

Self-Supervised Representation Learning for Geographical Data—A Systematic Literature Review


Abstract
:1. Introduction
2. Background
3. Methodology
- Formulate the research questions in order to describe the overall aims of the review.
- Design an efficient and reproducible search strategy to retrieve all relevant studies with respect to the research questions.
- Specify inclusion and exclusion criteria to control the review’s scope.
- Assess the quality of the included studies to ensure their scientific validity as well as the validity of the systematic review findings.
- Extract data from the included studies to gather specific evidence relevant to the research questions.
- Perform narrative synthesis of findings from the extracted data in order to answer the research questions.
3.1. Research Questions
- RQ1:
- What types of representations were learnt?
- RQ2:
- What SSRL models were used?
- RQ3:
- What downstream problems were the learnt representations used to solve?
- RQ4:
- What machine learning models were used to solve the downstream problems?
- RQ5:
- Did using a learnt representation improve performance relative to applying a machine learning model to the raw data or another representation not obtained using SSRL?
3.2. Search Strategy
- (geographic OR geographical OR geo OR GIS OR location OR place OR spatiotemporal OR spatial OR road or street OR address OR GPS OR route OR trajectory OR POI OR points of interest) (Title) and (encoding OR embedding OR representation OR vectorization OR metric learning OR self-supervised) (Title) and learning (Topic)
