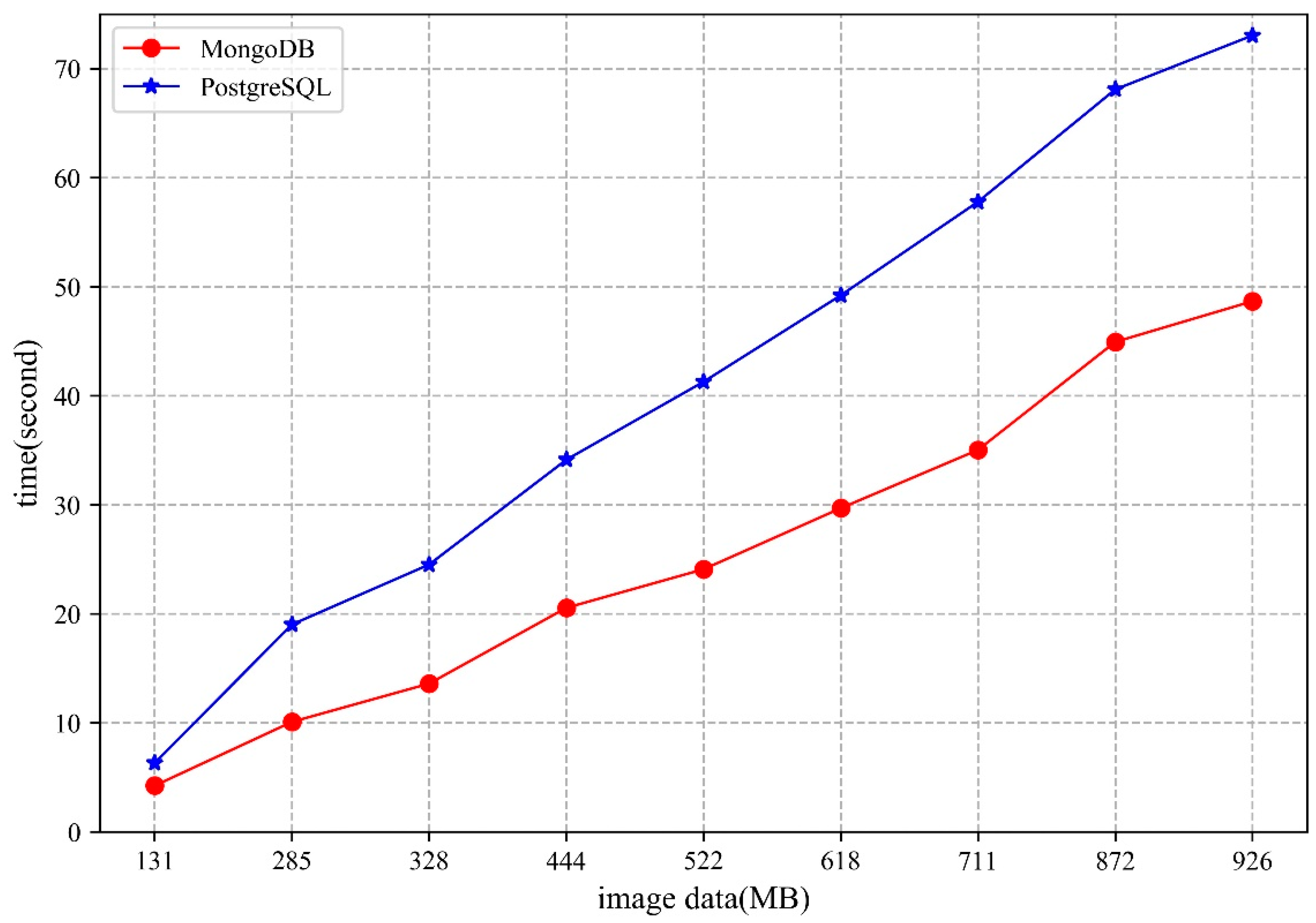
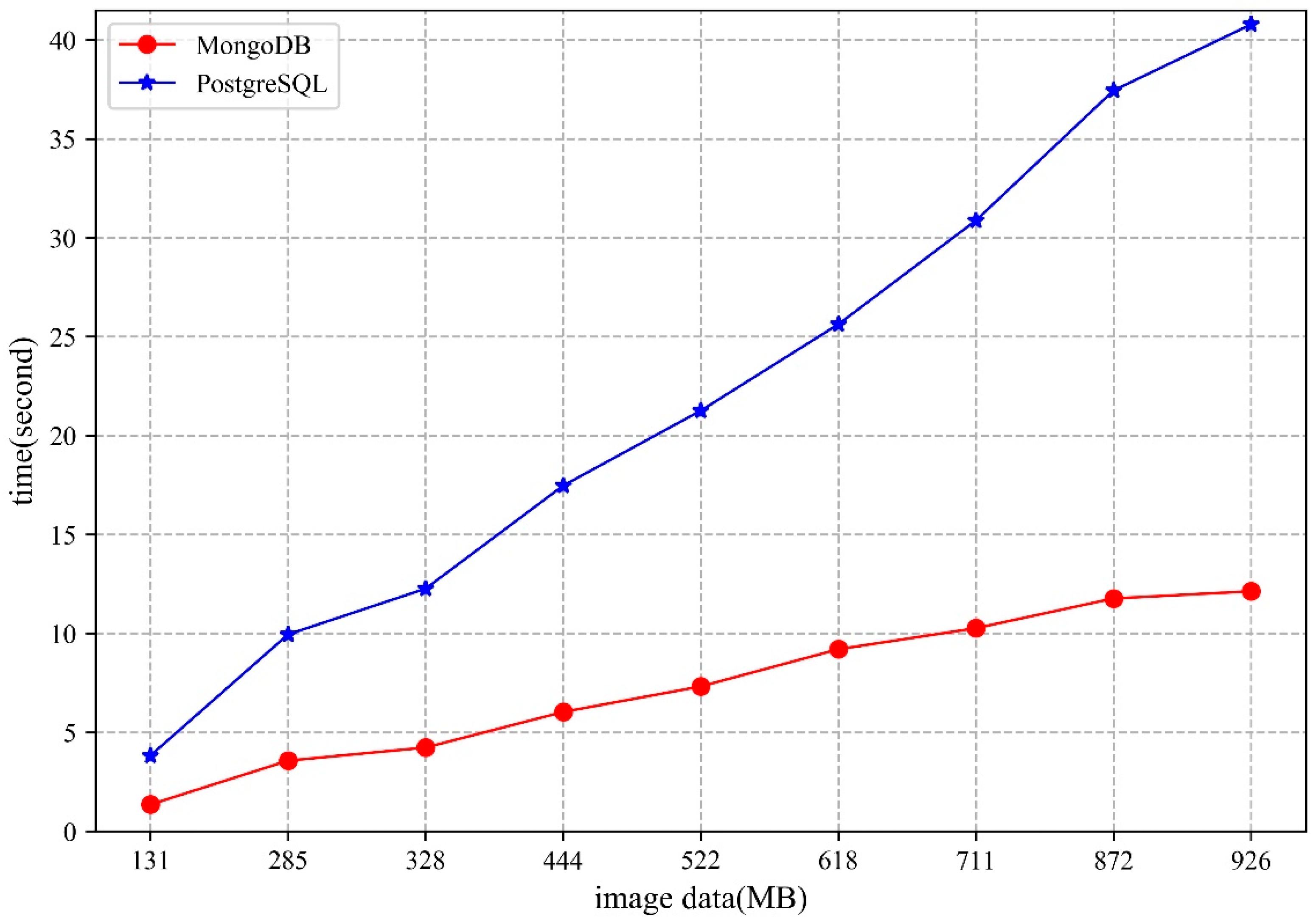
5.2. Image Data
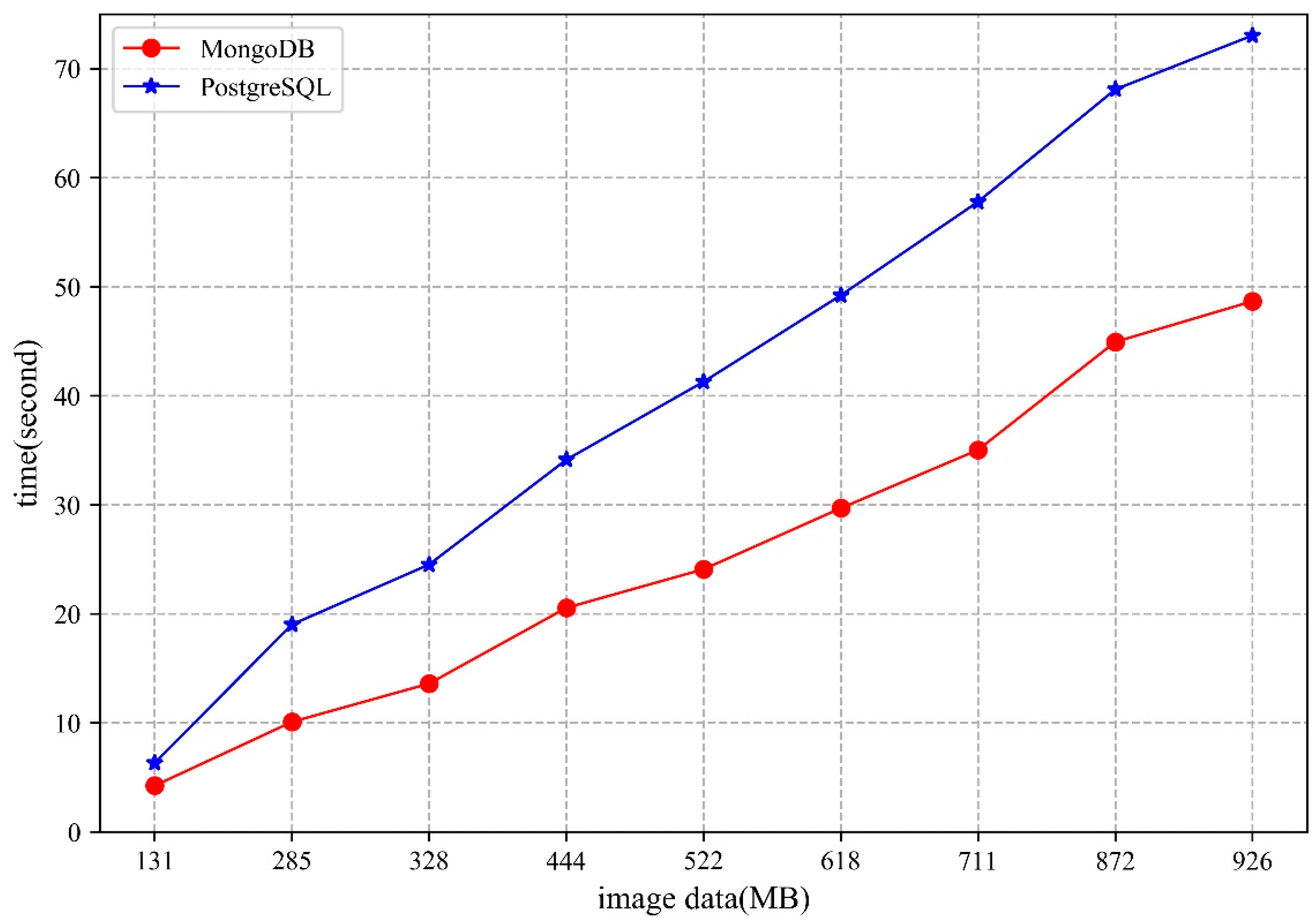
5.2.1. Storage
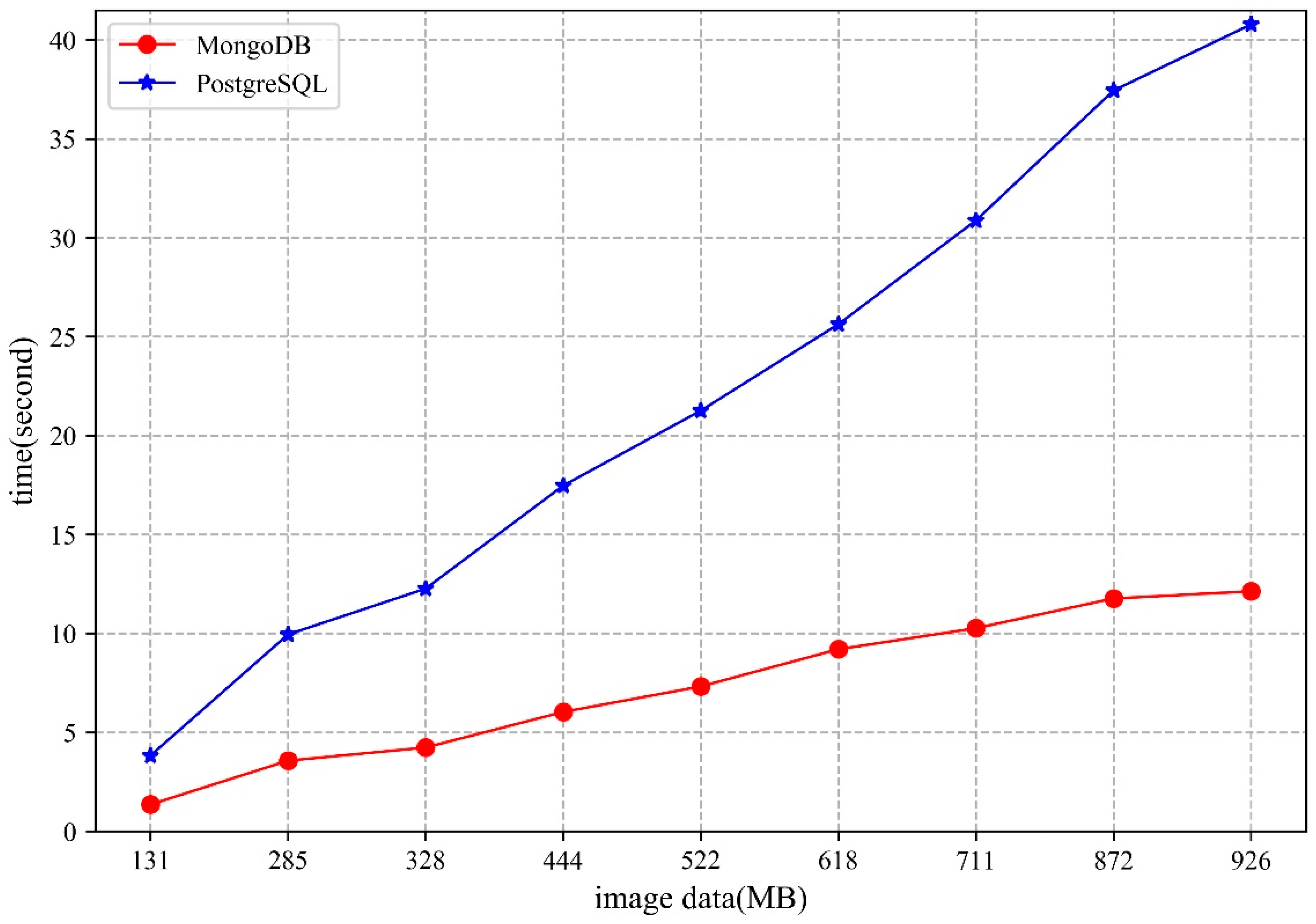
5.2.2. Access
5.3. Analysis
- The MongoDB database uses the WiredTiger storage engine, which stores the data as disk files. When there are sufficient memory resources to cope with the storage and access requests in the cluster, higher performance can be obtained. Moreover, the network bandwidth will also influence the storage and access performance of the MongoDB cluster.
- From the perspective of shard key strategy, the paper chooses two different shard keys to conduct the experiments, though neither of them can guarantee optimal performance in both storage and access. Therefore, when designing the shard key strategy, practicality should be considered.
6. Conclusions
7. Patents
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ma, Y.; Wu, H.; Wang, L.; Huang, B.; Ranjan, R.; Zomaya, A.; Jie, W. Remote sensing big data computing: Challenges and opportunities. Future Gener. Comput. Syst. 2015, 51, 47–60. [Google Scholar] [CrossRef]
