
Associative Analysis of Inefficiencies and Station Activity Levels in Emergency Response


Abstract
:1. Introduction
2. Related Work
3. Research Methodology
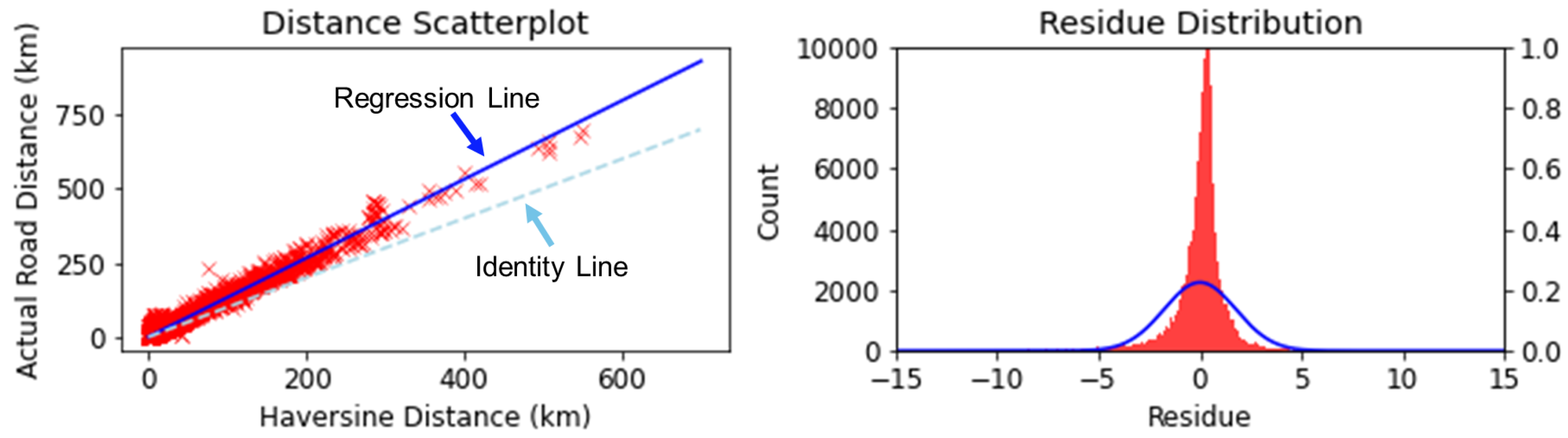
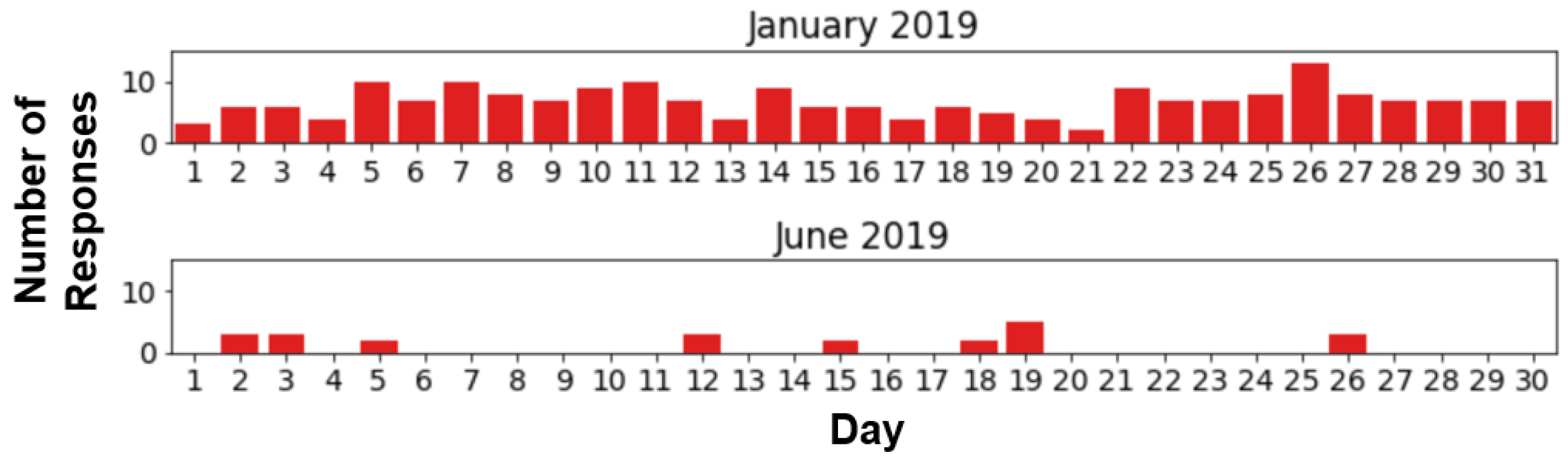
3.1. Portuguese Emergency Response Dataset
3.2. Task Description
- a set of stations S from which response vehicles are dispatched, where each station has a fixed location;
- a set of vehicles V, where each vehicle belongs to a well-established category (e.g., vehicles with basic versus advanced life support), is assigned to a base station , and is uniquely identified;
- a set of medical emergency response records E. Each response in E contains information about the time and location of its occurrence, as well as the station that responded to it. The responding vehicle is one of the vehicles stationed in s.
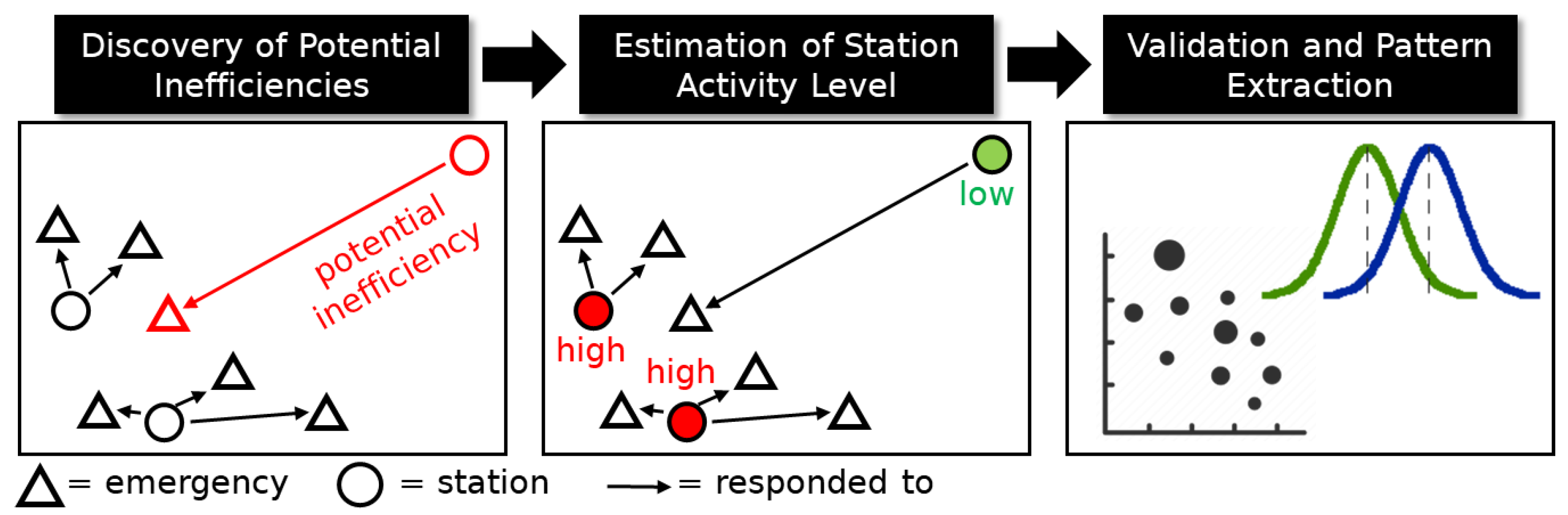
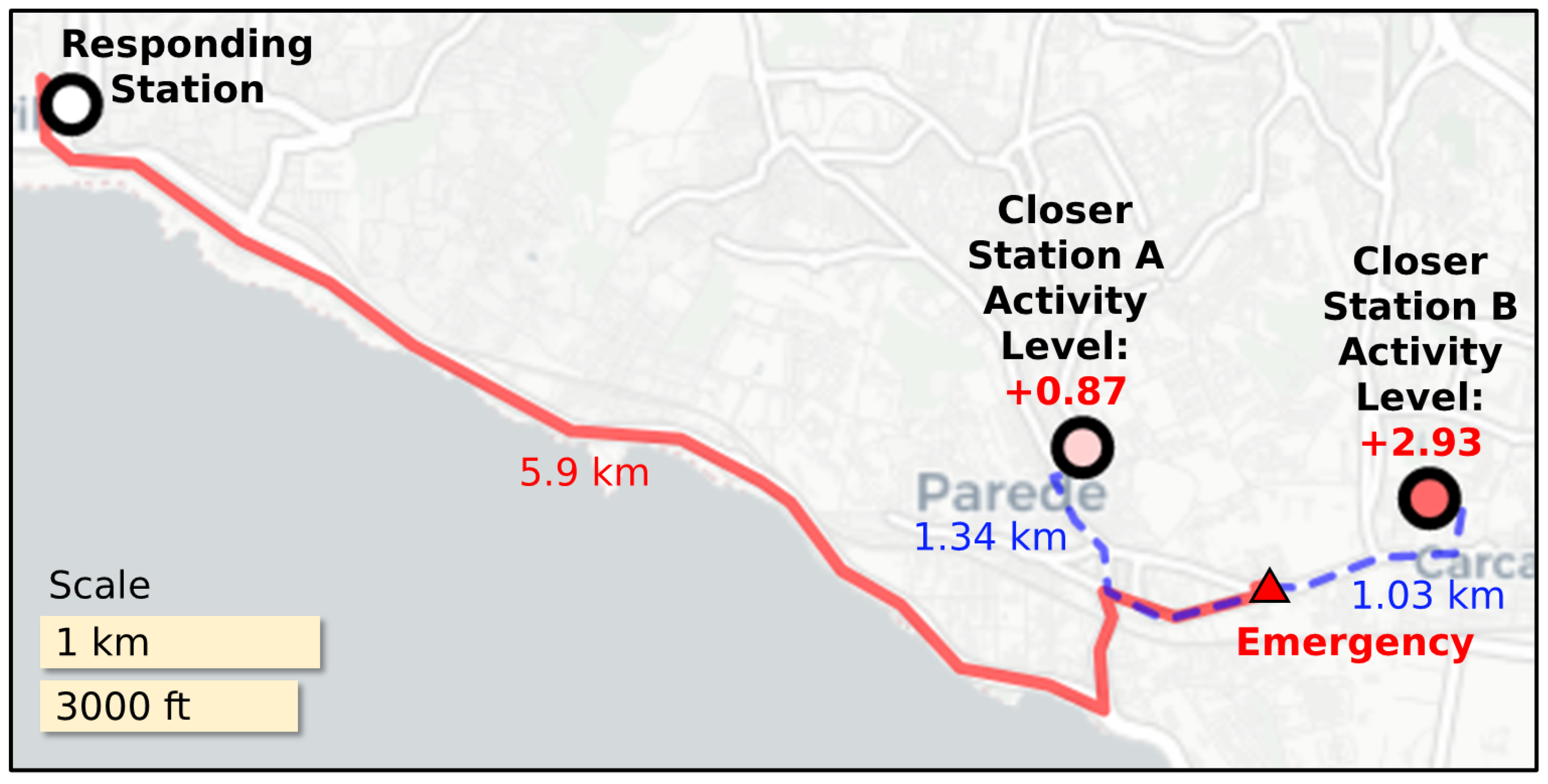
- How correlated are potential inefficiencies with the activity levels of closer stations?
