1. Introduction
The intelligent transportation system has become hot in recent years, many approaches on intelligent transportation have been proposed as a result. The excavation of flow can be used to support vehicle traffic planning [
1,
2], vehicle path recommendation [
3,
4], subway station location planning [
5,
6], vehicle emergency management [
7,
8], etc. The potential commercial value can be obtained through the analysis of vehicle trajectory [
9,
10]. At present, there are various analysis methods for vehicle trajectory. For example, through the historical trajectory data of vehicles, the prediction of urban traffic flow, the mining of interest points in the city, the prediction of the launching points of shared bikes, and even the planning of urban public transport service points through the analysis of taxi trajectory density and stop point detection.
The analysis of vehicle trajectory helps to analyze the travel pattern of citizens, etc. Tang et al. [
11] analyzed the car pooling travel patterns of passengers in that develop a Prefixspan-prediction using a partial matching (P-PPM) target prediction algorithm to mine frequent motion patterns from trajectory data and determine the confidence of motion rules. The method takes the total travel time as the matching target. Zhou et al. [
12] studied of the trajectory of the context information and the found extract information such as location information is through an analysis of the first to verify the knowledge, however, mobility management is an important problem is how to learn an accurate travel itinerary, so they proposed a trajectory of the encoder and decoder trip recommended method. This is a novel end-to-end approach that encodes historical trajectories as vectors while capturing the inherent characteristics of individual Point of Interest (POI) and the transformation patterns between POIs. The historical attention mechanism is incorporated into the sequential to sequential trip recommendation task of the method to improve effectiveness. Zou et al. [
13] proposed a geographic services recommendation model (GSRM), which roughly consists of three basic steps. First, the position sequence is obtained by clustering GPS positions. To improve efficiency, we adopt a programming model with distributed algorithm to accelerate clustering. Secondly, the position sequence to mine spatial and temporal information from cluster trajectories. The MiningMP algorithm is designed that the next possible location the user will travel to is predicted. A comprehensive framework can then be constructed for GSRM and provide appropriate geographic recommendation services by taking into account location information. The MiningMP algorithm provide appropriate geographic recommendation services by considering location sequences and other relevant semantic information.
The prediction of traffic flow can assist in directing traffic flow and other issues. Li et al. [
14] proposed a novel multi-sensor data correlation graph convolutional network model (MDCGCN). The MDCGCN model is composed of near-term, daily and weekly periods, and each part is composed of two parts: (1) reference adaptive mechanism and (2) multi-sensor data correlation convolution block. The first part can eliminate the differences between periodic data and effectively improve the quality of data input. The second part can effectively capture the dynamic temporal and spatial correlation caused by the change of traffic mode relationship between roads. Hou et al. [
