

Clustering Method for Edge and Inner Buildings Based on DGI Model and Graph Traversal

Abstract
1. Introduction
- Which building characteristics determine whether it can be designated as an edge building?
- Do alternative ways of identifying edge buildings affect the clustering results?
2. Related Work
3. Materials and Methods
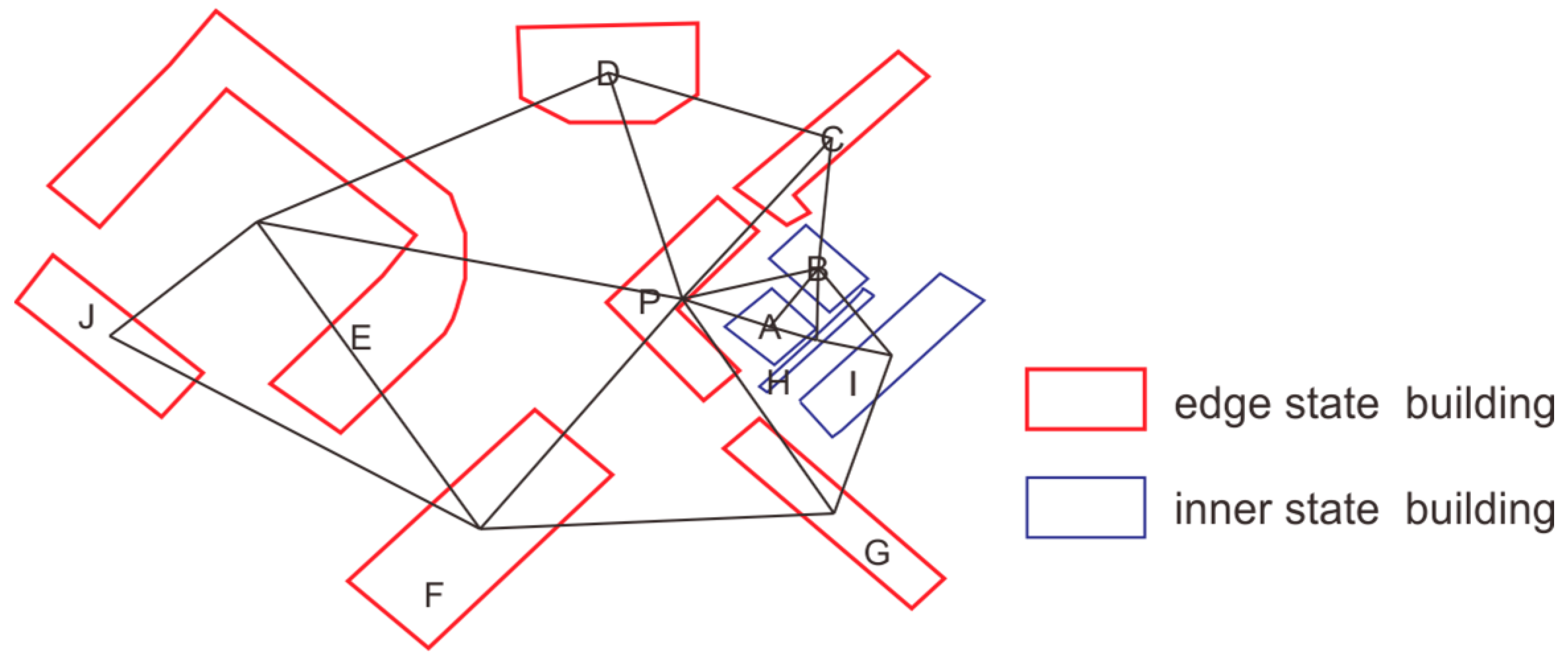
3.1. Descriptive Methods for Edge-Building Features
3.1.1. Expand the K-NN Neighborhoods in Graph
3.1.2. The LOF Characteristic of the Building [29]
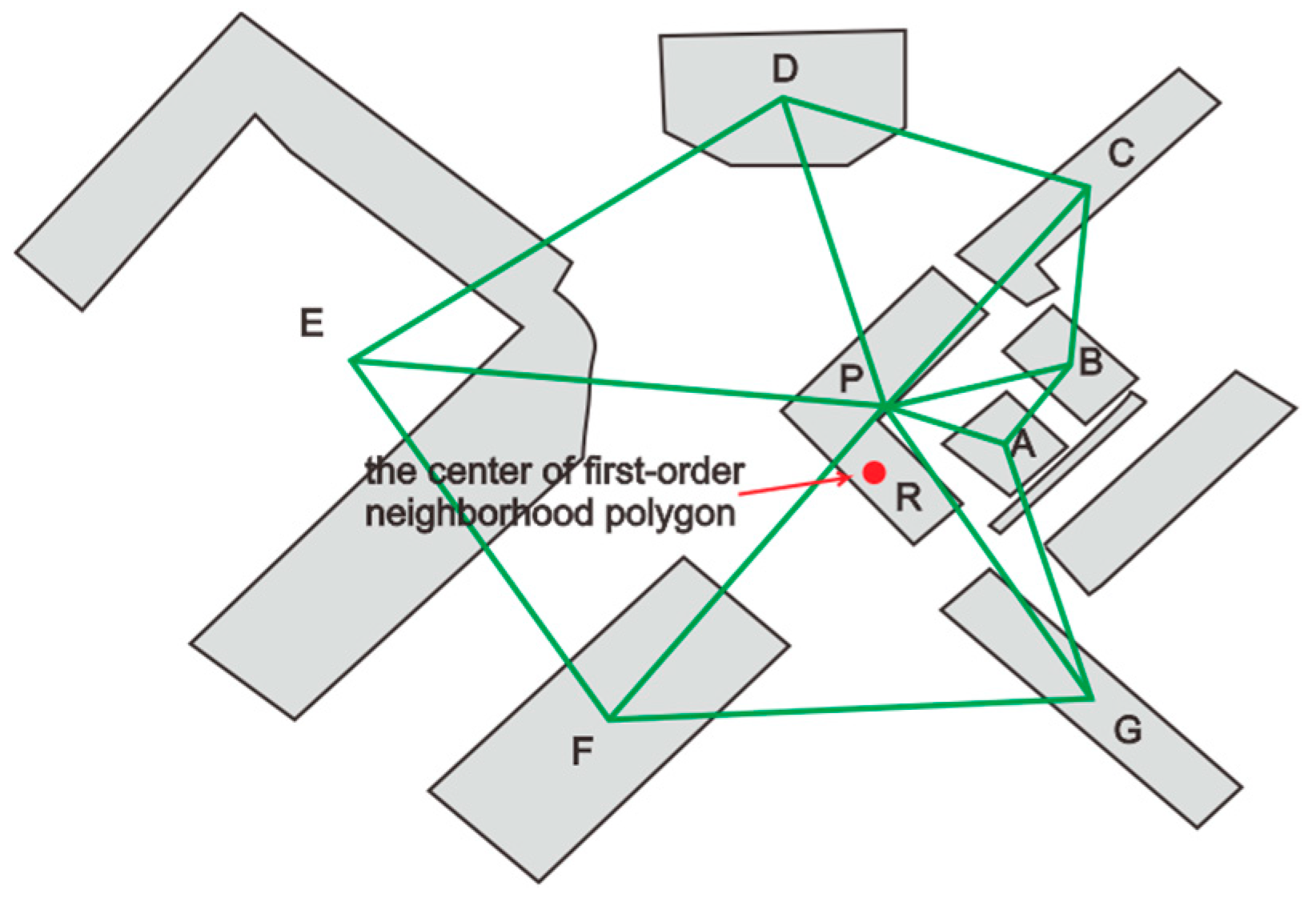
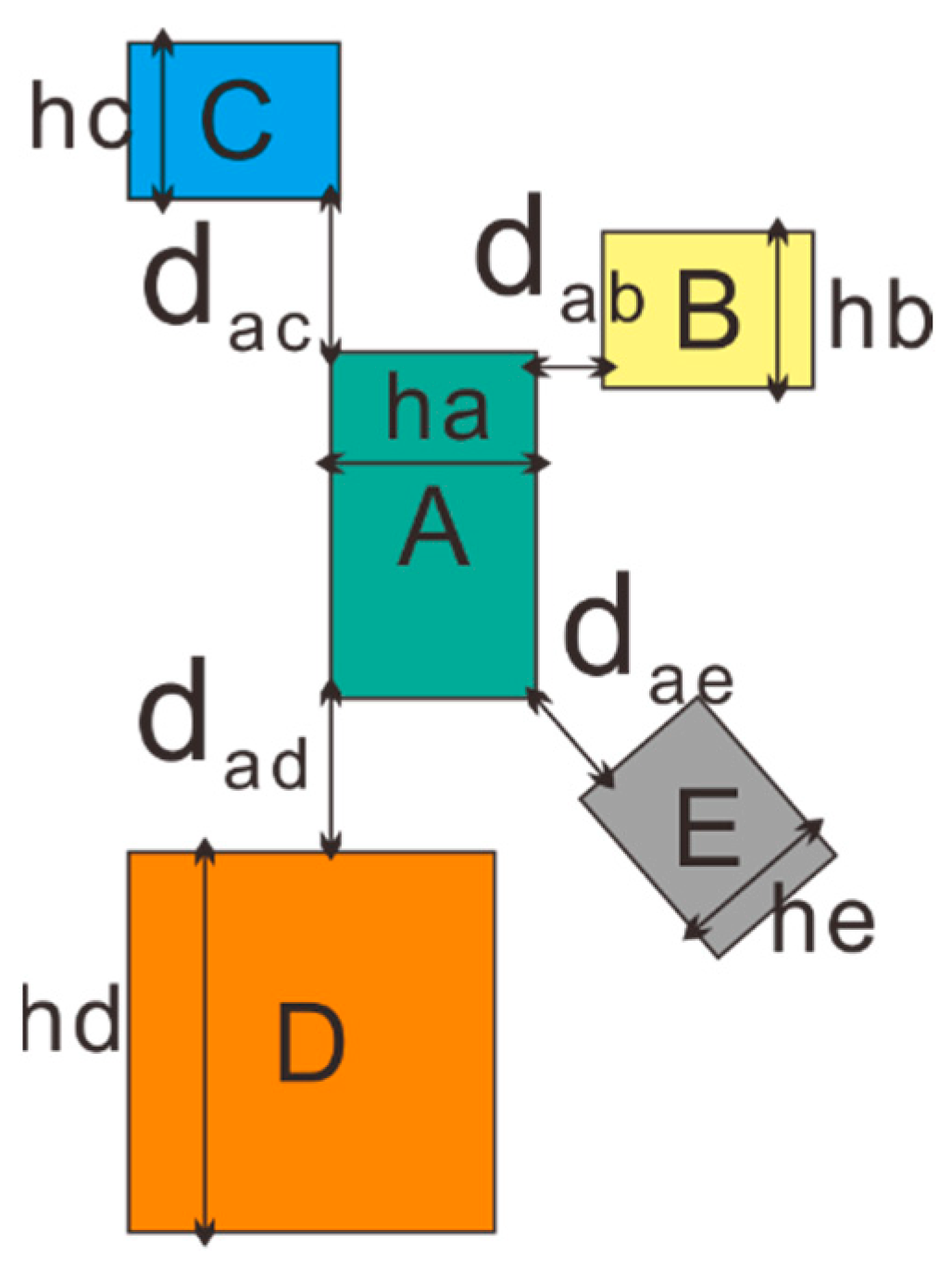
3.1.3. The Center_devia and First_neighbor_avg_r Features of Buildings
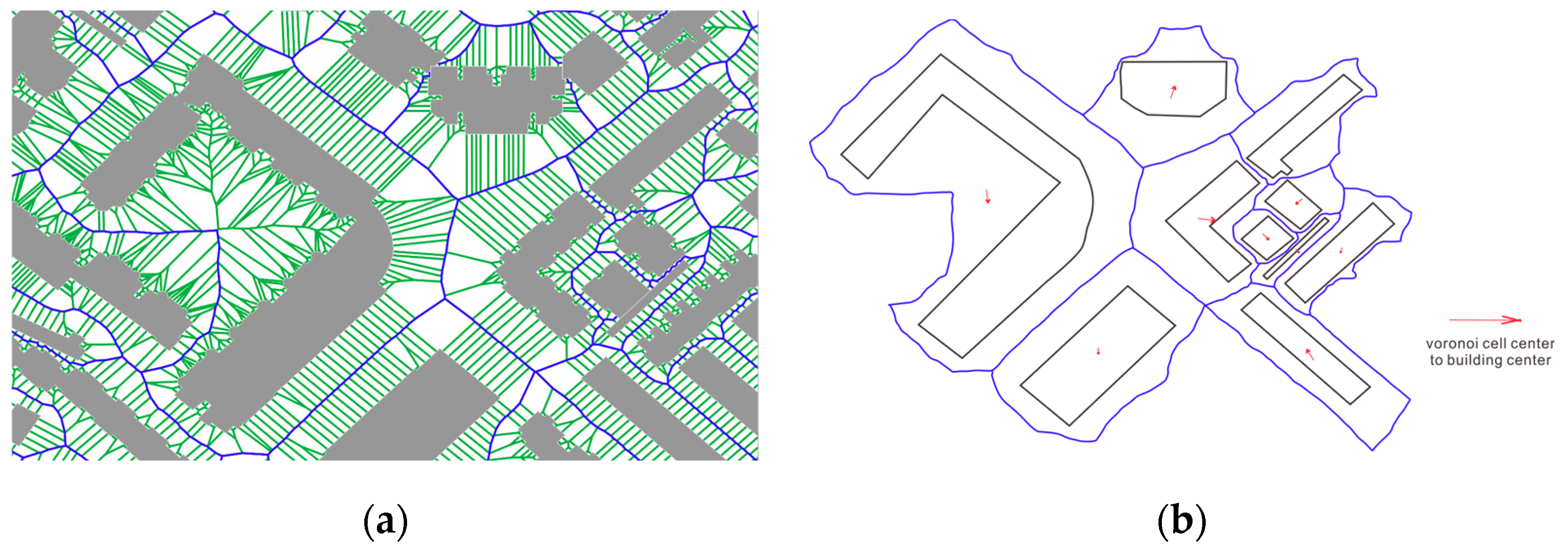
3.1.4. The Density and Vo_to_b_length Characters of the Building
3.1.5. The m_dis of Two Adjacent Buildings and the m_dis_cv Character of a Building
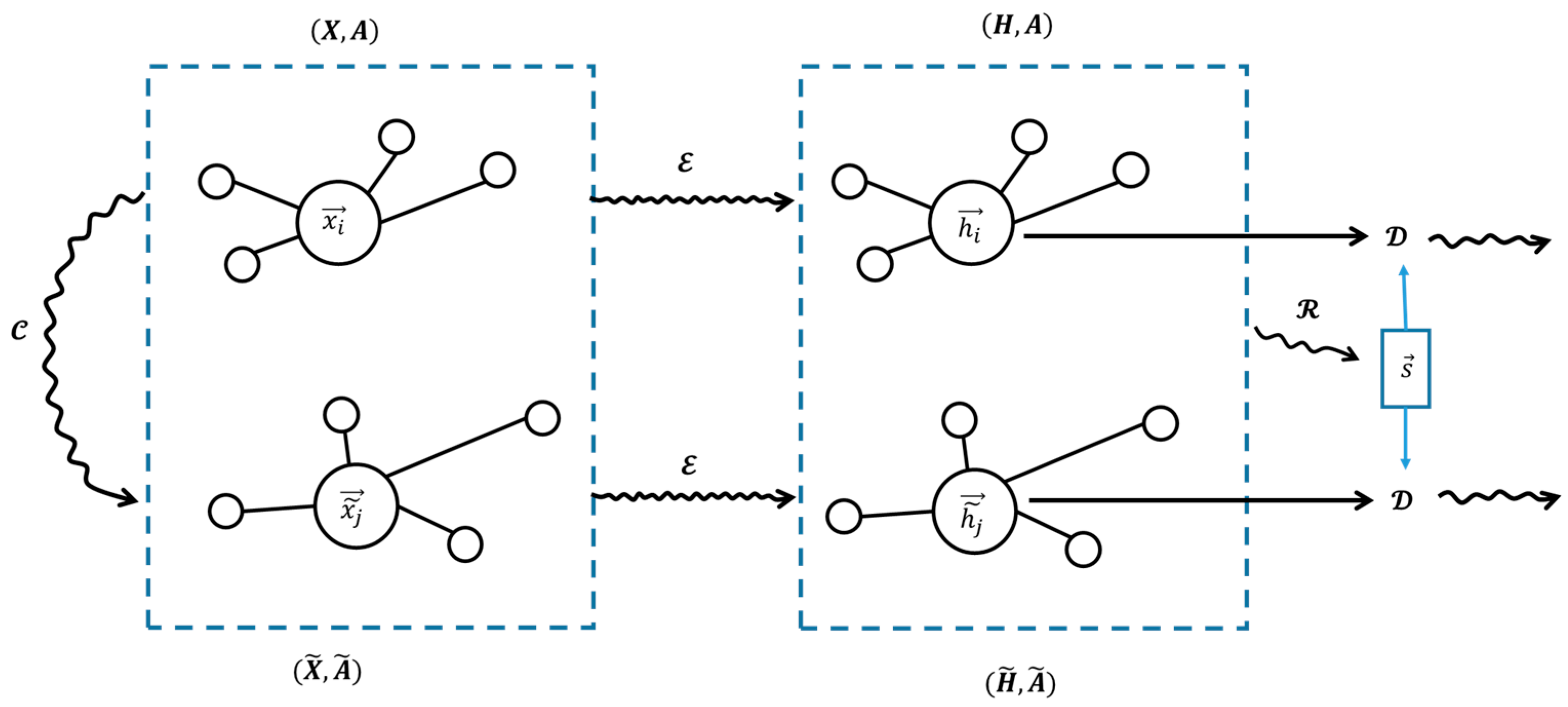
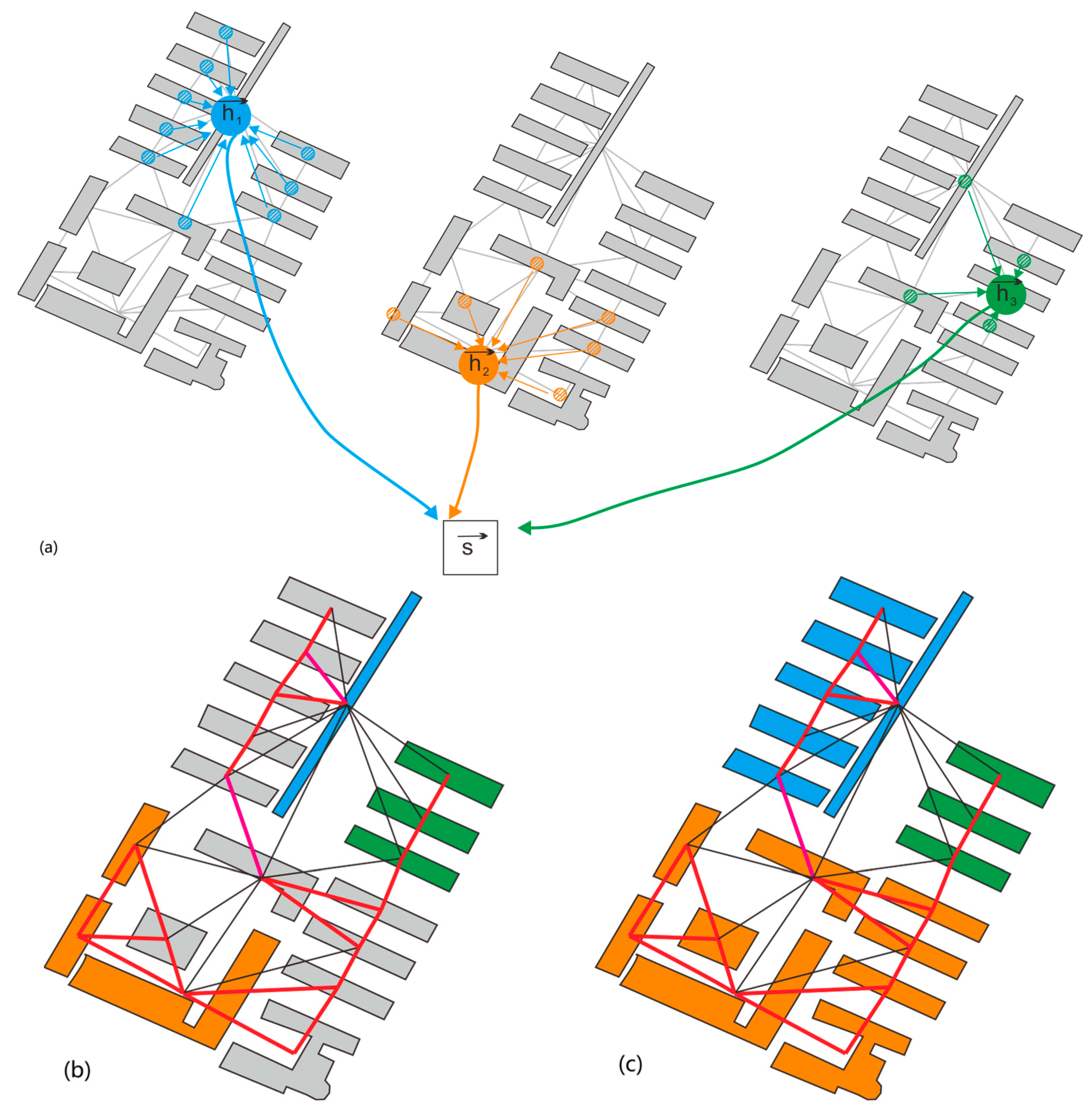
3.2. The Node Representation Learning Based on the DGI Model
3.3. The Traverse of Building Graph
| Algorithm 1. BFS with KY Value Limit for Graph Traversal | |
| 1 | Input: Graph G = (V,E) (where V represents buildings and E represents edges), starting building Vstart, threshold m_dis_limit |
| 2 | Initialize: visited: an empty set to store visited buildings. queue: a list initialized with Vstart. traversal_result: an empty list to store the result of BFS traversal. |
| 3 | While queue is not empty do: |
| 4 | Pop the first building Vcurrent from queue. |
| 5 | If Vcurrent ∉ visited and G[Vcurrent].we = 1: |
| 6 | Add Vcurrent to visited. |
| 7 | Append Vcurrent to traversal_result. |
| 8 | For each neighbor Vneighbor of Vcurrent: |
| 9 | If Vneighbor ∉ visited: |
| 10 | Retrieve edge_data for (Vcurrent,Vneighbor). |
| 11 | If edge_data exists and edge_data.m_dis ≤ m_dis_limit. |