- Are there specific areas or days in which potential inefficiencies occurred often?
- Can stations be profiled according to their activity level to promote actionability?
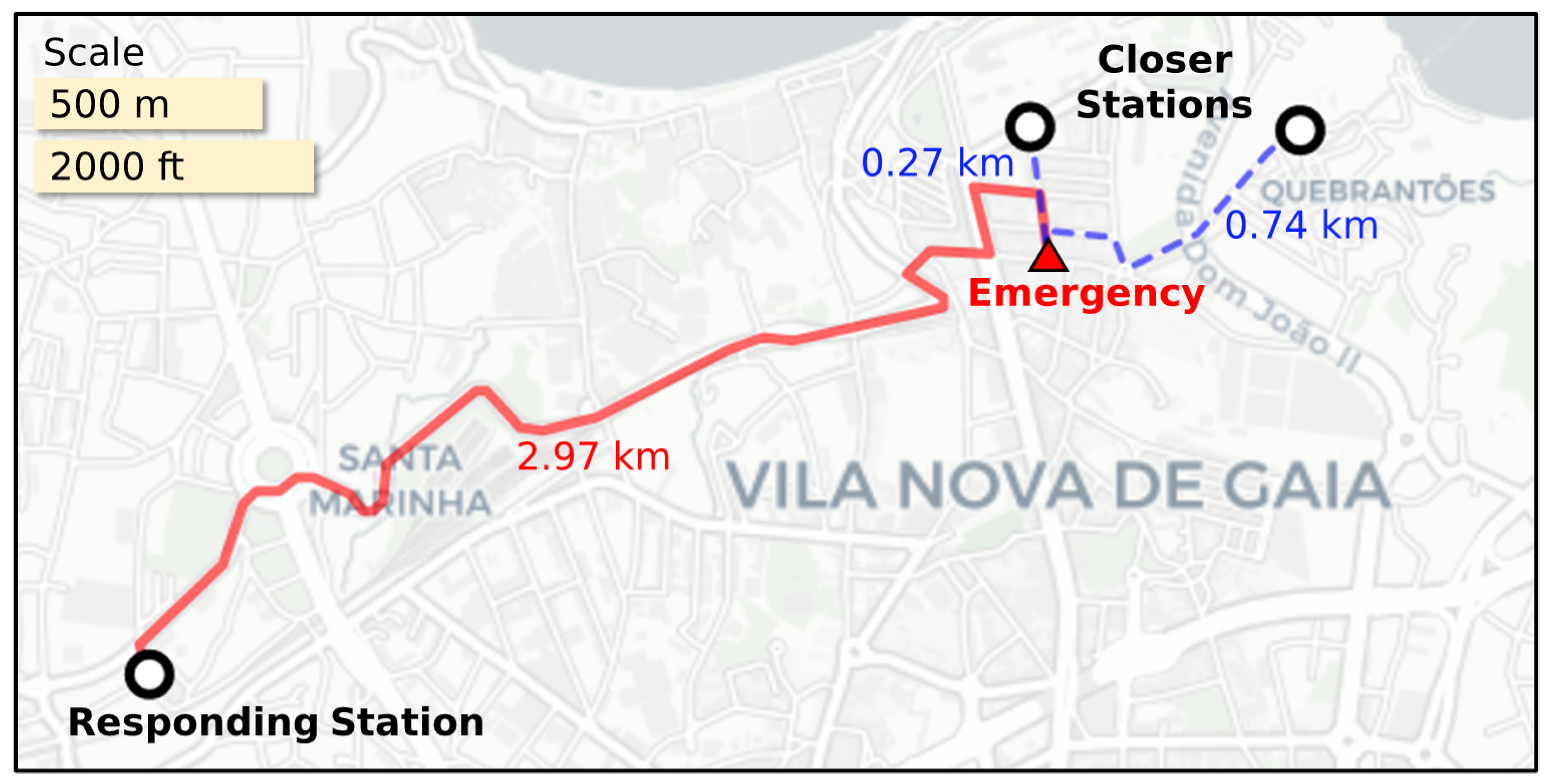
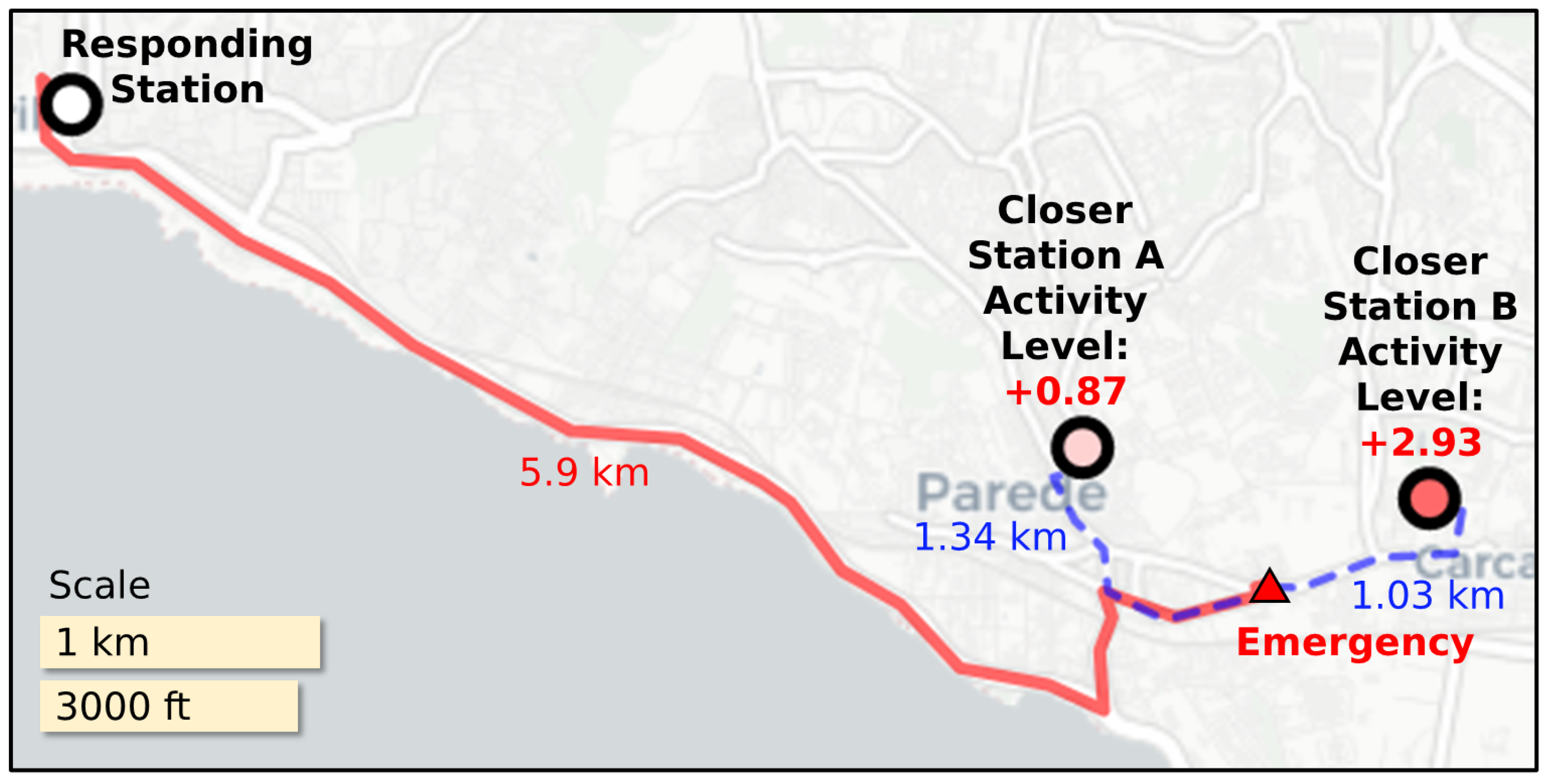
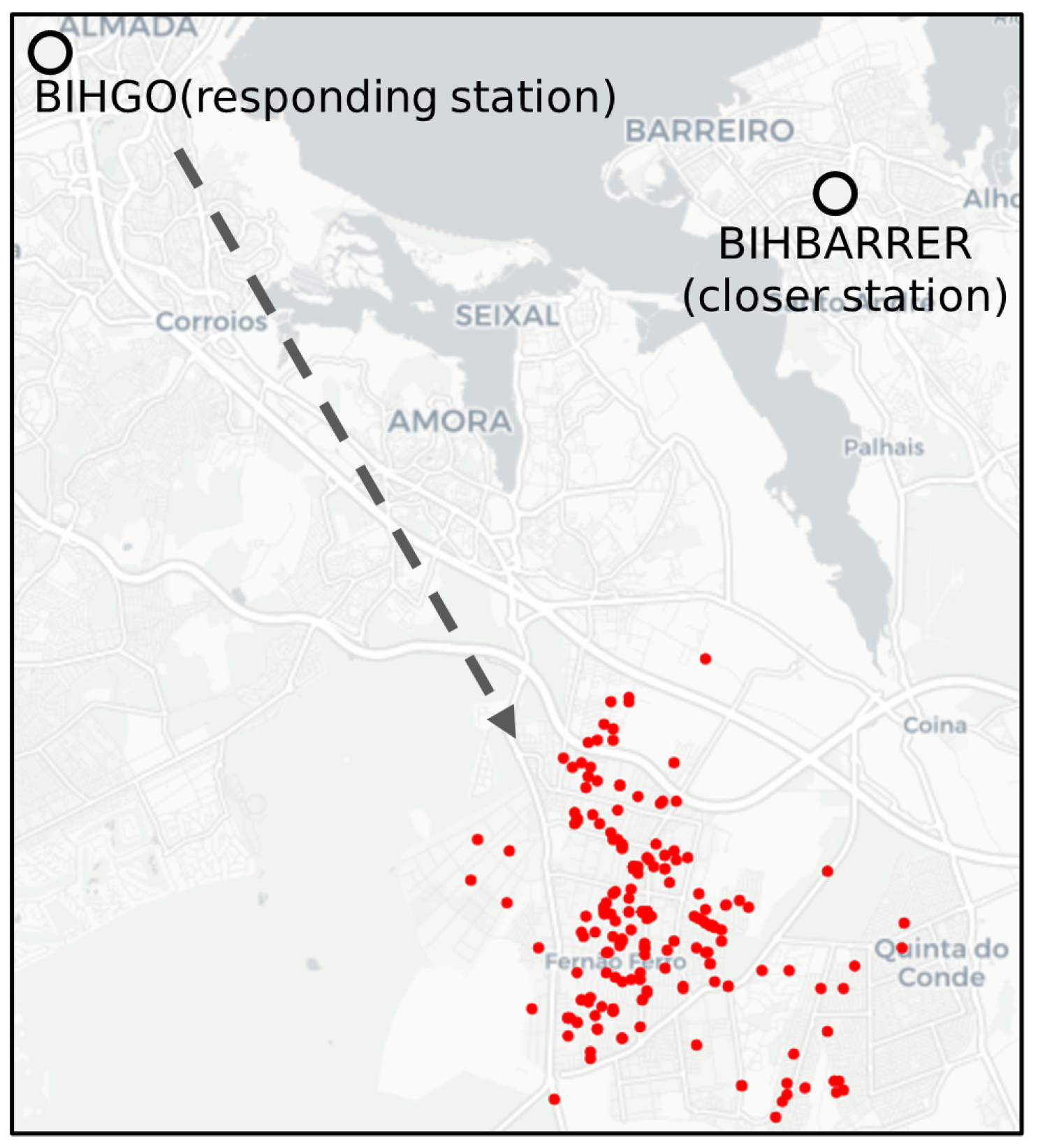
