

High-Resolution Global Land Cover Maps and Their Assessment Strategies




Abstract
1. Introduction
2. Data Inputs and Technologies
2.1. Data Sources
2.2. Preprocessing
2.3. Automatic Classification
3. Legends
Legend Harmonization
4. Validation
4.1. Sampling Method
4.1.1. Simple Sampling Method
4.1.2. Stratified Sampling Method
4.1.3. Systematic Sampling Method
4.1.4. Clustered Sampling Method
4.1.5. Sample Typologies
4.2. Sample Size Selection
4.3. Sample Interpretation
4.3.1. Manual Interpretation
4.3.2. Automated Interpretation
4.3.3. Imagery Data Used for Interpretation
4.3.4. Crowdsourced Data
4.4. Accuracy Metrics
5. Data Distribution and Cloud Platforms
5.1. Data Distribution
5.2. Trends in Platform Usage
6. Discussing Current Trends and Future Directions
6.1. Multi-Source Data Fusion
6.2. High Resolution and Real-Time Mapping
6.3. Computational Challenges
6.4. Standardized Datasets and Validation Protocols/Frameworks
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| LC | Land cover |
| HRLC | High-resolution land cover |
| GHRLC | Global high-resolution land cover |
| CAS | Chinese Academy of Sciences |
| ESA | European Space Agency |
| NASA | National Aeronautics and Space Administration |
| NGCC | National Geomatics Center of China |
| DLR | German Aerospace Center |
| JRC | Joint Research Centre |
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Access Point |
|---|---|
| GLC_FCS30D | https://zenodo.org/records/8239305 (accessed on 26 February 2025) |
| GWL_FCS30D | https://zenodo.org/records/10068479 (accessed on 26 February 2025) |
| GISD30 | https://zenodo.org/records/5220816 (accessed on 26 February 2025) |
| Dynamic World | GOOGLE_DYNAMICWORLD_V1 (accessed on 26 February 2025) |
| ESRI LULC | https://livingatlas.arcgis.com/landcover/ (accessed on 26 February 2025) |
| WorldCover | https://esa-worldcover.org/en/data-access (accessed on 26 February 2025) |
| GLanCE v001 | https://lpdaac.usgs.gov/products/glance30v001 (accessed on 26 February 2025) |
| GlobeLand30 | https://cloudcenter.tianditu.gov.cn/landCover (accessed on 26 February 2025) |
| FROM-GLC30 | https://data-starcloud.pcl.ac.cn/ (accessed on 26 February 2025) |
| FROM-GLC10 | https://data-starcloud.pcl.ac.cn/ (accessed on 26 February 2025) |
| World Settlement Footprint (WSF) | WSF2019 (accessed on 26 February 2025) |
| MapBiomas | https://brasil.mapbiomas.org/en/colecoes-mapbiomas/ (accessed on 26 February 2025) |
| GSW | https://global-surface-water.appspot.com/download (accessed on 26 February 2025) |
| GUF | https://www.dlr.de/en/eoc/research-transfer/projects-missions/global-urban-footprint/guf-data-and-access (accessed on 26 February 2025) |
| GHS-BUILT-S R2023A | GHS-BUILT-S R2023A (accessed on 26 February 2025) |
| GHS-BUILT-S1 2016 | GHS-BUILT-S1 2016 download link (accessed on 26 February 2025) |
| GFC | https://forobs.jrc.ec.europa.eu/GFC (accessed on 26 February 2025) |
| FNF | FNF download link (accessed on 26 February 2025) |
| Tree canopy cover | hansen_global_forest_change (accessed on 26 February 2025) |
References
- Sheykhmousa, M.; Kerle, N.; Kuffer, M.; Ghaffarian, S. Post-disaster recovery assessment with machine learning-derived land cover and land use information. Remote Sens. 2019, 11, 1174. [Google Scholar] [CrossRef]
- Ghaffarian, S.; Rezaie Farhadabad, A.; Kerle, N. Post-disaster recovery monitoring with google earth engine. Appl. Sci. 2020, 10, 4574. [Google Scholar] [CrossRef]
- Gaur, S.; Singh, R. A comprehensive review on land use/land cover (LULC) change modeling for urban development: Current status and future prospects. Sustainability 2023, 15, 903. [Google Scholar] [CrossRef]
- Carter, S.; Herold, M. Specifications of Land Cover Datasets for SDG Indicator Monitoring. 2019. Available online: https://ggim.un.org/documents/Paper_Land_cover_datasets_for_SDGs.pdf (accessed on 25 February 2025).
