

Mapping Street Patterns with Network Science and Supervised Machine Learning


Abstract
1. Introduction
2. Literature Review
2.1. Street Patterns in Urban Morphology
2.2. Machine Learning as a Quantitative Lever in Urban Morphological Studies
2.3. Machine Learning Framework for Street Morphology
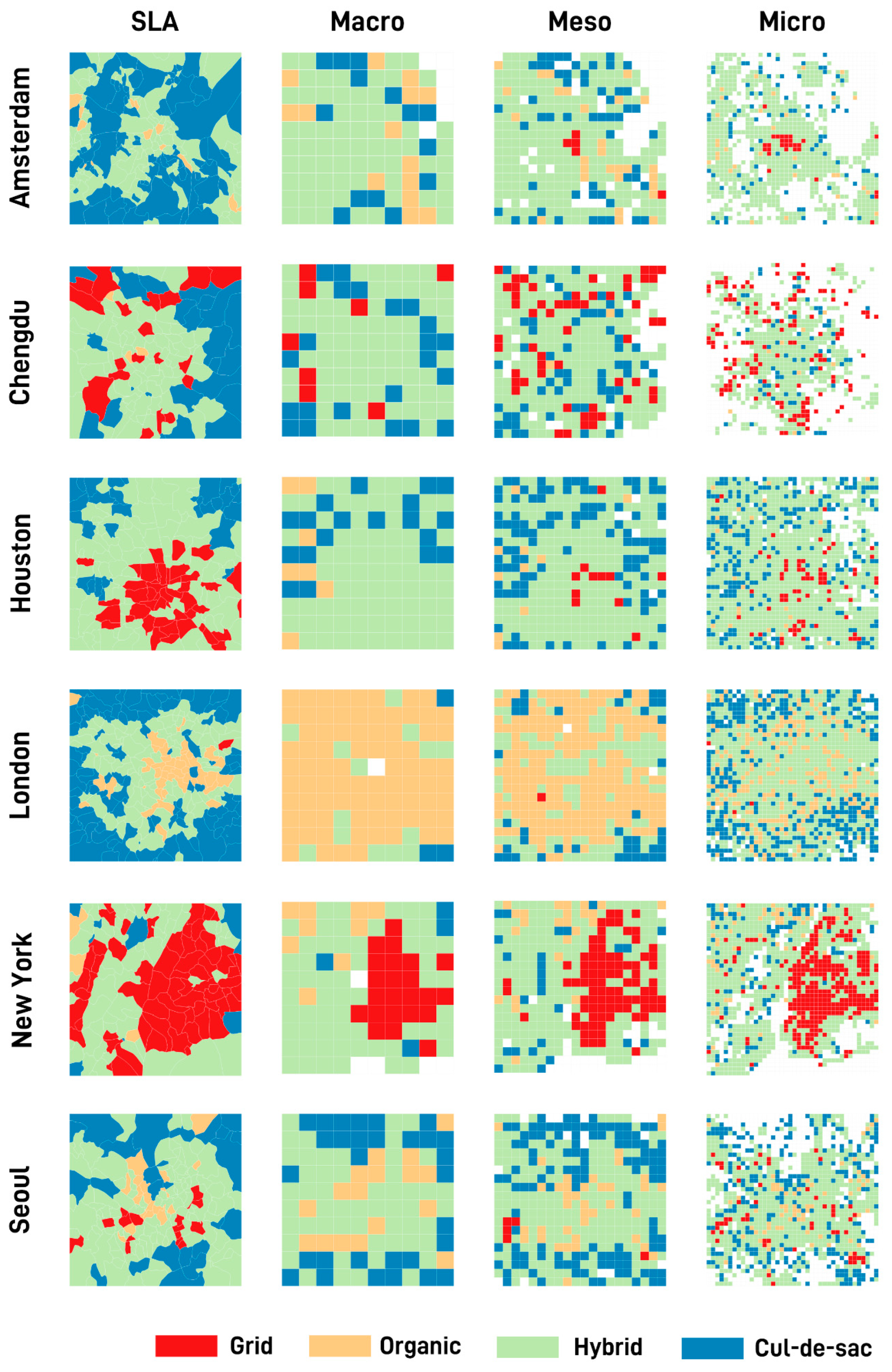
3. Methodology
3.1. Case Study Area and Unit of Analysis
3.2. Street Metrics and Patterns
3.3. Machine Learning Classification
4. Results and Discussion
4.1. Performance of Machine Learning Method
4.2. Street Pattern Features and Urban Spatial Structure with the Street Pattern
4.3. Impact of Different Units of Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Oliveira, V.; Medeiros, V. Morpho: Combining Morphological Measures. Environ. Plan. B Plan. Des. 2016, 43, 805–825. [Google Scholar] [CrossRef]
- Wheeler, S.M. Built Landscapes of Metropolitan Regions: An International Typology. J. Am. Plan. Assoc. 2015, 81, 167–190. [Google Scholar] [CrossRef]
- Alexander, C.; Ishikawa, S.; Silverstein, M. A Pattern Language: Towns, Buildings, Construction; Oxford University Press: New York, NY, USA, 1977; ISBN 0195019199. [Google Scholar]
- Lopes, M.N.; Camanho, A.S. Public Green Space Use and Consequences on Urban Vitality: An Assessment of European Cities. Soc. Indic. Res. 2013, 113, 751–767. [Google Scholar] [CrossRef]
- Bolleter, J.; Hooper, P.; Kleeman, A.; Edwards, N.; Foster, S. A Typological Study of the Provision and Use of Communal Outdoor Space in Australian Apartment Developments. Landsc. Urban Plan. 2024, 246, 105040. [Google Scholar] [CrossRef]
