

An Aggregated Shape Similarity Index: A Case Study of Comparing the Footprints of OpenStreetMap and INSPIRE Buildings

Abstract
1. Introduction
2. Materials and Methods
2.1. Calculation of the Shape Similarity Index
2.1.1. Matching Objects Identification
2.1.2. Calculation of Line Distances and Line Similarity Measures
2.1.3. Calculation of Similarity Measures of Sets
2.1.4. Calculation of Area, Perimeter, and Number of Vertices as Basic Characteristics to Determine the Shape Similarity of Areal Objects
2.1.5. Aggregation of Similarity Criteria to Determine the General Similarity Index
2.2. Case Study and Data Used
2.2.1. OpenStreetMap Data—OSM Buildings
2.2.2. INSPIRE Data—INSPIRE Buildings
2.2.3. Area of Study
2.2.4. Comparison of OSM and INSPIRE Buildings Data Based on the Shape Similarity Index
3. Results
3.1. Procedure for Calculation of the Shape Similarity Index
- Transformation of data sources tab_A and tab_B (spatial tables) into the same reference coordinate system (if they are not in a unified system).
- Merging of touching areal objects in sources tab_A and tab_B (can be implemented as 0 m buffers buf_A and buf_B).
- Count the polygons in polygon complexes buf_A and buf_B.
- Create intersections of buf_A and buf_B and calculate their basic parameters: area, perimeter, and number of vertices (this step leads to the creation of a table Similarity_A_B for calculating similarity indices).
- Calculation of auxiliary indices of similarity:
- Dice and Tanimoto indices (sim_SD, sim_T),
- Hausdorff and Fréchet distances (d_H, d_F) and their transformation to similarity indices (sim_H, sim_F),
- Similarity of areas, perimeters, numbers of vertices and numbers of polygons of buf_A and buf_B (sim_A, sim_P, sim_V, and sim_Polygons),
- Distance similarity, set similarity, and shape similarity (sim_D, sim_S, sim_SH).
- Calculate the aggregated similarity indices (sim_min, sim_max, sim_avg, and sim_agr).
- Assign a category of similarity or change type (sim_cat).
- Calculate the basic statistical characteristics of the results (number of objects in all categories, average values of aggregated similarity indices).
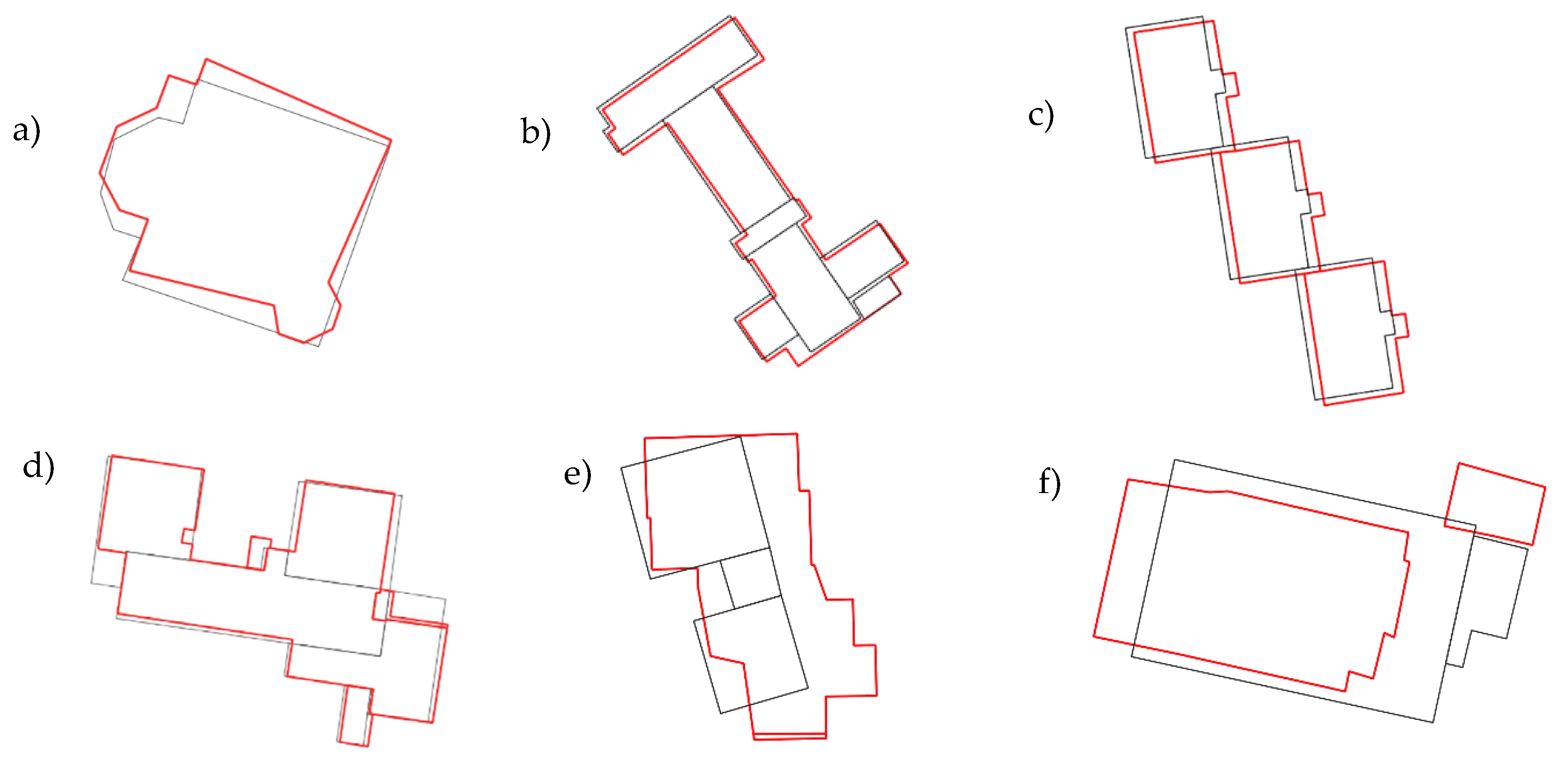
3.2. Classification of Objects According to Similarity Indices
- 1—identical,
- 2—generalised or slightly changed,
