Traffic Regulator Detection and Identification from Crowdsourced Data—A Systematic Literature Review

Abstract
1. Introduction
2. Materials and Methods
2.1. Literature Search
2.1.1. Channels for Literature Search
2.1.2. Query Terms
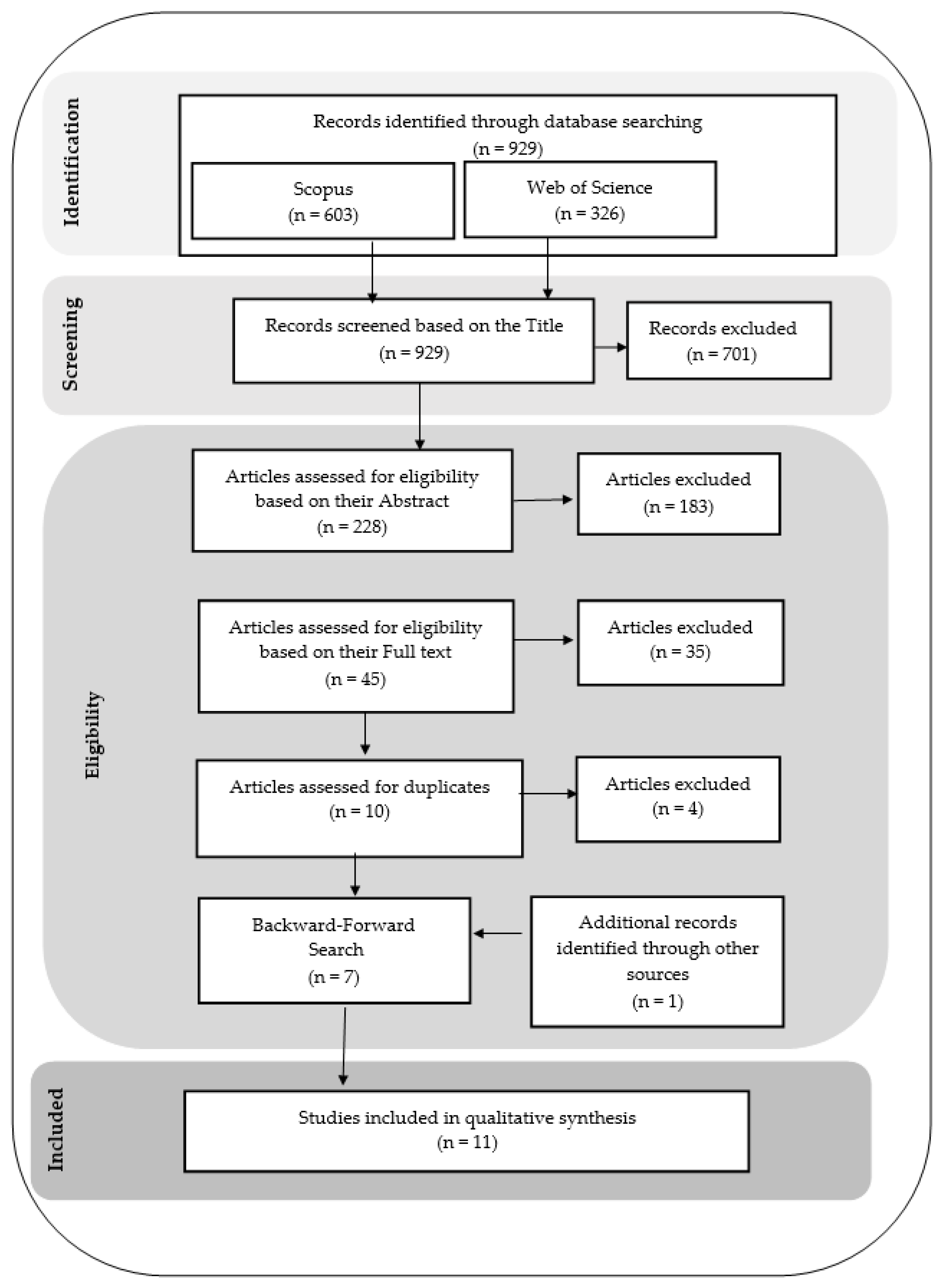
2.2. Screening and Eligibility Check
2.2.1. Inclusion and Exclusion Criteria
2.2.2. Applying the Inclusion and Exclusion Criteria
2.2.3. Snowballing Search and Personal Knowledge Enrichment
2.3. Information Extraction
3. Results
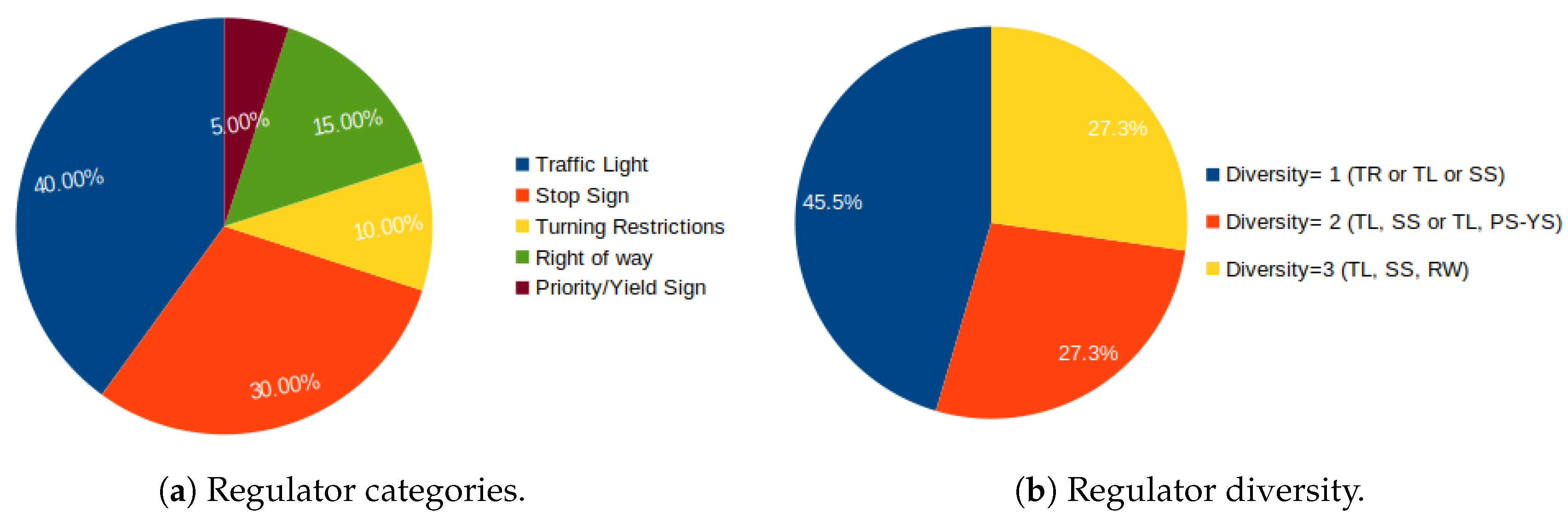
3.1. Regulators: Categories and Diversion
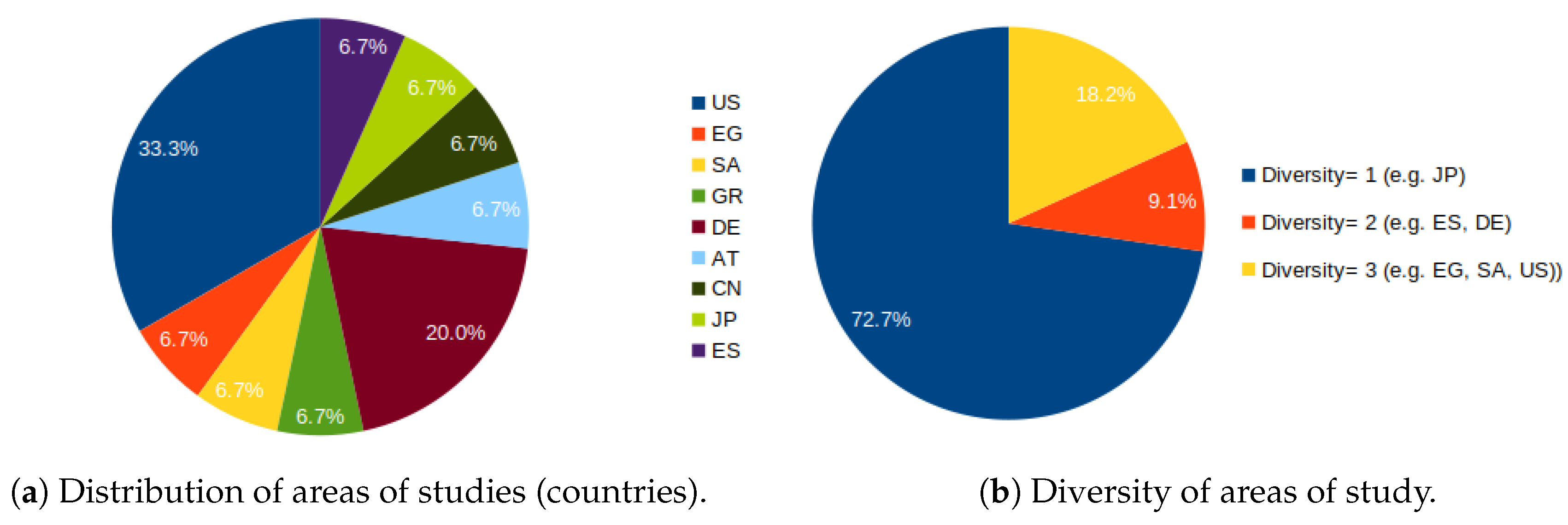
3.2. Area of Study
3.3. Participants
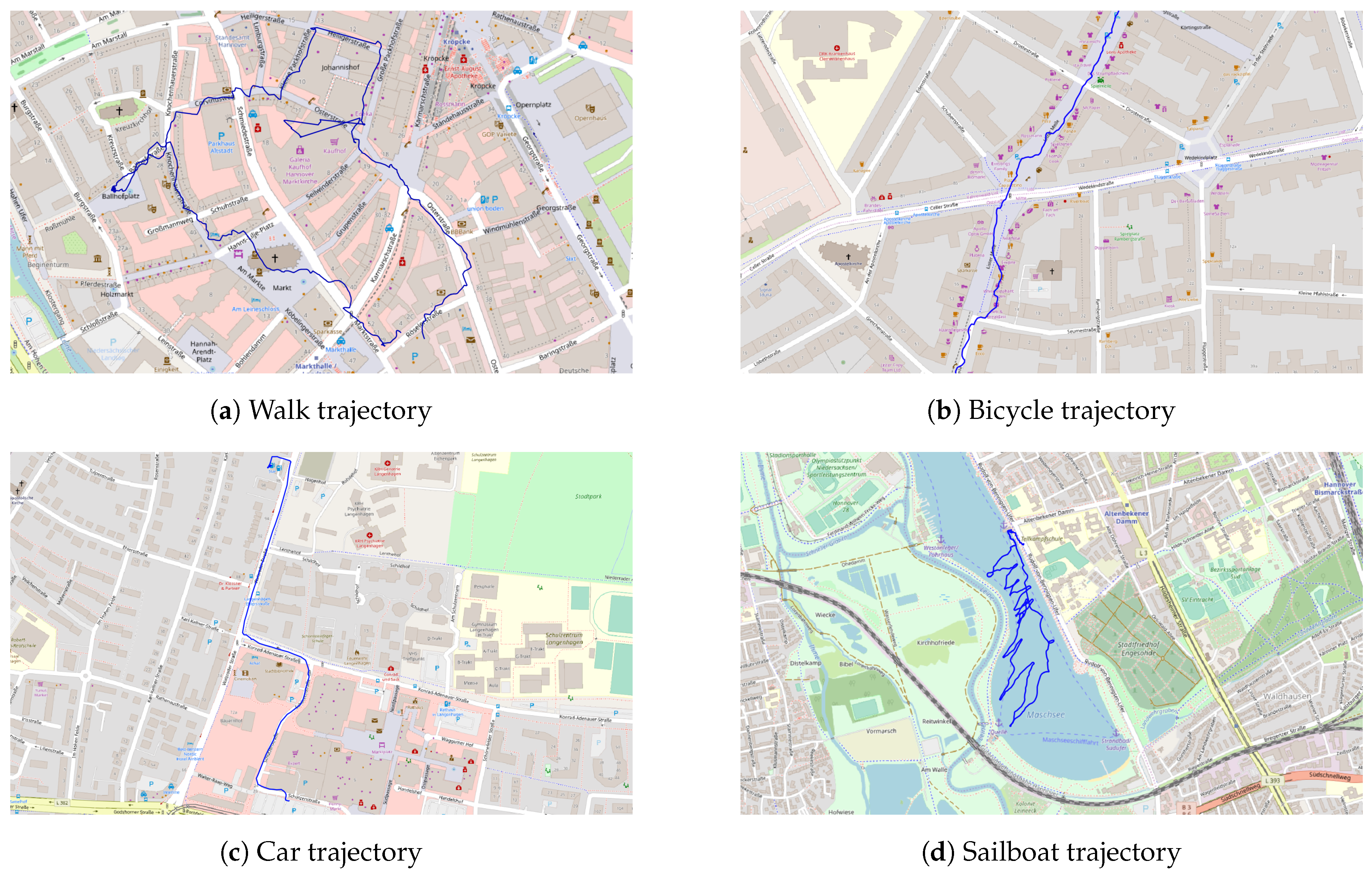
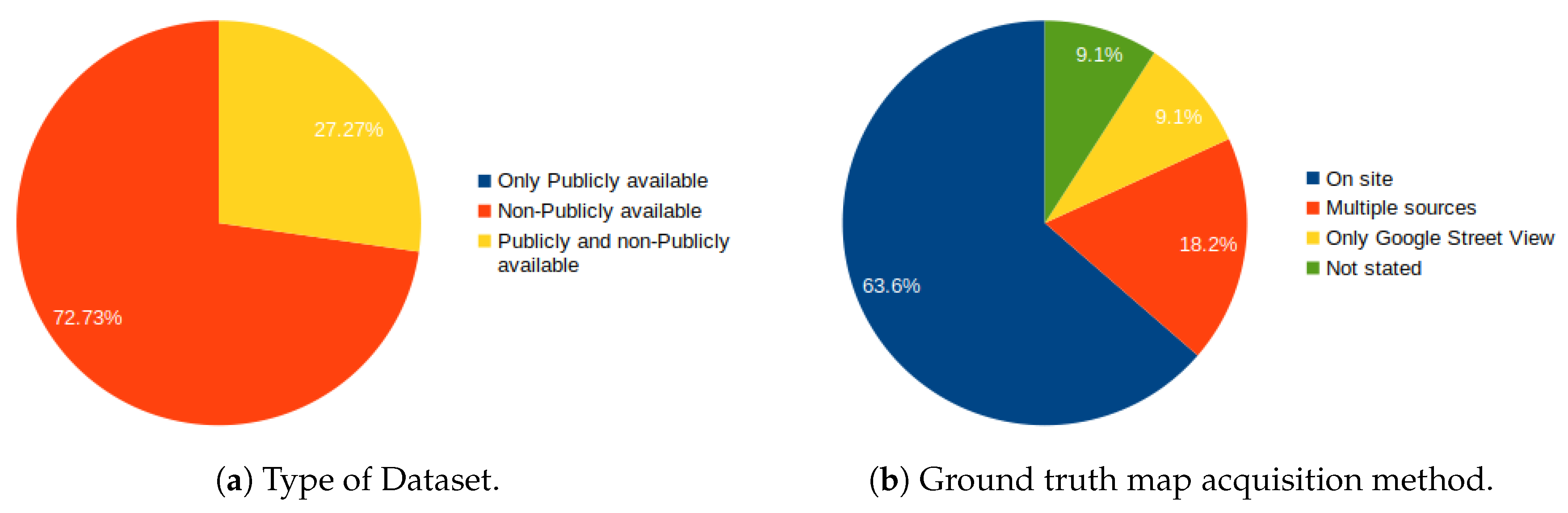
3.4. Dataset Type
3.5. Dataset Size
3.6. Dataset Timespan
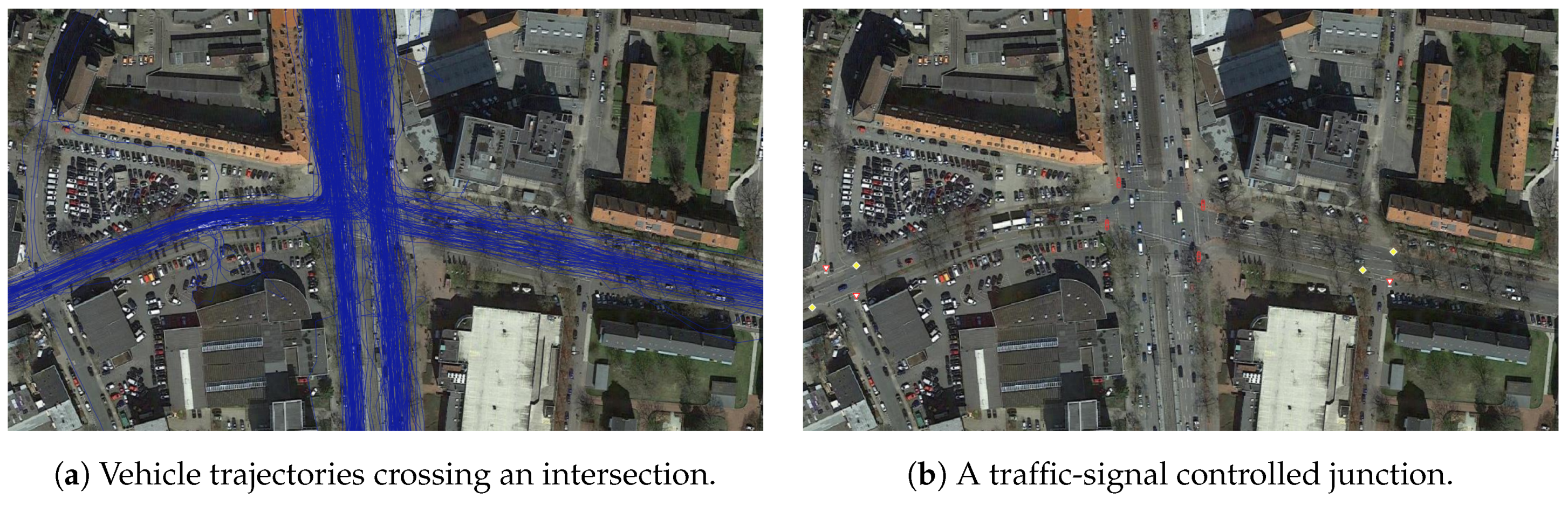
3.7. Ground Truth Map Acquisition Method
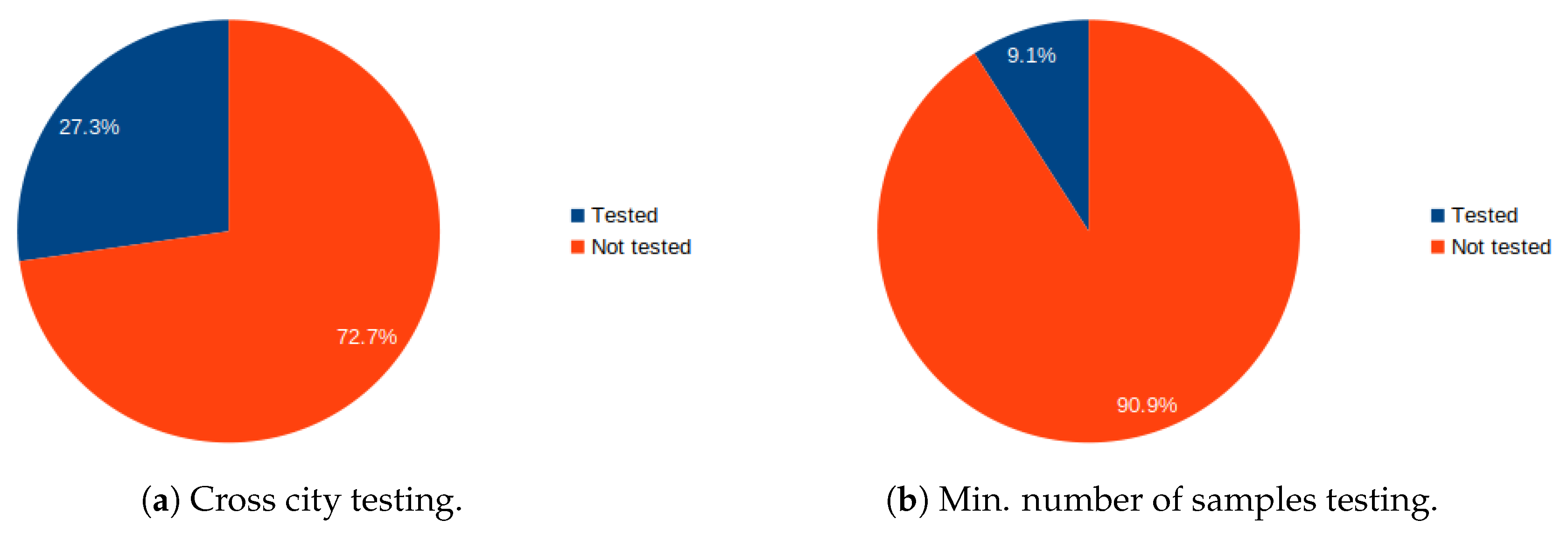
3.8. Cross-City Testing
3.9. Number of Passes
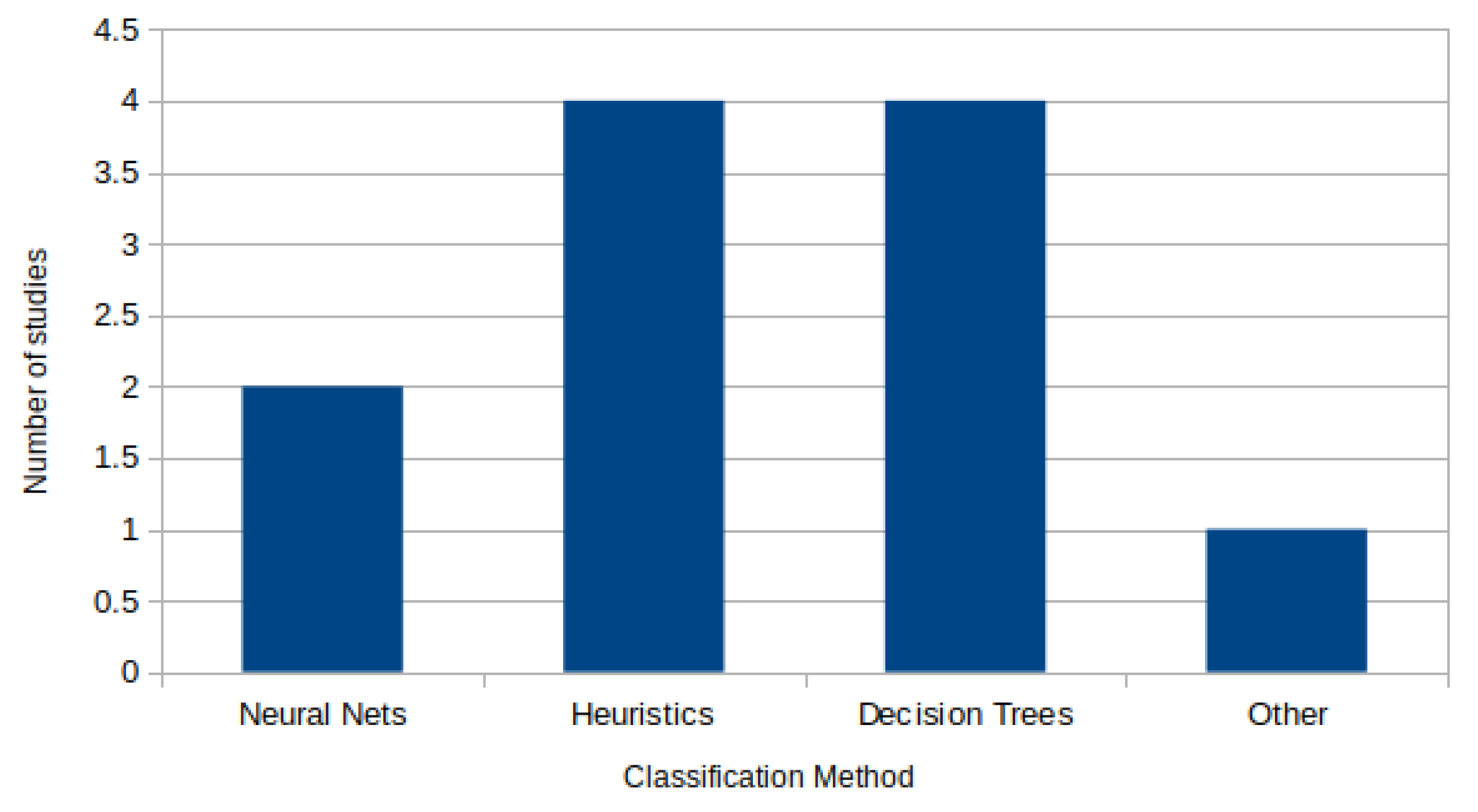
3.10. Classification Method
3.11. Classification Features
3.12. Classification Performance
4. Discussion
5. Future Directions
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Goodchild, M. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Heipke, C. Crowdsourcing geospatial data. ISPRS J. Photogramm. Remote Sens. 2010, 65, 550–557. [Google Scholar] [CrossRef]
- Guo, B.; Yu, Z.; Zhang, D.; Zhou, X. From Participatory Sensing to Mobile Crowd Sensing. In Proceedings of the 2014 IEEE International Conference on Pervasive Computing and Communication Workshops (PERCOM WORKSHOPS), Budapest, Hungary, 24–28 March 2014. [Google Scholar]
- Lane, N.D.; Eisenman, S.B.; Musolesi, M.; Miluzzo, E.; Campbell, A.T. Urban Sensing Systems: Opportunistic or Participatory. In Proceedings of the ACM 9th Workshop on Mobile Computing Systems and Applications (HOTMOBILE ’08), Napa, CA, USA, 25–26 February 2008. [Google Scholar]
- Agamennoni, G.; Nieto, J.; Nebot, E. Mining GPS data for extracting significant places. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009. [Google Scholar]
- Zheng, Y.; Zhang, L.; Xie, X.; Ma, W.Y. Mining Interesting Locations and Travel Sequences from GPS Trajectories. In Proceedings of the 18th International Conference on World Wide Web (WWW ’09), Madrid, Spain, 20–24 April 2009. [Google Scholar]