- Berghauser-Pont, M.; Haupt, P. Spacematrix: Space, Density and Urban Form; CiNii Books: Rotterdam, The Netherlands, 2010. [Google Scholar]
- Marshall, S. Streets and Patterns; Routledge: New York, NY, USA, 2004; ISBN 0203589394. [Google Scholar]
- Hansen, W.G. How Accessibility Shapes Land Use. J. Am. Plan. Assoc. 1959, 25, 73–76. [Google Scholar] [CrossRef]
- Batty, M. Accessibility: In Search of a Unified Theory. Environ. Plan. B Plan. Plan. Des. 2009, 36, 191–194. [Google Scholar] [CrossRef]
- Webster, C. Pricing Accessibility: Urban Morphology, Design and Missing Markets. Prog. Plan. 2010, 73, 77–111. [Google Scholar] [CrossRef]
- Wang, M.; Chen, Z.; Mu, L.; Zhang, X. Road Network Structure and Ride-Sharing Accessibility: A Network Science Perspective. Comput. Environ. Urban Syst. 2020, 80, 101430. [Google Scholar] [CrossRef]
- Turner, A. From Axial to Road-Centre Lines: A New Representation for Space Syntax and a New Model of Route Choice for Transport Network Analysis. Environ. Plan. B Urban Anal. City Sci. 2007, 34, 539–555. [Google Scholar] [CrossRef]
- Boeing, G. OSMnx: New Methods for Acquiring, Constructing, Analyzing, and Visualizing Complex Street Networks. Comput. Environ. Urban Syst. 2017, 65, 126–139. [Google Scholar] [CrossRef]
- Hagberg, A.; Swart, P.; Chult, D.S. Exploring Network Structure, Dynamics, and Function Using NetworkX; Los Alamos National Lab. (LANL): Los Alamos, NM, USA, 2008.