| 12 | Append Vneighbor to queue. |
| 13 | Return: traversal_result. |
4. Results
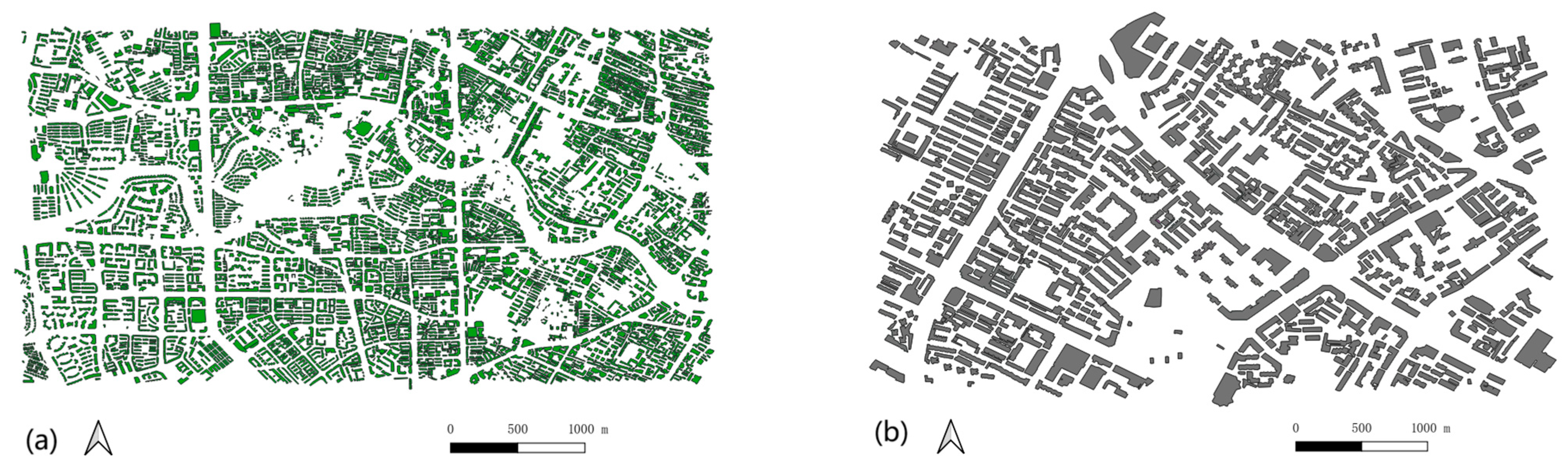
4.1. Experiment for Semi-Automatically Labeling Edge-Buildings
4.1.1. Attribute Definition and Grading
4.1.2. The Semi-Automated Labeling of Edge Buildings
- (1)
- When a building’s vo_to_b_length value falls within the high-value range (>8.690), it receives the label of an edge building (whether_edge = 1).
- (2)
- If the vo_to_b_length value falls within the medium-value range (3.236–8.690) and the corresponding LOF value falls within the high-value range (>1.055), it is also labeled as an edge building (whether_edge = 1).
- (3)
- Buildings that do not satisfy the above conditions are labeled as inner buildings (whether_edge = 0).
4.2. The DGI Model Training Phase
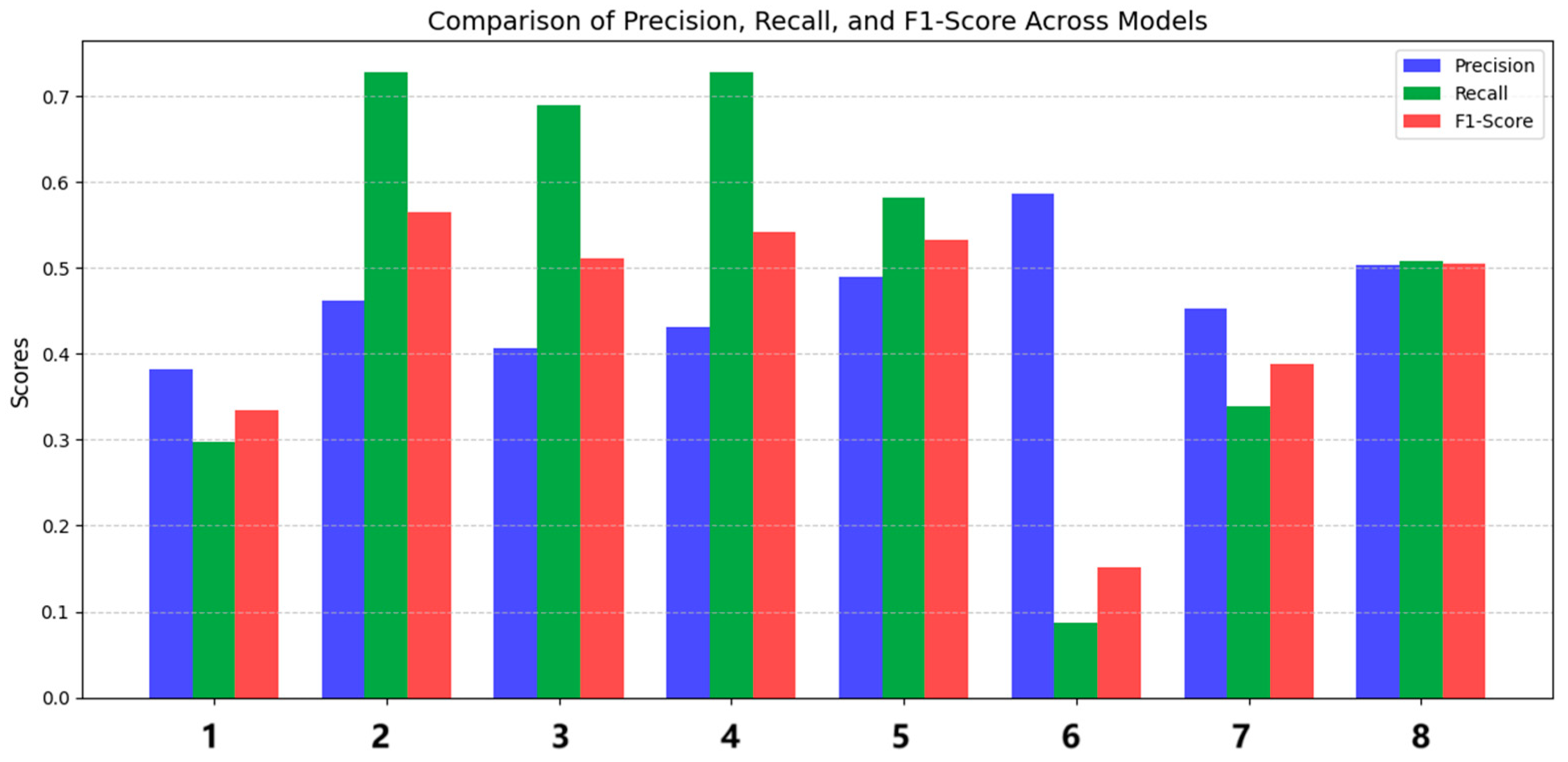
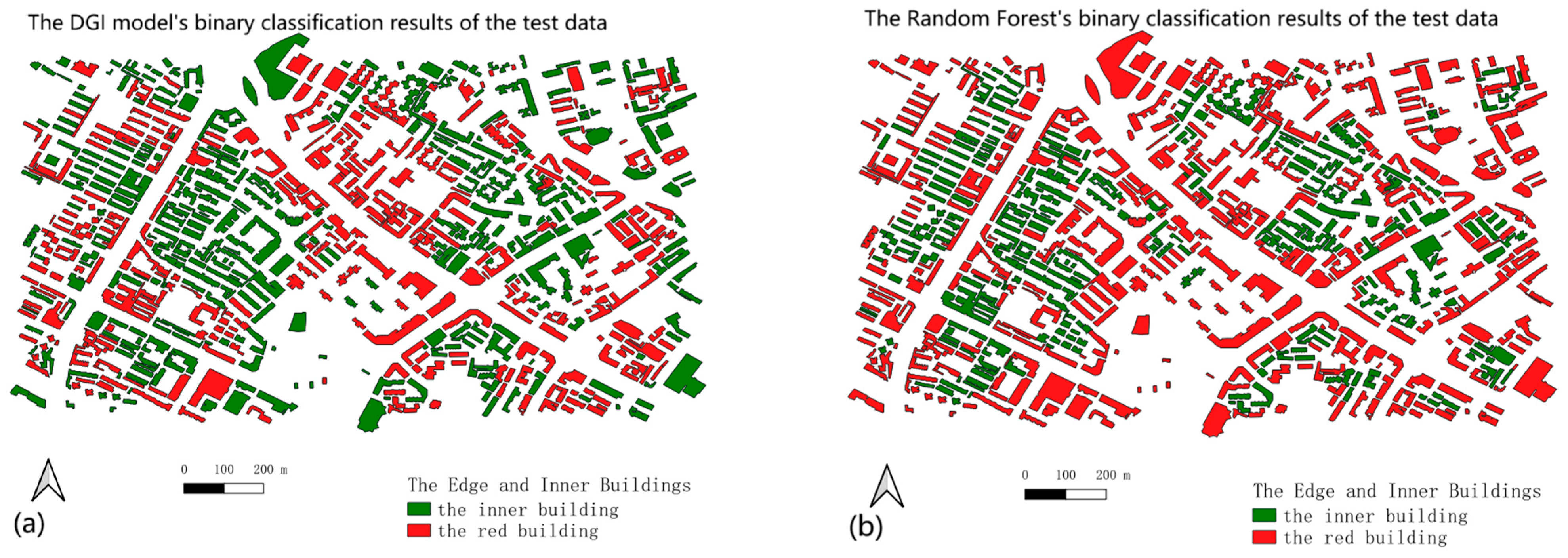
4.3. Clustering Comparison Experiment
5. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, Z.; Liu, Q.; Tang, J. Towards a Scale-driven Theory for Spatial Clustering. Acta Geod. Cartogr. Sin. 2017, 46, 1534–1548. [Google Scholar]
- Deng, M.; Tang, J.; Liu, Q.; Wu, F. Recognizing building groups for generalization: A comparative study. Cartogr. Geogr. Inf. Sci. 2018, 45, 187–204. [Google Scholar] [CrossRef]
- Basaraner, M.; Selcuk, M. A structure recognition technique in contextual generalisation of buildings and built-up areas. Cartogr. J. 2008, 45, 274–285. [Google Scholar] [CrossRef]
- Allouche, M.K.; Moulin, B. Amalgamation in cartographic generalization using Kohonen’s feature nets. Int. J. Geogr. Inf. Sci. 2005, 19, 899–914. [Google Scholar] [CrossRef]
- Huang, H.; Guo, Q.; Sun, Y.; Liu, Y. Reducing building conflicts in map generalization with an improved PSO algorithm. ISPRS Int. J. Geo-Inf. 2017, 6, 127. [Google Scholar] [CrossRef]