- Guo, H.; Wang, L.; Chen, F.; Liang, D. Scientific big data and digital earth. Chin. Sci. Bull. 2014, 59, 5066–5073. [Google Scholar] [CrossRef]
- He, G.; Wang, L.; Ma, Y.; Zhang, Z.; Wang, G.; Peng, Y.; Long, T.; Zhang, X. Processing of earth observation big data: Challenges and countermeasures. Chin. Sci. Bull. 2015, 60, 470–478. [Google Scholar] [CrossRef]
- Reichman, O.J.; Jones, M.B.; Schildhauer, M.P. Challenges and opportunities of open data in ecology. Science 2011, 331, 703–705. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Huang, Z. Data infrastructure for remote sensing big data: Integration, management and on-demand service. J. Comput. Res. Dev. 2017, 54, 267–283. [Google Scholar] [CrossRef]
- Wang, H.; Tang, X.; Li, Q. Research and implementation of the massive remote sensing image storage and management technology. Sci. Surv. Mapp. 2008, 133, 156–157. [Google Scholar] [CrossRef]
- Pendleton, C. The world according to Bing. IEEE Comput. Graph. Appl. 2010, 30, 15–17. [Google Scholar] [CrossRef] [PubMed]
- Qin, X.; Wang, H.; Li, F.; Li, C.; Chen, H.; Zhou, X.; Du, X.; Wang, S. New landscape of data management technologies. J. Softw. 2013, 24, 175–197. [Google Scholar] [CrossRef]
- Ramapriyan, H.; Pfister, R.; Weinstein, B. An overview of the EOS data distribution systems. In Land Remote Sensing and Global Environmental Change; Ramachandran, B., Justice, C.O., Abrams, M.J., Eds.; Springer: New York, NY, USA, 2011; pp. 183–202. [Google Scholar]
- Sun, J.; Gao, J.; Shi, S.; Wang, H.; Ai, B. Application of distributed spatial database in massive satellite images management. Bull. Surv. Mapp. 2017, 5, 56–61. [Google Scholar] [CrossRef]
- Sadalage, P.J.; Fowler, M. NoSQL Distilled: A Brief Guide to the Emerging World of Polyglot Persistence; Pearson Education: New Jersey, NJ, USA, 2013. [Google Scholar]
- Pokorny, J. NoSQL databases: A step to database scalability in web environment. Int. J. Web Inf. Syst. 2013, 9, 69–82. [Google Scholar] [CrossRef]