15] studied short-term traffic flow prediction model that a novel cloud-edge-IOT three-layer traffic flow edge computing architecture and a short-term traffic flow prediction method based on spatio-temporal correlation is proposed, which uses principal component analysis (PCA) to analyze intersection correlation. Convolutional gated recurrent unit (CONVL-GRU) and Bidirectional GRU (Bi-GRU) are used to extract the spatio-temporal and periodic characteristics of traffic flows. You et al. [
16] proposed an improved cellular automata (CA) model to reveal prediction of traffic flow at signalized intersections. Traffic density and average speed are calculated to study the characteristics and spatial evolution of traffic flow at signalized intersections based on CA model. On this basis, a new traffic rule control optimization model and a CA model with self-organizing traffic signal system is proposed. Sunflower cat optimization (SCO) algorithm was used to predict the flow effectively. The algorithm is designed by combining sunflower optimization algorithm (SFO) with cat swarm optimization algorithm (CSO). In addition, fitness function is designed to guide the control rules of CA model traffic simulation evaluation.
To sum up, the above studies are dependent on the accuracy of trajectory data. However, due to signal shielding or other reasons, a large number of trajectory points are often lost or discontinuous trajectory segments appear in the trajectory. Therefore, we will build a Trajectory Data Cube model (TDC)
{
,
,
} to store the trajectory data of taxis, and restore vehicle driving conditions at every moment in the road network through hierarchical compression method, where
is time,
stands vehicle position, and
represents vehicle velocity. A Hierarchical Trace-Back method (HTB) will be designed based on taxi historical trajectory to study the restoration of lost trajectory and missing information. Due to the particularity of taxi, its trajectory data are basically in the road network, and taxi can provide a large amount of trajectory data for data analysis.
Table 1 shows the main parameters mentioned in this paper.
In this paper, the traffic condition at any time in history is obtained by data compression and dilution, so as to integrate the incomplete vehicle trajectory data and provide more accurate help for the analysis of trajectory data. The main contributions of this paper are as follows:
We build a data cube with spatio-temporal characteristics by analyzing the trajectory data of taxis, store the trajectory data of each day in the cube, and finally merge the multi-day data into a TDC model.
We analyze the trajectory data of each layer through the established TDC, and compress the data layers by HTB-p, HTB-v, and HTB-KF methods. Gain the traffic condition of the road network at a certain time.
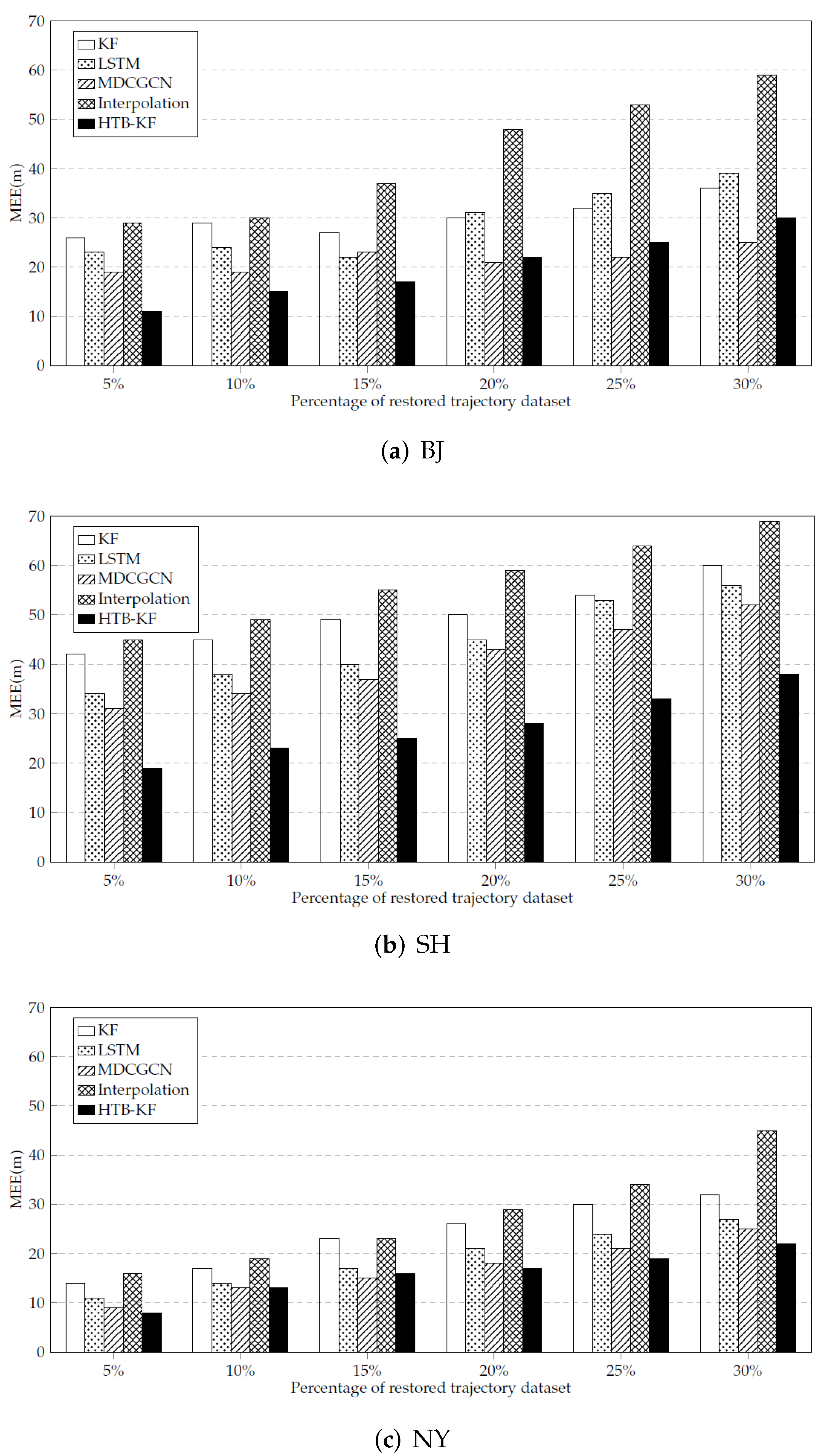
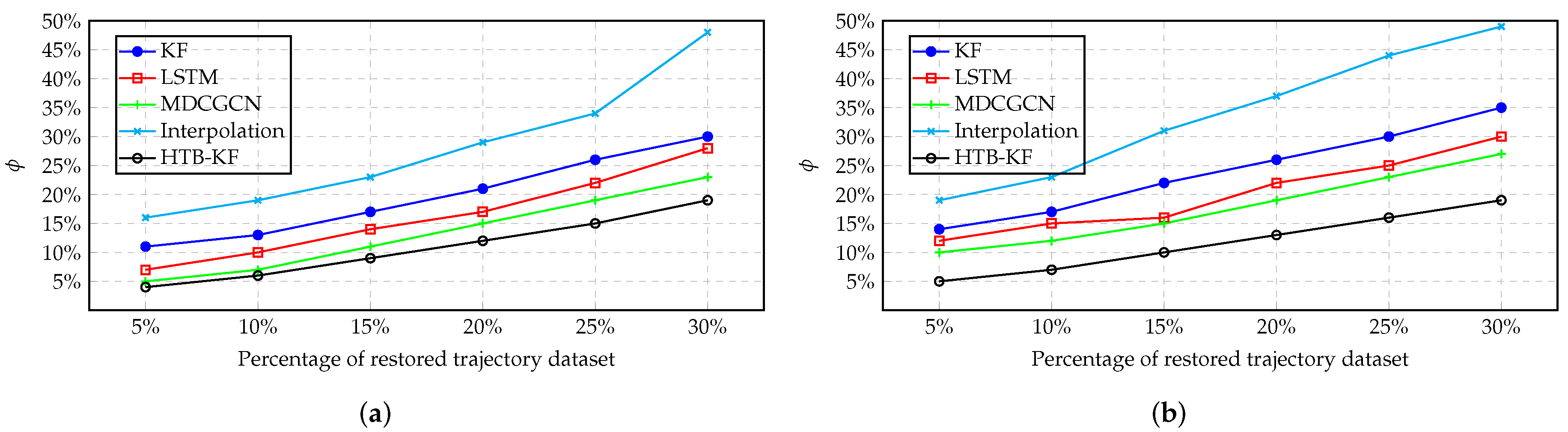
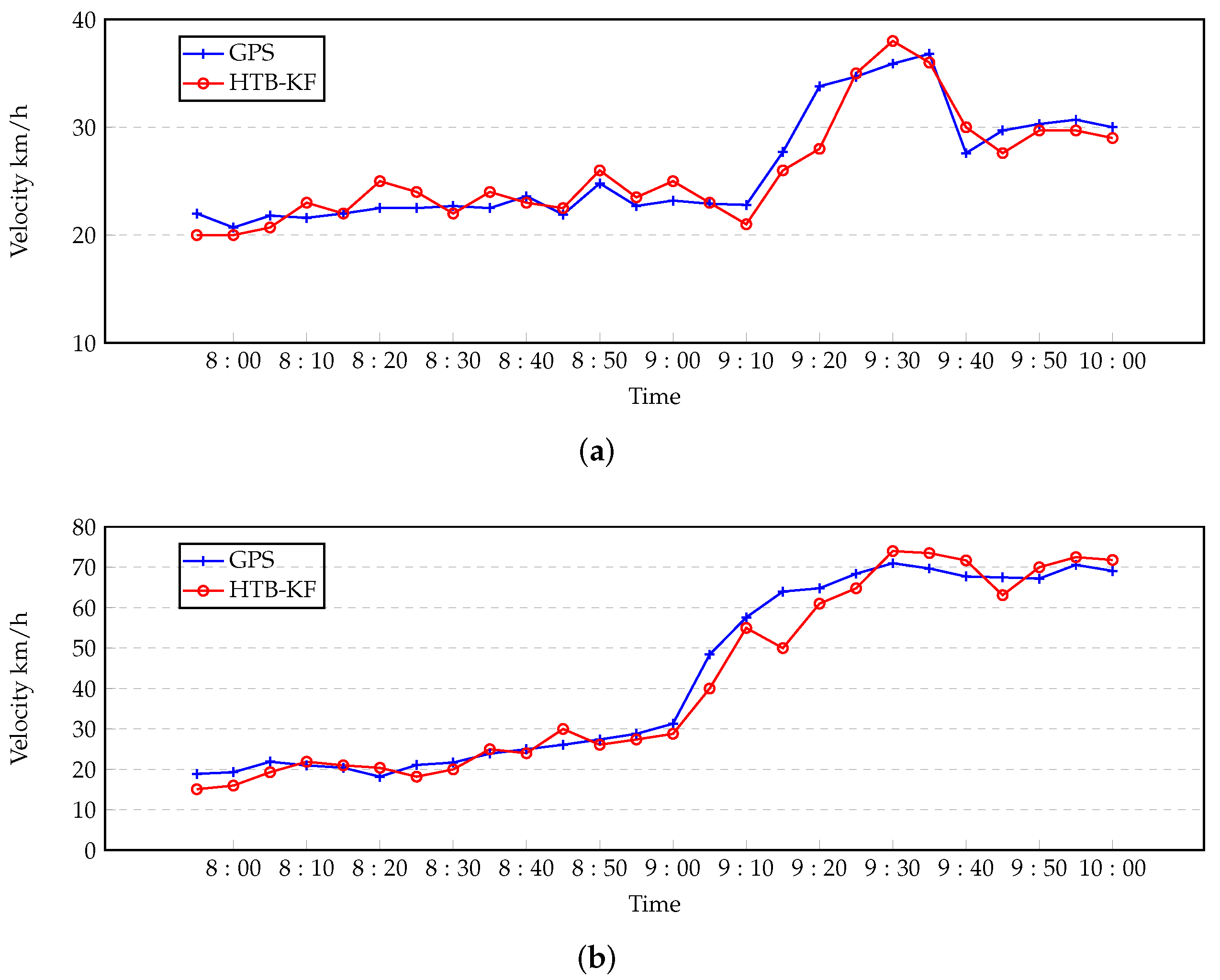
Finally, the thinning method is used to verify the effect of HTB-p, HTB-v, and HTB-KF methods and real historical road network traffic, and compared with existing traffic condition prediction methods and trajectory completion strategies.
The rest of this paper is organized as follows.
Section 2 introduces the traffic flow prediction methods and the completion trajectory strategy.
Section 3 presents trajectory data cube model based on incomplete taxi trajectory data.
Section 4 introduces a hierarchical track-back algorithm to restore the historical trajectory data of vehicles.
Section 5 conducts three experiments to verify our methods and the conclude in
Section 6.
