

A Multi-Semantic Feature Fusion Method for Complex Address Matching of Chinese Addresses
 ,
,
Abstract
1. Introduction
- (1)
- This study considers both the textual semantic features and hierarchical semantic features of addresses. Textual semantic features are used to capture the keywords and contextual information of address expressions, while hierarchical semantic features are used to capture the hierarchical nesting information between address elements.
- (2)
- This study proposes an address matching method based on an ESIM. This method reformulates the address matching task as a classification problem, thereby eliminating the need for predefined manual rules.
- (3)
- The proposed address matching method is designed to enhance key evaluation metrics such as precision, recall, and F1 score, which are crucial for applications like geocoding.
2. Related Work
2.1. Address Semantic Feature Extraction
- Statistical methods: These methods primarily rely on word frequency statistics within text to extract semantic features of words or phrases. The main methods include Term Frequency–Inverse Document Frequency (TF-IDF), n-gram, and Bag of Words [19,20,21]. These methods are simple and efficient, capable of handling large-scale text data. However, they overlook word order and contextual information, limiting their ability to capture complex semantic relationships and contextual features.
- Word embedding methods: These methods map words to a continuous vector space, where semantically similar words have closer spatial distances, thereby capturing semantic relationships. For example, Word2Vec trains word embeddings using the Contiguous Bag of Words or Skip-gram model on the input text corpus [22,23]. GloVe captures semantic relationships between words by constructing word co-occurrence matrices and generates word embeddings with enhanced semantic features [24]. The FastText model treats each word as a word sequence of n-gram sub-words, constructing a word embedding vector by learning sub-word vectors [25]. While word embedding methods effectively capture semantic relationships, they require large amounts of training data, and static models cannot handle polysemy.
- Contextual embedding methods: These methods learn word representations based on varying contextual environments to capture different semantic expressions of a word, overcoming the limitations of word embedding methods in handling polysemy. For example, ELMo learns word embeddings in different contexts using a Bi-directional Long Short-Term Memory network (Bi-LSTM) [26]. BERT generates dynamic and context-sensitive word embedding vectors through two pre-training tasks: the Masked Language Model (MLM) and Next Sentence Prediction (NSP) [27]. GPT, as an autoregressive model, generates context-dependent word embedding vectors through a pre-trained, unidirectional Transformer architecture [28]. Additionally, models like RoBERTa [29], XLNet [30], and T5 [31] further optimize Transformer-based methods, enhancing the ability to process long-distance dependencies and improve generalization capabilities.
2.2. Matching Algorithm Construction
- String similarity-based matching algorithms: These algorithms quantify the similarity between two addresses using string-similarity metrics and determine matches based on a predefined similarity threshold. The main string similarity metrics include Levenshtein distance, cosine similarity, Jaccard similarity coefficient, and n-gram similarity [33,34,35]. These methods are simple to implement and efficient, making them suitable for large-scale data processing. However, their limited understanding of address structure and semantics leads to a decrease in matching performance.
- Rule-based matching algorithms: These algorithms focus on specific address datasets, implementing address resolution and matching by defining rules that conform to structural characteristics and semantic relationships of address expression. For example, dictionary-tree matching uses tree data structures to effectively store and retrieve information, thereby accurately extracting and matching addresses [36,37]. Regular-expression matching methods define address expressions and matching rules using regular expressions that combine Chinese characters, English letters, numbers, and specific terms [38]. Although rule-based matching algorithms achieve high matching accuracy and efficiency for address data with specific structures, rule definition is complex, maintenance costs are high, and flexibility is limited.
- Machine learning and deep learning-based matching algorithms: These algorithms require large, labeled datasets for training to capture structural and semantic features of address data. Machine learning-based algorithms typically rely on feature engineering to train classifiers or regression models for matching. For example, Random Forests (RF), Support Vector Machines (SVM), and Conditional Random Fields (CRF) have been used for address matching [39,40]. Deep learning-based algorithms automatically extract address features through multi-layer neural networks, enabling efficient matching. For example, Convolutional Neural Networks (CNNs) capture local features of addresses [18,41]. Long Short-Term Memory (LSTM) captures contextual relationships in address sequences [42,43]. BERT captures deep semantics and global dependencies of addresses [44,45,46]. Graph structures capture hierarchical relationships of addresses [47,48]. Additionally, there are also address matching methods based on multi-task joint learning and region proposal [14,49]. These models can deal with the complexity, diversity, and irregularity of addresses and improve the accuracy and efficiency of address matching. However, they require large, labeled datasets and substantial computational resources, and the processes of model training and optimization are relatively complex.