- Gu, Y.; Wang, X.; Shen, S.; Wang, J.; Kim, J.-U. Analysis of data storage mechanism in NoSQL database MongoDB. In Proceedings of the 2015 IEEE International Conference on Consumer Electronics-Taiwan, Taipei, Taiwan, 6–8 June 2015; pp. 70–71. [Google Scholar]
- Li, S.; Yang, H.; Huang, Y.; Zhou, Q. Geo-spatial big data storage based on NoSQL database. Geomat. Inf. Sci. Wuhan Univ. 2017, 42, 163–169. [Google Scholar] [CrossRef]
- Xiang, L.; Huang, J.; Shao, X.; Wang, D. A mongodb-based management of planar spatial data with a flattened R-tree. ISPRS Int. J. Geo-Inf. 2016, 5, 119. [Google Scholar] [CrossRef]
- Wang, W.; Hu, Q. The method of cloudizing storing unstructured LiDAR point cloud data by MongoDB. In Proceedings of the 2014 22nd International Conference on Geoinformatics, Kaohsiung, Taiwan, 25–27 June 2014; pp. 1–5. [Google Scholar]
- Meng, X.; Ci, X. Big data management: Concepts, techniques and challenges. J. Comput. Res. Dev. 2013, 50, 146–169. [Google Scholar]
- Corbellini, A.; Mateos, C.; Zunino, A.; Godoy, D.; Schiaffino, S. Persisting big-data: The NoSQL landscape. Inf. Syst. 2017, 63, 1–23. [Google Scholar] [CrossRef]