- 3—moved or rotated,
- 4—different.
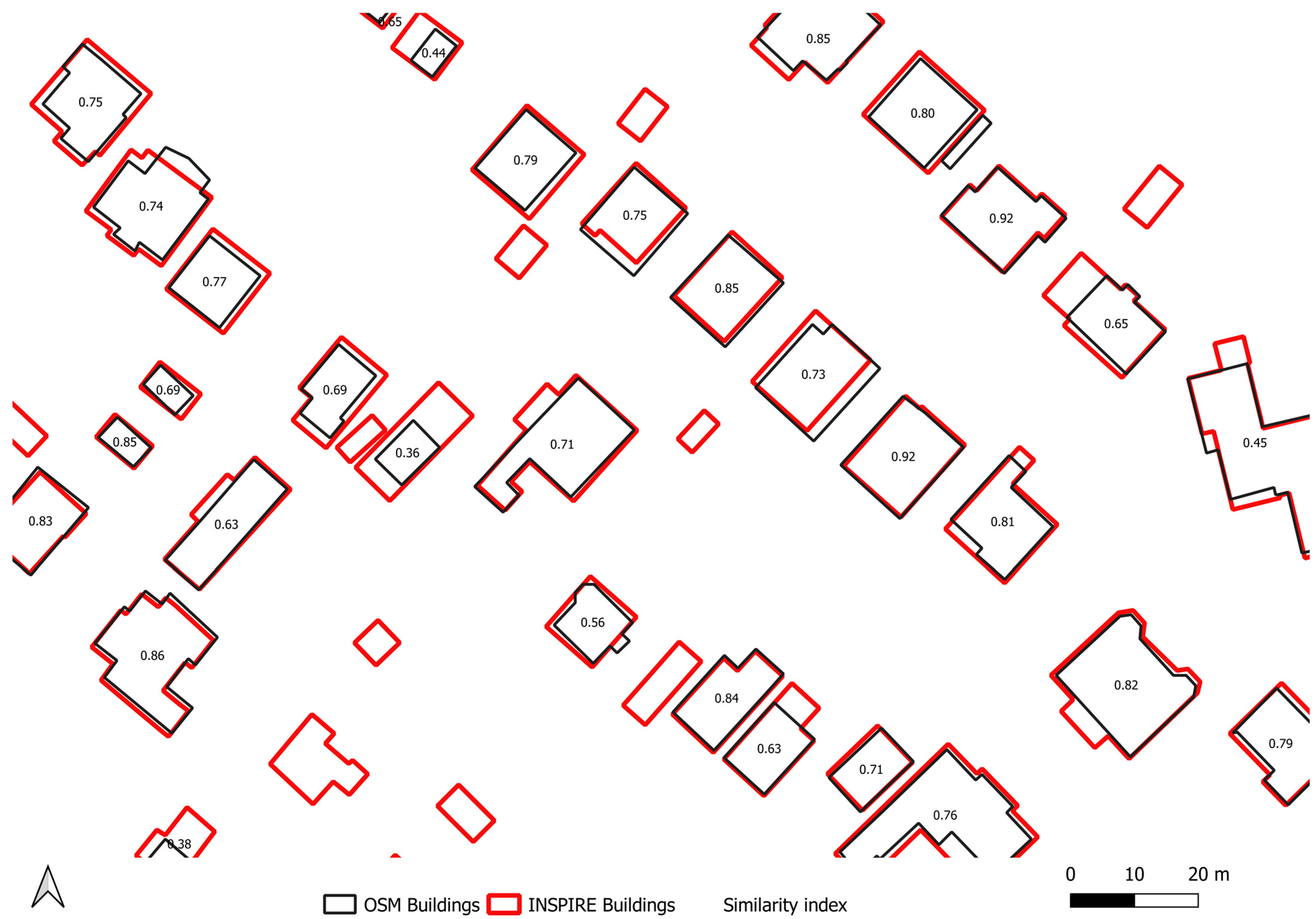
3.3. Implementation of the Calculation of Aggregated Shape Similarity Indices
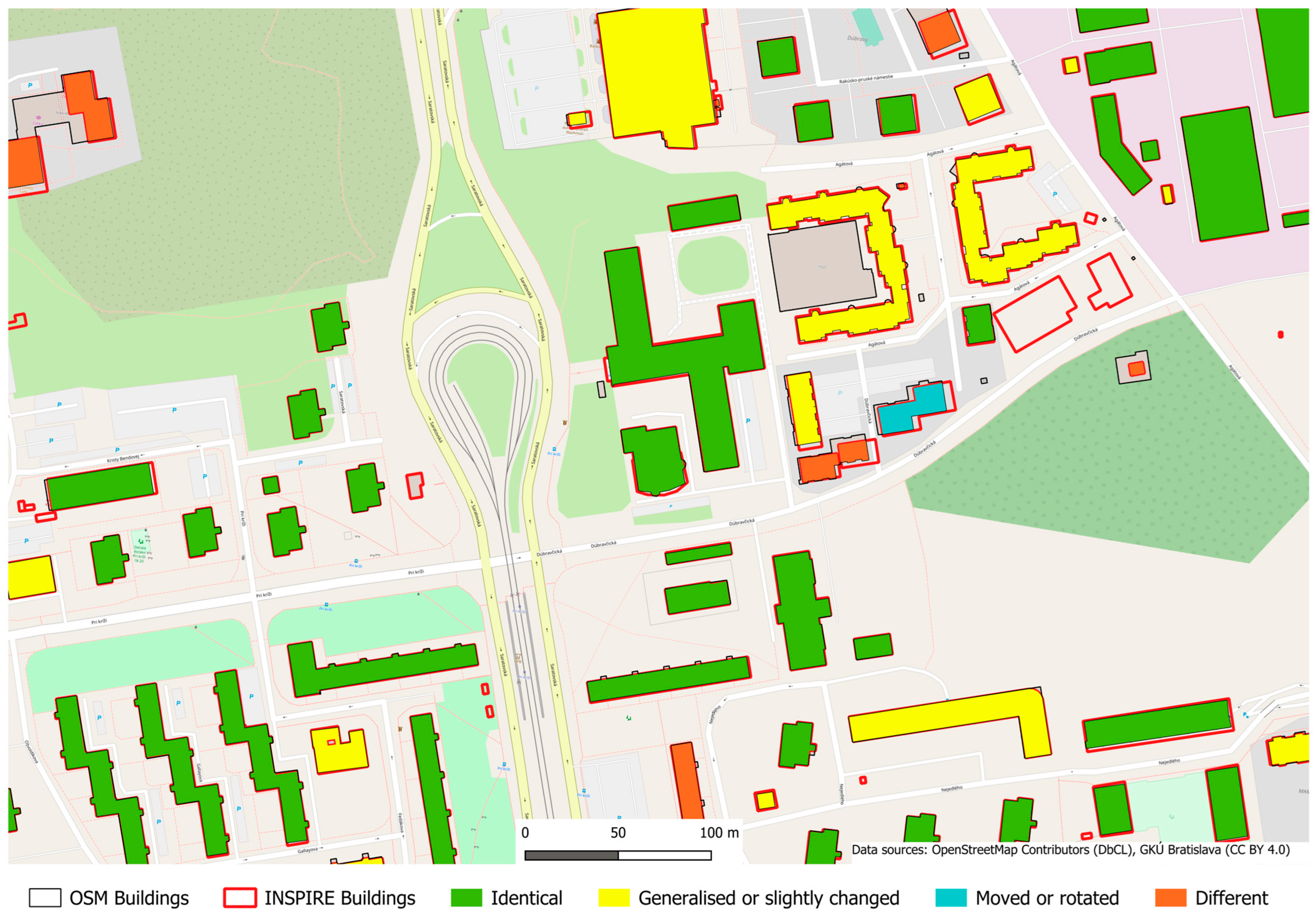
3.4. Comparison of OpenStreetMap and INSPIRE Building Complexes in Dúbravka Using Calculation and Visualisation of Similarity Indices of Building Footprints
3.5. OSM Buildings Data Quality Assessment
4. Discussion
4.1. Shape Similarity Index Calculation and Objects Classification
4.2. Case Study
5. Conclusions
Supplementary Materials
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lei, T.L. Geospatial Data Conflation. In The Geographic Information Science & Technology Body of Knowledge, 3rd Quarter 2019 ed.; Wilson, J.P., Ed.; UCGIS: Washington, DC, USA, 2019. [Google Scholar] [CrossRef]
- Chen, C.C.; Knoblock, C. Conflation of Geospatial Data. In Encyclopedia of GIS; Shekhar, S., Xiong, H., Eds.; Springer: Boston, MA, USA, 2008; pp. 133–140. [Google Scholar] [CrossRef]
- Yan, H.; Li, J. Spatial Similarity Relations in Multi-Scale Map Spaces; Springer International Publishing: Cham, Switzerland, 2015; 188p. [Google Scholar] [CrossRef]
- Yan, H. Fundamental theories of spatial similarity relations in multi-scale map spaces. Chin. Geogr. Sci. 2010, 20, 18–22. [Google Scholar] [CrossRef]
- Guo, N.; Shekhar, S.; Xiong, W.; Chen, L.; Jing, N. UTSM: A Trajectory Similarity Measure Considering Uncertainty Based on an Amended Ellipse Model. ISPRS Int. J. Geo-Inf. 2019, 8, 518. [Google Scholar] [CrossRef]
- Jiang, X.; Huang, Y.; Zhang, F. Study on Spatial Geometric Similarity Based on Conformal Geometric Algebra. Int. J. Environ. Res. Public Health 2022, 19, 10807. [Google Scholar] [CrossRef]
- Jiang, J.; Xu, J.; Lou, Y. Spatial Line Entity Matching Technology for Spatial Association of Multi-source Vector Data. In Proceedings of the 3rd International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Xi’an, China, 15–17 July 2022; pp. 523–527. [Google Scholar] [CrossRef]
- Shahbaz, K. Applied Similarity Problems Using Frechet Distance. Ph.D. Thesis, Carleton University, Ottawa, ON, Canada, 2013. [Google Scholar]
- Qiaoping, Z.; Deren, L.; Jianya, G. Shape similarity measures of linear entities. Geo-Spat. Inf. Sci. 2002, 5, 62–67. [Google Scholar] [CrossRef]
