1. Introduction
With the rapid development of science, technology, and productivity, mobile robots have now been widely applied in fields such as medical services, intelligent inspection, warehouse logistics, and augmented reality. As the intelligence and automation levels of mobile robots continue to improve, there is an increasing demand for enhanced capabilities in localization, autonomous navigation, and path planning. To meet these requirements, mobile robots must perceive their own positions and surrounding environments without prior knowledge. Consequently, Simultaneous Localization and Mapping (SLAM) has emerged as a core technology in related fields.
SLAM enables mobile robots to estimate their poses and construct environmental maps in real time using sensor data in unknown environments. Based on sensor types, SLAM systems can be categorized into Laser SLAM, visual SLAM, and multi-sensor fusion SLAM. Visual SLAM systems utilizing visual sensors offer advantages over Laser SLAM systems, including smaller size, lower power consumption, richer RGB information, and reduced hardware costs, making them more suitable for indoor dynamic environments. Furthermore, mobile robots equipped with RGB-D cameras can capture both color–texture-rich RGB images and depth information within meters.
Current visual SLAM systems typically rely on static environment assumptions [
1], assuming no dynamic objects. These systems leverage static features for localization and mapping, rendering them highly susceptible to dynamic interference. While advancements in machine learning for computer vision have driven efforts to integrate machine learning with visual SLAM, existing solutions still face limitations.
First, systems using object detection or semantic segmentation can remove most dynamic objects and key points but struggle with non-prior dynamic object recognition, leading to the erroneous incorporation of dynamic data into SLAM processes. This degrades pose estimation accuracy, map quality, and reliability. Second, traditional visual SLAM systems generate sparse point cloud maps [
2,
3], lacking geometric structures, textures, semantic information, and spatial occupancy details. Such maps fail to support advanced tasks like autonomous navigation and path planning.
To address the limitations of traditional visual SLAM systems—such as their ability to generate only sparse point cloud maps lacking geometric structures, textures, and semantic information, which fail to support autonomous navigation and path planning for mobile robots—as well as the challenges of dynamic interference and insufficient environmental data in dynamic scenarios, this study proposes an indoor mapping algorithm based on semantic fusion and hierarchical filtering.
By integrating a semantic mapping thread into ORB-SLAM3, the algorithm constructs clear, information-rich, and reliable semantic dense point cloud maps, semantic octree maps, and 2D grid maps, providing robust environmental representations for mobile robot navigation and path planning tasks.
The main contributions of this paper are as follows:
Dynamic Information Elimination Algorithm: To address the susceptibility of visual SLAM systems to dynamic object interference, we propose a dynamic information elimination algorithm based on semantic and depth information. First, the YOLOv8s semantic segmentation model processes RGB images to obtain environmental semantic information and object masks. Then, prior dynamic objects and non-prior dynamic objects are accurately identified using edge distance and depth relationships between prior dynamic objects and prior static objects. Finally, both pixel information and ORB feature points of prior and non-prior dynamic objects are eliminated, retaining only static information for mapping tasks. This algorithm significantly improves the mapping performance of SLAM systems and promotes the application and development of mobile robots in indoor dynamic environments.
Semantic Fusion and Layered Filtering-based Mapping Algorithm: To resolve issues of dynamic interference and insufficient information in dynamic environments, we propose an indoor mapping algorithm integrating semantic fusion and layered filtering. First, static features from semantic segmentation, semantic information, and camera poses are fused to construct an initial semantic point cloud map. Subsequently, statistical outlier removal (SOR) filtering eliminates abnormal outliers, while voxel filtering reduces point cloud density, resulting in a dense semantic point cloud map with richer textures, fewer dynamic artifacts, and 50–80% smaller file sizes. A recursive algorithm then segments the 3D point cloud to generate a semantic octree map representing spatial occupancy. Finally, through TF transformation, pass-through filtering, and grid projection, a 2D grid map is constructed to characterize navigability. This algorithm produces structurally clear, information-rich semantic maps (dense point cloud, octree, and 2D grid maps), providing reliable foundations for autonomous navigation and path planning in dynamic indoor environments.
Comprehensive Experimental Validation: The proposed algorithms were evaluated using four sequences from the TUM RGB-D dataset (including high-dynamic, low-dynamic, and static scenarios) and two real-world indoor dynamic environments. Experiments encompassed map construction and file size analysis. Results demonstrate that our approach generates maps with rich information, clear structure, and high reliability while achieving 50–80% reduction in map file sizes. These outcomes confirm the algorithm’s capability to meet the mapping requirements of mobile robots in dynamic indoor settings, showcasing broad application prospects.
2. Related Works
The research on Simultaneous Localization and Mapping (SLAM) can be traced back to a seminal academic paper in 1986 [
4], which innovatively proposed a six-degree-of-freedom spatial error analytical propagation model. Davison et al. introduced MonoSLAM [
5], the first monocular visual SLAM system, which addressed challenges in monocular feature initialization and feature orientation estimation. Klein et al. developed PTAM (Parallel Tracking and Mapping) [
6], pioneering the use of two independent threads for decoupled camera pose estimation and map construction tasks. Newcombe et al. proposed DTAM [
7], the first visual SLAM system employing dense direct methods. By constructing texture-depth maps from multiple frames, it generated surface models containing millions of vertices.
Kim et al. presented KinectFusion [
8], the first RGB-D camera-based visual SLAM system. Utilizing the Truncated Signed Distance Function (TSDF), it effectively filled holes caused by depth measurement noise and achieved geometrically faithful reconstructions through voxel-based surface representation. Forster et al. proposed SVO (Semi-direct Visual Odometry) [
9], which combined the advantages of feature-based and direct methods for pose estimation. Engel et al. introduced LSD-SLAM [
10], incorporating scale-drift-aware direct tracking algorithms and a probabilistic framework for depth uncertainty into semi-dense monocular SLAM. This enabled the CPU-based construction of large-scale semi-dense maps. Later, the same team developed DSO (Direct Sparse Odometry) [
11] in 2017, achieving high-precision pose estimation through the joint optimization of camera poses, intrinsic parameters, and inverse depth values.
Mur-Artal, R. et al. released ORB-SLAM2 [
2], the first open-source visual SLAM framework supporting monocular, stereo, and RGB-D cameras. This system employed Bundle Adjustment (BA) to optimize keyframe poses and 3D coordinates of sparse map points, enhancing both local and global mapping accuracy. In 2021, Campos, C. et al. from the same team further developed ORB-SLAM3 [
3], extending functionality to include inertial odometry, visual–inertial odometry, fisheye camera models, and multi-map SLAM capabilities.
Classical visual SLAM frameworks typically rely on static environment assumptions to simplify feature matching and pose estimation. However, real-world scenarios often contain dynamic elements. For instance, in indoor environments, moving personnel may be detected as dynamic ORB feature points, leading to erroneous camera pose calculations that degrade localization accuracy, mapping quality, and even cause system failure. To enhance robustness in dynamic environments, researchers have proposed SLAM systems integrating semantic information and geometric constraints. These approaches leverage semantic segmentation to identify dynamic objects and establish geometric constraint models, significantly improving localization precision and mapping effectiveness in dynamic scenarios.
2.1. Geometry-Based Visual SLAM Systems
Geometry-based visual SLAM systems typically leverage spatial geometric and temporal characteristics of data to establish algorithmic constraints that are satisfied only by static features, thereby mitigating the impact of dynamic objects on pose estimation and map construction. Lin, K. et al. proposed a binocular dynamic SLAM system [
12] based on SLAMMOT [
13], which employs an Extended Kalman Filter (EKF) to update each observed point and incorporates inverse depth parametrization for distant features, enabling SLAM tasks in dynamic environments. Cheng et al. [
14] introduced a sparse motion removal algorithm based on a Bayesian framework. Sun, Y. et al. developed a motion removal method [
15] that integrates a dedicated learning thread and an inference thread. Du, Z.-J. et al. [
16] leveraged GC-RANSAC to detect and eliminate dynamic feature points, achieving robust initial pose estimation. Song, S. et al. proposed DynaVINS [
17], which uses IMU integration to obtain prior poses and dynamically identifies and rejects dynamic object features through weight adjustment and regularization factors. Wang, C. et al. [
18] implemented 4D point cloud reconstruction in dynamic scenes by introducing multi-motion segmentation based on quantized residuals and super-pixel segmentation.
2.2. Semantic Information-Based Visual SLAM Systems
Semantic information-based visual SLAM systems typically employ segmentation models such as SegNet [
19], PSPNet [
20], BlitzNet [
21], and YOLO [
22] to perform semantic segmentation on RGB images, generating precise semantic masks. These systems then eliminate information within dynamic object mask regions, utilizing only the remaining static data for pose estimation and mapping tasks. By leveraging semantic mask information to efficiently filter out dynamic key points and pixel data, this approach enhances localization accuracy and mapping quality. However, it also increases computational complexity, imposing higher demands on hardware platforms for real-time processing. Consequently, current research focuses on integrating semantic information with geometric constraints to further optimize the robustness, localization precision, and map quality of SLAM systems while maintaining real-time performance.
2.3. Semantic–Geometric Fusion-Based Visual SLAM Systems
Gou et al. [
23] designed a lightweight segmentation network tailored for workshop environments and developed a feature-point dynamic probability calculation module integrating edge constraints, epipolar constraints, and positional constraints. Zhang, J. et al. [
24] constructed Gaussian models using optical flow and depth data post-segmentation, employing a non-parametric Kolmogorov–Smirnov (K-S) test to distinguish dynamic feature points. Zhong, M. et al. [
25] applied a sliding window mechanism and mask-matching algorithm to detection results for dynamic feature removal. Li, Y. et al. [
26] proposed a VSLAM system that first eliminates prior dynamic object regions using segmentation models and then removes residual dynamic key points via Lucas–Kanade (LK) optical flow. Ul, I. et al. [
27] leveraged dense optical tracking to initialize per-frame poses and employed K-means for spatial scene clustering to enhance dynamic object recognition.