3.3. Selection Criteria
4. Analysis
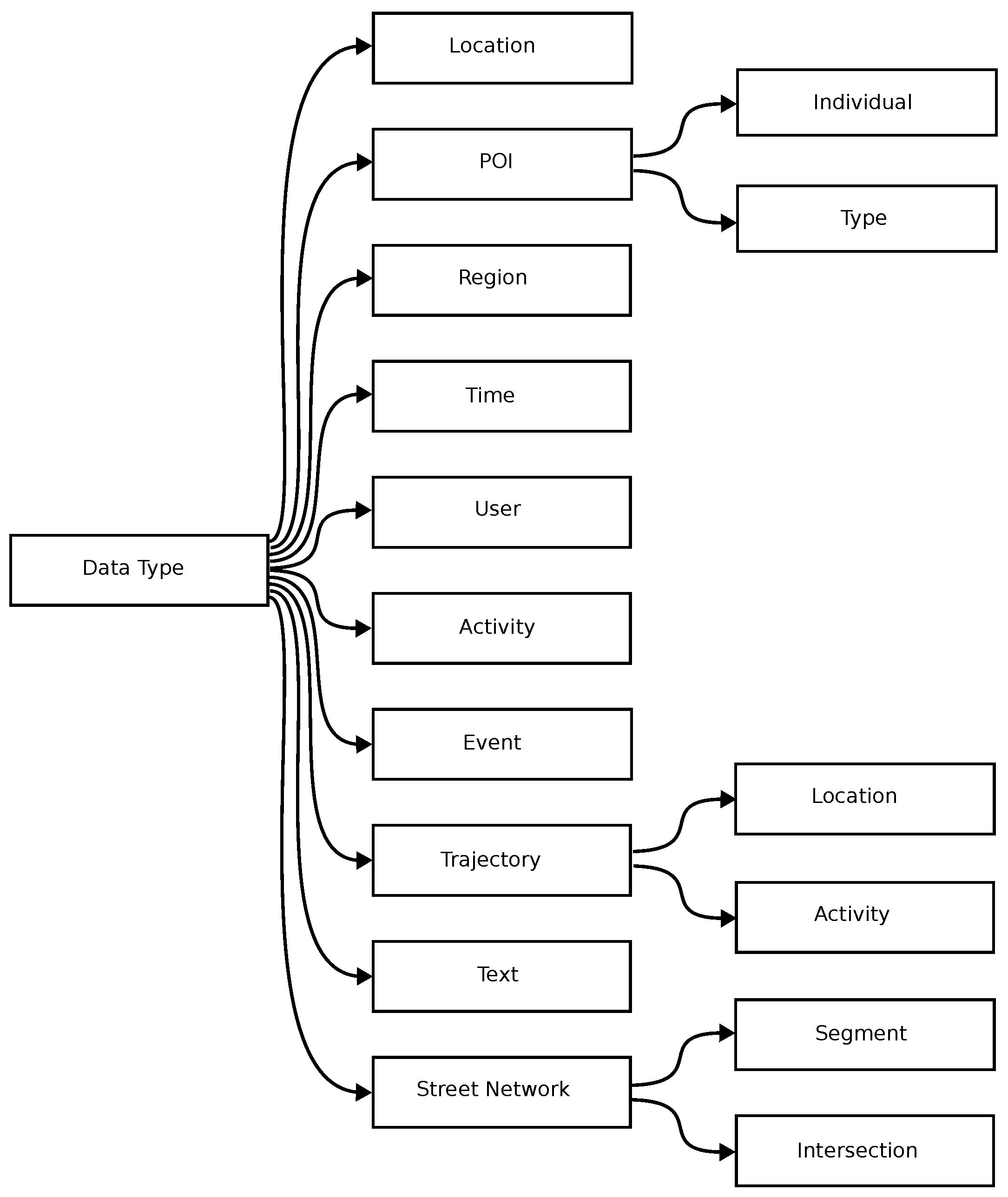
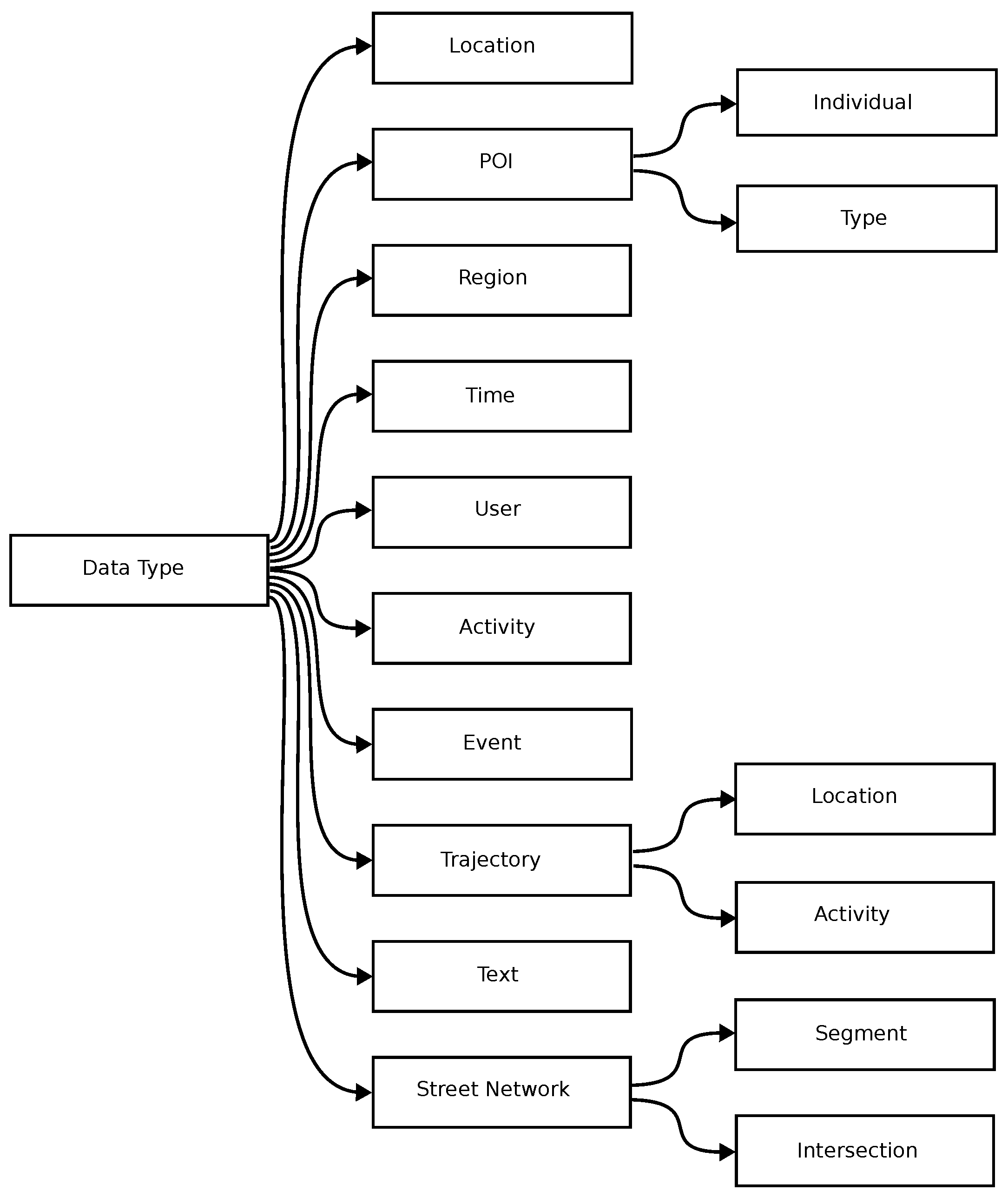
4.1. What Types of Representations Were Learnt?
4.1.1. Location Representations
4.1.2. Individual POI Representations
4.1.3. POI-Type Representations
4.1.4. Region Representations
4.1.5. Time Representations
4.1.6. User Representations
4.1.7. Activity Representations
4.1.8. Event Representations
4.1.9. Location Trajectory Representations
4.1.10. Activity Trajectory Representations
4.1.11. Text Representations
4.1.12. Street Segment & Intersection Representations
4.1.13. Other Representations
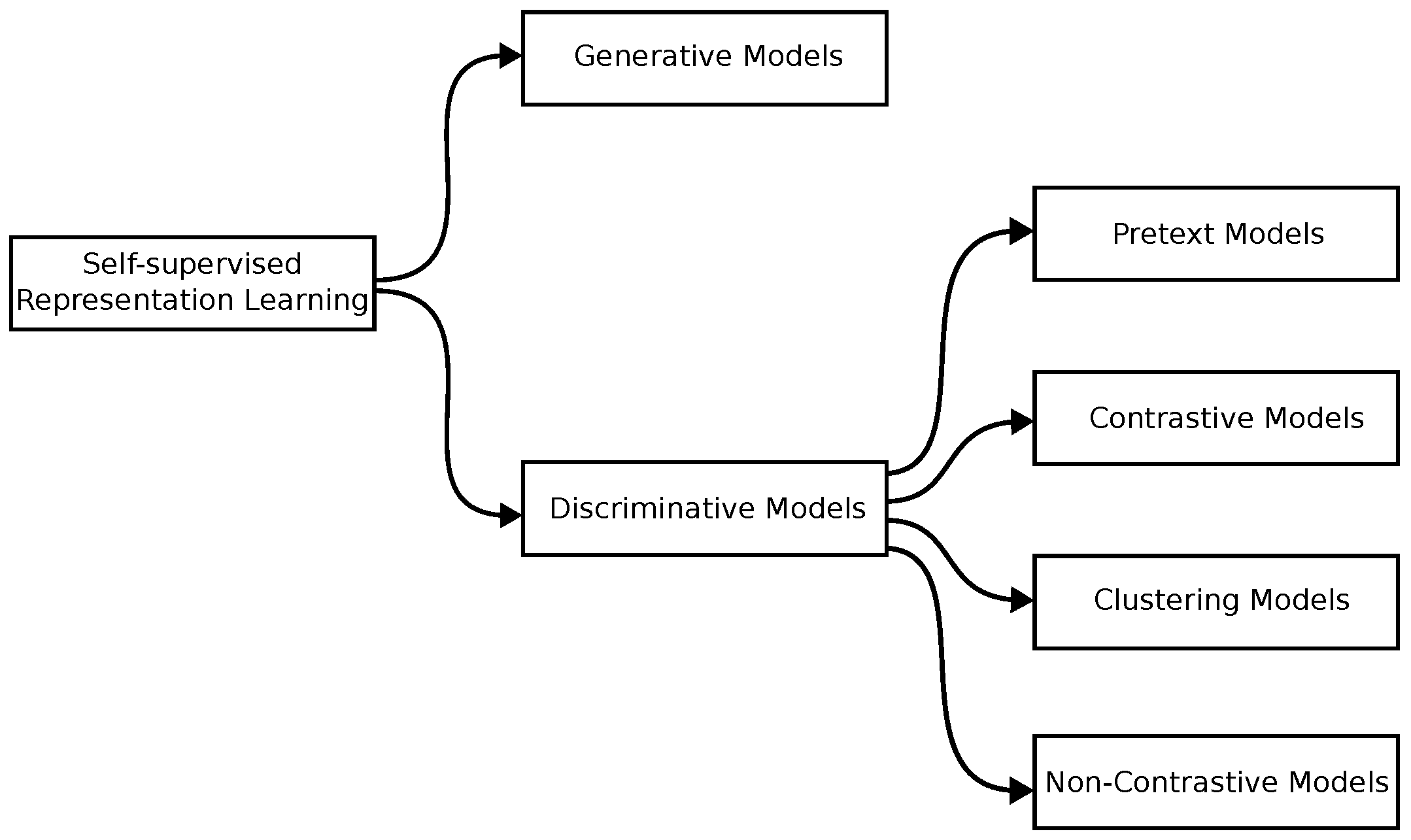
4.2. What SSRL Models Were Used?
4.2.1. SSRL Models Used
4.2.2. Learning Representations Independently
4.2.3. Learning Representations Hierarchically
4.3. What Downstream Problems Were the Learnt Representations Used to Solve?
4.3.1. Location Representations
4.3.2. Individual POI Representations
4.3.3. POI Type Representations
4.3.4. Region Representations
4.3.5. User Representations
4.3.6. Activity Representations
4.3.7. Event Representations
4.3.8. Location Trajectory Representations
4.3.9. Activity Trajectory Representations
4.3.10. Text Representations
4.3.11. Street Intersection and Segment Representations
4.3.12. Other Representations
4.3.13. Multiple Representations
4.4. What Machine Learning Models Were Used to Solve the Downstream Problems?
4.5. Did Using a Learnt Representation Provide Improved Performance?
5. Summary and Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| NLP | Natural language processing |
| SVM | Support vector machine |
| GIS | Geographical information science |
| POI | Point-of-interest |
| SSRL | Self-supervised representation learning |
| LBSN | Location-based social network |
References
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Derrow-Pinion, A.; She, J.; Wong, D.; Lange, O.; Hester, T.; Perez, L.; Nunkesser, M.; Lee, S.; Guo, X.; Wiltshire, B.; et al. ETA prediction with graph neural networks in Google Maps. In Proceedings of the ACM International Conference on Information & Knowledge Management, Online, 1–5 November 2021; pp. 3767–3776. [Google Scholar]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. Joint Deep Learning for land cover and land use classification. Remote Sens. Environ. 2019, 221, 173–187. [Google Scholar] [CrossRef]
- Spasic, I.; Nenadic, G. Clinical text data in machine learning: Systematic review. JMIR Med. Inform. 2020, 8, e17984. [Google Scholar] [CrossRef]
- Qian, T.; Liu, B.; Nguyen, Q.V.H.; Yin, H. Spatiotemporal representation learning for translation-based POI recommendation. ACM Trans. Inf. Syst. 2019, 37, 1–24. [Google Scholar] [CrossRef]
- Qiao, Y.; Luo, X.; Li, C.; Tian, H.; Ma, J. Heterogeneous graph-based joint representation learning for users and POIs in location-based social network. Inf. Process. Manag. 2020, 57, 102151. [Google Scholar] [CrossRef]
- Lin, Y.; Chiang, Y.Y.; Franklin, M.; Eckel, S.P.; Ambite, J.L. Building autocorrelation-aware representations for fine-scale spatiotemporal prediction. In Proceedings of the IEEE International Conference on Data Mining, Sorrento, Italy, 17–20 November 2020; pp. 352–361. [Google Scholar]
- Ericsson, L.; Gouk, H.; Loy, C.C.; Hospedales, T.M. Self-Supervised Representation Learning: Introduction, advances, and challenges. IEEE Signal Process. Mag. 2022, 39, 42–62. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics. pp. 4171–4186. [Google Scholar]
- Jeawak, S.S.; Jones, C.B.; Schockaert, S. Predicting environmental features by learning spatiotemporal embeddings from social media. Ecol. Inform. 2020, 55, 101031. [Google Scholar] [CrossRef]
- Deldari, S.; Xue, H.; Saeed, A.; He, J.; Smith, D.V.; Salim, F.D. Beyond Just Vision: A Review on Self-Supervised Representation Learning on Multimodal and Temporal Data. arXiv 2022, arXiv:2206.02353. [Google Scholar]
