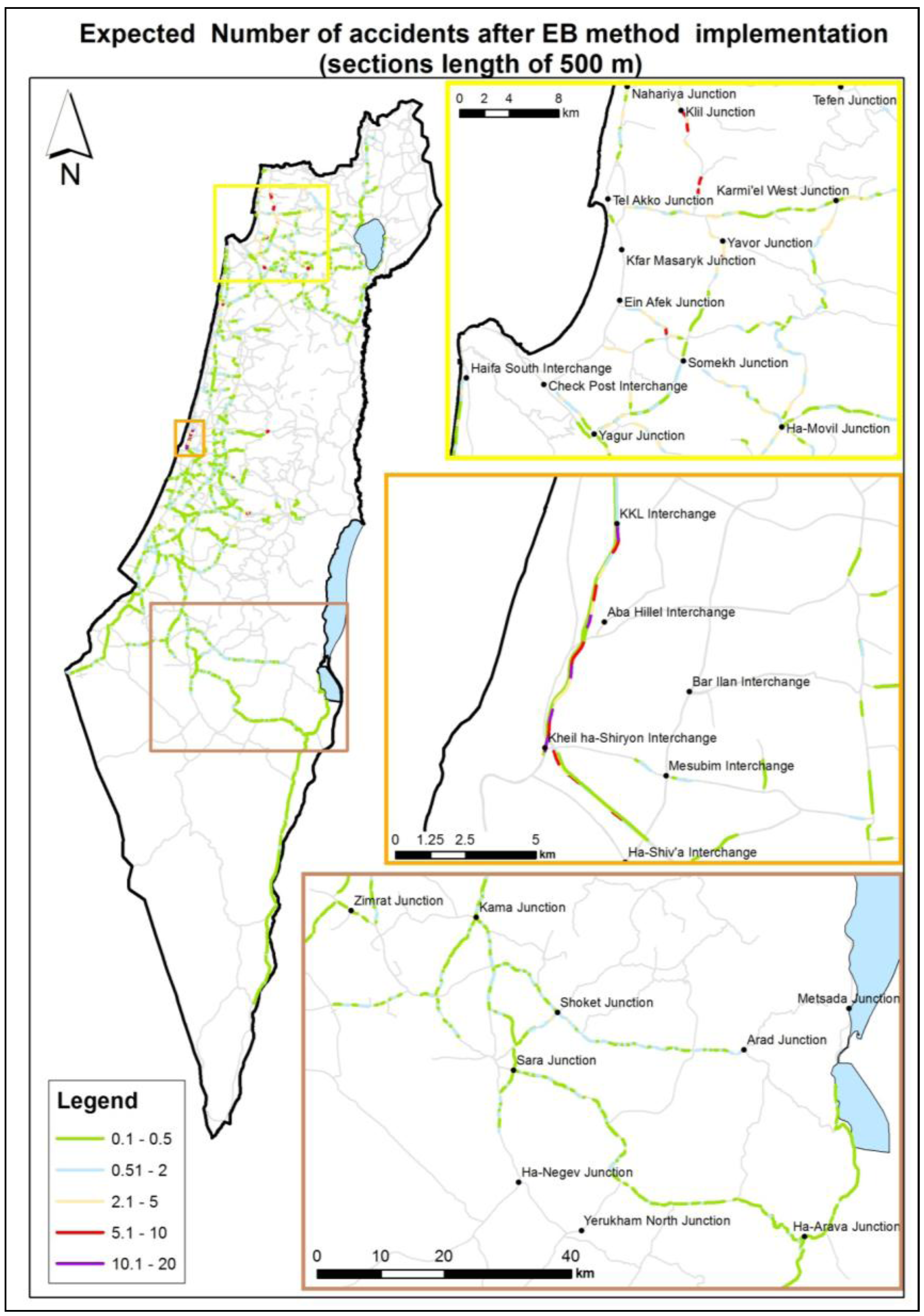
Of all the parameters that were examined in this study, the curvature of the road section, the region, and the traffic volume were found to be the most significant in terms of affecting accidents. Due to its high expected accident rates the northern region was designated for special observation and was divided into sub-regions that were analyzed separately.
3.2.2. Region
The third variable found to be significant was the region. In Israel, this variable is compatible with the major divisions of the “periphery” (North and South) and the central area (Tel Aviv metropolis). All of the analyses consistently showed the highest expected accident rates to be in the northern area and particularly in the Western Upper Galilee. Therefore, the results concerning this variable should be further analyzed and checked in several aspects.
The region variable was analyzed during the first step of building the models. This parameter appeared to be significant in all four models, as constructed for various lengths of road sections. In all four models, the accident rate for the northern part of Israel was expected to be higher (approximately twice as high) than the expected rate of accidents for the central and southern parts of Israel.
The second regional analysis examined the statistical differences between the northern, southern, and central regions. This analysis aimed to examine the statistical differences between the regions, and to learn whether a particular area will depict more or less accidents, regardless of the volume of traffic. The data set was divided into several traffic volume ranges: “low”, “medium-low”, “medium-high”, and “high”. Due to the need to maintain balanced groups for the statistical analysis, only groups with sufficient samples were analyzed. In practice, only the “medium–low” group (5000 to 15,000 vehicles per road section) and the “medium–high” group (15,000 to 30,000 vehicles per road section) were analyzed.
