The proposed CNN architecture is implemented via TensorFlow1.4.2. The experiments are conducted on a desktop PC with Windows 7 64-bit OS, Inter(R) Core(TM) i5-4460 CPU, 8 GB RAM and NVIDIA GeForce GTX 1070 8G GPU. Three benchmark datasets are used to evaluate the classification performance of the proposed method. This section introduces the datasets, provides details about the experimental design, and conducts analyses according to the experimental results.
4.2. Experimental Design
In this section, several comparative experiments are designed to evaluate the classification performance of the proposed method in HSI. The details of the experiments are as follows.
- (1)
Comparison of classification performances of proposed method under different parameter settings. Two comparisons are needed because different width expansion rates (g) and network depths lead to varying classification performances of the proposed method. ① The number of composite layers is denoted as nc_layer and set as 2, and the classification performances of the proposed method when the value of g is 8/20/32 are compared. ② g is set as 20, and the classification performances of the proposed method when the value of nc_layer is 2/4/8 are compared.
- (2)
Comparison with other methods. The classification performance of proposed method is compared with that of the deep learning method and non-deep learning method on the HSI.
In the training process, the training samples are divided into batches, and the number of samples per batch in our experiment is 64. For each epoch, the whole training set is learned by the proposed CNN. The total of epochs is 200 in each experiment. The Adam optimizer is applied to train the proposed CNN, and MSRA initialization method [
31] is used for weight initialization. The parameter of the Adam optimizer,
epsilon, is set as 1 ×10
−8. The initial learning rate for the Indian Pines dataset is 1 ×10
−2, which is reduced 10/100/200 times when epoch = 20/60/100, respectively. For the Salinas dataset and the Pavia University dataset, the initial learning rate is 1 ×10
−3, which is reduced 10/100/200 times when epoch = 40/100/150, respectively. If there is no special illustration, then all the parameters are set according to the aforementioned settings. These parameters may not be optimal, but at least effective for the proposed CNN.
Division of training set and test set. Generally, insufficient training samples will lead to serious overfitting of deep CNN models. However, the deep CNN model is equipped with strong feature extraction capacity due to its deep structure. Moreover, BN and MSRA initialization method are adopted for training the proposed CNN effectively, which improve the generalization performance of proposed CNN. Therefore, proposed method can extract deep features from small training samples set effectively. The limited available labeled pixels of HSI leads to insufficient training samples, which usually make it a challenge to improve the classification accuracy of the HSI. Considering this, to evaluate the effectiveness of proposed method under limited training samples, we randomly select 25% of samples in each HSI dataset for the training set, and the rest for the test set.
4.3. Experimental Results and Analyses
In this work, overall accuracy (OA), average accuracy (AA), and kappa coefficient (Kappa) are adopted to evaluate the classification performance of the proposed method in HSI data. Among them, OA refers to the ratio of the number of pixels correctly classified to the total number of all labeled pixels. AA is the average of classification accuracy of all classes. The Kappa coefficient is used to assess the agreement of classification for all the classes. The greater the kappa value, the better the overall classification effect. All the following data are the average of 10 experimental results under the same conditions to ensure the objectivity of the experimental results.
(1) Experimental Results in the Indian Pines Dataset
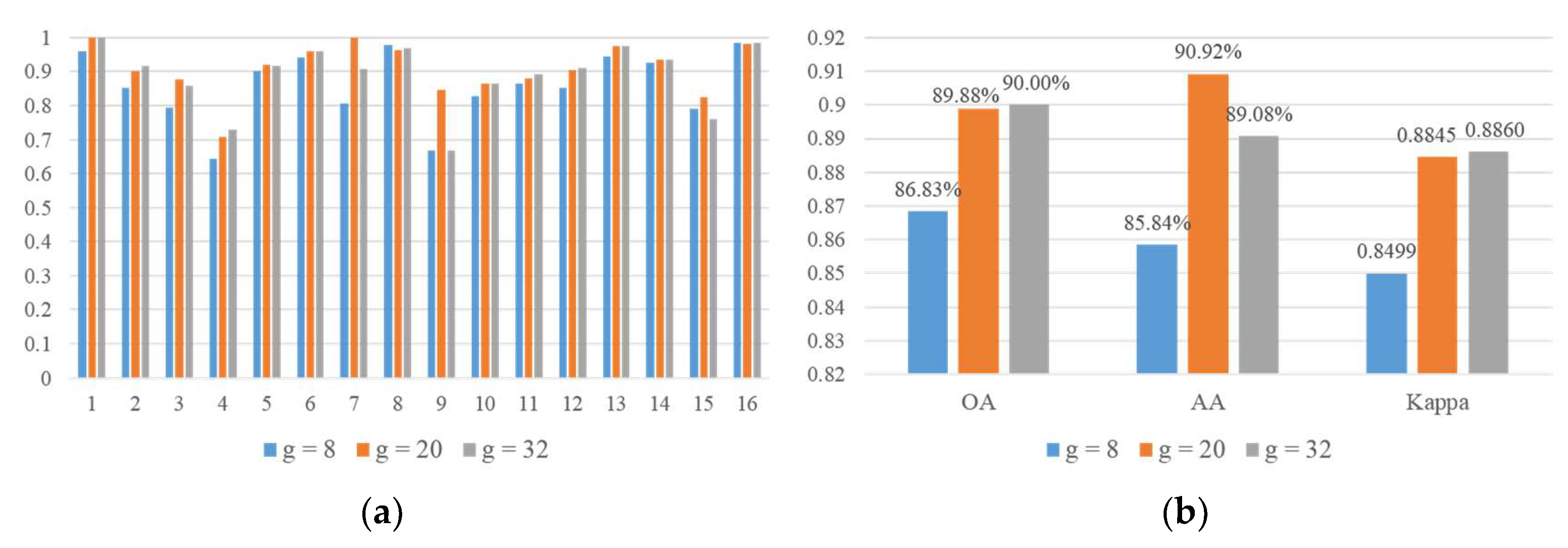
Classification performance of the proposed method under different width expansion rates:
Figure 12 displays the bar of the classification results when
nc_layer = 2 and
g = 8/20/32. According to
Figure 12, when the network depth is the same, the width of the network is increased gradually and the classification performance of the proposed method is improved gradually with the increase of width expansion rate (
g). However, the trend of this improvement gradually saturates. OA/AA/Kappa are increased by 3.05%/5.08%/0.0346, respectively, when
g is increased from 8 to 20. When
g is increased from 20 to 32, OA and Kappa are almost invariable and AA is slightly reduced. Within a certain range, the increase of network width can lead to improving the feature extraction of hyperspectral data, thus enhancing classification accuracy. However, this improvement has an upper limit. Widening the network width will certainly increase the computation of the network, thereby increasing the time consumed by classification. Therefore, the width of the network should be controlled when designing the HSI classification method.