- Roy, P.S.; Ramachandran, R.M.; Paul, O.; Thakur, P.K.; Ravan, S.; Behera, M.D.; Sarangi, C.; Kanawade, V.P. Anthropogenic land use and land cover changes—A review on its environmental consequences and climate change. J. Indian Soc. Remote Sens. 2022, 50, 1615–1640. [Google Scholar] [CrossRef]
- Szantoi, Z.; Geller, G.N.; Tsendbazar, N.E.; See, L.; Griffiths, P.; Fritz, S.; Gong, P.; Herold, M.; Mora, B.; Obregón, A. Addressing the need for improved land cover map products for policy support. Environ. Sci. Policy 2020, 112, 28–35. [Google Scholar] [CrossRef]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.; Zhao, Y.; Liang, L.; Niu, Z.; Huang, X.; Fu, H.; Liu, S.; et al. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global land cover mapping at 30 m resolution: A POK-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef]
- Pekel, J.F.; Cottam, A.; Gorelick, N.; Belward, A.S. High-resolution mapping of global surface water and its long-term changes. Nature 2016, 540, 418–422. [Google Scholar] [CrossRef]
- Friedl, M.A.; Woodcock, C.E.; Olofsson, P.; Zhu, Z.; Loveland, T.; Stanimirova, R.; Arevalo, P.; Bullock, E.; Hu, K.T.; Zhang, Y.; et al. Medium Spatial Resolution Mapping of Global Land Cover and Land Cover Change Across Multiple Decades from Landsat. Front. Remote Sens. 2022, 3, 894571. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, L.; Zhao, T.; Gao, Y.; Chen, X.; Mi, J. GISD30: Global 30 m impervious-surface dynamic dataset from 1985 to 2020 using time-series Landsat imagery on the Google Earth Engine platform. Earth Syst. Sci. Data 2022, 14, 1831–1856. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, L.; Zhao, T.; Chen, X.; Lin, S.; Wang, J.; Mi, J.; Liu, W. GWL_FCS30: A global 30 m wetland map with a fine classification system using multi-sourced and time-series remote sensing imagery in 2020. Earth Syst. Sci. Data 2023, 15, 265–293. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, L.; Chen, X.; Gao, Y.; Xie, S.; Mi, J. GLC_FCS30: Global land-cover product with fine classification system at 30 m using time-series Landsat imagery. Earth Syst. Sci. Data 2021, 13, 2753–2776. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, T.; Xu, H.; Liu, W.; Wang, J.; Chen, X.; Liu, L. GLC_FCS30D: The first global 30 m land-cover dynamics monitoring product with a fine classification system for the period from 1985 to 2022 generated using dense-time-series Landsat imagery and the continuous change-detection method. Earth Syst. Sci. Data 2024, 16, 1353–1381. [Google Scholar] [CrossRef]
- E. D. Chaves, M.; C. A. Picoli, M.; D. Sanches, I. Recent Applications of Landsat 8/OLI and Sentinel-2/MSI for Land Use and Land Cover Mapping: A Systematic Review. Remote Sens. 2020, 12, 3062. [Google Scholar] [CrossRef]
- Phiri, D.; Simwanda, M.; Salekin, S.; Nyirenda, V.R.; Murayama, Y.; Ranagalage, M. Sentinel-2 Data for Land Cover/Use Mapping: A Review. Remote Sens. 2020, 12, 2291. [Google Scholar] [CrossRef]
- Karra, K.; Kontgis, C.; Statman-Weil, Z.; Mazzariello, J.C.; Mathis, M.; Brumby, S.P. Global land use/land cover with Sentinel 2 and deep learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4704–4707. [Google Scholar] [CrossRef]
- Zanaga, D.; Van De Kerchove, R.; De Keersmaecker, W.; Souverijns, N.; Brockmann, C.; Quast, R.; Wevers, J.; Grosu, A.; Paccini, A.; Vergnaud, S.; et al. ESA WorldCover 10 m 2020 v100 (Version v100) [Data Set]. 2021. [CrossRef]
- Zanaga, D.; Van De Kerchove, R.; Daems, D.; De Keersmaecker, W.; Brockmann, C.; Kirches, G.; Wevers, J.; Cartus, O.; Santoro, M.; Fritz, S.; et al. ESA WorldCover 10 m 2021 v200 (Version v200) [Data Set]. 2022. [CrossRef]
- Brown, C.F.; Brumby, S.P.; Guzder-Williams, B.; Birch, T.; Hyde, S.B.; Mazzariello, J.; Czerwinski, W.; Pasquarella, V.J.; Haertel, R.; Ilyushchenko, S.; et al. Dynamic World, Near real-time global 10 m land use land cover mapping. Sci. Data 2022, 9, 251. [Google Scholar] [CrossRef]
- Pandey, P.C.; Koutsias, N.; Petropoulos, G.P.; Srivastava, P.K.; Ben Dor, E. Land use/land cover in view of earth observation: Data sources, input dimensions, and classifiers—A review of the state of the art. Geocarto Int. 2021, 36, 957–988. [Google Scholar] [CrossRef]
- Moharram, M.A.; Sundaram, D.M. Land use and land cover classification with hyperspectral data: A comprehensive review of methods, challenges and future directions. Neurocomputing 2023, 536, 90–113. [Google Scholar] [CrossRef]
- Digra, M.; Dhir, R.; Sharma, N. Land use land cover classification of remote sensing images based on the deep learning approaches: A statistical analysis and review. Arab. J. Geosci. 2022, 15, 1003. [Google Scholar] [CrossRef]
- Zhao, S.; Tu, K.; Ye, S.; Tang, H.; Hu, Y.; Xie, C. Land Use and Land Cover Classification Meets Deep Learning: A Review. Sensors 2023, 23, 8966. [Google Scholar] [CrossRef]
