1. Introduction
Vector geographic data are an essential resource in GIS-related industries and have found widespread applications in fields such as land surveying, military simulations, and urban planning. However, the conflict between data sharing and protection has become increasingly difficult to reconcile. Frequent copyright infringement incidents highlight the urgent need for effective protection measures [
1,
2,
3]. Digital watermarking is a key technology for copyright protection. It establishes a strong relationship between digital data and watermark information, safeguarding the copyright of vector geographic data [
4,
5,
6]. At the same time, attackers employ various methods to attack watermarks, making the improvement of watermark robustness a major research focus.
Current watermarking algorithms for vector geographic data can be broadly classified into embedded watermarking and constructive watermarking [
7]. Embedded watermarking modifies the coordinates (including features derived from coordinates), the attribute, or the storage order to embed watermark information directly into the vector geographic data. For example, Peng et al. [
8] used the Douglas–Peucker compression algorithm [
9] to construct the feature vertex distance ratio (FVDR), embedding the watermark by adjusting the FVDR. Other approaches include embedding invisible characters into the attribute values of road data [
10] or changing the storage order of vertices within polylines to embed the watermark information [
11]. While embedded watermarking increases the relationship between the data and the watermark, it inevitably alters the data. Methods that embed watermarks into coordinates affect data precision, making them unsuitable for high data accuracy scenarios. Methods embedding watermarks into attributes increase file size and storage demands, potentially exposing the watermark to attackers. Furthermore, embedding watermarks into storage order may disrupt the semantic or functional meaning of the data, such as river flow directions or pipeline pathways. Therefore, the robustness of embedded watermarking is achieved at the cost of data integrity, limiting its application.
The second type is constructive watermarking, often referred to as zero watermarking [
12,
13,
14]. Zero watermarking is distinguished by its non-intrusive nature, as it extracts features from the original data without introducing any modifications. The constructed watermark based on the features is then registered with third-party intellectual property rights (IPR) agencies for copyright protection. This type of method typically partitions data into sub-blocks using regular or irregular segmentation techniques, such as grids [
15], rings [
16], quadtrees [
17], Delaunay triangulation [
18], or object-based divisions [
19,
20,
21,
22,
23]. Features such as geometric properties, vertex counts, or storage orders are quantified into watermark bits or indices, which are then combined to construct the zero watermark. For instance, Zhang et al. [
15] employed a grid-based approach, partitioning the data into 64 × 64 blocks and subsequently quantifying the vertex count within each block to construct the watermark. Peng et al. [
19] adopted an alternative strategy, treating individual polylines as the fundamental operational units. This approach, analogous to the embedded watermarking method described in the literature [
8], utilized the FVDR as the basis for quantification, converting these features into watermark indices and bits. The constructed watermark was then refined through the majority voting mechanism. Similarly, Wang et al. [
23] leveraged both the vertex count and the storage order features. Specifically, the vertex counts of arbitrary polyline or polygon pairs were quantified into watermark indices, while the storage order was used to generate watermark bits. Notably, such methods preserve the integrity of the original data by avoiding any modifications, thereby addressing the inherent limitations associated with embedded watermarking.
However, existing zero-watermarking methods, while advantageous in preserving data integrity, are constrained by their reliance on constructing a single watermark derived from the overall characteristics of the data. This scheme inherently limits their adaptability in resisting diverse and complex attack types. For instance, FVDR-based methods demonstrate robust performance against simplification attacks but remain vulnerable to non-uniform scaling. In contrast, vertex count-based methods excel in resisting non-uniform scaling and other geometric transformations but struggle under simplification and attacks that significantly modify vertex statistics. Consequently, these methods exhibit robustness in isolated scenarios but fail to achieve comprehensive resistance across multiple attack types.
In summary, embedded watermarking methods enhance robustness by embedding watermarks directly into the data, tightly coupling the watermark with the data. However, this approach inevitably compromises the original data’s usability and precision, limiting its applicability in scenarios demanding high data accuracy. Constructive watermarking, on the other hand, constructs watermarks from the data without modifying the data, effectively addressing the precision degradation issue of embedded methods. Nonetheless, existing constructive watermarking approaches still face challenges in achieving comprehensive robustness against diverse attack types. Therefore, developing algorithms capable of simultaneously resisting multiple attack types remains a critical research problem in the field of digital watermarking for vector geographic data.
To address these issues, this paper proposes a multi-instance zero-watermarking method for vector geographic data, inspired by the class-instance paradigm in object-oriented programming. By applying different preprocessing techniques, the proposed method constructs multiple zero watermarks from a single dataset, enabling it to adapt to the variability and complexity of attack types. Unlike existing approaches that segment the dataset to construct separate watermarks, the proposed algorithm constructs each zero watermark using the full set of data features, differentiated only by the preprocessing applied. The remainder of this paper is structured as follows:
Section 2 introduces the methodology and its details,
Section 3 describes the experimental setup,
Section 4 presents the experimental results and analysis,
Section 5 discusses the broader implications of the findings, and
Section 6 concludes the study.
