





Spatio-Temporal Relevance Classification from Geographic Texts Using Deep Learning
Abstract
:1. Introduction
- (1)
- This paper proposes a deep learning-based BERT_RCNN spatio-temporal text classification model and compares it with mainstream deep learning-based text classification models. Experimental results show that using the BERT_RCNN model significantly improves the performance of spatio-temporal text classification.
- (2)
- Using the Wikipedia English corpus as the data source, this paper screens a series of geographically relevant texts, subsumes and extracts triples, and annotates the dataset according to the knowledge types and annotation rules, and finally constructs a spatio-temporal classification dataset.
2. Materials and Methods
2.1. Dataset Construction
2.1.1. Data Acquisition
2.1.2. Spatio-Temporal Correlation Classification Labeling Rules
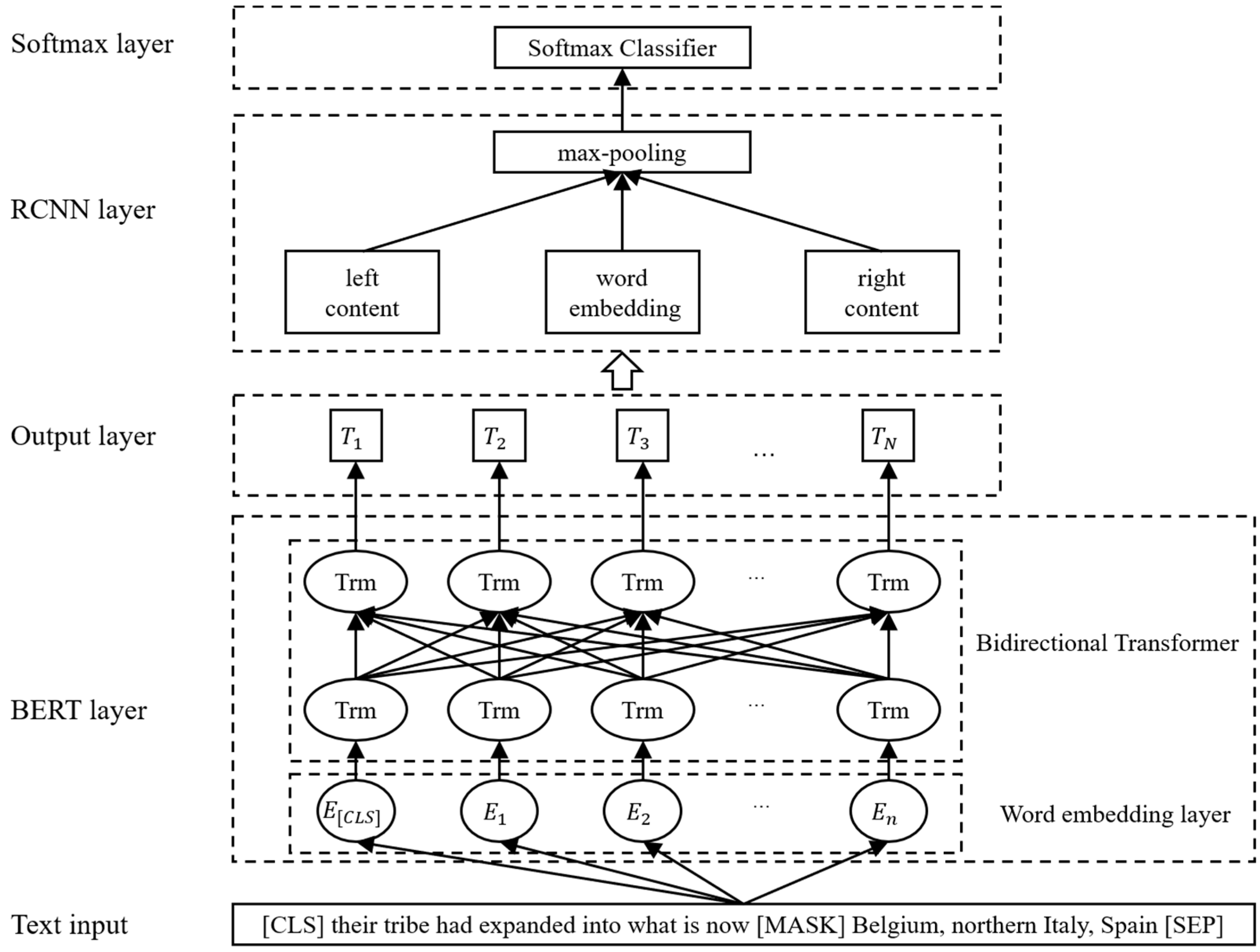
2.2. Sentence Classification Methods
3. Experiments and Results
3.1. Parameter Setting
3.2. Evaluation Metric
3.3. Temporal Correlation Classification
3.3.1. Comparative Analysis of Sentence Classification Models
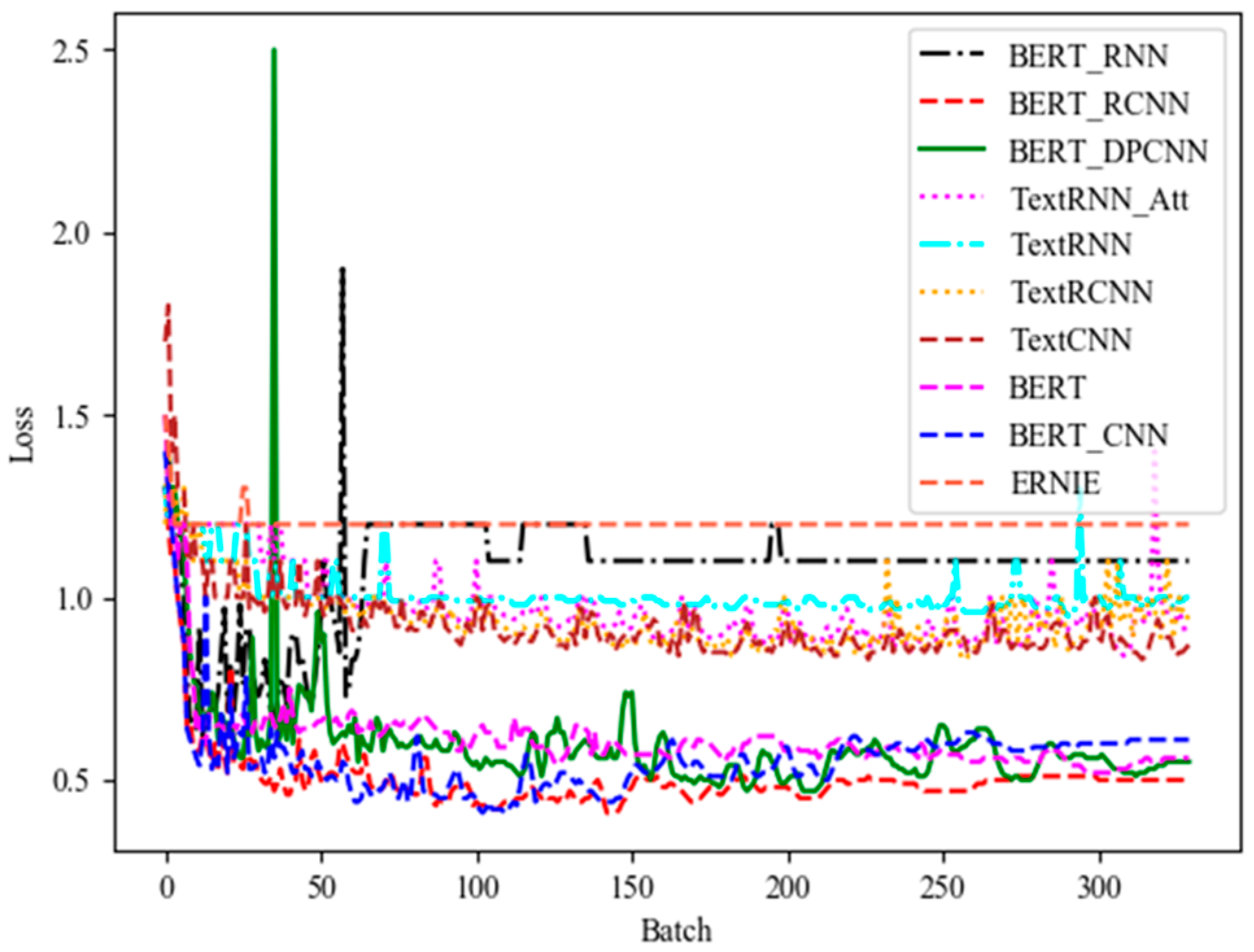
3.3.2. Loss Function Analysis Based on Different Classification Models
3.4. Spatial Correlation Classification
3.4.1. Comparative Analysis of Sentence Classification Models
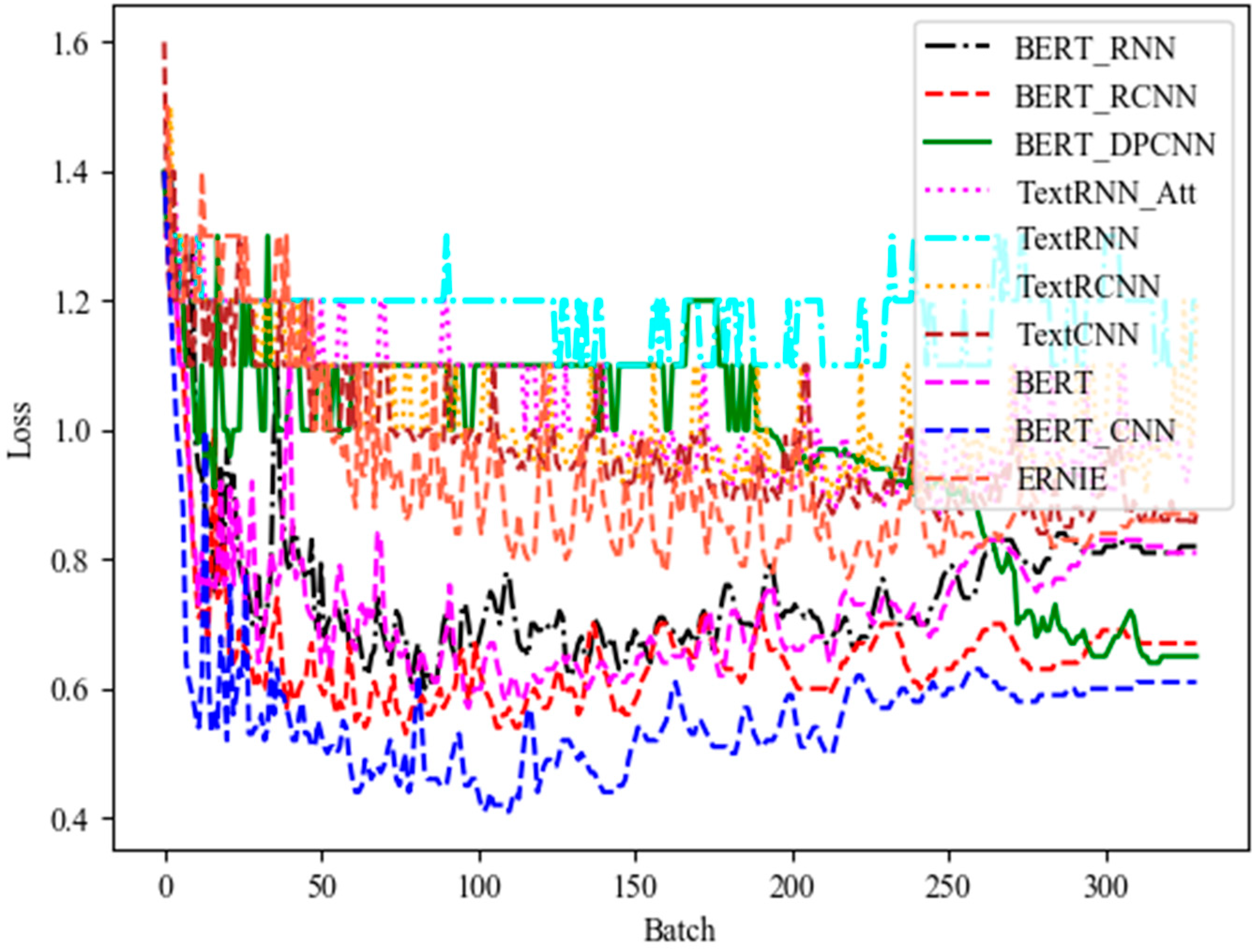
3.4.2. Loss Function Analysis Based on Different Classification Models
3.5. Classification of Spatial and Temporal Relevance
3.5.1. Comparative Analysis of Sentence Classification Models
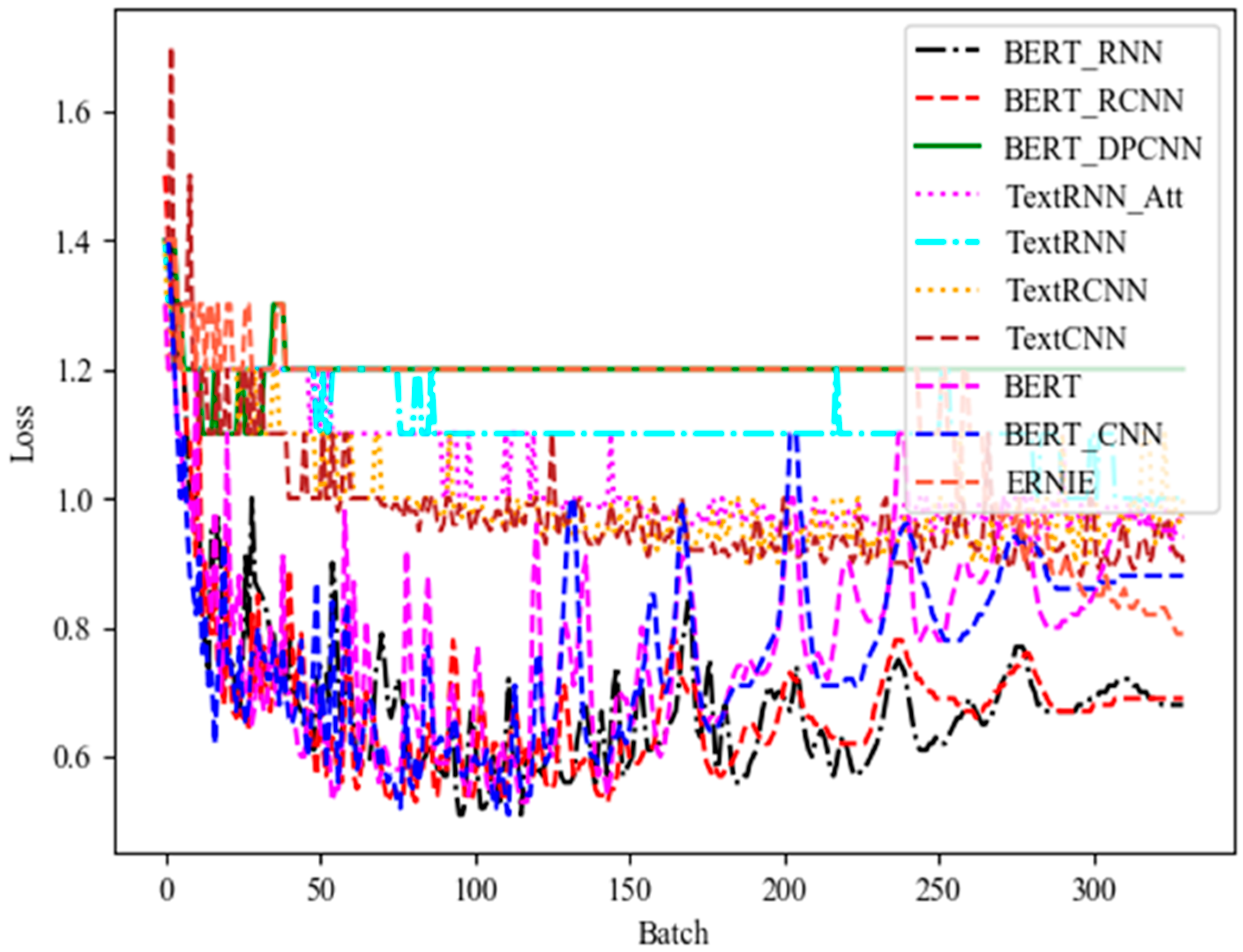
3.5.2. Loss Function Analysis Based on Different Classification Models
3.6. Text Categorization Prediction
4. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ruan, Y.Z.; Jia, D. Some thoughts on basic surveying and mapping production service system under the new system. Surv. Mapp. Sci. 2020, 45, 178–182. [Google Scholar]
- Chen, J.; Liu, W.Z.; Wu, H.; Li, Z.; Zhao, Y.; Zhang, L. Basic issues and research agenda of geospatial knowledge service. Geomat. Inf. Sci. Wuhan Univ. 2019, 44, 38–47. [Google Scholar]
- Liu, J.N.; Guo, W.F.; Guo, C.; Gao, K.; Cui, J. Rethinking ubiquitous mapping in the age of intelligence. J. Surv. Mapp. 2020, 49, 403–414. [Google Scholar]
- Zhang, X.; Zhang, C.; Wu, M.; Lv, G. Spatio-temporal features based geographical knowledge graph construction. Sci. Sin. Inform. 2020, 50, 1019–1032. [Google Scholar]
- Lu, F.; Zhu, Y.Q.; Zhang, X.Y. Spatio-temporal knowledge graph: Advances and perspectives. J. Geo-Inf. Sci. 2023, 25, 1091–1105. [Google Scholar]
- Brodt, A.; Nicklas, D.; Mitschang, B. Deep integration of spatial query processing into native RDF triple stores. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 33–42. [Google Scholar]
- Liagouris, J.; Mamoulis, N.; Bouros, P.; Terrovitis, M. An effective encoding scheme for spatial RDF data. Proc. VLDB Endow. 2014, 7, 1271–1282. [Google Scholar] [CrossRef]