- Alexander, C. “A City Is Not a Tree”: From Architectural Forum (1965). In The Urban Design Reader; Routledge: New York, NY, USA, 2013; pp. 152–166. ISBN 9781136205668. [Google Scholar]
- Boeing, G. Off the Grid… and Back Again?: The Recent Evolution of American Street Network Planning and Design. J. Am. Plan. Assoc. 2021, 87, 123–137. [Google Scholar] [CrossRef]
- Mohajeri, N.; Gudmundsson, A. Analyzing the Variation in Street Patterns: Implications for Urban Planning. J. Arch. Plan. Res. 2014, 31, 112–127. [Google Scholar]
- Pillsbury, R. The Urban Street Pattern as a Culture Indicator: Pennsylvania, 1682–1815. Ann. Assoc. Am. Geogr. 1970, 60, 428–446. [Google Scholar] [CrossRef]
- Liu, K.; Gao, S.; Lu, F. Identifying Spatial Interaction Patterns of Vehicle Movements on Urban Road Networks by Topic Modelling. Comput. Environ. Urban Syst. 2019, 74, 50–61. [Google Scholar] [CrossRef]
- Law, S.; Shen, Y.; Penn, A.; Karimi, K. Identifying Street-Character-Weighted Local Area Using Locally Weighted Community Detection Methods the Case Study of London and Amsterdam. In Proceedings of the 12th International Space Syntax Symposium, SSS 2019, Beijing, China, 8–13 July 2019. [Google Scholar]
- Al-Hinkawi, W.S.; Youssef, S.S.; Abd, H.A. Effects of Urban Growth on Street Networks and Land Use in Mosul, Iraq: A Case Study. Civ. Eng. Archit. 2021, 9, 1667–1676. [Google Scholar] [CrossRef]
- Boeing, G. Planarity and Street Network Representation in Urban Form Analysis. Environ. Plan. B Urban Anal. City Sci. 2020, 47, 855–869. [Google Scholar] [CrossRef]
- Hajrasouliha, A.; Yin, L. The Impact of Street Network Connectivity on Pedestrian Volume. Urban Stud. J. Ltd. 2015, 52, 2483–2497. [Google Scholar] [CrossRef]
- Chen, W.; Wu, A.N.; Biljecki, F. Classification of Urban Morphology with Deep Learning: Application on Urban Vitality. Comput. Environ. Urban Syst. 2021, 90, 101706. [Google Scholar] [CrossRef]
- Wu, A.N.; Biljecki, F. InstantCITY: Synthesising Morphologically Accurate Geospatial Data for Urban Form Analysis, Transfer, and Quality Control. ISPRS J. Photogramm. Remote Sens. 2023, 195, 90–104. [Google Scholar] [CrossRef]