- Yele, V.P.; Sedamkar, R.; Alegavi, S. Systematic Analysis of Effective Segmentation and Classification for Land Use Land Cover in Hyperspectral Image using Deep Learning Methods: A Review of the State of the Art: Reviewing Deep Learning Techniques for Land Use and Cover in Hyperspectral Images. In Proceedings of the 2024 20th CSI International Symposium on Artificial Intelligence and Signal Processing (AISP), Babol, Iran, 21–22 February 2024; pp. 1–8. [Google Scholar] [CrossRef]
- Zhang, C.; Li, X. Land Use and Land Cover Mapping in the Era of Big Data. Land 2022, 11, 1692. [Google Scholar] [CrossRef]
- Wang, J.; Bretz, M.; Dewan, M.A.A.; Delavar, M.A. Machine learning in modelling land-use and land cover-change (LULCC): Current status, challenges and prospects. Sci. Total Environ. 2022, 822, 153559. [Google Scholar] [CrossRef] [PubMed]
- Nedd, R.; Light, K.; Owens, M.; James, N.; Johnson, E.; Anandhi, A. A Synthesis of Land Use/Land Cover Studies: Definitions, Classification Systems, Meta-Studies, Challenges and Knowledge Gaps on a Global Landscape. Land 2021, 10, 994. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Y.; Cao, X.; Wang, Y.; Zhang, W.; Cheng, X. A review of regional and Global scale Land Use/Land Cover (LULC) mapping products generated from satellite remote sensing. ISPRS J. Photogramm. Remote Sens. 2023, 206, 311–334. [Google Scholar] [CrossRef]
- Shimada, M.; Itoh, T.; Motooka, T.; Watanabe, M.; Shiraishi, T.; Thapa, R.; Lucas, R. New global forest/non-forest maps from ALOS PALSAR data (2007–2010). Remote Sens. Environ. 2014, 155, 13–31. [Google Scholar] [CrossRef]
- Gong, P.; Liu, H.; Zhang, M.; Li, C.; Wang, J.; Huang, H.; Clinton, N.; Ji, L.; Li, W.; Bai, Y.; et al. Stable classification with limited sample: Transferring a 30-m resolution sample set collected in 2015 to mapping 10-m resolution global land cover in 2017. Sci. Bull. 2019, 64, 370–373. [Google Scholar] [CrossRef]
- Yu, L.; Wang, J.; Li, X.; Li, C.; Zhao, Y.; Gong, P. A multi-resolution global land cover dataset through multisource data aggregation. Sci. China Earth Sci. 2014, 57, 2317–2329. [Google Scholar] [CrossRef]
- Joint Research Centre (European Commission); Bourgoin, C.; Ameztoy, I.; Verhegghen, A.; Desclée, B.; Carboni, S.; Bastin, J.F.; Beuchle, R.; Brink, A.; Defourny, P.; et al. Mapping Global Forest Cover of the Year 2020 to Support the EU Regulation on Deforestation-Free Supply Chains; Publications Office of the European Union: Luxembourg, 2024. [Google Scholar]
- Pesaresi, M.; Schiavina, M.; Politis, P.; Freire, S.; Krasnodębska, K.; Uhl, J.H.; Carioli, A.; Corbane, C.; Dijkstra, L.; Florio, P.; et al. Advances on the Global Human Settlement Layer by joint assessment of Earth Observation and population survey data. Int. J. Digit. Earth 2024, 17, 2390454. [Google Scholar] [CrossRef]
- Corbane, C.; Pesaresi, M.; Politis, P.; Syrris, V.; Florczyk, A.J.; Soille, P.; Maffenini, L.; Burger, A.; Vasilev, V.; Rodriguez, D.; et al. Big earth data analytics on Sentinel-1 and Landsat imagery in support to global human settlements mapping. Big Earth Data 2017, 1, 118–144. [Google Scholar] [CrossRef]
- Esch, T.; Marconcini, M.; Felbier, A.; Roth, A.; Heldens, W.; Huber, M.; Schwinger, M.; Taubenböck, H.; Müller, A.; Dech, S. Urban Footprint Processor—Fully Automated Processing Chain Generating Settlement Masks from Global Data of the TanDEM-X Mission. IEEE Geosci. Remote Sens. Lett. 2013, 10, 1617–1621. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, L.; Zhao, T.; Wang, J.; Liu, W.; Chen, X. Global annual wetland dataset at 30 m with a fine classification system from 2000 to 2022. Sci. Data 2024, 11, 310. [Google Scholar] [CrossRef] [PubMed]
- Souza, C.M.; Z. Shimbo, J.; Rosa, M.R.; Parente, L.L.; A. Alencar, A.; Rudorff, B.F.T.; Hasenack, H.; Matsumoto, M.; G. Ferreira, L.; Souza-Filho, P.W.M.; et al. Reconstructing Three Decades of Land Use and Land Cover Changes in Brazilian Biomes with Landsat Archive and Earth Engine. Remote Sens. 2020, 12, 2735. [Google Scholar] [CrossRef]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef] [PubMed]
- Marconcini, M.; Metz-Marconcini, A.; Esch, T.; Gorelick, N. Understanding current trends in global urbanisation-the world settlement footprint suite. GI_Forum 2021, 9, 33–38. [Google Scholar] [CrossRef]
- Marconcini, M.; Metz-Marconcini, A.; Üreyen, S.; Palacios-Lopez, D.; Hanke, W.; Bachofer, F.; Zeidler, J.; Esch, T.; Gorelick, N.; Kakarla, A.; et al. Outlining where humans live, the World Settlement Footprint 2015. Sci. Data 2020, 7, 242. [Google Scholar] [CrossRef] [PubMed]
- ESA. ESA-Sentinel-2. Available online: https://www.esa.int/Applications/Observing_the_Earth/Copernicus/Sentinel-2 (accessed on 9 March 2025).
- ESA. ESA-Sentinel-1. Available online: https://www.esa.int/Applications/Observing_the_Earth/Copernicus/Sentinel-1 (accessed on 9 March 2025).
