Retrieving Landmark Salience Based on Wikipedia: An Integrated Ranking Model



Abstract
:1. Introduction
1.1. Landmarks and Human Spatial Cognition
1.2. Landmarks and Human Spatial Cognition Landmark Definition
1.3. Advantages of User-Generated Content for Landmark Mining
1.4. The Existing Knowledge Gap
2. Related Research
2.1. Data Mining of Wikipedia
2.2. The Properties of Landmark Salience
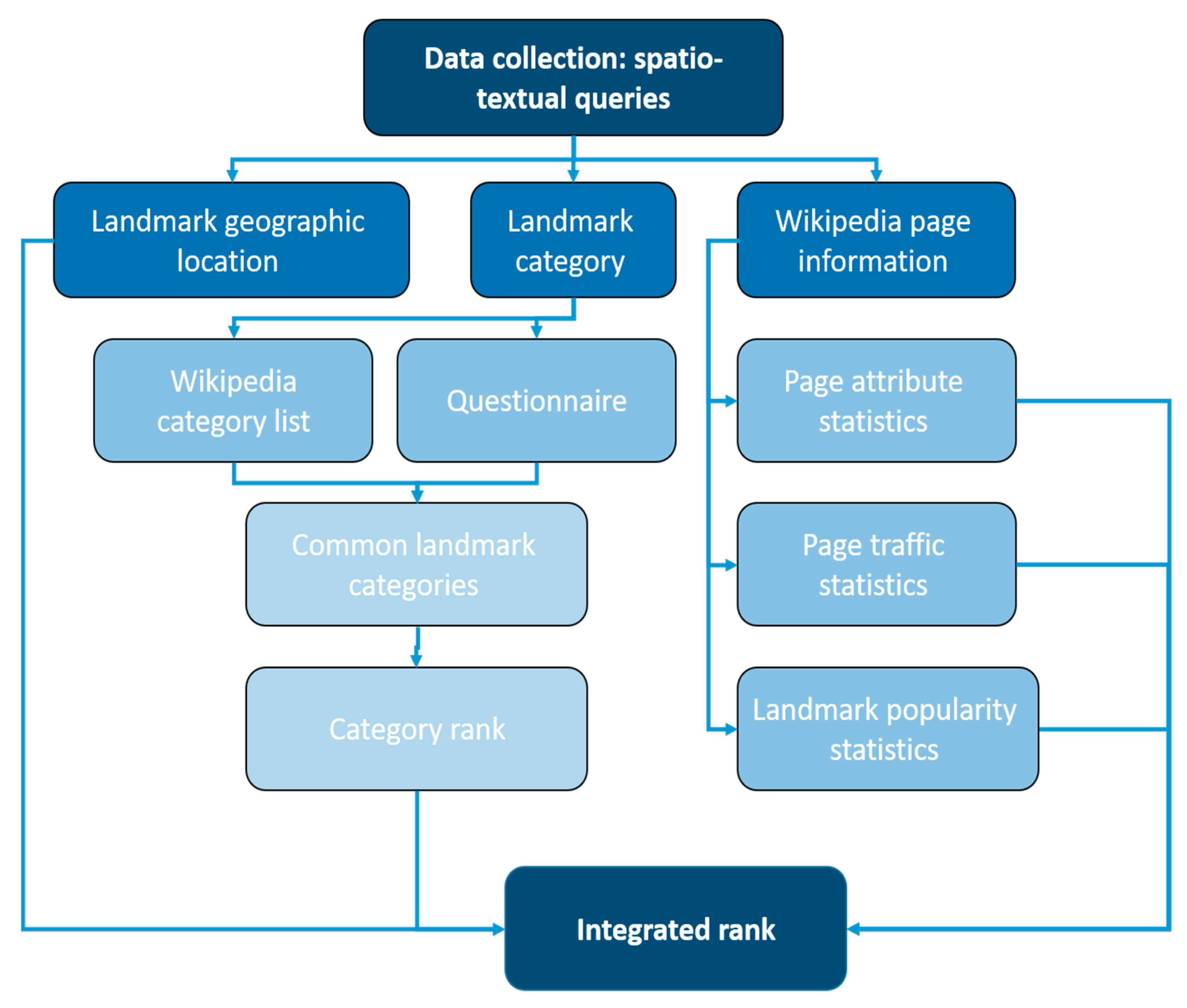
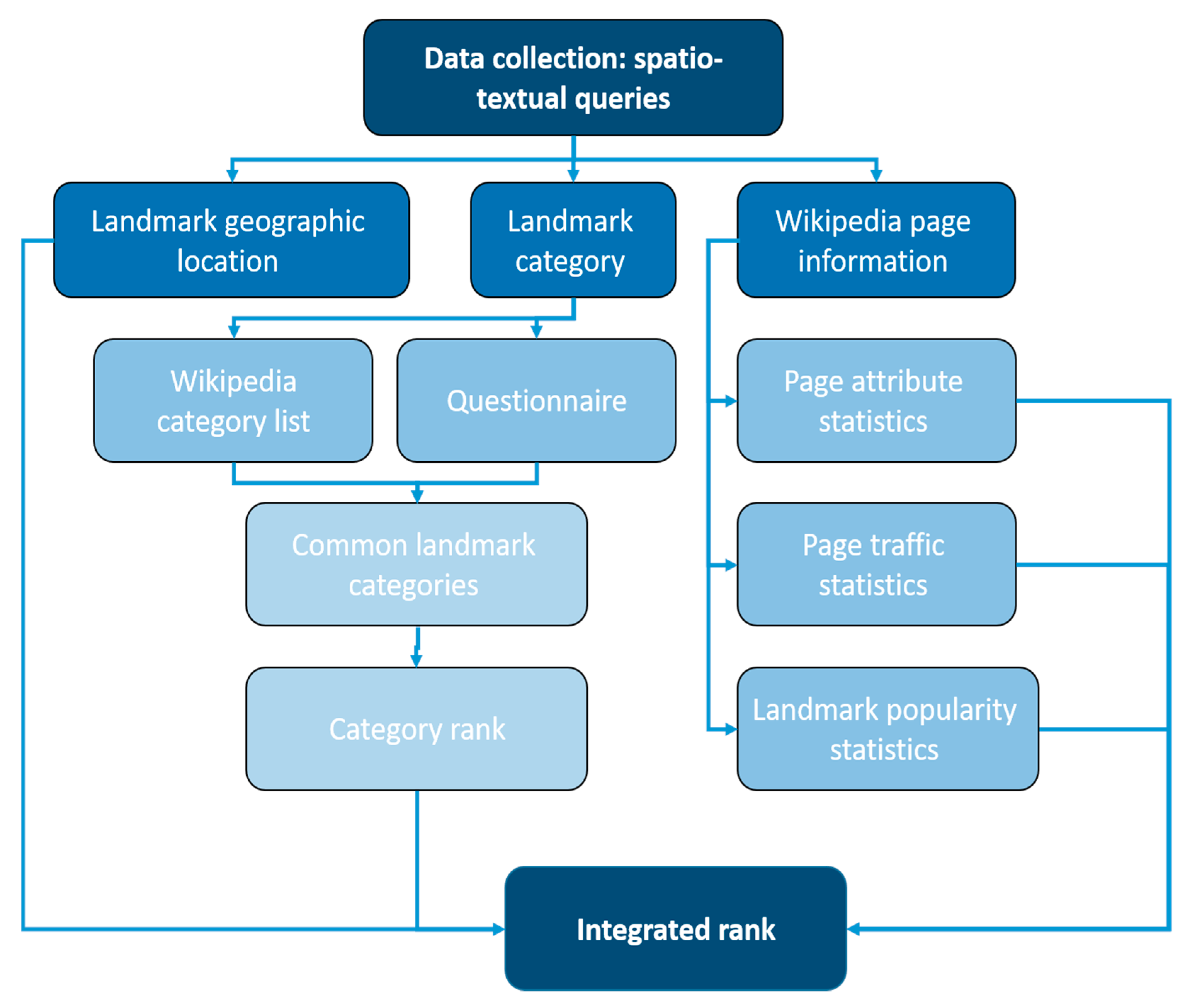
3. Methodology
- Landmark geographic location―data regarding the real-world geographic coordinates of the landmark entry (geotagged data).