- Wang, D.; Zou, L.; Feng, Y.; Shen, X.; Tian, J.; Zhao, D. S-store: An engine for large rdf graph integrating spatial information. In Proceedings of the Database Systems for Advanced Applications: 18th International Conference (DASFAA 2013), Wuhan, China, 22–25 April 2013; Proceedings, Part II 18. Springer: Berlin/Heidelberg, Germany, 2013; pp. 31–47. [Google Scholar]
- Lu, F.; Yu, L.; Qiu, P.Y. On geographic knowledge graph. J. Geo-Inf. Sci. 2017, 19, 723–734. [Google Scholar]
- Qiu, Q.; Xie, Z.; Ma, K.; Tao, L.; Zheng, S. NeuroSPE: A neuro-net spatial relation extractor for natural language text fusing gazetteers and pretrained models. Trans. GIS 2023, 27, 1526–1549. [Google Scholar] [CrossRef]
- Wang, R.W. Python and Data Science; East China Normal University Press: Shanghai, China, 2015; p. 267. [Google Scholar]
- Maron, M.E. Automatic indexing: An experimental inquiry. J. ACM 1961, 8, 404–417. [Google Scholar] [CrossRef]
- Santos, R.; Murrieta-Flores, P.; Calado, P.; Martins, B. Toponym matching through deep neural networks. Int. J. Geogr. Inf. Sci. 2018, 32, 324–348. [Google Scholar] [CrossRef]
- Wang, J.; Hu, Y. Enhancing spatial and textual analysis with EUPEG: An extensible and unified platform for evaluating geoparsers. Trans. GIS 2019, 23, 1393–1419. [Google Scholar] [CrossRef]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep learning based text classification: A comprehensive review. arXiv 2020, arXiv:2004.03705. [Google Scholar] [CrossRef]
- Tao, L.; Xie, Z.; Xu, D.; Ma, K.; Qiu, Q.; Pan, S.; Huang, B. Geographic Named Entity Recognition by Employing Natural Language Processing and an Improved BERT Model. ISPRS Int. J. Geo-Inf. 2022, 11, 598. [Google Scholar] [CrossRef]
- Hua, X.L.; Xu, F.; Wang, Z.Q.; Li, P.F. Fine-grained classification method for abstract sentence of scientific paper. Comput. Eng. 2012, 38, 138–140. [Google Scholar]
- Asghar, M.Z.; Khan, A.; Bibi, A.; Kundi, F.M.; Ahmad, H. Sentence-level emotion detection framework using rule-based classification. Cogn. Comput. 2017, 9, 868–894. [Google Scholar] [CrossRef]
- Tan, L.; San Phang, W.; Chin, K.O.; Patricia, A. Rule-based sentiment analysis for financial news. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015; pp. 1601–1606. [Google Scholar]
- Zhang, M.; Wang, J. Automatic Extraction of Flooding Control Knowledge from Rich Literature Texts Using Deep Learning. Appl. Sci. 2023, 13, 2115. [Google Scholar] [CrossRef]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Iyyer, M.; Manjunatha, V.; Boyd-Graber, J.; Daumé, H., III. Deep unordered composition rivals syntactic methods for text classification. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 1681–1691. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Johnson, R.; Zhang, T. Deep pyramid convolutional neural networks for text categorization. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 562–570. [Google Scholar]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef]