3. Method
3.1. Address Element Word Embedding Vector Generation
3.2. Address Multi-Semantic Feature Extraction
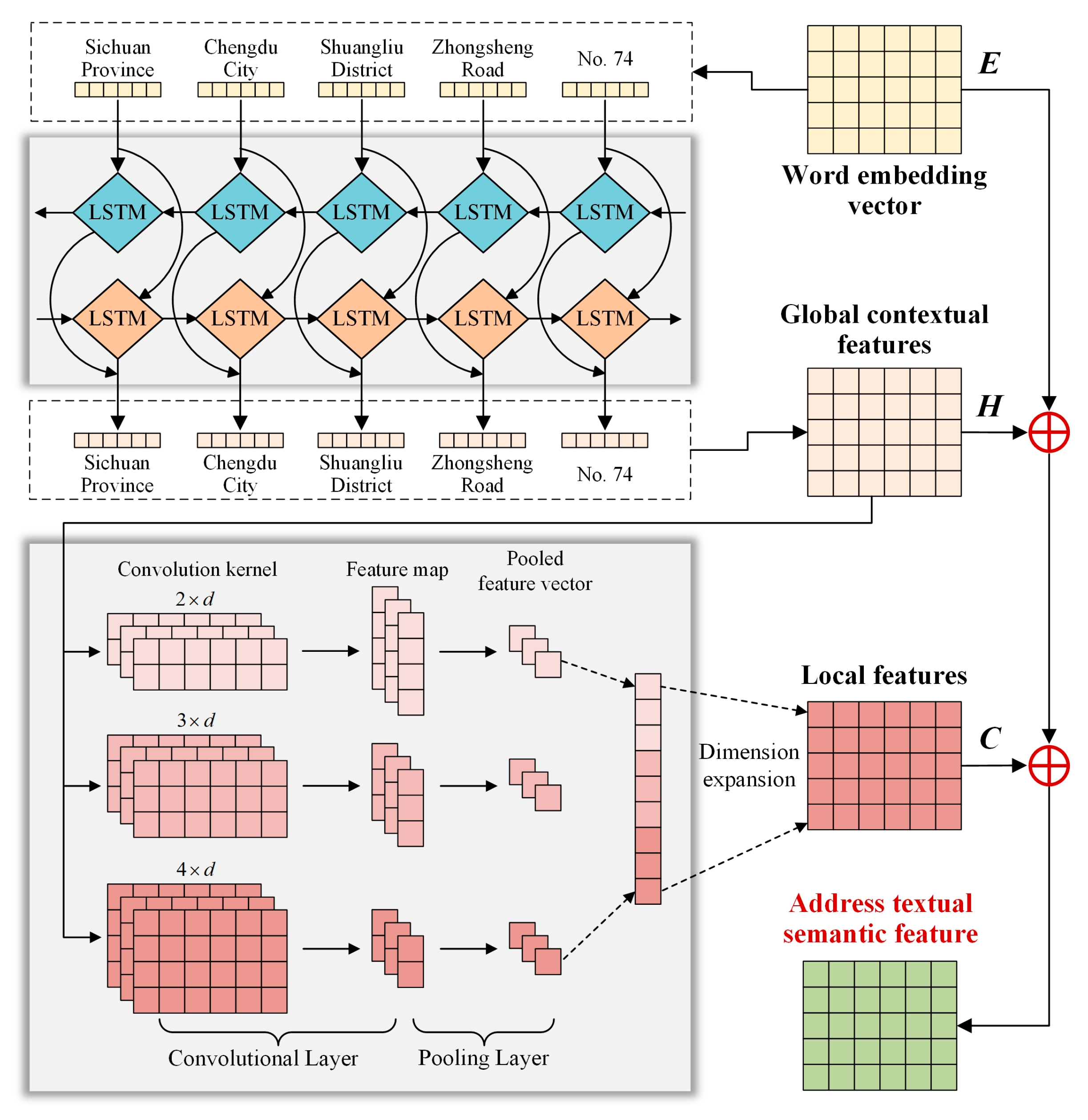
3.2.1. Address Textual Semantic Feature Extraction Based on Text-RCNN
- Global contextual feature extraction
- Local feature extraction
- Generation of textual semantic features
3.2.2. Address Hierarchical Semantic Feature Extraction Based on GAT
- Graph structure construction and initialization
- Graph node feature update and hierarchical semantic feature extraction
3.3. Address Matching Based on ESIM
- Input encoding layer: For the two addresses A and B to be matched, first, concatenate the textual and hierarchical semantic features of the two addresses to form multi-semantic feature vectors SA and SB. Then, Bi-LSTM is used to encode these feature vectors to generate the context-dependent representation HA and HB, capturing the contextual relationships of address elements. The specific calculation formula is as follows:
- Local inference layer: This layer calculates the local inference relationships between the two addresses using an attention mechanism. First, based on the context-dependent representations HA and HB, the attention matrix e is computed between each address element in addresses A and B. Then, the attention matrix is used to perform soft alignment on addresses A and B, generating the aligned representations and . Finally, the context-dependent representations and aligned representations perform difference and dot product operations, followed by concatenation, to generate the enhanced representations MA and MB. The specific calculation formulas are as follows:
- Inference combination layer: This layer integrates local inference information to generate a global inference representation. First, a Bi-LSTM encodes the enhanced representations MA and MB, capturing sentence-level inference relationships. Then, the encoded results are processed through pooling operations (average pooling and max pooling) to obtain fixed-length vectors. Finally, all pooling results are concatenated to generate the final matching vector vmatch. The specific calculation formulas are as follows:
