
Measuring the Influence of Multiscale Geographic Space on the Heterogeneity of Crime Distribution

Abstract
:1. Introduction
2. Related Work
2.1. Crime Distribution Pattern
2.2. Crime Association Analysis
2.3. Scale and Spatial Heterogeneity
2.4. Critical Analysis and Main Contributions
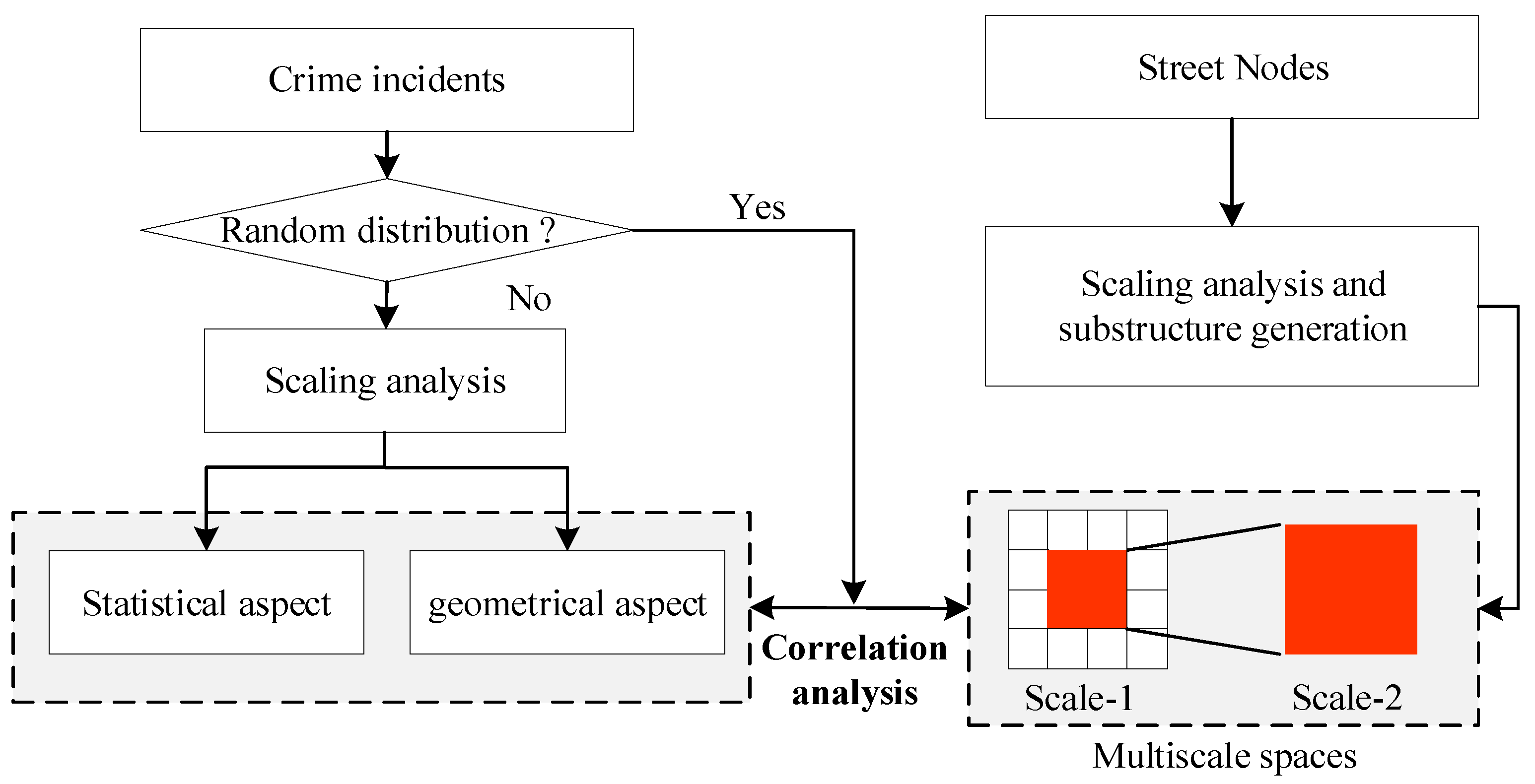
3. Methodology and Data
3.1. Methodology
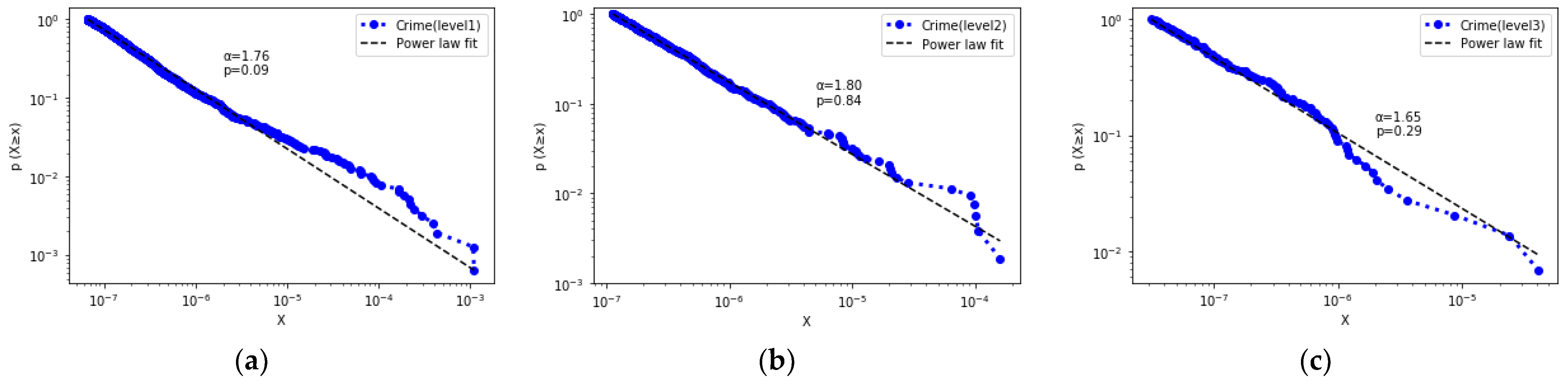
3.1.1. Scaling Analysis for Spatial Heterogeneity
- Scaling analysis on the statistical distribution
- 2.