- Li, J.; Qin, Q.; Han, J.; Tang, L.A.; Lei, K.H. Mining Trajectory Data and Geotagged Data in Social Media for Road Map Inference. Trans. GIS 2015, 19, 1–18. [Google Scholar] [CrossRef]
- Niehöfer, B.; Burda, R.; Wietfeld, C.; Bauer, F.; Lueert, O. GPS Community Map Generation for Enhanced Routing Methods Based on Trace-Collection by Mobile Phones. In Proceedings of the 2009 First International Conference on Advances in Satellite and Space Communications, Colmar, France, 20–25 July 2009. [Google Scholar]
- Mathur, S.; Jin, T.; Kasturirangan, N.; Chandrashekharan, J.; Xue, W.; Gruteser, M.; Trappe, W. ParkNet: Drive-by sensing of road-side parking statistics. In Proceedings of the 8th International Conference on Mobile Systems Applications and Services (MobiSys’10), San Francisco, CA, USA, 15–18 June 2010. [Google Scholar]
- Canepa, E.; Odat, E.; Dehwah, A.; Mousa, M.; Jiang, J.; Claudel, C. A Sensor Network Architecture for Urban Traffic State Estimation with Mixed Eulerian/Lagrangian Sensing Based on Distributed Computing. In Architecture of Computing Systems–ARCS 2014; Maehle, E., Römer, K., Karl, W., Tovar, E., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 147–158. [Google Scholar]
- Rana, R.; Chou, C.T.; Bulusu, N.; Kanhere, S.; Hu, W. Ear-Phone: A context-aware noise mapping using smart phones. Pervasive Mob. Comput. 2015, 17, 1–22. [Google Scholar] [CrossRef]
- Mohan, P.; Padmanabhan, V.N.; Ramjee, R. Nericell: Rich monitoring of road and traffic conditions using mobile smartphones. In Proceedings of the 6th International Conference on Embedded Networked Sensor Systems, SenSys 2008, Raleigh, NC, USA, 5–7 November 2008; pp. 323–336. [Google Scholar] [CrossRef]
- Ganti, R.K.; Pham, N.; Ahmadi, H.; Nangia, S.; Abdelzaher, T.F. GreenGPS: A Participatory Sensing Fuel-efficient Maps Application. In Proceedings of the 8th International Conference on Mobile Systems, Applications, and Services (MobiSys’10), San Francisco, CA, USA, 15–18 June 2010. [Google Scholar]
- Eriksson, J.; Girod, L.; Hull, B.; Newton, R.; Madden, S.; Balakrishnan, H. The Pothole Patrol: Using a Mobile Sensor Network for Road Surface Monitoring. In Proceedings of the 6th International Conference on Mobile Systems, Applications, and Services (MobiSys’08), Breckenridge, CO, USA, 17–20 June 2008. [Google Scholar]
- Sester, M.; Feuerhake, U.; Kuntzsch, C.; Zhang, L. Revealing Underlying Structure and Behaviour from Movement Data. KI-Künstliche Intell. 2012, 26, 223–231. [Google Scholar] [CrossRef]