- Xu, Y.; Xie, Z.; Chen, Z.; Xie, M. Measuring the similarity between multipolygons using convex hulls and position graphs. Int. J. Geogr. Inf. Sci. 2021, 35, 847–868. [Google Scholar] [CrossRef]
- Ďuračiová, R.; Rášová, A.; Lieskovský, T. Fuzzy similarity and fuzzy inclusion measures in polyline matching: A case study of potential streams identification for archaeological modelling in GIS. Rep. Geod. Geoinform. 2017, 104, 115–130. [Google Scholar] [CrossRef]
- Fan, H.; Zhao, Z.; Li, W. Towards Measuring Shape Similarity of Polygons Based on Multiscale Features and Grid Context Descriptors. ISPRS Int. J. Geo-Inf. 2021, 10, 279. [Google Scholar] [CrossRef]
- Fan, H.; Zipf, A.; Jin, Y. Estimation of Building Types on OpenStreetMap Based on Urban Morphology Analysis. In Lecture Notes in Geoinformation and Cartography; Springer: Cham, Switzerland, 2014; pp. 19–35. [Google Scholar] [CrossRef]
- Fan, H.; Zipf, A.; Jin, Y.; Neis, P. Quality assessment for building footprints data on OpenStreetMap. Int. J. Geogr. Inf. Sci. 2014, 28, 700–719. [Google Scholar] [CrossRef]
- Başaraner, M. Geometric and semantic quality assessments of building features in OpenStreetMap for some areas of Istanbul. Pol. Cartogr. Rev. 2020, 52, 94–107. [Google Scholar] [CrossRef]
- Saalfeld, A. Conflation Automated map compilation. Int. J. Geogr. Inf. Syst. 1988, 2, 217–228. [Google Scholar] [CrossRef]
- Li, L.; Goodchild, M.F. Automatically and accurately matching objects in geospatial datasets. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2010, 38, 98–103. [Google Scholar]
- Kim, J.O.; Yu, K.; Heo, J.; Lee, W.H. A new method for matching objects in two different geospatial datasets based on the geographic context. Comput. Geosci. 2010, 36, 1115–1122. [Google Scholar] [CrossRef]
- Walter, V.; Fritsch, D. Matching spatial data sets: A statistical approach. Int. J. Geogr. Inf. Sci. 1999, 13, 445–473. [Google Scholar] [CrossRef]
- Ware, J.M.; Jones, C.B. Matching and aligning features in overlayed coverages. In Proceedings of the ACM SIGSPATIAL International Workshop on Advances in Geographic Information Systems, Washington, DC, USA, 6–7 November 1998. [Google Scholar]
- Ledoux, H.; Ohori, K.A. Solving the horizontal conflation problem with a constrained Delaunay triangulation. J. Geogr. Syst. 2017, 19, 21–42. [Google Scholar] [CrossRef]
