

SP-GEM: Spatial Pattern-Aware Graph Embedding for Matching Multisource Road Networks

 ,
, 
Abstract
1. Introduction
2. Method
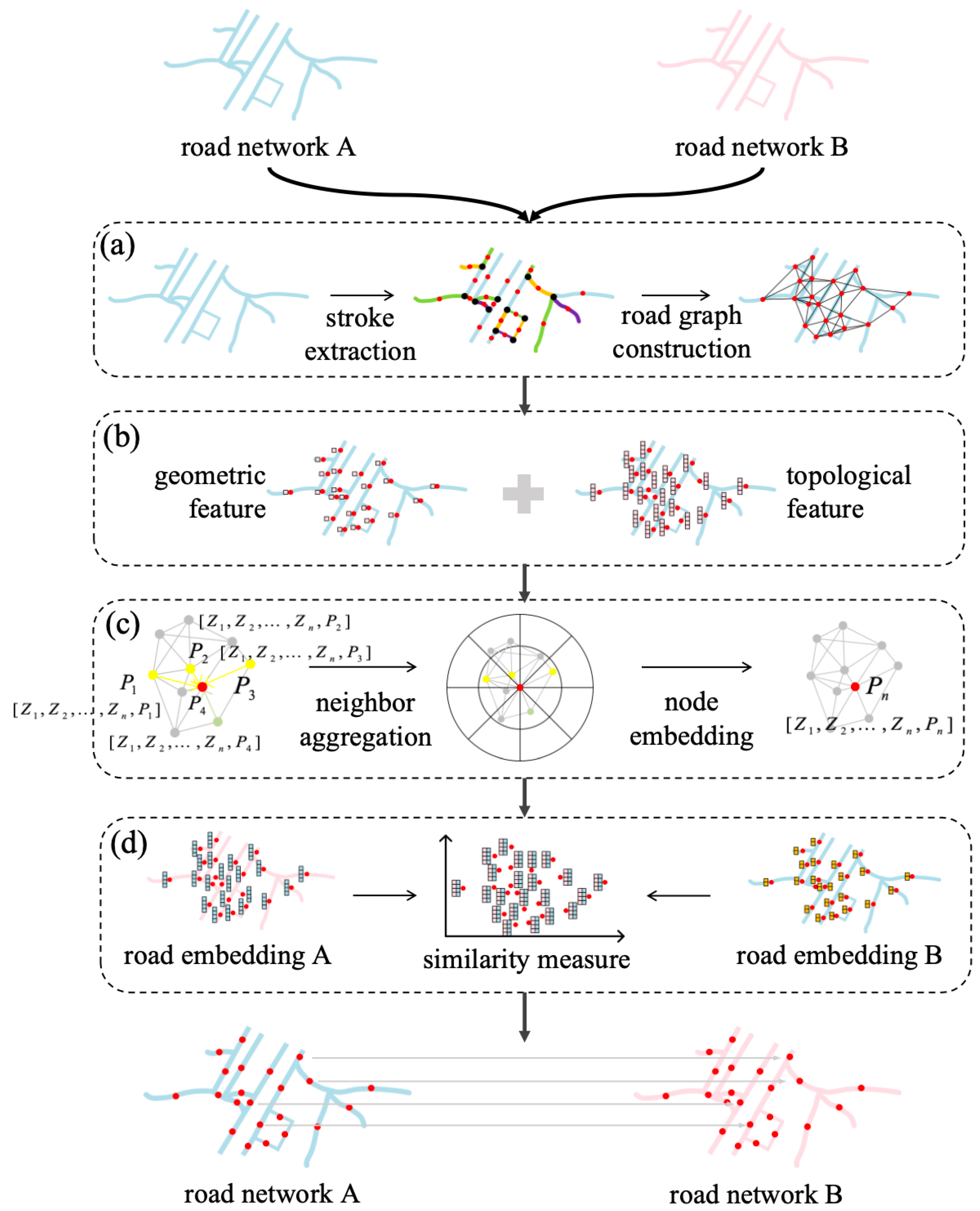
2.1. Methodology Framework
2.2. Road Graph Construction
2.3. Feature Extraction
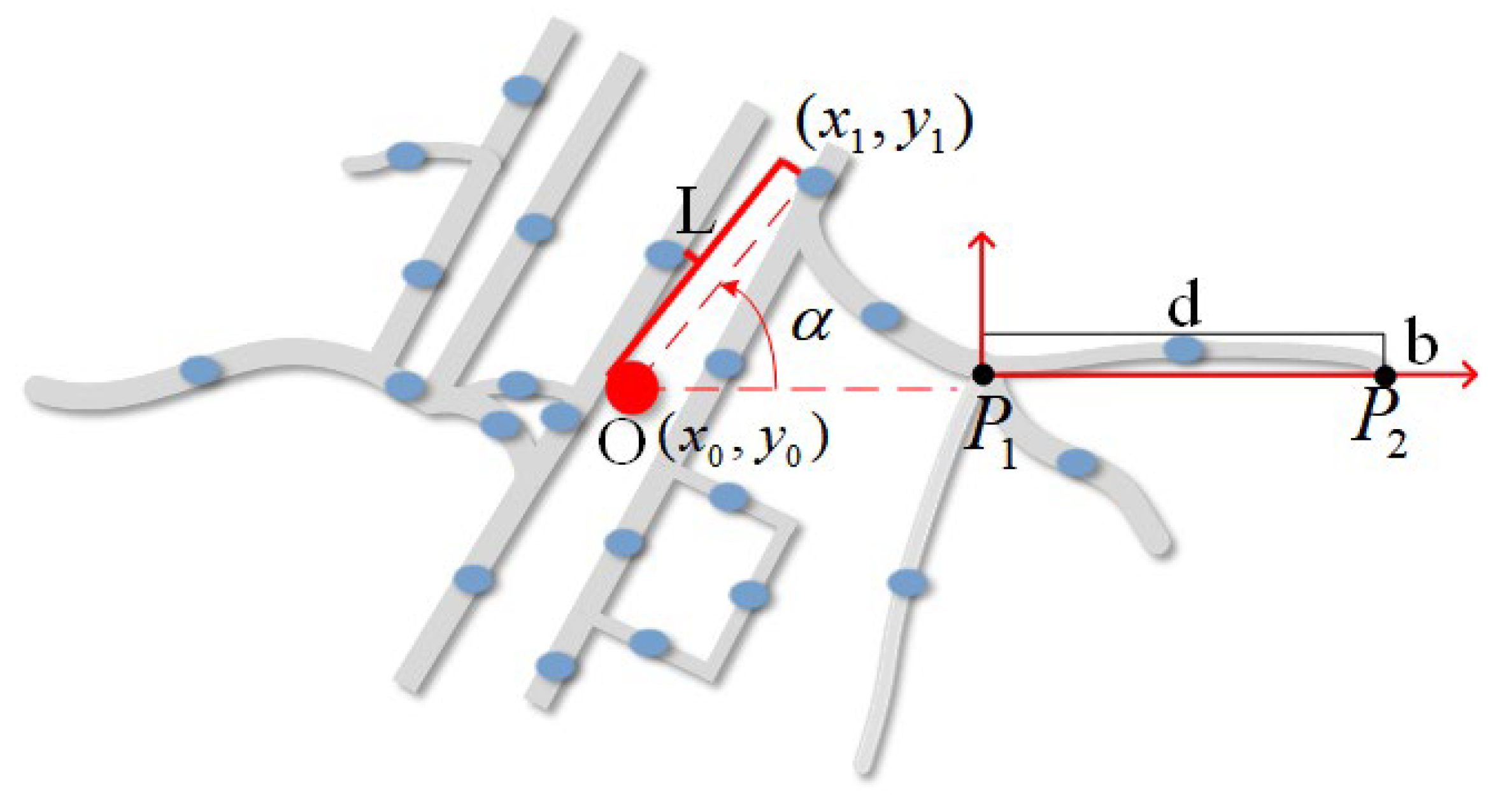
2.3.1. Geometric Feature
- (1)
- MBR feature
- Length-to-width ratio of the MBR is the aspect ratio of the geometric shape of the road segments, which quantifies the slenderness of the road, while identifying patterns of shapes and morphology of road segments.
- Direction of the longest side of the MBR is the angle between the longest side of the MBR and the due-north direction, which portrays the dominant direction of the road.
- (2)
- Center point feature
- Centre distance is the Euclidean distance between the midpoint of the neighboring road segment and the central road node, which quantifies the location relationship of the road segment and helps to analyze the spatial distribution and layout characteristics of the road network.
- Centre direction is the azimuth from the midpoint of a neighboring road segment to the central node of the road network, portraying the spatial distribution of roads and helping to identify radial structures and directional patterns.
- (3)
- Structural feature
- Log circuity is the ratio of the perimeter of a road segment’s spiral structure to its straight-line distance, reflecting the road network’s ability to adapt in elevated terrain. The feature with a value greater than 500 m indicates a loose spatial structure, while less than or equal to 500 m shows a compact, highly centralized network layout.
