

A Trajectory Big Data Storage Model Incorporating Partitioning and Spatio-Temporal Multidimensional Hierarchical Organization
Abstract
1. Introduction
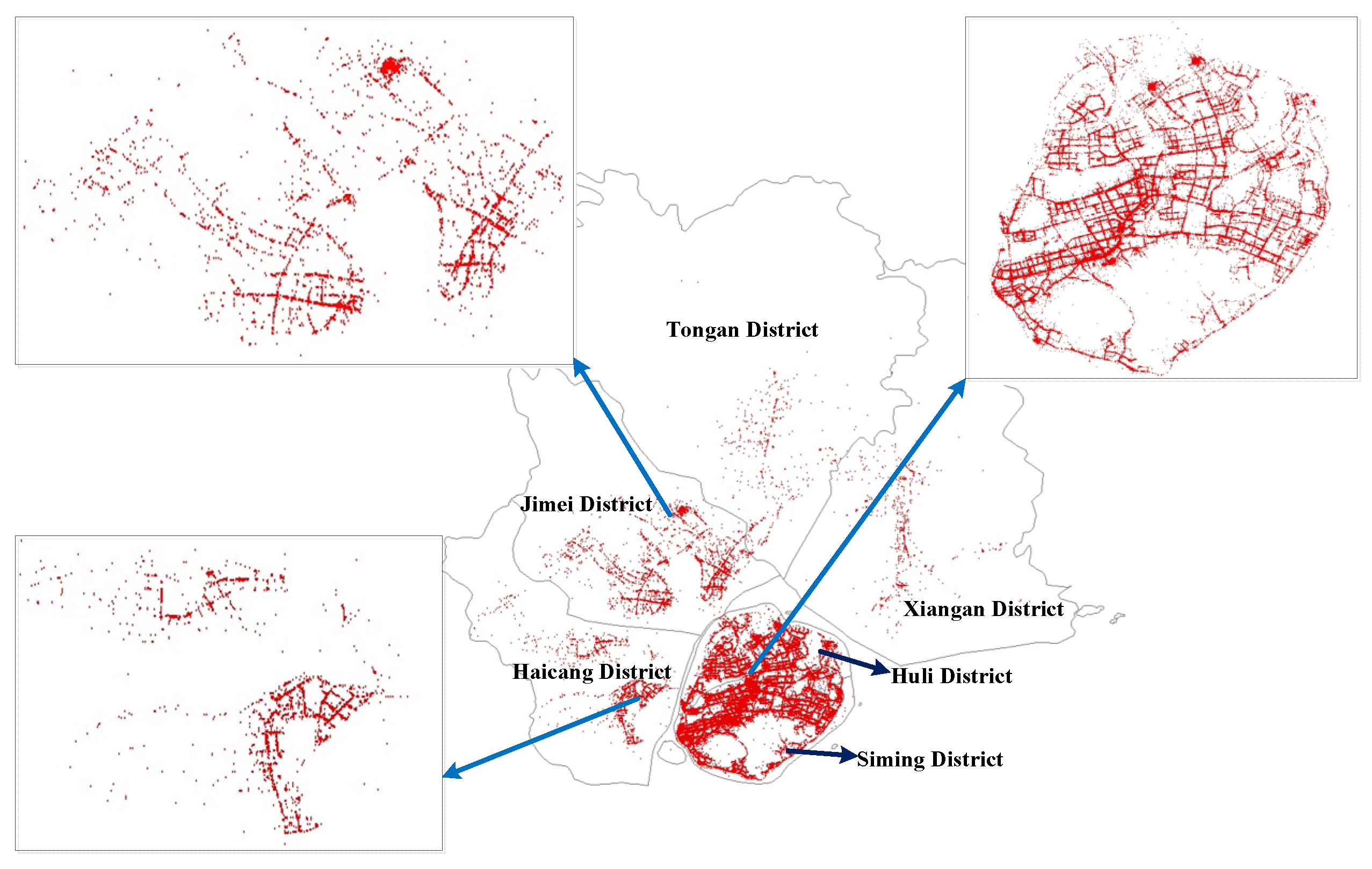
2. Study Area and Dataset
2.1. Study Area
2.2. Experimental Data
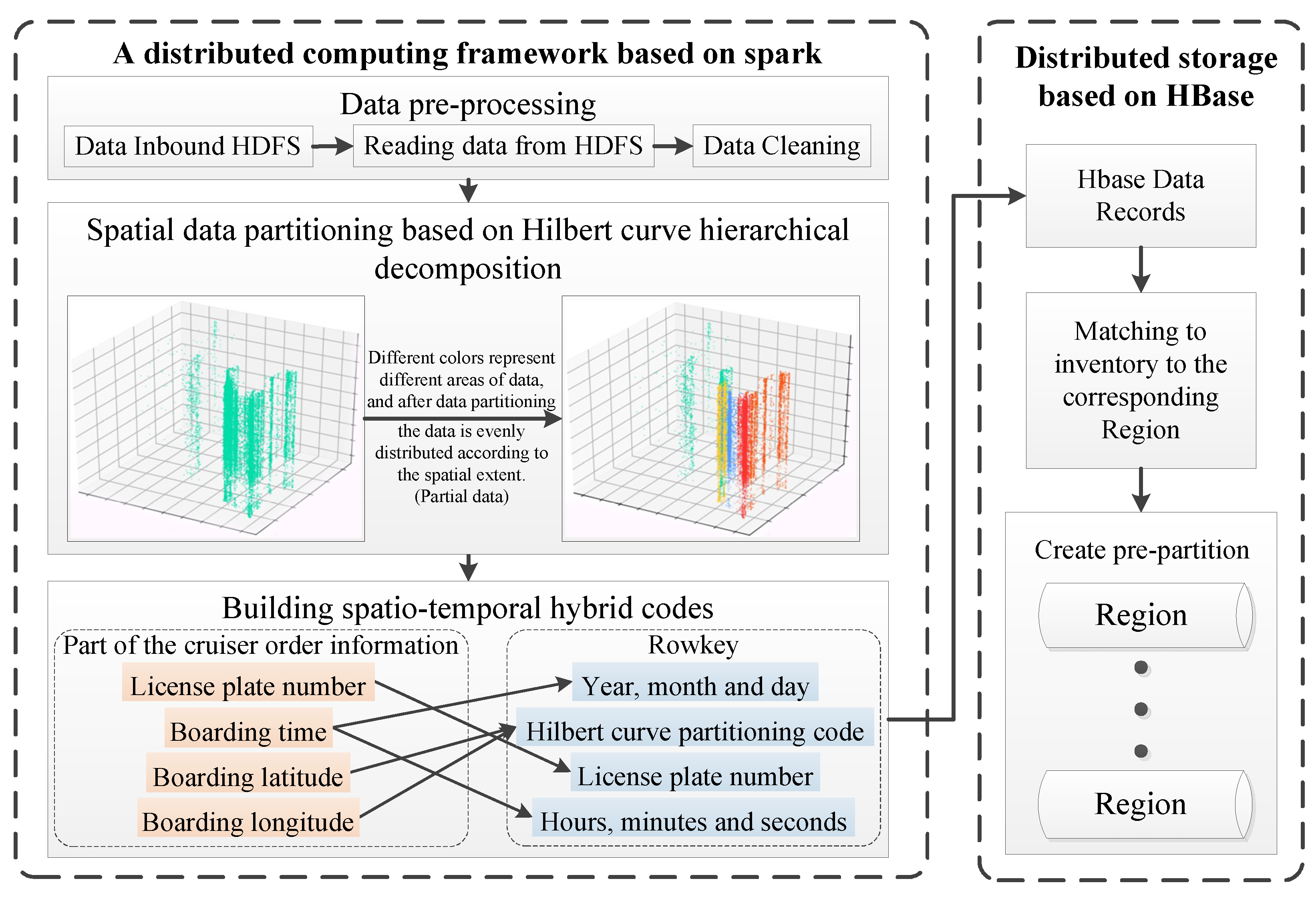
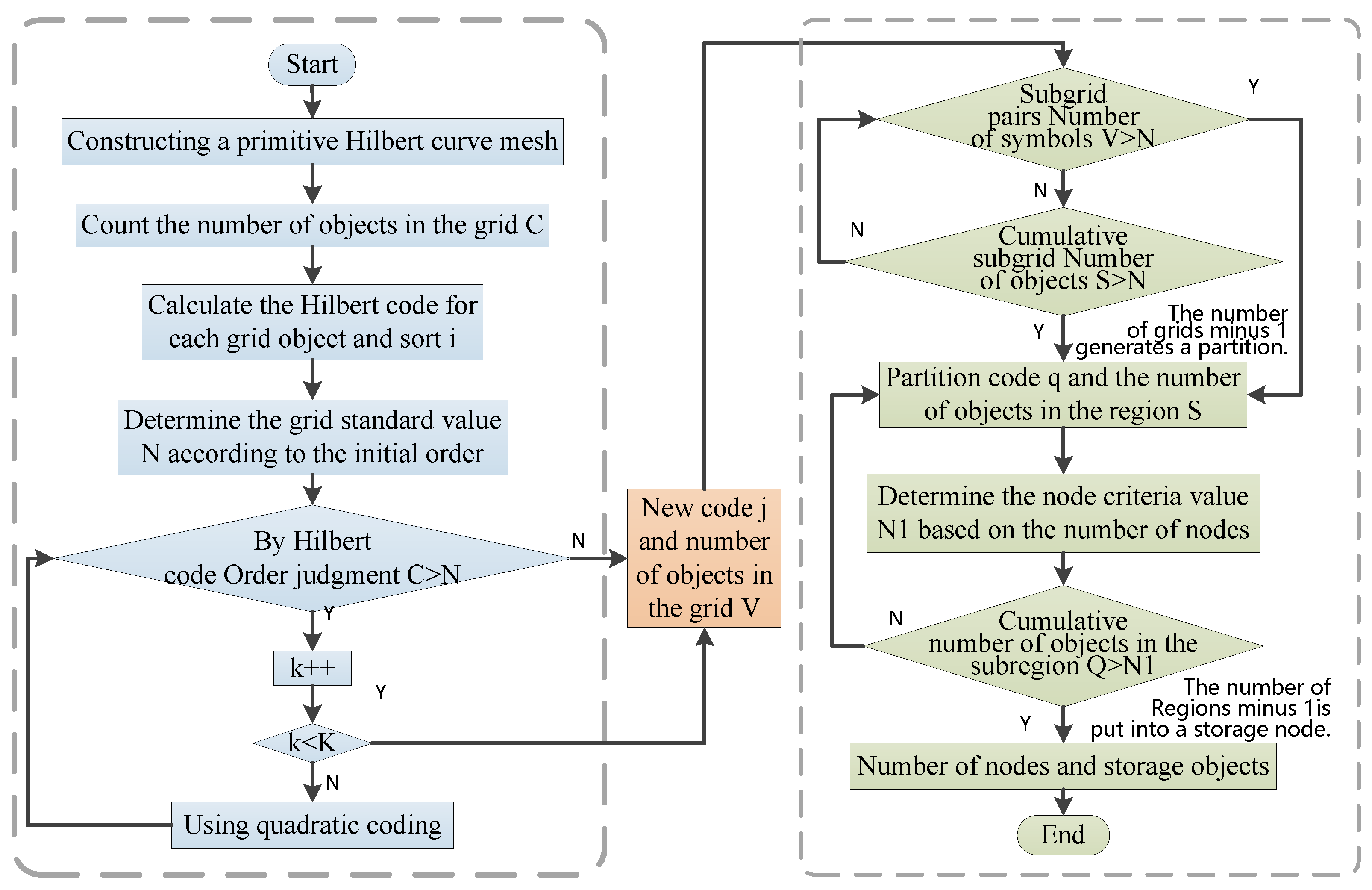
3. A Data Storage Model Incorporating Data Partitioning and Spatio-Temporal Multidimensional Hierarchical Organization
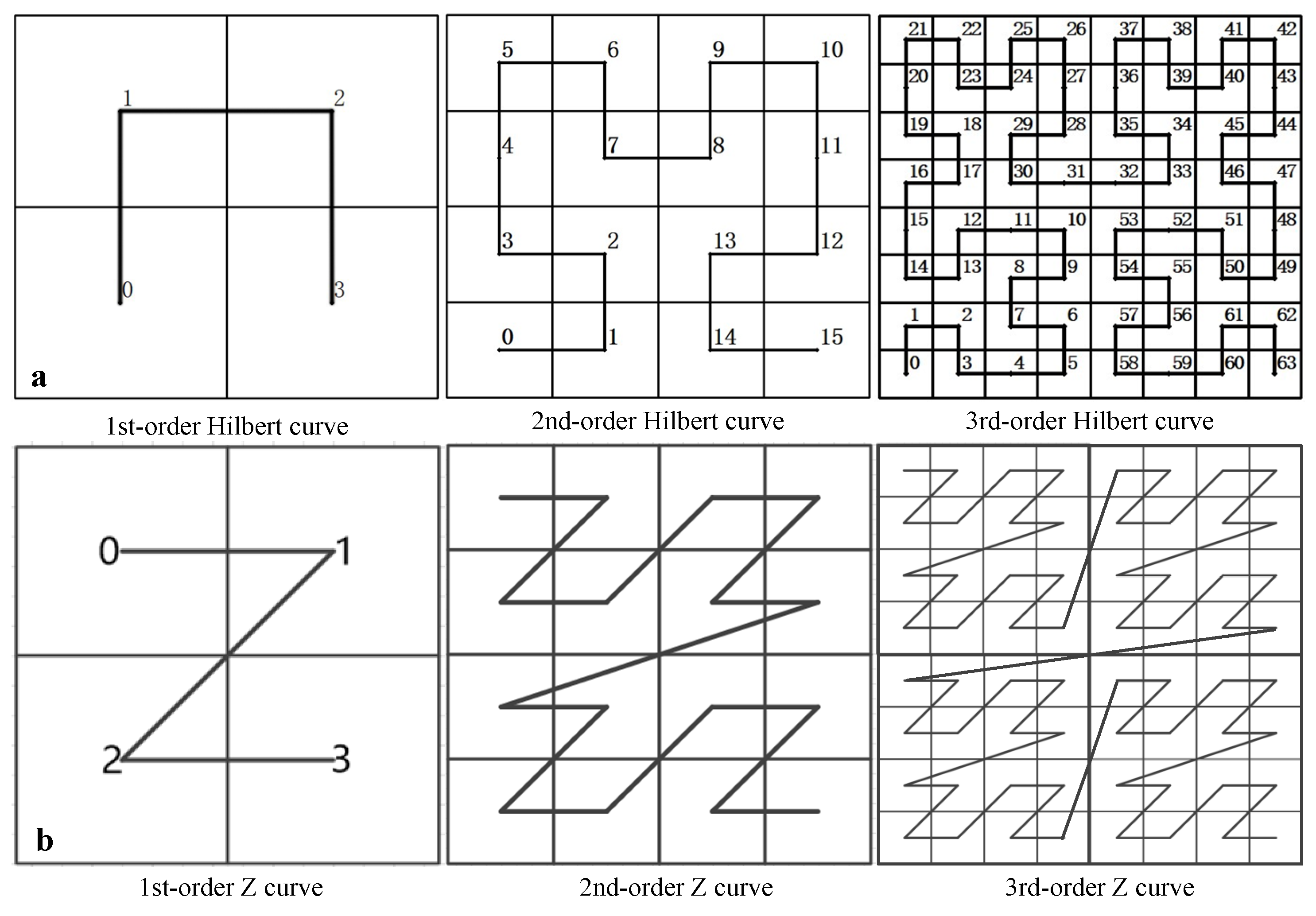
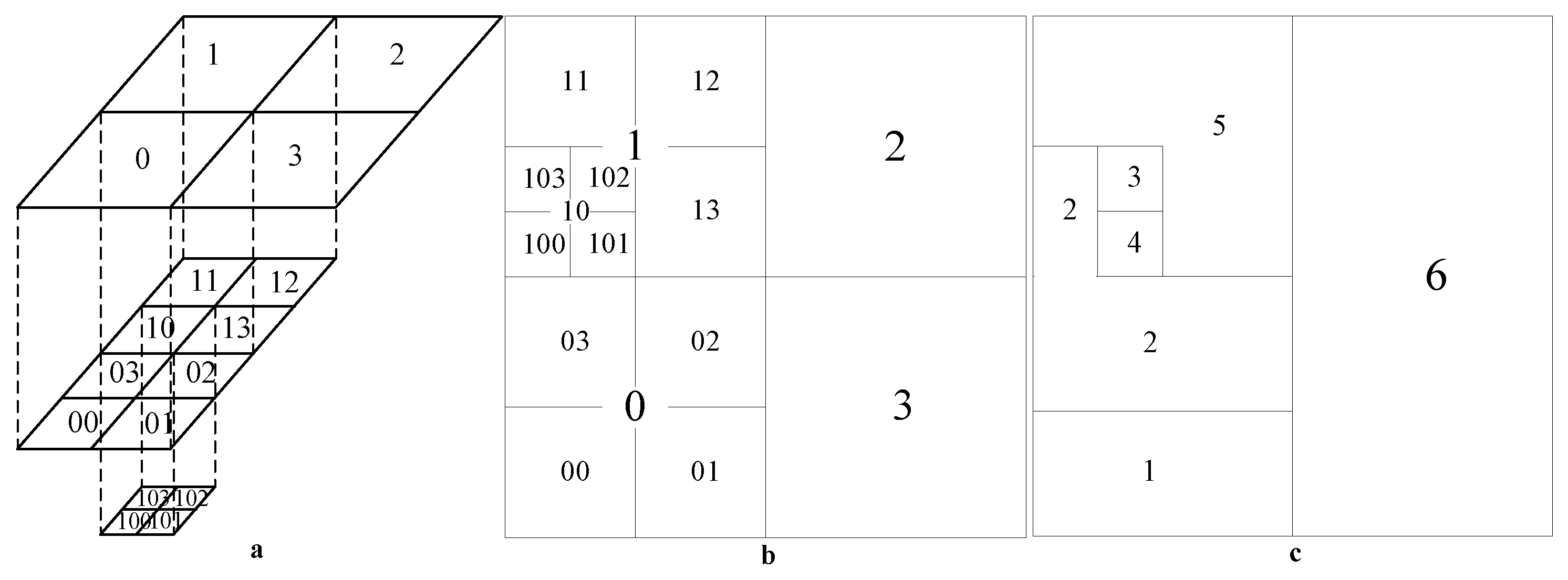
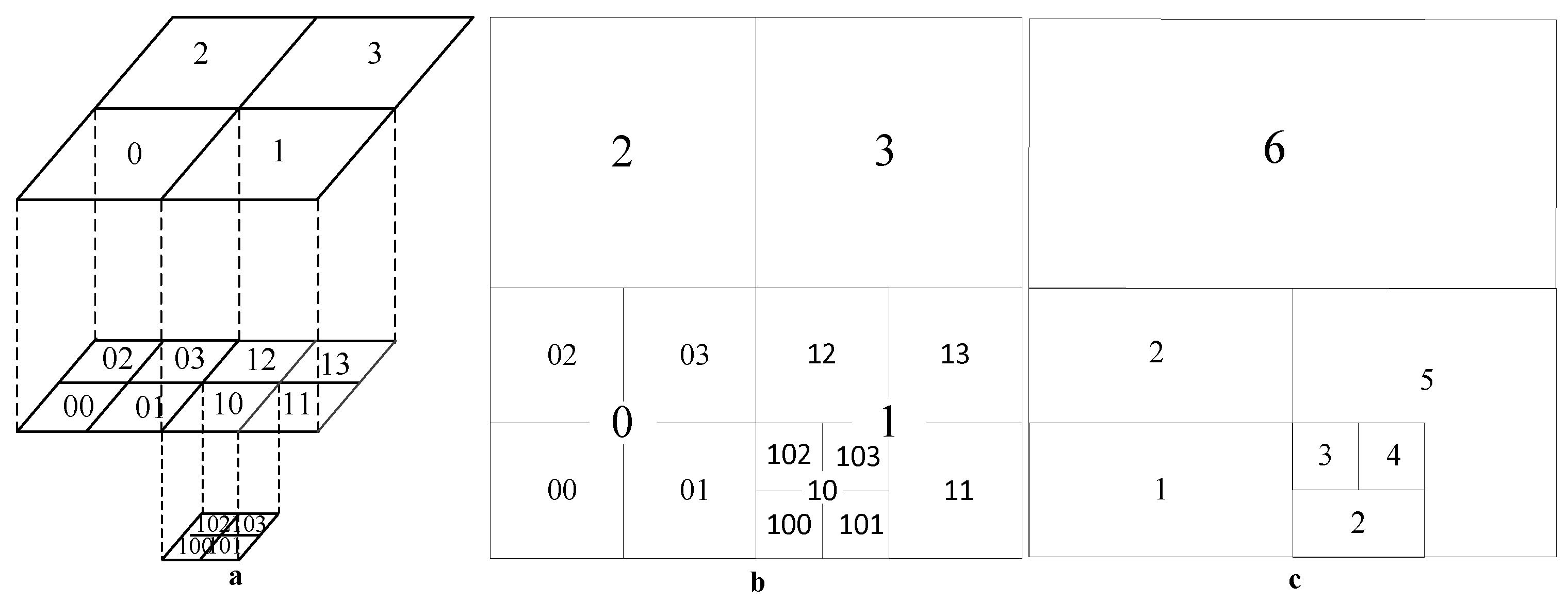
3.1. Principle of Hilbert Curve Space Partitioning
3.2. Multi-Level Spatio-Temporal Coding Model Based on Hilbert Curve Partitioning
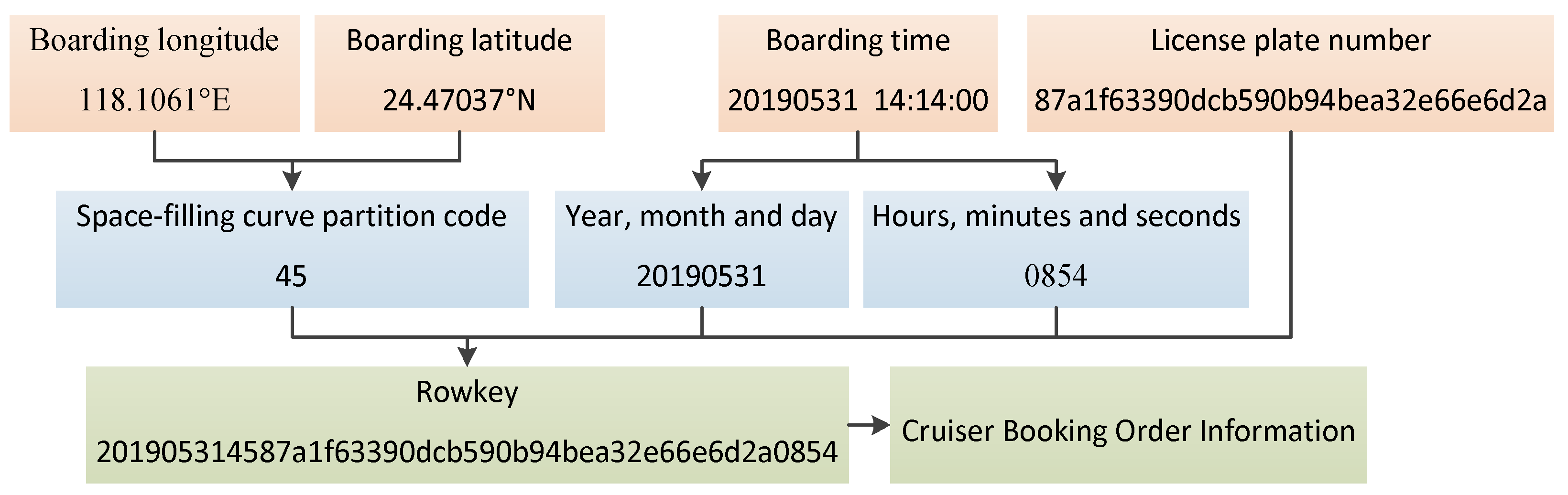
3.3. HBase RowKey Design
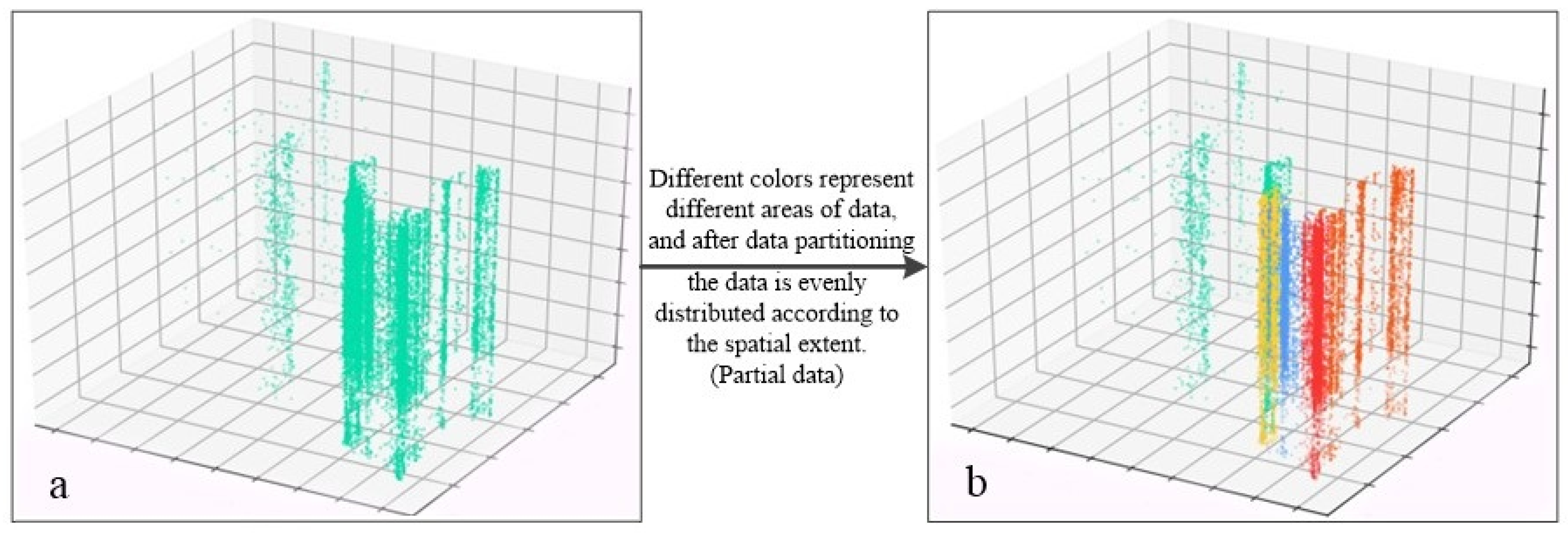
4. Validation Experiments and Analysis of Results
4.1. Experimental Environment
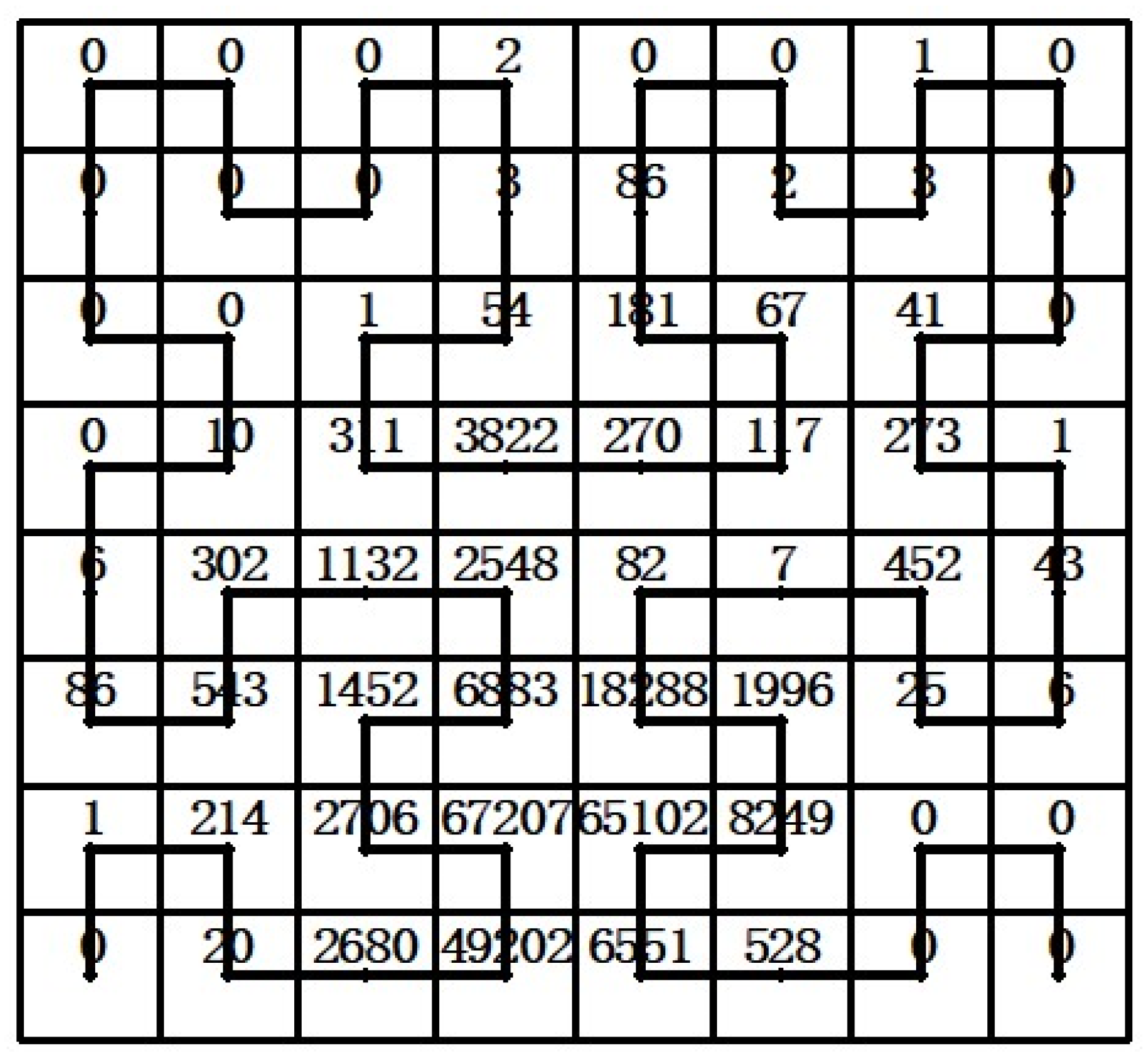
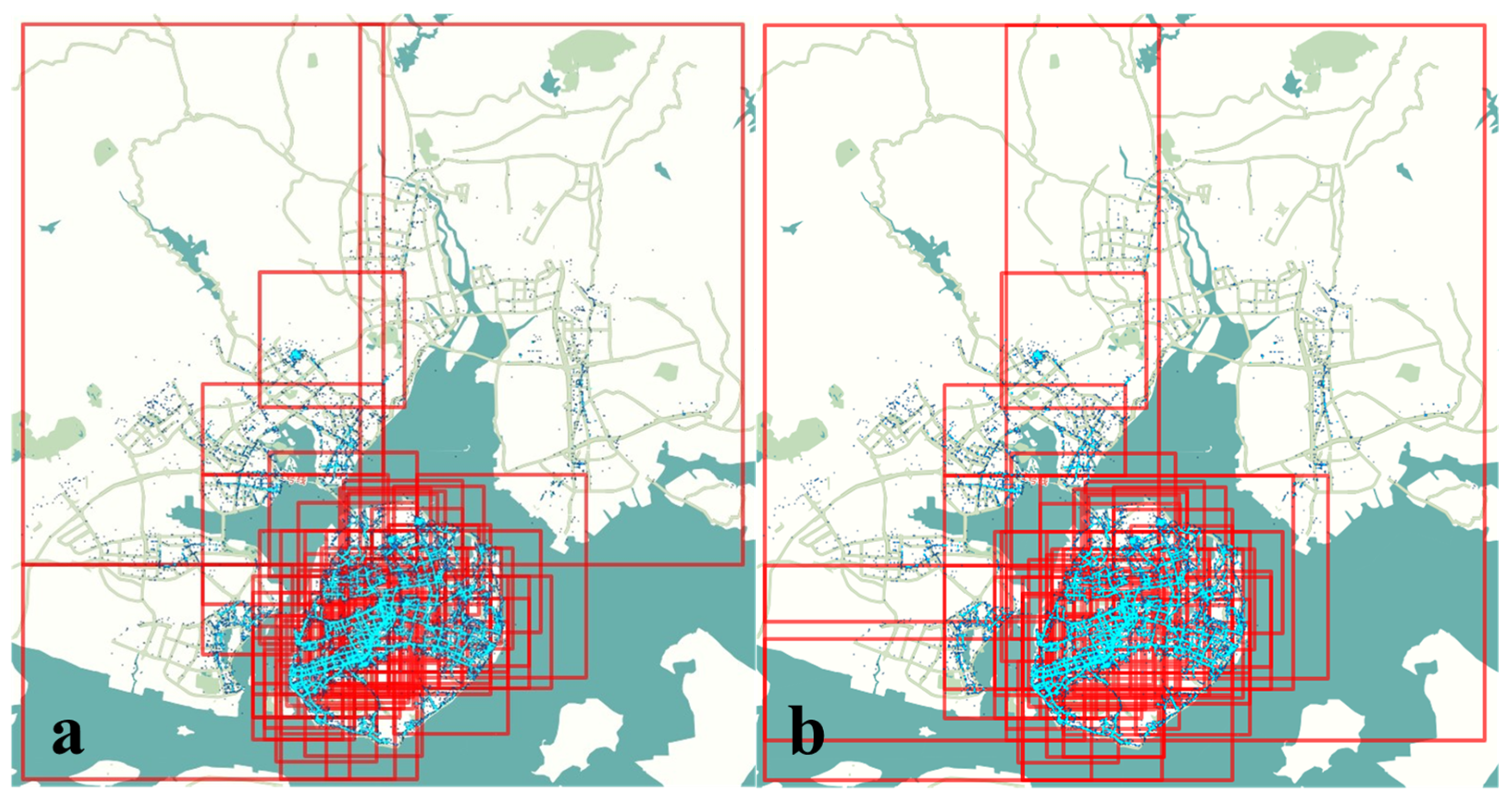
4.2. Hilbert Curve Space Partition Determination
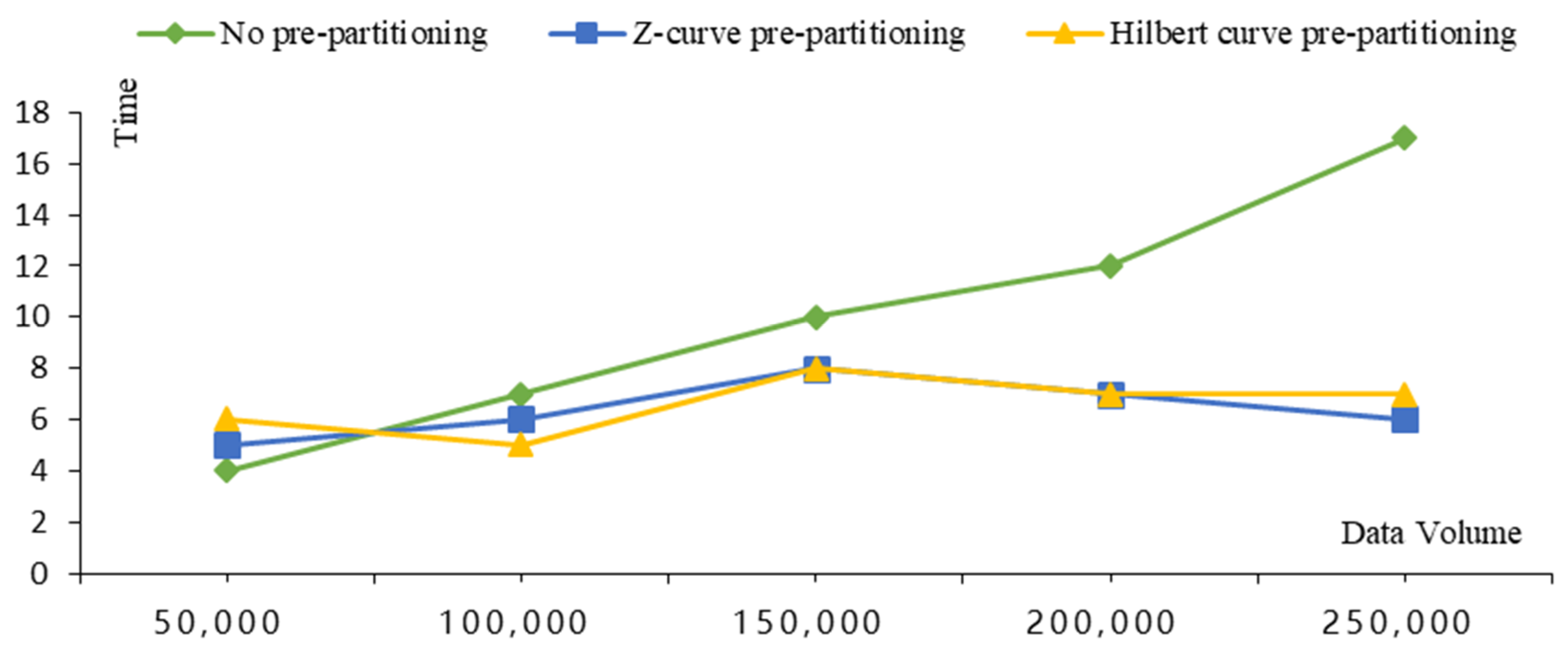
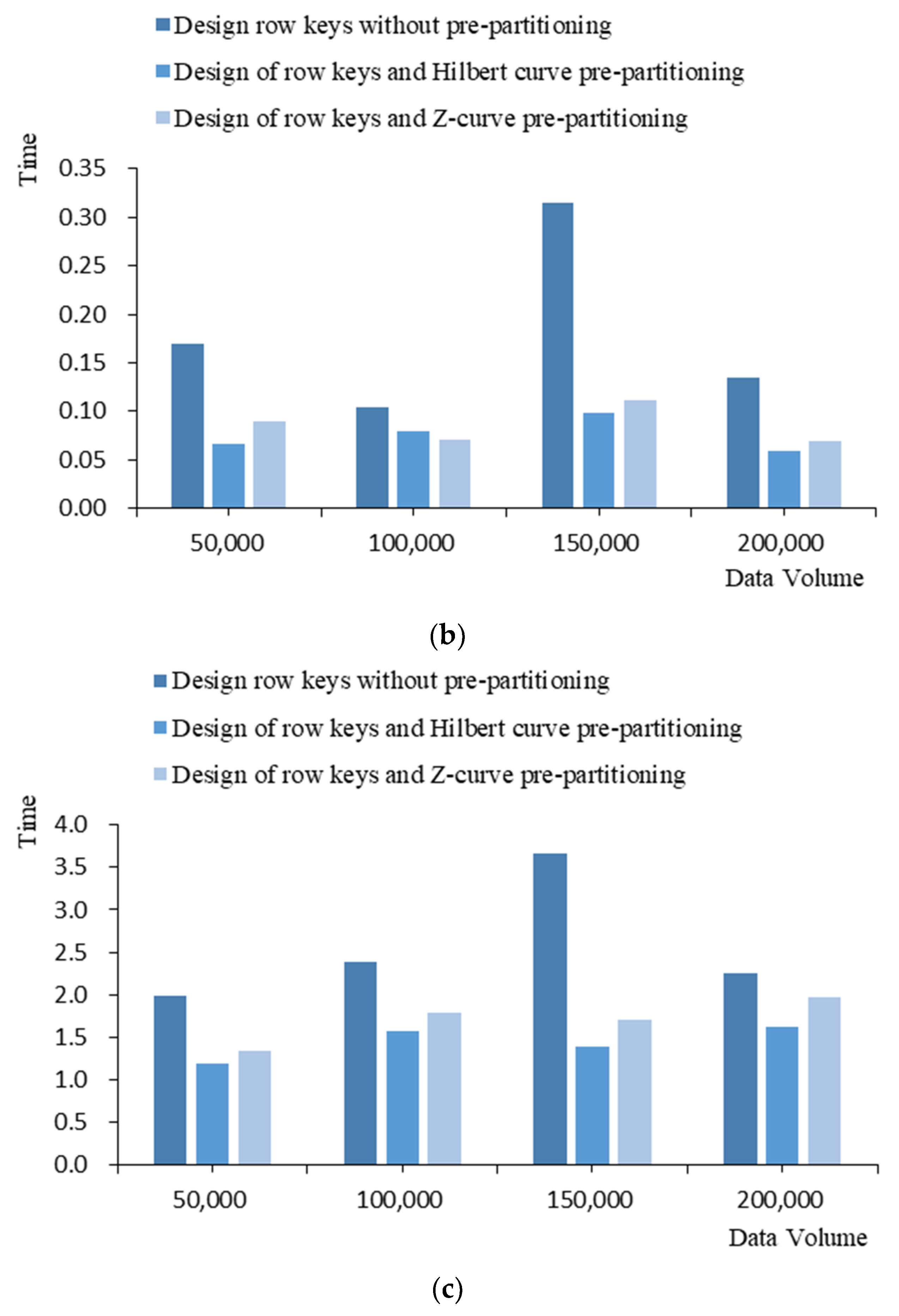
4.3. Write Speed Comparison Analysis
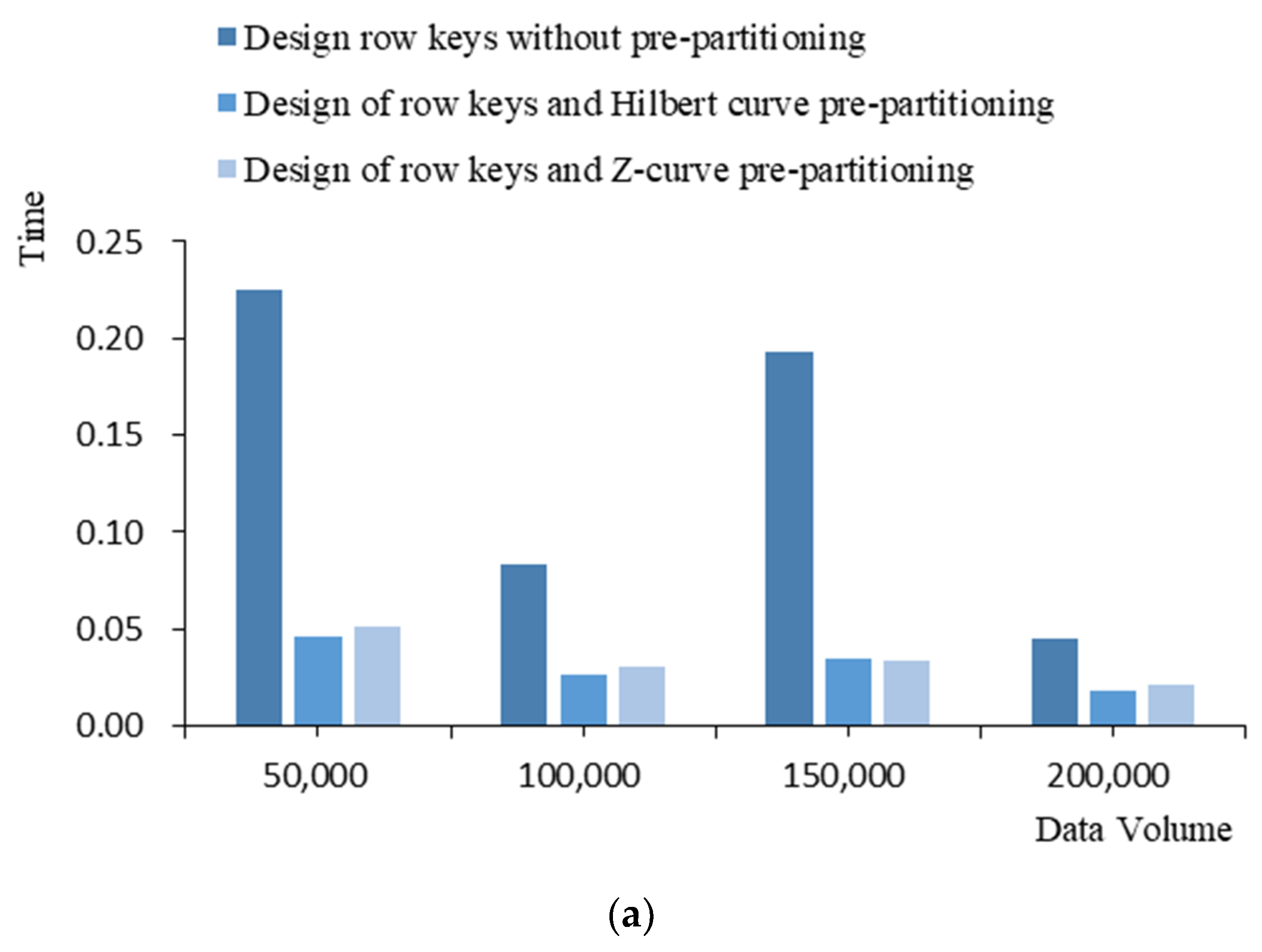
4.4. Comparative Analysis of Search Speed
