Spatial Characteristics of Twitter Users—Toward the Understanding of Geosocial Media Production

Abstract
1. Introduction
- Can geosocial content be treated as a single spatial representation or is this an averaged product of separate groups of users, very different in respect to their mode of social media use—in both spatial and non-spatial contexts? If the latter is true, it may indicate that a different research methodology is needed in the analysis of such data.
- What are the spatial characteristics of geosocial media producers? This can possibly allow us to identify various spatial behavior types for Twitter users.
- Is there a relation between the spatial behavior and posting activity of Twitter users? Are more active users also more mobile? If they are mobile and traveling while posting, this may suggest that the personal location information is used as a form of communication or even as a resource to increase their level of social capital [34]. If there is no such relation, this may indicate that user location may not be as important in the social media environment and by extension in research.
- Do these characteristics vary between different socio-spatial contexts? Investigating Twitter populations in cities with very different histories and geographies in various parts of the Europe gives us the opportunity to observe whether they have any impact on user behavior.
- If there are different groups of geosocial media producers or there are differences between socio-spatial contexts, this may introduce biases. In what respect may these biases influence the analysis of geosocial media data?
2. Methods
2.1. Data Gathering Process
2.2. Statistical Analysis
- Standard distance deviation (SDD)—calculated by using the calc_sdd function from R package aspace [37]. We used this parameter as a basic measure of spatial behavior. Although it can be strongly influenced by outliers, it can be used to quantify mobility of the Twitter users.
- Estimated home range (HR)—we used 75% home range from the utilization distribution calculated by the kernel method using the kernelUD function from R package adehabitatHR [38]. This value measures how large is the area in which users generate geosocial content and therefore can indicate how mobile they are. It is worth mentioning that contrary to its usage in ecological modeling we do not measure real spatial behavior but behavior in geosocial media, which may not be an accurate reflection of the former.
- Nearest Neighbor Index (NNI)—was used as a simple measure of spatial clustering, Although shape and structure of the urban space influences this parameter, it can be used to differentiate between user groups, for example, tourists that tweet from many places around the city and residents that tweet mainly from workplace and home. NNI was calculated by the following formula [39]:where d(NN) is Nearest Neighbor Distance and d(ran) Mean Random Distance—calculated as follows:where Min(dij) is the distance between given point and its nearest neighbor and N is the number of points in the distribution,where A is the area of the region and N is the number of points. It was not practical to calculate NNI for D2, since bounding boxes based on point distribution would be too greatly deformed by single outliers.
- Most frequently used language (Mode) of all machines detected (by Twitter) languages used for tweeting. For more than one mode, we applied the user declared language. We hoped that this will help us differentiate between local residents and visitors, but in the analysis this proved to not be the case. We believe that this is due to the fact that many tourists speak and tweet in the same language as the residents and in the same time many residents tweet in English—the most popular language of the Twitter population.
- Preferred time of the day for tweeting (Time)—posting time of each tweet was assigned to one of the three categories: daytime (6 a.m.–5 p.m.) evening (7 p.m.–12 p.m.) or nighttime (12 a.m.–5 a.m.), and users were classified based on the maximum value among the three periods. This parameter was hypothesized as being dependent upon socio-spatial characteristics of a city, with different values in western and post-socialist cities.
- Number of tweets (N)—an important characteristic that can indicate outliers and main producers of geolocated content,
- Number of followers (F)—this was used as an indicator of spam accounts, that is, users with large number of tweets and 0 followers.