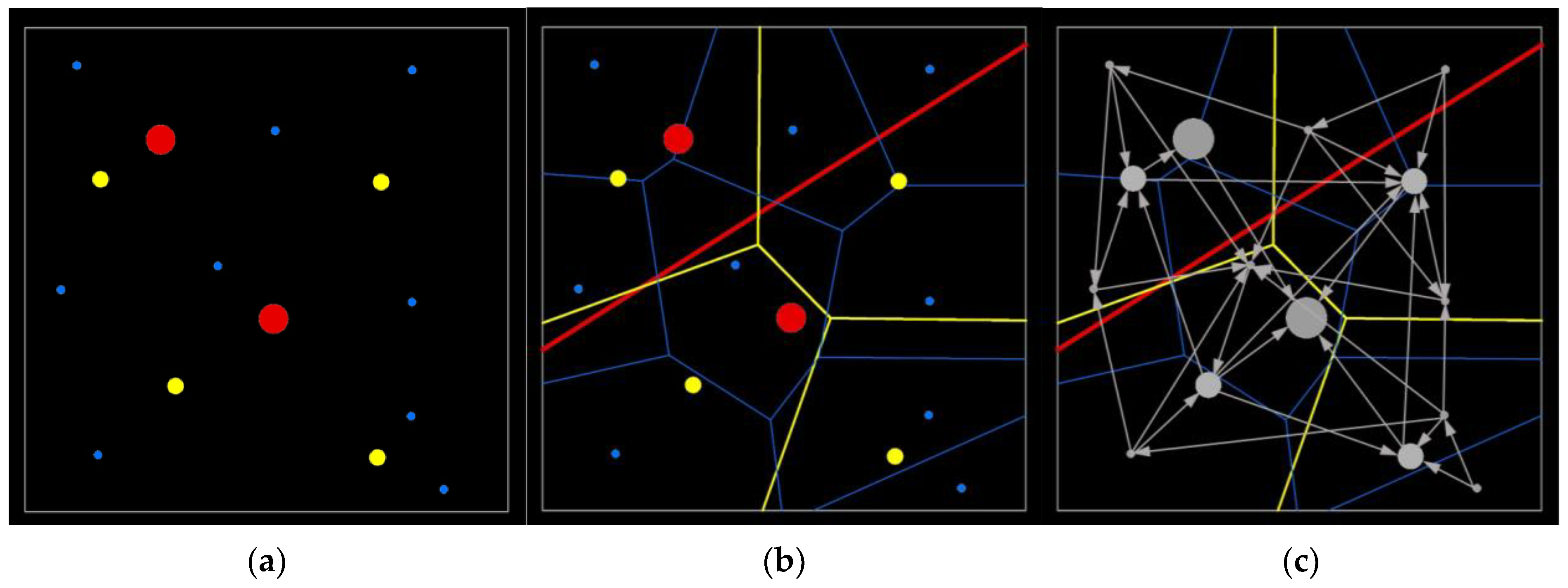
- Scaling analysis on geometric distribution
3.1.2. Multiscale Association between Geographic Space and Crime Distribution
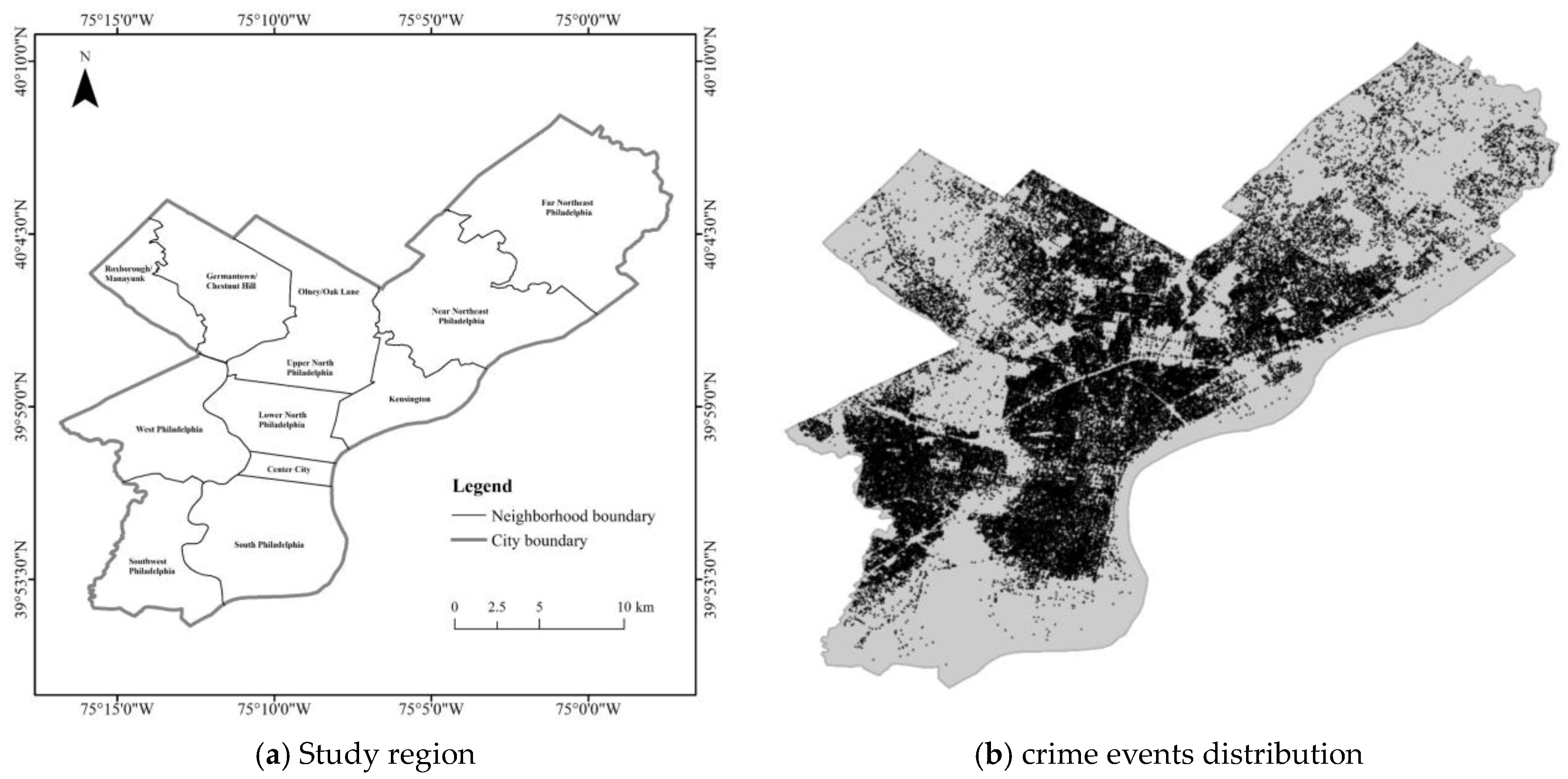
3.2. Data Description
4. Results and Discussions
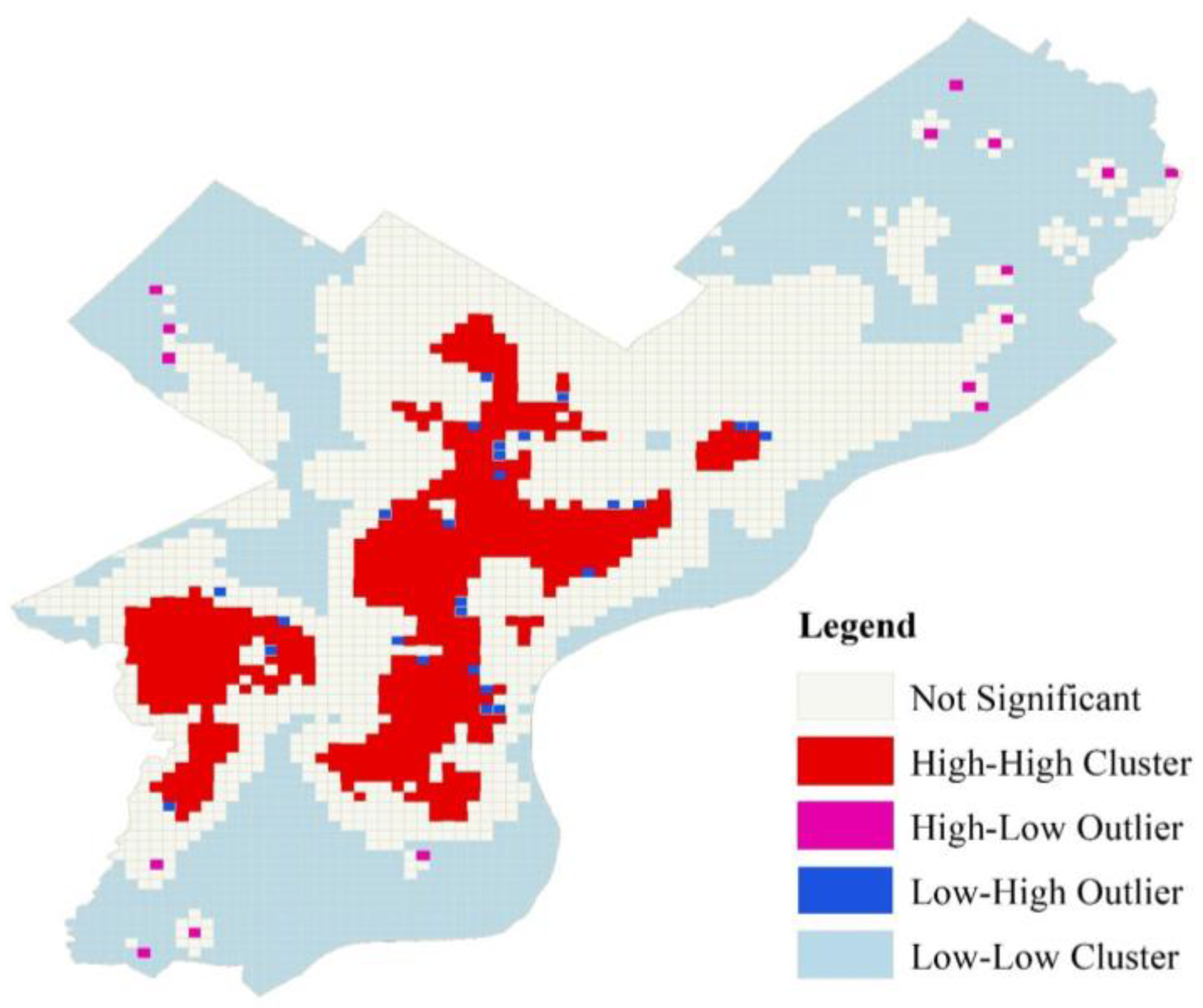
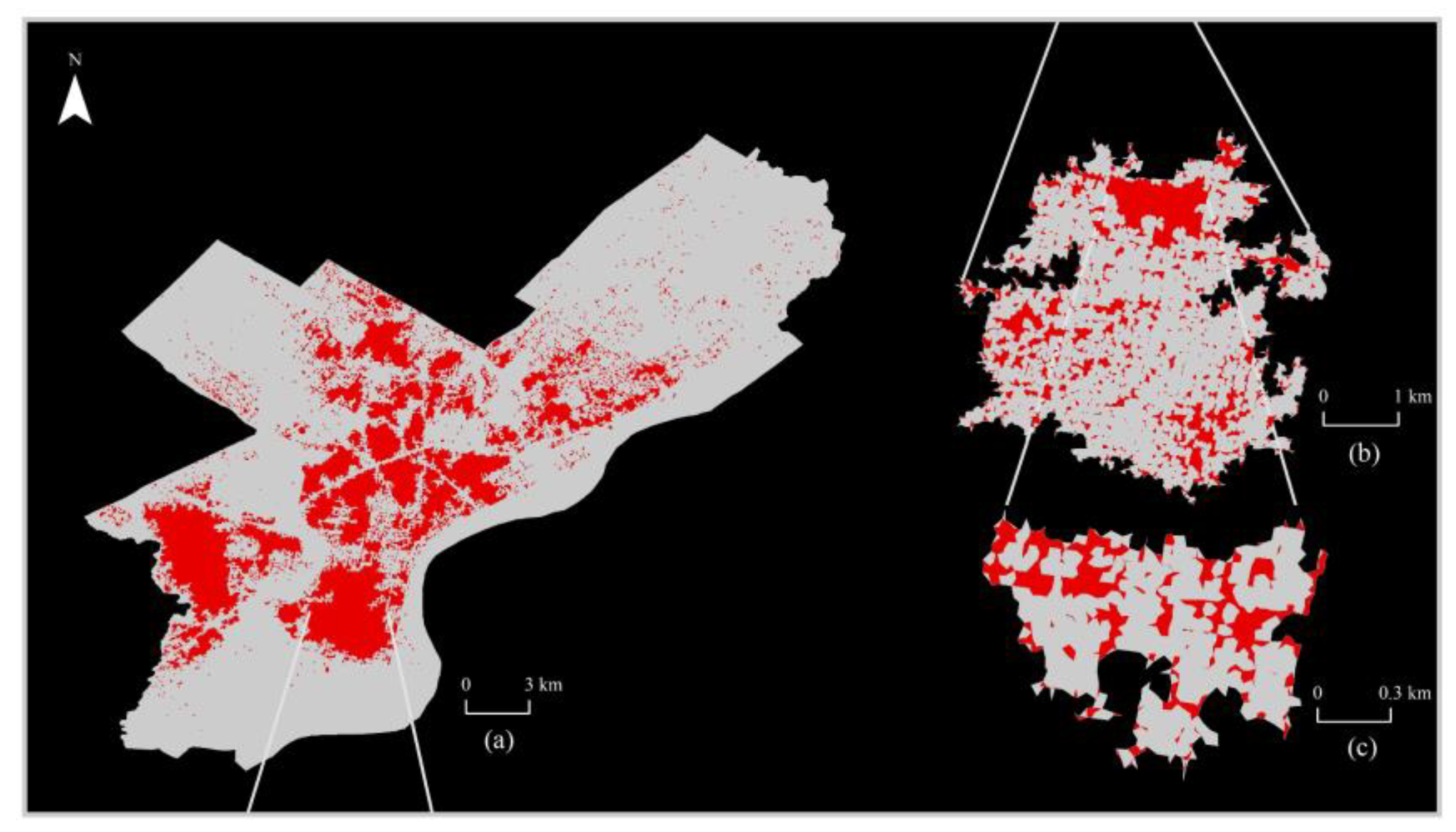
4.1. Scaling Analysis for the Heterogeneity of Crime Distribution
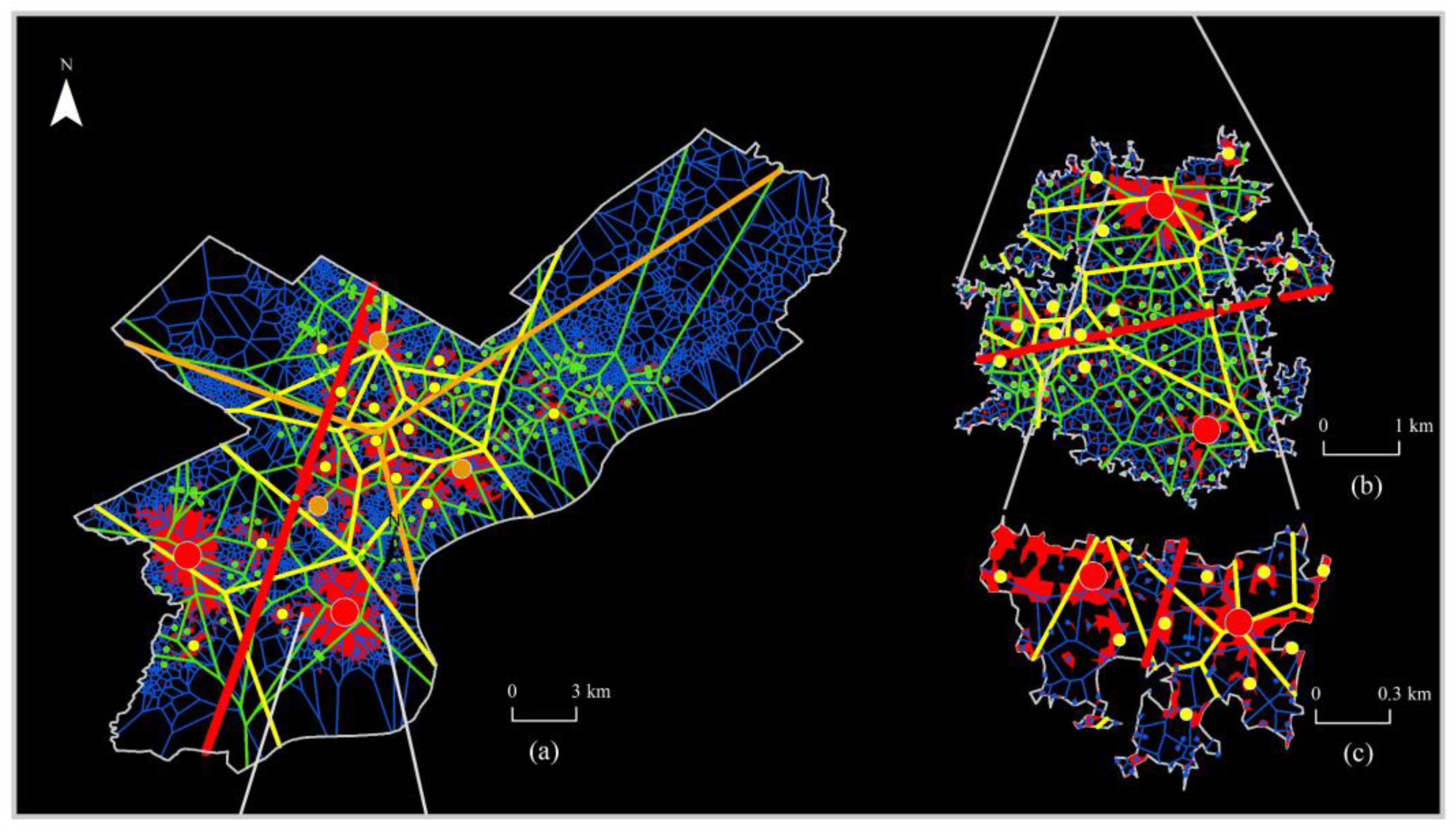
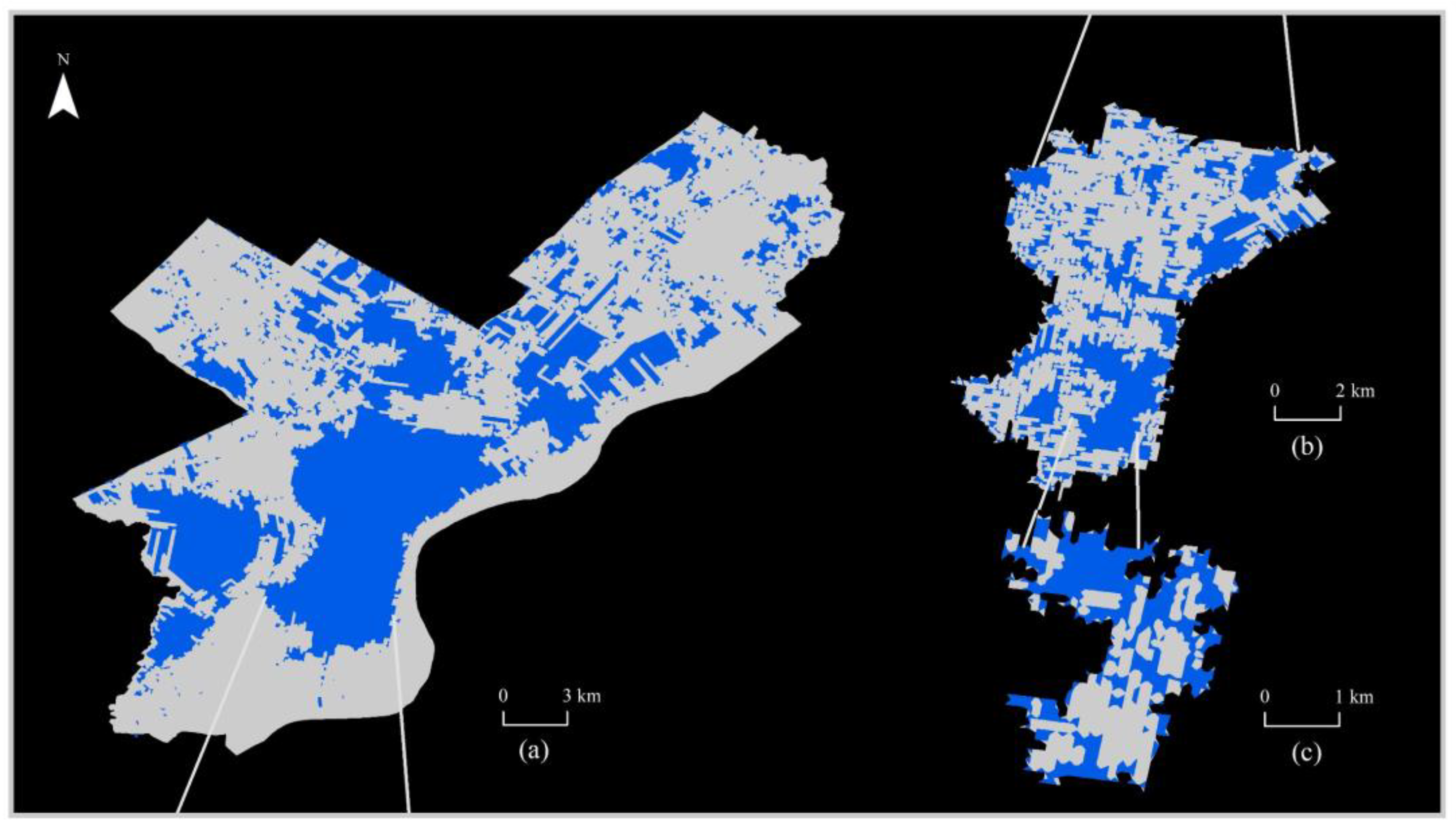
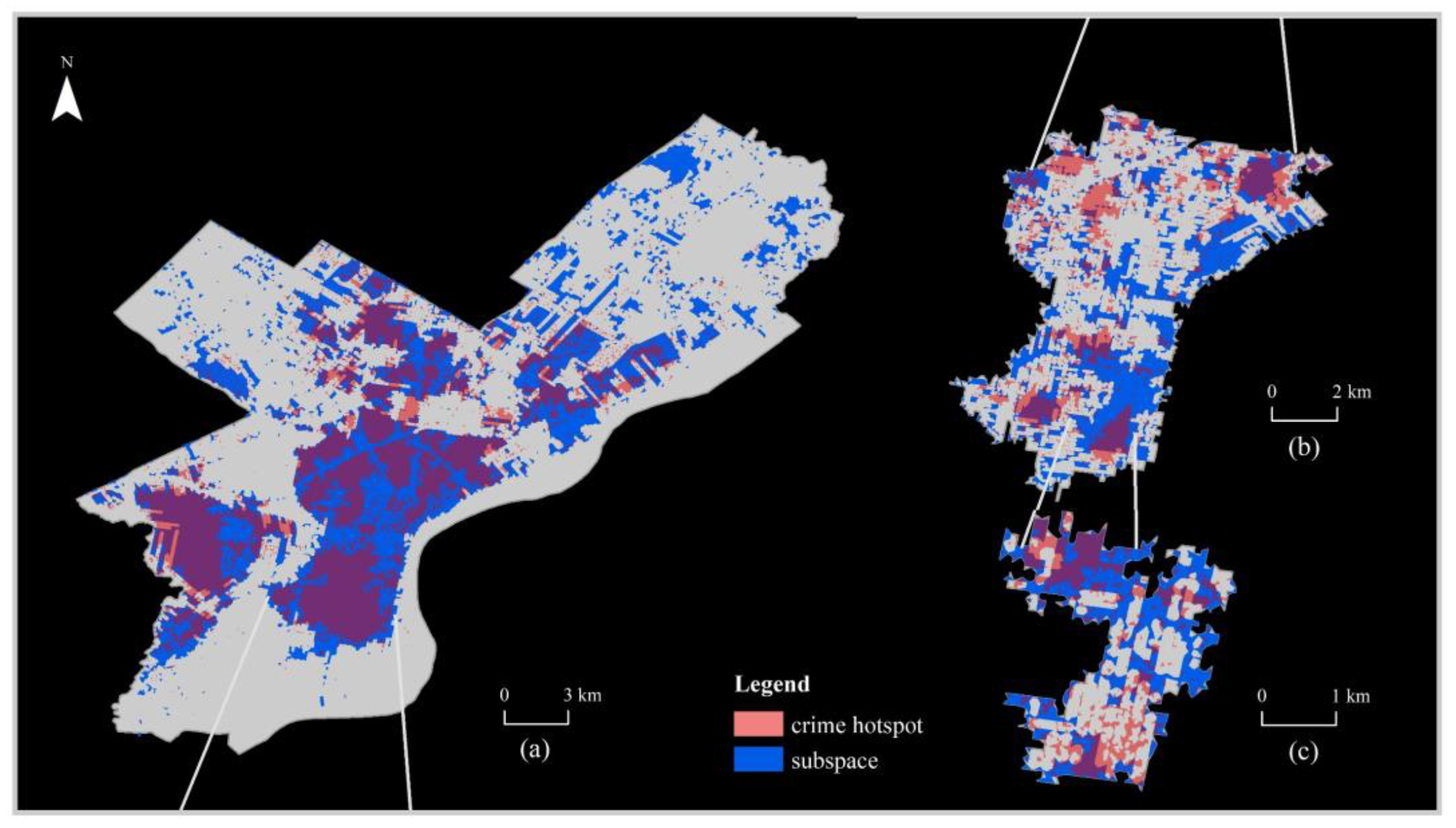
4.2. Multiscale Association between Crime and Spatial Environment
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, L. Progresses and Challenges of Crime Geography and Crime Analysis. In New Thinking in GIScience; Springer: Singapore, 2022; pp. 349–353. [Google Scholar]
- Shu, H.; Pei, T.; Song, C.; Ma, T.; Du, Y.; Fan, Z.; Guo, S. Quantifying the spatial heterogeneity of points. Int. J. Geogr. Inf. Sci. 2019, 33, 1355–1376. [Google Scholar] [CrossRef]
- Brantingham, P.L.; Brantingham, P.J. A theoretical model of crime hot spot generation. Stud. Crime Crime Prev. 1999, 8, 7–26. [Google Scholar]
- Weisburd, D.; Bushway, S.; Lum, C.; Yang, S.-M. Trajectories of crime at places: A longitudinal study of street segments in the city of Seattle. Criminology 2004, 42, 283–322. [Google Scholar] [CrossRef]
- Weisburd, D.; Morris, N.A.; Groff, E.R. Hot spots of juvenile crime: A longitudinal study of arrest incidents at street segments in Seattle, Washington. J. Quant. Criminol. 2009, 25, 443–467. [Google Scholar] [CrossRef]
- Weisburd, D.; Amram, S. The law of concentrations of crime at place: The case of Tel Aviv-Jaffa. Police Pract. Res. 2014, 15, 101–114. [Google Scholar] [CrossRef]