- Result prediction layer: The concatenated matching vector vmatch is input into a multi-layer perceptron (MLP) to predict the address matching result, and softmax activation is applied to obtain the matching probability. The specific calculation formula is as follows:where denotes the matching result, denotes the activation function, and W and b denote the trainable weight matrices and bias vectors.
4. Experiments
4.1. Experimental Environment and Dataset
4.2. Evaluation Metrics
4.3. Hyperparameter Settings
4.4. Experiment Results and Analysis
4.4.1. Comparison and Ablation Experiments
4.4.2. Transfer Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hashem, I.A.T.; Chang, V.; Anuar, N.B.; Adewole, K.; Yaqoob, I.; Gani, A.; Ahmed, E.; Chiroma, H. The role of big data in smart city. Int. J. Inf. Manag. 2016, 36, 748–758. [Google Scholar] [CrossRef]
- Lau, B.P.L.; Marakkalage, S.H.; Zhou, Y.; Hassan, N.U.; Yuen, C.; Zhang, M.; Tan, U.X. A survey of data fusion in smart city applications. Inf. Fusion 2019, 52, 357–374. [Google Scholar] [CrossRef]
- Kandt, J.; Batty, M. Smart cities, big data and urban policy: Towards urban analytics for the long run. Cities 2021, 109, 102992. [Google Scholar] [CrossRef]
- Ying, S.; Van Oosterom, P.; Fan, H. New techniques and methods for modelling, visualization, and analysis of a 3D city. J. Geovis. Spat. Anal. 2023, 7, 26. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, T.; Li, W. Automatic search of geospatial features for disaster and emergency management. Int. J. Appl. Earth Obs. 2010, 12, 409–418. [Google Scholar] [CrossRef]
- Esmaelian, M.; Tavana, M.; Santos Arteaga, F.J.; Mohammadi, S. A multicriteria spatial decision support system for solving emergency service station location problems. Int. J. Geogr. Inf. Sci. 2015, 29, 1187–1213. [Google Scholar] [CrossRef]
- Li, W.; Batty, M.; Goodchild, M.F. Real-time GIS for smart cities. Int. J. Geogr. Inf. Sci. 2020, 34, 311–324. [Google Scholar] [CrossRef]
- Liu, J.; Wang, Y.; Hu, Y.; Luo, A.; Che, X.; Li, P.; Cao, Y. A review of web-based ubiquitous geospatial information discovery and integration technology. Acta Geod. Cartogr. Sin. 2022, 51, 1618–1628. [Google Scholar]
- Goldberg, D.W.; Wilson, J.P.; Knoblock, C.A. From text to geographic coordinates: The current state of geocoding. URISA J. 2007, 19, 33–46. [Google Scholar]
- Melo, F.; Martins, B. Automated geocoding of textual documents: A survey of current approaches. Trans. GIS 2017, 21, 3–38. [Google Scholar] [CrossRef]