- Moradi, M.; Roche, S.; Mostafavi, M.A. Exploring five indicators for the quality of OpenStreetMap road networks: A case study of Québec, Canada. Geoinformatica 2022, 75, 178–208. [Google Scholar] [CrossRef]
- Girres, J.F.; Touya, G. Quality assessment of the French OpenStreetMap dataset. Trans. GIS 2010, 14, 435–459. [Google Scholar] [CrossRef]
- Jackson, S.P. Analyzing Contribution Patterns of Volunteered Geographic Point Features in Relation to Errors and Demographics. Doctoral Dissertation, George Mason University, Fairfax, VA, USA, 2014. [Google Scholar]
- Jonietz, D.; Zipf, A. Defining fitness-for-use for Crowdsourced points of interest (POI). ISPRS Int. J. Geo-Inf. 2016, 5, 149. [Google Scholar] [CrossRef]
- Gil de la Vega, P.; Ariza-López, F.J.; Mozas-Calvache, A.T. Models for positional accuracy assessment of linear features: 2D and 3D cases. Surv. Rev. 2016, 48, 347–360. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Hunter, G.J. A simple positional accuracy measure for linear features. Int. J. Geogr. Inf. Sci. 1997, 11, 299–306. [Google Scholar] [CrossRef]
- Cakmakov, D.; Arnautovski, V.; Davcev, D. A model for polygon similarity estimation. In Proceedings of the CompEuro 1992 Proceedings Computer Systems and Software Engineering, The Hague, The Netherlands, 4–8 May 1992; pp. 701–705. [Google Scholar] [CrossRef]
- Kim, J.; Yu, K. Areal feature matching based on similarity using critic method. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2015, XL-2/W4, 75–78. [Google Scholar] [CrossRef][Green Version]
- Mahmoody-Vanolya, N.; Jelokhani-Niaraki, M.R. Measuring the spatial similarities in volunteered geographic information. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2023, X-4/W1-2022, 411–416. [Google Scholar] [CrossRef]
- Song, W.; Haithcoat, T. Development of comprehensive accuracy assessment indexes for building footprint extraction. IEEE Trans. Geosci. Remote Sens. 2005, 43, 402–404. [Google Scholar] [CrossRef]
- Latecki, L.J.; Lakämper, R. Shape similarity measure based on correspondence of visual parts. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1185–1190. [Google Scholar] [CrossRef]