- Landmark category―data describing the Wikipedia category list to search for categories that are frequently associated with salient and notable landmark entries.
- Wikipedia page information/statistics―numerical attribute data (page statistics) of the Wikipedia entry that points to the community interest and cultural importance of the landmark.
3.1. Location Properties
3.2. Category Properties
3.2.1. Common Wikipedia Landmark Categories
3.2.2. Wikipedia Category Ranking
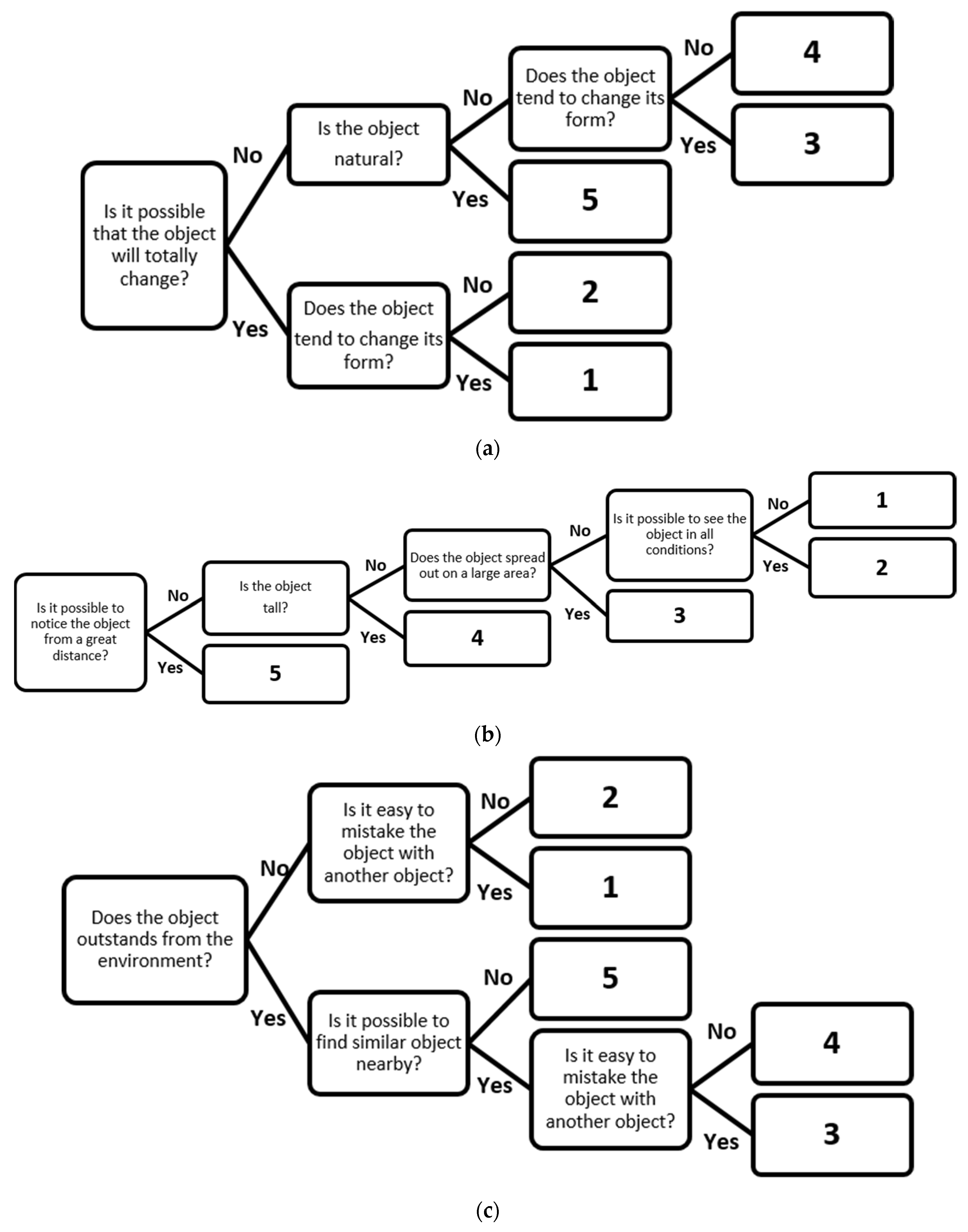
- Permanence―indicates the likelihood of the landmark to be present during navigation, which can be evaluated according to temporal aspects of the physical object, e.g., how likely is that the landmark will change over or completely disappear over time (e.g., restaurant, public transportation station), or will be permanent (e.g., mountain, airport). A permanent object receives a high score, while a temporary one receives a low score. This characteristic can also differentiate between a natural and an artificial landmark, in which case a natural landmark is considered a more permanent landmark.
- Visibility―indicates whether the landmark is clearly distinguished in relation to its surroundings. This characteristic illustrates general factors such as height, size, and shape on the big scale. A tall object is more noticeable from the distance, and as such it will receive a high score. In relation to size and shape, the larger and more complex the object is (in terms of area and footprint) the higher score it will gain. At this point we are occupied with overall landmark salience and consider only global landmarks, so this parameter does not necessarily reflect how the object is seen by the user. However, in the future, a more detailed spatial analysis is expected to adjust landmarks to the certain route, eyes direction, speed, transport mode, or environmental conditions.
- Uniqueness―indicates the possibility that the landmark will be confused with other landmarks in the vicinity. The landmark receives a high score if it has a distinct (individual) appearance or if it is located apart from similar landmarks (e.g., park, castle), as opposed to landmarks of the same category that are more likely to be close (e.g., public transportation station, pubs).
3.3. Wikipedia Page Properties
- The number of redirects (NR)―indicating the number of links that guide users from other Wikipedia pages to the analyzed article (landmark entry). A high number of redirects points to the importance and significance of the page. A prominent entry has many links and connections to other Wikipedia entries (not merely spatial ones). The frequent number of redirects is normally 1–3, thus a higher value indicates a greater importance.
- The date of page creation (DC)―the date the page was created on.
- The date of the latest edit (DE)―the last date the page was updated/edited on.Subtracting DC from DE to receive difference time (DT), we get the number of days that passed from the creation date to the recent edit date. A page created a long time ago and/or a page recently updated, will have a relatively high DT value, which indicates the relevance and importance of the page, and landmark, and its value and interest to the public.
- The total number of edits (TE)―the total number of times that a page was updated/edited from the date of its creation (DC). A page that shows continuous updates suggests that new physical, cultural or historical details are added by involved communities. Therefore, a large value of TE indicates considerable public interest in the page, and thus, in the associated landmark.