- Liu, X.; He, P.; Chen, W.; Gao, J. Multi-task deep neural networks for natural language understanding. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4487–4496. [Google Scholar]
- Qin, Q.; Yi, J.K. A BERT-CNN model for text classification. J. Beijing Univ. Inf. Sci. Technol. 2023, 38, 69–74. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.H.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; p. 29. [Google Scholar]
- Orosoo, M.; Govindasamy, S.; Bayarsaikhan, N.; Rajkumari, Y.; Fatma, G.; Manikandan, R.; Bala, B.K. Performance analysis of a novel hybrid deep learning approach in classification of quality-related English text. Meas. Sens. 2023, 28, 100852. [Google Scholar] [CrossRef]
- Kong, X.F.; Dong, B.; Xu, K.; Tan, Y.L. A text classification model for livelihood issues based on BERT—An example of Zhejiang provincial government hotline data. J. Peking Univ. 2023, 59, 456–466. [Google Scholar]
- Wang, H.C.; Sun, M.Z. Chinese short text classification based on ERNIE-RCNN model. Comput. Technol. Dev. 2022, 32, 28–33. [Google Scholar]
- Li, Y.C.; Qian, L.F.; Ma, J. Research on early detection of microblog rumours based on BERT-RCNN model. Intell. Theory Pract. 2021, 44, 173–177. [Google Scholar]
- Qiu, Q.; Xie, Z.; Ma, K.; Chen, Z.; Tao, L. Spatially oriented convolutional neural network for spatial relation extraction from natural language texts. Trans. GIS 2022, 26, 839–866. [Google Scholar] [CrossRef]
- Du, S.; Feng, C.C.; Guo, L. Integrative representation and inference of qualitative locations about points, lines, and polygons. Int. J. Geogr. Inf. Sci. 2015, 29, 980–1006. [Google Scholar] [CrossRef]
- Du, S.; Guo, L. Similarity measurements on multi-scale qualitative locations. Trans. GIS 2016, 20, 824–847. [Google Scholar] [CrossRef]
- Purves, R.S.; Clough, P.; Jones, C.B.; Arampatzis, A.; Bucher, B.; Finch, D.; Fu, G.; Joho, H.; Syed, A.K.; Vaid, S.; et al. The design and implementation of SPIRIT: A spatially aware search engine for information retrieval on the Internet. Int. J. Geogr. Inf. Sci. 2007, 21, 717–745. [Google Scholar] [CrossRef]
- Huang, C. Factual knowledge meta-identification and citation in digital resources of digital libraries. Sci. Technol. Entrep. Mon. 2020, 33, 58–62. [Google Scholar]
- Braithwaite, D.W.; Sprague, L. Conceptual knowledge, procedural knowledge, and metacognition in routine and nonroutine problem solving. Cogn. Sci. 2021, 45, e13048. [Google Scholar] [CrossRef] [PubMed]
- Souza, C.; Garrido, M.V.; Horchak, O.V.; Carmo, J.C. Conceptual knowledge modulates memory recognition of common items: The selective role of item-typicality. Mem. Cogn. 2022, 50, 77–94. [Google Scholar] [CrossRef]