- Vilalta, C.J. How exactly does place matter in crime analysis? Place, space, and spatial heterogeneity. J. Crim. Justice Educ. 2013, 24, 290–315. [Google Scholar] [CrossRef]
- Boivin, R. Routine activity, population(s) and crime: Spatial heterogeneity and conflicting Propositions about the neighborhood crime-population link. Appl. Geogr. 2018, 95, 79–87. [Google Scholar] [CrossRef]
- Fotheringham, A.S.; Yang, W.; Kang, W. Multiscale geographically weighted regression (MGWR). Ann. Am. Assoc. Geogr. 2017, 107, 1247–1265. [Google Scholar] [CrossRef]
- Brunsdon, C.; Fotheringham, S. Geographically weighted regression. J. R. Stat. Soc. Ser. D (Stat.) 1998, 47, 431–443. [Google Scholar] [CrossRef]
- Andresen, M.A.; Malleson, N. Spatial heterogeneity in crime analysis. In Crime Modeling and Mapping Using Geospatial Technologies; Springer: Dordrecht, The Netherlands, 2013; pp. 3–23. [Google Scholar]
- Becker, G.S. Crime and punishment: An economic approach. In The Economic Dimensions of Crime; Springer: Berlin/Heidelberg, Germany, 1968; pp. 13–68. [Google Scholar]
- Brantingham, P.J.; Brantingham, P.L. Patterns in Crime; Macmillan: New York, NY, USA, 1984. [Google Scholar]
- Cohen, L.E.; Felson, M. Social Change and Crime Rate Trends: A Routine Activity Approach. Am Sociol. Rev. 1979, 44, 588–608. [Google Scholar] [CrossRef]
- Hipp, J.R.; Lee, S.; Ki, D.; Kim, J.H. Measuring the Built Environment with Google Street View and Machine Learning: Consequences for Crime on Street Segments. J. Quant. Criminol. 2021, 38, 537–565. [Google Scholar] [CrossRef]
- He, L.; Páez, A.; Jiao, J.; An, P.; Lu, C.; Mao, W.; Long, D. Ambient population and larceny-theft: A spatial analysis using mobile phone data. ISPRS Int. J. Geo-Inf. 2020, 9, 342. [Google Scholar] [CrossRef]
