
VINS-Dimc: A Visual-Inertial Navigation System for Dynamic Environment Integrating Multiple Constraints


Abstract
:1. Introduction
- FVB constraints were combined with IMU data. The motion model and epipolar were calculated using IMU data, and the dynamic feature point offset along the epipolar was eliminated using the FVB constraints.
- This method combined multiple constraints and used epipolar, FVB, GMS, and sliding window constraints, to compensate for the shortcomings of a single constraint and help VINS achieve more accurate feature matching.
- The proposed algorithm was integrated with VINS-mono, and VINS-dimc is proposed. We have conducted experiments with VINS-dimc.
2. Materials and Methods
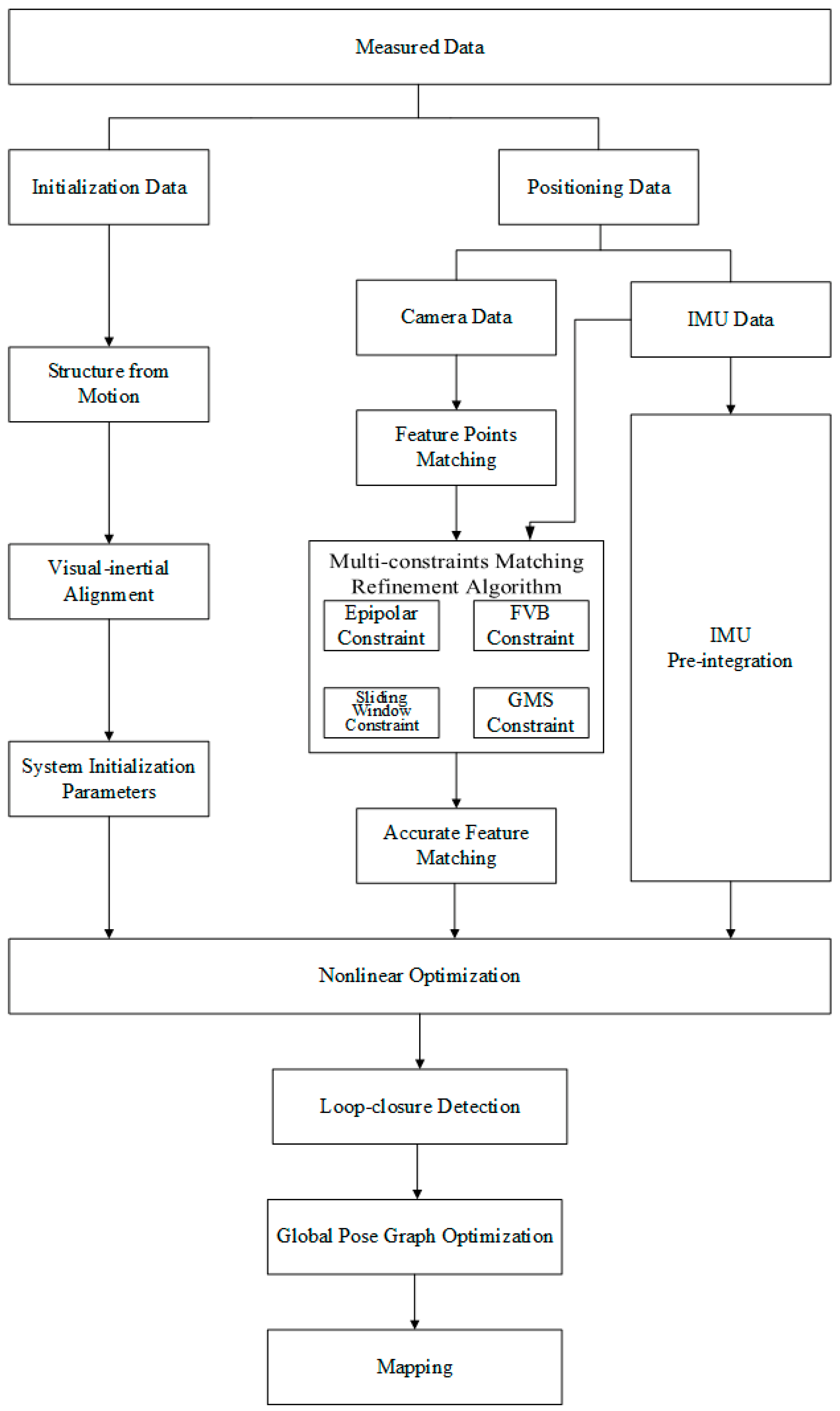
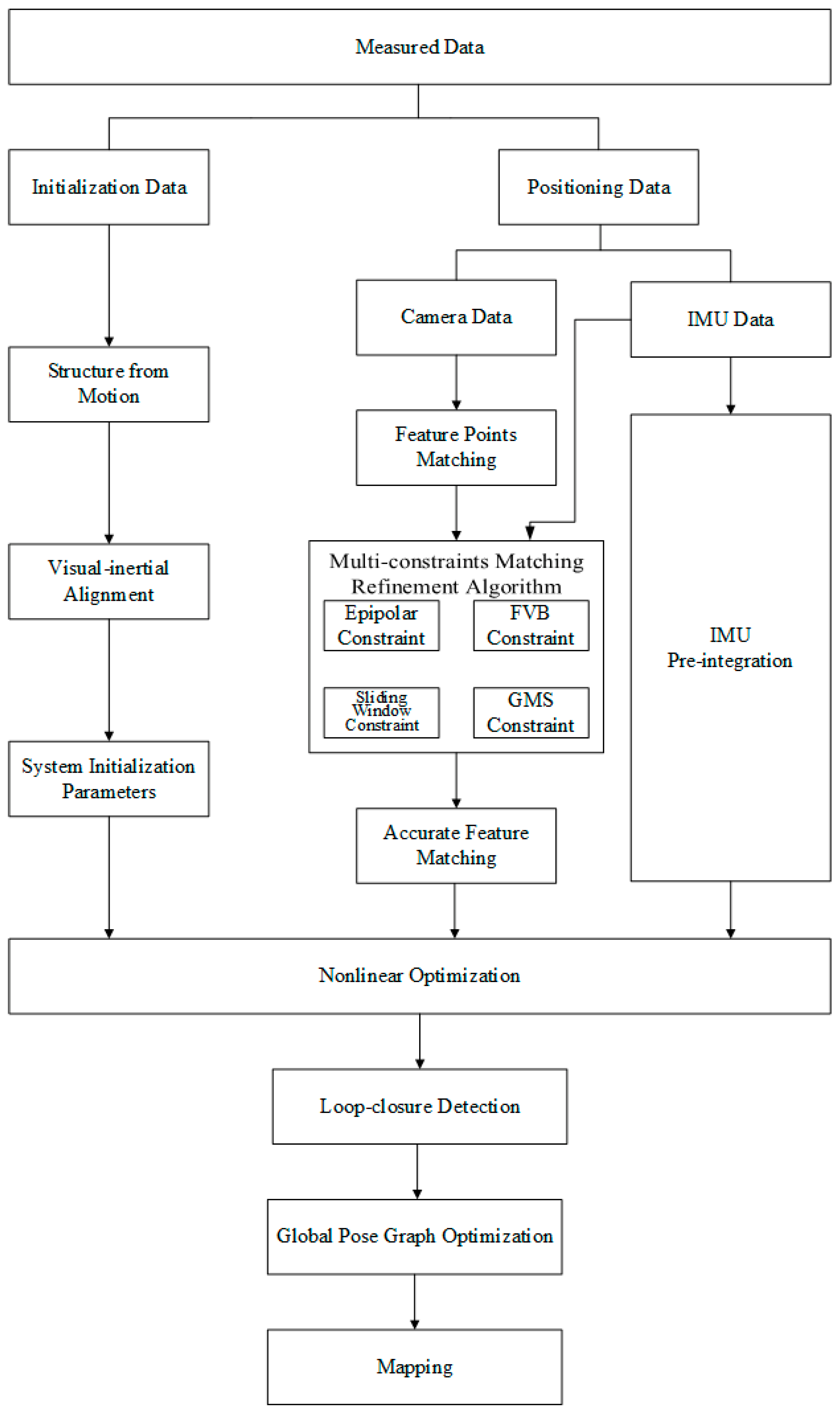
2.1. Overview
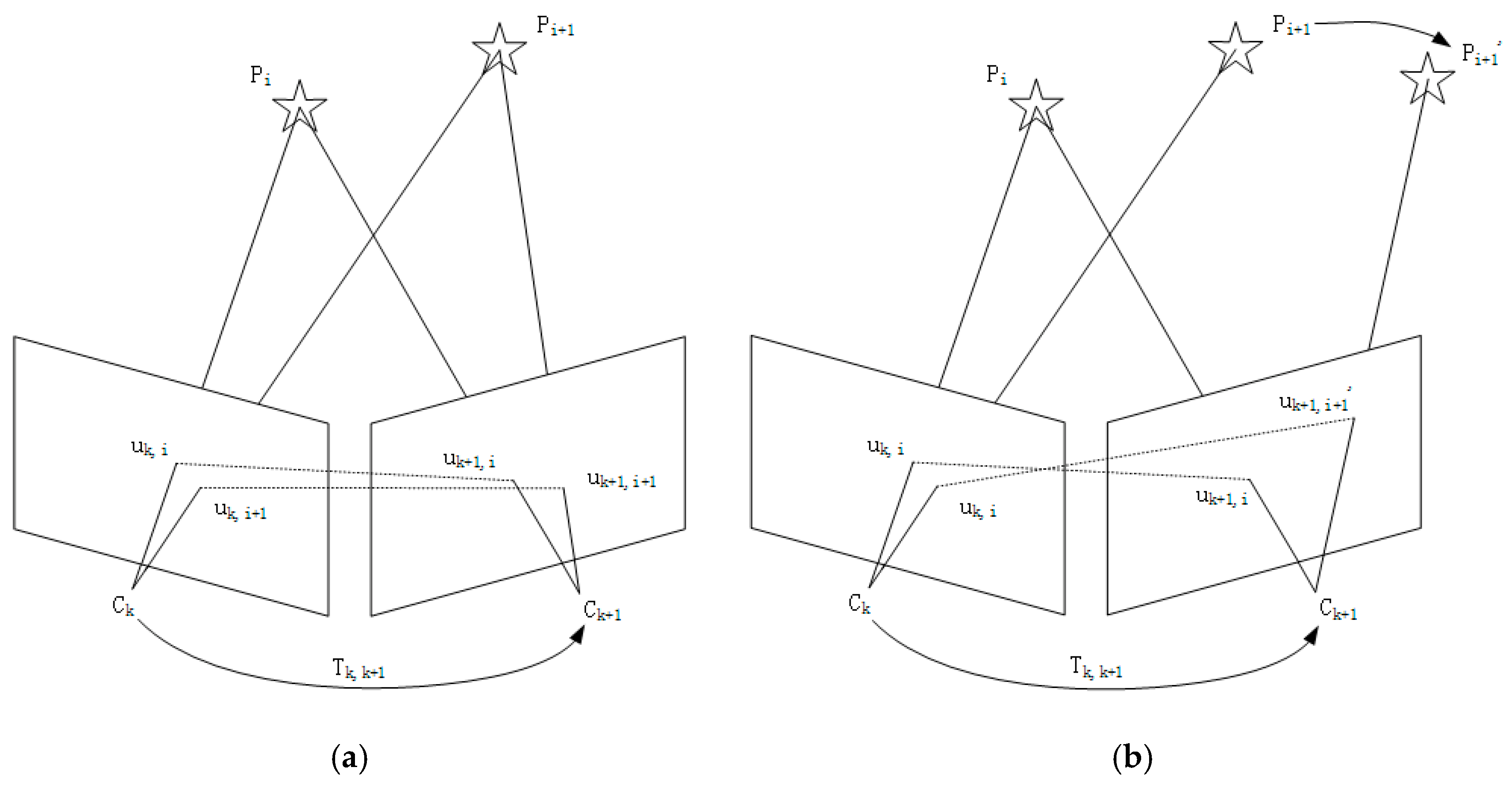
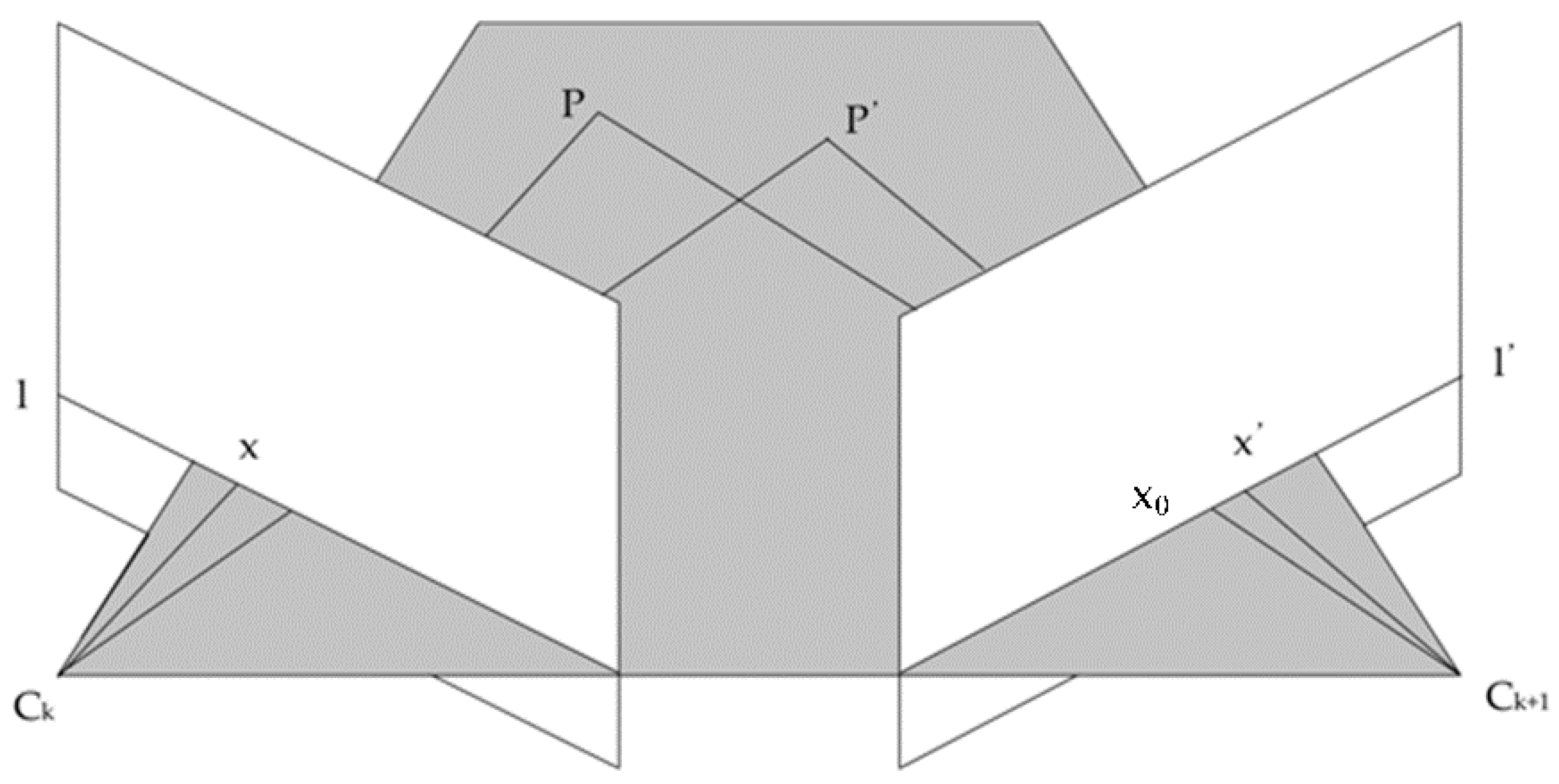
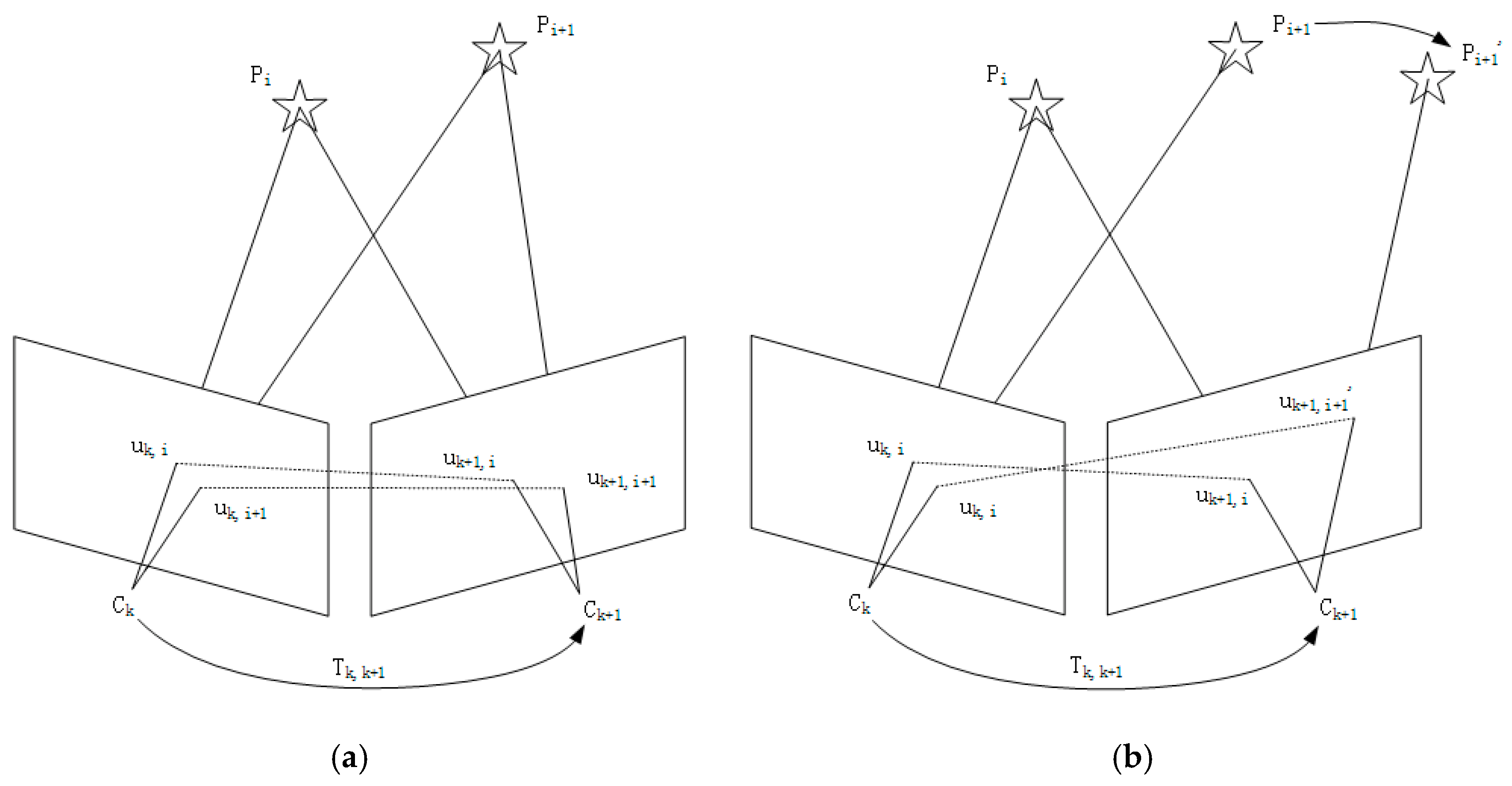
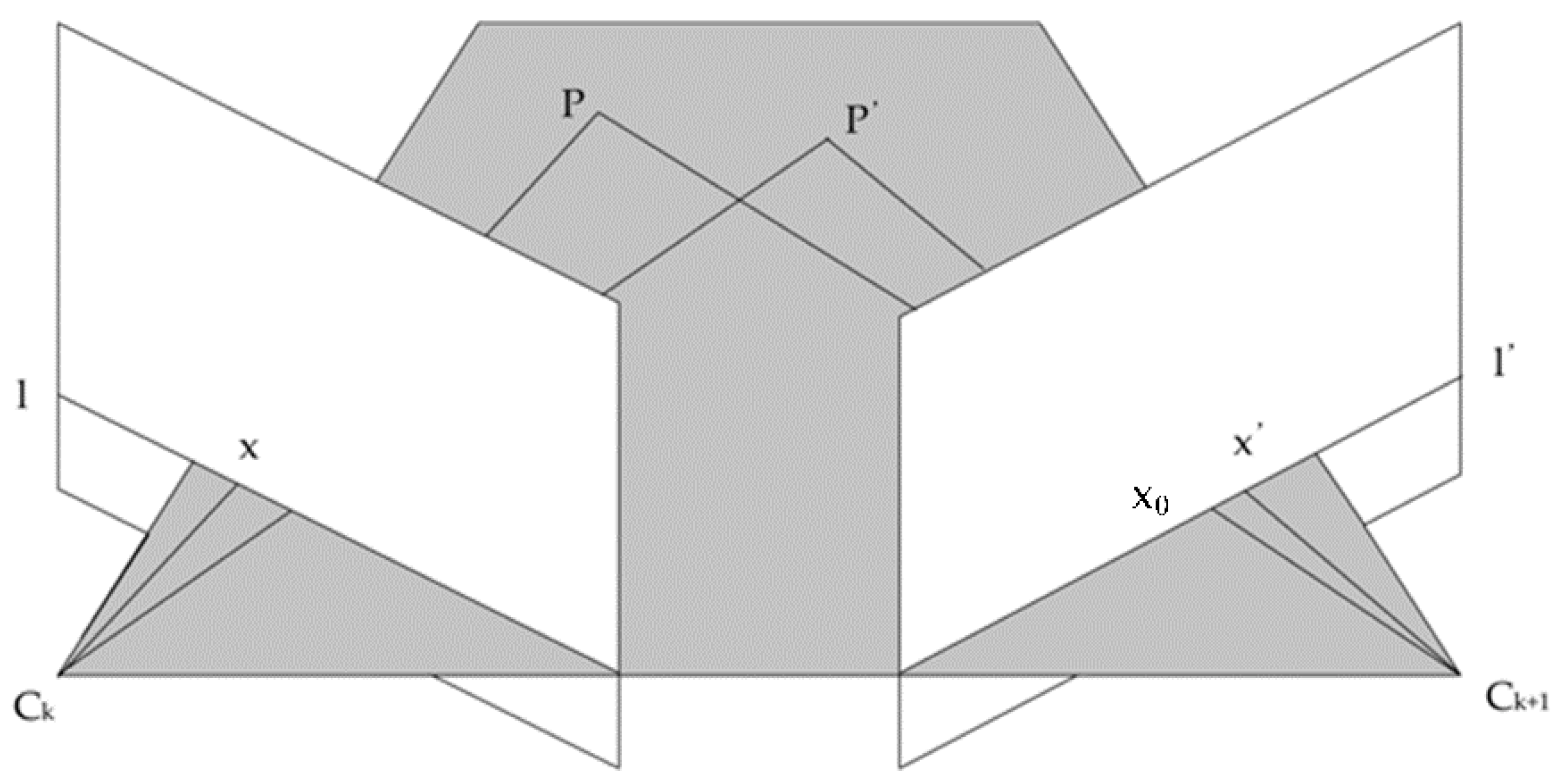
2.2. IMU Data Validity Discrimination and Epipolar Constraint
2.3. Multi Constraint Fusion Strategy
2.3.1. FVB Constraint
2.3.2. GMS Constraint
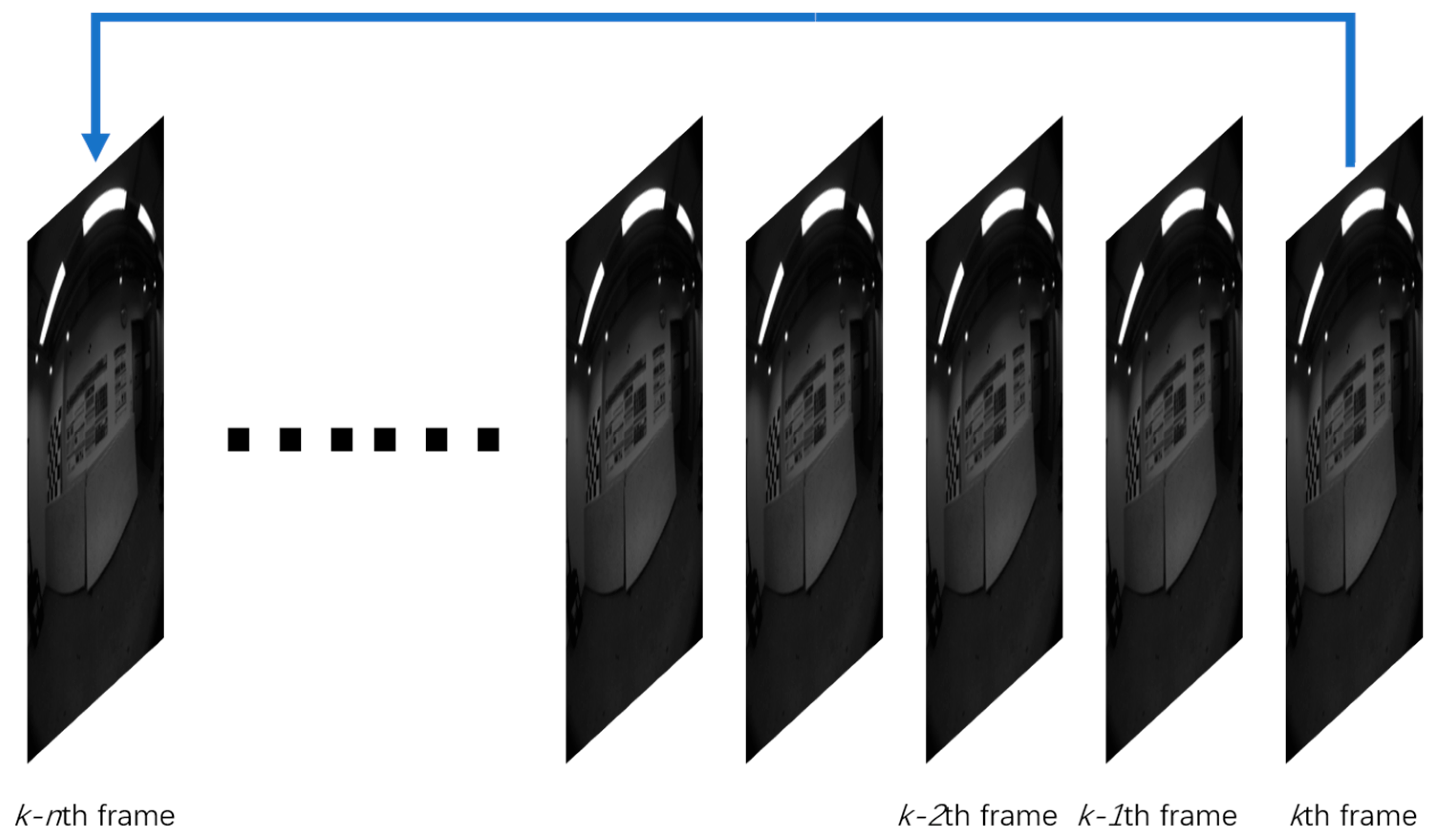
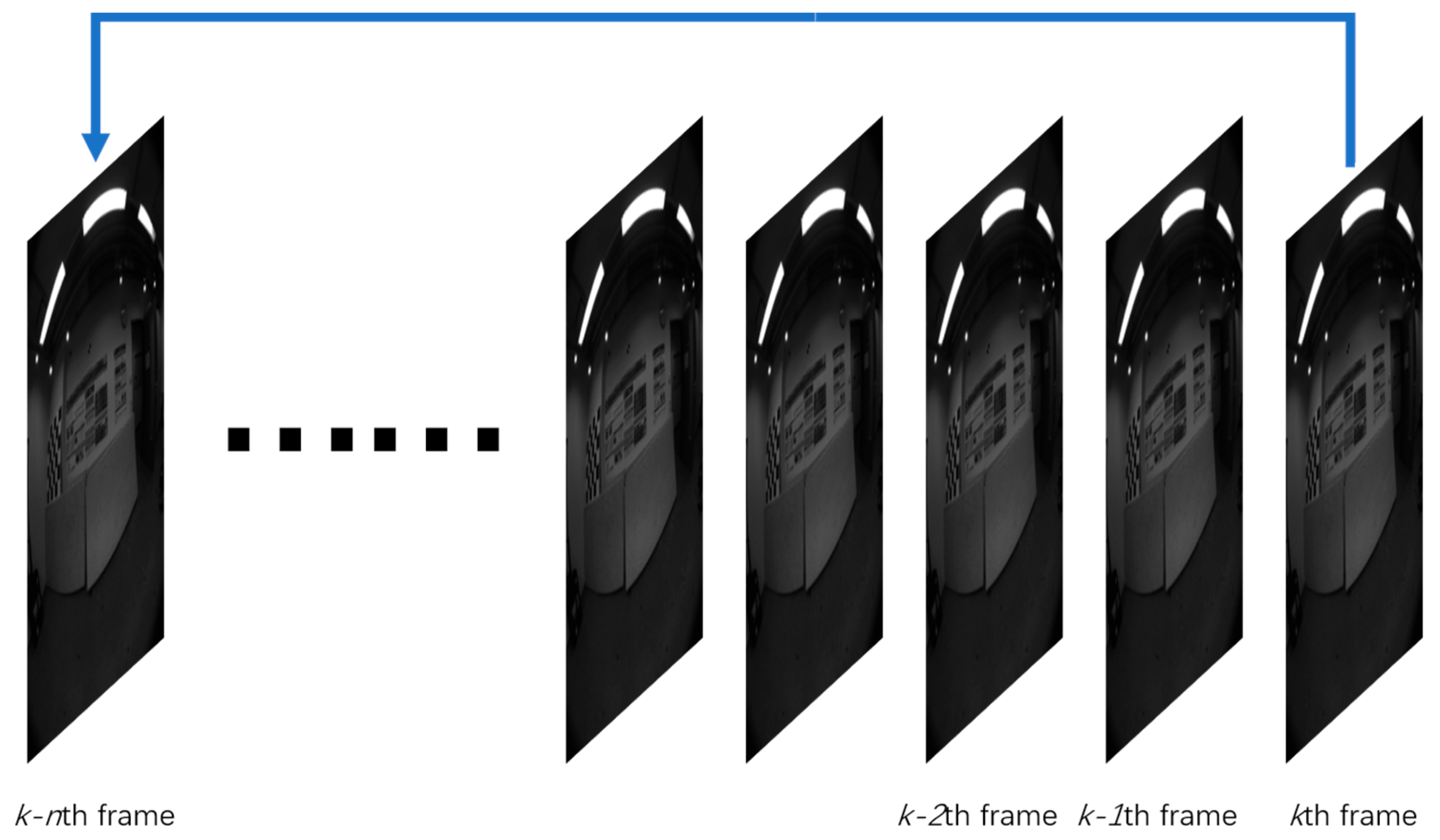
2.3.3. Sliding Window Constraint
2.3.4. Multi-Constraint Fusion Algorithm
3. Experiment
3.1. Feature Point Matching Experiment
3.1.1. Materials and Experimental Setup
3.1.2. Results
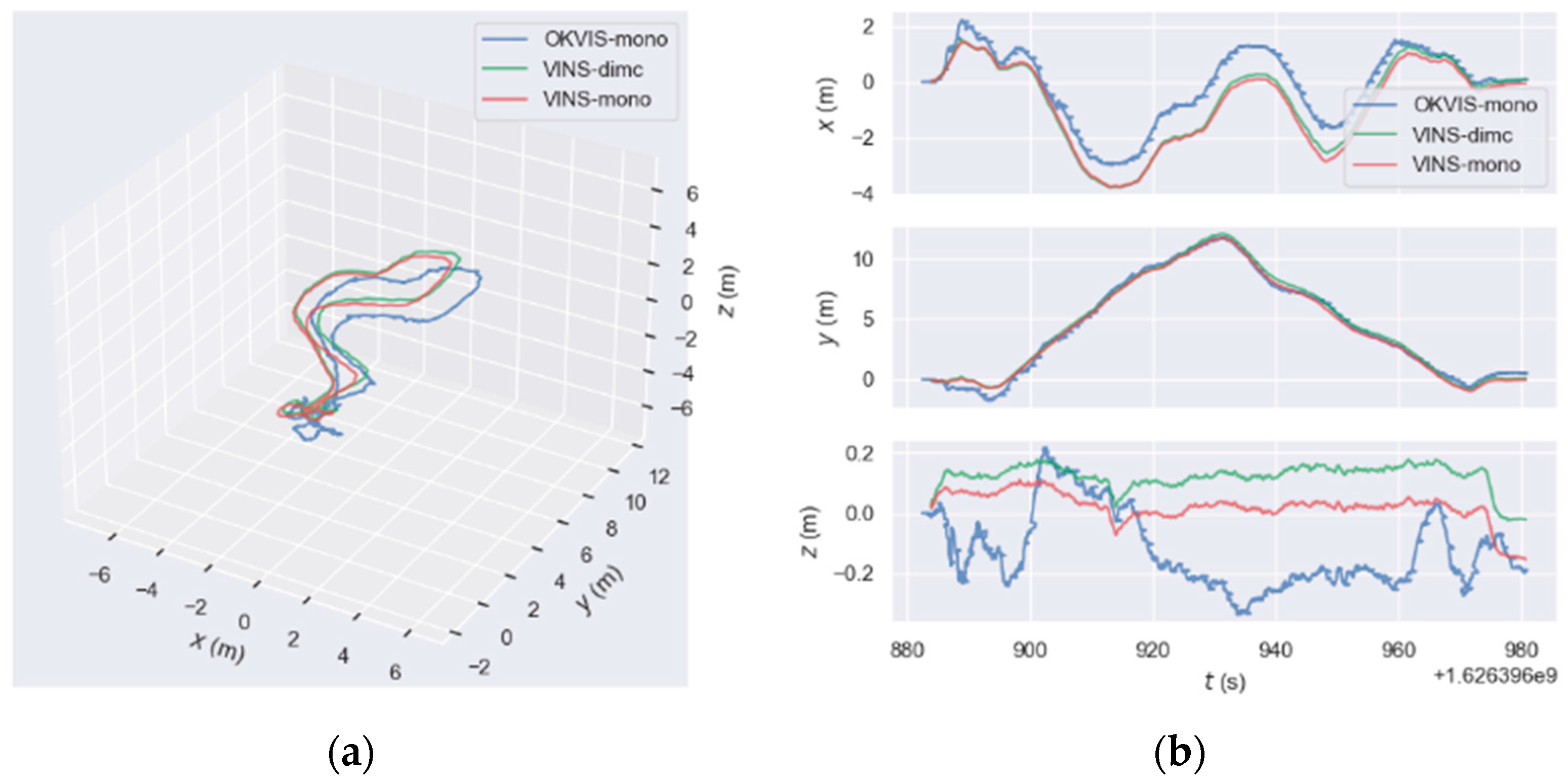