- Sha, Z.Y.; Bian, F.; Chen, J.P. Research on spatial reasoning based on rule-based knowledge. J. Wuhan Univ. 2003, 48, 45–50. [Google Scholar]
- Qiu, Q.; Xie, Z.; Wang, S.; Zhu, Y.; Lv, H.; Sun, K. ChineseTR: A weakly supervised toponym recognition architecture based on automatic training data generator and deep neural network. Trans. GIS 2022, 26, 1256–1279. [Google Scholar] [CrossRef]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Liu, P.; Qiu, X.; Huang, X. Recurrent neural network for text classificatio with multi-task learning. arXiv 2016, arXiv:1605.05101. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to fine-tune bert for text classification? In Proceedings of the Chinese Computational Linguistics: 18th China National Conference (CCL 2019), Kunming, China, 18–20 October 2019; Proceedings 18. Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 194–206. [Google Scholar]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Tian, H.; Wu, H.; Wang, H. Ernie 2.0: A continual pre-training framework for language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8968–8975. [Google Scholar]
- Lu, X.L.; Ni, B. Research on BERT-CNN multi-level patent classification based on pre-trained language model. J. Chin. Inf. 2021, 35, 70–79. [Google Scholar]
- Lin, D.P.; Wang, H.J. Comparison of news text classification based on BERT and RNN. J. Beijing Inst. Print. 2021, 29, 156–162. [Google Scholar]
- Peng, Y.; Jiang, X.Y. A spam filtering system based on BERT_DPCNN text classification algorithm. Comput. Knowl. Technol. 2022, 18, 66–69. [Google Scholar]
- Zhang, Z. Improved adam optimizer for deep neural networks. In Proceedings of the 2018 IEEE/ACM 26th International symposium on quality of service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–2. [Google Scholar]
- Sharma, S.; Mehra, R.; Kumar, S. Optimised CNN in conjunction with efficient pooling strategy for the multi-classification of breast cancer. IET Image Process. 2021, 15, 936–946. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sentence | Triple | Spatio-Temporal Quadruple | Spatio- and Temporal Relevance |
|---|---|---|---|
| Brown previously received degrees of Ph.D. | (Brown, received, degrees) | (Brown, received, degrees, previously) | Temporal weak relevance |
| Brown was elected to presidency of Cincinnati Wesleyan College. | (Brown, elected, presidency) | (Brown, elected, presidency, Cincinnati Wesleyan College) | Spatio-weak relevance |
| Brown went to New York City In 1877. | (Brown, went to, New York City) | (Brown, went to, New York City, 1877) | Temporal strong relevance |
| She accepted offer. | (She, accepted, offer) | - | Spatio-temporal no relevance |
| Brown was present in May 1869 at caucus for national organization of temperance party. | (Brown, caucus, national organization of temperance party) | (Brown, caucus, national organization of temperance party, in May 1869) | Temporal moderate relevance |
