1. Introduction
The International Maritime Organization mandates that ships of over 300 gross tonnage on international voyages, non-international ships of over 500 gross tonnage, and all passenger ships must be equipped with an Automatic Identification System (AIS) [
1]. An AIS autonomously transmits time-series data, known as the AIS trajectory, detailing a ship’s navigational status. The trajectory includes static information (e.g., maritime mobile service identifiers, ship dimensions), dynamic information (e.g., longitude, latitude, heading, and speed), and navigation details (e.g., destination, estimated time of arrival) [
2]. Spontaneously, AIS trajectories, hereinafter called trajectories, have become an essential data source for various analyses, such as in behavioral studies, logistics, and maritime safety [
3].
Given the vast volume of trajectories, effective filtering and querying are essential for various types of exploration and analysis [
4]. Trajectory queries are retrieved based on attribute characteristics, and are typically categorized into spatio-temporal and semantic methods [
5,
6]. Spatio-temporal trajectory query methods leverage temporal and spatial dimensions to formulate query conditions, thus filtering and constructing a subset of trajectories [
7]. However, these methods are limited to spatio-temporal attributes, and cannot identify higher-level semantic features, failing to address the growing complexity of AIS trajectory query tasks. Semantic trajectory query methods integrate trajectories with semantics (e.g., location names, functional categories, time descriptions) [
8]. These methods allow for more direct retrieval by specifying query conditions and matching synonymous relationships with keywords [
9], which simplifies the query process. However, there can be significant deviations between the query criteria and the results when semantic methods handle complex fuzzy queries [
10]. These challenges underscore the need for more flexible and adaptive semantic query methods to accommodate diverse and natural inputs.
Natural language, a more natural, intuitive, and descriptive method of expression, can easily describe semantic trajectory queries and facilitate a more effective and user-friendly process [
11]. Traditional spatio-temporal or semantic queries typically rely on structured parameters or predefined vocabularies. In contrast, natural language queries allow users to employ complete sentences encompassing location names (e.g., Taibei Port), functional categories (e.g., anchorage ground), and temporal descriptions (e.g., afternoon) to filter trajectories [
12]. For example, instead of specifying multiple structured parameters to query trajectories starting from Taibei Port, frequently changing speed while passing through the Taiwan Strait, and reaching Xiamen Port, users can simply ask the following: “obtaining the trajectories that quickly cross the Taiwan Strait and passes the ports of Taibei and Xiamen in the afternoon”. This makes the query process more accessible, especially for non-expert users.
Natural language queries make it easier for users to express their intentions, motivating us to explore a more effective natural language-based AIS trajectory query approach. In natural language applications, large language models (LLMs, e.g., Qwen 2) have become powerful tools for understanding and generating human-like text, making them invaluable for various tasks [
13]. These developments have positioned LLMs as versatile solvers for multiple tasks, fundamentally altering the trajectory query paradigms. Their integration of retrieval and generation ability enables more efficient queries from natural language inputs [
14].
We propose an LLM-based AIS trajectory query approach based on natural language to address complex queries, providing a more intelligent and user-friendly query experience. First, the AIS trajectory data are segmented into homogeneous episodes. Then, semantic information is extracted from the numerical data to construct trajectory documents with more intuitive textual descriptions, completing the textualization of the trajectory. Then, the semantic querying of trajectories is performed using the natural language processing capabilities of LLMs. Specifically, the query rewritten module aligns closely with user requirements, the document retrieval module retrieves and reorders semantic trajectories based on embedding, and the response generator module adopts LLMs to generate natural language responses. Finally, comparative experiments and a human study highlight the advantages of our approach in terms of precision and relevance. Additionally, an ablation study demonstrates the significant contributions of each module. The principal contributions of this work are summarized as follows:
An LLM-based AIS trajectory query framework is proposed that bridges the gap between natural language queries and AIS trajectories, which uses natural language queries and outputs trajectory query results along with natural language answers.
An AIS trajectory textualization method is proposed to construct semantic trajectory documents, a natural language modality that encapsulates the numerical values in understandable semantic descriptions.
An innovative AIS trajectory query method is proposed, which retrieves and reorders trajectories by semantic similarity calculations in the embedding space.
The remainder of this paper is organized as follows.
Section 2 comprehensively reviews related work on trajectory queries and LLMs for trajectory queries.
Section 3 presents our approach by detailing the conversion process of raw AIS trajectory data into semantic trajectory documents, and illustrating how LLMs enhance AIS trajectory queries from natural language.
Section 4 introduces the experimental design for evaluating our approach.
Section 5 discusses the strengths and weaknesses of our approach, and
Section 6 presents the conclusions of this work and charts future directions.
2. Related Work
2.1. Trajectory Queries
Trajectory querying is an essential technique for efficiently retrieving trajectory data based on specified query conditions, in which geographical coordinates and temporal features are initially used to filter out trajectories [
15]. As trajectory data are enriched with more semantics, the trajectory filtering conditions are extended to semantic features [
16].
The spatio-temporal trajectory query method refers to the process of retrieving subsets from datasets according to temporal and spatial information [
17]. These methods are commonly used to filter trajectories by establishing conditions between trajectories and spatio-temporal regions, as well as conditions between trajectories [
18]. For spatio-temporal region conditions, the query system aims to obtain the trajectories according to a combination of regional conditions [
19]. For conditions between trajectories, the query system retrieves the most similar trajectory in the database, where the target trajectory is measured based on factors such as distance, shape, and temporal alignment [
20]. For example, dynamic time warping (DTW) is a robust algorithm used for querying based on shape similarity between two temporal sequences [
21]. At the same time, the Longest Common Sub-sequence (LCSS) is a classic method for querying based on size similarity, i.e., the longest sub-sequence common to two sequences [
22], which is usually adopted to calculate trajectory similarity. Ahmed et al. [
23] proposed a spatio-temporal trajectory association algorithm based on spatio-temporal similarity. However, these spatio-temporal trajectory query methods face challenges in obtaining complete and precise query results based solely on strict spatio-temporal conditions, and they cannot support complex query intents.
Expanding query criteria to semantic attributes can retrieve more detailed and meaningful information by matching the synonymous relationships with keywords such as geographic entities and motion characteristics [
5]. Researchers have conducted various trajectory query methods based on either semantic similarity alone or spatio-temporal and semantic joint similarity [
24]. From the perspective of semantic similarity alone, Ribeiro et al. [
9] represented trajectories based on text semantic analysis and realized similarity matching through multi-modal feature fusion, optimizing query efficiency by incorporating contextual trajectory information. Zheng et al. [
25] took both the travel effort of sub-trajectories and textual proximity between query keywords to capture the semantic correlations between queries and semantic activities embedded in trajectories, which enabled the retrieval of more semantically similar trajectories. From another perspective of spatio-temporal and semantic joint similarity, Tian RJ et al. [
26] adopted a linear combination method to combine the textual, temporal, and spatial similarity into a semantic trajectory similarity metric in order to realize trajectory querying. Huang et al. [
12] extracted spatio-temporal constraints from text to support effective semantic querying of uncertain mobile trajectory data, and used Okapi BM25 and the Term Frequency–Inverse Document Frequency method to calculate the relevance between semantic trajectories and keywords in documents.
Although the above trajectory query methods have demonstrated their potential at spatio-temporal and semantic levels, they often require users to familiarize themselves with available options and enter query conditions strictly, preventing them from effectively establishing links between trajectories and complex queries. Therefore, it is better to enhance AIS trajectory queries with natural language input and response, which can accommodate diverse user requirements and make the query process more accessible, efficient, and user-centric.
2.2. LLMs for Information Queries
A trajectory query is a vertical application inherited from an information query [
16], in which natural language could be taken as the descriptive expression to retrieve the most pertinent results [
27]. Meanwhile, LLMs have revolutionized various application fields, due to their remarkable language understanding, generation, generalization, and reasoning abilities [
28]. There are many studies that adopt LLMs for information queries, mainly in relation to general and specific domains.
LLMs for general-domain information queries can be divided into web and text document-enhanced models [
29]. Regarding LLMs for web document queries, they usually use open web pages to access up-to-date information and generate concise summaries, thereby improving the relevance and timeliness of real-time data retrieval [
30]. For example, Xu et al. [
31] introduced LLMs that enable access to vast and dynamic information from any search engine, making it easy to query information from web documents. Meanwhile, Jinheon et al. [
32] augmented LLMs with relevant context from search engine interaction histories to complete the entire query process and answer long-form questions. In the realm of LLMs for text document queries, retrievers and reorder modules are usually designed to retrieve candidate documents from a large-scale text corpus, enhancing the retrieval effectiveness and query result quality. For instance, RankGPT adopts LLMs to create a list of document IDs ordered by relevance to the query [
33], demonstrating that LLMs can understand natural language queries, retrieve relevant documents, and generate responses. However, LLMs are suitable for directly handling text data but cannot be directly applied to multi-modal data.
In specific domain applications, Liu et al. [
34] encoded molecular graphs and their semantic information into structured text to predict molecular properties, and made LLMs perform sophisticated information queries. Lin [
35] transformed financial reports into numbers and characters by directly reading tabular data using a PDF parser, and adopted LLMs to convert them into coherent text; hence, this demonstrates that LLMs can query and analyze sophisticated information with structured data. Jiang et al. [
36] developed a geospatial information query system based on LLMs, which converted natural language questions into geospatial SQL queries. In conclusion, LLMs have been extended to multi-modal data by converting this data to text format, and have been shown to deliver accurate and efficient query results across diverse domains, demonstrating their broad applicability in information querying.
However, it has not yet been investigated whether LLMs can be applied to trajectory querying to achieve precise and relevant trajectory query responses. AIS trajectories comprise typical dynamic data with rich temporal, spatial, and attributes. However, they lack the structure and context necessary for LLMs, making it challenging to realize direct interaction between LLMs and raw trajectories. To address the above problems, we transform raw trajectories and queries into a format that LLMs can understand to obtain highly relevant data, thereby matching complex query requirements described in natural language with numerical AIS trajectories.