- Guo, D. Mining Traffic Condition from Trajectories. In Proceedings of the Fifth International Conference on Fuzzy Systems and Knowledge Discovery (FSKD ’08), Jinan, China, 8–20 October 2008. [Google Scholar]
- Atev, S.; Masoud, O.; Papanikolopoulos, N. Learning Traffic Patterns at Intersections by Spectral Clustering of Motion Trajectories. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006. [Google Scholar]
- Tang, L.; Kan, Z.; Zhang, X.; Yang, X.; Huang, F.; Li, Q. Travel time estimation at intersections based on low-frequency spatial-temporal GPS trajectory big data. Cartogr. Geogr. Inf. Sci. 2016, 43, 417–426. [Google Scholar] [CrossRef]
- Spaccapietra, S.; Parent, C.; Damiani, M.L.; de Macedo, J.A.; Porto, F.; Vangenot, C. A Conceptual View on Trajectories. Data Knowl. Eng. 2008, 65, 126–146. [Google Scholar] [CrossRef]
- Alvares, L.O.; Bogorny, V.; Kuijpers, B.; de Macedo, J.A.F.; Moelans, B.; Vaisman, A. A Model for Enriching Trajectories with Semantic Geographical Information. In Proceedings of the 15th Annual ACM International Symposium on Advances in Geographic Information Systems (GIS ’07), Seattle, WA, USA, 7–9 November 2007. [Google Scholar]
- Alvares, L.O.; Oliveira, G.; Heuser, C.A.; Bogorny, V. A Framework for Trajectory Data Preprocessing for Data Mining. In Proceedings of the 21st International Conference on Software Engineering & Knowledge Engineering (SEKE’2009), Boston, MA, USA, 1–3 July 2009. [Google Scholar]
- Palma, A.T.; Bogorny, V.; Kuijpers, B.; Alvares, L.O. A Clustering-based Approach for Discovering Interesting Places in Trajectories. In Proceedings of the 2008 ACM Symposium on Applied Computing (SAC ’08), Fortaleza, Ceara, Brazil, 16–20 March 2008. [Google Scholar]
- Spinsanti, L.; Celli, F.; Renso, C. Where You Stop Is Who You Are: Understanding People’s Activities by Places Visited. In Proceedings of the Behaviour Monitoring and Interpretation (BMI’10), Karlsruhe, Germany, 21 September 2010. [Google Scholar]
- Phithakkitnukoon, S.; Horanont, T.; Di Lorenzo, G.; Shibasaki, R.; Ratti, C. Activity-aware map: Identifying human daily activity pattern using mobile phone data. In Human Behavior Understanding: First International Workshop, HBU 2010, Istanbul, Turkey, August 22, 2010. Proceedings; Springer: Berlin/Heidelberg, Germany, 2010; pp. 14–25. [Google Scholar] [CrossRef]
