
Research and Modeling of Commercial Location Selection Based on Geographic Big Data and Mobile Signaling Data—A Case Study of the Central Urban Area of Beijing


Abstract
1. Introduction
2. Related Work
2.1. Digital Twins
2.2. Geolocation Prediction
2.3. Commercial Site Selection
3. Materials and Methods
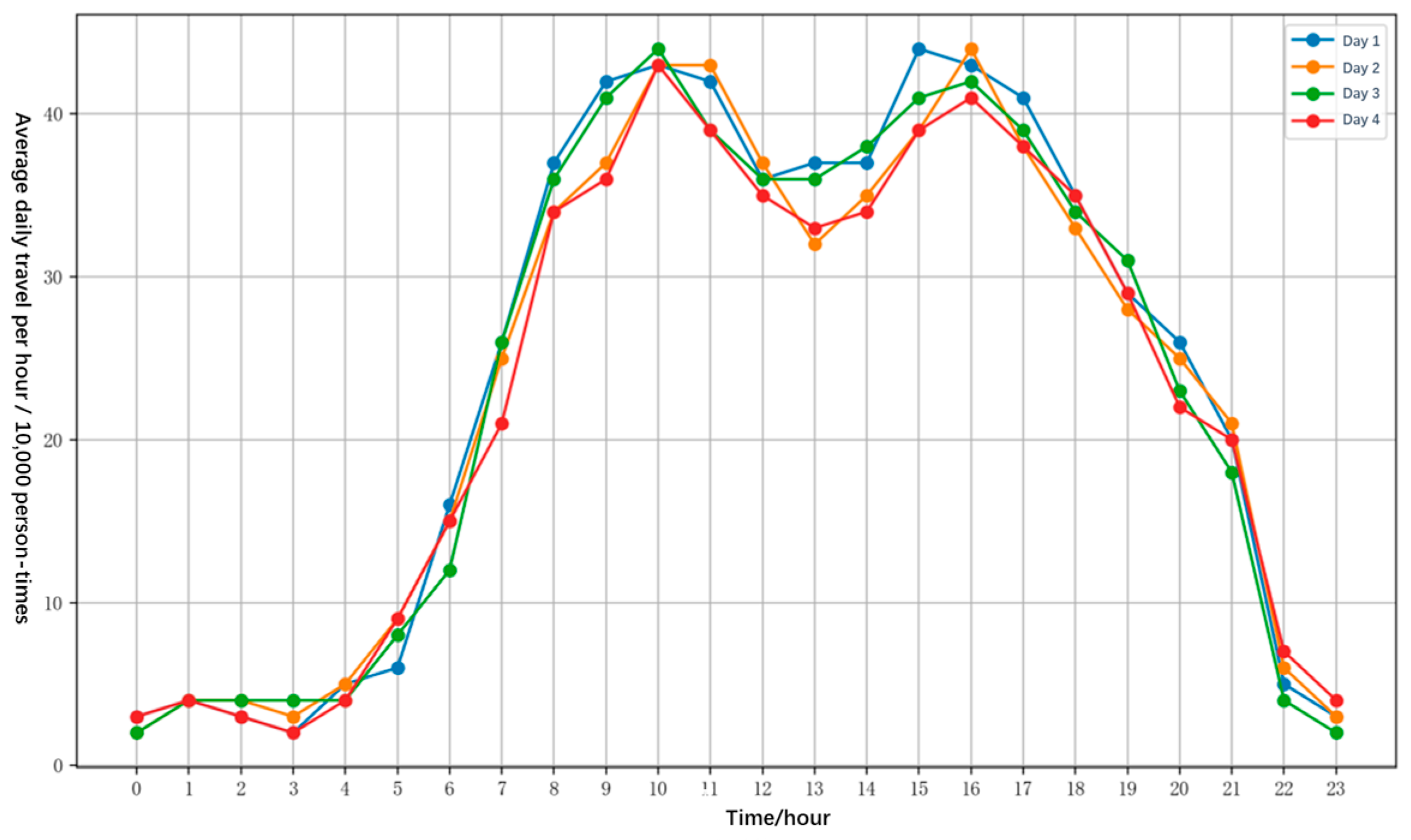
3.1. Study Area and Data
3.2. Methods
3.2.1. Crowd Distribution Prediction
- Stationary Point Identification
- 2.