3. Materials and Methods
Figure 1 illustrates the comprehensive framework, which integrates a consortium of LLMs working synergistically. The process commences with the AIS trajectory textualization phase, which includes trajectory segmentation, semantic extraction, and trajectory document construction modules. Specifically, the trajectory segmentation module converts raw trajectories into homogeneous episodes and forms segments. Then, the semantic extraction module maps motion numeric values to semantic descriptions, while geographic coordinates are linked to geographic entities. Furthermore, the trajectory document construction module takes individual trajectories as pending units and their extracted semantics as sources to construct documents, converting trajectory datasets into a coherent document corpus. Hence, the textualization method effectively mitigates the limitations of LLMs, which are adept at handling semantics but not numerical trajectory data. In the subsequent semantic trajectory query phase, LLMs are integrated using query rewritten, document retrieval, and response generator modules to retrieve trajectories and summarize responses. The query rewritten module is designed to transform natural language queries into standard queries by extracting, enhancing, and rewriting operations. Then, the document retriever module embeds standard queries and trajectory documents into a shared semantic vector space. It allows for the retrieval of relevant trajectory documents whose embeddings closely match the reformulated query embeddings. Then, these retrieved trajectory documents are reordered to prioritize relevant documents. Ultimately, the response generator module combines the rewritten query and the context from the retrieved trajectories to create meaningful responses. Therefore, the framework provides a more intelligent and user-friendly query experience that can understand natural language queries and respond with natural language answers, meeting complex and diverse query needs.
3.1. Problem Formulation
The LLM-based trajectory query approach based on natural language handles complex trajectory queries and generates responses with natural language answers and trajectory query results. It can be formalized as follows: let denote a natural language query and represent a pre-constructed trajectory document consisting of semantic trajectories. Each is described by macro travel information and micro motion information: . According to the trajectory characteristics of geographical coordinates, timestamps, and other attributes, our task categories predominantly focus on spatio-temporal queries, semantic queries, and generating summarized queries, illustrated as follows:
Task 1: Obtaining trajectories meeting particular spatio-temporal conditions (such as passing through specific moments or places).
Task 2: Obtaining trajectories characterized by specified semantic behaviors (such as heading or speed changes).
Task 3: Obtaining summarized information from trajectories based on specific requests.
As illustrated in
Figure 2, there is a natural language query, i.e., get the trajectories starting from Beira Port to Island View Port, where these trajectories should contain at least three speed change stages and have a change in heading towards the southeast direction. The spatio-temporal trajectory lacks precise semantics, such as Beira Port, Island View Port, speed change, and period information, resulting in no relevant results for natural language queries (
Figure 2a). In our approach, raw trajectories are textualized into documents to match approximate semantics (such as morning and acceleration) and complex conditions (such as three speed change stages and five passing ports) (
Figure 2b), so our approach introduces LLMs to understand natural language queries and generate natural language responses using the retrieved trajectories (
Figure 2c).
3.2. Trajectory Textualization
A trajectory consists of a sequence of sample points, each recorded at a specific time. Each point captures the instantaneous state of motion and relevant attributes, such as the identifier, timestamp, longitude, and latitude [
16]. Although these values are standard across various trajectory types, they present a significant challenge for users in understanding the semantics contained in trajectories, and align with complex query intents [
37]. Narrowing this interpretative gap necessitates the development of a trajectory textualization method, which offers a semantic trajectory lens to elucidate motion states instead of relying on instantaneous numerical values. This section proposes a trajectory segmentation method to convert discretely sampled trajectory points into internal coherent segments. These segments predominantly encapsulate continuous sequences of stop-and-move episodes, the fundamental semantic trajectory description building blocks. Building upon these foundational segments, we have defined a semantic extraction module that creates meaningful motion words to represent specific features of trajectory points, such as geographic coordinates, speed, and heading, in a linguistically meaningful manner. These motion words enrich the semantic description of trajectories and facilitate a deeper understanding of moving objects. On this basis, trajectory documents are constructed to integrate macro travel information with micro semantic movement words to form a coherent corpus. This innovative textualization method can encapsulate the numerical values of spatio-temporal motion in an understandable semantic description, empowering users to query trajectories in an interactive natural language.
3.2.1. Trajectory Segmentation
A trajectory can be a long and complex path with myriad mobility patterns, making semantic extraction or queries from these extensive, densely populated trajectories time-consuming. Therefore, trajectory segmentation is considered a fundamental process, wherein the “Stop-Move” semantic trajectory model is adopted, based on Description Logic [
38], to represent a long trajectory with structured yet non-overlapping stop-and-move episodes. These episodes are characterized by highly correlated spatio-temporal characteristics, albeit manifesting in irregular shapes. Then, two consecutive stop episodes and a singular move episode between these stop episodes are combined as a segment to provide a high-level semantic representation of travels. Moreover, each move episode can also contain multiple sub-move episodes. Given the sparsity issue commonly observed in AIS data, an improved trajectory segmentation algorithm based on DBSCAN is employed, which was proposed in our prior work [
1]. This method clusters adjacent trajectory points with varying sampling frequencies by leveraging their spatio-temporal characteristics. This process establishes a consistent temporal framework, ensuring the reliability and accuracy of subsequent trajectory segmentation.
In the first stage of clustering stop episodes, trajectory points with speeds lower than a given threshold for a minimal time are earmarked as potential stop points. However, directly identifying stop episodes confronts substantial hurdles: complex data distribution, noise, and outliers. Improved DBSCAN is utilized to cluster trajectories into homogeneous episodes to effectively manage the clustering of points dispersed in irregular formations and mitigate the influence of noisy data (
Figure 3). The algorithm uses adjustable parameters: the maximum distance between two points for one to be considered as being in the neighborhood of the other (Epsilon
), and the minimum number of neighbors required to form a stop cluster (MinPts). Specifically, the process begins with an arbitrary and unvisited potential stop point. Subsequently, points within the Epsilon radius of the current point are sought and assigned a cluster identifier. If the count of retrieved points exceeds MinPts, the current point is designated as a core point; otherwise, it is labeled as a border point. Once all neighborhoods have been traversed, the cluster identifier automatically increments. This process iterates until all points have been exhaustively traversed, forming homogeneous stop episodes. These stop episodes are defined by speeds remaining consistently below a given threshold for a minimal duration, spatial proximities adhering to the Epsilon criterion, and cluster densities exceeding the MinPts requirement. Consequently, the original trajectory is finely divided into stop events and sub-trajectories occurring between consecutive stop events. As illustrated in
Figure 3, the area circled by the dotted yellow line represents the clustering of stop episodes, and sub-trajectories are naturally yielded after dividing the stop episodes.
It is suboptimal to directly use sub-trajectories as move episodes, since they may contain heterogeneous subelements caused by prolonged signal absences and other factors [
39]. Consequently, a refinement stage becomes imperative, wherein sub-trajectories undergo further scrutiny and division. The second stage leverages improved DBSCAN to stratify sub-trajectories into coherent move episodes, each characterized by a continuous density pattern. This meticulous segmentation ensures that the resultant move episodes accurately reflect the intrinsic motion status, devoid of the distortions introduced by signal anomalies or other extraneous influences.
Figure 3 demonstrates that sub-move episodes are finally generated after layering sub-trajectories based on DBSCAN, each of which is delineated by an uninterrupted density continuity.
3.2.2. Semantic Extraction
Trajectories are generally still represented as tuples of numeric values, even when segmented into stop-and-move episodes [
40]. The raw numerical values in the trajectory have little intrinsic meaning to users, and semantic information embedded in trajectory data fails to be understood by users. Therefore, these numeric values cannot be directly utilized for semantic trajectory querying, which requires meaningful words and semantic descriptions as data sources. This section introduces methods for extracting semantics, including speed, heading, temporal, and location semantics, to achieve this goal.
Speed Semantics. Speed is a fundamental feature that indicates how fast an object travels. Analyzing speed change provides a more nuanced understanding of trajectory dynamics, allowing for the identification of significant patterns and transitions in motion behavior [
41]. Although absolute speed describes how quickly or slowly an object moves, capturing variations in the pace of motion along a trajectory can be difficult. The speed change can be identified by calculating whether the current speed
deviates from more than a predefined threshold
. The threshold value will be selected according to the speed range of the moving object and the requirement for fine-grained speed division. As illustrated in
Figure 4a, this deviation is calculated using the formula
, representing the speed difference between the previous trajectory point relative to the current point. The four symbols, cruise, acceleration, deceleration, and stationary, are defined to describe speed change semantically (Equation (1))
Stationary and cruising expressly represent that the speed change is less than the given threshold. The object may be considered stationary or cruising, depending on whether its instantaneous speed approaches 0. The acceleration and deceleration indicate that the absolute value of its speed change exceeds the threshold. For each trajectory point, its speed value
will be compared to the previous point and matched with the corresponding semantic symbol, represented as
. In Equation (2), speed semantics is defined by a tuple with a timestamp and a semantic symbol,
. Considering speed changes, this method provides a more nuanced understanding of trajectories, which is crucial for semantic trajectory queries and various applications.
Heading Semantics. The heading feature captures the changes in direction when an object moves to different locations [
42]. Unlike numeric heading angles, which can be difficult to interpret intuitively, this paper utilizes a cone-based direction model to extract trajectory semantics from heading features.
Figure 4b illustrates that the heading is divided into eight cone directions, each covering a 45-degree range centered around a central axis. A set of symbols,
, has been created and denoted in Equation (3) to express these cone directions semantically. Based on these heading semantic symbols, the heading value
of any trajectory point is compared with the angle ranges of each cone direction and labeled with a matching symbol. This process allows for a semantic description of the heading features, represented as
. The heading semantics is illustrated in a tuple, representing points with a semantic symbol and a timestamp (Equation (4)).
Figure 4.
Semantic extraction for trajectory episodes. (a) Speed semantics transformation rules; (b) Heading semantics transformation rules; (c) Location semantics transformation rules; (d) Temporal semantics transformation rules.
Figure 4.
Semantic extraction for trajectory episodes. (a) Speed semantics transformation rules; (b) Heading semantics transformation rules; (c) Location semantics transformation rules; (d) Temporal semantics transformation rules.
Temporal Semantics. Visiting times can precisely reflect the temporal patterns of trajectory episodes [
43]. However, they lack qualitative, contextual insights into the meaning and usage of time. Temporal semantics encodes time in natural language, facilitating flexible handling, understanding, and efficient acquisition of temporal information. Equation (5) demonstrates the creation of the symbol
to express temporal features semantically.