- Gong, L.; Liu, X.; Wu, L.; Liu, Y. Inferring trip purposes and uncovering travel patterns from taxi trajectory data. Cartogr. Geogr. Inf. Sci. 2016, 43, 103–114. [Google Scholar] [CrossRef]
- Dang, V.C.; Kubo, M.; Sato, H.; Yamaguchi, A.; Namatame, A. A simple braking model for detecting incidents locations by smartphones. In Proceedings of the 2014 Seventh IEEE Symposium on Computational Intelligence for Security and Defense Applications (CISDA), Cau Giay, Vietnam, 14–17 December 2014. [Google Scholar]
- Laureshyn, A.; ÅStrÖM, K.; Brundell-Freij, K. From Speed Profile Data to Analysis of Behavior Classification by Pattern Recognition Techniques. {IATSS} Res. 2009, 33, 88–98. [Google Scholar] [CrossRef]
- Jiang, F.; Tsaftaris, S.; Wu, Y.; Katsaggelos, A. Detecting Anomalous Trajectories from Highway Traffic Data. 2009. Available online: http://www.ccitt.northwestern.edu/documents/2009.Jiang_Tsaftaris_Wu_Katsaggelos_pub.pdf (accessed on 5 December 2015).
- Huang, H.; Zhang, L.; Sester, M. A Recursive Bayesian Filter for Anomalous Behavior Detection in Trajectory Data. In Connecting a Digital Europe Through Location and Place; Huerta, J., Schade, S., Granell, C., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 91–104. [Google Scholar] [CrossRef]
- Mapscape. Incremental Updating. Available online: http://www.mapscape.eu/telematics/incremental-updating.html (accessed on 14 August 2019).
- Davies, J.J.; Beresford, A.R.; Hopper, A. Scalable, Distributed, Real-Time Map Generation. IEEE Pervasive Comput. 2006, 5, 47–54. [Google Scholar] [CrossRef]
- Cao, L.; Krumm, J. From GPS Traces to a Routable Road Map. In Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (GIS’09), Seattle, WA, USA, 4–6 November 2009. [Google Scholar]
- Karagiorgou, S.; Pfoser, D. On vehicle tracking data-based road network generation. In Proceedings of the 20th International Conference on Advances in Geographic Information Systems (SIGSPATIAL’12), Redondo Beach, CA, USA, 7–9 November 2012. [Google Scholar]
- Mariescu-Istodor, R.; Fränti, P. CellNet: Inferring Road Networks from GPS Trajectories. ACM Trans. Spat. Algorithms Syst. 2018, 4, 8:1–8:22. [Google Scholar] [CrossRef]
- Ni, Z.; Xie, L.; Xie, T.; Shi, B.; Zheng, Y. Incremental Road Network Generation Based on Vehicle Trajectories. ISPRS Int. J. Geo-Inf. 2018, 7, 382. [Google Scholar] [CrossRef]