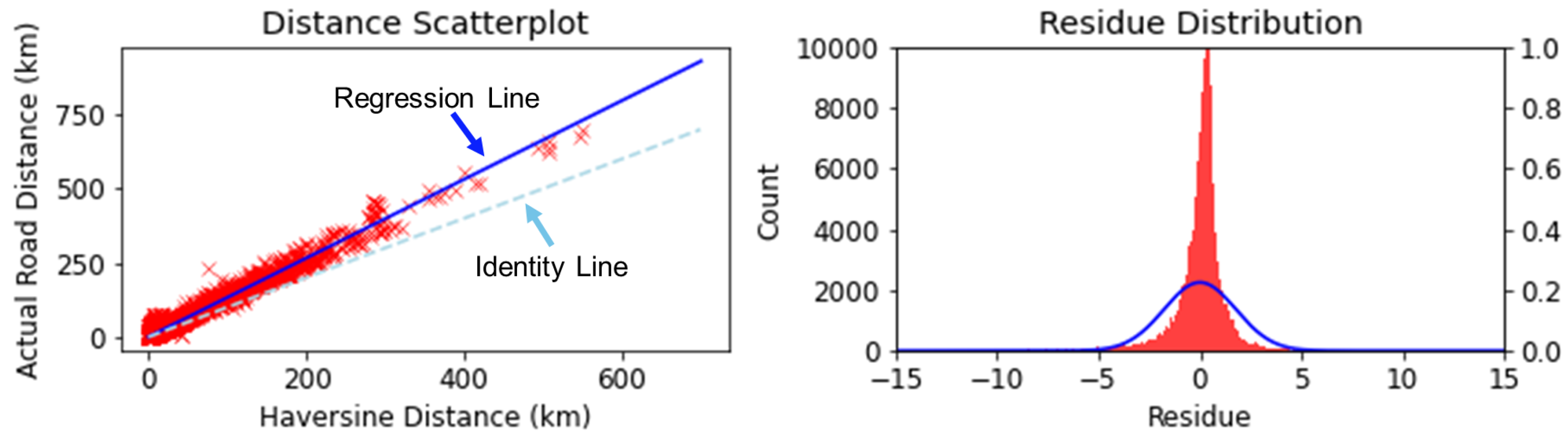
3.3. Discovery and Analysis of Potential Inefficiencies
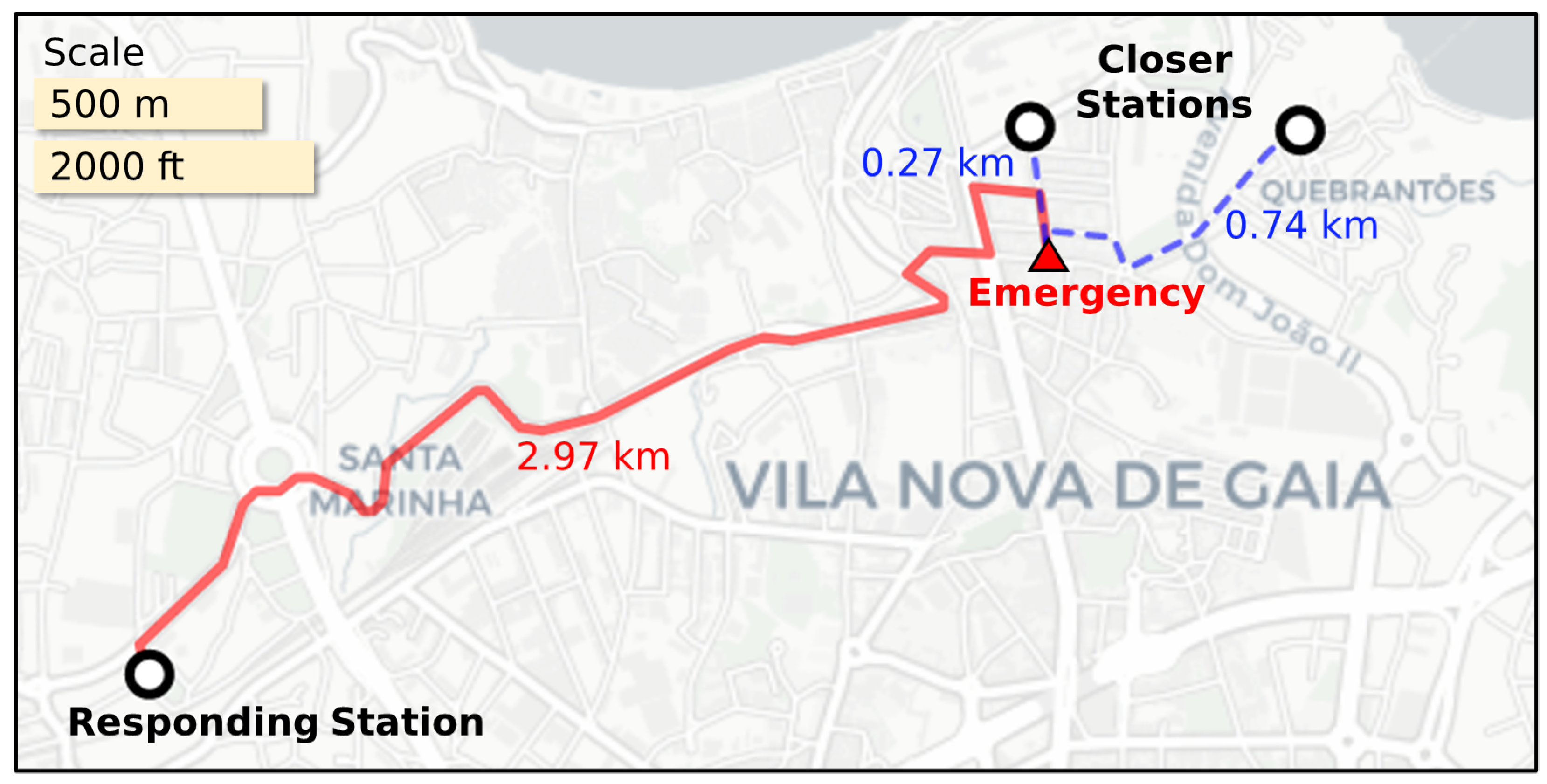
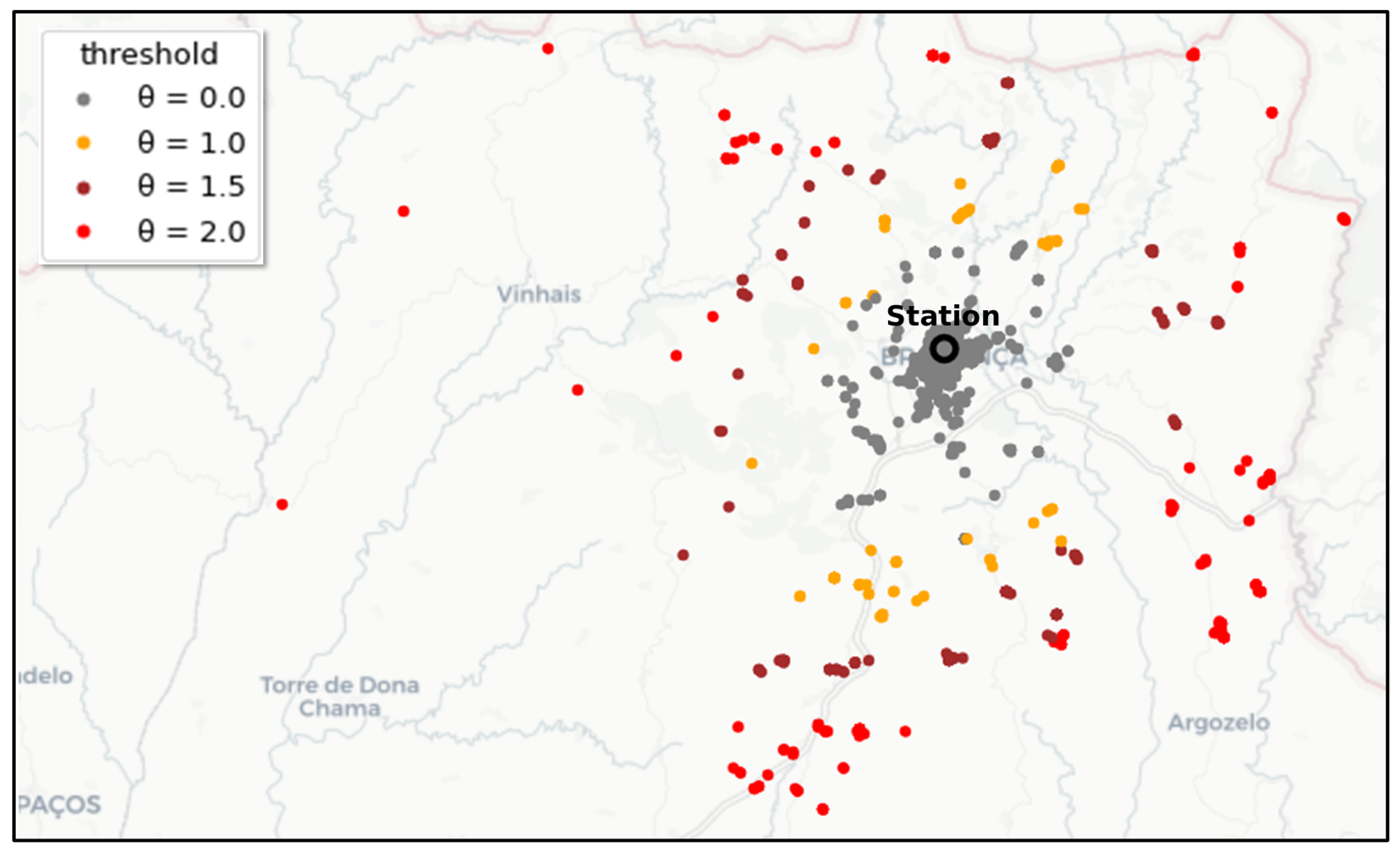
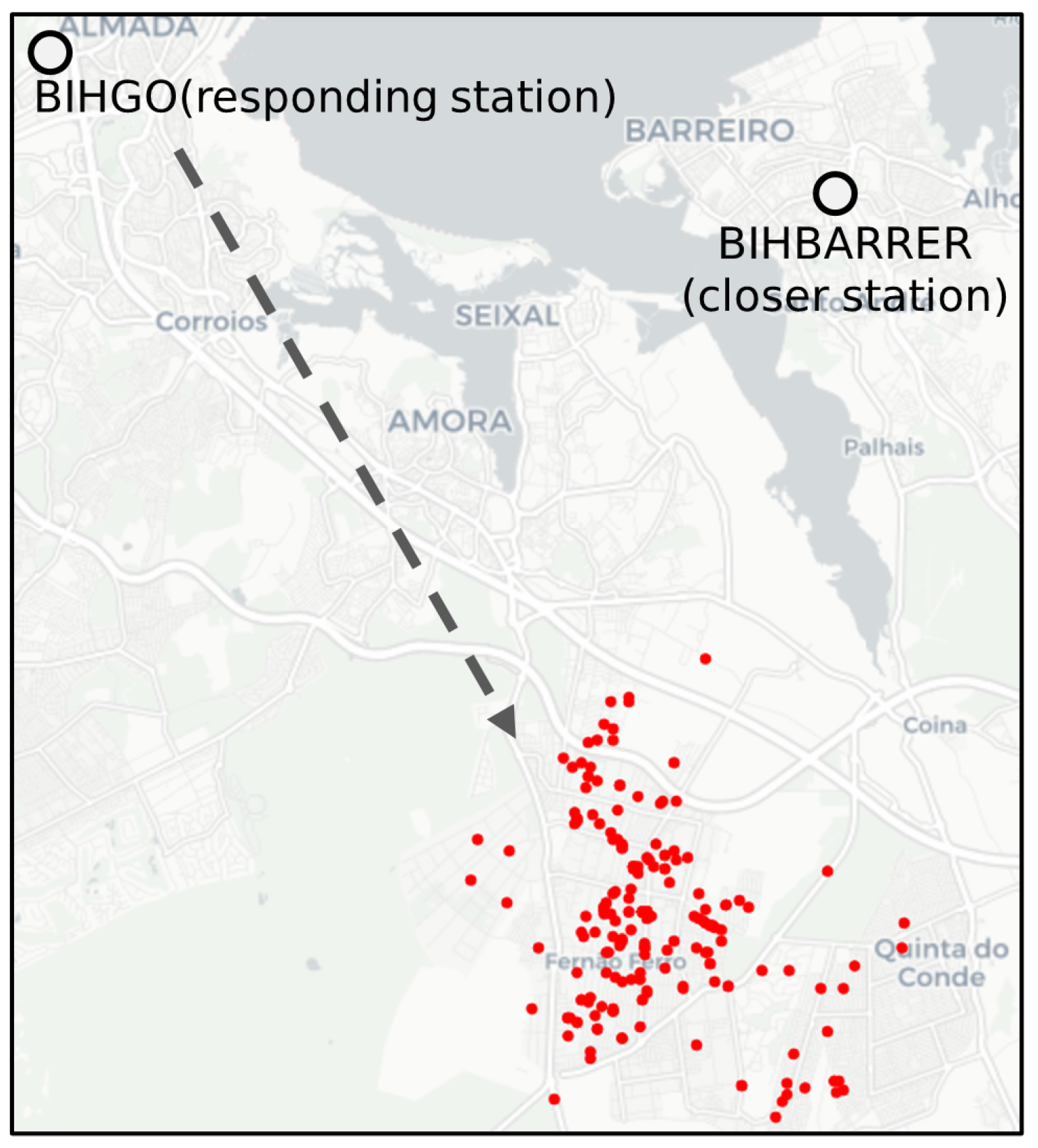
3.3.1. Identification of Potential Inefficiencies
| Algorithm 1 Potential inefficiencies identification algorithm |
|
Input: : emergencies, : stations, : threshold Output: list of potential inefficiencies
|
3.3.2. Estimation of Station Activity Level
| Algorithm 2 Activity level estimation algorithm |
| Input:: stations, : dates, : timestamps, : time span length, : window length Output: Activity level of each station
