3.1. Dataset and Parameter Determination
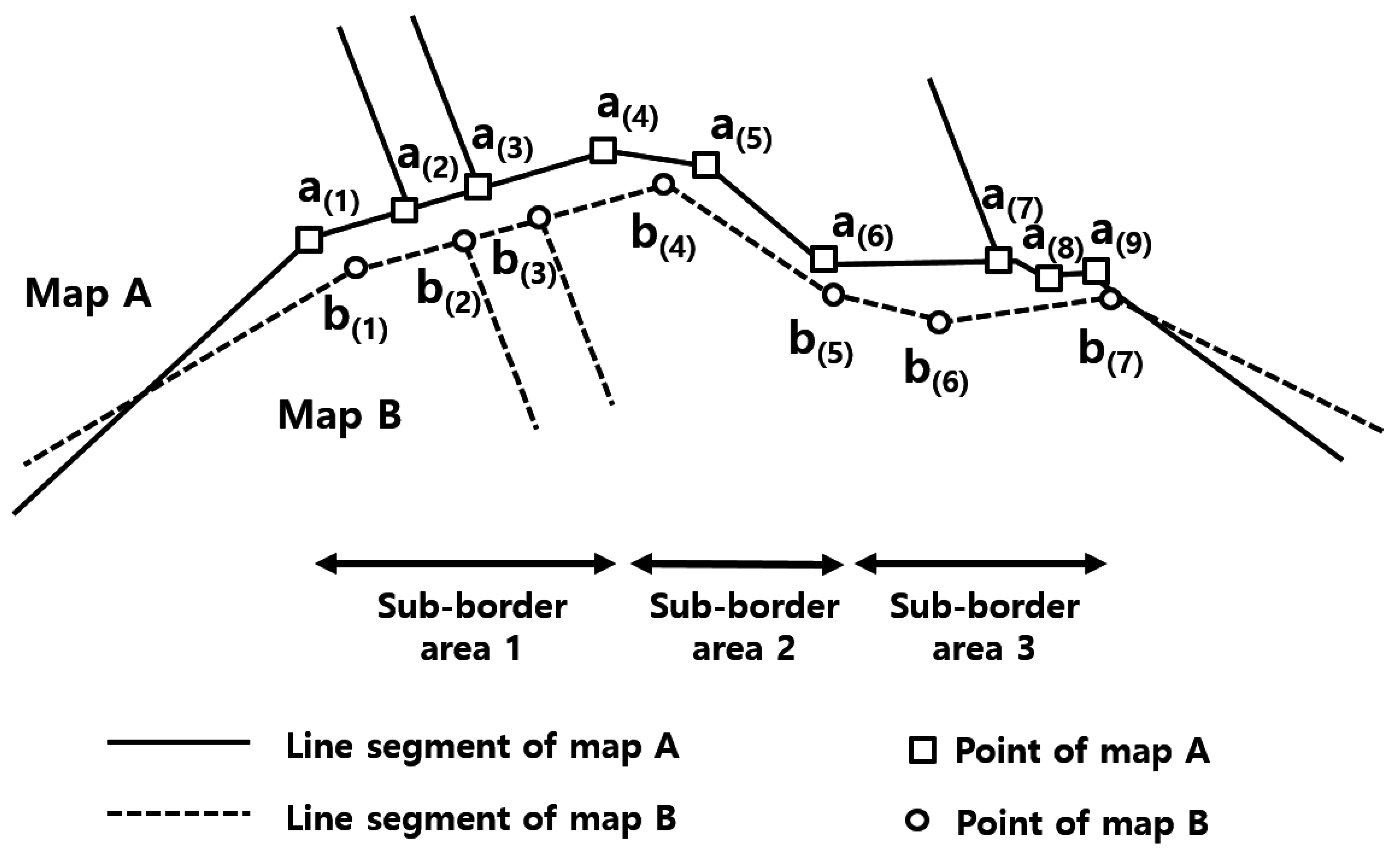
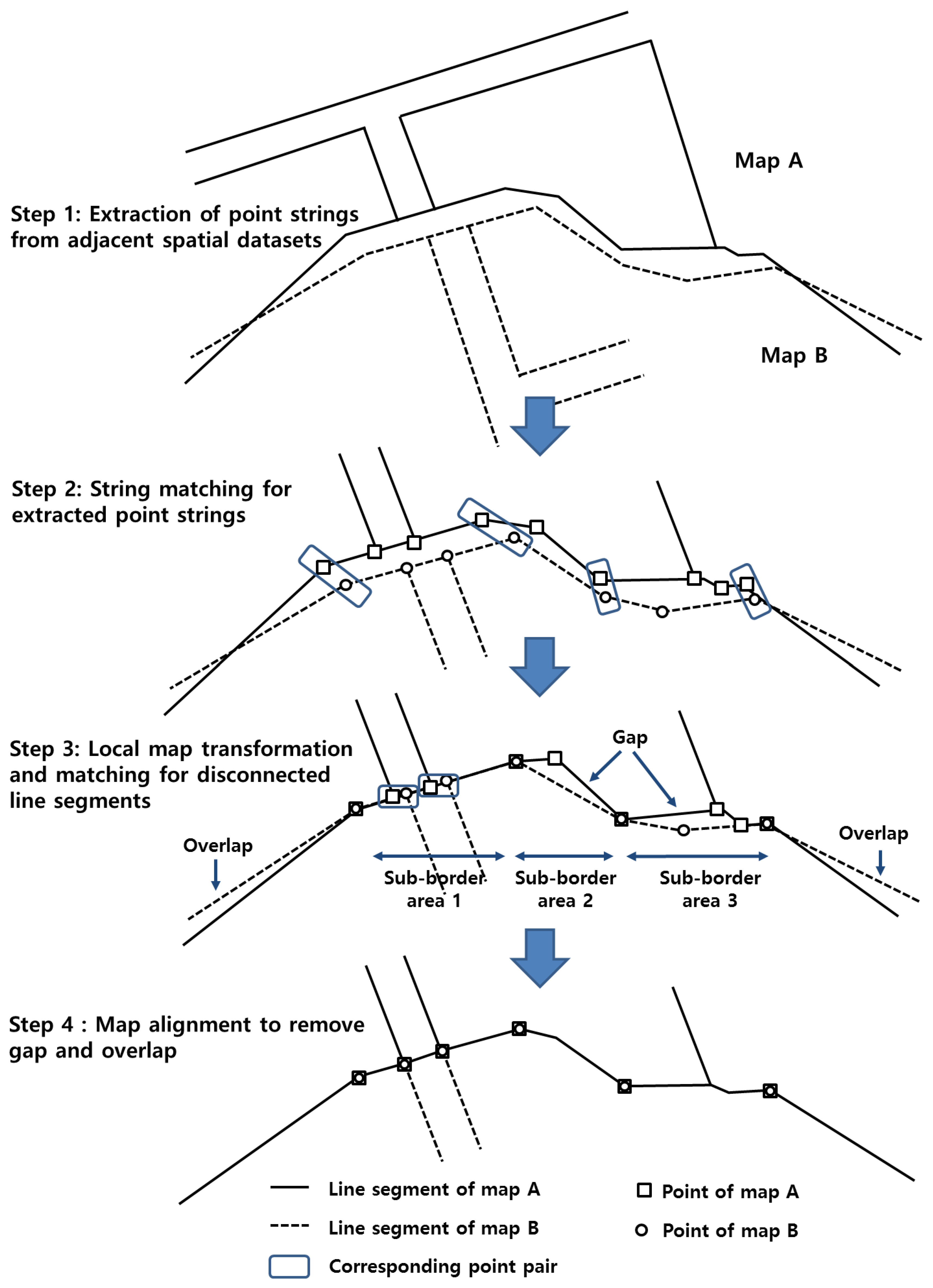
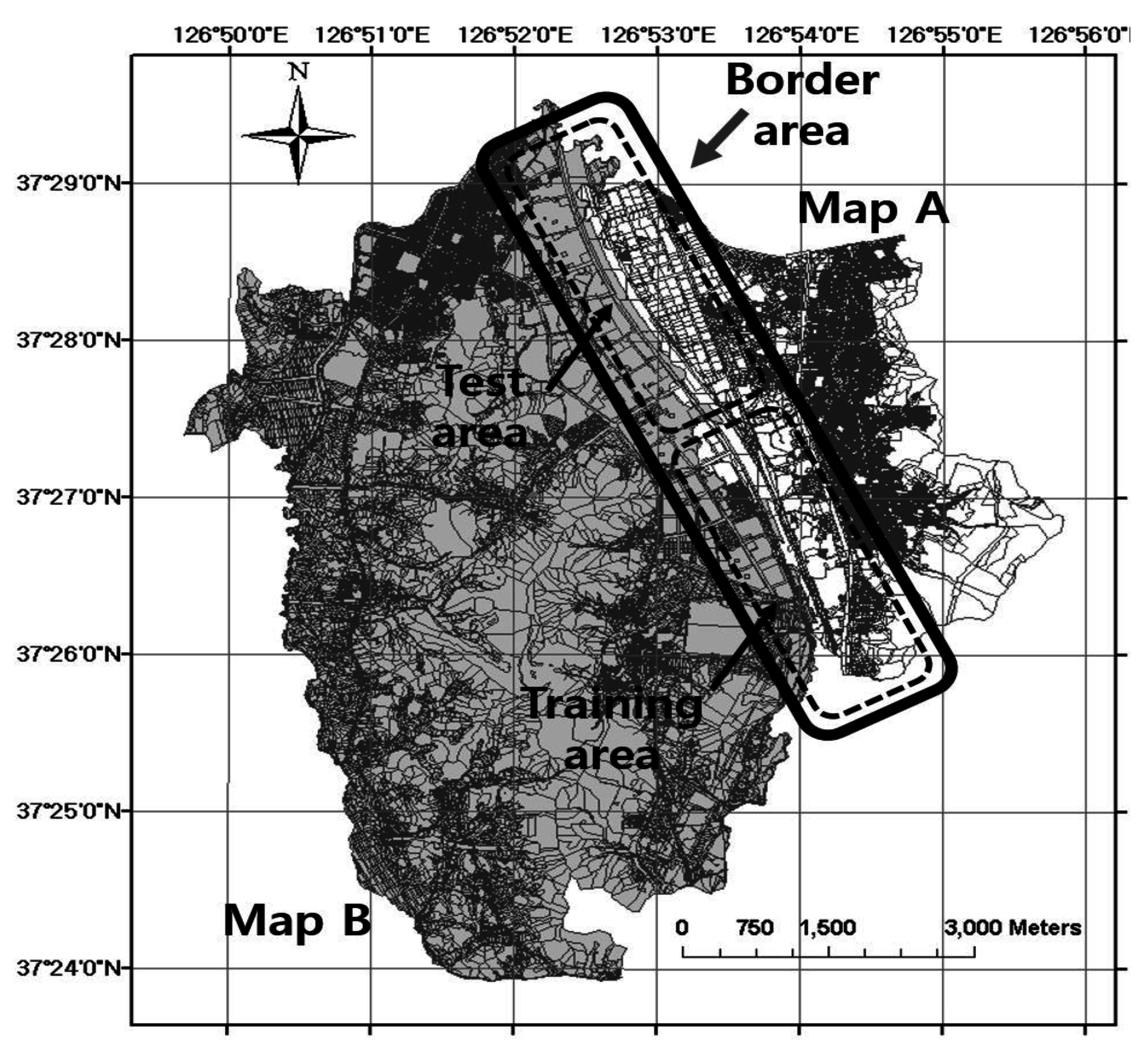
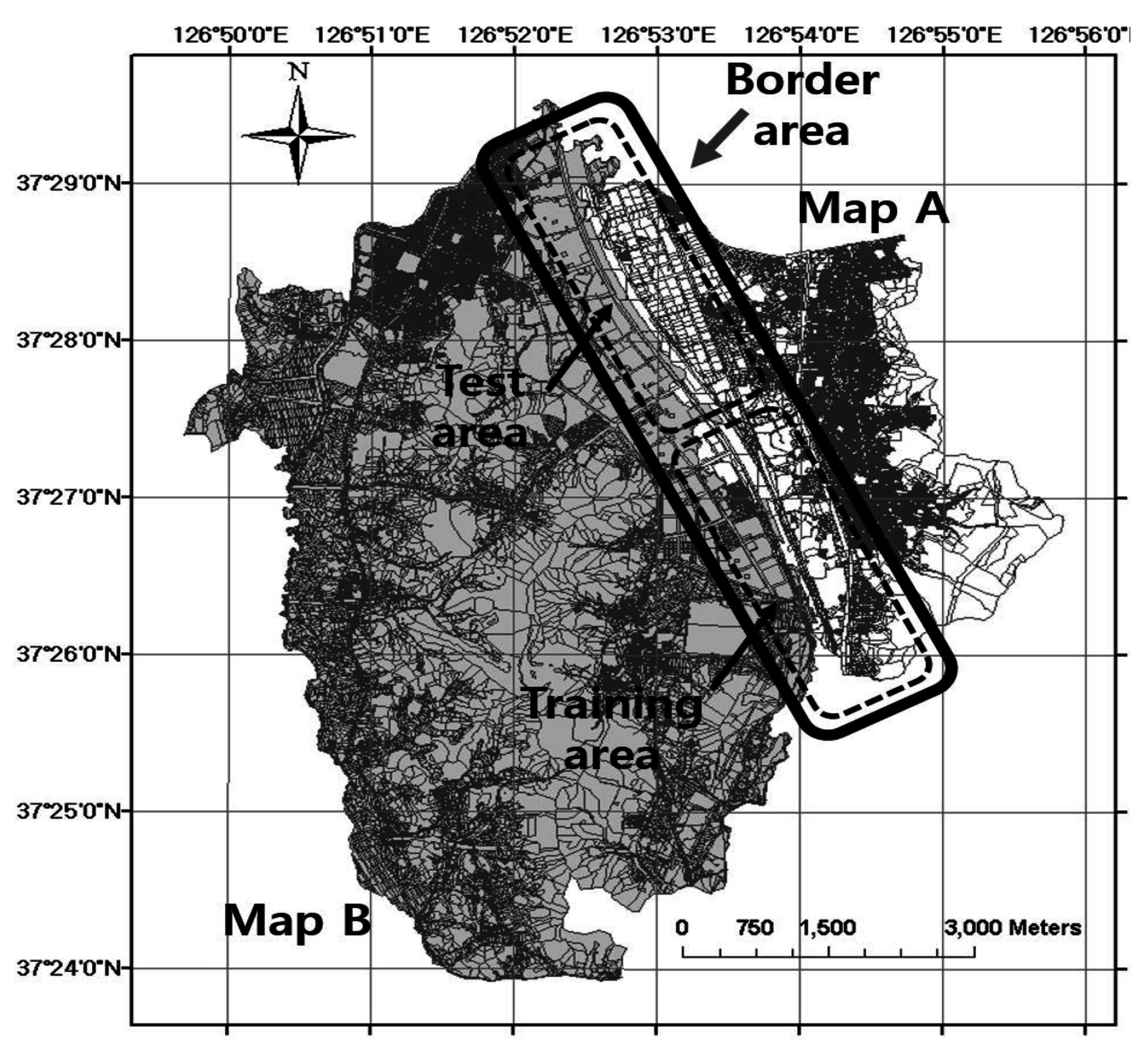
We applied the proposed method to two adjacent cadastral maps, as shown in
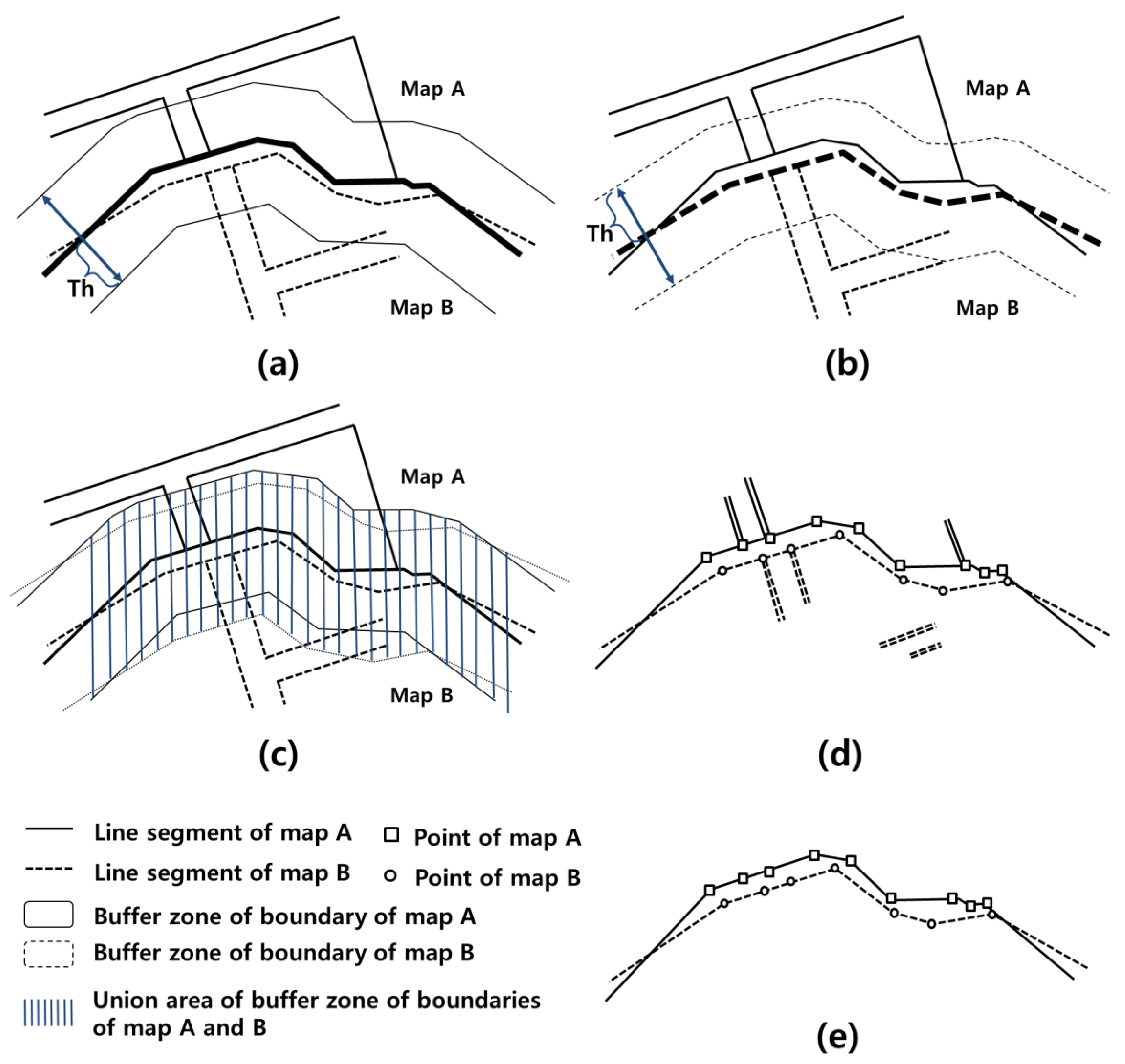
Figure 9. Map A is a cadastral map of the Geum-Cheon district in Seoul city, and map B is a cadastral map of the Gwang-Myeong city in the Gyeong-gi province. The length of the border area is approximately 10 km. Because these maps are created by joining the respective legacy parcel maps and they are maintained independently by local authorities, irregular positional discrepancies arise between the boundary edges of the maps.
