
RepDarkNet: A Multi-Branched Detector for Small-Target Detection in Remote Sensing Images

 , ,
, ,
Abstract
:1. Introduction
- 1.
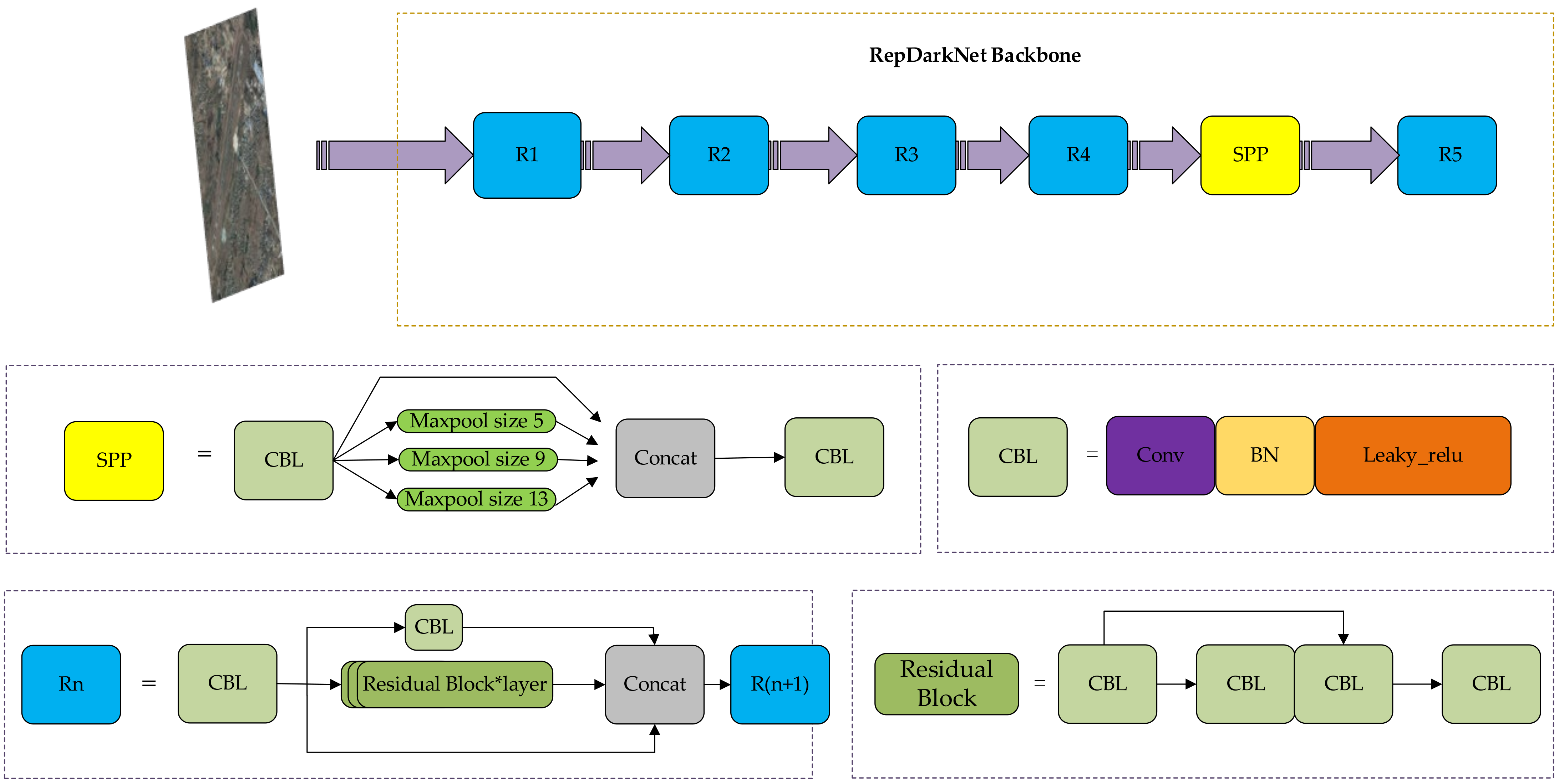
- Influenced by RepVgg [14], we proposed a backbone network named “RepDarkNet” that combines training accuracy and detection speed. Experiments show that RepDarkNet performs better when applied to the Dior dataset than do YOLOv3 and YOLOv4 with DarkNet style as the backbone.
- 2.