2. Proposed Approach
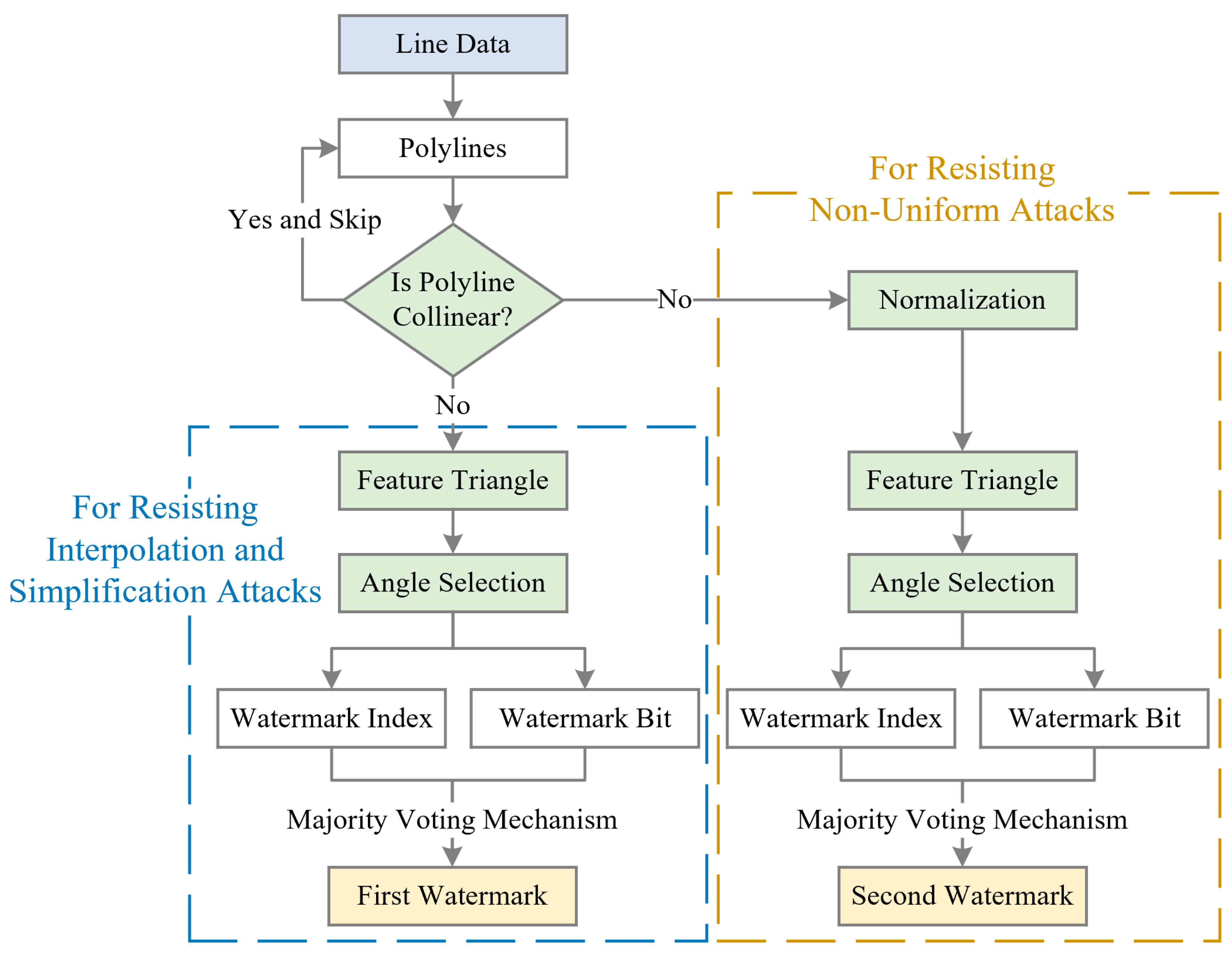
The proposed multi-instance zero-watermarking algorithm targets vector geographic data, specifically line data, as the watermarking carrier. Inspired by the class-instance paradigm in object-oriented programming, the algorithm treats the data as a “class” from which multiple “instances” (zero watermarks) are derived. By employing preprocessing techniques such as normalization, feature triangle construction, and angle selection, the algorithm generates multiple zero watermarks to resist various attack types. Normalization eliminates geometric deformations, enhancing robustness against non-uniform scaling attacks. Feature triangle construction and angle selection, inspired by the Douglas-Peucker algorithm, provide resilience against interpolation and simplification attacks. Furthermore, angle-based features are derived by quantizing the selected angles in the feature triangle. Previous studies [
24,
25,
26] have demonstrated that these features exhibit robustness against translation, uniform scaling, and rotation. Their incorporation into the proposed method enhances its resistance to these geometric attacks. To address non-uniform scaling, interpolation, and simplification attacks, two zero watermarks are constructed. The main framework of the proposed algorithm is shown in
Figure 1.