- Sahbaz, K.; Basaraner, M. A zonal displacement approach via grid point weighting in building generalization. ISPRS Int. J. Geo-Inf. 2021, 10, 105. [Google Scholar] [CrossRef]
- Li, Z.; Yan, H.; Ai, T.; Chen, J. Automated building generalization based on urban morphology and Gestalt theory. Int. J. Geogr. Inf. Sci. 2004, 18, 513–534. [Google Scholar] [CrossRef]
- Qi, H.B.; Li, Z.L. An approach to building grouping based on hierarchical constraints. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2008, XXXVII, 449–454. [Google Scholar]
- Yan, H.; Weibel, R.; Yang, B. A multi-parameter approach to automated building grouping and generalization. Geoinformatica 2008, 12, 73–89. [Google Scholar] [CrossRef]
- Zhang, L.; Deng, H.; Chen, D.; Wang, Z. A spatial cognition-based urban building clustering approach and its applications. Int. J. Geogr. Inf. Sci. 2013, 27, 721–740. [Google Scholar]
- Wang, W.; Du, S.; Guo, Z.; Luo, L. Polygonal clustering analysis using multilevel graph-partition. Trans. GIS 2015, 19, 716–736. [Google Scholar] [CrossRef]
- Chen, Z.; Ma, X.; Wu, L.; Xie, Z. An intuitionistic fuzzy similarity approach for clustering analysis of polygons. ISPRS Int. J. Geo-Inf. 2019, 8, 98. [Google Scholar] [CrossRef]
- Xu, D.; Tian, Y. A comprehensive survey of clustering algorithms. Ann. Data Sci. 2015, 2, 165–193. [Google Scholar] [CrossRef]
- Basaraner, M.; Cetinkaya, S. Performance of shape indices and classification schemes for characterising perceptual shape complexity of building footprints in GIS. Int. J. Geogr. Inf. Sci. 2017, 31, 1952–1977. [Google Scholar] [CrossRef]
- Bei, W.; Guo, M.; Huang, Y. A spatial adaptive algorithm framework for building pattern recognition using graph convolutional networks. Sensors 2019, 19, 5518. [Google Scholar] [CrossRef]