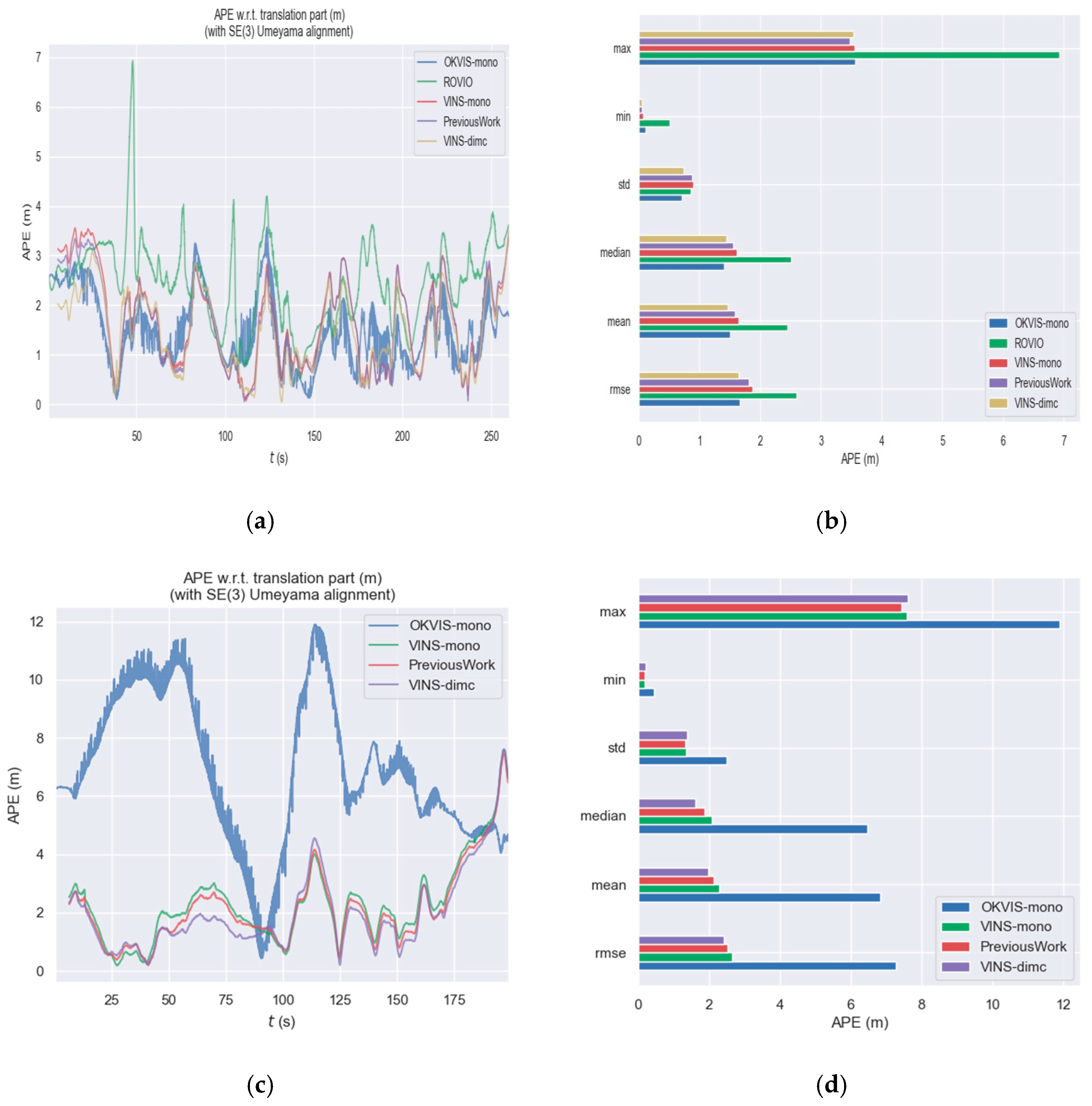
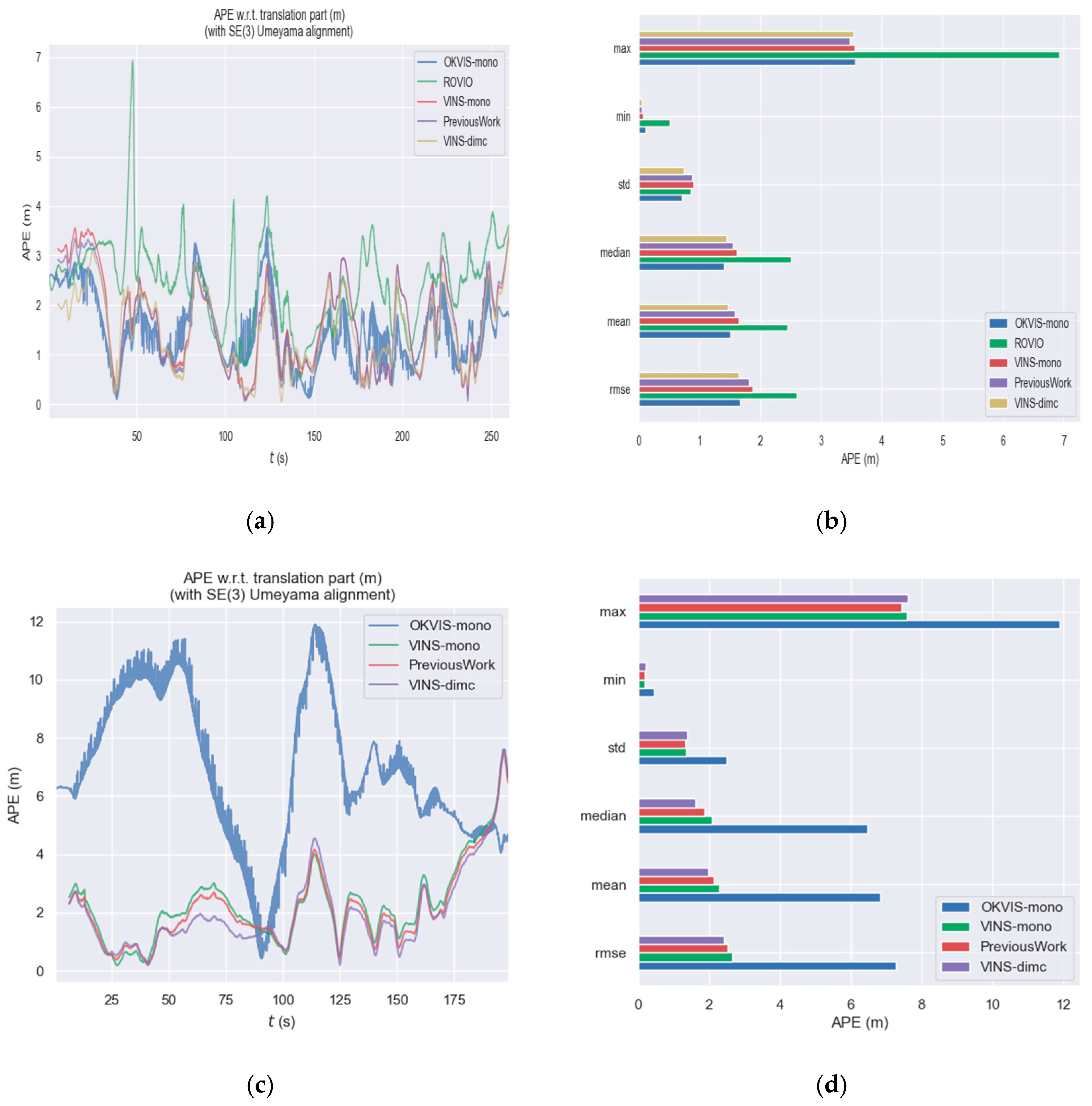
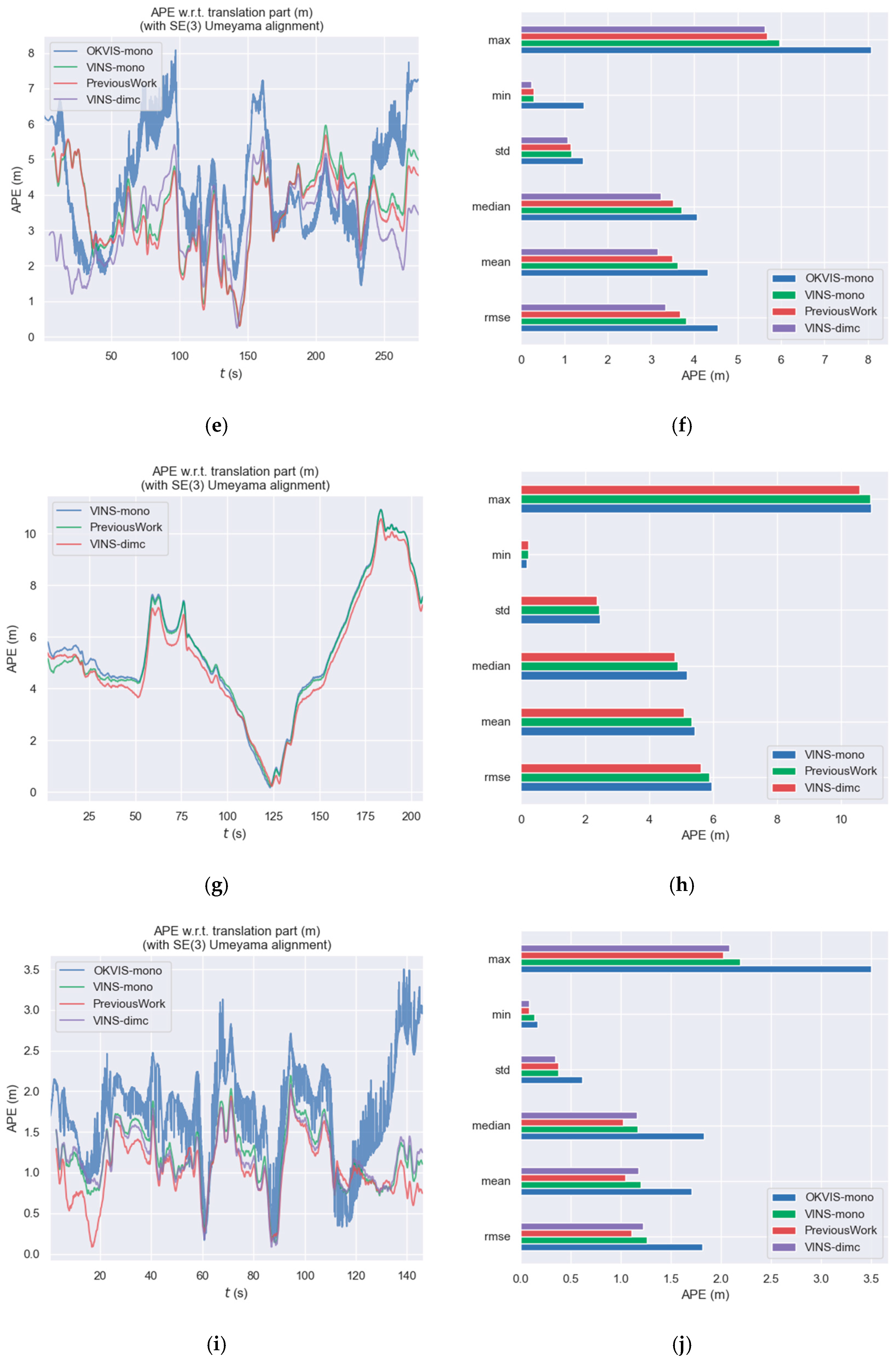
3.2. VINS Positioning Experiment
3.2.1. Materials and Experimental Setup
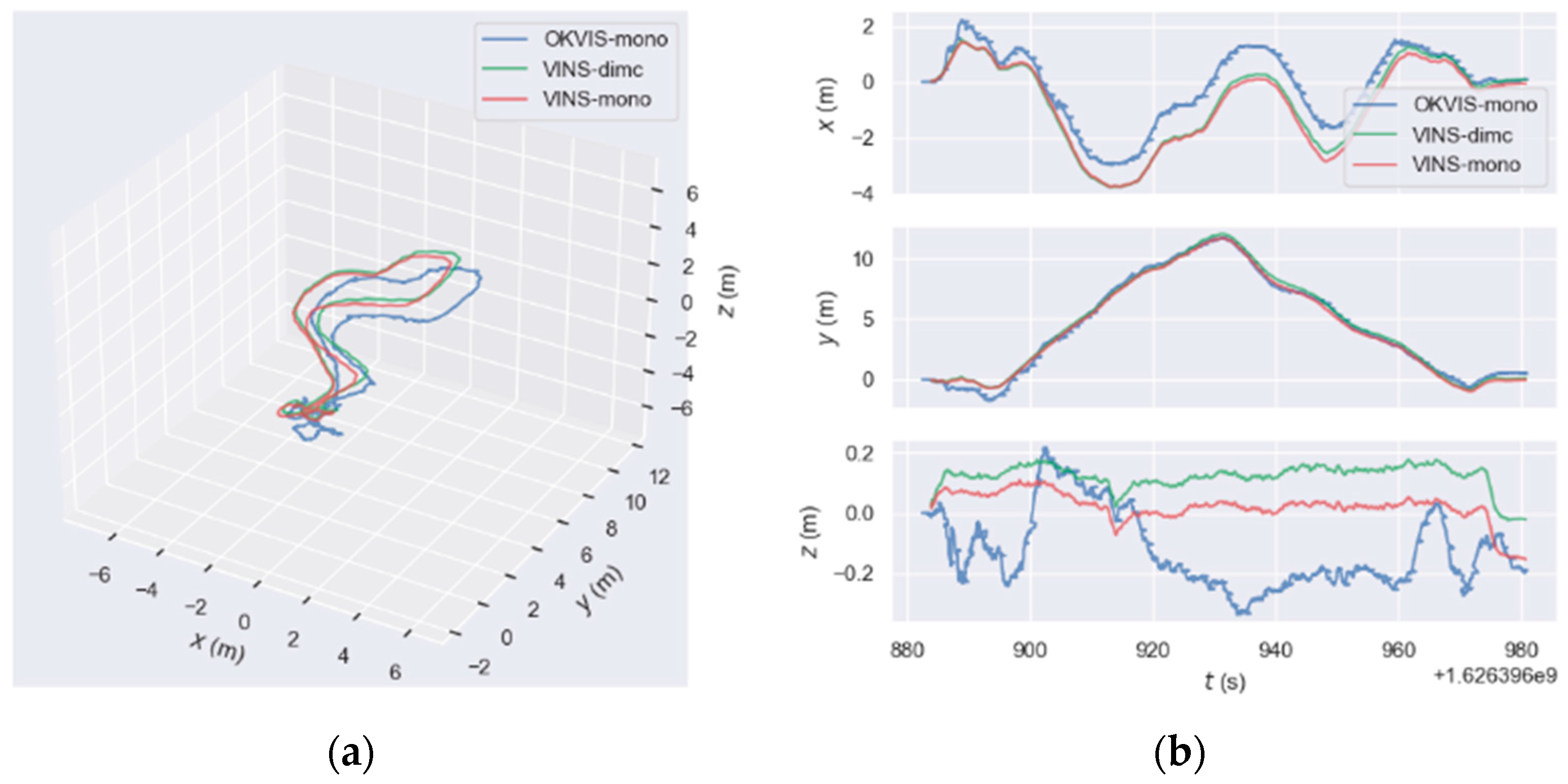
3.2.2. Results
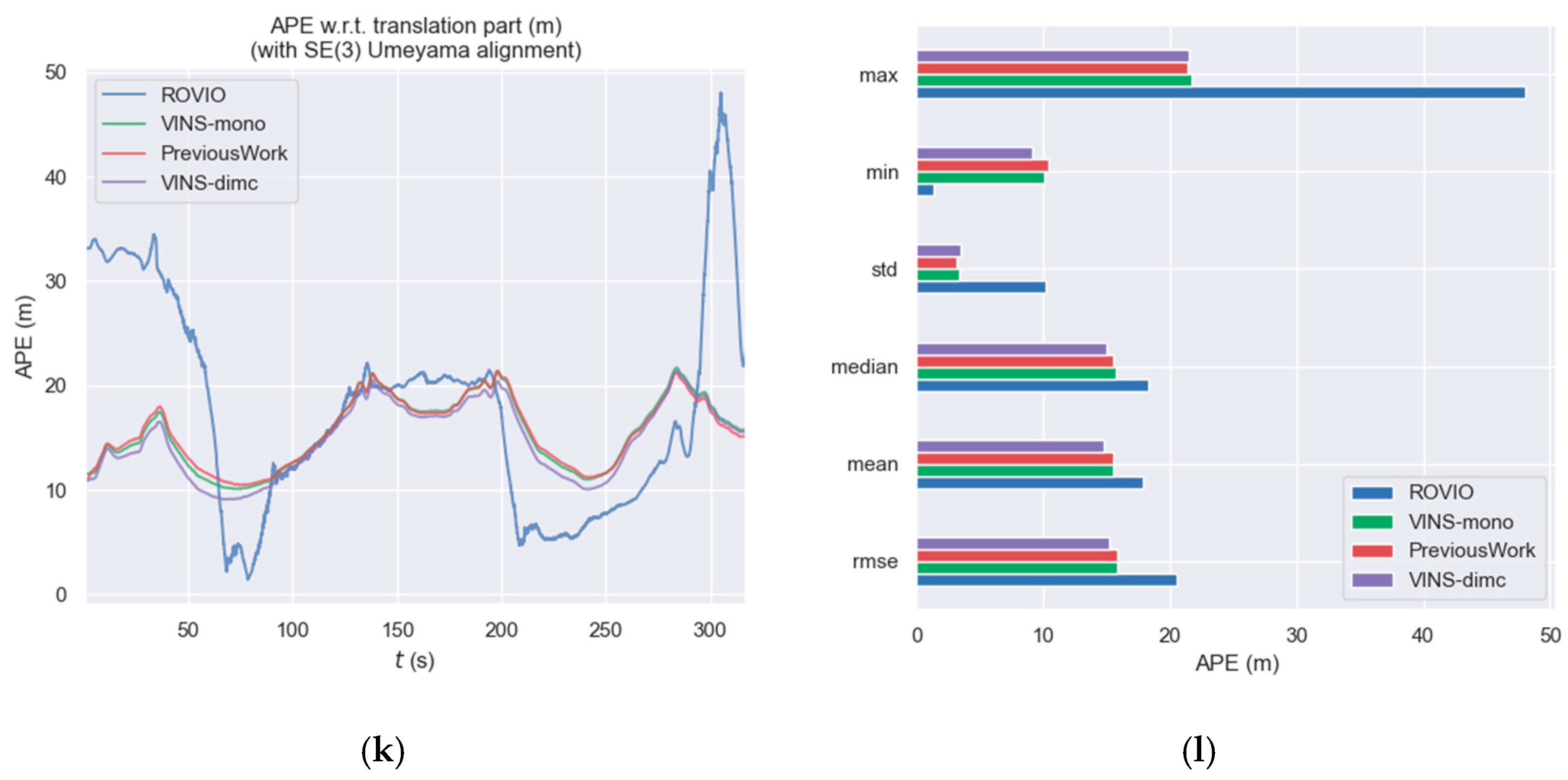
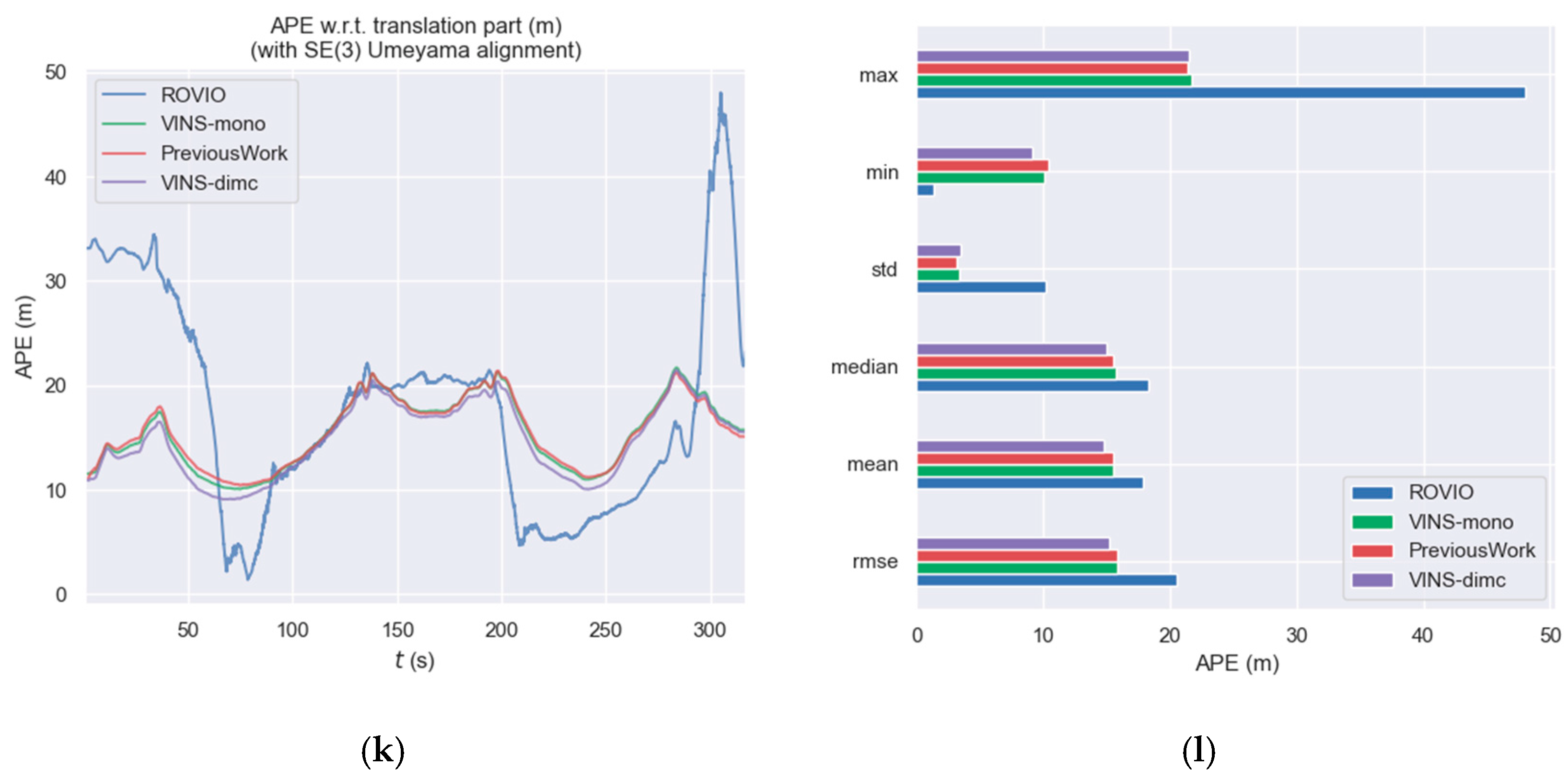
3.3. ADVIO Dataset Experiment
3.3.1. Materials and Experimental Setup
3.3.2. Experimental Results
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alliez, P.; Bonardi, F.; Bouchafa, S.; Didier, J.-Y.; Hadj-Abdelkader, H.; Muñoz, F.I.I.; Kachurka, V.; Rault, B.; Robin, M.; Roussel, D. Real-time multi-SLAM system for agent localization and 3D mapping in dynamic scenarios. In Proceedings of the International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 24–30 October 2020; IROS: Las Vegas, NV, USA, 2020. [Google Scholar]
- Ram, K.; Kharyal, C.; Harithas, S.S.; Krishna, K.M. RP-VIO: Robust plane-based visual-inertial odometry for dynamic environments. arXiv 2021, arXiv:2103.10400. [Google Scholar]
- Bonin-Font, F.; Ortiz, A.; Oliver, G. Visual navigation for mobile robots: A survey. J. Intell. Robot. Syst. 2008, 53, 263–296. [Google Scholar] [CrossRef]
- Yang, D.; Bi, S.; Wang, W.; Yuan, C.; Wang, W.; Qi, X.; Cai, Y. DRE-SLAM: Dynamic RGB-D encoder SLAM for a differential-drive robot. Remote Sens. 2019, 11, 380. [Google Scholar] [CrossRef] [Green Version]
