1. Introduction
Raster maps are among the most important data sources in geographic information science (GIS) [
1]. Maps contain rich cartographic information, such as the location of buildings, roads, contours, and hydrology [
2]. Essentially, these geographic elements of colored, dotted, linear, and regional features are used to represent geographic information about the Earth. In the past, many official maps were stored in paper form, but in recent years, they have been scanned into raster maps and stored in computers. To make full use of raster maps to carry out spatial analysis and thematic mapping, it is usually necessary to transform the points, lines, and polygons in a raster map into vector graphics for people to query and topologically analyze information. This process is called raster map vectorization.
According to the degree of automation of vectorization, raster map vectorization can be divided into manual, semi-automatic, and automatic vectorization. The manual vectorization method uses software to trace lines point-by-point along the raster map to form a line or polygon. This method is inefficient and subjective, which affects the accuracy of vectorization. The semi-automatic vectorization method firstly removes irrelevant elements manually by image processing and obtains binary images composed of line pixels and non-line pixels. Then, the line features are vectorized by the raster vectorization algorithm. It is difficult to apply this method when the map image has many annotations and a complex background. In the automatic vectorization method, line features are automatically extracted from a raster map and converted into binary images by the computer algorithm, and then transformed into vector graphics by a raster data conversion algorithm. The automatic algorithm of binary image to vector is mature, so the extraction of line features has become the key step in the automatic vectorization of line features, which could directly affect the efficiency and accuracy of vectorization.
At present, there has been substantial research on extracting geographical elements from maps [
3,
4,
5,
6,
7]. Such extraction is used, for example, to identify text elements from maps [
8,
9,
10] and map symbols by feature matching [