As illustrated in
Figure 1, the algorithm begins by extracting polylines from the line data. The overall process can be divided into three main parts: collinearity checks, the construction of the first zero watermark (for resisting interpolation and simplification attacks), and the construction of the second zero watermark (for resisting non-uniform scaling attacks). In the first part, for each polyline, collinearity checks are performed on its vertices. If all vertices of a polyline are collinear, it is skipped, and the next polyline is processed. Only non-collinear polylines are further proceeded to subsequent stages.
The second and third parts involve the generation of two zero watermarks. The primary difference between these two processes lies in the application of normalization. Specifically, normalization is applied in the construction of the second zero watermark to enhance robustness against non-uniform scaling attacks. However, normalization is avoided during the construction of the first zero watermark for robustness against interpolation and simplification attacks. This is because simplification may alter the bounding coordinates and lead to unintended deformations during normalization. Beyond normalization, the subsequent steps for generating both zero watermarks are identical, as summarized below: (1) Feature triangle construction: The polyline is reduced to its most essential form by retaining only three vertices, which form the feature triangle; (2) Angle selection: Two angles are selected from the three angles in the constructed feature triangle; (3) Watermark construction: The selected angles are quantified into watermark indices and bits, which are aggregated using the majority voting mechanism to construct two zero watermarks.
During copyright verification, the generated zero watermarks are evaluated for consistency. The steps of collinearity check, normalization, feature triangle construction, angle selection, zero-watermark construction, and watermark evaluation are detailed in the following subsections.
2.1. Collinearity Check
To ensure meaningful geometric features for watermark construction, the algorithm excludes polylines with collinear vertices. This process involves determining whether three vertices in a polyline are collinear based on their geometric properties. The collinearity check is divided into two cases: (1) For polylines with only two vertices, collinearity is inherent, and such polylines are skipped. (2) For polylines with more than two vertices, three vertices are iteratively selected from the vertex set to evaluate collinearity. This process is repeated times, where n is the total number of vertices in a polyline.
The collinearity of three vertices
,
, and
is determined using the area method, defined as follows:
If the calculated area is less than a predefined threshold (
), the vertices are considered collinear. The threshold is introduced to address the limitations of floating-point arithmetic, where numerical precision makes exact equality comparisons infeasible. Theoretically, collinearity requires the area formed by three vertices to be zero, but in practice, floating-point calculations may produce small non-zero values for collinear points. Thus, the threshold serves as a tolerance value to ensure robust and accurate detection of collinearity. Any polyline that does not contain at least one set of non-collinear vertices is excluded from subsequent steps. This ensures that all polylines used in watermark construction contribute to meaningful geometric features, improving the reliability of the resulting zero watermarks.
2.2. Normalization
Normalization is employed as a preprocessing step to eliminate deformation caused by non-uniform scaling. This ensures that the geometric features extracted from the data remain consistent, regardless of the scaling factors applied to the original coordinates. The process involves normalizing the
x and
y coordinates of the vertices using min–max normalization, as defined by the following equations:
Here,
and
represent the normalized coordinates, while
,
,
, and
denote the minimum and maximum values of the
x and
y coordinates within the polyline, respectively.
The stability of the normalized coordinates under non-uniform scaling has been validated theoretically. Zhang et al. [
27,
28] demonstrated that the normalized
x and
y coordinates remain invariant when the original coordinates are scaled by factors Sx and Sy. Specifically, after applying scaling, the normalized coordinates are recalculated as follows:
This invariance ensures that the geometric features extracted from the normalized coordinates remain robust against non-uniform scaling, a critical requirement for practical watermark construction.
Normalization is applied selectively. It is used to stabilize the geometry shape when addressing non-uniform scaling attacks. However, it is omitted when addressing interpolation and simplification attacks, as these attacks may alter the bounding coordinates, potentially introducing unintended deformations during normalization. This selective normalization provides the potential overall robustness to different attack scenarios.
2.3. Feature Triangle Construction
Feature triangle construction is a core step in the proposed algorithm, designed to extract robust geometric features from polylines. The method begins by connecting the first vertex A and the last vertex B of the polyline to form a line segment
AB. Then, the algorithm iteratively examines the remaining vertices to identify point C, which is farthest from
AB. The distance is calculated as the perpendicular distance from each vertex to the line segment. The three vertices, A, B, and C, form the feature triangle, encapsulating critical geometric properties of the polyline.
Figure 2 provides a demonstration of feature triangle construction.
As illustrated in
Figure 2, a polyline consisting of nine vertices is shown in
Figure 2a, where A and B represent the first and last points, respectively. The vertex C, identified as the farthest point from
AB, completes the feature triangle, as depicted in
Figure 2b. This construction method corresponds to the initial step of the Douglas–Peucker compression algorithm. However, unlike the Douglas–Peucker algorithm, which recursively divides the polyline to find additional feature points, the proposed method selects only the farthest point. This is not a simplification of the process but a deliberate choice to improve robustness against compression attacks. As noted in the literature [
13], when fewer feature points are retained, the watermarking scheme exhibits greater resistance to compression, as excessive simplification would be required to disrupt the constructed triangle.
