The Implications of Field Worker Characteristics and Landscape Heterogeneity for Classification Correctness and the Completeness of Topographical Mapping


Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area and Data
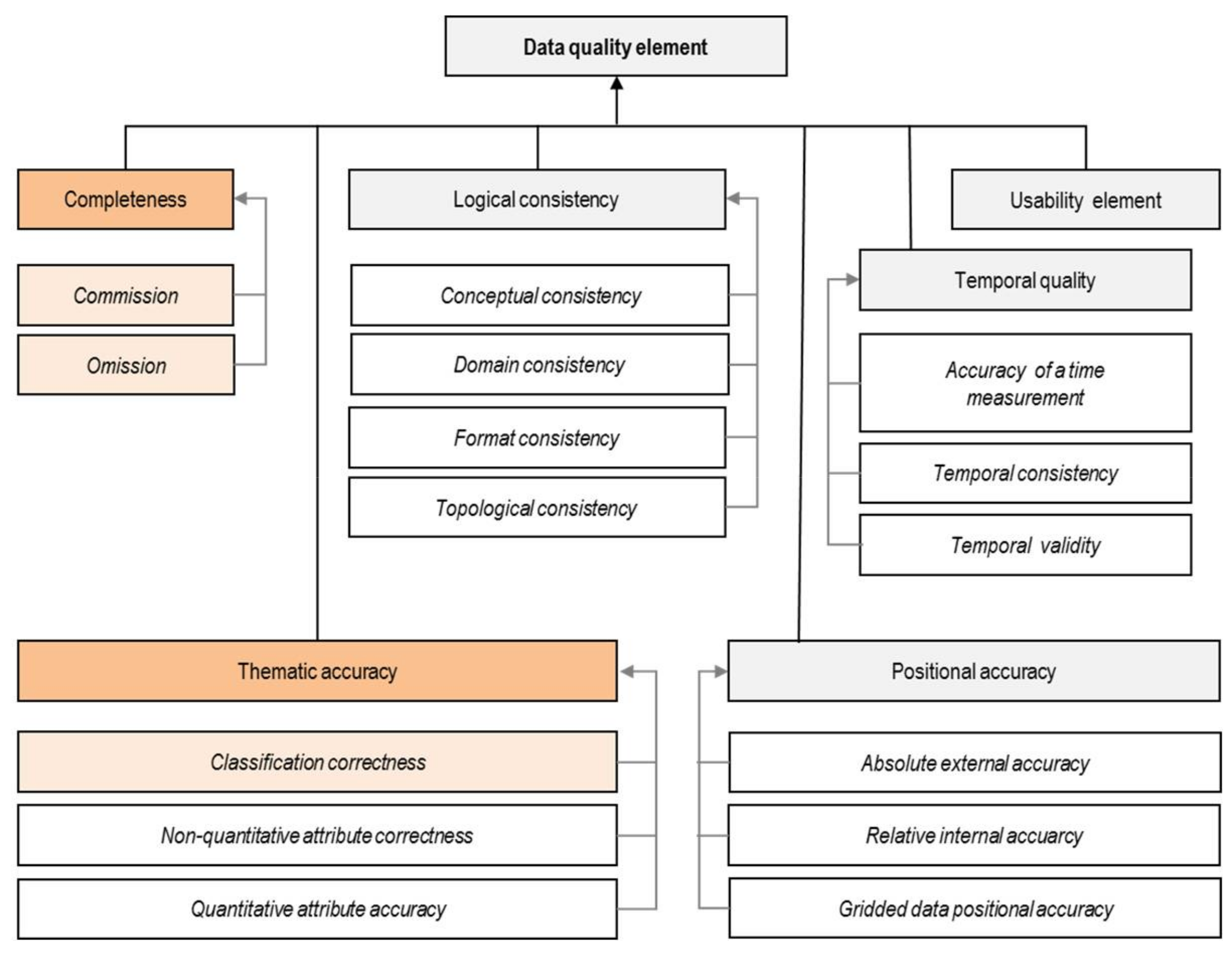
2.2. Quality Elements and Measures
2.3. Landscape Indicators
2.4. Statistical Analyses
3. Results
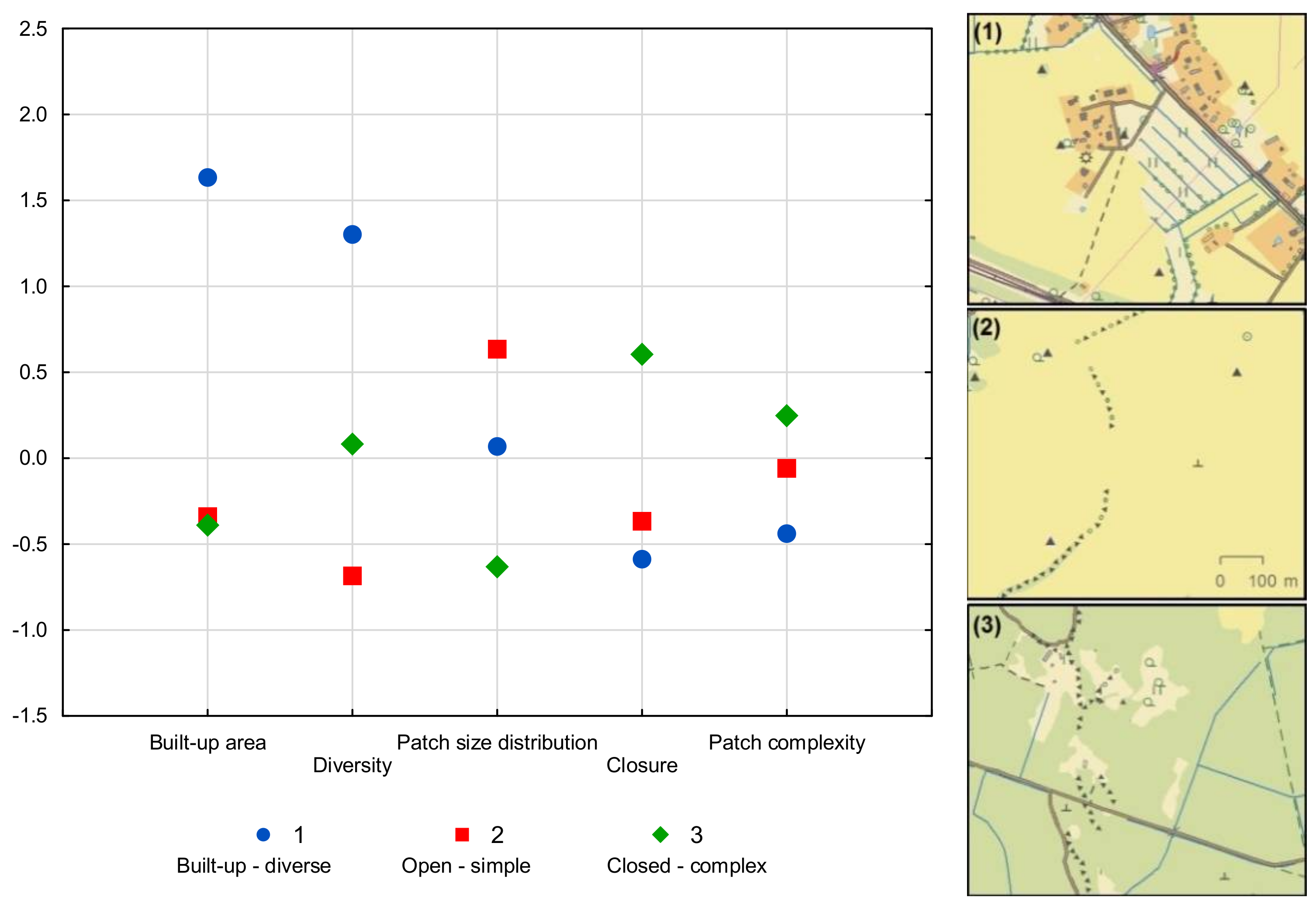
3.1. Landscape Metrics
3.2. Cluster Analysis of the Landscapes
3.3. Characteristics of Field Workers
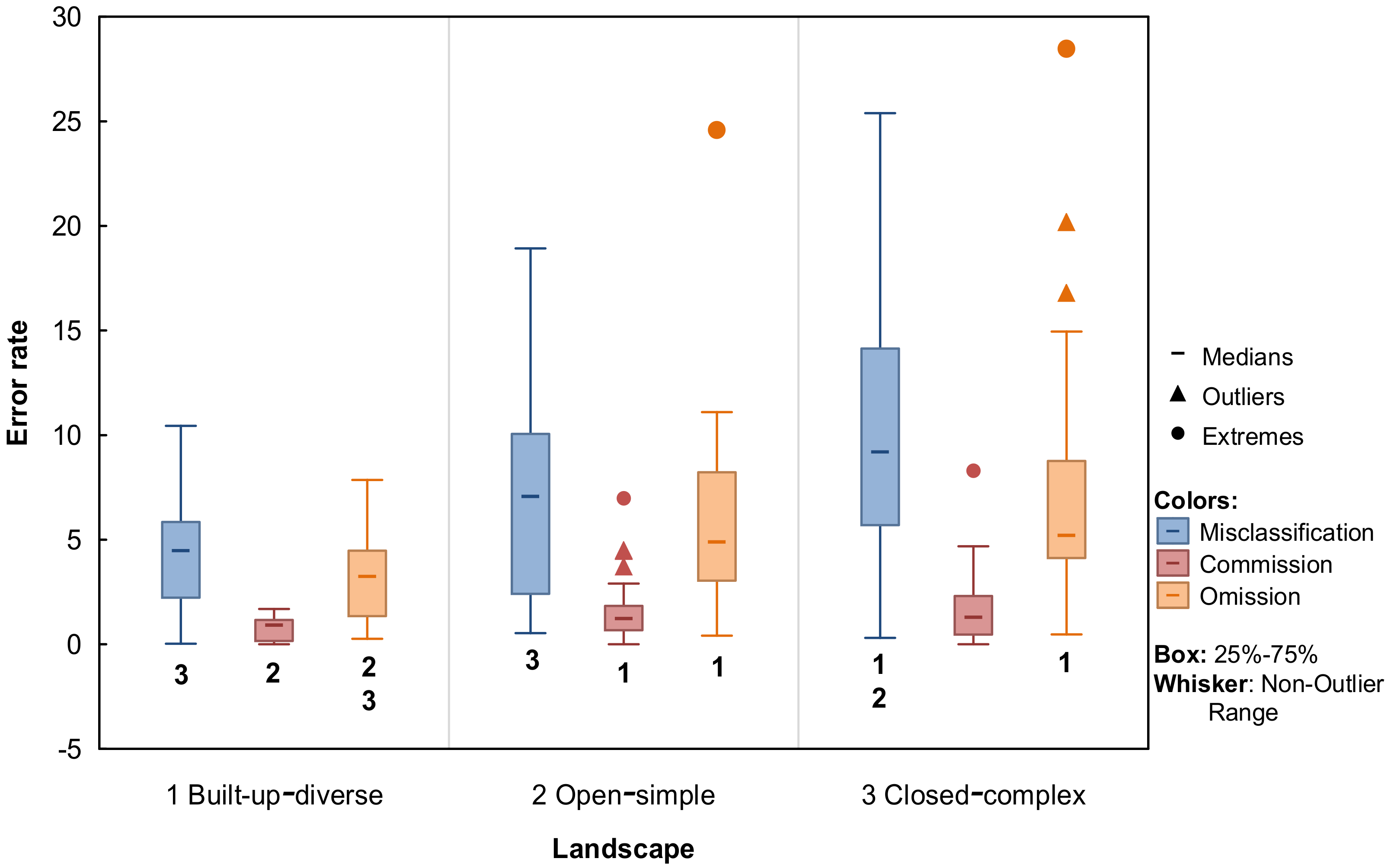
3.4. Misclassification, Commission, and Omission (MCO) Error Rates in Different Landscapes
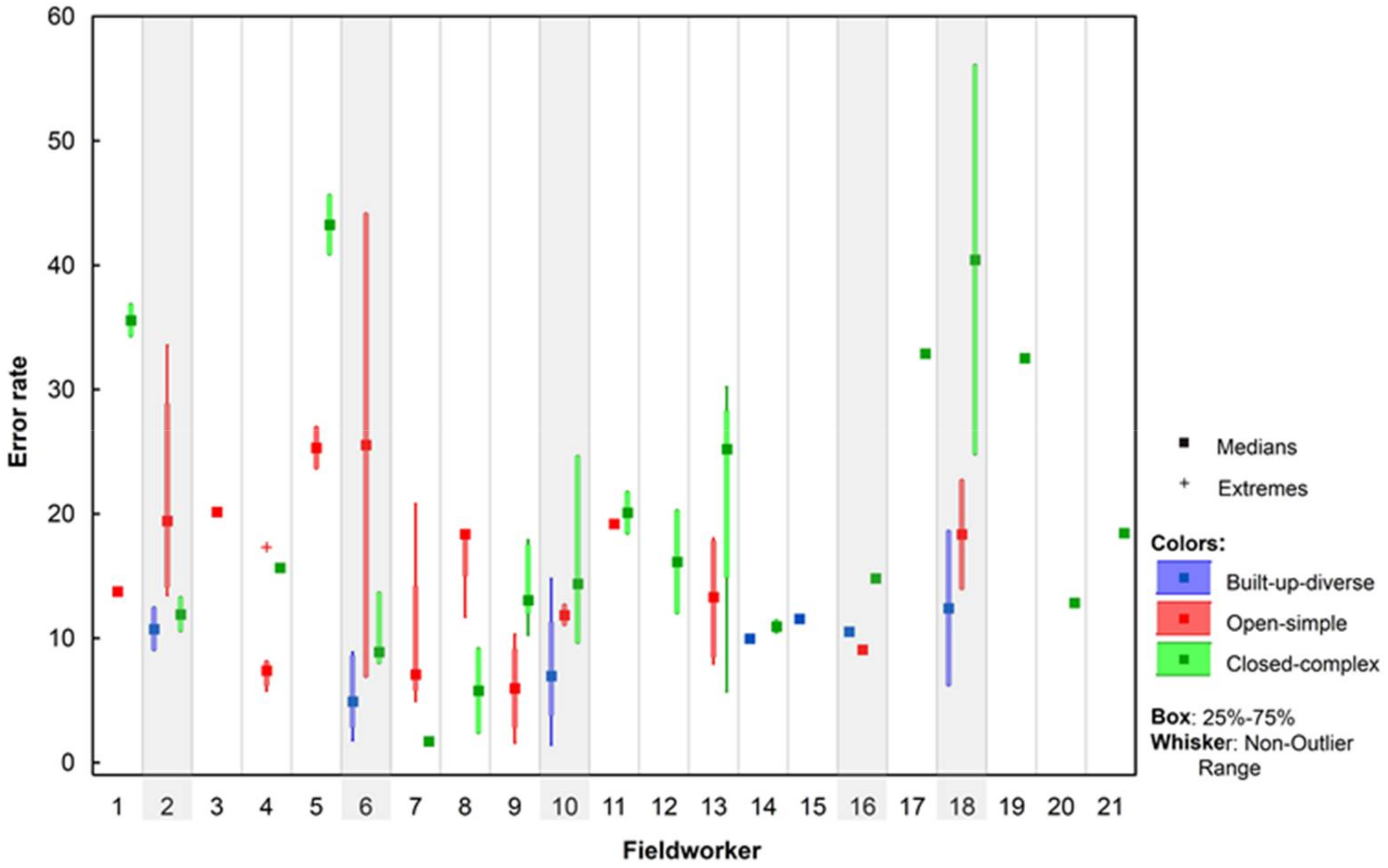
3.5. Misclassification, Commission, and Omission Error Rates among Field Workers in Different Landscapes
4. Discussion and Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Goodchild, M.F.; Gopal, S. Accuracy of Spatial Databases; Taylor and Francis: London, UK, 1989; ISBN 0-203-49023-1. [Google Scholar]
- Guptill, S.C.; Morrison, J.L.; Association, I.C. Elements of Spatial Data Quality; Guptill, S.C., Morrison, J.L., Eds.; Elsevier Science: New York, NY, USA, 1995; Volume 1, ISBN 9780080424323. [Google Scholar]