- Peng, D.; Gui, Z.; Wang, D.; Ma, Y.; Huang, Z.; Zhou, Y.; Wu, H. Clustering by measuring local direction centrality for data with heterogeneous density and weak connectivity. Nat. Commun. 2022, 13, 5455. [Google Scholar] [CrossRef] [PubMed]
- Zahn, C.T. Graph-theoretical methods for detecting and describing gestalt clusters. IEEE Trans. Comput. 1971, 100, 68–86. [Google Scholar] [CrossRef]
- Zhong, C.; Miao, D.; Wang, R. A graph-theoretical clustering method based on two rounds of minimum spanning trees. Pattern Recognit. 2010, 43, 752–766. [Google Scholar] [CrossRef]
- Anders, K.H. A hierarchical graph-clustering approach to find groups of objects. In Proceedings of the 5th Workshop on Progress in Automated Map Generalization, Paris, France, 28–30 April 2003; Citeseer: Princeton, NJ, USA, 2003; pp. 1–8. [Google Scholar]
- Liu, Q.; Deng, M.; Shi, Y.; Wang, J. A density-based spatial clustering algorithm considering both spatial proximity and attribute similarity. Comput. Geosci. 2012, 46, 296–309. [Google Scholar] [CrossRef]
- Cetinkaya, S.; Basaraner, M.; Burghardt, D. Proximity-based grouping of buildings in urban blocks: A comparison of four algorithms. Geocarto Int. 2015, 30, 618–632. [Google Scholar] [CrossRef]
- Yu, W.; Ai, T.; Liu, P.; Cheng, X. The analysis and measurement of building patterns using texton co-occurrence matrices. Int. J. Geogr. Inf. Sci. 2017, 31, 1079–1100. [Google Scholar] [CrossRef]
- Wei, Z.; Guo, Q.; Wang, L.; Yan, F. On the spatial distribution of buildings for map generalization. Cartogr. Geogr. Inf. Sci. 2018, 45, 539–555. [Google Scholar] [CrossRef]
- Liu, P.; Shao, Z.; Xiao, T. Second-order texton feature extraction and pattern recognition of building polygon cluster using CNN network. Int. J. Appl. Earth Obs. Geoinf. 2024, 129, 103794. [Google Scholar] [CrossRef]
