

A Sensor-Based Simulation Method for Spatiotemporal Event Detection


Abstract
1. Introduction
2. Related Work
3. Methodology
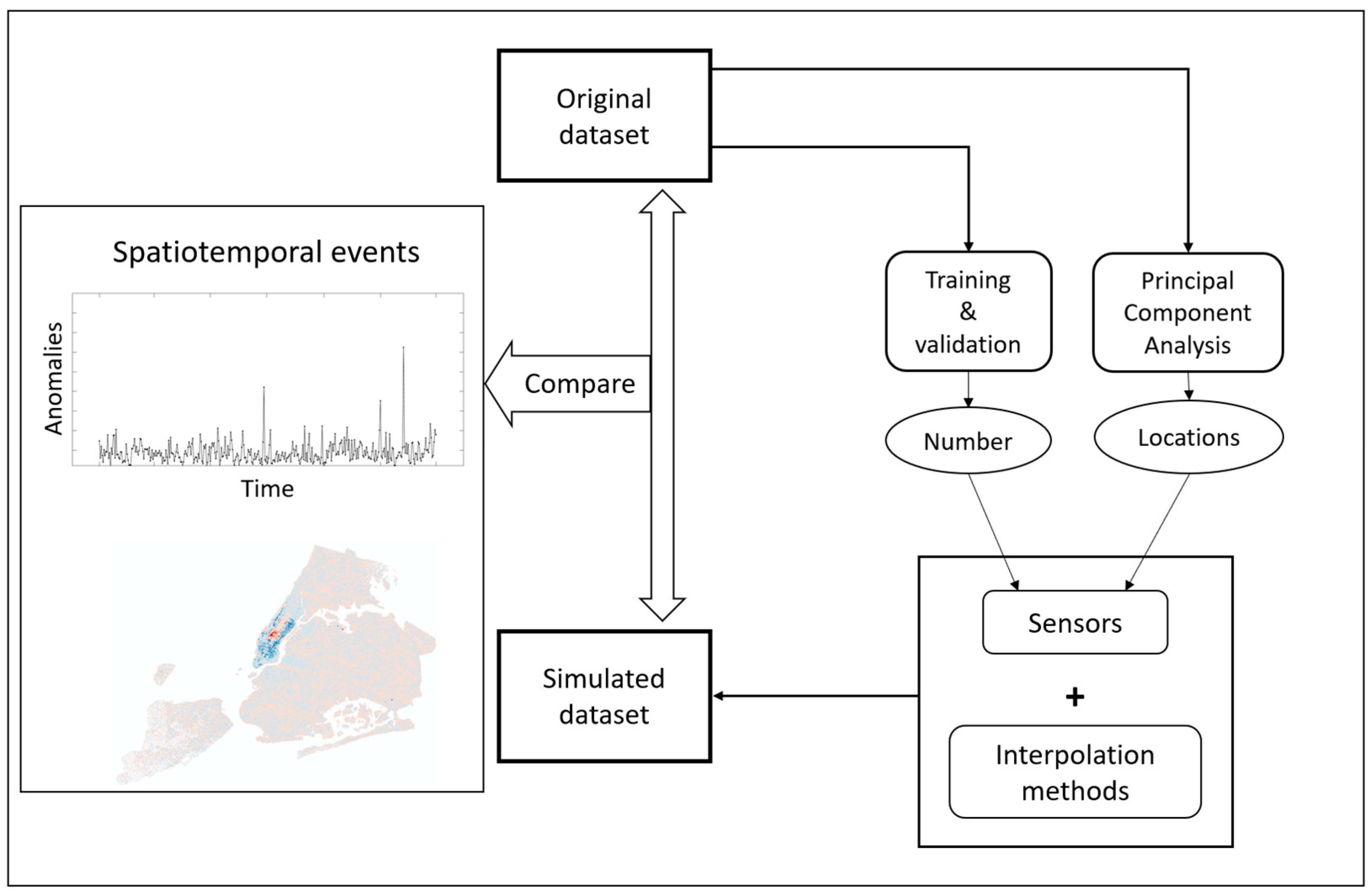
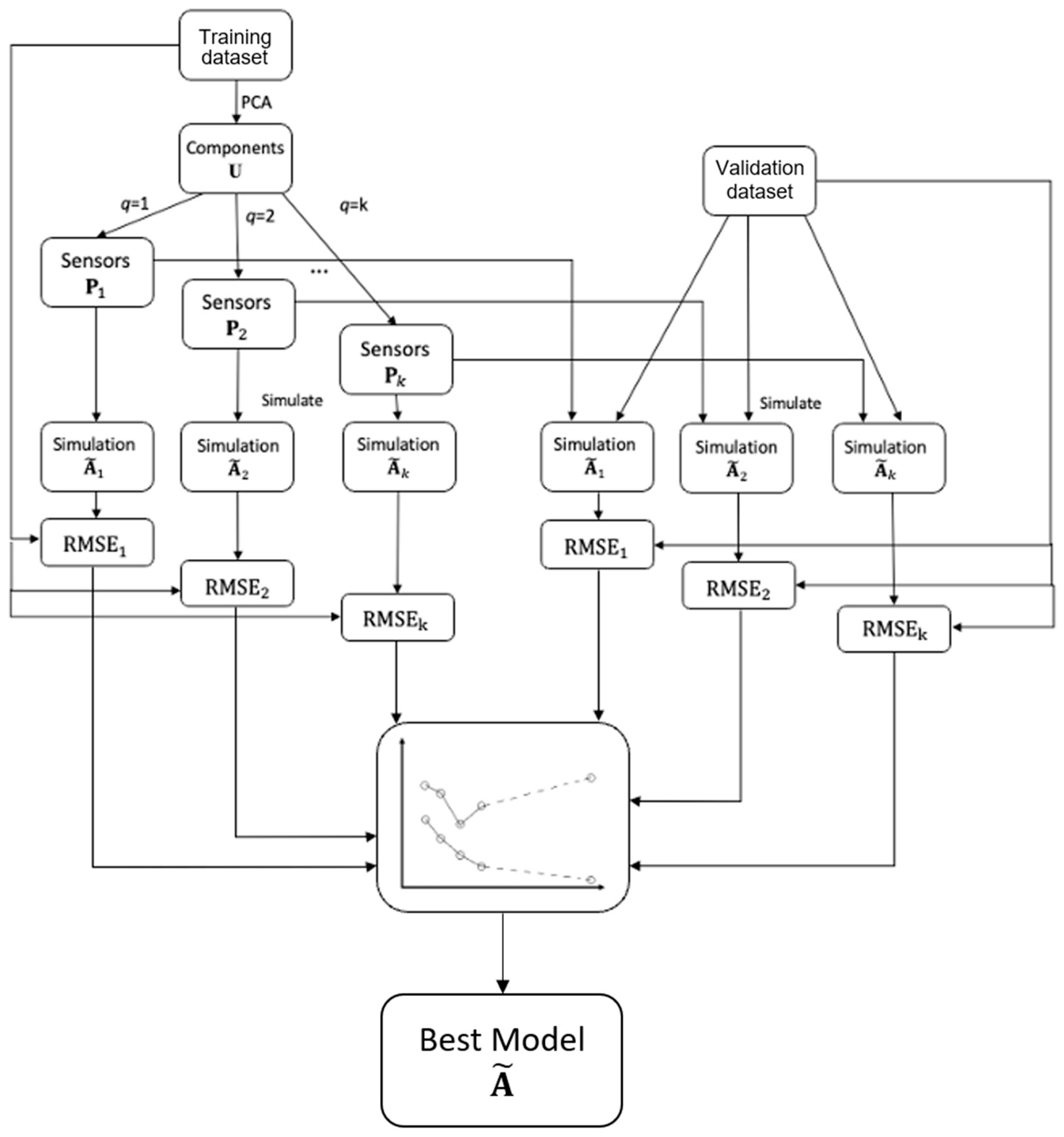
3.1. Method Overview
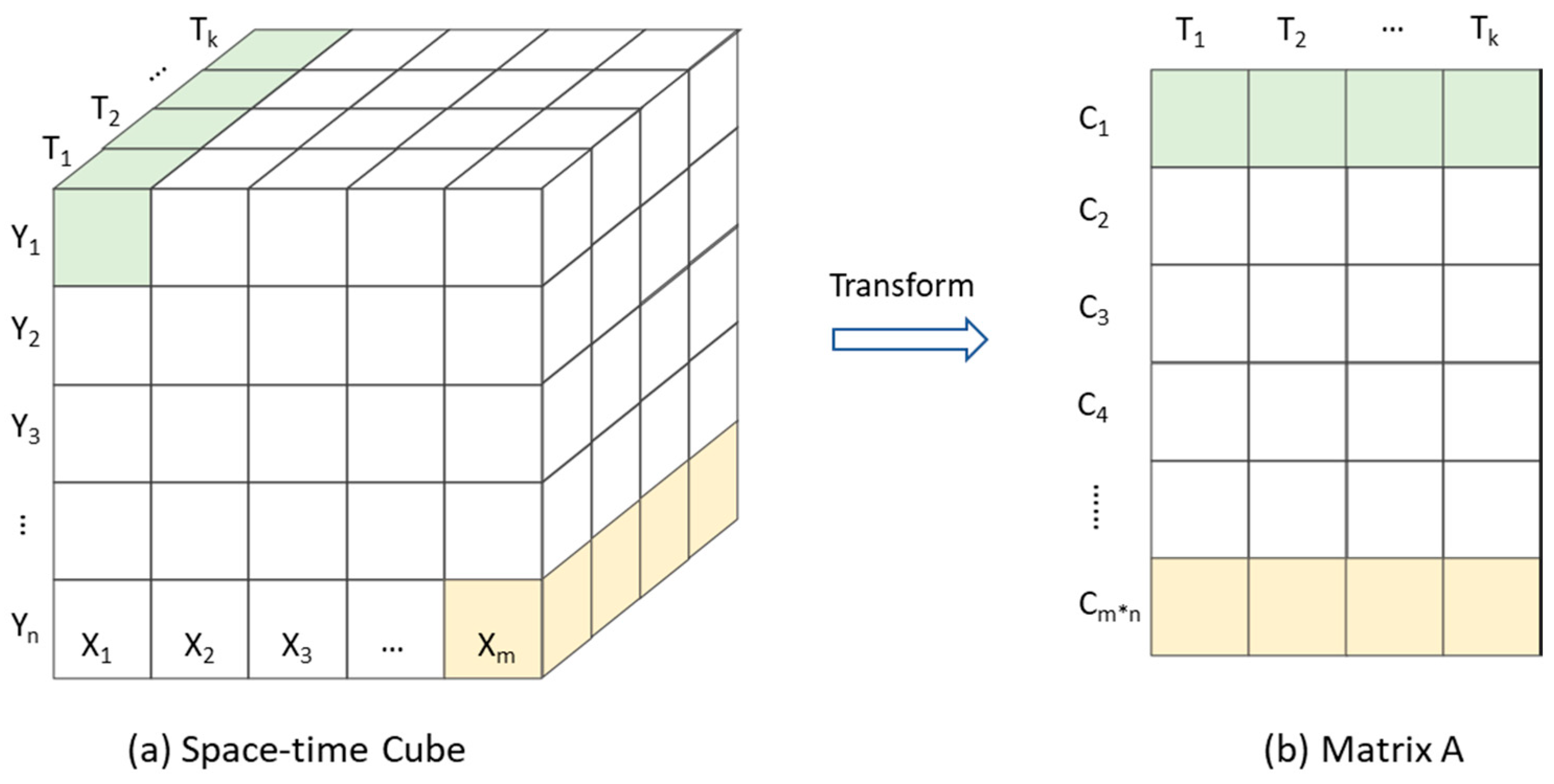
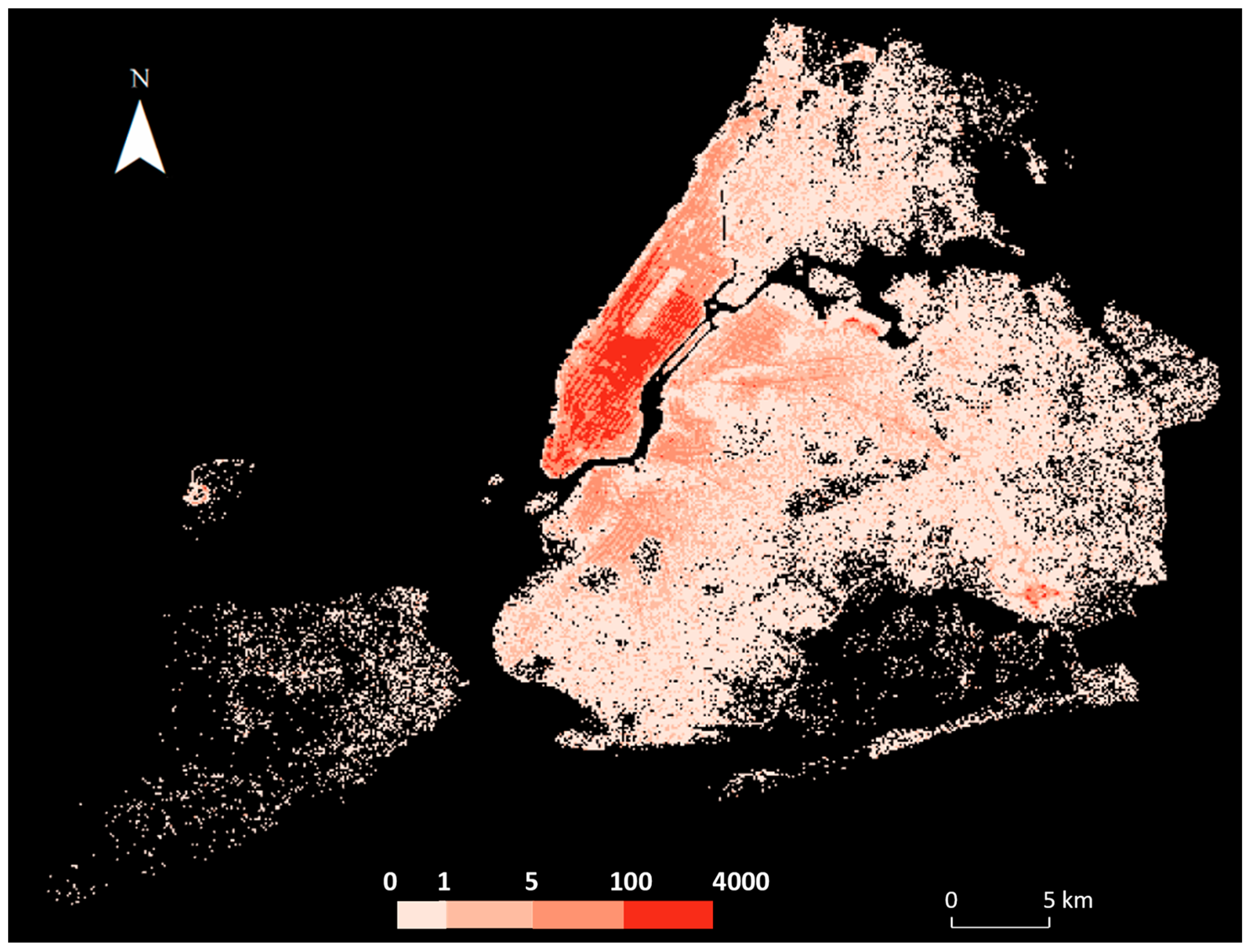
3.2. Model Human Mobility Data
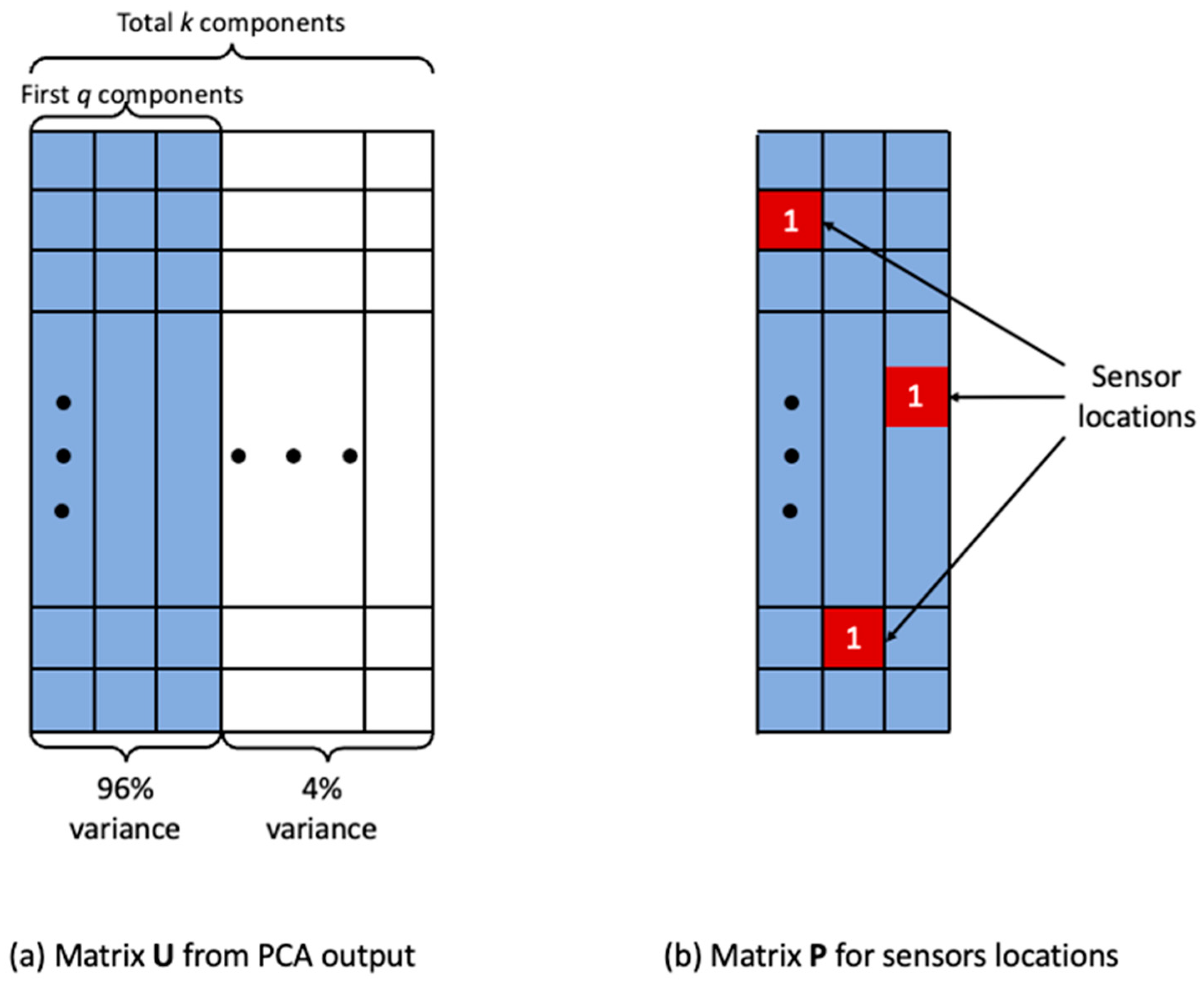
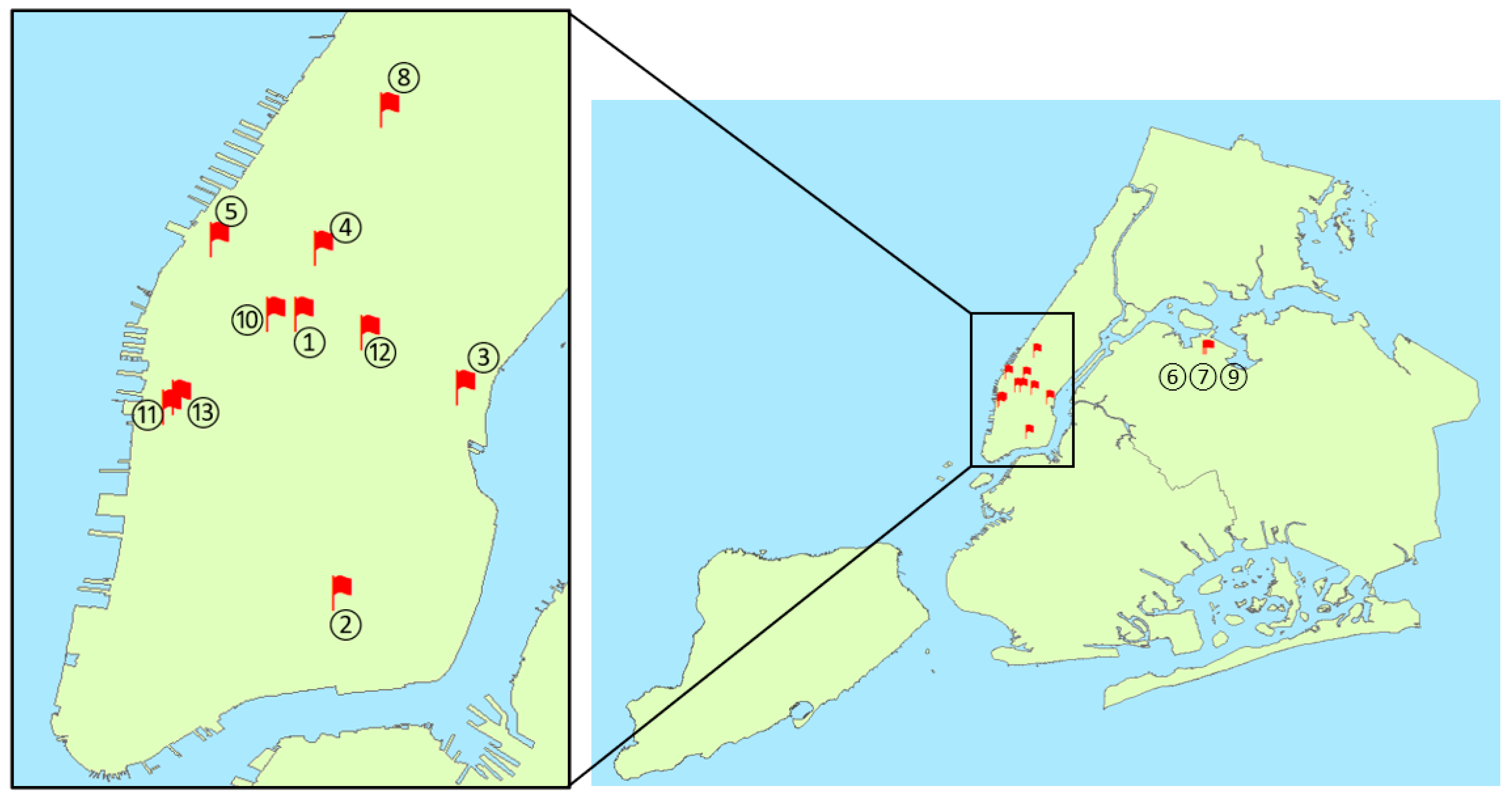
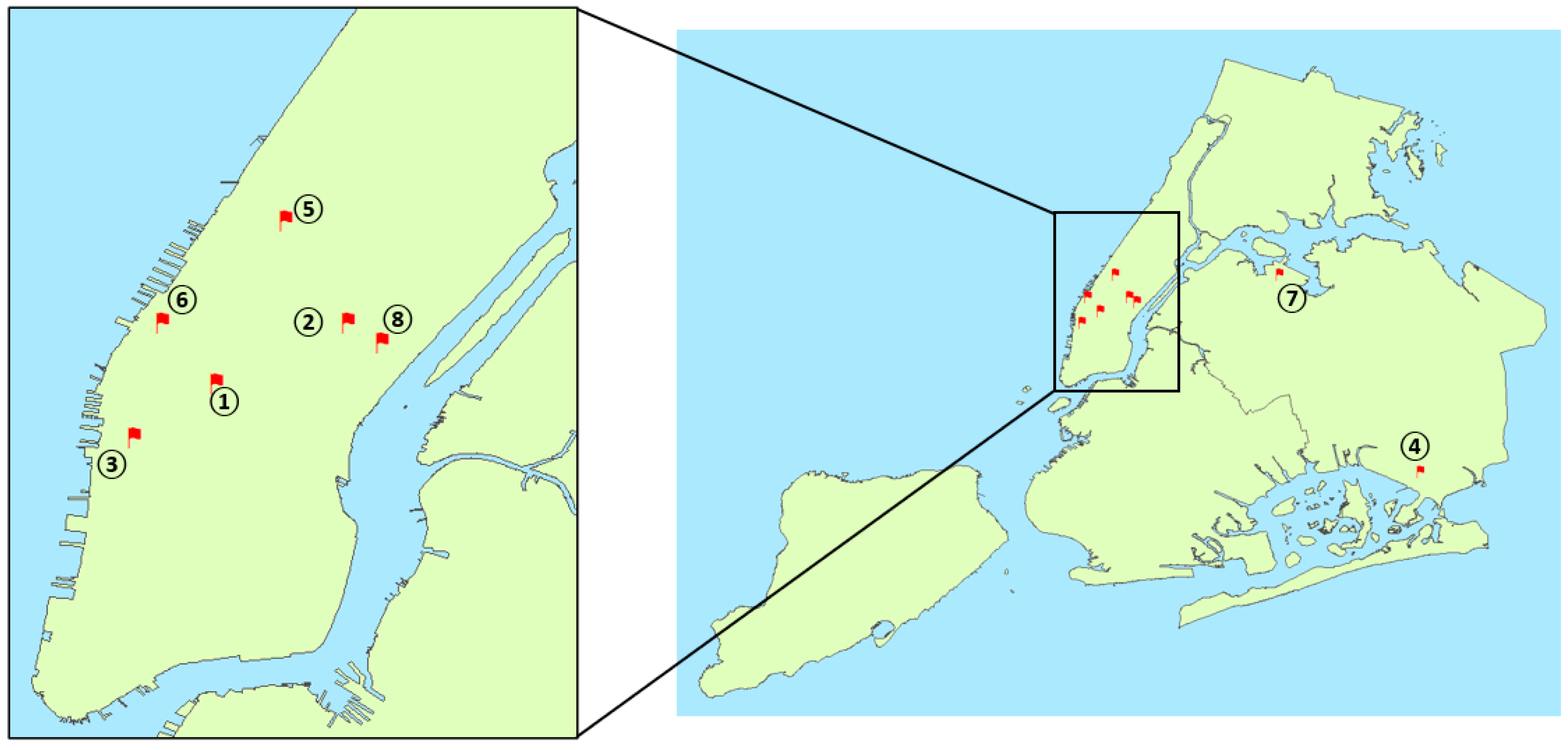
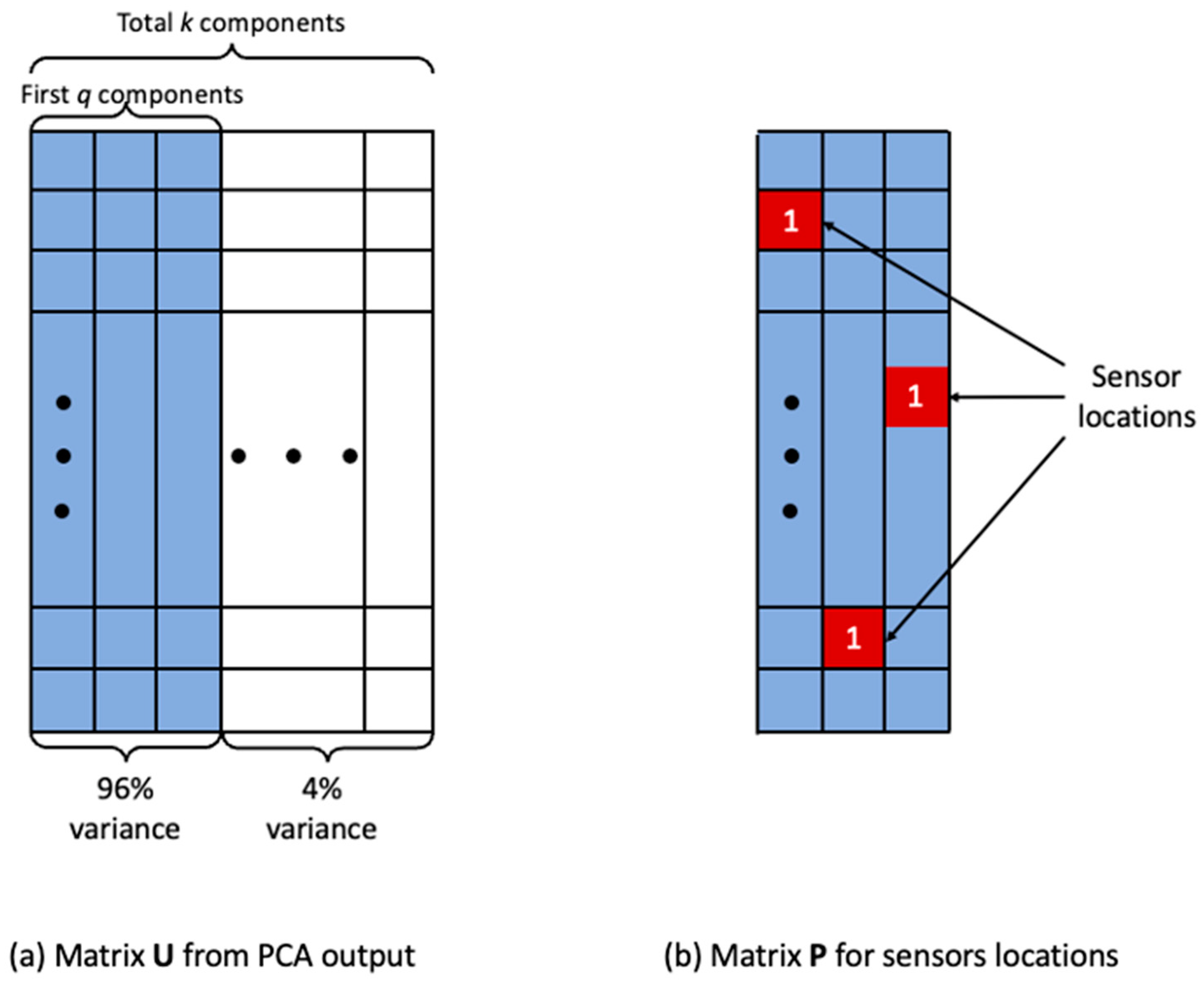
3.3. Determine the Locations of Sensors
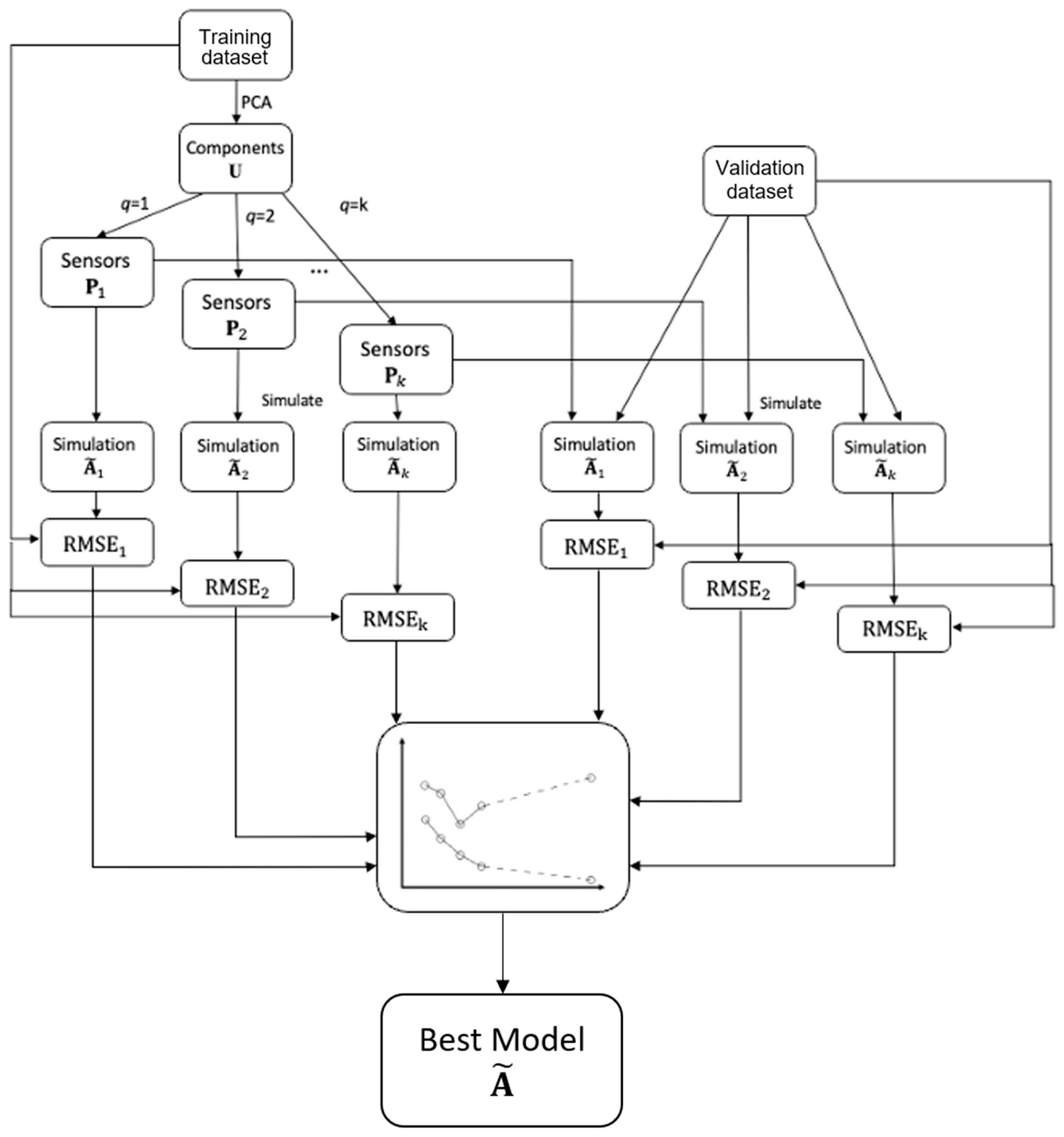
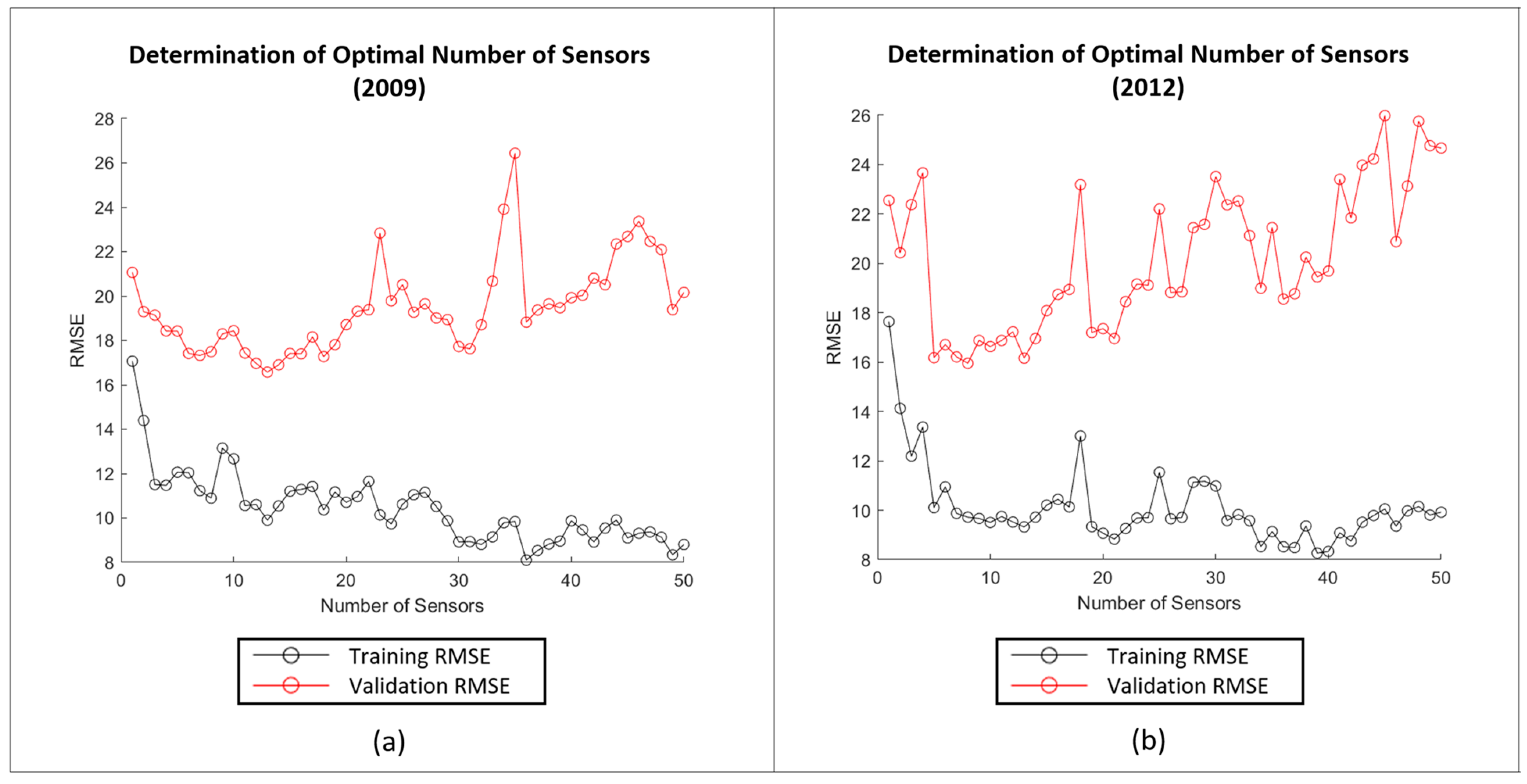
3.4. Determine the Optimal Number of Sensors
3.5. Simulate the Uneventful Scenario
3.6. Detect Events
4. Case Study
5. Results and Discussion
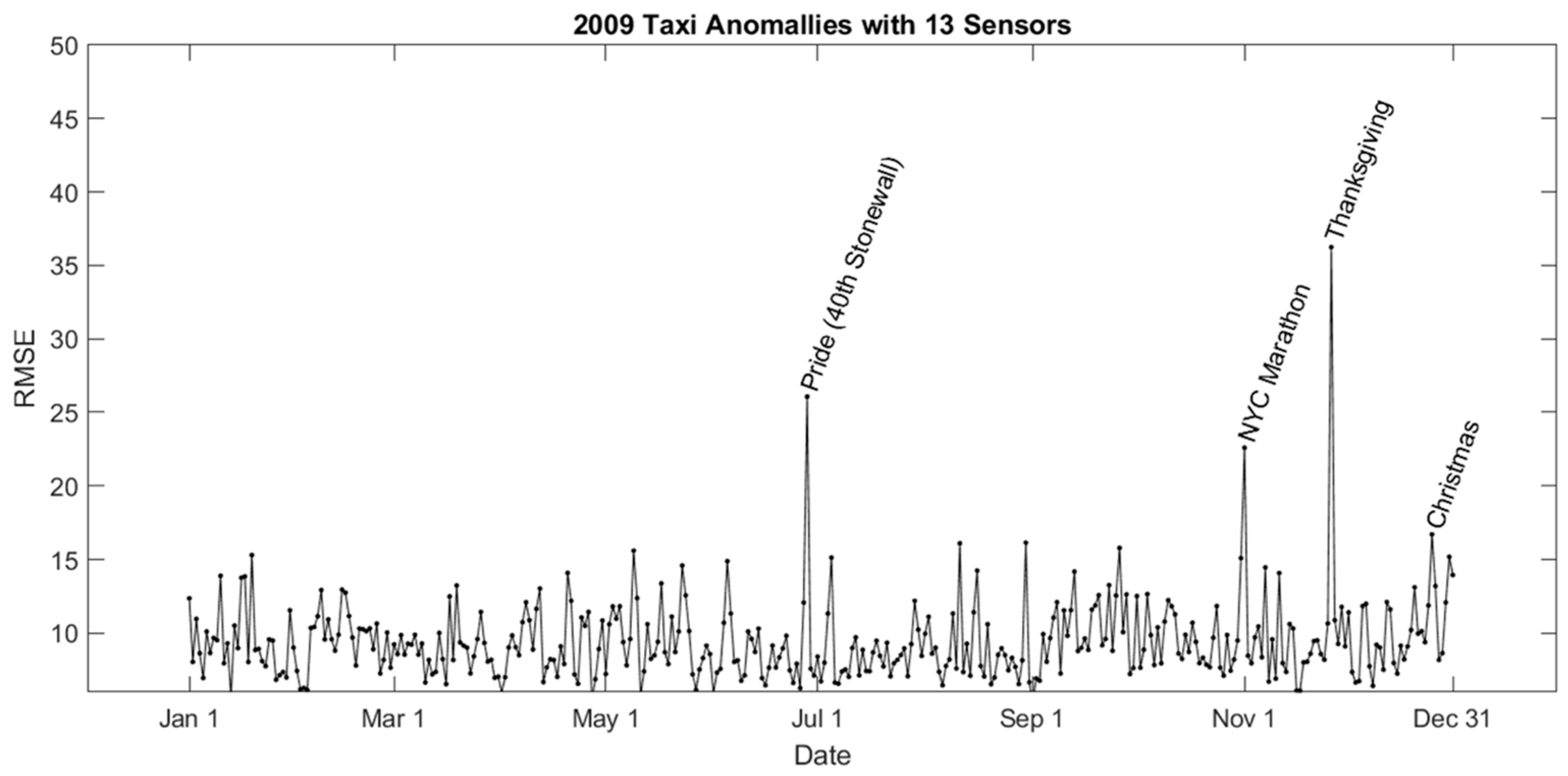
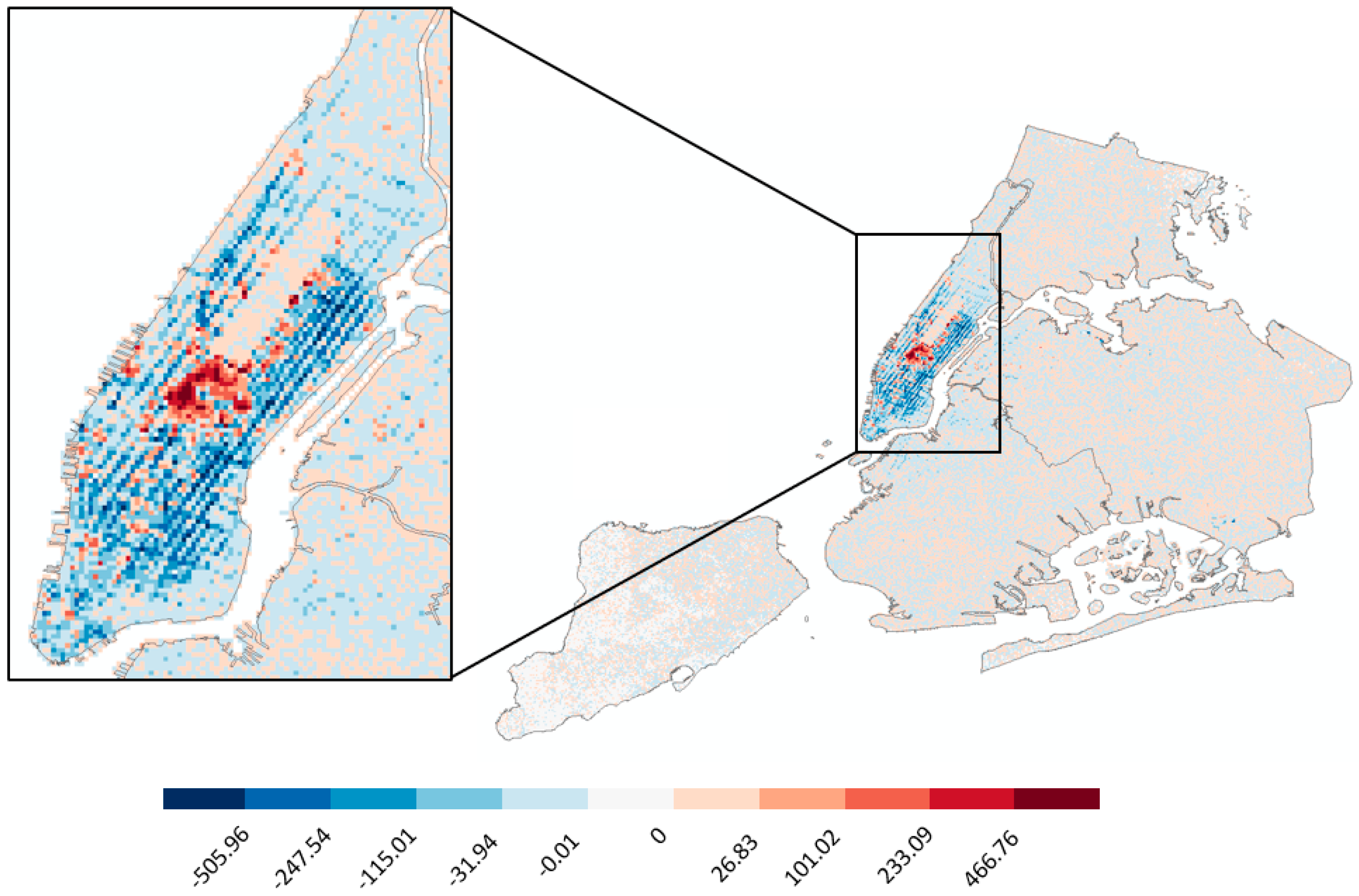
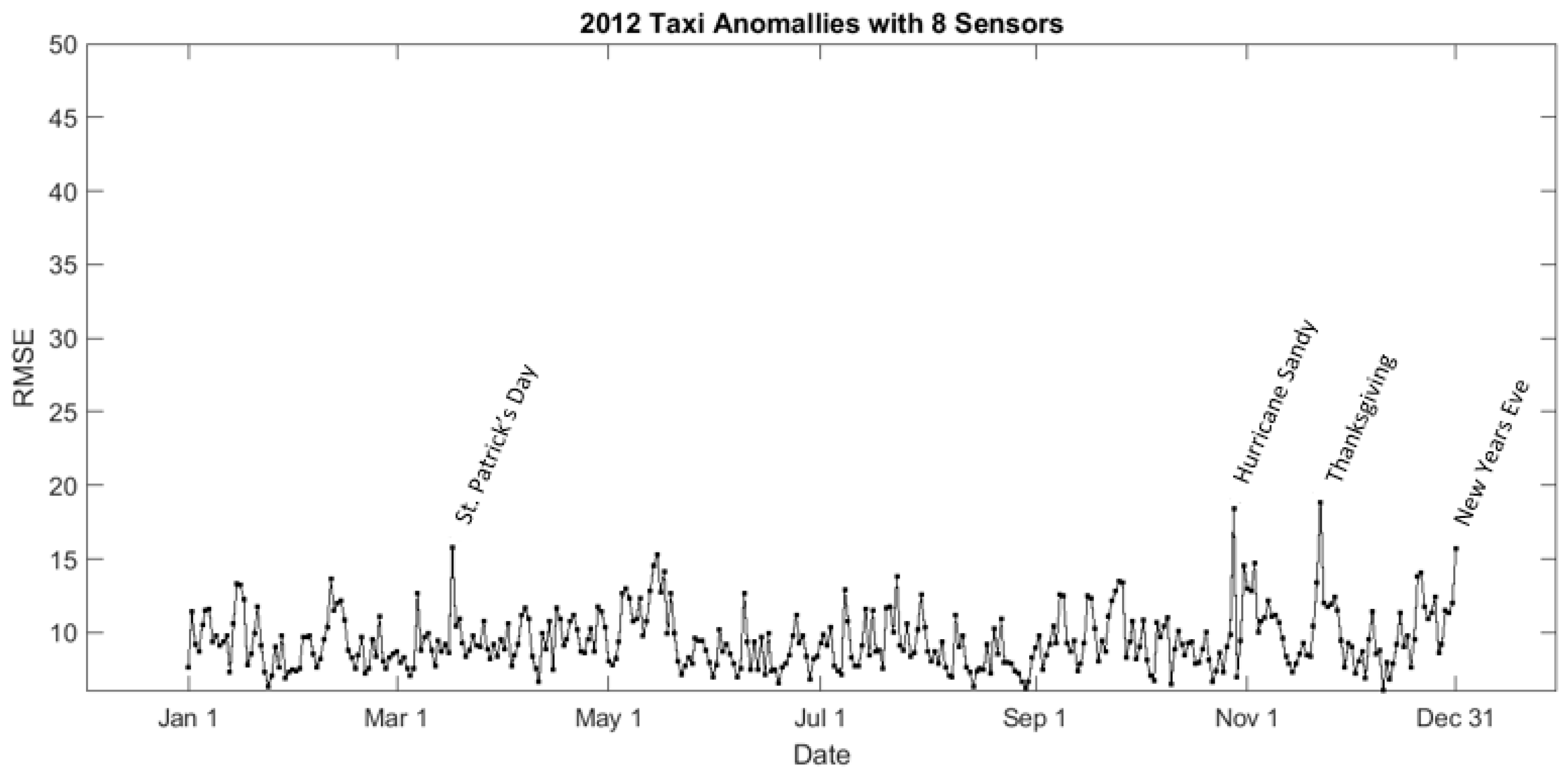
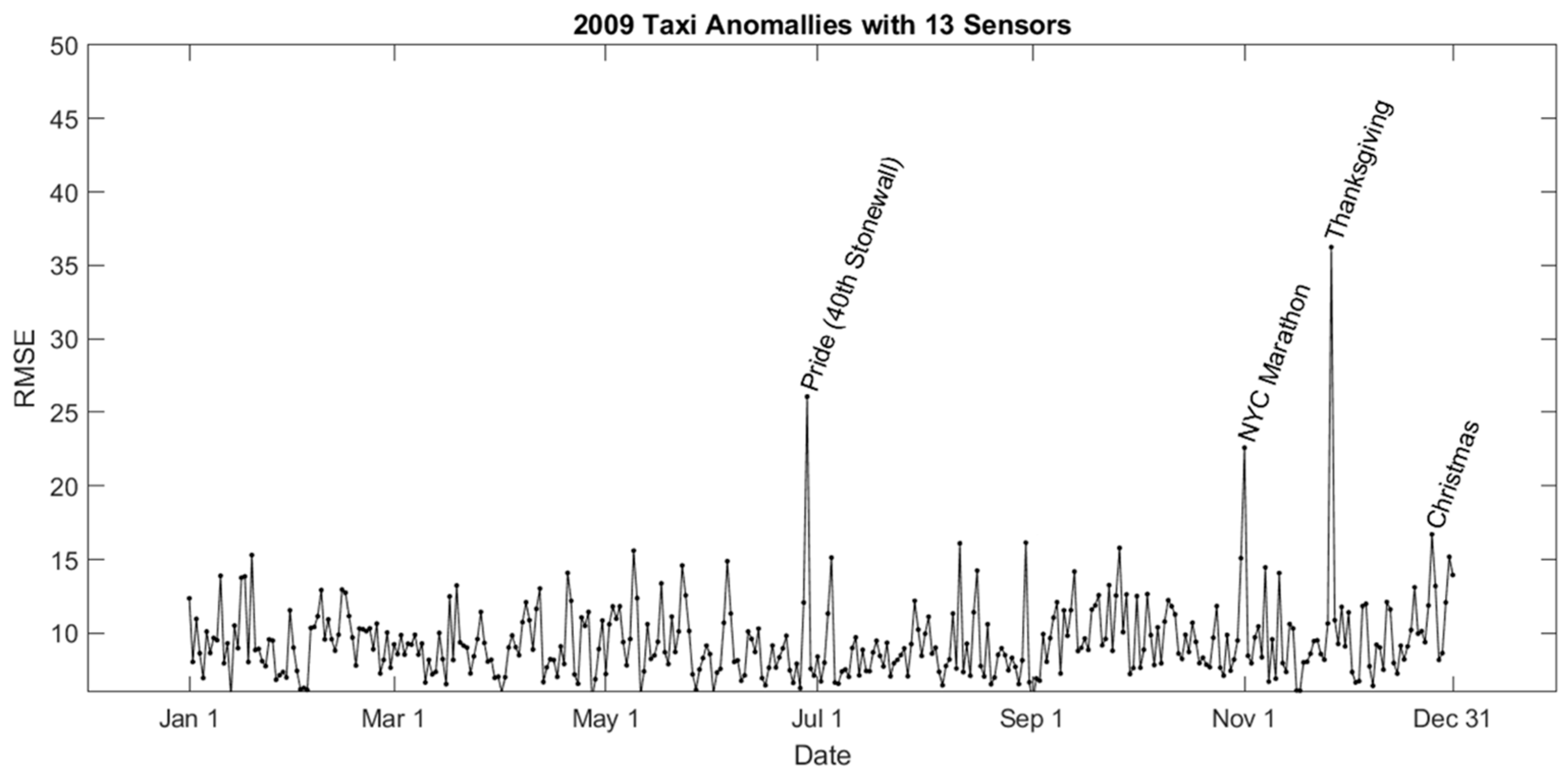
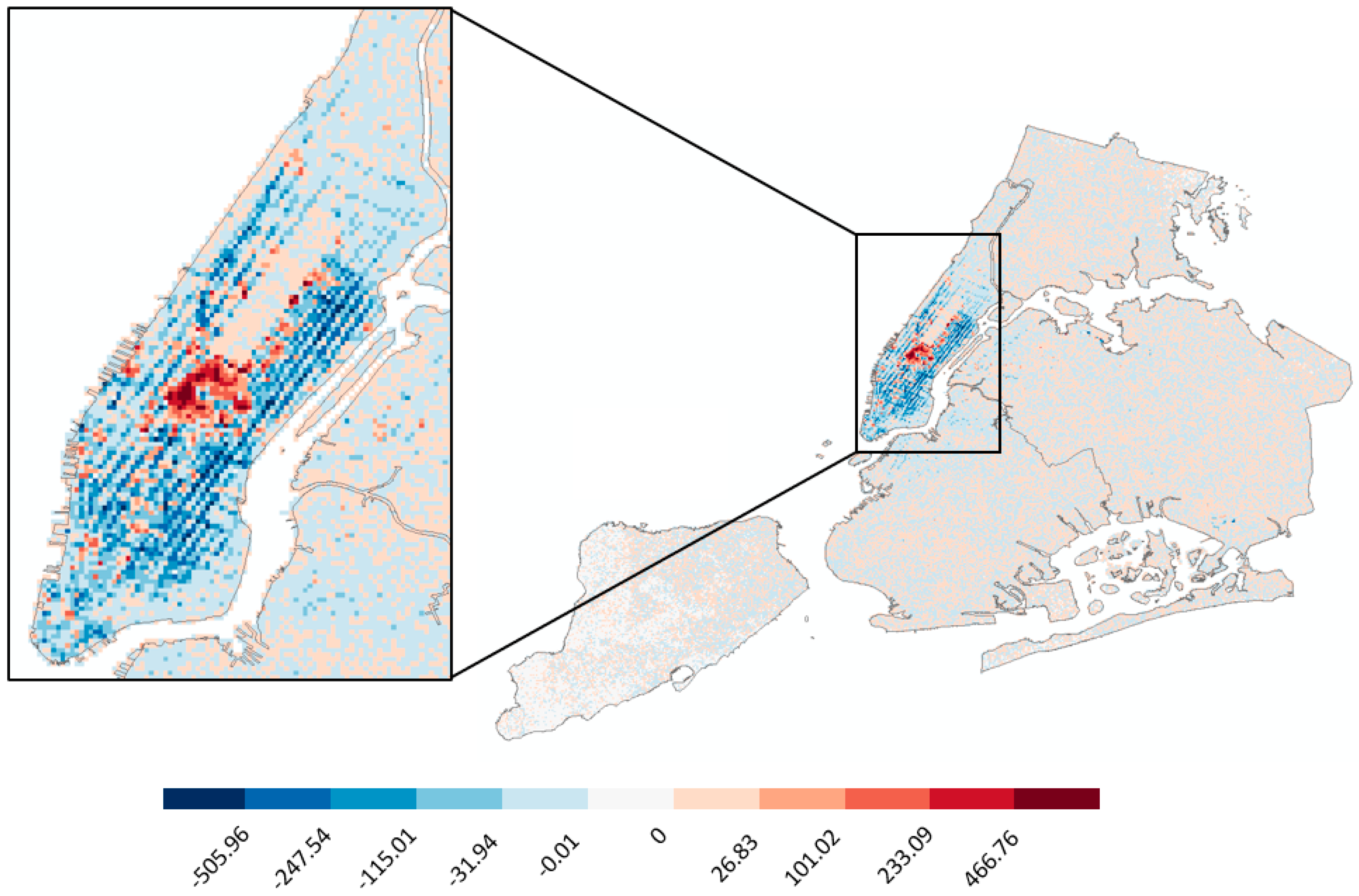
5.1. Spatiotemporal Events in 2009
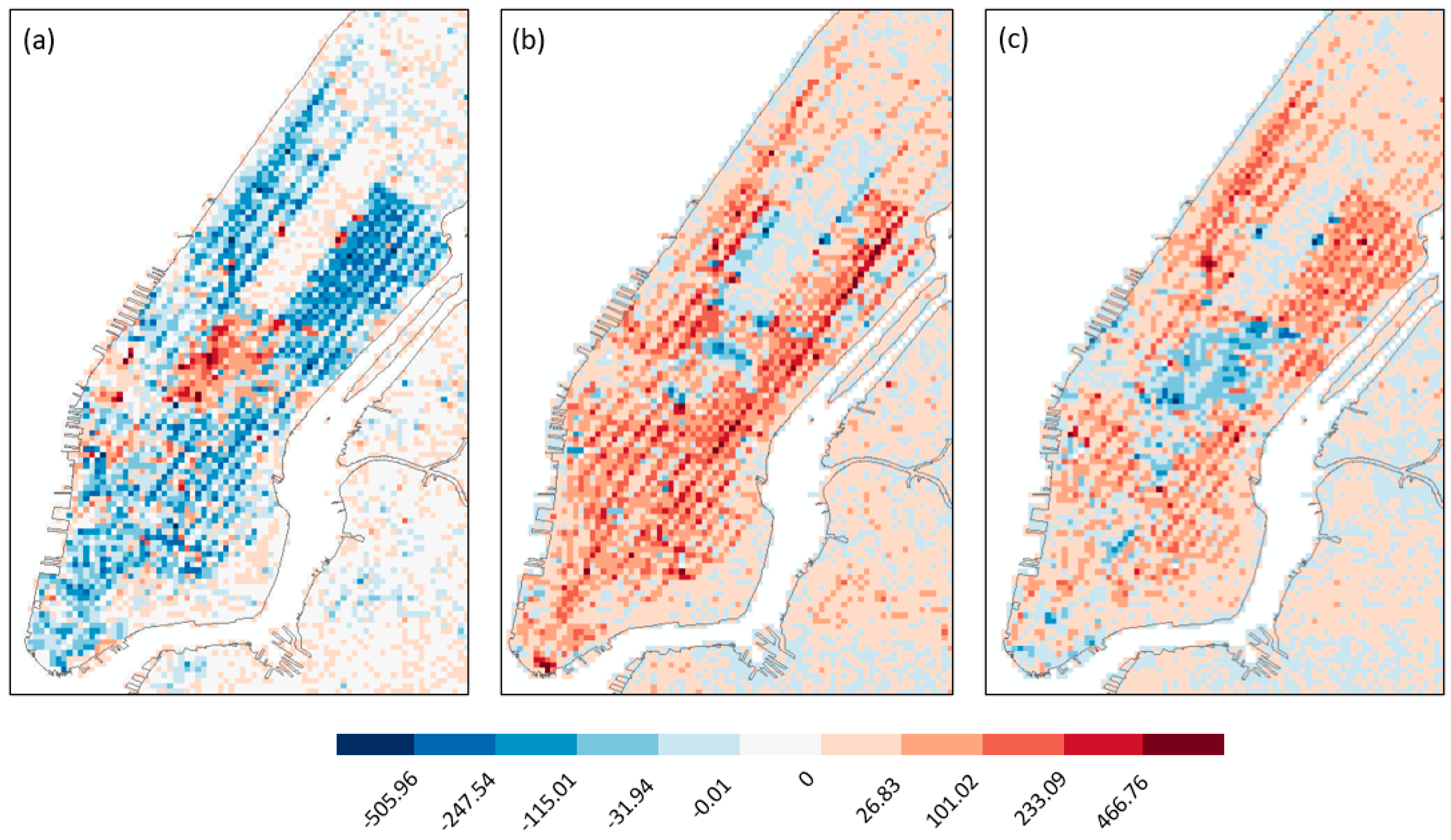
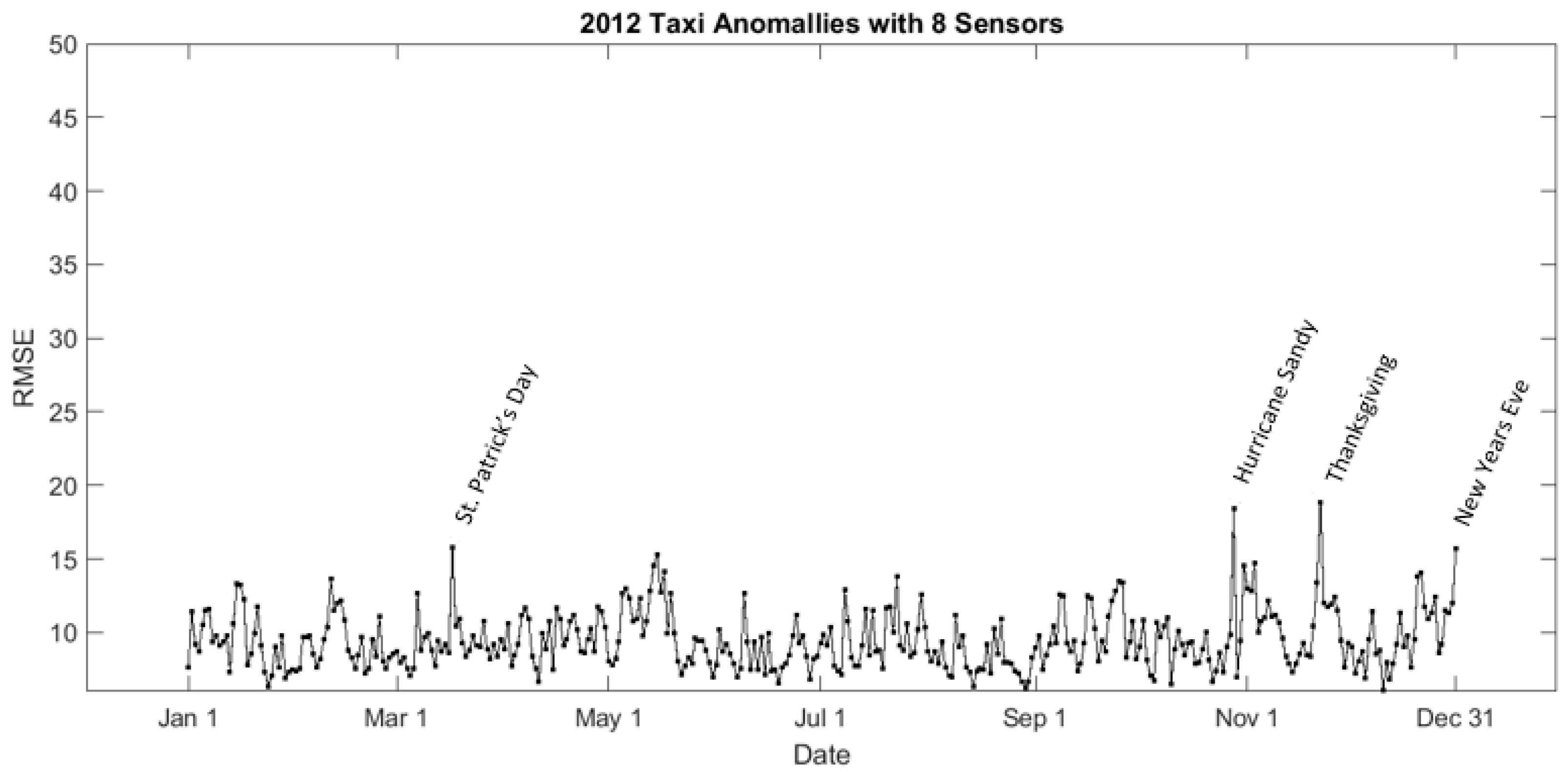
5.2. Spatiotemporal Events in 2012
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Peng, C.; Jin, X.; Wong, K.-C.; Shi, M.; Liò, P. Collective Human Mobility Pattern from Taxi Trips in Urban Area. PLoS ONE 2012, 7, e34487. [Google Scholar]
- Yuan, J.; Zheng, Y.; Xie, X. Discovering Regions of Different Functions in a City Using Human Mobility and POIs. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing China, 12–16 August 2012; pp. 186–194. [Google Scholar]
- Barbosa, H.; Barthelemy, M.; Ghoshal, G.; James, C.R.; Lenormand, M.; Louail, T.; Menezes, R.; Ramasco, J.J.; Simini, F.; Tomasini, M. Human mobility: Models and applications. Phys. Rep. 2018, 734, 1–74. [Google Scholar] [CrossRef]
- Isaacman, S.; Becker, R.; Cáceres, R.; Martonosi, M.; Rowland, J.; Varshavsky, A.; Willinger, W. Human mobility modeling at metropolitan scales. In MobiSys’12: The 10th International Conference on Mobile Systems, Applications, and Services, Low Wood Bay, Lake District, UK, June 25–29, 2012; ACM: New York, NY, USA, 2012; pp. 239–252. [Google Scholar]
- Chen, C.; Ma, J.; Susilo, Y.; Liu, Y.; Wang, M. The promises of big data and small data for travel behavior (aka human mobility) analysis. Transp. Res. Part C Emerg. Technol. 2016, 68, 285–299. [Google Scholar] [CrossRef]
- Huang, Z.; Ling, X.; Wang, P.; Zhang, F.; Mao, Y.; Lin, T.; Wang, F.-Y. Modeling real-time human mobility based on mobile phone and transportation data fusion. Transp. Res. Part C Emerg. Technol. 2018, 96, 251–269. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, Z.; Cutter, S.L. Social Network, Activity Space, Sentiment, and Evacuation: What Can Social Media Tell Us? Ann. Am. Assoc. Geogr. 2019, 109, 1795–1810. [Google Scholar] [CrossRef]