- Tian, Y.; Chen, X.; Ganguli, S. Understanding self-supervised learning dynamics without contrastive pairs. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 10268–10278. [Google Scholar]
- Liu, X.; Zhang, F.; Hou, Z.; Mian, L.; Wang, Z.; Zhang, J.; Tang, J. Self-supervised learning: Generative or contrastive. IEEE Trans. Knowl. Data Eng. 2021, 35, 857–876. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Caron, M.; Bojanowski, P.; Joulin, A.; Douze, M. Deep clustering for unsupervised learning of visual features. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 132–149. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. Adv. Neural Inf. Process. Syst. 2020, 33, 9912–9924. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow twins: Self-supervised learning via redundancy reduction. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 12310–12320. [Google Scholar]
- Jing, L.; Tian, Y. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4037–4058. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Jin, M.; Pan, S.; Zhou, C.; Zheng, Y.; Xia, F.; Yu, P. Graph self-supervised learning: A survey. IEEE Trans. Knowl. Data Eng. 2023. [Google Scholar] [CrossRef]
- Mai, G.; Janowicz, K.; Hu, Y.; Gao, S.; Yan, B.; Zhu, R.; Cai, L.; Lao, N. A review of location encoding for GeoAI: Methods and applications. Int. J. Geogr. Inf. Sci. 2022, 36, 639–673. [Google Scholar] [CrossRef]
- Wang, J.; Biljecki, F. Unsupervised machine learning in urban studies: A systematic review of applications. Cities 2022, 129, 103925. [Google Scholar] [CrossRef]
- Wang, Y.; Albrecht, C.M.; Braham, N.A.A.; Mou, L.; Zhu, X.X. Self-supervised Learning in Remote Sensing: A Review. IEEE Geosci. Remote. Sens. Mag. 2023; in press. [Google Scholar]
- Kitchenham, B. Guidelines for Performing Systematic Literature Reviews in Software Engineering; Technical Report EBSE-2007-01; Keele University: Keele, UK; University of Durham: Durham, UK, 2007. [Google Scholar]
- Zunic, A.; Corcoran, P.; Spasic, I. Sentiment analysis in health and well-being: Systematic review. JMIR Med. Inform. 2020, 8, e16023. [Google Scholar] [CrossRef]
- Yin, Y.; Zhang, Y.; Liu, Z.; Wang, S.; Shah, R.R.; Zimmermann, R. GPS2Vec: Pre-trained Semantic Embeddings for Worldwide GPS Coordinates. IEEE Trans. Multimed. 2021, 24, 890–903. [Google Scholar] [CrossRef]
- Feng, S.; Cong, G.; An, B.; Chee, Y.M. Poi2vec: Geographical latent representation for predicting future visitors. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Lu, X.; Zheng, X.; Yuan, Y. Remote sensing scene classification by unsupervised representation learning. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5148–5157. [Google Scholar] [CrossRef]
- Li, W.; Chen, K.; Chen, H.; Shi, Z. Geographical Knowledge-Driven Representation Learning for Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5405516. [Google Scholar] [CrossRef]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Hahmann, S.; Burghardt, D.; Weber, B. “80% of All Information is Geospatially Referenced”??? Towards a Research Framework: Using the Semantic Web for (In) Validating this Famous Geo Assertion. In Proceedings of the 14th AGILE Conference on Geographic Information Science, Utrecht, The Netherlands, 18–21 April 2011. [Google Scholar]
- Scheider, S.; Meerlo, R.; Kasalica, V.; Lamprecht, A.L. Ontology of core concept data types for answering geo-analytical questions. J. Spat. Inf. Sci. 2020, 20, 167–201. [Google Scholar] [CrossRef]
- Kim, J.Y.; Lim, K.H.; Cho, S.B. Personalized POI embedding for successive POI recommendation with large-scale smart card data. In Proceedings of the IEEE International Conference on Big Data, Los Angeles, CA, USA, 9–12 December 2019; pp. 3583–3589. [Google Scholar]