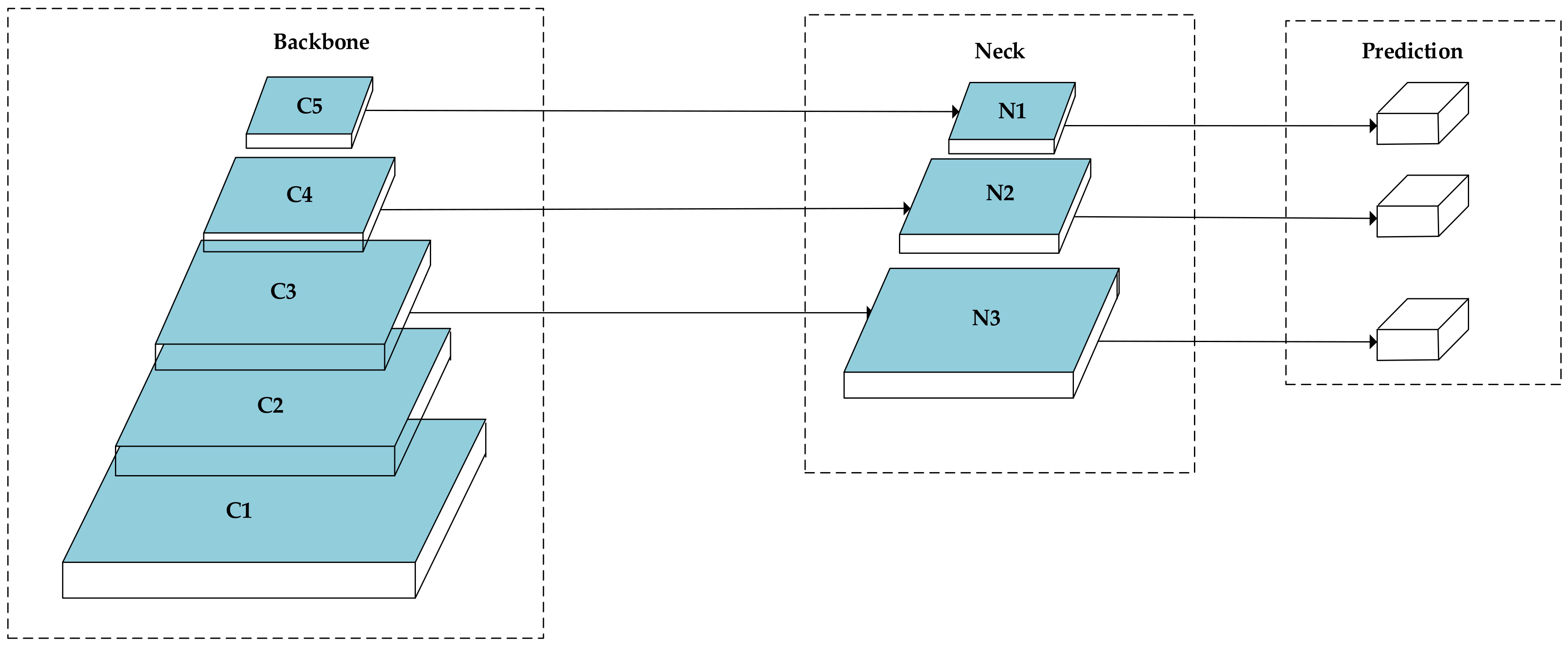
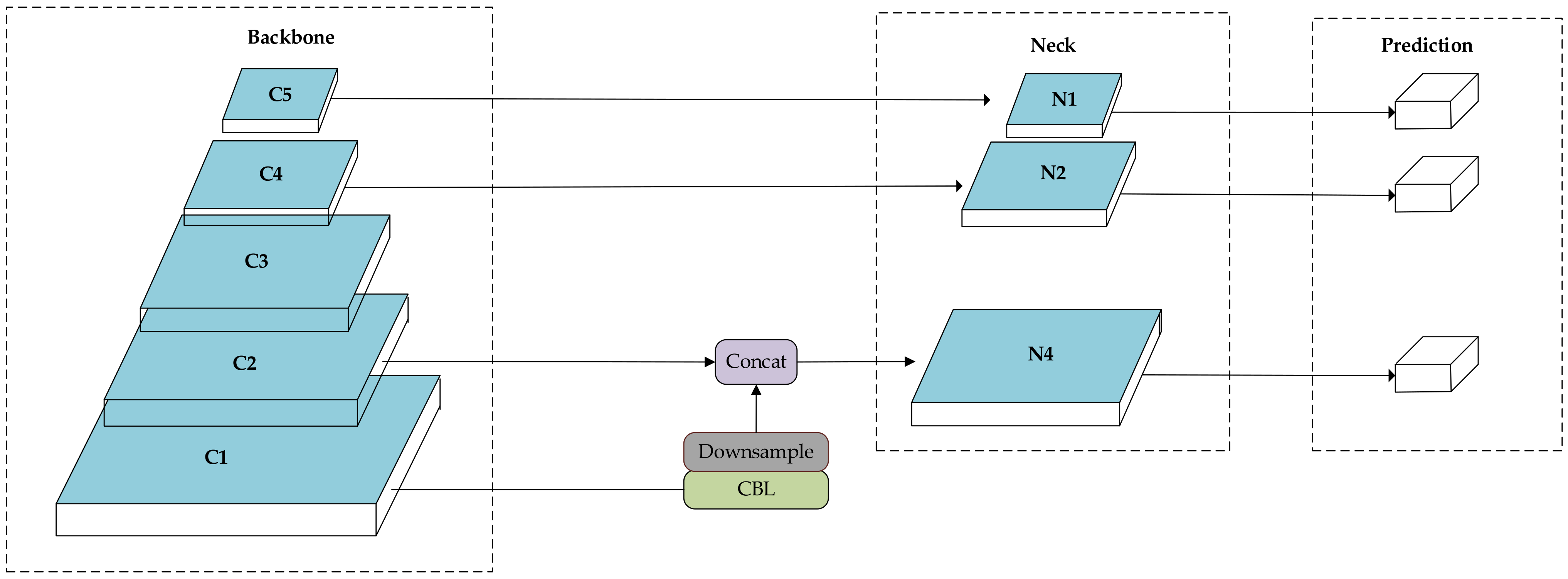
- We proposed a cross-layer converged network for small targets in optical remote sensing images. The network contains multi-scale cross-layer detection and feature fusion networks.