- Martín, Y.; Li, Z.; Cutter, S.L. Leveraging Twitter to gauge evacuation compliance: Spatiotemporal analysis of Hurricane Matthew. PLoS ONE 2017, 12, e0181701. [Google Scholar] [CrossRef]
- Huang, X.; Lu, J.; Gao, S.; Wang, S.; Liu, Z.; Wei, H. Staying at Home Is a Privilege: Evidence from Fine-Grained Mobile Phone Location Data in the United States during the COVID-19 Pandemic. Ann. Assoc. Am. Geogr. 2021, 112, 286–305. [Google Scholar] [CrossRef]
- Lu, X.; Bengtsson, L.; Holme, P. Predictability of population displacement after the 2010 Haiti earthquake. Proc. Natl. Acad. Sci. USA 2012, 109, 11576–11581. [Google Scholar] [CrossRef] [PubMed]
- Song, C.; Qu, Z.; Blumm, N.; Barabási, A.-L. Limits of Predictability in Human Mobility. Science 2010, 327, 1018–1021. [Google Scholar] [CrossRef]
- Huang, X.; Li, Z.; Jiang, Y.; Li, X.; Porter, D. Twitter reveals human mobility dynamics during the COVID-19 pandemic. PLoS ONE 2020, 15, e0241957. [Google Scholar] [CrossRef]
- Jiang, Y.; Huang, X.; Li, Z. Spatiotemporal Patterns of Human Mobility and Its Association with Land Use Types during COVID-19 in New York City. ISPRS Int. J. Geo-Inf. 2021, 10, 344. [Google Scholar] [CrossRef]
- Jiang, Y.; Guo, D.; Li, Z.; Hodgson, M.E. A novel big data approach to measure and visualize urban accessibility. Comput. Urban Sci. 2021, 1, 10. [Google Scholar] [CrossRef]
- Zhu, X.; Guo, D. Urban event detection with big data of taxi OD trips: A time series decomposition approach. Trans. GIS 2017, 21, 560–574. [Google Scholar] [CrossRef]
- Giannotti, F.; Nanni, M.; Pedreschi, D.; Pinelli, F.; Renso, C.; Rinzivillo, S.; Trasarti, R. Unveiling the complexity of human mobility by querying and mining massive trajectory data. VLDB J. 2011, 20, 695–719. [Google Scholar] [CrossRef]
- Pan, B.; Zheng, Y.; Wilkie, D.; Shahabi, C. Crowd Sensing of Traffic Anomalies Based on Human Mobility and Social Media. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Orlando, FL, USA, 5–8 November 2013; pp. 344–353. [Google Scholar]
- Khezerlou, A.V.; Zhou, X.; Li, L.; Shafiq, Z.; Liu, A.X.; Zhang, F. A Traffic Flow Approach to Early Detection of Gathering Events: Comprehensive Results. ACM Trans. Intell. Syst. Technol. (TIST) 2017, 8, 1–24. [Google Scholar] [CrossRef]
- Piciarelli, C.; Micheloni, C.; Foresti, G.L. Trajectory-Based Anomalous Event Detection. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1544–1554. [Google Scholar] [CrossRef]
- Wu, H.; Sun, W.; Zheng, B. A Fast Trajectory Outlier Detection Approach via Driving Behavior Modeling. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 837–846. [Google Scholar]