- Fathi, A.; Krumm, J. Detecting Road Intersections from GPS Traces. In Geographic Information Science; Lecture Notes in Computer Science; Fabrikant, S., Reichenbacher, T., van Kreveld, M., Schlieder, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6292, pp. 56–69. [Google Scholar] [CrossRef]
- Wu, J.; Zhu, Y.; Ku, T.; Wang, L. Detecting Road Intersections from Coarse-gained GPS Traces Based on Clustering. J. Comput. 2013, 8. [Google Scholar] [CrossRef]
- Zourlidou, S.; Sester, M. Intersection detection based on qualitative spatial reasoning on stopping point clusters. In Proceedings of the 23rd International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences Congress, ISPRS 2016, Prague, Czech Republic, 12–19 July 2016. [Google Scholar]
- Wang, C.; Hao, P.; Wu, G.; Qi, X.; Lyu, T.; Barth, M. Intersection and Stop Bar Position Extraction from Crowdsourced GPS Trajectories. In Proceedings of the Transportation Research Board 96th Annual Meeting, Washington, DC, USA, 8–12 January 2017. [Google Scholar]
- Krisp, J.M.; Keler, A. Car navigation—Computing routes that avoid complicated crossings. Int. J. Geogr. Inf. Sci. 2015, 1–13. [Google Scholar] [CrossRef]
- Zourlidou, S.; Sester, M. Towards regulation-aware navigation: A behavior-based mapping approach. In Proceedings of the 18th AGILE Conference on Geographic Information Science, Lisbon, Portugal, 9–12 June 2015. [Google Scholar]
- Armand, A.; Filliat, D.; Ibanez-Guzman, J. Detection of Unusual Behaviours for Estimation of Context Awareness at Road Intersections. In Proceedings of the 5th Workshop on Planning, Perception and Navigation for Intelligent Vehicles, Tokio, Japan, 3 November 2013. [Google Scholar]
- Armand, A.; Filliat, D.; Ibañez-Guzmán, J. Modelling stop intersection approaches using Gaussian processes. In Proceedings of the 16th International IEEE Conference on Intelligent Transportation Systems (ITSC 2013), The Hague, The Netherlands, 6–9 October 2013. [Google Scholar]
- Lefèvre, S.; Laugier, C.; Ibañez-Guzmán, J. Risk assessment at road intersections: Comparing intention and expectation. In Proceedings of the 2012 IEEE Intelligent Vehicles Symposium (IV), Madrid, Spain, 3–7 June 2012. [Google Scholar]
- Lefevre, S.; Laugier, C.; Ibanez-Guzman, J.; Bessiere, P. Modelling Dynamic Scenes at Unsignalised Road Intersections. Inria Research Report RR-7604. 2011. Available online: https://hal.inria.fr/inria-00588758/document (accessed on 25 October 2019).
- Here Road Signs. 2019. Available online: https://www.here.com/ (accessed on 30 September 2019).