Figure 4d illustrates the mapping of trajectory point timestamps to corresponding temporal semantic categories based on uniform time intervals. Specifically, we divide the 24 h day into twelve equal 2 h intervals and assign a meaningful temporal semantic description to each period. Consequently, the time value
can be translated into a sequence of temporal semantic descriptions
(Equation (6))
Location Semantics. Geographic coordinates are numeric values that accurately record the position on Earth of ships, with the most common using latitude and longitude. While these numeric values provide precise, quantitative information, they lack qualitative contextual insights into the coordinates’ meaning and usage. In contrast, location semantics offers context and meaning based on geographic entities [
33]. For example, the coordinates (34.0522° N, 118.2437° W) can be semantically described as “Downtown Los Angeles” by matching the geographic entity. This paper focuses on matching trajectory episodes to geographic entities (
Figure 4c). Specifically, we perform a proximity search for each trajectory episode to find the nearest geographic entities within a specified radius. Next, we calculate the geodesic distances between trajectory episodes and nearby geographic entities. Finally, a distance threshold is applied to determine whether the trajectory episodes are close enough to be considered a match, and the closest geographic entity is taken as the match result. In cases where no nearby geographic entity is identified within a predefined threshold, a two-stage strategy is employed. First, the original geographic coordinates are retained and mapped to broader maritime regions, providing a coarse-grained spatial reference. Second, trajectory contextual information is exploited to infer positional semantics. Specifically, if a trajectory segment exhibits consistent movement patterns with adjacent segments, it is semantically represented as “en route from [previously matched entity] to [next matched entity] within [maritime region]”. This strategy ensures semantic continuity across the trajectory, while mitigating the errors associated with forced nearest-neighbor assignments in sparsely mapped maritime areas. Consequently, the geographic coordinates
and
can be mapped into a sequence of geographic entities with timestamps, represented as
(Equation (7)).
The speed, heading, and temporal semantics of AIS trajectories are captured based on geographic information theory. Location semantics is obtained by matching trajectory episodes with geographical entities through proximity search. Then, the semantic symbols with the same timestamp are merged into a continuous sequence, and the corresponding semantic symbols represent the motion state. Therefore, raw numeric values can be translated into a semantic description by integrating a motion semantic sequence. This method ensures that the meaningful interpretation of raw trajectories is possible, facilitating advanced semantic queries and enhancing the usability of trajectory data.
3.2.3. AIS Trajectory Document Construction
Based on the trajectory semantic extraction detailed in
Section 3.2.2, semantic descriptions of the trajectory episodes are provided. Subsequently, trajectory documents are constructed, to which natural language-based queries can be applied. The documents define a set of motion words to enrich the trajectory with contextual information and transform it into semantic descriptions. As depicted in
Figure 5, we take individual objects as the target and the extracted semantics as the source to construct a document comprising macro and micro parts. The macro part encompassed by trajectory segments delineates travel information, such as origin location and timestamp fields, destination location and timestamp fields, duration, and additional distance information (
Figure 5a). Based on these semantic descriptions, the macro part is denoted as Equation (8), in which
is defined by a tuple with duration and distance values. Here,
, where each
is a trajectory point,
. Specifically,
represents the moving object identifier, while
,
, and
are the timestamp, longitude, and latitude of
, respectively. The additional attributes
and
denote the speed and heading of
Additionally, the micro part encapsulates semantic features extracted from trajectory episodes, with each word representing the speed, heading, temporal, and location semantics, denoted as a list of motion words,
. The documentation may include a total of
words. Here
and
represent constant numbers of words depicting speed and heading semantics, respectively. Moreover,
and
represent the number of words depicting temporal and location semantics, respectively. These values vary with detailed semantic modeling methods, depending on the application scene and the semantic query granularity.
Figure 5 describes the trajectory segments from both macro and micro perspectives. From a macro perspective, the trajectory starts from Qingdao port late at night and ends at Shanghai port, with a duration of approximately 76 h and a sailing distance of about 665 km. From a micro perspective, the ship stays at Qingdao until the late night, then passes through the Qingdao, Lanshan, Dafeng, Changjiangkou, Chuansha, and Shanghai ports, experiencing directional changes to the northwest, southeast, east, northeast, southwest, and west, with phases of constant speed cruising and deceleration. During the final segment, the ship changes direction from the west with deceleration phases, and stays at Shanghai until the morning.
This procedure converts all trajectories into documents to form a trajectory corpus in a vector database, which organizes trajectory documents to support trajectory semantic queries. Each document is defined by its distribution of the words associated with the contextual information for the raw trajectories, in which a motion word serves as a snapshot to capture crucial details of trajectories. Consequently, the trajectory document can enhance the efficacy of semantic queries across trajectories.
3.3. Semantic Trajectory Querying Using LLMs
After converting the AIS trajectory into documents, we will provide details on how to query these trajectory documents using natural language. Large language models (LLMs) are employed to rewrite queries, retrieve documents, and generate responses over multiple conversation rounds. Specifically, the query rewritten module extracts, enhances, and rewrites natural language queries to enhance semantic overlap between queries and trajectory documents and provide more pertinent information. The document retrieval module retrieves and reorders semantic trajectories in the same embedding vector space, while the response generator module adopts LLMs to generate natural language responses. The proposed approach can retrieve trajectories through natural language queries using LLMs, and provide more accurate trajectory query results and natural language answers. It ensures a robust and efficient querying system, significantly improving the accessibility and usability of trajectory data for various applications.
3.3.1. Query Rewritten
The core information from natural language query input is sparse, resulting in responses often flooded with relevant but non-critical information. Moreover, semantic trajectory queries using natural language result in semantic ambiguity, grammatical errors, and unclear descriptions. To mitigate these issues, the query rewritten module combines query input and historical dialogues to align closely with the user requirement. It is designed as a critical technique to improve semantic trajectory queries based on LLMs, providing an efficient and intelligent experience. Specially, the LLMs first conduct a deep semantic analysis of the original query to extract primary query conditions via a prompt, resulting in a condensed representation (Equation (9)). Subsequently, both and are also attached to a prompt to correct potential ambiguities, enhance clarity, and improve logical coherence, yielding an enhanced query (Equation (10)).
To enhance information overlap between the query and the trajectory document, we further rewrite the query by expanding
with additional information terms. As illustrated in Equation (11),
is repeated twice in the prompt to reinforce its semantic importance and guide the LLM’s attention [
44,
45]. This repeated input, together with the critical information
and the original query
, is used to generate a final rewritten query
. This process leverages the natural language processing capabilities embedded in LLMs to rewrite a more expressive and context-aware query, thereby enhancing retrieval relevance.
As illustrated in
Figure 6, consider an initial user query: “I want to query the ship that passed by Damaiyu and also went to Dongjiakou Port, maybe it slowed down and headed southwest sometime between 12:00 and 24:00?” This type of query has vague expression and obvious colloquial characteristics, which makes it unsuitable for direct trajectory retrieval. In the first stage (
Figure 6a), the model extracts critical information such as the ports (Damaiyu and Qingdao Dongjiakou), period (12:00 to 24:00), movement heading (southwest), and speed state (deceleration). During the enhancement phase (
Figure 6b), the query is reformulated to “Query all trajectories that passed through Damaiyu and Qingdao Dongjiakou ports between 12:00 and 24:00, and had a southwest heading and a deceleration state”. Finally, to enhance the fluency of the query and improve its semantic alignment with the predefined semantic descriptors, the enhanced query is further rewritten to generate the final refined version, which is represented as “Retrieve all vessel trajectories that traveled from Damaiyu to Qingdao Dongjiakou between noon and night, showing a southwest heading and a deceleration trend”. This rewritten query provides a clearer and semantically enriched representation, facilitating more precise and effective retrieval of relevant trajectories.
3.3.2. Document Retrieval
We introduce the main module in natural language-based semantic trajectory querying in this section, the document retrieval module, which consists of retriever and reorder steps. The retriever step searches for relevant trajectory documents to enhance the semantic understanding capabilities for trajectory queries. Our retriever step employs an encoder
in LLMs to embed trajectory documents
and the query
into a continuous vector space, where
is the number of trajectory documents. The algorithm consists of three stages: (1) Trajectory document encoding:
projects all trajectory documents
into hidden representations
in the vector space, where
represents the dimension of the output, and
is the dimension of the embedding vectors; (2) Query encoding:
also encodes the rewritten query
into a vector
; (3) Trajectory document retrieval: We retrieve trajectory documents based on the standard cosine similarity between each pair of
and
:
where
and
are vector representations of the query and trajectory documents in the embedding space, while
and
denote the vector length. We also utilize Chroma, a vector database built upon SQLite, to enhance performance when retrieving an extensive collection of trajectory documents. Therefore, the retriever step offers greater flexibility and potential for the semantic query to retrieve relevant trajectory documents, as queries and documents are embedded into continuous vectors based on specific criteria.
However, the documents retrieved in the continuous vector space may sometimes be irrelevant or contain noise, hindering the performance of the generation model or even degrading the quality of the generated responses. To re-prioritize positions in retrieved trajectory documents, we design the reorder step to address these problems by formalizing the task as a probabilistic sequencing problem, which adjusts the orders of the retrieved relevant trajectory documents based on a set of keywords in macro and micro semantic descriptions. Okapi BM25 [
33], a classic information retrieval method, is used to compute relevance scores and rank retrieved trajectory documents based on their relevance to crucial information extracted by Equation (12). In Okapi BM25, Term Frequency–Inverse Document Frequency (TF-IDF) [
46] is adopted to measure the importance of each word in a trajectory document. The relevance score of a trajectory document
for an input query contains
keywords
, and it is computed as follows:
where
is the weighted sum of the relevance for each
and
. Therein,
is the keyword in the query,
represents the length of the trajectory document
, and
denotes the average document length of all trajectory documents. The parameters
and
, respectively, adjust the term frequency saturation and document length normalization. Specifically,
low value causes faster word frequency saturation, while a high value causes slower saturation changes. The parameter
controls the normalization effect of document length, with the value 0 disabling normalization and the value 1 enabling full normalization. Following Manning et al. [
47], the default values for
and
are 1.2 and 0.75. Additionally,
is the frequency of
in document
, and
denotes the inverse document frequency of
, which are calculated as follows:
where
denotes the number of
in trajectory document
,
is the number of trajectory documents containing
, and
is the total number of trajectory documents. Through the retriever and reorder steps, the relevant trajectory documents are retrieved and recorded in the vector database according to relevance, which utilizes natural language to understand and accurately perform semantic trajectory queries efficiently.