- He, Z.; Deng, M.; Xie, Z.; Wu, L.; Chen, Z.; Pei, T. Discovering the joint influence of urban facilities on crime occurrence using spatial co-location pattern mining. Cities 2020, 99, 102612. [Google Scholar] [CrossRef]
- Ma, D.; Osaragi, T.; Oki, T. Exploring the heterogeneity of human urban movements using geo-tagged tweets. Int. J. Geogr. Inf. Sci. 2020, 34, 2475–2496. [Google Scholar] [CrossRef]
- Zeng, M.; Mao, Y.; Wang, C. The relationship between street environment and street crime: A case study of Pudong New Area, Shanghai, China. Cities 2021, 112, 103143. [Google Scholar] [CrossRef]
- Tobler, W.R. A computer movie simulating urban growth in the Detroit region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- He, Z.; Tao, L.; Xie, Z.; Xu, C. Discovering spatial interaction patterns of near repeat crime by spatial association rules mining. Sci. Rep. 2020, 10, 17262. [Google Scholar] [CrossRef]
- Leong, K.; Sung, A. A review of spatio-temporal pattern analysis approaches on crime analysis. Int. E-J. Crim. Sci. 2015, 9, 1–33. [Google Scholar]
- Kennedy, L.W.; Caplan, J.M.; Piza, E. Risk clusters, hotspots, and spatial intelligence: Risk terrain modeling as an algorithm for police resource allocation strategies. J. Quant. Criminol. 2011, 27, 339–362. [Google Scholar] [CrossRef]
- Anselin, L. The Local indicators of spatial association—LISA. Geogr. Anal. 1995, 27, 93–115. [Google Scholar] [CrossRef]
- Ord, J.K.; Getis, A. Local spatial autocorrelation statistics: Distributional issues and an application. Geogr. Anal. 1995, 27, 286–306. [Google Scholar] [CrossRef]
- Besag, J. Discussion of Dr Ripley’s paper. J. R. Stat. Soc. Ser. B 1977, 39, 193–195. [Google Scholar]
- Kulldorff, M. A spatial scan statistic. Commun. Stat.-Theory Methods 1997, 26, 1481–1496. [Google Scholar] [CrossRef]