- Veregin, H. Data quality parameters. In Geographical Information Systems; Longley, P.A., Goodchild, M.F., Maguire, D.J., Rhind, D.W., Eds.; John Wiley & Sons: New York, NY, USA, 1999; pp. 177–190. ISBN 0471-33132-5. [Google Scholar]
- Shi, W.; Fisher, P.F.; Goodchild, M.F. Spatial Data Quality; Taylor & Francis: New York, NY, USA, 2002; ISBN 9780415258357. [Google Scholar]
- Devillers, R.; Jeansoulin, R. Fundamentals of Spatial Data Quality; ISTE: London, UK, 2006; ISBN 9781905209569. [Google Scholar]
- Shi, W.; Wu, B.; Stein, A. Uncertainty Modelling and Quality Control. for Spatial Data; CRC Press: Boca Raton, FL, USA, 2016; ISBN 9781498733281. [Google Scholar]
- Hunter, G.J.; Beard, K. Understanding error in spatial databases. Aust. Surv. 1992, 37, 108–119. [Google Scholar] [CrossRef]
- Collins, F.C.; Smith, J.L. Taxonomy for error in GIS. In International Symposium on Spatial Accuracy in Natural Resource Data Bases: Unlocking the Puzzle; Congalton, R.G., Ed.; American Society for Photogrammetry and Remote Sensing: Williamsburg, VA, USA, 1994; pp. 1–7. [Google Scholar]
- Fisher, P.F. Models of uncertainty in spatial data. In Geographical Information Systems; Longley, P.A., Goodchild, M.F., Maguire, D.J., Rhind, D.W., Eds.; John Wiley & Sons: New York, NY, USA, 1999; pp. 191–205. ISBN 9780470870013. [Google Scholar]
