
WiGeR: WiFi-Based Gesture Recognition System



Abstract
:1. Introduction
- We present a gesture recognition system that enables humans to interact with WiFi-connected devices throughout the entire home, using seven hand gestures as interactive gestures, three air-drawn hand gestures that function in the security scheme as users’ authenticated gestures, and three additional air-drawn hand gestures that function as device selection gestures. Unlike previous WiFi-based gesture recognition systems, our system can work in different scenarios—even through multiple walls. Moreover, our system is the first device-free gesture recognition system that provides security for users and devices.
- We design a novel segmentation method based on wavelet analysis and Short-Time Energy (STE). Our novel algorithm intercepts CSI segments and analyzes the variations in CSI caused by hand motions, revealing the unique patterns of gestures. Furthermore, the algorithm can determine both the beginning and the end of the gesture (the gesture duration).
- We design a classification method based on Dynamic Time Warping to classify all proposed hand gestures. Our classification algorithm achieves high accuracy in various scenarios.
- We conduct exhaustive experiments. Each gesture has been tested several hundred times. The experiments provide us with important insights and improve our system classification ability by letting us choose the best parameters—gained through experience—to build a gesture learning category profile that can handle gestures with various users’ physical shapes in different positions.
2. Related Works
2.1. Device-Based Gesture Recognition Systems
2.2. Device-Free Gesture Recognition Systems
2.2.1. RSS
2.2.2. SDR