3.3.3. Response Generator
The relevant trajectory documents corresponding to the query are retrieved and then reordered by calculating relevance scores, which ensures that the most pertinent information is prioritized to generate a high-quality response. The response generator module utilizes the rewritten query
and the
reordered trajectory documents
, to construct a customized prompt that is sent to the LLMs for a natural language answer Ans (Equation (16)).
As illustrated in
Figure 7, the prompt designed for answer generation consists of specification, current input, and output format components. The specification prompt serves as the system-level instruction defining the response generation objective. The current input consists of the rewritten query and reordered trajectory documents, which together provide the semantic grounding necessary for generating accurate and contextually appropriate answers. Additionally, the output format explicitly defines the response template to guide the LLMs in producing natural language outputs that are both coherent and structured.
Through the above steps, the LLMs leverage both tacit knowledge stored within parametric memory, and external knowledge in trajectory documents. Therefore, the proposed approach can advance a user-friendly query experience, adept at comprehending natural language queries and generating natural language answers. This approach not only delivers comprehensive and contextually enriched responses, but also enhances the interaction between users and the trajectory query system, making it more intuitive and accessible for a wide range of users, from domain experts to novices.
4. Experimental Results
Our proposed approach adopts a large-scale language model, Qwen2-7B, to comprehend complex natural language queries, retrieve semantic trajectories, and generate natural language responses. The model has 7 billion parameters, is trained on a self-constructed dataset exceeding 2.2 trillion tokens, and demonstrates strong natural language understanding capabilities. Moreover, the model at this parameter level allows for local deployment, maintaining high performance without consuming large amounts of computing resources. To illustrate the effectiveness and advancement of the proposed approach, all the experiments were implemented by Python and performed on a computer with an AMD Ryzen processor 9 5900HX, a NVIDIA GeForce RTX 3070 Laptop GPU 8GB, and 32 GB of RAM.
4.1. Data Description
To validate our approach, we conducted a case study using ship trajectories at sea. The trajectories covered multiple periods, span global spatial distribution, and contain comprehensive information (such as coordinates, timestamps, and motion states). At the same time, due to sparse spatio-temporal information, such as geographical entities at sea, it was necessary to meet complex query requirements through semantic trajectory querying. Therefore, employing AIS trajectories provided a solid foundation for evaluating our semantic trajectory query approach.
The raw experimental dataset included tanker trajectories from 1 January 2017 to 28 February 2017, with a data size of 8 GB, where the trajectory points contained fundamental attributes such as identifier, longitude, latitude, timestamp, heading, and speed. Due to the uncertainty of equipment acquisition and sampling frequency, there were many anomalies and duplicate values, which had the potential to confuse the semantic extraction. Therefore, it was essential to perform preprocessing operations on the data to ensure that the proposed approach could obtain accurate results. Specifically, trajectory points that deviated too far from adjacent trajectory points were eliminated, and duplicated trajectory points with the same identifier and timestamp were also excluded. After preprocessing, the cleaned trajectories were reduced to 7.58 GB with 5,755,315 trajectory points, which were taken as the dataset for our approach.
4.2. Evaluation Methods
We applied different methods to evaluate the three tasks in
Section 3.1, covering both trajectory retrieval and response generation. First, we conducted comparative experiments on Task 1 and Task 2 to assess the effectiveness of the proposed method in accurately retrieving relevant trajectories. Second, a human study was conducted on three tasks to evaluate both user satisfaction with the query results and the quality of generated natural language responses. Finally, an ablation study was performed to investigate the individual contributions of each module within the overall framework. The following subsections detail the evaluation metrics and questionnaire survey employed in our experiments.
4.2.1. Evaluation Metrics
To evaluate the retrieval capacity, we adopted a number of metrics to evaluate the retrieved trajectories. Firstly, we employed
,
, and
score [
48] to evaluate the effectiveness of the retrieved results. These metrics provide a comprehensive analysis by measuring the proportion of correctly retrieved trajectories both among all relevant trajectories (
) and among all retrieved trajectories (
). The
score provides the harmonic mean of these two metrics. These evaluation metrics are defined as follows:
where
is the number of relevant trajectories retrieved for query
among the
outputs,
represents the number of irrelevant trajectories among them, and
is the total number of relevant trajectories for query
. Here, we average the
and
values over the query set
for Task 1 and Task 2, respectively.
In addition, we employed two typical ranking metrics, discounted cumulative gain (
) and normalized discounted cumulative gain (
) [
49], to evaluate the effectiveness of query results in prioritizing relevant trajectories. Specifically,
is a weighted sum of the “gains” of presenting specific retrieved trajectory documents. As illustrated in Equation (20),
represents the relevance score of the trajectory document queried at position
, and
represents the discount factor based on the current rank
. Moreover, to assess how closely the output ranking approximates the ideal ordering,
adjusts the
score by normalizing the ideal discounted cumulative gain (
) of the natural language queries
, in which
is the
score of the ideal ranking of retrieved trajectories (Equation (21)).
4.2.2. Questionnaire Survey
In order to more comprehensively evaluate the ability of the proposed method to provide users with a more intelligent and friendly query experience, we also evaluated the performance of the proposed method from the user’s perspective through a questionnaire survey. We also implemented our approach using different parameter scales (0.5 B, 1.5 B, and 7 B) of the publicly available Qwen model to understand the impact of model size on the effectiveness of the trajectory queries. We used a five-point system (i.e., 1 for poor, 2 for marginal, 3 for acceptable, 4 for good, and 5 for excellent) [
50].
Figure 8 illustrates the questionnaire designed, which is divided into two main parts [
51]. The first two questions assess the effectiveness of the proposed model in terms of query relevance and completeness. Specifically, relevance reflects that how well the query results align with user intent, and completeness represents whether the response sufficiently addresses the query. The remaining two questions verify whether our approach can automatically respond with more rich, intuitive, and easily understood natural language answers [
52,
53]. The third question evaluates the naturalness of the generated response, specifically, whether it is coherent, fluent, and human-like in expression. The final question assesses whether the response provides valuable supplementary information that could inspire further user insight.
Based on the designed questionnaire, we could conduct a human study to further assess the effectiveness, in which volunteers were required to interact with our approach and score the natural language answers from the queries in the questionnaire within a 10 min time limit. Specifically, the experiment was completed by a panel of 20 general master students and 2 dominant experts specializing in trajectory data mining. Importantly, none of the panel members were co-authors of this paper. Before the formal experiment began, all volunteers received a comprehensive tutorial to familiarize them with the purpose and evaluation measures of the experiment and to ensure the smooth execution of the experiment. Additionally, we provided detailed background knowledge of the trajectory data to support volunteers in accurately scoring the response results. In the comparative study involving different scales of Qwen models, to ensure a fair and unbiased evaluation, the volunteers were blind to the specific model scale that generated each natural language response. Additionally, we allowed participants to use the Internet to facilitate their understanding of the information in the questions.
4.3. Implementation Details
4.3.1. Segmentation Sensitivity Analysis
Long and complex original trajectories increase the query time and reduce the effect of semantic queries, and ship trajectories are usually sparse and uneven. Therefore, we used an improved trajectory segmentation algorithm based on DBSCAN to convert long trajectories into segments at a finer granularity level [
1]. This method clusters adjacent trajectory points with different sampling frequencies based on spatial-temporal characteristics and movement states, making the segmentation applicable to sparse ship trajectories. To achieve optimal segmentation, it is crucial to balance the size of the trajectory segments. If the segments are too large, they may overlook important internal motion semantic details, while segments that are too small will result in redundant and trivial data. Specifically, we first obtained a list of candidate MinPts and Epsilon values based on the distance distribution of the trajectory, to identify the optimal parameter interval. To identify the optimal parameters, we introduced the silhouette coefficient to measure how similar an object was to its own cluster compared to other clusters. The clustering result was effective when the value of the silhouette coefficient was close to 1. We could analyze the changing pattern of the parameter
. As shown in
Figure 9a,
increases as the average distance from each point to the nearest neighbor increases, and the inflection points show that the optimal
basically appears at
.
directly affects the number of clusters obtained after clustering. As shown in
Figure 9b, if
is too small, the number of clusters will be too redundant; if
is too large, the clustering effect will no longer be obvious. Therefore, we selected
Meanwhile, it can be seen from
Figure 9c that the optimal parameters of the improved DBSCAN algorithm are
and
. Based on the determined parameters of improved DBSCAN, the original trajectories (
Figure 9d) were divided into move and stop episodes. Finally, the original trajectories were converted into 2,877,657 segments based on the above method, including 908,733 stop episodes, 1,968,923 move episodes, and 98,446 sub-move episodes.
Figure 9e illustrates a sample trajectory is divided into stop, move and sub-move episodes.
4.3.2. Natural Language Query Generation
In the experiment, we automatically generated the required queries to ensure the objectivity of query tasks. Specifically, the randomly selected trajectory documents and task descriptions in
Section 3.2 were injected into LLMs to generate queries, ensuring the generated information was closely aligned with trajectory data and query tasks. Then, generated queries were manually refined and evaluated by two dominant experts specializing in trajectory data mining, guaranteeing that these queries could better verify the effectiveness in processing complex natural language queries. In the end, thirty queries
(each task corresponds to 10 queries) were retained to verify the effectiveness of spatio-temporal queries, semantic queries, and generating summarized queries. The generated sample queries are listed in
Table 1.
4.4. Experiment Analysis
Our approach can retrieve trajectories that satisfy specific spatio-temporal and semantic conditions and generate responses with natural language answers. To demonstrate the effectiveness of our approach, we conducted comparative analyses of Task 1 and Task 2, respectively, by using classic spatio-temporal query and semantic query methods, as well as a human study of Task 3 to evaluate the query response quality.