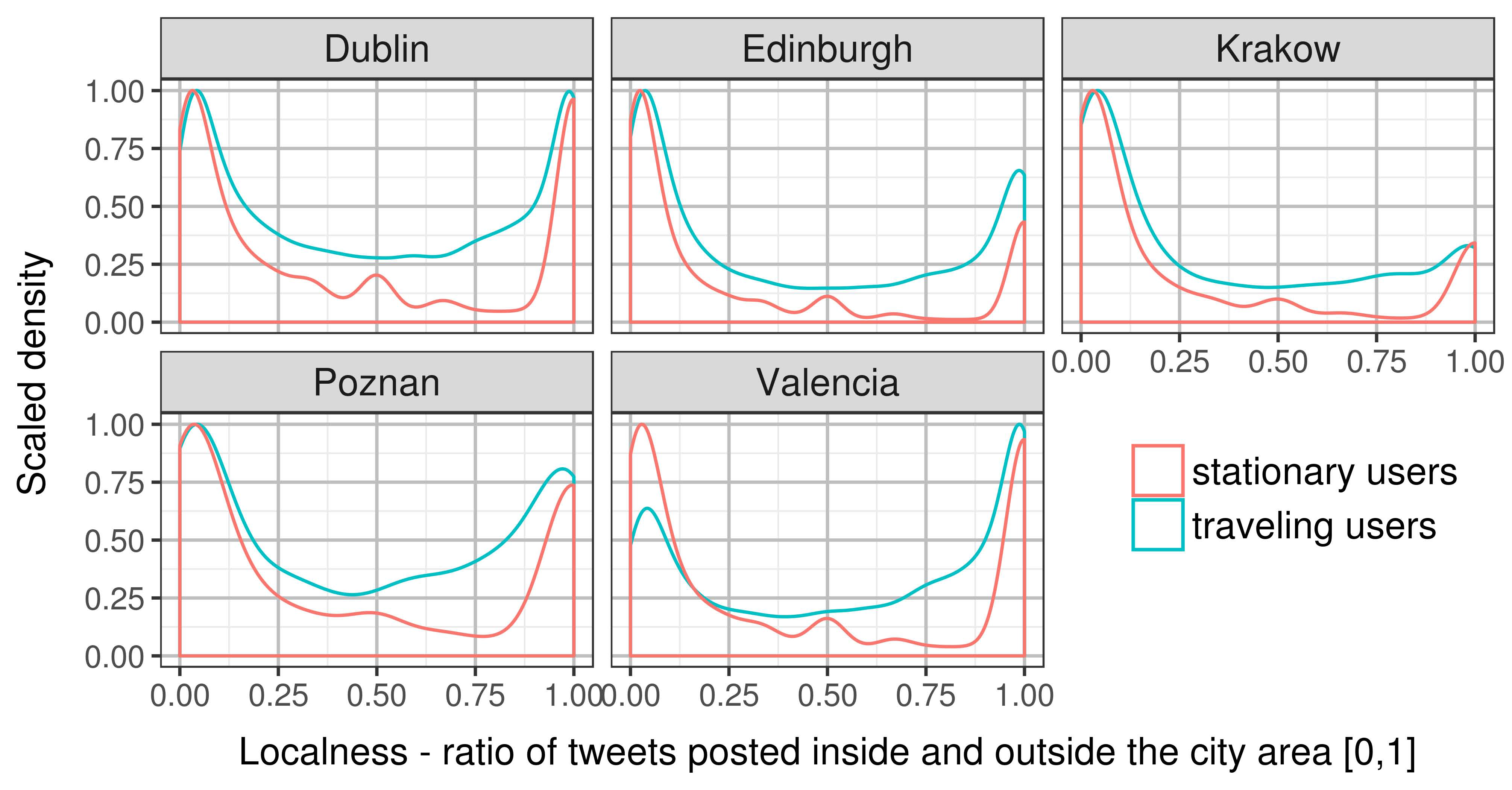
- Localness—defined as the ratio [0, 1] of tweets in D1 in comparison to D2; a value of 1 indicated that user post tweets only within a single city bounding box. This parameter was constructed to aid in discriminating between local residents and visitors. While it is entirely possible that users with low localness index are in fact city-dwellers that are only tweeting while traveling, we assumed that this will have marginal effect on the data.