Li, A. et al. [
28] iteratively updated dynamic key point motion probabilities using Bayesian theorem, combining geometric models with Mask-RCNN semantic segmentation results to filter dynamic features. Ran, T. et al. [
29] introduced a Bayesian update-based contextual mask refinement method to improve segmentation accuracy. Jin, S. et al. [
30] generated saliency maps by fusing geometric, semantic, and depth information. Gong, H. et al. [
31] integrated LK optical flow with adaptive threshold-based uniform feature extraction, utilizing YOLOv5 to eliminate dynamic features. Hu, Z. et al. [
32] enhanced mask outputs from STDC networks through a detail-guided refinement module. Krishna, G.S. et al. [
33] adopted a lightweight 3D hybrid Transformer architecture for semantic acquisition and applied HDBSCAN clustering to geometric constraints. Jeon, H. et al. [
34] combined scene flow analysis with filtered conditional random field optimization, exploiting static features within dynamic objects for pose estimation. Yang, L. et al. [
35] introduced adaptive dynamic object segmentation and scene semantics-based feature updating. Wang, C. et al. [
36] generated dynamic probability grids via super-point segmentation, reserving only low-probability grid features for camera motion estimation. Wei, B. et al. [
37] optimized dynamic feature filtering by assigning motion levels to different dynamic object categories. Yang, L. et al. [
38] utilized dual deep learning models to extract depth images and semantic features, integrating semantic cues, local depth contrast, and multi-view projection constraints for dynamic feature rejection. Mei et al. [
39] proposed a dynamic RGB-D visual SLAM dense map building method based on pyramidal L-K (Lucas–Kanade) optical flow with multi-view geometric constraints. Wei et al. [
40] proposed a semantic information-based optimized vSLAM algorithm by adding the modules of dynamic region detection and semantic segmentation to ORB-SLAM2. 41. Song et al. [
41] reviewed the primary approaches of semantic mapping proposed over the last few decades.
Purely geometric visual dynamic SLAM systems eliminate the need for complex and resource-intensive deep learning models, offering superior computational efficiency and real-time performance. However, their performance heavily relies on the quality and quantity of feature points—scenes with abundant dynamic features and insufficient static features can severely degrade system accuracy. Meanwhile, the absence of semantic understanding restricts their ability to interpret scene semantics or object functionalities. Visual SLAM systems integrating geometric constraints with semantic information demonstrate distinct advantages. First, deep learning models enable semantic awareness, enhancing robustness against dynamic object interference by reducing the misclassification of feature motion states, thereby improving pose estimation accuracy and mapping quality. Second, the dual filtering mechanism combining semantic and geometric constraints further suppresses residual dynamic information while generating semantically labeled maps, which better support autonomous navigation and path planning for mobile robots.
Despite advancements, map construction in visual SLAM systems still faces challenges. For instance, effectively identifying non-prior dynamic objects—such as default static objects interacting with dynamic elements (e.g., chairs being moved)—remains difficult. This results in map pollution from dynamic artifacts and degraded map clarity. Additionally, point cloud maps often suffer from insufficient semantic labeling, excessive noise points, and oversized data volumes, limiting their practical utility.
3. System Description
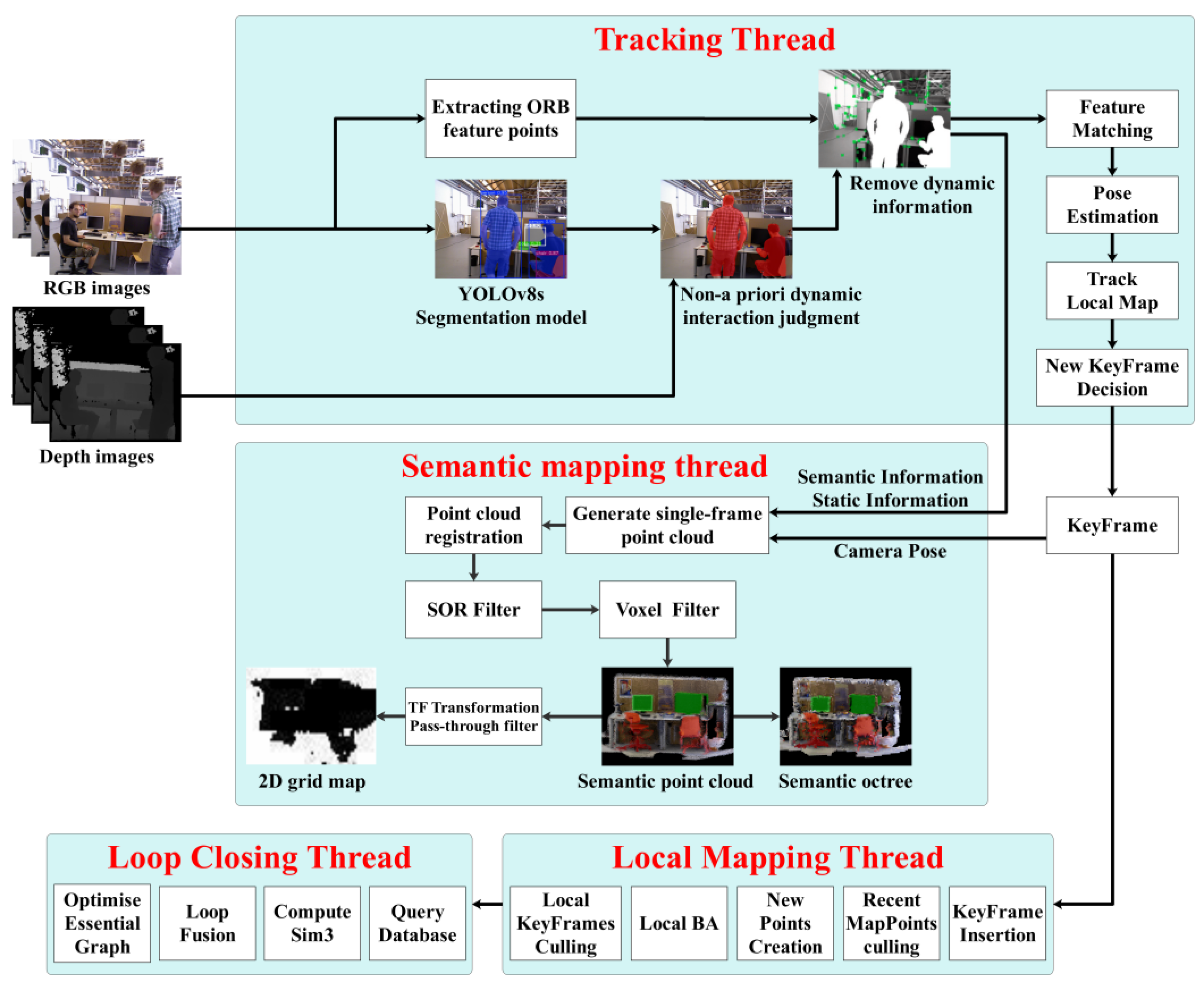
Building upon ORB-SLAM3, our algorithm enhances the tracking thread by integrating a semantic segmentation module, a non-prior dynamic object interaction detection module, and a dynamic information elimination module. We propose a dynamic information removal algorithm based on depth data and semantic segmentation, alongside a semantic mapping thread that implements an indoor map construction algorithm combining semantic fusion and hierarchical filtering. The overall architecture is illustrated in
Figure 1.
First, the YOLOv8s semantic segmentation module processes RGB images to extract semantic information and object masks. Next, the interaction detection module identifies non-prior dynamic objects (e.g., default static objects interacting with dynamic elements) by analyzing geometric relationships between prior dynamic and static objects. The dynamic elimination module then removes all pixel data and ORB feature points associated with both prior and non-prior dynamic objects. Subsequent tasks, including pose estimation and mapping, rely solely on the retained static information.
For semantic mapping, the algorithm fuses semantic labels, static data, and camera poses to construct an initial semantic dense point cloud map. SOR filtering is applied to eliminate noise, followed by voxel filtering to reduce point cloud density, resulting in a compact, high-fidelity semantic map with minimized dynamic artifacts. A recursive algorithm segments the point cloud to generate a semantic octree map encoding spatial occupancy information, enhancing autonomous navigation and environmental awareness. Finally, the system adjusts the point cloud orientation via TF transformation, restricts spatial bounds using passthrough filtering, and projects the 3D data into a 2D navigability grid via grid projection, forming a foundation for path planning. This approach constructs clear, information-rich semantic maps and 2D navigation grids, providing reliable support for mobile robot autonomy in dynamic environments.
3.1. Semantic Information and Mask Acquisition Based on YOLOv8 Model
In the proposed algorithm, the YOLOv8 segmentation model is utilized to acquire semantic information and masks of environmental objects. The YOLOv8s-seg model, trained on the COCO-Seg dataset, can identify 80 common object categories and generate their corresponding masks, including person, cat/dog, chair, sofa, potted plant, bed, dining table, and others.