In this analysis, the trends were similar at road lengths of 500 and 750 m for the “medium–low” and the “medium–high” road sections, with the expected accident rate in the northern region greater than expected in the southern region and the expected accident rate in the northern region greater than expected in the central region. These trends are also consistent with the results obtained in the previous regions analysis performed on the training model (the expected accident rate at north is higher than expected at the central and southern regions.
When comparing the predicted accident rates of the central and southern regions, different relations were found:
(1) At “medium-low” traffic volumes, the expected accident rates in the central region were greater than expected in the southern region. This may be explained by the fact that in the south, despite dealing with accidents at so-called medium-low traffic volumes, the traffic volumes are truly lower, meaning that the roads actually carry very sparse traffic. The logic is simple: Given that very few vehicles (low range value) are present, the probability for accidents drastically decreases in this region, as compared to the central region, where vehicles are present at the higher end of the “medium-low” traffic volume range.
(2) At “medium-high” traffic volumes, the expected accident rates in the southern region were greater than expected in the central region. The presumed explanation is that as traffic increases, it is more vulnerable to the effects of the infrastructure quality, such as unregulated intersections that flow directly into the highways, fewer lanes, and lack of lane separation. As the infrastructure in the southern region was much poorer than in the central region at the time of the study, it affected the accident sensitivity rates.