- Boeing, G. Methods and Measures for Analyzing Complex Street Networks and Urban Form. Doctor Thesis, University of California, Berkeley, CA, USA, 2017. [Google Scholar]
- Goerlich Gisbert, F.J.; Cantarino Martí, I.; Gielen, E. Clustering Cities through Urban Metrics Analysis. J. Urban Des. 2017, 22, 689–708. [Google Scholar] [CrossRef]
- Fontana, A.G.; Nascimento, V.F.; Ometto, J.P.; do Amaral, F.H.F. Analysis of Past and Future Urban Growth on a Regional Scale Using Remote Sensing and Machine Learning. Front. Remote Sens. 2023, 4, 1123254. [Google Scholar] [CrossRef]
- Gruber, C.J.; Schweighart, M.; Seebauer, S.; Felbermair, S. Machine Learning for Land Use Scenarios and Urban Design. In CITIES 20.50—Creating Habitats for the 3rd Millennium: Smart—Sustainable—Climate Neutral, Proceedings of the REAL CORP 2021, 26th International Conference on Urban Development, Regional Planning and Information Society, Vienna, Austria, 7–9 September 2021; Schrenk, M., Zeile, P., Eds.; CORP—Competence Center of Urban and Regional Planning: Vienna, Austria, 2021; p. 489. [Google Scholar] [CrossRef]
- Koutra, S.; Ioakimidis, C.S. Unveiling the Potential of Machine Learning Applications in Urban Planning Challenges. Land 2022, 12, 83. [Google Scholar] [CrossRef]
- Wu, C.; Smith, D.; Wang, M. Simulating the Urban Spatial Structure with Spatial Interaction: A Case Study of Urban Polycentricity under Different Scenarios. Comput. Environ. Urban Syst. 2021, 89, 101677. [Google Scholar] [CrossRef]
- Herold, M.; Goldstein, N.C.; Clarke, K.C. The Spatiotemporal Form of Urban Growth: Measurement, Analysis and Modeling. Remote Sens. Environ. 2003, 86, 286–302. [Google Scholar] [CrossRef]
- Andrews, R.B. Elements in the Urban-Fringe Pattern. J. Land Public Util. Econ. 1942, 18, 169. [Google Scholar] [CrossRef]
- Schirmer, P.M.; Axhausen, K.W. A Multiscale Clustering of the Urban Morphology for Use in Quantitative Models; Modeling and Simulation in Science, Engineering and Technology; Birkhäuser: Cham, Switzerland, 2019; pp. 355–382. [Google Scholar] [CrossRef]
- Wang, J.; Fleischmann, M.; Venerandi, A.; Romice, O.; Kuffer, M.; Porta, S. EO + Morphometrics: Understanding Cities through Urban Morphology at Large Scale. Landsc. Urban Plan. 2023, 233, 104691. [Google Scholar] [CrossRef]