- Li, X.; Li, Z.; Han, J.; Lee, J.-G. Temporal Outlier Detection in Vehicle Traffic Data. In Proceedings of the 2009 IEEE 25th International Conference on Data Engineering, Shanghai, China, 29 March–2 April 2009; pp. 1319–1322. [Google Scholar]
- Zheng, Y.; Zhang, H.; Yu, Y. Detecting Collective Anomalies from Multiple Spatio-Temporal Datasets across Different Domains. In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems, Bellevue, WA, USA, 3–6 November 2015; pp. 1–10. [Google Scholar]
- Dhiman, A.; Toshniwal, D. An Approximate Model for Event Detection from Twitter Data. IEEE Access 2020, 8, 122168–122184. [Google Scholar] [CrossRef]
- Weng, J.; Lee, B.-S. Event Detection in Twitter. In Proceedings of the International AAAI Conference on Web and Social Media, Barcelona, Spain, 17–21 July 2011; Volume 5. [Google Scholar]
- Zhou, X.; Chen, L. Event detection over twitter social media streams. VLDB J. 2014, 23, 381–400. [Google Scholar] [CrossRef]
- Dobra, A.; Williams, N.E.; Eagle, N. Spatiotemporal Detection of Unusual Human Population Behavior Using Mobile Phone Data. PLoS ONE 2015, 10, e0120449. [Google Scholar] [CrossRef]
- Traag, V.A.; Browet, A.; Calabrese, F.; Morlot, F. Social Event Detection in Massive Mobile Phone Data Using Probabilistic Location Inference. In Proceedings of the 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust and 2011 IEEE Third International Conference on Social Computing, Boston, MA, USA, 9–11 October 2011; pp. 625–628. [Google Scholar]
- Adam, A.; Rivlin, E.; Shimshoni, I.; Reinitz, D. Robust Real-Time Unusual Event Detection using Multiple Fixed-Location Monitors. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 555–560. [Google Scholar] [CrossRef]
- Lu, C.; Shi, J.; Jia, J. Abnormal Event Detection at 150 Fps in Matlab. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2720–2727. [Google Scholar]
- Oh, S.; Hoogs, A.; Perera, A.; Cuntoor, N.; Chen, C.-C.; Lee, J.T.; Mukherjee, S.; Aggarwal, J.K.; Lee, H.; Davis, L.; et al. A large-scale benchmark dataset for event recognition in surveillance video. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA, 20–25 June 2011; pp. 3153–3160. [Google Scholar]
- Wan, S.; Xu, X.; Wang, T.; Gu, Z. An Intelligent Video Analysis Method for Abnormal Event Detection in Intelligent Transportation Systems. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4487–4495. [Google Scholar] [CrossRef]
- Ştefănescu, R.; Sandu, A.; Navon, I. POD/DEIM reduced-order strategies for efficient four dimensional variational data assimilation. J. Comput. Phys. 2015, 295, 569–595. [Google Scholar] [CrossRef]
- Brunton, S.L.; Kutz, J.N. Data-Driven Science and Engineering: Machine Learning, Dynamical Systems, and Control; Cambridge University Press: Cambridge, UK, 2019; ISBN 1-108-38658-X. [Google Scholar]