- Bridge-edge length ratio is the ratio of the bridge-edge segment’s length to the road network’s total length, reflecting the degree of dependence and connectivity relationships of key connections in the road network.
- End-edge length ratio is the ratio of the end-edge segment’s length to the road network’s total length, reflecting the degree of branching and structural integrity of the road network.
2.3.2. Topological Feature
- (1)
- Ratio of node degree features
- Node degree is the count of the road segments directly connected to the target road segment, indicating the connectivity complexity and the density of the local road network.
- Ratio of nodes with degree of k is the proportion of road segments connected with only k road segments in the road network. When k = 1, the feature indicates the distribution of end edges and the openness of the network; when k = 2, the feature indicates the linear continuity of the network and the distribution of transmission-type road segments; when k = 3, the feature indicates the distribution of intersections and the underlying branching structure of the road network; and when k ≥ 4, the feature indicates the distribution of complex intersections and the advanced connectivity structure.
- (2)
- Structural features
- Bridge-edge ratio indicates the proportion of bridge-edge segments in the road network, indicating the distribution density of the key connectivity edge and the connectivity dependency of the road network.
- End-edge ratio indicates the proportion of end-edge segments in the road network, indicating the degree of openness and the boundary characteristics of the road network.
2.4. Spatial Pattern-Aware Road Embedding
2.4.1. GraphSAGE Framework
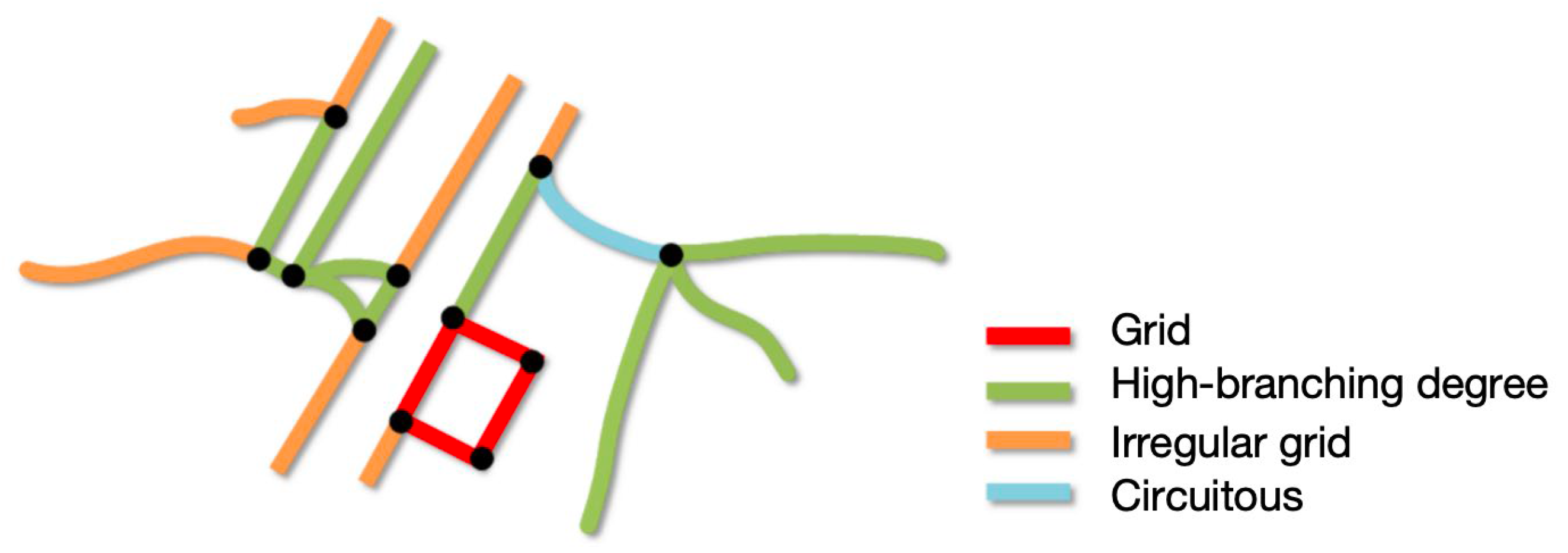
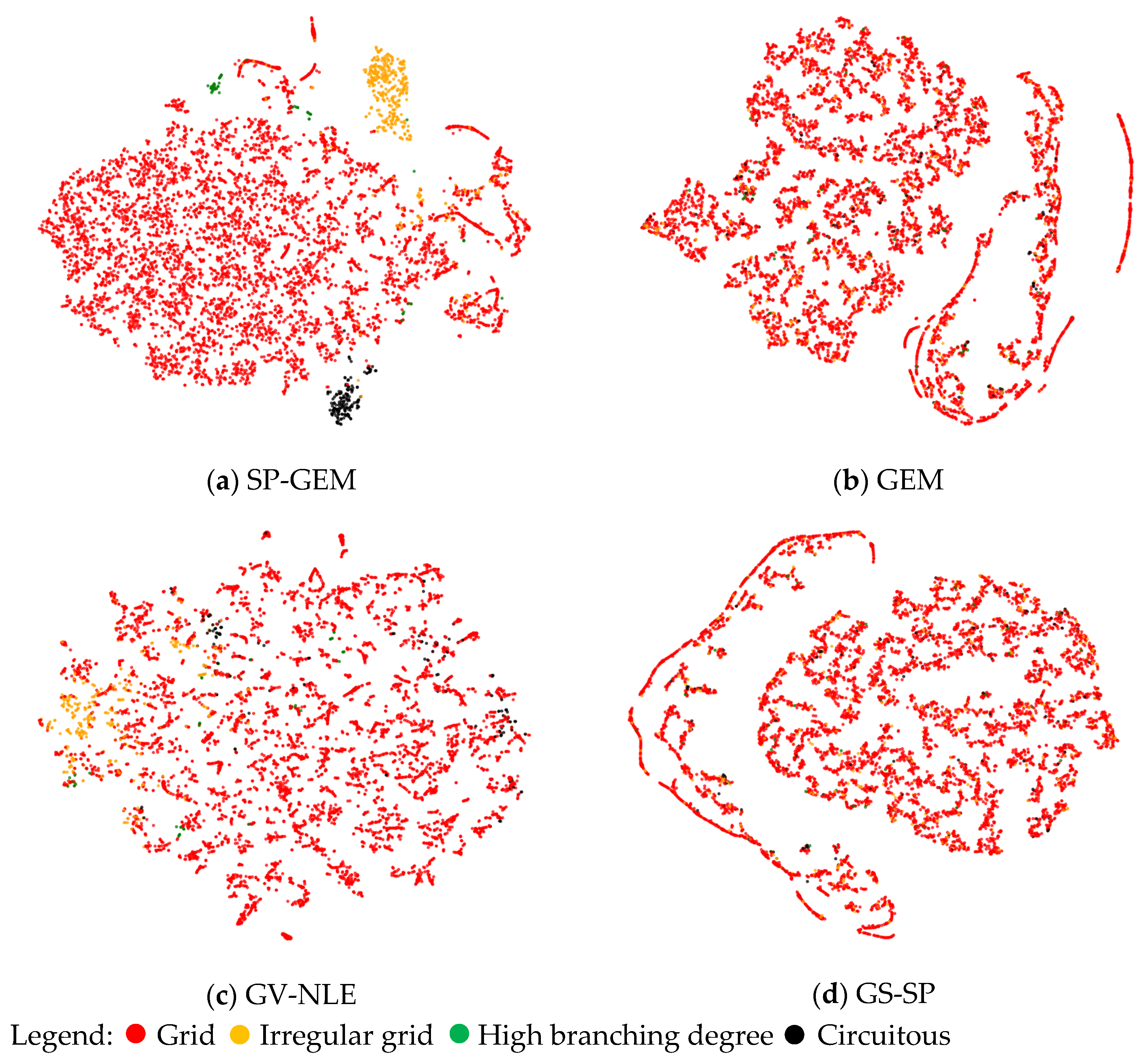
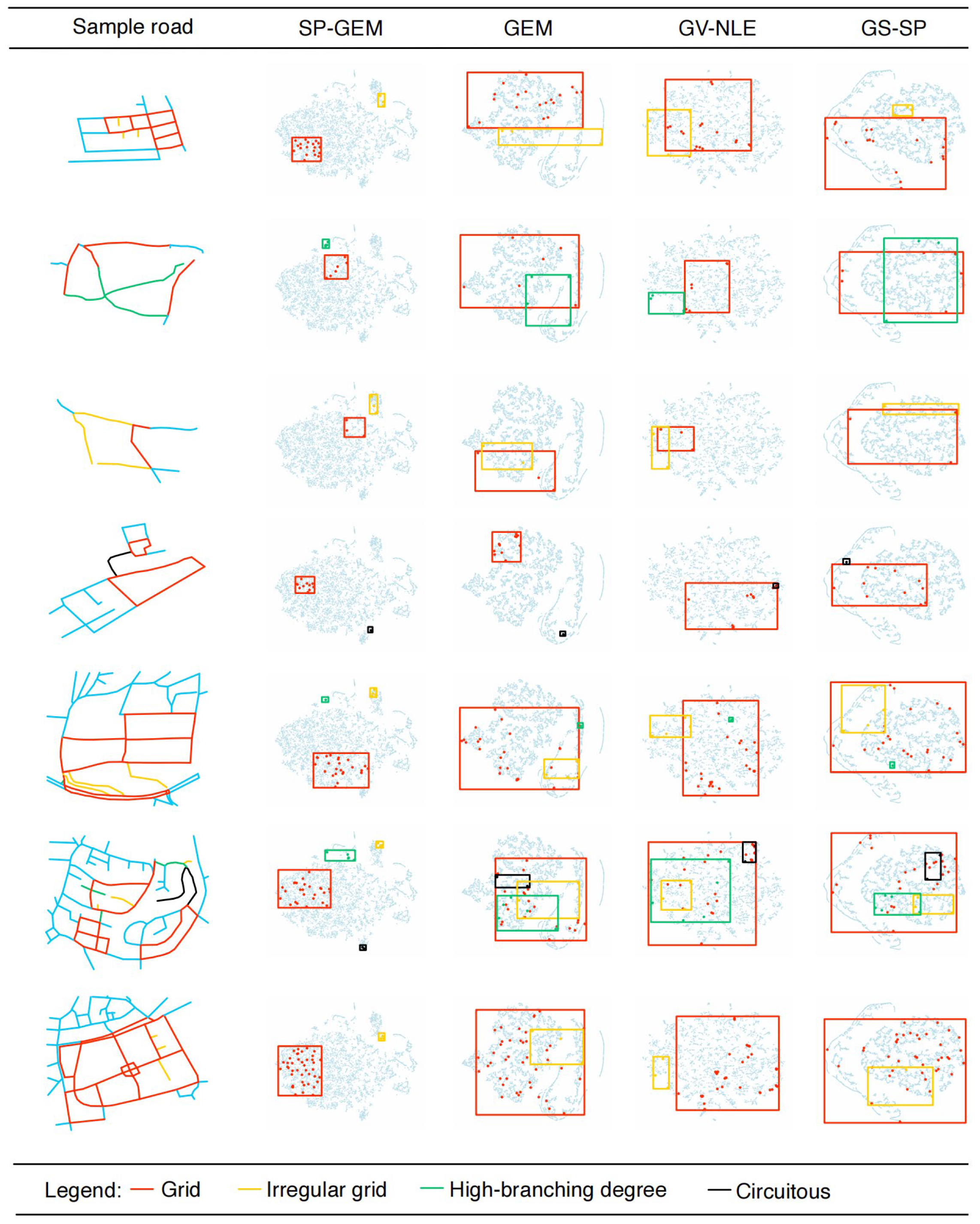
2.4.2. Spatial Patterns of the Road Network
- Grid type has high average node degree, accompanied by low log circuity, bridge-edge ratio and end-edge ratio, reflecting a highly regular grid structure and homogeneous connectivity.
- High-branching degree type has the core feature that the proportion of nodes with node degree greater than or equal to 3 is significantly higher than that of other categories, and the average node degree reaches the maximum value, reflecting the complex multi-directional connection structure and high-density intersection attributes.
- Irregular grid type has a relatively high proportion of nodes with node degree of 1 and significant end-edge value, reflecting the existence of more termination points, incomplete connectivity areas in the network and the weak structural coherence.
- Circuitous type has significant high circuity value, bridge-edge ratio and end-edge ratio, showing obvious dependence on structural critical connectivity.
2.4.3. Spatial Pattern-Aware Neighbor Aggregation
- (1)
- Spatial division of node neighborhood. To capture the spatial patterns of a node’s neighborhood, we first establish a spatial orientation reference for the central node . We divide the spatial neighborhood of the central node into eight orientation regions, , where the base division of orientation is based on the four quadrants of the Cartesian coordinate system, with additional composite orientations (, etc.) determined by azimuthal intervals of . This creates a subgraph partition that depicts the spatial distribution of the neighbor nodes. Next, we sample the neighbor nodes of the central node and calculate the Euclidean distance between each sampled neighbor node and the central node , where and denote the coordinates of the two nodes, respectively.
- (2)
- Pattern-aware division aggregation. Considering that nodes with similar patterns in a road network often exhibit comparable spatial attributes and characteristics, we calculate the aggregated representation of neighboring divisions based on the spatial patterns of these neighboring nodes. For each division , the nodes that share the same spatial pattern are summed up in terms of their features. The resulting sums are then normalized by dividing them by a normalization factor , which represents the number of nodes sharing the same spatial pattern t within the neighbor division of the central node . This normalization ensures that the aggregation process is not influenced by variations in the number of nodes, and balances the contributions of different patterned nodes within the same neighbor division. This approach helps prevent any single node from having too much or too little influence on the final node embedding.
- (3)
- Division-based neighbor aggregation. We weighted and summed the pattern embeddings of the eight divisions to obtain a comprehensive representation of the neighbor pattern of the central node. This neighbor representation integrates the spatial pattern features of different directions, providing a richer spatial pattern of the road network for updating the central node embedding.