- User Travel Behavior Recognition
3.2.2. Location Prediction Model
- Spatiotemporal Semantic Vectors
- Spatiotemporal Mobility Pattern Learning
- Attention Mechanism
- Local Feature Fusion
- Global Attention Allocation
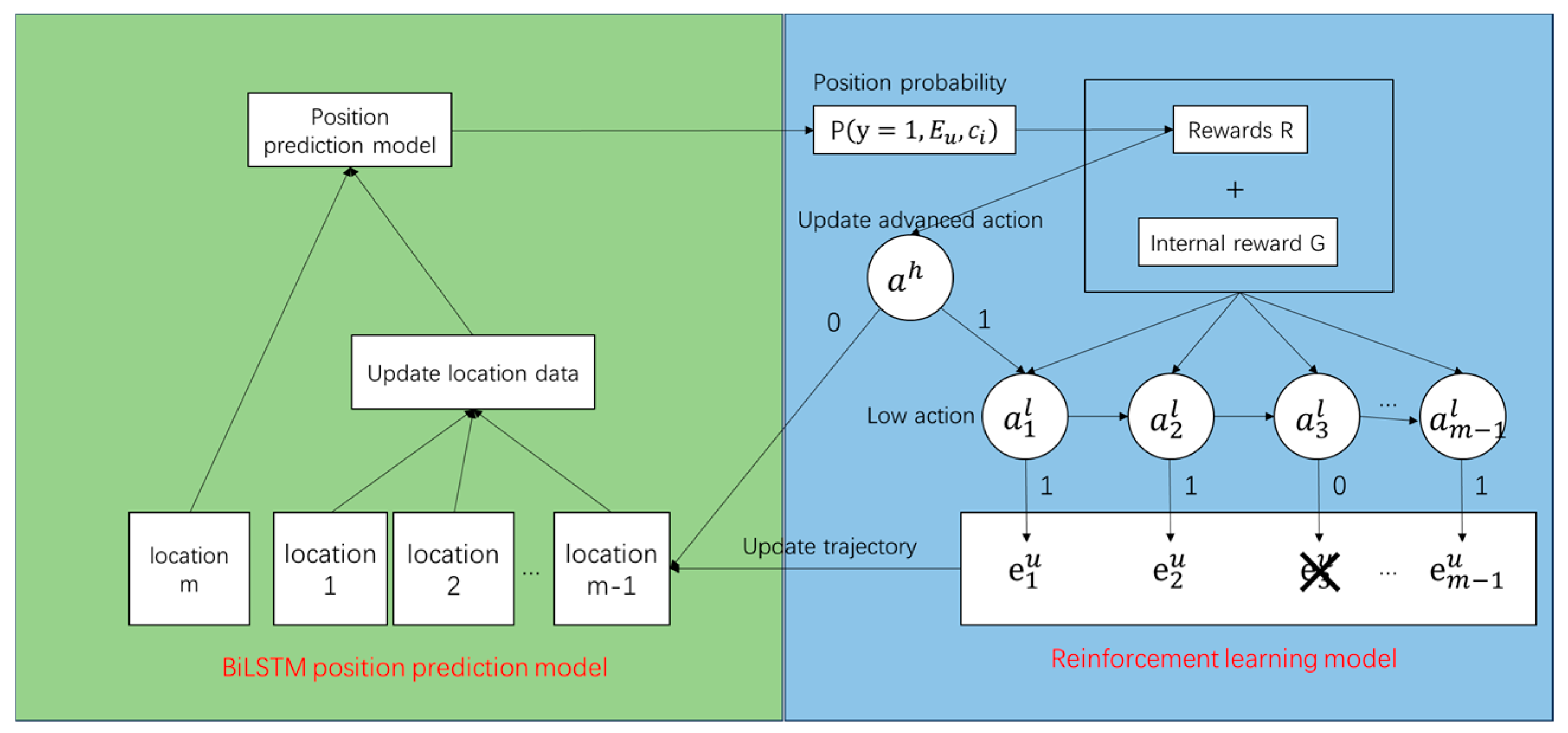
3.2.3. Hierarchical Reinforcement Learning
- Low-Level Actions
- High-Level Actions
- Reward
3.2.4. Commercial Site Selection Calculation
- Prosperity
- Competitiveness
- Traffic Flow
- Transportation Accessibility
4. Results and Analysis
4.1. Comparative Experiments
4.2. Regional Analysis
5. Digital Twin Business Location System
5.1. Simulation Software
5.2. Urban Building Simulation
- Digital City Construction
5.3. Site Selection Area Simulation
- Key area display
- Recommended Location for Business Siting
6. Discussion and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Triantaphyllou, E.; Triantaphyllou, E. Multi-Criteria Decision Making Methods; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Önüt, S.; Efendigil, T.; Kara, S.S. A combined fuzzy MCDM approach for selecting shopping center site: An example from Istanbul, Turkey. Expert Syst. Appl. 2010, 37, 1973–1980. [Google Scholar] [CrossRef]
- Semih, T.; Seyhan, S. A multi-criteria factor evaluation model for gas station site selection. Evaluation 2011, 2, 12–21. [Google Scholar]
- Karamshuk, D.; Noulas, A.; Scellato, S.; Nicosia, V.; Mascolo, C. Geo-spotting: Mining online location-based services for optimal retail store placement. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; Association for Computing Machinery: New York, NY, USA; pp. 793–801. [Google Scholar]
- Neirotti, P.; Marco, A.D.; Cagliano, A.C.; Mangano, G.; Scorrano, F. Current trends in Smart City initiatives: Some stylised facts. Cities 2014, 38, 25–36. [Google Scholar] [CrossRef]
- Hou, J.; Zhao, H.; Zhao, X.; Zhang, J. Predicting mobile users’ behaviors and locations using dynamic Bayesian networks. J. Manag. Anal. 2016, 3, 191–205. [Google Scholar] [CrossRef]
- White, G.; Zink, A.; Codecá, L.; Clarke, S. A digital twin smart city for citizen feedback. Cities 2021, 110, 103064. [Google Scholar] [CrossRef]
- Kaur, M.J.; Mishra, V.P.; Maheshwari, P. The convergence of digital twin, IoT, and machine learning: Transforming data into action. In Digital Twin Technologies and Smart Cities; Springer: Berlin/Heidelberg, Germany, 2020; pp. 3–17. [Google Scholar]
- Alam, K.M.; El Saddik, A. C2PS: A digital twin architecture reference model for the cloud-based cyber-physical systems. IEEE Access 2017, 5, 2050–2062. [Google Scholar] [CrossRef]
- Grieves, M. Digital twin: Manufacturing excellence through virtual factory replication. White Pap. 2014, 1, 1–7. [Google Scholar]