2.2.3. CSI
3. System Overview
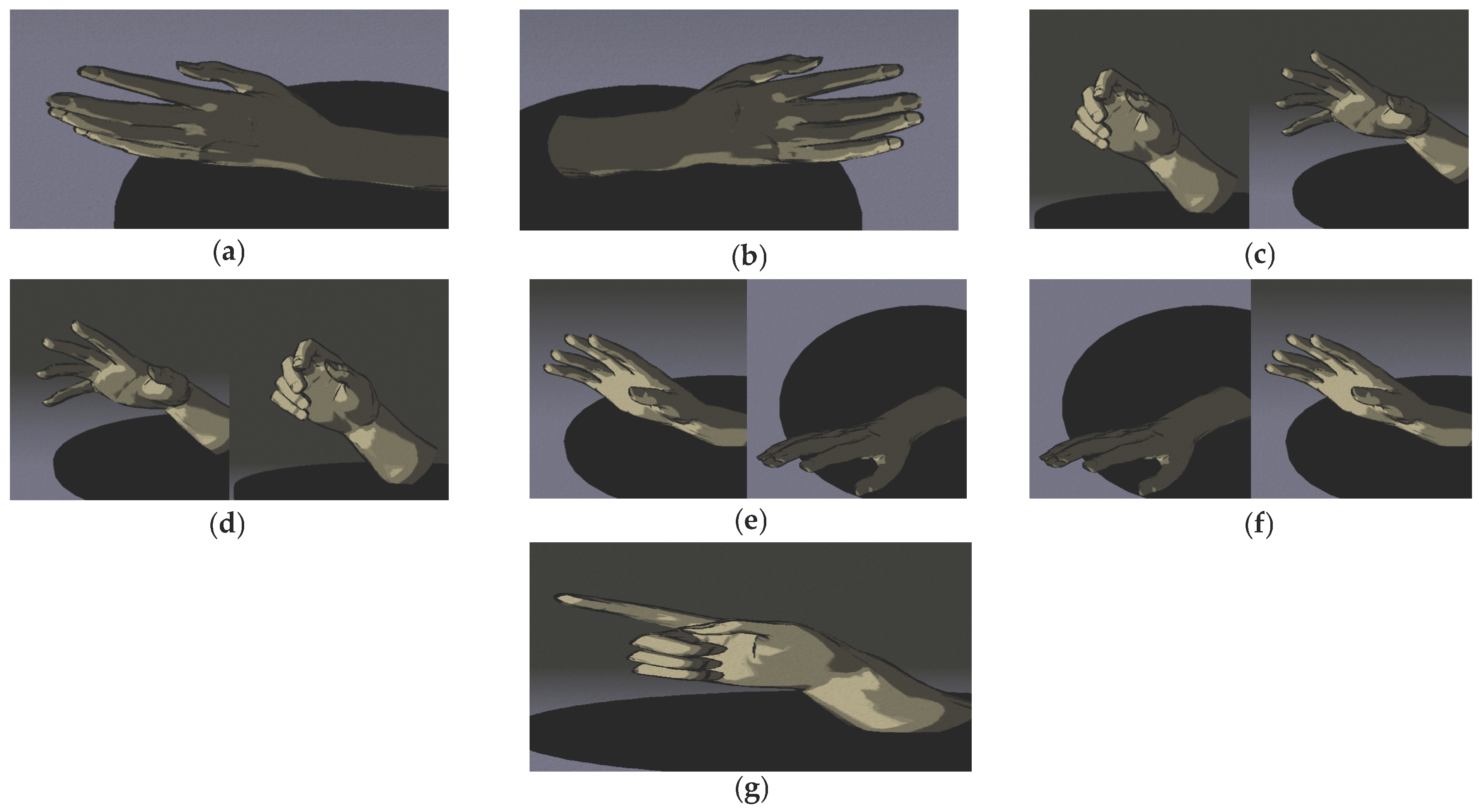
3.1. Gestures Overview
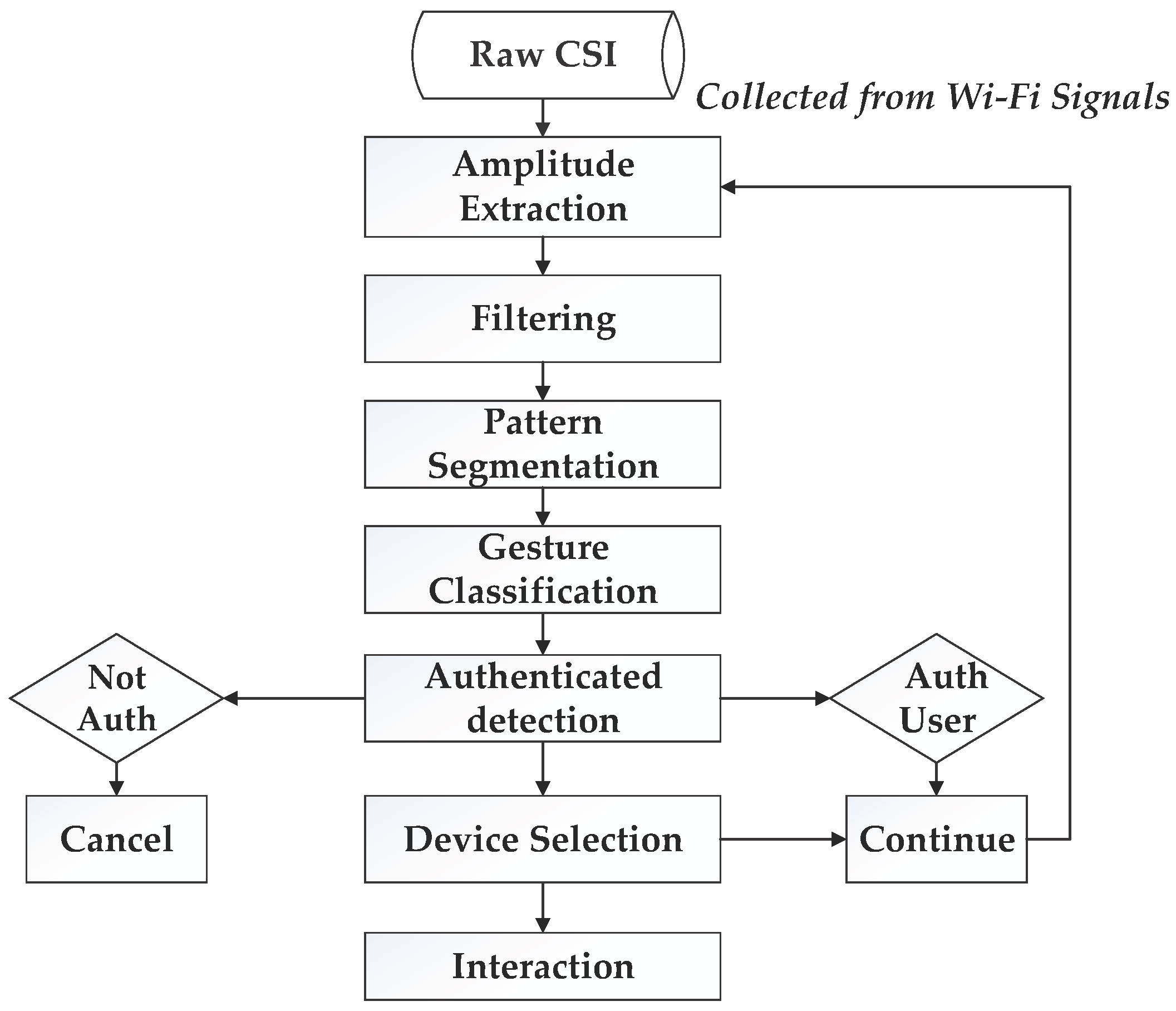
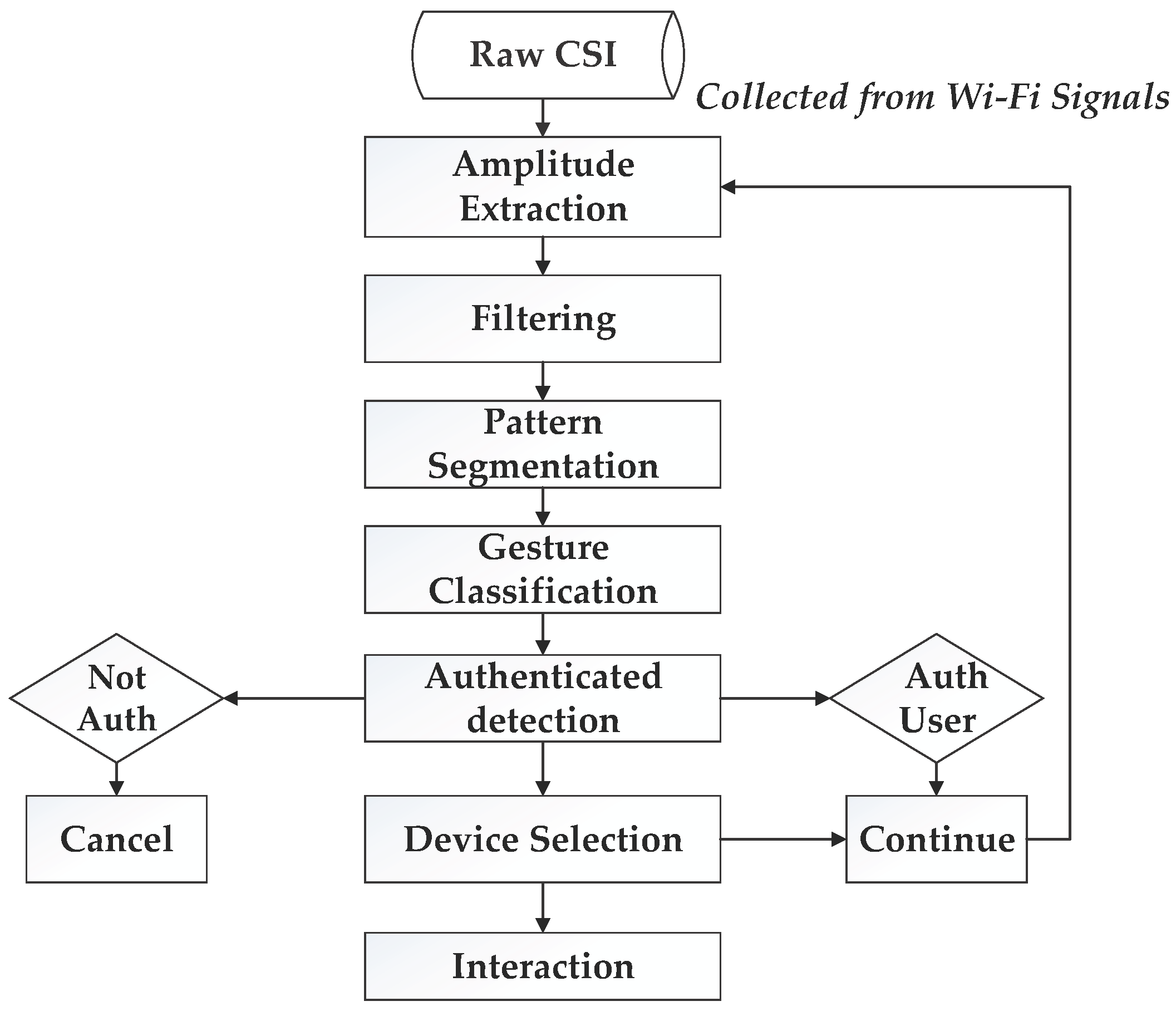
3.2. System Architecture
- Preparation: In this stage, WiGeR collects information from the WiFi access point, extracts amplitude information, and then filters out the noise.
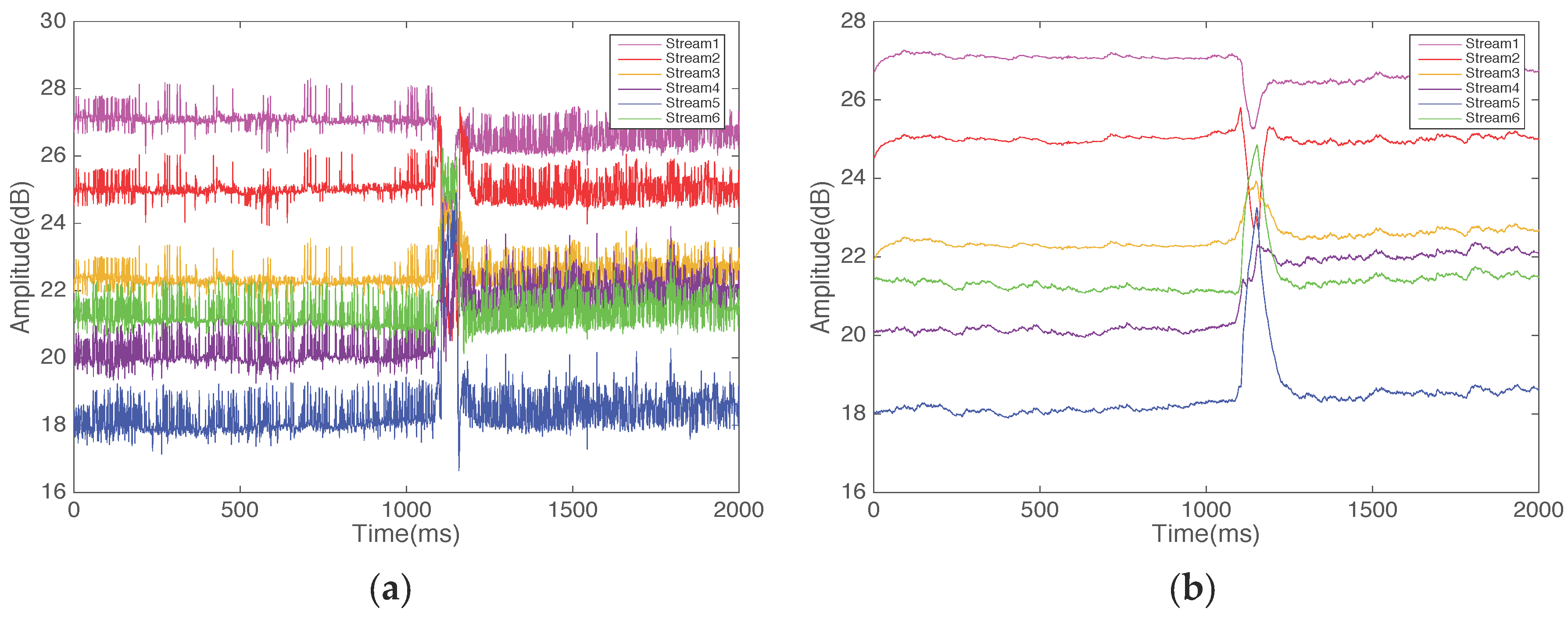
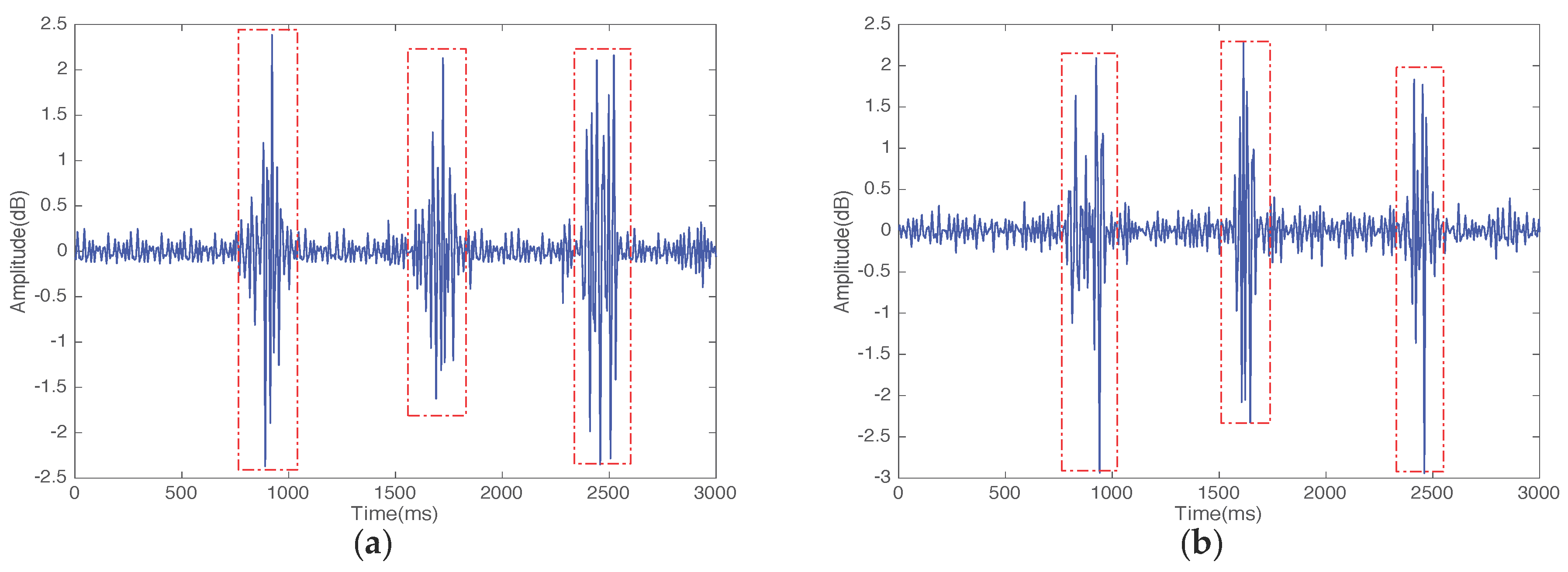
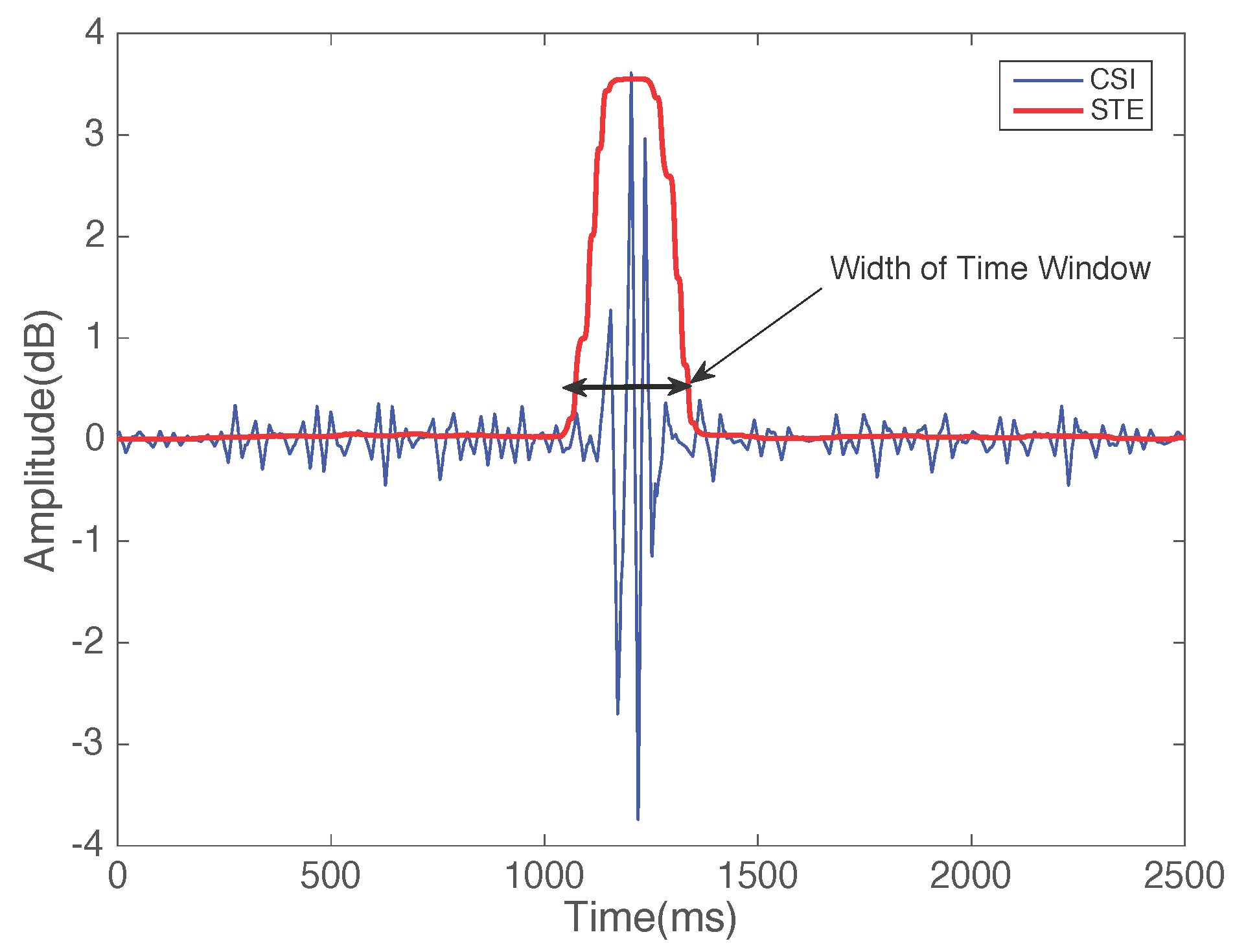
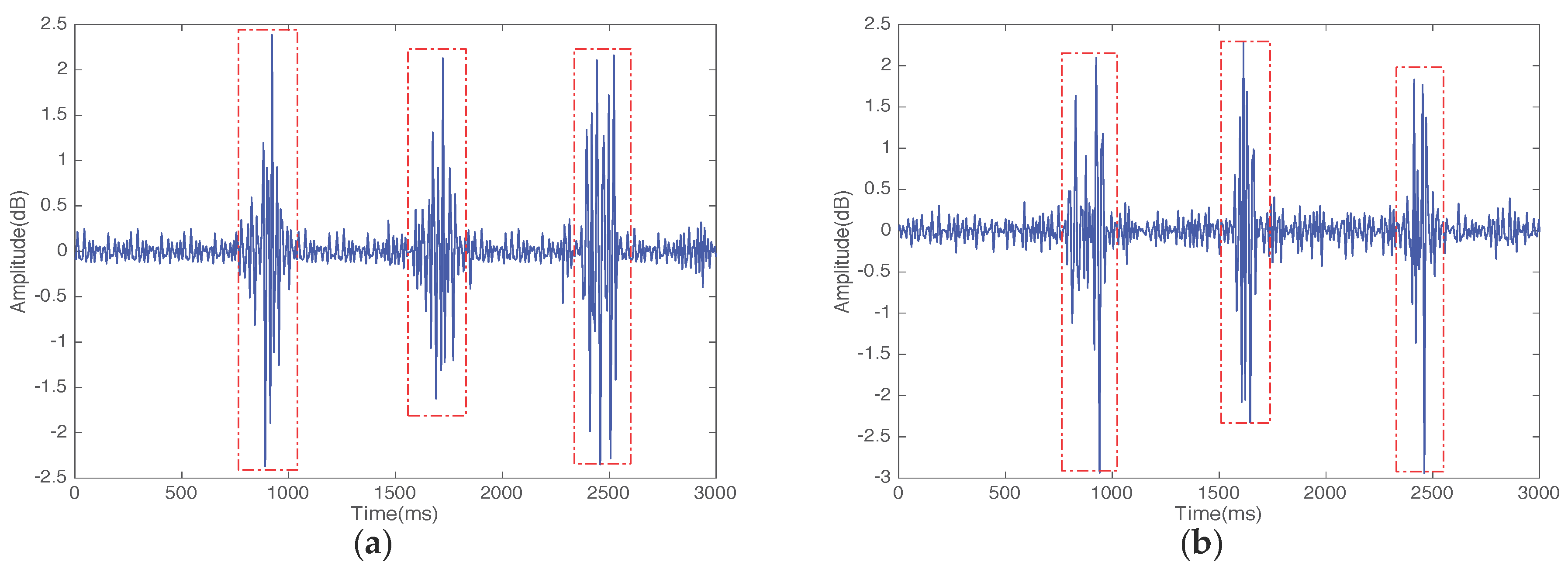
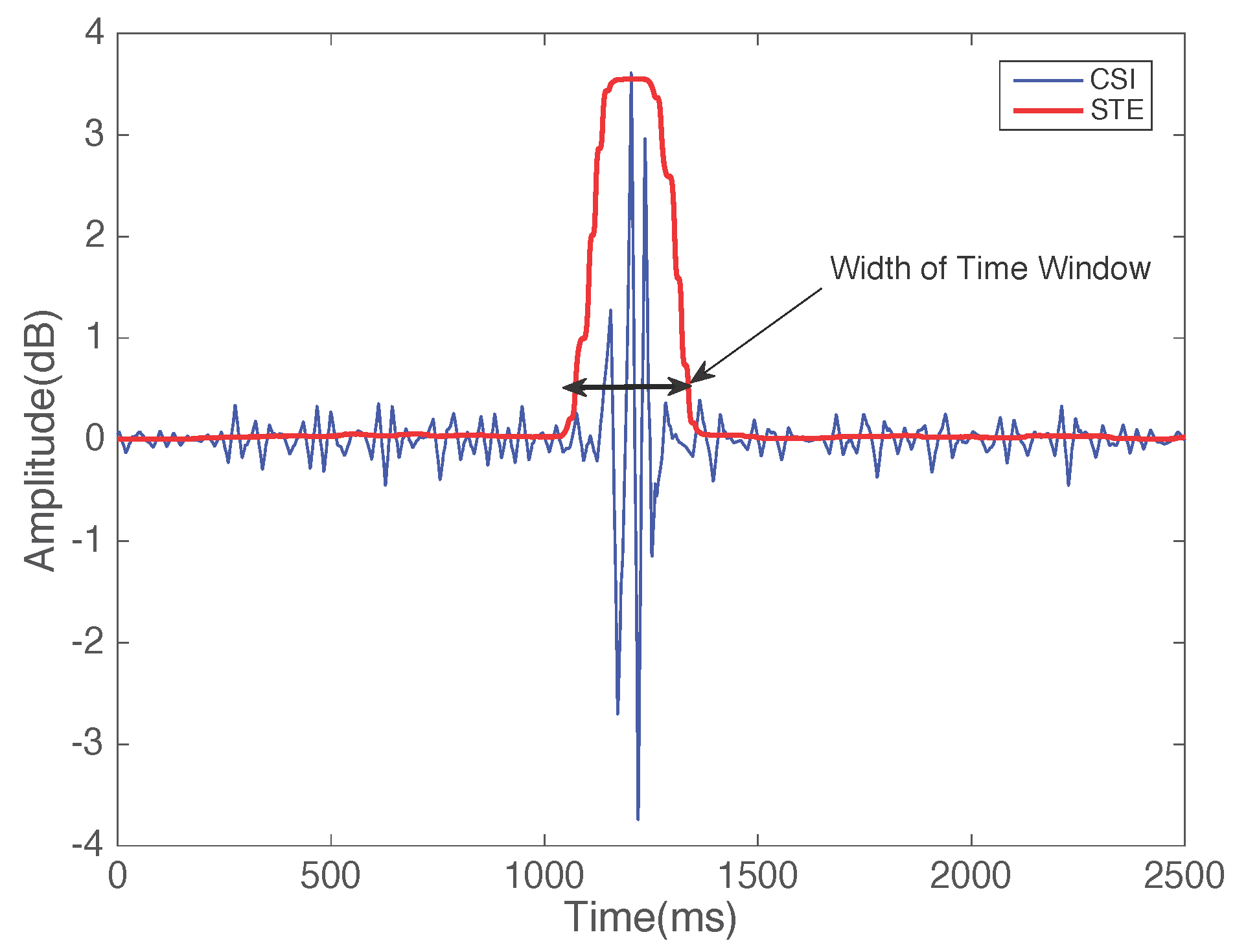
- Pattern segmentation: In this stage, the system differentiates between gestures. We apply a multi-level wavelet decomposition algorithm and the short-time energy algorithm to extract gesture patterns and detect the start and end point of a gesture, respectively, and detect the width of the motion window.