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, Y.; Chen, Q.; Shan, B.; Jiang, F.; Pang, Y. A Distributed Storage Strategy for Trajectory Data Based On Nosql Database. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Tian, R.; Zhai, H.; Zhang, W.; Wang, F.; Guan, Y. A Survey of Spatio-Temporal Big Data Indexing Methods in Distributed Environment. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4132–4155. [Google Scholar] [CrossRef]
- Pimpalkar, A.P.; Raj, R.J.R. Influence of pre-processing strategies on the performance of ML classifiers exploiting TF-IDF and BOW features. ADCAIJ: Adv. Distrib. Comput. Artif. Intell. J. 2020, 9, 49. [Google Scholar] [CrossRef]
- Cao, B.Y.; Feng, H.S.; Liang, J.H.; Li, X. Using Hilbert curve and Cassandra technology to realize spatiotemporal big data storage and indexing. J. Wuhan Univ. 2021, 46, 620–629. [Google Scholar]
- Xiang, L.G.; Wang, D.H.; Gong, J.Y. Geohash coding organization and efficient range query of large-scale trajectory data. J. Wuhan Univ. 2017, 42, 21–27. [Google Scholar]
- Ai Jawarneh, I.M.; Bellavista, P.; Corradi, A.; Foschini, L.; Montanari, R. Efficient QoS-Aware Spatial Join Processing for Scalable NoSQL Storage Frameworks. IEEE Trans. Netw. Serv. Manag. 2021, 18, 2437–2449. [Google Scholar] [CrossRef]
- Zhou, C.; Lu, H.M.; Xiang, Y.; Wu, J.; Wang, F. GeohashTile: Vector Geographic Data Display Method Based on Geohash. ISPRS Int. J. Geo-Inf. 2020, 9, 418. [Google Scholar] [CrossRef]
- Huang, K.Y.; Li, G.Q.; Wang, J. Rapid retrieval strategy for massive remote sensing metadata based on GeoHash coding. Remote Sens. Lett. 2019, 10, 111–119. [Google Scholar] [CrossRef]