- Avbelj, J.; Müller, R.; Bamler, R. A metric for polygon comparison and building extraction evaluation. IEEE Geosci. Remote Sens. Lett. 2015, 12, 170–174. [Google Scholar] [CrossRef]
- Padilla-Ruiz, M.; López-Vázquez, C. Measuring conflation success. Rev. Cart. 2017, 94, 41–64. [Google Scholar] [CrossRef]
- OpenStreetMap. Available online: https://www.openstreetmap.org (accessed on 10 July 2023).
- Minghini, M.; Frassinelli, F. OpenStreetMap history for intrinsic quality assessment: Is OSM up-to-date? Open Geospat. Data Softw. Stand. 2019, 4, 9. [Google Scholar] [CrossRef]
- Minghini, M.; Kotsev, A.; Lutz, M. Comparing INSPIRE and OpenStreetMap data: How to make the most out of the two worlds. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2019, XLII-4/W14, 167–174. [Google Scholar] [CrossRef]
- Heris, M.P.; Foks, N.L.; Bagstad, K.J.; Troy, A.; Ancona, Z.H. A rasterized building footprint dataset for the United States. Sci. Data 2020, 7, 207. [Google Scholar] [CrossRef]
- Basiri, A.; Jackson, M.; Amirian, P.; Pourabdollah, A.; Sester, M.; Winstanley, A.C.; Moore, T.; Zhang, L. Quality assessment of OpenStreetMap data using trajectory mining. Geo-Spat. Inf. Sci. 2016, 19, 56–68. [Google Scholar] [CrossRef]
- Zhoua, Q.; Zhanga, Y.; Changa, K.; Brovellic, M.A. Assessing OSM building completeness for almost 13,000 cities Globally. Int. J. Digit. Earth 2022, 15, 2400–2421. [Google Scholar] [CrossRef]
- Siebritz, L.-A. Assessing the Accuracy of OpenStreetMap Data in South Africa for the Purpose of Integrating it with Authoritative Data. Master’s Thesis, University of Cape Town, Cape Town, South Africa, 2014. [Google Scholar]
- Müller, F.; Iosifescu, I.; Hurni, L. Assessment and visualization of OSM building footprint quality. In Proceedings of the 27th International Cartographic Conference, Rio de Janeiro, Brazil, 23–28 August 2015. [Google Scholar]
- Zhang, H. Quality Assessment of the Canadian OpenStreetMap Road Networks. Master’s Thesis, University of Western Ontario, London, ON, Canada, 2017. [Google Scholar]
- Borkowska, S.; Pokonieczny, K. Analysis of OpenStreetMap Data Quality for Selected Counties in Poland in Terms of Sustainable Development. Sustainability 2022, 14, 3728. [Google Scholar] [CrossRef]
- OQ_Analysis. OpenStreetMap Quality Analysis Tools. Available online: https://github.com/pierzen/OQ_Analysis (accessed on 21 September 2023).