- Glaessgen, E.; Stargel, D. The digital twin paradigm for future NASA and US Air Force vehicles. In Proceedings of the 53rd AIAA/ASME/ASCE/AHS/ASC Structures, Structural Dynamics and Materials Conference 20th AIAA/ASME/AHS Adaptive Structures Conference 14th AIAA, Honolulu, HI, USA, 23–26 April 2012; p. 1818. [Google Scholar]
- Qi, Q.; Tao, F. Digital twin and big data towards smart manufacturing and industry 4.0: 360 degree comparison. IEEE Access 2018, 6, 3585–3593. [Google Scholar] [CrossRef]
- Deng, T.; Zhang, K.; Shen, Z.-J.M. A systematic review of a digital twin city: A new pattern of urban governance toward smart cities. J. Manag. Sci. Eng. 2021, 6, 125–134. [Google Scholar] [CrossRef]
- Soon, K.; Khoo, V. CityGML modelling for Singapore 3D national mapping. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 37–42. [Google Scholar] [CrossRef]
- Pennacchiotti, M.; Popescu, A.-M. A machine learning approach to twitter user classification. In Proceedings of the International AAAI Conference on Web and Social Media, Barcelona, Spain, 17–21 July 2011; pp. 281–288. [Google Scholar]
- Rodrigues, E.; Assunção, R.; Pappa, G.L.; Renno, D.; Meira, W., Jr. Exploring multiple evidence to infer users’ location in Twitter. Neurocomputing 2016, 171, 30–38. [Google Scholar] [CrossRef]
- Li, W.; Eickhoff, C.; de Vries, A.P. Want a coffee? Predicting users’ trails. In Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval, Portland, OR, USA, 12–16 August 2012; Association for Computing Machinery: New York, NY, USA; pp. 1171–1172. [Google Scholar]
- Yin, H.; Hu, Z.; Zhou, X.; Wang, H.; Zheng, K.; Nguyen, Q.V.H.; Sadiq, S. Discovering interpretable geo-social communities for user behavior prediction. In Proceedings of the 2016 IEEE 32nd International Conference on Data Engineering (ICDE), Helsinki, Finland, 16–20 May 2016; pp. 942–953. [Google Scholar]
- Chang, H.-W.; Lee, D.; Eltaher, M.; Lee, J. @ Phillies tweeting from Philly? Predicting Twitter user locations with spatial word usage. In Proceedings of the 2012 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Istanbul, Turkey, 26–29 August 2012; pp. 111–118. [Google Scholar]
- Iso, H.; Wakamiya, S.; Aramaki, E. Density estimation for geolocation via convolutional mixture density network. arXiv 2017, arXiv:1705.02750 2017. [Google Scholar]
- Mousset, P.; Pitarch, Y.; Tamine, L. End-to-end neural matching for semantic location prediction of tweets. ACM Trans. Inf. Syst. TOIS 2020, 39, 1–35. [Google Scholar] [CrossRef]