- Zhou, Y.C.; De, S.; Wang, W.; Moessner, K.; Palaniswami, M.S. Spatial Indexing for Data Searching in Mobile Sensing Environments. Sensors 2017, 17, 1427. [Google Scholar] [CrossRef]
- Qian, C.; Yi, C.; Cheng, C.; Wei, X.; Zhang, H. Geosot-based spatiotemporal index of massive trajectory data. ISPRS Int. J. Geo-Inf. 2019, 8, 284. [Google Scholar] [CrossRef]
- Wu, Y.H.; Cao, X.F. Hilbert code index method for spatiotemporal data in virtual battlefield environment. J. Wuhan Univ. 2020, 45, 1403–1411. [Google Scholar]
- Jiang, L.Y.; Li, B.B.; Li, M.J.; Chen, Y.; Ding, J. Efficient 3D Hilbert Curve Encoding and Decoding Algorithms. Chin. J. Electron. 2022, 31, 277–284. [Google Scholar]
- Wu, Y.H.; Cao, X.F.; Yu, A.Z.; Sun, W.Z. Three-dimensional Hilbert curve hierarchical evolution model and coding calculation. J. Surv. Mapp. 2022, 51, 104–114. [Google Scholar]
- Jia, L.Y.; Kong, M.; Wang, W.C.; Li, M.J.; You, J.G.; Ding, J.M. A two-dimensional Hilbert codec algorithm under skewed data distribution. J. Tsinghua Univ. 2022, 62, 1426–1434. [Google Scholar]
- Kang, Y.X.; Gui, Z.P.; Ding, J.C.; Wu, J.H.; Wu, Y.H. Parallel Ripley’s K-function based on Hilbert space partitioning and Geohash indexing. J. Geomat. 2022, 24, 74–86. [Google Scholar]
- Wu, Y.H.; Cao, X.F. Neighborhood lattice element computation algorithm for Hilbert octree. J. Wuhan Univ. 2022, 47, 613–622. [Google Scholar]