- Upadhyaya, B.R.; Li, F. Optimal sensor placement strategy for anomaly detection and isolation. In Proceedings of the 2011 Future of Instrumentation International Workshop (FIIW), Oak Ridge, TN, USA, 7–8 November 2011; pp. 95–98. [Google Scholar]
- Liu, S.; Auckenthaler, P. Optimal sensor placement for event detection and source identification in water distribution networks. J. Water Supply Res. Technol. 2014, 63, 51–57. [Google Scholar] [CrossRef]
- Jayaraman, B.; Al Mamun, S.M.A.; Lu, C. Interplay of Sensor Quantity, Placement and System Dimension in POD-Based Sparse Reconstruction of Fluid Flows. Fluids 2019, 4, 109. [Google Scholar] [CrossRef]
- Abdelhaq, H.; Sengstock, C.; Gertz, M. Eventweet: Online Localized Event Detection from Twitter. Proc. VLDB Endow. 2013, 6, 1326–1329. [Google Scholar] [CrossRef]
- Costa, D.G.; Duran-Faundez, C.; Andrade, D.C.; Rocha-Junior, J.B.; Peixoto, J.P.J. TwitterSensing: An Event-Based Approach for Wireless Sensor Networks Optimization Exploiting Social Media in Smart City Applications. Sensors 2018, 18, 1080. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Wang, Y.; Li, P. Online city-scale hyper-local event detection via analysis of social media and human mobility. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 626–635. [Google Scholar]
- Zhang, W.; Qi, G.; Pan, G.; Lu, H.; Li, S.; Wu, Z. City-Scale Social Event Detection and Evaluation with Taxi Traces. ACM Trans. Intell. Syst. Technol. (TIST) 2015, 6, 1–20. [Google Scholar] [CrossRef]
- Zhang, S.; Tang, J.; Wang, H.; Wang, Y. Enhancing Traffic Incident Detection by Using Spatial Point Pattern Analysis on Social Media. Transp. Res. Rec. J. Transp. Res. Board 2015, 2528, 69–77. [Google Scholar] [CrossRef]
- Jiang, W.; Wang, Y.; Tsou, M.-H.; Fu, X. Using Social Media to Detect Outdoor Air Pollution and Monitor Air Quality Index (AQI): A Geo-Targeted Spatiotemporal Analysis Framework with Sina Weibo (Chinese Twitter). PLoS ONE 2015, 10, e0141185. [Google Scholar] [CrossRef]
- Resch, B.; Usländer, F.; Havas, C. Combining machine-learning topic models and spatiotemporal analysis of social media data for disaster footprint and damage assessment. Cartogr. Geogr. Inf. Sci. 2018, 45, 362–376. [Google Scholar] [CrossRef]
- Zhang, F.; Li, Z.; Li, N.; Fang, D. Assessment of urban human mobility perturbation under extreme weather events: A case study in Nanjing, China. Sustain. Cities Soc. 2019, 50, 101671. [Google Scholar] [CrossRef]
- Gao, Y.; Wang, S.; Padmanabhan, A.; Yin, J.; Cao, G. Mapping spatiotemporal patterns of events using social media: A case study of influenza trends. Int. J. Geogr. Inf. Sci. 2018, 32, 425–449. [Google Scholar] [CrossRef]