3.4. Integrated Ranking Model
X = (ATA) − 1ATL
V = AX − L
- Popularity Statistics―these values are retrieved from the internet website ‘150 most famous landmarks in the world’ (http://www.listchallenges.com/150-most-famous-landmarks-in-the-world). This website gives a score for landmarks (from the top 150 landmarks around the world) according to close to 370,000 users’ votes, who were asked: “How many of the 150 most famous landmarks in the world have you experienced?” The idea of using these values is of crowdsourcing, relying on the assumption that if many users have visited a specific landmark, then there must exist noteworthy values and attributes on its Wikipedia page. Forty-three landmarks are selected from this list, all having a high percentage of votes of more than 30%. The 43 landmarks generate 43 equations in the LSA model, ensuring redundancy and robustness to solve the four weight unknowns.
- Traffic Statistics―these values are retrieved from the internet website ‘pageview analysis’ (https://tools.wmflabs.org/pageviews/?project=en.wikipedia.org) representing the number of views of the Wikipedia article. We use the traffic statistics of 90 days to get a more comprehensive and evident perspective on the Wikipedia entry significance. The assumption is that a high value of views of a certain article gives an indication of its overall importance and interest. These values are retrieved for the same 43 landmarks used in the Popularity Statistics.
4. Experimental Trials
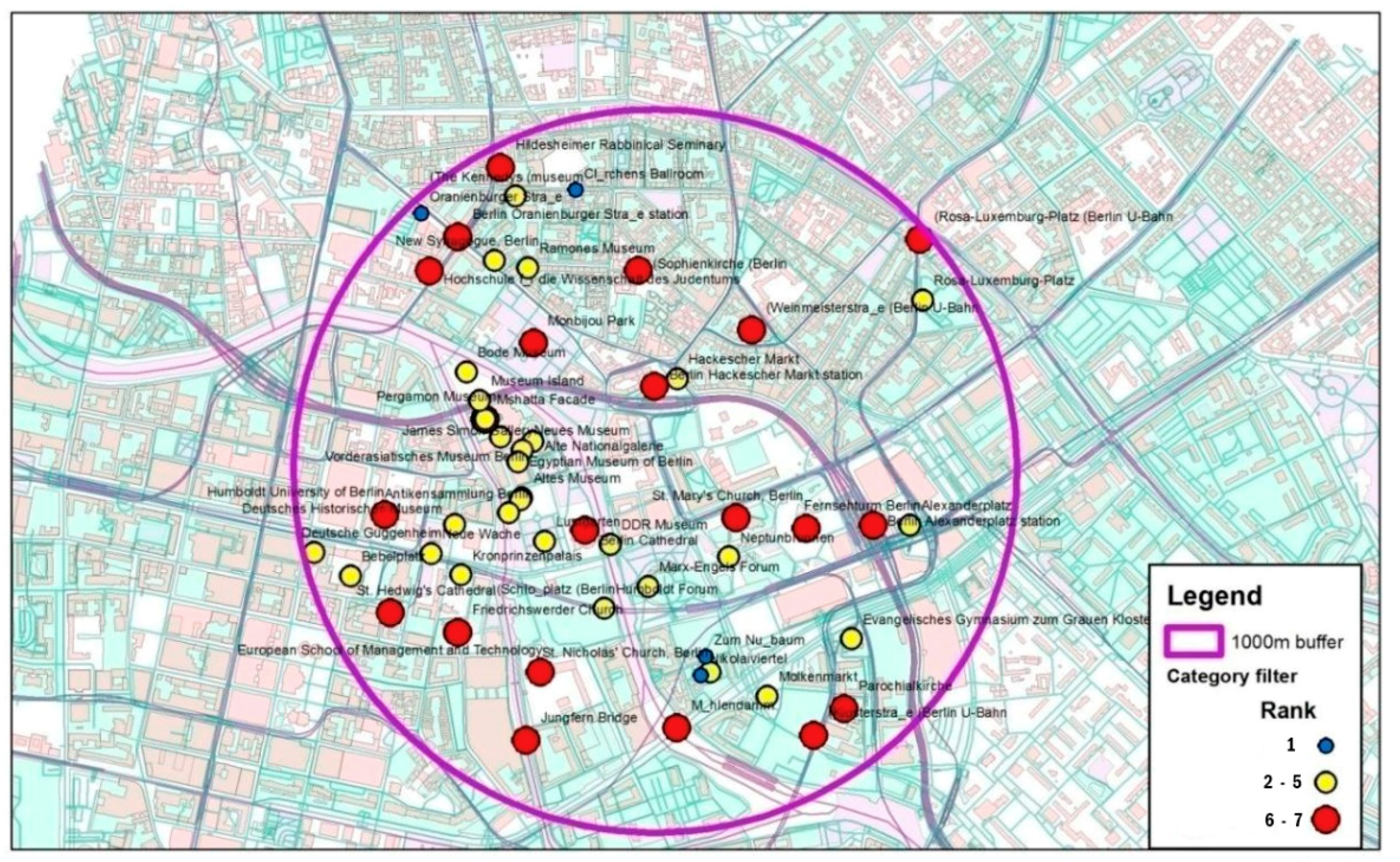
4.1. Category-Based Ranking
4.2. Integrated Ranking Model
4.3. Comparative Evaluation
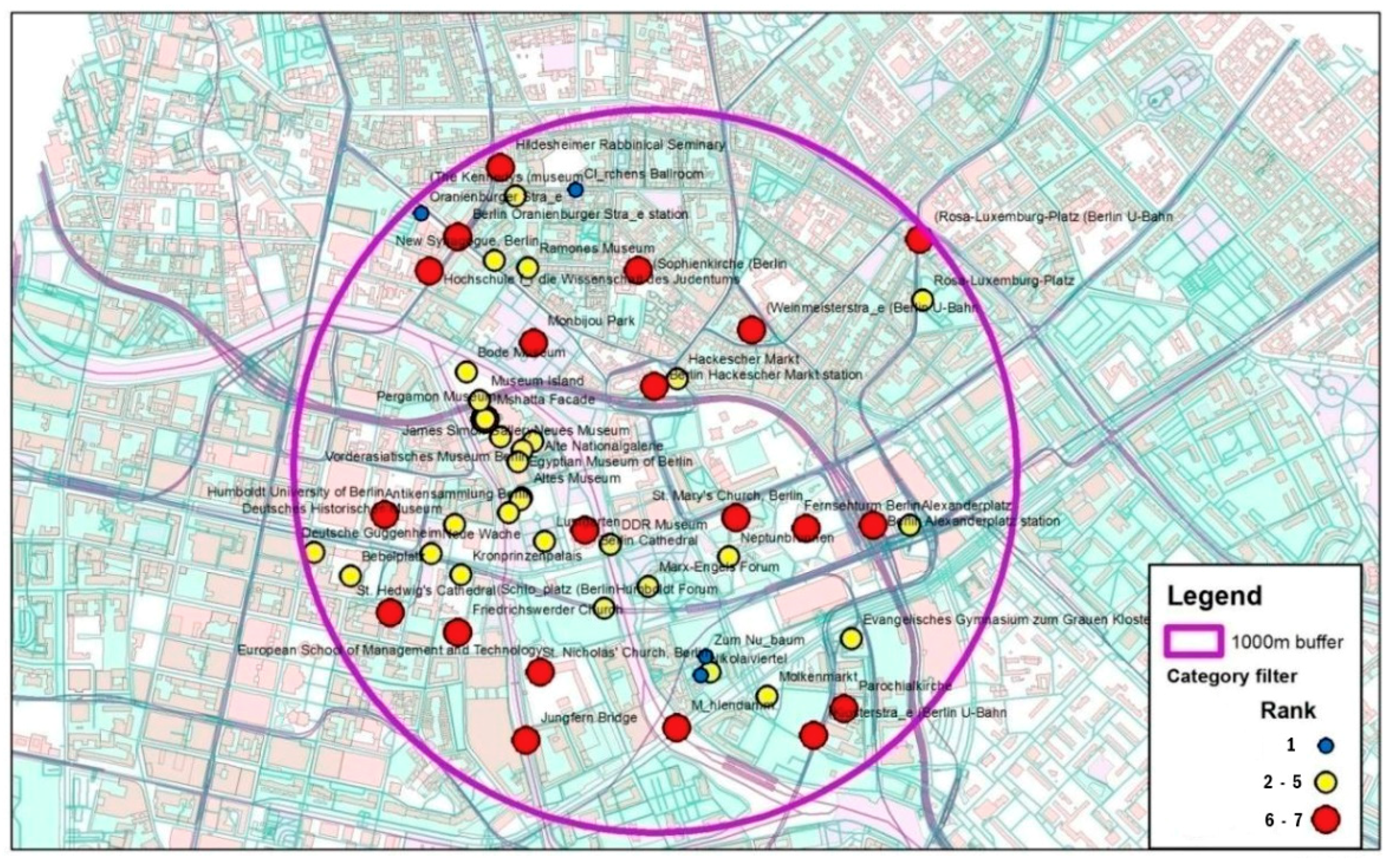
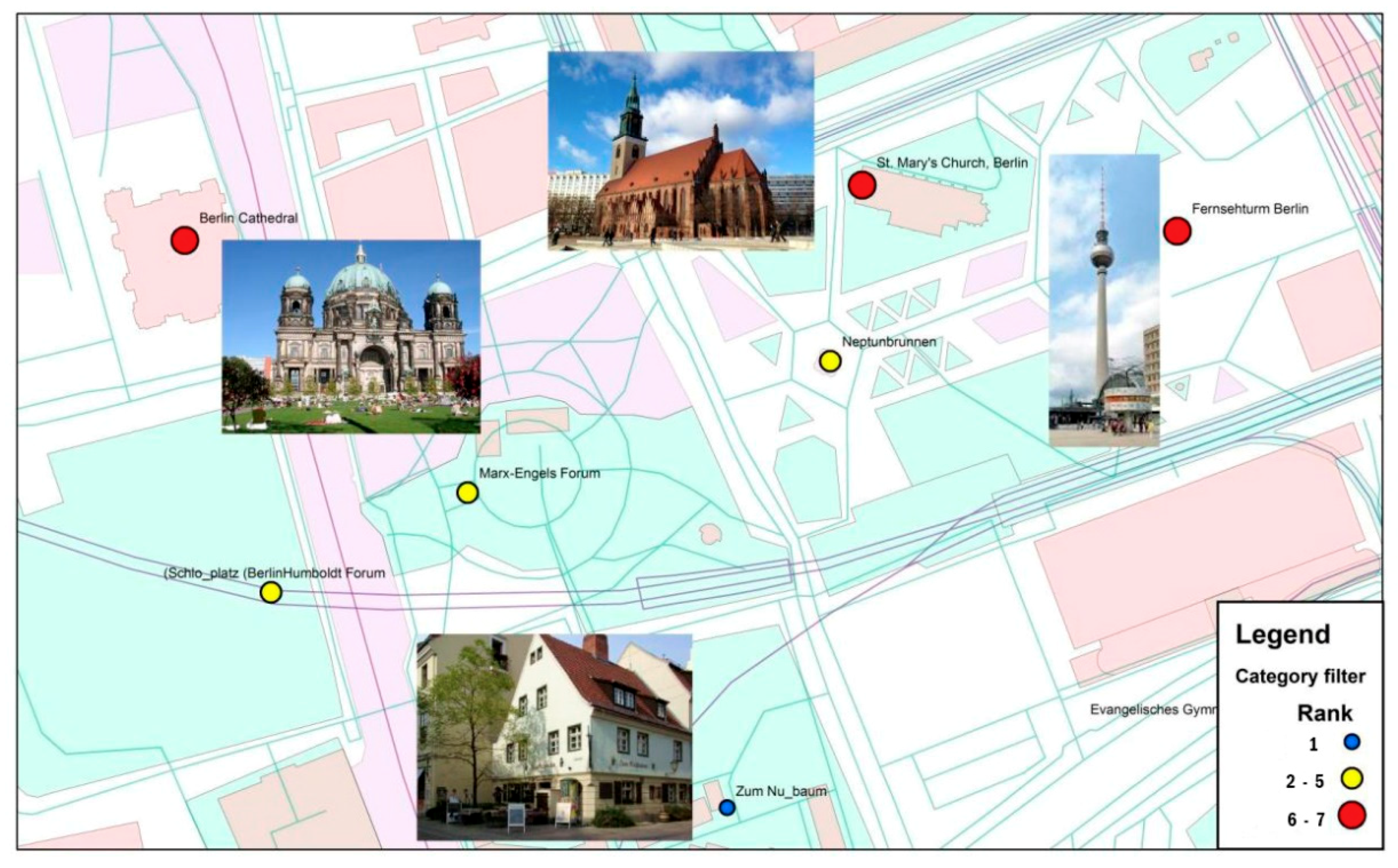
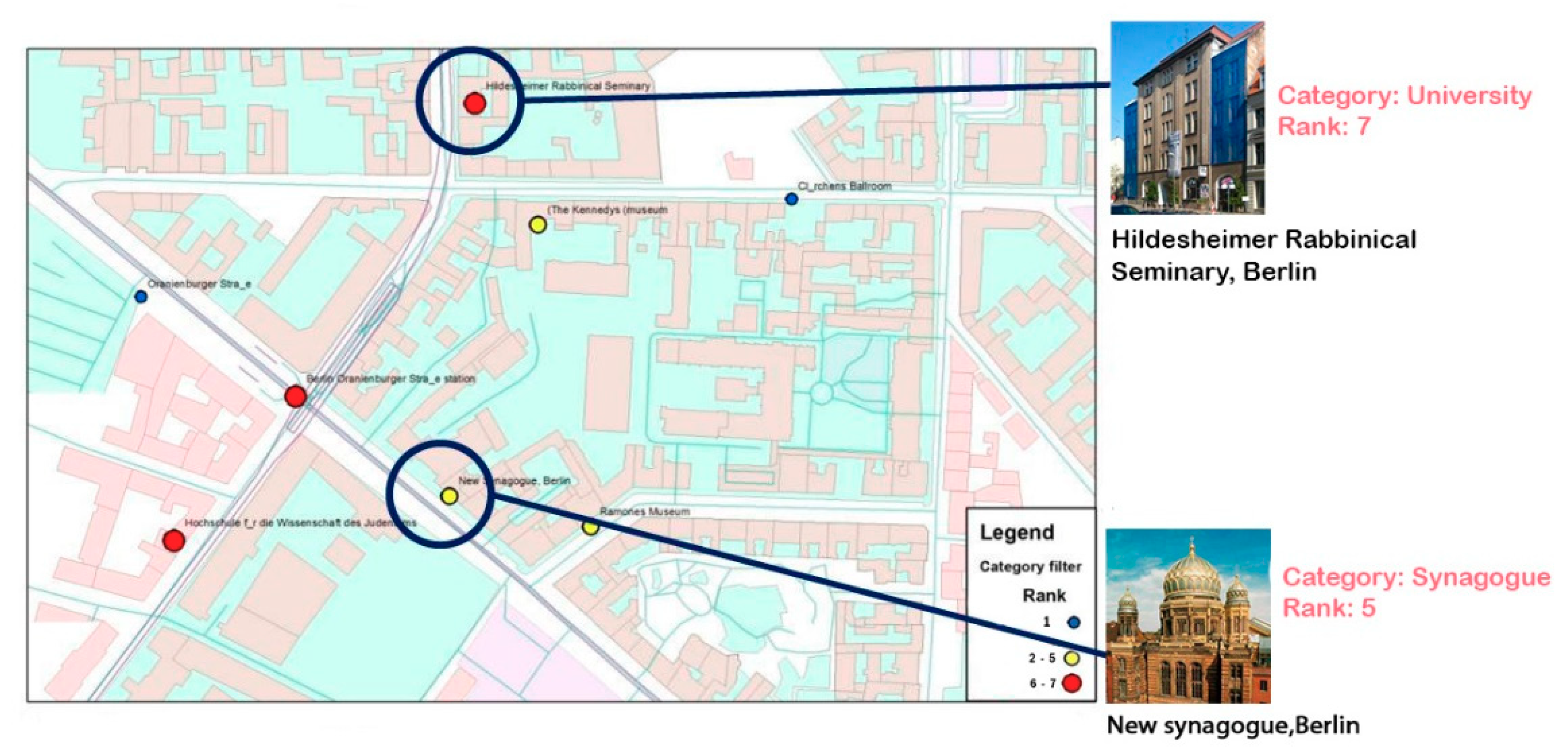
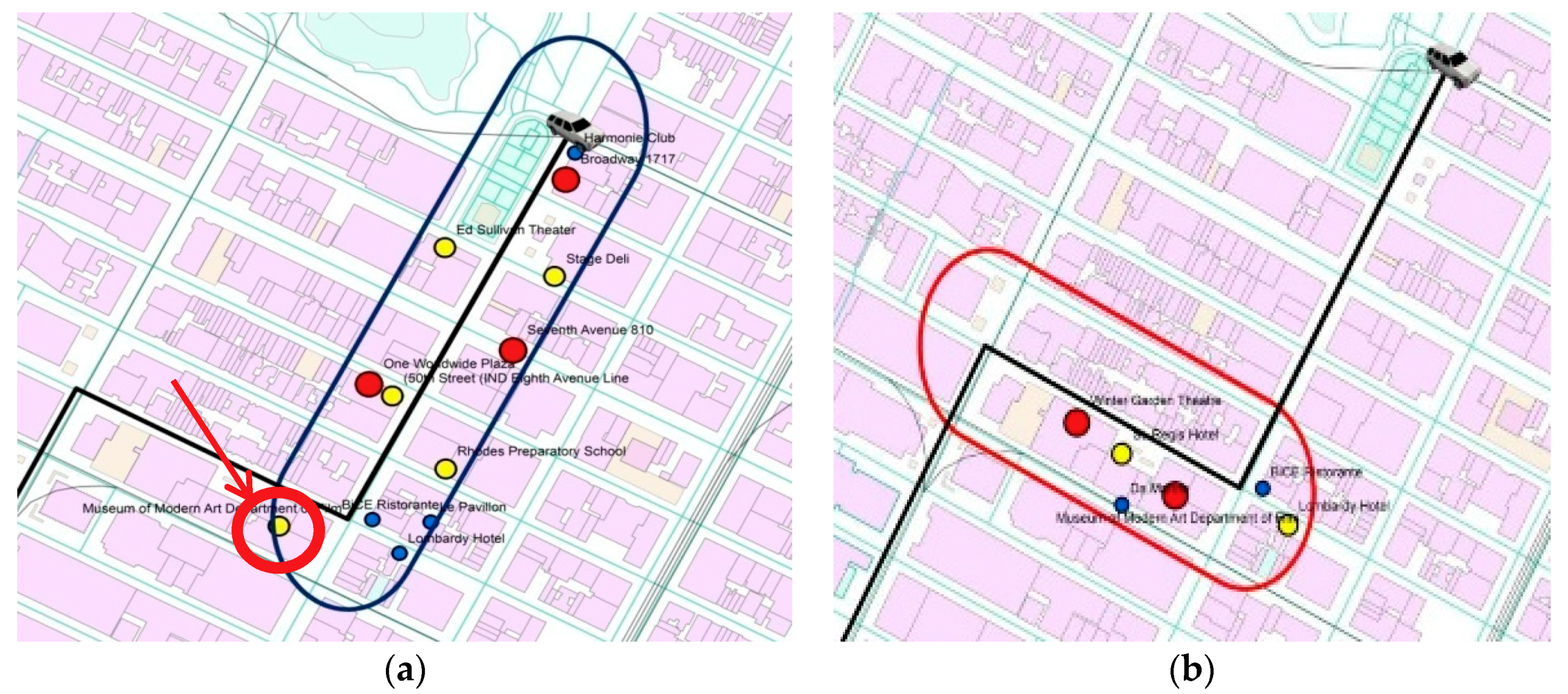
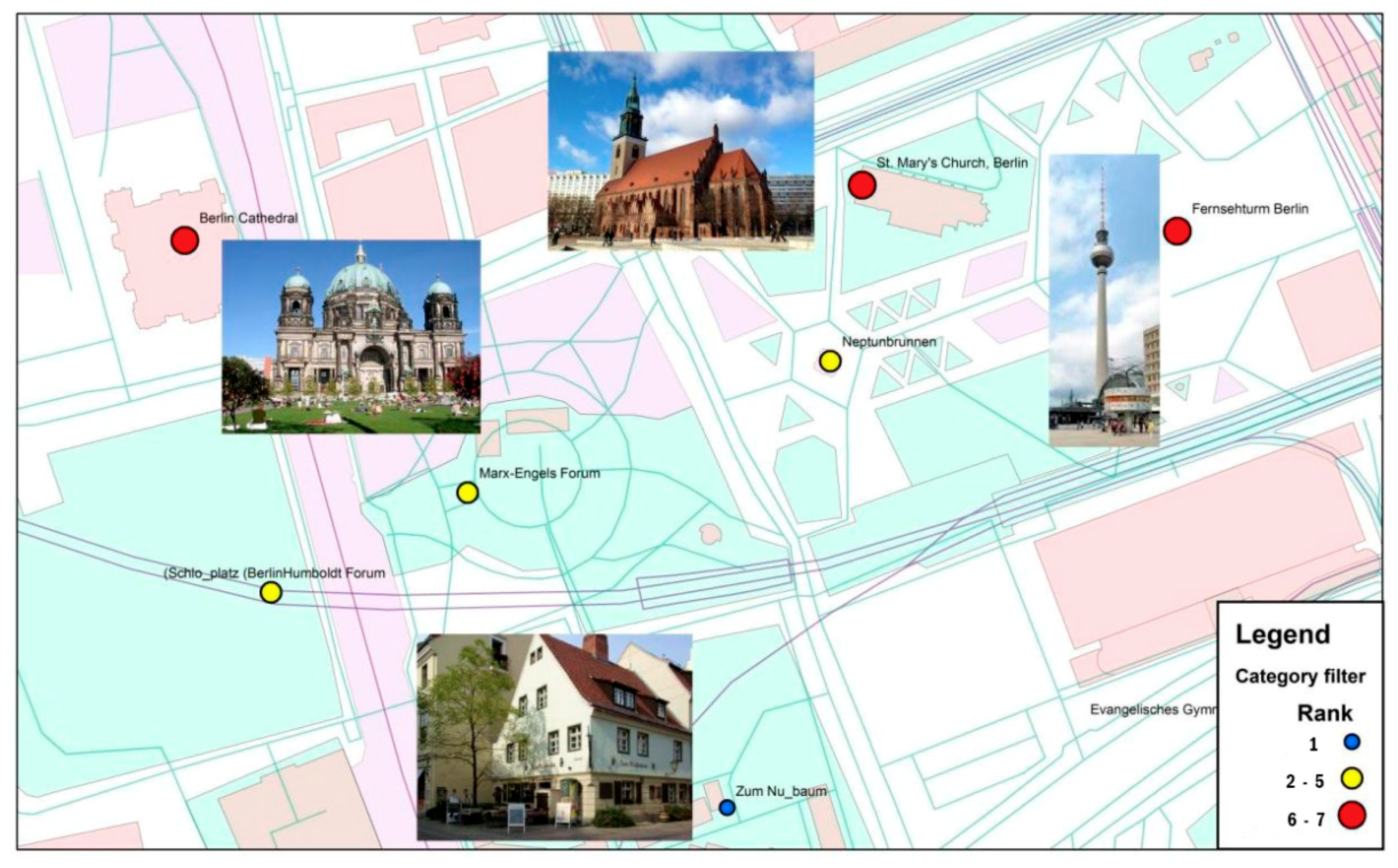
4.3.1. New York
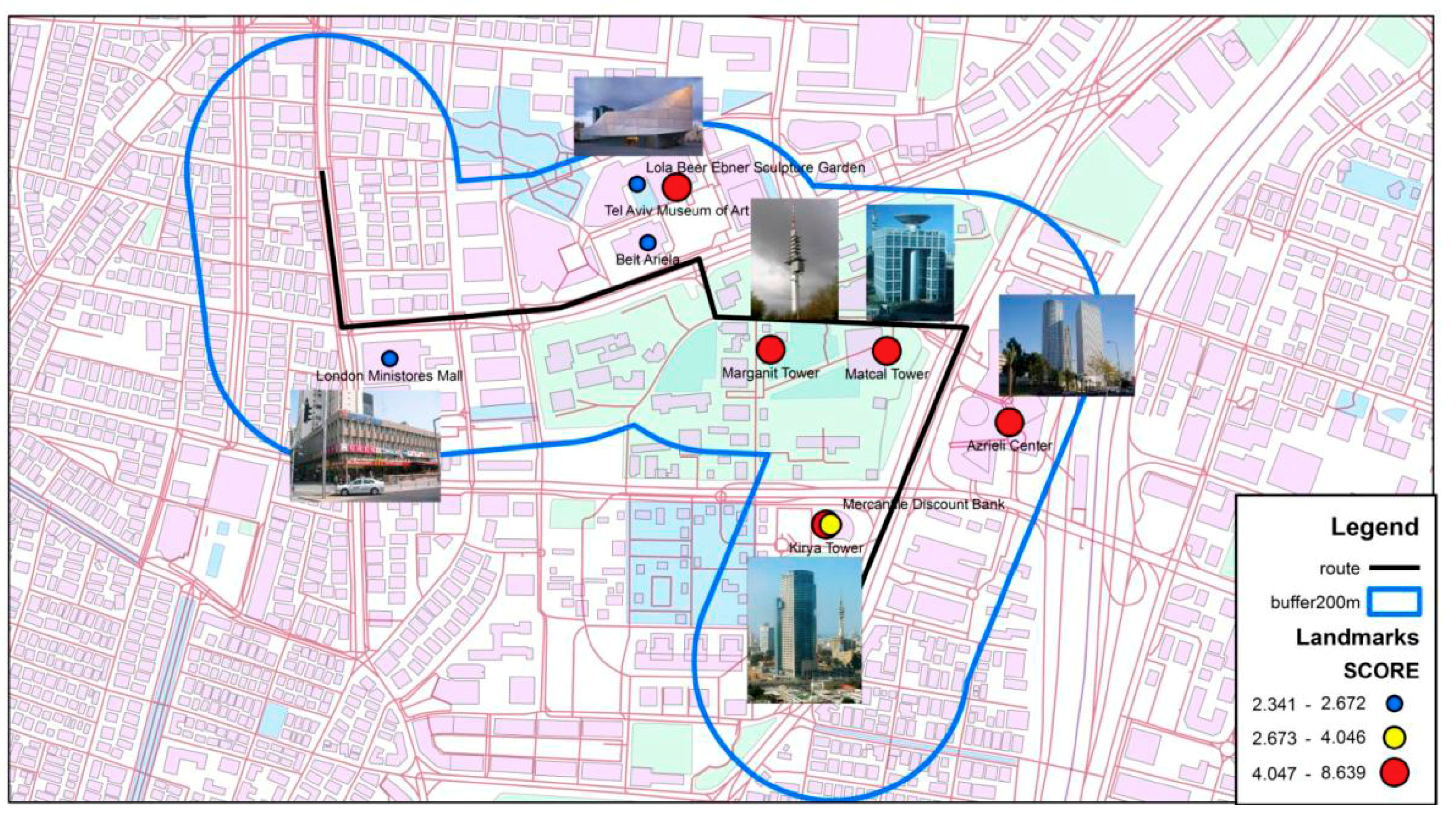
4.3.2. Tel Aviv
5. Discussion and Future Work
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Tom, A.; Denis, M. Referring to landmark or street information in route directions: What difference does it make? Spatial information theory. In Foundations of Geographic Information Science; Springer: Berlin/Heidelberg, Germany, 2003; pp. 362–374. [Google Scholar]
- Schwering, A.; Li, R.; Anacta, V.J.A. Orientation information in different forms of route instructions. In Proceedings of the 16th AGILE Conference on Geographic Information Science, Leuven, Belgium, 14–17 May 2013. [Google Scholar]
- Chersi, F.; Burgess, N. The Cognitive Architecture of Spatial Navigation: Hippocampal and Striatal Contributions. Neuron 2015, 88, 64–77. [Google Scholar] [CrossRef] [PubMed]