- Yang, F.; Hua, X.; Yang, Z.K.; Li, X.; Zhao, X.K.; Zhang, X.N. A fast algorithm for filling curve generation in non-uniform Hilbert space based on iterative method. J. Wuhan Univ. 2022, 1–15. [Google Scholar] [CrossRef]
- Xia, J.Z.; Yang, C.W.; Li, Q.Q. Building a spatiotemporal index for Earth Observation Big Data. Int. J. Appl. Earth Obs. Geoinf. 2018, 73, 245–252. [Google Scholar] [CrossRef]
- Zhang, K.; Shang, S.; Yuan, N.J.; Yang, Y. Towards efficient search for activity trajectories. In Proceedings of the 2013 IEEE 29th International Conference on Data Engineering (ICDE), Brisbane, QLD, Australia, 8–12 April 2013; IEEE: Piscataway, NJ, USA, 2013. [Google Scholar]
- Le, H.V.; Takasu, A. G-HBase: A High Performance Geographical Database Based on HBase. IEICE Trans. Inf. Syst. 2018, E101D, 1053–1065. [Google Scholar] [CrossRef]
- Zhang, J.W.; Yang, C.; Yang, Q.; Lin, Y.; Zhang, Y. HGeoHashBase: An optimized storage model of spatial objects for location-based services. Front. Comput. Sci. 2020, 14, 208–218. [Google Scholar] [CrossRef]
- Kumar, S.; Madria, S.; Linderman, M. M-Grid: A distributed framework for multidimensional indexing and querying of location based data. Distrib. Parallel Databases 2017, 35, 55–81. [Google Scholar] [CrossRef]