2.4. Angle Selection and Zero-Watermark Construction
From the feature triangle, two angles,
and
, are selected and denoted as
α and
β, respectively. These angles are calculated using the cosine rule as follows:
where
AB,
BC, and
AC are the side lengths of the feature triangle, calculated from the coordinates of the vertices A, B, and C. The angles
α and
β are measured in radians, ensuring their range lies within (0, π). As ensured by the collinearity check in
Section 2.1, the feature triangle is always valid with non-collinear vertices.
Next,
α is used for quantifying the watermark index. The quantization process involves retaining all digits from the start of
α up to and including the
q-th digit after the decimal point:
where the round( ) function rounds the value to the nearest integer. The resulting
is then passed as a seed to a uniformly distributed pseudorandom integer generator, denoted as
. The watermark index, denoted as WI, is computed as follows:
where N is the watermark length. The last two arguments of the
function represent the minimum and maximum values of the discrete uniform distribution, defining the range of the watermark index as [1, N]. Similarly, the angle
β is processed to generate the watermark bit. After extracting the integer
in the same manner as
, the watermark bit, denoted as WB, is calculated as follows:
Here, the watermark bit takes a value of either 0 or 1.
Since a line dataset typically contains multiple polylines, multiple watermark indices and bits are generated. These are aggregated using a majority voting mechanism, as described in the literature [
8,
21]. Specifically, an array Stat, equal in length to the watermark, is initialized with all elements set to 0. For each watermark index and its corresponding watermark bit, the following update rules are applied:
where
refers to the specific index in the watermark corresponding to
i-th polyline, and
represents the corresponding bit. After processing all indices and bits, the binary watermark W is finalized based on the values in Stat:
The resulting W is a binary sequence composed of 0 s and 1 s, completing the construction of the zero watermark.
2.5. Watermark Evaluation
The proposed algorithm constructs two zero watermarks from the original dataset, which are registered with an authoritative third-party IPR agency. In the event of a copyright dispute, two zero watermarks are also constructed from the suspicious dataset for comparison. The normalized correlation (NC) is introduced as a quantitative metric to evaluate the similarity between the watermarks, calculated using the following formula:
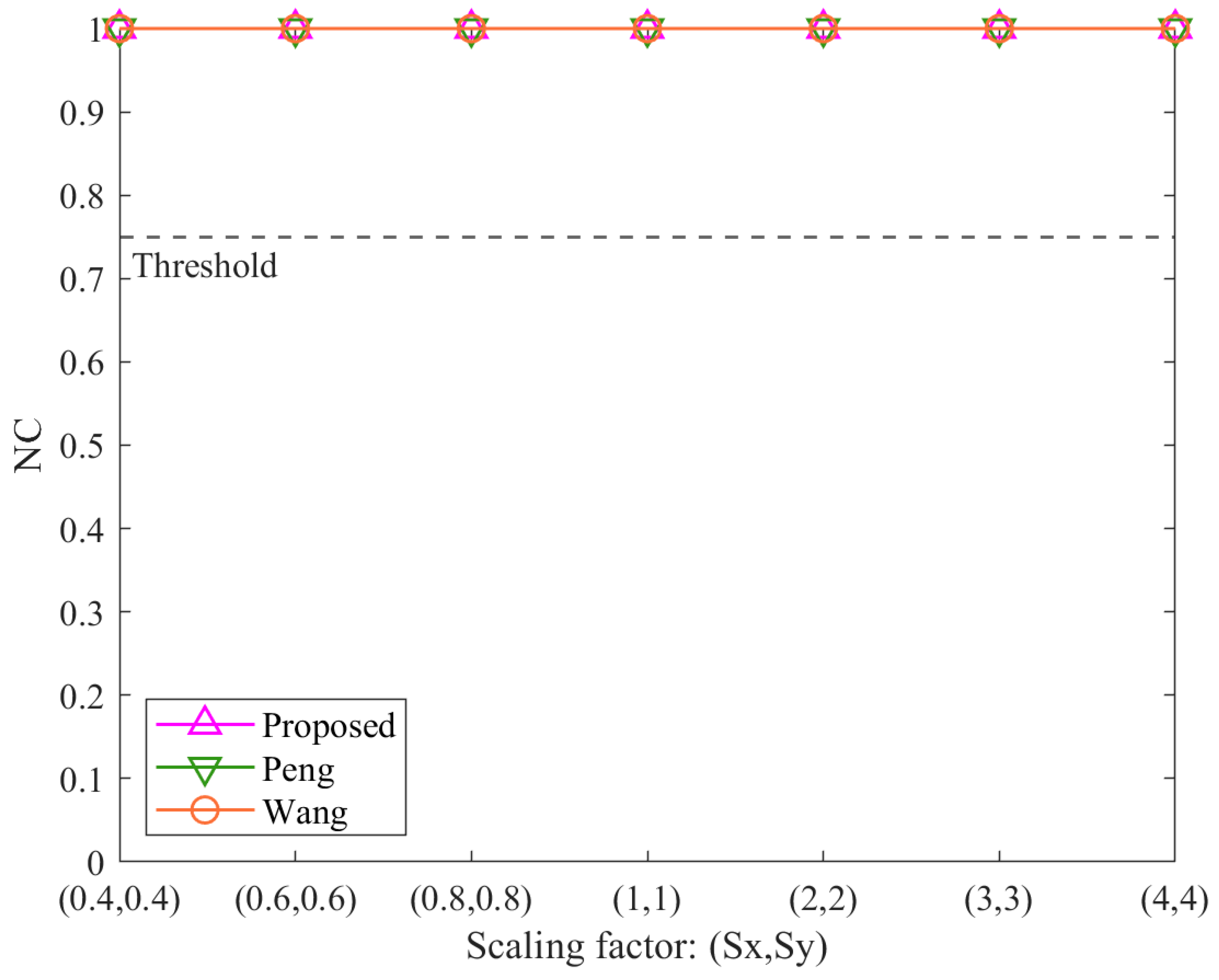
where W and W′ represent the binary sequences of the registered and reconstructed watermarks, respectively. The NC value lies within the range of (0, 1], where a value closer to 1 indicates greater similarity.