The third aspect of the regional analysis was the interaction analysis. Unlike the previous analyses, here, the traffic volume serves as a parameter. Thus, there is difference in division of the traffic volume thresholds. This was carried out by partitioning the segments into three groups: “low” traffic volume, characterized by values ranging from 0 to 10,766; “medium” traffic volume, characterized by values ranging between 10,767 and 20,033; and “high” traffic volume, characterized by values over 20,033.
An interaction between the region and the traffic volume variables was found for both data sets examined. This means that the effect of traffic volume on the expected rate of accidents is not uniform and depends on the region as well (see
Table 7). The interaction analysis findings match the results of the first and second analyses. All other interactions such as region and curvature, and region and slope were not found significant, and thus, were not further examined as were the AADT and region. The significance test was carried out by comparing AIC value of “Null model” (The “Null Model” containing the variables: curvature, area and volume of traffic without variable representing interaction), with three other models that contained also interactions as parameters.
The anomaly as depicted at
Table 7 where the expected results for “Medium traffic” is higher than for the “High” in the southern area is intriguing indeed. This is biased due to the division of the traffic groups. The maximum daily traffic in the south area was 23,000. This further implies that the “High traffic” group almost does non exit in this area. Only 72 records were found in the south area for this group and this actually biased the results.
Table 7.
Interactions—number of expected accidents divided into regions (Section lengths of 500 m and 750 m).
Table 7.
Interactions—number of expected accidents divided into regions (Section lengths of 500 m and 750 m).
| Data Set | AADT | Area | Expected Number of Accidents |
|---|
| 500 m | Low | south | 0.51 |
| medium | south | 1.51 |
| High | south | 1.19 |
| Low | north | 1.64 |
| medium | north | 2.29 |
| High | north | 4.10 |
| Low | center | 1.32 |
| medium | center | 1.05 |
| High | center | 2.38 |
| 750 m | Low | south | 0.74 |
| medium | south | 2.3 |
| High | south | 1.89 |
| Low | north | 2.22 |
| medium | north | 3.55 |
| High | north | 5.45 |
| Low | center | 2.06 |
| medium | center | 1.41 |
| High | center | 3.74 |
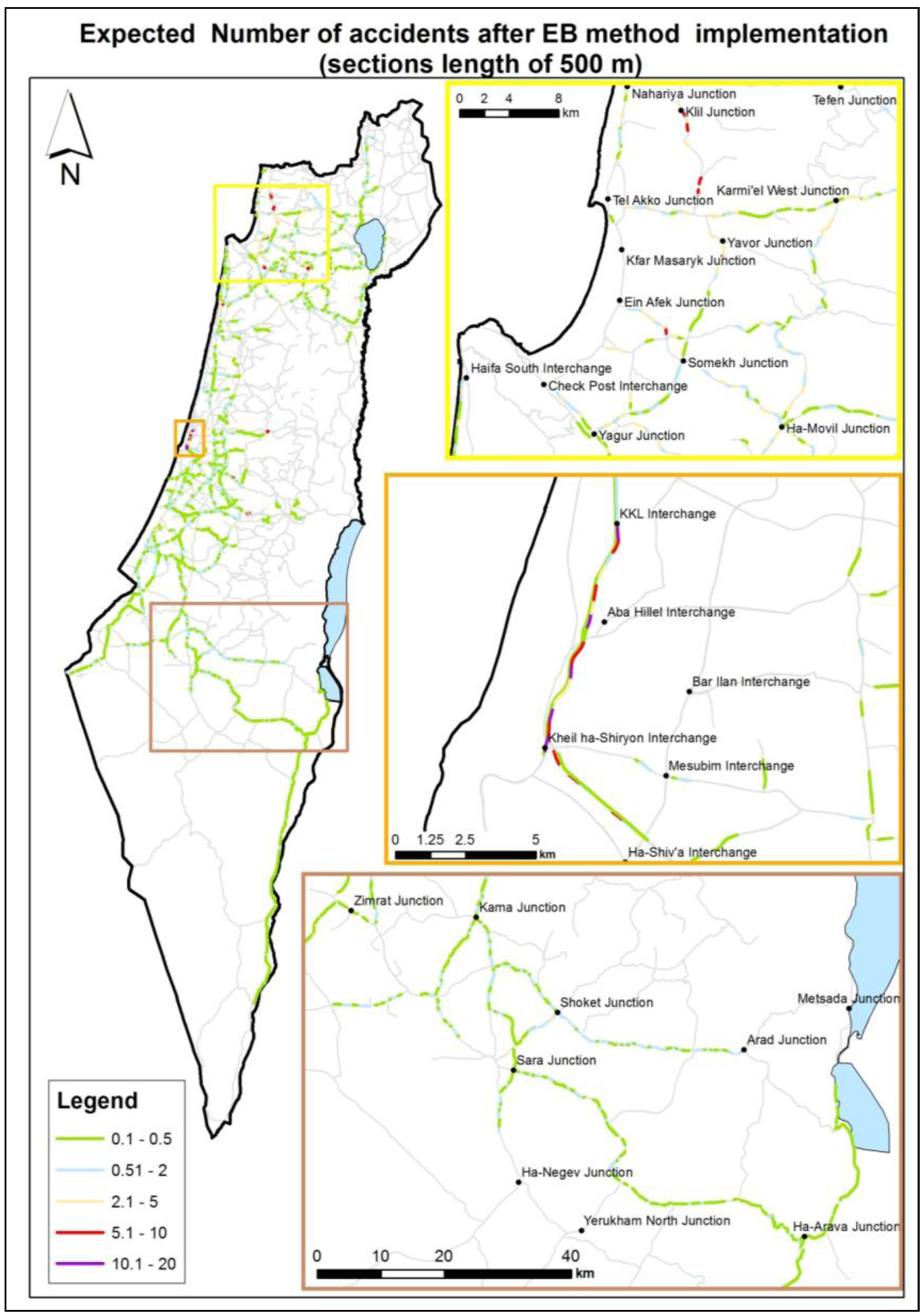
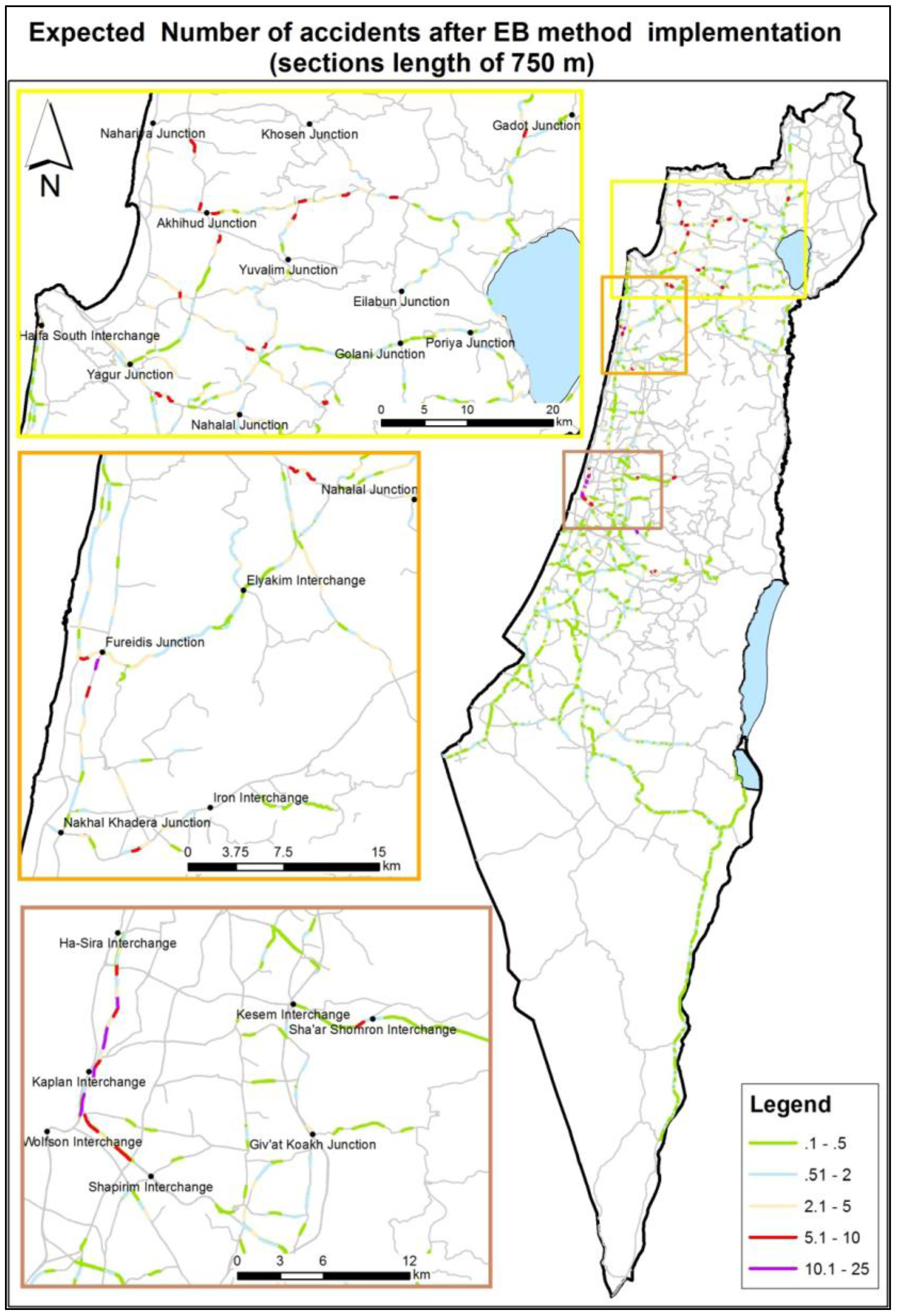
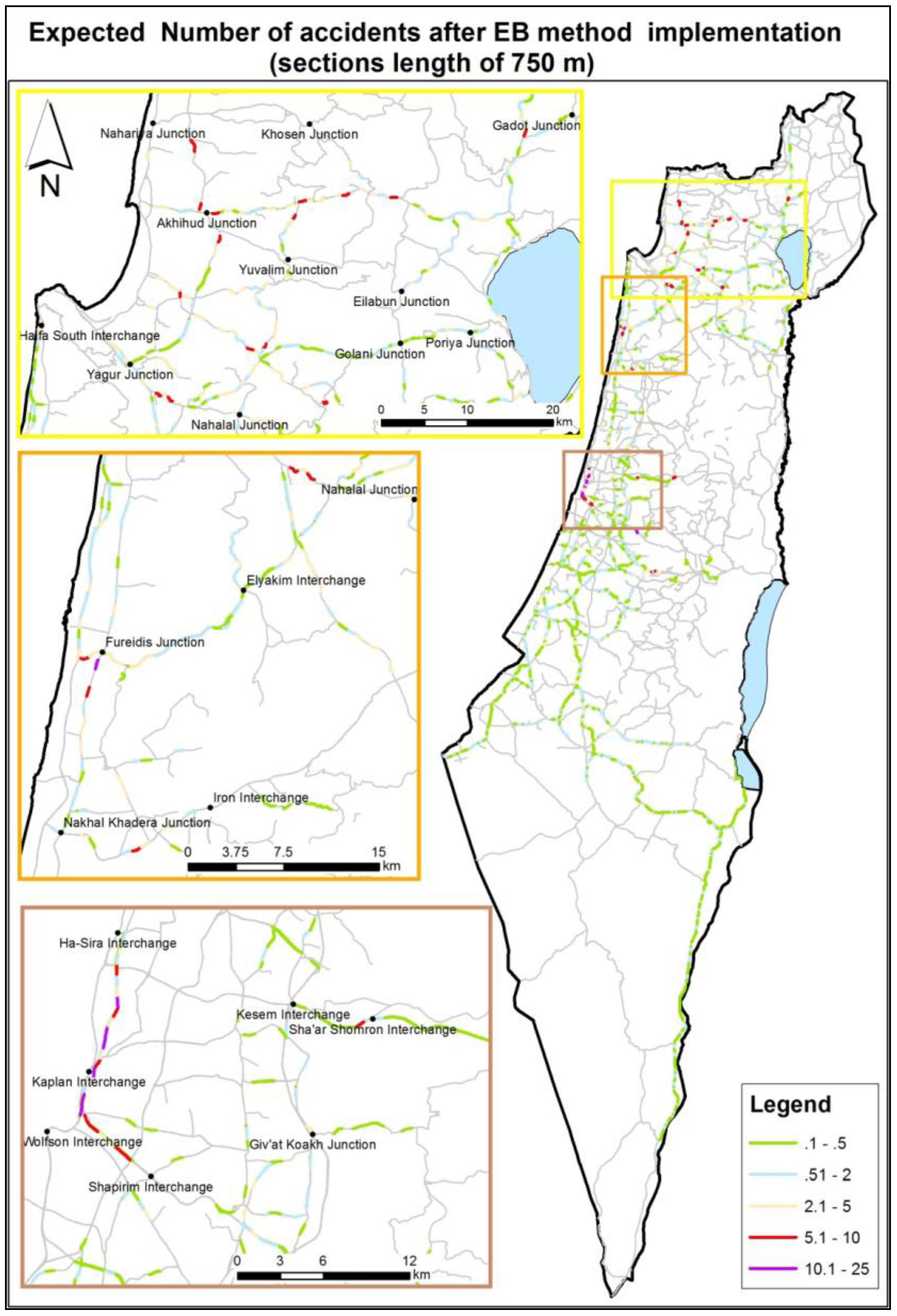
In the last analysis of the region variable, the northern area was designated for special observation due to its high expected accident rates. The area was divided into eight sub-regions, and the analysis was performed on the full accident data (without dividing into 2/3 and 1/3). One sub area, “Golan Heights”, was eliminated from the analysis due to low number of accidents events during the research period. The Linear Step-up procedure was applied in order for detecting false discovery rate. The analysis results showed significant high expected accident rates in the Western Upper Galilee sub-region. According to this finding, it is recommended that a range of practical activities be carried out, from improvement of infrastructure to education and advocacy.