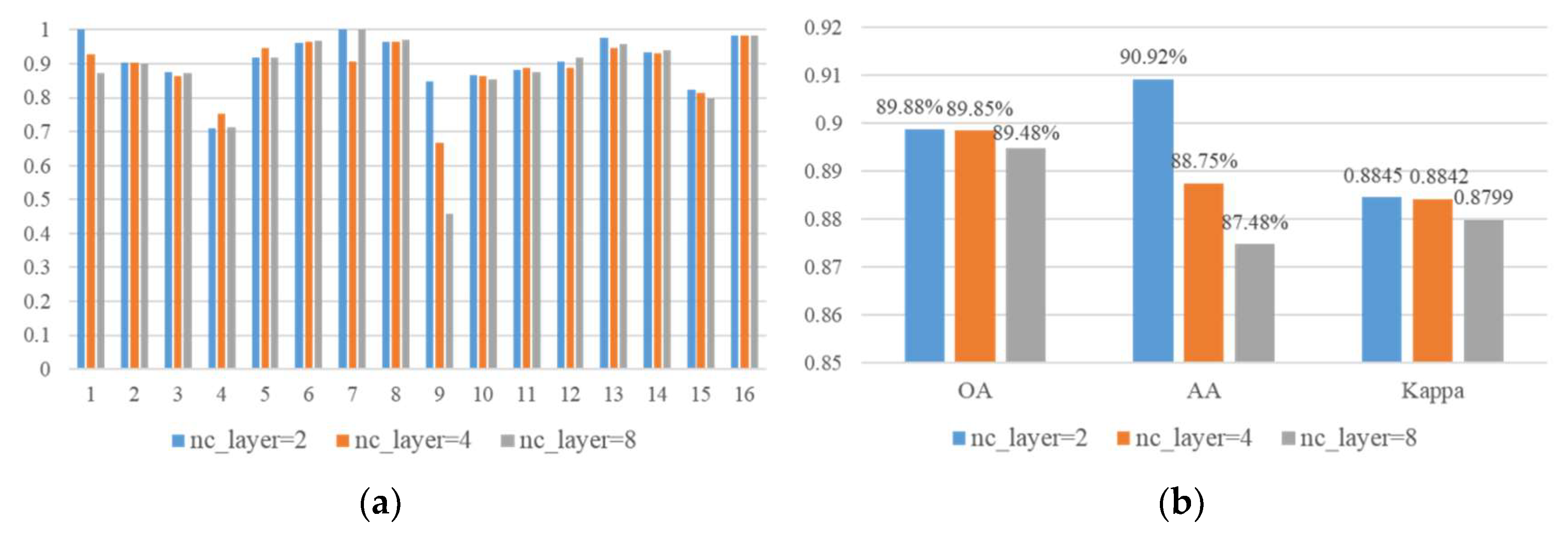
Classification performance of the proposed method under different number of composite layers.
Figure 13 displays the bar of classification results when
nc_layer = 2 and
g = 8/20/32. Increasing the number of composite layers cannot increase the classification accuracy of the proposed method when the width expansion rate remains the same. An increase in network depth will greatly increase the computation of the network and prolong the time for network training. Considering the large computation of hyperspectral data, the network depth should be controlled on the premise of ensuring high classification accuracy.
In summary, in terms of classification accuracy and speed, setting g = 20 and nc_layer = 2 is suitable.