- Epstein, R.A.; Zita Patai, E.; Julian, J.B.; Spiers, H.J. The cognitive map in humans: Spatial navigation and beyond. Nat. Neurosci. 2017, 20, 1504–1513. [Google Scholar] [CrossRef] [PubMed]
- Moser, E.I.; Kropff, E.; Moser, M.B. Place cells, grid cells, and the brain's spatial representation system. Annu. Rev. Neurosci. 2008, 31, 69–89. [Google Scholar] [CrossRef] [PubMed]
- Javadi, A.H.; Emo, B.; Howard, L.R.; Zisch, F.E.; Yu, Y.; Knight, R.; Silva, J.P.; Spiers, H. Hippocampal and prefrontal processing of network topology to simulate the future. Nat. Commun. 2017, 8, 14652. [Google Scholar] [CrossRef]
- Raubal, M.; Winter, S. Enriching wayfinding instructions with local landmarks. In Proceedings of the International Conference on Geographic Information Science; Springer: Berlin/Heidelberg, Germany, September 2002; pp. 243–259. [Google Scholar]
- Elias, B.; Sester, M. Incorporating landmarks with quality measures in routing procedures. In Geographic Information Science; Springer: Berlin/Heidelberg, Germany, 2006; pp. 65–80. [Google Scholar]
- Kettunen, P.; Irvankoski, K.; Krause, C.M.; Sarjakoski, L.T. Landmarks in nature to support wayfinding: The effects of seasons and experimental methods. Cogn. Process. 2013, 14, 245–253. [Google Scholar] [CrossRef]
- Marcus, A.; Abromowitz, S.; Abulkhair, M.F. Design, User Experience, and Usability; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Siegel, A.W.; White, S.H. The development of spatial representations of large-scale environments. In Advances in Child Development and Behavior; Reese, H.W., Ed.; Academic Press: New York, NY, USA, 1975; Volume 10, pp. 9–55. [Google Scholar]
- Deakin, A.K. Landmarks as navigational aids on street maps. Cartogr. Geogr. Inf. Syst. 1996, 23, 21–36. [Google Scholar] [CrossRef]
- Michon, P.E.; Denis, M. When and why are visual landmarks used in giving directions? In Proceedings of the International Conference on Spatial Information Theory; Springer: Berlin/Heidelberg, Germany, 13 November 2001; pp. 292–305. [Google Scholar]
- Brenner, C.; Elias, B. Extracting landmarks for car navigation systems using existing GIS databases and laser scanning. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2003, 34, 131–138. [Google Scholar]
- Richter, K.F. Prospects and challenges of landmarks in navigation services. In Proceedings of the Cognitive and Linguistic Aspects of Geographic Space; Springer: Berlin/Heidelberg, Germany, 30 January 2013; pp. 83–97. [Google Scholar]
- Giannopoulos, I.; Kiefer, P.; Raubal, M.; Richter, K.F.; Thrash, T. Wayfinding decision situations: A conceptual model and evaluation. In Proceedings of the International Conference on Geographic Information Science; Springer: Cham, Switzerland, 24–26 September 2014; pp. 221–234. [Google Scholar]
