1. Introduction
OpenStreetMap is a global mapping project where anyone can collect and contribute geographical information. This information, along with its history, is freely accessible [
1]. OSM is an example of so-called volunteered geographic information (VGI), which is an alternative to professionally collected geographic information [
2]. The popularity of OSM has been increasing ever since the project was started in 2004 [
3]. Given that the usage of OSM is free of cost and the data are frequently updated, OSM plays an important role in many different applications and in research. Moreover, for specific regions on the globe, OSM is the only source of geographical information. Therefore, OSM represents an alternative to map or geodata providers such as Google (
https://www.google.de/maps, accessed on 15 February 2020) and Here (
https://wego.here.com/, accessed on 15 February 2020) [
2]. Given the availability and decreasing costs of hardware and software, the collection and maintenance of geographic information on a voluntary basis will continue to grow in popularity [
2,
4]. However, the quality of VGI, particularly OpenStreetMap data, cannot be easily determined and therefore has to be evaluated [
5]. Since OpenStreetMap is one of the most prominent examples of VGI, the interest in OSM research is growing continuously [
5,
6,
7]. Not only are the data of importance, but the social processes and interactions between the volunteers who are contributing to OSM are too [
8]. Crowdsourced geographical information has many relevant applications (e.g., emergency responses, spatial decision making, participatory planning and citizen science), and with the availability and accuracy of global navigation satellite systems (GNSSs) and information technology (IT), their popularity will continually increase [
7,
8].
Not only do individuals contribute their knowledge to OSM, but imports of external data sources are conducted. These data sets range from small scale (e.g., a tree data set for a city (
https://wiki.openstreetmap.org/wiki/Birmingham_City_Council_trees_data, accessed on 2 February 2020)) to large scale (e.g., road network for a country (
https://wiki.openstreetmap.org/wiki/AND_data, accessed on 2 February 2020)) and are being provided by institutions, governments and companies [
9,
10]. The question arises of if and how data imports are benefiting community mapping projects such as OpenStreetMap. This issue is controversially discussed by contributors, the community [
11,
12,
13] and researchers [
14,
15]. Some contributors point out that importation of external data sets has a negative impact on the development of the local community. Without an active group of contributors (also called mappers), OSM would not be updated as frequently [
11]. It is important to investigate how the community acts before, during and after an import to see whether imported data stay untouched or not. Imports of large data sets especially, such as road networks, bring a lot of information to OSM in a short period of time. Publications (e.g., by Grinberger et al. [
9], Zielstra et al. [
15]) have shown rising interest in investigations of large-scale imports of data to OSM, and interest in whether these imports add value to OSM. Therefore, it is important to analyse and understand the effects that large data imports exert on OpenStreetMap. For investigating the effects of large data imports on OSM, the history of the data needs to be taken into account. By analysing the evolution of imported data, it is possible to make statements about the impacts on OSM.
Related Work
Different aspects of OSM are being investigated by researchers, e.g., motivations for participation, community development and the quality of OSM data. In Neis and Zielstra [
7], the authors summarise the recent developments of OSM and outline future trends. OpenStreetMap has high accuracy and coverage in urban areas, resulting in applications utilising this free source of information, for example, for the creation of city maps or routing software [
16,
17]. Given that OSM is a global project where anyone can contribute, it is important to understand who participates and why. Budhathoki and Haythornthwaite [
18] investigated the motivations for collecting geographic information and found differences between so-called serious and casual mappers. Coleman et al. [