- Wadhw, B.; Byna, S.; Butt, A.R. Toward transparent data management in multi-layer storage hierarchy of hpc systems. In Proceedings of the 2018 IEEE International Conference on Cloud Engineering (IC2E), Orlando, FL, USA, 17–20 April 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Guan, X.; Xie, C.; Han, L.; Zeng, Y.; Shen, D.; Xing, W. Map-vis: A distributed spatio-temporal big data visualization framework based on a multi-dimensional aggregation pyramid model. Appl. Sci. 2020, 10, 598. [Google Scholar] [CrossRef]
- Guan, X.; Bo, C.; Li, Z.; Yu, Y. ST-hash: An efficient spatiotemporal index for massive trajectory data in a NoSQL database. In Proceedings of the 2017 25th International Conference on Geoinformatics, Buffalo, NY, USA, 2–4 August 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Zhou, Y.; Zhu, Q.; Zhang, Y.T. Spatial data partition method based on hierarchical decomposition of Hilbert curve. Geogr. Geogr. Inf. Sci. 2007, 4, 13–17. [Google Scholar]
- Le, P.; Wu, Z.Y.; Shangguan, B.Y. Design and implementation of distributed spatial data storage structure based on spark. J. Wuhan Univ. 2018, 43, 2295–2302. [Google Scholar]
- Huang, Z.; Chen, Y.R.; Wan, L.; Peng, X. GeoSpark SQL: An Effective Framework Enabling Spatial Queries on Spark. ISPRS Int. J. Geo-Inf. 2017, 6, 285. [Google Scholar] [CrossRef]
- Lei, B. A Hadoop-Based Spatial Computation Framework for Large-Scale AIS Data. In Proceedings of the 2019 IEEE 2nd International Conference on Elsectronics Technology (ICET), Chengdu, China, 10–13 May 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Chen, W.; Huang, Z.S.; Wu, F.R.; Zhu, M.; Guan, H.; Maciejewski, R. VAUD: A Visual Analysis Approach for Exploring Spatio-Temporal Urban Data. IEEE Trans. Vis. Comput. Graph. 