- Wang, J.; Zhao, L.; Ye, Y.; Zhang, Y. Adverse event detection by integrating twitter data and VAERS. J. Biomed. Semant. 2018, 9, 19. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Y.; Li, Z.; Cutter, S.L. Social distance integrated gravity model for evacuation destination choice. Int. J. Digit. Earth 2021, 14, 1004–1018. [Google Scholar] [CrossRef]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake Shakes Twitter Users: Real-Time Event Detection by Social Sensors. In Proceedings of the 19th International Conference on World Wide Web 2010, Raleigh, NC, USA, 26–30 April 2010; pp. 851–860. [Google Scholar]
- Wang, Y.; Taylor, J.E. Coupling sentiment and human mobility in natural disasters: A Twitter-based study of the 2014 South Napa Earthquake. Nat. Hazards 2018, 92, 907–925. [Google Scholar] [CrossRef]
- Yu, M.; Huang, Q.; Qin, H.; Scheele, C.; Yang, C. Deep Learning for Real-Time Social Media Text Classification for Situation Awareness–Using Hurricanes Sandy, Harvey, and Irma as Case Studies. Int. J. Digit. Earth 2019, 12, 1230–1247. [Google Scholar] [CrossRef]
- Zhang, C.; Zhou, G.; Yuan, Q.; Zhuang, H.; Zheng, Y.; Kaplan, L.; Wang, S.; Han, J. Geoburst: Real-Time Local Event Detection in Geo-Tagged Tweet Streams. In Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 513–522. [Google Scholar]
- Andrienko, G.; Andrienko, N.; Hurter, C.; Rinzivillo, S.; Wrobel, S. From movement tracks through events to places: Extracting and characterizing significant places from mobility data. In Proceedings of the 2011 IEEE Conference on Visual Analytics Science and Technology (VAST), Providence, RI, USA, 23–28 October 2011; pp. 161–170. [Google Scholar]
- Cui, J.; Liu, F.; Janssens, D.; An, S.; Wets, G.; Cools, M. Detecting urban road network accessibility problems using taxi GPS data. J. Transp. Geogr. 2016, 51, 147–157. [Google Scholar] [CrossRef]
- Ying, J.J.-C.; Lee, W.-C.; Tseng, V.S. Mining geographic-temporal-semantic patterns in trajectories for location prediction. ACM Trans. Intell. Syst. Technol. 2014, 5, 1–33. [Google Scholar] [CrossRef]
- Jahnke, M.; Ding, L.; Karja, K.; Wang, S. Identifying Origin/Destination Hotspots in Floating Car Data for Visual Analysis of Traveling Behavior. In Progress in Location-Based Services 2016; Springer: Berlin/Heidelberg, Germany, 2017; pp. 253–269. [Google Scholar]
- Kaiser, M.S.; Lwin, K.T.; Mahmud, M.; Hajializadeh, D.; Chaipimonplin, T.; Sarhan, A.; Hossain, M.A. Advances in Crowd Analysis for Urban Applications Through Urban Event Detection. IEEE Trans. Intell. Transp. Syst. 2017, 19, 3092–3112. [Google Scholar] [CrossRef]
- Fekih, M.; Bellemans, T.; Smoreda, Z.; Bonnel, P.; Furno, A.; Galland, S. A data-driven approach for origin–destination matrix construction from cellular network signalling data: A case study of Lyon region (France). Transportation 2020, 48, 1671–1702. [Google Scholar] [CrossRef]