- Yang, K.; Zhu, J.; Guo, X. POI neural-rec model via graph embedding representation. Tsinghua Sci. Technol. 2020, 26, 208–218. [Google Scholar] [CrossRef]
- Cruz, M.; Barbosa, L. Learning GPS Point Representations to Detect Anomalous Bus Trajectories. IEEE Access 2020, 8, 229006–229017. [Google Scholar] [CrossRef]
- Wan, H.; Li, F.; Guo, S.; Cao, Z.; Lin, Y. Learning time-aware distributed representations of locations from spatio-temporal trajectories. In Proceedings of the International Conference on Database Systems for Advanced Applications, Chiang Mai, Thailand, 22–25 April 2019; pp. 268–272. [Google Scholar]
- Crivellari, A.; Beinat, E. From motion activity to geo-embeddings: Generating and exploring vector representations of locations, traces and visitors through large-scale mobility data. ISPRS Int. J. Geo-Inf. 2019, 8, 134. [Google Scholar] [CrossRef]
- Sassi, A.; Brahimi, M.; Bechkit, W.; Bachir, A. Location embedding and deep convolutional neural networks for next location prediction. In Proceedings of the LCN Symposium on Emerging Topics in Networking, Osnabrück, Germany, 14–17 October 2019; pp. 149–157. [Google Scholar]
- Li, Y.; Chen, H.; Wang, L.; Xiao, Q. POI representation learning by a hybrid model. In Proceedings of the IEEE International Conference on Mobile Data Management, Hong Kong, 10–13 June 2019; pp. 485–490. [Google Scholar]
- Keerthi Chandra, D.; Wang, P.; Leopold, J.; Fu, Y. Collective Embedding with Feature Importance: A Unified Approach for Spatiotemporal Network Embedding. In Proceedings of the ACM International Conference on Information & Knowledge Management, Galway, Ireland, 19–23 October 2020; pp. 615–624. [Google Scholar]
- Yan, B.; Janowicz, K.; Mai, G.; Gao, S. From itdl to place2vec: Reasoning about place type similarity and relatedness by learning embeddings from augmented spatial contexts. In Proceedings of the ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 7–10 November 2017; pp. 1–10. [Google Scholar]
- Liu, X.; Andris, C.; Rahimi, S. Place niche and its regional variability: Measuring spatial context patterns for points of interest with representation learning. Comput. Environ. Urban Syst. 2019, 75, 146–160. [Google Scholar] [CrossRef]
- Niu, H.; Silva, E.A. Delineating urban functional use from points of interest data with neural network embedding: A case study in Greater London. Comput. Environ. Urban Syst. 2021, 88, 101651. [Google Scholar] [CrossRef]
- Dadoun, A.; Troncy, R.; Ratier, O.; Petitti, R. Location embeddings for next trip recommendation. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 896–903. [Google Scholar]
- Crivellari, A.; Ristea, A. CrimeVec-Exploring Spatial-Temporal Based Vector Representations of Urban Crime Types and Crime-Related Urban Regions. ISPRS Int. J. Geo-Inf. 2021, 10, 210. [Google Scholar] [CrossRef]
- Zhao, S.; Zhao, T.; King, I.; Lyu, M.R. Geo-teaser: Geo-temporal sequential embedding rank for point-of-interest recommendation. In Proceedings of the International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; pp. 153–162. [Google Scholar]
- Chen, M.; Zhao, Y.; Liu, Y.; Yu, X.; Zheng, K. Modeling spatial trajectories with attribute representation learning. IEEE Trans. Knowl. Data Eng. 2020, 34, 1902–1914. [Google Scholar] [CrossRef]
- Silva, A.; Karunasekera, S.; Leckie, C.; Luo, L. USTAR: Online multimodal embedding for modeling user-guided spatiotemporal activity. In Proceedings of the IEEE International Conference on Big Data, Los Angeles, CA, USA, 9–12 December 2019; pp. 1211–1217. [Google Scholar]
- Tian, H.; Zhang, M.; Luo, X.; Liu, F.; Qiao, Y. Twitter user location inference based on representation learning and label propagation. In Proceedings of the The Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 2648–2654. [Google Scholar]
