1. Introduction
Vegetation cover is one of the most important indicators for ecological environment. Thus, it is important to study vegetation cover indicators and their relations with the influenced factors. Normalized Difference Vegetation Index (NDVI) has been proved to be an effective indicator for green vegetation cover on the earth surface, which is defined as NDVI = (NIR − Red)/(NIR + Red), in which NIR is the reflectance of the near-infrared wavelength band and Red is the reflectance of the red wavelength band [
1]. The relationship has been established well between NDVI and vegetation cover [
2]. Environmental factors for green vegetation growth and the relationship between NDVI and other factors have been detected. Possible factors come as precipitation, elevation, moisture, soil compositions, and so on [
3,
4,
5,
6]. The correlation between NDVI, temperature, and precipitation varies considerably in different places and in different seasons [
3,
7,
8,
9,
10]. However, conventional analysis methods are often based on regression analysis with observation data from meteorological stations or sampling schemes like random, regular, and stratified, which take a subset out to represent the population from remote sensing imagery data. Absence of spatial information in regression models may cause variance inflation and increase model uncertainty [
11,
12]. For example, an algorithm was reported to predict NDVI using precipitation data and air temperature data on the earth surface with a spatial resolution of 0.25° × 0.25° on the globe [
13]. However, it has limited values for inference and prediction, as the model does not account for spatial autocorrelation; it works only in arid and semi-arid regions, and the resolution is too coarse for a broad application [
13].
In recent years, spatial statistics models considering spatial autocorrelation are being used by econometrics scientists. From the dynamic classification pattern based on formal concept analysis for spatial statistics services, the Spatial Autoregressive (SAR) model and Spatial Filtering model can be used to deal with regression matters containing spatial autocorrelation [
14]. However, the usefulness of the SAR model is limited for large datasets, because the maximum likelihood estimation for parameters may be computationally prohibitive for large datasets [
15]. Eigenvector Spatial Filtering provides a flexible approach with which to solve the problem of spatial autocorrelation in regression by separating spatial effects from the variables’ total effects [
16]. In spatial data analysis, enhanced and robust results can be obtained by spatial filtering [
17]. Not only trends and spatially structured random components can be decomposed from the variable, but spatial noise can be filtered out. Griffith proposed eigenvector spatial filtering (ESF) methodology to filter out spatial autocorrelation from the variables’ total effects. Filtering is based on a decomposition of the spatial weights matrix used for computing the Moran Coefficient (MC) [
18]. Spatial autocorrelation can be accounted for successfully by the ESF method, which can be incorporated to not only OLS but also Generalized Linear Models and Generalized Linear Mixed Models [
19,
20]. The usefulness of separating spatial effects from variables’ total effects by ESF approach has been demonstrated in ecological and socio-economic fields [
21,
22,
23] in which ESF regression analysis usually takes administrative units as the study unit or sampling points to represent the study region. In other words, these applications are vector-based and today’s computers can handle the amount of computation. Modeling with NDVI, however, is best done in the raster data model, which in turn is facing the computational problem as the spatial weights matrix is prohibitively large, because for an n-by-n image, the SWM is
. Even though one can use analytical methods to approximate the eigenfunction for regular lattices [
24], the selection of eigenvectors would take too long to complete within a reasonable duration. A temporal filtering algorithm was reported to minimize the contamination by cloud and noise in the NDVI time series, but it does not deal with spatial effects in regression modeling and is suitable in Australia [
25]. Although a Fourier Filter was applied to minimize the influence of high-frequency noise in NDVI classification, it does not take environmental factors into consideration [
26].
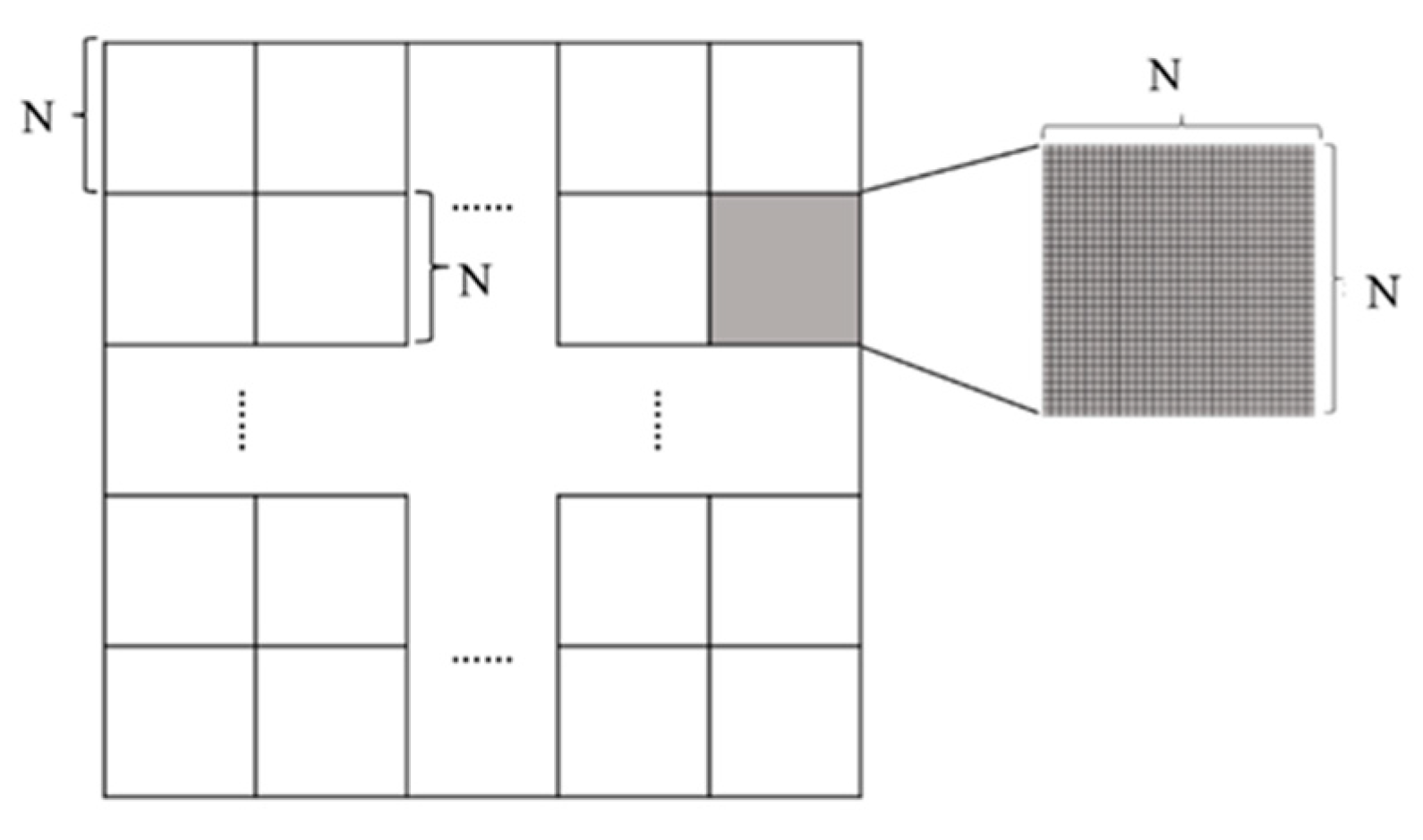
We explored a parallel ESF method to address the computational problem. The parallel ESF method resolves the large datasets to smaller ones and utilizes the multicore CPU of personal computers as workers to construct a cluster to execute the ESF regression process simultaneously [
27]. An optimum segmented size of 32 × 32 is selected through experiments as the basic unit for image segmentation. The large datasets are segmented to a group of datasets of the same size 32 × 32 and launched together with a new copy of ESF regression code to each worker in the cluster. After the compute tasks for each segments are completed, the client will collect the results from all worker sessions [
28]. In this way, the resolved smaller datasets can be calculated easily, and the compute process is accelerated efficiently.