- Shen, D.; Yu, G.; Wang, X.; Nie, T.; Kou, Y. Survey on NoSQL for management of big data. J. Softw. 2013, 8, 1786–1803. [Google Scholar] [CrossRef]
- Han, J.; Haihong, E.; Le, G.; Du, J. Survey on NoSQL database. In Proceedings of the 2011 6th International Conference on Pervasive Computing and Applications, Port Elizabeth, South Africa, 26–28 October 2011; pp. 363–366. [Google Scholar]
- Chodorow, K. MongoDB: The Definitive Guide: Powerful and Scalable Data Storage, 2nd ed.; O’Reilly Media, Inc.: California, CA, USA, 2013. [Google Scholar]
- Sharma, S.; Shandilya, R.; Patnaik, S.; Mahapatra, A. Leading NoSQL models for handling big data: A brief review. Int. J. Bus. Inf. Syst. 2016, 22, 1–25. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Y.; Jin, Y. Research on the improvement of MongoDB Auto-Sharding in cloud environment. In Proceedings of the 2012 7th International Conference on Computer Science & Education (ICCSE), Melbourne, VIC, Australia, 14–17 July 2012; pp. 851–854. [Google Scholar]
- GridFS—MongoDB Manual. Available online: https://docs.mongodb.com/manual/core/gridfs/#gridfs (accessed on 10 June 2019).