Based on the motion states of objects, this study categorizes objects into three classes as shown in
Table 1. Prior dynamic objects refer to those with a high inherent probability of movement, such as humans, cats, dogs, and other animals commonly found in indoor environments. These objects typically exhibit unreliable poses due to their dynamic nature. Prior static objects encompass all objects excluding prior dynamic ones, including items like chairs, cups, books, and keyboards in indoor settings. However, prior static objects may undergo movement under specific circumstances, such as chairs, tables, or books being displaced by human interaction. When such prior static objects are actively interacting with prior dynamic objects, they are classified as non-prior dynamic objects, which can adversely affect pose estimation and mapping accuracy.
3.2. Interaction Criteria for Non-Prior Dynamic Objects
When a prior dynamic object physically interacts with a prior static object, the latter’s motion state changes, transforming it into a non-prior dynamic object. For example, if a prior dynamic object (e.g., a person) moves or sits on a prior static object (e.g., a chair), the probability of the chair being dynamic increases significantly. In such cases, the “chair being interacted with” is classified as a non-prior dynamic object. Failure to process such objects would degrade the localization accuracy and mapping performance of SLAM systems.
To address this, our algorithm identifies potential interactions by examining pairs of pixels lying close to the boundary between a prior dynamic object (A) and a prior static object (B). Specifically, this is illustrated in
Figure 2.
- 1.
Identify Close Pixel Pairs: We find all pairs of pixels. , where and are pixels on the prior dynamic object A and the prior static object B, respectively. For each pair, , the Euclidean distance in the image plane satisfies
where
is the maximum allowable Euclidean distance (set to 6 in this work) indicating the minimum proximity for interaction.
This step ensures we only consider pixels that are spatially close enough to potentially belong to parts of the objects that are interacting.
- 2.
Compute Depth Differences: For each qualifying pixel pair, , we calculate the absolute depth difference at those pixels.
- 3.
Calculate Average Depth Difference: We compute the average of these absolute depth differences across all N qualifying pixel pairs:
- 4.
Interaction Decision: If , then objects A and B are judged to be interacting. Consequently, the prior static object B is reclassified as a non-prior dynamic object (and can be removed from the SLAM system). If , no interaction is confirmed, and object B remains classified as prior static. The threshold defines the minimum average depth difference for an interaction to be considered likely; a small average difference suggests the objects are at similar depths, consistent with physical contact or proximity causing motion coupling.
Figure 3 illustrates the interaction judgment process. In this example, a prior dynamic object (person) interacts with a prior static object (chair) by moving or sitting on it. The chair is reclassified as a non-prior dynamic object.
Figure 3a,b show the depth map and prior dynamic object mask, respectively. After processing,
Figure 3c successfully marks the chair as non-prior dynamic, ensuring the both prior and non-prior dynamic objects are excluded from SLAM tasks.
3.3. Semantic Dense Point Cloud Map Construction
Compared to sparse point cloud maps composed of feature points, dense point cloud maps provide richer information, accurately describing scene geometry and texture details, thereby enabling a more precise and comprehensive representation of environmental characteristics. To achieve this, we construct a semantic dense point cloud map in the semantic mapping thread by integrating semantic labels, static object data, and camera poses from the tracking thread. Subsequently, SOR filtering is applied to eliminate abnormal outliers, reducing noise and residual dynamic artifacts in the point cloud. Following this, voxel filtering down-samples the semantic dense point cloud to optimize its density and computational footprint. The final output is a texture-rich semantic dense point cloud map with minimized dynamic interference and a compact file size.
3.3.1. Point Cloud Generation and Registration
There exists a transformation relationship between the 3D spatial point
in the camera coordinate system and the pixel point
in the pixel coordinate system:
where
K is the camera intrinsic matrix, an inherent property of the camera.
and
represent the scaling factors in the horizontal and vertical directions, respectively;
and
denote the displacements between the image origin and the imaging point in the horizontal and vertical directions.
, the distance from the spatial point
to the imaging plane, can be measured by a depth camera.
The transformation relationship between the 3D spatial point
in the camera coordinate system and the point
in the world coordinate system is
where
R∈SO(3) (rotation matrix) and
T∈R3 (translation vector) represent the camera’s extrinsic parameters, which are typically time-varying in visual SLAM systems for mobile robots. These parameters can be calculated through feature point matching in the tracking thread.
We can rewrite the above equation:
Combining Equations (4) and (7), the transformation relationship from the pixel coordinate point
to the world coordinate point
is derived:
In the tracking thread, the YOLOv8 instance segmentation model is used to obtain semantic masks of static objects in the scene. Pixels in the static object regions of the current frame are overlaid with semi-transparent masks of specific colors to visualize the semantic dense point cloud map. Using Equation (8) and the PCL (Point Cloud Library), the static information containing semantic labels in the current frame is mapped to generate a semantic dense point cloud map corresponding to the current keyframe. Finally, multiple local point clouds are registered into the same world coordinate system to construct a global semantic dense point cloud map.
3.3.2. SOR Filtering
Due to the limitations of mask processing algorithms and dynamic information removal algorithms in eliminating all dynamic artifacts, residual point cloud data from dynamic objects may persist in the map, as illustrated in the red squares in
Figure 4a. These noise points exhibit sparse and scattered distribution characteristics. Additionally, depth measurement errors inherent to RGB-D cameras introduce radially distributed outlier noise points, shown in the red squares in
Figure 4b. Such scattered noise degrades the reliability of dense point cloud maps.
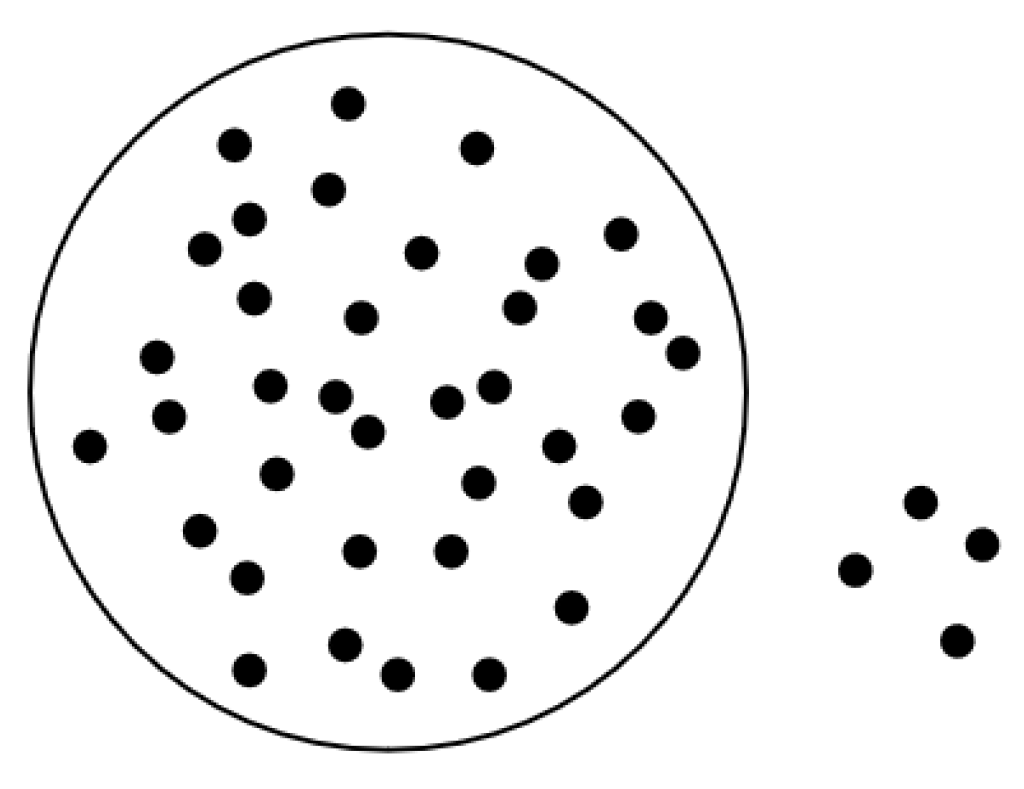
Therefore, during the processing of the point cloud map, the SOR algorithm is employed to filter out abnormal outliers in the point cloud. The SOR algorithm assumes that normal point clouds adhere to Gaussian distribution characteristics in their local neighborhoods, meaning most points densely cluster on object surfaces, while outliers deviate from the main structure. As shown in
Figure 5, the neighborhood distances of these outliers significantly exceed the mean range.
Within the point cloud data, given the total number of neighboring points,
k, associated with each point, the average distance from each point to its
k nearest neighbors is calculated iteratively. For instance, consider a point
in the point cloud and its
k nearest neighbors
. The average distance
d is defined as shown in Equation (9):
The average distance
d should follow a Gaussian distribution with the mean
μ and standard deviation
σ:
When
d ∉ (
μ − 2.5
σ,
μ + 2.5
σ), the point
P is identified as an outlier and removed from the point cloud map, as illustrated in
Figure 6.