3. Trajectory Data Cube Model Based on Incomplete Vehicle Trajectory
In this section we will introduce a novel form of trajectory data storage. Trajectory data has spatio-temporal characteristics, so the storage structure is usually , where T is the time set at the trajectory point, and P is the latitude and longitude coordinate set. The traditional trajectory model storage structure is mainly based on position variables and time series , thus forming a continuous trajectory segment for storage. The direction of the trajectory can be judged by time series. The characteristic of spatio-temporal data is that position information can be derived from time factors, or time variables can be derived from position information. This kind of data structure that can be mutually extrapolated constitutes the unique characteristic of spatio-temporal data.
3.1. Trajectory Data Structure with Point Velocity Factor
The velocity information of trajectory points is particularly important as a factor of vehicle trajectory data. The velocity information of the vehicle trajectory point can reflect the form of the vehicle at the moment. For example, the higher the velocity value, the better the road network traffic condition, and the lower the velocity value, the worse the road network traffic condition. However, there is another potential knowledge of velocity information that can be mined that is vehicle position. Therefore, this section will describe the relationship between vehicle trajectory point velocity information and position information and road network status information.
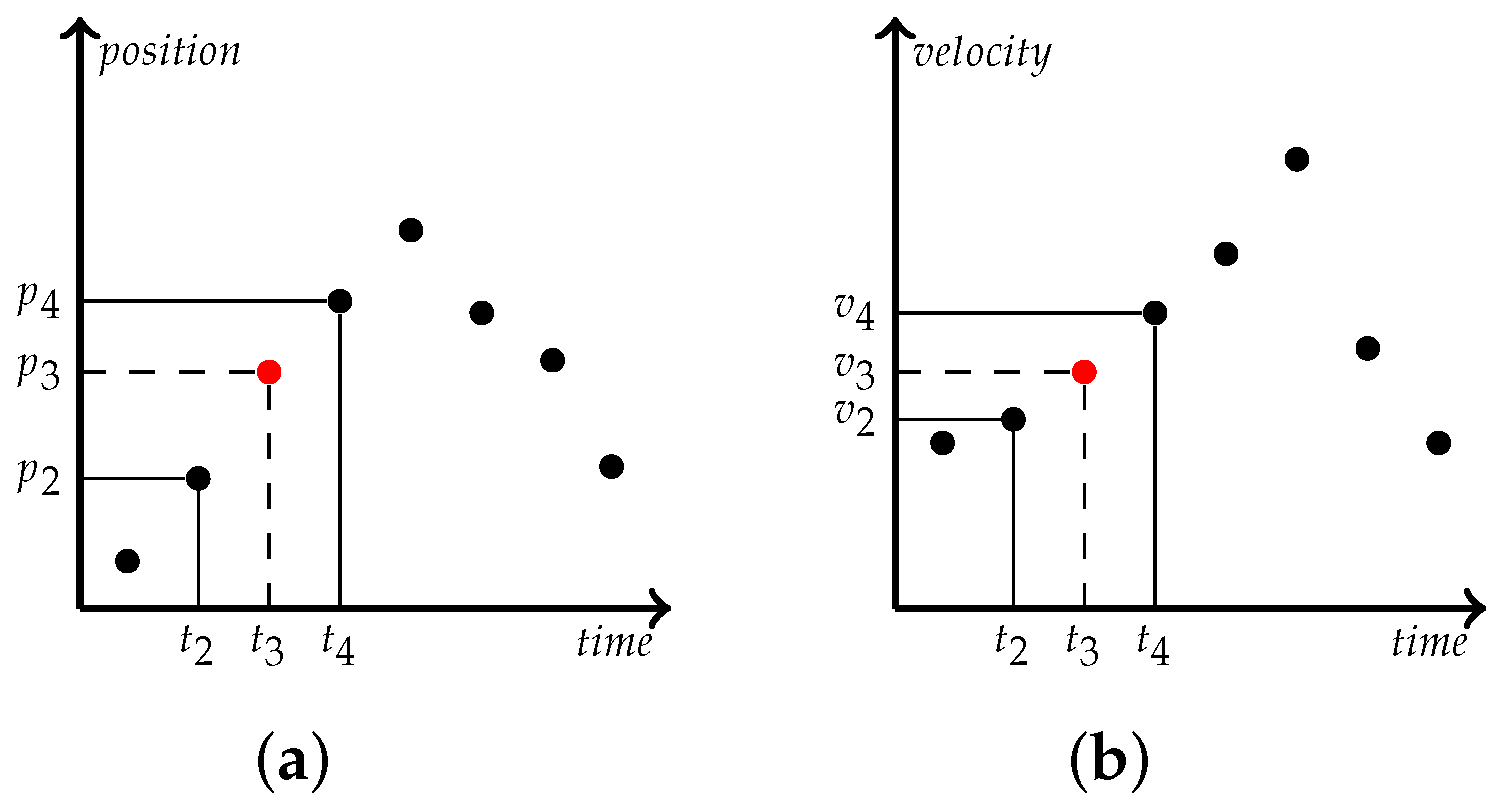
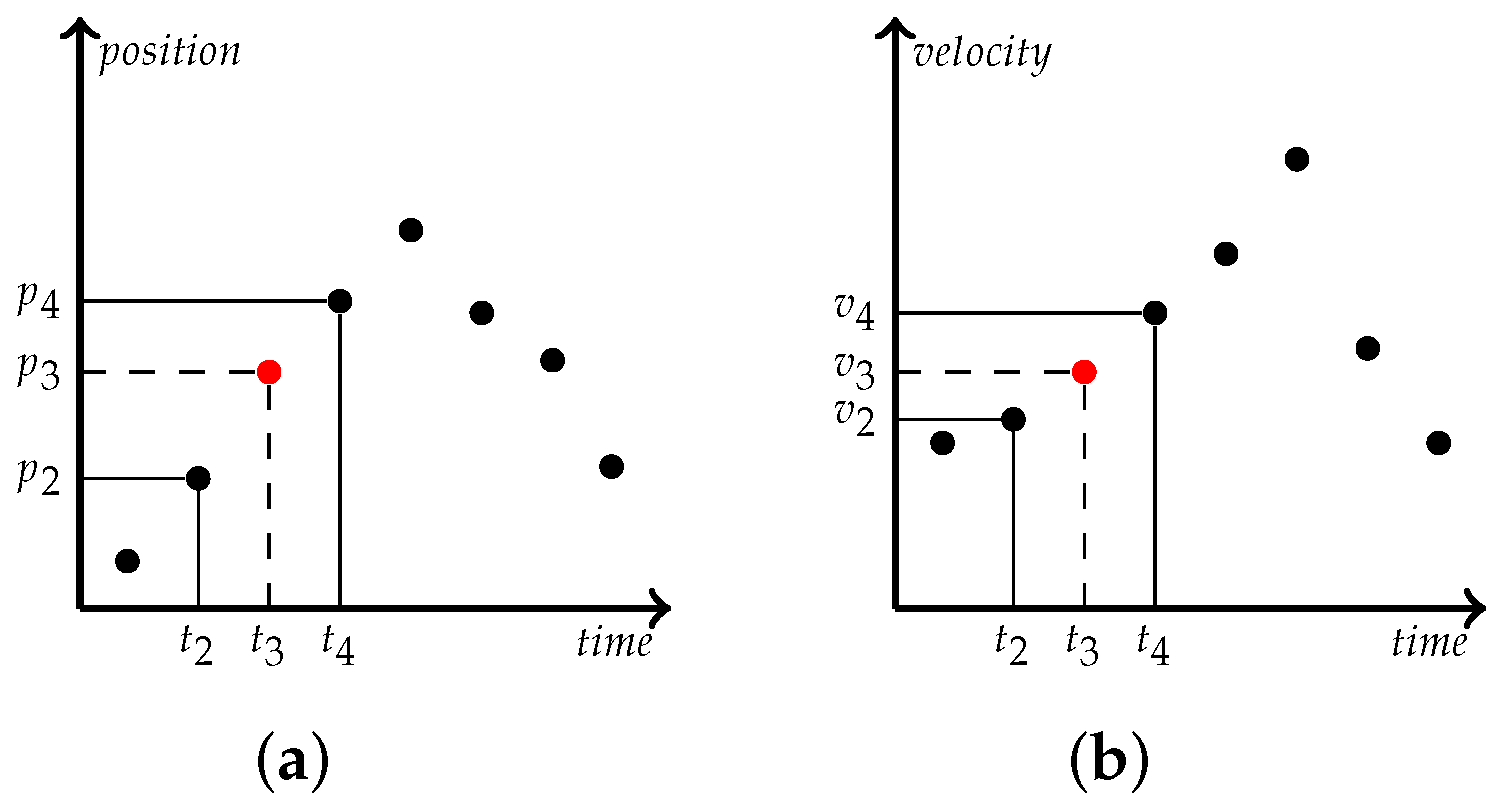
From
Figure 2a, we can see several continuous trajectory points, and the position information of trajectory points can be deduced according to the time information, which is the traditional vehicle trajectory mining knowledge. In
Figure 2b that the relationship between the velocity information of the trajectory point and time can be obtained. Due to the frequency of trajectory acquisition, trajectory points present discrete point states. We can find the acceleration
between any two points in the trajectory at any time from Equation (
1).