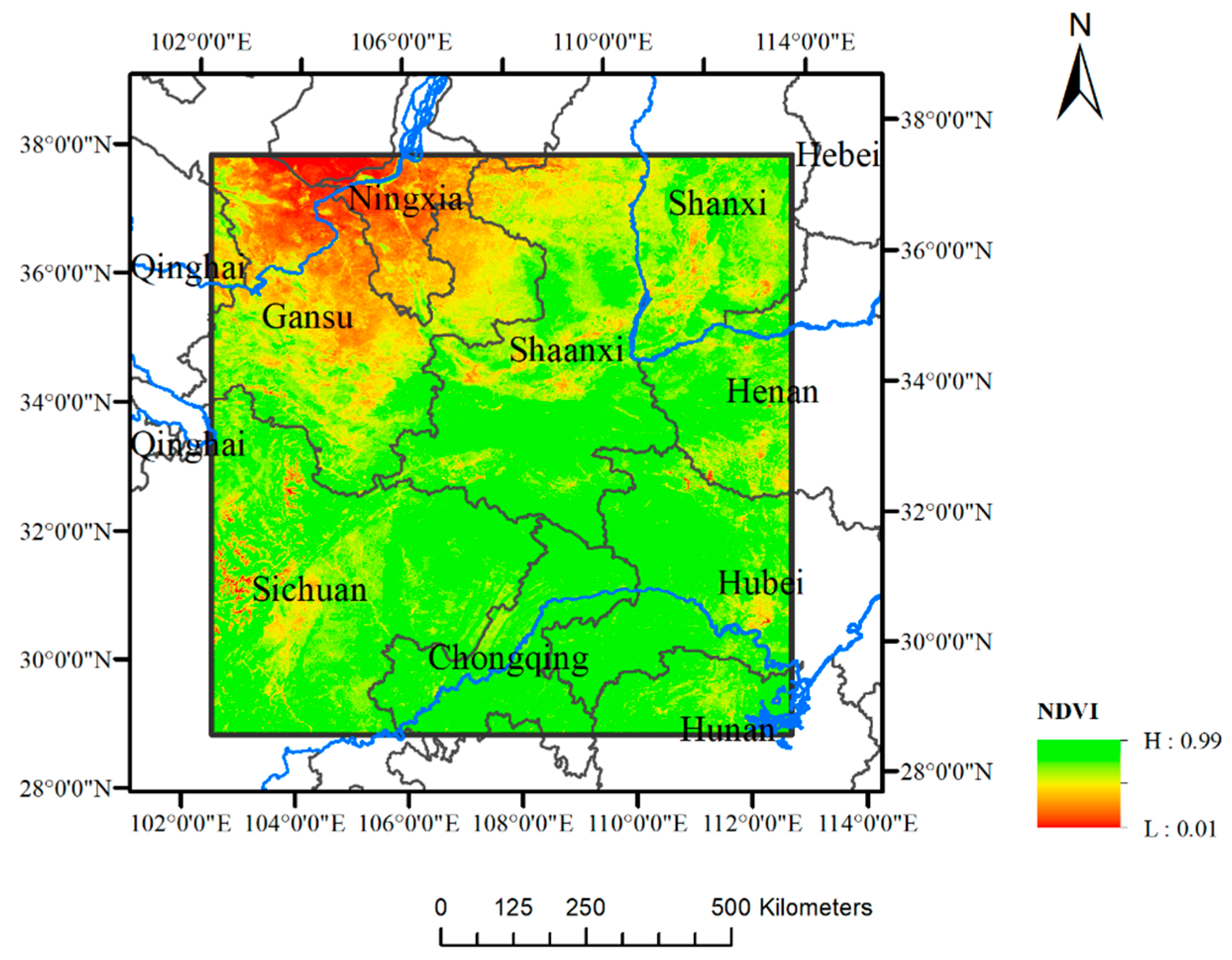
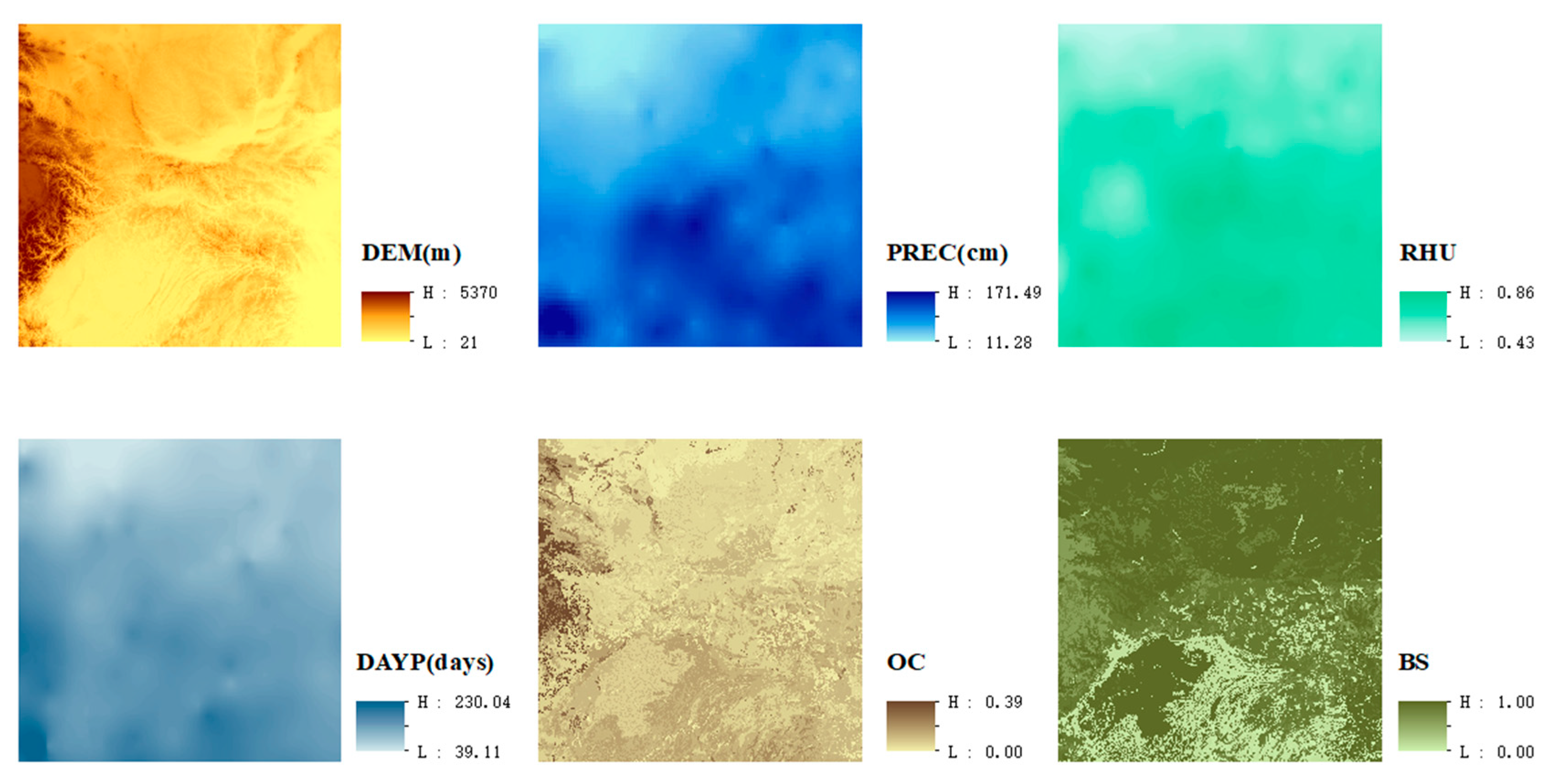
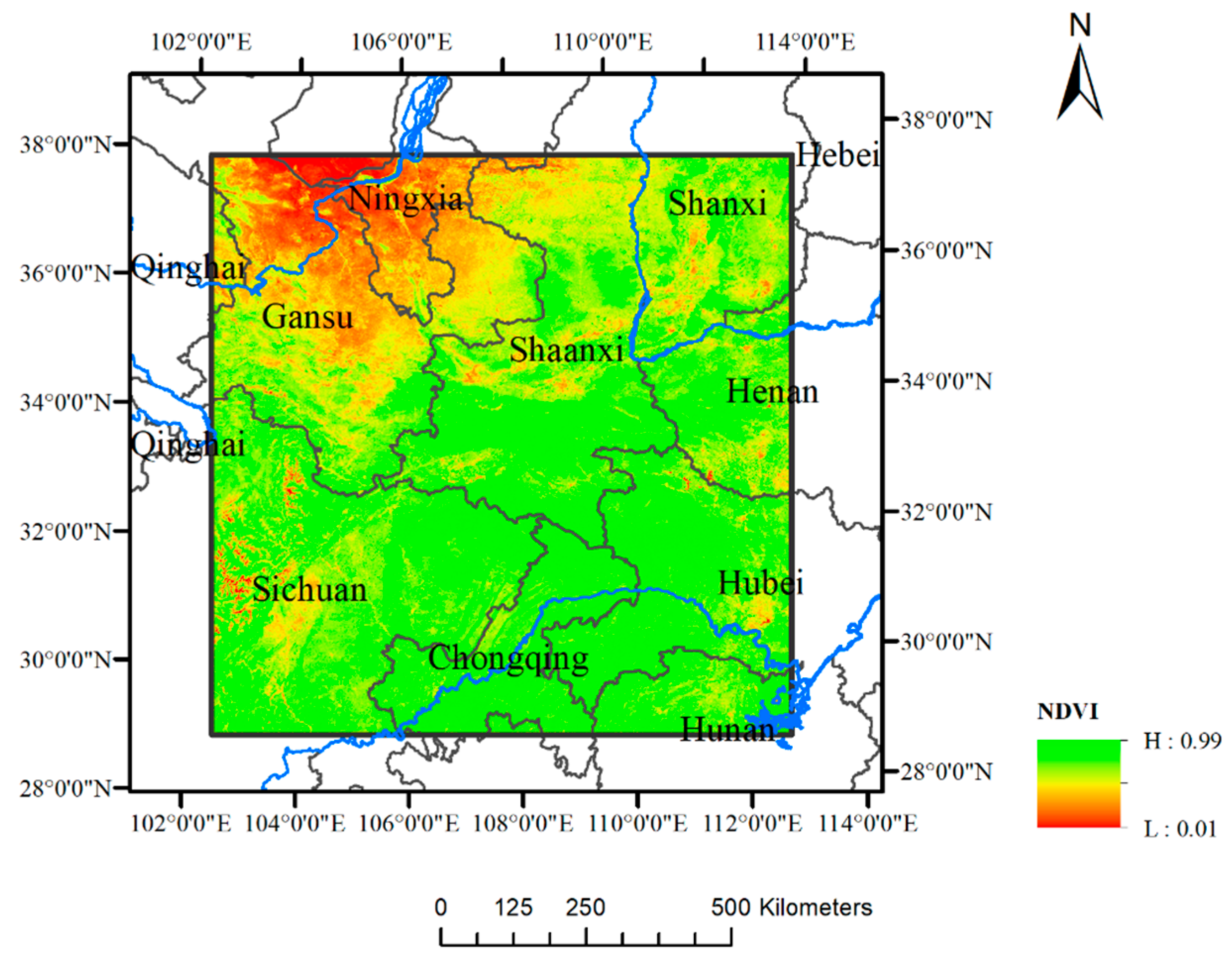
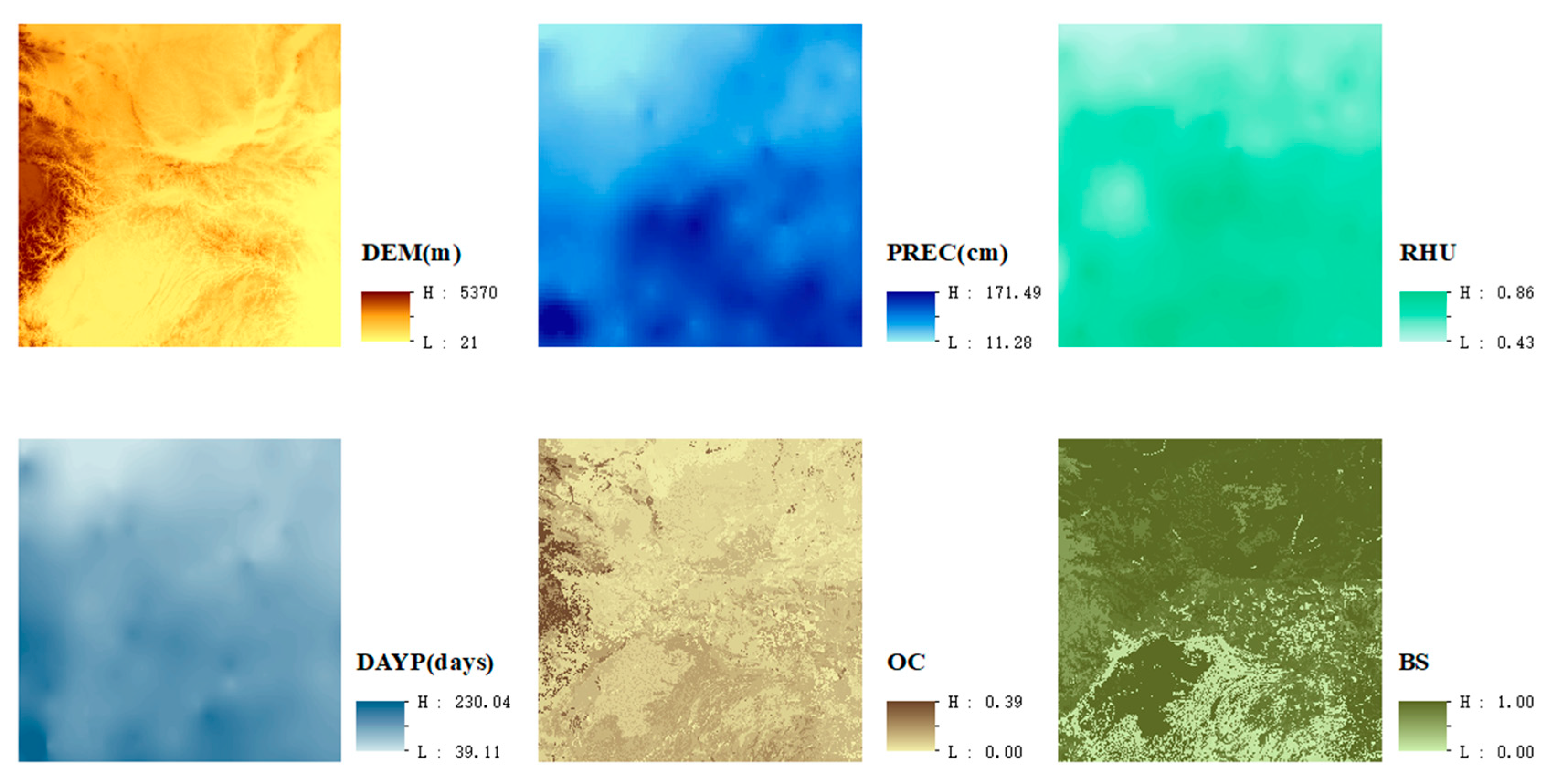
In this study, raster datasets of NDVI and environmental factors including DEM, precipitation (PREC), relative humidity (RHU), precipitation days greater than 0.1 mm (DAYP), soil organic carbon (OC), and soil base saturation (BS) content in central China are employed and segmented to squared blocks to construct the Parallel-ESF regression model. This method is expected to improve the goodness of fit of the regression model by taking the spatial autocorrelation of variables into consideration and accelerating the computation process for large raster datasets. The aim is to study the correlation of environmental factors for NDVI in central China, which will consider the spatial effects that existed in variables. Moreover, this paper attempts to provide the feasible access of the segmented processing approach to solve the problem of spatial autocorrelation and the memory insufficiency of eigenvectors generation using the ESF regression approach for large size raster datasets.