3.3.3. Voxel Filtering
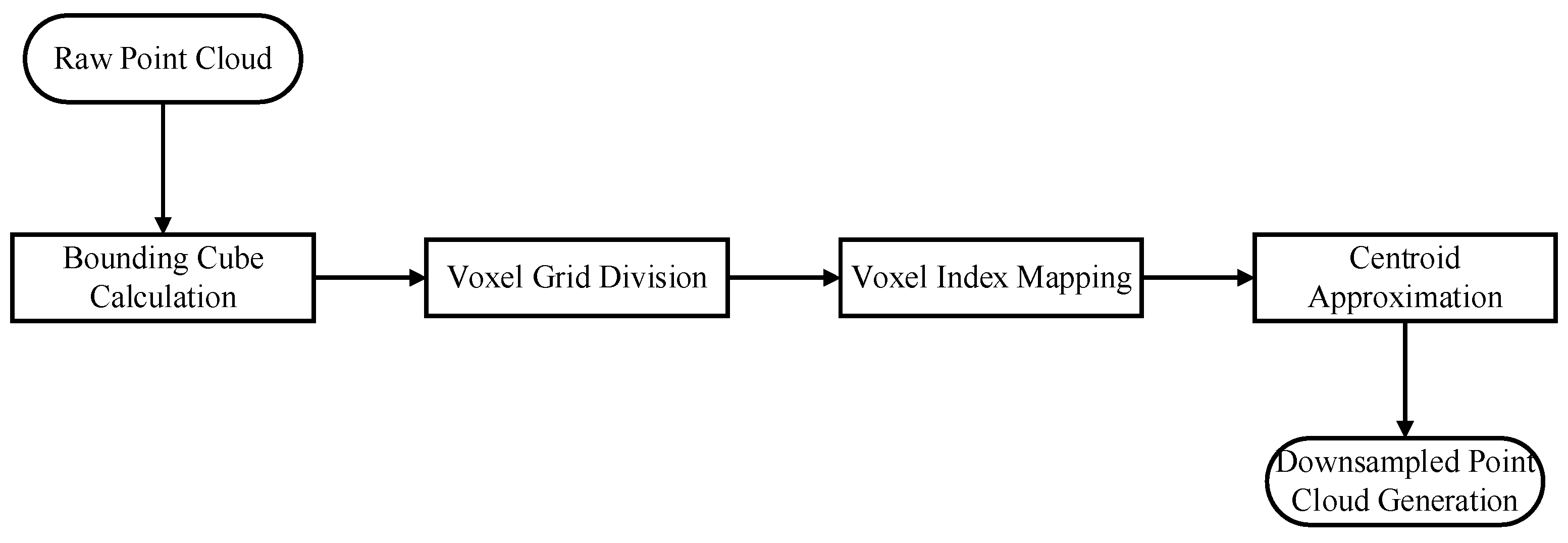
Over time, SLAM systems accumulate, construct, and maintain vast amounts of point cloud data, significantly increasing the computational complexity of subsequent tasks such as navigation. To address this, voxel filtering is applied to down-sample the semantic dense point cloud map, resulting in a more compact map with reduced file size. The core principle of the voxel filter lies in dividing the 3D space into a grid of voxels and selecting representative points to approximate all points within each voxel, as illustrated in
Figure 7.
Specifically, the workflow involves the following steps, as illustrated in
Figure 8:
Bounding Cube Calculation: Compute the minimum axis-aligned bounding cube enclosing the entire point cloud;
Voxel Grid Division: Subdivide the cube into smaller voxels based on a predefined voxel size;
Voxel Index Mapping: Iterate through each point in the original cloud, converting its coordinates into corresponding voxel indices;
Centroid Approximation: For each non-empty voxel, calculate the average centroid of its constituent points and use this centroid’s coordinates to represent all points within the voxel;
Down-sampled Map Generation: Construct a new point cloud map composed of the selected voxel centroids.
3.3.4. Semantic Octree Map Construction
The semantic dense point cloud map still has limitations. First, point cloud maps cannot represent spatial occupancy information, making them ineffective for mobile robot navigation and path planning. Second, details such as wrinkles and shadows in the point cloud are unnecessary for robotic tasks. Third, even after down-sampling, the point cloud map occupies significant memory resources. To address these issues, a recursive algorithm is employed to partition point clouds, constructing a semantic octree map that encodes spatial occupancy information, thereby enhancing autonomous navigation and environmental perception capabilities.
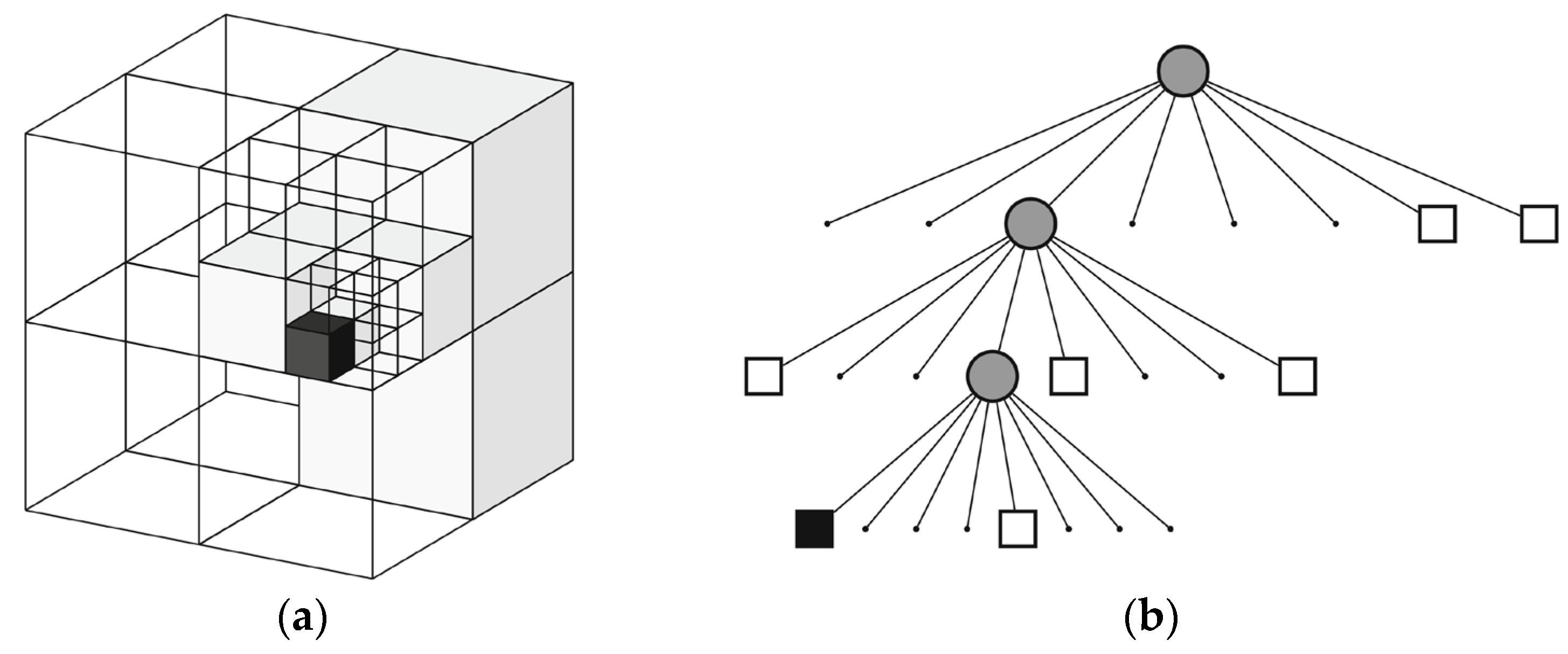
As illustrated in
Figure 9, an octree is a hierarchical data structure for 3D spatial subdivision. The octree map recursively divides 3D space into smaller voxel nodes using a recursive algorithm and stores them in a tree-like structure. By adjusting the maximum depth parameter, it achieves multi-resolution representations of the environment. This map format only creates nodes in occupied regions, avoiding resource allocation for empty spaces, making it ideal for representing complex 3D environments.
The core concept is to recursively partition space into a series of cubic volumes. During each recursion, a cubic volume is subdivided into eight smaller cubic volumes until a termination condition is met. Each cubic volume is referred to as a node, which can exist in three states: empty nodes, leaf nodes, and intermediate nodes. Empty nodes indicate no spatial occupancy; leaf nodes are terminal nodes in the octree that are no longer subdivided and represent occupied regions; intermediate nodes further subdivide space into eight smaller leaf nodes. For example, in the tree representation of
Figure 9b, white cubes denote empty nodes, black cubes represent leaf nodes, and gray circles signify intermediate nodes.
Implementation Steps:
Set the maximum recursion depth;
Determine the maximum scene dimensions and create the first parent node with this size;
Insert the point cloud into the parent node;
Subdivide the parent node into eight child nodes and distribute the parent node’s point cloud to the child nodes;
Terminate recursion if a child node receives either zero points or the same number of points as its parent;
Repeat Step 4 until the maximum recursion depth is reached.
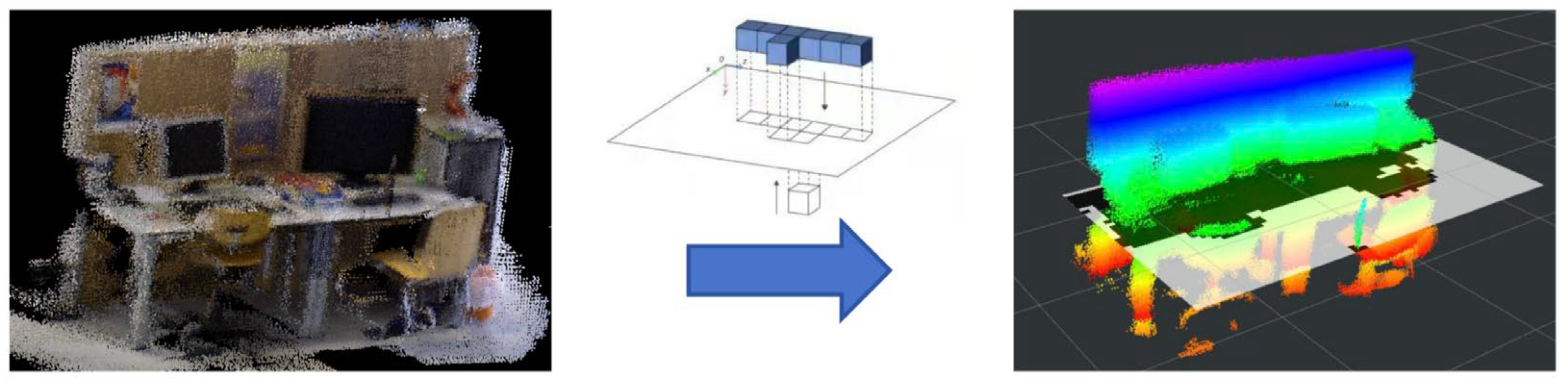
3.3.5. Two-Dimensional Occupancy Grid Map Construction
The octree map effectively represents 3D spatial occupancy, but mobile robots require a 2D obstacle-marked map for indoor path planning. To address this, a 2D occupancy grid map is generated by projecting the point cloud, as shown in
Figure 10. First, TF transformations align the ground plane of the point cloud with the projection plane to ensure parallelism. Next, a passthrough filter restricts the height range of the projected points, preventing ceiling and ground points from being erroneously mapped to the 2D grid (which could incorrectly label free cells as occupied). Finally, the 2D plane is divided into uniformly sized grid cells, with binary values indicating occupancy: a cell is marked as occupied (1) if it contains projected 3D points; otherwise, it is free (0).