- Lian, J.; Zhang, F.; Xie, X.; Sun, G. Restaurant survival analysis with heterogeneous information. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; Association for Computing Machinery: New York, NY, USA; pp. 993–1002. [Google Scholar]
- Cheema, M.A.; Lin, X.; Zhang, W.; Zhang, Y. Influence zone: Efficiently processing reverse k nearest neighbors queries. In Proceedings of the 2011 IEEE 27th International Conference on Data Engineering, Hannover, Germany, 11–16 April 2011; pp. 577–588. [Google Scholar]
- Xu, M.; Wang, T.; Wu, Z.; Zhou, J.; Li, J.; Wu, H. Demand driven store site selection via multiple spatial-temporal data. In Proceedings of the 24th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Burlingame, CA, USA, 31 October–3 November 2016; Association for Computing Machinery: New York, NY, USA; pp. 1–10. [Google Scholar]
- Shi, J.; Lu, H.; Lu, J.; Liao, C. A skylining approach to optimize influence and cost in location selection. In Proceedings of the International Conference on Database Systems for Advanced Applications, Bali, Indonesia, 21–24 April 2014; pp. 61–76. [Google Scholar]
- Yang, Y.; Tang, J.; Luo, H.; Law, R. Hotel location evaluation: A combination of machine learning tools and web GIS. Int. J. Hosp. Manag. 2015, 47, 14–24. [Google Scholar] [CrossRef]
- Lu, Y.; Zhu, S.; Zhang, L. A machine learning approach to trip purpose imputation in GPS-based travel surveys. In Proceedings of the 4th Conference on Innovations in Travel Modeling, Tampa, FL, USA, 30 April–2 May 2012. [Google Scholar]
- Liu, D.; Weng, D.; Li, Y.; Bao, J.; Zheng, Y.; Qu, H.; Wu, Y. Smartadp: Visual analytics of large-scale taxi trajectories for selecting billboard locations. IEEE Trans. Vis. Comput. Graph. 2016, 23, 1–10. [Google Scholar] [CrossRef]
- Wang, L.; Fan, H.; Wang, Y. Site selection of retail shops based on spatial accessibility and hybrid BP neural network. ISPRS Int. J. Geo-Inf. 2018, 7, 202. [Google Scholar] [CrossRef]
- Shaikh, S.A.; Memon, M.A.; Prokop, M.; Kim, K.-S. An AHP/TOPSIS-based approach for an optimal site selection of a commercial opening utilizing geospatial data. In Proceedings of the 2020 IEEE International Conference on Big Data and Smart Computing (BigComp), Busan, Republic of Korea, 19–20 February 2020; pp. 295–302. [Google Scholar]
- Perez-Benitez, V.; Gemar, G.; Hernández, M. Multi-criteria analysis for business location decisions. Mathematics 2021, 9, 2615. [Google Scholar] [CrossRef]
- Liu, Y.; Li, J.; Yang, Y. Strategic adjustment of land use policy under the economic transformation. Land Use Policy 2018, 74, 5–14. [Google Scholar] [CrossRef]