11]. The computer science and geographic information science communities have been developing technologies for automatic and semi-automatic map understanding (digital map processing) for almost 40 years [
12].
At present, there are two main ways to extract map line elements. The first is to draw lines point-by-point along the map with the help of relevant vectorization software to form line features or polygons. The related software includes ArcGIS, WideImage, SuperMap, MapGIS, etc. For example, Beattie [
13] spent over 70 h on the human task of extracting contour lines from two USGS historical maps. This method requires considerable manpower and resources. The second main way to extract map line elements is to use a traditional algorithm. These algorithms mainly include the threshold segmentation algorithm [
14,
15,
16], mathematical morphology operation [
17], and the color segmentation algorithm [
18,
19]. For example, the threshold segmentation algorithm is used to realize line feature extraction of a contour color map. The existence of divergent color and mixed color makes the extracted lines appear as fragments, breakpoints, adhesions, etc., increasing the corresponding processing procedures. Both mathematical morphology algorithms and skeleton line extraction algorithms are used to extract map line features. These methods involve multiple manual adjustment parameters at the same time, and the accuracy is unstable, the degree of automation is not high, and it is difficult to directly apply to the common scanning map.
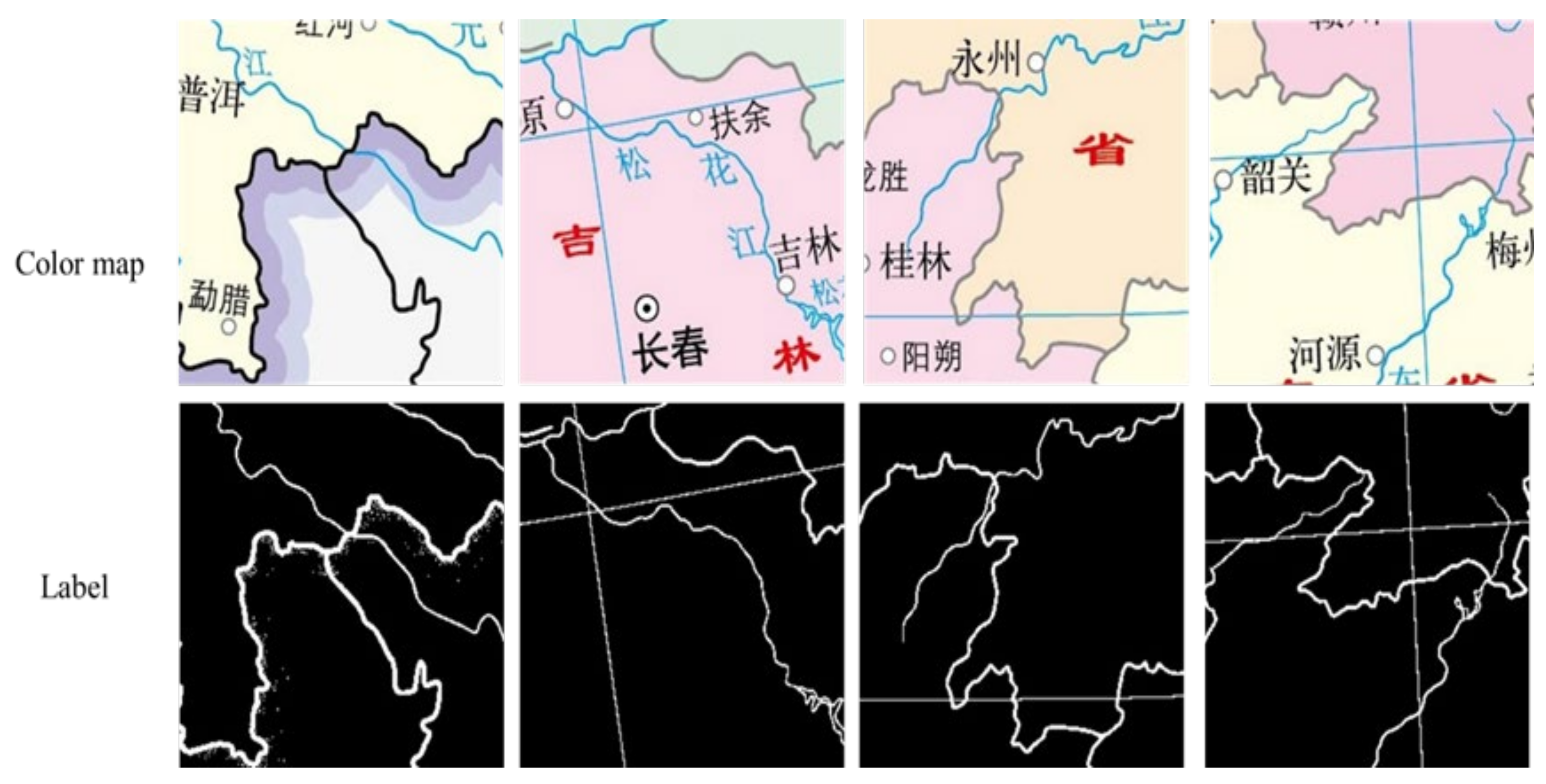
The main difficulties in extracting line features from raster maps by traditional methods are as follows. (1) The mixing of point markers and line features makes it easy to identify the part of point markers as lines. (2) There are background colors or fill markets in polygon features, which bring difficulties in line recognition. (3) The mixing of map annotations and line features may be mistaken for lines. These problems lead to low accuracy of traditional methods in online feature extraction.
The deep learning method can form more abstract high-level representation attribute categories or features by combining low-level features, which provides the possibility for the accurate extraction of raster map line features [