- Wu, C.; Wang, J.; Wang, M.; Kraak, M.-J. Machine Learning-Based Characterisation of Urban Morphology with the Street Pattern. Comput. Environ. Urban Syst. 2024, 109, 102078. [Google Scholar] [CrossRef]
- Chen, C.-Y.; Koch, F.; Reicher, C. Developing a Two-Level Machine-Learning Approach for Classifying Urban Form for an East Asian Mega-City. Environ. Plan. B Urban Anal. City Sci. 2023, 51, 1–16. [Google Scholar] [CrossRef]
- Yue, H.; Zhu, X. Exploring the Relationship between Urban Vitality and Street Centrality Based on Social Network Review Data in Wuhan, China. Sustainability 2019, 11, 4356. [Google Scholar] [CrossRef]
- Sheng, Q.; Jiao, J.; Pang, T. Understanding the Impact of Street Patterns on Pedestrian Distribution: A Case Study in Tianjin, China. Urban Rail Transit. 2021, 7, 209–225. [Google Scholar] [CrossRef]
- Wong, D.W.S. The Modifiable Areal Unit Problem (MAUP). In WorldMinds: Geographical Perspectives on 100 Problems; Springer: Dordrecht, The Netherlands, 2004; pp. 571–575. [Google Scholar] [CrossRef]
- Kwan, M.-P. The Uncertain Geographic Context Problem. Ann. Assoc. Am. Geogr. 2012, 102, 958–968. [Google Scholar] [CrossRef]
- Chen, W.; Huang, H.; Liao, S.; Gao, F.; Biljecki, F. Global Urban Road Network Patterns: Unveiling Multiscale Planning Paradigms of 144 Cities with a Novel Deep Learning Approach. Landsc. Urban Plan. 2024, 241, 104901. [Google Scholar] [CrossRef]
- Shinde, P.P.; Shah, S. A Review of Machine Learning and Deep Learning Applications. In Proceedings of the 2018 4th International Conference on Computing, Communication Control and Automation, ICCUBEA 2018, Pune, India, 16–18 August 2018. [Google Scholar] [CrossRef]
- Janiesch, C.; Zschech, P.; Heinrich, K. Machine Learning and Deep Learning. Electron. Mark. 2021, 31, 685–695. [Google Scholar] [CrossRef]
- Ma, J.; Cheng, J.C.P.; Jiang, F.; Chen, W.; Zhang, J. Analyzing Driving Factors of Land Values in Urban Scale Based on Big Data and Non-Linear Machine Learning Techniques. Land Use Policy 2020, 94, 104537. [Google Scholar] [CrossRef]