3.2.3. Speed
Interestingly, the speed variable was not determined to be significant by this study. This conclusion is in agreement with other published studies, such as [
15], which found that the accident rate rose in accordance with increasing speed on non-major roads. Yet, on main roads, it was found that the path width, the density of nodes, and traffic had higher correlations with the accident rate.
The speed parameter, as integrated into this study, was only estimated. In order to be able to assess this parameter more accurately in future studies, it is necessary to acquire and integrate more accurate speed data, perhaps even from different points in time, such as day and night, weekdays and weekends, and so on.
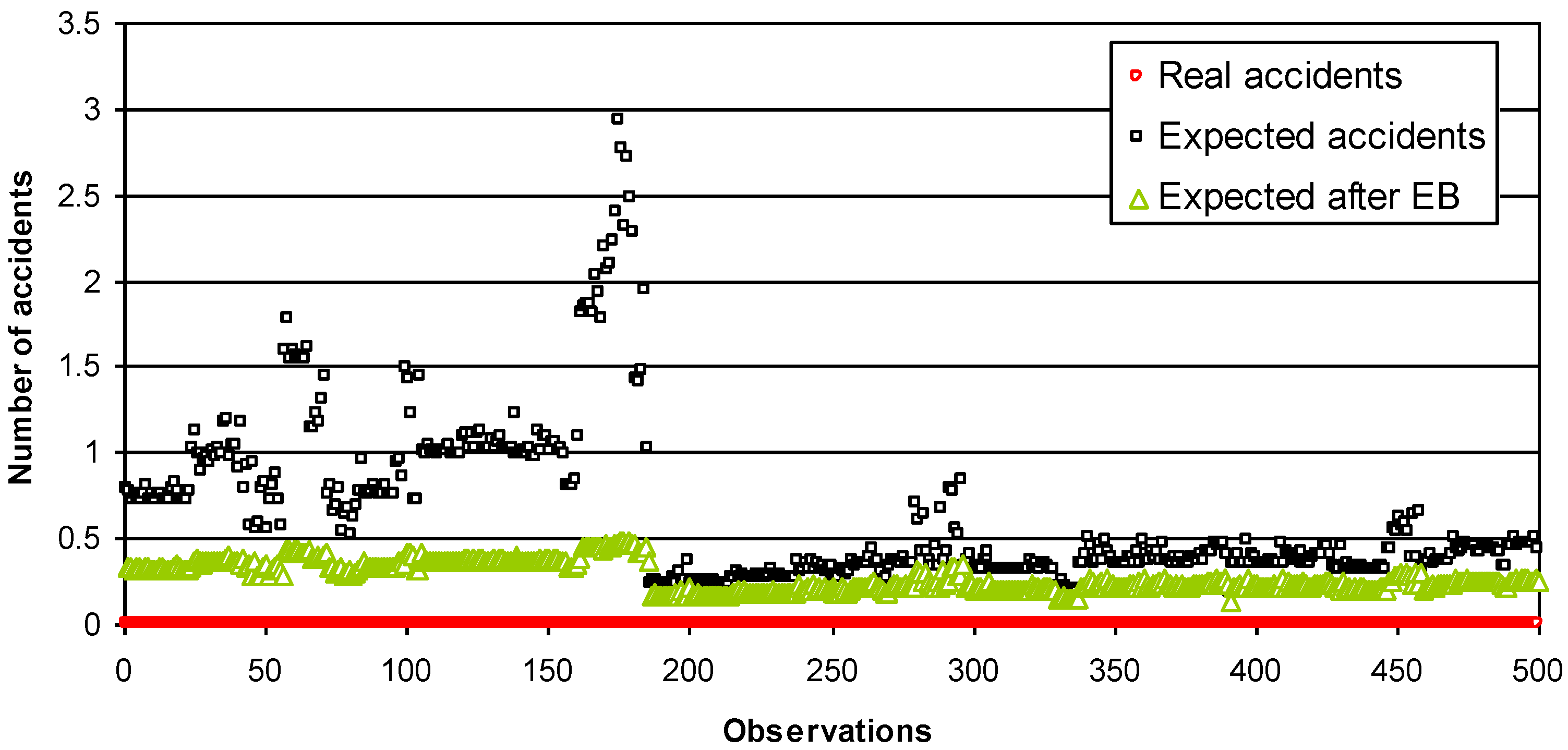
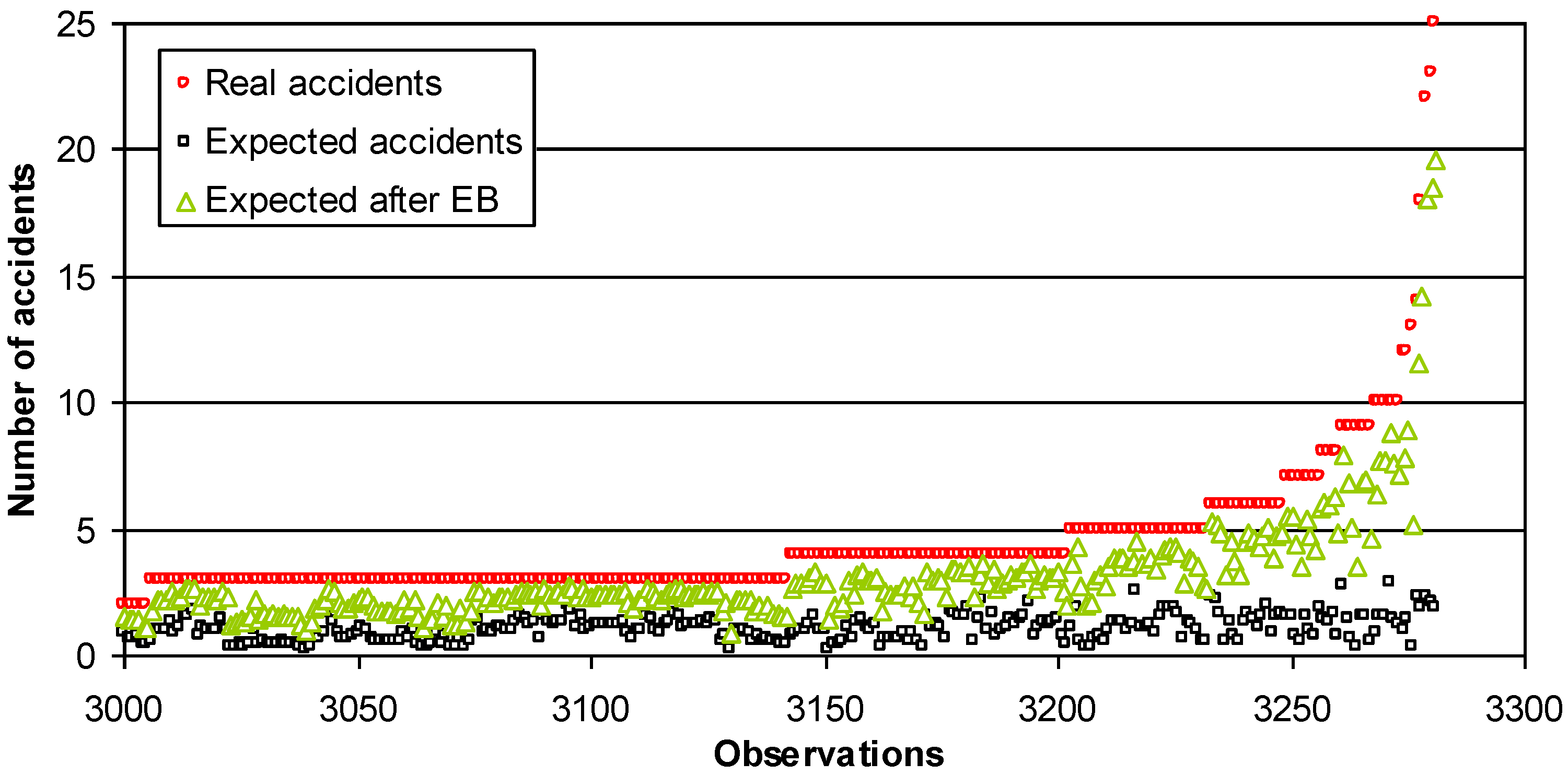
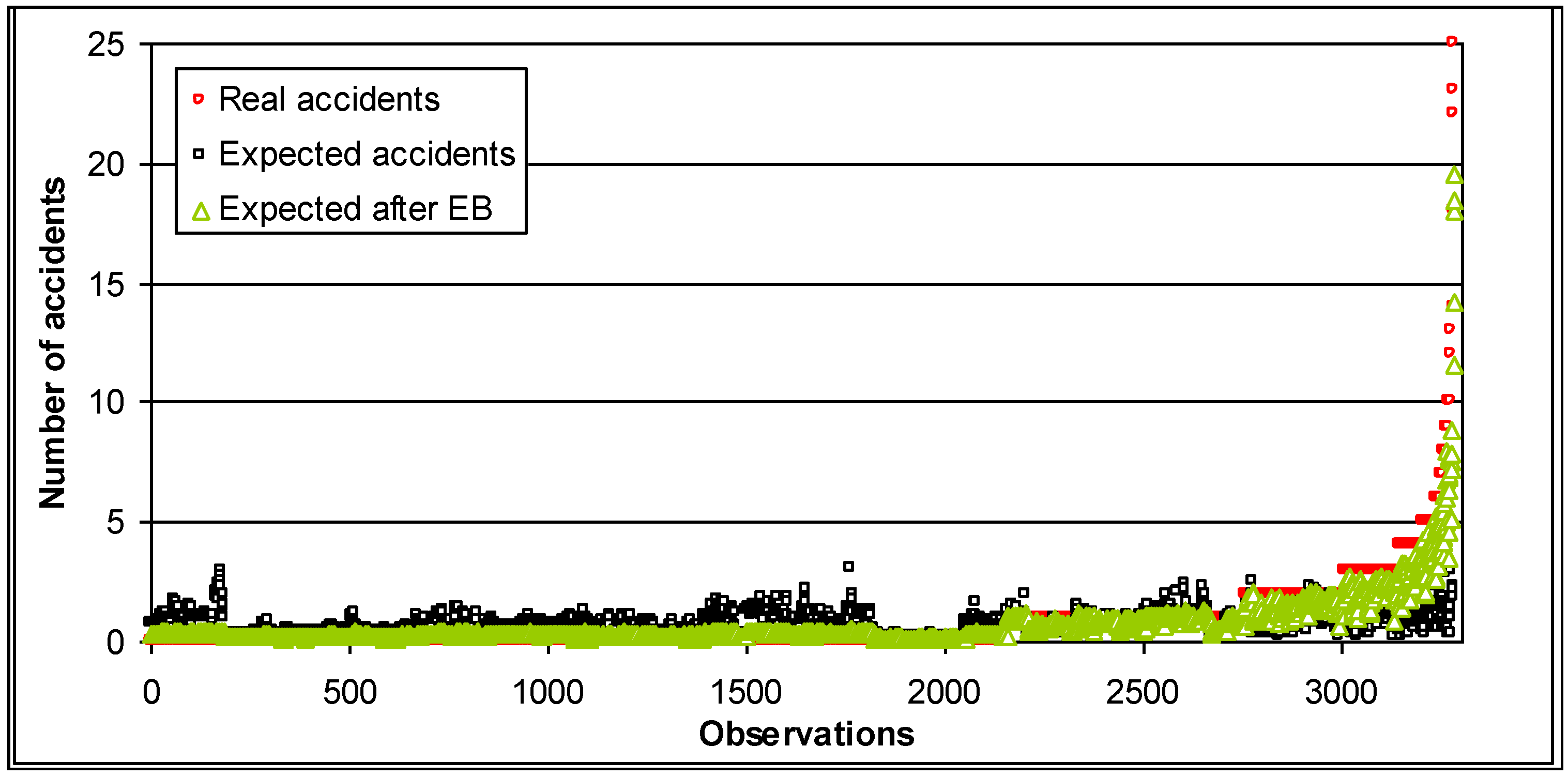