- 3.
- Besides, larger input and GIoU [15] were used to improve very-small-target detection and tested separately by applying them to the Dior-vehicle dataset.
2. Related Work
3. Materials and Methods
3.1. Reasons for Choosing DarkNet Style
3.2. Overview of DarkNet-Style Backbone Network
3.3. Cross-Layer Fusion Network
3.4. Options for Improving Accuracy of Small-Target Detection
3.4.1. GIoU
3.4.2. Larger Input Size
4. Experiments, Results, and Discussion
4.1. Dataset
4.1.1. Dior-Vehicle Dataset
4.1.2. Dior Dataset
4.1.3. NWPU VHR-10 Dataset
4.2. Evaluation Standards
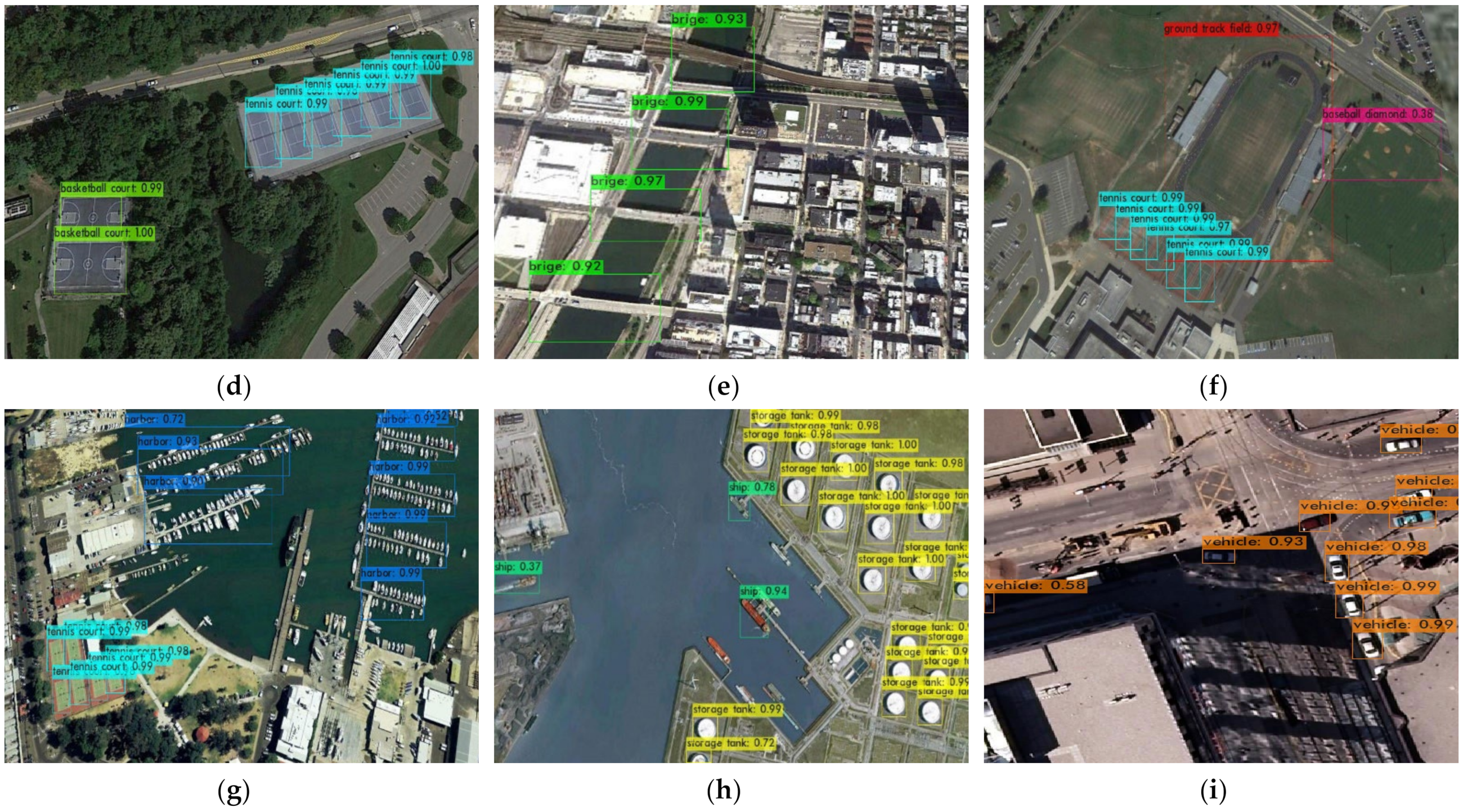
4.3. Experimental Results and Analyses
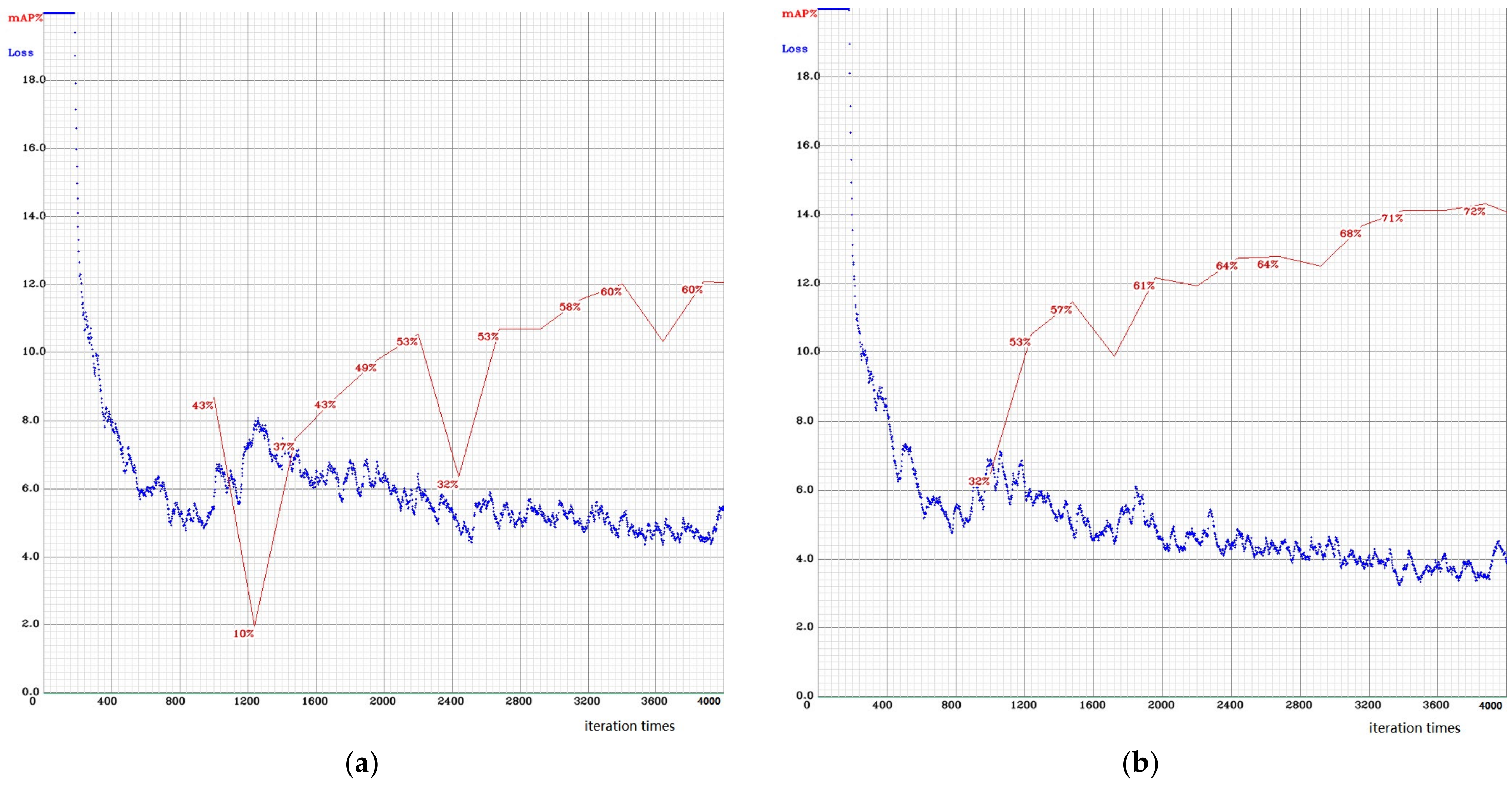
4.3.1. Result of Dior-Vehicle and Analyses
4.3.2. Results of the Dior Dataset and Analyses
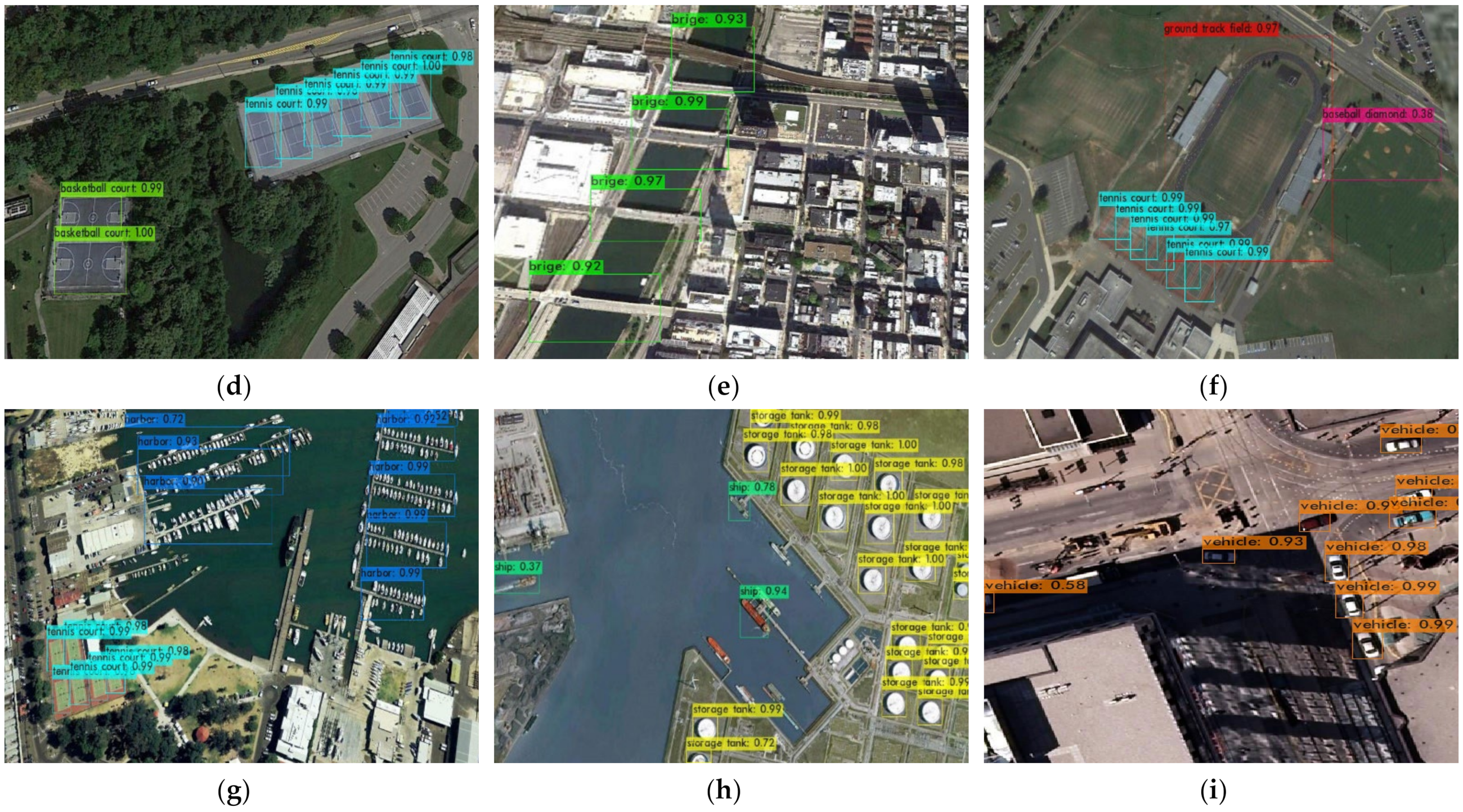
4.3.3. Results of NWPU VHR-10 and Analyses
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Rabbi, J.; Ray, N.; Schubert, M.; Chowdhury, S.; Chao, D. Small-Object Detection in Remote Sensing Images with End-to-End Edge-Enhanced GAN and Object Detector Network. Remote Sens. 2020, 12, 1432. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V. Searching for MobileNetV3. arXiv 2019, arXiv:1905.02244. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-style ConvNets Great Again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhang, Y.; Yuan, Y.; Feng, Y.; Lu, X. Hierarchical and Robust Convolutional Neural Network for Very High-Resolution Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5535–5548. [Google Scholar] [CrossRef]