- Bordogna, G.; Fugazza, C.; Cetin, Z.; Yastikli, N. The Use of Machine Learning Algorithms in Urban Tree Species Classification. ISPRS Int. J. Geo-Inf. 2022, 11, 226. [Google Scholar] [CrossRef]
- Kim, D.; Shim, J.; Park, J.; Cho, J.; Kumar, S. Supervised Machine Learning Approaches to Modeling Residential Infill Development in the City of Los Angeles. J. Urban Plan. Dev. 2022, 148, 04021060. [Google Scholar] [CrossRef]
- Samaniego, L.; Schulz, K. Supervised Classification of Agricultural Land Cover Using a Modified K-NN Technique (MNN) and Landsat Remote Sensing Imagery. Remote Sens. 2009, 1, 875–895. [Google Scholar] [CrossRef]
- Longley, P.A.; Tobón, C. Spatial Dependence and Heterogeneity in Patterns of Hardship: An Intra-Urban Analysis. Ann. Assoc. Am. Geogr. 2004, 94, 503–519. [Google Scholar] [CrossRef]
- Park, Y.S.; Lek, S. Artificial Neural Networks: Multilayer Perceptron for Ecological Modeling. Dev. Environ. Model. 2016, 28, 123–140. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Vanderplas, J.; Cournapeau, D.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 2016, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Hengl, T.; Miller, M.A.E.; Križan, J.; Shepherd, K.D.; Sila, A.; Kilibarda, M.; Antonijević, O.; Glušica, L.; Dobermann, A.; Haefele, S.M.; et al. African Soil Properties and Nutrients Mapped at 30 m Spatial Resolution Using Two-Scale Ensemble Machine Learning. Sci. Rep. 2021, 11, 6130. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Khodadadzadeh, M.; Zurita-Milla, R. Spatial+: A New Cross-Validation Method to Evaluate Geospatial Machine Learning Models. Int. J. Appl. Earth Obs. Geoinf. 2023, 121, 103364. [Google Scholar] [CrossRef]
- Batty, M. Unpredictability. Environ. Plan. B Urban Anal. City Sci. 2020, 47, 739–744. [Google Scholar] [CrossRef]
- Batty, M. Defining Complexity in Cities; Springer: Cham, Switzerland, 2020; pp. 13–26. [Google Scholar] [CrossRef]
- Meijers, E. Measuring Polycentricity and Its Promises. Eur. Plan. Stud. 2008, 16, 1313–1323. [Google Scholar] [CrossRef]
- Kwan, M.-P. How GIS Can Help Address the Uncertain Geographic Context Problem in Social Science Research. Ann. GIS 2012, 18, 245–255. [Google Scholar] [CrossRef]
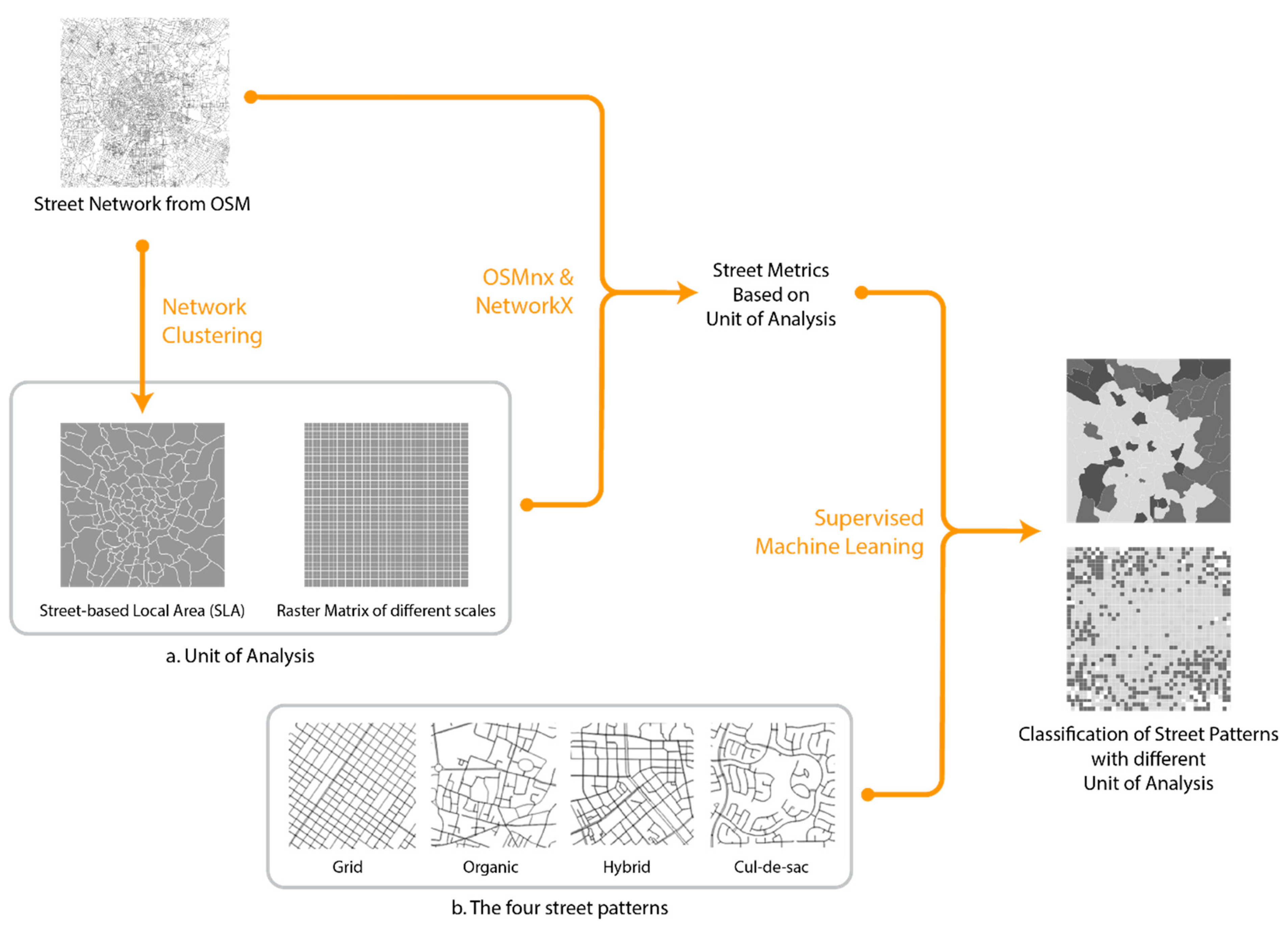


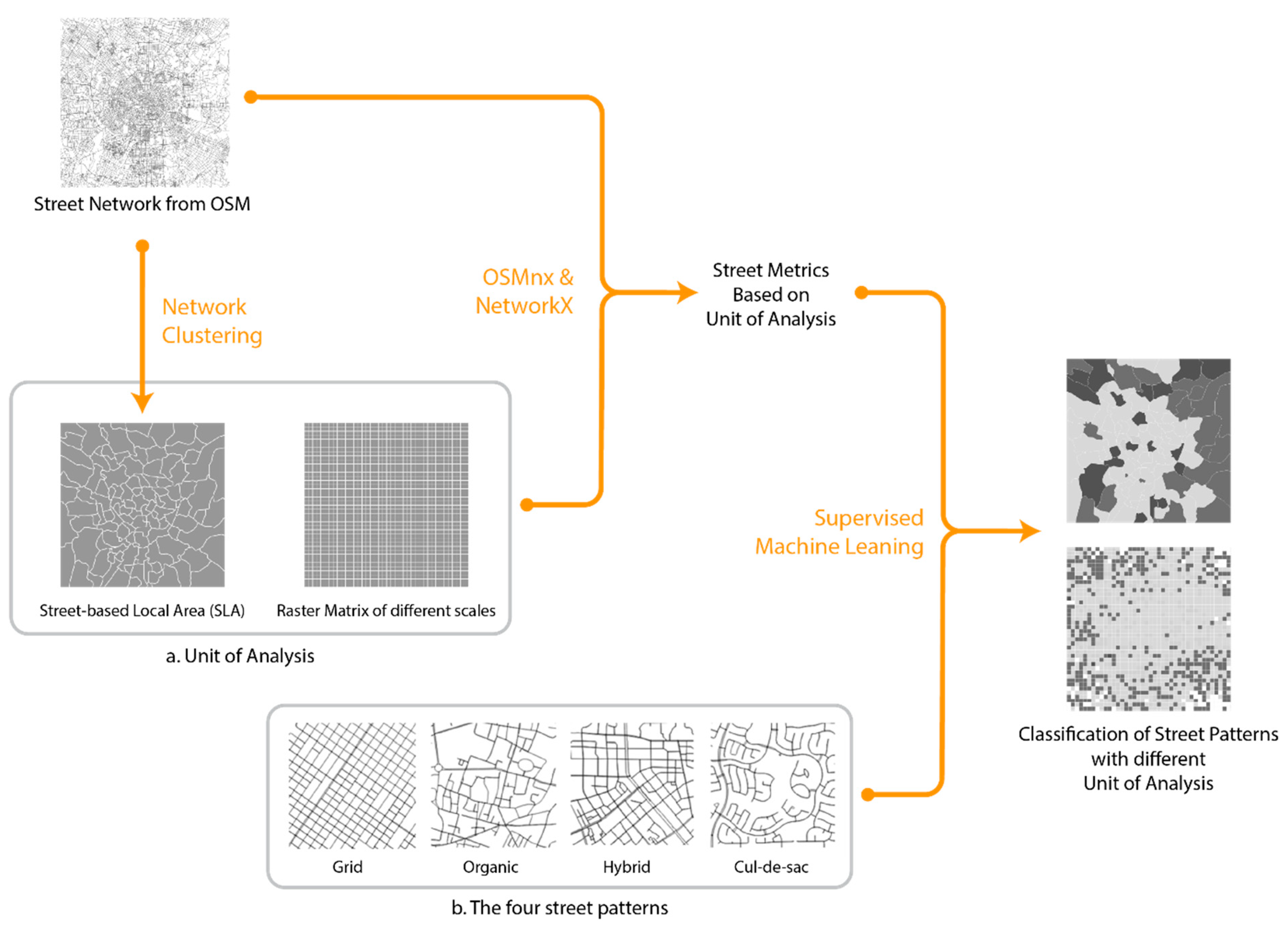{kind=link}