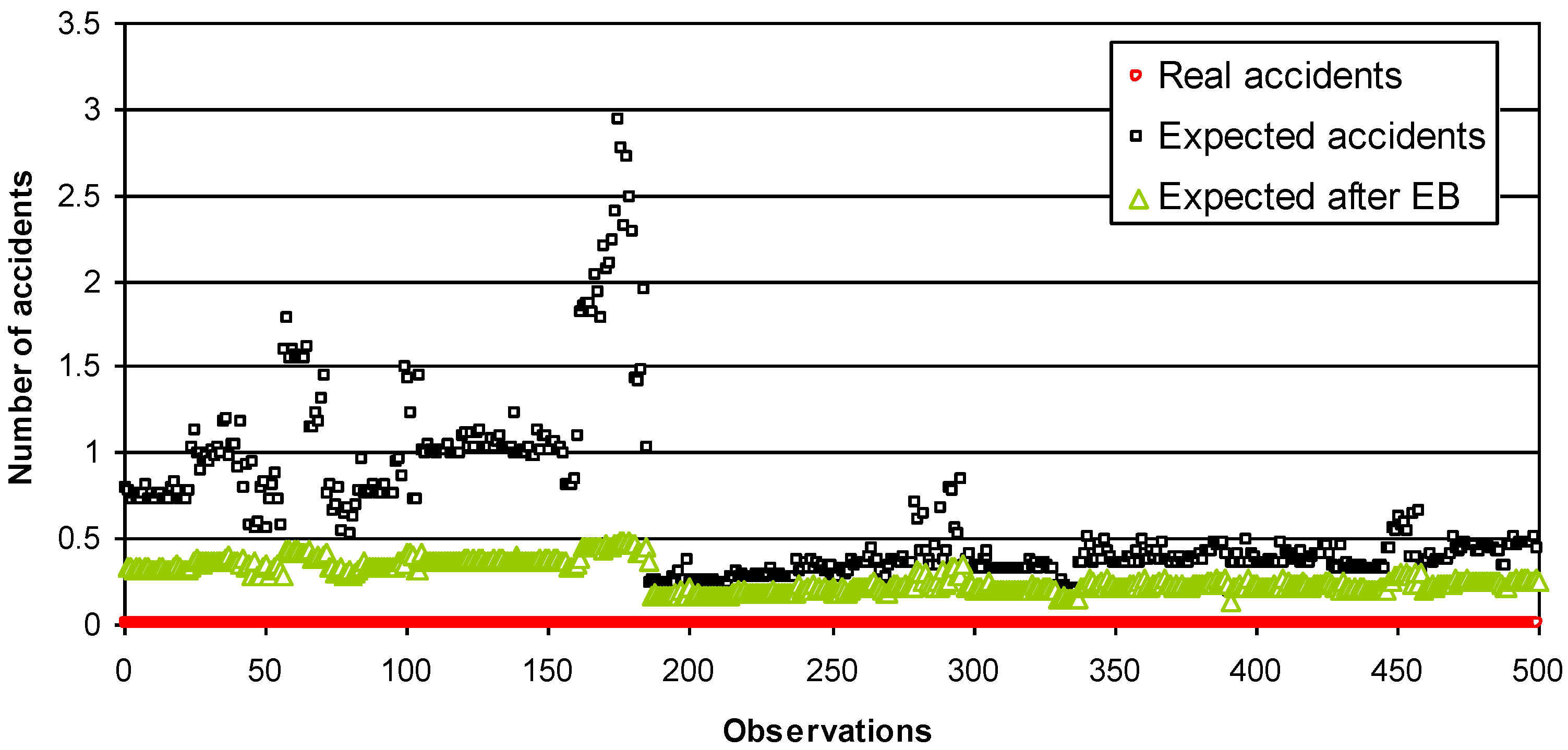
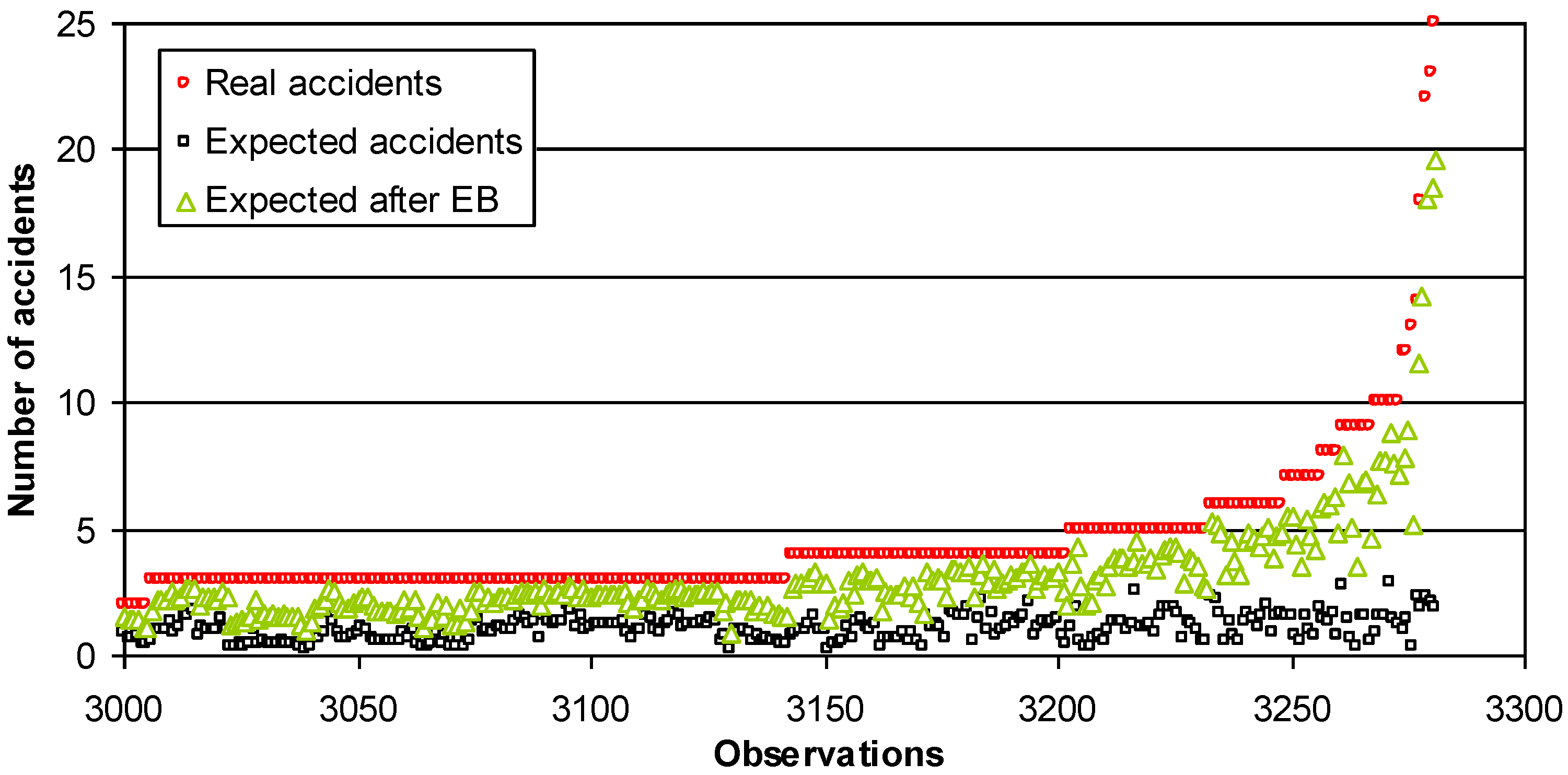
Figure 5.
Expected number of accidents (road sections at length of 500 m).
Figure 5.
Expected number of accidents (road sections at length of 500 m).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}