- Feng, L.; Huang, Y.; Tsang, I.W.; Gupta, A.; Tang, K.; Tan, K.C.; Ong, Y.S. Towards faster vehicle routing by transferring knowledge from customer representation. IEEE Trans. Intell. Transp. Syst. 2020, 23, 952–965. [Google Scholar] [CrossRef]
- Liu, Y.; Ao, X.; Dong, L.; Zhang, C.; Wang, J.; He, Q. Spatiotemporal activity modeling via hierarchical cross-modal embedding. IEEE Trans. Knowl. Data Eng. 2020, 34, 462–474. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, L.; Lei, D.; Yuan, Q.; Zhuang, H.; Hanratty, T.; Han, J. Triovecevent: Embedding-based online local event detection in geo-tagged tweet streams. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 3–17 August 2017; pp. 595–604. [Google Scholar]
- Wei, H.; Anjaria, J.; Samet, H. Learning embeddings of spatial, textual and temporal entities in geotagged tweets. In Proceedings of the ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Chicago, IL, USA, 5–8 November 2019; pp. 484–487. [Google Scholar]
- Liyong, W.; Vateekul, P. Traffic Prediction Using Attentional Spatial-Temporal Deep Learning with Accident Embedding. In Proceedings of the International Conference on Computational Intelligence and Applications (ICCIA), Nanchang, China, 21–23 June 2019; pp. 98–103. [Google Scholar]
- Wang, Y.; Tang, J. Event2Vec: Learning event representations using spatial-temporal information for recommendation. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Macau, China, 14–17 April 2019; pp. 314–326. [Google Scholar]
- Fu, T.Y.; Lee, W.C. Trembr: Exploring road networks for trajectory representation learning. ACM Trans. Intell. Syst. Technol. 2020, 11, 1–25. [Google Scholar] [CrossRef]
- Boonchoo, T.; Ao, X.; He, Q. Multi-Aspect Embedding for Attribute-Aware Trajectories. Symmetry 2019, 11, 1149. [Google Scholar] [CrossRef]
- Lv, M.; Zeng, D.; Chen, L.; Chen, T.; Zhu, T.; Ji, S. Private Cell-ID Trajectory Prediction Using Multi-Graph Embedding and Encoder-Decoder Network. IEEE Trans. Mob. Comput. 2021, 21, 2967–2977. [Google Scholar] [CrossRef]
- Yang, K.; Zhu, J. Next poi recommendation via graph embedding representation from h-deepwalk on hybrid network. IEEE Access 2019, 7, 171105–171113. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, A.; Liu, G.; Li, Z.; Li, Q. Deep representation learning of activity trajectory similarity computation. In Proceedings of the IEEE International Conference on Web Services, Milan, Italy, 8–13 July 2019; pp. 312–319. [Google Scholar]
- Shan, S.; Li, Z.; Yang, Q.; Liu, A.; Zhao, L.; Liu, G.; Chen, Z. Geographical address representation learning for address matching. World Wide Web 2020, 23, 2005–2022. [Google Scholar] [CrossRef]
- Yassine, M.; Beauchemin, D.; Laviolette, F.; Lamontagne, L. Leveraging Subword Embeddings for Multinational Address Parsing. In Proceedings of the Congress on Information Science and Technology (CiSt), Virtual, 28–31 July 2021; pp. 353–360. [Google Scholar]
- Liu, A.; Zhang, Y.; Zhang, X.; Liu, G.; Zhang, Y.; Li, Z.; Zhao, L.; Li, Q.; Zhou, X. Representation learning with multi-level attention for activity trajectory similarity computation. IEEE Trans. Knowl. Data Eng. 2020, 34, 2387–2400. [Google Scholar] [CrossRef]
- Wang, M.X.; Lee, W.C.; Fu, T.Y.; Yu, G. On Representation Learning for Road Networks. ACM Trans. Intell. Syst. Technol. 2020, 12, 1–27. [Google Scholar] [CrossRef]
- Zhang, R.; Rong, Y.; Wu, Z.; Zhuo, Y. Trajectory Similarity Assessment On Road Networks Via Embedding Learning. In Proceedings of the International Conference on Multimedia Big Data, New Delhi, India, 24–26 September 2020; pp. 1–8. [Google Scholar]
- Das, S.S.S.; Ali, M.E.; Li, Y.F.; Kang, Y.B.; Sellis, T. Boosting house price predictions using geo-spatial network embedding. Data Min. Knowl. Discov. 2021, 35, 2221–2250. [Google Scholar] [CrossRef]
- Mai, G.; Janowicz, K.; Cai, L.; Zhu, R.; Regalia, B.; Yan, B.; Shi, M.; Lao, N. SE-KGE: A location-aware knowledge graph embedding model for geographic question answering and spatial semantic lifting. Trans. GIS 2020, 24, 623–655. [Google Scholar] [CrossRef]