- MacEachren, A.M. Visualizing uncertain information. Cartogr. Perspect. 1992, 13, 10–19. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Clark, K.C. Data quality in massive data sets. In Handbook of Massive Data Sets; Abello, J., Pardalos, P.M., Resende, M.G.C., Eds.; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2002; pp. 643–659. ISBN 978-1-4020-0489-6. [Google Scholar]
- Devillers, R.; Beard, K. Communication and use of spatial data quality information in GIS. In Fundamentals of Spatial Data Quality; Devillers, R., Jeansoulin, R., Eds.; ISTE: London, UK, 2006; pp. 237–253. ISBN 9781905209569. [Google Scholar]
- Kresse, W.; Danko, D.M.; Fadaie, K. Standardization. In Springer Handbook of Geographical Information; Kresse, W., Danko, D.M., Eds.; Springer: New York, NY, USA, 2012; pp. 393–566. ISBN 978-3-540-72680-7. [Google Scholar]
- International Organization for Standardization. ISO 19157:2013 Geographic Information—Data Quality; ISO: Geneva, Switzerland, 2013. [Google Scholar]
- Senaratne, H.; Mobasheri, A.; Ali, A.L.; Capineri, C.; Haklay, M. A review of volunteered geographic information quality assessment methods. Int. J. Geogr. Inf. Sci. 2017, 31, 139–167. [Google Scholar] [CrossRef]