- Sibley, G.; Mei, C.; Reid, I.; Newman, P. Vast-scale outdoor navigation using adaptive relative bundle adjustment. Int. J. Robot. Res. 2010, 29, 958–980. [Google Scholar] [CrossRef]
- Yang, S.; Scherer, S.A.; Yi, X.; Zell, A. Multi-camera visual SLAM for autonomous navigation of micro aerial vehicles. Robot. Auton. Syst. 2017, 93, 116–134. [Google Scholar] [CrossRef]
- Gao, Q.H.; Wan, T.R.; Tang, W.; Chen, L.; Zhang, K.B. An improved augmented reality registration method based on visual SLAM. In E-Learning and Games; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; pp. 11–19. [Google Scholar]
- Mahmoud, N.; Grasa, Ó.G.; Nicolau, S.A.; Doignon, C.; Soler, L.; Marescaux, J.; Montiel, J. On-patient see-through augmented reality based on visual SLAM. Int. J. Comput. Assist. Radiol. Surg. 2017, 12, 1–11. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. Vins-Mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef] [Green Version]
- Leutenegger, S.; Lynen, S.; Bosse, M.; Siegwart, R.; Furgale, P. Keyframe-based visual–inertial odometry using nonlinear optimization. Int. J. Robot. Res. 2015, 34, 314–334. [Google Scholar] [CrossRef] [Green Version]
- Bloesch, M.; Omari, S.; Hutter, M.; Siegwart, R. Robust visual inertial odometry using a direct EKF-based approach. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 298–304. [Google Scholar]
- Mourikis, A.I.; Roumeliotis, S.I. A multi-state constraint Kalman filter for vision-aided inertial navigation. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007; pp. 3565–3572. [Google Scholar]