- Regnauld, N. Contextual building typification in automated map generalization. Algorithmica 2001, 30, 312–333. [Google Scholar] [CrossRef]
- Pilehforooshha, P.; Karimi, M. An integrated framework for linear pattern extraction in the building group generalization process. Geocarto Int. 2019, 34, 1000–1021. [Google Scholar] [CrossRef]
- Nosovskiy, G.V.; Liu, D.; Sourina, O. Automatic clustering and boundary detection algorithm based on adaptive influence function. Pattern Recognit. 2008, 41, 2757–2776. [Google Scholar] [CrossRef]
- Sander, J.; Ester, M.; Kriegel, H.-P.; Xu, X. Density-based clustering in spatial databases: The algorithm gdbscan and its applications. Data Min. Knowl. Discov. 1998, 2, 169–194. [Google Scholar] [CrossRef]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; pp. 93–104. [Google Scholar]
- Zhang, X.; Ai, T.; Stoter, J. The evalutation of spatial distribution density in map generalization, ISPRS 2008. In Proceedings of the XXI Congress: Silk Road for Information from Imagery: The International Society for Photogrammetry and Remote Sensing, Beijing, China, 3–11 July 2008; Comm. II, WG II/2. International Society for Photogrammetry and Remote Sensing (ISPRS): Beijing, China, 2008; pp. 181–187. [Google Scholar]
- Deng, M.; Liu, Q.; Cheng, T.; Shi, Y. An adaptive spatial clustering algorithm based on Delaunay triangulation. Comput. Environ. Urban. Syst. 2011, 35, 320–332. [Google Scholar] [CrossRef]
- Jahirabadkar, S.; Kulkarni, P. Algorithm to determine ε-distance parameter in density based clustering. Expert. Syst. Appl. 2014, 41, 2939–2946. [Google Scholar] [CrossRef]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef]