2018, 24, 2636–2648. [Google Scholar] [CrossRef]
- Zhang, Y.; Lin, Y.P. An interactive method for identifying the stay points of the trajectory of moving objects. J. Vis. Commun. Image Represent. 2019, 59, 387–392. [Google Scholar] [CrossRef]
- Kim, S.; Jeong, S.; Woo, I.; Jang, Y.; Maciejewski, R.; Ebert, D.S. Data Flow Analysis and Visualization for Spatiotemporal Statistical Data without Trajectory Information. IEEE Trans. Vis. Comput. Graph. 2018, 24, 1287–1300. [Google Scholar] [CrossRef]
- Li, Z.; Zhao, Z.M. Geohash: Trajectory data index method based on historical data pre-partitioning. In Proceedings of the 2021 7th International Conference on Big Data Computing and Communications (BigCom), Deqing, China, 13–15 August 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Wu, M.G. Hilbert filling curve and space division method of point data set for spatial distribution pattern detection Chinese. J. Image Graph. 2013, 18, 1336–1342. [Google Scholar]
- Lu, Y.L.; Li, J.W.; Ye, S.X.; Jiang, J.W.; Yin, M.; Zhou, Y.L. GIS spatiotemporal big data organization method based on extended stream data cube. J. Bull. Surv. Mapp. 2018, 8, 115–118. [Google Scholar]