- Zhou, Y.; Huang, Y. Place Representation Based Bike Demand Prediction. In Proceedings of the IEEE International Conference on Big Data, Los Angeles, CA, USA, 9–12 December 2019; pp. 1577–1586. [Google Scholar]
- Xie, M.; Yin, H.; Wang, H.; Xu, F.; Chen, W.; Wang, S. Learning graph-based poi embedding for location-based recommendation. In Proceedings of the ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 15–24. [Google Scholar]
- Zhu, X.; Wu, Y.; Chen, L.; Jing, N. Spatial keyword query of region-of-interest based on the distributed representation of point-of-interest. ISPRS Int. J. Geo-Inf. 2019, 8, 287. [Google Scholar] [CrossRef]
- Jiang, J.; Ni, B.; Wang, C. Financial fraud detection on micro-credit loan scenario via fuller location information embedding. In Proceedings of the Web Conference, Ljubljana, Slovenia, 19–23 April 2021; pp. 238–246. [Google Scholar]
- Zhao, W.X.; Zhou, N.; Sun, A.; Wen, J.R.; Han, J.; Chang, E.Y. A time-aware trajectory embedding model for next-location recommendation. Knowl. Inf. Syst. 2018, 56, 559–579. [Google Scholar] [CrossRef]
- Canturk, D.; Karagoz, P. SgWalk: Location Recommendation by User Subgraph-Based Graph Embedding. IEEE Access 2021, 9, 134858–134873. [Google Scholar] [CrossRef]
- Chandra, D.K.; Wang, P.; Leopold, J.; Fu, Y. Collective representation learning on spatiotemporal heterogeneous information networks. In Proceedings of the ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Chicago, IL, USA, 5–8 November 2019; pp. 319–328. [Google Scholar]
- Zhou, Y.; Huang, Y. Deepmove: Learning place representations through large scale movement data. In Proceedings of the IEEE International Conference on Big Data, Langkawi, Malaysia, 21–22 November 2018; pp. 2403–2412. [Google Scholar]
- Huang, J.; Wang, H.; Fan, M.; Zhuo, A.; Li, Y. Personalized prefix embedding for POI auto-completion in the search engine of Baidu Maps. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020; pp. 2677–2685. [Google Scholar]
- Hu, S.; He, Z.; Wu, L.; Yin, L.; Xu, Y.; Cui, H. A framework for extracting urban functional regions based on multiprototype word embeddings using points-of-interest data. Comput. Environ. Urban Syst. 2020, 80, 101442. [Google Scholar] [CrossRef]
- Jenkins, P.; Farag, A.; Wang, S.; Li, Z. Unsupervised representation learning of spatial data via multimodal embedding. In Proceedings of the ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1993–2002. [Google Scholar]
- Shimizu, T.; Yabe, T.; Tsubouchi, K. Improving land use classification using human mobility-based hierarchical place embeddings. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications, Kassel, Germany, 22–26 March 2021; pp. 305–311. [Google Scholar]
- Du, J.; Zhang, Y.; Wang, P.; Leopold, J.; Fu, Y. Beyond geo-first law: Learning spatial representations via integrated autocorrelations and complementarity. In Proceedings of the IEEE International Conference on Data Mining, Beijing, China, 8–11 November 2019; pp. 160–169. [Google Scholar]
- Fu, Y.; Wang, P.; Du, J.; Wu, L.; Li, X. Efficient region embedding with multi-view spatial networks: A perspective of locality-constrained spatial autocorrelations. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 906–913. [Google Scholar]
- Xu, Y.; Li, X.; Li, J.; Wang, C.; Gao, R.; Yu, Y. SSSER: Spatiotemporal sequential and social embedding rank for successive point-of-interest recommendation. IEEE Access 2019, 7, 156804–156823. [Google Scholar] [CrossRef]
- Fang, X.; Huang, J.; Wang, F.; Liu, L.; Sun, Y.; Wang, H. SSML: Self-supervised meta-learner for en route travel time estimation at Baidu maps. In Proceedings of the ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual, 14–18 August 2021; pp. 2840–2848. [Google Scholar]