20]. In particular, the emergence of convolutional neural networks (CNNs) and fully convolutional neural networks (FCNs) realizes the classification of every pixel of the image—that is, the semantic segmentation of the image. This is helpful in image processing. Duan et al. [
21] used convolutional neural networks to build a system for automatic recognition of geographical features on historical maps. Uhl et al. [
22] used the LeNet network to identify map symbols, and CNN to identify buildings and urban areas on the map [
23]. All these studies indicate that convolutional neural networks have effective applications in map image processing.
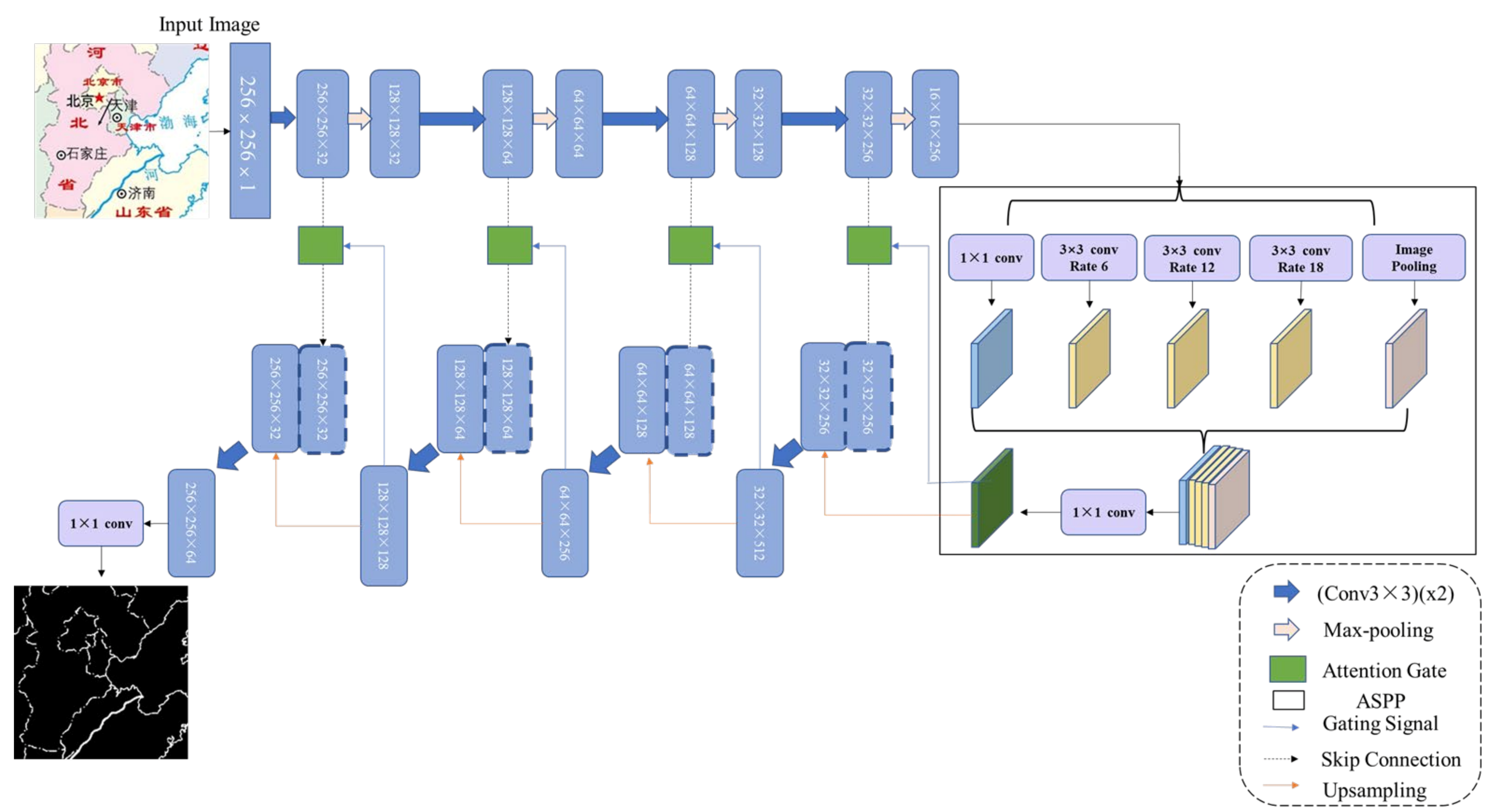
Semantic segmentation uses deep learning technology for autonomous feature learning of input data. The low-level, middle-level, and high-level features are extracted from the image to consider local and global features at the same time. By fusing the features of different levels and regions, the implicit contextual information in the image is captured, thus realizing the segmentation, cognition, and understanding of the image at a higher level. At present, many deep learning image segmentation networks are the improvement of full convolutional neural networks. The U-Net network is the classic encoder and decoder network, and there are many improved networks based on it, such as U-Net ++ [
24] and U-Net +++, which can realize the convolution operation of images of any size and obtain the contextual information of the image through the maximum pooling sampling to reduce the amount of computation [
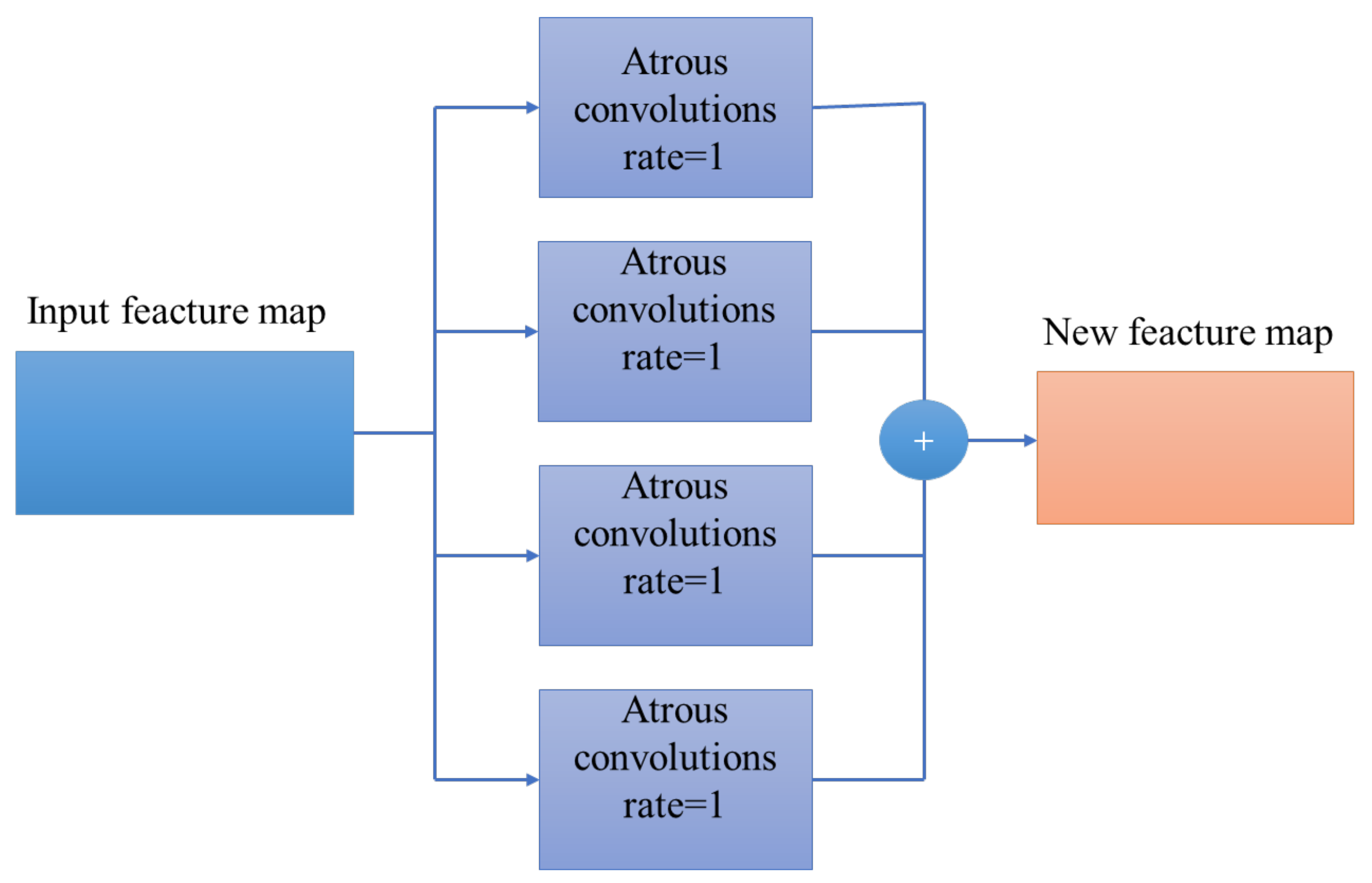
25]. However, due to the repeated use of pooling operations in U-Net, the resolution of feature maps is reduced, leading to rough predicted results. Using down-sampling operations to extract abstract semantic information as features will lead to the loss of some detailed semantic information, causing the problem of missing details and semantic ambiguity in the extracted results. When the U-Net model is directly used to extract line features of the raster map, there will be text interference and broken lines. Therefore, it is necessary to combine other network modules to improve the performance.