{kind=link}
{kind=link}
| Metric | Definition | Value Remark | |
|---|---|---|---|
| Composition | Street Length | Calculate the graph’s average edge length. | In metres |
| Diameter | It is the shortest distance between the two most distant nodes in the network. | In metres A higher value implies slower movement through the network. | |
| Circuity | Circuity is the sum of edge lengths divided by the sum of straight-line distances between edge endpoints. | 1 to ½ π A higher value implies the street is more circular. | |
| Orientation Entropy | Orientation entropy is the entropy of its edges’ bidirectional bearings across evenly spaced bins. | 1.386 to 3.584 A higher value implies the streets are more ordered. | |
| Configuration | k_avg | graph’s average node degree (in-degree and out-degree) | A higher value implies better connectivity with more route choices. |
| Self-loop | Calculate the percentage of edges that are self-loops in a graph. | 0 to 1 | |
| L-junction | The proportion of nodes with two streets connected. | 0 to 1 | |
| T-junction | The proportion of nodes with three streets connected. | 0 to 1 | |
| X-junction | The proportion of nodes with four streets connected. | 0 to 1 | |
| Explanatory | Degree Pearson | Compute the degree assortativity, the similarity of connections in the graph concerning the node degree, which means the number of streets connected to a street junction. | −1 to 1 A higher value implies that the streets are more ordered. |
| Transitivity | The ratio between the observed number of triangles and the number of closed triplets in the graph. | 0 to 1 A higher value implies that the network contains internal communities. | |
| Global reaching centrality | The global reaching centrality of a weighted directed graph is the average over all nodes of the difference between the local reaching centrality of the node and the greatest local reaching centrality of any node in the graph. | 0 to 1 A higher value means the network shows a more hierarchical structure. | |
| Global Efficiency | The average efficiency of all pairs of nodes in a graph is the average multiplicative inverse of the shortest path distance between the nodes. | 0 to 1 A higher value means the network shows better accessibility. |