- Talhofer, V.; Hošková-Mayerová, S.; Hofmann, A. Improvement of digital geographic data quality. Int. J. Prod. Res. 2012, 50, 4846–4859. [Google Scholar] [CrossRef]
- Fonte, C.C.; Antoniou, V.; Bastin, L.; Estima, J.; Arsanjani, J.J.; Bayas, J.-C.L.; See, L.; Vatseva, R. Assessing VGI data quality. In Mapping and the Citizen Sensor; Foody, G., See, L., Fritz, S., Mooney, P., Olteanu-Raimond, A.-M., Fonte, C.C., Antoniou, V., Eds.; Ubiquity Press: London, UK, 2017; pp. 137–163. ISBN 978-1-911529-16-3. [Google Scholar]
- Mõisja, K.; Oja, T.; Uuemaa, E.; Hastings, J.T. Completeness and classification correctness of features on topographic maps: An analysis of the Estonian Basic Map. Trans. GIS 2017, 21, 954–968. [Google Scholar] [CrossRef]
- Estonian Land Board. Estonian Basic Map. Available online: https://geoportaal.maaamet.ee/index.php?page_id=306&lang_id=2 (accessed on 20 March 2018).
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Stehman, S.V. Sampling designs for accuracy assessment of land cover. Int. J. Remote Sens. 2009, 30, 5243–5272. [Google Scholar] [CrossRef]
- Van Oort, P.A.J.; Bregt, A.K.; De Bruin, S.; De Wit, A.J.W.; Stein, A. Spatial variability in classification accuracy of agricultural crops in the Dutch national land-cover database. Int. J. Geogr. Inf. Sci. 2004, 18, 611–626. [Google Scholar] [CrossRef]