- Masek, J.G.; Vermote, E.F.; Saleous, N.E.; Wolfe, R.; Hall, F.G.; Huemmrich, K.F.; Gao, F.; Kutler, J.; Lim, T.K. A Landsat surface reflectance dataset for North America, 1990–2000. IEEE Geosci. Remote Sens. Lett. 2006, 3, 68–72. [Google Scholar] [CrossRef]
- Vermote, E.; Justice, C.; Claverie, M.; Franch, B. Preliminary analysis of the performance of the Landsat 8/OLI land surface reflectance product. Remote Sens. Environ. 2016, 185, 46–56. [Google Scholar] [CrossRef]
- Adler-Golden, S.M.; Matthew, M.W.; Bernstein, L.S.; Levine, R.Y.; Berk, A.; Richtsmeier, S.C.; Acharya, P.K.; Anderson, G.P.; Felde, J.W.; Gardner, J.; et al. Atmospheric correction for shortwave spectral imagery based on MODTRAN4. In Proceedings of the Imaging Spectrometry V, Denver, CO, USA, 27 October 1999; Volume 3753, pp. 61–69. [Google Scholar]
- Roy, D.; Kovalskyy, V.; Zhang, H.; Vermote, E.; Yan, L.; Kumar, S.; Egorov, A. Characterization of Landsat-7 to Landsat-8 reflective wavelength and normalized difference vegetation index continuity. Remote Sens. Environ. 2016, 185, 57–70. [Google Scholar] [CrossRef]
- Zanaga, D.; Van De Kerchove, R.; Daems, D.; De Keersmaecker, W.; Brockmann, C.; Kirches, G.; Wevers, J.; Cartus, O.; Santoro, M.; Fritz, S.; et al. WorldCover Product User Manual 2021 v200. 2022. Available online: https://pure.iiasa.ac.at/id/eprint/18983/1/WorldCover_PUM_V2.0.pdf (accessed on 9 March 2025).
- Vali, A.; Comai, S.; Matteucci, M. Deep learning for land use and land cover classification based on hyperspectral and multispectral earth observation data: A review. Remote Sens. 2020, 12, 2495. [Google Scholar] [CrossRef]
- Yao, J.; Zhang, B.; Li, C.; Hong, D.; Chanussot, J. Extended Vision Transformer (ExViT) for Land Use and Land Cover Classification: A Multimodal Deep Learning Framework. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Khan, M.; Hanan, A.; Kenzhebay, M.; Gazzea, M.; Arghandeh, R. Transformer-based land use and land cover classification with explainability using satellite imagery. Sci. Rep. 2024, 14, 16744. [Google Scholar] [CrossRef] [PubMed]
- Roy, S.K.; Sukul, A.; Jamali, A.; Haut, J.M.; Ghamisi, P. Cross Hyperspectral and LiDAR Attention Transformer: An Extended Self-Attention for Land Use and Land Cover Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–15. [Google Scholar] [CrossRef]
- Anderson, J.R.; Hardy, E.E.; Roach, J.T.; Witmer, R.E. A Land Use and Land Cover Classification System for Use with Remote Sensor Data; U.S. Geological Survey: Reston, VA, USA, 1976; Report 964. [CrossRef]
- Commission, E.; Centre, J.R.; Jones, A.; Fernández-Ugalde, O.; Scarpa, S. LUCAS 2015 Topsoil Survey—Presentation of Dataset and Results; Publications Office: Luxembourg, 2020. [Google Scholar] [CrossRef]
- Penman, J.; Gytarsky, M.; Hiraishi, T.; Krug, T.; Kruger, D.; Pipatti, R.; Buendia, L.; Miwa, K.; Ngara, T.; Tanabe, K.; et al. Good Practice Guidance for Land Use, Land-Use Change and Forestry; Institute for Global Environmental Strategies: Hayama, Japan, 2003. [Google Scholar]
- Brown, J.F.; Tollerud, H.J.; Barber, C.P.; Zhou, Q.; Dwyer, J.L.; Vogelmann, J.E.; Loveland, T.R.; Woodcock, C.E.; Stehman, S.V.; Zhu, Z.; et al. Lessons learned implementing an operational continuous United States national land change monitoring capability: The Land Change Monitoring, Assessment, and Projection (LCMAP) approach. Remote Sens. Environ. 2020, 238, 111356. [Google Scholar] [CrossRef]
- Bratic, G.; Yordanov, V.; Brovelli, M.A. High-resolution land cover classification: Cost-effective approach for extraction of reliable training data from existing land cover datasets. Int. J. Digit. Earth 2023, 16, 3618–3636. [Google Scholar] [CrossRef]
- Duarte, D.; Fonte, C.; Costa, H.; Caetano, M. Thematic Comparison between ESA WorldCover 2020 Land Cover Product and a National Land Use Land Cover Map. Land 2023, 12, 490. [Google Scholar] [CrossRef]
- Li, Z.; White, J.C.; Wulder, M.A.; Hermosilla, T.; Davidson, A.M.; Comber, A.J. Land cover harmonization using Latent Dirichlet Allocation. Int. J. Geogr. Inf. Sci. 2021, 35, 348–374. [Google Scholar] [CrossRef]
- Venter, Z.S.; Barton, D.N.; Chakraborty, T.; Simensen, T.; Singh, G. Global 10 m Land Use Land Cover Datasets: A Comparison of Dynamic World, World Cover and Esri Land Cover. Remote Sens. 2022, 14, 4101. [Google Scholar] [CrossRef]
- Mushtaq, F.; Henry, M.; O’Brien, C.D.; Di Gregorio, A.; Jalal, R.; Latham, J.; Muchoney, D.; Hill, C.T.; Mosca, N.; Tefera, M.G.; et al. An International Library for Land Cover Legends: The Land Cover Legend Registry. Land 2022, 11, 1083. [Google Scholar] [CrossRef]
- Strahler, A.H.; Boschetti, L.; Foody, G.M.; Friedl, M.A.; Hansen, M.C.; Herold, M.; Mayaux, P.; Morisette, J.T.; Stehman, S.V.; Woodcock, C.E. Global land cover validation: Recommendations for evaluation and accuracy assessment of global land cover maps. Eur. Communities, Luxemb. 2006, 51, 1–60. [Google Scholar]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Stehman, S.V. Sampling designs for accuracy assessment of land cover. Int. J. Remote Sens. 2009, 30, 5243–5272. [Google Scholar] [CrossRef]
- Stehman, S.V.; Foody, G.M. Key issues in rigorous accuracy assessment of land cover products. Remote Sens. Environ. 2019, 231, 111199. [Google Scholar] [CrossRef]
- Hay, A.M. Sampling Designs to Test Land-Use Map Accuracy. 1979. Available online: https://www.asprs.org/wp-content/uploads/pers/1979journal/apr/1979_apr_529-533.pdf (accessed on 9 March 2025).