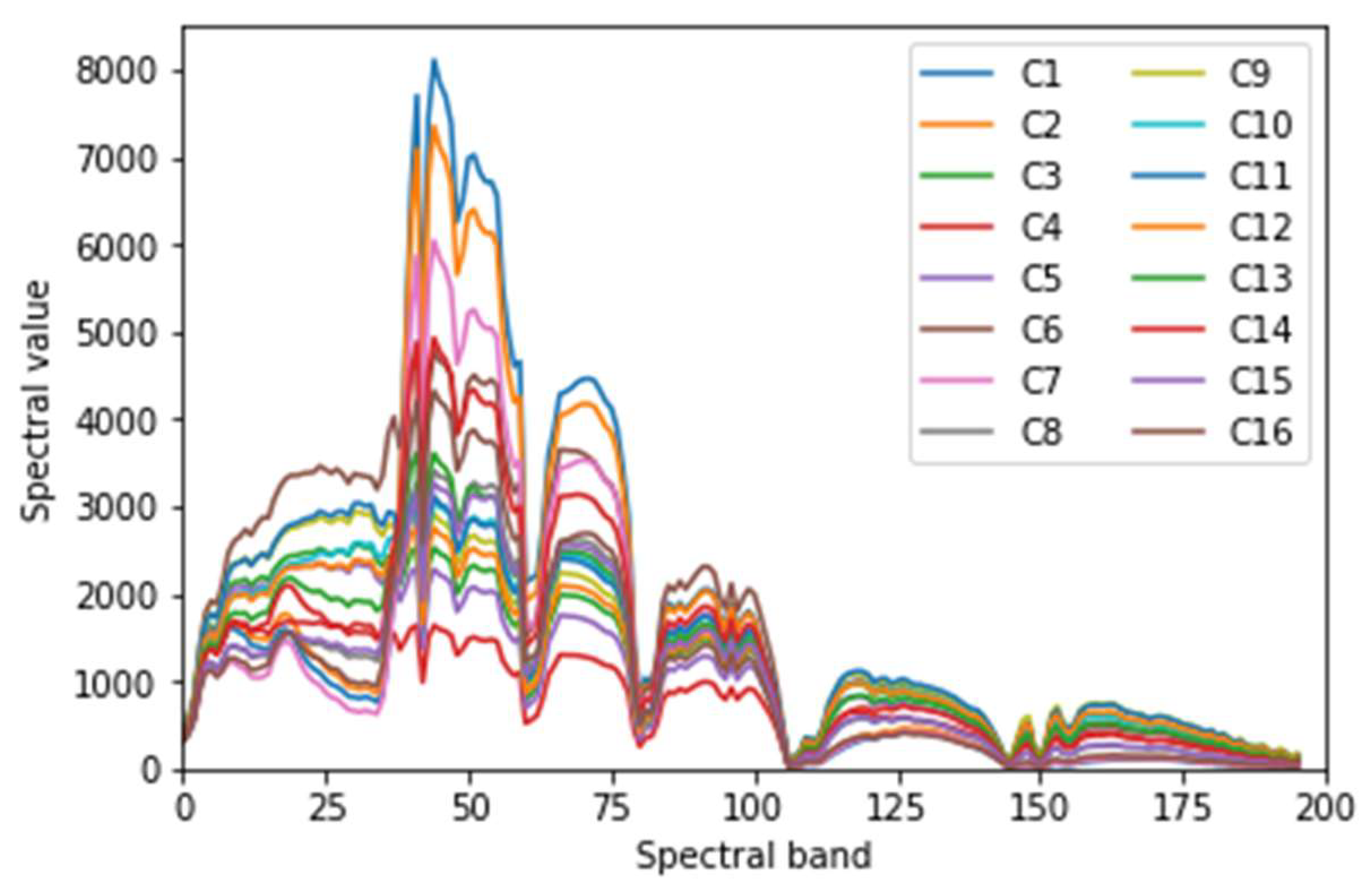
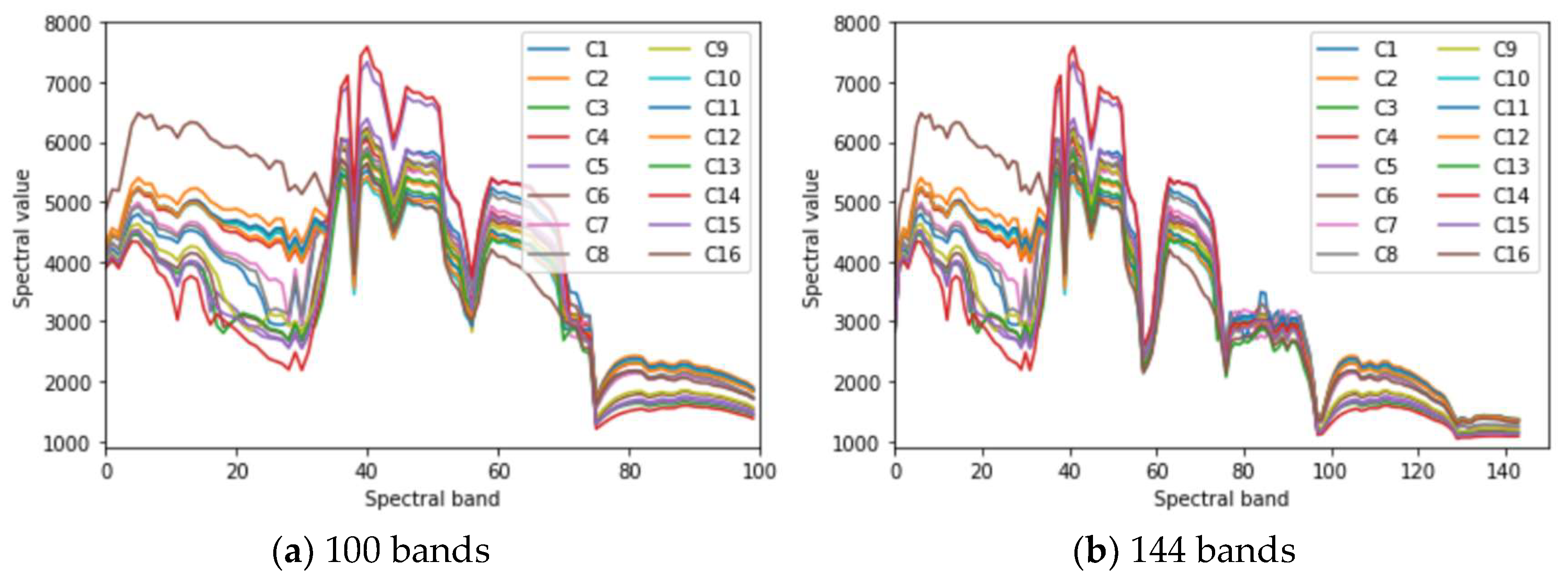
Impact of band number. As can be seen from
Figure 4, when the number of reserved bands is 196, many spectral curves still have serious aliasing at some bands, which is unfavorable for classification. In order to obtain the optimal number of reserved bands, the classification results of 100, 144 and 196 bands under
nc_layer = 2,
g = 20 are compared (
Table 4). According to
Figure 4 and
Figure 14, after removing more bands, the aliasing of spectral curves is much less, which enhances the inter class separability of Indian Pines data effectively. Unfortunately, and simultaneously, it also leads to the loss of much useful information. The enhancement of inter class separability bring benefits to the improvement of classification accuracy, while the loss of useful information cause damage to the improvement of classification accuracy. For the reason that the disadvantage outweighs the advantage, compared with 196-bands OA, 144-bands OA decreases by only 0.12%, and 100-bands OA decreases by 2.74% (see