4] analysed and characterised the motivations of volunteers and tried to classify a spectrum of contributors. Haklay and Weber [
19] summarised general motivations and technical details of OSM.
The heterogeneity of OSM is one of the main reasons for the importance of OSM data quality assessments [
20]. Mooney et al. [
6] developed quality metrics to assess and compare OSM data quality. The authors stated that if OSM is used in research, the variability of data quality has to be considered in the analysis. In the study by Keßler and de Groot [
21], the authors defined trust measures to evaluate the quality of OSM (e.g., a high number of contributors is a positive indicator; corrections of elements are seen as a negative indicator).
Degrossi et al. [
22] present a taxonomy of methods for data quality evaluation if no reference data sets are available. On the basis of a systematic review, 11 methods were identified which are useful for quality evaluation. A detailed review on the various subject areas of VGI in general can be found in Yan et al. [
23]. The authors identify three different scientific subject areas: “VGI contributions and contributors”, “Main fields applying VGI” and “Conceptions and envisions.” The area “VGI contributions and contributors” is particularly relevant for this article and shows the importance of scientific studies dealing with the issues of data quality of VGI. In Arsanjani et al. [
24], the authors developed a contribution index to better examine the dynamics of the contributions and forecast the future development of the contributions for the larger region of Stuttgart. In accordance with their results, they come to the conclusion that increasing contributions can be expected in the future. A corresponding review of the results has not yet taken place, but would be valuable and possible, since a review with real data is possible today. For this article, the outlook on data imports is particularly relevant, as the authors identified the influence of data importation as an important parameter for expanding their contribution index.
Depending on the application of OSM, a comparison to an external data set (so-called ground truth) is inevitable to decide whether to use OSM or not. In the context of evaluating quality, the intrinsic data quality analysis is suitable for the assessment [
25]. Comparable data sets are often expensive or access to them is limited due to licensing processes. By using an intrinsic approach, no ground truth reference data set is needed; the data are compared with themselves [
25]. Barron et al. [
25] introduced a framework for intrinsic quality analysis which evaluates OSM data quality based on its history. Minghini et al. [
26] also utilised an intrinsic approach to assess OSM data quality with the history of the data. Nasiri et al. [
27] investigated the history of OSM to improve the quality of the data as well. They concluded that the historic contributions to OSM have mostly been neglected by the literature and that OSM’s history should be exploited for intrinsic quality analysis.
In regard to data imports in OpenStreetMap, several studies were already carried out. Zielstra et al. [
15] analysed and evaluated the effect of data imports on the completeness of OpenStreetMap. The publication specifically focused on the TIGER/Line (
https://wiki.openstreetmap.org/wiki/TIGER, accessed on 8 February 2020) (Topologically Integrated Geographic Encoding and Referencing System) import in the United States. The researchers assessed the accuracy of the imported data. Furthermore, they argued and discussed whether the road network of OSM should be updated through data imports from the public domain, or by edits of active contributors. The authors concluded that an interplay of data imports and updates by contributors could improve OSM data the most—e.g., by adding road traces of an external data set as an overlay in OSM editors. The paper by Juhász and Hochmair [
14] analysed whether an import task leads to community growth or not. The authors found that there are differences in editing patterns between newly recruited users and established mappers. Moreover, they could not confirm a long-term engagement of the new mappers (GIS students who earned credits for import tasks). Neis et al. [