|
3.3.3. Validation and Analysis
4. Results and Discussion
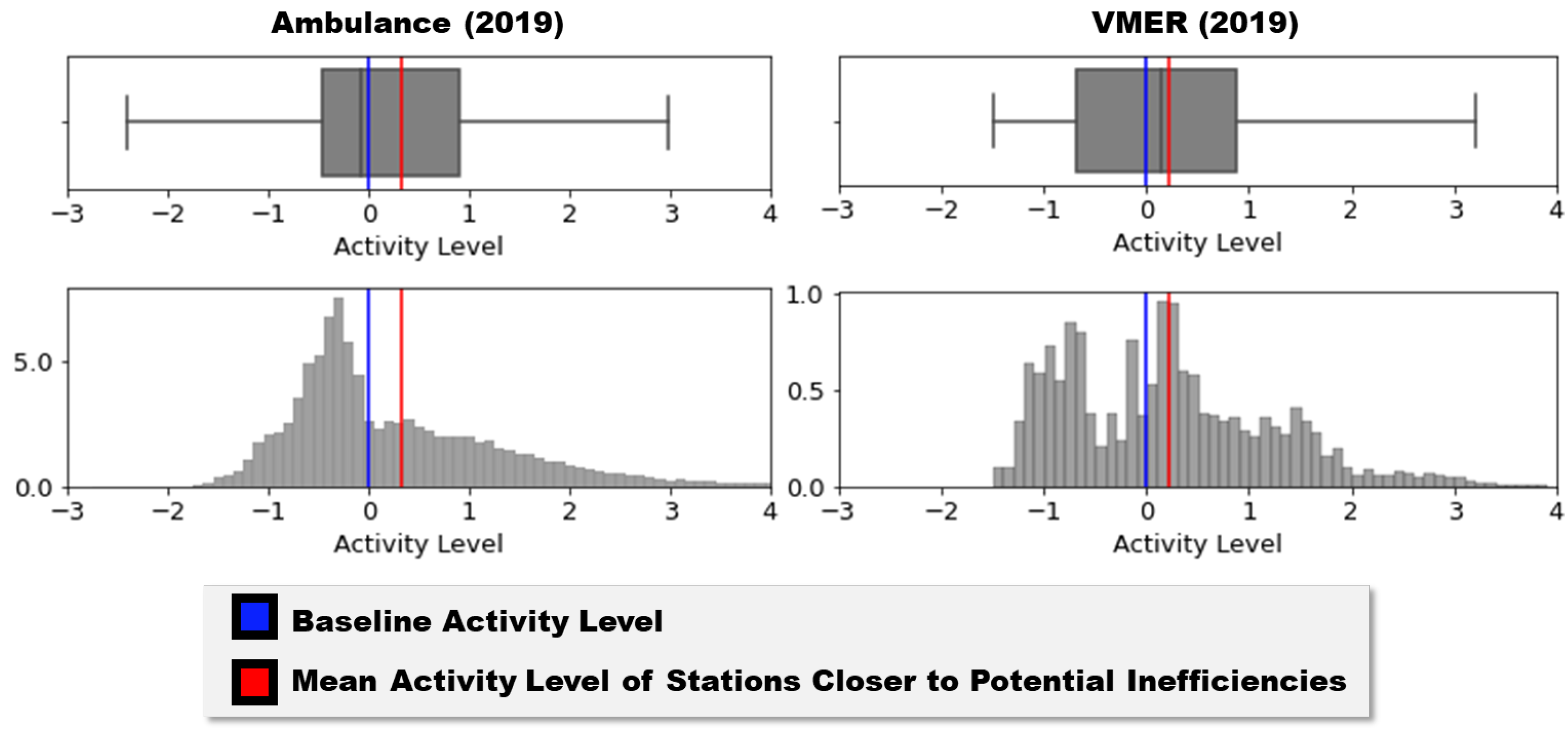
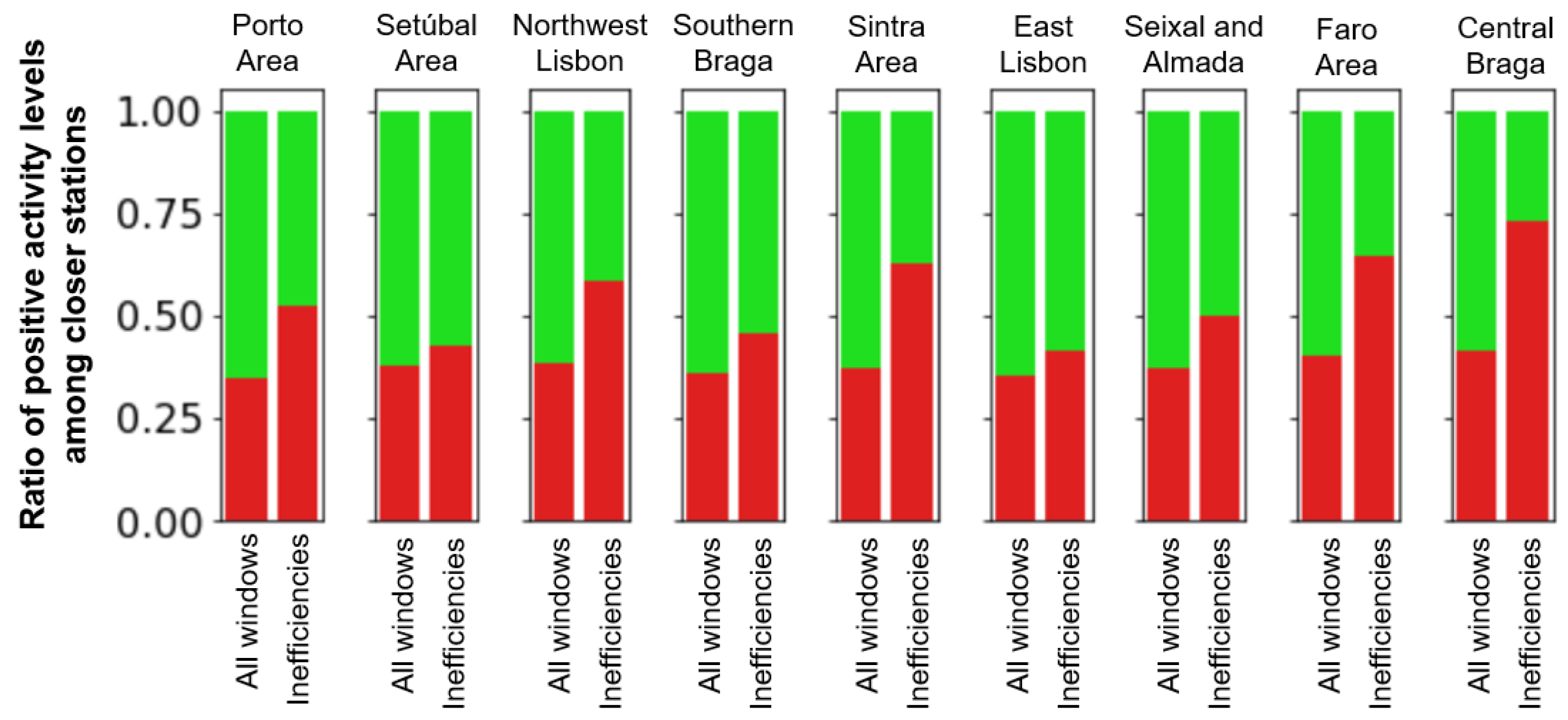
4.1. RQ1: How Correlated Are Potential Inefficiencies with Activity Levels of Closer Stations?
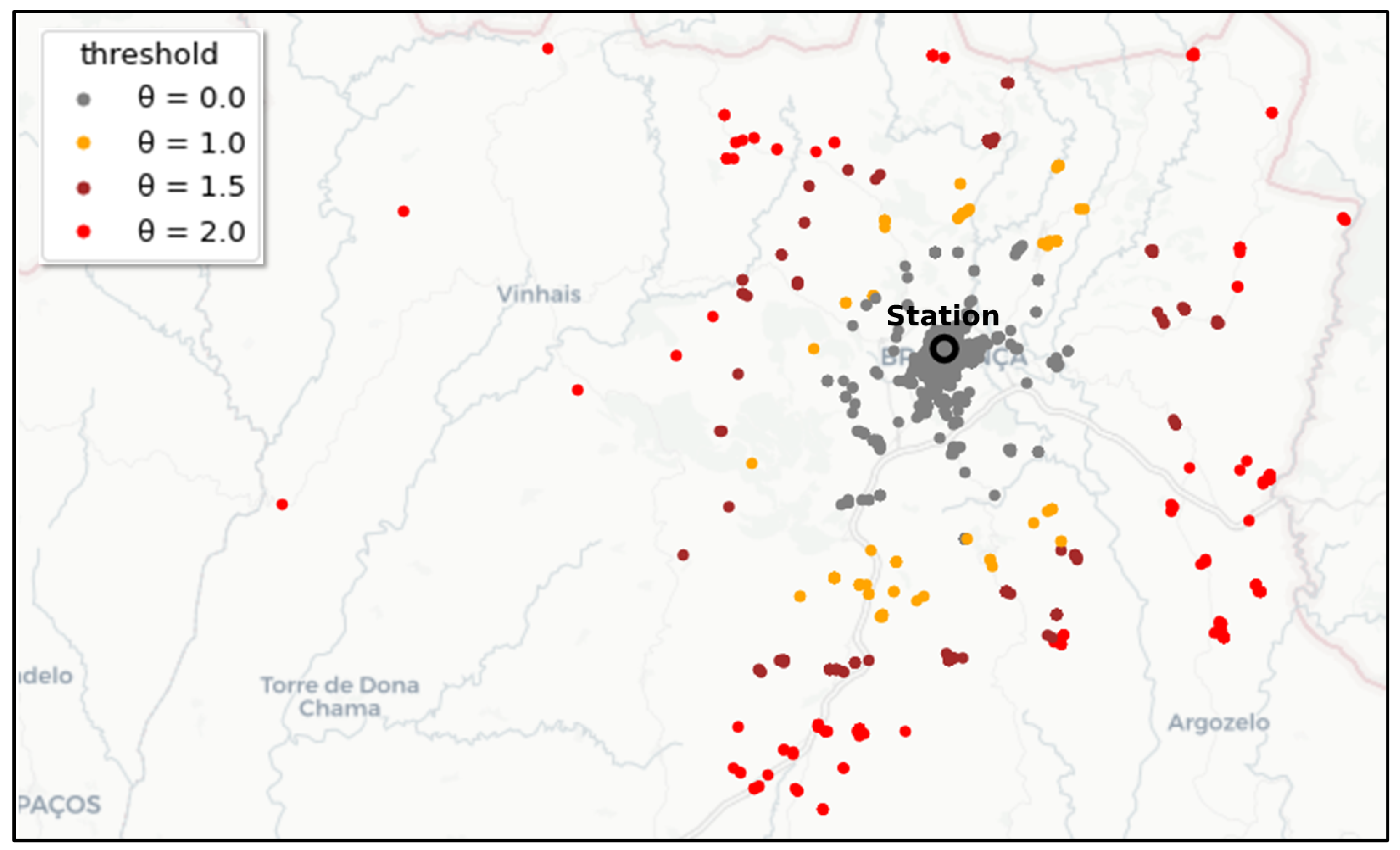
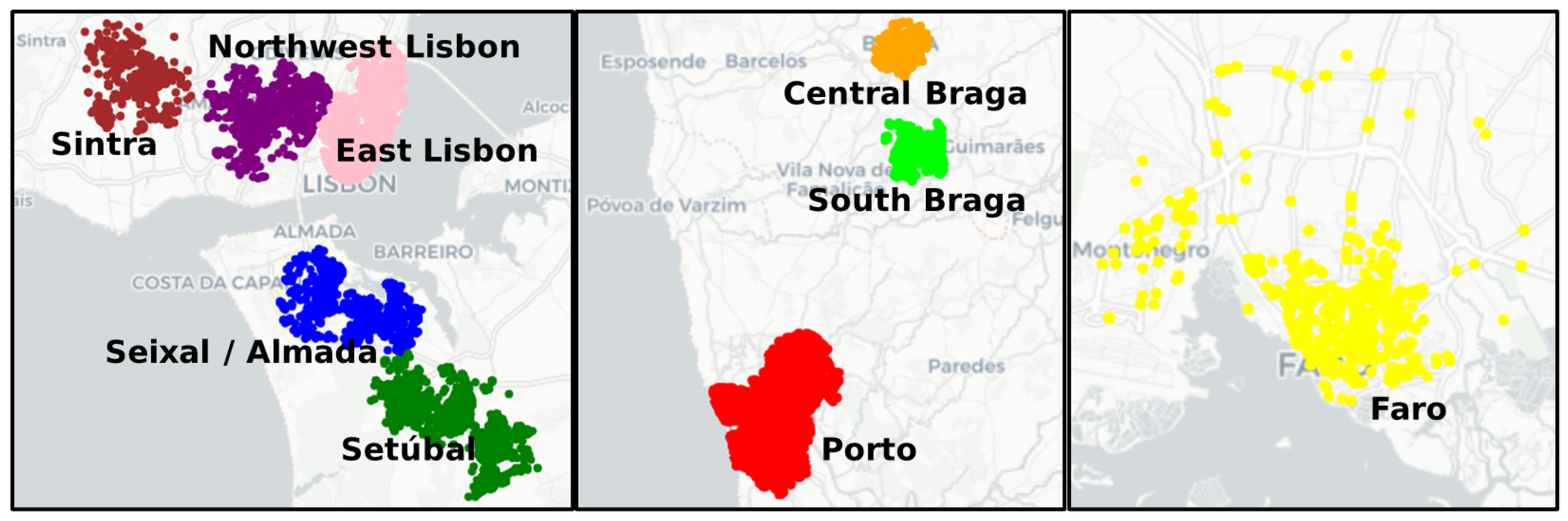
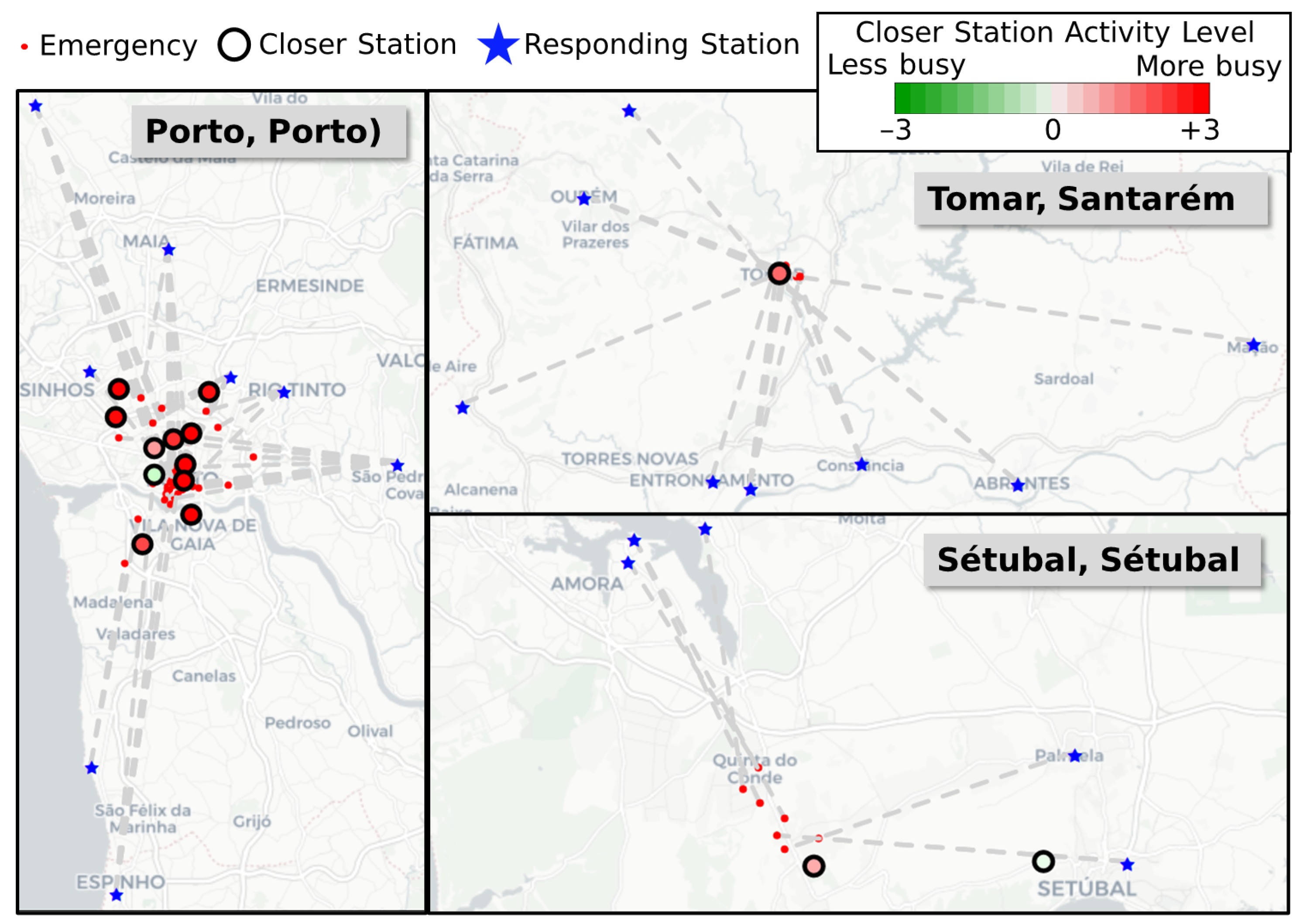
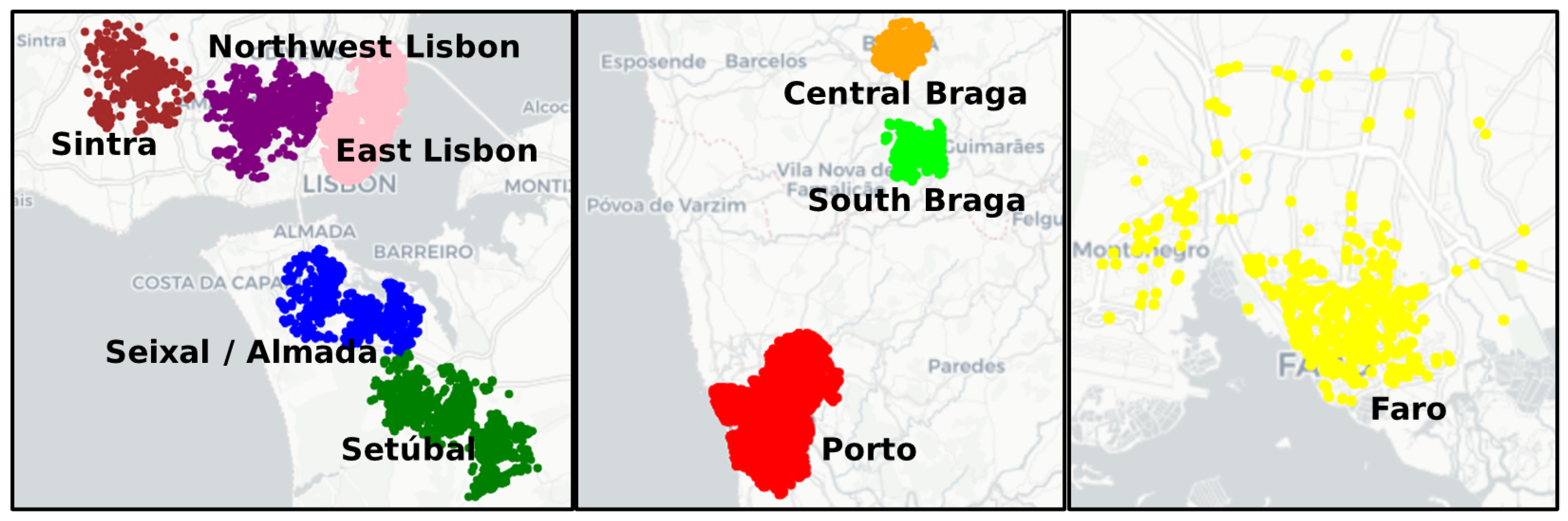
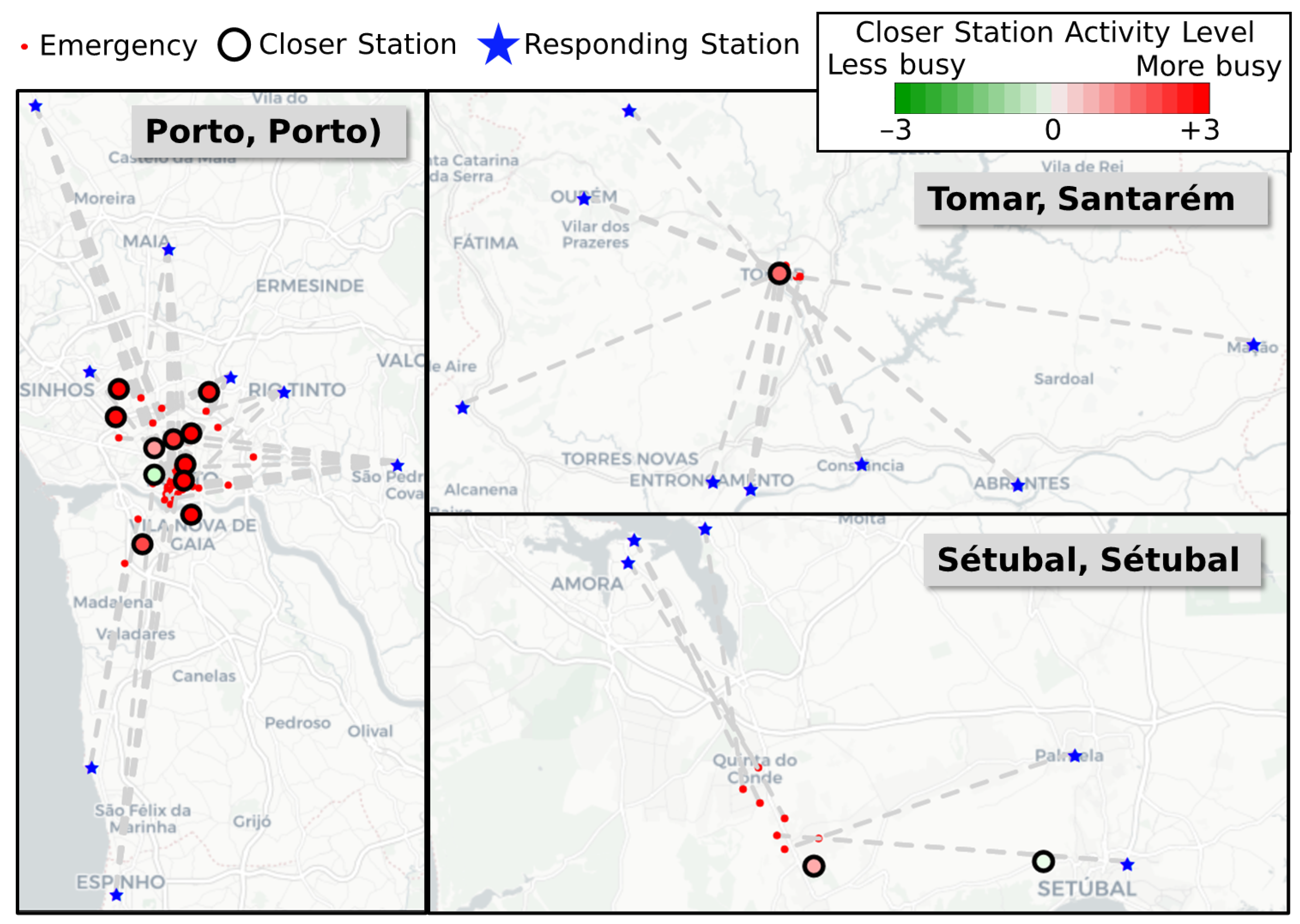
4.2. RQ2: Are There Specific Areas or Days in Which Potential Inefficiencies Occurred Often?
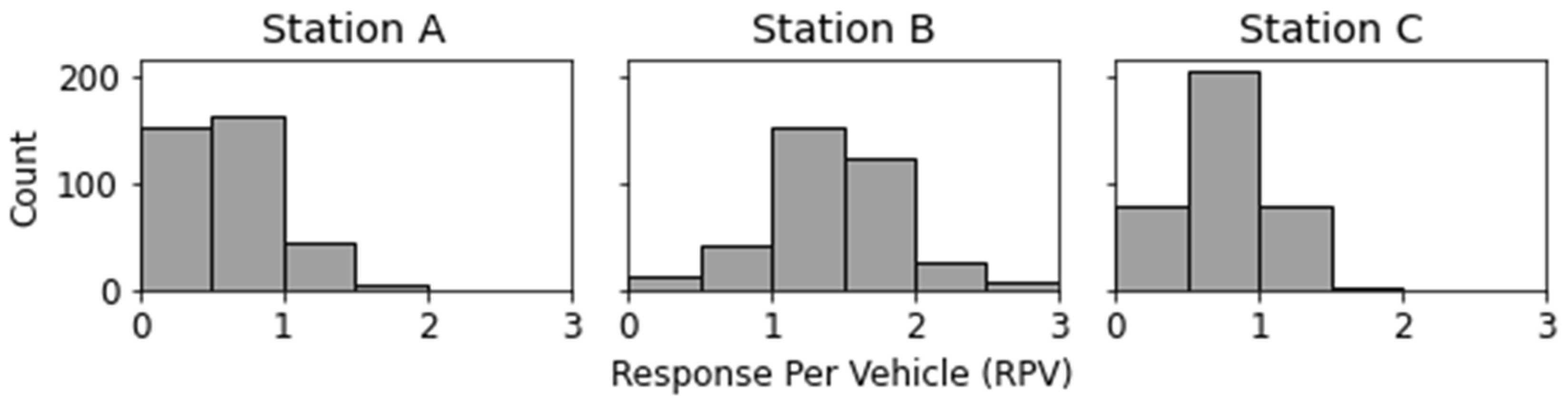
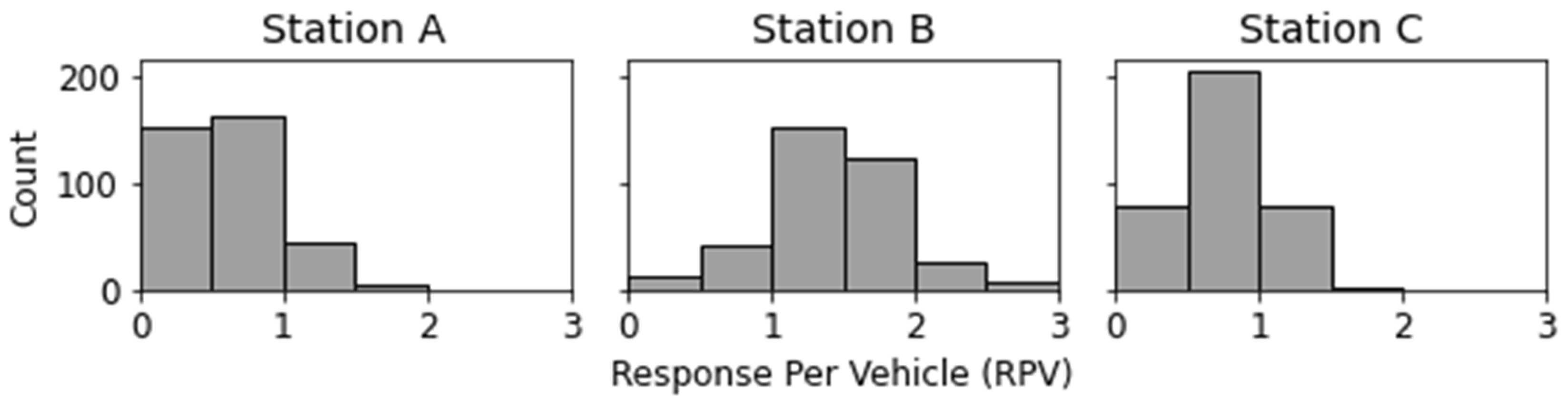
4.3. RQ3: Can Stations Be Profiled According to Their Activity Level to Promote Actionability?
5. Conclusions
- 1.
- We introduce a robust and efficient approach for the identification of potential inefficiencies in emergency response data that is sensitive to differences in the areas of coverage of stations. A tool, DAPI, is made available to this end.
- 2.
- Furthermore, said approach is able to perform statistical analysis on response bottlenecks in relation to station activity levels with the aim of assessing potential causes. DAPI is able to perform this assessment in the presence of spatiotemporal dispatch information only, thus being applicable to EMS systems with minimal records of historical emergency data.
- 3.
- We offer the possibility of visualizing potential inefficiencies in interactive maps under a parameterizable spatiotemporal footprint. DAPI integrates these graphical facilities with guarantees of statistical significance, serving as a valuable decision support tool for EMS stakeholders.
- –
- The majority of potential inefficiencies are significantly correlated with high activity levels among closer stations for both ambulance and VMER data across different years.
- –
- Potential inefficiencies appear to be geographically located according to dense clusters. Some clusters show evidence of a correlation between potential inefficiencies and high activity levels, while some clusters do not, suggesting that inefficiencies are associated with some unknown factors.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sheu, J.B. A novel dynamic resource allocation model for demand-responsive city logistics distribution operations. Transp. Res. Part Logist. Transp. Rev. 2006, 42, 445–472. [Google Scholar] [CrossRef]
- Aminzadegan, S.; Tamannaei, M.; Fazeli, M. An integrated production and transportation scheduling problem with order acceptance and resource allocation decisions. Appl. Soft Comput. 2021, 112, 107770. [Google Scholar] [CrossRef]
- Araújo, A.; Cacho, N.; Bezerra, L.; Vieira, C.; Borges, J. Towards a crime hotspot detection framework for patrol planning. In Proceedings of the 2018 IEEE 20th International Conference on High Performance Computing and Communications, Exeter, UK, 28–30 June 2018; pp. 1256–1263. [Google Scholar]
- Mukhopadhyay, A.; Pettet, G.; Vazirizade, S.M.; Lu, D.; Jaimes, A.; El Said, S.; Baroud, H.; Vorobeychik, Y.; Kochenderfer, M.; Dubey, A. A review of incident prediction, resource allocation, and dispatch models for emergency management. Accid. Anal. Prev. 2022, 165, 106501. [Google Scholar] [CrossRef] [PubMed]
- Rathore, M.M.; Ahmad, A.; Paul, A.; Wan, J.; Zhang, D. Real-time medical emergency response system: Exploiting IoT and big data for public health. J. Med. Syst. 2016, 40, 283. [Google Scholar] [CrossRef] [PubMed]
- Yu, D.; Yin, J.; Wilby, R.L.; Lane, S.N.; Aerts, J.C.; Lin, N.; Liu, M.; Yuan, H.; Chen, J.; Prudhomme, C.; et al. Disruption of emergency response to vulnerable populations during floods. Nat. Sustain. 2020, 3, 728–736. [Google Scholar] [CrossRef]
- Carlson, J.N.; Karns, C.; Mann, N.C.; E. Jacobson, K.; Dai, M.; Colleran, C.; Wang, H.E. Procedures performed by emergency medical services in the United States. Prehospital Emerg. Care 2016, 20, 15–21. [Google Scholar] [CrossRef]