| Algorithm 1: Spatial Pattern-aware Neighbor Aggregation |
| Input: : center node u: neighbor node k: the number of layer : coordinates of center node : coordinates of neighbor nodes G: road graph : embeding vector of the node at k-th layer : center node’s weight at k-th layer : embedding vector of the node at k-th layer : orientation-pattern weight matrices of pattern in the r-th neighbor division : normalization factor for of pattern in the r-th neighbor division of node Output: : the node-embedding vector of center node at (k + 1)-th layer Initialize eight orientation regions R = {N,NE,E,SE,S,SW,W,NW} for orient_region r in R do for neighbor_node u in G do if u is not v then current_orient_region = ComputOrientRegion(, ) if current_orient_region == r then euclidean_distance = sqrt(, ) = ··euclidean_distance/ end if end if end for end for = + · = () end |
2.5. Similarity Measure Using Road Embedding
3. Experiments and Analysis
3.1. Experimental Setup
3.1.1. Experimental Design
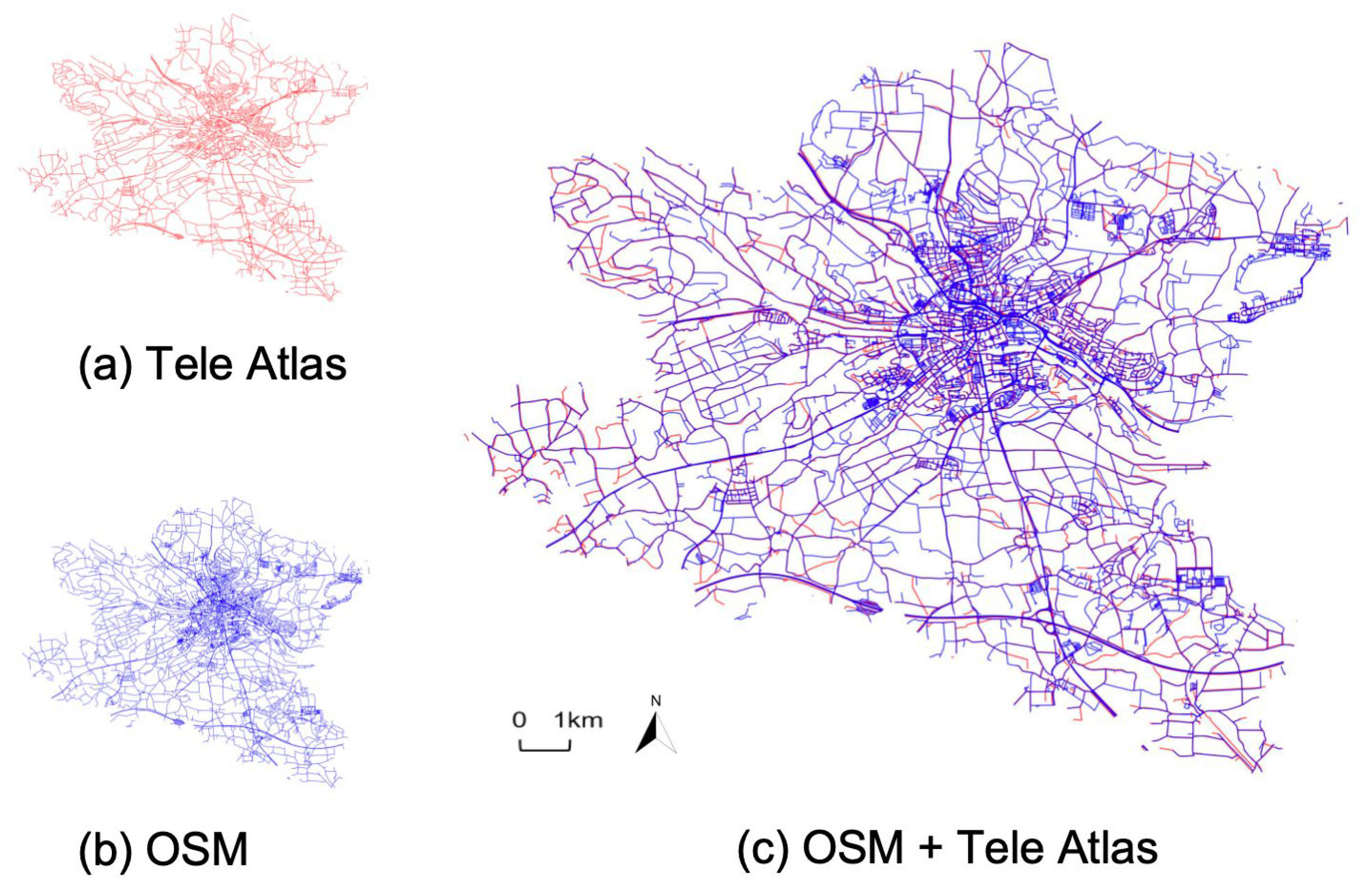
- The algorithmic accuracy experiment is used to compare SP-GEM with baseline algorithms using metrics of accuracy, recall and match rate. The experiments are conducted on road network data of the city Ansbach in Germany from both OSM and Tele Atlas, which reveal significant differences in road data modeling and acquisition time.
- The embedding analysis experiment evaluates the embedding performance of the algorithms in recognizing different road network patterns, as well as the effectiveness of integrating such capability into road neighbor modeling.
3.1.2. Evaluation Metrics
3.1.3. Implementation Details
3.2. Experimental Results and Analysis
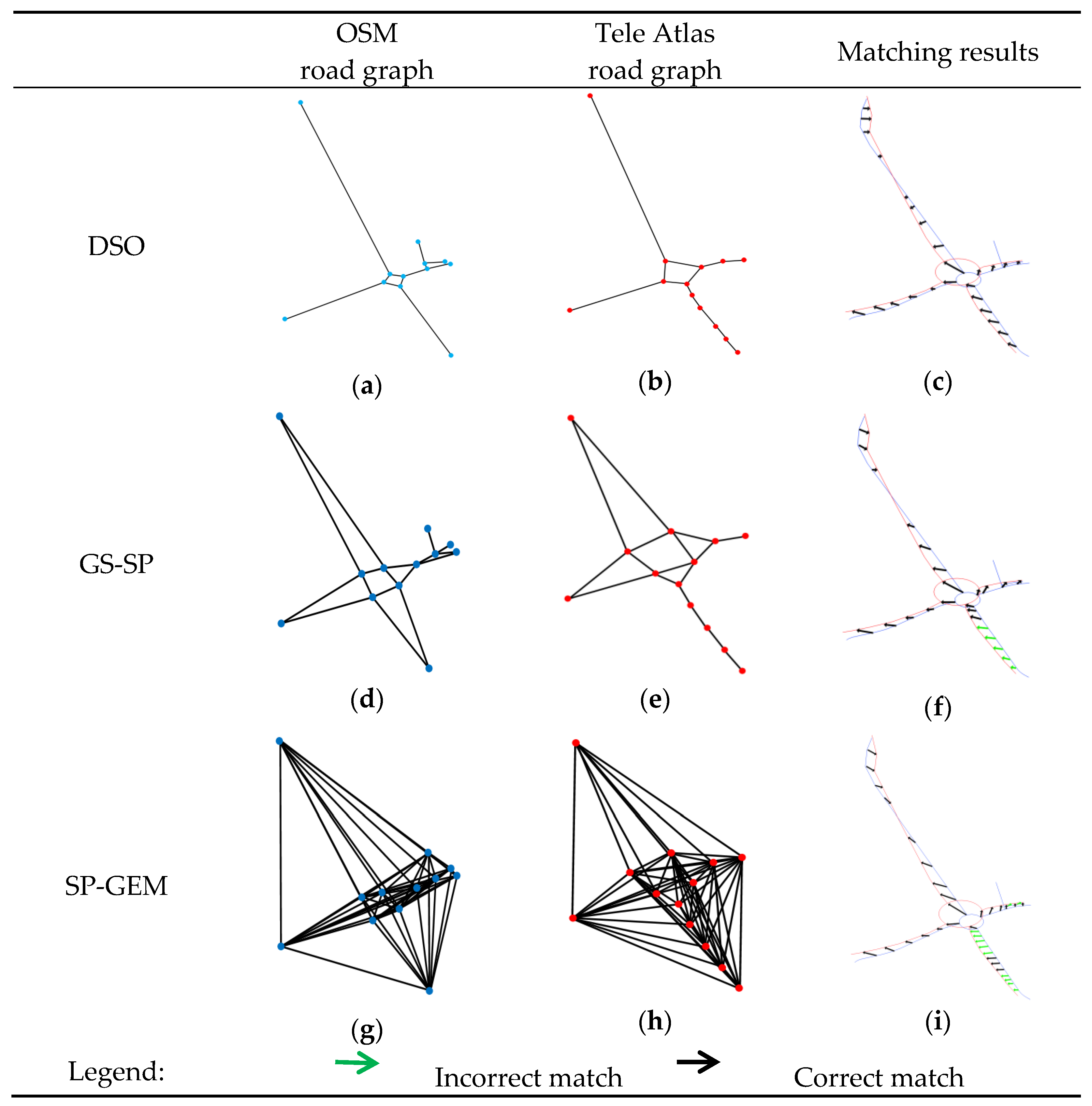
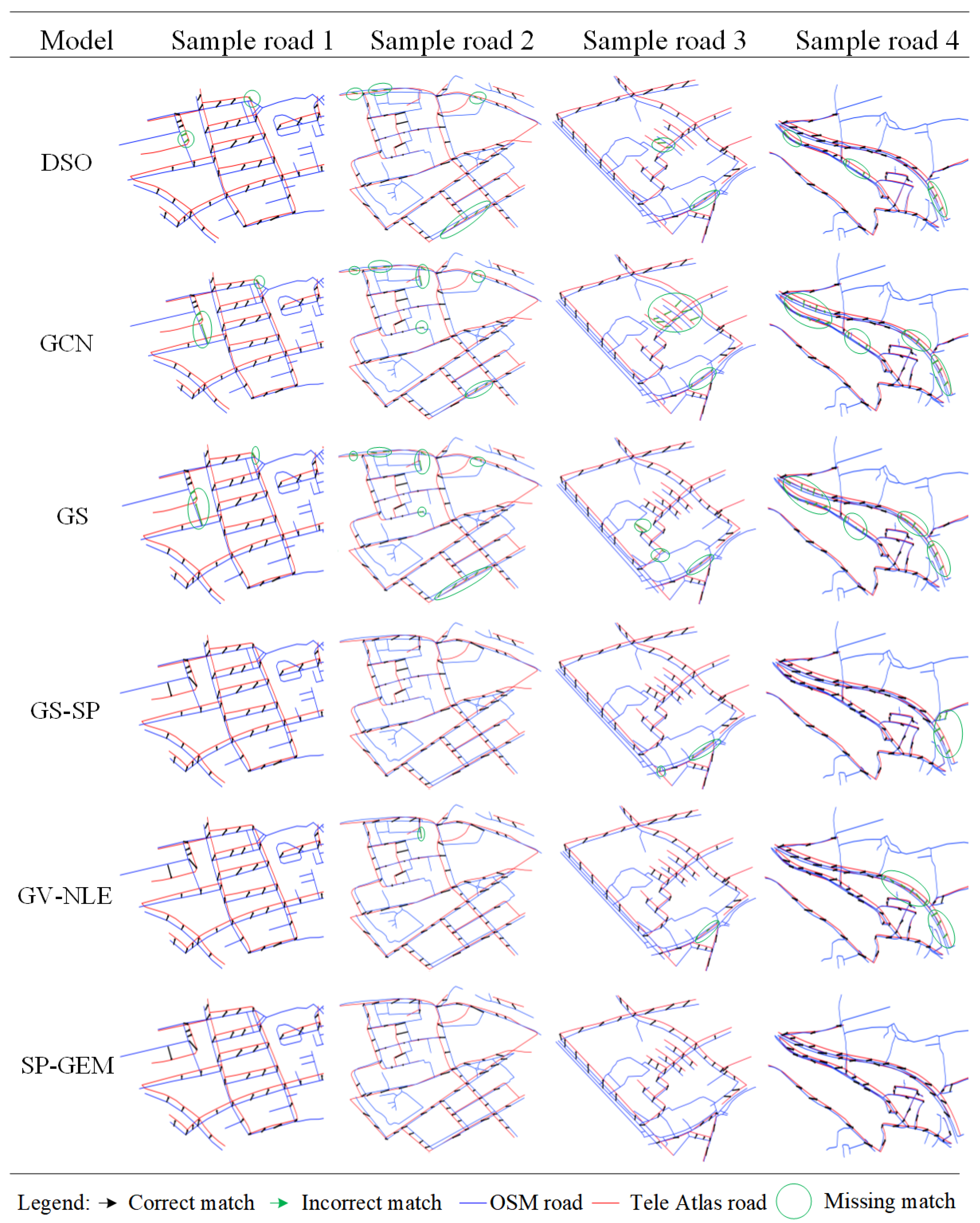
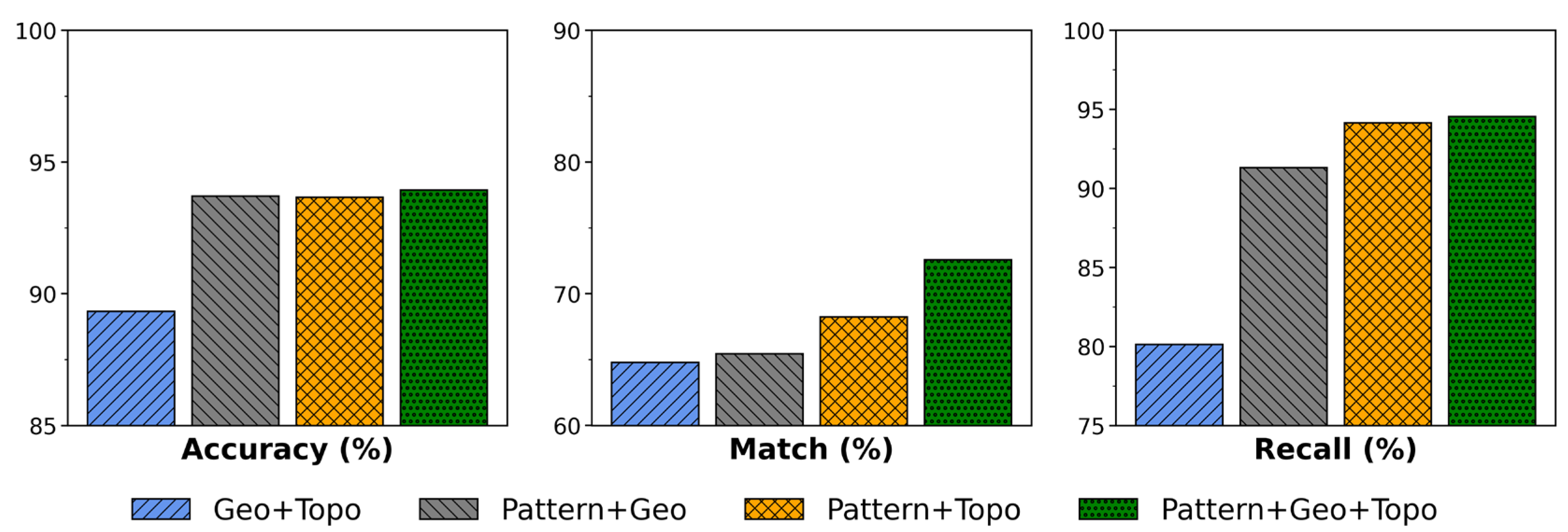
3.2.1. Experiment 1: Algorithmic Accuracy
3.2.2. Experiment 2: Road Embedding Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, Y.; Yan, H.; Lu, X. Hierarchical semantic similarity metric model oriented to road network matching. J. Geo-Inf. Sci. 2023, 25, 714–725. [Google Scholar]
- Yang, J.; Zhang, M.; Fang, L.; Jia, F.; Zhou, G.; Zhang, J.; Yang, M.; Hou, Y. Quality assessment of OpenStreetMap road network data using multisourced data matching and conflation. J. Geomat. Sci. Technol. 2024, 40, 526–533. [Google Scholar]
- Sun, Q. Research on some fundamental issues of spatial data similarity. J. Geomat. Sci. Technol. 2013, 30, 439–442. [Google Scholar]
- Sun, Q. Research on the progress of multi-sources geospatial vector data fusion. Acta Geod. Et Cartogr. Sin. 2017, 46, 1627–1636. [Google Scholar]