Table 4). As a result, it is the best choice to reserve 196 bands.
(2) Experimental Results on the Salinas Dataset
The classification performance of the proposed method for the Salinas dataset under different width expansion rates or network depths.
Table 5 shows the classification results of the proposed method on the Salinas dataset when
nc_layer = 2 and
g = 8/20/32 and when
g = 20 and
nc_layer = 2/4/8. When
g is increased from 8 to 20 under the same network depth, OA/AA/Kappa increase by 1.19%/0.48%/0.0132, respectively. When
g is increased from 20 to 32, OA/AA/Kappa are nearly unchanged. The increase of network width can improve the classification performance of the proposed method in a certain range. If the width is sufficient, widening the network will not affect the classification capability of the proposed method. When the width expansion rate is the same, the classification accuracy is nearly unchanged with the increase of network depth. This phenomenon may be caused by the sufficiently large number of samples in the Salinas dataset, which is remarkably close to or may even reach the maximum capacity of the proposed method.
(3) Experimental Results on the Pavia University Dataset
To demonstrate the relationship between classification accuracies and inter-class separability,
Table 6 and
Table 7 display the details of the classification results for Pavia University data at
nc_layer = 2 and
g = 20. In
Table 6, the value in the
ith row,
jth column means the number of samples of the
jth class which is classified to the
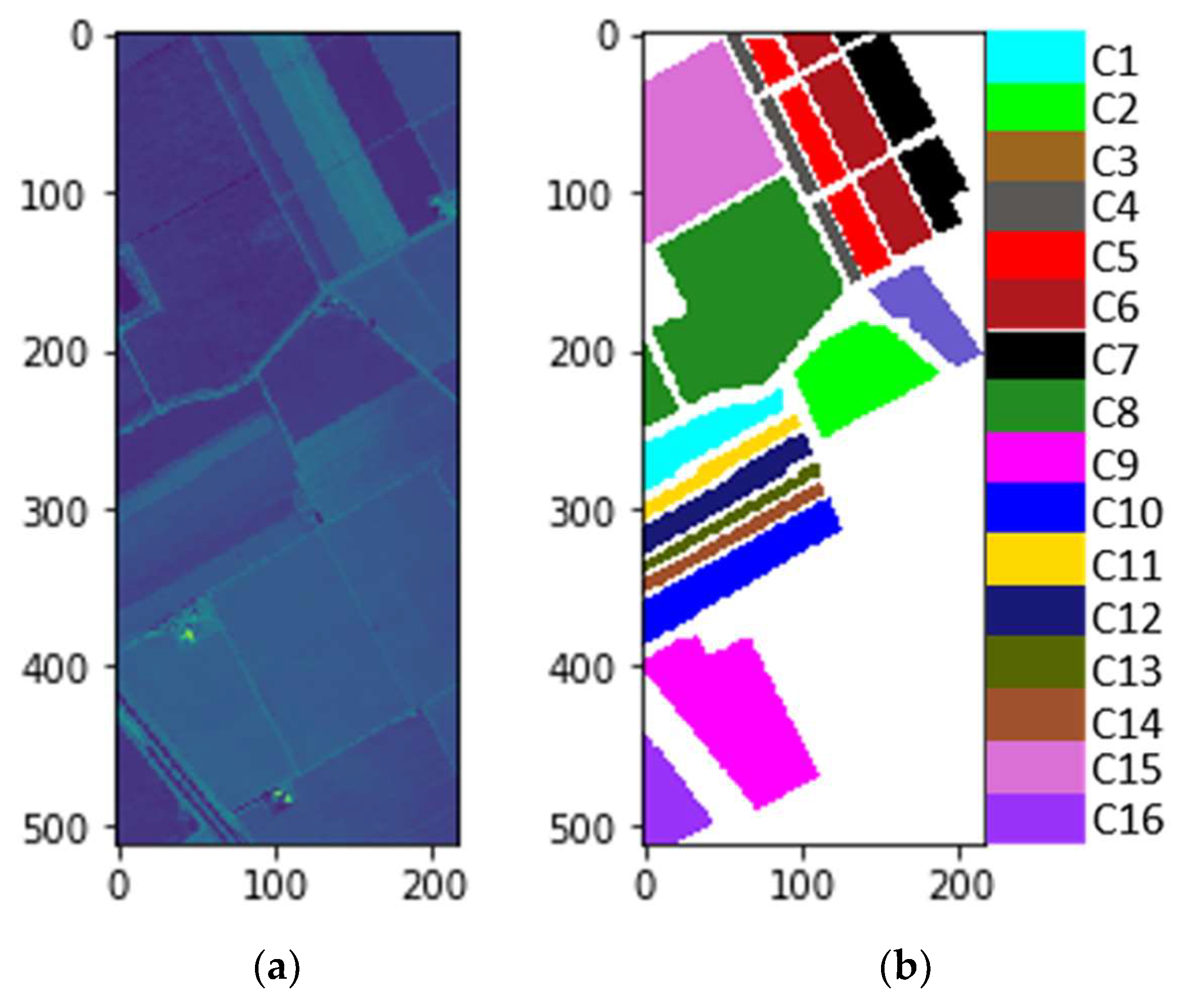
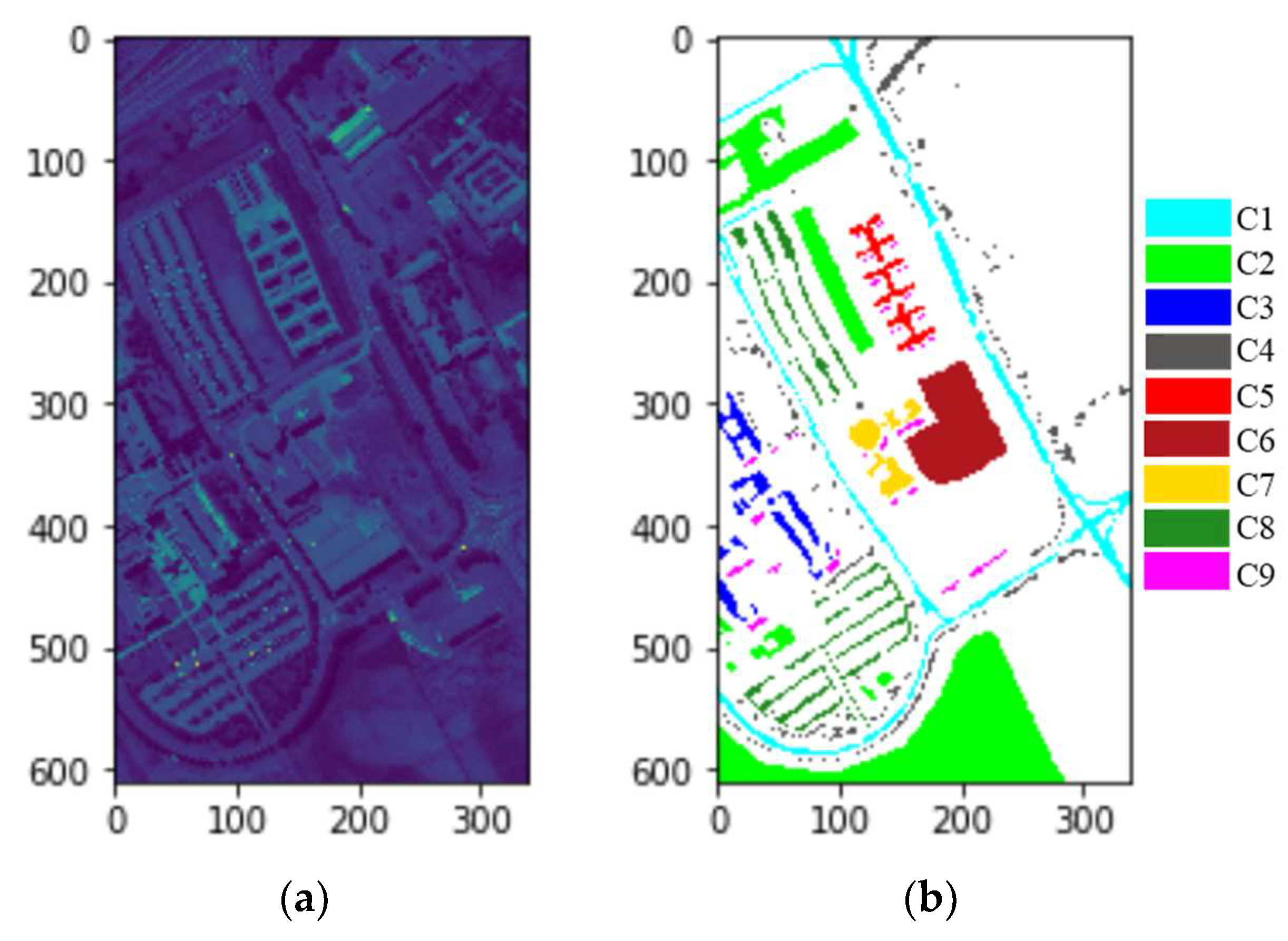
ith class. Each row represents the samples in a predicted class, and each class represents the samples in an actual class. The values on diagonal line means the number of samples which are classified correctly. Those values not on diagonal line means false positives or false negatives. For example, in the first row, 4790 samples of C1 are classified correctly, while 31 samples of C3 are misclassified into C1, which means false positives. In the seventh column, 887 samples of C7 are classified correctly, while 108 samples are misclassified into C1, which means false negatives.