- Geodesy, Cartography and Cadastre Authority of the Slovak Republic (GCCA SR). Geoportál. INSPIRE. Available online: https://www.geoportal.sk/en/inspire/download-data/ (accessed on 10 July 2023).
- QGIS. Available online: http://qgis.com (accessed on 15 October 2023).
- PostgreSQL. Available online: https://www.postgresql.org/ (accessed on 15 October 2023).
- PostGIS. Available online: http://postgis.net (accessed on 21 September 2023).
- Hausdorff, F. Grundzüge der Mengenlehre; Veit: Leipzig, Germany, 1914. [Google Scholar]
- Alt, H.; Godau, M. Computing the Fréchet distance between two polygonal curves. Int. J. Comput. Geom. Appl. 1995, 5, 75–91. [Google Scholar] [CrossRef]
- Ewing, G.M. Calculus of Variations with Applications; Dover Publications: New York, NY, USA, 1985. [Google Scholar]
- Bajusz, D.; Rácz, A.; Héberger, K. Why is Tanimoto index an appropriate choice for fingerprint-based similarity calculations? J. Cheminform. 2015, 7, 20. [Google Scholar] [CrossRef]
- Todeschini, R.; Ballabio, D.; Consonni, V.; Mauri, A.; Pavan, M. CAIMAN (classification and influence matrix analysis): A new approach to the classification based on leverage-scaled functions. Chemom. Intell. Lab. Syst. 2007, 87, 3–17. [Google Scholar] [CrossRef]
- Bandemer, H. Mathematics of Uncertainty: Ideas, Methods, Application Problems; Springer: Berlin/Heidelberg, Germany, 2006; 190p. [Google Scholar]
- Jaccard, P. Étude comparative de la distribution orale dans une portion des Alpes et des Jura. Bull. Soc. Vaudoise Sci. Nat. 1901, 37, 547–579. [Google Scholar]
- Jaccard, P. Lois de distribution florale dans la zone alpine. Bull. Soc. Vaudoise Sci. Nat. 1902, XXXVIII, 68–130. [Google Scholar]
- Ďuračiová, R.; Igondová, M. Integration of spatial data representing buildings by determining the degree of similarity. Czech J. Civ. Eng. 2017, 3, 29–35. [Google Scholar] [CrossRef]
- Tanimoto, T. An Elementary Mathematical Theory of Classification and Prediction; Tech. Rep., IBM Report; IBM: New York, NY, USA, 1958. [Google Scholar]
- Dice, L.R. Measures of the Amount of Ecologic Association Between Species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Sørensen, T. A method of establishing groups of equal amplitude in plant sociology based on similarity of species and its application to analyses of the vegetation on Danish commons. Biol. Skr. 1948, 5, 1–34. [Google Scholar]
- Gragera, A.; Suppakitpaisarn, V. Relaxed triangle inequality ratio of the Sørensen–Dice and Tversky indexes. Theor. Comput. Sci. 2017, 718, 37–45. [Google Scholar] [CrossRef]
- Grabisch, M.; Marichal, J.-L.; Mesiar, R.; Pap, E. Aggregation Functions, Encyclopedia of Mathematics and Its Applications; No 127; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Geodesy, Cartography and Cadastre Authority of the Slovak Republic (GCCA SR). ZBGIS. 2023. Available online: https://zbgis.skgeodesy.sk/mkzbgis/en/ (accessed on 15 October 2023).
- INSPIRE. Available online: https://inspire.ec.europa.eu (accessed on 21 September 2023).
- Commission of the European Communities. Directive 2007/2/EC of the European Parliament and of the Council of 14 March 2007 Establishing an Infrastructure for Spatial Information in the European Community (INSPIRE). 2007. Available online: https://eur-lex.europa.eu/eli/dir/2007/2/2019-06-26 (accessed on 21 September 2023).