- Gesture classification: In this stage, the system compares the patterns in each gesture window. The DTW algorithm is applied and accurately classifies the candidate gestures.
4. Methodology
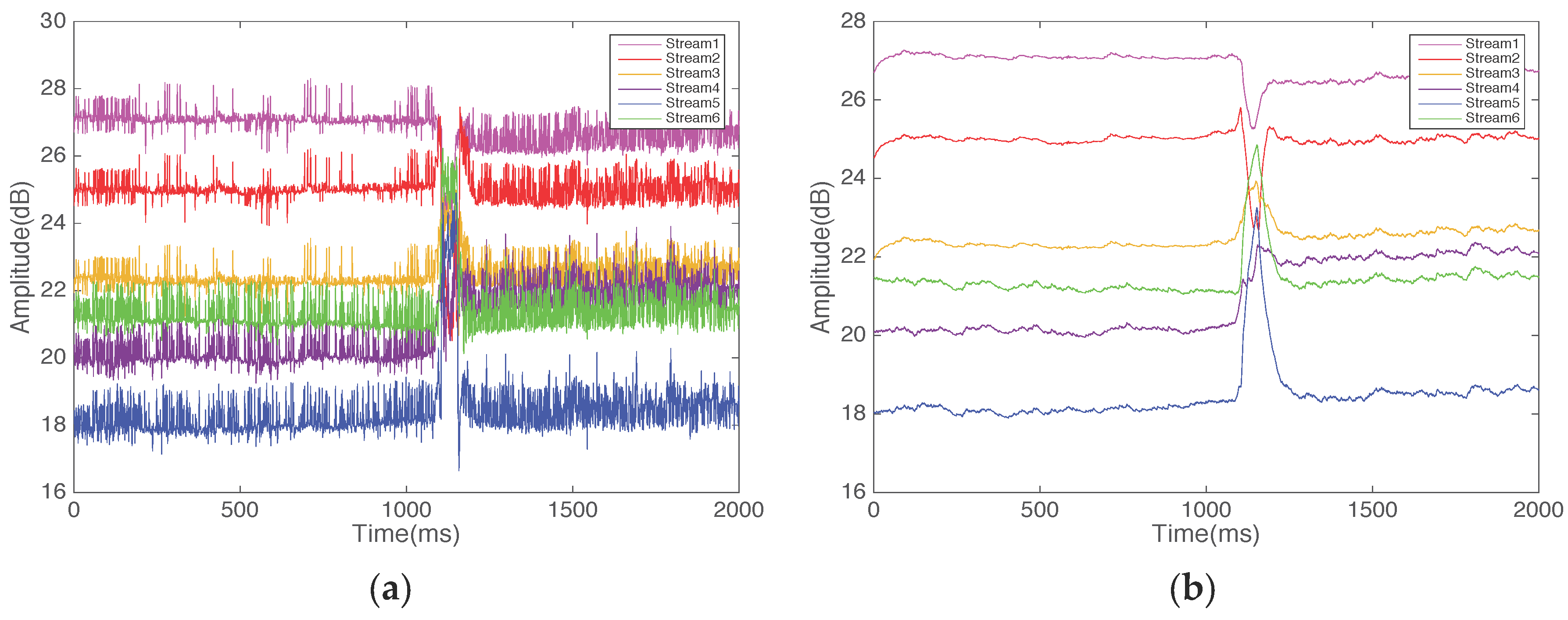
4.1. Preparation
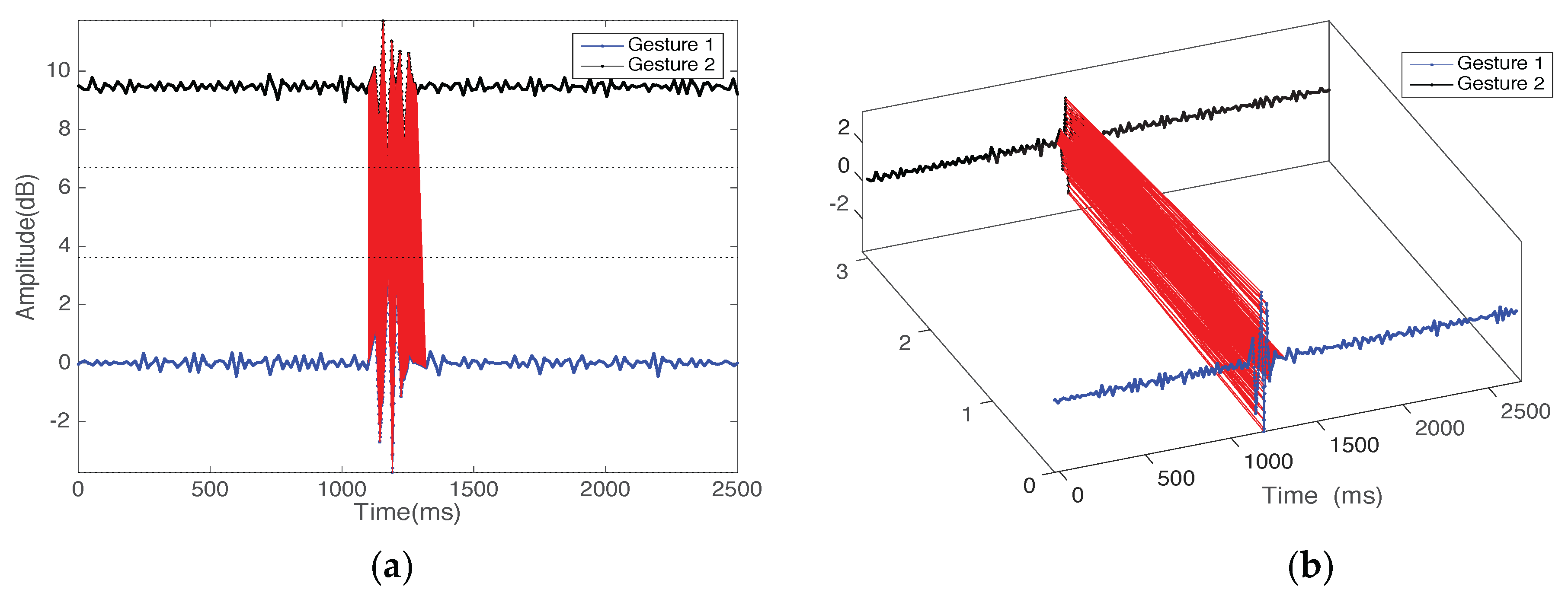
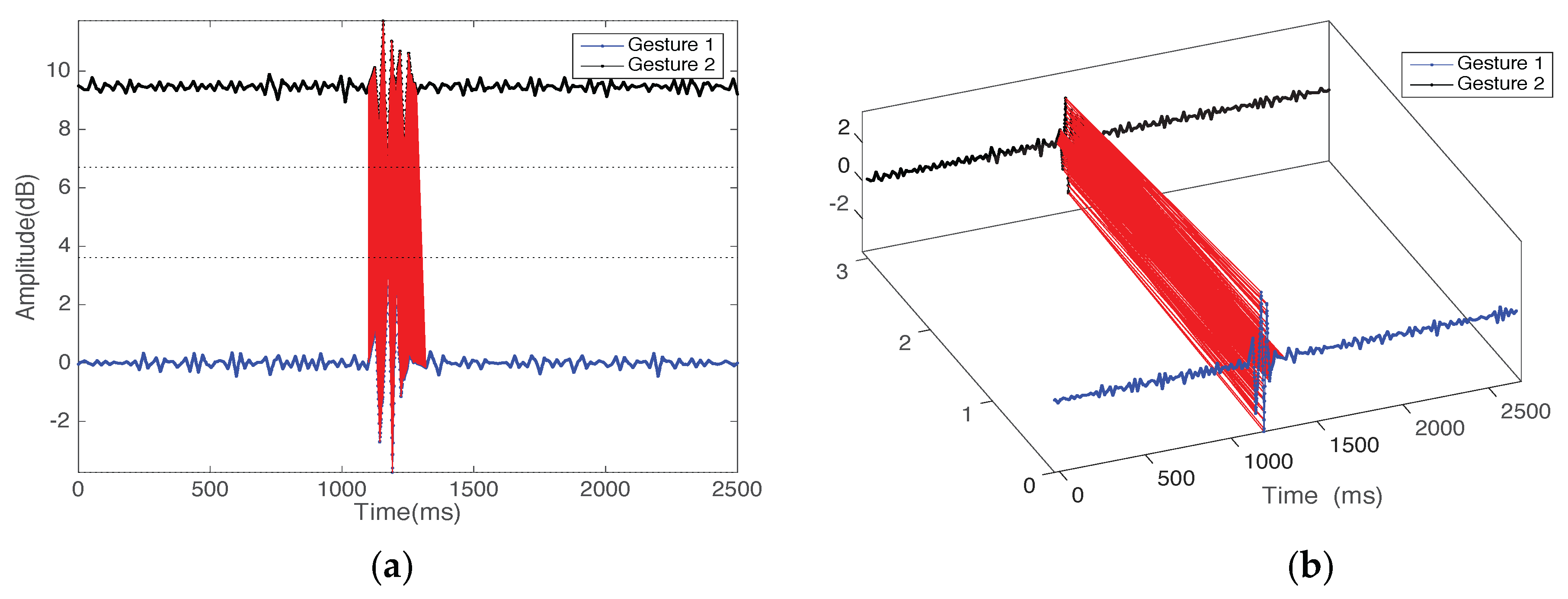
4.2. Pattern Segmentation
4.3. Classification
5. Experiments and Results
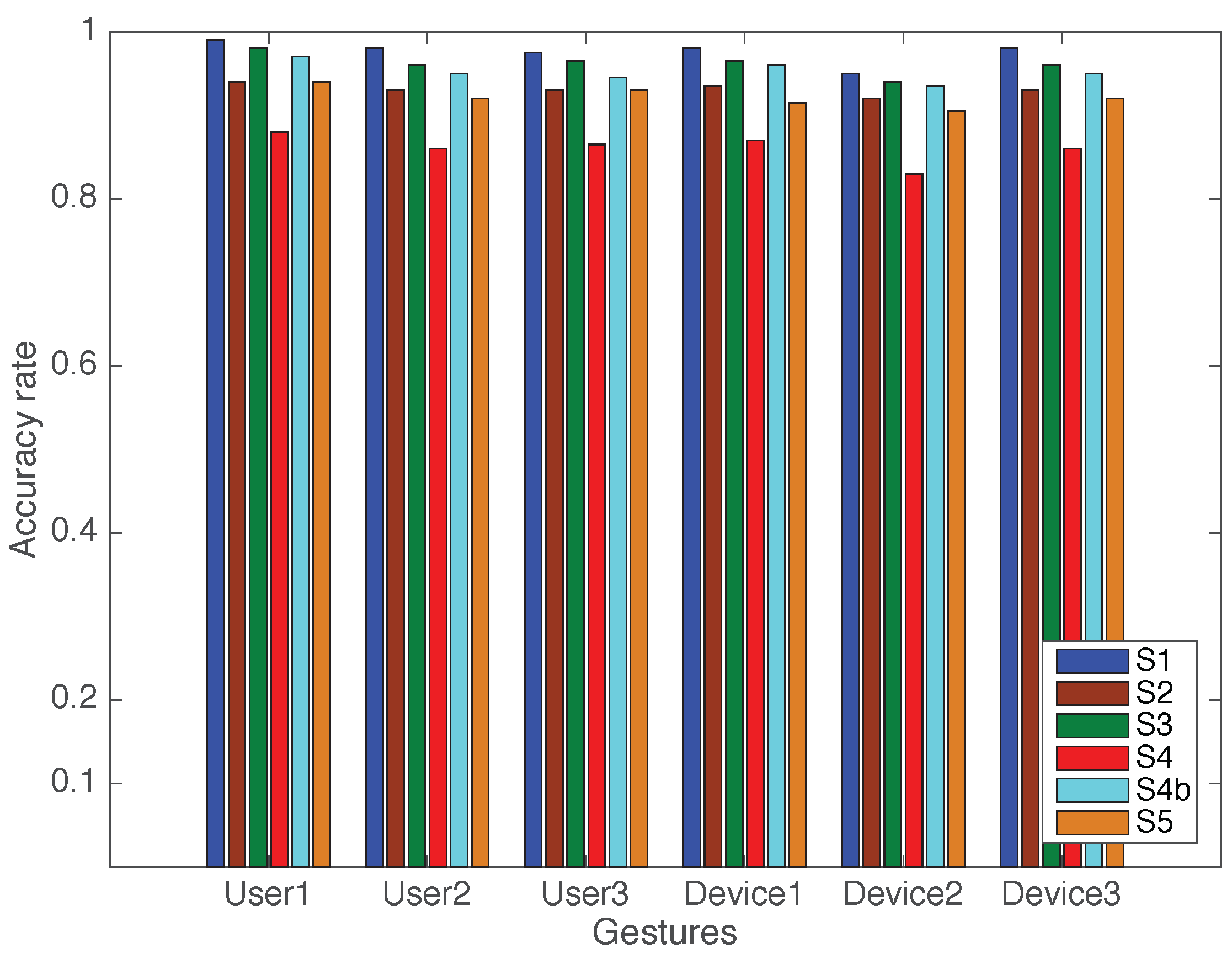
5.1. Experimental Set up
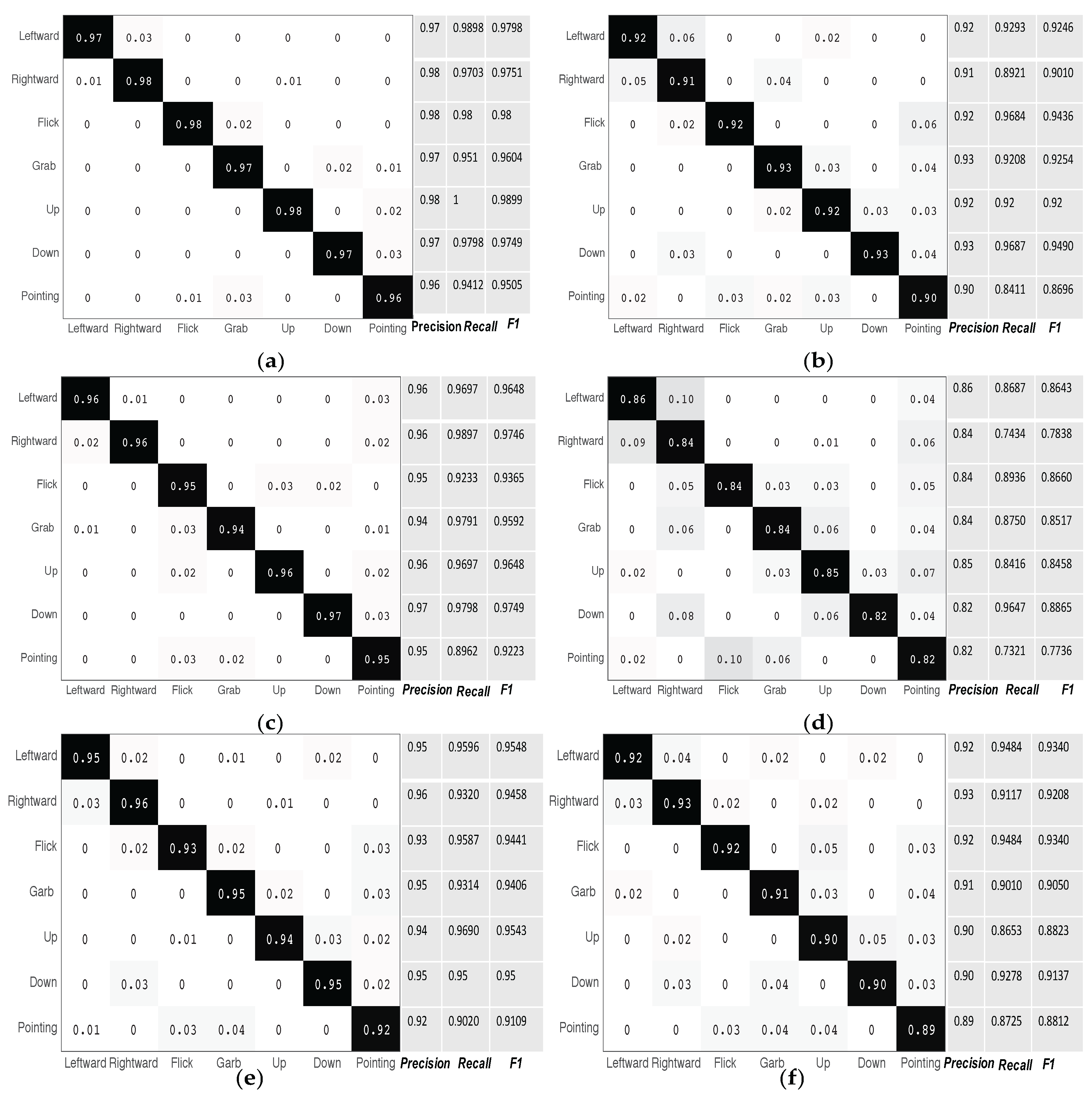
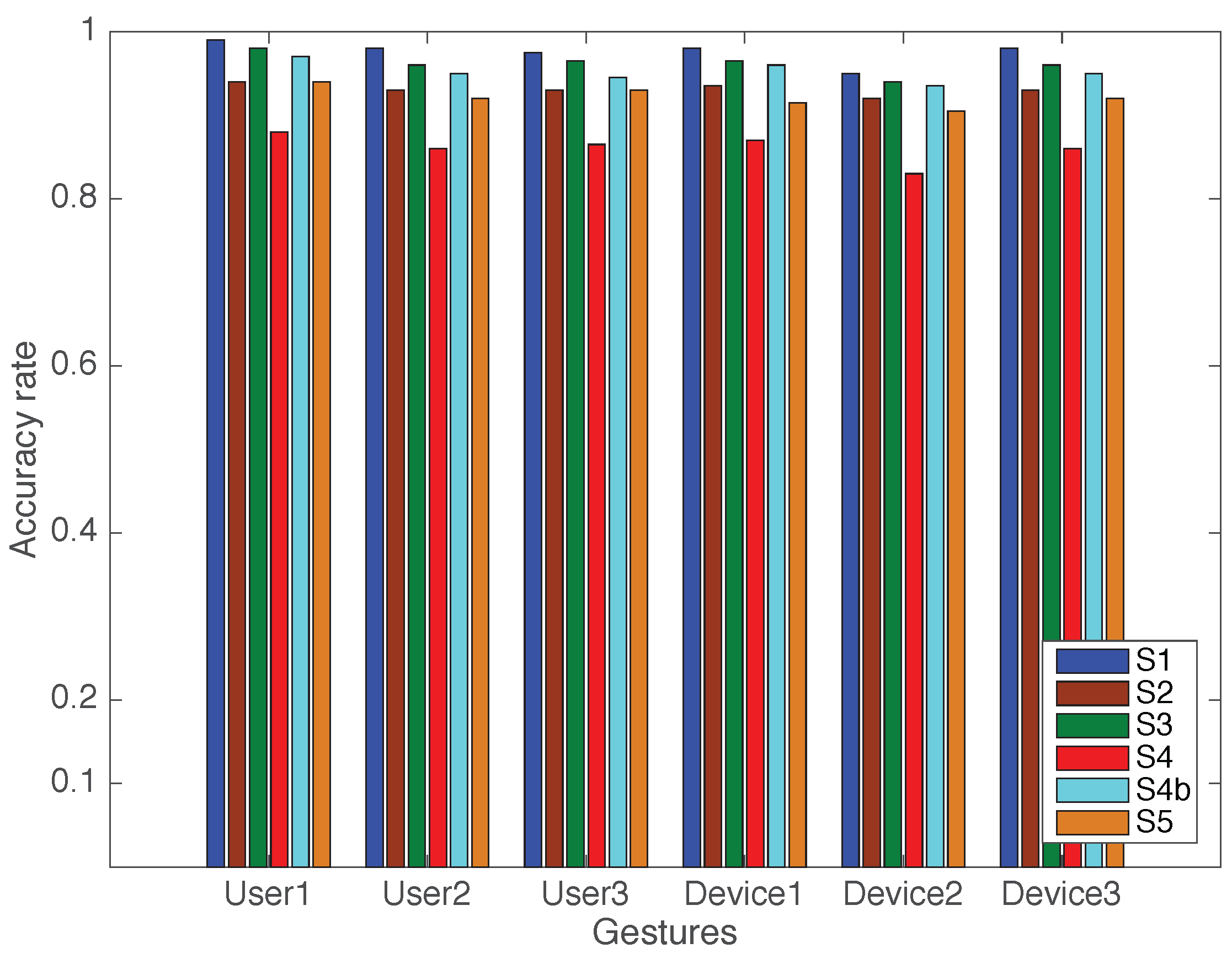
- Scenario 1: The AP, DP, and user are all in the main lab room. The user performs the gestures between the AP and DP, positioned as shown in Figure 8 (label S1).
- Scenario 2: The AP and the user are in the same room, but the DP is in the interior lab room separated by one wall. The distance between the AP and the DP is approximately 3.5 m, and the distance between the DP and the user is approximately 3 m. The user is approximately 2 m from the AP, as shown in Figure 8 (label S2).
- Scenario 3: The DP and the user are in the interior lab room, while the AP is in the main lab room separated by one wall. The distance between the AP and the DP is 3.5 m, and the distance between the DP and the user is 2 m. The user is approximately 4 m away from the AP.
- Scenario 4: The AP and the DP are both in the main lab room. The user is asked to perform gestures in the corridor, approximately 7 m and 5 m away from the AP and the DP, respectively. There is one intervening wall.
- Scenario 5: The AP and the DP are both in the small interior room, while the user is in the corridor separated from them by two walls at a distance of approximately 8 m.