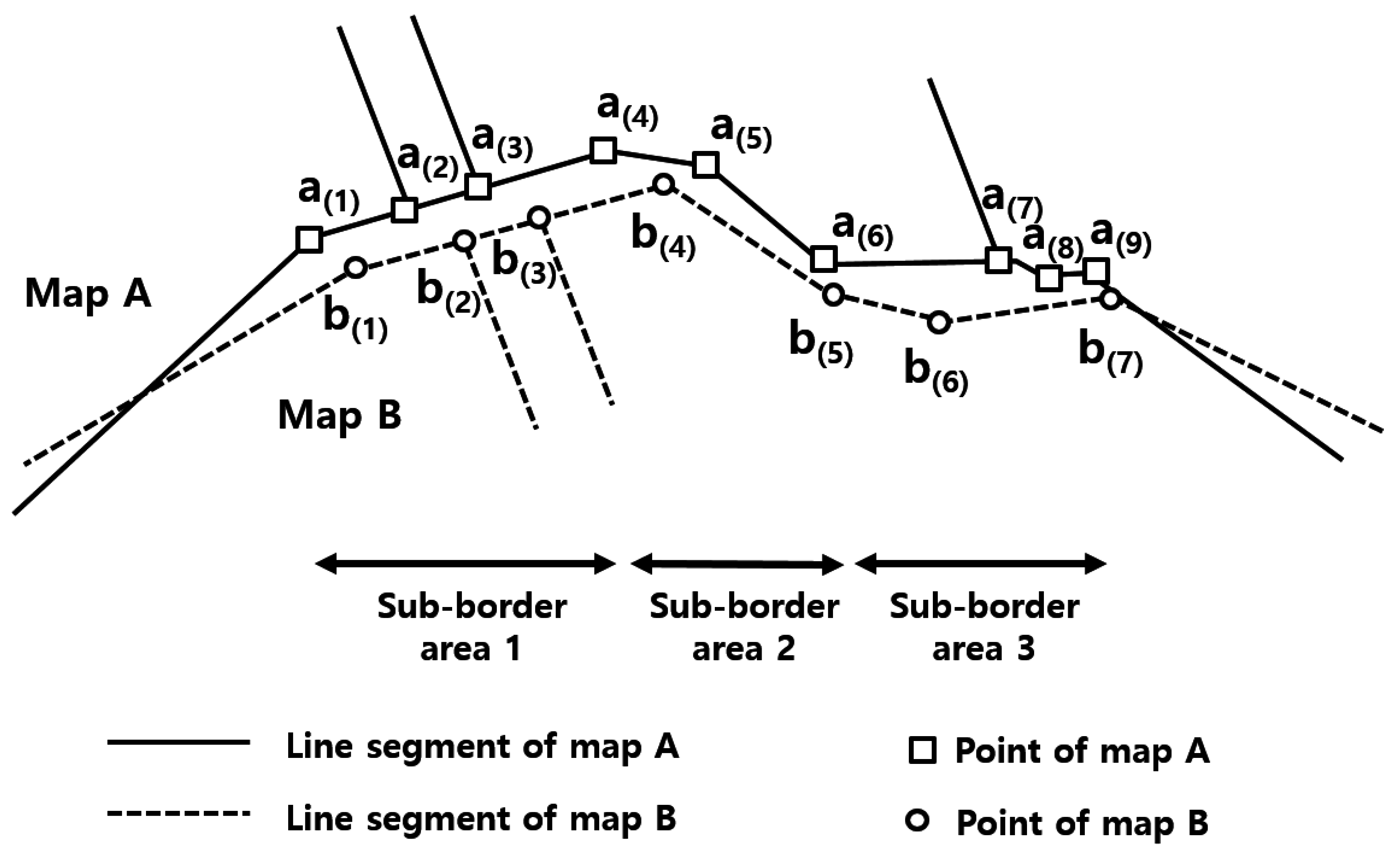
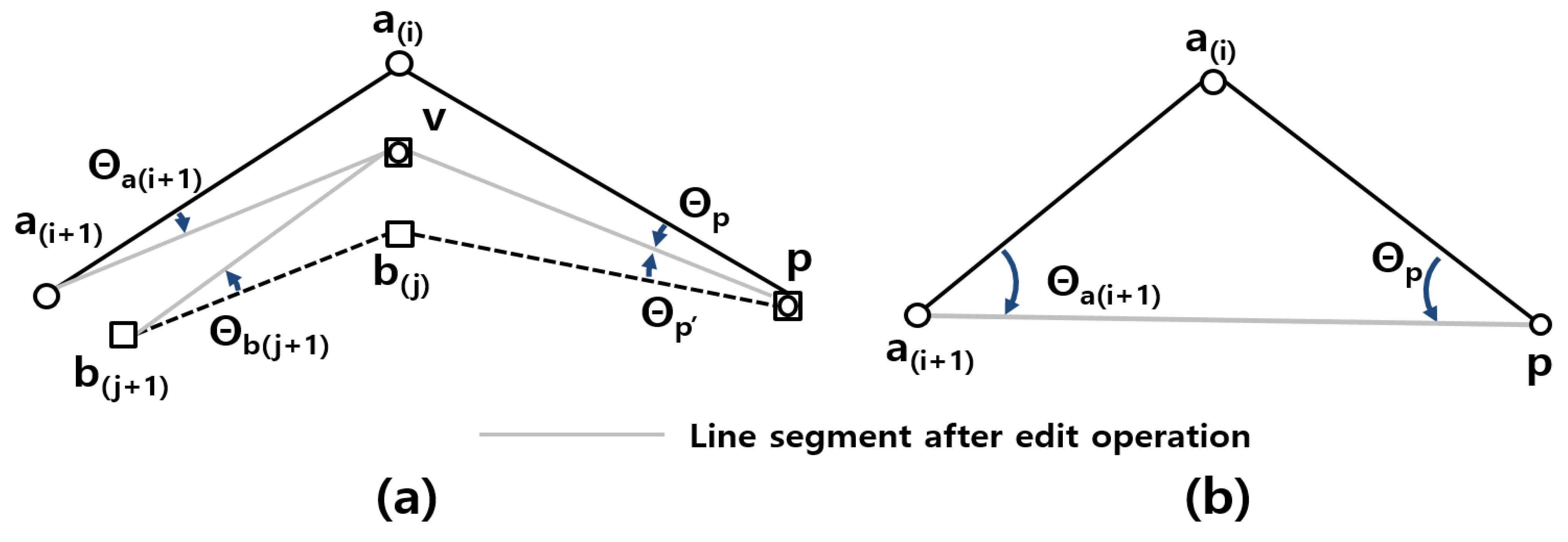
The proposed method has three parameters:
,
and
. Among them,
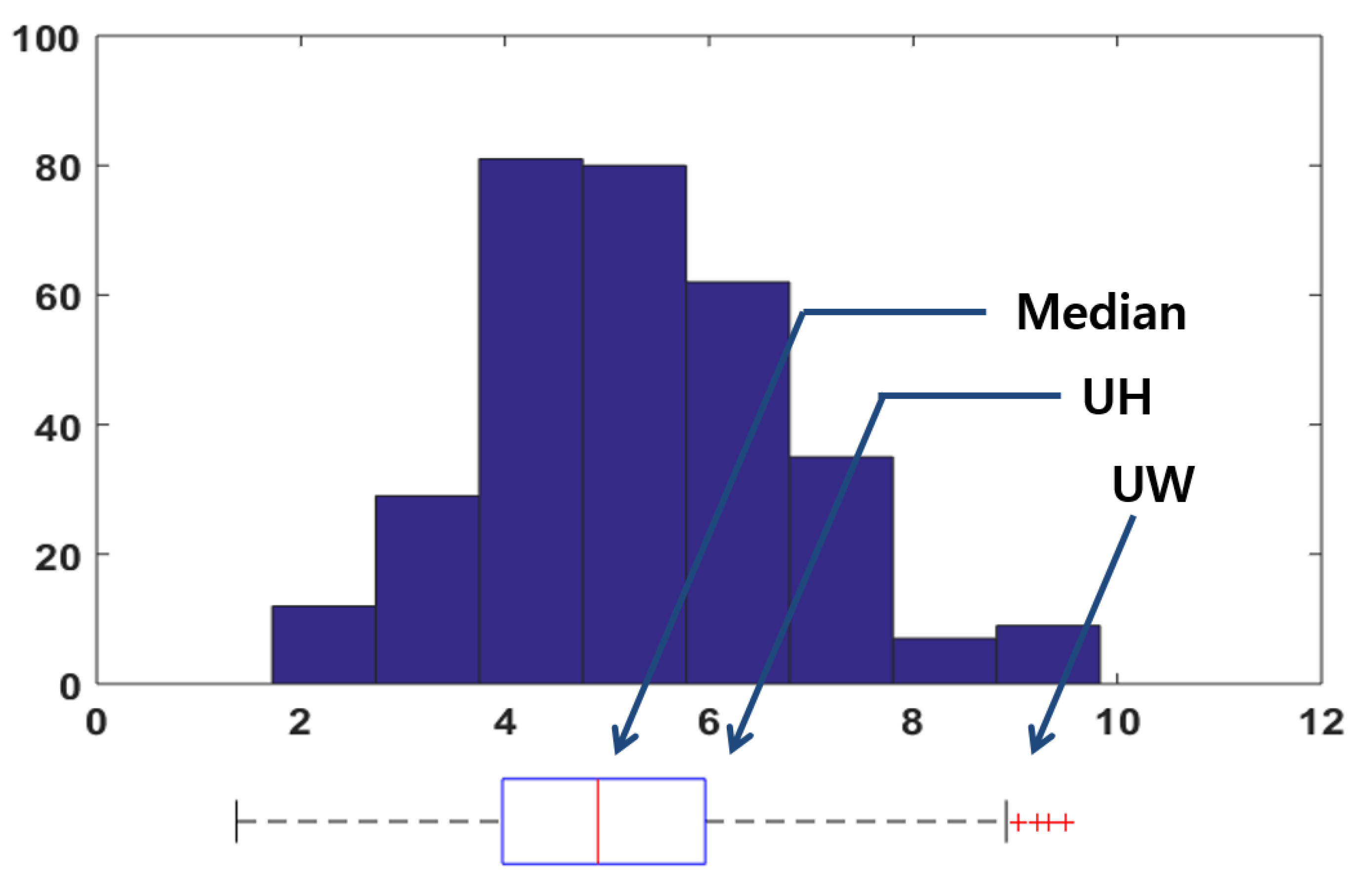
is determined by a statistical analysis of 351 corresponding point pairs in the training area of
Figure 9. We apply the boxplot method [
16] to determine
because the threshold should be a feasible upper limit of the lengths for the corresponding point pairs. The method begins by finding the median of the training data and then doing the same for each of the halves. These upper and lower quartiles define the centre box and are often referred to as the upper hinge (
) and lower hinge (
), respectively. The upper inner fence (
) is defined as an upper fence of the box that is extended by 1.5 times the length of the box towards the maximum, and the upper whisker (
) is defined as the farthest observation inside the
, as expressed by Equations (6) and (7), respectively, and as used for
.