2. Methodology
The proposed methodology contains 4 steps in this study. The first step is to estimate the optimum size of the N × N image blocks and segment the large datasets in a mutually exclusive and collectively exhaustive manner. The second step is to construct the spatial weights matrix based on contiguity relation for N × N squared blocks and its eigenfunction. The third step is to estimate regression model with selected eigenvectors included for each segmented blocks. The last step is to compare the model performance of the local ESF regression models with the conventional multiple linear regression model and the spatial autoregressive model.
2.1. Raster Segmentation
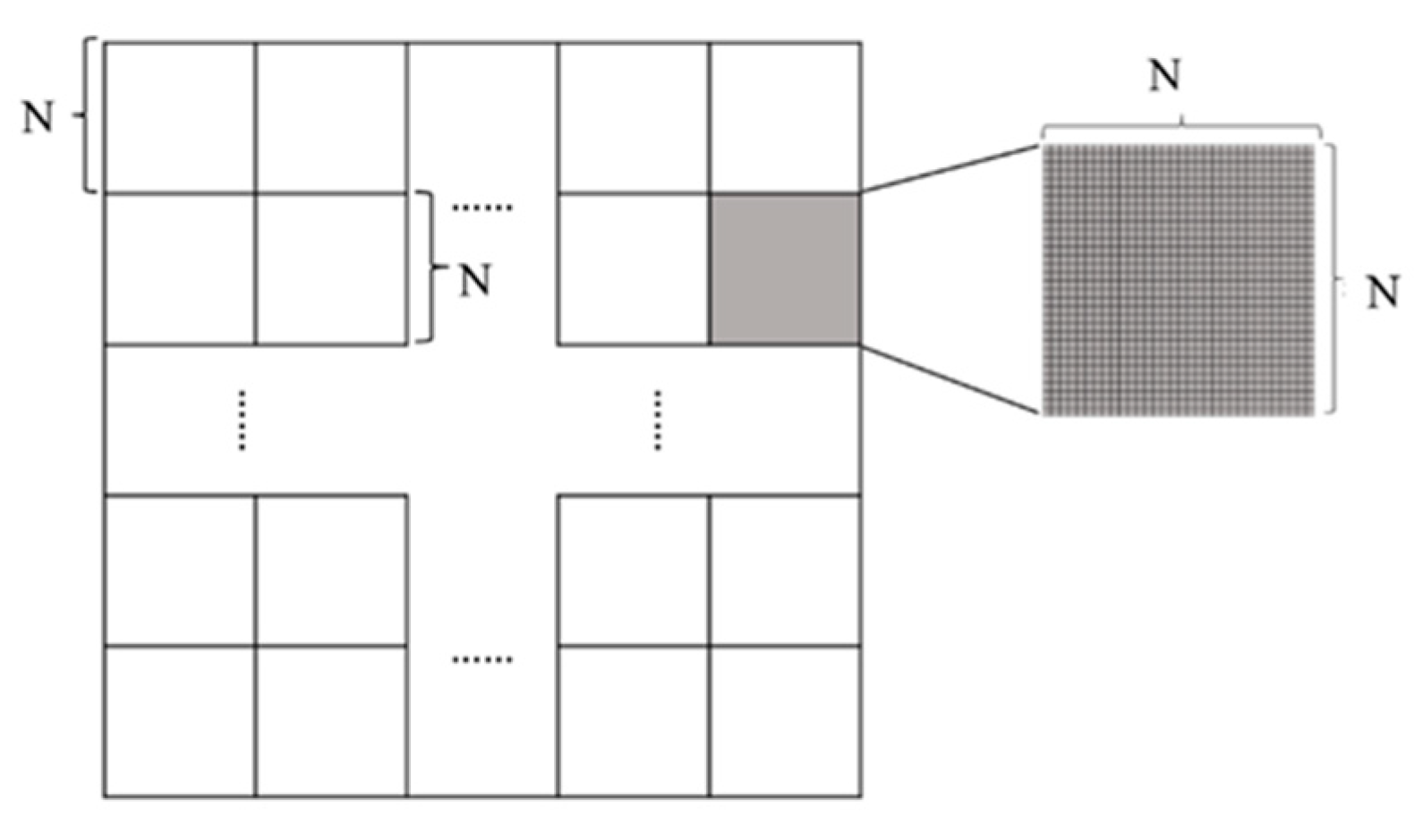
As indicated earlier, calculation of the eigenfunction and selection of eigenvector through step-wise regression can be very time consuming, especially for raster data. Tests of linear ESF are conducted on various size such as 8 × 8, 16 × 16, 32 × 32, 64 × 64, and so on, as
Figure 1 shows. The optimum subset size takes both time costs of eigenvectors selection for a single block and the number of all segmented blocks into consideration. Smaller size of subsets is more efficient for calculation, but more subsets mean more information loss from more separated pixels. Time costs of eigenvector selection in various size images are obtained to choose acceptable elapsed time for a single image block. The result shows that the computer is stress-free for the raster of the sizes 8 × 8, 16 × 16, and 32 × 32 to generate eigenvectors from spatial weights matrix, and it takes a few minutes for size 64 × 64 to generate eigenvectors. However, in the process of identifying eigenvectors, especially the permutation test in stepwise regression, the computer exports no result, causing computers to halt for the size 64 × 64. Considering the number of segmented blocks and loss of efficiency in task and data transmitting procedure, size 32 × 32 is selected as the basic unit for image segmentation. Once the optimum subset size is determined, the image datasets representing the dependent variable and the predictor variables are segmented to a group of squared blocks. Note that preprocess of resize should be conducted to ensure all datasets have the same resolution.
2.2. Eigenvector Generation Based on SWM
Topology-based spatial weights matrix for the image block serves as the base for representing spatial relationship in regression models [
18]. For square tessellations, queen contiguity is adopted to construct the binary spatial weights matrix
with
if the two cells are neighbors and
otherwise [
29]. The spatial weights matrices are the same for all segmented blocks and can be calculated only once, because the image blocks have identical spatial weights matrices. The spatial weights matrix is subsequently centered through the projection matrix as follows:
in which
is an n × 1 vectors of ones. The symbol T donated the matrix transpose operator.
The eigenfunction, containing eigenvectors and associated eigenvalues, is calculated from decomposition of the modified spatial weights matrix [
30]. The decomposition can be expressed as
in which
. The character
is an n × n diagonal matrix of eigenvalues
in descending order.
are the eigenvectors corresponding to the eigenvalues
[
22]. For being orthogonal and uncorrelated, each eigenvector can portray distinct map patterns with achievable level of spatial autocorrelation for a given geographic landscape [
31]. The function relation has been detected between MC value for a mapped eigenvector and its corresponding eigenvalue as follows:
Based upon these properties, the eigenvectors can be interpreted as follows: The first eigenvector
is the set of real numbers that has the largest MC achievable by any set for the geographic arrangement defined by the spatial connectivity matrix
. The second eigenvector
is the set of real numbers that has the largest achievable MC by any set that is orthogonal and uncorrelated with
. So on through the nth eigenvector
, which is the set of real numbers that has the largest negative MC achievable by any set that is orthogonal and uncorrelated with the preceding
eigenvectors [
32]. Being mutually orthogonal and uncorrelated, these eigenvectors can cause the emergence of latent spatial autocorrelation in variables [
21], and those eigenvectors that are significant can be filtered out and act as proxies in explanatory variable to capture its spatial stochastic component [
19].