- Etten, A.V. You Only Look Twice: Rapid Multi-Scale Object Detection in Satellite Imagery. arXiv 2018, arXiv:1805.09512. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning RoI Transformer for Detecting Oriented Objects in Aerial Images. arXiv 2018, arXiv:1812.00155. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Zhou, L.; Wei, H.; Li, H.; Zhao, W.; Zhang, Y. Arbitrary-Oriented Object Detection in Remote Sensing Images Based on Polar Coordinates. IEEE Access 2020, 8, 223373–223384. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Segment-before-Detect: Vehicle Detection and Classification through Semantic Segmentation of Aerial Images. Remote Sens. 2017, 9, 368. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Liu, Y.; Liu, T.; Lin, Z.; Wang, S. DAGN: A Real-Time UAV Remote Sensing Image Vehicle Detection Framework. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1884–1888. [Google Scholar] [CrossRef]
- Shi, F.; Zhang, T.; Zhang, T. Orientation-Aware Vehicle Detection in Aerial Images via an Anchor-Free Object Detection Approach. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5221–5233. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Huang, G.; Liu, Z.; Laurens, V.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016. [Google Scholar]
- Veit, A.; Wilber, M.; Belongie, S. Residual networks behave like ensembles of relatively shallow networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Qing, Y.; Liu, W.; Feng, L.; Gao, W. Improved YOLO Network for Free-Angle Remote Sensing Target Detection. Remote Sens. 2021, 13, 2171. [Google Scholar] [CrossRef]
- Lim, J.S.; Astrid, M.; Yoon, H.J.; Lee, S.I. Small Object Detection using Context and Attention. In Proceedings of the 2021 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Korea, 20–23 April 2021. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Gao, Z.; Huang, T. UnitBox: An Advanced Object Detection Network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016. [Google Scholar]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object Detection in Optical Remote Sensing Images: A Survey and A New Benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Huang, W.; Li, G.; Chen, Q.; Ju, M.; Qu, J. CF2PN: A Cross-Scale Feature Fusion Pyramid Network Based Remote Sensing Target Detection. Remote Sens. 2021, 13, 847. [Google Scholar] [CrossRef]
- Yuan, Z.; Liu, Z.; Zhu, C.; Qi, J.; Zhao, D. Object Detection in Remote Sensing Images via Multi-Feature Pyramid Network with Receptive Field Block. Remote Sens. 2021, 13, 862. [Google Scholar] [CrossRef]
- Li, Y.; Huang, Q.; Pei, X.; Chen, Y.; Jiao, L.; Shang, R. Cross-Layer Attention Network for Small Object Detection in Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2148–2161. [Google Scholar] [CrossRef]
- Xiong, S.; Tan, Y.; Li, Y.; Wen, C.; Yan, P. Subtask Attention Based Object Detection in Remote Sensing Images. Remote Sens. 2021, 13, 1925. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
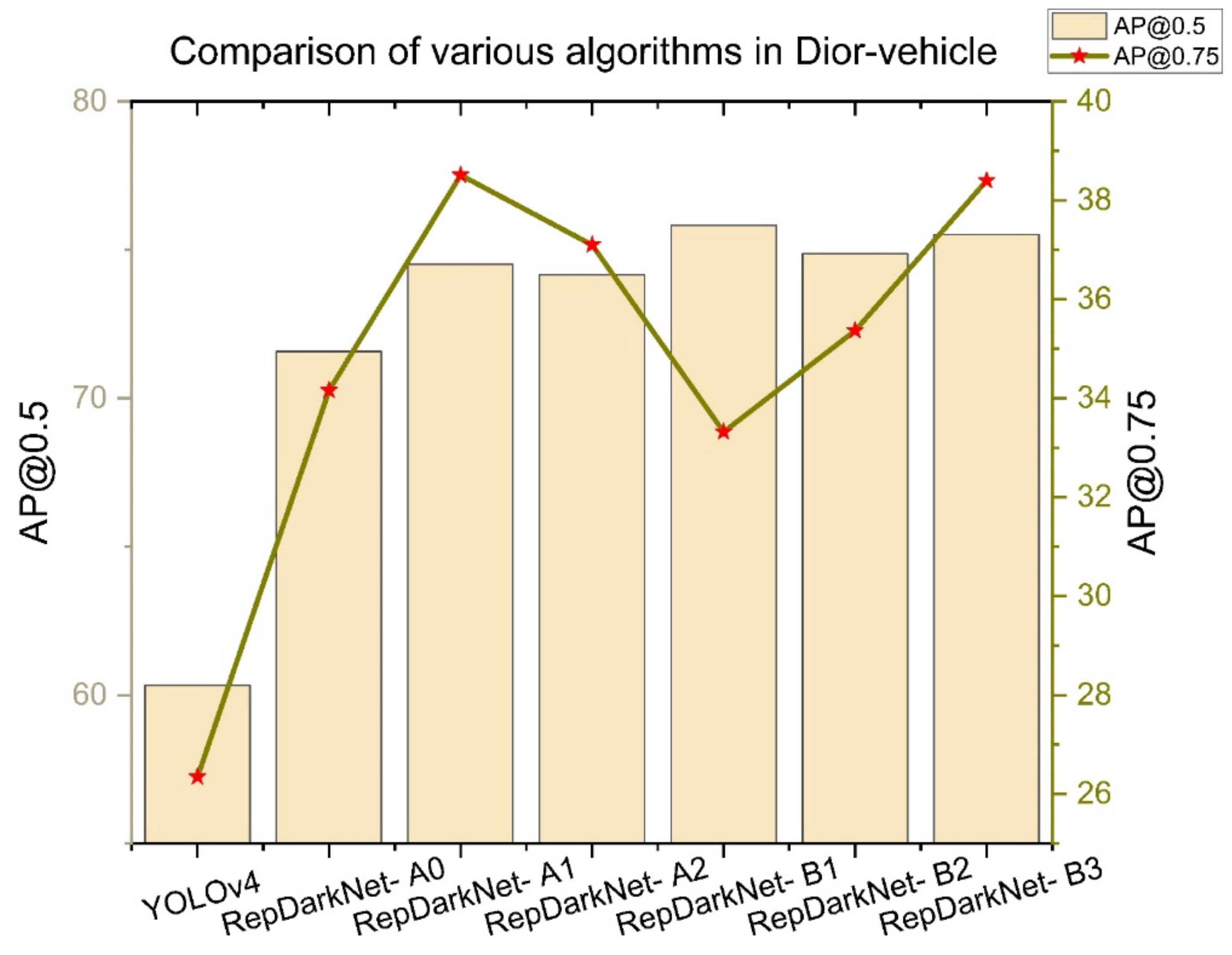
| a | b | c | d | e | AP@0.5(%) | AP@0.75(%) | |
|---|---|---|---|---|---|---|---|
| YOLOv4 | - | - | - | - | - | 60.33 | 26.35 |
| RepDarkNet-A0 | √ | - | - | - | - | 71.58 | 34.16 |
| RepDarkNet-A1 | √ | √ | - | - | - | 74.51 | 38.51 |
| RepDarkNet-A2 | √ | - | √ | - | - | 74.16 | 37.10 |
| RepDarkNet-B1 | √ | - | - | √ | - | 75.82 | 33.32 |
| RepDarkNet-B2 | √ | - | - | √ | √ | 74.87 | 35.37 |
| RepDarkNet-B3 | √ | √ | √ | √ | √ | 75.52 | 38.40 |
| Method | F1-Score | Recall | Precision | IoU |
|---|---|---|---|---|
| YOLOv4 | 58% | 59% | 57% | 42.90% |
| RepDarkNet-A0 | 69% | 68% | 71% | 53.89% |