To determine whether the watermarks match, a predefined NC threshold is introduced. The two watermarks are considered identical if the NC value exceeds the threshold. The suspicious dataset’s two zero watermarks are compared against the two registered zero watermarks, resulting in four NC values theoretically. In practice, a fixed one-to-one mapping is enforced, whereby the first constructed watermark is aligned with the first registered watermark, and the second constructed watermark is aligned with the second registered watermark. This mapping reduces the comparison to two NC values, denoted as NC1 and NC2, which quantify the similarity between each pair of corresponding watermarks. The final detection result is determined by selecting the maximum value between NC1 and NC2. This approach ensures that even if one instance of the watermark is affected by an attack, the other instance can still provide a reliable match. The redundancy introduced by the multi-instance scheme enhances the robustness of the algorithm, allowing it to handle diverse attack scenarios. Therefore, this evaluation process ensures that the algorithm effectively quantifies the similarity between watermarks, providing a robust copyright validation and infringement detection mechanism.
5. Discussion
5.1. Adaptation for Two-Vertex Polylines
As highlighted in
Section 2.3, feature triangle construction serves as the core of the proposed algorithm, requiring at least three vertices. Consequently, the algorithm is not applicable to polylines containing only two vertices. To address this limitation, an adaptation can be introduced for such datasets.
The algorithm can be modified for polylines with only two vertices by normalizing all points in the dataset instead of normalizing each polyline individually. For a given two-vertex polyline, the nearest vertex from other polylines is identified to construct a feature triangle. The remaining steps of the algorithm remain unchanged. This adaptation effectively transforms the process of finding the farthest point within a polyline into finding the nearest point between polylines. By selecting the nearest vertex, the algorithm can retain a certain resistance to cropping attacks while extending its applicability to two-vertex polylines. This modification enhances the versatility of the proposed algorithm, making it suitable for a broader range of vector geographic datasets.
5.2. Performance Under Composite Attacks
To further assess the robustness of the proposed algorithm, its performance under composite attacks was analyzed. Composite attacks involve combining multiple types of distortions, which may create challenging scenarios for watermark detection. The two zero watermarks in the proposed algorithm, one incorporating normalization and the other not, serve a pivotal role in mitigating these challenges. However, the complementary design introduces variations in robustness when specific types of attacks are combined.
Attacks are classified into conflicting combinations and non-conflicting combinations. Conflicting combinations involve attacks that require normalization (e.g., non-uniform scaling) paired with attacks that must avoid normalization (e.g., simplification or rotation). Non-conflicting combinations, on the other hand, do not involve such conflicts.
Table 2 illustrates the experimental results for eight composite attack scenarios. The results demonstrate that the algorithm maintains strong robustness under non-conflicting combinations (IDs 1–6), with NC values consistently above the threshold of 0.75. In contrast, conflicting combinations (IDs 7 and 8) result in a significant decline in NC values. Specifically, ID 8, which combines rotation and non-uniform scaling, reduces the NC to 0.50, falling below the threshold.
These findings highlight the algorithm’s limitations under conflicting combinations while reaffirming its strong robustness under non-conflicting scenarios. The results validate the complementary nature of the multi-instance scheme in most scenarios but underscore the need for further enhancements to address conflicts. Future work could focus on developing techniques to resist non-uniform scaling without relying on normalization or mitigating simplification attacks independently of feature triangle-based methods.
5.3. Integration into Real-World Applications
The proposed algorithm is designed to enhance the security of vector geographic data, making it highly relevant for integration into GIS workflows and other real-world applications. In modern GIS platforms, vector geographic data are frequently processed for tasks such as mapping, analysis, and sharing across multiple stakeholders. The algorithm can be integrated as either a preprocessing or validation step to ensure that copyrighted datasets are protected during these processes.