2.3. Parallel Eigenvector Filtering
Since the eigenvectors of spatial weights matrix portray a different map pattern exhibiting a specified level of spatial autocorrelation, a parallel processing approach is adopted to select the significant eigenvectors in each block as control variables in a linear combination and construct a global ESF regression model for all the segmented blocks. The identification of can be achieved by a forward stepwise selection procedure. The criteria to identify eigenvectors contain significance level of the estimated coefficients and Akaike Information Criteria (AIC) of model at each step.
Before the stepwise selection, a candidate set of eigenvectors, a smaller subset of the entire eigenvectors, can be demarcated by the properties of eigenvectors to reduce workload. Eigenvectors whose MC values can be eliminated, because these eigenvectors do not explain much spatial variation. Second, eigenvectors that represent negative SA can be excluded, because empirical NDVI displays positive SA. A feasible criterion for eigenvectors identification is
divided by the largest eigenvalue
that is greater than 0.25 [
33].
The parallel processing approach takes segmented dataset in each block and the candidate set of eigenvectors together to run the stepwise process. For each block, eigenvectors are selected via conventional stepwise regression procedures from the candidate set of eigenvectors. AIC is a criterion for stepwise selection that takes both goodness of fit and complexity of the model into consideration. The parallel ESF regression is conducted simultaneously in each worker and each task for each block is distributed to workers automatically to search for the model that has the lowest AIC. Forward selection adds the variable whose inclusion gives the lowest AIC value and repeats this process until none improves the model to a statistically significant extent. A global ESF model specification exists as follows. The item
stands for the eigenvectors spatial filters in each block.
After all the blocks finishing the forward selection procedure, the ESFs item are added to the regression model with a linear combination as missing proxies. The coefficients are estimated by OLS (ordinary least squared) method and returned to construct global ESF model.
2.4. Validation