- Geneva, P.; Eckenhoff, K.; Lee, W.; Yang, Y.; Huang, G. Openvins: A research platform for visual-inertial estimation. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation, Paris, France, 31 May–31 August 2020; pp. 4666–4672. [Google Scholar]
- Wang, R.; Wan, W.; Wang, Y.; Di, K. A new RGB-D SLAM method with moving object detection for dynamic indoor scenes. Remote Sens. 2019, 11, 1143. [Google Scholar] [CrossRef] [Green Version]
- Cheng, J.; Sun, Y.; Meng, M.Q.-H. Improving monocular visual SLAM in dynamic Environments: An Optical-Flow-Based Approach. Adv. Robot. 2019, 33, 576–589. [Google Scholar] [CrossRef]
- Shimamura, J.; Morimoto, M.; Koike, H. Robust vSLAM for dynamic scenes. In Proceedings of the MVA, Nara, Japan, 6–8 June 2011; Volume 2011, pp. 344–347. [Google Scholar]
- Tan, W.; Liu, H.; Dong, Z.; Zhang, G.; Bao, H. Robust monocular SLAM in dynamic environments. In Proceedings of the 2013 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Adelaide, Australia, 1–4 October 2013; Volume 2013, pp. 209–218. [Google Scholar]
- Rünz, M.; Agapito, L. Co-Fusion: Real-time segmentation, tracking and fusion of multiple objects. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May 2017; pp. 4471–4478. [Google Scholar]
- Sun, Y.; Liu, M.; Meng, M.Q.-H. Improving RGB-D SLAM in dynamic environments: A motion removal approach. Robot. Auton. Syst. 2017, 89, 110–122. [Google Scholar] [CrossRef]