is used for
, and it has a value of 8.89 m as calculated from the pairs in the training data, as shown in
Figure 10.
Figure 9.
Two adjacent cadastral maps (map A and map B) for the experiments.
Figure 9.
Two adjacent cadastral maps (map A and map B) for the experiments.
Figure 10.
A histogram and boxplot analysis of manually chosen corresponding point pairs.
Figure 10.
A histogram and boxplot analysis of manually chosen corresponding point pairs.
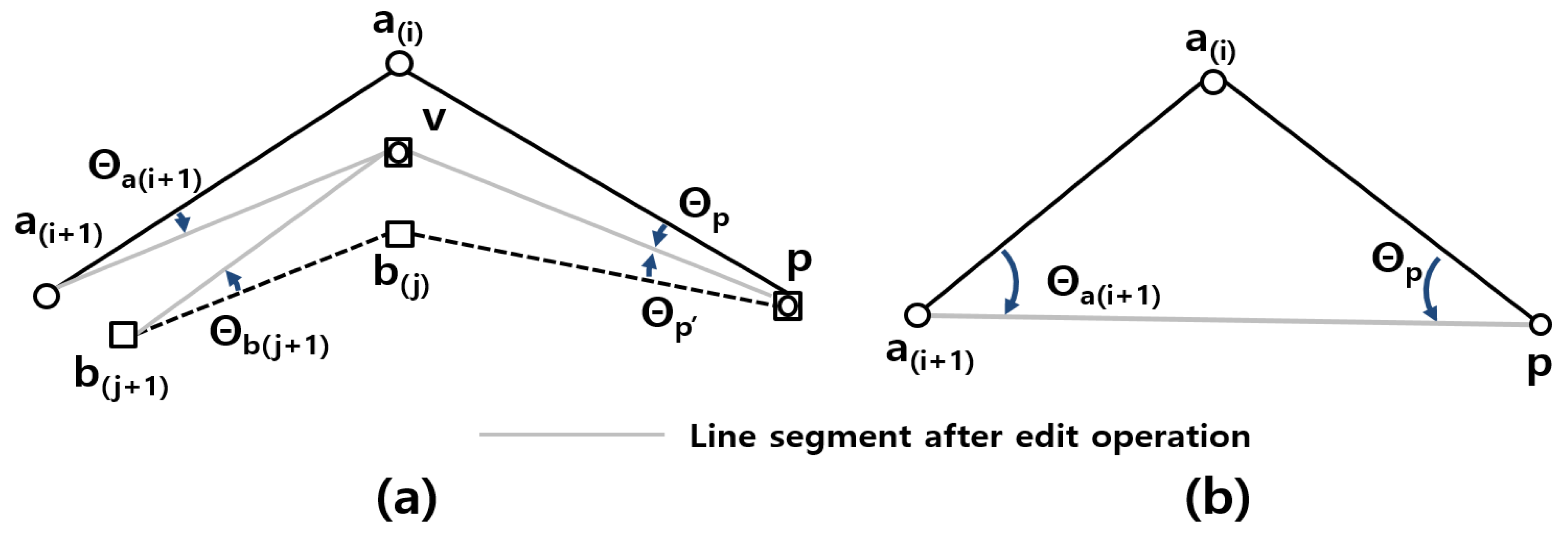
Meanwhile, the remaining parameters
and
cannot be directly trained by this analysis. Thus, various values of the parameters are evaluated and then the optimal parameters with the highest level of matching accuracy are obtained. We used three types of measures for the accuracy: precision, recall and the F-measure. Precision refers to the ratio of correctly found pairs over the total number of found pairs and recall denotes the ratio of correctly found pairs to the total number of correct pairs. The F-measure is defined by Equation (8). In this equation,
and
represent precision and recall, respectively.
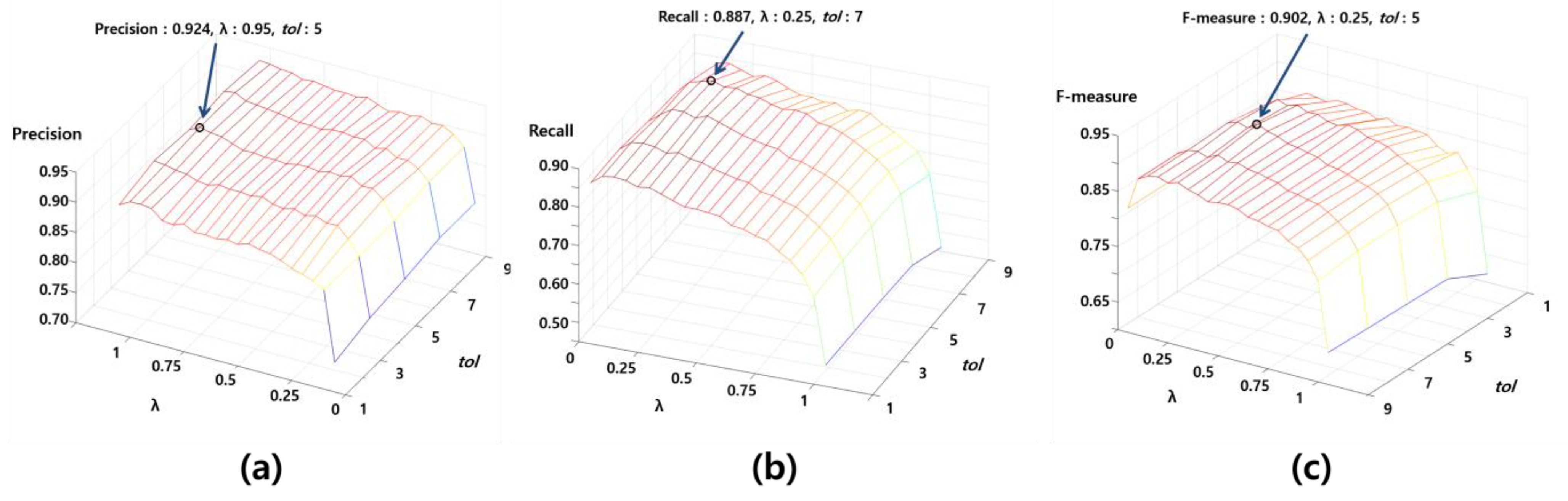
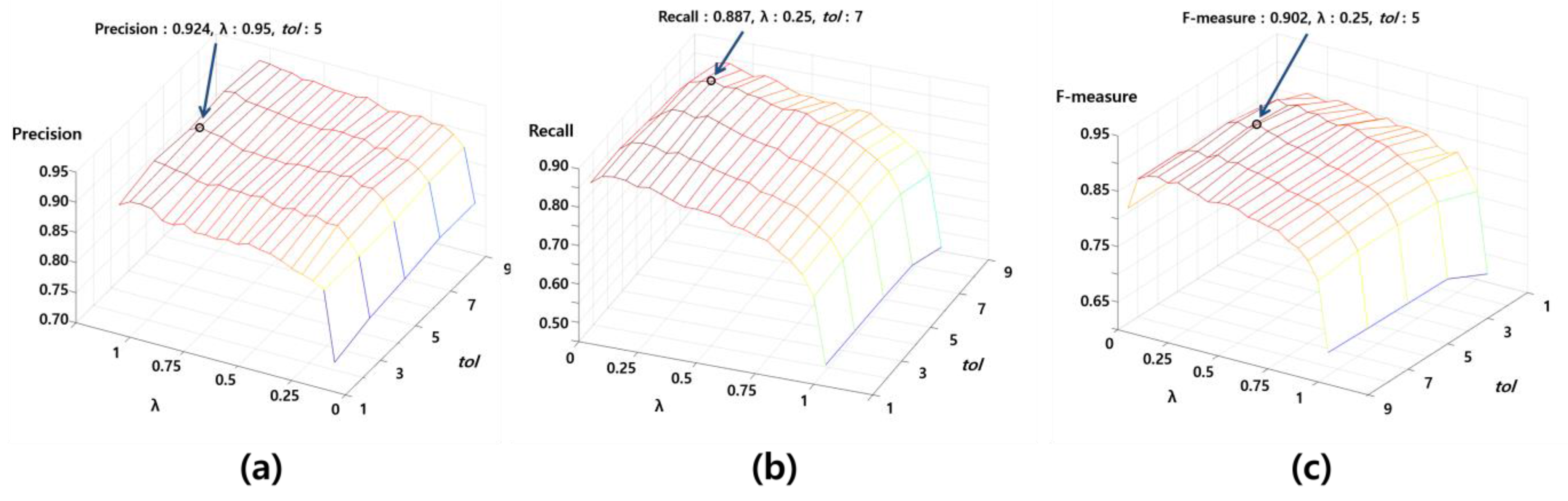
We applied 21 candidate
s from 0 to 1 with 0.05 intervals and five candidate
s from 1 m to 9 m with 2 m intervals. The highest precision (0.924) was obtained when
and
were 0.95 and 5 m, respectively, as shown in
Figure 11a. In addition, the highest recall (0.887) was obtained when
and
were 0.25 and 7 m, respectively, as shown in
Figure 11b. According to
, precision and recall presented a trade-off relationship. When
increased and became closer to one, the degree of precision increased. Meanwhile, when
decreased and became closer to zero, the degree of recall increased. Thus,