| Type of Association | Number | Proportions | Label | Example |
|---|---|---|---|---|
| Temporal strong relevance | 869 | 33% | 3 | He was rector in 1989–2002. |
| Temporal moderate relevance | 424 | 16% | 2 | University named alumnus of year in 2003. |
| Temporal weak relevance | 126 | 5% | 1 | CSM joined Federation of European Mineral Programs in 2003. |
| Temporal no relevance | 1215 | 46% | 0 | CSM joined Federation of European Mineral Programs. |
| Spatial strong relevance | 242 | 9% | 3 | Switzerland is bordered by France to the west. |
| Spatial moderate relevance | 363 | 14% | 2 | Pope Paul VI separated territory from Lansing Diocese. |
| Spatial weak relevance | 895 | 34% | 1 | Candidates completing programmers in Camborne School Mines. |
| Spatial no relevance | 1134 | 43% | 0 | Selection is based on achievement. |
| Spatio-temporal strong relevance | 362 | 14% | 3 | He was from 1990 to 1996 chair of board of governors of University of Calgary. |
| Spatio-temporal moderate relevance | 794 | 30% | 2 | October 26 has been designated as the National Olympic Day. |
| Spatio-temporal weak relevance | 1183 | 45% | 1 | It signed a contract with Hungary. |
| Spatio-temporal no relevance | 295 | 11% | 0 | Countries raced yachts Prior to ratification in 1907. |
| Type of Knowledge | Example |
|---|---|
| Factual knowledge [4] | (1) The first mass extinction of species occurred at the end of the Ordovician period, 440 million years ago. (2) 210 years ago, Qin Shi Huang’s imperial tours died in Xingtai dunes on his way to the east. |
| Conceptual knowledge [4] | (1) The Ordovician Period is the second period of the Paleozoic, which began in 500 million BC and lasted for 65 million years. (2) Sandstorm is a general term for both sandstorms and dust storms. It refers to the severe sandstorm weather phenomenon where strong winds blow up a large amount of sand and dust on the ground, causing the air to be particularly turbid and the horizontal visibility to be less than 1 km. |
| Rule-based knowledge [4] | Quartz sandstone: feldspar content < 10%, rock debris content < 10%. |
| Type of Knowledge | Marking Specification | Example |
|---|---|---|
| Factual knowledge | Explicit temporal information generally acts as a gerund and acts as an entity when the subject of an event occurs only at a certain time, and when the time changes, the subject of the event is affected and thus changes, considering the time to be strongly associated. | Brown went to New York City In 1877. |
| When an event does not change with the event, time is considered unrelated. | She withdrew her name. | |
| A sentence is considered to be temporal weak relevance when there is a time in it, but not a subject event that depends on the time, but a local subject event or a secondary event that depends on that time. | She shortly thereafter was called to headship of order in State of Ohio. | |