- Haklay, M. How good is volunteered geographical information? A comparative study of OpenStreetMap and ordnance survey datasets. Environ. Plan. B Plan. Des. 2010, 37, 682–703. [Google Scholar] [CrossRef]
- Girres, J.F.; Touya, G. Quality assessment of the French OpenStreetMap dataset. Trans. GIS 2010, 14, 435–459. [Google Scholar] [CrossRef]
- Jackson, S.; Mullen, W.; Agouris, P.; Crooks, A.; Croitoru, A.; Stefanidis, A. Assessing completeness and spatial error of features in volunteered geographic information. ISPRS Int. J. Geo-Inf. 2013, 2, 507–530. [Google Scholar] [CrossRef]
- Dorn, H.; Törnros, T.; Zipf, A. Quality evaluation of VGI using authoritative data—A Comparison with land use data in southern Germany. ISPRS Int. J. Geo-Inf. 2015, 4, 1657–1671. [Google Scholar] [CrossRef]
- Robinson, A.H.; Morrison, J.L.; Muehrcke, P.C.; Kimerling, A.J.; Guptill, S.C. Elements of Cartography, 6th ed.; John Wiley & Sons: New York, NY, USA, 1995; ISBN 0471555797. [Google Scholar]
- Jakobsson, A.; Giversen, J. Guidelines for Implementing the ISO 19100 Geographic Information Quality Standards in National Mapping and Cadastral Agencies. Available online: http://www.eurogeographics.org (accessed on 20 March 2018).