serves as a matching threshold for the proposed method. In general, a tighter threshold presents a smaller number of matching pairs with higher precision and lower recall, whereas a looser threshold presents a larger number of matching pairs with lower precision and higher recall. In this study, the proposed method uses the snapping and removing edit operations. In addition, one of the operations that presents the minimum total cost is chosen for a given point. Accordingly, a matching result with high precision and low recall according to a large
indicates an increase in the cost of the snapping operation. Meanwhile, a matching result with low precision and high recall according to a small
indicates a decrease in the cost of the snapping operation. Compared with
,
does not have a meaningful effect on the matching performance. As a result, the highest F-measure (0.902) was obtained when
and
were 0.25 and 5 m, respectively, as shown in
Figure 11c.
Figure 11.
Accuracy evaluations of the proposed method according to the two parameters and : (a) precision, (b) recall and (c) the F-measure.
Figure 11.
Accuracy evaluations of the proposed method according to the two parameters and : (a) precision, (b) recall and (c) the F-measure.
3.2. Result and Discussion
To compare the performance and find the corresponding point pairs for edge matching, a statistical evaluation of the proposed method and a distance threshold method is performed in the test area. As shown in
Table 1, precision, recall and F-measure values of the distance threshold method with
Th of 8.89 m were 0.761, 0.927 and 0.835, respectively. Meanwhile, the proposed method with the parameters determined in the previous section showed higher precision and F-measure values; however, they also showed a lower recall value. These findings indicate that the proposed method has a tighter matching criterion and that the overall matching result of the proposed method was better than that of the conventional distance threshold method in terms of the F-measures.
Table 1.
The statistical evaluation of the proposed method and a distance threshold method in the test area in
Figure 9.
Table 1.