| RepDarkNet-A1 | 71% | 72% | 70% | 53.84% |
| RepDarkNet-A2 | 72% | 72% | 71% | 54.76% |
| RepDarkNet-B1 | 70% | 75% | 66% | 49.38% |
| RepDarkNet-B2 | 72% | 72% | 72% | 54.75% |
| RepDarkNet-B3 | 72% | 70% | 77% | 59.46% |
| c1 | Airplane | c6 | Chimney | c11 | Ground track field | c16 | Storage tank |
| c2 | Airport | c7 | Dam | c12 | Harbor | c17 | Tennis court |
| c3 | Baseball field | c8 | Expressway service area | c13 | Overpass | c18 | Train station |
| c4 | Basketball court | c9 | Expressway toll station | c14 | Ship | c19 | Vehicle |
| c5 | Bridge | c10 | Golf court | c15 | Stadium | c20 | Windmill |
| Method | Backbone | c1 | c2 | c3 | c4 | c5 | c6 | c7 | c8 | c9 | c10 | c11 | c12 | c13 | c14 | c15 | c16 | c17 | c18 | c19 | c20 | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SSD [30] | VGG16 | 59.5 | 72.7 | 72.4 | 75.7 | 29.7 | 65.8 | 56.6 | 63.5 | 53.1 | 65.3 | 68.6 | 49.4 | 48.1 | 59.2 | 61.0 | 46.6 | 76.3 | 55.1 | 27.4 | 65.7 | 58.6 |
| YOLOv3 [30] | Darknet-53 | 72.2 | 29.2 | 74.0 | 78.6 | 31.2 | 69.7 | 26.9 | 48.6 | 54.4 | 31.1 | 61.1 | 44.9 | 49.7 | 87.4 | 70.6 | 68.7 | 87.3 | 29.4 | 48.3 | 78.7 | 57.1 |
| Faster RCNNwith FPN [30] | ResNet-50 | 54.1 | 71.4 | 63.3 | 81.0 | 42.6 | 72.5 | 57.5 | 68.7 | 62.1 | 73.1 | 76.5 | 42.8 | 56.0 | 71.8 | 57.0 | 53.5 | 81.2 | 53.0 | 43.1 | 80.9 | 63.1 |
| ResNet-101 | 54.0 | 74.5 | 63.3 | 80.7 | 44.8 | 72.5 | 60.0 | 75.6 | 62.3 | 76.0 | 76.8 | 46.4 | 57.2 | 71.8 | 68.3 | 53.8 | 81.1 | 59.5 | 43.1 | 81.2 | 65.1 | |
| Mask-RCNNwith FPN [30] | ResNet-50 | 53.8 | 72.3 | 63.2 | 81.0 | 38.7 | 72.6 | 55.9 | 71.6 | 67.0 | 73.0 | 75.8 | 44.2 | 56.5 | 71.9 | 58.6 | 53.6 | 81.1 | 54.0 | 43.1 | 81.1 | 63.5 |