- Pilehforooshha, P.; Karimi, M. A local adaptive density-based algorithm for clustering polygonal buildings in urban block polygons. Geocarto Int. 2020, 35, 141–167. [Google Scholar] [CrossRef]
- Meng, N.; Wang, Z.; Gao, C.; Li, L. A vector building clustering algorithm based on local outlier factor. Geomat. Inf. Sci. Wuhan Univ. 2024, 49, 562–571. [Google Scholar]
- Cheng, B.; Liu, Q.; Li, X. Local perception-based intelligent building outline aggregation approach with back propagation neural network. Neural Process. Lett. 2015, 41, 273–292. [Google Scholar] [CrossRef]
- Yan, X.; Ai, T.; Yang, M.; Tong, X.; Liu, Q. A graph deep learning approach for urban building grouping. Geocarto Int. 2022, 37, 2944–2966. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Zhao, R.; Ai, T.; Yu, W.; He, Y.; Shen, Y. Recognition of building group patterns using graph convolutional network. Cartogr. Geogr. Inf. Sci. 2020, 47, 400–417. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Veličković, P.; Fedus, W.; Hamilton, W.L.; Liò, P.; Bengio, Y.; Hjelm, R.D. Deep Graph Infomax. arXiv 2018, arXiv:1809.10341. [Google Scholar]
- Wu, J.; Dai, P.; Hu, X.; Zhao, Y.; Xiong, J.; Hu, L.; Wei, N.; Tu, H. An adaptive approach for generating Voronoi diagrams for residential areas containing adjacent polygons. Int. J. Digit. Earth 2024, 17, 2431100. [Google Scholar] [CrossRef]
- Edsger, W.D. A note on two problems in connexion with graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar]
- Yan, X.; Ai, T.; Yang, M.; Yin, H. A graph convolutional neural network for classification of building patterns using spatial vector data. ISPRS J. Photogramm. Remote Sens. 2019, 150, 259–273. [Google Scholar] [CrossRef]
- Chen, J.; Yang, S.T.; Li, H.W.; Zhang, B.; Lv, J.R. Research on geographical environment unit division based on the method of natural breaks (Jenks). Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, 40, 47–50. [Google Scholar] [CrossRef]