- Wenig, N.; Wenig, D.; Ernst, S.; Malaka, R.; Hecht, B.; Johannes, S. Pharos: Improving Navigation Instructions on Smartwatches by Including Global Landmarks. In Proceedings of the MobileHCI 17; ACM: New York, NY, USA, 2017; pp. 1–13. [Google Scholar]
- Conrad, F.; Schweikart, J. Mental representation of landmarks on maps: Investigating cartographic visualization methods with eye tracking technology. Spat. Cogn. Comput. 2017, 17, 20–38. [Google Scholar]
- Löwen, H.; Krukar, J. Spatial Learning with Orientation Maps: The Influence of Different Environmental Features on Spatial Knowledge Acquisition. Int. J. Geo-Inf. 2019, 8, 149. [Google Scholar] [CrossRef]
- Montello, D.R. Landmarks are Exaggerated. KI—Künstliche Intelligenz 2017, 31, 193–197. [Google Scholar] [CrossRef]
- Klippel, A.; Hansen, S.; Richter, K.F.; Winter, S. Urban granularities—A data structure for cognitively ergonomic route directions. GeoInformatica 2009, 13, 223. [Google Scholar] [CrossRef]
- Kim, J.; Vasardani, M.; Winter, S. Similarity matching for integrating spatial information extracted from place descriptions. Int. J. Geogr. Inf. Sci. 2017, 31, 56–80. [Google Scholar] [CrossRef]
- Lovelace, K.L.; Hegarty, M.; Montello, D.R. Elements of good route directions in familiar and unfamiliar environments. In Spatial Information Theory. Cognitive and Computational Foundations of Geographic Information Science (COSIT 1999’); Freksa, C., Mark, D.M., Eds.; Volume 1661 of Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 16 December 1999; pp. 65–82. [Google Scholar]
- Haklay, M. How good is volunteered geographical information? A comparative study of OpenStreetMap and Ordnance Survey datasets. Environ. Plan. B Plan. Des. 2010, 37, 682–703. [Google Scholar] [CrossRef]
- Sester, M.; Dalyot, S. Enriching Navigation Instructions to Support the Formation of Mental Maps. In Proceedings of the Advances in Spatial Data Handling and Analysis; Springer International Publishing: Cham, Switzerland, 2015; pp. 15–33. [Google Scholar]
- Schlieder, C.; Matyas, C. Photographing a city: An analysis of place concepts based on spatial choices. Spat. Cogn. Comput. 2009, 9, 212–228. [Google Scholar] [CrossRef]
- Mor, M.; Dalyot, S. Computing Touristic Walking Routes using Geotagged Photographs from Flickr. In Adjunct Proceedings of the 14th International Conference on Location Based Services; ETH: Zurich, Switzerland, 15–17 January 2018; pp. 63–68. [Google Scholar]