- Li, M.; Gao, S.; Lu, F.; Zhang, H. Reconstruction of human movement trajectories from large-scale low-frequency mobile phone data. Comput. Environ. Urban Syst. 2019, 77, 101346. [Google Scholar] [CrossRef]
- Bao, Y.; Huang, Z.; Li, L.; Wang, Y.; Liu, Y. A BiLSTM-CNN model for predicting users’ next locations based on geotagged social media. Int. J. Geogr. Inf. Sci. 2021, 35, 639–660. [Google Scholar] [CrossRef]
- Luong, M.-T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025 2015. [Google Scholar]
- Feng, J.; Li, Y.; Zhang, C.; Sun, F.; Meng, F.; Guo, A.; Jin, D. Deepmove: Predicting human mobility with attentional recurrent networks. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1459–1468. [Google Scholar]
- Ustinovičius, L.; Stasiulionis, A. Multicriteria-based estimation of selection of commercial property construction site. Statyba 2001, 7, 474–480. [Google Scholar] [CrossRef]
- Turhan, G.; Akalın, M.; Zehir, C. Literature review on selection criteria of store location based on performance measures. Procedia-Soc. Behav. Sci. 2013, 99, 391–402. [Google Scholar] [CrossRef]
- Hoch, S.J.; Kim, B.-D.; Montgomery, A.L.; Rossi, P.E. Determinants of store-level price elasticity. J. Mark. Res. 1995, 32, 17–29. [Google Scholar] [CrossRef]
- Durvasula, S. A Retail Store Location Model Based on Managerial Judgements. J. Retail. 1992, 68, 402–404. [Google Scholar]
- Ahmed, M.; Muhammad, N.; Mohammed, M.; Idris, Y. A GIS-Based analysis of police stations distributions in kano metropolis. IOSR J. Comput. Eng. 2013, 8, 72–78. [Google Scholar] [CrossRef]
- Sanders, A. An Introduction to Unreal Engine 4; AK Peters/CRC Press: Natick, MA, USA, 2016. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Field | Data Examples | Type |
|---|---|---|
| grid_id | 1001403016115366 | bigint |
| length | data | int |
| centroid_lat | 39.8883603308591 | double |
| centroid_lon | 115.548248843125 | double |
| wkt | POLGON((115.54676354663768 39.88946791718516, 115.54973413961343 39.88946791718516, 115.54973413961343 39.887252744533036, 115.54676354663768 39.887252744533036, 115.54676354663768 39.88946791718516)) | string |
| zone_id | 110109 | string |
| province | 011 | string |
| city | V0110000 | string |
| Field | Data Examples | Type |
|---|---|---|
| uid | 2038792652410140000 | string |
| move_id | 1 | int |
| move_vp_id | 37 | bigint |
| stime | 1 October 202117:34:10 | timestamp |
| grid_id | 3003403592115440 | bigint |
| cid | 116998 | bigint |
| province | 011 | string |
| city | V0110000 | string |
| date | 20211001 | int |
| Field | Data Examples | Type |
|---|---|---|
| uid | 1594256208358330000 | string |
| gender | 02 | string |
| age | 09 | string |
| arpu | 26 | double |