- Abd-Alrazaq, A.; Alhuwail, D.; Househ, M.; Hamdi, M.; Shah, Z. Top Concerns of Tweeters During the COVID-19 Pandemic: Infoveillance Study. J. Med. Internet Res. 2020, 22, e19016. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Wang, S.; Tang, Y.; Hao, T. A bibliometric analysis of event detection in social media. Online Inf. Rev. 2019, 43, 29–52. [Google Scholar] [CrossRef]
- Jelodar, H.; Wang, Y.; Yuan, C.; Feng, X.; Li, Y.; Zhao, L. Latent Dirichlet Allocation (LDA) and Topic modeling: Models, applications, a survey. Multimed. Tools Appl. 2019, 78, 15169–15211. [Google Scholar] [CrossRef]
- Alqhtani, S.M.; Luo, S.; Regan, B. Fusing Text and Image for Event Detection in Twitter. arXiv 2015, arXiv:1503.03920. [Google Scholar] [CrossRef]
- Huang, X.; Li, Z.; Wang, C.; Ning, H. Identifying disaster related social media for rapid response: A visual-textual fused CNN architecture. Int. J. Digit. Earth 2019, 13, 1017–1039. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, Z.; Ye, X. Understanding demographic and socioeconomic biases of geotagged Twitter users at the county level. Cartogr. Geogr. Inf. Sci. 2019, 46, 228–242. [Google Scholar] [CrossRef]
- Malik, M.; Lamba, H.; Nakos, C.; Pfeffer, J. Population Bias in Geotagged Tweets. People 2015, 1, 3–759. [Google Scholar] [CrossRef]
- Mellon, J.; Prosser, C. Twitter and Facebook are not representative of the general population: Political attitudes and demographics of British social media users. Res. Politics 2017, 4, 2053168017720008. [Google Scholar] [CrossRef]
- Toch, E.; Lerner, B.; Ben-Zion, E.; Ben-Gal, I. Analyzing large-scale human mobility data: A survey of machine learning methods and applications. Knowl. Inf. Syst. 2019, 58, 501–523. [Google Scholar] [CrossRef]
- Zhou, S.; Shen, W.; Zeng, D.; Zhang, Z. Unusual event detection in crowded scenes by trajectory analysis. In Proceedings of the ICASSP 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 1300–1304. [Google Scholar]
- Tang, J.; Liu, F.; Wang, Y.; Wang, H. Uncovering urban human mobility from large scale taxi GPS data. Phys. A Stat. Mech. Appl. 2015, 438, 140–153. [Google Scholar] [CrossRef]
- Luo, F.; Cao, G.; Mulligan, K.; Li, X. Explore spatiotemporal and demographic characteristics of human mobility via Twitter: A case study of Chicago. Appl. Geogr. 2016, 70, 11–25. [Google Scholar] [CrossRef]
- Tang, J.; Zhang, S.; Chen, X.; Liu, F.; Zou, Y. Taxi trips distribution modeling based on Entropy-Maximizing theory: A case study in Harbin city—China. Phys. A Stat. Mech. Appl. 2018, 493, 430–443. [Google Scholar] [CrossRef]