- Congalton, R.; Gu, J.; Yadav, K.; Thenkabail, P.; Ozdogan, M. Global Land Cover Mapping: A Review and Uncertainty Analysis. Remote Sens. 2014, 6, 12070–12093. [Google Scholar] [CrossRef]
- Castillo-Santiago, M.Á.; Mondragón-Vázquez, E.; Domínguez-Vera, R. Sample Data for Thematic Accuracy Assessment in QGIS. In Land Use Cover Datasets and Validation Tools: Validation Practices with QGIS; García-Álvarez, D., Camacho Olmedo, M.T., Paegelow, M., Mas, J.F., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2022; pp. 85–96. [Google Scholar] [CrossRef]
- Cochran, W.G. Sampling Techniques, 3rd ed.; John Wiley & Sons: New York, NY, USA, 1977; Available online: https://archive.org/details/cochran-1977-sampling-techniques (accessed on 9 March 2025).
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Fritz, S.; See, L.; Perger, C.; McCallum, I.; Schill, C.; Schepaschenko, D.; Duerauer, M.; Karner, M.; Dresel, C.; Laso-Bayas, J.C.; et al. A global dataset of crowdsourced land cover and land use reference data. Sci. Data 2017, 4, 170075. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.K.; Roy, D.P. Using the 500m MODIS land cover product to derive a consistent continental scale 30m Landsat land cover classification. Remote Sens. Environ. 2017, 197, 15–34. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Yang, L.; Driscol, J.; Sarigai, S.; Wu, Q.; Chen, H.; Lippitt, C.D. Google Earth Engine and Artificial Intelligence (AI): A Comprehensive Review. Remote Sens. 2022, 14, 3253. [Google Scholar] [CrossRef]
- Jin, H.; Mountrakis, G. Fusion of optical, radar and waveform LiDAR observations for land cover classification. ISPRS J. Photogramm. Remote Sens. 2022, 187, 171–190. [Google Scholar] [CrossRef]
- Basheer, S.; Wang, X.; Nawaz, R.A.; Pang, T.; Adekanmbi, T.; Mahmood, M.Q. A comparative analysis of PlanetScope 4-band and 8-band imageries for land use land cover classification. Geomatica 2024, 76, 100023. [Google Scholar] [CrossRef]
- Li, C.; Gong, P.; Wang, J.; Zhu, Z.; Biging, G.S.; Yuan, C.; Hu, T.; Zhang, H.; Wang, Q.; Li, X.; et al. The first all-season sample set for mapping global land cover with Landsat-8 data. Sci. Bull. 2017, 62, 508–515. [Google Scholar] [CrossRef] [PubMed]

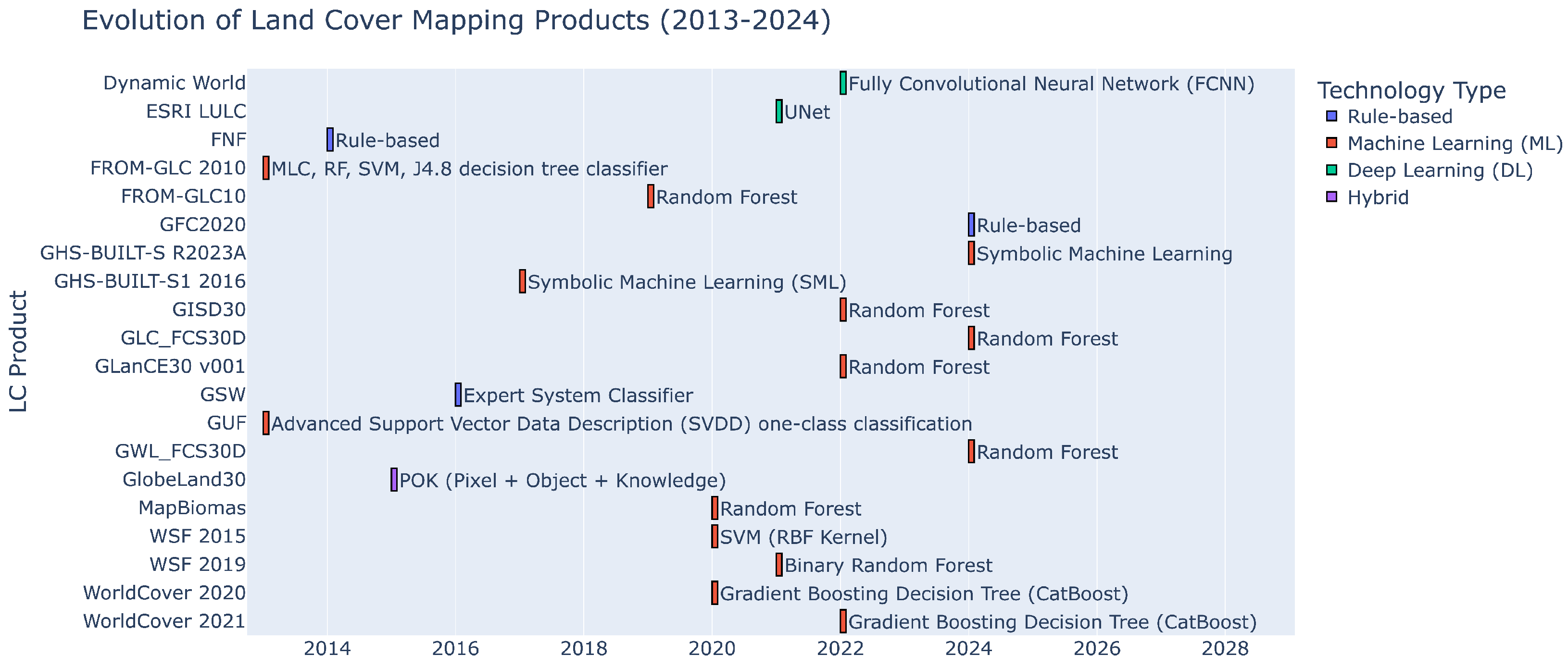
| Dataset Name | Provider | Spatial Resolution (m) | Temporal Resolution | LC Focus |
|---|---|---|---|---|
| Dynamic World (DW) [20] | World Resources Institute Google | 10 | Near real-time from 2015-06-27 to present | General (9 classes) |
| ESRI LULC [17] | Impact Observatory, Microsoft, and Esri | 10 | Annual (2017–2023) | General (10 classes) |
| Forest/Non-Forest (FNF) [30] | JAXA-EORC | 25 | Annual (2007–2010) | Forest (3 classes) |
| FROM-GLC10 [31] | Tsinghua University | 10 | 2017 | General (10 classes) |
| FROM-GLC30 [7,31,32] | Tsinghua University | 30 | 2010, 2015, 2017 | General (10 classes) |
| Global Forest Cover (GFC) [33] | JRC | 10 | 2020 | Forest (1 class) |