Variable selection should be conducted to select explanatory variables with higher correlation for NDVI before the parallel ESF regression. The raster datasets of the environmental variables, together with dependent variable of the whole region, are transferred to a column vectors for convenience. Both Pearson correlation coefficient and stepwise selection are conducted. The stepwise regression can choose the predictive variables by an automatic procedure. For forward selection, the procedure starts with no variables in the model. Each variable is considered for addition using a chosen model fit criterion, and the process is repeated until there are no improvements for the chosen criterion. Pearson correlation coefficient is selected to measure the linear dependence correlation between NDVI and other factors, and is defined as
in which
μ and
σ are the mean and standard deviation and
N is the scalar observations of the
A and
B variable. The value of correlation coefficient varies from +1 to −1 corresponding to a high positive correlation to a high negative linear correlation. While the coefficient relates to 0, it means there is nearly no linear correlation between
X and
Y [
34].
Conventional ordinary least squared multiple linear regression (OLS) model and Spatial Autoregressive (SAR) model are selected to compare with ESF model. To ensure consistency and comparability for the same number of observations, OLS model and SAR model are performed in segmented block groups. Another reason is that a spatial weights matrix of 65,536 (256 × 256) observations is extremely large for SAR model. SAR model combines a spatially lagged dependent item
in the standard regression to account for the influence of nearby in surface scale [
35]. The SAR model takes the form
in which
W is spatial weights matrix and
represents the influence of the explanatory variables
to the dependent variable
. The parameter
ρ(rho) in SAR model can reflect the level of spatial dependence in dependent variable [
36]. Moran Coefficient (MC) is also selected to measure the extent of spatial autocorrelation in the residuals before and after adding the selected eigenvectors into the regression model.
RSE (residual standard error) is a criterion evaluating the difference between the observed value and the estimated value of dependent variable. In this study, RSE is calculated to measure the difference between the exact values and the estimated values by OLS, ESF, and SAR model. R-Squared, also being called coefficient of determination, can represent the ratio of the dependent variable fitted from the model. Adjusted R-Squared can take account of the increase by adding extra explanatory variable, the filtered eigenvectors, to the model. This study takes both R-Squared and Adjusted R-Squared to represent the goodness of fit of the three regression models. AIC is also taken to estimate relative information loss in regression models, which is based on information theory. A smaller AIC value represents a better model for relative information lost. All these criteria are adopted to evaluate the performance of parallel ESF model.