| area | V0310000 | string |
| brand | iPhone | string |
| type | iPhone | string |
| weight | 5.4741700725862 | decimal(28,8) |
| gw | 8.44297150858395 | decimal(28,8) |
| province | 011 | string |
| is_core | Y | string |
| is_local | Y | string |
| home_district | 110108 | string |
| work_district | 110108 | string |
| home_lon | 116.332570558765 | double |
| home_lat | 39.9142582560604 | double |
| work_lon | 116.322234356429 | double |
| work_lat | 39.9372904232794 | double |
| id_area | 130721 | string |
| city | V0310000 | string |
| date | 20170101 | int |
| Grid | Type | Distance |
|---|---|---|
| 46,88 | Tourist attractions | 37 m |
| 46,88 | Hotel accommodation | 62 m |
| 46,88 | Leisure and entertainment | 138 m |
| 47,88 | Life services | 90 m |
| 48,85 | Hotel accommodation | 213 m |
| 48,85 | Company | 32 m |
| Method | MAE | RMSE | Accuracy |
|---|---|---|---|
| Markov | 142.3 | 172.53 | 0.5085 |
| LSTM | 107.2301 | 131.65 | 0.5472 |
| BiLSTM | 87.711 | 103.129 | 0.6295 |
| BiLSTM-RF | 79.3 | 88.164 | 0.7323 |
| Study Area | Statistical Point | Accuracy Rate |
|---|---|---|
| Haidian | 52 | 0.721 |
| Xicheng | 31 | 0.779 |
| Dongcheng | 48 | 0.715 |
| Chaoyang | 90 | 0.716 |
| Shijingshan | 11 | 0.728 |
| Fengtai | 24 | 0.738 |
| Tongzhou | 63 | 0.754 |
| Daxing | 8 | 0.675 |
| Fangshan | 9 | 0.653 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, J.; Zhang, X.; Cong, Y.; Gao, Z.; Shi, J. Research and Modeling of Commercial Location Selection Based on Geographic Big Data and Mobile Signaling Data—A Case Study of the Central Urban Area of Beijing. ISPRS Int. J. Geo-Inf. 2024, 13, 432. https://doi.org/10.3390/ijgi13120432
Zou J, Zhang X, Cong Y, Gao Z, Shi J. Research and Modeling of Commercial Location Selection Based on Geographic Big Data and Mobile Signaling Data—A Case Study of the Central Urban Area of Beijing. ISPRS International Journal of Geo-Information. 2024; 13(12):432. https://doi.org/10.3390/ijgi13120432
Chicago/Turabian StyleZou, Jin, Xun Zhang, Yangxiao Cong, Zhentong Gao, and Jinlian Shi. 2024. "Research and Modeling of Commercial Location Selection Based on Geographic Big Data and Mobile Signaling Data—A Case Study of the Central Urban Area of Beijing" ISPRS International Journal of Geo-Information 13, no. 12: 432. https://doi.org/10.3390/ijgi13120432
APA StyleZou, J., Zhang, X., Cong, Y., Gao, Z., & Shi, J. (2024). Research and Modeling of Commercial Location Selection Based on Geographic Big Data and Mobile Signaling Data—A Case Study of the Central Urban Area of Beijing. ISPRS International Journal of Geo-Information, 13(12), 432. https://doi.org/10.3390/ijgi13120432