4. Experimental Results
4.1. Experimental Environment
4.1.1. TUM RGB-D Dataset
The TUM RGB-D Dataset [
42] is a publicly available indoor scene dataset created and released by the Computer Vision Group at the Technical University of Munich (TUM). It is widely used as a benchmark platform for SLAM algorithms. The dataset contains RGB and depth image sequences synchronously captured by a Microsoft Kinect sensor at 30 Hz with a resolution of 640 × 480, as well as ground-truth camera poses obtained via a high-precision optical motion capture system.
Based on the dynamic levels of objects, the data sequences in this paper are categorized into static sequences, low-dynamic sequences, and high-dynamic sequences. Additionally, the camera in the TUM RGB-D dataset follows four distinct motion patterns: (1) xyz sequences: The camera moves slowly along the x, y, and z axes with minimal rotational components. (2) rpy sequences: The camera undergoes roll, pitch, and yaw rotations around its principal axes with little translational motion. (3) Halfsphere sequences: The camera moves along a hemispherical trajectory. (4) Static sequences: The camera exhibits almost no pose changes.
4.1.2. Real Indoor Dynamic Environments
To evaluate the performance of the proposed algorithm in real indoor dynamic environments, experiments were conducted in the office and laboratory scenarios illustrated in
Figure 11. In these environments, furniture arrangements and object placements resembled typical indoor settings, with continuously moving dynamic objects (humans) present.
For experiments in real-world environments, the Panda-4WD mobile robot shown in
Figure 12 was utilized. Its chassis employs a metal multi-link spring suspension system with a maximum payload capacity of 20 kg and is equipped with a 20,000 mAh lithium battery, providing power interfaces at 16.8 V and 5 V. The lower-level controller uses an STM32F407VET6 (STMicroelectronics, Paris, France) microcontroller for chassis control and offers extensive peripheral interfaces to accommodate diverse sensor and actuator connections. The upper-level controller employs the NVIDIA Jetson Orin Nano 8 GB Developer Kit (NVIDIA, Santa Clara, CA, USA), providing robust support for semantic visual SLAM algorithm research and experimentation. The mobile robot captures RGB images and depth data using a RealSense D455 camera (Intel, Santa Clara, CA, USA).
For real-world mapping experiments, the RealSense D455 camera based on infrared structured-light technology (shown in
Figure 13) was used. Its key specifications are listed in
Table 2.
4.2. Mapping Experiments
4.2.1. Semantic Dense Point Cloud Mapping Experiment
The semantic dense point cloud mapping experiments were conducted using four image sequences from the TUM dataset: fr3/w/static and fr3/w/xyz (high-dynamic sequences), fr2/desk/p (low-dynamic sequence), and fr2/rpy (static sequence). The high- and low-dynamic sequences contained moving dynamic objects, while the static sequence included only stationary objects in an indoor environment. In all sequences, the RGB-D camera was in motion. For these four sequences, we constructed three types of maps: (1) dense point cloud maps based on ORB-SLAM3, (2) point cloud maps based on the proposed algorithm, and (3) semantic point cloud maps based on the proposed algorithm.
A comparative visualization of these maps is shown in
Figure 14 and
Figure 15. The proposed algorithm achieves semantic visualization by coloring object-specific point clouds (e.g., monitors and chairs) to highlight their semantic information.
From the experimental results of dynamic sequences in
Figure 14, it can be seen that the proposed algorithm demonstrates significantly improved point cloud mapping capabilities and map quality in both high-dynamic and low-dynamic scenarios. ORB-SLAM3 lacks the ability to handle dynamic object interference. When ORB-SLAM3 utilizes unreliable ORB features on dynamic objects for pose estimation, it leads to increased localization errors, distorted object points clouds in the map, and the excessive inclusion of dynamic object information in the point cloud. In contrast, the point cloud maps generated by the proposed algorithm are clear, complete, and exhibit significantly reduced residual dynamic artifacts, enabling the precise and accurate representation of semantic information in indoor environments.
Figure 15 compares the point cloud maps constructed by ORB-SLAM3 and the proposed algorithm using the fr2/rpy static sequence. The point cloud maps generated by the proposed algorithm display sharp textures and structurally intact geometries. The SLAM results between ORB-SLAM3 and the proposed algorithm in static sequences are nearly identical, as expected. This confirms that the proposed improvements do not negatively impact mapping performance in static environments.
4.2.2. Semantic Octree Map Construction Experiment
To enhance the mobile robot’s autonomous navigation and environmental perception capabilities, the proposed algorithm constructs a semantic octree map. In this experiment, three image sequences from the TUM dataset were utilized: (1) fr3/w/static (high-dynamic sequence); (2) fr2/desk/p (low-dynamic sequence); (3) fr2/rpy (static sequence).
The high- and low-dynamic sequences contained moving dynamic objects, while the static sequence included only stationary objects in an indoor scene. In all sequences, the RGB-D camera was in motion. For these three sequences, three types of maps were generated: (1) octree maps based on ORB-SLAM3; (2) octree maps based on the proposed algorithm; (3) semantic octree maps based on the proposed algorithm. A comparative visualization of these maps is presented in
Figure 16.
As clearly shown in
Figure 16, the octree maps constructed by ORB-SLAM3 in dynamic scenes exhibit significant clutter, including abundant residual information from dynamic objects (e.g., humans) and noise voxels. Some static objects in the octree maps suffer from distorted or deformed voxel structures. Due to the pervasive ghosting artifacts caused by dynamic objects, the representation of static scene information is severely compromised, drastically reducing the map’s readability.
In contrast, the proposed algorithm generated octree maps containing only static scene information. In the semantic octree maps, the proposed algorithm achieved the visualization of semantic information by altering voxel colors corresponding to object categories. As illustrated in
Figure 16, the semantic octree maps constructed by the proposed algorithm are clear and concise, with almost no residual dynamic object artifacts or noise voxels. For the static sequence (fr2/rpy), the mapping results in
Figure 16 reveal minimal differences between the proposed algorithm and ORB-SLAM3. The results confirm that the proposed modifications do not degrade visual SLAM performance in static environments.
4.2.3. Two-Dimensional Grid Map Construction Experiment
This section presents 2D grid map construction experiments conducted on the fr3/w/xyz and fr3/w/static sequences from the TUM dataset. The experimental results, shown in
Figure 17, compare the top–down view of the point cloud maps with the generated 2D grid maps.
The point clouds were aligned via TF transformation to ensure that the ground plane was parallel to the projection plane. Passthrough filtering was then applied to remove ceiling and floor points, retaining only object point clouds that obstruct mobile robot navigation. Finally, the point clouds were projected onto a 2D grid plane, where each grid cell’s occupancy status was represented by a binary value: (1) black: occupied regions (blocked areas); (2) white: free regions (navigable areas).
The 2D grid maps generated from the fr3/w/xyz and fr3/w/static sequences exhibit structurally coherent layouts, demonstrating that the proposed algorithm produces grid maps capable of supporting mobile robot navigation and path planning deployment.
4.3. Real Indoor Dynamic Environment Experiments
4.3.1. Dynamic Object Masking Experiment in Real Indoor Dynamic Environments
Figure 18 demonstrates the dynamic object masking results of the proposed algorithm in a real indoor dynamic environment. The first column displays the input depth map of the current frame. The second column shows the prior dynamic mask generated by YOLOv8 for the current frame, while the third column presents the refined dynamic object mask obtained using the proposed algorithm. Both the second and third columns visualize the dynamic object masks to highlight their effectiveness. The fourth column illustrates the distribution of ORB feature points extracted from the current frame, demonstrating the algorithm’s ability to maintain feature integrity while handling dynamic interference.
In the first and second image groups of
Figure 18, the proposed algorithm successfully identifies the chair interacted with by a human as a dynamic object. By leveraging edge distances and depth relationships between a priori dynamic objects (e.g., humans) and a priori static objects (e.g., furniture), the algorithm infers the motion states of the latter and removes non-prioritized dynamic objects from the SLAM system. This further mitigates adverse impacts on visual SLAM tasks caused by dynamically moving objects under human interaction.
In the ORB feature point extraction results shown in
Figure 18, no ORB feature points are extracted from the dynamic object mask regions (i.e., the human and the interacted chair). Additionally, the selected ORB feature points are evenly distributed across the scene, with no excessive clustering or sparsity, ensuring robust feature matching for localization and mapping.