where
is initial velocity,
is terminal velocity,
is represent use time. The driving state of the vehicle can be obtained by the acceleration change between each trajectory point. The distance formula between two points in the road network is Equation (
2).
where
x and
y represent the map coordinates of two adjacent trajectory points in the road network respectively,
is
distance between adjacent trajectory points (Manhattan distance is used because it avoids two adjacent points in a continuous trajectory from appearing in two roads). The relationship between position information and velocity information of trajectory points is expressed by Equation (
3).
where
is velocity difference between trajectory points,
is time difference between trajectory points. The mathematical relationships between the
,
and
of trajectory points are established by Equations (1)–(3).
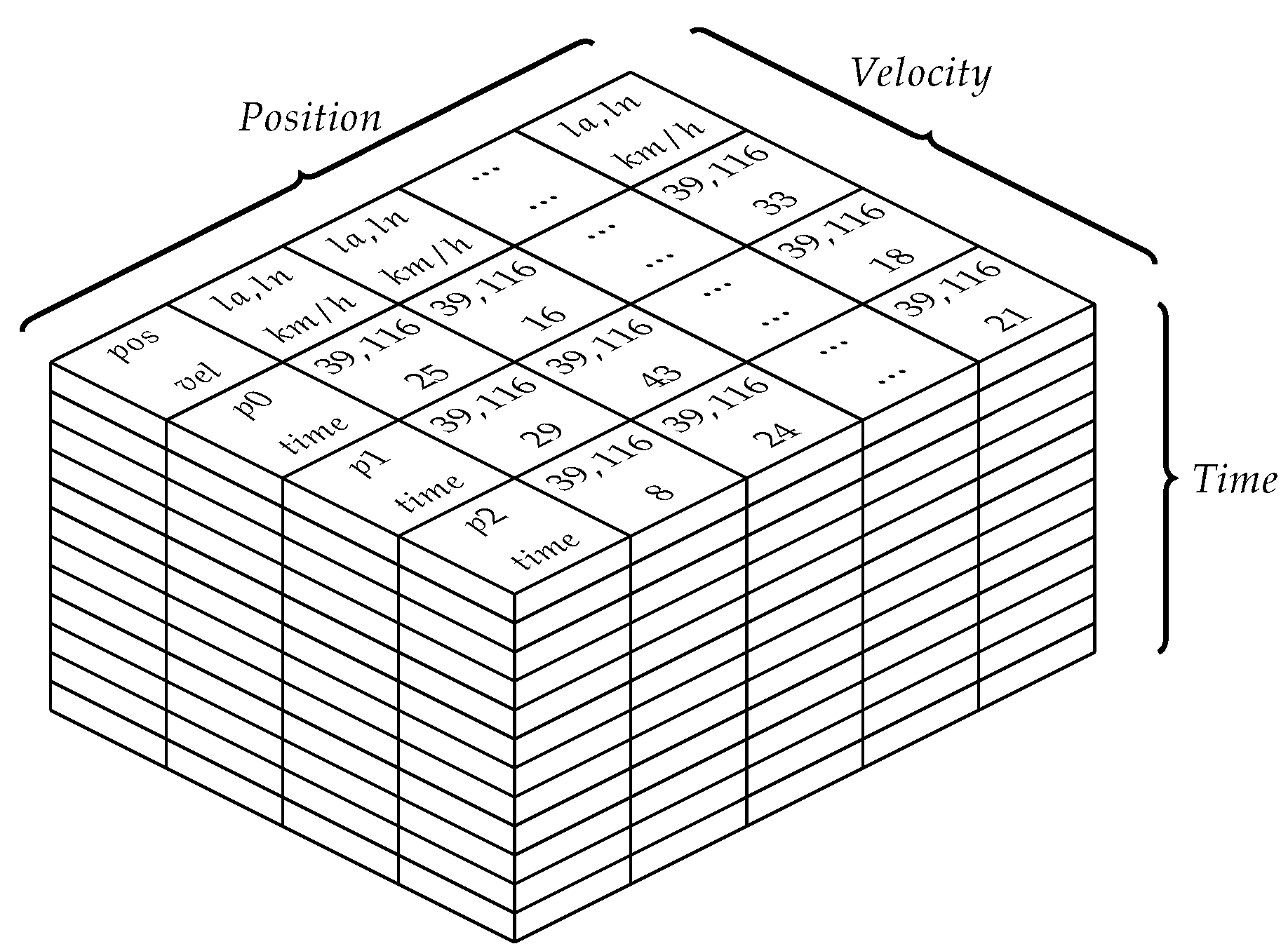
3.2. Trajectory Data Cube Model
This section describes trajectory data cube model to store the position, velocity and time of trajectory points. The purpose is to better represent the temporal and spatial characteristics of trajectory data. The velocity representation of trajectory points is to more accurately restore the position of missing points in the trajectory, which will be introduced in
Section 4.
Figure 3 shows the trajectory data cube model, where
is trajectory point position,
represents trajectory point velocity,
is trajectory point time-stamp, each row represents a continuous trajectory segment in unit time, each cube piece represents the information of trajectory points. In this paper, trajectory data cube model will be established in unit of minute according to paper [
39].
The cube consists of three parts: the position of the trajectory, the velocity, and the time. We design two time unit cubes from the level, so each layer represents the date and hour respectively. Position information of trajectory points in each column of the data cube. We specify that the trajectory points within each road be stored in the same piece (the position points of the road can be determined by two adjacent intersections of the road network dataset), thus, each column represents the same road. Each row is represented as a continuous trajectory in a unit time.
It can be seen from
Figure 3 that each time unit is stored in the form of data blocks, and the data time-stamp stored in each layer is the data in the same unit time. The purpose of this design is due to the characteristics of the trajectory data. The amount of trajectory data at each moment is small and sparse. Therefore, if the time-stamp is used as the time unit for storage, a large amount of space will be wasted.
It is worth noting that since latitude and longitude information is not necessarily adjacent to each other in the actual road network when stored (i.e., topology relation is missing), a pointer is added into the small module in each layer named , the pointer points to the next position ID adjacent to it. We specify a set = {} to represent the points in a trajectory. Therefore, the TDC has the characteristics of vector representation.