- Lotwick, H.; Silverman, B. Methods for analysing spatial processes of several types of points. J. R. Stat. Soc. Ser. B (Methodol.) 1982, 44, 406–413. [Google Scholar] [CrossRef]
- Miethe, T.D.; Hart, T.C.; Regoeczi, W.C. The conjunctive analysis of case configurations: An exploratory method for discrete multivariate analyses of crime data. J. Quant. Criminol. 2008, 24, 227–241. [Google Scholar] [CrossRef]
- Summers, L.; Caballero, M. Spatial conjunctive analysis of (crime) case configurations: Using Monte Carlo methods for significance testing. Appl. Geogr. 2017, 84, 55–63. [Google Scholar] [CrossRef]
- Bernasco, W.; Block, R. Robberies in Chicago: A block-level analysis of the influence of crime generators, crime attractors, and offender anchor points. J. Res. Crime Delinq. 2011, 48, 33–57. [Google Scholar] [CrossRef]
- Hipp, J.R.; Kim, Y.-A. Explaining the temporal and spatial dimensions of robbery: Differences across measures of the physical and social environment. J. Crim. Justice 2019, 60, 1–12. [Google Scholar] [CrossRef]
- Song, G.; Liu, L.; Bernasco, W.; Xiao, L.; Zhou, S.; Liao, W. Testing indicators of risk populations for theft from the person across space and time: The significance of mobility and outdoor activity. Ann. Am. Assoc. Geogr. 2018, 108, 1370–1388. [Google Scholar] [CrossRef]
- Song, G.; Bernasco, W.; Liu, L.; Xiao, L.; Zhou, S.; Liao, W. Crime feeds on legal activities: Daily mobility flows help to explain thieves’ target location choices. J. Quant. Criminol. 2019, 35, 831–854. [Google Scholar] [CrossRef]
- Deng, M.; Yang, W.; Chen, C.; Liu, C. Exploring associations between streetscape factors and crime behaviors using Google Street View images. Front. Comput. Sci. 2022, 16, 164316. [Google Scholar] [CrossRef]
- Connealy, N.T. Understanding the predictors of street robbery hot spots: A matched pairs analysis and systematic social observation. Crime Delinq. 2021, 67, 1319–1352. [Google Scholar] [CrossRef]