4.4.1. Comparison with Spatio-Temporal Query Methods
Based on the randomly generated queries mentioned above, we selected two classic spatio-temporal query algorithms (i.e., DTW and LCSS) to construct the first comparative experiment on Task 1. These methods primarily query trajectories by calculating the spatio-temporal distance similarity, which coincides with the trajectory document similarity in this paper. However, it should be noted that the query inputs in our experiments are natural language queries rather than specific trajectories, which render classic trajectory query methods ineffective. To ensure fairness and consistency with the DTW and LCSS algorithms, we extracted critical spatio-temporal query conditions from natural language queries, and then formalized them into reference trajectories. After obtaining the trajectories through the query methods, we used
,
, and
score to evaluate the retrieval capacity, and used
and
to evaluate the effectiveness of the reordering process in different methods (
Table 2).
Table 2 demonstrates that our approach has a
of 84.16%, a
of 85.63%, and an
score of 84.89%, illustrating that our approach provides more relevant and accurate results for natural language queries. Due to the semantic understanding ability of LLMs, our approach could align trajectory semantic descriptions with spatio-temporal conditions in natural language queries. It ensures that trajectory similarity calculation is unaffected by the distribution of trajectory point sequences, eliminating the interference caused by the uneven distribution and insufficient proximity of trajectory points. Moreover, our approach employs a reordering module to put relevant trajectories at the front, increasing the proportion of pertinent trajectories of the output. Compared with DTW, our approach achieves 2.4% higher
, 4.18% higher
, and a 3.28% higher
score. Since the DTW method calculates the similarity of a continuous sequence of trajectory points, which may be infected by the significant distance deviation at some sparse trajectory points converted from natural language queries, this leads to a lower
,
and
score. For LCSS, it can skip some unnecessary points during processing and reduce the impact of noise points, thus making its performance better than that of DTW. That is, the
is 1.92% higher than that of DTW. However, LCSS primarily focuses on the gaps between trajectories of different lengths, which makes it less effective in distinguishing trajectories with similar common sub-sequences. Consequently, many irrelevant trajectories are mixed into the query results, resulting in inferior performance to that of our approach, that is, the
,
, and
score are reduced by 0.48%, 2.62%, and 1.57%, respectively.
In terms of and metrics, our approach illustrates significant improvement, outperforming DTW and LCSS by 0.83 and 0.39 points in , and achieving 6.71% and 3.14% increases in . Specifically, our is the highest, at 11.66, indicating that the output results are most relevant to the natural language queries. At the same time, our reaches 94.57%, representing that the output results are closer to the ideal ranking. These improvements can be attributed to the inclusion of a reorder module, which prioritizes candidate results according to their trajectory relevance before outputting them, instead of directly presenting the original query results. Our approach ensures that more relevant query results appear at the top of the output list, preventing users from being overwhelmed by irrelevant results.
4.4.2. Comparison with Semantic Query Methods
To verify the effectiveness of semantic querying, two classic semantic query algorithms (i.e., BM25 and TF-IDF) were selected to conduct comparative experiments on Task 2. These methods primarily obtain results by measuring the semantic similarity between semantic trajectories and natural language queries. Hence, we performed semantic trajectory queries through two comparative algorithms and our own. Furthermore, we also used the
,
and
score to evaluate the query results, and
and
to evaluate the reorder process.
Table 3 presents the comparative experimental results of BM25, TF-IDF, and our approach, indicating that our approach outperforms these classic methods.
Our approach achieves a
of 92.6%, a
of 87%, and an
score of 89.62%, demonstrating the best performance among the three methods (
Table 3). Unlike traditional semantic query methods, our approach extends LLMs to comprehend the semantic information in trajectory documents and eliminate the influence of semantic ambiguity and grammatical errors in natural language queries. As a result, the LLMTrajQueryour approach outperforms TF-IDF and BM25 by 2.61% and 5.93% in Recall, and 16.99% and 5.33% in
. However, TF-IDF is easily influenced by document length and is susceptible to interference from common non-feature words, such as “the” and “this”, leading to the misidentification of irrelevant trajectory documents. Its
is only 70.01%, and its
score is only 76.67%, which are the lowest among the three methods. Additionally, BM25 incorporates multiple weight parameters and factors to better capture the relationship between documents and queries. It does not directly use the frequency of query terms in the document when calculating the relevance between documents and queries. Instead, it first calculates the weight of each query term, which helps to reduce the impact of unimportant words on document similarity. Consequently, while BM25 is still inferior to our approach, it shows an 11.66% higher
and a 4.76% higher
score than TF-IDF.
In the and metrics, our approach achieves excellent values of 12.01 and 97.38%. In comparison, the values of BM25 and TF-IDF are lower by 0.32 and 0.75, and our approach also has improvements of 2.53% and 6.01% in compared with BM25 and TF-IDF, respectively. Because classic semantic query algorithms only order query results based on text similarity, which is limited by the frequency of co-occurrence words between trajectory documents and queries, consequently, some documents with high co-occurrence word frequencies that are irrelevant may be mistakenly considered to be relevant documents. These comparative experiments show that the results of our approach are closer to the ideal output, because of the higher priority given to the relevant trajectory documents.
4.4.3. Evaluation of Query Response Quality
Figure 10 demonstrates the scoring results of the answers generated by Qwen at different parameter scales, and illustrates a positive correlation between the number of parameters and the quality of the generated responses. It can be observed that the score distribution range of Qwen2-7B is significantly higher than that of Qwen2-0.5B and Qwen2-1.5B. It is well known that models with larger parameter sizes have better task processing capabilities. However, other publicly distributed models with more parameters (such as Qwen2-72B) consume large amounts of computing resources, which is not supported by ordinary laptop graphics cards. Therefore, the number of Qwen2-7B parameters can maintain high performance without consuming large amounts of computing resources, and supports local deployment to specify the model for our semantic trajectory queries.
As illustrated in
Figure 10, our approach with Qwen2-7B demonstrates that the average level of four perspectives exceeds “Acceptable”. Specifically, regarding relevance and completeness, most participants responded “Good” and “Excellent”, indicating that our approach can effectively understand and accurately capture semantic information in natural language queries and trajectories. It leverages the query rewritten module to align more closely with user requirements and enhance the relevance of answers. In terms of naturalness and informativeness, positive feedback was received from participants, with 82% and 37% of participants considering the generated information to be better than “Good” in both dimensions, respectively. The text-understanding capability of LLMs ensures the fluency and naturalness of the generated responses. Moreover, the generated responses reduce the barriers for non-professional users to understand and engage with the semantic trajectory queries. In addition, about 9% of the volunteers noted that the answers lacked integration with additional domain-specific knowledge, and gave a “Poor” option in informativeness, which could be a key focus for improvement in our future work.
4.5. Ablation Study
Ablation experiments were conducted to evaluate the contribution of each module in our approach by selectively removing key components. The semantic extraction, trajectory document construction, and document retrieval modules were regarded as core processes, and were therefore retained in all settings. Three simplified variants were constructed by individually removing the modules of trajectory segmentation (
), query rewritten (
), and results reordering (
), while maintaining consistency of the rest of the architecture with the original approach. These ablated models were evaluated for all queries in Task 1 and Task 2 to evaluate the overall generalization ability.
Figure 11 presents the average evaluation metric values across all query statements in Task 1 and Task 2 for each simplified model.
Compared to the simplified model, our approach demonstrates that the of the query results is increased by 5.05%, the is increased by 14.65%, and the score is increased by 10.2%. Through the trajectory segmentation module, smaller split homogeneous segments transform long sentences detailing the entire trajectory into short sentences, enhancing the critical semantic information in each sentence. This can support the identification of critical semantic details, thereby better aligning semantic trajectories with natural language queries and improving and . At the same time, the increase in means that more relevant trajectories are retrieved, reducing the proportion of irrelevant trajectories and indirectly improving and .
Unlike trajectory segmentation, the query rewritten module focuses on refining and correcting natural language queries, eliminating the interference of irrelevant and redundant input. Therefore, our approach acquires trajectories from rewritten queries, which can return more relevant trajectories and reduce the probability of misidentifying trajectories. As a result, the , , and score of our approach are 6.49%, 3.66%, and 4.99% higher than those of the simplified model, respectively.
For the simplified model, , the , , and score are decreased by 6.72%, 10.29%, and 8.51%, respectively, compared with our approach. Based on the reorder module, our approach prioritizes relevant trajectories in the candidate list, ensures that more relevant trajectories appear in the response, and improves evaluation metric values. Furthermore, the simplified model eliminates the post-processing operation of reordering according to semantic similarity, leading to the trajectories being placed randomly in the result. Consequently, the and of this simplified model are both the lowest values.
Although these simplified models can retrieve trajectories based on the document retrieval module and generate natural language responses based on the response generator, they still suffer from inaccurate trajectories. Hence, these models cannot be compared with the complete model in terms of relevance, naturalness, informativeness, and completeness. In conclusion, the comparative analysis in the ablation study demonstrates the significant impact of the core modules in our approach on the overall performance. Also, it highlights the outstanding contribution of each module in enhancing our approach.
5. Discussion
To enable efficient natural language semantic trajectory queries, we employed a natural language-based AIS trajectory query approach using LLMs. The framework first converts the AIS trajectory data into semantic descriptions. Then, it integrates a query rewritten module, a document retriever, and a response generator to complete the retrieval process, enabling a deep understanding of queries, while ensuring that the retrieved results closely align with user intent.
We conducted comprehensive experiments to evaluate the performance of our approach. Compared with traditional spatio-temporal and semantic query methods, our approach outperformed other models across all metrics, demonstrating strong effectiveness in trajectory retrieval. By leveraging an embedding-based retriever, our approach achieves deeper semantic understanding and better alignment with user intent. It also prioritizes relevant trajectories, improving user experience by reducing irrelevant results. A human study further confirmed the usability and user-friendliness of the proposed approach, showing that natural language querying and responses can significantly lower usage barriers and cognitive load. The ablation study revealed that each core module plays a critical role, and removing any of them leads to a notable performance drop. This confirms the effectiveness and well-balanced design of the entire pipeline. The reordering module has the most significant impact on NDCG and DCG, as these metrics are directly related to result ranking. In contrast, the trajectory segmentation module more significantly affects the other three metrics, since segmentation is closely tied to subsequent semantic extraction. Important semantic features may be missed without proper segmentation, leading to incomplete query understanding. In conclusion, the proposed approach provides accurate retrieval results and corresponding natural language responses, overcoming barriers to understanding trajectories.