| KNN | MLP | SVM | XGBoost | RF | |
|---|---|---|---|---|---|
| Accuracy_weighted | 0.35 | 0.40 | 0.41 | 0.54 | 0.56 |
| Precision_weighted | 0.34 | 0.28 | 0.30 | 0.56 | 0.57 |
| Recall_weighted | 0.35 | 0.39 | 0.41 | 0.54 | 0.54 |
| F1_weighted | 0.34 | 0.30 | 0.27 | 0.52 | 0.54 |
| AUC | 0.54 | 0.63 | 0.54 | 0.75 | 0.78 |
| circuity_avg | 0.132234 |
| k_avg | 0.070243 |
| diameter | 0.048768 |
| edge_length_avg | 0.092476 |
| streets_per_node_proportions_2 | 0.051252 |
| streets_per_node_proportions_3 | 0.074068 |
| streets_per_node_proportions_4 | 0.118955 |
| self_loop_proportion | 0.046852 |
| degree_pearson | 0.090698 |
| orientation_entropy | 0.074808 |
| transitivity | 0.047868 |
| average_clustering | 0.047775 |
| global_reaching_centrality | 0.052981 |
| global_efficiency | 0.051022 |
| Gridiron | Organic | Hybrid | Cul-De-Sac | |
|---|---|---|---|---|
| Circuity | 1.023 | 1.071 | 1.063 | 1.098 |
| X-junction (%) | 38.4 | 13.5 | 18.8 | 12.0 |
| Street Length (m) | 119.3 | 82.8 | 115.5 | 131.7 |
| Degree Pearson | 0.343 | 0.104 | 0.160 | 0.047 |
| Orientation Entropy | 2.803 | 3.349 | 3.132 | 3.265 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, C.; Wang, Y.; Wang, J.; Kraak, M.-J.; Wang, M. Mapping Street Patterns with Network Science and Supervised Machine Learning. ISPRS Int. J. Geo-Inf. 2024, 13, 114. https://doi.org/10.3390/ijgi13040114
Wu C, Wang Y, Wang J, Kraak M-J, Wang M. Mapping Street Patterns with Network Science and Supervised Machine Learning. ISPRS International Journal of Geo-Information. 2024; 13(4):114. https://doi.org/10.3390/ijgi13040114
Chicago/Turabian StyleWu, Cai, Yanwen Wang, Jiong Wang, Menno-Jan Kraak, and Mingshu Wang. 2024. "Mapping Street Patterns with Network Science and Supervised Machine Learning" ISPRS International Journal of Geo-Information 13, no. 4: 114. https://doi.org/10.3390/ijgi13040114
APA StyleWu, C., Wang, Y., Wang, J., Kraak, M.-J., & Wang, M. (2024). Mapping Street Patterns with Network Science and Supervised Machine Learning. ISPRS International Journal of Geo-Information, 13(4), 114. https://doi.org/10.3390/ijgi13040114