- Alcantarilla, P.F.; Yebes, J.J.; Almazán, J.; Bergasa, L.M. On combining visual SLAM and dense scene flow to increase the robustness of localization and mapping in dynamic environments. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Bielefeld, Germany, 13–17 August 2012; Volume 2012, pp. 1290–1297. [Google Scholar]
- Lee, D.; Myung, H. Solution to the SLAM problem in low dynamic environments using a pose graph and an RGB-D sensor. Sensors 2014, 14, 12467–12496. [Google Scholar] [CrossRef]
- Li, A.; Wang, J.; Xu, M.; Chen, Z. DP-SLAM: A visual SLAM with moving probability towards dynamic environments. Inf. Sci. 2021, 556, 128–142. [Google Scholar] [CrossRef]
- Nam, D.V.; Gon-Woo, K.J.S. Robust stereo visual inertial navigation system based on multi-stage outlier removal in dynamic environments. Sensors 2020, 20, 2922. [Google Scholar] [CrossRef]
- Wang, Y.; Huang, S. Towards dense moving object segmentation based robust dense RGB-D SLAM in dynamic scenarios. In Proceedings of the 2014 13th International Conference on Control Automation Robotics & Vision (ICARCV), Singapore, 10–12 December 2014; Volume 2014, pp. 1841–1846. [Google Scholar]
- Yang, S.; Scherer, S. Cubeslam: Monocular 3-D Object Slam. IEEE Trans. Robot. 2019, 35, 925–938. [Google Scholar] [CrossRef] [Green Version]