- Sun, Y.; Fan, H.; Bakillah, M.; Zipf, A. Road-based travel recommendation using geo-tagged images. Comput. Environ. Urban Syst. 2015, 53, 110–122. [Google Scholar] [CrossRef]
- Graser, A. Towards landmark-based instructions for pedestrian navigation systems using openstreetmap. In Proceedings of the AGILE 2017 Conference on Geographic Information Science, Wageningen, The Netherlands, 9–12 May 2017. [Google Scholar]
- Rousell, A.; Hahmann, S.; Bakillah, M.; Mobasheri, A. Extraction of landmarks from OpenStreetMap for use in navigational instructions. In Proceedings of the AGILE Conference on Geographic Information Science, Lisbon, Portugal, 9–12 June 2015; Volume 83. [Google Scholar]
- Nuhn, E.; Wolfgang, R.; Haske, B. Generation of Landmarks from 3D City Models and OSM Data. In Proceedings of the AGILE 2012 International Conference on Geographic Information Science, AGILE, Avignon, France, 24–27 April 2012; pp. 365–369. [Google Scholar]
- Quesnot, T.; Roche, S. Measure of Landmark Semantic Salience through Geosocial Data Streams. ISPRS Int. J. Geo-Inf. 2014, 4, 1–31. [Google Scholar] [CrossRef]
- Ponzetto, S.P.; Strube, M. Deriving a large-scale taxonomy from Wikipedia. In Proceedings of the AAAI, Vancouver, BC, Canada, 22–26 July 2007; Volume 7, pp. 1440–1445. [Google Scholar]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Bizer, C. DBpedia—A large-scale, multilingual knowledge base extracted from Wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar]
- Zirn, C.; Nastase, V.; Strube, M. Distinguishing between instances and classes in the wikipedia taxonomy. In Proceedings of the European Semantic Web Conference; Springer: Berlin/Heidelberg, Germany, 1–5 June 2008; pp. 376–387. [Google Scholar]
- Overell, S.E.; Rüger, S.M. Identifying and grounding descriptions of places. In Proceedings of the 3rd ACM Workshop on Geographic Information Retrieval (GIR 2006), Seattle, WA, USA, 10 August 2006. [Google Scholar]
- Hoffart, J.; Suchanek, F.M.; Berberich, K.; Weikum, G. YAGO2: A spatially and temporally enhanced knowledge base from Wikipedia. Artif. Intell. 2013, 194, 28–61. [Google Scholar] [CrossRef]
- Clough, P.D.; Joho, H.; Purves, R. Judging the spatial relevance of documents for GIR. In Proceedings of the European Conference on Information Retrieval; Springer: London, UK, 10–12 April 2006; pp. 548–552. [Google Scholar]
- Medelyan, O.; Milne, D.; Legg, C. Witten IH Mining meaning from Wikipedia. Int. J. Hum. Comput. Stud. 2009, 67, 716–754. [Google Scholar] [CrossRef]
- Santos, D.; Cardoso, N.; Carvalho, P.; Dornescu, I.; Hartrumpf, S.; Leveling, J.; Skalban, Y. GikiP at GeoCLEF 2008: Joining GIR and QA forces for querying Wikipedia. In Workshop of the Cross-Language Evaluation Forum for European Languages; Springer: Aarhus, Denmark, 17–19 September 2008; pp. 894–905. [Google Scholar]