In
Table 7, the value in the
ith row,
jth column means the percentage of the samples classified into the
ith class from the
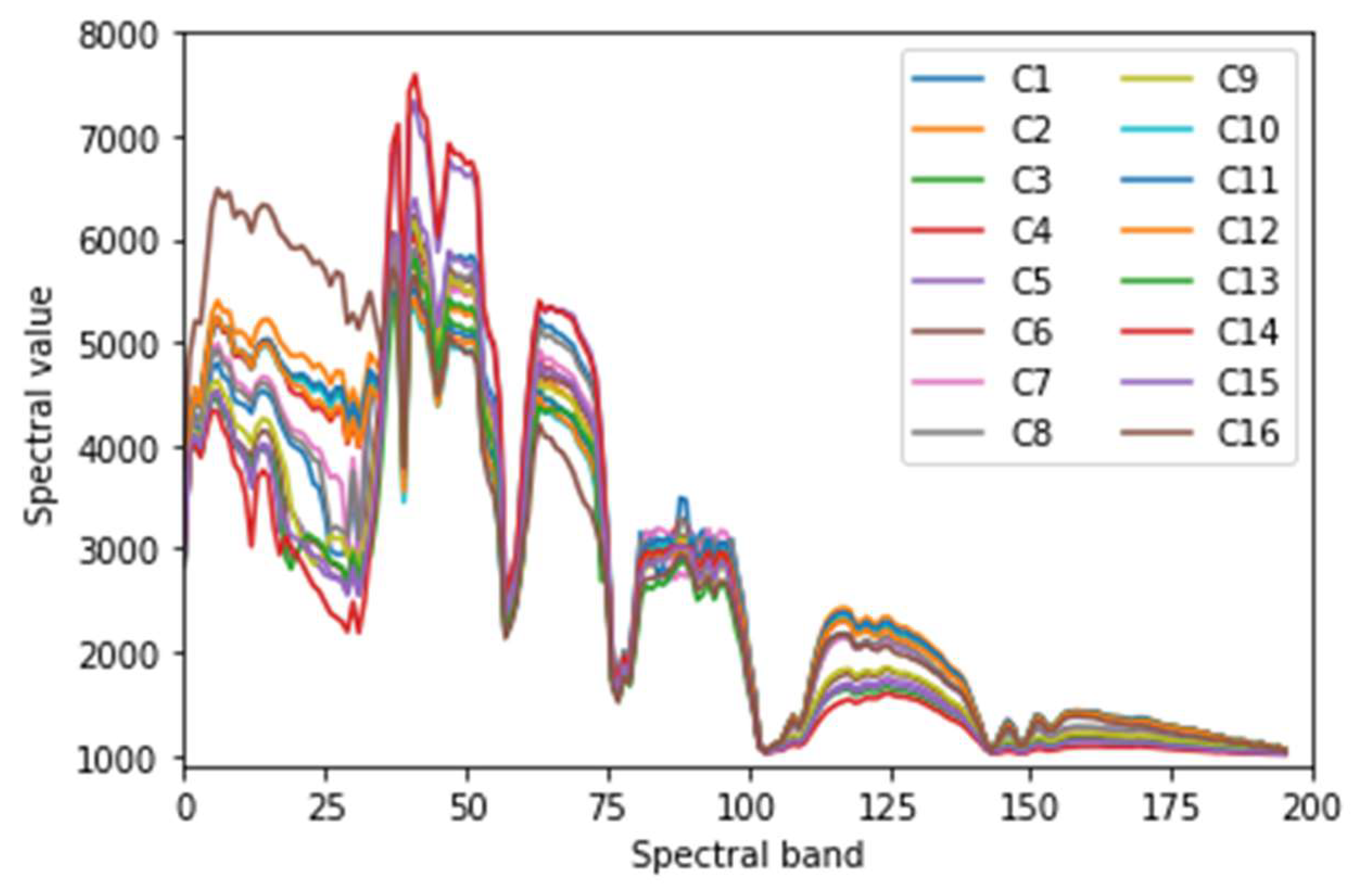
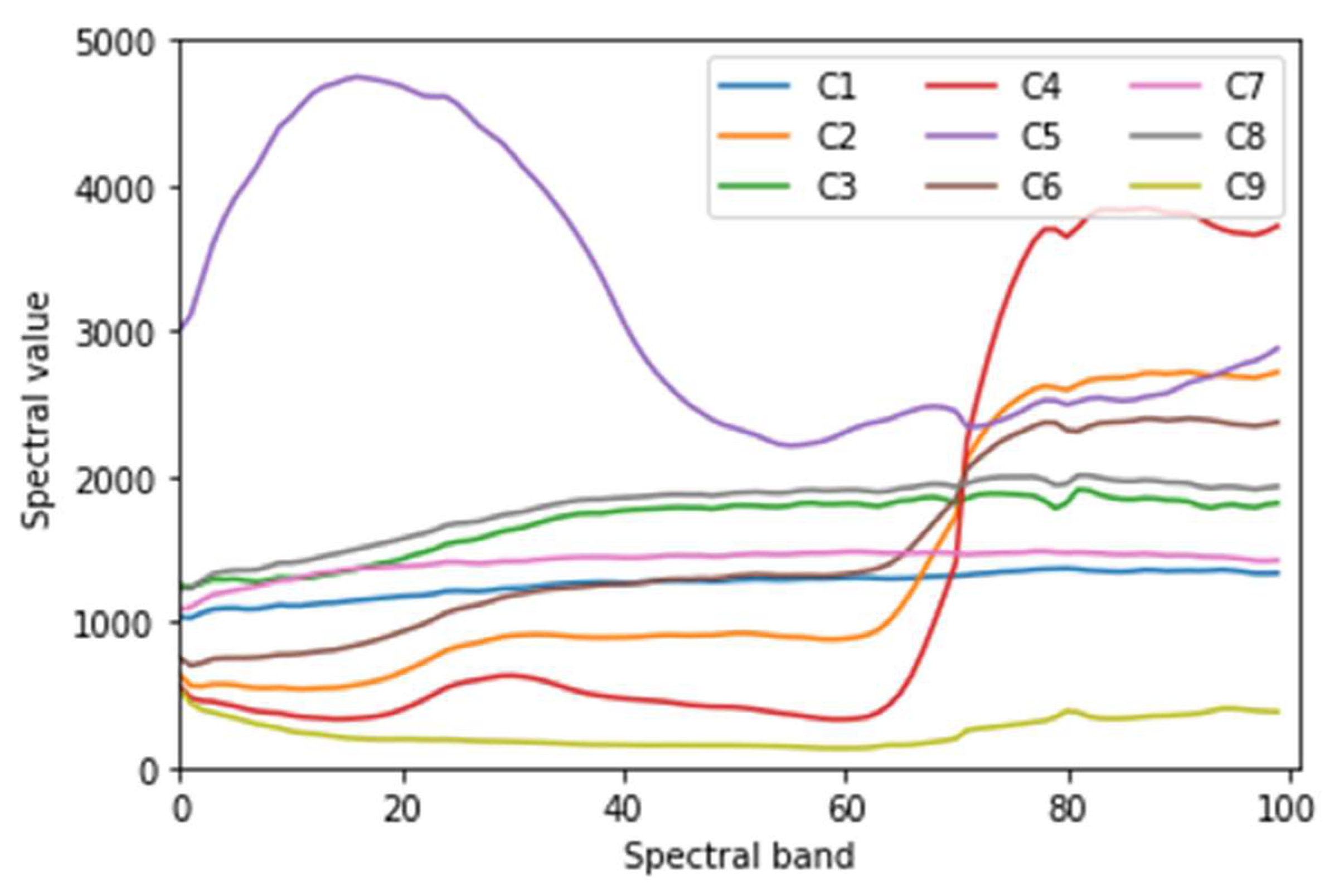
jth class. The values on diagonal line are just the classification accuracies of corresponding classes. For example, 93.37% of C7 samples are classified correctly, but 6.32% of the samples classified into C7 are from C1, which are misclassified. The smaller the difference of mean spectral curves, the smaller the difference among spectral feature maps from a different class, the worse the inter-class separability, the easier it is to cause misclassification. As shown in
Figure 12, the curves of C3 and C8 are very similar, that is, the difference between C3 and C8 is small. So, many samples (212) of C3 are misclassified into C8. Similarly, many samples (179) of C8 are misclassified into C3. In this way, it is not difficult to explain that the OA of proposed method is only 89.95% on the Indian Pines dataset, while 96.01% on the Salinas dataset and 96.15% on the Pavia University dataset. Because at many bands, there is serious aliasing in the spectral mean curves of the Indian Pines dataset (
Figure 4), which means poor inter-class separability. Therefore, there exist serious misclassification in some classes, resulting in the decline of overall classification accuracy for the Indian Pines dataset.
(4) Comparison with Other Methods
In order to further evaluate the effectiveness of the proposed method, we implement two classical CNN architectures, NIN and LeNet-5. We take
nc_layer = 2 and
g = 20, the architectures of which are shown in
Table 8. The classification results on three datasets are shown in
Table 9.
Table 10 displays the total run time for training and testing on the Indian Pines dataset classification, respectively.