- CireşAn, D.; Meier, U.; Masci, J.; Schmidhuber, J. Multi-column deep neural network for traffic sign classification. Neural Netw. 2012, 32, 333–338. [Google Scholar] [CrossRef] [PubMed]
- Chigorin, A.; Konushin, A. A system for large-scale automatic traffic sign recognition and mapping. In Proceedings of the ISPRS Annals of Photogrammetry, Remote Sensing and Spatial Information Sciences, Antalya, Turkey, 12–13 November 2013. [Google Scholar]
- Madeira, S.R.; Bastos, L.C.; Sousa, A.M.; Sobral, J.F.; Santos, L.P. Automatic Traffic Signs Inventory Using a Mobile Mapping System for GIS Applications. 2004. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.96.598 (accessed on 25 October 2019).
- Reisi Gahrooei, M.; Work, D.B. Inferring Traffic Signal Phases From Turning Movement Counters Using Hidden Markov Models. IEEE Trans. Intell. Transp. Syst. 2015, 16, 91–101. [Google Scholar] [CrossRef]
- Protschky, V.; Ruhhammer, C.; Feit, S. Learning Traffic Light Parameters with Floating Car Data. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, Gran Canaria, Spain, 15–18 September 2015. [Google Scholar]
- Carisi, R.; Giordano, E.; Pau, G.; Gerla, M. Enhancing in vehicle digital maps via GPS crowdsourcing. In Proceedings of the 2011 Eighth International Conference on Wireless On-Demand Network Systems and Services (WONS), Bardonecchia, Italy, 26–28 January 2011. [Google Scholar]
- Unrau, R.; Kray, C. Usability evaluation for geographic information systems: A systematic literature review. Int. J. Geogr. Inf. Sci. 2019, 33, 645–665. [Google Scholar] [CrossRef]
- Klonner, C.; Marx, S.; Usón, T.; de Albuquerque, J.P.; Höfle, B. Volunteered Geographic Information in Natural Hazard Analysis: A Systematic Literature Review of Current Approaches with a Focus on Preparedness and Mitigation. ISPRS Int. J. Geo-Inf. 2016, 5, 103. [Google Scholar] [CrossRef]
- Steiger, E.; De Albuquerque, J.; Zipf, A. An Advanced Systematic Literature Review on Spatiotemporal Analyses of Twitter Data. Trans. GIS 2015, 19. [Google Scholar] [CrossRef]
- Dos Santos Rocha, R.; Degrossi, L.C.; de Albuquerque, J.P. A Systematic Literature Review of Geospatial Web Service Composition. In Proceedings of the 12th Workshop on Experimental Software Engineering (ESELAW), Lima, Peru, 22–24 April 2015. [Google Scholar]
- Torraco, R.J. Writing Integrative Literature Reviews: Guidelines and Examples. Hum. Resour. Dev. Rev. 2005, 4, 356–367. [Google Scholar] [CrossRef]
- Randolph, J.J. A guide to writing the dissertation literature review. Pract. Assess. Res. Eval. 2009, 14, 1–13. [Google Scholar]
- Green, B.N.; Johnson, C.D.; Adams, A. Writing narrative literature reviews for peer-reviewed journals: secrets of the trade. J. Chiropr. Med. 2006, 5, 101–117. [Google Scholar] [CrossRef]
- Xiao, Y.; Watson, M. Guidance on Conducting a Systematic Literature Review. J. Plan. Educ. Res. 2019, 39, 93–112. [Google Scholar] [CrossRef]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.; Group, T.P. Preferred Reporting Items for Systematic Reviews and Meta-Analyses: The PRISMA Statement. PLoS Med. 2009, 6, 1–6. [Google Scholar] [CrossRef]
- Scopus. 2019. Available online: https://www.scopus.com (accessed on 1 July 2019).
- Web od Science. 2019. Available online: https://www.webofknowledge.com (accessed on 1 July 2019).
- Greenhalgh, T.; Peacock, R. Effectiveness and efficiency of search methods in systematic reviews of complex evidence: Audit of primary sources. BMJ 2005, 331, 1064–1065. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, J.; Tang, J.; Liu, B. You Take Care of the Drive, I Take Care of the Rule: A Traffic-Rule Awareness System Using Vehicular Sensors and Mobile Phones. Int. J. Distrib. Sens. Netw. 2012, 8, 319276. [Google Scholar] [CrossRef]
- Mozas-Calvache, A.T. Analysis of behaviour of vehicles using VGI data. Int. J. Geogr. Inf. Sci. 2016, 1–20. [Google Scholar] [CrossRef]
- Marginean, A.; Petrovai, A.; Slavescu, R.R.; Negru, M.; Nedevschi, S. Enhancing digital maps to support reasoning on traffic sign compliance. In Proceedings of the 2016 IEEE 12th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 8–10 September 2016. [Google Scholar]
- Yun, M.; Ji, J. Delay Analysis of Stop Sign Intersection and Yield Sign Intersection based on VISSIM. Procedia Soc. Behav. Sci. 2013, 96, 2024–2031. [Google Scholar] [CrossRef][Green Version]
- Kuntzsch, C.; Zourlidou, S.; Feuerhake, U. Learning the Traffic Regulation Context of Intersections from Speed Profile Data. In Proceedings of the GIScience 2016 Workshop on Analysis of Movement Data (AMD’16), Montreal, QC, Canada, 27 September 2016. [Google Scholar]
- Wang, D.; Abdelzaher, T.; Kaplan, L.; Ganti, R.; Hu, S.; Liu, H. Exploitation of Physical Constraints for Reliable Social Sensing. In Proceedings of the 2013 IEEE 34th Real-Time Systems Symposium (RTSS), Vancouver, BC, Canada, 3–6 December 2013. [Google Scholar]
- Hu, S.; Su, L.; Liu, H.; Wang, H.; Abdelzaher, T. Poster Abstract: SmartRoad: A Crowd-sourced Traffic Regulator Detection and Identification System. In Proceedings of the 12th International Conference on Information Processing in Sensor Networks (IPSN ’13), Philadelphia, PA, USA, 8–11 April 2013. [Google Scholar]
- Aly, H.; Basalamah, A.; Youssef, M. Map++: A crowd-sensing system for automatic map semantics identification. In Proceedings of the 2014 Eleventh Annual IEEE International Conference on Sensing, Communication, and Networking (SECON), Singapore, 30 June–3 July 2014. [Google Scholar]
- Efentakis, A.; Brakatsoulas, S.; Grivas, N.; Pfoser, D. Crowdsourcing turning restrictions for OpenStreetMap. In Proceedings of the Workshop Pro-ceedings of the EDBT/ICDT 2014 Joint Conference, Athens, Greece, 28 March 2014. [Google Scholar]