- Qin, S.-M.; Verkasalo, H.; Mohtaschemi, M.; Hartonen, T.; Alava, M. Patterns, Entropy, and Predictability of Human Mobility and Life. PLoS ONE 2012, 7, e51353. [Google Scholar] [CrossRef]
- Kulldorff, M. A Spatial Scan Statistic. Commun. Stat. Theory Methods 1997, 26, 1481–1496. [Google Scholar] [CrossRef]
- Austwick, M.Z.; O’brien, O.; Strano, E.; Viana, M. The Structure of Spatial Networks and Communities in Bicycle Sharing Systems. PLoS ONE 2013, 8, e74685. [Google Scholar] [CrossRef]
- Alfieri, L.; Thielen, J.; Pappenberger, F. Ensemble hydro-meteorological simulation for flash flood early detection in southern Switzerland. J. Hydrol. 2012, 424–425, 143–153. [Google Scholar] [CrossRef]
- Younis, J.; Anquetin, S.; Thielen, J. The benefit of high-resolution operational weather forecasts for flash flood warning. Hydrol. Earth Syst. Sci. 2008, 12, 1039–1051. [Google Scholar] [CrossRef]
- Kalnay, E. Atmospheric Modeling, Data Assimilation and Predictability; Cambridge University Press: Cambridge, UK, 2003; ISBN 0-521-79179-0. [Google Scholar]
- Evensen, G. Data Assimilation: The Ensemble Kalman Filter; Springer Science & Business Media: Berlin, Germany, 2009; ISBN 3-642-03711-9. [Google Scholar]
- Shead, T.; Tezaur, I.; Davis IV, W.; Carlson, M.; Dunlavy, D.; Parish, E.; Blonigan, P.; Tencer, J.; Rizzi, F.; Kolla, H. A Novel In Situ Machine Learning Framework for Intelligent Data Capture and Event Detection. In Machine Learning and Its Application to Reacting Flows: ML and Combustion; Springer International Publishing: Cham, Switzerland, 2023; pp. 53–87. [Google Scholar]
- Chawla, S.; Zheng, Y.; Hu, J. Inferring the Root Cause in Road Traffic Anomalies. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining, Brussels, Belgium, 10–13 December 2012; pp. 141–150. [Google Scholar]
- Yang, S.; Kalpakis, K.; Biem, A. Detecting Road Traffic Events by Coupling Multiple Timeseries with a Nonparametric Bayesian Method. IEEE Trans. Intell. Transp. Syst. 2014, 15, 1936–1946. [Google Scholar] [CrossRef]
- Yang, S.; Zhou, W. Anomaly Detection on Collective Moving Patterns: Manifold Learning Based Analysis of Traffic Streams. In Proceedings of the 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust (PASSAT)/2011 IEEE Third International Conference on Social Computing (SocialCom), Boston, MA, USA, 9–11 October 2011; pp. 704–707. [Google Scholar]
- Abdi, H.; Williams, L.J. Principal Component Analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Ringnér, M. What Is Principal Component Analysis? Nat. Biotechnol. 2008, 26, 303–304. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal Component Analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Good, P.I.; Hardin, J.W. Common Errors in Statistics (and How to Avoid Them); John Wiley & Sons: Hoboken, NJ, USA, 2012; ISBN 1-118-36011-7. [Google Scholar]