Specifically, the collinearity checks and feature triangle construction steps can be seamlessly incorporated into existing data preparation pipelines, while the watermark generation and verification stages can be integrated as additional modules in GIS software (e.g., QGIS 3.28). For example, during data sharing, zero watermarks generated using the proposed method can be registered with intellectual property agencies, enabling robust copyright protection. When disputes arise, the registered watermarks can be compared with reconstructed watermarks to verify data authenticity and ownership.
Moreover, the multi-instance design enhances resilience against geometric transformations commonly encountered in real-world workflows. For instance, routine updates to geographic datasets often involve geometric transformations such as RST attacks. Data modifications tailored to meet specific application requirements may lead to interpolation and simplification attacks. Two case studies illustrating these applications include the following:
- (1)
Transportation Planning and Road Network Simplification
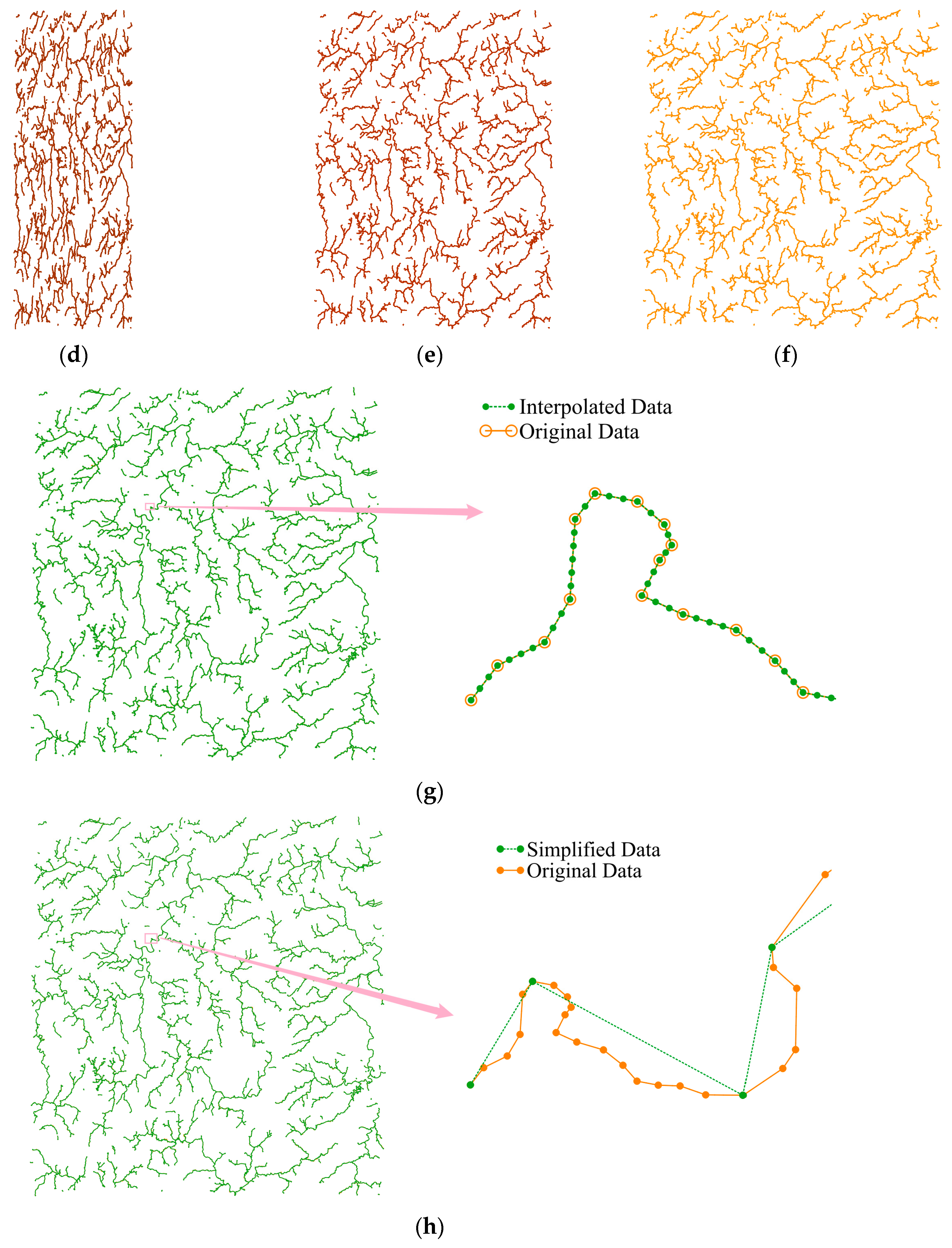
In large-scale transportation planning, road networks are often represented as polylines in GIS systems. These datasets may undergo simplification to reduce computational complexity for routing or network analysis. For instance, a GIS database of a city’s road network may involve removing minor routes or reducing segment density for visualization purposes. Such modifications can distort the geometry of the original data, complicating copyright enforcement. By applying the proposed algorithm before simplification, zero watermarks embedded into the dataset remain detectable after these modifications, ensuring copyright verification even under significant simplification attacks.