- Bescos, B.; Fácil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, mapping, and inpainting in dynamic scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef] [Green Version]
- Yu, C.; Liu, Z.; Liu, X.-J.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. DS-SLAM: A semantic visual SLAM towards dynamic environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1168–1174. [Google Scholar]
- Brasch, N.; Bozic, A.; Lallemand, J.; Tombari, F. Semantic monocular SLAM for highly dynamic environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; Volume 2018, pp. 393–400. [Google Scholar]
- Jiao, J.; Wang, C.; Li, N.; Deng, Z.; Xu, W. An adaptive visual dynamic-SLAM method based on fusing the semantic information. IEEE Publ. Sens. J. 2021. [Google Scholar] [CrossRef]
- Zhang, C.; Huang, T.; Zhang, R.; Yi, X. PLD-SLAM: A new RGB-D SLAM method with point and line features for indoor dynamic scene. Inf. Sci. 2021, 10, 163. [Google Scholar] [CrossRef]
- Fu, D.; Xia, H.; Qiao, Y. Monocular visual-inertial navigation for dynamic environment. Remote Sens. 2021, 13, 1610. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D.; Letters, A. visual-inertial monocular SLAM with map reuse. IEEE Robot. Autom. Lett. 2017, 2, 796–803. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Shen, S. Monocular visual–inertial state estimation with online initialization and camera–IMU extrinsic calibration. IEEE Trans. Robot. 