- Harada, Y.; Shimada, T. Examining the impact of the precision of address geocoding on estimated density of crime locations. Comput. Geosci. 2006, 32, 1096–1107. [Google Scholar] [CrossRef]
- Li, P.; Luo, A.; Liu, J.; Wang, Y.; Zhu, J.; Deng, Y.; Zhang, J. Bidirectional gated recurrent unit neural network for Chinese address element segmentation. ISPRS Int. J. Geo-Inf. 2020, 9, 635. [Google Scholar] [CrossRef]
- Xu, L.; Du, Z.; Mao, R.; Zhang, F.; Liu, R. GSAM: A deep neural network model for extracting computational representations of Chinese addresses fused with geospatial feature. Comput. Environ. Urban Syst. 2020, 81, 101473. [Google Scholar] [CrossRef]
- Li, F.; Lu, Y.; Mao, X.; Duan, J.; Liu, X. Multi-task deep learning model based on hierarchical relations of address elements for semantic address matching. Neural Comput. Applic. 2022, 34, 8919–8931. [Google Scholar] [CrossRef]
- Peng, M.; Li, Z.; Liu, H.; Meng, C.; Li, Y. Weighted geocoding method based on Chinese word segmentation and its application to spatial positioning of COVID-19 epidemic prevention and control. Geomat. Inf. Sci. Wuhan Univ. 2020, 45, 808–815. [Google Scholar]
- Lin, Y.; Kang, M.; Wu, Y.; Du, Q.; Liu, T. A deep learning architecture for semantic address matching. Int. J. Geogr. Inf. Sci. 2020, 34, 559–576. [Google Scholar] [CrossRef]
- Li, P.; Wang, Y.; Liu, J.; Luo, A.; Xu, S.; Zhang, Z. Enhanced semantic representation model for multisource point of interest attribute alignment. Inf. Fusion 2023, 98, 101852. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; She, X.; Mao, J.; Chen, G. Deep contrast learning approach for address semantic matching. Appl. Sci. 2021, 11, 7608. [Google Scholar] [CrossRef]
- Zhao, R.; Mao, K. Fuzzy bag-of-words model for document representation. IEEE Trans. Fuzzy Syst. 2017, 26, 794–804. [Google Scholar] [CrossRef]
- Kaur, G.; Sharma, A. A deep learning-based model using hybrid feature extraction approach for consumer sentiment analysis. J. Big Data 2023, 10, 5. [Google Scholar] [CrossRef]
- Semary, N.; Ahmed, W.; Amin, K.; Pławiak, P.; Hammad, M. Enhancing machine learning-based sentiment analysis through feature extraction techniques. PLoS ONE 2024, 19, e0294968. [Google Scholar] [CrossRef] [PubMed]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://api.semanticscholar.org/CorpusID:49313245 (accessed on 8 July 2024).