4. Results
4.1. Comparison of 3 Models in Each Block
The number of filtered eigenvectors is shown as
Table 4. Only part of the ESF model of the segmented blocks and filtered eigenvectors is selected to the table due to there being limited space. The procedure selects an average of 92 eigenvectors for all blocks.
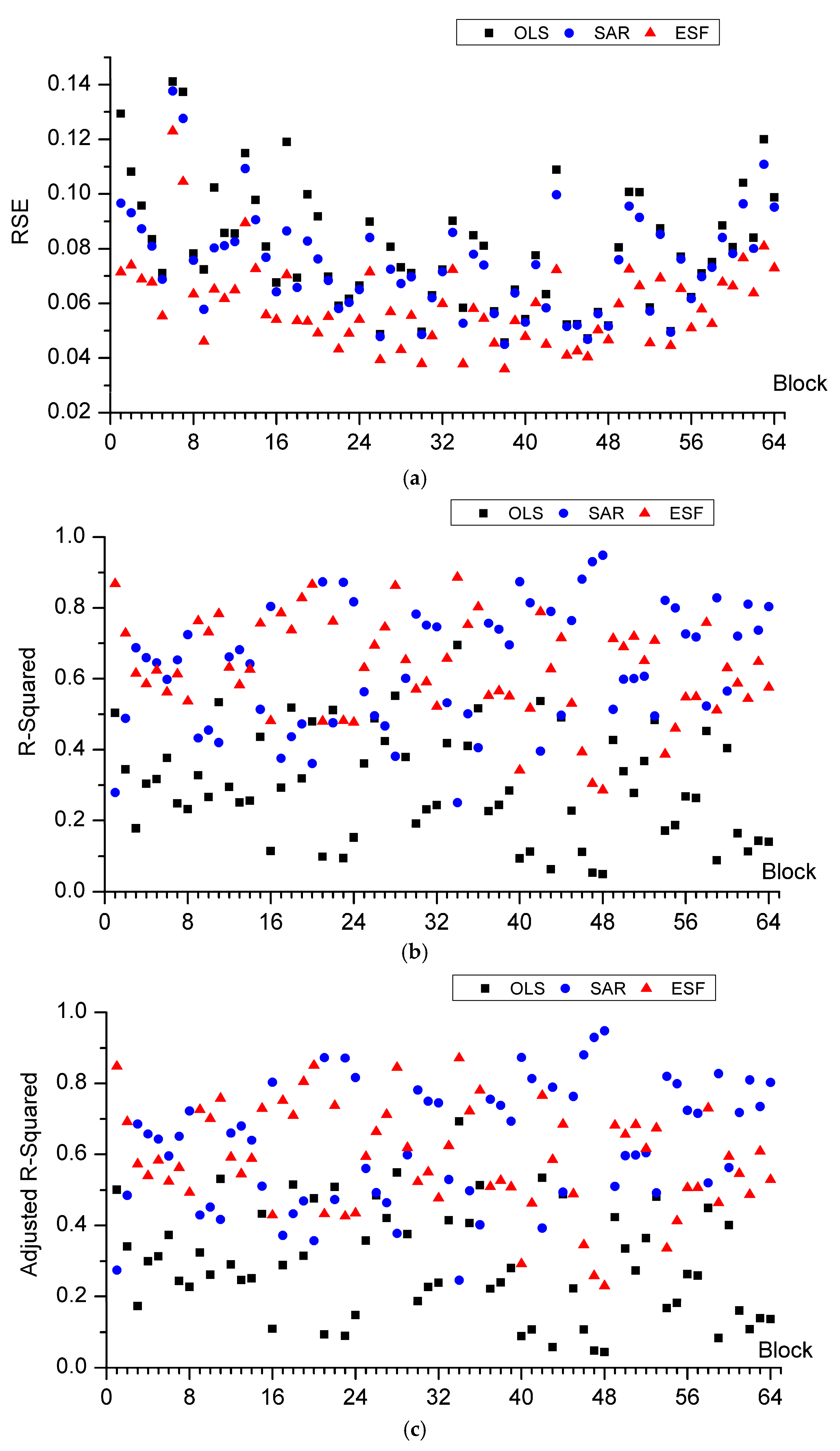
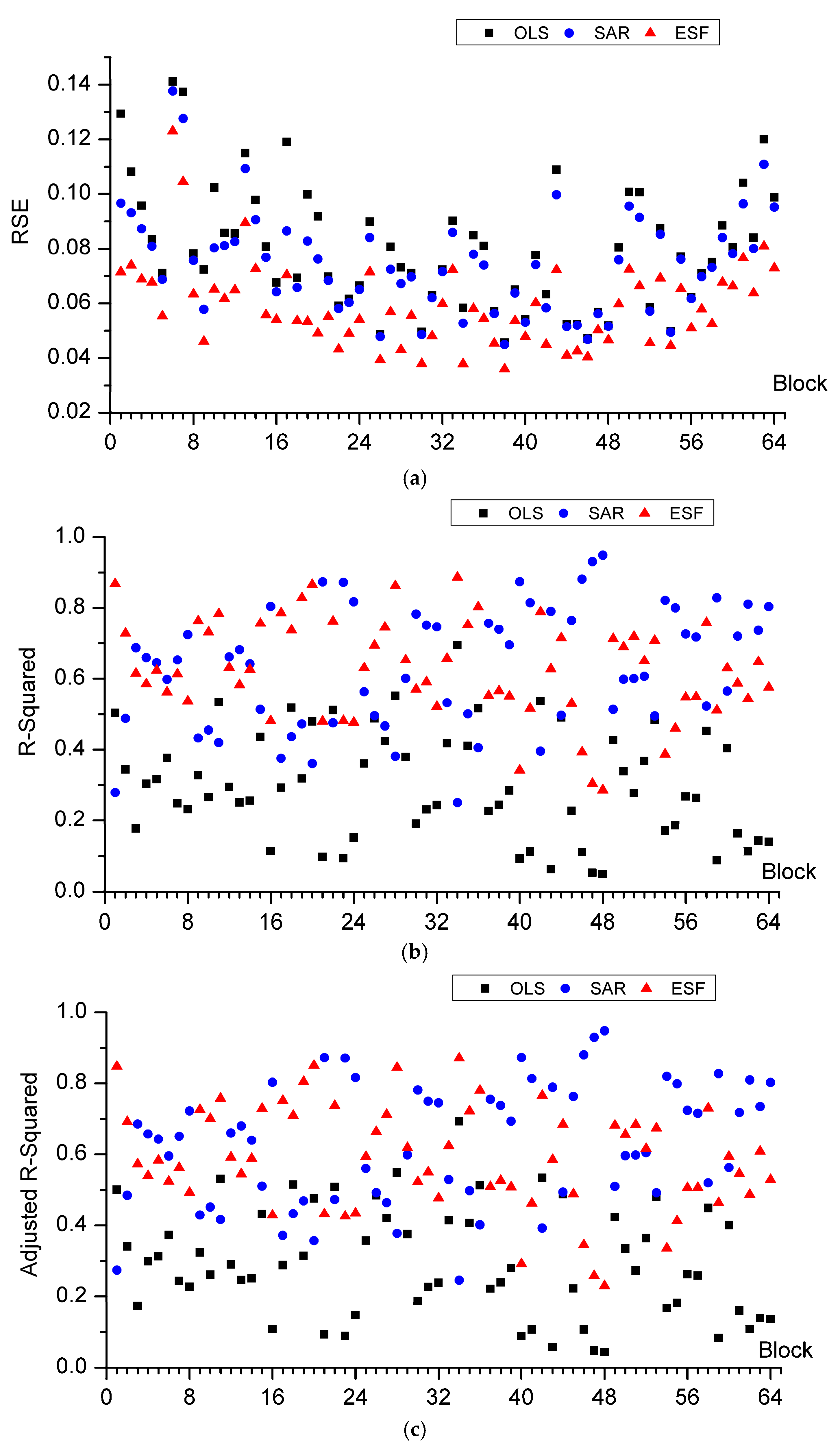
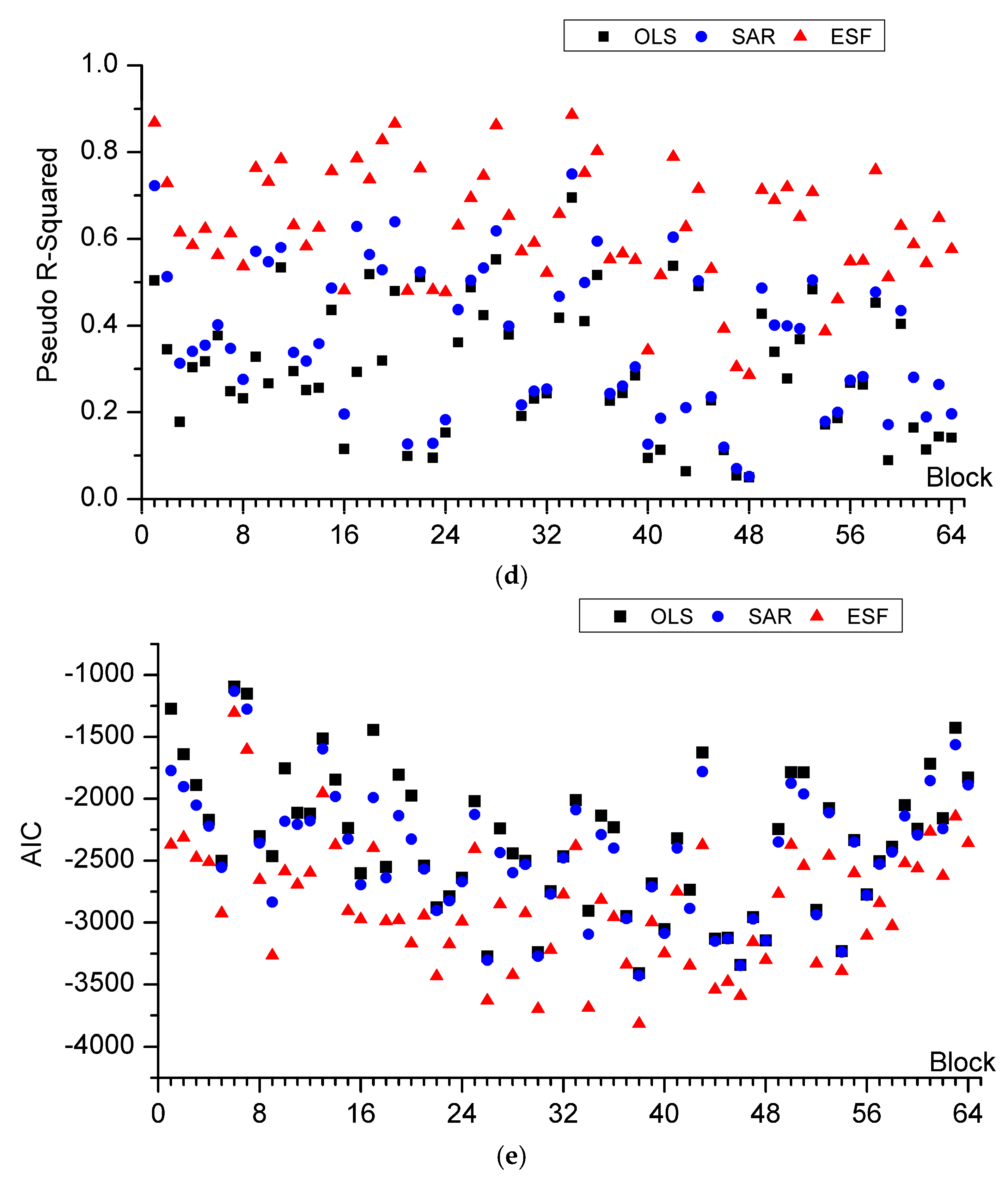
Criteria of OLS, SAR, and ESF for the segmented raster image blocks are computed to validate the goodness of fit for the three models as
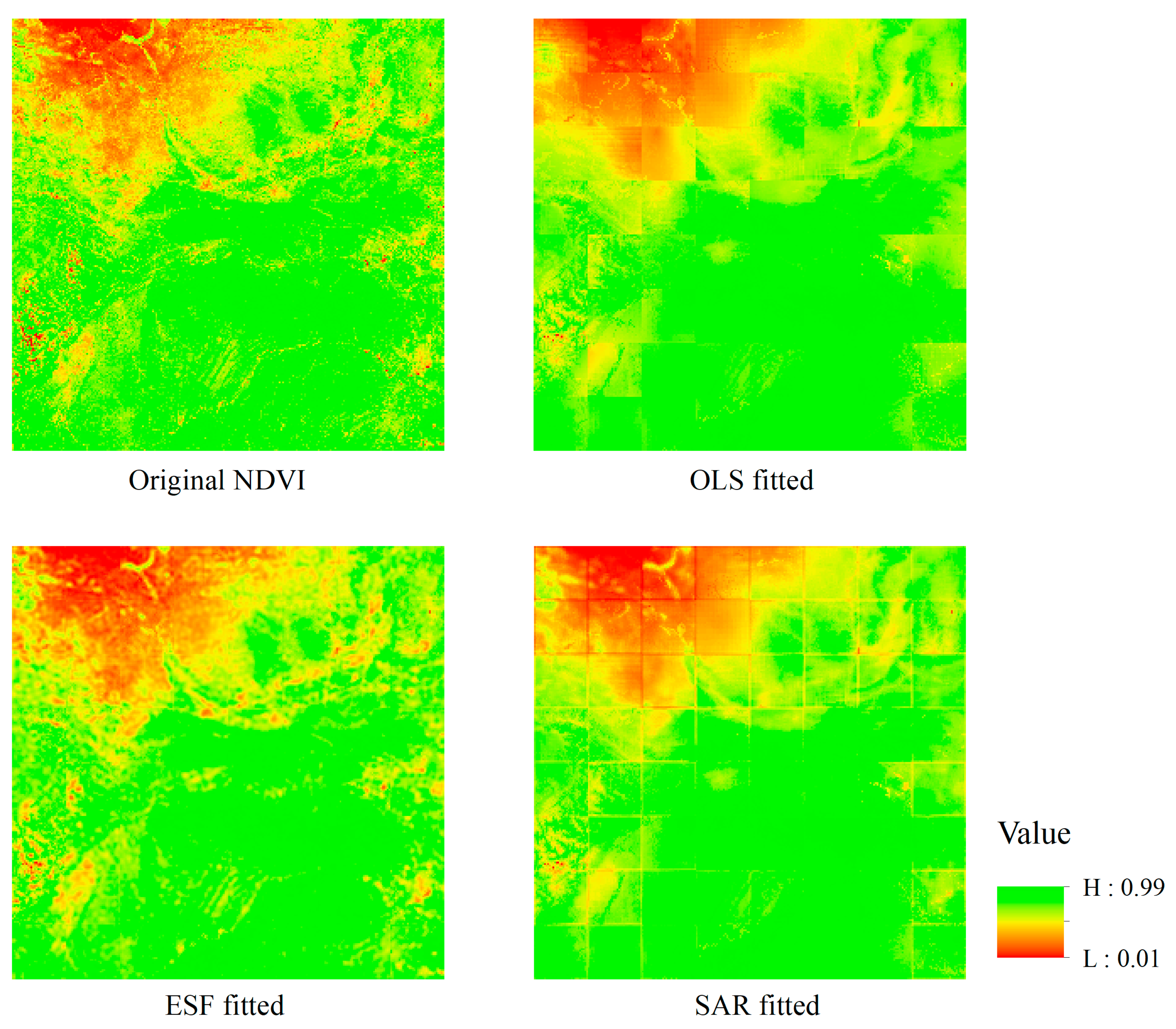
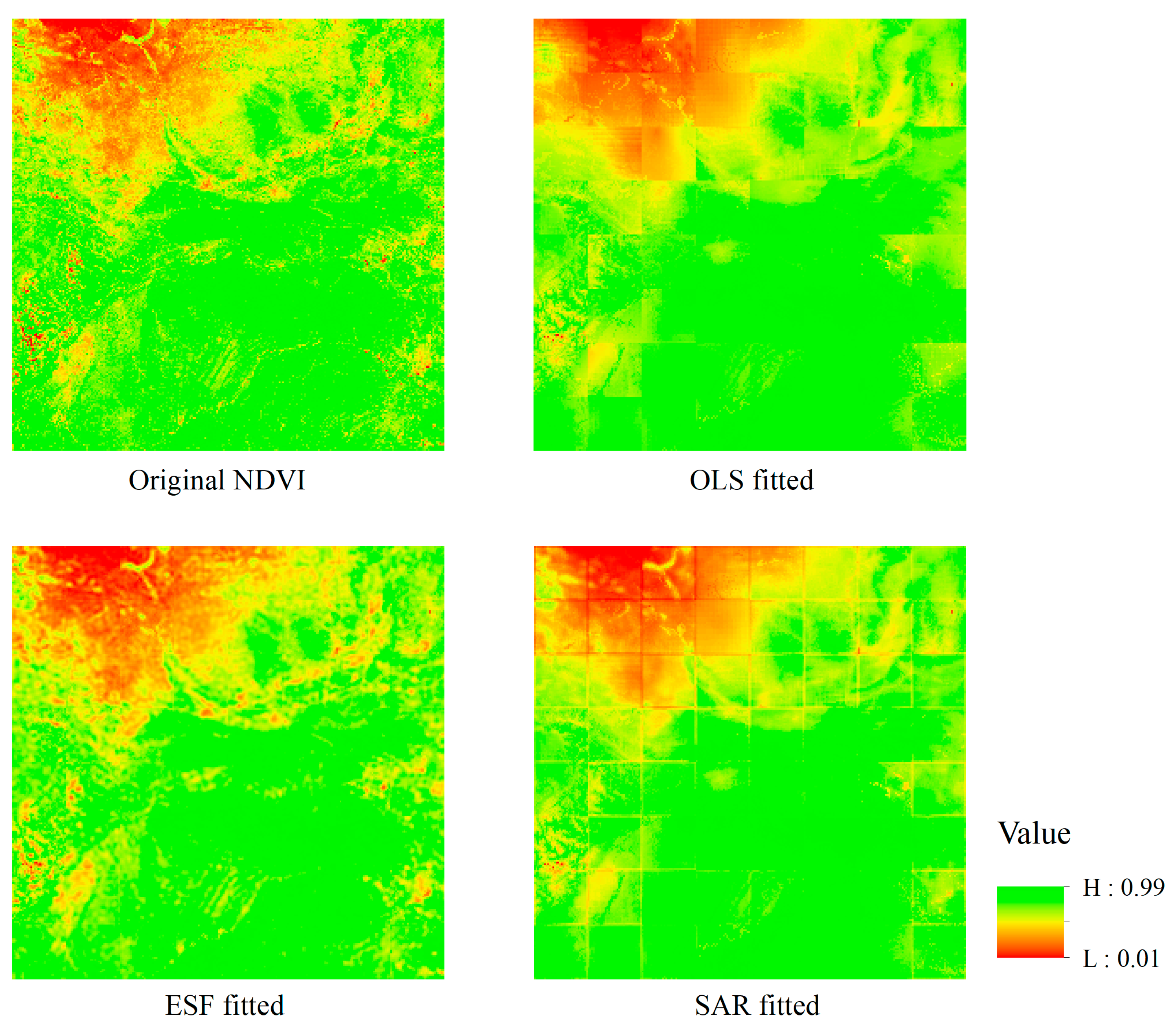
Figure 4 shows. The RSE of ESF model is smaller than SAR and much smaller than OLS model. ESF model almost gets the minimum RSE value among the three models, which means less difference between observed value and predicted value. R-Squared of both ESF model and SAR model is greater than OLS model, mainly because of the filtered eigenvectors and spatial interaction component explaining the spatial effects in the regression model. For some blocks, the R-Squared of SAR is greater than ESF, while in other blocks it is the opposite. Considering the spuriously increasing effects by adding extra explanatory variables to the model, Adjusted R-Squared are calculated to modify R-Squared. Adjusted R-Squared of ESF decrease a little bit compared to the other two models, due to a set of synthetic proxy variables, the filtered eigenvectors, being added to the explanatory variables. For R-Squared and Adjusted R-Squared, it is hard to say whether SAR is better than ESF or not. However, what is certain is that both of the R-Squared and Adjusted R-Squared show an increased proportion of the dependent variable that can be explained by explanatory variables of regression model. Pseudo R-Squared for the 3 models are calculated, which can measure the goodness of fit between fitted values and observed values. It is obvious that ESF model gets the greatest value in all blocks. AIC of the three models are compared, which takes both model complexity and goodness of fit into consideration. Lower AIC represents better model. ESF model gets the smallest AIC, while OLS gets the greatest AIC in all blocks. Considering all these criteria, ESF and SAR models are much better than OLS, owing to their consideration of spatial dependent component. ESF model is better than SAR model for its better fit and relative high comprehensive comparison.