3. Results
3.1. Twitter Users in Different Spatial Contexts
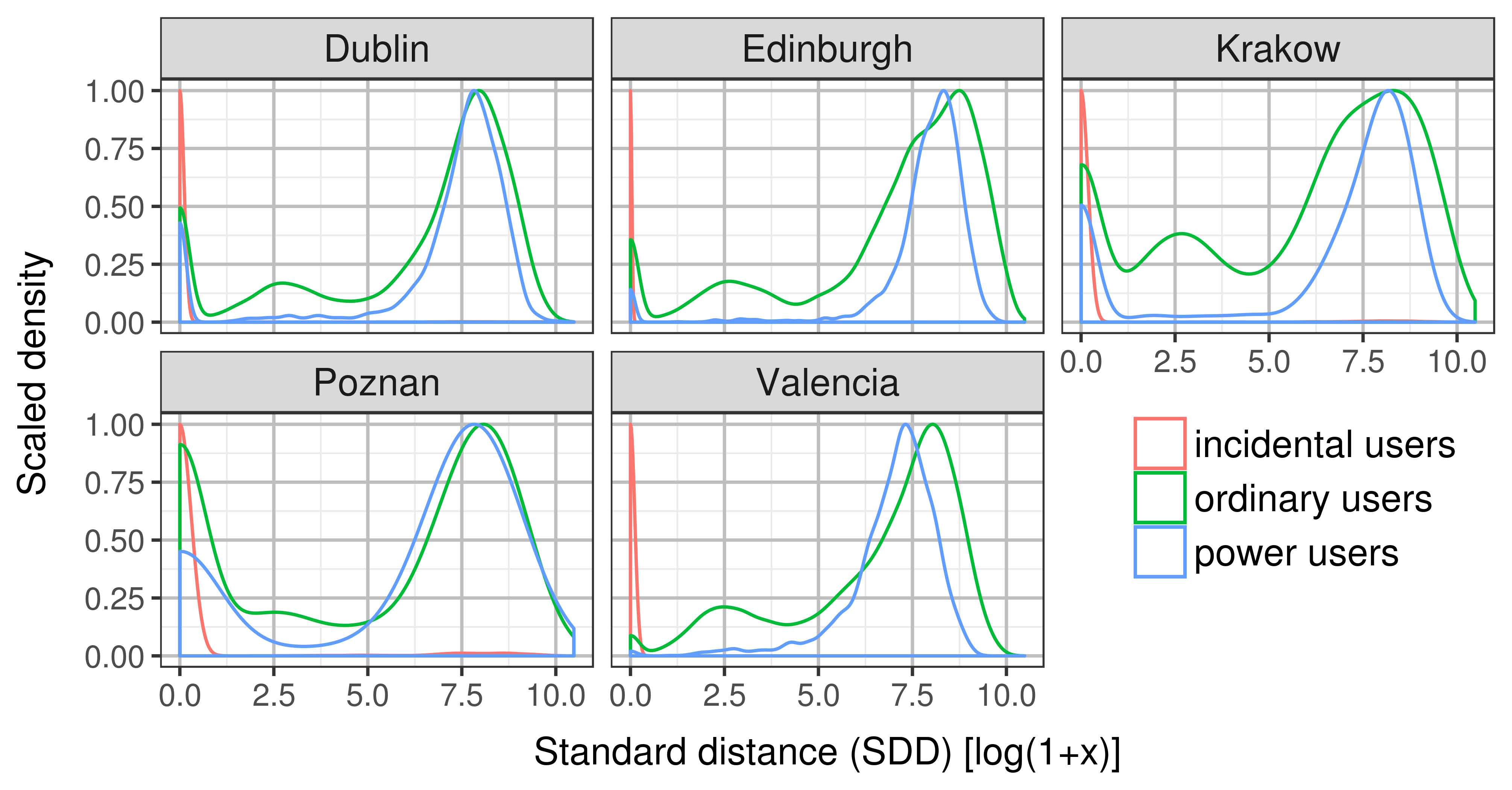
3.2. Spatial Classification of Twitter Users
4. Conclusions and Discussion
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Mayer-Schönberger, V.; Cukier, K. Big Data: A Revolution that Will Transform How We Live, Work, And Think; Houghton Mifflin Harcourt: Boston, MA, USA, 2013. [Google Scholar]
- Kitchin, R. The Data Revolution; SAGE Publications Ltd.: Thousand Oaks, CA, USA, 2014; ISBN 978-1-4462-8748-4. [Google Scholar]
- Kitchin, R. Big data and human geography: Opportunities, challenges and risks. Dialogues Hum. Geogr. 2013, 3, 262–267. [Google Scholar] [CrossRef]
- Gonzalez-Bailon, S. Big data and the fabric of human geography. Dialogues Hum. Geogr. 2013, 3, 292–296. [Google Scholar] [CrossRef]
- Ruppert, E. Rethinking empirical social sciences. Dialogues Hum. Geogr. 2013, 3, 268–273. [Google Scholar] [CrossRef]
- Housley, W.; Procter, R.; Edwards, A.; Burnap, P.; Williams, M.; Sloan, L.; Rana, O.; Morgan, J.; Voss, A.; Greenhill, A. Big and broad social data and the sociological imagination: A collaborative response. Big Data Soc. 2014, 1. [Google Scholar] [CrossRef]
- Asur, S.; Huberman, B.A. Predicting the future with social media. In Proceedings of the 2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT), Toronto, ON, Canada, 31 August–3 September 2010; Volume 1, pp. 492–499. [Google Scholar]
- O’Connor, B.; Balasubramanyan, R.; Routledge, B.R.; Smith, N.A. From tweets to polls: Linking text sentiment to public opinion time series. ICWSM 2010, 11, 1–2. [Google Scholar]
- Achrekar, H.; Gandhe, A.; Lazarus, R.; Yu, S.-H.; Liu, B. Predicting flu trends using twitter data. In Proceedings of the 2011 IEEE Conference on the Computer Communications Workshops (INFOCOM WKSHPS), Shanghai, China, 10–15 April 2011; pp. 702–707. [Google Scholar]
- De Albuquerque, J.P.; Herfort, B.; Brenning, A.; Zipf, A. A geographic approach for combining social media and authoritative data towards identifying useful information for disaster management. Int. J. Geogr. Inf. Sci. 2015, 29, 667–689. [Google Scholar] [CrossRef]
- Gordon, E.; de Souza e Silva, A. Net Locality: Why Location Matters in a Networked World; Wiley-Blackwell: Chichester, MA, USA, 2011; ISBN 978-1-4051-8061-0. [Google Scholar]
- Sui, D.; Goodchild, M. The convergence of GIS and social media: Challenges for GIScience. Int. J. Geogr. Inf. Sci. 2011, 25, 1737–1748. [Google Scholar] [CrossRef]