- Bach, B.; Dragicevic, P.; Archambault, D.; Hurter, C.; Carpendale, S. A Descriptive Framework for Temporal Data Visualizations Based on Generalized Space-Time Cubes. Comput. Graph. Forum 2017, 36, 36–61. [Google Scholar] [CrossRef]
- Chen, D.N.; Guan, X.F.; Han, L.X.; Xiang, L.G.; Wu, H.Y. VA HBase: An adaptive distributed management scheme for vector data. J. Wuhan Univ. 2021, 46, 1–11. [Google Scholar]
- Li, X. Discussion on traffic flow data storage and index model based on spark/HBase. J. Geogr. Geogr. Inf. Science 2019, 35, 1–8. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial Number | Field Name | Field Meaning | Example |
|---|---|---|---|
| 1 | CAR_NO | License plate number | 87a1f63390dcb590b94bea32e66e6d2a |
| 2 | GETON_DATE | Boarding time | 31 May 2019 14:14:00 |
| 3 | GETON_LONGITUDE | Boarding longitude (WGS84 GPS Standard) | 118.1061 |
| 4 | GETON_LATITUDE | Boarding latitude (WGS84 GPS Standard) | 24.47037 |
| 5 | GETOFF_DATE | Disembarkation time | 31 May 2019 14:24:00 |
| 6 | GETOFF_LONGITUDE | Downtime longitude (WGS84 GPS Standard) | 118.115031 |
| 7 | GETOFF_LATITUDE | Dismount latitude (WGS84 GPS Standard) | 24.470555 |
| 8 | PASS_MILE | Metered kilometers | 2.2 |
| 9 | NOPASS_MILE | Empty kilometers | 1.2 |
| 10 | WAITING_TIME | Waiting time | 333 |
| Frame Name | Version Number |
|---|---|
| JDK | JDK1.8 |
| Spark | Spark-2.2.0-bin-2.6.0-cdh5.14.0 |
| Hadoop | hadoop-2.6.0-cdh5.14.0 |
| HBase | hbase-1.2.0-cdh5.14.0 |