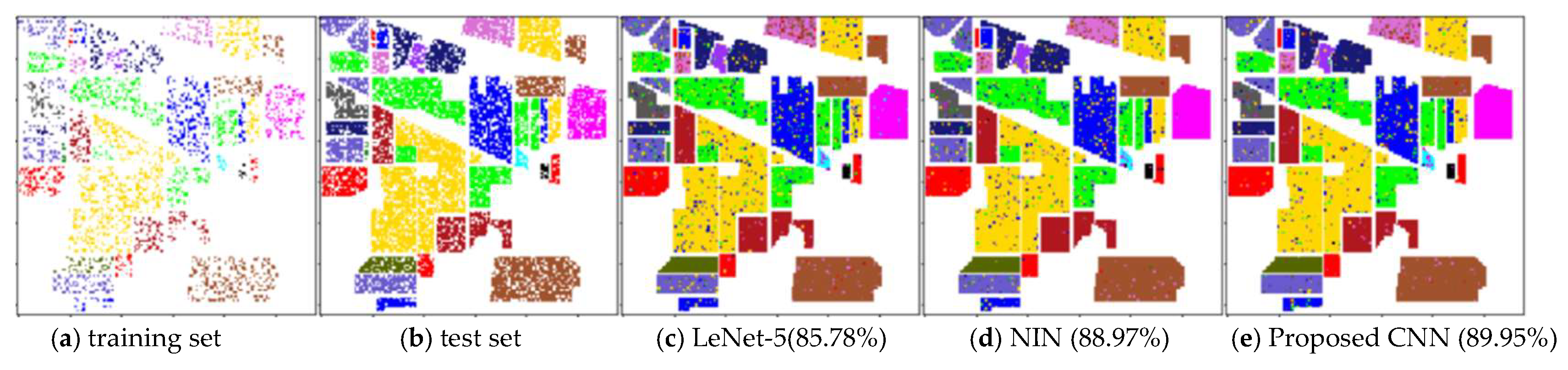
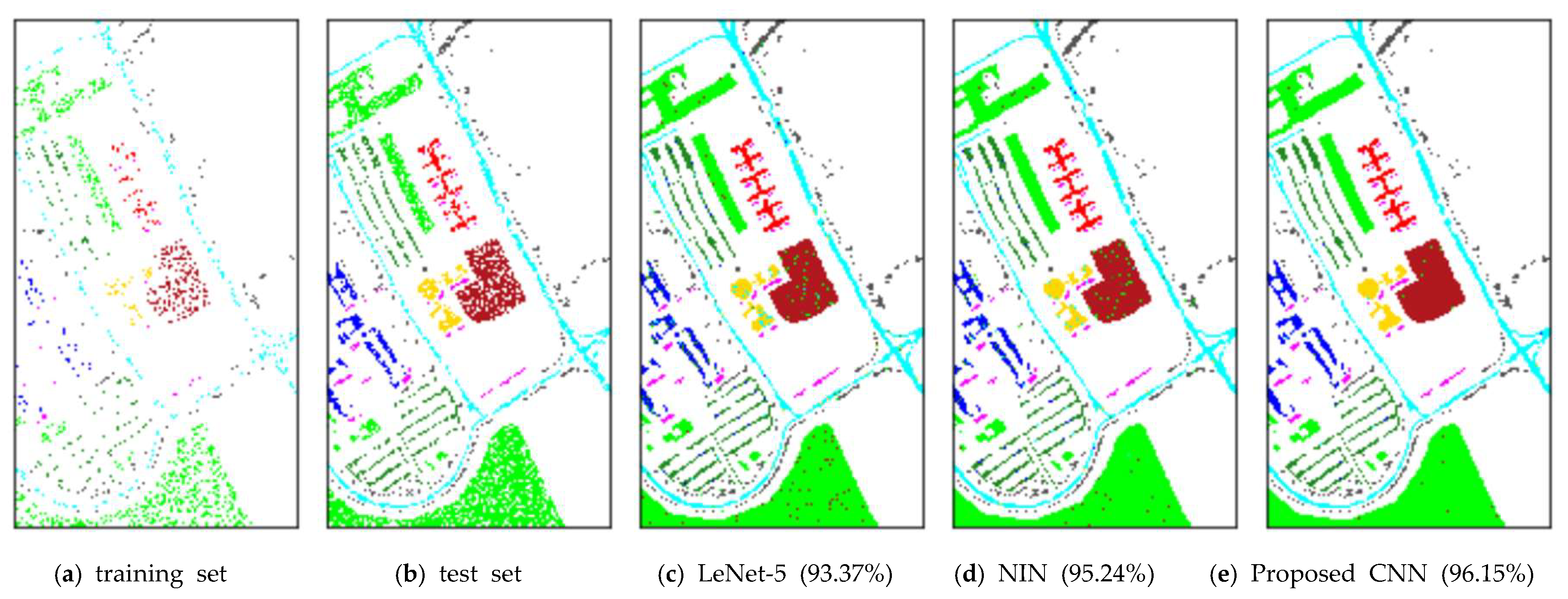
Figure 15,
Figure 16 and
Figure 17 display the corresponding classification maps. It is easy to know that the classification performance of the proposed method is better than all the comparison methods. Furthermore, as can be seen from
Table 8 and
Table 10, the FLOPS (floating-point operations) of proposed CNN is 10
6 less than that of NIN, and the training time and testing time in Indian Pines data classification are also significantly less than that of NIN. The OA of the proposed CNN is 0.98% more than that of NIN, which demonstrates the effectiveness of the ASC–FR module. However, FLOPS and computing consumption of LeNet-5 are much less than that of proposed CNN and NIN. Its shallow structure and insufficient training samples of HSI severely restrict the classification performance of LeNet-5. As a result, the OA of LeNet-5 is 3.19% less than that of NIN, and 4.17% less than that of proposed CNN.
Finally, the classification performance of the proposed method is compared with some other HSI classification methods, as shown in
Table 11. In this table, the accuracies outside brackets are taken from corresponding references directly, and those accuracies in brackets are obtained by the proposed method. It should be noted that we obtain the classification accuracy by dividing the training set and the test set according to the corresponding reference. The table demonstrates that the classification performance of proposed method outperforms all the comparison methods. In addition, DBN means deep belief network and DAE means denoising autoencoders in
Table 11.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}