- Zhang, F.; Fan, Z.; Kang, Y.; Hu, Y.; Ratti, C. “Perception bias”: Deciphering a mismatch between urban crime and perception of safety. Landsc. Urban Plan. 2021, 207, 104003. [Google Scholar] [CrossRef]
- Cozens, P.; Love, T. Manipulating permeability as a process for controlling crime: Balancing security and sustainability in local contexts. Built Environ. 2009, 35, 346–365. [Google Scholar] [CrossRef]
- Davies, T.; Johnson, S.D. Examining the relationship between road structure and burglary risk via quantitative network analysis. J. Quant. Criminol. 2015, 31, 481–507. [Google Scholar] [CrossRef]
- Jiang, B.; Ren, Z. Geographic space as a living structure for predicting human activities using big data. Int. J. Geogr. Inf. Sci. 2019, 33, 764–779. [Google Scholar] [CrossRef]
- Jiang, B.; de Rijke, C. Representing geographic space as a hierarchy of recursively defined subspaces for computing the degree of order. Comput. Environ. Urban Syst. 2022, 92, 101750. [Google Scholar] [CrossRef]
- Anselin, L.; O’Loughlin, J. Geography of international conflict and cooperation: Spatial dependence and regional context in Africa. In The New Geopolitics; Taylor & Francis: Abingdon, UK, 1992; pp. 39–75. [Google Scholar]
- Wu, J.; Li, H. Concepts of scale and scaling. In Scaling and Uncertainty Analysis in Ecology; Springer: Berlin/Heidelberg, Germany, 2006; pp. 3–15. [Google Scholar]
- Deng, M.; He, Z.; Liu, Q.; Cai, J.; Tang, J. Multi-scale approach to mining significant spatial co-location patterns. Trans. GIS 2017, 21, 1023–1039. [Google Scholar] [CrossRef]
- Sherman, L.W.; Gartin, P.R.; Buerger, M.E. Hot spots of predatory crime: Routine activities and the criminology of place. Criminology 1989, 27, 27–56. [Google Scholar] [CrossRef]