- Ahlers, D. Where the streets have no name: Experiences in GIR for a developing country. In Proceedings of the 7th Workshop on Geographic Information Retrieval, Orlando, FL, USA, 5 November 2013; ACM: New York, NY, USA, 2013; pp. 47–48. [Google Scholar]
- Gensel, J.; Tomko, M. Web and Wireless Geographical Information Systems: 14th International Symposium, (W2GIS 2015), Grenoble, France, 21–22 May 2015 Proceedings; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2015; Volume 9080, pp. 3–19. [Google Scholar]
- Popescu, A.; Grefenstette, G. Mining social media to create personalized recommendations for tourist visits. In Proceedings of the 2nd International Conference on Computing for Geospatial Research and Applications, Washington, DC, USA, 23–25 May 2011; ACM: New York, NY, USA, 2011; p. 37. [Google Scholar]
- Vercoustre, A.M.; Pehcevski, J.; Thom, J.A. Using wikipedia categories and links in entity ranking. In Proceedings of the International Workshop of the Initiative for the Evaluation of XML Retrieval, December 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 321–335. [Google Scholar]
- Vinson, N.G. Design guidelines for landmarks to support navigation in virtual environments. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Pittsburgh, PA, USA, 15–20 May 1999; pp. 278–285. [Google Scholar]
- Burnett, G.; Smith, D.; May, A. Supporting the navigation task: Characteristics of ‘good’ landmarks. Contemp. Ergon. 2001, 1, 441–446. [Google Scholar]
- Brin, S.; Page, L. The anatomy of a large-scale hypertextual web search engine. Comput. Netw. ISDN Syst. 1998, 33, 107–117. [Google Scholar] [CrossRef]
- Wikimapia. Wikipedia, the Free Encyclopedia. 2017. Available online: https://en.wikipedia.org/w/index.php?title=Wikimapiaandoldid=812872935 (accessed on 6 October 2017).
- Duckham, M.; Winter, S.; Robinson, M. Including landmarks in routing instructions. J. Locat. Based Serv. 2010, 4, 28–52. [Google Scholar] [CrossRef]
- Anacta, V.J.A.; Schwering, A.; Muenzer, S. Orientation information in wayfinding instructions: Evidences from human verbal and visual instructions. Geo J. 2017, 82, 567–583. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Final Rank | Category | Final Rank | Category | Final Rank |
|---|---|---|---|---|---|
| Restaurant | 1 | Court | 3 | University | 7 |
| Nightclub | 1 | Market | 4 | Tall building | 7 |
| Coffee shop | 1 | School | 4 | Natural landmark | 7 |
| Pub | 1 | Museum | 4 | Cemetery | 7 |
| Bus station | 1 | Hall | 4 | Tower | 7 |