- European Commission. D2.8.III.2 INSPIRE Specification on Buildings—Technical Guidelines. 2013. Available online: https://inspire.ec.europa.eu/documents/Data_Specifications/INSPIRE_DataSpecification_BU_v3.0.pdf (accessed on 21 September 2023).
- Geodesy, Cartography and Cadastre Authority of the Slovak Republic (GCCA SR). Zoznam Stavieb (List of Buildings). 2023. Available online: https://www.skgeodesy.sk/sk/ugkk/kataster-nehnutelnosti/zoznam-stavieb/ (accessed on 10 July 2023).
- Kraak, M.; Ormeling, F. Cartography: Visualization of Geospatial Data, 4th ed.; CRC Press: Boca Raton, FL, USA, 2020; 261p. [Google Scholar]
- ST_FrechetDistance. Available online: https://postgis.net/docs/ST_FrechetDistance.html (accessed on 21 September 2023).
- ST_HausdorffDistance. Available online: https://postgis.net/docs/ST_HausdorffDistance.html (accessed on 21 September 2023).
- Eiter, T.; Mannila, H. Computing Discrete Fréchet Distance. Technical University of Vienna. 1994. Available online: http://www.kr.tuwien.ac.at/staff/eiter/et-archive/cdtr9464.pdf (accessed on 21 September 2023).
- ST_NPoints. Available online: https://postgis.net/docs/ST_NPoints.html (accessed on 21 September 2023).
- Luque-Suárez, F.; López-López, J.L.; Chávez, E. Indexed polygon matching under similarities. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2021; pp. 295–306. [Google Scholar] [CrossRef]
- Zhang, X.; Ai, T.; Stoter, J.; Zhao, X. Data matching of building polygons at multiple map scales improved by contextual information and relaxation. ISPRS J. Photogramm. Remote Sens. 2014, 92, 147–163. [Google Scholar] [CrossRef]
- Liu, L.; Zhu, X.; Zhu, D.; Ding, X. M:N Object matching on multiscale datasets based on MBR combinatorial optimization algorithm and spatial district. Trans. GIS 2008, 22, 1573–1595. [Google Scholar] [CrossRef]
- ESRI. Data Classification Methods. ArcGIS. Available online: https://pro.arcgis.com/en/pro-app/latest/help/mapping/layer-properties/data-classification-methods.htm (accessed on 24 November 2023).
- QGIS. 3. Module: Classifying Vector Data. Available online: https://docs.qgis.org/3.28/en/docs/training_manual/vector_classification/index.html (accessed on 24 November 2023).
- Jenks, G.F. The Data Model Concept in Statistical Mapping. Int. Yearb. Cartogr. 1967, 7, 186–190. [Google Scholar]
- Hagen, A. Fuzzy set approach to assessing similarity of categorical maps. Int. J. Geogr. Inf. Sci. 2003, 17, 235–249. [Google Scholar] [CrossRef]