It is also worth noting that the selection of unit time requires experimental verification, but we cannot guarantee that vehicles will not run on the same road in unit time. Therefore, this paper has done some processing. Based on our previous research, it is appropriate to change the road network condition in 10–15 min, but data storage at such time interval is still sparse. Therefore, we extend the unit time of the data cube to 30–60 min, so if the same track point appears on the same road in unit time, calculate the average speed of the cube according to Equation (
4) and store.
where
is the average road network speed expressed between vertices
and
.
is the trajectory point velocity at a certain time. The trajectory point velocities in all time units and on the same road are added and averaged. In this way, all trajectory data is stored in the data cube.
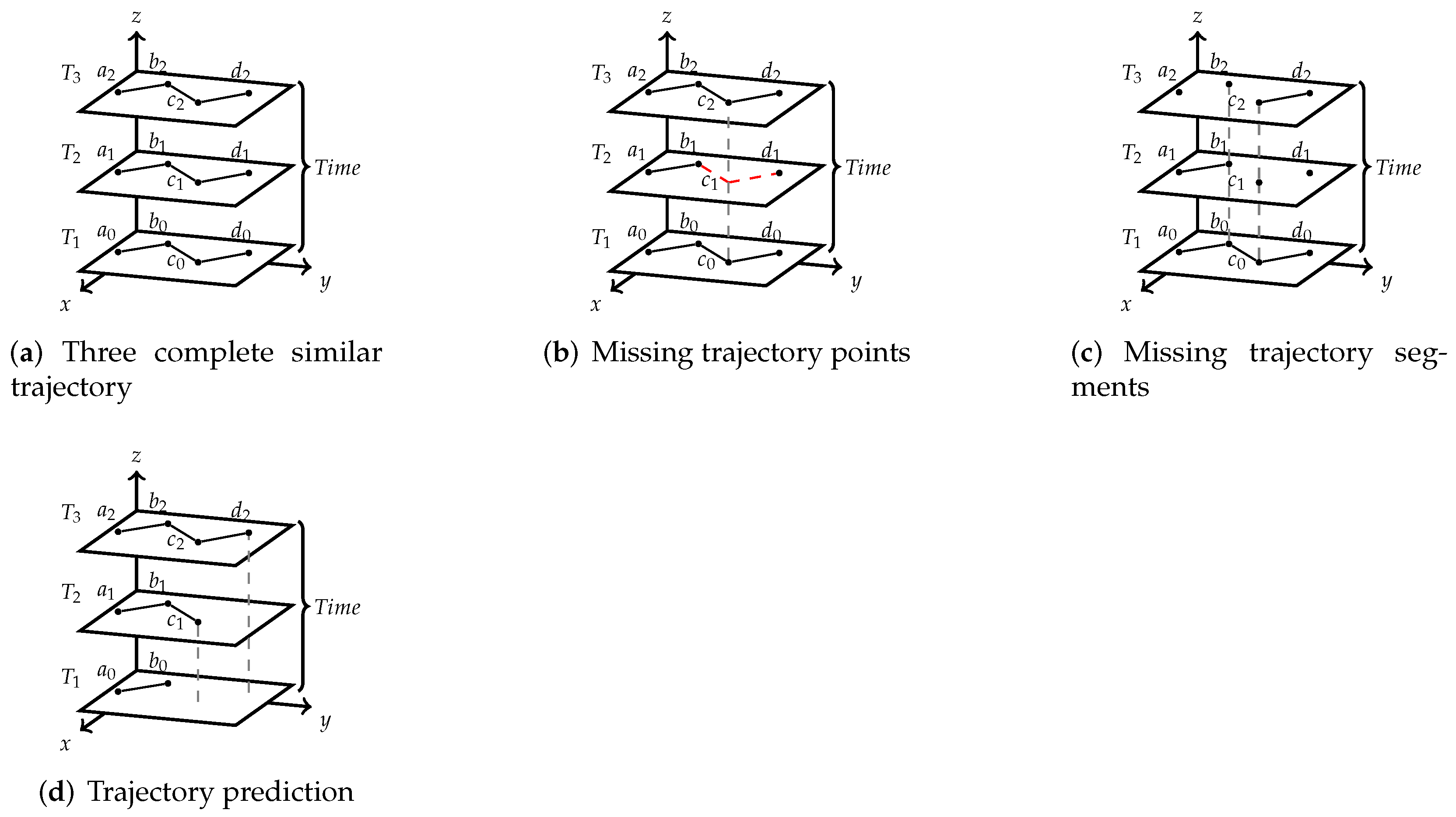
4. Hierarchical Trace-Back Method Based on Trajectory Data Cube
In this section, a hierarchical trace-back (HTB) algorithm based on spatio-temporal trajectory data will be introduced. This method includes a Bayesian probability method, which is used to restore the missing points or missing trajectory segments in the trajectory. The purpose of classifying trajectory data according to time hierarchy is to find out the spatio-temporal features hidden in the trajectory.
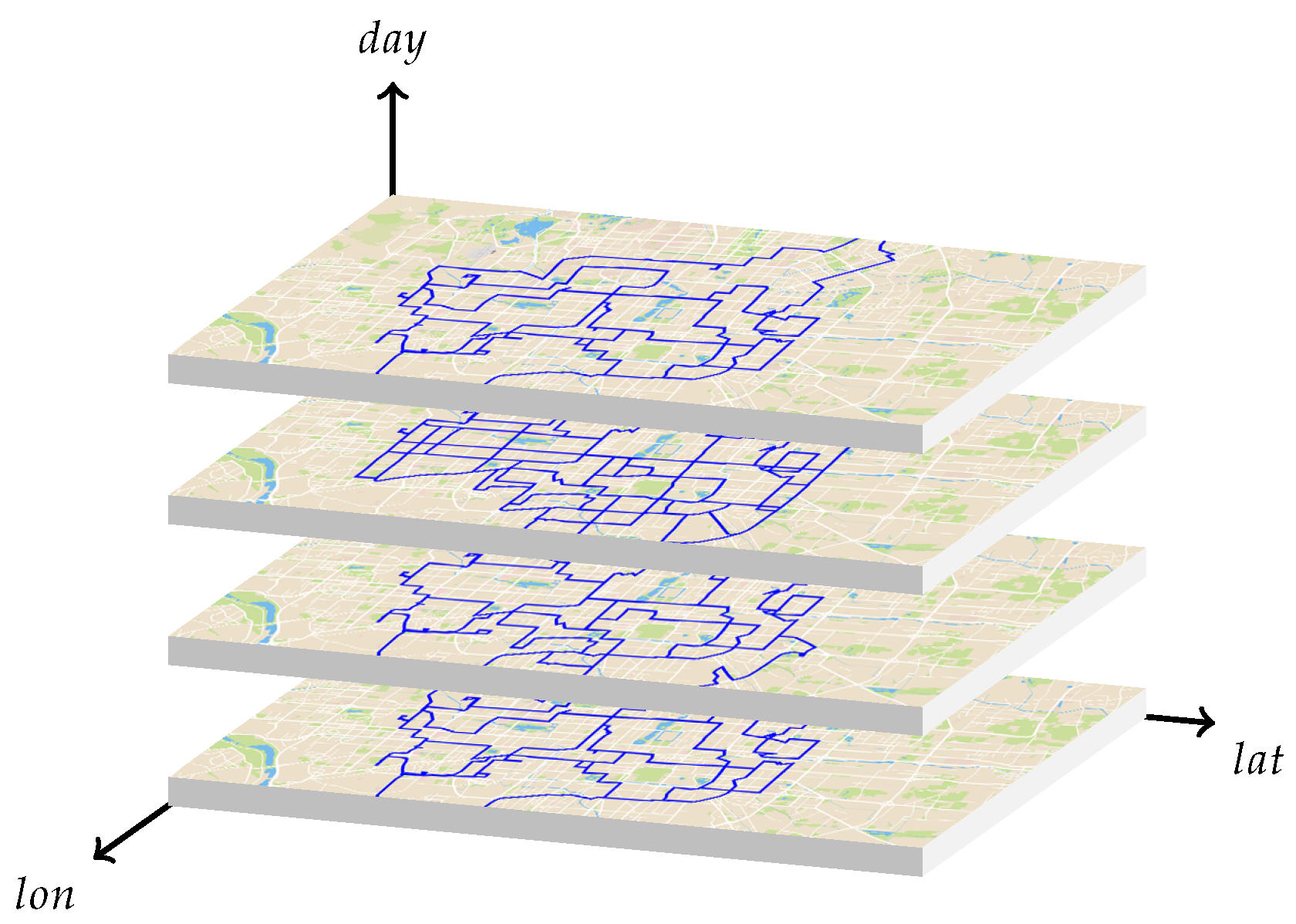
Figure 4 shows the trajectory chart of a vehicle in four days, from which it can be seen that the same path or different paths occurred in four days. The purpose of HTB algorithm is to focus on the similar trajectories that appear in the same time period in different dates, and these trajectories are classified and stored by TDC model. In trajectory data, time information is generally not lost or missing, and what the equipment usually records is the time information when the data is generated (especially the trajectory data collected under the condition of constant frequency). Even in the case of unequal frequency there is still a definite time period. Therefore, the most important information restoration is the position information and velocity information of trajectory points.