| Brown was elected Grand Vice-Templar after founding in August 1874. | |
| Conceptual knowledge | Judging from the semantic information, the emphasis on time can be judged as a strong association with time. | Pomegranate trees usually bloom in May. |
| FBI investigates crime in most cases. | |
| The main meaning expressed in the sentence is not related to time, it only modifies small fragments of knowledge in the main triad; then, it is judged to be weakly associated with time. | A region in the northwest experiences dust storms throughout the year. | |
| Rule-based knowledge | If the time information does not modify the main clause in the triple, but only the minor clauses in entity 1 or entity 2, and does not modify the content of the main clause, the highest degree of association is judged to be moderate. | Their tribe had expanded into what is now France, Belgium, northern Italy, Spain, and the vast Rhine Valley. |
| For simple structural triples that exist in regular triples and are essentially unrelated to time. | International rule was created for the measuring and rating of yachts. |
| Type of Knowledge | Marking Specification | Example |
|---|---|---|
| Factual knowledge | An event space is considered strongly associated when it can only be performed in a specific space and not in other spaces. | Pomegranates are suitable for cultivation on both sides of the three river basins. |
| When all events expressed in a triad are unaffected by space, the knowledge is judged to be unrelated to space. | The Mohe gold mine is mentioned in the historical records of the Qing Dynasty. | |
| When spatial terms appear in a sentence but the occurrence of an event is less dependent on space, the knowledge is judged to be unrelated to space. | He was influenced by Columba Marmion. | |
| After excluding strong spatial association, weak spatial association, and no spatial association, the other is moderate spatial association. | By the second century BC their tribe had expanded into what is now France, Belgium, northern Italy, Spain, and the vast Rhine Valley. | |
| Conceptual knowledge | Explanation of abstract concepts, disconnected from space, generally unconnected to space. | The Confederacy dissolved In 1866. |
| Conceptual knowledge that explains entities and phenomena in which geospatial emphasis is placed and therefore can be judged to be strongly associated with space. | Pomegranates are suitable for cultivation on both sides of the three river basins. | |
| The main meaning expressed in the sentence is not spatially relevant and it only modifies small fragments of knowledge in the main triad; then, it is judged to be spatially weakly relevant. | It formed the Austro-Hungarian Empire In 1867. | |