| Zookeeper | zookeeper-3.4.5-cdh5.14.0 |
| Serial Number | K Value | Edge | Number of Grids | Number of Grids Greater than Standard Value |
|---|---|---|---|---|
| 1 | 3 | 8 | 8 × 8 | 8 |
| 2 | 4 | 16 | 16 × 16 | 18 |
| 3 | 5 | 32 | 32 × 32 | 22 |
| 4 | 6 | 64 | 64 × 64 | 6 |
| 5 | 7 | 128 | 128 × 128 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, Z.; Zhang, J.; Li, T.; Ding, Y. A Trajectory Big Data Storage Model Incorporating Partitioning and Spatio-Temporal Multidimensional Hierarchical Organization. ISPRS Int. J. Geo-Inf. 2022, 11, 621. https://doi.org/10.3390/ijgi11120621
Yao Z, Zhang J, Li T, Ding Y. A Trajectory Big Data Storage Model Incorporating Partitioning and Spatio-Temporal Multidimensional Hierarchical Organization. ISPRS International Journal of Geo-Information. 2022; 11(12):621. https://doi.org/10.3390/ijgi11120621
Chicago/Turabian StyleYao, Zhixin, Jianqin Zhang, Taizeng Li, and Ying Ding. 2022. "A Trajectory Big Data Storage Model Incorporating Partitioning and Spatio-Temporal Multidimensional Hierarchical Organization" ISPRS International Journal of Geo-Information 11, no. 12: 621. https://doi.org/10.3390/ijgi11120621
APA StyleYao, Z., Zhang, J., Li, T., & Ding, Y. (2022). A Trajectory Big Data Storage Model Incorporating Partitioning and Spatio-Temporal Multidimensional Hierarchical Organization. ISPRS International Journal of Geo-Information, 11(12), 621. https://doi.org/10.3390/ijgi11120621