- Chen, Z.; Ma, X.; Wu, L.; Xie, Z. An intuitionistic fuzzy similarity approach for clustering analysis of polygons. ISPRS Int. J. Geo-Inf. 2019, 8, 98. [Google Scholar] [CrossRef]
- Ullah, T.; Lautenbach, S.; Herfort, B.; Reinmuth, M.; Schorlemmer, D. Assessing completeness of OpenStreetMap building footprints using MapSwipe. ISPRS Int. J. Geo-Inf. 2023, 12, 143. [Google Scholar] [CrossRef]
- Hecht, R.; Kunze, C.; Hahmann, S. Measuring Completeness of Building Footprints in OpenStreetMap over Space and Time. ISPRS Int. J. Geo-Inf. 2013, 2, 1066–1091. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distance Similarity | Set Similarity | Shape Similarity | Result | Example |
|---|---|---|---|---|
| ~1 * | ~1 | ~1 | Similarity/Identity |  |
| ~1 | ~1 | ~0 | Changed or generalized object |  |
| ~1 | ~0 | ~1 | Impossible situations ** | --- |
| ~1 | ~0 | ~0 | ||
| ~0 | ~1 | ~1 | ||
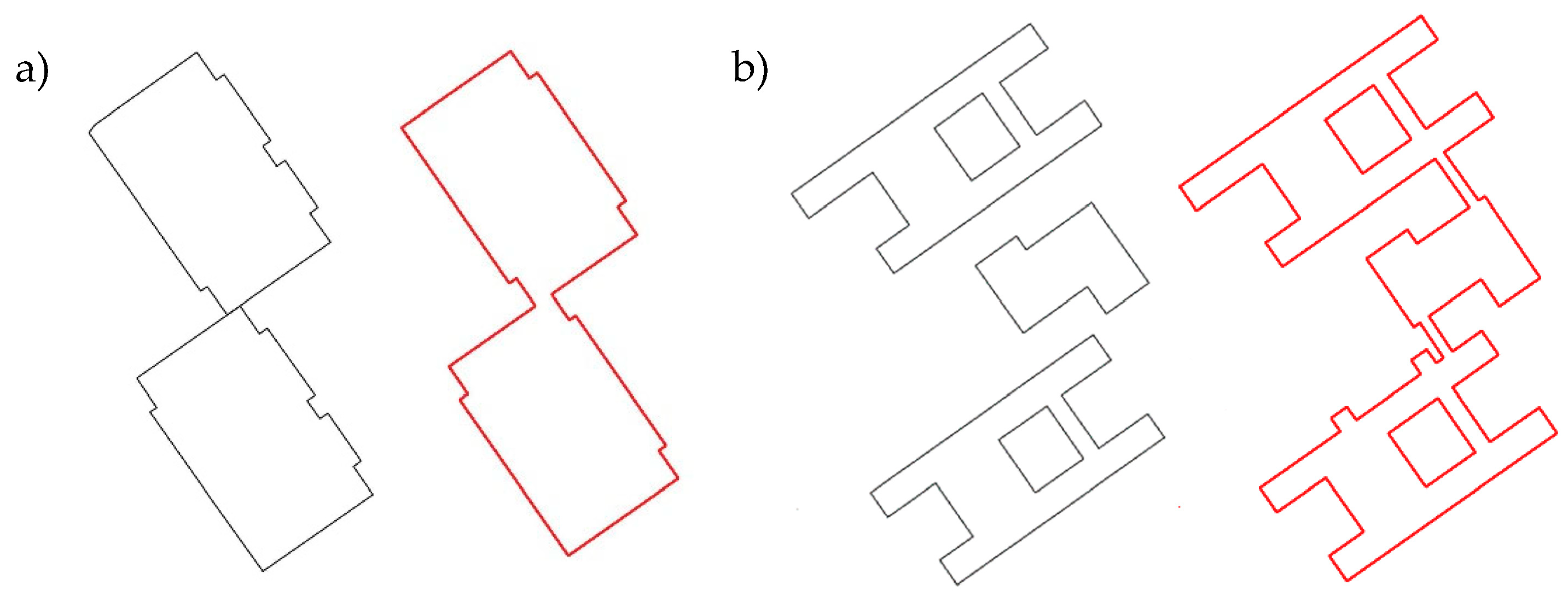
| ~0 | ~1 | ~0 | A generalisation or, for example, an object contains a distant detail |  |
| ~0 | ~0 | ~1 | Moved or/and rotated object |  |
| ~0 | ~0 | ~0 | Changed object |  |
| OSM (Black) and INSPIRE (Red) Buildings (Footprints) | Sim_H Sim_T Sim_A Sim_P Sim_V | OSM (Black) and INSPIRE (Red) Buildings (Footprints) | Sim_H Sim_T Sim_A Sim_P Sim_V |
|---|---|---|---|
 | 0.44 0.64 0.21 0.57 1.00 |  | 0.59 0.82 0.49 0.71 0.71 |
 | 0.88 0.96 0.93 0.96 0.88 |  | 0.99 0.98 0.98 0.99 0.93 |
| Category of Object Similarity | Count | |
|---|---|---|
| 1. | Identical | 1144 |
| 2. | Generalised or slightly changed | 518 |
| 3. | Moved or rotated | 10 |
| 4. | Different | 453 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ďuračiová, R. An Aggregated Shape Similarity Index: A Case Study of Comparing the Footprints of OpenStreetMap and INSPIRE Buildings. ISPRS Int. J. Geo-Inf. 2023, 12, 495. https://doi.org/10.3390/ijgi12120495
Ďuračiová R. An Aggregated Shape Similarity Index: A Case Study of Comparing the Footprints of OpenStreetMap and INSPIRE Buildings. ISPRS International Journal of Geo-Information. 2023; 12(12):495. https://doi.org/10.3390/ijgi12120495
Chicago/Turabian StyleĎuračiová, Renata. 2023. "An Aggregated Shape Similarity Index: A Case Study of Comparing the Footprints of OpenStreetMap and INSPIRE Buildings" ISPRS International Journal of Geo-Information 12, no. 12: 495. https://doi.org/10.3390/ijgi12120495
APA StyleĎuračiová, R. (2023). An Aggregated Shape Similarity Index: A Case Study of Comparing the Footprints of OpenStreetMap and INSPIRE Buildings. ISPRS International Journal of Geo-Information, 12(12), 495. https://doi.org/10.3390/ijgi12120495