- Henderson, S.G.; Mason, A.J. Ambulance service planning: Simulation and data visualisation. In Operations Research and Health Care; Springer: Berlin/Heidelberg, Germany, 2005; pp. 77–102. [Google Scholar]
- Boutilier, J.J.; Chan, T.C. Ambulance emergency response optimization in developing countries. Oper. Res. 2020, 68, 1315–1334. [Google Scholar] [CrossRef]
- Ferrari, T.; Camara, M.V.O.; Nassi, C.D.; Ribeiro, G.M.; Costa Junior, R.R.; Ribeiro Junior, C.; Bilate, A. Analysis of the location of rescue ambulance dispatch bases: A case study in Rio de Janeiro, Brazil. Geogr. Anal. 2018, 50, 397–421. [Google Scholar] [CrossRef]
- Brotcorne, L.; Laporte, G.; Semet, F. Ambulance location and relocation models. Eur. J. Oper. Res. 2003, 147, 451–463. [Google Scholar] [CrossRef]
- Talarico, L.; Meisel, F.; Sorensen, K. Ambulance routing for disaster response with patient groups. Comput. Oper. Res. 2015, 56, 120–133. [Google Scholar] [CrossRef] [Green Version]
- Tassone, J.; Choudhury, S. A comprehensive survey on the ambulance routing and location problems. arXiv 2020, arXiv:1603.00278. [Google Scholar]
- Bish, D.R.; Agca, E.; Glick, R. Decision support for hospital evacuation and emergency response. Ann. Oper. Res. 2014, 221, 89–106. [Google Scholar] [CrossRef]
- Yazdani, M.; Mojtahedi, M.; Loosemore, M.; Sanderson, D.; Dixit, V. Hospital evacuation modelling: A critical literature review on current knowledge and research gaps. Int. J. Disaster Risk Reduct. 2021, 66, 102627. [Google Scholar] [CrossRef]
- Wang, D.; Guo, D.; Zhang, H. Spatial temporal data visualization in emergency management: A view from data-driven decision. In Proceedings of the 3rd ACM SIGSPATIAL Workshop on Emergency Management using, Beach, CA, USA, 7–10 November 2017; pp. 1–7. [Google Scholar]
- Dusse, F.; Júnior, P.S.; Alves, A.T.; Novais, R.; Vieira, V.; Mendonça, M. Information visualization for emergency management: A systematic mapping study. Expert Syst. Appl. 2016, 45, 424–437. [Google Scholar] [CrossRef]
- Aringhieri, R.; Bruni, M.E.; Khodaparasti, S.; van Essen, J.T. Emergency medical services and beyond: Addressing new challenges through a wide literature review. Comput. Oper. Res. 2017, 78, 349–368. [Google Scholar] [CrossRef]
- Sudtachat, K.; Mayorga, M.E.; McLay, L.A. Recommendations for dispatching emergency vehicles under multitiered response via simulation. Int. Trans. Oper. Res. 2014, 21, 581–617. [Google Scholar] [CrossRef]
- Yoon, S.; Albert, L.A. Dynamic dispatch policies for emergency response with multiple types of vehicles. Transp. Res. Part Logist. Transp. Rev. 2021, 152, 102405. [Google Scholar] [CrossRef]
- Budge, S.; Ingolfsson, A.; Erkut, E. Approximating vehicle dispatch probabilities for emergency service systems with location-specific service times and multiple units per location. Oper. Res. 2009, 57, 251–255. [Google Scholar] [CrossRef] [Green Version]
- Tiam-Lee, T.J.Z.; Henriques, R.; Costa, J.; Manquinho, V.M.; Galhardas, H. Consolidation of Massive Medical Emergency Events with Heterogeneous Situational Context Data Sources. In Proceedings of the EDBT/ICDT Workshops, Edinburgh, UK, 29 March–1 April 2022. [Google Scholar]
- Bélanger, V.; Ruiz, A.; Soriano, P. Recent optimization models and trends in location, relocation, and dispatching of emergency medical vehicles. Eur. J. Oper. Res. 2019, 272, 1–23. [Google Scholar] [CrossRef]
- Theeuwes, N.; Houtum, G.J.V.; Zhang, Y. Improving ambulance dispatching with machine learning and simulatio. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Bilbao, Spain, 13–17 September 2021; Springer: Berlin/Heidelberg, Germany; pp. 302–318. [Google Scholar]
- Liu, K.; Li, X.; Zou, C.C.; Huang, H.; Fu, Y. Ambulance Dispatch via Deep Reinforcement Learning. In Proceedings of the 28th International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2020; pp. 123–126. [Google Scholar]