- Wu, B.; Wang, Z.; Yang, F. A semantic similarity computational model for multi-scale road network matching. Sci. Surv. Mapp. 2022, 47, 166–173. [Google Scholar]
- Tan, Y.; Tang, Y.; Li, X.; Liu, B.; Wei, X. Semantic-based geographic feature property similarity measurement model. Remote Sens. Inf. 2017, 32, 126–133. [Google Scholar]
- Wang, H.; Zhai, R.; Zhou, M.; Zhu, L. A road matching method based on complex networks. J. Geomat. Sci. Technol. 2016, 33, 88–93. [Google Scholar]
- Zhang, M.; Shi, W.; Meng, L. A generic matching algorithm for line networks of different resolutions. In Proceedings of the Workshop of ICA Commission on Generalization and Multiple Representation Computering Faculty of a Coruña University-Campus de Elviña, La Coruña, Spain, 7–8 July 2005. [Google Scholar]
- Zhang, M.; Wang, Q.; Haizhong, Q. A generic algorithm for automatic road-network matching between different data sets. J. Geomat. Sci. Technol. 2018, 35, 82–86. [Google Scholar]
- Almotairi, M.; Alsahfi, T.; Elmasri, R. Using local and global divergence measures to identify road similarity in different road network datasets. In Proceedings of the 11th ACM SIGSPATIAL International Workshop on Computational Transportation Science, Seattle, WA, USA, 6 November 2018. [Google Scholar]
- Qin, Y.; Song, W.; Zhang, Z.; Sun, X. Matching method for road networks considering geometric features and topological continuity. Bull. Surv. Mapp. 2021, 8, 55–60. [Google Scholar]
- Wanpeng, C.; Pinghu, C. An urban road network entity matching algorithm based on similarity metric. Mapp. Spat. Geogr. Inf. 2018, 41, 39–42+46. [Google Scholar]
- Li, C.; Li, T.; Zhou, X.; Tang, H.; Zhang, X.; Hu, K. Urban Road Network Matching Model Based on Fuzzy Hierarchy Theory and Its Application. Earth Sci. 2024, 49, 3020–3028. [Google Scholar]
- Hacar, M.; Gökgöz, T. A new, score-based multi-stage matching approach for road network conflation in different road patterns. ISPRS Int. J. Geo-Inf. 2019, 8, 81. [Google Scholar] [CrossRef]
- Kong, X.; Yang, J. A scenario-based map-matching algorithm for complex urban road network. J. Intell. Transp. Syst. 2019, 23, 617–631. [Google Scholar] [CrossRef]
- Lu, H.; Feng, L.; Boya, W.; Lei, T.; Zong, Z. A dynamic social robot detection method based on link prediction matching. J. Inf. Eng. Univ. 2024, 25, 285–291. [Google Scholar]
- Qingjie, M.; Dongxu, Y.; Yang, L. Prediction of molecular properties by graph neural networks incorporating sequence and structural features. J. Hunan Coll. Arts Sci. (Nat. Sci. Ed.) 2024, 36, 12–18+56. [Google Scholar]
- Wang, M.; Ai, T.; Yan, X.; Xiao, Y. Graph convolutional network model for recognizing road orthogonal grid patterns. J. Wuhan Univ. (Inf. Sci. Ed.) 2020, 45, 1960–1969. [Google Scholar]