- Pribe, C.A.; Rogers, S.O. Learning To Associate Observed Driver Behavior with Traffic Controls. Transp. Res. Rec. J. Transp. Res. Board 1999, 1679, 95–100. [Google Scholar] [CrossRef]
- Hu, S.; Su, L.; Liu, H.; Wang, H.; Abdelzaher, T.F. SmartRoad: Smartphone-Based Crowd Sensing for Traffic Regulator Detection and Identification. ACM Trans. Sen. Netw. 2015, 11, 55:1–55:27. [Google Scholar] [CrossRef]
- Saremi, F.; Abdelzaher, T. Combining Map-Based Inference and Crowd-Sensing for Detecting Traffic Regulators. In Proceedings of the 2015 IEEE 12th International Conference on Mobile Ad Hoc and Sensor Systems (MASS), Dallas, TX, USA, 19–22 October 2015. [Google Scholar]
- Aly, H.; Basalamah, A.; Youssef, M. Automatic Rich Map Semantics Identification Through Smartphone-Based Crowd-Sensing. IEEE Trans. Mob. Comput. 2017, 16, 2712–2725. [Google Scholar] [CrossRef]
- Efentakis, A.; Grivas, N.; Pfoser, D.; Vassiliou, Y. Crowdsourcing turning-restrictions from map-matched trajectories. Inf. Syst. 2017, 64, 221–236. [Google Scholar] [CrossRef]
- Wang, J.; Wang, C.; Song, X.; Raghavan, V. Automatic intersection and traffic rule detection by mining motor vehicle {GPS} trajectories. Comput. Environ. Urban Syst. 2017, 64, 19–29. [Google Scholar] [CrossRef]
- Méneroux, Y.; Kanasugi, H.; Pierre, G.S.; Guilcher, A.L.; Mustière, S.; Shibasaki, R.; Kato, Y. Detection and Localization of Traffic Signals with GPS Floating Car Data and Random Forest. In Proceedings of the 10th International Conference on Geographic Information Science (GIScience 2018), Melbourne, Australia, 28–31 August 2018. [Google Scholar]
- Munoz-Organero, M.; Ruiz-Blaquez, R.; Sánchez-Fernández, L. Automatic detection of traffic lights, street crossings and urban roundabouts combining outlier detection and deep learning classification techniques based on GPS traces while driving. Comput. Environ. Urban Syst. 2018, 68, 1–8. [Google Scholar] [CrossRef]
- Qiu, H.; Chen, J.; Jain, S.; Jiang, Y.; McCartney, M.; Kar, G.; Bai, F.; Grimm, D.K.; Gruteser, M.; Govindan, R. Towards Robust Vehicular Context Sensing. IEEE Trans. Veh. Technol. 2018, 67, 1909–1922. [Google Scholar] [CrossRef]
- Zourlidou, S.; Fischer, C.; Sester, M. Classification of street junctions according to traffic regulators. In Proceedings of the 22nd AGILE Conference on Geo-Information Science, Limassol, Cyprus, 17–20 June 2019. [Google Scholar]
- Mapillary. Mapillary: A Street-Level Imagery Platform. 2019. Available online: https://www.mapillary.com/ (accessed on 30 September 2019).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SLR Research Questions | |
|---|---|
| What | What traffic regulators have been detected and recognised based on crowdsourced non-image data? |
| How | What methods have been used for this purpose? Under what settings the methods have been tested? (dataset, participants, ground truth map )? |
| How well | What is the performance of these methods? |
| Other | Are there any under-explored aspects of the topic? |
| Source | URL | Step 1 | Step 2 (Title) | Step 3 (Abstract) | Step 4 (Full-text) | Step 5 (Author) |
|---|---|---|---|---|---|---|
| Scopus | https://www.scopus.com/ | 603 | 171 | 36 | 8 | 6 |
| Web of Science | https://apps.webofknowledge.com/ | 326 | 57 | 9 | 6 | 4 |
| Total | 929 | 228 | 45 | 14 | 10 |
| Query Terms | |
|---|---|
| traffic regulator * | traffic rule * |
| traffic restriction * | turning restriction * |
| crowdsourc * traffic | crowdsens * traffic |
| intersection classification | intersection regulation |
| intersection control * | intersection regulat * |
| junction control * | junction regulat * |
| junction regulat * | junction classification |
| traffic sign * | GPS |
| Search Query String |
|---|
| TITLE (“traffic regulator *” OR (“traffic rule *”) OR (“traffic restriction *”) OR (“turning restriction *”) OR (“crowdsourc * traffic”) OR (“crowdsens * traffic”) OR (“intersection classification”) OR (“intersection regulation”) OR (“intersection control *”) OR (“intersection regulat *”) OR (“junction control *”) OR (“junction regulat *”) OR (“junction regulat *”) OR (“junction classification”) ) OR TITLE-ABS-KEY (“traffic sign *” AND “GPS”) |
| Incl1 | The article is relevant with the detection and recognition of traffic regulators using non imagery crowdsourced gps tracks. |
| Incl2 | The article describes in a clear way the objectives, methods and results of the research. |
| Incl3 | The article is the most recent work of an author that has written earlier a short paper or a similar article on exactly the same topic, decribing the same method. |
| Excl1 | The article refers to a computer-vision based traffic-regulator detection approach, e.g., detection based on camera or satellite image. |
| Excl2 | The article lacks of clarity in depicting its objectives, methods and results or\and it mentions the applicability of their method on SLR’s objective but it does not report any results on that. |
| Excl3 | Authors have published a more detailed or advanced article on the same topic with the same objective and method. |
| Dimensions | Description |
|---|---|
| Regulator category | Regulators for which a detection methodology is proposed |
| Number of regulators | Diversion of regulator categories |
| Study area | Country, City |
| Participants | Number of participants whose data are crowdsourced |
| Dataset type | Publicly available dataset or not |
| Dataset size | Size of crowdsourced data |
| Dataset timespan | Time range of the dataset used in the study |
| Ground truth map source | Acquisition method of ground truth map (on-site inspection, official public or non-public provider) |
| Cross-city testing | Results from cross-city testing are provided in the study or not |
| Minimum number of samples | Minimum number of crossings per junction needed for sufficient classification performance |