- (2)
Hydrological Modeling and River Network Interpolation
In hydrological modeling, river networks represented as vector polylines often require interpolation to fill missing segments or connect disjointed features for flow analysis. For example, in flood modeling, missing tributary connections may be interpolated to provide a complete representation of the network. Such modifications can alter the geometry of the dataset, making copyright protection challenging. Embedding zero watermarks into the river network before interpolation ensures that the dataset retains its copyright markers, allowing robust verification of ownership after modifications.
To facilitate efficient implementation in large-scale systems, computational optimizations such as parallel processing and database indexing can accelerate steps like angle selection and watermark evaluation. Future research could explore integrating the algorithm into distributed GIS platforms and cloud-based services to ensure scalability and real-time copyright enforcement.
6. Conclusions
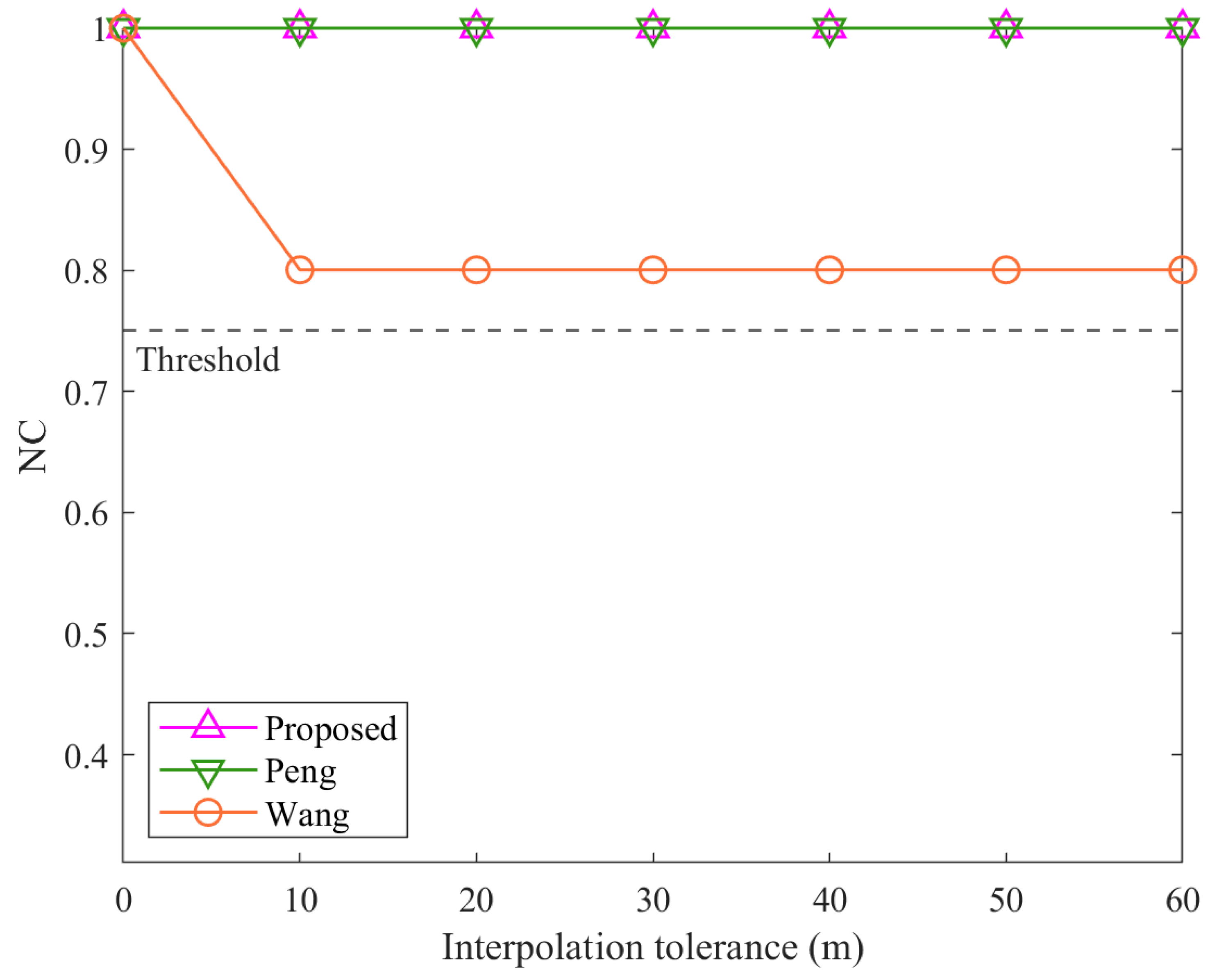
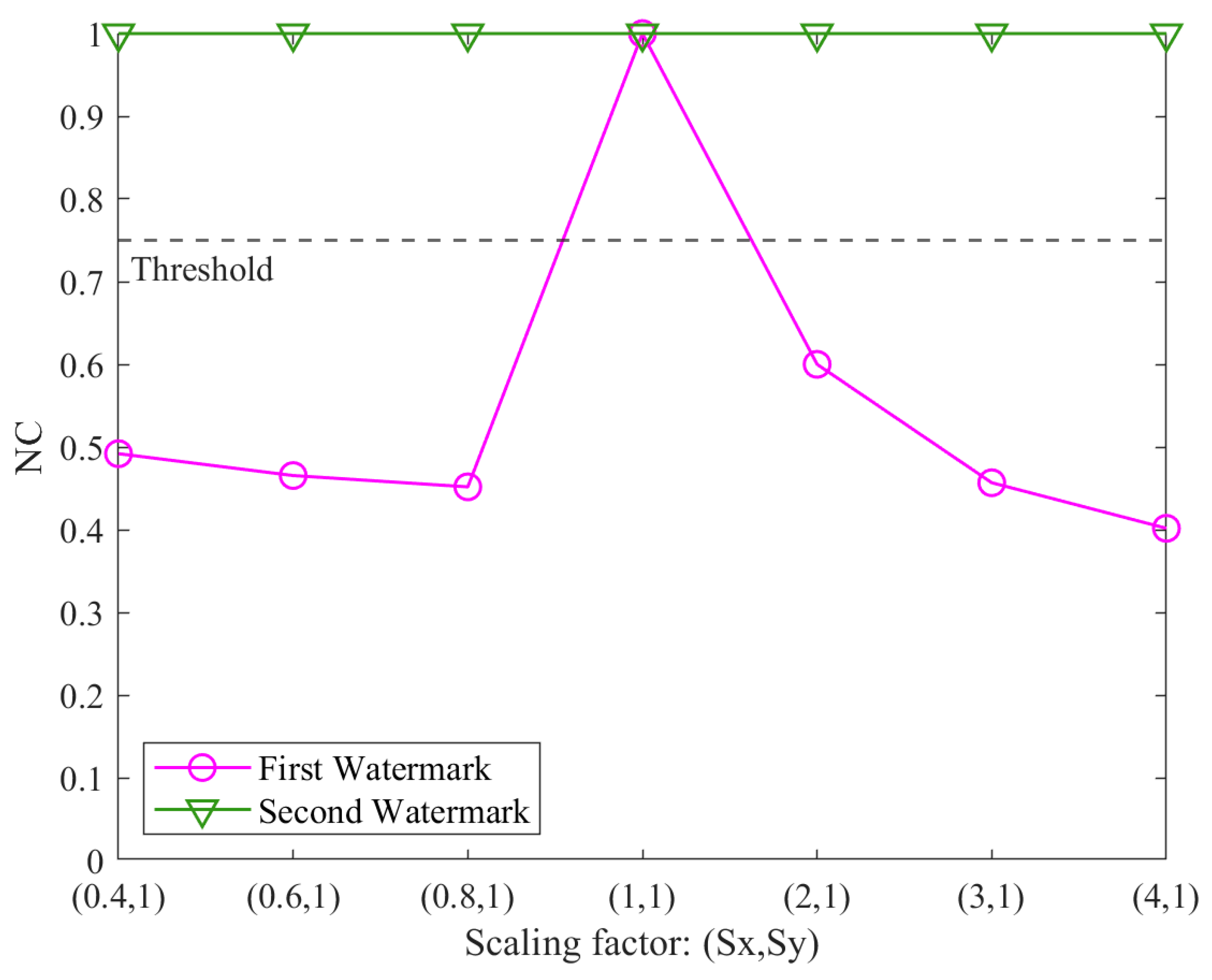
How to address the diversity and complexity of attacks in the copyright protection of vector geographic data remains a critical scientific challenge. This study proposes a multi-instance zero-watermarking algorithm for vector geographic data to solve this issue. The method constructs two robust zero watermarks by employing key techniques such as normalization, feature triangle construction, angle selection, and quantization. The following capabilities are demonstrated as follows: (1) leveraging angle-based features ensures resistance to common geometric transformations, including rotation, uniform scaling, and translation; (2) incorporating normalization effectively eliminates distortions caused by non-uniform scaling; and (3) adopting principles from the Douglas–Peucker algorithm enables resilience against interpolation and simplification attacks. Experimental results validate the theoretical advantages of the proposed method, highlighting its superior overall robustness compared to existing algorithms.
Moreover, introducing the multi-instance scheme broadens the theoretical and technical scope of robustness in zero watermarking. This study also discusses an adaptation to extend the algorithm’s applicability to two-vertex polylines, further demonstrating its flexibility and practicality for diverse vector geographic data. Future research could explore ways to improve scalability and integrate the algorithm into distributed GIS platforms and cloud-based services to support large-scale applications.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}