Despite the strong performance of our approach, it still has limitations. While the generated responses are accurate, fluent, and relevant, they lack depth and expansion. Specifically, the answers mainly summarize the retrieval results, without incorporating domain-specific knowledge. This is due to the training data being limited to trajectory information, which restricts the ability to generate more insightful responses. This feedback has encouraged us to integrate domain knowledge to enhance response richness, diversity, and completeness.
Secondly, although our approach achieves strong retrieval performance, there is no obvious performance improvement for some problems. This is mainly due to the embedding method’s difficulty in fully capturing complex or nonlinear semantic relationships in overly intricate queries.
Additionally, it is well known that the scale of LLMs parameters significantly impacts their ability to process data and understand natural language, with larger models tending to achieve better performance. However, due to hardware constraints, we utilized the Qwen2-7B model in this experiment, balancing deployment feasibility and high performance without excessive resource consumption. In future work, we will explore higher-capacity LLMs versions based on actual application needs to enhance performance further.
6. Conclusions
To address the limitations of traditional trajectory query methods, we propose a natural language-based AIS trajectory query approach using LLMs. It acquires trajectories from natural language queries and responds with natural language answers and semantic trajectory query results, thus delivering a more intelligent and user-friendly querying experience.
Above all, the trajectory textualization process begins by segmenting trajectories into smaller, meaningful segments. Then, a sophisticated semantic extraction method is applied to extract macro-motion and micro-motion semantics from these segments and transform the raw trajectory data into structured trajectory documents. The process can transform numerical data into natural language semantic descriptions, thus enabling state-of-the-art LLMs to comprehend and process trajectory data.
Subsequently, we utilize LLMs to perform semantic queries on trajectory documents. This process starts with a query rewritten module that rewrites the original query into a refined natural language query. Then, a retriever module is designed to retrieve and reorder trajectory documents to align natural language queries with the trajectory documents. Finally, the reordered trajectories are integrated with the rewritten query to generate final natural language responses that deliver comprehensive and contextually enriched information.
Thorough evaluations were conducted to confirm the effectiveness of querying trajectories from natural language, in which our approach achieved superior , , scores, , and , and surpassed traditional spatio-temporal and semantic query methods. In conclusion, our approach can overcome barriers to understanding trajectory data and complex trajectory query requirements, thus allowing more natural and effective interaction with trajectory data for domain experts and novices.
In the future, we will explore multi-source heterogeneous trajectory queries to integrate and analyze data from various sources, such as social media check-ins and transportation networks. We must develop more robust approaches to comprehending more complex natural language queries by leveraging diverse data sources. In addition, we will incorporate more domain background knowledge into the model to make the generated response content richer, rather than just limited to trajectory data. These expansions will enable our framework to handle a broader range of natural language queries and provide more detailed and contextually relevant responses.
Author Contributions
Conceptualization, Xuan Guo, Shutong Yu and Junnan Liu; methodology, Xuan Guo, Shutong Yu and Junnan Liu; software, Jinxue Zhang and Junnan Liu; validation, Xuan Guo, Shutong Yu and Junnan Liu; formal analysis, Shutong Yu; investigation, Xuan Guo and Shutong Yu; resources, Xiaohui Chen and Junnan Liu; data curation, Jinxue Zhang; writing—original draft preparation, Xuan Guo, Shutong Yu and Junnan Liu; writing—review and editing, Shutong Yu and Huanyu Bi; visualization, Shutong Yu; supervision, Xuan Guo, Xiaohui Chen and Junnan Liu; project administration, Jinxue Zhang; funding acquisition, Xuan Guo, Xiaohui Chen and Junnan Liu. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Key Laboratory of Smart Earth (KF2023YB02-05), the State Key Laboratory of Spatial Datum (SKLGIE2023-M-4-1 and SKLGIE2024-M-4-1), the National Natural Science Foundation of China (42301526 and 42371438), the National Earth Observation Data Center (NODAOP2024006), and the Natural Science Foundation of Henan (252300421799).
Data Availability Statement
The data presented in this study are available on request from the corresponding author, due to privacy restrictions.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Guo, X.; Wang, N.; Ren, Y.; Liu, J.; Wang, H.; Chen, X.; Zhang, B.; Xu, M. Ship trajectory segmentation by movement states while addressing uncertainty and sparsity. Ocean Eng. 2024, 312, 119218. [Google Scholar] [CrossRef]
- Guo, S.; Mou, J.; Chen, L.; Chen, P. Improved kinematic interpolation for AIS trajectory reconstruction. Ocean Eng. 2021, 234, 109256. [Google Scholar] [CrossRef]
- Yang, D.; Wu, L.; Wang, S.; Jia, H.; Li, K.X. How big data enriches maritime research–a critical review of Automatic Identification System (AIS) data applications. Transp. Rev. 2019, 39, 755–773. [Google Scholar] [CrossRef]
- Xu, J.; Lu, H.; Bao, Z. A Query Optimizer for Range Queries over Multi-Attribute Trajectories. ACM Trans. Intell. Syst. Technol. 2023, 14, 1–28. [Google Scholar] [CrossRef]
- Cao, K.; Sun, Q.; Liu, H.; Liu, Y.; Meng, G.; Guo, J. Social space keyword query based on semantic trajectory. Neurocomputing 2021, 428, 340–351. [Google Scholar] [CrossRef]
- Li, W.; Jun, Z.; Qing, Z.; Jinbin, Z.; Xiao, H.; Dehbi, Y. Visual attention-guided augmented representation of geographic scenes: A case of bridge stress visualization. Int. J. Geogr. Inf. Sci. 2024, 38, 527–549. [Google Scholar] [CrossRef]
- Zheng, K.; Zhao, Y.; Lian, D.F.; Zheng, B.L.; Liu, G.F.; Zhou, X.F. Reference-Based Framework for Spatio-Temporal Trajectory Compression and Query Processing. IEEE Trans. Knowl. Data Eng. 2020, 32, 2227–2240. [Google Scholar] [CrossRef]
- Huang, L.; Wen, Y.; Guo, W.; Zhu, X.; Zhou, C.; Zhang, F.; Zhu, M. Mobility pattern analysis of ship trajectories based on semantic transformation and topic model. Ocean Eng. 2020, 201, 107092. [Google Scholar] [CrossRef]
- De Almeida, D.R.; Baptista, C.D.; De Andrade, F.G. Similarity Search on Semantic Trajectories Using Text Processing. ISPRS Int. J. Geo-Inf. 2022, 11, 412. [Google Scholar] [CrossRef]
- Hosseini-Asl, E.; McCann, B.; Wu, C.-S.; Yavuz, S.; Socher, R. A simple language model for task-oriented dialogue. Adv. Neural Inf. Process. Syst. 2020, 33, 20179–20191. [Google Scholar]
- Swamidorai, S.; Murthy, T.S.; Sriharsha, K. Translating natural language questions to SQL queries (nested queries). Multimed. Tools Appl. 2023, 83, 45391–45405. [Google Scholar] [CrossRef]
- Huang, Z.; Zhao, Y.; Chen, W.; Gao, S.; Yu, K.; Xu, W.; Tang, M.; Zhu, M.; Xu, M. A Natural-language-based Visual Query Approach of Uncertain Human Trajectories. IEEE Trans. Vis. Comput. Graph. 2020, 26, 1256–1266. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Ma, C.; Feng, X.Y.; Zhang, Z.Y.; Yang, H.; Zhang, J.S.; Chen, Z.Y.; Tang, J.K.; Chen, X.; Lin, Y.K.; et al. A survey on large language model based autonomous agents. Front. Comput. Sci. 2024, 18, 186345. [Google Scholar] [CrossRef]
- Wilkerson, K.; Leake, D. On Implementing Case-Based Reasoning with Large Language Models. In Case-Based Reasoning Research and Development: 32nd International Conference, ICCBR 2024, Cork, Ireland, 29 September–1 October 2014 Proceedings; Lecture Notes in Computer Science; Lecture Notes in Artificial Intelligence (14775); Springer: Cham, Switzerland, 2024; pp. 404–417. [Google Scholar]