The statistical evaluation of the proposed method and a distance threshold method in the test area in Figure 9.
| | The Proposed Method with
Th: 8.89 m, λ:0.25 and tol: 5 m | A Distance Threshold Method with
Th: 8.89 m |
|---|
| Precision | 0.912 | 0.761 |
| Recall | 0.895 | 0.927 |
| F-measure | 0.903 | 0.835 |
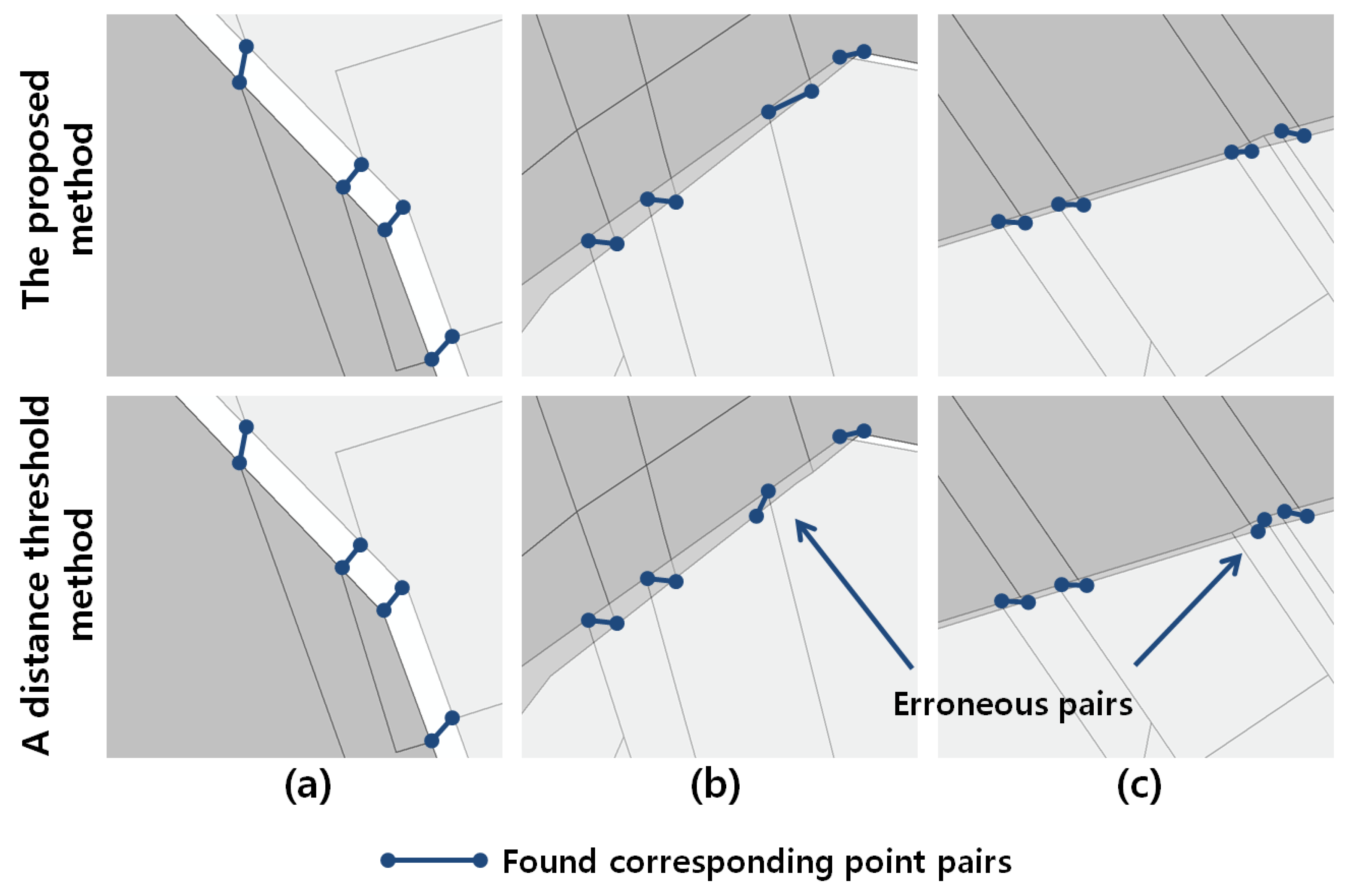
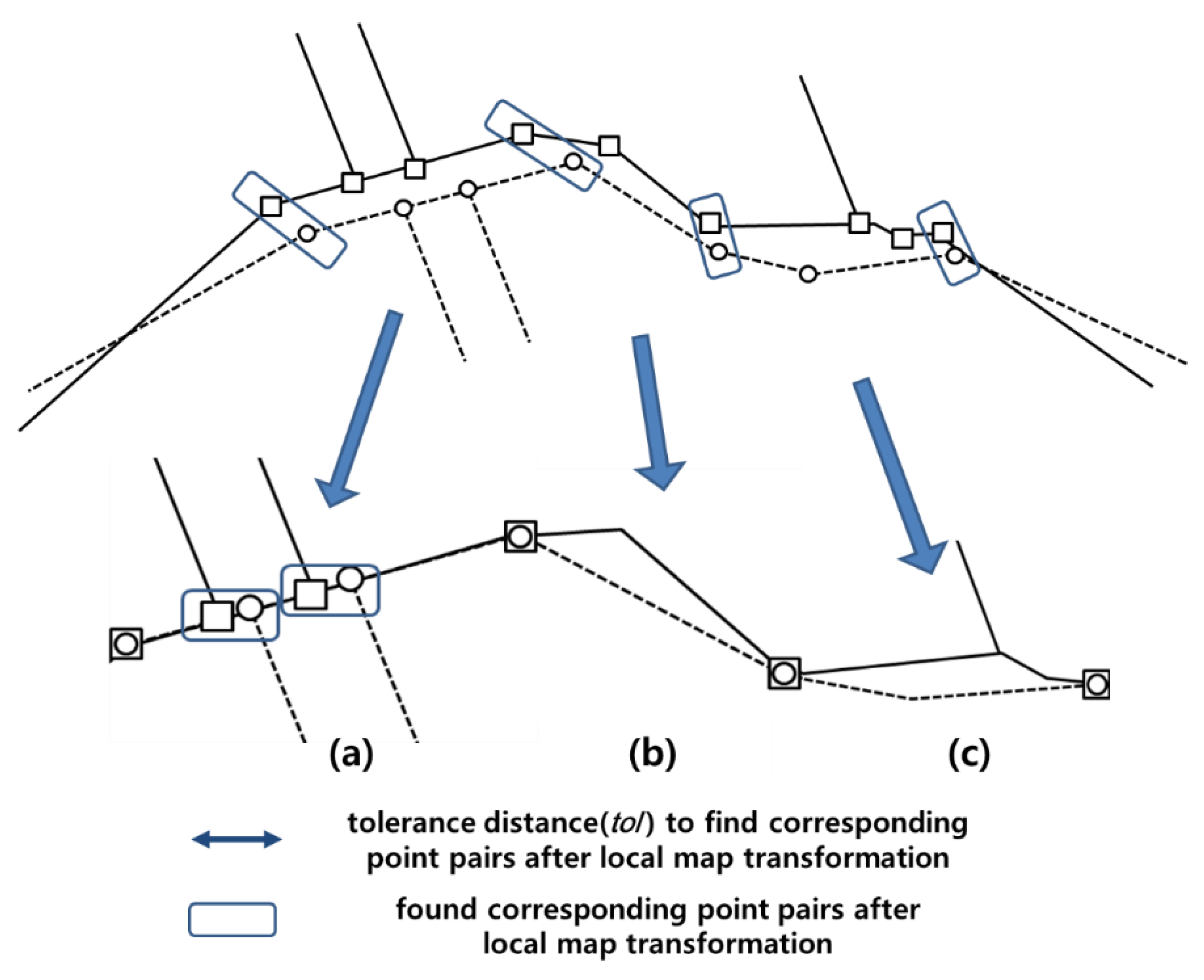
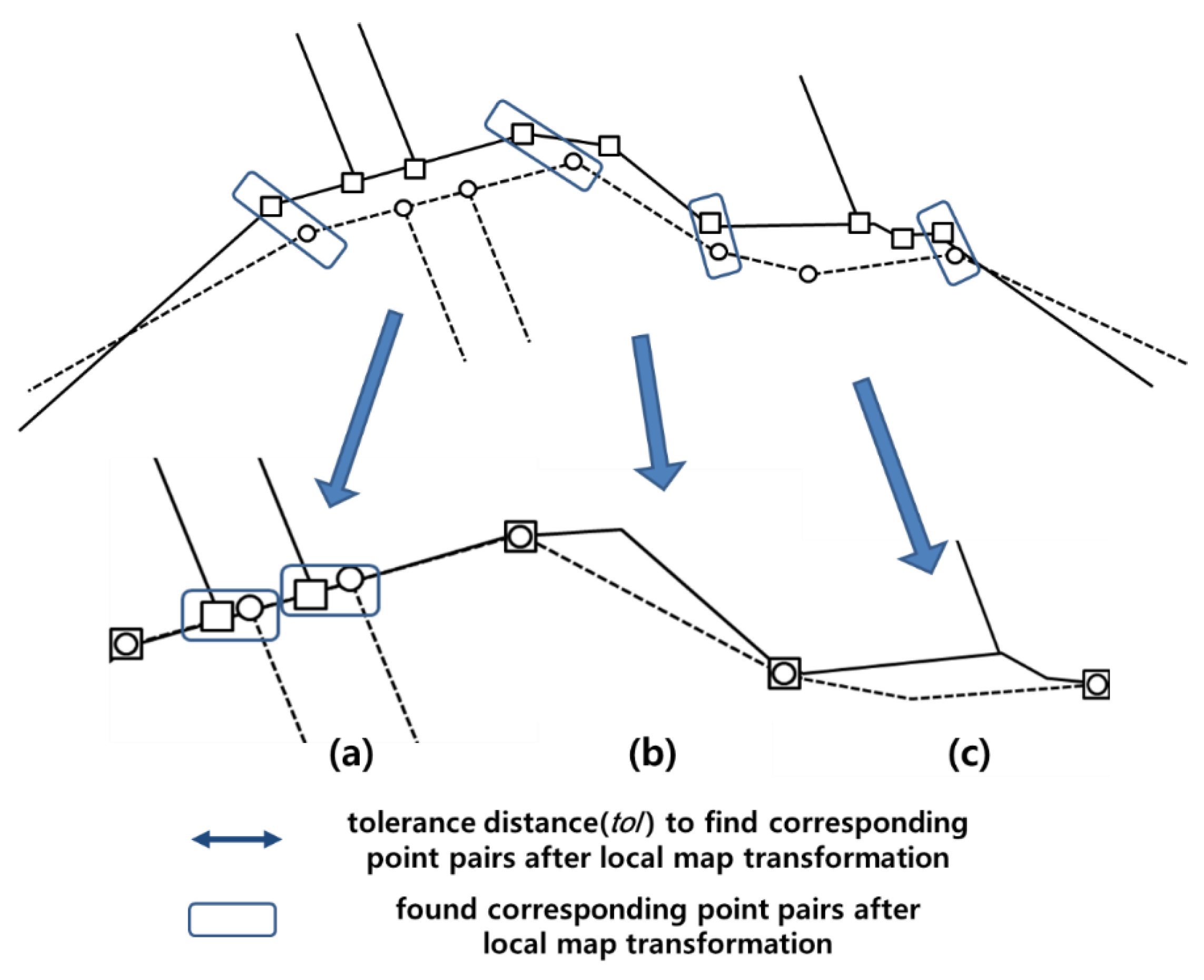
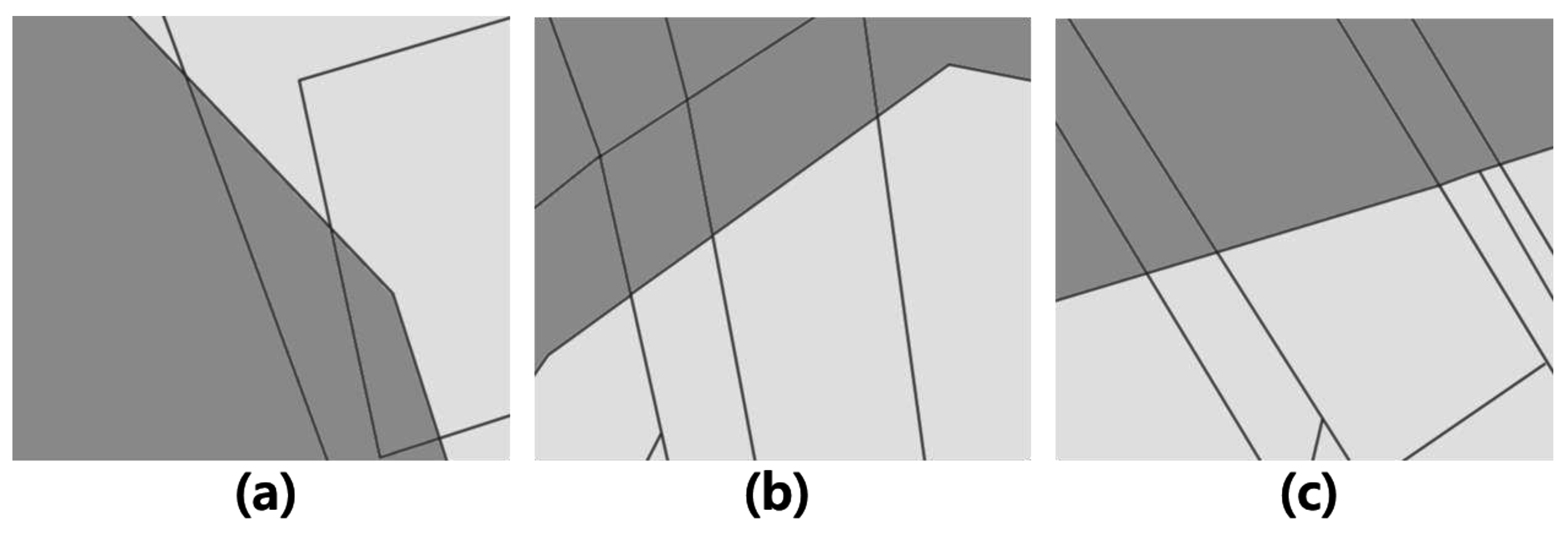
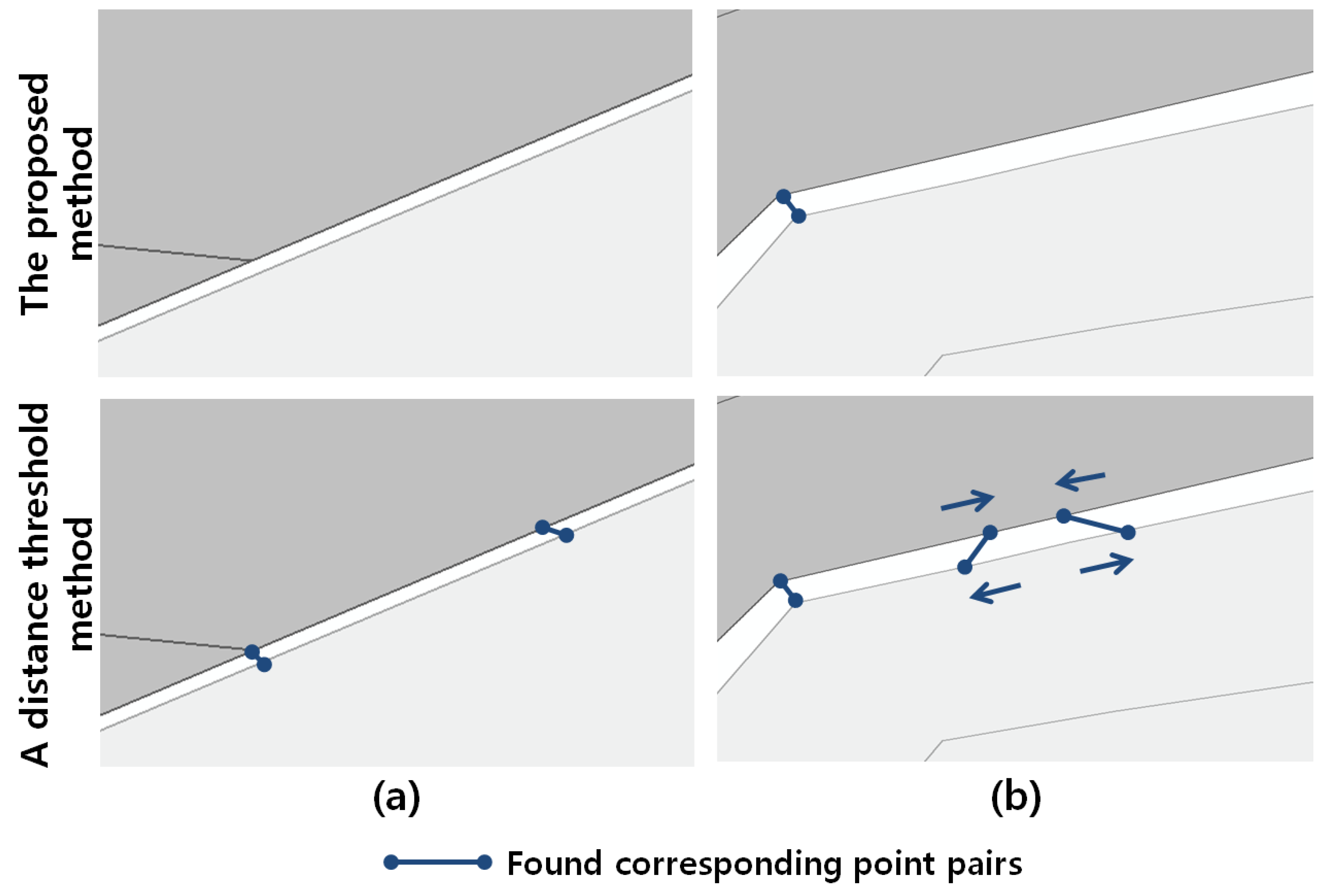
A higher precision for the proposed method was obtained especially from points on disconnected line segments, as shown in
Figure 12b,c. When the distances between these points are sufficient compared with the positional discrepancies between adjacent maps, as shown in
Figure 12a, the two methods presented nearly the same results. However, the distances for the erroneous point pairs are coincidently shorter than those of true point pairs, as shown in
Figure 12b, which shows that the distance threshold method was vulnerable to this problem and presented an inaccurate result with low precision. This problem became even more severe for the points on parallel disconnected line segments, which describe the roads as shown in
Figure 12c. Occasionally, the widths of these roads are not sufficient compared with the positional discrepancies between the maps. Therefore, many erroneous point pairs can be obtained by the distance threshold method because the closest points are simply chosen for the pairs regardless of the neighbouring auto-correlated positional discrepancies. Meanwhile, the proposed method performs a matching process by considering these discrepancies; hence, it presents an improved matching performance in terms of precision.
Figure 13 is the result of map alignment with these corresponding point pairs.
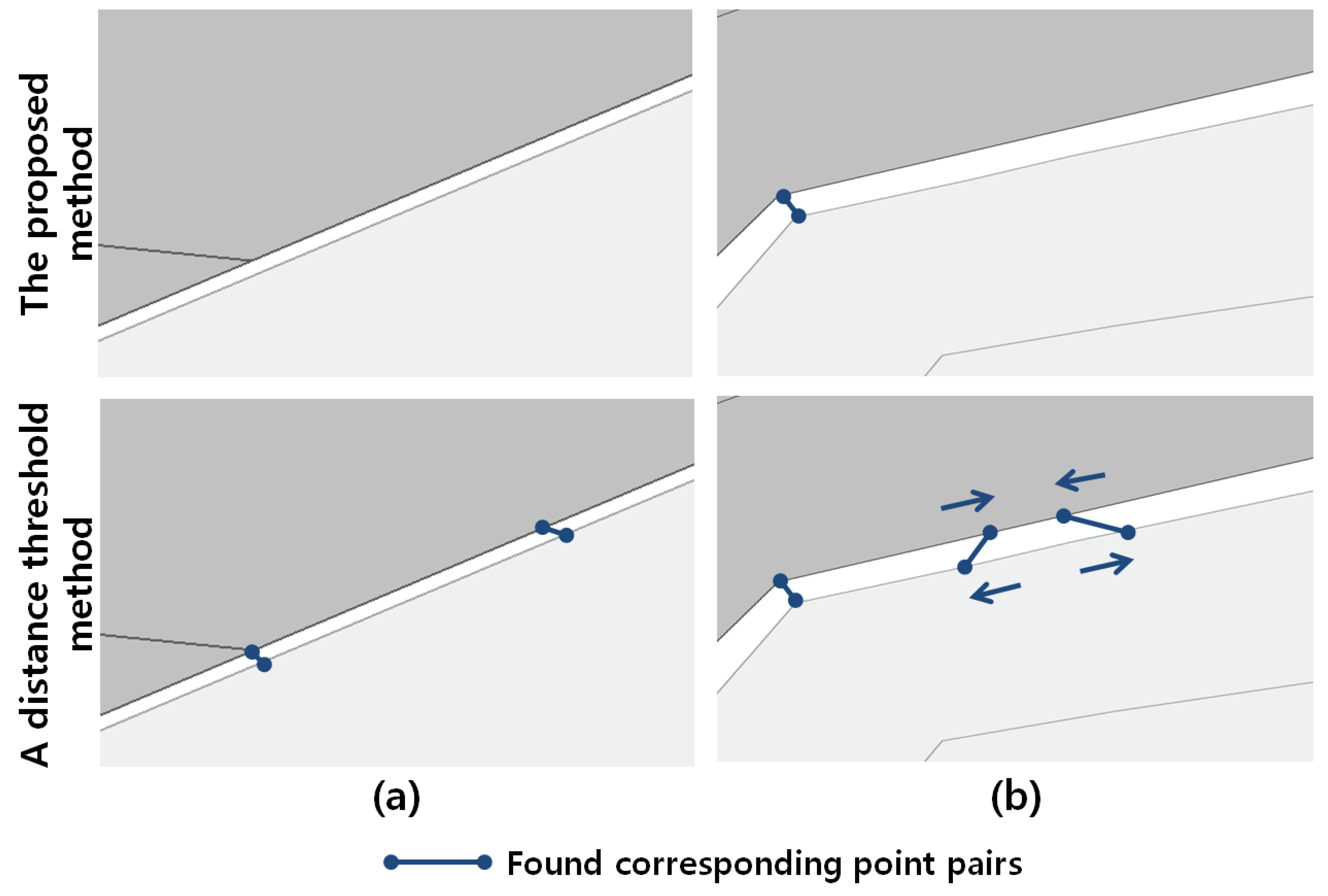
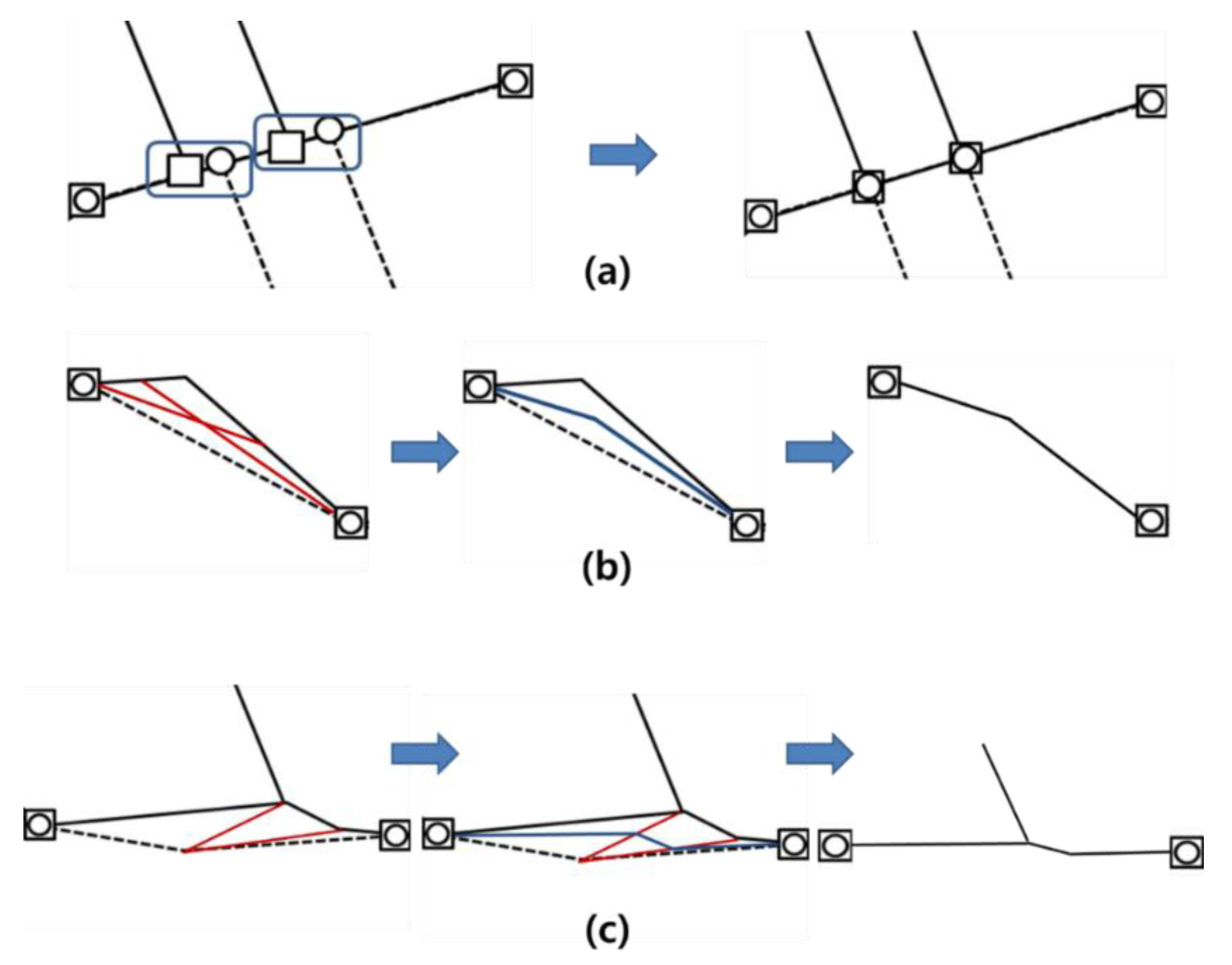