- Richardson, A. Logistic Regression: A Self-Learning Text, by David G. Kleinbaum, Mitchel Klein. Int. Stat. Rev. 2011, 79, 296. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Arbelaitz, O.; Gurrutxaga, I.; Muguerza, J.; Pérez, J.M.; Perona, I. An extensive comparative study of cluster validity indices. Pattern Recognit. 2013, 46, 243–256. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Name | Notation/Equation | Description |
|---|---|---|---|
| 1 | concavity | The area ratio of the building to its convex hull [44] | |
| 2 | LOF | Section 3.1.2 | |
| 3 | Density | The area of the building is divided by the area of the Voronoi map unit where it is located [44] | |
| 4 | vo_to_b_length | The vector length of the Voronoi graph unit center pointing to the center of the building it contains | |
| 5 | center_devia | Illustrated in Section 3.1.3 | |
| 6 | first_neighbor_avg_r | - | Average radius of first-order neighborhood polygons of a building |
| 7 | m_dis_cv | Illustrated in Section 3.1.5 |
| Dataset | Number of Buildings | Percent of Concave Polygon (%) | Percent of Rectangles (ERI index [14]) (%), | Location |
|---|---|---|---|---|
| Train | 4851 | 91.4 | 17.3 | 104.00 E, 30.66 N |
| Test | 689 | 94.0 | 16.5 | 104.05 E, 30.68 N |
| Training Number | Feature Combination Used in Training | Feature Combination Description |
|---|---|---|
| 1 | [concavity,lof,density,vo_to_b_length,center_devia,first_neighbor_avg_r] | Remove m_dis_cv from all seven features |
| 2 | [concavity,lof,density,vo_to_b_length,center_devia,m_dis_cv] | Remove first_neighbor_avg_r from all seven features |
| 3 | [concavity,lof,density,vo_to_b_length,first_neighbor_avg_r,m_dis_cv] | Remove center_devia from all seven features |