2016, 14, 39–51. [Google Scholar] [CrossRef]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Kundu, A.; Krishna, K.M.; Sivaswamy, J. Moving object detection by multi-view geometric techniques from a single camera mounted robot. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009; Volume 2009, pp. 4306–4312. [Google Scholar]
- Bian, J.; Lin, W.; Liu, Y.; Zhang, L.; Yeung, S.; Cheng, M.; Reid, I. GMS: Grid-based motion statistics for fast, ultra-robust feature correspondence. Int. J. Comput. Vis. 2020, 128, 1580–1593. [Google Scholar] [CrossRef] [Green Version]
- Intel. RealSense. Available online: https://www.intelrealsense.com/depth-camera-d435i (accessed on 28 September 2020).
- Cortés, S.; Solin, A.; Rahtu, E.; Kannala, J. ADVIO: An authentic dataset for visual-inertial odometry. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 425–440. [Google Scholar]
- Solin, A.; Cortes, S.; Rahtu, E.; Kannala, J. Inertial odometry on handheld smartphones. In Proceedings of the 2018 21st International Conference on Information Fusion (Fusion), Cambridge, UK, 10–13 July 2018; Volume 2018, pp. 1–5. [Google Scholar]
- Grupp, M. Evo: Python Package for the Evaluation of Odometry and SLAM. Available online: https://github.com/MichaelGrupp/evo (accessed on 20 April 2021).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | Venue | Object | People | OKVIS-Mono | ROVIO | VINS-Mono | Previous Work | VINS-dimc |
|---|---|---|---|---|---|---|---|---|