- Zhang, H.; Yang, J. Spatio-temporal generative adversarial clustering graph convolutional network for anomalous traffic flow prediction. Comput. Eng. 2025; in press. [Google Scholar]
- Yu, H.; Ai, T.; Yang, M.; Huang, L.; Yuan, J. A recognition method for drainage patterns using a graph convolutional network. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 1–15. [Google Scholar] [CrossRef]
- Yang, M.; Jiang, C.; Yan, X.; Ai, T.; Cao, M.; Chen, W. Detecting interchanges in road networks using a graph convolutional network approach. Int. J. Geogr. Inf. Sci. 2022, 36, 1119–1139. [Google Scholar] [CrossRef]
- Soni, A.; Boddhu, S. Finding map feature correspondences in heterogeneous geospatial datasets. In Proceedings of the 1st ACM SIGSPATIAL International Workshop on Geospatial Knowledge Graphs, Seattle, WA, USA, 1 November 2022. [Google Scholar]
- Gadi, H.K.; Liu, L.; Meng, L. Road Networks Matching Supercharged with Embeddings. In Proceedings of the 7th ACM SIGSPATIAL International Workshop on AI for Geographic Knowledge Discovery, Atlanta, GA, USA, 18 November 2024. [Google Scholar]
- Yang, M.; Yang, J.; Hou, Y.; Lang, L.; Zhang, Z.; Zhang, B.; Zhang, J. A method of road network matching using graph embedding via improved neighbor aggregations. J. Geo-Form. Sci. 2024, 26, 2335–2351. [Google Scholar]
- Xue, J.; Jiang, N.; Liang, S.; Pang, Q.; Yabe, T.; Ukkusuri, S.V.; Ma, J. Quantifying the spatial homogeneity of urban road networks via graph neural networks. Nat. Mach. Intell. 2022, 4, 246–257. [Google Scholar] [CrossRef]
- Tempelmeier, N.; Simon, G.; Demidova, E. GeoVectors: A linked open corpus of OpenStreetMap Embeddings on world scale. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Gold Coast, QLD, Australia, 1–5 November 2021. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Feature | Equation |
|---|---|---|
| MBR feature | Length-to-width ratio of the MBR | : The longer side of the MBR : The shorter side of the MBR |
| Direction of the longest side of the MBR | ||
| Center point feature | Center distance | : The latitude of the midpoint : The longitude of the midpoint : The latitude of the center point O : The longitude of the center point O |
| Centre direction | : The latitude of the midpoint : The longitude of the midpoint : The latitude of the center point O : The longitude of the center point O | |
| Structural feature | Log circuity (r ≤ 500 m) | : The total length of the shortest paths between all pairs of nodes : The total straight-line distances between all pairs of nodes |