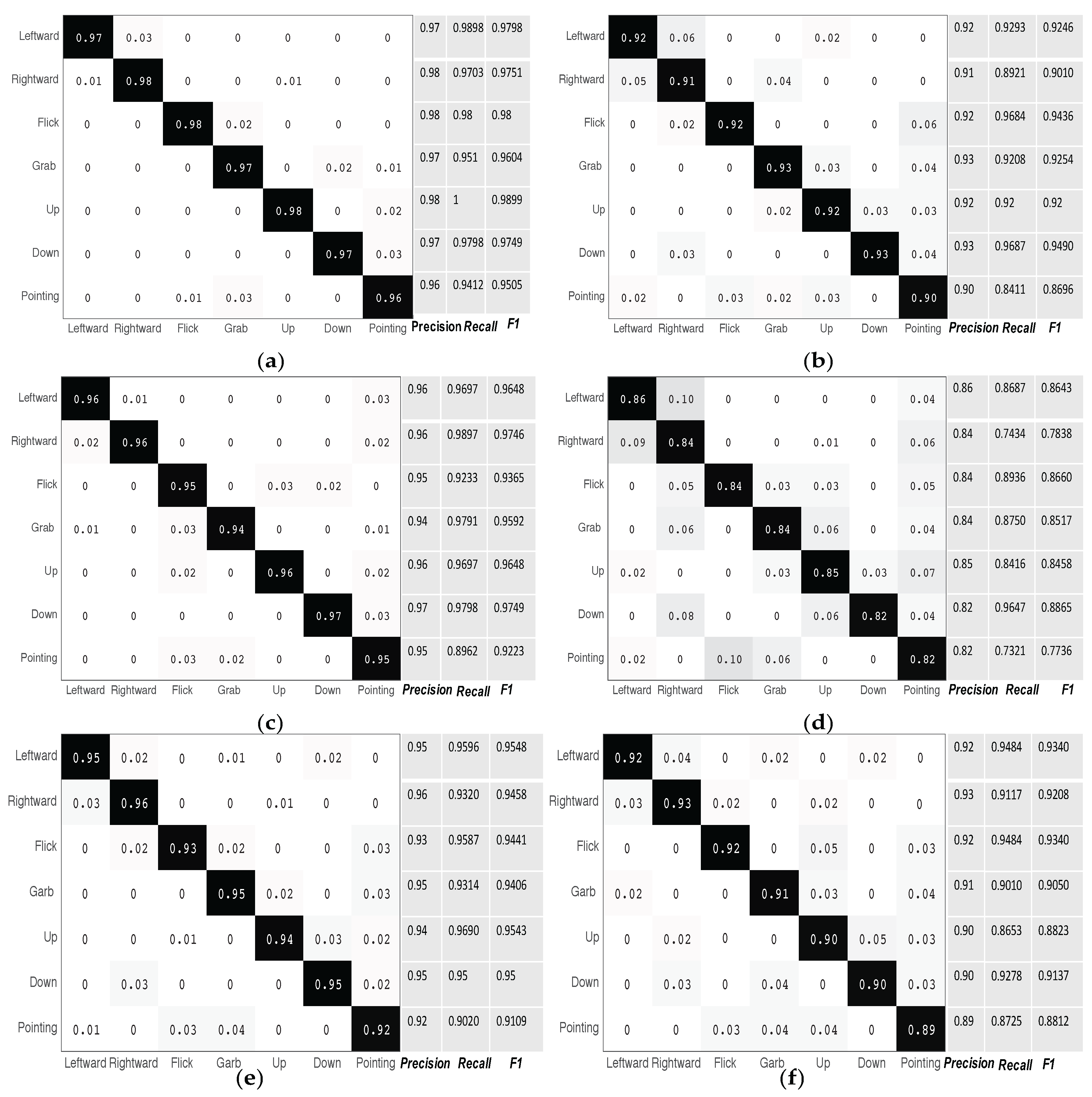
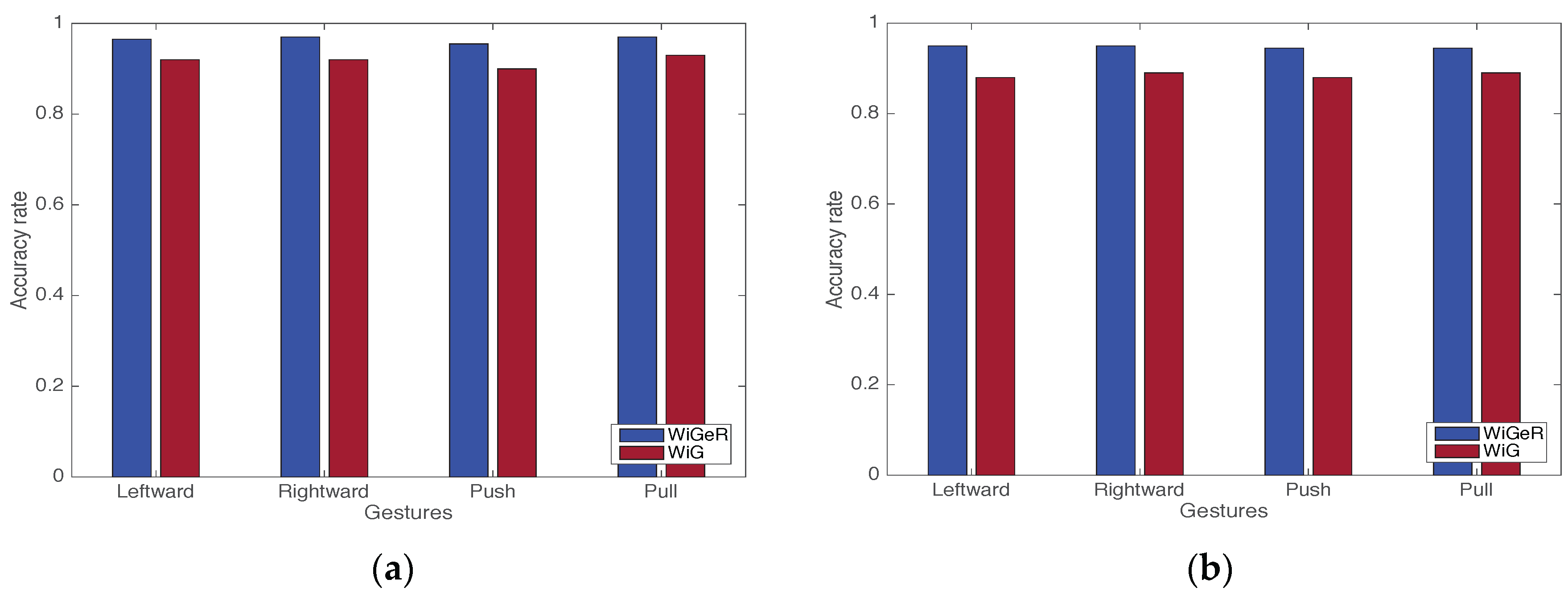
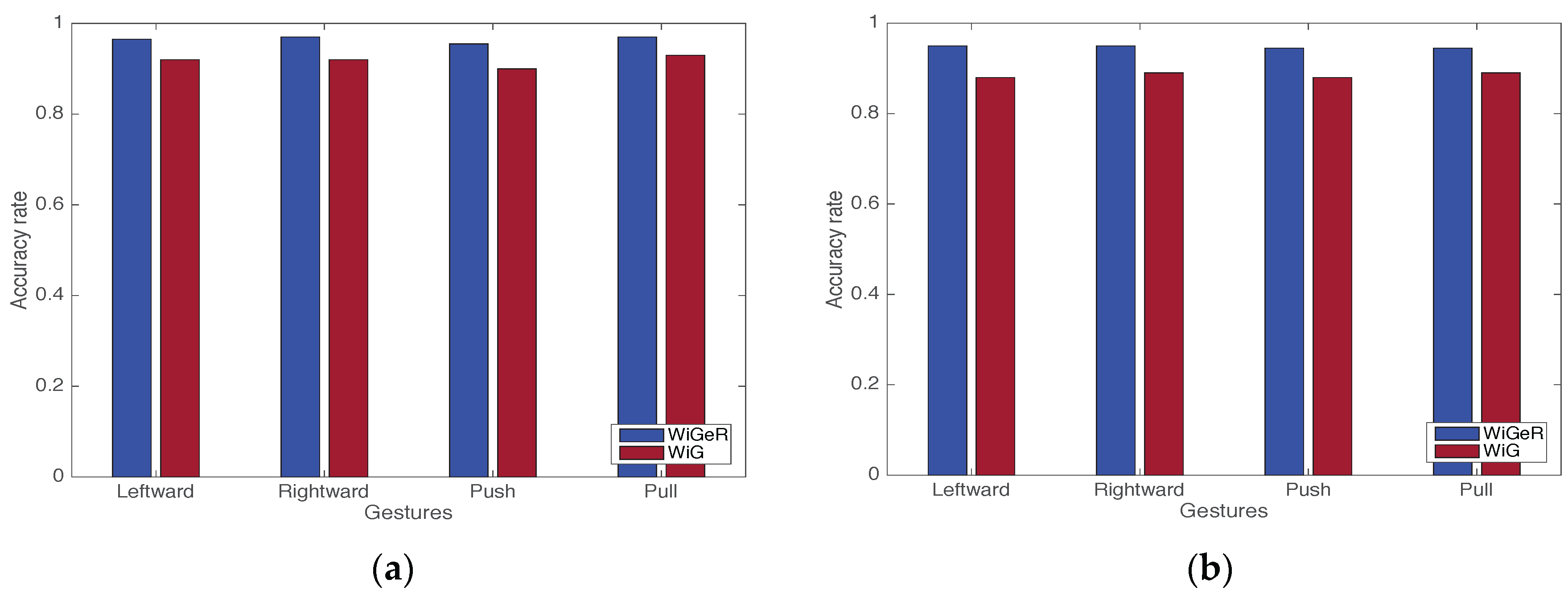
5.2. Experiment Results
6. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| WiGeR | WiFi-based gesture recognition system |
| CSI | Channel State Information |
| AP | Access Point |
| DP | Detection Point |
| STE | Short-Time Energy |
| DTW | Dynamic Time Warping |
| LOS | Line-of-sight |
| NLOS | Non-line-of-sight |
| RSS | Received signal strength |
| OFDM | Orthogonal frequency-division multiplexing |
| SDR | Software Defined Radio |
| TP | True positive |
| FP | False positive |
| TN | True negative |
| FN | False negative |
| USRP | Universal Software Radio Peripheral |
| RFID | Radio-frequency identification |
References
- Microsoft Kinect. Available online: http://www.microsoft.com/en-us/kinectforwindows (accessed on 27 November 2012).
- Jing, L.; Zhou, Y.; Cheng, Z.; Huang, T. Magic ring: A finger-worn device for multiple appliances control using static finger gestures. Sensors 2012, 12, 5775–5790. [Google Scholar] [CrossRef] [PubMed]
- Adib, F.; Katabi, D. See through walls with WiFi! In Proceedings of the the ACM SIGCOMM 2013 conference on SIGCOMM, Hong Kong, China, 12–16 August 2013; Volume 43, pp. 75–86.
- Pu, Q.; Gupta, S.; Gollakota, S.; Patel, S. Whole-home gesture recognition using wireless signals. In Proceedings of the 19th Annual International Conference on Mobile Computing and Networking, Miami, FL, USA, 30 September–4 October 2013; pp. 27–38.