- Pätynen, V.; Kemppainen, I.; Ronkainen, R. Testing for completeness and thematic accuracy of the national topographic data system in Finland. In Proceedings of the 18th International Cartographic Conference, Stockholm, Sweden, 23–27 June 1997; Ottoson, L., Ed.; Gävle Offset AB: Gävle, Sweden, 1997; pp. 1360–1367. [Google Scholar]
- Stevens, J.P.; Blackstock, T.H.; Howe, E.A.; Stevens, D.P. Repeatability of Phase 1 habitat survey. J. Environ. Manag. 2004, 73, 53–59. [Google Scholar] [CrossRef] [PubMed]
- Kyriakidis, P.C.; Dungan, J.L. A geostatistical approach for mapping thematic classification accuracy and evaluating the impact of inaccurate spatial data on ecological model predictions. Environ. Ecol. Stat. 2001, 8, 311–330. [Google Scholar] [CrossRef]
- Smith, J.H.; Wickham, J.D.; Stehman, S.V.; Yang, L. Impacts of patch size and land-cover heterogeneity on thematic image classification accuracy. Photogramm. Eng. Remote Sens. 2002, 68, 65–70. [Google Scholar]
- Tran, T.; Julian, J.; de Beurs, K. Land cover heterogeneity effects on sub-pixel and per-pixel classifications. ISPRS Int. J. Geo-Inf. 2014, 3, 540–553. [Google Scholar] [CrossRef]
- Cherrill, A.; Mcclean, C. Between-observer variation in the application of a standard method of habitat mapping by environmental consultants in the UK. J. Appl. Ecol. 1999, 36, 989–1008. [Google Scholar] [CrossRef]
- Hearn, S.M.; Healey, J.R.; McDonald, M.A.; Turner, A.J.; Wong, J.L.G.; Stewart, G.B. The repeatability of vegetation classification and mapping. J. Environ. Manag. 2011, 92, 1174–1184. [Google Scholar] [CrossRef] [PubMed]
- Lawton, C.A. Gender differences in way-finding strategies: Relationship to spatial ability and spatial anxiety. Sex Roles 1994, 30, 765–779. [Google Scholar] [CrossRef]
- Coluccia, E.; Louse, G. Gender differences in spatial orientation: A review. J. Environ. Psychol. 2004, 24, 329–340. [Google Scholar] [CrossRef]
- Coluccia, E.; Iosue, G.; Brandimonte, M.A. The relationship between map drawing and spatial orientation abilities: A study of gender differences. J. Environ. Psychol. 2007, 27, 135–144. [Google Scholar] [CrossRef]
- Matthews, M.H. The influence of gender on the environmental cognition of young boys and girls. J. Genet. Psychol. 1986, 147, 295–302. [Google Scholar] [CrossRef]
- Reilly, D.; Neumann, D.L.; Andrews, G. Gender Differences in Spatial Ability: Implications for STEM Education and Approaches to Reducing the Gender Gap for Parents and Educators. In Visual-Spatial Ability: Transforming Research into Practice; Khine, M.S., Ed.; Springer International: Basel, Switzerland, 2017; pp. 195–224. [Google Scholar]
- Mõisja, K. Estonian Basic Map and its quality management. Trans. Estonia Agric. Univ. 2016 Balt. Surv. ’03 2003, 216, 135–142. [Google Scholar]
- Mardiste, H. Consequences of the Soviet map secrecy to national cartography in Estonia. In Geheimhaltung und Staatssicherheit. Zur Kartographie des Kaltes Krieges. Archiv zur DDR-Staatssicherheit; Unverhau, D., Ed.; LIT Verlag 9.1: Münster, Germany, 2009; pp. 107–118. ISBN 9783643100702. [Google Scholar]
- Li, D.; Zhang, J.; Wu, H. Spatial data quality and beyond. Int. J. Geogr. Inf. Sci. 2012, 26, 2277–2290. [Google Scholar] [CrossRef]
- Mander, Ü.; Uuemaa, E.; Kull, A.; Kanal, A.; Maddison, M.; Soosaar, K.; Salm, J.-O.; Lesta, M.; Hansen, R.; Kuller, R.; et al. Assessment of methane and nitrous oxide fluxes in rural landscapes. Landsc. Urban Plan. 2010, 98, 172–181. [Google Scholar] [CrossRef]
- Estonian Land Board. Eesti Põhikaardi 1:10,000 Digitaalkaardistuse Juhend. Available online: http://geoportaal.maaamet.ee/est/Andmed-ja-kaardid/Topograafilised-andmed/Eesti-pohikaart-110-000/Juhendid-ja-abifailid-p130.html (accessed on 2 April 2018).