- Wang, W.; Xia, F.; Nie, H.; Chen, Z.; Gong, Z.; Kong, X.; Wei, W. Vehicle trajectory clustering based on dynamic representation learning of internet of vehicles. IEEE Trans. Intell. Transp. Syst. 2020, 22, 3567–3576. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, M.; Liu, Z.; Yang, C.; Zhang, L.; Han, J. Spatiotemporal activity modeling under data scarcity: A graph-regularized cross-modal embedding approach. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Li, Y.; Zhu, Z.; Kong, D.; Xu, M.; Zhao, Y. Learning heterogeneous spatial-temporal representation for bike-sharing demand prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 1004–1011. [Google Scholar]
- Chen, Y.; Yu, P.; Chen, W.; Zheng, Z.; Guo, M. Embedding-based similarity computation for massive vehicle trajectory data. IEEE Internet Things J. 2021, 9, 4650–4660. [Google Scholar] [CrossRef]
- Wang, Z.; Yuan, G.; Pei, H.; Zhang, Y.; Liu, X. Unsupervised learning trajectory anomaly detection algorithm based on deep representation. Int. J. Distrib. Sens. Netw. 2020, 16, 1550147720971504. [Google Scholar] [CrossRef]
- Wang, P.; Li, X.; Zheng, Y.; Aggarwal, C.; Fu, Y. Spatiotemporal representation learning for driving behavior analysis: A joint perspective of peer and temporal dependencies. IEEE Trans. Knowl. Data Eng. 2019, 33, 728–741. [Google Scholar] [CrossRef]
- Zhao, L.; Gao, M.; Wang, Z. ST-GSP: Spatial-Temporal Global Semantic Representation Learning for Urban Flow Prediction. In Proceedings of the ACM International Conference on Web Search and Data Mining, Houston, TX, USA, 5–9 February 2022; pp. 1443–1451. [Google Scholar]
- Yao, D.; Zhang, C.; Zhu, Z.; Hu, Q.; Wang, Z.; Huang, J.; Bi, J. Learning deep representation for trajectory clustering. Expert Syst. 2018, 35, e12252. [Google Scholar] [CrossRef]
- Zhou, F.; Yue, X.; Trajcevski, G.; Zhong, T.; Zhang, K. Context-aware variational trajectory encoding and human mobility inference. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3469–3475. [Google Scholar]
- Cao, H.; Xu, F.; Sankaranarayanan, J.; Li, Y.; Samet, H. Habit2vec: Trajectory semantic embedding for living pattern recognition in population. IEEE Trans. Mob. Comput. 2019, 19, 1096–1108. [Google Scholar] [CrossRef]
- Zhou, F.; Dai, Y.; Gao, Q.; Wang, P.; Zhong, T. Self-supervised human mobility learning for next location prediction and trajectory classification. Knowl.-Based Syst. 2021, 228, 107214. [Google Scholar] [CrossRef]
- Xu, L.; Du, Z.; Mao, R.; Zhang, F.; Liu, R. GSAM: A deep neural network model for extracting computational representations of Chinese addresses fused with geospatial feature. Comput. Environ. Urban Syst. 2020, 81, 101473. [Google Scholar] [CrossRef]
- Joko, H.; Oka, R.; Uchide, H.; Itsui, H.; Otsuka, T. Learning Word Embeddings Using Spatial Information. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Bari, Italy, 6–9 October 2019; pp. 2959–2964. [Google Scholar]
- Arendt, D.; Volkova, S. Esteem: A novel framework for qualitatively evaluating and visualizing spatiotemporal embeddings in social media. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 25–30. [Google Scholar]
- Hasni, S.; Faiz, S. Word embeddings and deep learning for location prediction: Tracking Coronavirus from British and American tweets. Soc. Netw. Anal. Min. 2021, 11, 1–20. [Google Scholar] [CrossRef]
- Gharaee, Z.; Kowshik, S.; Stromann, O.; Felsberg, M. Graph representation learning for road type classification. Pattern Recognit. 2021, 120, 108174. [Google Scholar] [CrossRef]
- Jepsen, T.S.; Jensen, C.S.; Nielsen, T.D.; Torp, K. On network embedding for machine learning on road networks: A case study on the danish road network. In Proceedings of the IEEE International Conference on Big Data, Seattle, WA, USA, 10–13 December 2018; pp. 3422–3431. [Google Scholar]