| Classification method | Classification methods that were used for learning to detect and recognise regulators |
| Classification features | Features used for classification |
| Classification Accuracy | Classifier’s accuracy (best performance) |
| Eligibility Processing Steps after Full-Text Reading | Articles |
|---|---|
| Articles after full-text reading | 10 |
| After duplicate exclusion | 6 |
| After adding from other sources | 7 |
| After Backward-Forward Search | 11 |
| Final | 11 |
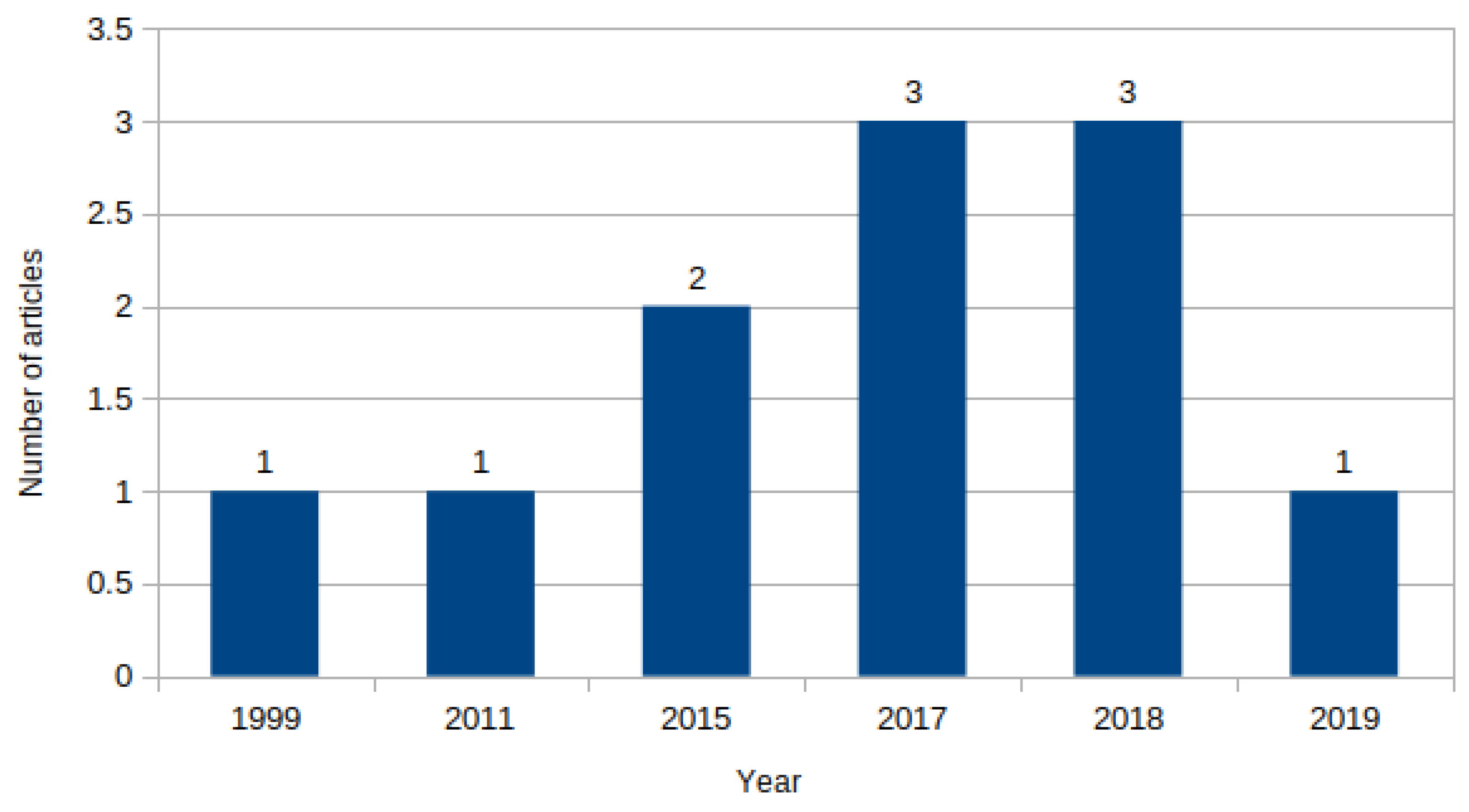
| a/a | Reference | Author(s) | Title of the Article | Type | Year | Classified Regulator |
|---|---|---|---|---|---|---|
| 1 | [74] | Pribe & Rogers | Learning To Associate Observed Driver Behavior with Traffic Controls | Journal | 1999 | Stop-Signs, Traffic-Signals |
| 2 | [52] | Carisi et al. | Enhancing in Vehicle Digital Maps via GPS Crowdsourcing | Conference | 2011 | Stop-Signs, Traffic-Signals |
| 3 | [75] | Hu et al. | SmartRoad: Smartphone-Based Crowd Sensing for Traffic Regulator Detection and Identification | Journal | 2015 | Stop-Signs, Traffic-Signals, Uncontrolled |
| 4 | [76] | Seremi & Abdelzahe | Combining Map-Based Inference and Crowd-Sensing for Detecting Traffic Regulators | Conference | 2015 | Stops, Traffic-Signals |
| 5 | [77] | Aly et al. | Automatic Rich Map Semantics Identification Through Smartphone-Based Crowd-Sensing | Journal | 2017 | Stops, Traffic-Signals |
| 6 | [78] | Efentakis et al. | Crowdsourcing Turning Restrictions from Map-matched Trajectories | Journal | 2017 | Turning restrictions |
| 7 | [79] | Wang Chao et al. | Automatic Intersection and Traffic Rule Detection by Mining Motor Vehicle GPS Trajectories | Journal | 2017 | Traffic-Signals |
| 8 | [80] | Méneroux et al. | Detection and Localization of Traffic Signals with GPS Floating Car Data and Random Forest | Conference | 2018 | Traffic-Signals |
| 9 | [81] | Munoz-Organero et al. | Automatic Detection of Traffic Lights, Street Crossings and Urban Roundabouts Combining Outlier Detection and Deep Learning Classification Techniques Based on GPS Traces while Driving | Journal | 2018 | Traffic-Signals, Street Crossings, Roundabouts |
| 10 | [82] | Qiu et al. | Towards Robust Vehicular Context Sensing | Journal | 2018 | Stop-Signs |
| 11 | [83] | Zourlidou et al. | Classification of Street Junctions According to Traffic Regulators | Conference | 2019 | Traffic-Signals, Yied/Priority Junctions, Uncontrolled |
| Word | Occurrences | Frequency | Rank |
|---|---|---|---|
| traffic | 7 | 6.9% | 1 |
| sensing | 5 | 4.9% | 2 |
| detection | 5 | 4.9% | 2 |
| gps | 4 | 3.9% | 3 |
| based | 4 | 3.9% | 3 |
| automatic | 3 | 2.9% | 4 |
| map | 3 | 2.9% | 4 |
| crowd | 3 | 2.9% | 4 |
| vehicle | 2 | 2% | 5 |
| identification | 2 | 2% | 5 |
| regulators | 2 | 2% | 5 |
| street | 2 | 2% | 5 |
| trajectories | 2 | 2% | 5 |
| learning | 2 | 2% | 5 |
| smartphone | 2 | 2% | 5 |
| combining | 2 | 2% | 5 |
| classification | 2 | 2% | 5 |
| crowdsourcing | 2 | 2% | 5 |
| Ref. | Reg. Category | Reg. Diversity | Study Area ▽ | Particip. | Open Dataset | Dataset Size | Dataset Timespan | Ground Truth Map Source | Cross-city Test. | Min Samples | Classif. Method | Classif. Features | Classif. Perform. ⋄ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1. [74] | TL, SS, RW | 3 | US | - | No | 50 Reg. | - | Various | No | No | Neural Nets | Statist. | 100% |
| 2. [52] | TL, SS | 2 | US | - | Both | 32 Inter. | 3 Days | On site | Yes | Yes | Heuristics | Slowdowns, Standstills | >90% |
| 3. [75] | TL, SS, RW | 3 | US | 35 | No | 463 Reg. | 2 Mon. | On site | No | No | Random Forest, Spectral Clust. | Statist. | >90% |
| 4. [76] | TL, SS, RW | 3 | US | 46 | Both | >1K Inter. | - | Google Street Views | Yes | No | Random Forest | OSM, Statist. | >95% |
| 5. [77] | TL, SS | 2(9) | EG, SA, US | 5 | No | 24 km foot | - | On site | No | No | Heuristics | Dwell. Dur. | Optimal Prec., Rec.: 0.8 |
| 6. [78] | TR | 1(4) | GR, DE, AT | >2K | No | Mi./Bi. Turns | 1 Year | Various | Yes | No | Heuristics | %Turns | 66–77% |
| 7. [79] | TR | 1(12) | CN | 5 | No | 285 Inters. | - | On site | No | No | Clustering | Headings, Time-Series Points | - |
| 8. [80] | TL | 2 | JP | - | No | 253 TL Inter. | 1 Mon. | On site | No | No | Random Forest | Stop Dur. | >85% |
| 9. [81] | TL | 1(3) | ES, DE | 1/10 | Both | 8.1 km, 55 Traj/ 23.6 km, 20 TL | - | On site | No | No | Deep Belief Net. | Speed, Accel. | Rec.: 0.89, Prec.: 0.88 |
| 10. [82] | SS | 1(4) | - | 6 | No | 55 Int. | 9 Mon. | On site | No | No | Heurisitcs | Stop patterns | Rec.: 0.86, Prec.: 0.90 |
| 11. [83] | TL, PS-YS | 2 | DE | - | No | 31 Inter. | - | On site | No | No | C4.5 | Speed Seq. | Rec.: 0.83, Prec.: 0.31, F-score: 0.45 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zourlidou, S.; Sester, M. Traffic Regulator Detection and Identification from Crowdsourced Data—A Systematic Literature Review. ISPRS Int. J. Geo-Inf. 2019, 8, 491. https://doi.org/10.3390/ijgi8110491
Zourlidou S, Sester M. Traffic Regulator Detection and Identification from Crowdsourced Data—A Systematic Literature Review. ISPRS International Journal of Geo-Information. 2019; 8(11):491. https://doi.org/10.3390/ijgi8110491
Chicago/Turabian StyleZourlidou, Stefania, and Monika Sester. 2019. "Traffic Regulator Detection and Identification from Crowdsourced Data—A Systematic Literature Review" ISPRS International Journal of Geo-Information 8, no. 11: 491. https://doi.org/10.3390/ijgi8110491
APA StyleZourlidou, S., & Sester, M. (2019). Traffic Regulator Detection and Identification from Crowdsourced Data—A Systematic Literature Review. ISPRS International Journal of Geo-Information, 8(11), 491. https://doi.org/10.3390/ijgi8110491