- Ding, Y.C.; Li, Y.H.; Zhou, X.; Huang, Z.J.; You, S.M.; Luo, J. Sampling Big Trajectory Data for Traversal Trajectory Aggregate Query. IEEE Trans. Big Data 2019, 5, 550–563. [Google Scholar] [CrossRef]
- Gao, C.; Zhang, Z.; Huang, C.; Yin, H.; Yang, Q.; Shao, J. Semantic trajectory representation and retrieval via hierarchical embedding. Inf. Sci. 2020, 538, 176–192. [Google Scholar] [CrossRef]
- Bao, Y.; Huang, Z.; Gong, X.; Zhang, Y.; Yin, G.; Wang, H. Optimizing segmented trajectory data storage with HBase for improved spatio-temporal query efficiency. Int. J. Digit. Earth 2023, 16, 1124–1143. [Google Scholar] [CrossRef]
- Li, R.Y.; He, H.J.; Wang, R.B.; Ruan, S.J.; He, T.F.; Bao, J.; Zhang, J.B.; Hong, L.; Zheng, Y. TrajMesa: A Distributed NoSQL-Based Trajectory Data Management System. IEEE Trans. Knowl. Data Eng. 2023, 35, 1013–1027. [Google Scholar] [CrossRef]
- Chen, B.Y.; Luo, Y.B.; Jia, T.; Chen, H.P.; Chen, X.Y.; Gong, J.Y.; Li, Q.Q. A spatiotemporal data model and an index structure for computational time geography. Int. J. Geogr. Inf. Sci. 2023, 37, 550–583. [Google Scholar] [CrossRef]
- Ramadhan, H.; Kwon, J. X-FIST: Extended flood index for efficient similarity search in massive trajectory dataset. Inf. Sci. 2022, 606, 549–572. [Google Scholar] [CrossRef]
- Zhang, X.; Xie, X.H.; Wen, L.; Lai, J.H. Person group detection with global trajectory extraction in a disjoint camera network. Neurocomputing 2024, 574, 127281. [Google Scholar] [CrossRef]
- Boroumand, F.; Alesheikh, A.A.; Sharif, M.; Farnaghi, M. FLCSS: A fuzzy-based longest common subsequence method for uncertainty management in trajectory similarity measures. Trans. GIS 2022, 26, 2244–2262. [Google Scholar] [CrossRef]
- Ahmed, I.; Jun, M.; Ding, Y. A spatio-temporal track association algorithm based on marine vessel automatic identification system data. IEEE Trans. Intell. Transp. Syst. 2022, 23, 20783–20797. [Google Scholar] [CrossRef]
- Wu, X.; Liu, Y.; Zhao, X.; Chen, J. STKST-I: An Efficient Semantic Trajectory Search by Temporal and Semantic Keywords. Expert Syst. Appl. 2023, 225, 120064. [Google Scholar] [CrossRef]
- Zheng, B.L.; Zheng, K.; Scheuermann, P.; Zhou, X.; Nguyen, Q.V.H.; Li, C. Searching activity trajectory with keywords. World Wide Web-Internet Web Inf. Syst. 2019, 22, 967–1000. [Google Scholar] [CrossRef]
- Tian, R.J.; Li, J.J.; Zhang, W.S.; Wang, F. A distributed framework for large-scale semantic trajectory similarity join. Multimed. Tools Appl. 2024, 83, 16205–16229. [Google Scholar] [CrossRef]
- Kumar, S.; Deepika, D.; Slater, K.; Kumar, V. AOPWIKI-EXPLORER: An interactive graph-based query engine leveraging large language models. Comput. Toxicol. 2024, 30, 100308. [Google Scholar] [CrossRef]
- Zhao, Z.; Fan, W.; Li, J.; Liu, Y.; Mei, X.; Wang, Y.; Wen, Z.; Wang, F.; Zhao, X.; Tang, J.; et al. Recommender Systems in the Era of Large Language Models (LLMs). IEEE Trans. Knowl. Data Eng. 2024, 36, 6889–6907. [Google Scholar] [CrossRef]
- Wang, H.; Na, T. Rethinking E-Commerce Search. ACM SIGIR Forum 2023, 57, 1–19. [Google Scholar] [CrossRef]
- Bai, J.W.; Kamatchinathan, S.; Kundu, D.J.; Bandla, C.; Vizcaino, J.A.; Perez-Riverol, Y. Open-source large language models in action: A bioinformatics chatbot for PRIDE database. Proteomics 2024, 24, 2400005. [Google Scholar] [CrossRef]
- Xu, S.; Pang, L.; Shen, H.; Cheng, X.; Chua, T.S. Search-in-the-Chain: Interactively Enhancing Large Language Models with Search for Knowledge-intensive Tasks. In Proceedings of the WWW '24: Proceedings of the ACM on Web Conference 2024, Singapore, 13–17 May 2024; pp. 1362–1373. [Google Scholar]
- Baek, J.; Chandrasekaran, N.; Cucerzan, S.; Herring, A.; Jauhar, S.K. Knowledge-Augmented Large Language Models for Personalized Contextual Query Suggestion. In Proceedings of the WWW '24: Proceedings of the ACM on Web Conference 2024, Singapore, 13–17 May 2024; pp. 3355–3366. [Google Scholar]
- Kim, W.; Yeganova, L.; Comeau, D.C.; Wilbur, W.J.; Lu, Z. Towards a unified search: Improving PubMed retrieval with full text. J. Biomed. Inform. 2022, 134, 104211. [Google Scholar] [CrossRef]
- Liu, S.; Nie, W.; Wang, C.; Lu, J.; Qiao, Z.; Liu, L.; Tang, J.; Xiao, C.; Anandkumar, A. Multi-modal molecule structure–text model for text-based retrieval and editing. Nat. Mach. Intell. 2023, 5, 1447–1457. [Google Scholar] [CrossRef]
- Lin, D. Revolutionizing Retrieval-Augmented Generation with Enhanced PDF Structure Recognition. arXiv 2024, arXiv:2401.12599. [Google Scholar] [CrossRef]
- Jiang, Y.Y.; Yang, C.W. Is ChatGPT a Good Geospatial Data Analyst? Exploring the Integration of Natural Language into Structured Query Language within a Spatial Database. ISPRS Int. J. Geo-Inf. 2024, 13, 26. [Google Scholar] [CrossRef]
- Cao, Y.; Xue, F.; Chi, Y.Y.; Ding, Z.M.; Guo, L.M.; Cai, Z.; Tang, H.L. Effective spatio-temporal semantic trajectory generation for similar pattern group identification. Int. J. Mach. Learn. Cybern. 2020, 11, 287–300. [Google Scholar] [CrossRef]
- Izquierdo, Y.T.; Monteagudo García, G.; Casanova, M.A.; Paes Leme, L.A.P.; Sardianos, C.; Tserpes, K.; Varlamis, I.; Ruback Rodrigues, L.C. Stop-and-move sequence expressions over semantic trajectories. Int. J. Geogr. Inf. Sci. 2021, 35, 793–818. [Google Scholar] [CrossRef]
- Gao, Y.; Huang, L.; Feng, J.; Wang, X. Semantic trajectory segmentation based on change-point detection and ontology. Int. J. Geogr. Inf. Sci. 2020, 34, 2361–2394. [Google Scholar] [CrossRef]
- Liu, M.; He, G.; Long, Y. A Semantics-Based Trajectory Segmentation Simplification Method. J. Geovisualization Spat. Anal. 2021, 5, 1–15. [Google Scholar] [CrossRef]
- Huang, J.C.; Zhang, Y.F.; Deng, M.; He, Z.B. Mining crowdsourced trajectory and geo-tagged data for spatial-semantic road map construction. Trans. GIS 2022, 26, 735–754. [Google Scholar] [CrossRef]
- De Almeida, D.R.; Baptista, C.D.; de Andrade, F.G.; Soares, A. A Survey on Big Data for Trajectory Analytics. ISPRS Int. J. Geo-Inf. 2020, 9, 88. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhang, Y.H.; Zhang, F.F.; Zhang, Y.T.; Wang, X.D. Trajectory Compression with Spatio-Temporal Semantic Constraints. ISPRS Int. J. Geo-Inf. 2024, 13, 212. [Google Scholar] [CrossRef]
- Jagerman, R.; Zhuang, H.; Qin, Z.; Wang, X.; Bendersky, M. Query expansion by prompting large language models. arXiv 2023, arXiv:2305.03653. [Google Scholar]
- Wang, L.; Yang, N.; Wei, F. Query2doc: Query expansion with large language models. arXiv 2023, arXiv:2303.07678. [Google Scholar]
- Huang, R. Improved content recommendation algorithm integrating semantic information. J. Big Data 2023, 10, 84. [Google Scholar] [CrossRef]
- Schütze, H.; Manning, C.D.; Raghavan, P. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; Volume 39. [Google Scholar]
- Abad-Navarro, F.; Martínez-Costa, C.; Fernández-Breis, J.T. Semankey: A Semantics-Driven Approach for Querying RDF Repositories Using Keywords. IEEE Access 2021, 9, 91282–91302. [Google Scholar] [CrossRef]
- Stathopoulos, E.A.; Karageorgiadis, A.I.; Kokkalas, A.; Diplaris, S.; Vrochidis, S.; Kompatsiaris, I. A Query Expansion Benchmark on Social Media Information Retrieval: Which Methodology Performs Best and Aligns with Semantics? Computers 2023, 12, 119. [Google Scholar] [CrossRef]
- Zhu, J.; Pei, D.; Yungang, C.; Jianbo, L.; Yukun, G.; Ping, W.; Li, W. A flood knowledge-constrained large language model interactable with GIS: Enhancing public risk perception of floods. Int. J. Geogr. Inf. Sci. 2024, 38, 603–625. [Google Scholar] [CrossRef]
- Li, W.; Jun, Z.; Lin, F.; Qing, Z.; Yakun, X.; Hu, Y. An augmented representation method of debris flow scenes to improve public perception. Int. J. Geogr. Inf. Sci. 2021, 35, 1521–1544. [Google Scholar] [CrossRef]
- Callison-Burch, C.; Osborne, M.; Koehn, P. Re-evaluating the role of BLEU in machine translation research. In Proceedings of the 11th conference of the european chapter of the association for computational linguistics, Trento, Italy, 3–7 April 2006. [Google Scholar]
- See, A.; Roller, S.; Kiela, D.; Weston, J. What makes a good conversation? How controllable attributes affect human judgments. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 1702–1723. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).