4.1. Trajectory Position Restoration Based on TDC Model
In the actual trajectory dataset, there are often trajectory points with inaccurate trajectory positions, which are often caused by unstable equipment signals or vehicles in a space blocked by signals. Therefore, the missing or offset of trajectory position information in this paper can be completed by TDC and hierarchical trace-back position (HTB-p) algorithm. The calculation process of HTB-p will be described the following.
Definition 1. Given a missing dataset M, according to the trajectory data characteristics, there is a continuous trajectory segment P , where is the missing trajectory point, then the time information of the point can obtain the time range of missing data from the time of and the time of .
Definition 1 gives the time range of missing data. Similarly, the position area of the missing trajectory can be determined according to the front and rear position information segments of the missing trajectory data.
Definition 2. Given a missing dataset M, there is a continuous trajectory segment P , where is the missing trajectory point, then the position information of the point can obtain the position area of missing data from the position of and the position of .
Definition 2 gives the position area of missing data. According to Definition 1, Definition 2 and TDC, the trajectory data information of all lost data in the same time period in history can be obtained. The information related to missing data is extracted hierarchically from TDC.
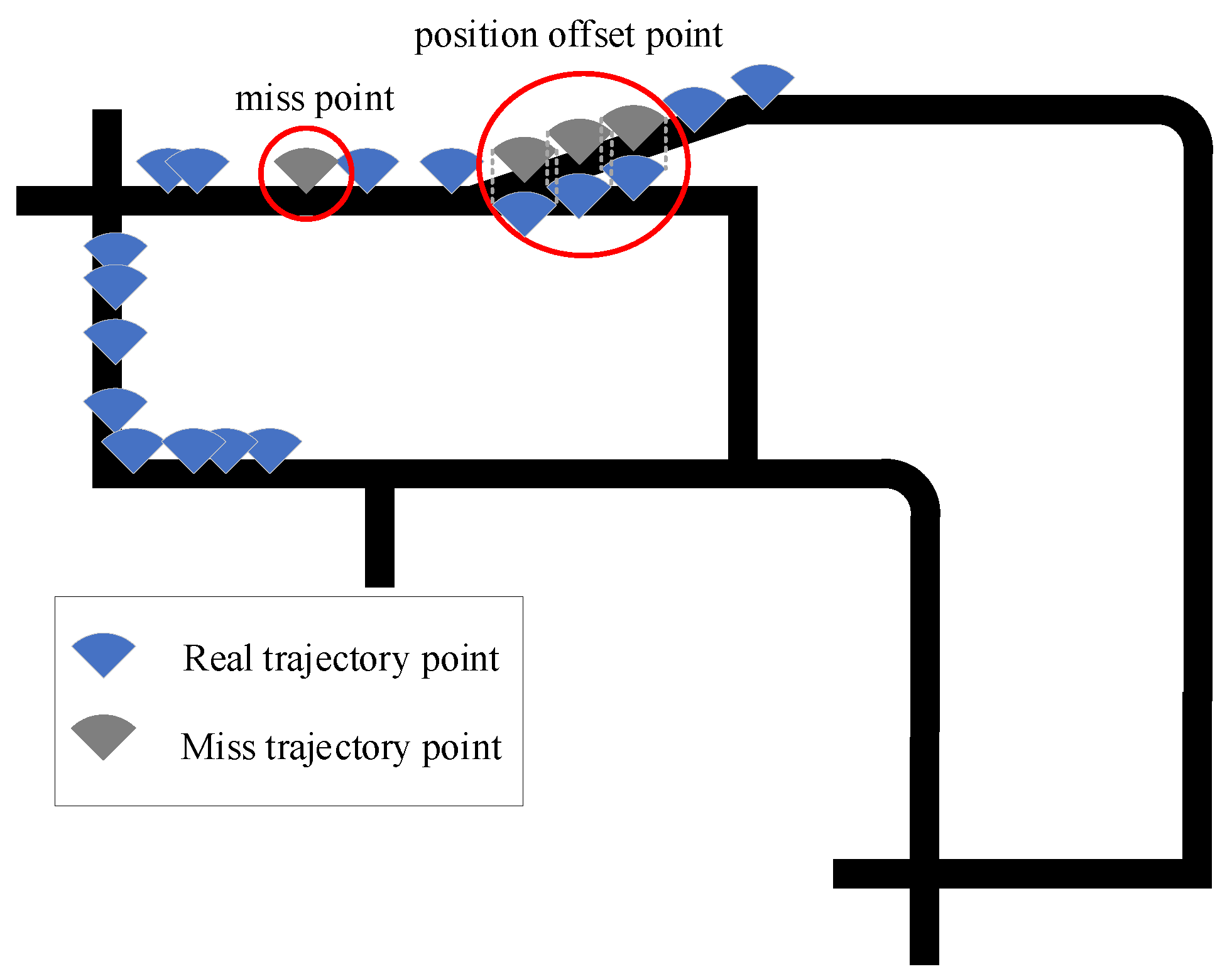
Figure 5 shows the examples of missing position information and position offset of trajectory points.
The core of HTB-p algorithm is the process of calculating the information in the time period extracted by TDC. HTB-p algorithm is divided into two steps; 1. By lack of traversal path set point data, matching with the data in the TDC and search, through the corresponding time to get the corresponding TDC layer, and return loss trajectory points corresponding to the data information in the TDC, with this information as the keyword as a search condition, then return all trajectory data information of different levels in the same time. 2. All the qualified information obtained from TDC is calculated for conditional probability. According to the condition of time and velocity, the probability statistics of all possible road ID are carried out. Finally, the road ID with higher probability is returned to the missing trajectory data, and the position is marked as the position information of the missing trajectory point. Algorithm 1 introduces a HTB-p method with position information of the missing trajectory point.
| Algorithm 1 HTB-p |
- 1:
Input: TDC, M - 2:
Output: - 3:
Initialization, MapSet - 4:
forMdo - 5:
search from TDC - 6:
compare in each level - 7:
if then - 8:
Calculation = - 9:
.put(,) - 10:
end if - 11:
get with maximum value from - 12:
= - 13:
TDC = - 14:
end for - 15:
RETURN TDC
|
Where M is missing trajectory set, is contain the position, velocity, and time with one point in the trajectory. is time of loss trajectory point, represents the probability of candidate position. stores the probability of each candidate position. is the time of missing trajectory point, is miss point ID. Lines 4–6 describe obtaining the ID of trajectory points from the missing trajectory set M in turn, and obtaining all trajectory information in the same time layer in TDC by comparing with the time in TDC. Lines 7–9 find the trajectory data block with the same time as that in the M set from the TDC, return all the trajectory information in the block, calculate all candidate points in the TDC through Bayesian conditional probability. Line 11–15 finally return the value with the maximum probability, and supplement the information of the missing points to the TDC. Since there is only one loop in the algorithm, the time complexity of the algorithm is , where n is the number of missing trajectory points.