- Yang, Z.; Zhou, Z.; Liu, Y. From RSSI to CSI: Indoor Accuracy rate localization via channel response. ACM Comput. Surv. 2014, 46, 1–33. [Google Scholar] [CrossRef]
- Kim, K.; Kim, J.; Choi, J.; Kim, J.; Lee, S. Depth camera-based 3D hand gesture controls with immersive tactile feedback for natural mid-air gesture interactions. Sensors 2015, 15, 1022–1046. [Google Scholar] [CrossRef] [PubMed]
- PointGrab. Available online: http://www.pointgrab.com/ (accessed on 6 April 2015).
- Block, R. Toshiba Qosmio G55 Features SpursEngine, Visual Gesture Controls. Available online: http://www.engadget.com/2008/06/14/toshiba-qosmio-g55-features-spursengine-visual-gesture-controls/ (accessed on 14 June 2008).
- Fisher, M. Sweet Moves: Gestures and Motion-Based Controls on the Galaxy S III. Available online: http://pocketnow.com/2012/06/28/sweet-moves-gestures-and-motion-based-controls-on-the-galaxy-s-iii (accessed on 28 June 2012).
- Gupta, S.; Morris, D.; Patel, S.; Tan, D. Soundwave: Using the doppler effect to sense gestures. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Austin, TX, USA, 5–10 May 2012; pp. 1911–1914.
- Santos, A. Pioneer’s Latest Raku Navi GPS Units Take Commands from Hand Gestures. Available online: http://www.engadget.com/2012/10/07/pioneer-raku-navi-gps-hand-gesture-controlled/ (accessed on 7 October 2012).
- Palacios, J.M.; Sagüés, C.; Montijano, E.; Llorente, S. Human-computer interaction based on hand gestures using RGB-D sensors. Sensors 2013, 13, 11842–11860. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Pan, G.; Zhang, D.; Qi, G.; Li, S. Gesture recognition with a 3-D accelerometer. In Ubiquitous Intelligence and Computing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 25–38. [Google Scholar]