- Jung, S.; Marron, J.S. PCA consistency in high dimension, low sample size context. Ann. Stat. 2009, 37, 4104–4130. [Google Scholar] [CrossRef] [PubMed]
- R: Jenks Natural Breaks Classification. Available online: https://search.r-project.org/CRAN/refmans/BAMMtools/html/getJenksBreaks.html (accessed on 28 January 2022).
- Jenks, G.F. The Data Model Concept in Statistical Mapping. Int. Yearb. Cartogr. 1967, 7, 186–190. [Google Scholar]
- Chen, J.; Yang, S.T.; Li, H.W.; Zhang, B.; Lv, J.R. Research on geographical environment unit division based on the method of natural breaks (Jenks). Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, 40, 47–50. [Google Scholar] [CrossRef]
- McMaster, R. In Memoriam: George f. Jenks (1916–1996). Cartogr. Geogr. Inf. Syst. 1997, 24, 56–59. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor Number | Location |
|---|---|
| 1 | Penn Station |
| 2 | Intersection of Essex St. and Rivington St. |
| 3 | 1st Ave outside Tisch Hospital/NYU Langone Hospital |
| 4 | Intersection of W 42nd St. and 8th Ave. near Port Authority Bus Terminal |
| 5 | Javits Center |
| 6 | LGA drop-off area |
| 7 | LGA drop-off area |
| 8 | Lincoln Center for the Performing Arts |
| 9 | LGA taxi pick-up area |
| 10 | Madison Square Garden |
| 11 | 9th Ave between W 13th St and W 12th St |
| 12 | Empire State Building |
| 13 | 9th Ave and W 14th St. |
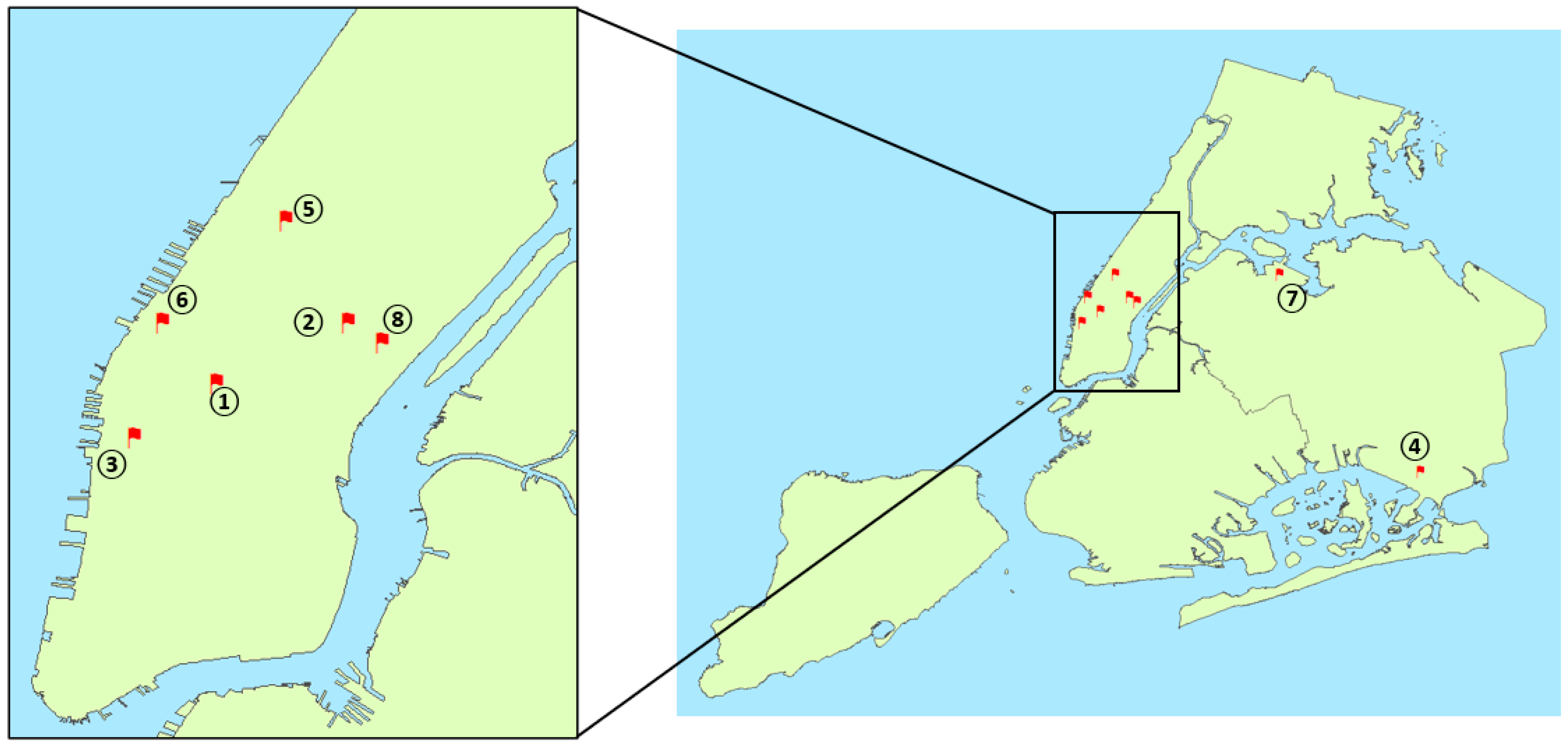
| Sensor Number | Location |
|---|---|
| 1 | Penn Station |
| 2 | Park Ave and E 53rd St. |
| 3 | 9th Ave and W 16th St—Google Building |
| 4 | JFK Terminal 4 departure |
| 5 | Broadway and W 66th |
| 6 | 11th Ave and W 39th St—Lincoln Tunnel Manhattan end |
| 7 | LGA taxi pick-up area |
| 8 | 2nd Ave and E 52nd St. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Y.; Popov, A.A.; Li, Z.; Hodgson, M.E.; Huang, B. A Sensor-Based Simulation Method for Spatiotemporal Event Detection. ISPRS Int. J. Geo-Inf. 2024, 13, 141. https://doi.org/10.3390/ijgi13050141
Jiang Y, Popov AA, Li Z, Hodgson ME, Huang B. A Sensor-Based Simulation Method for Spatiotemporal Event Detection. ISPRS International Journal of Geo-Information. 2024; 13(5):141. https://doi.org/10.3390/ijgi13050141
Chicago/Turabian StyleJiang, Yuqin, Andrey A. Popov, Zhenlong Li, Michael E. Hodgson, and Binghu Huang. 2024. "A Sensor-Based Simulation Method for Spatiotemporal Event Detection" ISPRS International Journal of Geo-Information 13, no. 5: 141. https://doi.org/10.3390/ijgi13050141
APA StyleJiang, Y., Popov, A. A., Li, Z., Hodgson, M. E., & Huang, B. (2024). A Sensor-Based Simulation Method for Spatiotemporal Event Detection. ISPRS International Journal of Geo-Information, 13(5), 141. https://doi.org/10.3390/ijgi13050141