| 4 | [concavity,lof,density,center_devia,first_neighbor_avg_r,m_dis_cv] | Remove vo_to_b_length from all seven features |
| 5 | [concavity,lof,vo_to_b_length,center_devia,first_neighbor_avg_r,m_dis_cv] | Remove density from all seven features |
| 6 | [concavity,density,vo_to_b_length,center_devia,first_neighbor_avg_r,m_dis_cv] | Remove lof from all seven features |
| 7 | [lof,density,vo_to_b_length,center_devia,first_neighbor_avg_r,m_dis_cv] | Remove concavity from all seven features |
| 8 | [concavity,lof,density,vo_to_b_length,center_devia,first_neighbor_avg_r,m_dis_cv] | All seven features |
| Experiment Data | Method | Silhouette Coefficient | Davies Bouldin Index | Calinski Harabasz Index | ARI |
|---|---|---|---|---|---|
| Test | DGI-EIC | −0.44 | 4.03 | 5.15 | 0.45 |
| RF-EIC | −0.47 | 3.85 | 4.60 | 0.39 | |
| CDC | −0.37 | 4.52 | 5.90 | 0.32 | |
| MGP | −0.46 | 2.26 | 5.70 | 0.37 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, H.; Zhang, Y. Clustering Method for Edge and Inner Buildings Based on DGI Model and Graph Traversal. ISPRS Int. J. Geo-Inf. 2025, 14, 222. https://doi.org/10.3390/ijgi14060222
Huang H, Zhang Y. Clustering Method for Edge and Inner Buildings Based on DGI Model and Graph Traversal. ISPRS International Journal of Geo-Information. 2025; 14(6):222. https://doi.org/10.3390/ijgi14060222
Chicago/Turabian StyleHuang, Hesheng, and Yijun Zhang. 2025. "Clustering Method for Edge and Inner Buildings Based on DGI Model and Graph Traversal" ISPRS International Journal of Geo-Information 14, no. 6: 222. https://doi.org/10.3390/ijgi14060222
APA StyleHuang, H., & Zhang, Y. (2025). Clustering Method for Edge and Inner Buildings Based on DGI Model and Graph Traversal. ISPRS International Journal of Geo-Information, 14(6), 222. https://doi.org/10.3390/ijgi14060222