- Fotheringham, A.S.; Wong, D.W. The modifiable areal unit problem in multivariate statistical analysis. Environ. Plan. A 1991, 23, 1025–1044. [Google Scholar] [CrossRef]
- Andresen, M.A. Testing for similarity in area-based spatial patterns: A nonparametric Monte Carlo approach. Appl. Geogr. 2009, 29, 333–345. [Google Scholar] [CrossRef]
- Newman, M.E. Power laws, Pareto distributions and Zipf’s law. Contemp. Phys. 2005, 46, 323–351. [Google Scholar] [CrossRef]
- Jiang, B.; Miao, Y. The evolution of natural cities from the perspective of location-based social media. Prof. Geogr. 2015, 67, 295–306. [Google Scholar] [CrossRef]
- Jiang, B. Head/tail breaks: A new classification scheme for data with a heavy-tailed distribution. Prof. Geogr. 2013, 65, 482–494. [Google Scholar] [CrossRef]
- Jiang, B. A topological representation for taking cities as a coherent whole. In The Mathematics of Urban Morphology; Birkhäuser: Cham, Switzerland, 2019; pp. 335–352. [Google Scholar]
- Clauset, A.; Shalizi, C.R.; Newman, M.E. Power-law distributions in empirical data. SIAM Rev. 2009, 51, 661–703. [Google Scholar] [CrossRef]
- Huang, Y.; Zhang, P. On the relationships between clustering and spatial co-location pattern mining. In Proceedings of the 2006 18th IEEE International Conference on Tools with Artificial Intelligence (ICTAI’06), Arlington, VA, USA, 13–15 November 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 513–522. [Google Scholar]
- Zhanjun, H.; Wang, Z.; Xie, Z.; Wu, L.; Chen, Z. Multiscale analysis of the influence of street built environment on crime occurrence using street-view images. Comput. Environ. Urban Syst. 2022, 97, 101865. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ht | #NC | #NC_head | %NC_head | MaxArea | MeanArea | #crime | %crime_head | |