4.3.2. Mapping Experiments in Real Indoor Dynamic Environments
Figure 19 and
Figure 20 compare the dense point cloud maps with dynamic artifacts constructed by ORB-SLAM3 and the semantic dense point cloud maps, semantic octree maps, and 2D grid projection maps generated by the proposed algorithm in real indoor dynamic environments.
Figure 19 and
Figure 20 present a comparative analysis of mapping results in real indoor dynamic environments. The dense point cloud maps generated by ORB-SLAM3 (
Figure 19a and
Figure 20a) exhibit significant ghosting artifacts from dynamic objects and numerous radially distributed outlier point clouds. These issues arise because ORB-SLAM3 fails to eliminate dynamic object information and suffers from incorrect camera poses estimated due to dynamic interference, leading to misaligned multi-view point cloud reconstructions.
For
Figure 19b and
Figure 20b: The semantic dense point cloud maps constructed by the proposed algorithm are notably clearer and more accurate. The algorithm successfully removes most dynamic artifacts and outlier point clouds, resulting in clean and precise dense point cloud representations. Additionally, it achieves the visualization of semantic information by assigning specific colors to object categories: chairs are colored red, books blue, and monitors green. This color-coded semantic encoding enables reliable and interpretable environmental understanding.
For
Figure 19c and
Figure 20c: The proposed algorithm generates semantic octree maps that clearly represent spatial occupancy and semantic details. Key objects, such as chairs (red) and monitors (green), are color-labeled to highlight their semantic attributes, ensuring intuitive visualization of both geometric and contextual scene information.
For
Figure 19d and
Figure 20d: The proposed algorithm utilizes a projection method to convert dense point clouds into 2D grid maps. These maps effectively reflect the top–down occupancy status of the indoor environment and provide actionable insights into navigable regions for mobile robots, demonstrating robust applicability in real-world navigation tasks.
4.4. Map File Size Analysis
4.4.1. Map File Size Analysis on the TUM Dataset
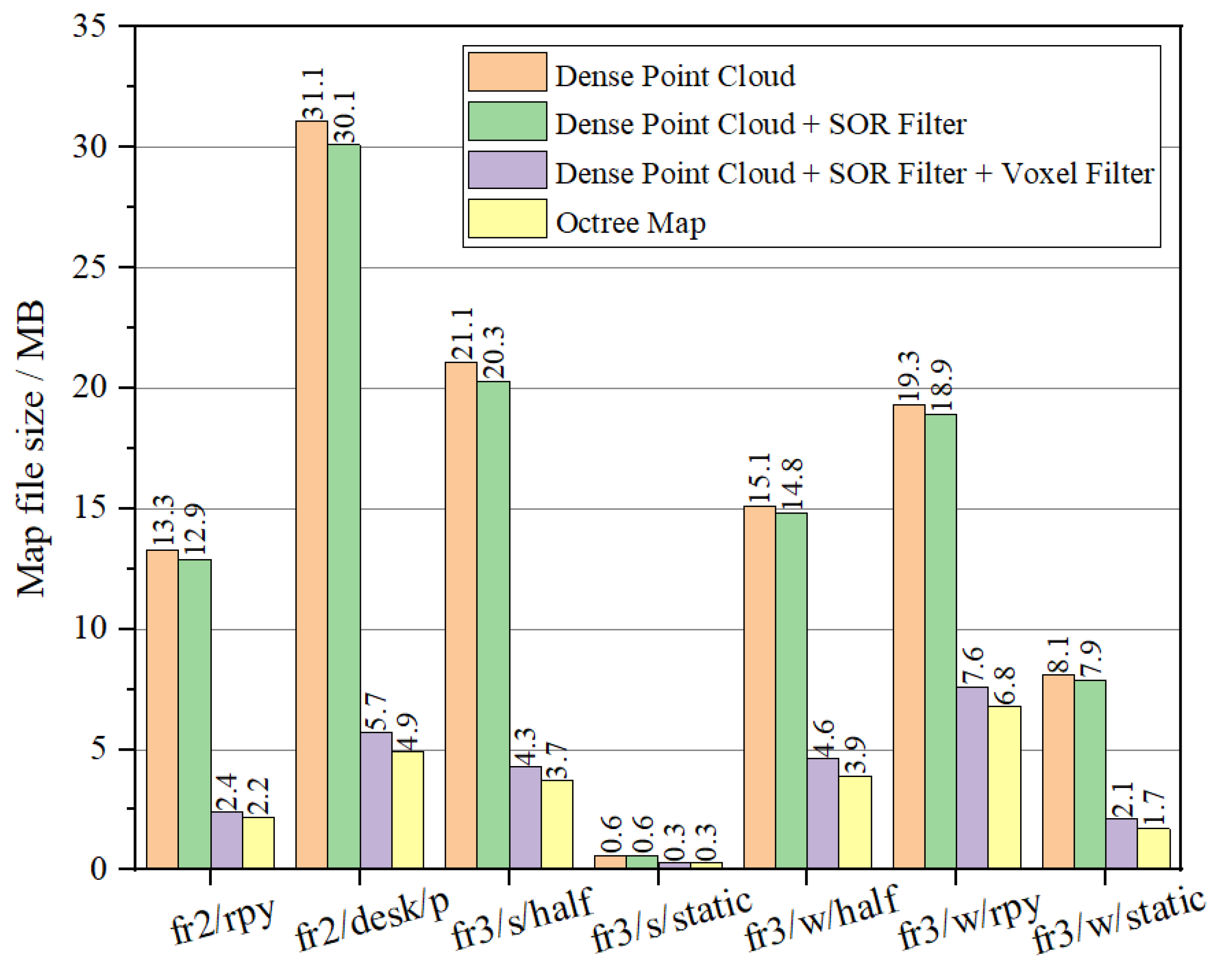
This section details how the proposed algorithm was evaluated by performing map construction tasks on the TUM dataset, with a comparative analysis of file sizes generated in different stages. In the tracking thread, the algorithm first removes all dynamic objects and utilizes static information for pose estimation. Subsequently, the semantic mapping thread generates and merges point clouds to produce a “dense point cloud map” file. In this stage, the map contains minor noise points and residual dynamic object information. To address this, the SOR algorithm is applied to eliminate outliers, resulting in a “dense point cloud + SOR filtering” file. However, the camera may redundantly reconstruct point clouds for the same object across multiple frames and viewpoints over time, leading to excessive local point cloud density, redundant information, and a significant increase in map file size. To balance point cloud quality and file size, a voxel filtering down-sampling method is employed to optimize point cloud density and reduce file size, yielding a “dense point cloud + SOR filtering + voxel filtering” file. Finally, a recursive segmentation algorithm is applied to partition the point cloud, constructing a semantic octree map that represents spatial occupancy information, thereby generating an “octree map” file.
Figure 21 illustrates the comparison of map file sizes. The SOR filtering method primarily removed outliers; the algorithm used a threshold of 2.5 standard deviations, which eliminated approximately 1.24% of the point cloud, offering limited compression of the map file size. As shown in
Figure 21, voxel filtering reduced the file size to 20–50% of the original (voxel filtering significantly compressed dense point cloud maps across TUM RGB-D sequences: fr2/rpy: 13.3 MB → 2.4 MB (18%); fr2/desk/p: 31.3 MB → 5.7 MB (18.2%); fr3/s/half:21.1 MB → 4.3 MB (20.4%); fr3/s/static:0.6 MB → 0.3 MB(50%); fr3/w/half:15.1 MB → 4.6 MB (30.5%); fr3/w/rpy: 19.3 MB → 7.6 MB (39.4%); fr3/w/static:8.1 MB → 2.1 MB (25.9%)). The octree map further compressed the processed dense point cloud, achieving a file size of only 16.5–35% of the original dense point cloud.