- Rautenstrauss, M.; Martin, L.; Minner, S. Ambulance dispatching during a pandemic: Tradeoffs of categorizing patients and allocating ambulances. Eur. J. Oper. Res. 2021; in press. [Google Scholar]
- Nordin, N.A.M.; Kadir, N.; Zaharudin, Z.A.; Nordin, N.A. An application of the A* algorithm on the ambulance routing. In Proceedings of the 2011 IEEE Colloquium on Humanities, Science and Engineering, Penang, Malaysia, 5–6 December 2011; pp. 855–859. [Google Scholar]
- Repoussis, P.P.; Paraskevopoulos, D.C.; Vazacopoulos, A.; Hupert, N. Optimizing emergency preparedness and resource utilization in mass-casualty incidents. Eur. J. Oper. Res. 2016, 255, 531–544. [Google Scholar] [CrossRef] [Green Version]
- Tlili, T.; Harzi, M.; Krichen, S. Swarm-based approach for solving the ambulance routing problem. Procedia Comput. Sci. 2017, 112, 350–357. [Google Scholar] [CrossRef]
- Yazdani, M.; Mojtahedi, M.; Loosemore, M.; Sanderson, D. A modelling framework to design an evacuation support system for healthcare infrastructures in response to major flood events. Prog. Disaster Sci. 2022, 13, 100218. [Google Scholar] [CrossRef]
- Yazdani, M.; Mojtahedi, M.; Loosemore, M. Enhancing evacuation response to extreme weather disasters using public transportation systems: A novel simheuristic approach. J. Comput. Des. Eng. 2020, 7, 195–210. [Google Scholar] [CrossRef]
- Rambha, T.; Nozick, L.K.; Davidson, R.; Yi, W.; Yang, K. A stochastic optimization model for staged hospital evacuation during hurricanes. Transp. Res. Part Logist. Transp. Rev. 2021, 151, 102321. [Google Scholar] [CrossRef]
- Kim, K.Y.; Kutanoglu, E.; Hasenbein, J.J.; Wu, W.Y.; Yang, Z.L. A Large-Scale Patient Evacuation Modeling Framework using Scenario Generation and Stochastic Optimization. In Proceedings of the IISE Annual Conference, New Orleans, LA, USA, 30 May–2 June 2020. [Google Scholar]
- Campbell, B.D.; Mete, H.O.; Furness, T.; Weghorst, S.; Zabinsky, Z. Emergency response planning and training through interactive simulation and visualization with decision support. In Proceedings of the 2008 IEEE Conference on Technologies for Homeland Security, Waltham, MA, USA, 12–13 May 2008; pp. 176–180. [Google Scholar]
- Wu, A.; Convertino, G.; Ganoe, C.; Carroll, J.M.; Zhang, X.L. Supporting collaborative sense-making in emergency management through geo-visualization. Int. J. Hum.-Comput. Stud. 2013, 71, 4–23. [Google Scholar] [CrossRef]
- Zhang, A.; Qi, Q.; Jiang, L. GeoRSS based emergency response information sharing and visualization. In Proceedings of the Third International Conference on Semantics, Knowledge and Grid (SKG 2007), Xi’an, China, 29–31 October 2007; pp. 596–597. [Google Scholar]
- Wang, P.; Bishop, I.; Stock, C. Real-time data visualization in Collaborative Virtual Environments for emergency response. In Proceedings of the Surveying & Spatial Sciences Institute Biennial International Conference, Adelaide, Surveying & Spatial Sciences Institute, Adelaide, Australia, 28 September–2 October 2009; pp. 435–441. [Google Scholar]
- Kim, S.Y.; Jang, Y.; Mellema, A.; Ebert, D.S.; Collinss, T. Visual analytics on mobile devices for emergency response. In Proceedings of the 2007 IEEE Symposium on Visual Analytics Science and Technology, Sacramento, CA, USA, 30 October–1 November 2007; pp. 35–42. [Google Scholar]
- Onorati, T.; Díaz, P.; Carrion, B. From social networks to emergency operation centers: A semantic visualization approach. Future Gener. Comput. Syst. 2019, 95, 829–840. [Google Scholar] [CrossRef]
- Rhudy Jr, J.P.; Alexandrov, A.W.; Rike, J.; Bryndziar, T.; Maleki, A.H.Z.; Swatzell, V.; Dusenbury, W.; Metter, E.J.; Alexandrov, A.V. Geospatial visualization of mobile stroke unit dispatches: A method to optimize service performance. Interv. Neurol. 2018, 7, 464–470. [Google Scholar] [CrossRef]
- Špatenková, O.; Demšar, U.; Krisp, J.M. Self-organising maps for exploration of spatio-temporal emergency response data. In Proceedings of the Geocomputation, Galway, Ireland, 3–5 September 2007; Volume 2007. [Google Scholar]