- Liu, Y. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yang, Z. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv 2019, arXiv:1906.08237. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Xu, L.; Mao, R.; Zhang, C.; Wang, Y.; Zheng, X.; Xue, X.; Xia, F. Deep Transfer Learning Model for Semantic Address Matching. Appl. Sci. 2022, 12, 10110. [Google Scholar] [CrossRef]
- Xia, P.; Zhang, L.; Li, F. Learning similarity with cosine similarity ensemble. Inf. Sci. 2015, 307, 39–52. [Google Scholar] [CrossRef]
- Zhang, S.; Hu, Y.; Bian, G. Research on string similarity algorithm based on Levenshtein Distance. In Proceedings of the 2017 IEEE 2nd Advanced Information Technology, Electronic and Automation Control Conference, Chongqing, China, 25–26 March 2017; pp. 2247–2251. [Google Scholar]
- Costa, E.; Mali, V.S. Tetun Language Plagiarism Detection with Text Mining Approach Using N-gram and Jaccard Similarity Coefficient. Timor-Leste J. Eng. Sci. 2021, 2, 11–20. [Google Scholar]
- Jiang, Y.; Ding, X.; Ren, Z. A suffix tree based handwritten Chinese address recognition system. In Proceedings of the Ninth International Conference on Document Analysis and Recognition, Curitiba, Parana, Brazil, 23–26 September 2007; pp. 292–296. [Google Scholar]
- Kang, M.; Du, Q.; Wang, M. A new method of Chinese address extraction based on address tree model. Acta Geod. Cartogr. Sin. 2015, 44, 99–107. [Google Scholar]
- Ling, G.; Xu, A.; Wang, C.; Wu, J. REBDT: A regular expression boundary-based decision tree model for Chinese logistics address segmentation. Appl. Intell. 2023, 53, 6856–6872. [Google Scholar] [CrossRef]
- Comber, S.; Arribas-Bel, D. Machine learning innovations in address matching: A practical comparison of word2vec and CRFs. Trans. GIS 2019, 23, 334–348. [Google Scholar] [CrossRef]
- Lee, K.; Claridades, A.R.C.; Lee, J. Improving a street-based geocoding algorithm using machine learning techniques. Appl. Sci. 2020, 10, 5628. [Google Scholar] [CrossRef]
- Li, P.; Liu, J.; Luo, A.; Wang, Y.; Zhu, J.; Xu, S. Deep learning method for Chinese multisource point of interest matching. Comput. Environ. Urban Syst. 2022, 96, 101821. [Google Scholar] [CrossRef]
- Shan, S.; Li, Z.; Qiang, Y.; Liu, A.; Xu, J.; Chen, Z. DeepAM: Deep semantic address representation for address matching. In Proceedings of the Web and Big Data: Third International Joint Conference, Chengdu, China, 1–3 August 2019; pp. 45–60. [Google Scholar]
- Shan, S.; Li, Z.; Yang, Q.; Liu, A.; Zhao, L.; Liu, G.; Chen, Z. Geographical address representation learning for address matching. World Wide Web 2020, 23, 2005–2022. [Google Scholar] [CrossRef]
- Zhang, H.; Ren, F.; Li, H.; Yang, R.; Zhang, S.; Du, Q. Recognition method of new address elements in Chinese address matching based on deep learning. ISPRS Int. J. Geo-Inf. 2020, 9, 745. [Google Scholar] [CrossRef]
- Gupta, V.; Gupta, M.; Garg, J.; Garg, N. Improvement in semantic address matching using natural language processing. In Proceedings of the 2021 2nd International Conference for Emerging Technology, Belagavi, India, 21–23 May 2021; pp. 1–5. [Google Scholar]
- Duarte, A.V.; Oliveira, A.L. Improving Address Matching using Siamese Transformer Networks. In Proceedings of the EPIA Conference on Artificial Intelligence, Faial Island, Portugal, 5–8 September 2023; pp. 413–425. [Google Scholar]
- Liu, C.; He, X.; Su, S.; Kang, M. A graph-based method for Chinese address matching. Trans. GIS 2023, 27, 859–876. [Google Scholar] [CrossRef]
- Zhang, Z.; Balsebre, P.; Luo, S.; Hai, Z.; Huang, J. StructAM: Enhancing Address Matching through Semantic Understanding of Structure-aware Information. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Torino, Italia, 20–25 May 2024; pp. 15350–15361. [Google Scholar]
- Quan, Y.; Chang, Y.; Liang, L.; Qiao, Y.; Wang, C. A Novel Address-Matching Framework Based on Region Proposal. ISPRS Int. J. Geo-Inf. 2024, 13, 138. [Google Scholar] [CrossRef]
- ISO 19160–1:2015; Addressing Part 1: Conceptual Model. International Organization for Standardization: Geneva, Switzerland, 2015.