4.2. Summarized Results
Table 5 summarizes criterion of the three models by calculating mean of parameters from the segmented blocks. Due to the variations of ESFs in ESF model, only coefficients of environmental factors are calculated for global ESF model.
The coefficients estimated for explanatory variables vary in the three models. For DEM, the average estimated coefficients of the three models are similar, together with a similar standard error average. The p value for SAR and ESF models is less than 0.05, which means a significant relationship under 95% confidence level. For PREC, the coefficient estimates for OLS model and SAR model are similar and greater than ESF model. The average standard error for ESF is better than the other two models. The p values for PREC of the three models are all greater than 0.05, representing no significance.
For RHU and DAYP, ESF model produces the largest slope value among all three models but gets a higher standard error for estimated coefficients. The p values are similar and not significant. For OC, the estimated coefficients show difference, while the standard errors of SAR and ESF models decrease. The p values of the three models for BS are not significant. Residuals’ MC is an indicator to detect spatial autocorrelation in residuals. The smaller residuals’ MC means more spatial structure components are interpreted by regression model. The residuals’ MC for SAR model decreases compared to OLS model, but for ESF it decreases nearly to excepted level (). The p values of residuals’ MC for OLS and SAR are significant but no more significant for ESF.
Table 6 shows the parameter estimation result in Block Group 35 randomly selected. There are several differences between the average of all blocks and Block 35. The estimated coefficient for DAYP is much larger in Block 35. The
p value of estimated coefficients for all three models is significant, except for OC in OLS and SAR, and RHU in ESF.
Criteria of all blocks are summarized to compare the parallel ESF model with OLS and SAR model. The RSE, R-Squared, Adjusted R-Squared, and Pseudo R-squared are recalculated from the estimated value and observed value. The mean of AIC value, Residuals’ MC, and degree of freedom (DF) are calculated. The results are shown in
Table 7.
Compare the results from the table, what the integrated results show is in accordance with the segmented results. The RSE of SAR model is smaller than OLS and for ESF is much smaller, which shows less difference between fitted values and observed values using the SAR model and ESF model. Residuals’ MC is an indicator to detect spatial autocorrelation in residuals. It is obvious that ESF is much more effective than the other two models. R-Squared of SAR model and ESF model increases compared to OLS model. These environmental factors explain only 30% of the variation in NDVI, while spatial autocorrelation captured by ESF term explains addtional 30%. This is mainly because new variables that explain spatial effects are added to global ESF model. Considering the automatically and spuriously increasing effect by adding extra explanatory variable to regression model, Adjusted R-Squared of ESF model decreases slightly, because its number of variables is more than the other two models. The average DF is calculated, representing good performance for OLS and SAR. Pseudo R-Squared is also calculated, which can reflect the goodness of fit between observed values and fitted values. It is obvious than ESF model is better than SAR and much better than OLS. Taking both model complexity and goodness of fit into consideration, AIC gives the best choice. AIC for ESF is smaller than SAR and much smaller than OLS. Considering all these criteria, it is obvious that ESF is relatively better than SAR and much better than OLS.
4.3. Time Cost Comparison in Parallel Computation
In this study, parallel computation based on different clusters of different number of cores is conducted to verify the speed-up ratio. The experiment is conducted on an ordinary PC configured with 4 cores in total. The time cost of parallel computation on different number of workers is shown as
Table 8. It is obvious that the calculation procedure can be accelerated dramatically by adding workers to cluster; cluster with 4 workers can be 3.2 times faster than cluster with only one worker or serial computation.
6. Conclusions
In this study, the influence of environmental factors and spatial effects on vegetation cover in central China are studied. A parallel ESF regression model based on raster segmentation is proposed for regression analysis of large, regular-squared raster datasets and applied to NDVI and its factors of DEM, PREC, RHU, DAYP, OC, and BS. The influences on NDVI distribution are studied that regional effects can influence the correlation relation between NDVI and environmental variables. The result shows that goodness of fit for the parallel ESF model is greatest compared to the conventional OLS model and the SAR model. Moreover, spatial effects account for nearly 32% variation for NDVI distribution. By using the proposed parallel ESF regression approach, a more accurate model is constructed for NDVI and its environmental factors in central China. That is to say, spatial effects, especially spatial autocorrelation, plays an important role in vegetation cover distribution in central China. Despite the filtered eigenvectors added to regression model that cause an increase of model complexity, the parallel ESF model still has the best goodness of fit and the best performance by criteria as R-Squared, Adjusted R-Squared, Pseudo R-Squared, and AIC, interpreting spatial autocorrelation and improving the goodness of fit.
The ESF approach can account for influence caused by spatial autocorrelation and improve the degree of fitting, but it produces no results for large size rasters because of the calculation bottleneck of eigenvector generation and eigenvector selection. In this study, the parallel approach is proposed for the long-consuming stepwise process for large size eigenvectors derived from SWM responding to spatial relation among pixels in the raster image. The large datasets are segmented to smaller ones and distributed to a multi-core cluster for parallel computation of eigenvector spatial filtering in each segmented block, which can be extended to a cluster with more cores to improve the computing speed for much larger datasets. The parallel technique for ESF regression provides a feasible approach to solve the problem of inaccuracy and uncertainty caused by spatial autocorrelation in regression analysis for large raster datasets and computational burdens of the eigenvector spatial filtering algorithm, which can be used not only in NDVI analysis but also to construct more accurate regression models for variables of large size raster datasets, which is very promising for applying spatial regression modeling to a wide range of real world problem solving and forecasting.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}