|---|---|---|---|---|---|---|---|---|
| Level Ⅰ | 5 | 2943 | 114 | 3.87 | 10.556 | 0.021 | 159313 | 69.2 |
| Level Ⅱ | 4 | 711 | 88 | 12.38 | 0.616 | 0.003 | 19194 | 56.14 |
| Level Ⅲ | 3 | 71 | 12 | 16.9 | 0.034 | 0.002 | 4539 | 73.23 |
| Subspace Area (km2) | Hotspots Area (km2) | Overlapped Area (km2) | CS | CC | |
|---|---|---|---|---|---|
| Level 1 | 120.017 | 62.441 | 53.967 | 44.97% | 86.43% |
| Level 2 | 15.636 | 11.325 | 4.819 | 30.82% | 42.55% |
| Level 3 | 2.036 | 1.114 | 0.654 | 32.12% | 58.71% |
| Size/Crime | Life/Crime | Street Node/Crime | %Street Node | %Crime | |
|---|---|---|---|---|---|
| Level 1 | 0.993 ** | 0.937 ** | 0.995 ** | 0.87 | 0.74 |
| Level 2 | 0.864 ** | 0.858 ** | 0.834 ** | 0.74 | 0.37 |
| Level 3 | 0.930 ** | 0.961 ** | 0.905 ** | 0.88 | 0.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Z.; Wang, Z.; Gu, Y.; An, X. Measuring the Influence of Multiscale Geographic Space on the Heterogeneity of Crime Distribution. ISPRS Int. J. Geo-Inf. 2023, 12, 437. https://doi.org/10.3390/ijgi12100437
He Z, Wang Z, Gu Y, An X. Measuring the Influence of Multiscale Geographic Space on the Heterogeneity of Crime Distribution. ISPRS International Journal of Geo-Information. 2023; 12(10):437. https://doi.org/10.3390/ijgi12100437
Chicago/Turabian StyleHe, Zhanjun, Zhipeng Wang, Yu Gu, and Xiaoya An. 2023. "Measuring the Influence of Multiscale Geographic Space on the Heterogeneity of Crime Distribution" ISPRS International Journal of Geo-Information 12, no. 10: 437. https://doi.org/10.3390/ijgi12100437
APA StyleHe, Z., Wang, Z., Gu, Y., & An, X. (2023). Measuring the Influence of Multiscale Geographic Space on the Heterogeneity of Crime Distribution. ISPRS International Journal of Geo-Information, 12(10), 437. https://doi.org/10.3390/ijgi12100437