| ResNet-101 | 53.9 | 76.6 | 63.2 | 80.9 | 40.2 | 72.5 | 60.4 | 76.3 | 62.5 | 76.0 | 75.9 | 46.5 | 57.4 | 71.8 | 68.3 | 53.7 | 81.0 | 62.3 | 43.0 | 81.0 | 65.2 | |
| RetinaNet [30] | ResNet-50 | 53.7 | 77.3 | 69.0 | 81.3 | 44.1 | 72.3 | 62.5 | 76.2 | 66.0 | 77.7 | 74.2 | 50.7 | 59.6 | 71.2 | 69.3 | 44.8 | 81.3 | 54.2 | 45.1 | 83.4 | 65.7 |
| ResNet-101 | 53.3 | 77.0 | 69.3 | 85.0 | 44.1 | 73.2 | 62.4 | 78.6 | 62.8 | 78.6 | 76.6 | 49.9 | 59.6 | 71.1 | 68.4 | 45.8 | 81.3 | 55.2 | 44.4 | 85.5 | 66.1 | |
| PANet [30] | ResNet-50 | 61.9 | 70.4 | 71.0 | 80.4 | 38.9 | 72.5 | 56.6 | 68.4 | 60.0 | 69.0 | 74.6 | 41.6 | 55.8 | 71.7 | 72.9 | 62.3 | 81.2 | 54.6 | 48.2 | 86.7 | 63.8 |
| ResNet-101 | 60.2 | 72.0 | 70.6 | 80.5 | 43.6 | 72.3 | 61.4 | 72.1 | 66.7 | 72.0 | 73.4 | 45.3 | 56.9 | 71.7 | 70.4 | 62.0 | 80.9 | 57.0 | 47.2 | 84.5 | 66.1 | |
| CF2PN [33] | VGG16 | 78.3 | 78.3 | 76.5 | 88.4 | 37 | 71 | 59.9 | 71.2 | 51.2 | 75.6 | 77.1 | 56.8 | 58.7 | 76.1 | 70.6 | 55.5 | 88.8 | 50.8 | 36.9 | 80.4 | 67.3 |
| MFPnet [34] | VGG16 | 76.6 | 83.4 | 80.6 | 82.1 | 44.3 | 75.6 | 68.5 | 85.9 | 63.9 | 77.3 | 77.2 | 62.1 | 58.8 | 77.2 | 76.8 | 60.3 | 86.4 | 64.5 | 41.5 | 80.2 | 71.2 |
| CANet [35] | ResNet-101 | 70.3 | 82.4 | 72 | 87.8 | 55.7 | 79.9 | 67.7 | 83.5 | 77.2 | 77.3 | 83.6 | 56.0 | 63.6 | 81.0 | 79.8 | 70.8 | 88.2 | 67.6 | 51.2 | 89.6 | 74.3 |
| YOLOv4 | CSPDarkNet | 96.0 | 87.9 | 94.7 | 91.9 | 60.0 | 90.8 | 69.9 | 92.1 | 87.5 | 87.6 | 83.7 | 55.6 | 68.7 | 94.6 | 83.8 | 88.4 | 95.7 | 44.4 | 62.1 | 90.4 | 81.3 |
| ours | RepDarkNet | 97.7 | 89.5 | 94.9 | 92.5 | 62.2 | 91.4 | 68.2 | 94.5 | 85.8 | 87.1 | 91.4 | 62.9 | 72.9 | 95.7 | 92.3 | 89.5 | 95.5 | 56.7 | 71.4 | 93.6 | 84.3 |
| Method | AP (%) for Each Target Category | mAP (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PL | SH | ST | BD | TC | BC | GT | HA | BR | VE | ||