Compared with the higher degree of precision, the proposed method presented lower recall, as shown in
Table 1. This occurred because it tends to choose corresponding point pairs between salient corner points rather than those on nearly straight line segments, as shown in
Figure 14a. The proposed method determines corresponding point pairs as the point pairs for which the snapping operation is chosen in the optimal sequence with which two point strings are aligned at the minimum total cost. In general, the removing operation of a salient corner point causes a considerable amount of shape deformation on the line segments involved, which results in a larger edit operation cost than that of the snapping operation. This relationship is opposite for the points connected by nearly straight line segments. Thus, as shown in the previous figures, the proposed method accurately found the corresponding point pairs between salient corner areas with a higher degree of recall accuracy. However, except for those disconnected line segments, the corresponding point pairs between points connected by nearly straight line segments were not sufficiently found because the choices in removing operations for them present a lower cost. This property prevents irregular stretching or shrinking of the neighbouring border areas, as shown in
Figure 14b. The proposed method found the corresponding point pairs between salient corner areas by allowing gradual map alignments along the border area to be obtained. However, when all of the mutually closest points are used, the map alignment result by itself could be abrupt, which decreases the overall performance. Based on the above comparisons to the manually chosen corresponding point pairs and the matching property, the proposed method is superior to previous distance threshold methods.
Figure 12.
Comparison of corresponding point pairs found by the proposed method and the distance threshold method; (a) both methods find correct pairs, (b,c) the proposed method finds correct pairs of disconnected line segments between two maps meanwhile the distance threshold methods finds erroneous pairs.