| GHS-BUILT-S R2023A [34] | JRC | 10 | 2018 | Built-Up surface proportion (continuous 0–100%) |
| GHS-BUILT-S1 2016 [35] | JRC | 20 | 2016 | Built-Up (2 classes) |
| Global 30m impervious-surface dynamic dataset (GISD30) [11] | CAS | 30 | Interval-encoded (per pixel): before 1985, 1985–1990, 1990–1995, 1995–2000, 2000–2005, 2005–2010, 2010–2015, 2015–2020 | Built-Up (1 class) |
| GlobeLand30 (GL30) [8] | NGCC | 30 | 2000, 2010, 2019 | General (10 classes) |
| Global Land Cover Estimation (GLanCE) v001 [10] | BU/EE/ NASA ES/ USGS EROS | 30 | Annual (2001–2019) | General (7 classes) |
| Global 30 m land-cover (dynamics monitoring) product with a fine classification system (GLC_FCS30/D) [13,14] | CAS | 30 | Every 5 years (1985, 1990, 1995) and Annual (2000–2022) | General (35 classes) |
| Global Surface Water (GSW) [9]) | JRC | 30 | Annual (1984–2021) | Water (3 classes) |
| Global Urban Footprint (GUF) [36] | DLR | 12 | 2011 | Built-Up (2 classes) |
| Global annual wetland dataset at 30m with a fine classficiation system (GWL_FCS30/D) [12,37] | CAS | 30 | Annual (2000–2022) | Wetland (8 classes) |
| MapBiomas [38] | SEEG and Climate Observatory | 30 | Annual (1985–2023) | General (6 classes) |
| Tree canopy cover [39] | Hansen/ UMD/ Google/ USGS/ NASA | 30 | 2000 | Tree canopy cover proportion (continuous 0–100%) |
| World Settlement Footprint (WSF) [40,41] | DLR | 10 | 2015, 2019 | Built-Up (2 classes) |
| WorldCover [18,19] | ESA | 10 | 2020, 2021 | General (11 classes) |
| Data Type | Data Name | Used In |
|---|---|---|
| Optical Multispectral Imagery | Landsat | GLC_FCS30D [14], GWL_FCS30D [37], GISD30 [11], GLanCE v001 [10], GL30 [8], FROM-GLC30 [7,31], WSF [41], MapBiomas [38], GSW [9], Tree canopy cover [39] |
| Sentinel-2 | DW [20], ESRI LULC [17], WorldCover [18,19], FROM-GLC10 [31], GHS-BUILT-S R2023A [34], WSF [40] | |
| HJ-1 | GL30 [8] | |
| Synthetic Aperture Radar (SAR) | Sentinel-1 | WorldCover [18,19], WSF [40,41], GHS-BUILT-S1 2016 [35] |
| TanDEM-X (TDM) | GUF [36] | |
| ALOS PALSAR | FNF [30] |
| Classification Method | Used In |
|---|---|
| Random Forest | FROM-GLC30 and FROM-GLC10 [7,31], MapBiomas [38], WSF [40], GISD30 [11], GLanCE v100 [10], GWL_FCS30D [37], GLC_FCS30D [14] |
| Support Vector Machine | FROM-GLC30 [7], GUF [36], WSF [41] |
| Gradient Boosting Decision Tree (CatBoost) | WorldCover [18,19] |
| Symbolic Machine Learning (SML) | GHS-BUILT-S1 2016 [35], GHS-BUILT-S R2023A [34] |
| Decision Tree | FROM-GLC30 [7] |
| Dataset | Study | Validation Sampling Approach | Number of Validation Samples |
|---|---|---|---|
| DW | Brown et al. [20] | Stratified random sampling by regions and biomes | 409 tiles; 1636 annotations |
| ESRI LULC | Karra et al. [17] | Random stratified sampling of 5 km × 5 km image chips | 409 gold standard tiles |
| FNF | Shimada et al. [30] | Targeted selection from multi-resolution segmentation | 4114 points (1456 and 2548 for forest and nonforest, respectively) |