- Mõisja, K.; Uuemaa, E.; Oja, T. Integrating small-scale landscape elements into land use/cover: The impact on landscape metrics’ values. Ecol. Indic. 2016, 67, 714–722. [Google Scholar] [CrossRef]
- McGarigal, K.; Cushman, S.A.; Neel, M.C.; Ene, E. FRAGSTATS v4: Spatial Pattern Analysis Program for Categorical and Continuous Maps; Umass Landscape Ecology Lab: Amherst, MA, USA, 2012. [Google Scholar]
- Rempel, R.S.; Kaukinen, D.; Carr, A.P. Patch Analyst and Patch Grid; Ontario Ministry of Natural Resources, Centre for Northern Forest Ecosystem Research: Ontario, CA, USA, 2012. [Google Scholar]
- Bishop, C.M. Neural networks for pattern recognition. J. Am. Stat. Assoc. 1995, 92, 1642–1645. [Google Scholar]
- StataCorp LP. StataCorp LP Stata Statistical Software: Release 12; StataCorp LP: College Station, TX, USA, 2011. [Google Scholar]
- Riitters, K.H.; O’Neill, R.V.; Hunsaker, C.T.; Wickham, J.D.; Yankee, D.H.; Timmins, S.P.; Jones, K.B.; Jackson, B.L. A factor analysis of landscape pattern and structure metrics. Landsc. Ecol. 1995, 10, 23–39. [Google Scholar] [CrossRef]
- Lausch, A.; Herzog, F. Applicability of landscape metrics for the monitoring of landscape change: Issues of scale, resolution and interpretability. Ecol. Indic. 2002, 2, 3–15. [Google Scholar] [CrossRef]
- Cushman, S.A.; McGarigal, K.; Neel, M.C. Parsimony in landscape metrics: Strength, universality, and consistency. Ecol. Indic. 2008, 8, 691–703. [Google Scholar] [CrossRef]
- Schindler, S.; Poirazidis, K.; Wrbka, T. Towards a core set of landscape metrics for biodiversity assessments: A case study from Dadia National Park, Greece. Ecol. Indic. 2008, 8, 502–514. [Google Scholar] [CrossRef]
- Fisher, P.; Comber, A.; Wadsworth, R. Approaches to uncertainty in spatial data. In Fundamentals of Spatial Data Quality; Devillers, R., Jeansoulin, R., Eds.; ISTE: London, UK, 2006; pp. 43–59. ISBN 9781905209569. [Google Scholar]
- Cherrill, A. Inter-observer variation in habitat survey data: Investigating the consequences for professional practice. J. Environ. Plan. Manag. 2016, 59, 1813–1832. [Google Scholar] [CrossRef]
- Antoniou, V.; Skopeliti, A. Measures and indicators of VGI quality: An overview. In Proceedings of the ISPRS Annals of Photogrammetry, Remote Sensing and Spatial Information Sciences, La Grande Motte, France, 28 September–3 October 2015; Volume II-3/W5, pp. 345–351. [Google Scholar]
- Schmitz, S. Gender-related strategies in environmental development: Effects of anxiety on wayfinding in and representation of a three-dimensional maze. J. Environ. Psychol. 1997, 17, 215–228. [Google Scholar] [CrossRef]
- Lawton, C.A.; Kallai, J. Gender differences in wayfinding strategies and anxiety about wayfinding: A cross-cultural comparison. Sex Roles 2002, 47, 389–401. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Quality Element | Quality Measure |
|---|---|
| Misclassification | Error rate of lines |
| Error rate of points | |
| Error rate of polygons | |
| Omission | Error rate of lines |
| Error rate of points | |
| Commission | Error rate of lines |
| Error rate of points |
| Landscape Indicator Type | Landscape Indicator |
|---|---|
| Diversity metrics | SDI: Shannon’s diversity index |
| SEI: Shannon’s evenness index | |
| Shape metrics | AWMSI: area-weighted mean shape index |
| MSI: mean shape index | |
| MPAR: mean perimeter–area ratio | |
| MPFD: mean patch fractal dimension | |
| AWMPFD: area-weighted mean patch fractal dimension | |
| Edge metrics | ED: edge density |
| MPE: mean patch edge | |
| Patch density and size metrics | MPS: mean patch size |
| PD: patch density | |
| PRD: patch richness density | |
| MedPS: median patch size | |
| PSCoV: patch size coefficient of variance | |
| PSSD: patch size standard deviation | |
| Land use composition | OV: proportion of land use creating open viewsheds in the landscape |
| CV: proportion of land use creating closed viewsheds in the landscape | |