- Liu, J.; Zhong, L.; Wickramasuriya, J.; Vasudevan, V. uWave: Accelerometer-based personalized gesture recognition and its applications. Pervasive Mob. Comput. 2009, 5, 657–675. [Google Scholar] [CrossRef]
- Nirjon, S.; Gummeson, J.; Gelb, D.; Kim, K.H. TypingRing: A wearable ring platform for text input. In Proceedings of the 13th Annual International Conference on Mobile Systems, Applications, and Services, Florence, Italy, 19–22 May 2015; pp. 227–239.
- Myo. Available online: https://www.thalmic.com/en/myo/ (accessed on 6 April 2014).
- Cohn, G.; Morris, D.; Patel, S.; Tan, D. Humantenna: Using the body as an antenna for real-time whole-body interaction. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Austin, TX, USA, 5–10 May 2012; pp. 1901–1910.
- Kim, D.; Hilliges, O.; Izadi, S.; Butler, A.D.; Chen, J.; Oikonomidis, I.; Olivier, P. Digits: Freehand 3D interactions anywhere using a wrist-worn gloveless sensor. In Proceedings of the 25th Annual ACM Symposium on User Interface Software and Technology, Cambridge, MA, USA, 7–10 October 2012; pp. 167–176.
- Abdelnasser, H.; Youssef, M.; Harras, K.A. WiGest: A ubiquitous WiFi-based gesture recognition system. In Proceedings of 2015 IEEE Conference on Computer Communications (INFOCOM), Kowloon, Hong Kong, China, 26 April–1 May 2015; pp. 1472–1480.
- Adib, F.; Kabelac, Z.; Katabi, D.; Miller, R.C. 3D tracking via body radio reflections. In Proceedings of the 11th USENIX Conference on Networked Systems Design and Implementation, Seattle, WA, USA, 2–4 April 2014; pp. 317–329.