| Roundabout | 2 | Architecture structure | 5 | Hospital | 7 |
| Parking lot | 2 | Historic site | 5 | Bridge | 7 |
| Yard | 2 | Highway road | 5 | Fortress | 8 |
| Sculpture | 3 | Theatre | 5 | Airport | 8 |
| Square | 3 | Shopping centre | 6 | River | 8 |
| Landmark | 3 | College | 6 | Sky scrapper | 8 |
| Synagogue | 3 | Park | 6 | Castle | 8 |
| Library | 3 | Railway station | 6 | Mountain | 8 |
| Subway | 3 | Church | 6 | Lake | 9 |
| Hotel | 3 | Mall | 7 | Sea | 10 |
| Landmark | Category | Category Rank (CR) | Number of Redirects to This Page (NR) | Latest edit- Creation Date (DT) | Number of Edits (TE) | L |
|---|---|---|---|---|---|---|
| Notre Dame | Church | 6 | 2 | 5 | 1 | 6 |
| Buckingham Palace | Museum | 4 | 2 | 9 | 5 | 7 |
| Central Park | Park | 6 | 4 | 8 | 4 | 6 |
| Empire State Building | Skyscraper | 8 | 3 | 9 | 7 | 8 |
| Times Square | Square | 3 | 3 | 8 | 3 | 8 |
| Statue of Liberty | Sculpture | 3 | 4 | 9 | 10 | 6 |
| Big Ben | Tower | 7 | 4 | 9 | 4 | 10 |
| Tower of London | Tower | 7 | 3 | 9 | 5 | 7 |
| Landmar.k | CR | NR | DT | TE | Rank |
|---|---|---|---|---|---|
| Church of Our Lady of the Assumption and St Gregory | 6 | 1 | 2 | 1 | 3 |
| Piccadilly Market | 6 | 1 | 2 | 1 | 3 |
| Supreme Court of the United Kingdom | 3 | 6 | 8 | 5 | 6 |
| Landmark | CR | NR | DT | TE | Rank |
|---|---|---|---|---|---|
| Big Ben | 7 | 7 | 10 | 10 | 8 |
| St Martin-in-the-Fields | 6 | 10 | 9 | 2 | 8 |
| London Eye | 8 | 6 | 10 | 10 | 8 |
| Selection by | Number of Landmarks | Number of Landmarks after Filtering | % Filtered |
|---|---|---|---|
| Common category list | 463 | 269 | 42 |
| Buffer | 269 | 45 | 90 |
| Category rank value | 45 | 13 | 97 |
| Integrated (score) value | 13 | 8 | 98 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Binski, N.; Natapov, A.; Dalyot, S. Retrieving Landmark Salience Based on Wikipedia: An Integrated Ranking Model. ISPRS Int. J. Geo-Inf. 2019, 8, 529. https://doi.org/10.3390/ijgi8120529
Binski N, Natapov A, Dalyot S. Retrieving Landmark Salience Based on Wikipedia: An Integrated Ranking Model. ISPRS International Journal of Geo-Information. 2019; 8(12):529. https://doi.org/10.3390/ijgi8120529
Chicago/Turabian StyleBinski, Noa, Asya Natapov, and Sagi Dalyot. 2019. "Retrieving Landmark Salience Based on Wikipedia: An Integrated Ranking Model" ISPRS International Journal of Geo-Information 8, no. 12: 529. https://doi.org/10.3390/ijgi8120529
APA StyleBinski, N., Natapov, A., & Dalyot, S. (2019). Retrieving Landmark Salience Based on Wikipedia: An Integrated Ranking Model. ISPRS International Journal of Geo-Information, 8(12), 529. https://doi.org/10.3390/ijgi8120529