- Hudson-Smith, A.; Batty, M.; Crooks, A.; Milton, R. Mapping for the Masses. Soc. Sci. Comput. Rev. 2009, 27, 524–538. [Google Scholar] [CrossRef]
- Morstatter, F.; Pfeffer, J.; Liu, H.; Carley, K.M. Is the Sample Good Enough? Comparing Data from Twitter’s Streaming API with Twitter’s Firehose. In Proceedings of the 7th International AAAI Conference on Weblogs and Social Media, ICWSM 2013, Cambridge, MA, USA, 8–11 July 2013. [Google Scholar]
- Sloan, L.; Morgan, J. Who Tweets with Their Location? Understanding the Relationship between Demographic Characteristics and the Use of Geoservices and Geotagging on Twitter. PLoS ONE 2015, 10, e0142209. [Google Scholar] [CrossRef] [PubMed]
- Boyd, D.; Crawford, K. Critical questions for big data: Provocations for a cultural, technological, and scholarly phenomenon. Inf. Commun. Soc. 2012, 15, 662–679. [Google Scholar] [CrossRef]
- Goodchild, M.F. The quality of big (geo) data. Dialogues Hum. Geogr. 2013, 3, 280–284. [Google Scholar] [CrossRef]
- Barnes, T.J. Big data, little history. Dialogues Hum. Geogr. 2013, 3, 297–302. [Google Scholar] [CrossRef]
- Hollenstein, L.; Purves, R. Exploring place through user-generated content: Using Flickr tags to describe city cores. J. Spat. Inf. Sci. 2010, 2010, 21–48. [Google Scholar]
- Xiang, Z.; Gretzel, U. Role of social media in online travel information search. Tour. Manag. 2010, 31, 179–188. [Google Scholar] [CrossRef]
- Frias-Martinez, V.; Soto, V.; Hohwald, H.; Frias-Martinez, E. Characterizing urban landscapes using geolocated tweets. In Proceedings of the 2012 International Conference on Privacy, Security, Risk and Trust (PASSAT) and 2012 International Confernece on Social Computing (SocialCom), Amsterdam, The Netherlands, 3–5 September 2012; pp. 239–248. [Google Scholar]
- Hawelka, B.; Sitko, I.; Beinat, E.; Sobolevsky, S.; Kazakopoulos, P.; Ratti, C. Geo-located Twitter as proxy for global mobility patterns. Cartogr. Geogr. Inf. Sci. 2014, 41, 260–271. [Google Scholar] [CrossRef] [PubMed]
- Steiger, E.; Ellersiek, T.; Resch, B.; Zipf, A. Uncovering latent mobility patterns from twitter during mass events. GI Forum 2015, 1, 525–534. [Google Scholar] [CrossRef]
- Li, Y.; Li, Q.; Shan, J. Discover Patterns and Mobility of Twitter Users—A Study of Four US College Cities. ISPRS Int. J. Geo-Inf. 2017, 6, 42. [Google Scholar] [CrossRef]