| SSD512 [36] | 90.40 | 60.90 | 79.80 | 89.90 | 82.60 | 80.60 | 98.30 | 73.40 | 76.70 | 52.10 | 78.40 |
| SAPNet [36] | 97.80 | 87.60 | 67.20 | 94.80 | 99.50 | 99.50 | 95.90 | 96.80 | 68.00 | 85.10 | 89.20 |
| StAN-Enh [36] | 94.80 | 79.10 | 98.20 | 96.70 | 89.10 | 89.60 | 93.50 | 91.00 | 62.70 | 93.80 | 88.9 |
| CANet [35] | 100.0 | 81.9 | 94.6 | 90.3 | 90.7 | 90.6 | 99.8 | 89.8 | 93.9 | 89.9 | 92.2 |
| YOLOv4 | 99.99 | 81.33 | 98.80 | 97.41 | 97.40 | 95.52 | 99.37 | 82.27 | 77.30 | 93.70 | 92.31 |
| ours | 99.96 | 93.71 | 98.07 | 97.47 | 99.56 | 99.17 | 99.59 | 84.94 | 74.24 | 94.29 | 94.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, L.; Zheng, C.; Yan, H.; Zuo, X.; Liu, Y.; Qiao, B.; Yang, Y. RepDarkNet: A Multi-Branched Detector for Small-Target Detection in Remote Sensing Images. ISPRS Int. J. Geo-Inf. 2022, 11, 158. https://doi.org/10.3390/ijgi11030158
Zhou L, Zheng C, Yan H, Zuo X, Liu Y, Qiao B, Yang Y. RepDarkNet: A Multi-Branched Detector for Small-Target Detection in Remote Sensing Images. ISPRS International Journal of Geo-Information. 2022; 11(3):158. https://doi.org/10.3390/ijgi11030158
Chicago/Turabian StyleZhou, Liming, Chang Zheng, Haoxin Yan, Xianyu Zuo, Yang Liu, Baojun Qiao, and Yong Yang. 2022. "RepDarkNet: A Multi-Branched Detector for Small-Target Detection in Remote Sensing Images" ISPRS International Journal of Geo-Information 11, no. 3: 158. https://doi.org/10.3390/ijgi11030158
APA StyleZhou, L., Zheng, C., Yan, H., Zuo, X., Liu, Y., Qiao, B., & Yang, Y. (2022). RepDarkNet: A Multi-Branched Detector for Small-Target Detection in Remote Sensing Images. ISPRS International Journal of Geo-Information, 11(3), 158. https://doi.org/10.3390/ijgi11030158