| Rule-based knowledge | If the spatial information does not modify the main sentence in the triple, but only the secondary sentence in entity 1 or entity 2, and does not modify the content of the main sentence, the highest degree of association is judged to be moderate. | Chiasso is located in the state of Ticino. |
| For simple structural triples that exist in regular triples and are essentially unrelated to time. | The sum of the interior angles of a triangle is 180. |
| Batch_Size | Epoch | Optimizer | Learn Rate | Loss |
|---|---|---|---|---|
| 32 | 10 | Adam | 5 × 10−5 | Categorical_crossentropy |
| Model | No Relevance | Weak Relevance | Moderate Relevance | Strong Relevance | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| BERT | 0.98 | 0.95 | 0.96 | 0.20 | 0.20 | 0.20 | 0.52 | 0.62 | 0.57 | 0.81 | 0.77 | 0.79 |
| BERT_CNN | 0.98 | 0.98 | 0.97 | 0.42 | 0.50 | 0.45 | 0.69 | 0.69 | 0.68 | 0.85 | 0.85 | 0.85 |
| ERNIE | 0.49 | 0.53 | 0.64 | 0.56 | 0.42 | 0.48 | 0.52 | 0.57 | 0.62 | 0.44 | 0.39 | 0.55 |
| BERT_DPCNN | 0.95 | 0.97 | 0.97 | 0.68 | 0.71 | 0.42 | 0.55 | 0.79 | 0.64 | 0.85 | 0.79 | 0.64 |
| BERT_RCNN | 0.98 | 0.97 | 0.96 | 0.89 | 0.91 | 0.78 | 0.70 | 0.79 | 0.71 | 0.88 | 0.82 | 0.85 |
| BERT_RNN | 0.94 | 0.98 | 0.97 | 0.68 | 0.79 | 0.76 | 0.56 | 0.39 | 0.43 | 0.62 | 0.67 | 0.76 |
| TextCNN | 0.79 | 0.93 | 0.85 | 0.67 | 0.21 | 0.31 | 0.41 | 0.21 | 0.28 | 0.73 | 0.77 | 0.75 |
| TextRNN | 0.63 | 0.88 | 0.73 | 0.41 | 0.52 | 0.66 | 0.20 | 0.23 | 0.42 | 0.62 | 0.59 | 0.61 |
| TextRCNN | 0.80 | 0.87 | 0.83 | 0.40 | 0.20 | 0.27 | 0.50 | 0.21 | 0.30 | 0.60 | 0.73 | 0.66 |
| TextRNN_Att | 0.77 | 0.91 | 0.83 | 0.67 | 0.20 | 0.31 | 0.52 | 0.29 | 0.37 | 0.73 | 0.76 | 0.74 |
| Model | No Relevance | Weak Relevance | Moderate Relevance | Strong Relevance | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| BERT | 0.92 | 0.80 | 0.86 | 0.67 | 0.76 | 0.71 | 0.60 | 0.54 | 0.57 | 0.74 | 0.88 | 0.80 |
| BERT_CNN | 0.94 | 0.93 | 0.89 | 0.42 | 0.50 | 0.45 | 0.69 | 0.69 | 0.69 | 0.85 | 0.85 | 0.86 |
| ERNIE | 0.83 | 0.84 | 0.84 | 0.72 | 0.69 | 0.70 | 0.51 | 0.54 | 0.53 | 0.75 | 0.75 | 0.75 |
| BERT_DPCNN | 0.88 | 0.85 | 0.87 | 0.69 | 0.73 | 0.71 | 0.38 | 0.67 | 0.48 | 0.42 | 0.38 | 0.47 |
| BERT_RCNN | 0.91 | 0.88 | 0.89 | 0.75 | 0.69 | 0.71 | 0.57 | 0.77 | 0.65 | 0.87 | 0.88 | 0.90 |
| BERT_RNN | 0.89 | 0.84 | 0.87 | 0.68 | 0.69 | 0.689 | 0.56 | 0.49 | 0.53 | 0.70 | 0.91 | 0.79 |
| TextCNN | 0.75 | 0.78 | 0.77 | 0.63 | 0.67 | 0.65 | 0.41 | 0.44 | 0.43 | 0.76 | 0.50 | 0.60 |
| TextRNN | 0.61 | 0.70 | 0.65 | 0.45 | 0.52 | 0.48 | 0.48 | 0.36 | 0.41 | 0.50 | 0.22 | 0.30 |
| TextRCNN | 0.75 | 0.68 | 0.71 | 0.56 | 0.71 | 0.62 | 0.53 | 0.41 | 0.46 | 0.70 | 0.59 | 0.64 |
| TextRNN_Att | 0.73 | 0.70 | 0.72 | 0.53 | 0.72 | 0.61 | 0.55 | 0.28 | 0.37 | 0.64 | 0.50 | 0.56 |
| Model | No Relevance | Weak Relevance | Moderate Relevance | Strong Relevance | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| BERT | 0.88 | 0.77 | 0.82 | 0.74 | 0.85 | 0.80 | 0.71 | 0.55 | 0.62 | 0.69 | 0.78 | 0.73 |