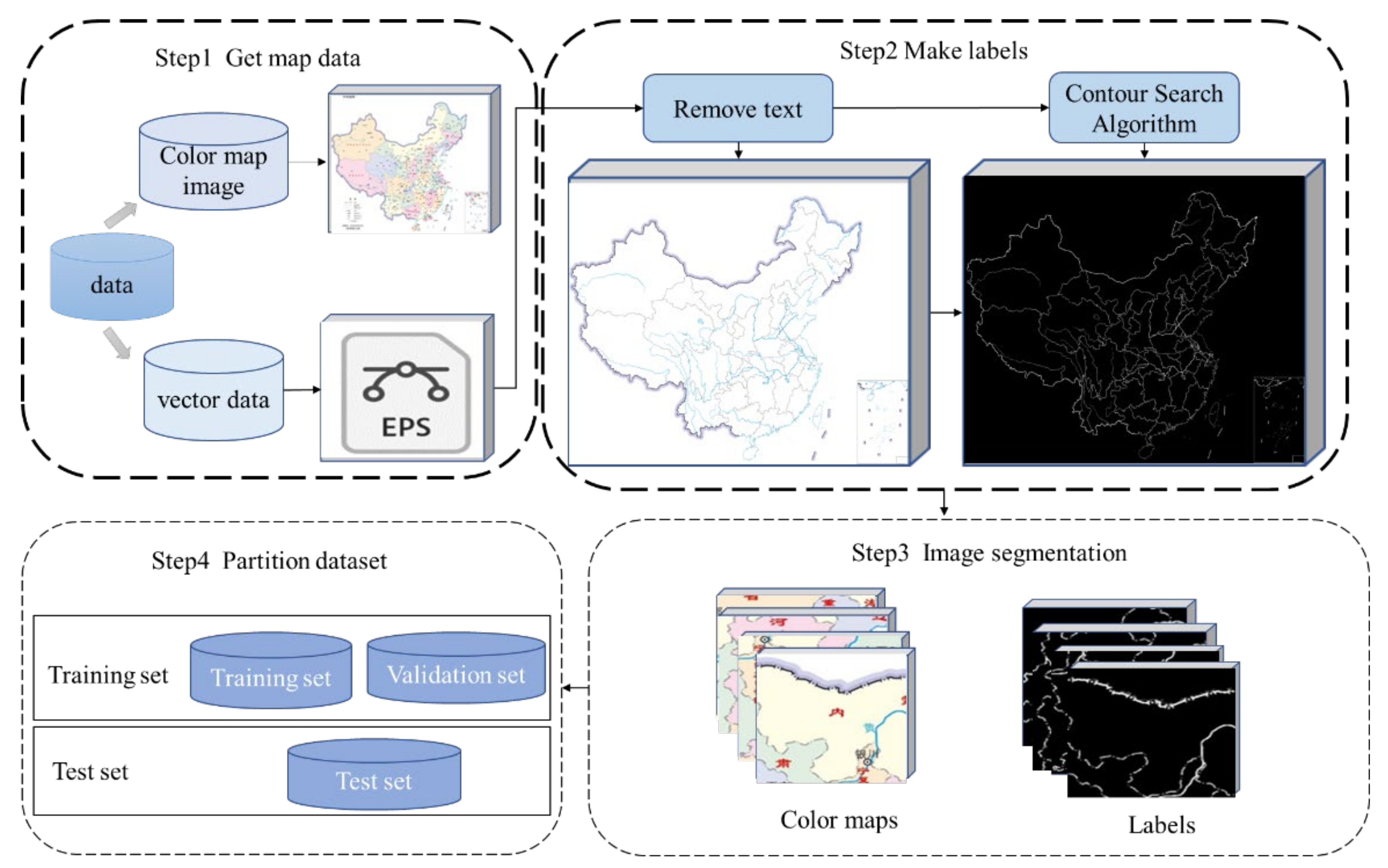
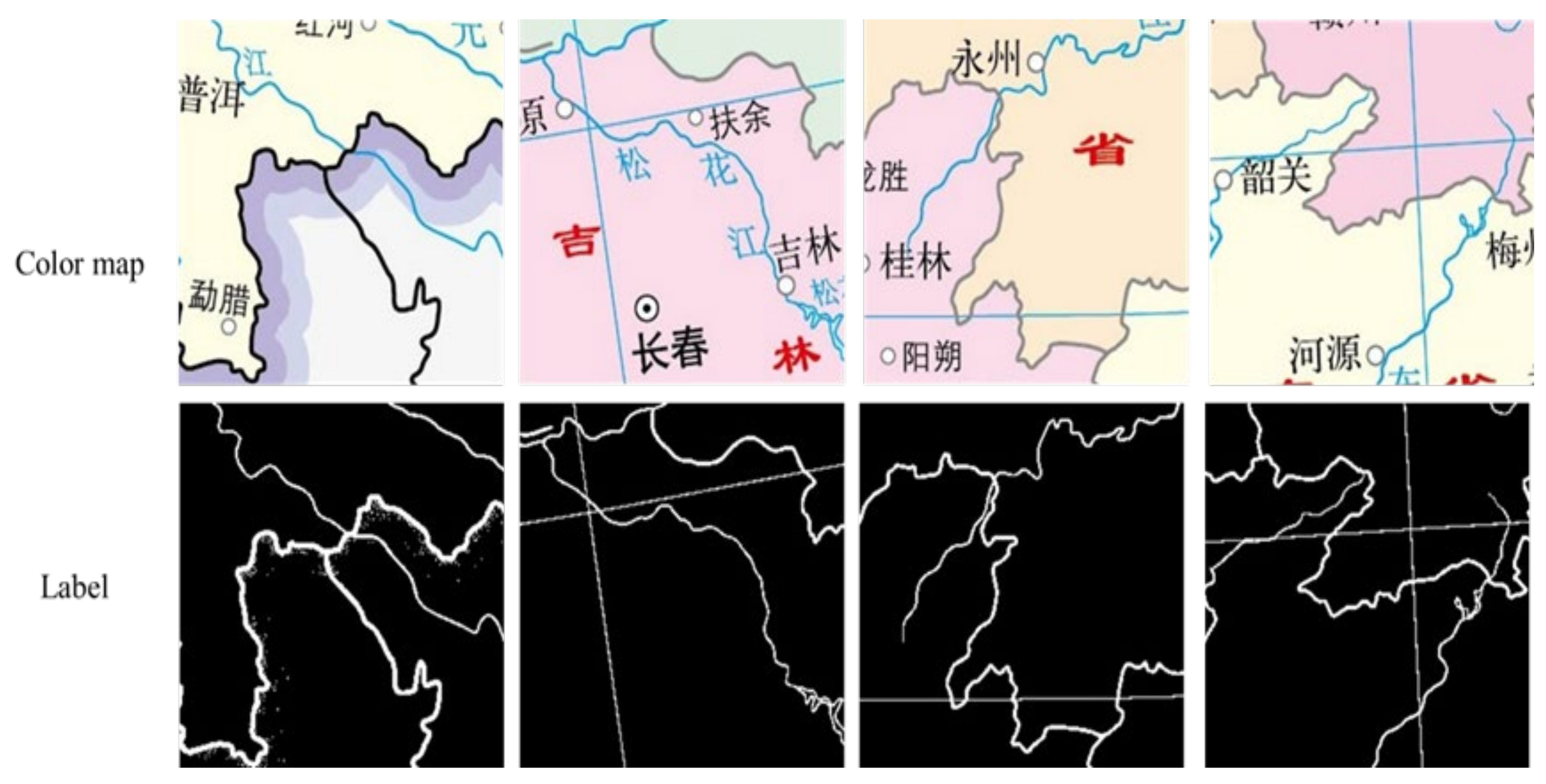
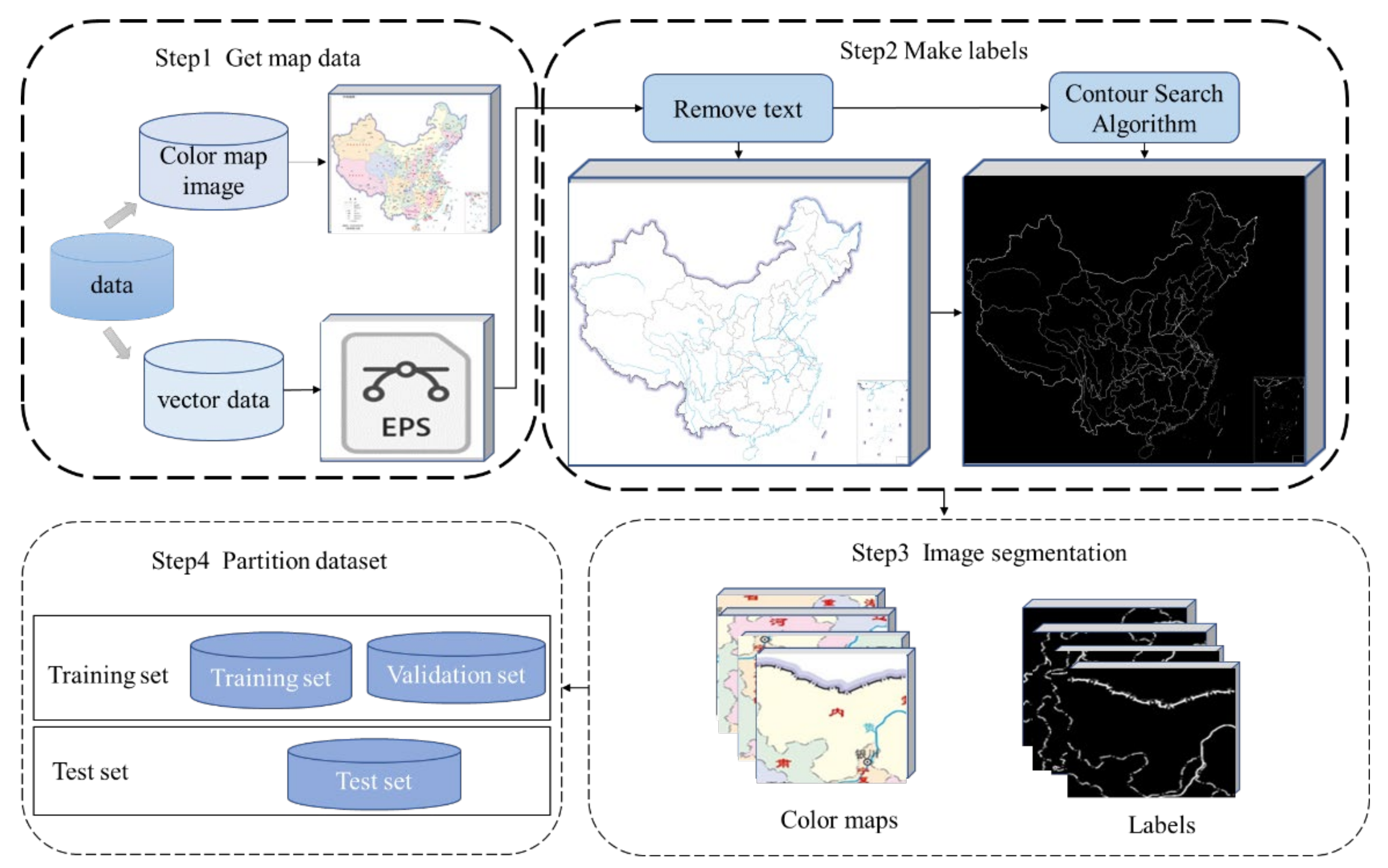
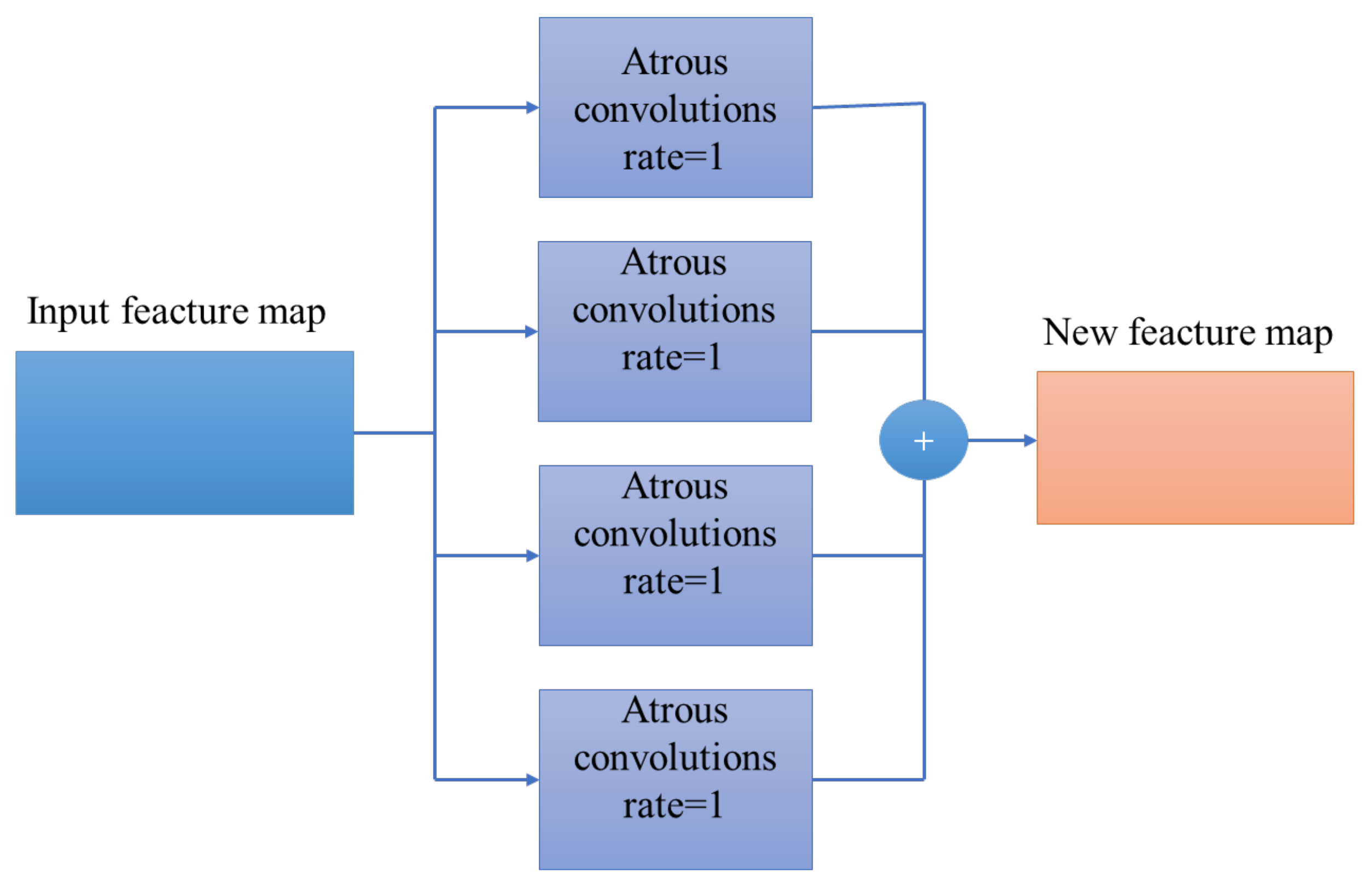
To solve the problems existing in line feature extraction of scanned maps, we constructed test and training datasets based on a raster map. Based on the original U-Net network model, the AG and ASPP modules were added, and an improved U-Net deep network model was proposed to realize the automatic extraction of raster map line features.