- Stefanidis, A.; Crooks, A.; Radzikowski, J. Harvesting ambient geospatial information from social media feeds. GeoJournal 2013, 78, 319–338. [Google Scholar] [CrossRef]
- Mislove, A.; Lehmann, S.; Ahn, Y.-Y.; Onnela, J.-P.; Rosenquist, J.N. Understanding the Demographics of Twitter Users. ICWSM 2011, 11, 5. [Google Scholar]
- Kulshrestha, J.; Kooti, F.; Nikravesh, A.; Gummadi, P.K. Geographic Dissection of the Twitter Network. In Proceedings of the Sixth International AAAI Conference on Weblogs and Social Media, Dublin, Ireland, 4–8 June 2012. [Google Scholar]
- Hofer, B.; Lampoltshammer, T.J.; Belgiu, M. Demography of Twitter Users in the City of London: An Exploratory Spatial Data Analysis Approach. In Modern Trends in Cartography; Brus, J., Vondrakova, A., Vozenilek, V., Eds.; Springer: Cham, Switzerland, 2015; pp. 199–211. ISBN 978-3-319-07925-7. [Google Scholar]
- Longley, P.A.; Adnan, M.; Lansley, G. The geotemporal demographics of Twitter usage. Environ. Plan. A 2015, 47, 465–484. [Google Scholar] [CrossRef]
- Graham, M.; Hale, S.A.; Gaffney, D. Where in the world are you? Geolocation and language identification in Twitter. Prof. Geogr. 2014, 66, 568–578. [Google Scholar] [CrossRef]
- Robertson, C.; Feick, R. Bumps and bruises in the digital skins of cities: Unevenly distributed user-generated content across US urban areas. Cartogr. Geogr. Inf. Sci. 2016, 43, 283–300. [Google Scholar] [CrossRef]
- Kitchin, R.; Dodge, M. Code/Space: Software and Everyday Life; Software Studies; MIT Press: Cambridge, MA, USA, 2011; ISBN 978-0-262-04248-2. [Google Scholar]
- Michelle, F. Technologies of the Self: A Seminar with Michel Foucault; Foucault, M., Martin, L.H., Gutman, H., Hutton, P.H., Eds.; University of Massachusetts Press: Amherst, MA, USA, 1988; ISBN 978–0-87023–592–4. [Google Scholar]
- Leighton, E. Locative Social Media; Palgrave Mcmilan: Basingstoke, UK, 2015. [Google Scholar]
- Beluch, L. Twitter Jako Zródlo Informacji Geograficznej/the Twitter as a Source of Geographic Information. Pr. Geogr. 2015, 7, 7–24. [Google Scholar]
- Zafarani, R.; Abbasi, M.A.; Liu, H. Social Media Mining: An Introduction; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Bui, R.; Buliung, R.N.; Remmel, T.K.; Buliung, M.R.N. Aspace: A Collection of Functions for Estimating Centrographic Statistics and Computational Geometries for Spatial Point Patterns, R Package Version 3.2; CRAN, 2012. Available online: https://cran.r-project.org/web/packages/aspace/index.html (accessed on 1 December 2012).