| 1 | Mall | Escalator | Moderate | 1.6606 | 2.5990 | 1.8393 | 1.8140 | 1.6428 |
| 2 | Mall | None | Moderate | 7.2727 | - | 2.5336 | 2.5160 | 2.4170 |
| 6 | Mall | None | High | 4.5450 | - | 3.8394 | 3.6688 | 3.3327 |
| 11 | Metro | Vehicles | High | - | - | 5.8722 | 5.8740 | 5.6198 |
| 16 | Office | Stairs | None | 1.8130 | - | 1.2584 | 1.1092 | 1.2231 |
| 21 | Urban | Vehicles | Low | - | 20.5237 | 15.8333 | 15.8889 | 15.1988 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, D.; Xia, H.; Liu, Y.; Qiao, Y. VINS-Dimc: A Visual-Inertial Navigation System for Dynamic Environment Integrating Multiple Constraints. ISPRS Int. J. Geo-Inf. 2022, 11, 95. https://doi.org/10.3390/ijgi11020095
Fu D, Xia H, Liu Y, Qiao Y. VINS-Dimc: A Visual-Inertial Navigation System for Dynamic Environment Integrating Multiple Constraints. ISPRS International Journal of Geo-Information. 2022; 11(2):95. https://doi.org/10.3390/ijgi11020095
Chicago/Turabian StyleFu, Dong, Hao Xia, Yujie Liu, and Yanyou Qiao. 2022. "VINS-Dimc: A Visual-Inertial Navigation System for Dynamic Environment Integrating Multiple Constraints" ISPRS International Journal of Geo-Information 11, no. 2: 95. https://doi.org/10.3390/ijgi11020095
APA StyleFu, D., Xia, H., Liu, Y., & Qiao, Y. (2022). VINS-Dimc: A Visual-Inertial Navigation System for Dynamic Environment Integrating Multiple Constraints. ISPRS International Journal of Geo-Information, 11(2), 95. https://doi.org/10.3390/ijgi11020095