- Espinoza-Molina, D.; Datcu, M. Earth-observation image retrieval based on content, semantics, and metadata. IEEE Trans. Geosci. Remote Sens. 2013, 51, 5145–5159. [Google Scholar] [CrossRef]
- Li, G.; Zhang, H.; Zhang, L.; Wang, Y.; Tian, C. Development and trend of Earth observation data sharing. J. Remote Sens. 2016, 20, 979–990. [Google Scholar] [CrossRef]
- Huang, K.; Li, G.; Wang, J. Rapid retrieval strategy for massive remote sensing metadata based on GeoHash coding. Remote Sens. Lett. 2018, 9, 1070–1078. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Field Name | Data Type | Description |
|---|---|---|---|
| 1 | ImageName | varchar | Image data name |
| 2 | SatelliteID | varchar | Satellite id |
| 3 | SensorID | varchar | Sensor id |
| 4 | ReceiveDate | varchar | Receive date |
| 5 | StartTime | varchar | Start time |
| 6 | StopTime | varchar | Stop time |
| 7 | ProductLevel | varchar | Product level |
| 8 | ProductFormat | varchar | Product format |
| 9 | Resolution | float | Image resolution |
| 10 | CloudPercent | float | Cloud value |
| 11 | ImageQuality | int | Image quality |
| 12 | CenterLatitude | float | Center latitude |
| 13 | CenterLongitude | float | Center longitude |
| 14 | TopLeftLatitude | float | Latitude in upper left corner |
| 15 | TopLeftLongitude | float | Longitude in upper left corner |
| 16 | TopRightLatitude | float | latitude in upper right corner |
| 17 | TopRightLongitude | float | Longitude in upper right corner |
| 18 | BottomRightLatitude | float | latitude in lower right corner |
| 19 | BottomRightLongitude | float | Longitude in lower right corner |
| 20 | BottomLeftLatitude | float | latitude in lower left corner |
| 21 | BottomLeftLongitude | float | Longitude in lower left corner |
| 22 | FileStorePath | varchar | Store path of image file |
| 23 | DataDownloadURL | varchar | Download link of data |
| 24 | DataOwner | varchar | Owner of the data |
| 25 | DataProvider | varchar | Provider of the data |
| Data Filename | Satellite | Data Source | Data Amount |
|---|---|---|---|
| LT05_L1GS_123046_* | Landsat5 | https://earthexplorer.usgs.gov/ | 131 MB |
| LC08_L1GT_123046_* | Landsat8 | 926 MB | |
| FY3A_MERSI_GBAL_L1_* | FY3A | http://satellite.nsmc.org.cn/portalsite/default.aspx | 285 MB |
| FY3B_MERSI_GBAL_L1_* | FY3B | 328 MB | |
| FY3C_MERSI_GBAL_L1_* | FY3C | 444 MB | |
| S1A_IW_GRDH_1SDV_* | Sentinel1 | https://scihub.copernicus.eu/dhus/#/home | 872 MB |
| S2A_MSIL1C_* | Sentinel2 | 522 MB | |
| S3A_OL_1_EFR____2016* | Sentinel3 | 711 MB | |
| S3A_OL_1_EFR____2017* | Sentinel3 | 618 MB |
| Node | IP Address | Port |
|---|---|---|
| Ubuntu01 | 10.3.102.199 | Shard 1-1: 27001 Shard 2-1: 27002 Shard 3-1: 27003 Mongos 1: 20000 Config 1: 21000 |
| Ubuntu02 | 10.3.102.204 | Shard 1-2: 27001 Shard 2-2: 27002 Shard 3-2: 27003 Mongos 2: 20000 Config 2: 21000 |
| Ubuntu03 | 10.3.102.205 | Shard 1-3: 27001 Shard 2-3: 27002 Shard 3-3: 27003 Mongos 3: 20000 Config 3: 21000 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Li, G.; Yao, X.; Zeng, Y.; Pang, L.; Zhang, L. A Distributed Storage and Access Approach for Massive Remote Sensing Data in MongoDB. ISPRS Int. J. Geo-Inf. 2019, 8, 533. https://doi.org/10.3390/ijgi8120533
Wang S, Li G, Yao X, Zeng Y, Pang L, Zhang L. A Distributed Storage and Access Approach for Massive Remote Sensing Data in MongoDB. ISPRS International Journal of Geo-Information. 2019; 8(12):533. https://doi.org/10.3390/ijgi8120533
Chicago/Turabian StyleWang, Shuang, Guoqing Li, Xiaochuang Yao, Yi Zeng, Lushen Pang, and Lianchong Zhang. 2019. "A Distributed Storage and Access Approach for Massive Remote Sensing Data in MongoDB" ISPRS International Journal of Geo-Information 8, no. 12: 533. https://doi.org/10.3390/ijgi8120533
APA StyleWang, S., Li, G., Yao, X., Zeng, Y., Pang, L., & Zhang, L. (2019). A Distributed Storage and Access Approach for Massive Remote Sensing Data in MongoDB. ISPRS International Journal of Geo-Information, 8(12), 533. https://doi.org/10.3390/ijgi8120533