4. Discussion
Maps store valuable information documenting human activities and natural features on Earth over long periods of time. Understanding how to make full use of the data information in maps has become a difficult point in research. Due to the complexity of map images compared with general images, various elements on maps are interlaced and overlapped, which increases the complexity of map elements’ extraction. Much existing research on maps is aimed at the recognition or detection of symbols on maps [
7,
9,
16,
23], such as identifying urban districts, hotels, and architectural markers on a map. The recognition and extraction of map line features are mostly based on traditional algorithms.
There are two major challenges in applying semantic segmentation CNNs to maps for automatically extracting geographic features. The first challenge is generating accurate object boundaries, which is still an open research topic in semantic segmentation. The second challenge is that semantic segmentation models trained with the publicly available labeled datasets do not work well for maps without a sufficient amount of labeled training data from map scans. To fully take advantage of the valuable content in historical map series, advanced semantic segmentation methods that can handle small objects and extract precise boundaries still need to be developed.
The model for extracting geographic line features trained in this paper has certain limitations. Since the dataset used in training the model is relatively simple, there is no adequate generalization for maps with different characters in different countries and languages. To make the model more generalized, it is necessary to enrich the types of map samples in the training set. Overall, the sample size of the current dataset is not large enough to apply the model to more kinds of maps.
5. Conclusions