- Calenge, C. The package “adehabitat” for the R software: A tool for the analysis of space and habitat use by animals. Ecol. Model. 2006, 197, 516–519. [Google Scholar] [CrossRef]
- Levine, N. CrimeStat III; Ned Levine Association: Houston, TX, USA; National Institute of Justice: Washington, DC, USA, 2004.
- Warf, B. Segueways into cyberspace: Multiple geographies of the digital divide. Environ. Plan. B Plan. Des. 2001, 28, 3–19. [Google Scholar] [CrossRef]
- Dimitrova, D.V.; Beilock, R. Where Freedom Matters: Internet Adoption among the Former Socialist Countries. Int. Commun. Gaz. 2005, 67, 173–187. [Google Scholar] [CrossRef]
- Graham, M. Time machines and virtual portals the spatialities of the digital divide. Prog. Dev. Stud. 2011, 11, 211–227. [Google Scholar] [CrossRef]
- Liu, Y.; Kliman-Silver, C.; Mislove, A. The Tweets They Are a-Changin: Evolution of Twitter Users and Behavior. ICWSM 2014, 30, 5–314. [Google Scholar]
- Calenge, C. Home Range Estimation in R: The Adehabitathr Package; Office National de la Classe et de la Faune Sauvage: Saint Benoist, Auffargis, France, 2011. [Google Scholar]
- Graham, M.; Zook, M. Visualizing global cyberscapes: Mapping user-generated placemarks. J. Urban Technol. 2011, 18, 115–132. [Google Scholar] [CrossRef]
- Welles, B.F. On minorities and outliers: The case for making Big Data small. Big Data Soc. 2014, 1. [Google Scholar] [CrossRef]
- Agresti, A. An Introduction to Categorical Data Analysis, 2nd ed.; Wiley Series in Probability and Mathematical Statistics; Wiley-Interscience: Hoboken, NJ, USA, 2007; ISBN 978-0-471-22618-5. [Google Scholar]
- Cohen, J. Statistical Power Analysis for the Social Sciences, 2nd ed.; Erlbaum: Hillsdale, NJ, USA, 1988. [Google Scholar]
- Graham, M. Geography/internet: Ethereal alternate dimensions of cyberspace or grounded augmented realities? Geogr. J. 2013, 179, 177–182. [Google Scholar] [CrossRef]
- Yin, J.; Gao, Y.; Du, Z.; Wang, S. Exploring Multi-Scale Spatiotemporal Twitter User Mobility Patterns with a Visual-Analytics Approach. ISPRS Int. J. Geo-Inf. 2016, 5, 187. [Google Scholar] [CrossRef]
- Zhang, W.; Gelernter, J. Geocoding location expressions in Twitter messages: A preference learning method. J. Spat. Inf. Sci. 2014, 2014, 37–70. [Google Scholar]
- Rzeszewski, M. Geosocial capta in geographical research—A critical analysis. Cartogr. Geogr. Inf. Sci. 2016, 1–13. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| City | Population | Area [km2] | Twitter Points | Twitter Population | Tweets Per User | Mean SDD [km] | Mean HR [km2] | Mean NNI | Localness |
|---|---|---|---|---|---|---|---|---|---|
| Dublin | 530,000 | 115 | 1,647,376 | 77,893 | 21 | 1.40 | 13.26 | 0.12 | 0.46 |
| Edinburgh | 478,000 | 263 | 1,291,392 | 68,847 | 19 | 1.93 | 15.97 | 0.14 | 0.35 |
| Krakow | 762,000 | 327 | 207,351 | 13,876 | 15 | 1.27 | 11.16 | 0.08 | 0.30 |