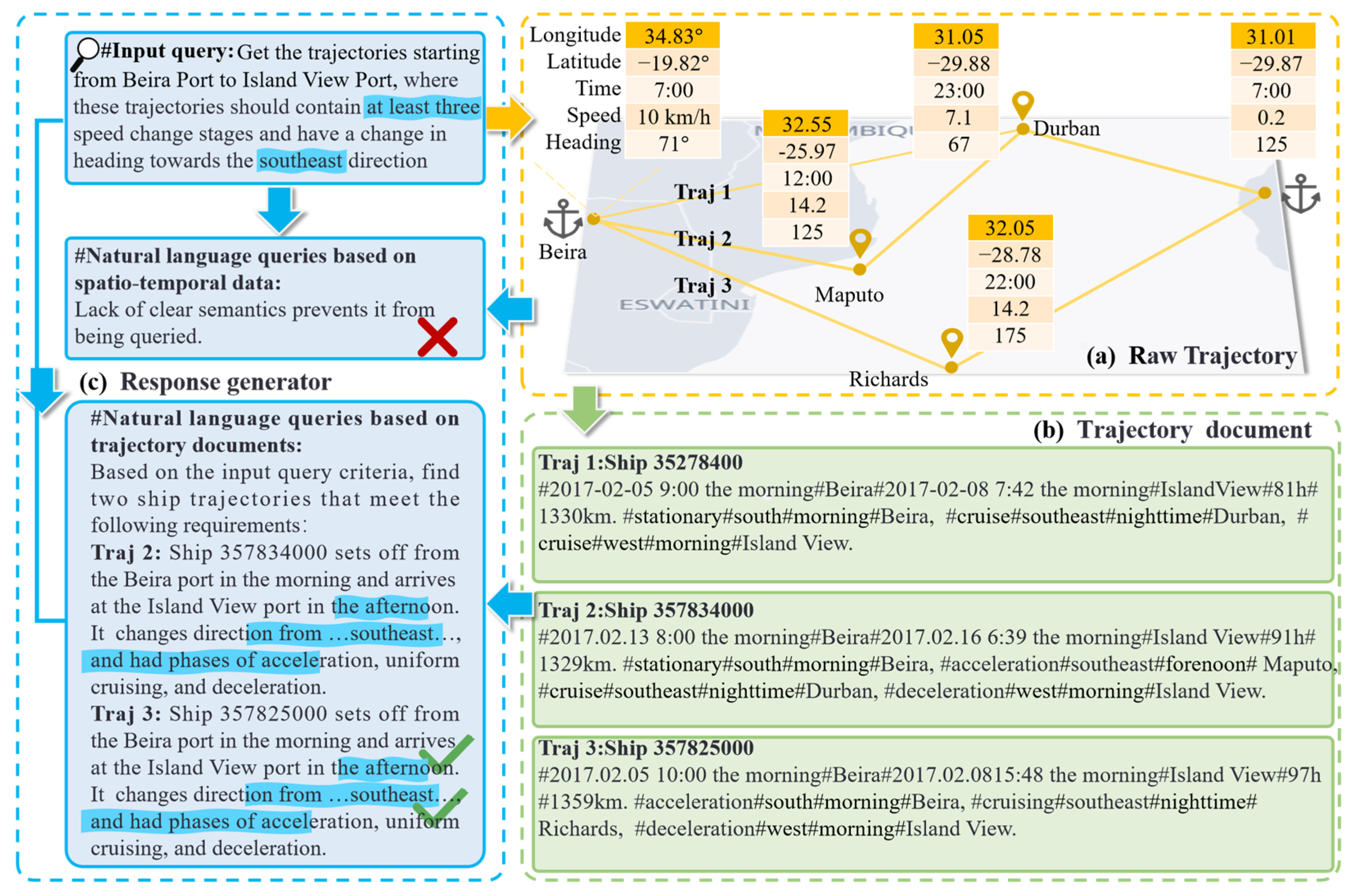


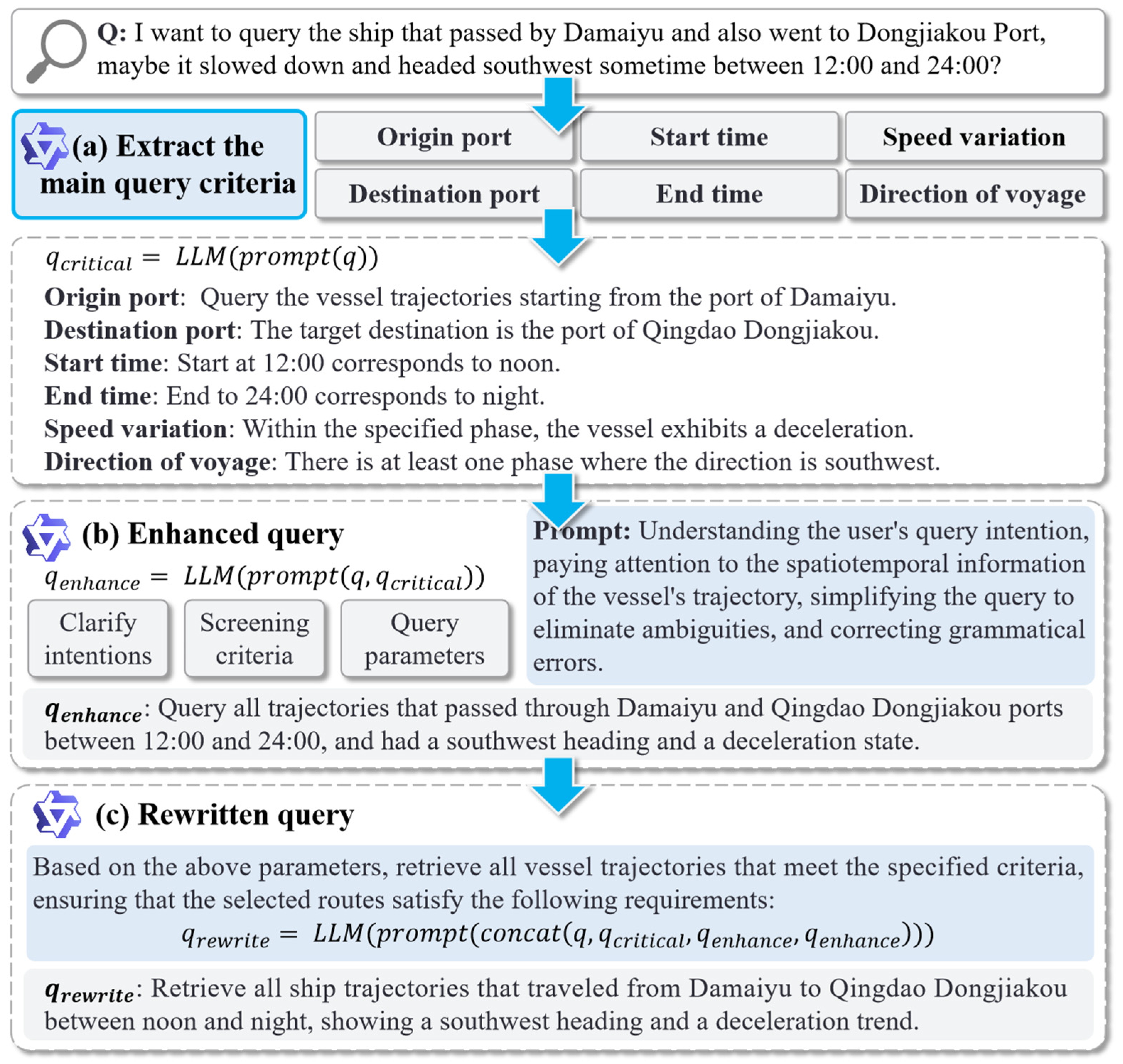



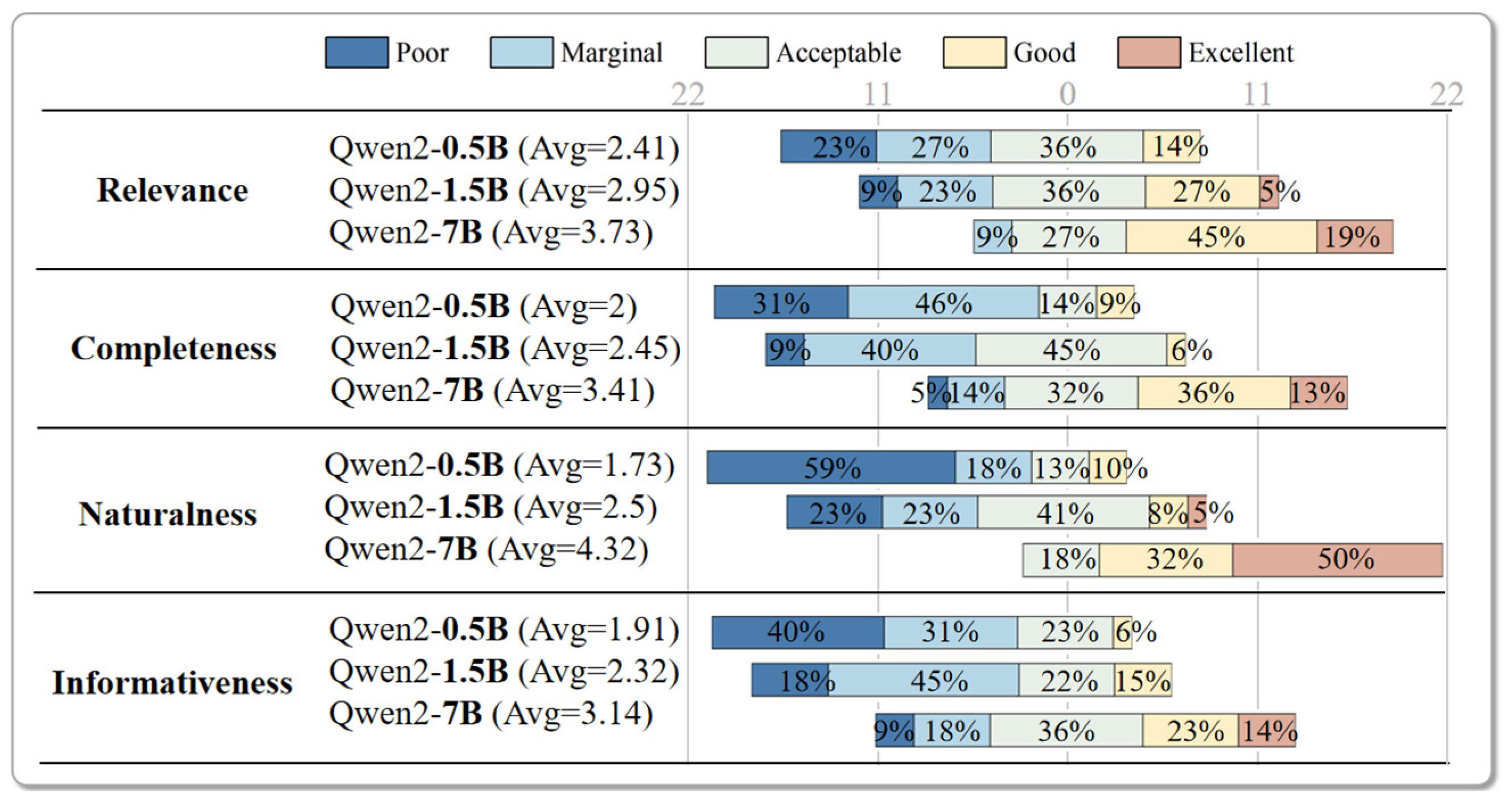


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}