- Adib, F.; Kabelac, Z.; Katabi, D. Multi-person localization via RF body reflections. In Proceedings of the 12th USENIX Conference on Networked Systems Design and Implementation, Oakland, CA, USA, 4–6 May 2015; pp. 279–292.
- Wang, J.; Vasisht, D.; Katabi, D. RF-IDraw: Virtual touch screen in the air using RF signals. In Proceedings of the SIGCOMM’14, Chicago, IL, USA, 17–22 August 2014; pp. 235–246.
- Kellogg, B.; Talla, V.; Gollakota, S. Bringing gesture recognition to all devices. In Proceedings of the 11th USENIX Conference on Networked Systems Design and Implementation, Seattle, WA, USA, 2–4 April 2014; pp. 303–316.
- Chapre, Y.; Ignjatovic, A.; Seneviratne, A.; Jha, S. CSI-MIMO: Indoor Wi-Fi fingerprinting system. In Proceedings of the IEEE 39th Conference on Local Computer Networks (LCN), Edmonton, AB, Canada, 8–11 September 2014; pp. 202–209.
- Qian, K.; Wu, C.; Yang, Z.; Liu, Y.; Zhou, Z. PADS: Passive detection of moving targets with dynamic speed using PHY layer information. In Proceedings of THE IEEE ICPADS’14, Hsinchu, Taiwan, 16–19 December 2014; pp. 1–8.
- Xi, W.; Zhao, J.; Li, X.Y.; Zhao, K.; Tang, S.; Liu, X.; Jiang, Z. Electronic frog eye: Counting crowd using WiFi. In Proceedings of the IEEE INFOCOM, Toronto, ON, Canada, 27 April–2 May 2014; pp. 361–369.
- Han, C.; Wu, K.; Wang, Y.; Ni, L.M. Wifall: Device-free fall detection by wireless networks. In Proceedings of the IEEE INFOCOM, Toronto, ON, Canada, 27 April–2 May 2014; pp. 271–279.
- Wang, Y.; Liu, J.; Chen, Y.; Gruteser, M.; Yang, J.; Liu, H. E-eyes: Device-free location-oriented activity identification using fine-grained wifi signatures. In Proceedings of the 20th annual International Conference on Mobile Computing and Networking, Maui, HI, USA, 7–11 September 2014; pp. 617–628.
- Wang, G.; Zou, Y.; Zhou, Z.; Wu, K.; Ni, L.M. We can hear you with Wi-Fi! In Proceedings of the 20th Annual International Conference on Mobile Computing and Networking, Maui, HI, USA, 7–11 September 2014; pp. 593–604.
- Nandakumar, R.; Kellogg, B.; Gollakota, S. Wi-Fi Gesture Recognition on Existing Devices. Available online: http://arxiv.org/abs/1411.5394 (accessed on 8 June 2016).
- He, W.; Wu, K.; Zou, Y.; Ming, Z. WiG: WiFi-based gesture recognition system. In Proceedings of the 24th International Conference on Computer Communication and Networks (ICCCN), Las Vegas, NV, USA, 3–6 August 2015; pp. 1–7.
- Goldsmith, A. Wireless Communications; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Rabiner, L.R.; Schafer, R.W. Introduction to digital speech processing. Found. Trends Signal Process. 2007, 1, 1–194. [Google Scholar] [CrossRef]
- Salvador, S.; Chan, P. Toward accurate dynamic time warping in linear time and space. Intell. Data Anal. 2007, 11, 561–580. [Google Scholar]
- Jang, J.S.R. Machine Learning Toolbox Software. Available online: http://mirlab.org/jang/matlab/toolbox/machineLearning (accessed on 23 December 2014).
- Halperin, D.; Hu, W.; Sheth, A.; Wetherall, D. Tool release: Gathering 802.11n traces with channel state information. ACM SIGCOMM Comput. Commun. Rev. 2011, 41, 53–53. [Google Scholar] [CrossRef]
- WB-2400D300 Antenna. Available online: https://item.taobao.com/item.htm?spm=a1z09.2.0.0.NXy0fP&id=39662476575&_u=d1kraq3mf31b (accessed on 9 June 2014).
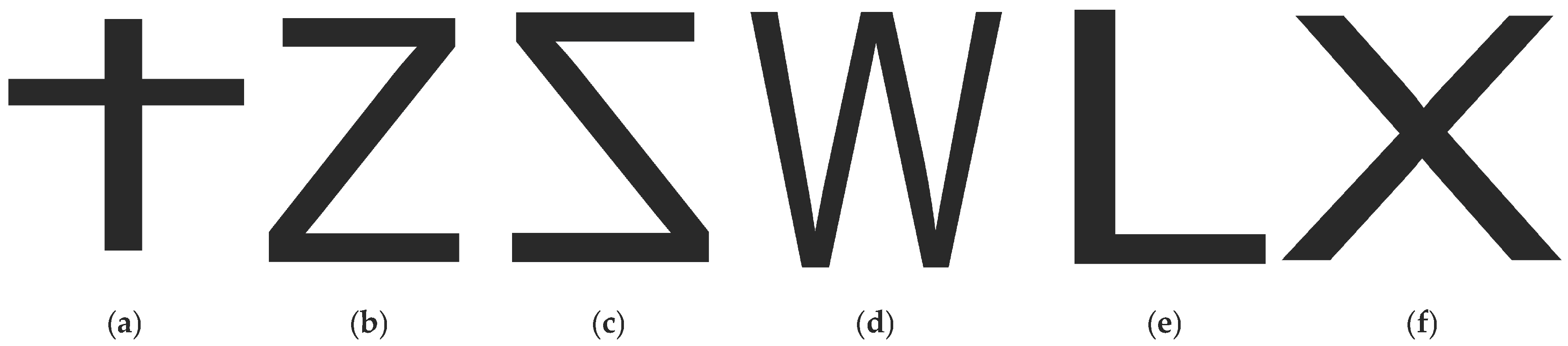


{kind=link}
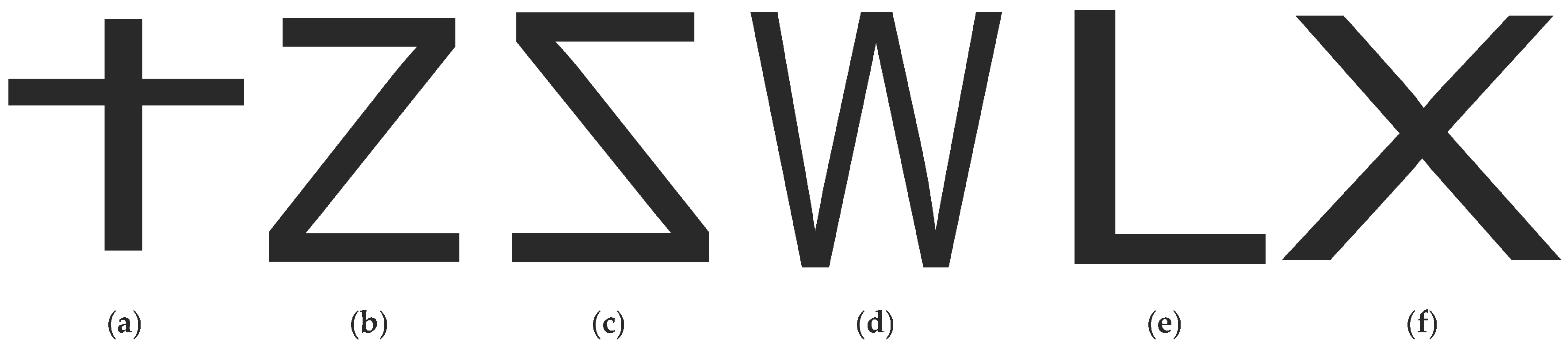{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gesture | TV | Laptop, Smart Device | Air-Conditioner |
|---|---|---|---|
| Leftward | (−) Change channel | Swipe files leftward | (−) Temperature setting |
| Rightward | (+) Change channel | Swipe files rightward | (+) Temperature setting |
| Flick | Zoom in | Zoom in | (+) Fan speed |
| Grab | Zoom out | Zoom out | (−) Fan speed |
| Scroll up | (+) Volume | Scroll pages/files up | Change mode heat/cold |
| Scroll down | (−) Volume | Scroll pages/files down | Change mode cold/heat |
| Point | Open/Close/Enter | Open/Close/Enter | On/Off |
| Session | Samples from 3 Users | Samples-per-User | Training Samples | Testing Samples |
|---|---|---|---|---|
| Session 1 | 90 | 30 | 60 | 30 |
| Session 2 | 90 | 30 | 60 | 30 |
| Session 2 | 120 | 40 | 80 | 40 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-qaness, M.A.A.; Li, F. WiGeR: WiFi-Based Gesture Recognition System. ISPRS Int. J. Geo-Inf. 2016, 5, 92. https://doi.org/10.3390/ijgi5060092
Al-qaness MAA, Li F. WiGeR: WiFi-Based Gesture Recognition System. ISPRS International Journal of Geo-Information. 2016; 5(6):92. https://doi.org/10.3390/ijgi5060092
Chicago/Turabian StyleAl-qaness, Mohammed Abdulaziz Aide, and Fangmin Li. 2016. "WiGeR: WiFi-Based Gesture Recognition System" ISPRS International Journal of Geo-Information 5, no. 6: 92. https://doi.org/10.3390/ijgi5060092
APA StyleAl-qaness, M. A. A., & Li, F. (2016). WiGeR: WiFi-Based Gesture Recognition System. ISPRS International Journal of Geo-Information, 5(6), 92. https://doi.org/10.3390/ijgi5060092