- Chen, Q.; Zhu, X.D.; Ling, Z.; Wei, S.; Jiang, H.; Inkpen, D. Enhanced LSTM for Natural Language Inference. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1657–1668. [Google Scholar]
- Levenshtein, V. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- Jaccard, P. Nouvelles recherches sur la distribution florale. Bull. Soc. Vaud. Sci. Nat. 1908, 44, 223–270. [Google Scholar]
- Tata, S.; Patel, J.M. Estimating the selectivity of tf-idf based cosine similarity predicates. ACM Sigmod Rec. 2007, 36, 7–12. [Google Scholar] [CrossRef]
- Lilleberg, J.; Zhu, Y.; Zhang, Y. Support vector machines and word2vec for text classification with semantic features. In Proceedings of the 2015 IEEE 14th International Conference on Cognitive Informatics & Cognitive Computing, Beijing, China, 6–8 July 2015; pp. 136–140. [Google Scholar]
- Hitesh, M.S.R.; Vaibhav, V.; Kalki, Y.A.; Kamtam, S.H.; Kumari, S. Real-time sentiment analysis of 2019 election tweets using word2vec and random forest model. In Proceedings of the 2019 2nd International Conference on Intelligent Communication and Computational Techniques, Jaipur, India, 28–29 September 2019; pp. 146–151. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Address 1 | Address 2 | |
|---|---|---|
| 1 | 长寿路成都市科华中路小学 (Changshou Road, Chengdu Kehua Zhonglu Primary School) | 长寿路/成都市科华中路小学 (Changshou Road, Chengdu Kehua Zhonglu Primary School) |
| 2 | 四川省成都市武侯区长寿路2号科华中路小学 (No. 2, Changshou Road, Wuhou District, Chengdu City, Sichuan Province, Kehua Zhonglu Primary School) | 四川省/成都市/武侯区/长寿路/2号/科华中路小学 (No. 2, Changshou Road, Wuhou District, Chengdu City, Sichuan Province, Kehua Zhonglu Primary School) |
| 3 | 金牛区一环路北二段32号附4号 (No. 32 with No. 4, North Section 2 of First Ring Road, Jinniu District) | 金牛区/一环路北二段/32号附4号 (No. 32 with No. 4, North Section 2 of First Ring Road, Jinniu District) |
| 4 | 府通路与春桂路交叉口西100米 (Futong Road, Chungui Road, intersection, 100 m west) | 府通路/与/春桂路/交叉口/西100米 (Futong Road, Chungui Road, intersection, 100 m west) |
| Address 1 | Address 2 | Label | |
|---|---|---|---|
| 1 | 长寿路成都市科华中路小学 (Changshou Road, Chengdu Kehua Zhonglu Primary School) | 四川省成都市武侯区长寿路2号科华中路小学 (No. 2, Changshou Road, Wuhou District, Chengdu City, Sichuan Province, Kehua Zhonglu Primary School) | 1 |
| 2 | 长寿路成都市科华中路小学 (Changshou Road, Chengdu Kehua Zhonglu Primary School) | 四川省成都市双流区月星路 (Yuexing Road, Shuangliu District, Chengdu City, Sichuan Province) | 0 |
| 3 | 青白江区怡湖东路131号附7号 (No. 131 with No. 7, Yihu East Road, Qingbaijiang District) | 怡湖东路137正东方向20米大弯派出所旁 (No. 137, Yihu East Road, 20 m east, next to Dawan Police Station) | 1 |
| 4 | 青白江区怡湖东路131号附7号 No. 131 with No. 7, Yihu East Road, Qingbaijiang District | 四川省成都市邛崃市大东街187号 (No. 187, Dadong Street, Qionglai City, Chengdu City, Sichuan Province) | 0 |
| Actual Match (Positive) | Actual Mismatch (Negative) | |
|---|---|---|
| Predicted Match (Positive) | True Positive (TP) | False Positive (FP) |
| Predicted Mismatch (Negative) | False Negative (FN) | True Negative (TN) |
| Hyperparameter | Description | Value |
|---|---|---|
| Hidden Size | Number of neurons in the hidden layer (LSTM) | 64 |