- Liu, H.; Han, J.; Fu, Y.; Zhou, J.; Lu, X.; Xiong, H. Multi-modal transportation recommendation with unified route representation learning. VLDB Endow. 2020, 14, 342–350. [Google Scholar] [CrossRef]
- Chang, B.; Jang, G.; Kim, S.; Kang, J. Learning graph-based geographical latent representation for point-of-interest recommendation. In Proceedings of the ACM International Conference on Information & Knowledge Management, Online, 19–23 October 2020; pp. 135–144. [Google Scholar]
- Feng, S.; Tran, L.V.; Cong, G.; Chen, L.; Li, J.; Li, F. Hme: A hyperbolic metric embedding approach for next-poi recommendation. In Proceedings of the ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 1429–1438. [Google Scholar]
- Xiong, X.; Qiao, S.; Li, Y.; Han, N.; Xiong, F.; He, L. Affective impression: Sentiment-awareness POI suggestion via embedding in heterogeneous LBSNs. IEEE Trans. Affect. Comput. 2019, 13, 272–284. [Google Scholar] [CrossRef]
- Jin, Z.; Shang, J.; Ni, W.; Zhao, L.; Liu, D.; Qiang, B.; Xie, W.; Min, G. IM2Vec: Representation learning-based preference maximization in geo-social networks. Inf. Sci. 2022, 604, 170–196. [Google Scholar] [CrossRef]
- Zhao, W.X.; Fan, F.; Wen, J.R.; Chang, E.Y. Joint representation learning for location-based social networks with multi-grained sequential contexts. ACM Trans. Knowl. Discov. Data 2018, 12, 1–21. [Google Scholar] [CrossRef]
- Zhou, N.; Zhao, W.X.; Zhang, X.; Wen, J.R.; Wang, S. A general multi-context embedding model for mining human trajectory data. IEEE Trans. Knowl. Data Eng. 2016, 28, 1945–1958. [Google Scholar] [CrossRef]
- Yang, C.; Hoang, D.H.; Mikolov, T.; Han, J. Place deduplication with embeddings. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3420–3426. [Google Scholar]
- Yang, J.; Eickhoff, C. Unsupervised learning of parsimonious general-purpose embeddings for user and location modeling. ACM Trans. Inf. Syst. 2018, 36, 1–33. [Google Scholar] [CrossRef]
- Wang, G.; Liao, D.; Li, J. Complete user mobility via user and trajectory embeddings. IEEE Access 2018, 6, 72125–72136. [Google Scholar] [CrossRef]
- Dai, S.; Yu, Y.; Fan, H.; Dong, J. Spatio-Temporal Representation Learning with Social Tie for Personalized POI Recommendation. Data Sci. Eng. 2022, 7, 44–56. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| ID | Criterion |
|---|---|
| IN1 | The article is written in English |
| IN2 | The article considers the problem of SSRL for geographical data. |
| ID | Criterion |
|---|---|
| EX1 | The article is not peer-reviewed. |
| EX2 | The article is a review article. |
| EX3 | The full text of the article is not available to the academic community. |
| EX4 | The article was published before 1 January 2013. |
| EX5 | The article was published after 23 August 2022 (the Web of Science search date). |
| EX6 | The article considers the problem of SSRL for remotely sensed data. |
| EX7 | The article does not use SSRL. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Corcoran, P.; Spasić, I. Self-Supervised Representation Learning for Geographical Data—A Systematic Literature Review. ISPRS Int. J. Geo-Inf. 2023, 12, 64. https://doi.org/10.3390/ijgi12020064
Corcoran P, Spasić I. Self-Supervised Representation Learning for Geographical Data—A Systematic Literature Review. ISPRS International Journal of Geo-Information. 2023; 12(2):64. https://doi.org/10.3390/ijgi12020064
Chicago/Turabian StyleCorcoran, Padraig, and Irena Spasić. 2023. "Self-Supervised Representation Learning for Geographical Data—A Systematic Literature Review" ISPRS International Journal of Geo-Information 12, no. 2: 64. https://doi.org/10.3390/ijgi12020064
APA StyleCorcoran, P., & Spasić, I. (2023). Self-Supervised Representation Learning for Geographical Data—A Systematic Literature Review. ISPRS International Journal of Geo-Information, 12(2), 64. https://doi.org/10.3390/ijgi12020064