| BU: proportion of built-up areas in the landscape |
| Factor Number | ||||
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |
| Diversity | Patch Size Distribution | Closure | Patch Shape Complexity | |
| Eigenvalue | 6.93 | 4.39 | 2.43 | 1.06 |
| Cumulative % of variance | 38.52 | 62.92 | 76.41 | 82.32 |
| % Total variance | 38.52 | 24.40 | 13.49 | 5.91 |
| Factor Loadings (after Varimax Rotation) | ||||
| SDI | 0.92 | 0.12 | −0.07 | 0.11 |
| SEI | 0.90 | 0.04 | 0.01 | 0.17 |
| AWMSI | 0.41 | 0.56 | 0.10 | −0.04 |
| MSI | −0.07 | 0.09 | 0.30 | 0.90 |
| MPAR | −0.10 | −0.78 | 0.00 | 0.51 |
| MPFD | 0.22 | 0.86 | 0.29 | −0.06 |
| AWMPFD | 0.83 | −0.34 | 0.14 | −0.22 |
| ED | 0.94 | 0.17 | 0.15 | −0.05 |
| MPE | −0.36 | 0.71 | 0.40 | 0.37 |
| MPS | −0.76 | 0.43 | 0.10 | 0.26 |
| MedPS | −0.32 | 0.38 | 0.46 | 0.21 |
| PSCoV | −0.03 | 0.92 | −0.04 | 0.07 |
| PSSD | −0.51 | 0.75 | 0.06 | 0.20 |
| PRD | 0.15 | −0.74 | −0.03 | −0.31 |
| PD | 0.92 | −0.14 | −0.13 | −0.23 |
| OV | −0.15 | −0.10 | −0.94 | −0.08 |
| CV | 0.65 | −0.02 | −0.45 | −0.33 |
| BU | −0.10 | 0.08 | 0.92 | 0.19 |
| Landscape Indicator or Factor | Cluster 1 | Cluster 2 | Cluster 3 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Built-Up-Diverse | Open-Simple | Closed-Complex | |||||||
| (N = 17; FW = 7) | (N = 37; FW = 14) | (N = 39; FW = 19) | |||||||
| Mean | St.Dev. | Variance | Mean | St.Dev. | Variance | Mean | St.Dev. | Variance | |
| Built-up area | 1.63 | 1.19 | 1.41 | −0.34 | 0.44 | 0.2 | −0.39 | 0.42 | 0.18 |
| Diversity | 1.3 | 1.01 | 1.02 | −0.68 | 0.67 | 0.45 | 0.08 | 0.58 | 0.34 |
| Patch size distribution | 0.07 | 0.98 | 0.96 | 0.63 | 0.99 | 0.97 | −0.63 | 0.54 | 0.29 |
| Closure | −0.59 | 0.51 | 0.26 | −0.37 | 0.81 | 0.66 | 0.6 | 1.01 | 1.03 |
| Patch complexity | −0.44 | 0.84 | 0.71 | −0.06 | 0.74 | 0.54 | 0.25 | 1.21 | 1.46 |
| Field Worker ID | Gender | Years of Experience | Total Number of Inspected Sites | Number of Sites in the Landscape | ||
|---|---|---|---|---|---|---|
| Built-Up-Diverse | Open-Simple | Closed-Complex | ||||
| 1 | M | 6 | 3 | 0 | 1 | 2 |
| 2 | F | 6 | 8 | 2 | 4 | 2 |
| 3 | M | 5 | 1 | 0 | 1 | 0 |
| 4 | M | 2 | 6 | 0 | 5 | 1 |
| 5 | M | 4 | 4 | 0 | 2 | 2 |
| 6 | M | 7 | 11 | 6 | 2 | 3 |
| 7 | M | 7 | 5 | 0 | 4 | 1 |
| 8 | F | 11 | 6 | 0 | 4 | 2 |
| 9 | M | 7 | 10 | 0 | 4 | 6 |
| 10 | M | 7 | 9 | 4 | 2 | 3 |
| 11 | M | 5 | 3 | 0 | 1 | 2 |
| 12 | M | 5 | 2 | 0 | 0 | 2 |
| 13 | M | 6 | 8 | 0 | 4 | 4 |
| 14 | M | 7 | 3 | 1 | 0 | 2 |
| 15 | F | 7 | 1 | 1 | 0 | 0 |
| 16 | F | 8 | 3 | 1 | 1 | 1 |
| 17 | M | 3 | 1 | 0 | 0 | 1 |
| 18 | F | 8 | 6 | 2 | 2 | 2 |
| 19 | M | 5 | 1 | 0 | 0 | 1 |
| 20 | F | 8 | 1 | 0 | 0 | 1 |
| 21 | M | 7 | 1 | 0 | 0 | 1 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mõisja, K.; Uuemaa, E.; Oja, T. The Implications of Field Worker Characteristics and Landscape Heterogeneity for Classification Correctness and the Completeness of Topographical Mapping. ISPRS Int. J. Geo-Inf. 2018, 7, 205. https://doi.org/10.3390/ijgi7060205
Mõisja K, Uuemaa E, Oja T. The Implications of Field Worker Characteristics and Landscape Heterogeneity for Classification Correctness and the Completeness of Topographical Mapping. ISPRS International Journal of Geo-Information. 2018; 7(6):205. https://doi.org/10.3390/ijgi7060205
Chicago/Turabian StyleMõisja, Kiira, Evelyn Uuemaa, and Tõnu Oja. 2018. "The Implications of Field Worker Characteristics and Landscape Heterogeneity for Classification Correctness and the Completeness of Topographical Mapping" ISPRS International Journal of Geo-Information 7, no. 6: 205. https://doi.org/10.3390/ijgi7060205
APA StyleMõisja, K., Uuemaa, E., & Oja, T. (2018). The Implications of Field Worker Characteristics and Landscape Heterogeneity for Classification Correctness and the Completeness of Topographical Mapping. ISPRS International Journal of Geo-Information, 7(6), 205. https://doi.org/10.3390/ijgi7060205