- Rashed, E.A.; Kodera, S.; Shirakami, H.; Kawaguchi, R.; Watanabe, K.; Hirata, A. Knowledge discovery from emergency ambulance dispatch during COVID-19: A case study of Nagoya City, Japan. J. Biomed. Inform. 2021, 117, 103743. [Google Scholar] [CrossRef]
- Ugalde, B.H.; Vinluan, A.A.; Carpio, J.T. Graph representation of road network for mobility-impaired persons. In Proceedings of the 2021 4th International Conference on Information and Computer Technologies (ICICT), Kahului, HI, USA, 11–14 March 2021; pp. 194–198. [Google Scholar]
- Dwivedi, A.K.; Mallawaarachchi, I.; Alvarado, L.A. Analysis of small sample size studies using nonparametric bootstrap test with pooled resampling method. Stat. Med. 2017, 36, 2187–2205. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the The Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean Activity | p-Value of | |||
|---|---|---|---|---|
| No. of | No. of Potential | Level of | Wilcoxon Signed | |
| Group | Responses | Inefficiencies | Closer Stations | Rank Test |
| 2017 | ||||
| Ambulance | 933,349 | 70,069 (7.51%) | +0.4022 | <10 |
| VMER | 90,145 | 8510 (9.44%) | +0.2598 | |
| 2018 | ||||
| Ambulance | 1,321,464 | 118,523 (8.97%) | +0.3814 | <10 |
| VMER | 93,686 | 8066 (8.61%) | +0.2340 | |
| 2019 | ||||
| Ambulance | 1,154,622 | 78,765 (6.82%) | +0.3208 | <10 |
| VMER | 95,640 | 8826 (9.23%) | +0.2306 |
| No. of | Mean Activty | p-Value of | |
|---|---|---|---|
| Potential | Level of | Wilcoxon Signed | |
| Cluster | Inefficiencies | Closer Stations | Ranked Test |
| Porto area (red) | 6611 | +0.2150 | |
| Setúbal area (dark green) | 3122 | +0.1333 | |
| Northwest Lisbon (purple) | 1739 | +0.2448 | |
| South Braga (light green) | 1546 | +0.0463 | |
| Sintra area (brown) | 1501 | +0.2789 | |
| East Lisbon (pink) | 1306 | +0.1348 | |
| Seixal and Almada (blue) | 779 | +0.1053 | |
| Faro area (yellow) | 774 | +0.3171 | |
| Central Braga (orange) | 695 | +0.3204 |
| No. of | Mean Activty | p-Value of | |
|---|---|---|---|
| Cluster | Potential | Level of | Wilcoxon Signed |
| Area | Inefficiencies | Closer Stations | Ranked Test |
| Porto, Porto | 61 | +2.9322 | |
| Porto, Porto | 42 | +1.4623 | |
| Setúbal, Setúbal | 17 | +0.7214 | |
| Tomar, Santarém | 16 | +1.7720 |
| No. of | Mean Activity | p-Value of | |
|---|---|---|---|
| Potential | Level of | Wilcoxon Signed | |
| Cluster | Inefficiencies | Closer Stations | Ranked Test |
| Espinho, Aveiro | 233 | +0.3229 | |
| Seixal, Setúbal | 203 | +0.0201 | |
| Oieras and Cascais, Lisbon | 161 | +0.2308 | |
| M: Sesimbra, Setúbal | 154 | +0.1046 | |
| Loulé, Faro | 116 | +0.1463 | |
| Porto Area | 115 | +0.0765 |
| Mean Activity | Median Activty | Ratio of | |
|---|---|---|---|
| Station | Level | Level | + Activity Level |
| BSBRAGA | +0.5629 | +0.4087 | 68.06% |
| BISMARCOS | +0.3826 | +0.2006 | 60.29% |
| BVBRAGA | +0.3488 | +0.1989 | 55.83% |
| BIBRAGA2 | 32.66% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tiam-Lee, T.J.; Henriques, R.; Manquinho, V. Associative Analysis of Inefficiencies and Station Activity Levels in Emergency Response. ISPRS Int. J. Geo-Inf. 2022, 11, 356. https://doi.org/10.3390/ijgi11070356
Tiam-Lee TJ, Henriques R, Manquinho V. Associative Analysis of Inefficiencies and Station Activity Levels in Emergency Response. ISPRS International Journal of Geo-Information. 2022; 11(7):356. https://doi.org/10.3390/ijgi11070356
Chicago/Turabian StyleTiam-Lee, Thomas James, Rui Henriques, and Vasco Manquinho. 2022. "Associative Analysis of Inefficiencies and Station Activity Levels in Emergency Response" ISPRS International Journal of Geo-Information 11, no. 7: 356. https://doi.org/10.3390/ijgi11070356
APA StyleTiam-Lee, T. J., Henriques, R., & Manquinho, V. (2022). Associative Analysis of Inefficiencies and Station Activity Levels in Emergency Response. ISPRS International Journal of Geo-Information, 11(7), 356. https://doi.org/10.3390/ijgi11070356