| Attention Heads | Number of attention heads in the multi-head attention mechanism | 4 |
| Dropout Rate | Proportion of neurons randomly dropped during training | 0.1 |
| Batch Size | Number of samples processed in each update of model parameters | 2048 |
| Size of Filters | Size of the convolutional filters | [2, 3, 4] |
| Learning Rate | Step size used for updating model parameters during training | 0.001 |
| Embedding Dimension | Dimension of word embedding vectors | 200 |
| Epochs | The total number of passes of the training dataset | 30 |
| Number of Filters | Number of convolutional filters | 100 |
| Sequence Length | Length of the input Chinese address sequences | 10 |
| Experiment Type | Method | P | R | F1 | |
|---|---|---|---|---|---|
| 1 | Comparison experiments | Levenshtein Distance | 100.00% | 18.35% | 31.01% |
| 2 | Jaccard Similarity | 100.00% | 15.02% | 26.12% | |
| 3 | Cosine Similarity (IF-IDF) | 100.00% | 14.24% | 24.93% | |
| 4 | RF (Word2vec) | 89.24% | 85.81% | 87.49% | |
| 5 | SVM (Word2vec) | 89.52% | 86.58% | 88.02% | |
| 6 | Word2Vec + ESIM | 93.57% | 94.40% | 93.98% | |
| 7 | ABLC | 94.89% | 94.63% | 94.76% | |
| 8 | AMGCN + node2vec | 94.55% | 95.24% | 94.89% | |
| 9 | StructAM | 95.97% | 94.86% | 95.41% | |
| 10 | Ablation experiments | Text-RCNN + ESIM | 94.80% | 94.11% | 94.45% |
| 11 | GAT + ESIM | 93.61% | 93.83% | 93.72% | |
| 12 | Text-RCNN + GAT + ESIM | 95.85% | 95.83% | 95.84% |
| Method | Beijing | Shanghai | Xi’an | Guangzhou | Wuhan | |
|---|---|---|---|---|---|---|
| 1 | RF (Word2vec) | 49.40% | 31.97% | 39.93% | 49.52% | 54.96% |
| 2 | SVM (Word2vec) | 60.47% | 63.74% | 63.56% | 63.16% | 63.94% |
| 3 | Word2Vec + ESIM | 61.63% | 65.85% | 55.46% | 58.42% | 68.35% |
| 4 | ABLC | 76.73% | 71.75% | 82.48% | 70.40% | 73.12% |
| 5 | AMGCN + node2vec | 70.56% | 69.57% | 70.89% | 68.63% | 70.05% |
| 6 | StructAM | 78.78% | 79.79% | 76.96% | 74.78% | 77.25% |
| 7 | Text-RCNN + GAT + ESIM | 81.34% | 77.52% | 84.36% | 75.22% | 84.05% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, P.; Zhu, Q.; Liu, J.; Liu, T.; Du, P.; Liu, S.; Zhang, Y. A Multi-Semantic Feature Fusion Method for Complex Address Matching of Chinese Addresses. ISPRS Int. J. Geo-Inf. 2025, 14, 227. https://doi.org/10.3390/ijgi14060227
Li P, Zhu Q, Liu J, Liu T, Du P, Liu S, Zhang Y. A Multi-Semantic Feature Fusion Method for Complex Address Matching of Chinese Addresses. ISPRS International Journal of Geo-Information. 2025; 14(6):227. https://doi.org/10.3390/ijgi14060227
Chicago/Turabian StyleLi, Pengpeng, Qing Zhu, Jiping Liu, Tao Liu, Ping Du, Shuangtong Liu, and Yuting Zhang. 2025. "A Multi-Semantic Feature Fusion Method for Complex Address Matching of Chinese Addresses" ISPRS International Journal of Geo-Information 14, no. 6: 227. https://doi.org/10.3390/ijgi14060227
APA StyleLi, P., Zhu, Q., Liu, J., Liu, T., Du, P., Liu, S., & Zhang, Y. (2025). A Multi-Semantic Feature Fusion Method for Complex Address Matching of Chinese Addresses. ISPRS International Journal of Geo-Information, 14(6), 227. https://doi.org/10.3390/ijgi14060227