28] investigated vandalism in OSM. Since anyone can alter OSM data, it is important to detect intentional deletions or manipulations of elements. With OSMPatrol, they introduced a tool to help identify users who damage OSM. For the analysis, it was crucial to include the history of OSM and the fact that a lot of data can be automatically changed via scripts or bots. The researchers were able to discover “illegal” imports and mass edits with the software. The work of Gröchenig et al. [
29] tried to identify regional and temporal differences in the mapping progress by analysing the history of OSM. The authors stated that VGI data sets are heterogeneous because of technical, social, environmental and economic factors, resulting in neither a spatial nor a temporal equal distribution. The researchers found that regions benefit from imports in terms of data availability, but the imports had a negative influence on the community development. Furthermore, they stated that after an import or a crisis which triggers remote mapping activities, the affected regions lack continuous maintenance.
Yang et al. [
30] examined the inequality of contributions and were able to determine that there were differences between the amounts of contributions in countries in which there were no large data imports into OSM (a small number of users who make the most contributions contrasts with the growing number of users who only make a small number of contributions). In countries with larger imports, they found higher fluctuations in contributions from contributors. In [
31] the authors differentiated between professional and amateur mappers based on skill level. It is important to investigate the contributors and the influences of their affiliation and commitment towards OSM. Neis et al. [
32] differentiated between three groups of mappers, “Senior Mappers” (>1000 nodes created), “Junior Mappers” (<1000 nodes created) and “Nonrecurring Mappers” (<10 nodes created).
Detailed and very up-to-date investigations of larger data production events were carried out by Schott et al. [
33] and Grinberger et al. [
34]. In this study, however, the focus does not lie on event-based data production, but the importation of data sets.
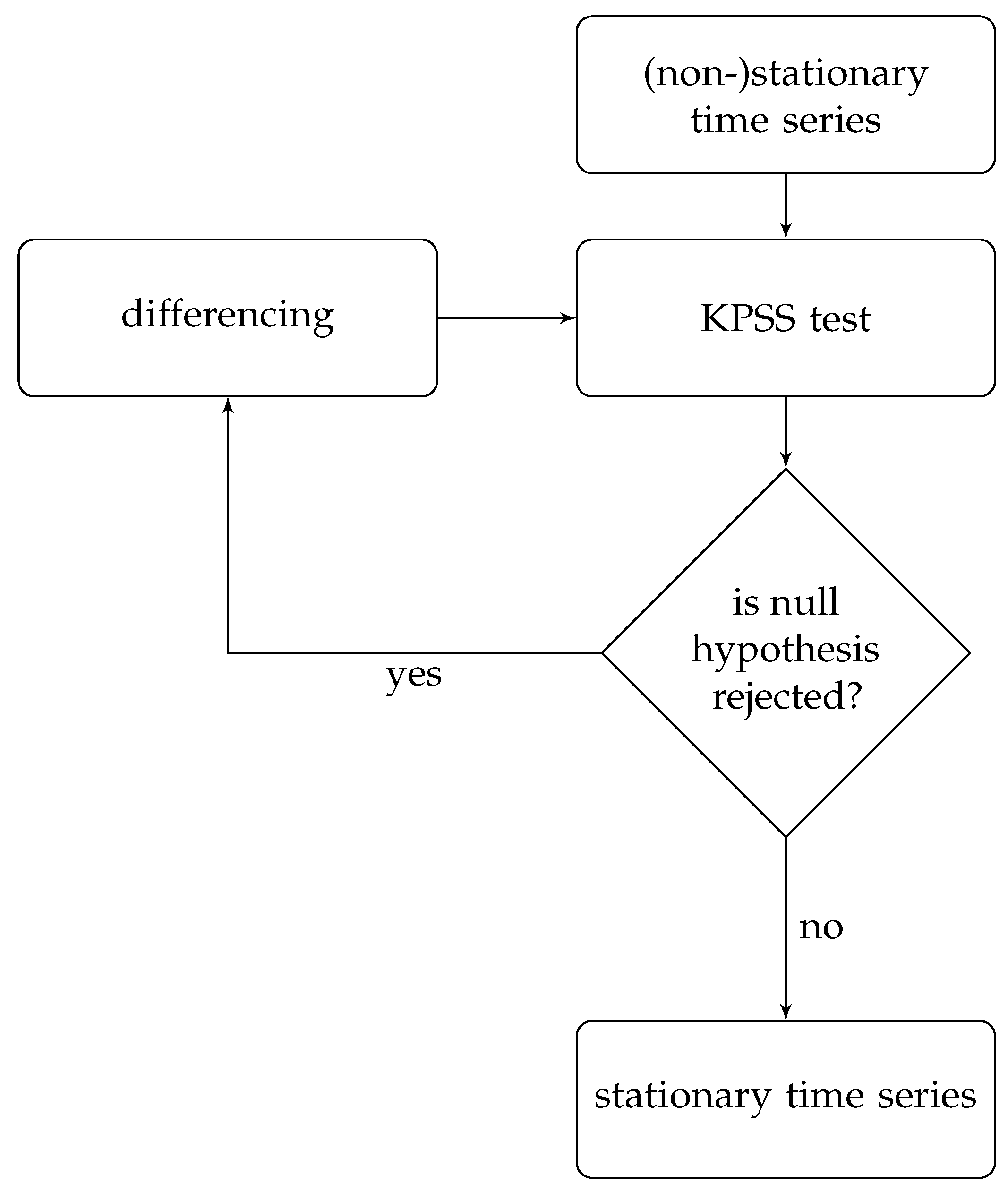
4. Discussion
4.1. Evaluation of the Results
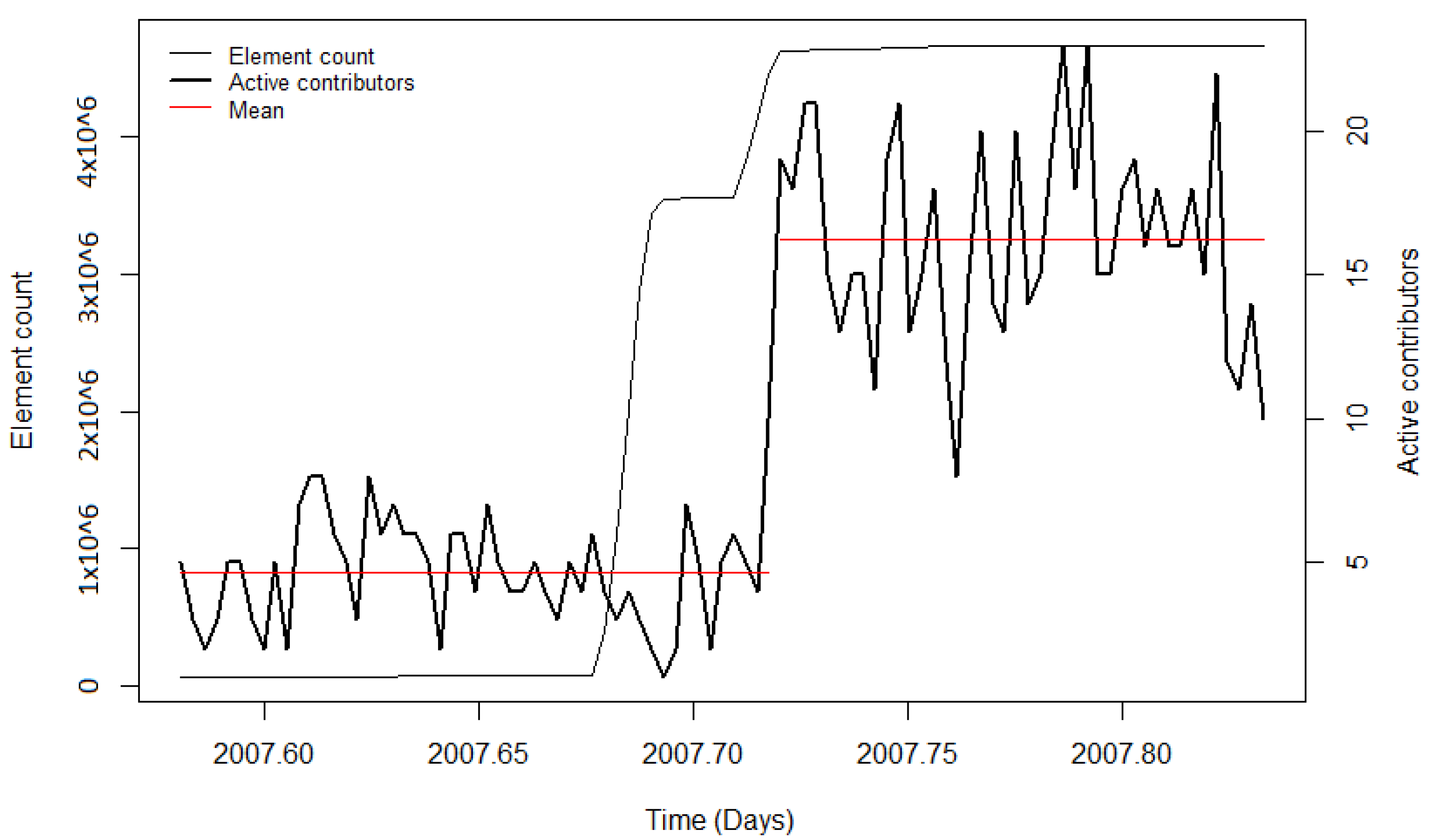
4.1.1. Contributors
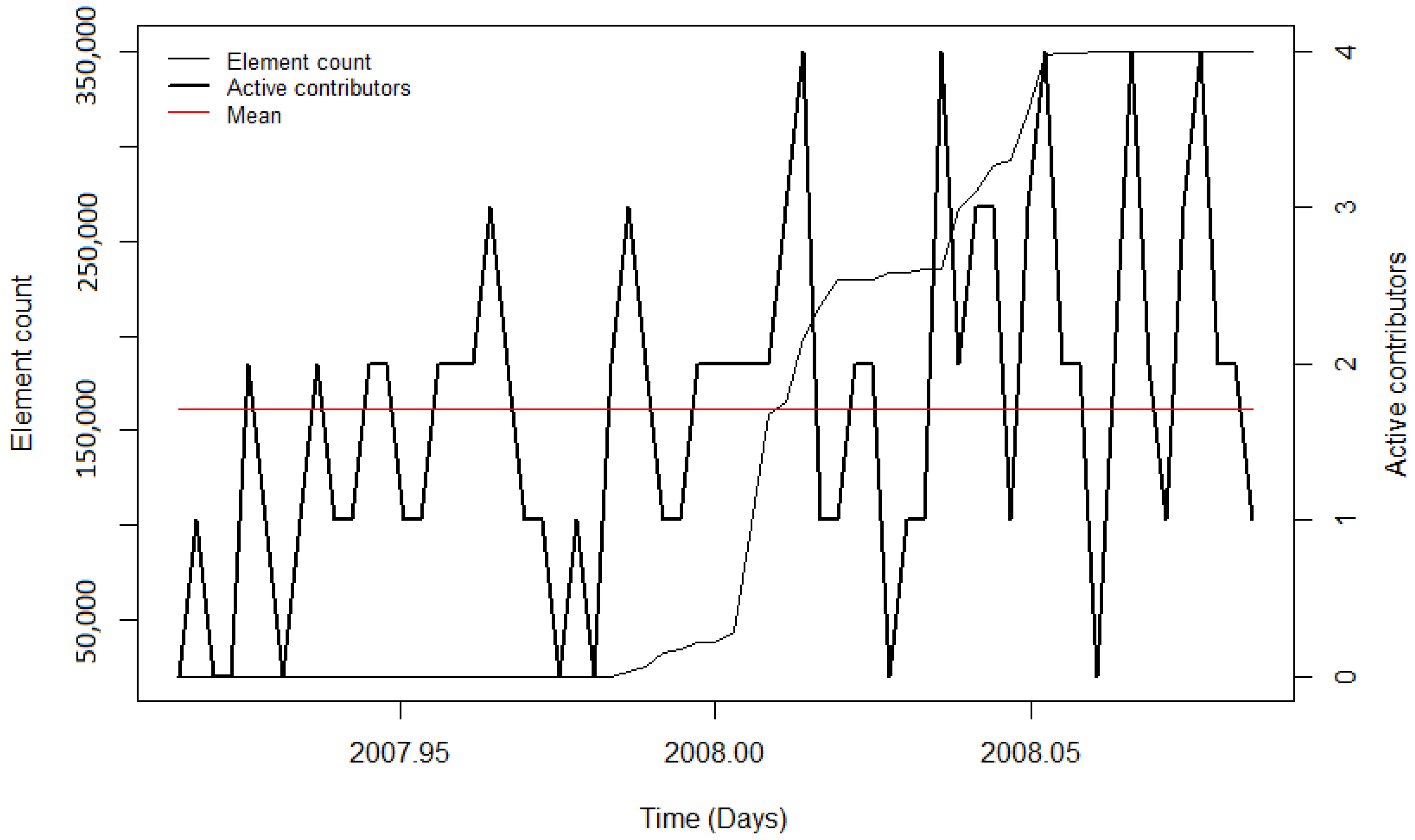
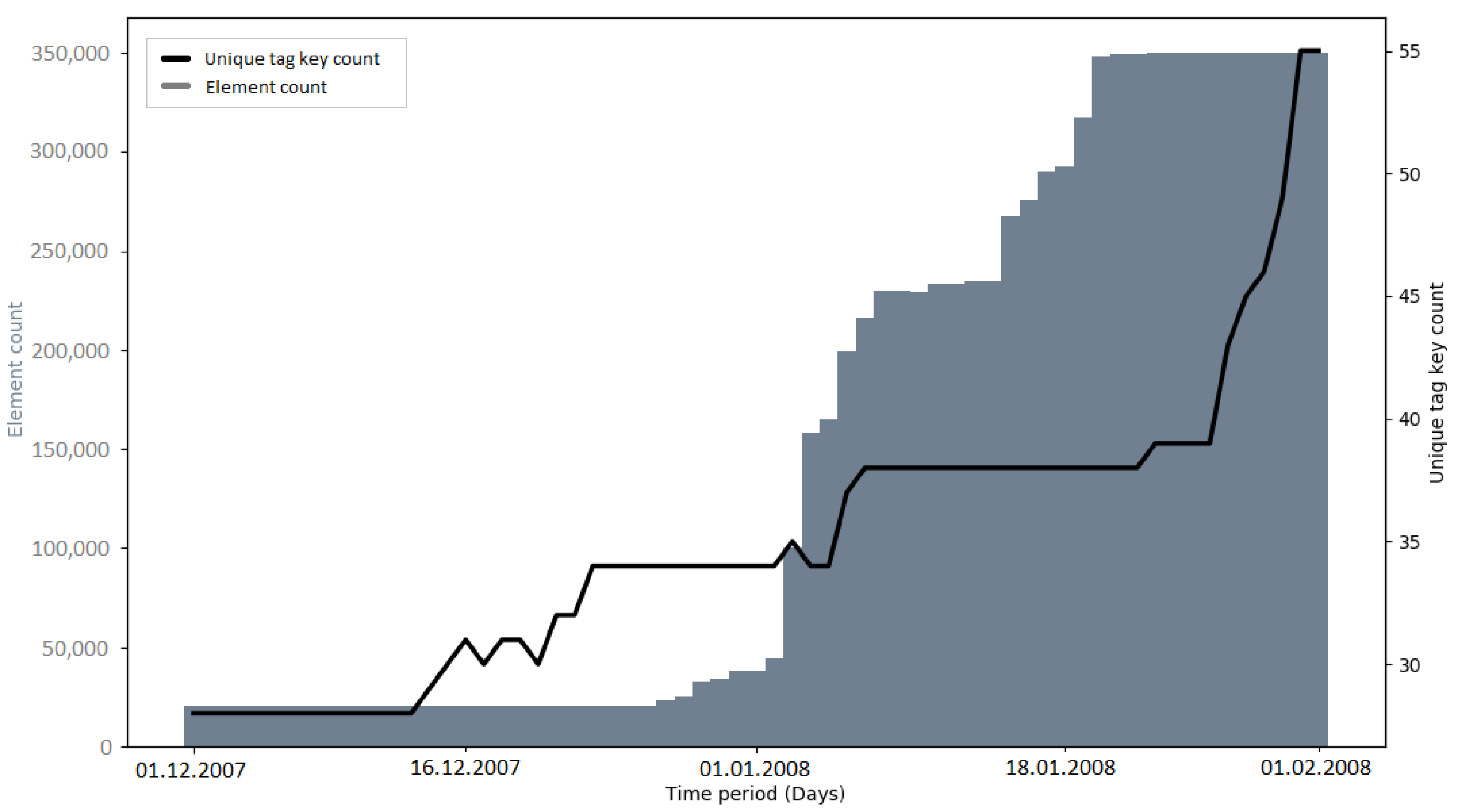
The number of active contributors during an import gives insights into how imports influence OSM contributor activity. The changepoint detection revealed that after the AND imports in the Netherlands and India, the mean number of active contributors rose significantly (by more than 200% in both study areas). A reason for that could be the state of OpenStreetMap itself at that time, since it only existed for about two and a half years. Consequently, the total number of contributors was relatively low. The publicity which was caused by the donation of the data set (through blog posts, radio interviews, etc. [
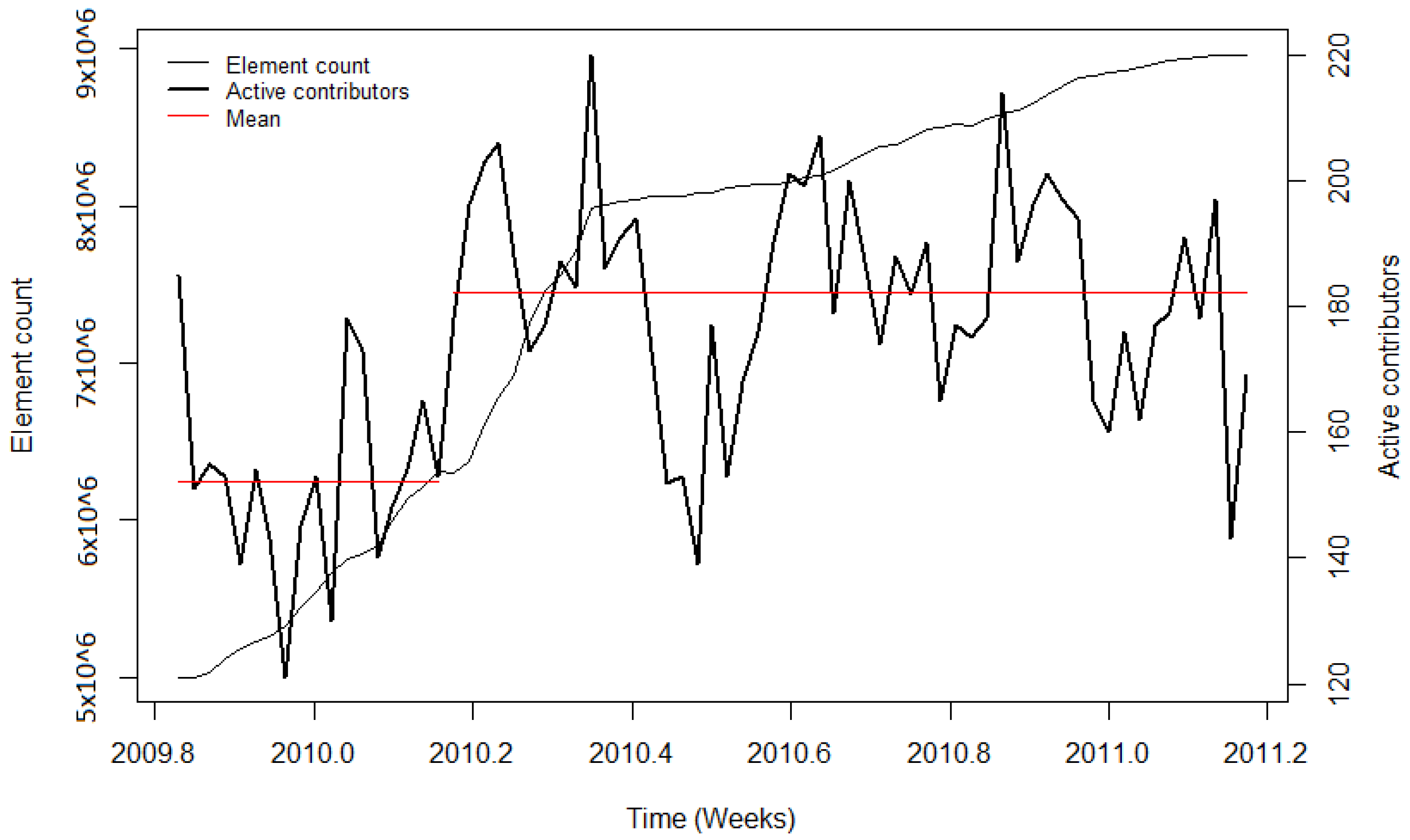
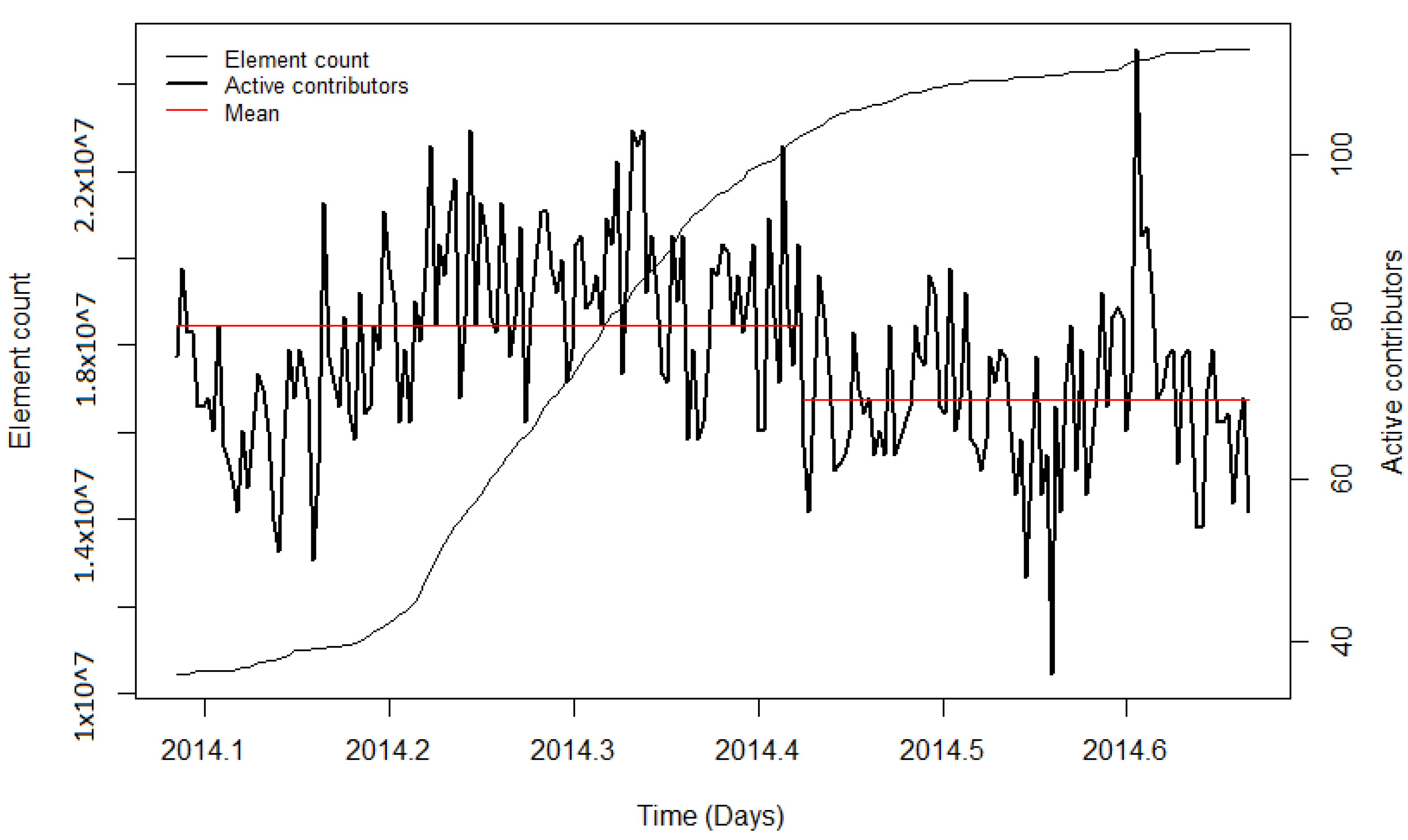
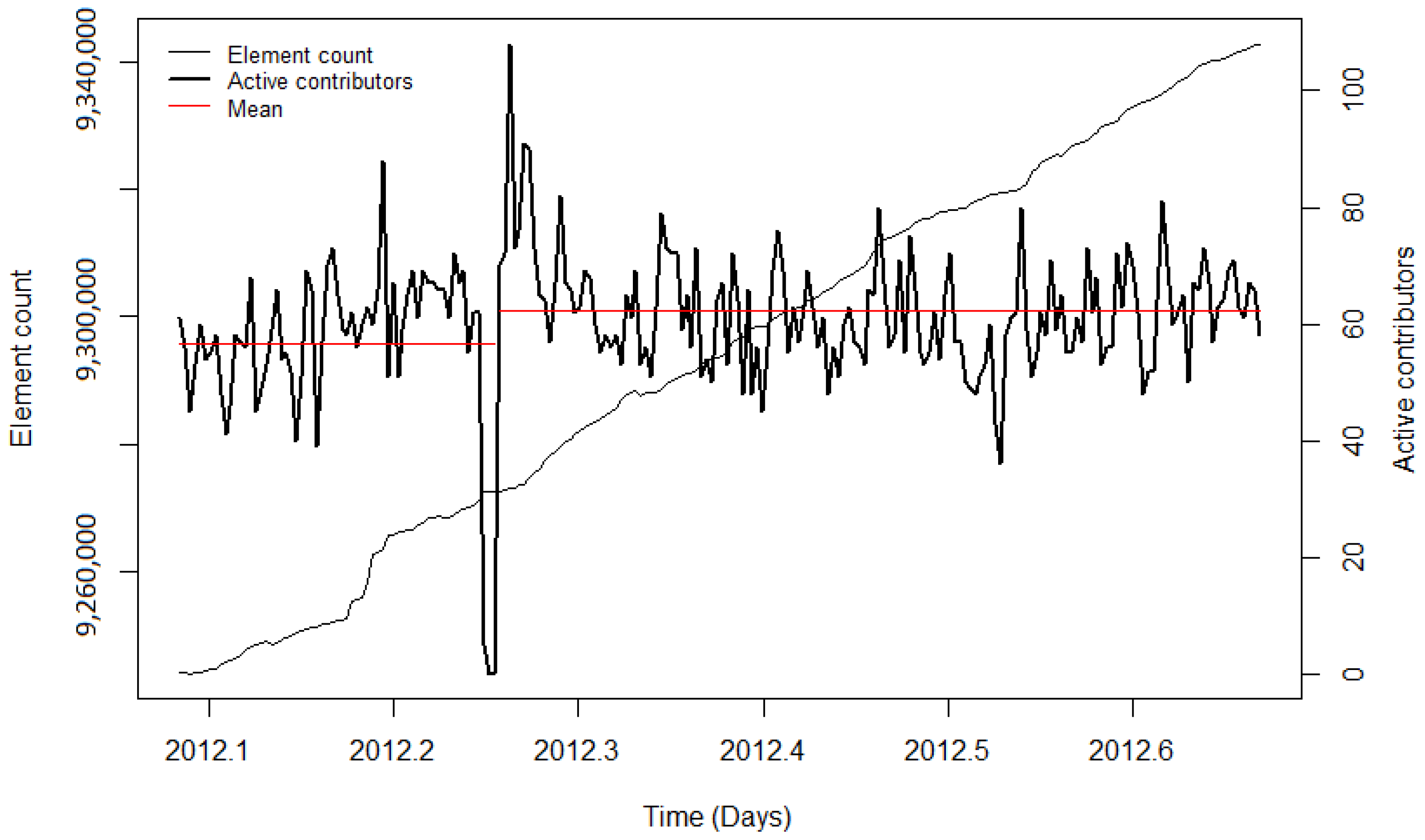
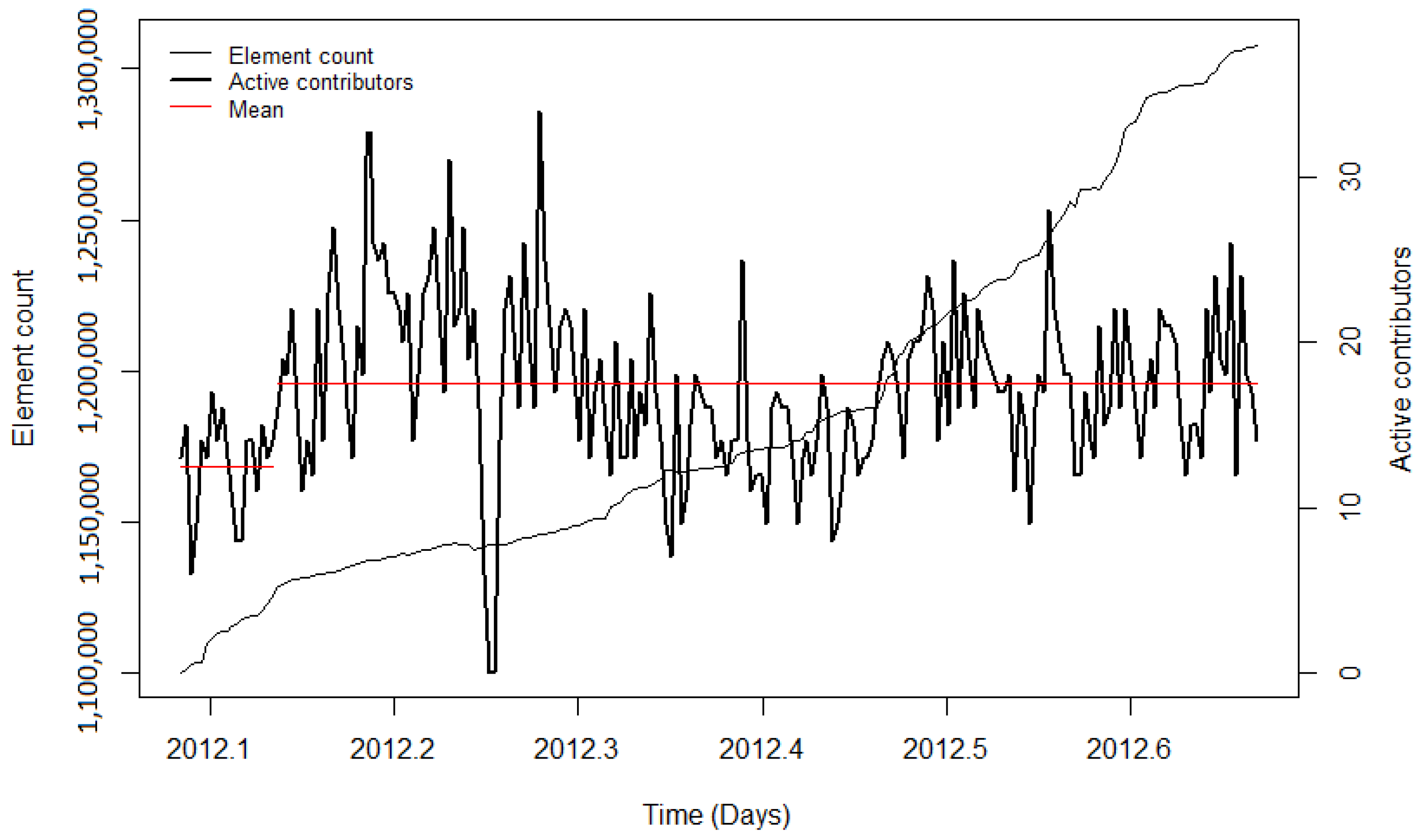
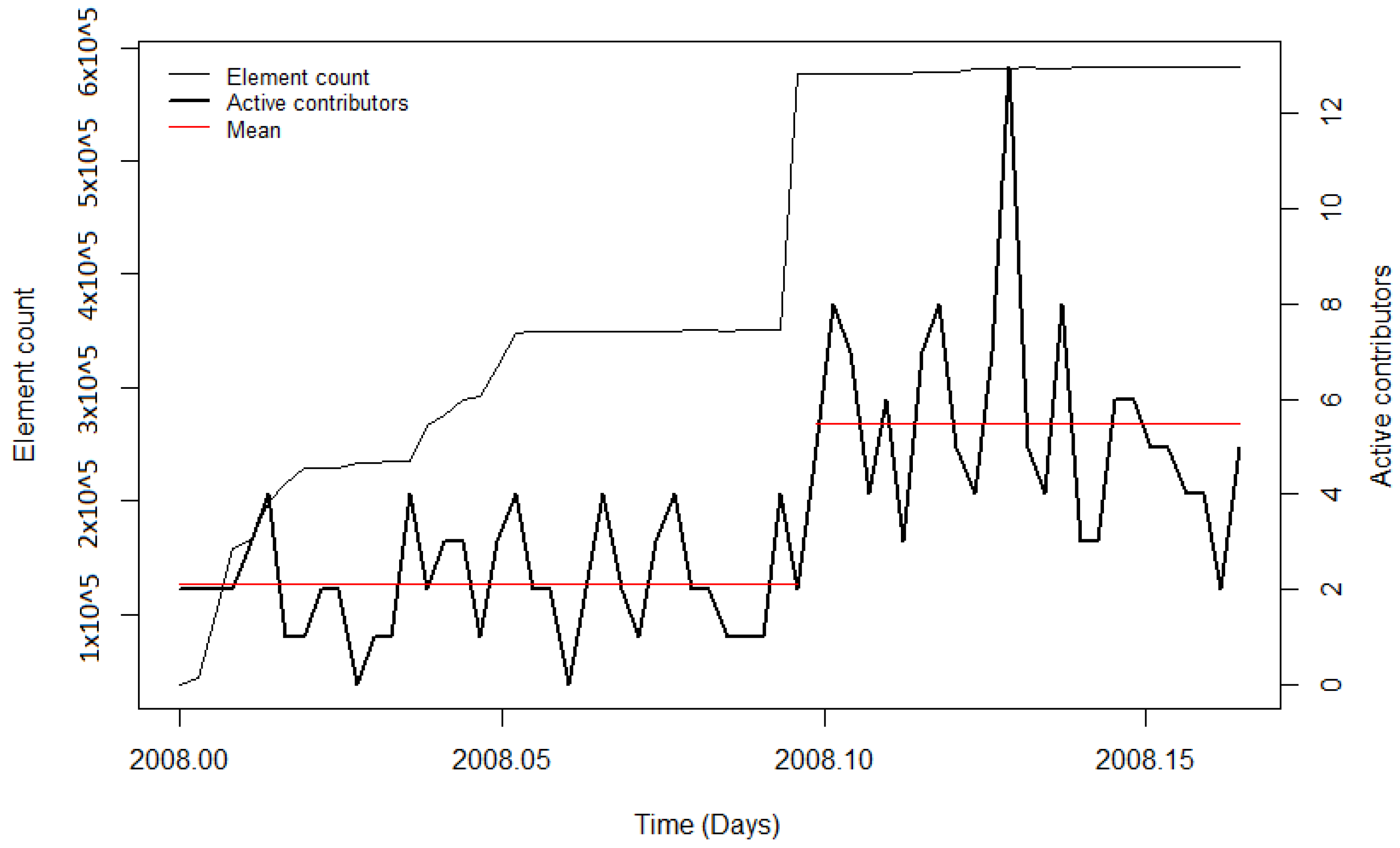
41]) likely benefitted the project, resulting in more volunteers who got involved in OSM to help with the execution of the import and the integration of the data. For the remaining imports, diverse results for the contributor activity were found. During the PGS import, no significant change in the user activity was detected. Additionally, for this import, the low activity could be explained by the newness of OSM, particularly in India. The observation periods of the BAG import and the first phase of the building import in India showed a decrease in mean contributor activity. Nonetheless, when looking at the diagrams, it can be seen that during both imports, the mean number of active contributors was high, indicating stronger user activity while importing the data, but decreased involvement afterwards. For the time periods without a large data import, the CP algorithm also detected changes in the mean. However, the changes could have been caused by other events (for example, in India) or because of the downtime of the servers (for example in the Netherlands). Summarising for the contributor activity, it was found that during and after most of the large data imports, the contributor activity was higher than before the import. Nonetheless, this was also the case for the analysed time intervals without large data imports.