Figure 12.
Comparison of corresponding point pairs found by the proposed method and the distance threshold method; (a) both methods find correct pairs, (b,c) the proposed method finds correct pairs of disconnected line segments between two maps meanwhile the distance threshold methods finds erroneous pairs.
Additionally, it is necessary to discuss the effect of point string order. In
Section 2.1, the orders were determined to be counter-clockwise. However, according to the order of whether it is counter-clockwise or clockwise, matching results for the corresponding point pairs can be different. Although both results are nearly the same, this cannot be explained at this stage and further research is necessary.
Figure 14.
Comparison of corresponding point pairs found by the proposed method and the distance threshold method for straight line segments; (a) the proposed method does not find corresponding point pairs between points on nearly straight line segments meanwhile the distance threshold method finds correct pairs, (b) the distance threshold method finds corresponding point pairs which result irregular stretching or shrinking after map alignment meanwhile the proposed method does not cause such problem.
Figure 14.
Comparison of corresponding point pairs found by the proposed method and the distance threshold method for straight line segments; (a) the proposed method does not find corresponding point pairs between points on nearly straight line segments meanwhile the distance threshold method finds correct pairs, (b) the distance threshold method finds corresponding point pairs which result irregular stretching or shrinking after map alignment meanwhile the proposed method does not cause such problem.




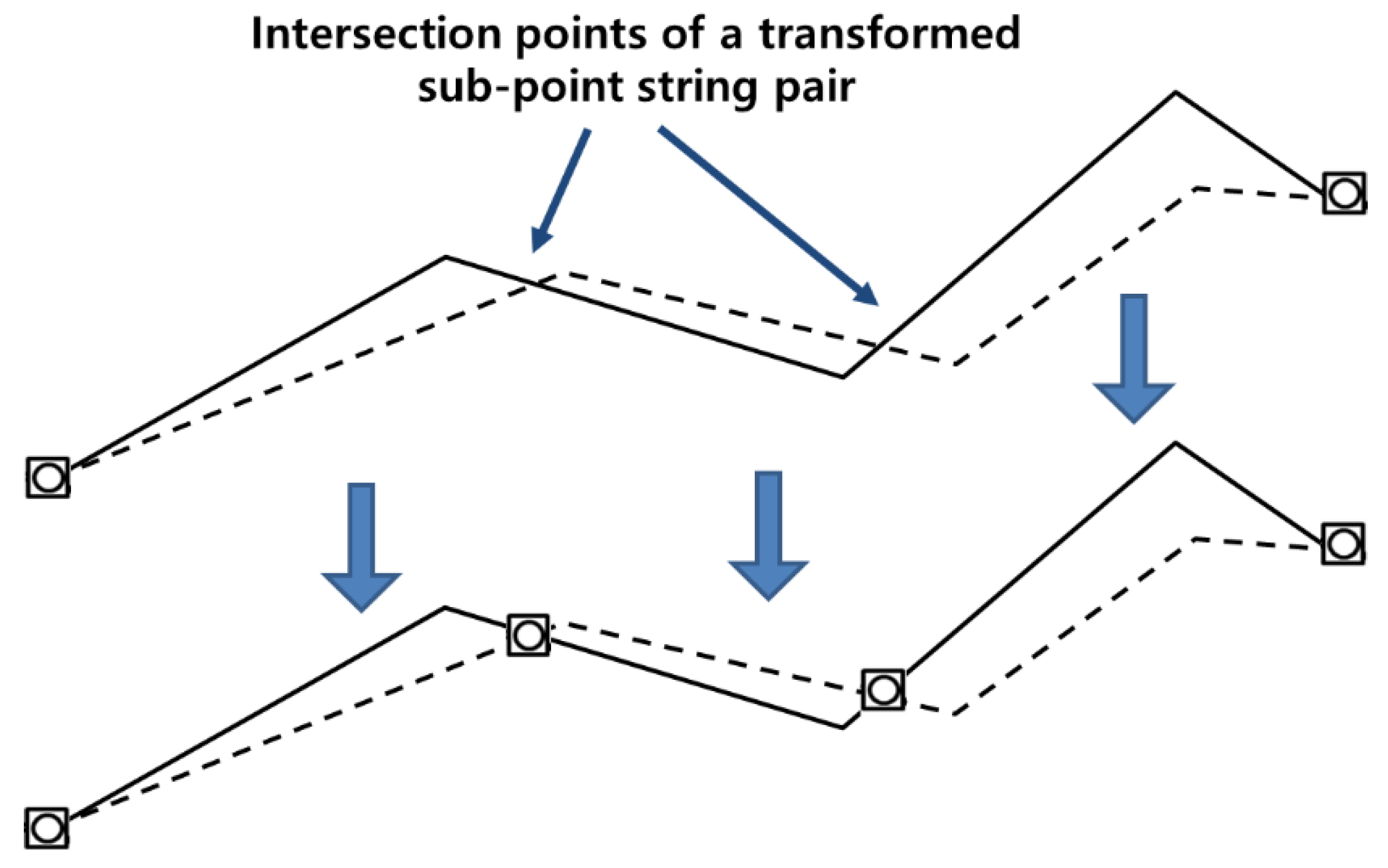


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}