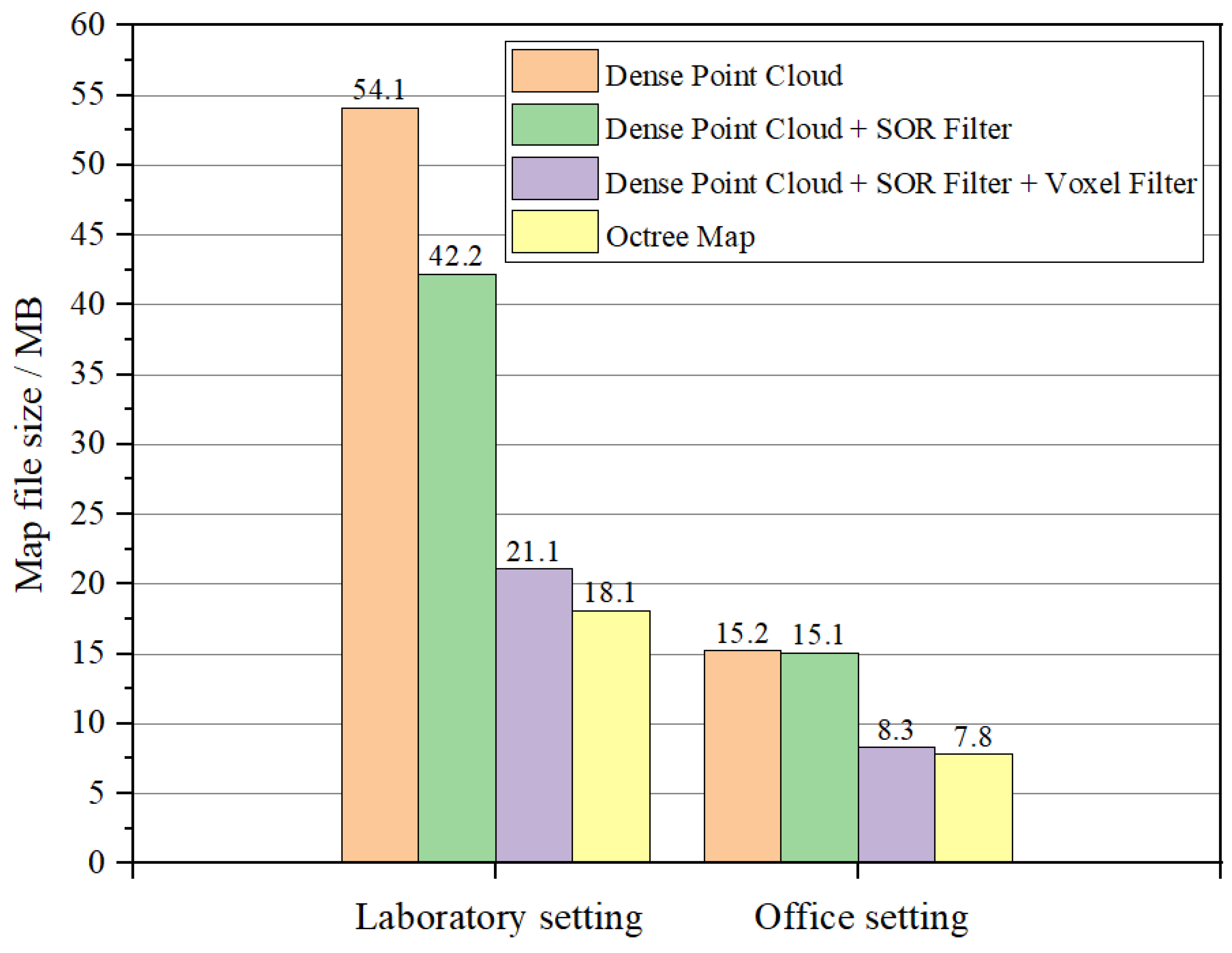
4.4.2. Map File Size Analysis in Real Indoor Dynamic Environments
Figure 22 presents the file sizes of various maps generated by the proposed algorithm after completing SLAM tasks in two real indoor dynamic scenarios. The dense point cloud map directly generated by the SLAM system exhibited a large file size. After applying SOR filtering to eliminate outliers, the file size slightly decreased. Subsequent voxel filtering down-sampling further reduced point cloud density, significantly decreasing the file size to approximately 39–54.6% of the original. (In laboratory environments, after applying voxel filtering, the size of the dense point cloud map was reduced from 54.1 MB to 21.1 MB, retaining only 39% of the original file volume. In office environments, voxel filtering reduced the dense point cloud map size from 15.2 MB to 8.3 MB, preserving 54.6% of the initial file volume.) Finally, conversion to an octree map not only represented spatial occupancy information but also further compressed the file size, providing essential support for mobile robot navigation and path planning.
5. Conclusions and Future Work
The experimental results demonstrate that the proposed indoor dynamic environment mapping method based on semantic fusion and hierarchical filtering can effectively eliminate both prior and non-prior dynamic features. This provides the ability to construct multi-level semantic maps with rich information, clear structure, and high reliability in indoor dynamic scenarios. Additionally, the map file size is compressed by 50–80%, which can significantly enhance the reliability of mobile robot navigation and the efficiency of path planning. The specific conclusions are as follows:
Dynamic Information Elimination Algorithm: The semantic–depth fusion algorithm removes dynamic interference in SLAM by identifying prior/non-prior dynamic objects via YOLOv8s segmentation and depth–edge analysis, eliminating their pixels and ORB features. This ensures static-only mapping, enhancing robustness in dynamic indoor scenes.
Semantic Fusion and Layered Mapping Algorithm: Combining semantic fusion with SOR/voxel filtering, this method reduces point cloud file sizes by 50–80% and generates multi-layer maps, a semantic octree for 3D occupancy and a 2D grid for navigation, balancing precision and efficiency.
Experimental Validation: Tests on TUM datasets and real-world environments confirmed 50–80% map size reduction, minimal dynamic artifacts, and practical navigation-ready outputs (octree/2D grid), validating robustness in complex dynamic settings.
Although the semantic octree maps and 2D grid maps constructed in this work provide a foundational framework for mobile robot navigation, they are not yet directly deployable. To bridge this gap, future work may perform the following:
Integrate the map data with multimodal large language models to achieve deeper scene understanding and task-aware environmental interaction.
Explore semantic-aware path planning algorithms (e.g., A*, D*), incorporating semantic weights into path cost functions or generating semantic-guided trajectories aligned with mission requirements.
Author Contributions
Conceptualization, Yiming Li and Luying Na; methodology, Yiming Li; software, Luying Na; validation, Yiming Li, Luying Na and Xianpu Liang; formal analysis, Xianpu Liang; investigation, Qi An; resources, Qi An; data curation, Xianpu Liang; writing—original draft preparation, Yiming Li; writing—review and editing, Yiming Li and Luying Na; visualization, Luying Na and Xianpu Liang; supervision, Qi An; project administration, Yiming Li; funding acquisition, Yiming Li. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Young Backbone Teachers Support Plan of Beijing Information Science & Technology University, grant no. YBT 202405 and the Higher Education Research Project of Beijing Information Science & Technology University, grant no. 2023GJYB12.
Data Availability Statement
Acknowledgments
The authors have reviewed and edited the output and take full responsibility for the content of this publication.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wang, Y.; Tian, Y.; Chen, J.; Xu, K.; Ding, X. A Survey of Visual SLAM in Dynamic Environment: The Evolution from Geometric to Semantic Approaches. IEEE Trans. Instrum. Meas. 2024, 73, 1–21. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2016, 33, 1255–1262. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodriguez, J.J.G.; Montiel, J.M.; Tardós, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Smith, R.C.; Cheeseman, P. On the Representation and Estimation of Spatial Uncertainty. Int. J. Rob. Res. 1986, 5, 56–68. [Google Scholar] [CrossRef]
- Davison, A.; Reid, I.; Molton, N.; Stasse, O. MonoSLAM: Real-Time Single Camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef]
- Klein, G.; Murray, D. Parallel Tracking and Mapping for Small AR Workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; IEEE: Piscataway, NJ, USA, 2007. [Google Scholar] [CrossRef]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense tracking and mapping in real-time. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2011. [Google Scholar] [CrossRef]
- Kim, D.; Hilliges, O.; Molyneaux, D.; Molyneaux, D.; Newcombe, R.; Kohli, P.; Shotton, J.; Hodges, S.; Freeman, D.; Davison, A.; et al. KinectFusion: Real-time 3D reconstruction and interaction using a moving depth camera. In Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology, Santa Barbara, CA, USA, 16–19 October 2011; ACM: New York, NY, USA, 2011. [Google Scholar]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; IEEE: Piscataway, NJ, USA, 2014. [Google Scholar] [CrossRef]
- Engel, J.J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct Monocular SLAM. Comput. Vis.–ECCV 2014, 2014, 834–849. [Google Scholar]
- Engel, J.J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 40, 611–625. [Google Scholar] [CrossRef]
- Lin, K.; Wang, C. Stereo-based simultaneous localization, mapping and moving object tracking. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 3975–3980. [Google Scholar]
- Wang, C.; Thorpe, C.; Thrun, S.; Hebert, M.; Durrant-Whyte, H. Simultaneous Localization, Mapping and Moving Object Tracking. Int. J. Rob. Res. 2007, 26, 889–916. [Google Scholar] [CrossRef]
- Cheng, J.; Wang, C.; Meng, M.Q.H. Robust Visual Localization in Dynamic Environments Based on Sparse Motion Removal. IEEE Trans. Autom. Sci. Eng. 2020, 17, 658–669. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, M.; Meng, M.Q.-H. Motion removal for reliable RGB-D SLAM in dynamic environments. Robot. Auton. Syst. 2018, 108, 115–128. [Google Scholar] [CrossRef]
- Du, Z.-J.; Huang, S.-S.; Mu, T.-J.; Zhao, Q.; Martin, R.R.; Xu, K. Accurate Dynamic SLAM Using CRF-Based Long-Term Consistency. IEEE Trans. Vis. Comput. Graph. 2020, 28, 1745–1757. [Google Scholar] [CrossRef] [PubMed]
- Song, S.; Lim, H.; Lee, A.; Myung, H. DynaVINS: A Visual-Inertial SLAM for Dynamic Environments. IEEE Robot Autom. Lett. 2022, 7, 11523–11530. [Google Scholar] [CrossRef]
- Wang, C.; Luo, B.; Zhang, Y.; Zhao, Q.; Yin, L.; Wang, W.; Su, X.; Wang, Y.; Li, C. DymSLAM: 4D Dynamic Scene Reconstruction Based on Geometrical Motion Segmentation. IEEE Robot Autom. Lett. 2020, 6, 550–557. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Handa, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling. arXiv 2015, arXiv:1505.07293. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2016; pp. 6230–6239. [Google Scholar]
- Dvornik, N.; Shmelkov, K.; Mairal, J.; Schmid, C. BlitzNet: A Real-Time Deep Network for Scene Understanding. arXiv 2017, arXiv:1708.02813. [Google Scholar]
- Terven, J.R.; Córdova-Esparza, D.-M.; Romero-González, J. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Gou, R.; Chen, G.; Yan, C.; Pu, X.; Wu, Y.; Tang, Y. Three-dimensional dynamic uncertainty semantic SLAM method for a production workshop. Eng. Appl. Artif. Intell. 2022, 116, 105325. [Google Scholar] [CrossRef]
- Zhang, J.; Yuan, L.; Ran, T.; Peng, S.; Tao, Q.; Xiao, W.; Cui, J. A dynamic detection and data association method based on probabilistic models for visual SLAM. Displays 2024, 82, 102663. [Google Scholar] [CrossRef]