| Log circuity (r > 500 m) | : The total length of the shortest paths between all pairs of nodes : The total straight-line distances between all pairs of nodes | |
| Bridge-edge–length ratio | : The total length of edges classified as bridge edges in the graph : The total length of all edges in the graph | |
| End-edge–length ratio | : The total length of edges classified as end edges in the graph : The total length of all edges in the graph |
| Category | Feature | Equation |
|---|---|---|
| Ratio of node-degree feature | Node degree | - |
| Average node degree | : Sum of degree for all nodes : Number of nodes | |
| Ratio of nodes with degree of 1 | : Number of nodes with degree of 1 : Number of nodes | |
| Ratio of nodes with degree of 2 | : Number of nodes with degree of 2 : Number of nodes | |
| Ratio of nodes with degree of 3 | : Number of nodes with degree of 3 : Number of nodes | |
| Ratio of nodes with degree greater than or equal to 4 | : Number of nodes with degree greater than or equal to 4 : Number of nodes | |
| Structural feature | Bridge-edge ratio | : Number of bridge-edge segments : Number of edges |
| End-edge ratio | : Number of end-edge segments : Number of edges |
| DSO | GCN | GS | GS-SP | GV-NLE | SP-GEM | |
|---|---|---|---|---|---|---|
| Accuracy | 81.25% | 76.21% | 75.66% | 87.27% * | 93.14% | 93.94% |
| Recall | 82.60% | 76.24% | 77.51% | 84.37% * | 87.69% | 94.54% |
| Match | 73.87% | 68.21% | 69.31% | 75.26% | 57.97% | 72.58% * |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, C.; Qiu, Y.; Yang, J.; Zhang, B.; Li, Z.; Lin, Z.; Zhang, X.; Hou, Y.; Fang, L. SP-GEM: Spatial Pattern-Aware Graph Embedding for Matching Multisource Road Networks. ISPRS Int. J. Geo-Inf. 2025, 14, 275. https://doi.org/10.3390/ijgi14070275
Zheng C, Qiu Y, Yang J, Zhang B, Li Z, Lin Z, Zhang X, Hou Y, Fang L. SP-GEM: Spatial Pattern-Aware Graph Embedding for Matching Multisource Road Networks. ISPRS International Journal of Geo-Information. 2025; 14(7):275. https://doi.org/10.3390/ijgi14070275
Chicago/Turabian StyleZheng, Chenghao, Yunfei Qiu, Jian Yang, Bianying Zhang, Zeyuan Li, Zhangxiang Lin, Xianglin Zhang, Yang Hou, and Li Fang. 2025. "SP-GEM: Spatial Pattern-Aware Graph Embedding for Matching Multisource Road Networks" ISPRS International Journal of Geo-Information 14, no. 7: 275. https://doi.org/10.3390/ijgi14070275
APA StyleZheng, C., Qiu, Y., Yang, J., Zhang, B., Li, Z., Lin, Z., Zhang, X., Hou, Y., & Fang, L. (2025). SP-GEM: Spatial Pattern-Aware Graph Embedding for Matching Multisource Road Networks. ISPRS International Journal of Geo-Information, 14(7), 275. https://doi.org/10.3390/ijgi14070275