Table 6 displays the outcomes of the changepoint detection analysis, including the differences and growth rates for all observation periods.
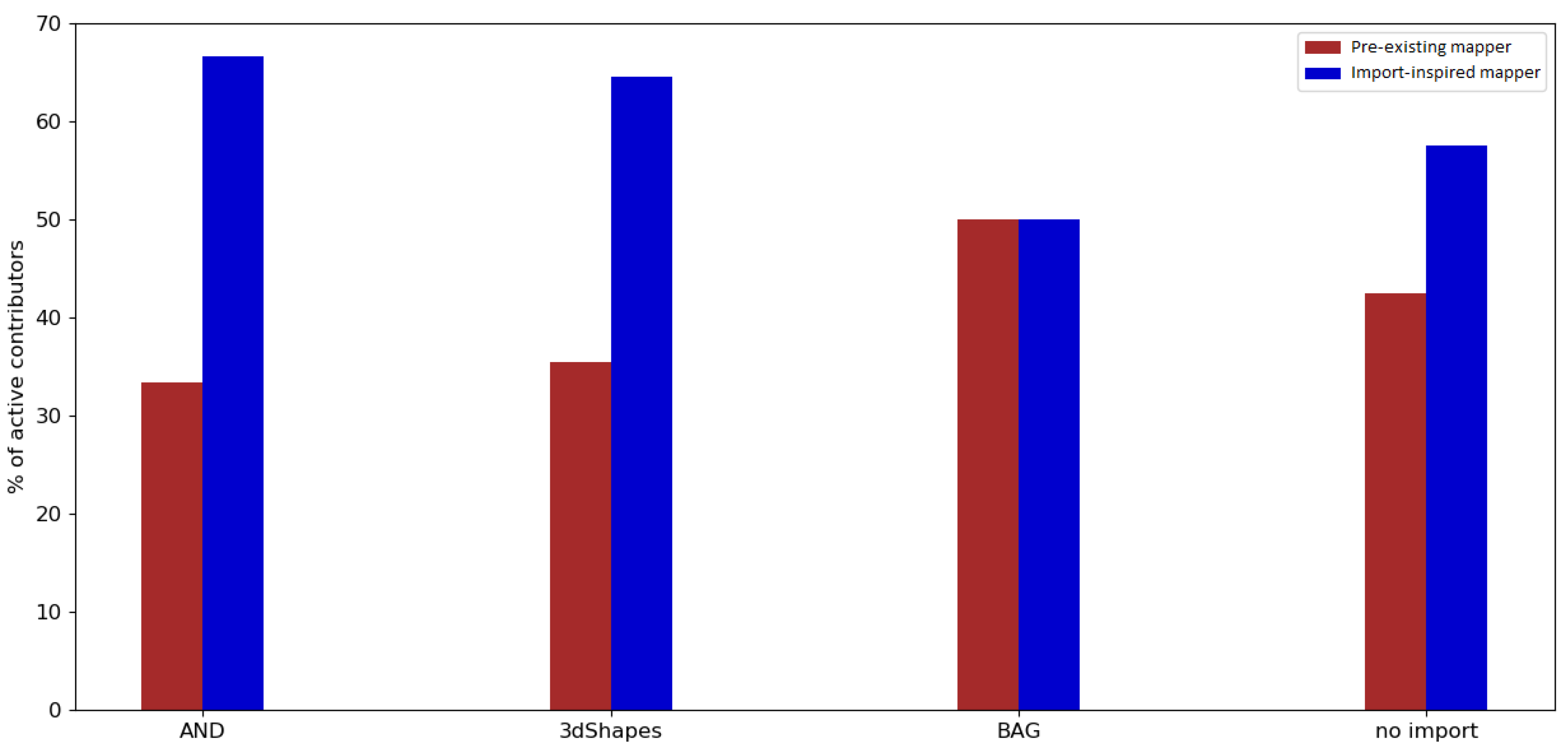
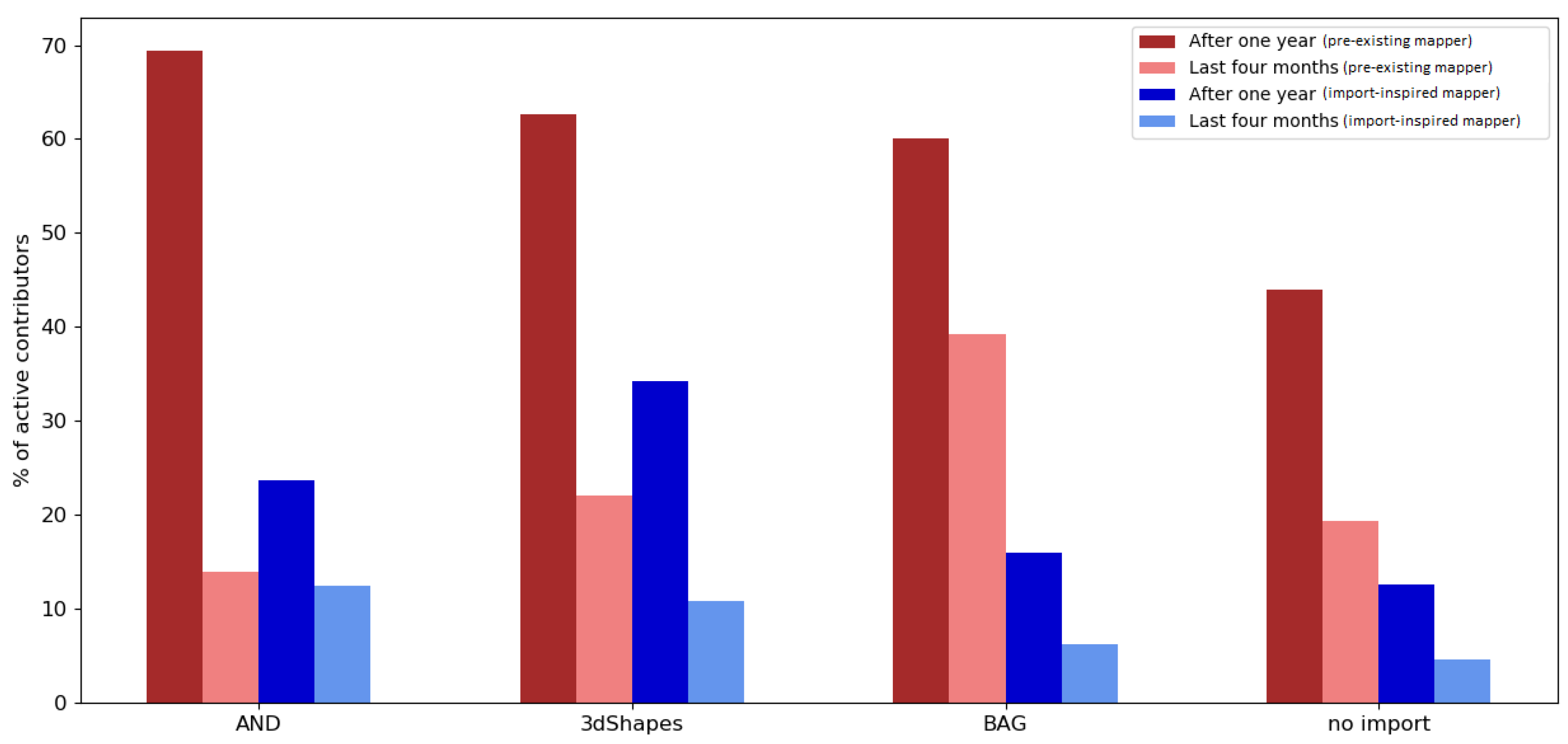
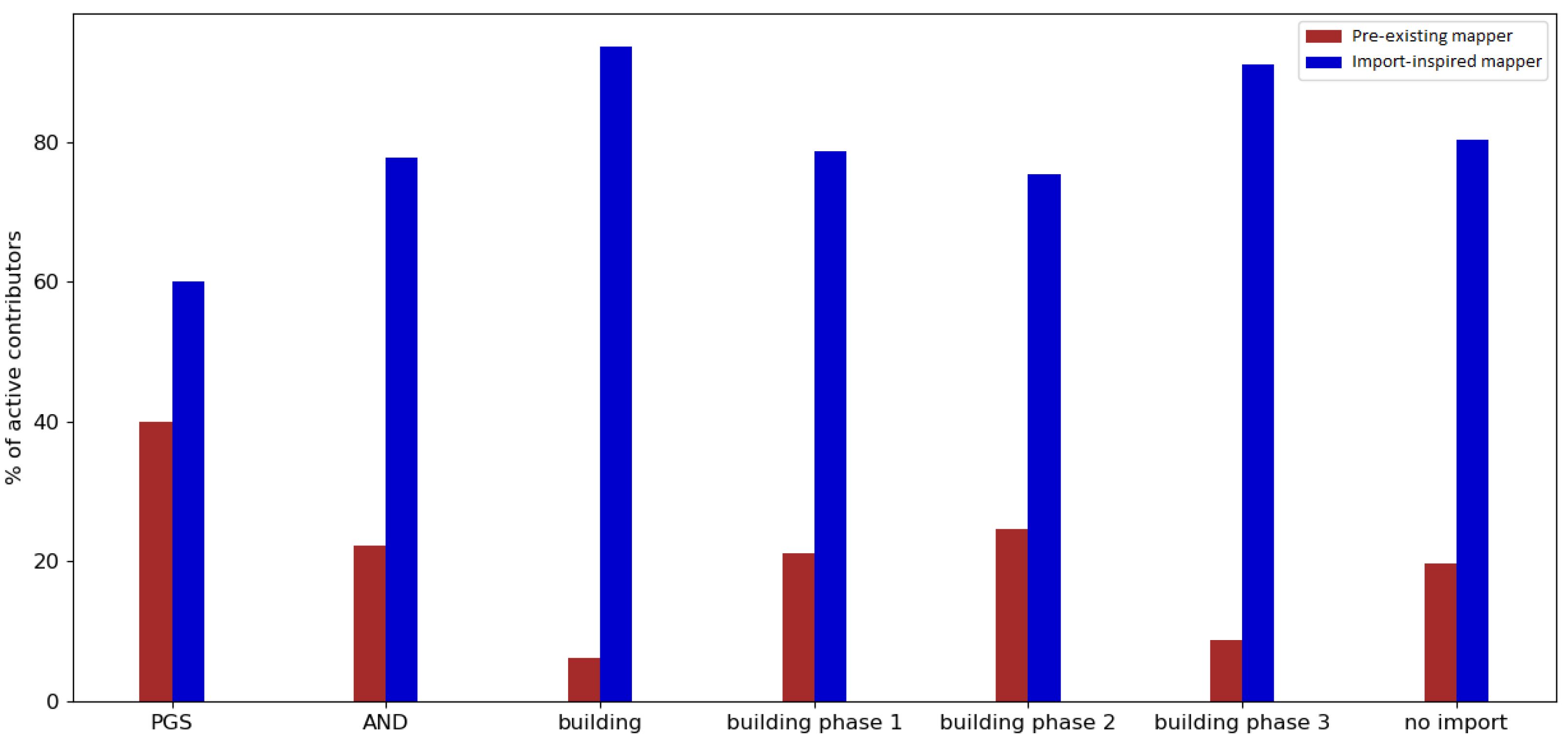
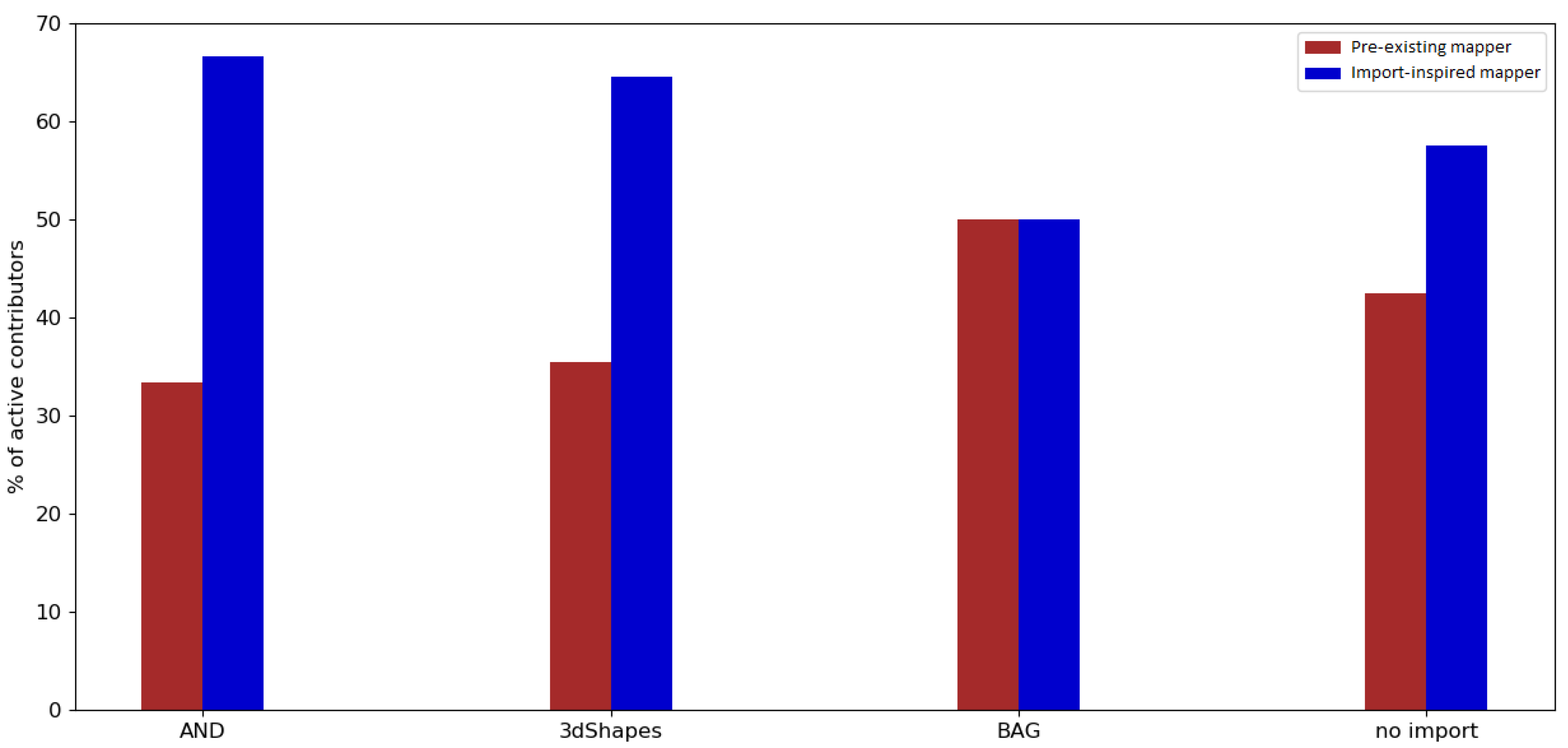
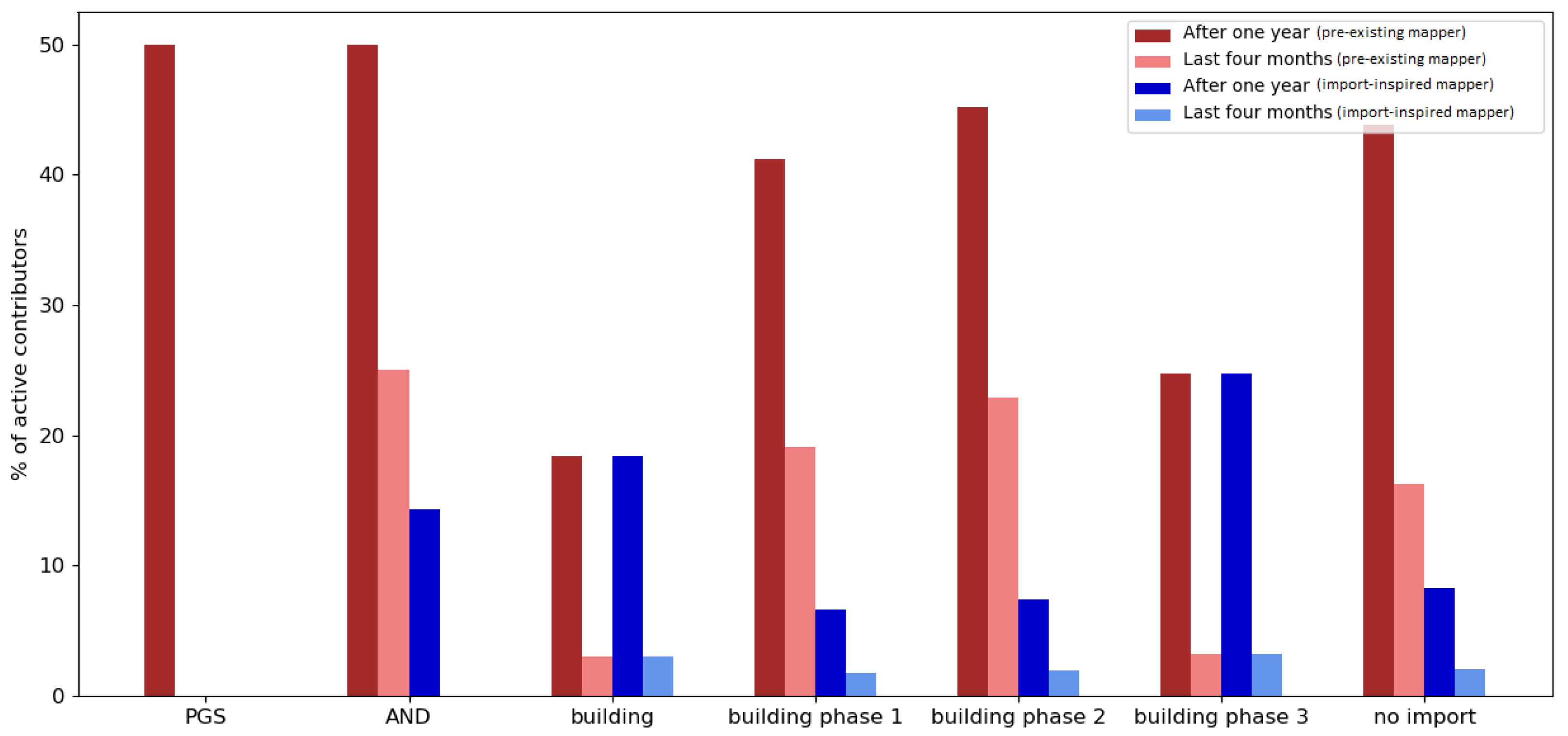
Regarding the engagement of contributors who were involved in an import, it was found that the majority of contributors who took part in a large data import were import-inspired mappers (contributors who made at least their first edits during the observation period). The same applied for the periods without any large data import. However, the involvement of contributors changed drastically after one year.
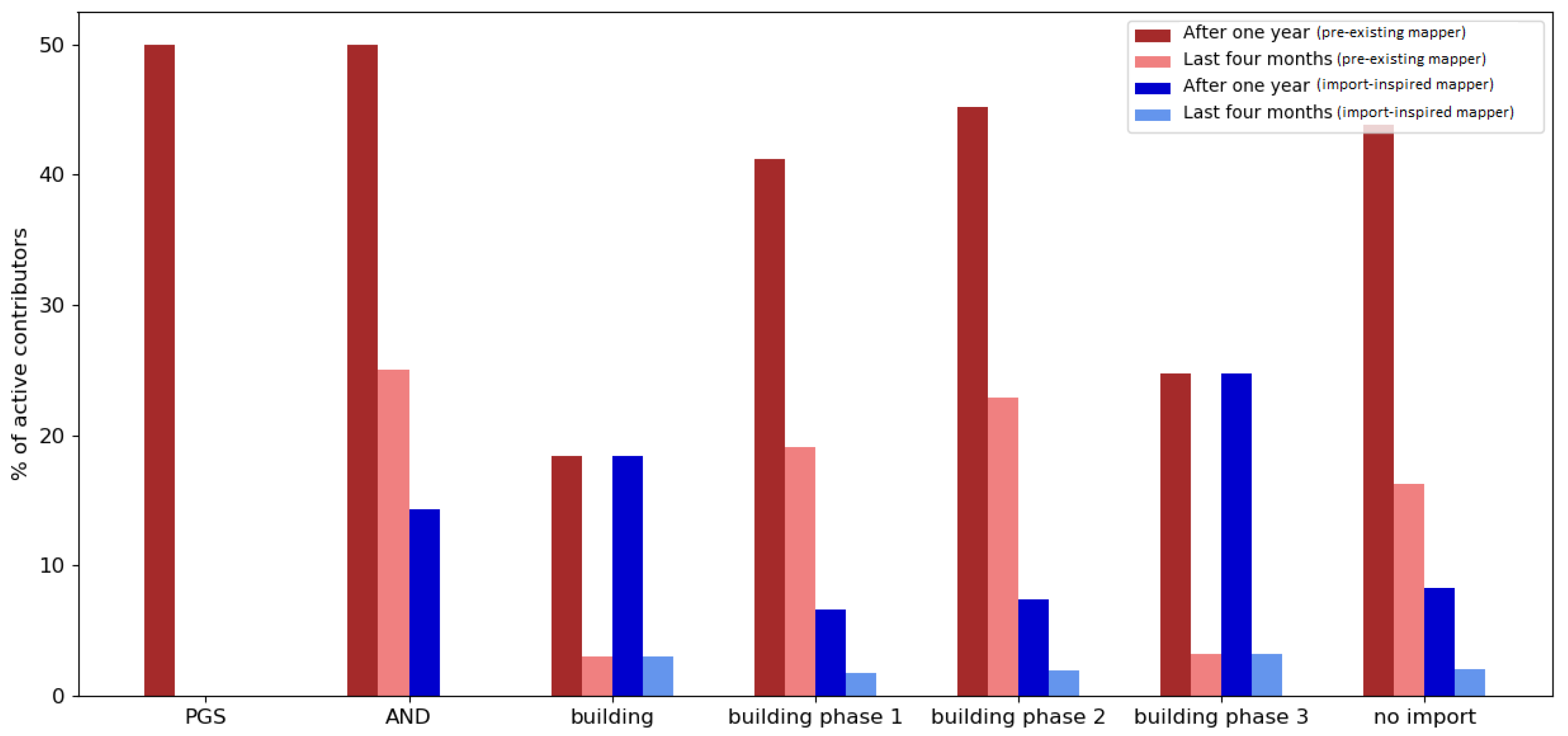
Pre-existing mappers who were editing or creating data in OSM before an import were more likely to remain active in OSM (e.g., for all the imports in the Netherlands, more than 60% of the pre-existing mappers were still contributing one year after the observation period). Most of the pre-existing mappers in the control group contributed to OSM after one year (approximately 50% in the Netherlands; approximately 40% in India).
Import-inspired mappers were found to not normally stay involved for longer than one year after the import (e.g., for the imports in the Netherlands, less than 35% of import-inspired mappers were still contributing one year after the observation period). A similar development can be seen when looking at the engagement of import-inspired mappers of the control group (less than 20% in the Netherlands and less than 10% in India were still active).
Looking at the ratio of pre-existing mappers who were contributing to OSM between 1 May 2019 and 31 August 2019, only a fraction of the users remained active. An example that stands out contradictorily is the BAG import in the Netherlands. More than 40% of pre-existing mappers were still active between 1 May 2019 and 31 August 2019. This could be explained with the timing of the import, given that it happened late in the project.
For import-inspired mappers who were participating in an import, less than 15% contributed to OSM between 1 May 2019 and 31 August 2019 overall, indicating a relatively low rate of involvement.
Altogether, it was found that the majority of OSM users who were involved in an import made their first edits within the import observation period. However, users who already had experience before being involved in an import were more likely to stay active. This applied to both the contributors who participated in large data imports and the contributors of the control group.