- Zhong, M.; Hong, C.; Jia, Z.; Wang, C.; Wang, Z. DynaTM-SLAM: Fast filtering of dynamic feature points and object-based localization in dynamic indoor environments. Robot. Auton. Syst. 2024, 174, 104634. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Y.; Lu, L.; Guo, Y.; An, Q. Semantic Visual SLAM Algorithm Based on Improved DeepLabV3+ Model and LK Optical Flow. Appl. Sci. 2024, 14, 5792. [Google Scholar] [CrossRef]
- Ul Islam, Q.; Ibrahim, H.; Kok Chin, P.; Lim, K.; Abdullah, M.Z.; Khozaei, F. ARD-SLAM: Accurate and robust dynamic SLAM using dynamic object identification and improved multi-view geometrical approaches. Displays 2024, 82, 102654. [Google Scholar] [CrossRef]
- Li, A.; Wang, J.; Xu, M.; Chen, Z. DP-SLAM: A visual SLAM with moving probability towards dynamic environments. Inf. Sci. 2021, 556, 128–142. [Google Scholar] [CrossRef]
- Ran, T.; Yuan, L.; Zhang, J.; Tang, D.; He, L. RS-SLAM: A Robust Semantic SLAM in Dynamic Environments Based on RGB-D Sensor. IEEE Sens. J. 2021, 21, 20657–20664. [Google Scholar] [CrossRef]
- Jin, S.; Dai, X.; Meng, Q. “Focusing on the right regions”—Guided saliency prediction for visual SLAM. Expert Syst. Appl. 2022, 213, 119068. [Google Scholar] [CrossRef]
- Gong, H.; Gong, L.; Ma, T.; Sun, Z.; Li, L. AHY-SLAM: Toward Faster and More Accurate Visual SLAM in Dynamic Scenes Using Homogenized Feature Extraction and Object Detection Method. Sensors 2023, 23, 4241. [Google Scholar] [CrossRef]
- Hu, Z.; Chen, J.; Luo, Y.; Zhang, Y. STDC-SLAM: A Real-Time Semantic SLAM Detect Object by Short-Term Dense Concatenate Network. IEEE Access 2022, 10, 129419–129428. [Google Scholar] [CrossRef]
- Krishna, G.S.; Supriya, K.; Baidya, S. 3DS-SLAM: A 3D Object Detection based Semantic SLAM towards Dynamic Indoor Environments. arXiv 2023, arXiv:2310.06385. [Google Scholar]
- Jeon, H.; Han, C.; You, D.; Oh, J. RGB-D Visual SLAM Algorithm Using Scene Flow and Conditional Random Field in Dynamic Environments. In Proceedings of the 2022 22nd International Conference on Control, Automation and Systems (ICCAS), Busan, Republic of Korea, 27 November–1 December 2022; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar] [CrossRef]
- Yang, L.; Cai, H. Enhanced visual SLAM for construction robots by efficient integration of dynamic object segmentation and scene semantics. Adv. Eng. Inform. 2024, 59, 102313. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, Y.; Li, X. PMDS-SLAM: Probability Mesh Enhanced Semantic SLAM in Dynamic Environments. In Proceedings of the 2020 5th International Conference on Control, Robotics and Cybernetics (CRC), Wuhan, China, 16–18 October 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Wei, B.; Zhao, L.; Li, L.; Li, X. Research on RGB-D Visual SLAM Algorithm Based on Adaptive Target Detection. In Proceedings of the 2023 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Zhengzhou, China, 14–17 November 2023; IEEE: Piscataway, NJ, USA, 2023. [Google Scholar] [CrossRef]
- Yang, L.; Wang, L. A semantic SLAM-based dense mapping approach for large-scale dynamic outdoor environment. Measurement 2022, 204, 112001. [Google Scholar] [CrossRef]
- Mei, J.; Zuo, T.; Song, D. Highly dynamic visual SLAM dense map construction based on indoor environments. IEEE Access 2024, 12, 12345–12356. [Google Scholar] [CrossRef]
- Wei, S.; Wang, S.; Li, H.; Liu, G.; Yang, T.; Liu, C. A Semantic Information-Based Optimized vSLAM in Indoor Dynamic Environments. Appl. Sci. 2023, 13, 8790. [Google Scholar] [CrossRef]
- Song, X.; Liang, X.; Zhang, H. Semantic mapping techniques for indoor mobile robots: Review and prospect. Meas. Control 2025, 58, 377–393. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Vilamoura-Algarve, Portugal, 7–12 October 2012; IEEE: Piscataway, NJ, USA, 2012. [Google Scholar] [CrossRef]
Figure 1.
Algorithm architecture.
Figure 1.
Algorithm architecture.
Figure 2.
Workflow diagram of interaction criteria for non-prior dynamic objects.
Figure 2.
Workflow diagram of interaction criteria for non-prior dynamic objects.
Figure 3.
Interaction judgment for non-prior dynamic objects. (a) Depth map; (b) prior dynamic object mask; (c) prior and non-prior dynamic object mask.
Figure 3.
Interaction judgment for non-prior dynamic objects. (a) Depth map; (b) prior dynamic object mask; (c) prior and non-prior dynamic object mask.
Figure 4.
Sparse outliers in the dense point cloud map. (a) Residual dynamic object points. (b) Measurement-error-induced noise points.
Figure 4.
Sparse outliers in the dense point cloud map. (a) Residual dynamic object points. (b) Measurement-error-induced noise points.
Figure 5.
Illustration of outlier noise points.
Figure 5.
Illustration of outlier noise points.
Figure 6.
SOR filtering workflow diagram.
Figure 6.
SOR filtering workflow diagram.
Figure 7.
Schematic diagram of voxel filtering.
Figure 7.
Schematic diagram of voxel filtering.
Figure 8.
Voxel filtering workflow diagram.
Figure 8.
Voxel filtering workflow diagram.
Figure 9.
Octree structure. (a) Volumetric model. (b) Tree representation.
Figure 9.
Octree structure. (a) Volumetric model. (b) Tree representation.
Figure 10.
This figure demonstrates the projection-based 2D mapping process.
Figure 10.
This figure demonstrates the projection-based 2D mapping process.
Figure 11.
Sample images of real indoor dynamic environments. (a) Office environment (View 1). (b) Office environment (View 2). (c) Laboratory environment (View 1). (d) Laboratory environment (View 2).
Figure 11.
Sample images of real indoor dynamic environments. (a) Office environment (View 1). (b) Office environment (View 2). (c) Laboratory environment (View 1). (d) Laboratory environment (View 2).
Figure 12.
Mobile robot experimental platform.
Figure 12.
Mobile robot experimental platform.
Figure 13.
RealSense D455 camera.
Figure 13.
RealSense D455 camera.
Figure 14.
Semantic dense point cloud mapping experiment—dynamic sequences.
Figure 14.
Semantic dense point cloud mapping experiment—dynamic sequences.
Figure 15.
Semantic dense point cloud mapping experiment—static sequences.
Figure 15.
Semantic dense point cloud mapping experiment—static sequences.
Figure 16.
Semantic octree map construction experiment.
Figure 16.
Semantic octree map construction experiment.
Figure 17.
2D grid map construction experiment.
Figure 17.
2D grid map construction experiment.
Figure 18.
Mask processing experiment.
Figure 18.
Mask processing experiment.
Figure 19.
Office scene map construction experiments. (a) ORB-SLAM3 dense point cloud; (b) semantic dense point cloud of proposed algorithm; (c) semantic octree of proposed algorithm; (d) 2D grid map of proposed algorithm.
Figure 19.
Office scene map construction experiments. (a) ORB-SLAM3 dense point cloud; (b) semantic dense point cloud of proposed algorithm; (c) semantic octree of proposed algorithm; (d) 2D grid map of proposed algorithm.
Figure 20.
Laboratory scene map construction experiments. (a) ORB-SLAM3 dense point cloud; (b) semantic dense point cloud of proposed algorithm; (c) semantic octree of proposed algorithm; (d) 2D grid map of proposed algorithm.
Figure 20.
Laboratory scene map construction experiments. (a) ORB-SLAM3 dense point cloud; (b) semantic dense point cloud of proposed algorithm; (c) semantic octree of proposed algorithm; (d) 2D grid map of proposed algorithm.
Figure 21.
Map file size analysis.
Figure 21.
Map file size analysis.
Figure 22.
Map file size analysis in real-world environments.
Figure 22.
Map file size analysis in real-world environments.
Table 1.
Motion state classification.
Table 1.
Motion state classification.
| Object | Category | Participation in SLAM Tasks |
|---|
| Person or animal | Prior dynamic object | Cannot participate |
| Book on table, chair on floor | Prior static object | Can participate |
| Chair being used by person | Non-prior dynamic object | Cannot participate |
Table 2.
RealSense D455 camera specifications.
Table 2.
RealSense D455 camera specifications.
| Key Specification | Parameter |
|---|
| Depth Sensing Principle | Active IR stereo |
| Operating Environment | Indoor and outdoor |
| Depth FoV (H × V) | 87° × 58° |
| Depth Resolution | 1280 × 720 |
| Depth Accuracy | <2% at 4 m |
| Depth Frame Rate | Up to 90 FPS |
| Minimum Depth Distance | 0.52 m |
| Ideal Depth Range | 0.6 m–6 m |
| RGB Resolution and Frame Rate | 1280 × 800 @ 30 fps |
| RGB FoV (H × V) | 90° × 65° |
| Interface | USB 3 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}