| FROM-GLC10 | Gong et al. [31] | Multi-seasonal sampling; non-systematic training, systematic validation not specified | 140,000 validation units |
| FROM-GLC30 | Gong et al. [7] | Non-systematic training; systematic unaligned testing | 38,664 test samples |
| Yu et al. [32] | Manual sampling from Landsat imagery with MODIS time series | 38,664 testing samples | |
| GFC | JRC [33] | Random stratified sampling | 49,942 samples |
| GHS-BUILT-S R2023A | Pesaresi et al. [34] | Stratified sampling | 95,210 data blocks of 25 × 25 km size |
| GHS-BUILT-S1 2016 | Corbane et al. [35] | Not applicable | 23,134 tiles of 150 × 150 km (using GUF as reference) |
| GISD30 | Zhang et al. [11] | Automated derivation from impervious surface products with refinement rules | 23,322 validation samples |
| GL30 | Chen et al. [8] | Two-rank sampling (map sheet and feature sampling) | 159,874 pixel samples |
| GLanCE | Friedl et al. [10] | Simple and stratified random sampling | North America: 1630 reference points |
| GLC_FCS30/D | Zhang et al. [13] | Automated extraction using CCI_LC and refinement rules; stratified random sampling for validation | 44,043 validation samples |
| Zhang et al. [14] | Automated training using change detection masks; stratified random sampling with independent datasets for validation | 84,526 global validation samples; additional regional datasets (LCMAP, LUCAS) | |
| GSW | Pekel et al. [9] | Stratified random sampling using 1° × 1° grid cells | 40,124 control points |
| GUF | Esch et al. [36] | Randomly distributed sample points; photointerpretation of VHR by GIS experts | 2000 for New Delhi; 1500 per each other city mask |
| GWL_FCS30/D | Zhang et al. [12] | Stratified random sampling for wetland mapping with multi-sourced training | 25,709 validation samples |
| Zhang et al. [37] | Refinement of a global sample pool with multi-temporal consistency checks; stratified random sampling for validation | Preliminary sample size: 24,000; Final: 22,719 validation points | |
| MapBiomas | Souza et al. [38] | Stratified random sampling; photointerpretation 3 + 1 (senior) | 75,000 samples |
| Tree canopy cover | Hansen et al. [39] | Probability-based stratified sampling; Photointerpretation using Landsat, MODIS and VHR | 1500 sampling blocks |
| WorldCover | Zanaga et al. [18] | Stratified one-stage cluster approach | 21,624 PSU (primary sampling unit), 1,935,650 SSUs (secondary sampling units) |
| Zanaga et al. [19] | Stratified one-stage cluster approach | 21,624 PSU (primary sampling unit), 2,162,366 SSUs (secondary sampling units) | |
| WSF | Marconcini et al. [41] | Stratified random sampling per 1° unit | 500 settlement and 500 non-settlement per unit; 900,000 cells total |
| Marconcini et al. [40] | Iterative sampling with crowdsourcing validation | 180,000 reference cells (WSF-Evolution); 700,000 for WSF2019 |
| Data Source | Resolution | Advantages | Used In |
|---|---|---|---|