4.2. Trajectory Velocity Restoration Based on TDC Model
A HTB-v method will be introduced in this section, which aims to supplement the trajectory points without measured velocity information in the trajectory. Since the known information includes position information and time information, the missing velocity information is calculated according to the structural characteristics of the TDC. Firstly, the position points with missing velocity information can be obtained according to the position information. In this process, the position of the missing velocity trajectory point set can be classified through the position classification module of the TDC to screen the accurate position. Secondly, the time of the missing trajectory point set is matched with the time layer divided by the data cube, and the missing trajectory point set is divided into the corresponding time layer. Through the above two steps, all points in the trajectory point set with missing velocity information are divided into TDC blocks.
Definition 3. Given a missing velocity dataset M, according to the trajectory data characteristics, there is a continuous trajectory segment P , where is the missing velocity trajectory point, then the position information of the point can obtain from the and , the time information of the point can obtain the time range of missing data from the and .
Definition 3 gives the position information and the time range of missing data. the following we need to calculate the missing velocity information in the trajectory point. We still need to calculate the probability of the trajectory block in the TDC with the help of Bayesian conditional probability formula, and finally return the maximum speed probability value, and the result is returned to the specific missing point. Algorithm 2 describes the process of restoring trajectory points with missing velocity information by HTB algorithm.
| Algorithm 2 HTB-v |
- 1:
Input: TDC, M - 2:
Output: - 3:
Initialization, MapSet - 4:
forMdo - 5:
search from TDC - 6:
compare in TDC - 7:
if then - 8:
search from TDC - 9:
compare in each level - 10:
if then - 11:
Calculation = - 12:
.put(,) - 13:
end if - 14:
end if - 15:
get with maximum value from - 16:
= - 17:
TDC = - 18:
end for - 19:
RETURN TDC
|
Where M is missing trajectory set, is contain the position, velocity, and time with one point in the trajectory. is position of loss trajectory point, is time of loss trajectory point, represents the probability of candidate position. stores the probability of each candidate position. is the time of missing trajectory point, is miss point ID. Lines 4–9 describe obtaining the ID of trajectory points from the missing trajectory set M in turn, and obtaining all trajectory information in the same time layer in TDC by comparing with the time in TDC. Lines 10–12 find the trajectory data block with the same time as that in the M set from the TDC, return all the trajectory information in the block, calculate all candidate points in the TDC through Bayesian conditional probability. Line 15–19 finally return the value with the maximum probability, and supplement the information of the missing points to the TDC. Since there is only one loop in the algorithm, the time complexity of the algorithm is , where n is the number of missing trajectory points.
4.3. Trajectory Position and Velocity Restoration Based on TDC Model
The road network state restoration method when there are continuous and missing position information and trajectory velocity in the trajectory segment will be introduced in this section. Kalman-Filtering (KF) [
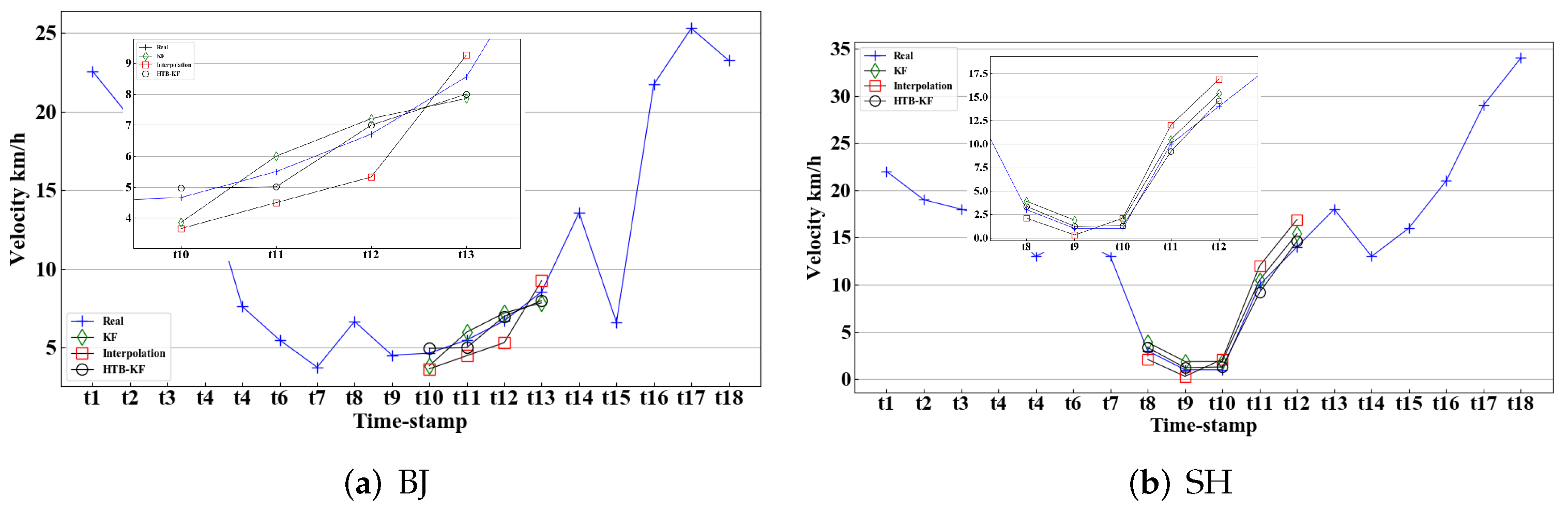
40] and variants can effectively restore the missing trajectory, but the restoration strategy for multi vehicle trajectory loss in the road section and road network traffic flow still needs to be improved. Therefore, this section will introduce a hierarchical backtracking algorithm HTB-KF that combines KF and TDC.
Firstly, the missing position information in the trajectory data is restored for the first time by KF algorithm. The restored information is returned to the missing trajectory set and TDC. The position information in TDC and the missing trajectory is compared, and the position information and time information are matched once. Secondly, the velocity information of missing trajectory points is assigned. The result of matching the position information restored by KF with TDC is returned to the missing trajectory point, the matching velocity information value is found from the TDC block, the probability superposition is carried out through the position front-rear information and time information, and finally the velocity information with the greatest probability is returned to the missing trajectory point. Equations (5) and (6) describe the trajectory data process of KF. It is worth noting that this paper compares the position information and velocity information of lost trajectory points as restored separately, so only a single element of information restore is considered when using KF method. A trace-back mechanism will be added in this section to verify the missing information.
where
A is the state transition matrix and
w is the process noise. The state transition matrix
A is determined according to the kinematic formula,
B is the matrix that takes part of influencing the system state change.
where
z represents the predicted value, and
H is the conversion matrix from the current measured value to the predicted measured value.
e represents noise. In this paper, the position of the missing trajectory is predicted for the first time with the assistance of KF [
40]. The velocity information of the missing trajectory data is assigned by the restored position information and TDC. The position information is checked by TDC again after the assignment. Algorithm 3 describes the calculation process of HTB-KF.