| BERT_CNN | 0.89 | 0.83 | 0.86 | 0.74 | 0.83 | 0.78 | 0.66 | 0.54 | 0.62 | 0.63 | 0.73 | 0.67 |
| ERNIE | 0.63 | 0.67 | 0.65 | 0.67 | 0.64 | 0.65 | 0.51 | 0.40 | 0.45 | 0.40 | 0.62 | 0.49 |
| BERT_DPCNN | 0.56 | 0.58 | 0.66 | 0.55 | 0.78 | 0.65 | 0.42 | 0.51 | 0.46 | 0.51 | 0.44 | 0.62 |
| BERT_RCNN | 0.93 | 0.73 | 0.81 | 0.75 | 0.87 | 0.80 | 0.70 | 0.55 | 0.62 | 0.73 | 0.73 | 0.73 |
| BERT_RNN | 0.91 | 0.73 | 0.81 | 0.73 | 0.84 | 0.78 | 0.68 | 0.56 | 0.59 | 0.57 | 0.70 | 0.64 |
| TextCNN | 1 | 0.33 | 0.50 | 0.56 | 0.82 | 0.67 | 0.55 | 0.40 | 0.46 | 0.69 | 0.49 | 0.57 |
| TextRNN | 0.46 | 0.20 | 0.28 | 0.50 | 0.65 | 0.57 | 0.40 | 0.41 | 0.40 | 0.44 | 0.22 | 0.29 |
| TextRCNN | 0.79 | 0.50 | 0.61 | 0.60 | 0.80 | 0.69 | 0.57 | 0.46 | 0.51 | 0.72 | 0.49 | 0.58 |
| TextRNN_Att | 0.72 | 0.43 | 0.54 | 0.58 | 0.72 | 0.64 | 0.51 | 0.43 | 0.46 | 0.59 | 0.54 | 0.56 |
| Type | Sentence | Real Classification Result | Predicted Classification Result |
|---|---|---|---|
| No correct classification | Switzerland was conquered by Caesar’s army in 58 BC. | Temporal moderate relevance | Temporal weak relevance |
| Correct classification | Switzerland is located in central Europe. | Spatio-strong relevance | Spatio-strong relevance |
| Correct classification | It became an independent state in the mid-12th century under the Babenburg family. | Temporal strong relevance | Temporal strong relevance |
| No correct classification | Klingenbeck attended Allegany College of Maryland State University. | Spatio-moderate relevance | Spatio-weak relevance |
| Correct classification | Michael James Todd QPM was Chief Constable of Greater Manchester Police from October 2002 until his death. | Spatio-temporal strong relevance | Spatio-temporal strong relevance |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, M.; Hu, X.; Huang, J.; Ma, K.; Li, H.; Zheng, S.; Tao, L.; Qiu, Q. Spatio-Temporal Relevance Classification from Geographic Texts Using Deep Learning. ISPRS Int. J. Geo-Inf. 2023, 12, 359. https://doi.org/10.3390/ijgi12090359
Tian M, Hu X, Huang J, Ma K, Li H, Zheng S, Tao L, Qiu Q. Spatio-Temporal Relevance Classification from Geographic Texts Using Deep Learning. ISPRS International Journal of Geo-Information. 2023; 12(9):359. https://doi.org/10.3390/ijgi12090359
Chicago/Turabian StyleTian, Miao, Xinxin Hu, Jiakai Huang, Kai Ma, Haiyan Li, Shuai Zheng, Liufeng Tao, and Qinjun Qiu. 2023. "Spatio-Temporal Relevance Classification from Geographic Texts Using Deep Learning" ISPRS International Journal of Geo-Information 12, no. 9: 359. https://doi.org/10.3390/ijgi12090359
APA StyleTian, M., Hu, X., Huang, J., Ma, K., Li, H., Zheng, S., Tao, L., & Qiu, Q. (2023). Spatio-Temporal Relevance Classification from Geographic Texts Using Deep Learning. ISPRS International Journal of Geo-Information, 12(9), 359. https://doi.org/10.3390/ijgi12090359