In this paper, we introduced ASPP and AG modules into the traditional U-Net network, constructed the sample set of map line feature extraction, and proposed an improved U-Net network model for scanning map line feature extraction. The AG module increased the weight of line feature extraction and reduced the interference of background text. The ASPP module was used to extract features of different scales to improve the segmentation effect. Through comparative analysis of experiments designed with different network depths, network modules, and robustness testing, our conclusions are as follows:
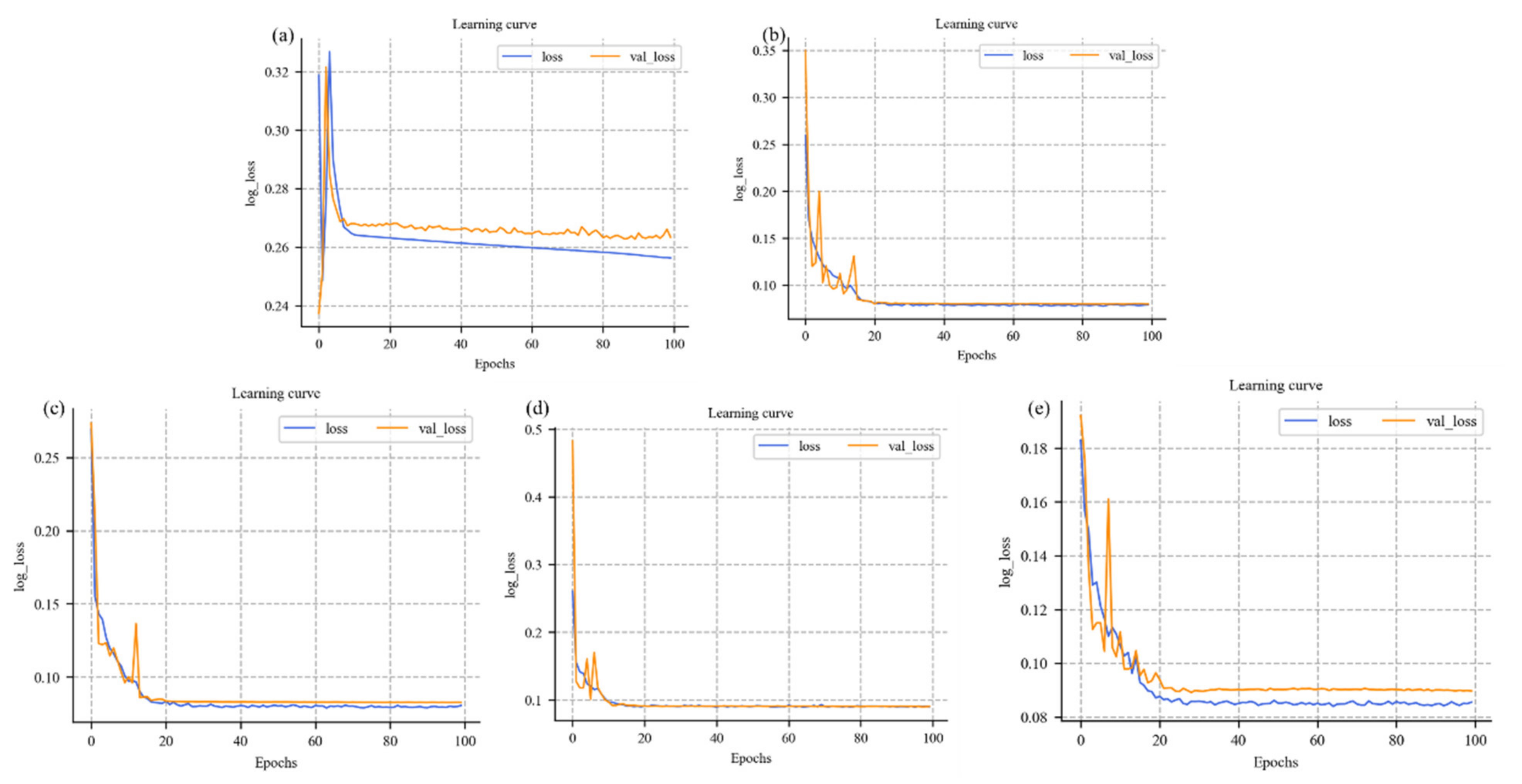
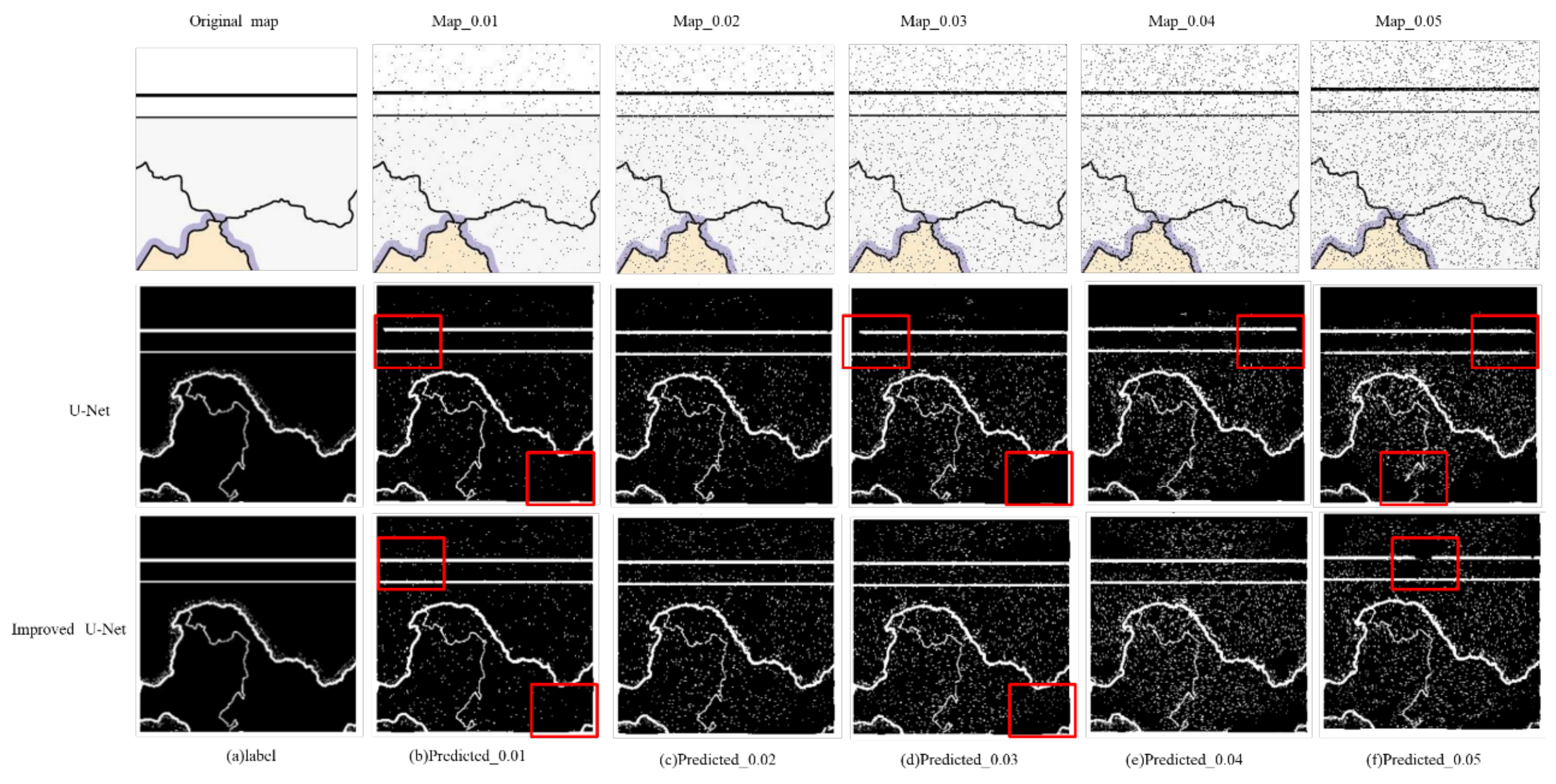
The improved U-Net network we proposed achieved the accurate automatic extraction of grid map line features, and the DSC accuracy of the extraction results reached 93.3%. Compared with the traditional U-Net network model, the DSC was increased by 7.1%, the accuracy was increased by 6.39%, and the recall rate was increased by 8.16%. In the presence of noise, when the SNR was 0.01, the accuracy of DSC was improved by 17.05%. When the SNR was 0.02, DSC increased by 15.11%. When the SNR was 0.03, DSC increased by 14.41%. When the SNR was 0.04, DSC increased by 13.18%. When the SNR was 0.05, DSC increased by 14.55%.
The improved U-Net network proposed here had better anti-noise ability and better robustness in raster map line feature extraction than the traditional U-Net network, indicating its superior extensibility.
In this work, we achieved automatic extraction of raster map line features based on the deep learning method. However, due to the limitations of data sources and the heavy workload of manual vectorization of maps, the map styles and types in the sample dataset created in this paper are slightly monotonous. The network model proposed in this paper must be further tested and improved for more line feature extraction sample sets in the future.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}