Where
M is missing trajectory set,
is contain the position, velocity, and time with one point in the trajectory. Lines 4–6 describe the preliminary judgment of the missing trajectory position using KF. Lines 7–17 calculate the position information obtained through KF, so as to deduce the velocity information of missing trajectory points. Line 18 is to recheck the position obtained by KF, so as to further reduce the error. Lines 19–23 return the final result and store it in TDC. The time complexity of the HTB-KF algorithm is
, where
n is the number of missing trajectory points.
| Algorithm 3 HTB-KF |
- 1:
Input: TDC, M - 2:
Output: - 3:
Initialization, MapSet - 4:
forMdo - 5:
Calculation of M by KF - 6:
end for - 7:
forM with position information do - 8:
search from TDC - 9:
compare in TDC - 10:
if then - 11:
search from TDC - 12:
compare in each level - 13:
if then - 14:
Calculation = - 15:
.put(,) - 16:
end if - 17:
end if - 18:
HTB-p - 19:
get with maximum value from - 20:
= - 21:
TDC = - 22:
end for - 23:
RETURN TDC
|
6. Conclusions
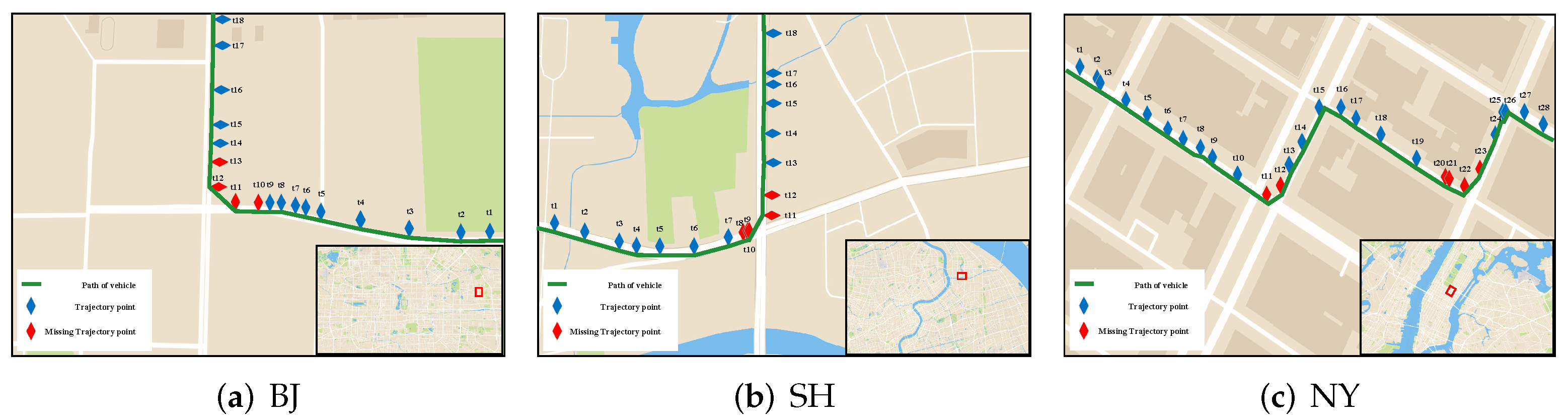
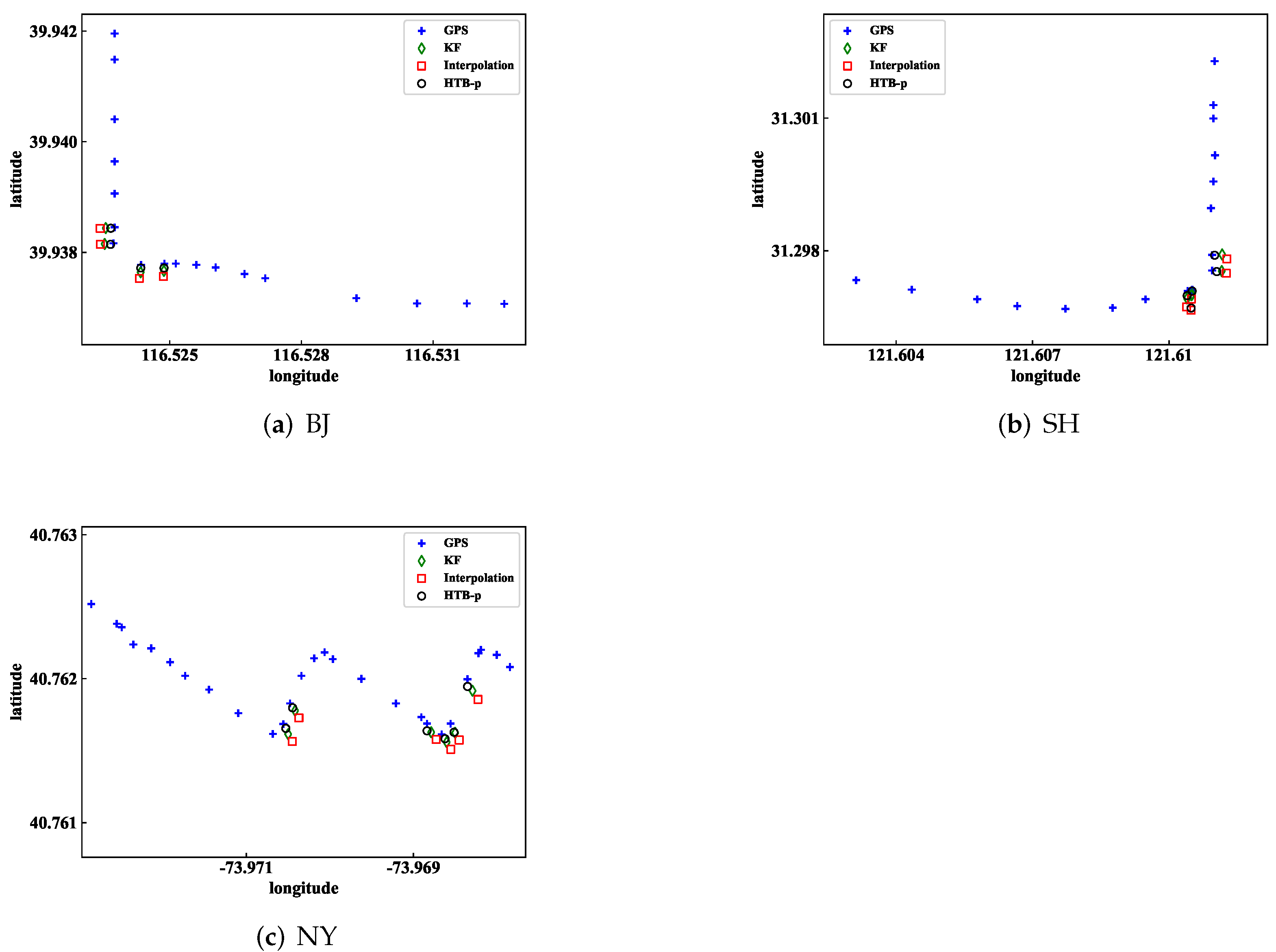
In conclusion, a novel trajectory data cube (TDC) is introduced to model, analyze and process trajectory data in this paper. Three trajectory hierarchical trace-back algorithms based on the TDC model are designed to restore the missing information in the trajectory, and to restore the traffic flow of the missing trajectory. Because the position information and velocity information in the trajectory information can effectively explain the traffic manifold at that time. Finally, in the experimental part, the trajectory restoration of the HTB-p, HTB-v, and HTB-KF algorithms is verified. Firstly, the HTB-p method is verified the restoration of the missing position of individual trajectory points in the trajectory segment by HTB-p method (there are few training sample sets in this experiment, and all trajectory sets are not processed), and its MEE and error rate are less than those of other methods. Secondly, the HTB-v method is verified to restore the velocity information of individual trajectory points in the trajectory segment. Through experimental comparison, it can be concluded that the HTB-v method has a better restoration effect. Thirdly, the restoration of missing trajectory segment information by HTB-KF algorithm is verified. It is also verified that HTB-KF algorithm can restore driving conditions, and it is found that HTB-KF algorithm still has good restoration ability when the sample training set is limited.
In future work that we will add the deviation angle of trajectory information as a factor of trajectory information, and try to complete the missing part of trajectory datasets with less training sample size.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}