| Poznan | 544,000 | 262 | 134,549 | 5344 | 25 | 1.23 | 13.74 | 0.07 | 0.44 |
| Valencia | 831,000 | 135 | 1,456,125 | 67,385 | 22 | 1.27 | 8.70 | 0.13 | 0.49 |
| Mobility | |
|---|---|
| Standard Distance (SDD) | |
| Stationary user | <150 m |
| Traveling user | ≥150 m |
| Posting Activity | |
| Number of Tweets (N) | |
| Power user | >95 percentile |
| Ordinary user | >2 and <95 percentile |
| Incidental user | 1–2 tweets |
| Incidental User | Ordinary User | Power User | ||
|---|---|---|---|---|
| Dublin | Total | |||
| Stationary user | 35,133 (76%) | 10,246 (22%) | 881 (2%) | 46,260 (100%) |
| Traveling user | 561 (2%) | 28,083 (89%) | 2989 (9%) | 31,633 (100%) |
| Total | 35,694 (46%) | 38,329 (49%) | 3870 (5%) | |
| Edinburgh | Total | |||
| Stationary user | 34,956 (86%) | 5727 (14%) | 136 (0.3%) | 40,819 (100%) |
| Traveling user | 49 (0.2%) | 24,676 (88%) | 3303 (12%) | 28,028 (100%) |
| Total | 35,005 (51%) | 30,403 (44%) | (5%)3439 | |
| Krakow | ||||
| Stationary user | 7583 (77%) | 2033 (21%) | 197 (2%) | 9813 (100%) |
| Traveling user | 191 (5%) | 3377 (83%) | 495 (12%) | 4063 (100%) |
| Total | 7774 (56%) | 5410 (39%) | 692 (5%) | |
| Poznan | Total | |||
| Stationary user | 2556 (69%) | 1064 (29%) | 105 (3%) | 3725 (100%) |
| Traveling user | 111 7(%) | 1345 (83%) | 163 (10%) | 1619 (100%) |
| Total | 2667 (50%) | 2409 (45%) | 268 (5%) | |
| Valencia | Total | |||
| Stationary user | 30,923 (81%) | 7107 (19%) | 197 (1%) | 38,227 (100%) |
| Traveling user | 5 (0.02%) | 25,996 (89%) | 3162 (11%) | 29,163 (100%) |
| Total | 30,928 (46%) | 33,103 (49%) | 3359 (5%) |
| Cramer’s V (df = 2) | Cramers’s V (df = 1) | Goodman-Kruskal γ (df = 2) | Goodman-Kruskal γ (df = 1) | |
|---|---|---|---|---|
| Dublin | 0.74 | 0.17 | 0.95 | 0.69 |
| Edinburgh | 0.84 | 0.26 | 0.99 | 0.95 |
| Krakow | 0.67 | 0.21 | 0.93 | 0.74 |
| Poznan | 0.57 | 0.15 | 0.87 | 0.59 |
| Valencia | 0.81 | 0.25 | 0.98 | 0.92 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rzeszewski, M.; Beluch, L. Spatial Characteristics of Twitter Users—Toward the Understanding of Geosocial Media Production. ISPRS Int. J. Geo-Inf. 2017, 6, 236. https://doi.org/10.3390/ijgi6080236
Rzeszewski M, Beluch L. Spatial Characteristics of Twitter Users—Toward the Understanding of Geosocial Media Production. ISPRS International Journal of Geo-Information. 2017; 6(8):236. https://doi.org/10.3390/ijgi6080236
Chicago/Turabian StyleRzeszewski, Michal, and Lukasz Beluch. 2017. "Spatial Characteristics of Twitter Users—Toward the Understanding of Geosocial Media Production" ISPRS International Journal of Geo-Information 6, no. 8: 236. https://doi.org/10.3390/ijgi6080236
APA StyleRzeszewski, M., & Beluch, L. (2017). Spatial Characteristics of Twitter Users—Toward the Understanding of Geosocial Media Production. ISPRS International Journal of Geo-Information, 6(8), 236. https://doi.org/10.3390/ijgi6080236