| Landsat | 30 m (Multispectral), 15 m (Panchromatic) | Long-term data record, time-series analysis, surface reflectance, identification of land cover dynamics | FROM-GLC30 [32], GHS-BUILT-S1 2016 [35], GL30 [8], GLC_FCS30/D [14,59], GLanCE [10], MapBiomas [38], Tree canopy cover [39] |
| Google Earth VHR Imagery | 0.15 m to 1.5 m (Varies depending on source) | Very high spatial resolution, validation of other satellite data, reference data source | FNF [30], FROM-GLC30 [32], GLC_FCS30/D [14,59], GLanCE [10], GUF [36], MapBiomas [38], Tree canopy cover [39], WSF [41] |
| Sentinel-2 | 10 m, 20 m, 60 m (Varies by band) | High spatial, spectral, and temporal resolution, surface reflectance, land cover classification | ESRI LULC [17], GHS-BUILT-S1 2016 [35], GLC_FCS30/D [14] |
| MODIS | 250 m to 1 km (Varies by product) | Time series vegetation indices (e.g., NDVI, EVI), extraction of seasonal vegetation information | FROM-GLC30 [7], FROM-GLC30 [32], GL30 [8], GLC_FCS30/D [59], GLanCE [10], MapBiomas [38], Tree canopy cover [39] |
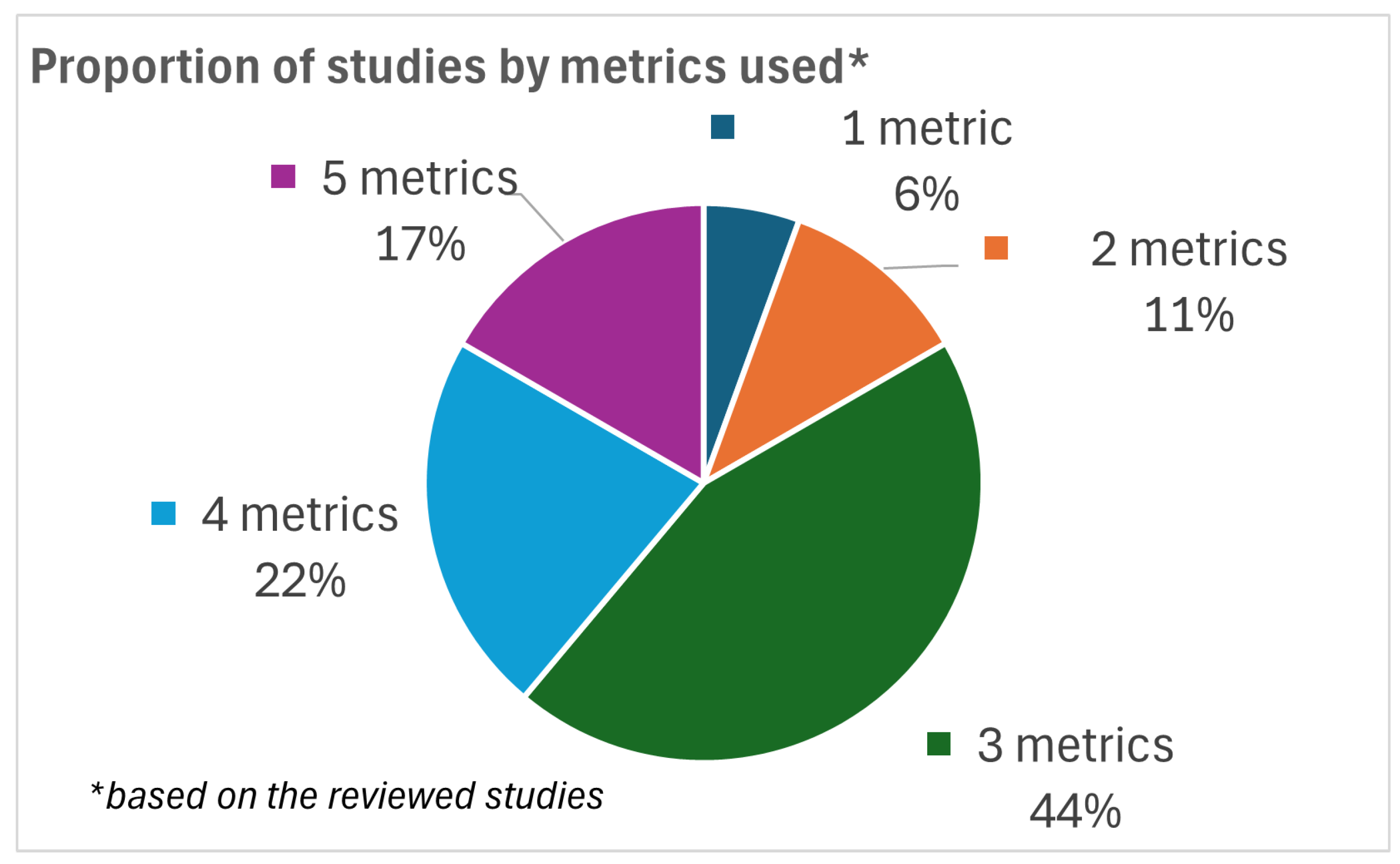
| Dataset | OA | UA | PA | Kappa | CE | OE | F1 | AA | Var(K) | Total per Product |
|---|---|---|---|---|---|---|---|---|---|---|
| DW [20] | X | X | X | 3 | ||||||
| ESRI LULC [17] | X | X | X | 3 | ||||||
| FNF [30] | X | 1 | ||||||||
| FROM-GLC10 [31] | X | X | X | 3 | ||||||
| FROM-GLC30 [7,32] | X | X | X | X | X | 5 | ||||
| GFC [33] | X | X | X | X | X | 5 | ||||
| GHS-BUILT-S R2023A [34] | not applicable | 3 | ||||||||
| GHS-BUILT-S1 2016 [35] | X | X | X | 3 | ||||||
| GISD30 [11] | X | X | X | X | 4 | |||||
| GL30 [8] | X | X | X | X | 4 | |||||
| GLanCE [10] | X | X | X | 3 | ||||||
| GLC_FCS30/D [13,14] | X | X | X | X | X | 5 | ||||
| GSW [9] | X | X | 2 | |||||||
| GUF [36] | X | X | X | X | 4 | |||||
| GWL_FCS30/D [12,37] | X | X | X | X | 4 | |||||
| MapBiomas [38] | X | X | X | 3 | ||||||
| Tree canopy cover [39] | X | X | X | 3 | ||||||
| WorldCover [18,19] | X | X | X | 3 | ||||||
| WSF [41] | X | X | X | X | 4 | |||||
| Total per metric | 15 | 15 | 15 | 8 | 3 | 3 | 1 | 1 | 1 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Q.; Yordanov, V.; Bruzzone, L.; Brovelli, M.A. High-Resolution Global Land Cover Maps and Their Assessment Strategies. ISPRS Int. J. Geo-Inf. 2025, 14, 235. https://doi.org/10.3390/ijgi14060235
Xu Q, Yordanov V, Bruzzone L, Brovelli MA. High-Resolution Global Land Cover Maps and Their Assessment Strategies. ISPRS International Journal of Geo-Information. 2025; 14(6):235. https://doi.org/10.3390/ijgi14060235
Chicago/Turabian StyleXu, Qiongjie, Vasil Yordanov, Lorenzo Bruzzone, and Maria Antonia Brovelli. 2025. "High-Resolution Global Land Cover Maps and Their Assessment Strategies" ISPRS International Journal of Geo-Information 14, no. 6: 235. https://doi.org/10.3390/ijgi14060235
APA StyleXu, Q., Yordanov, V., Bruzzone, L., & Brovelli, M. A. (2025). High-Resolution Global Land Cover Maps and Their Assessment Strategies. ISPRS International Journal of Geo-Information, 14(6), 235. https://doi.org/10.3390/ijgi14060235