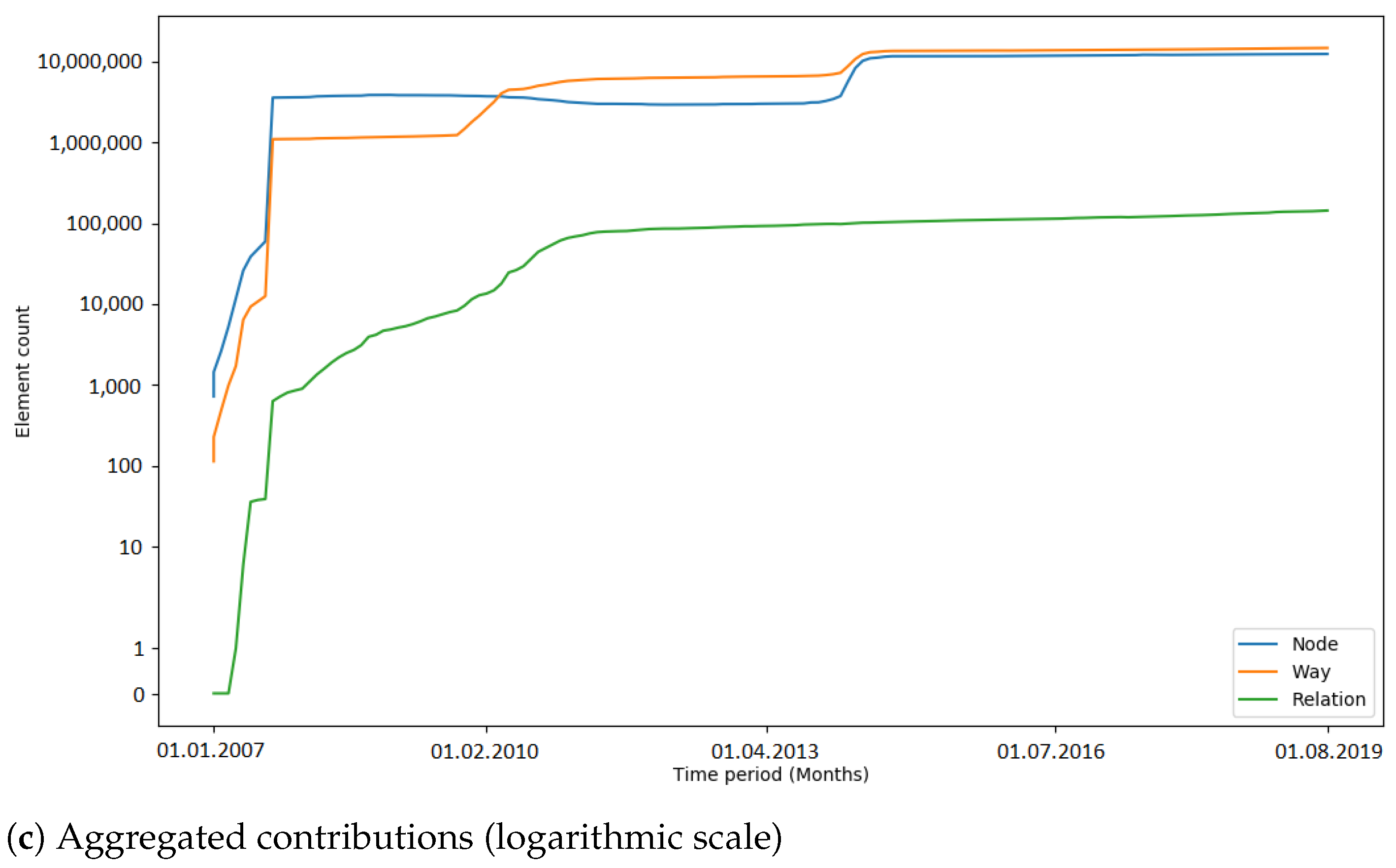
4.1.2. Contribution Types
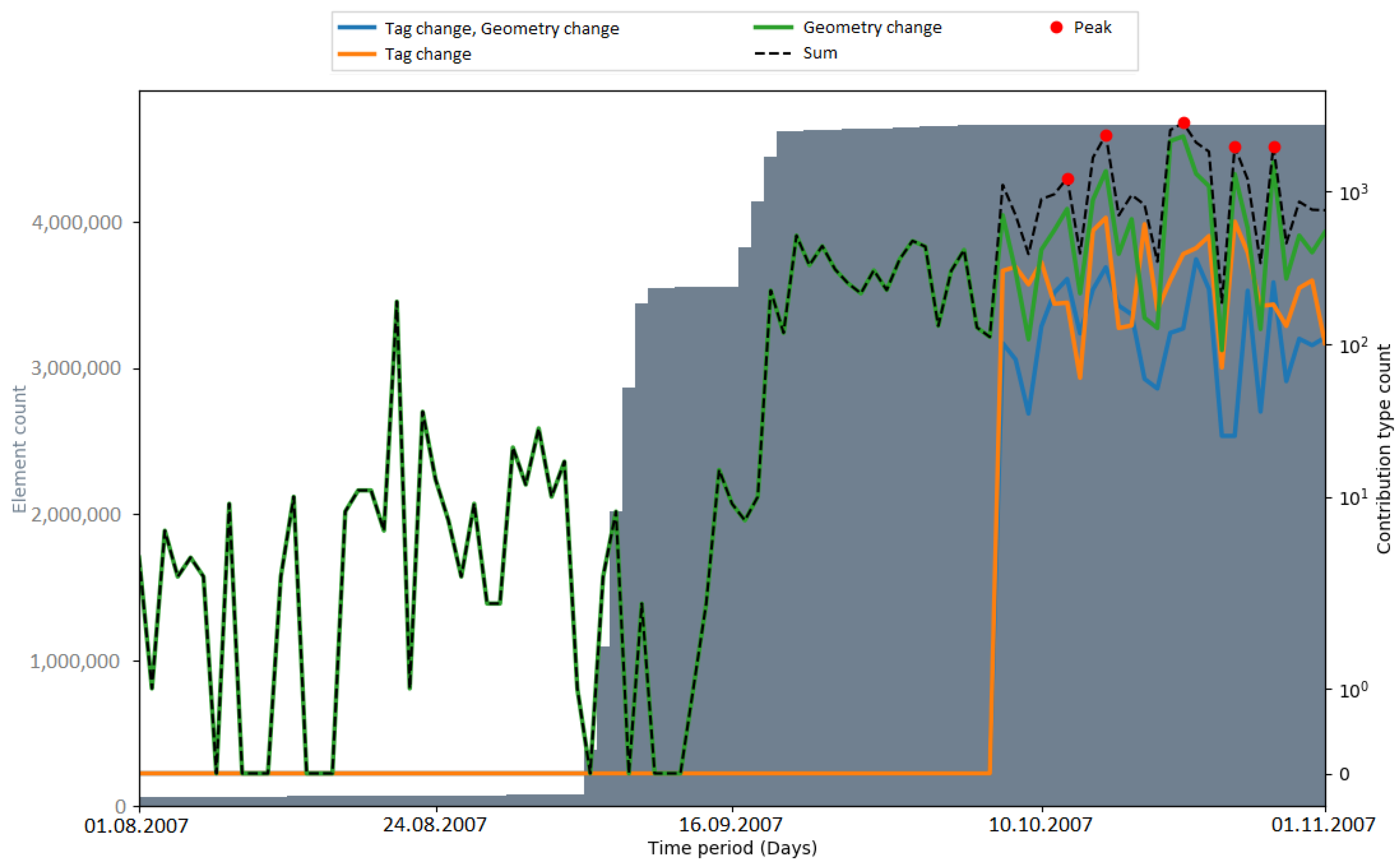
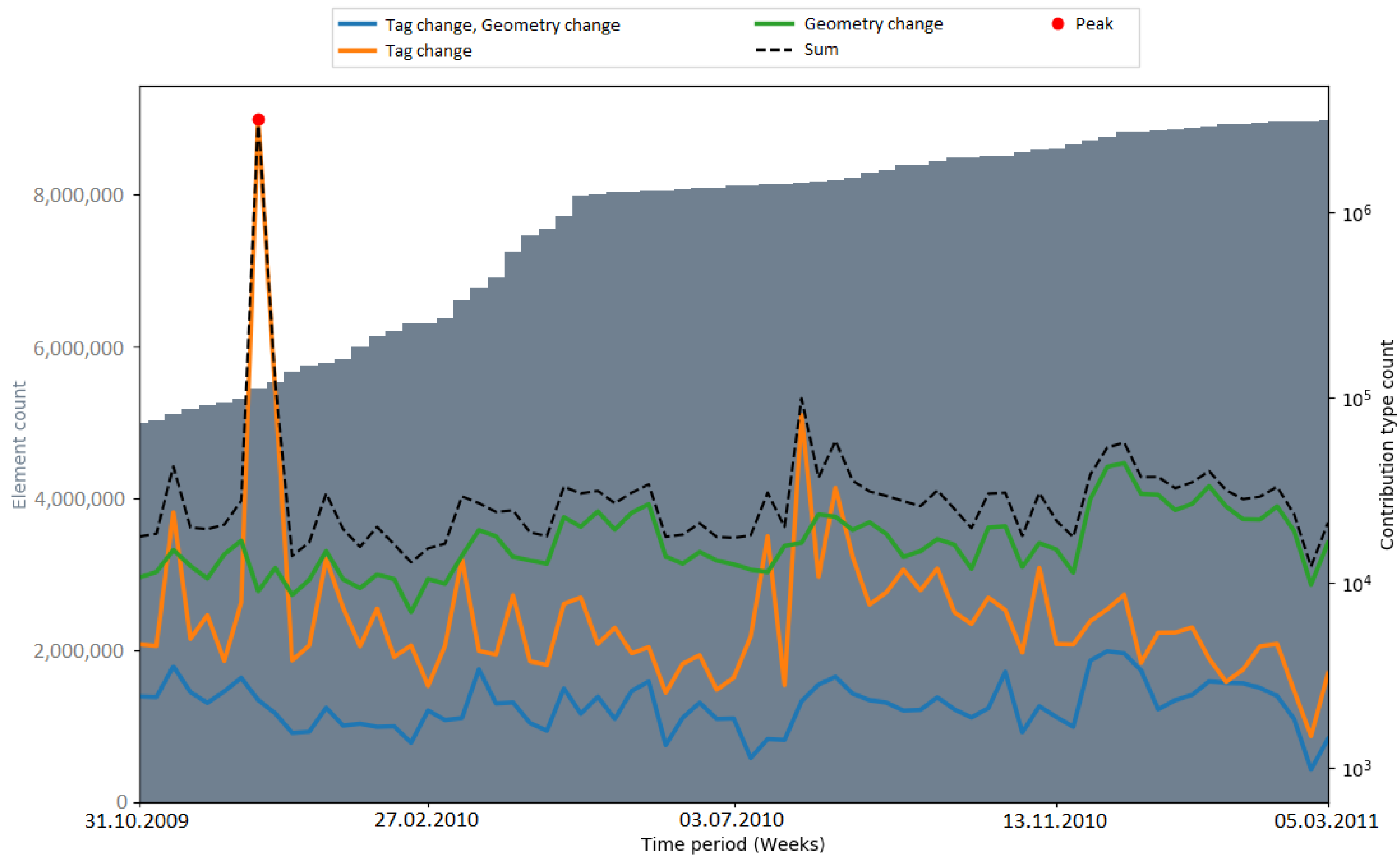
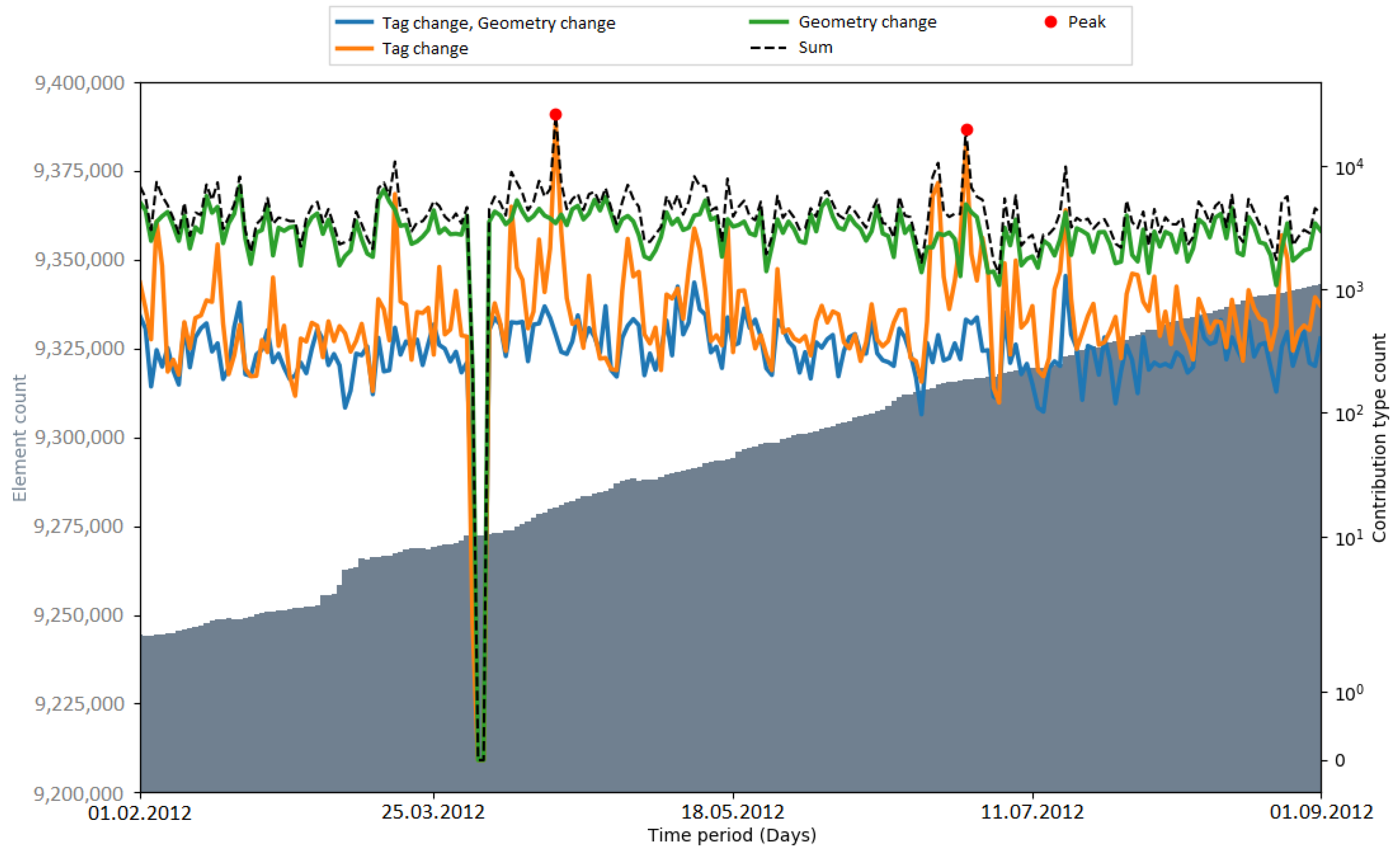
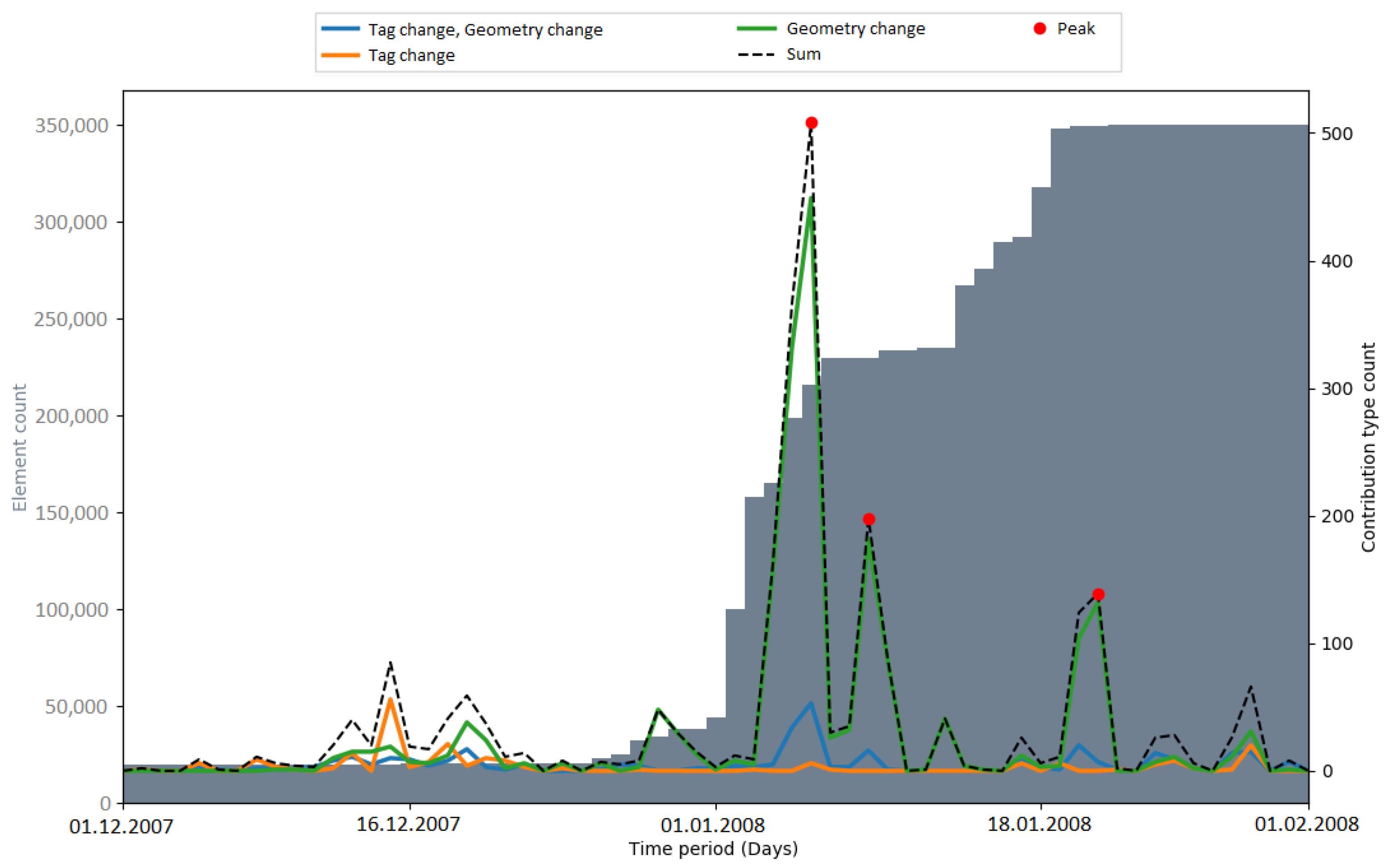
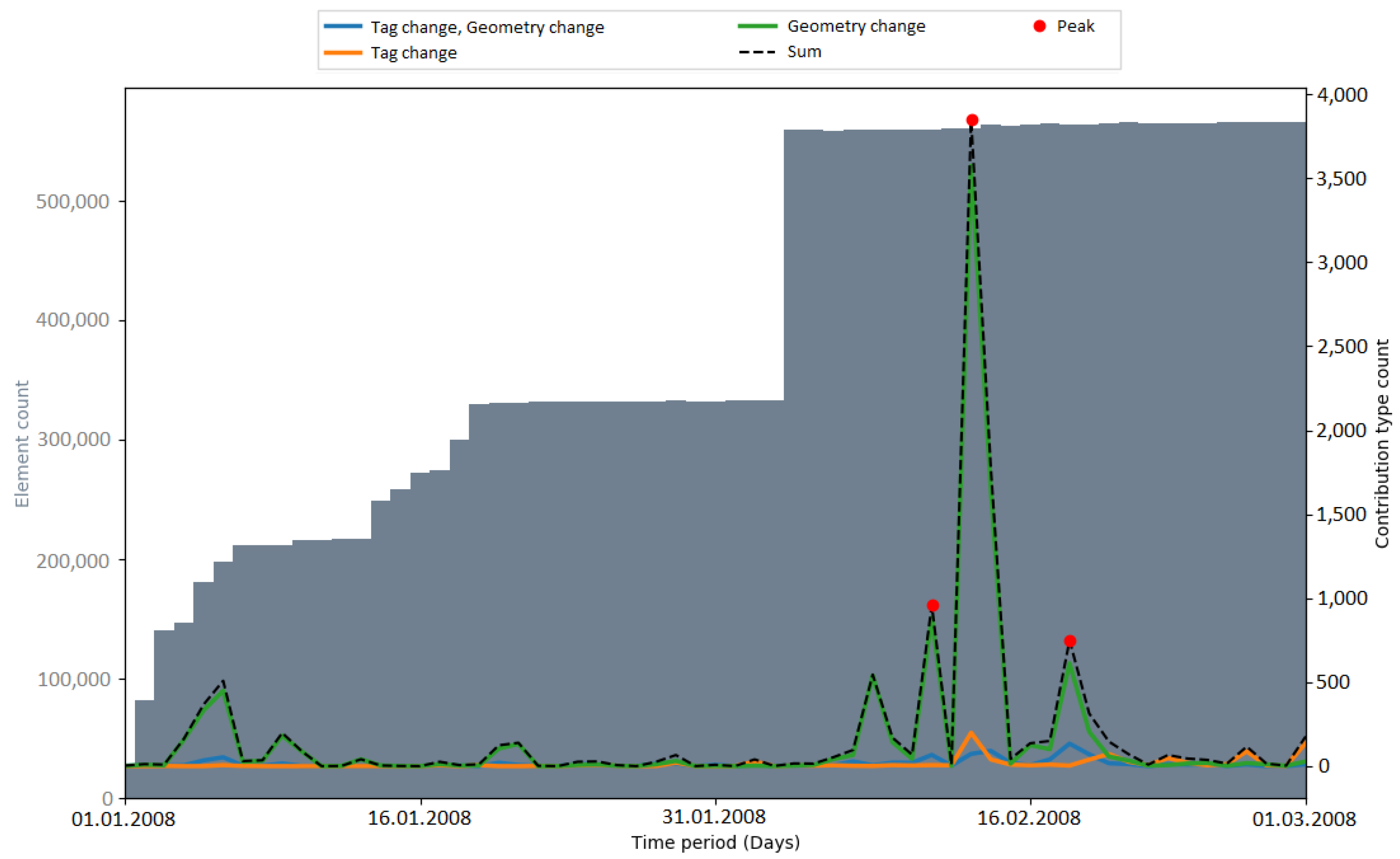
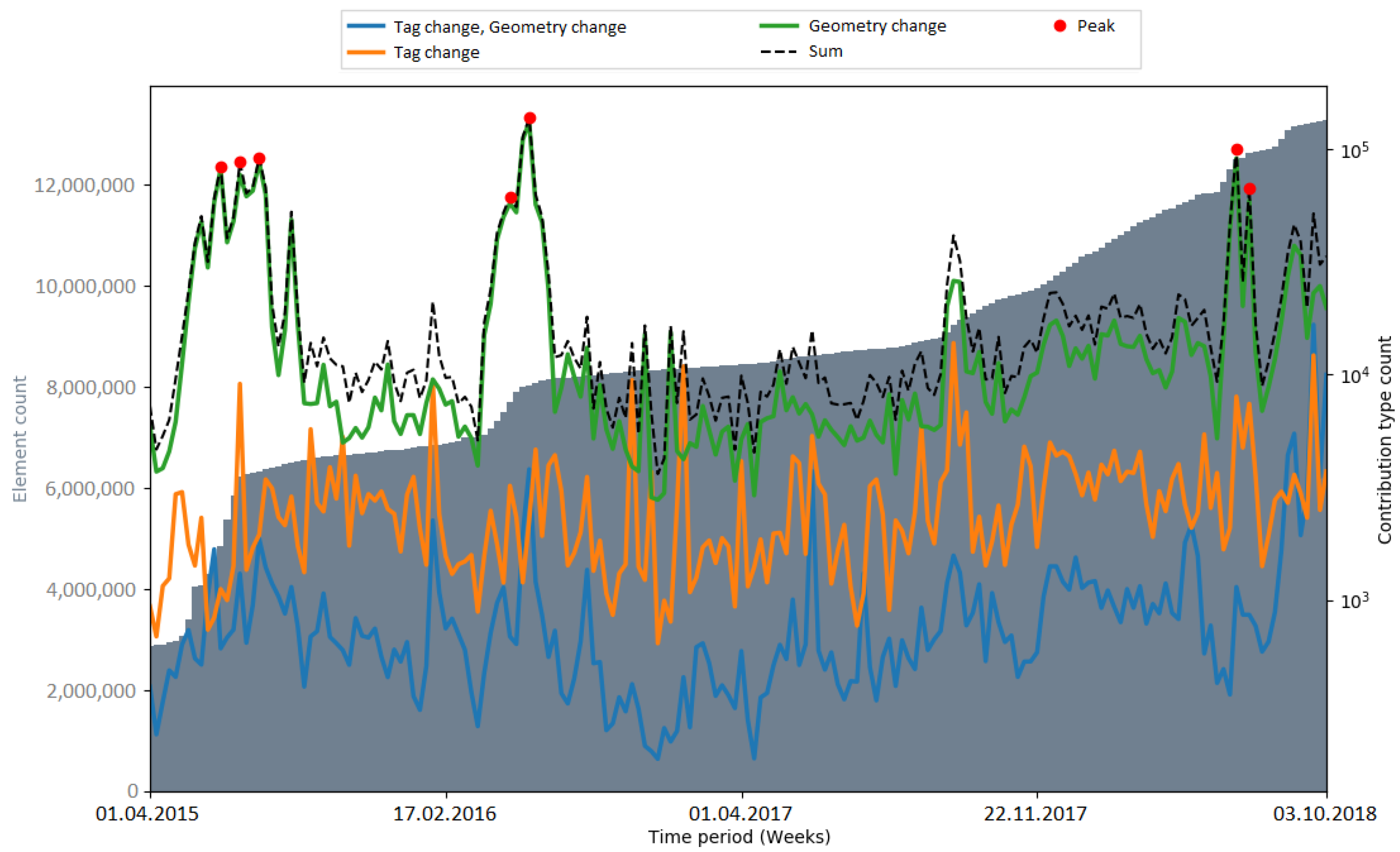
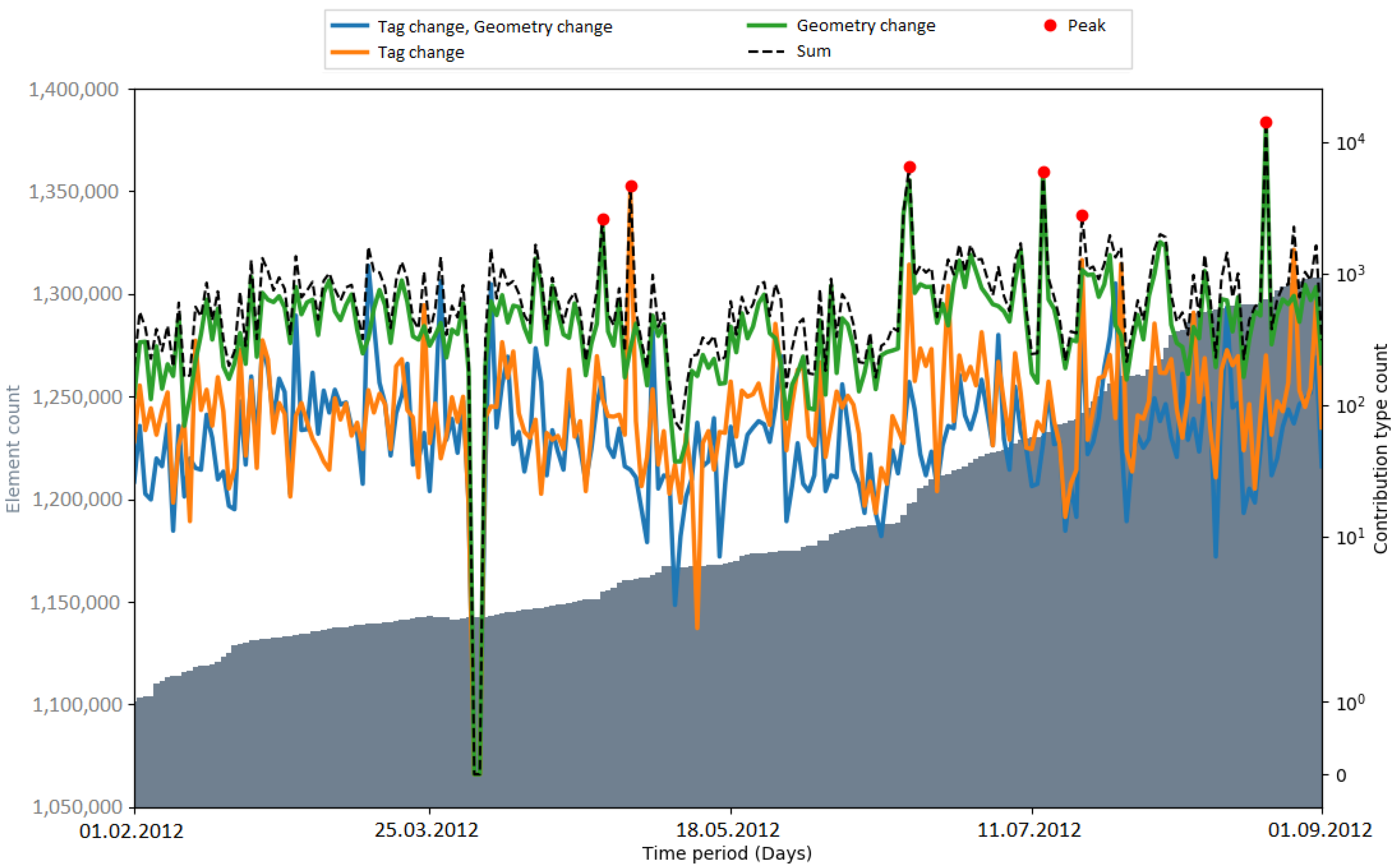
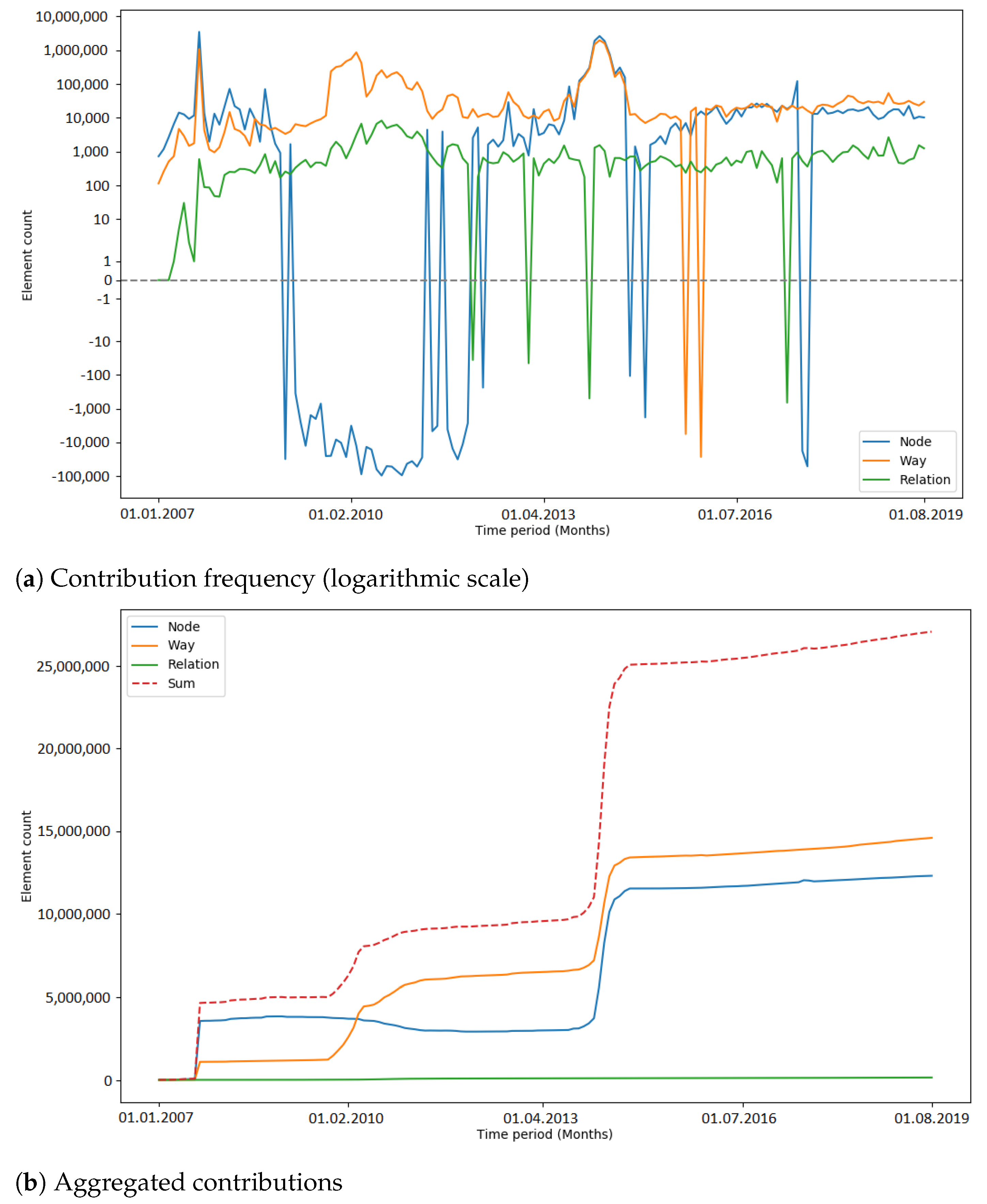
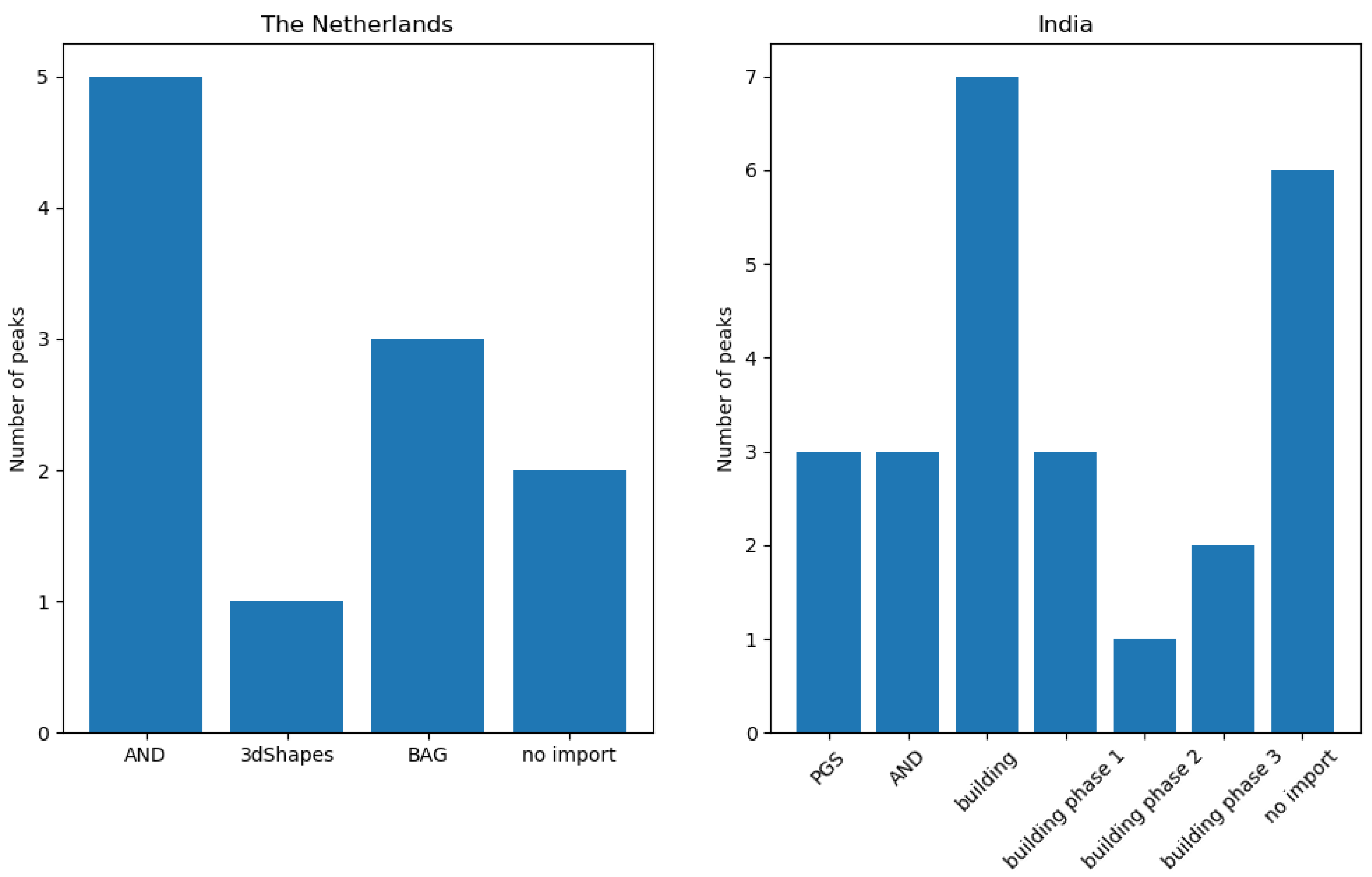
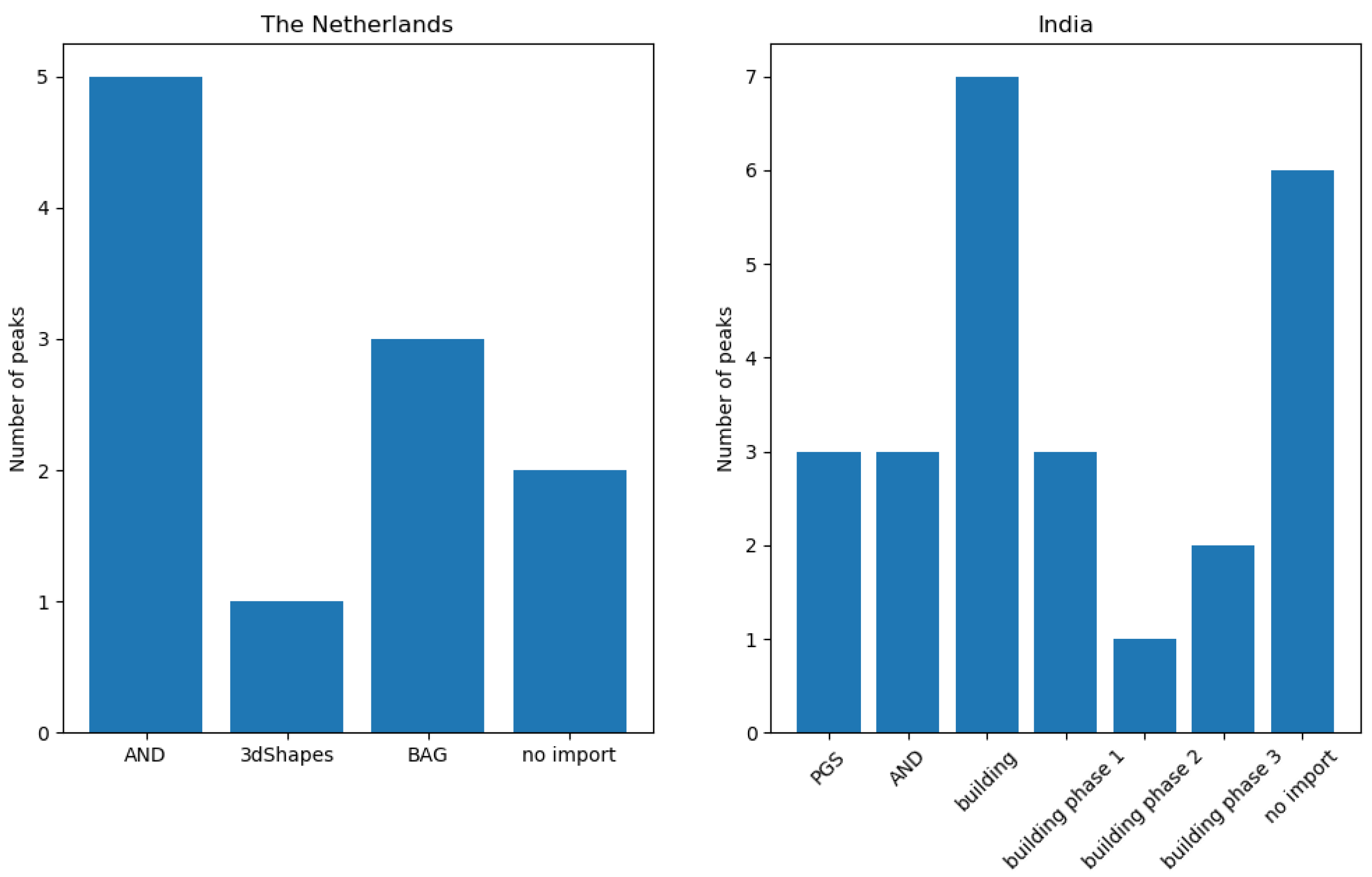
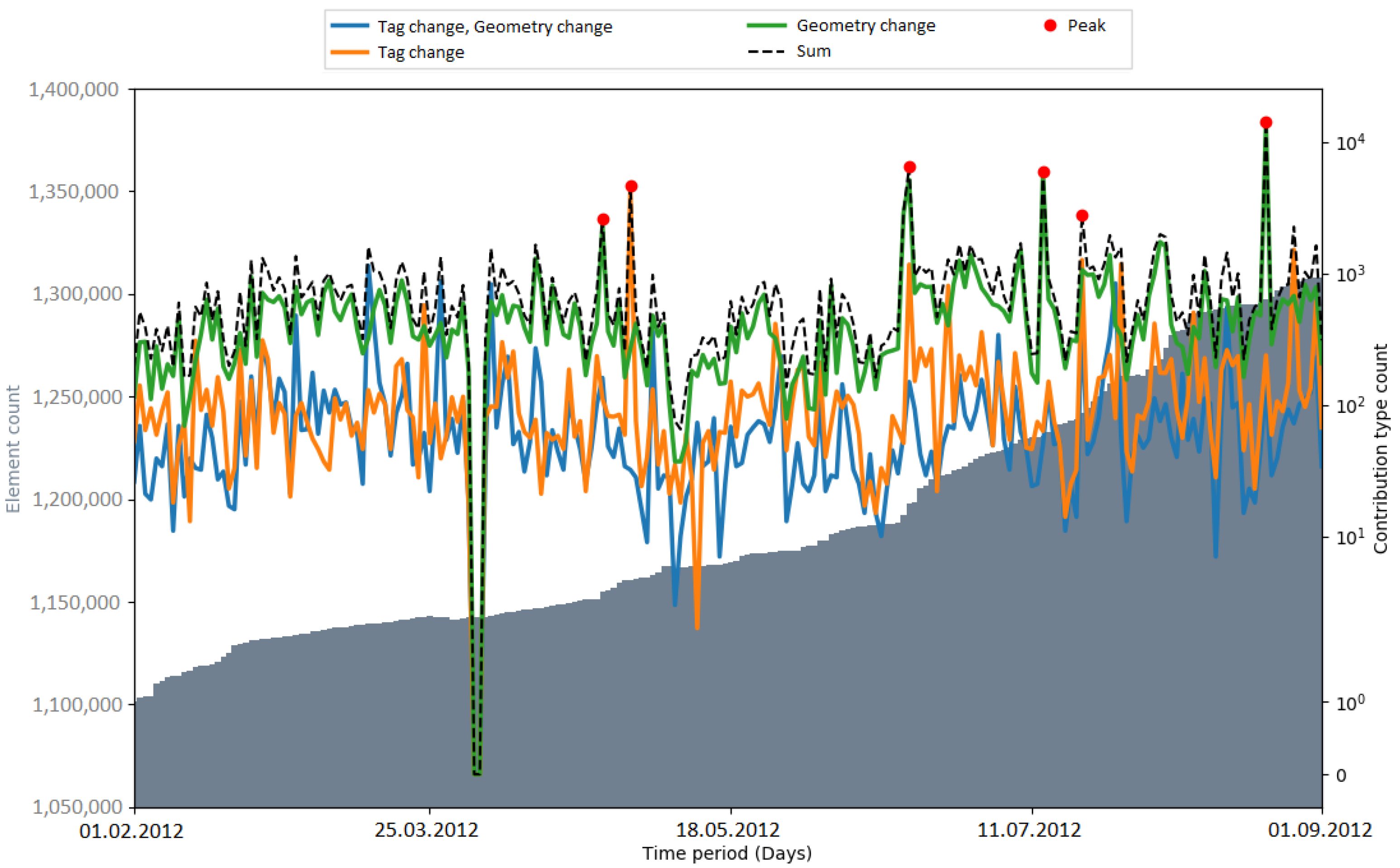
Peaks in the number of contribution types were used as an indicator for automated processes (i.e., bots or scripts) which update or change OSM data. Hence, the number of peaks that occurred during an import gives a metric about how OSM data were subsequently changed. In
Figure 9, the number of detected peaks within the respective observation periods of the imports is displayed. The amount varied among the different imports. When comparing the time periods without an import, the number of peaks differs by a considerable margin (two peaks in the Netherlands, six peaks in India). The gap between the total numbers of peaks (11 in the Netherlands, 19 (18) in India) could be explained with the differences in the state of the map and the communities of both countries. Generally, it is more likely that mass changes via bots happen in India because of the lack of local communities which maintain and update the data.
It could be seen that peaks in the number of contribution types were not necessarily caused by the large data import. After a short investigation of the PGS import, it was found that the peaks were caused by four contributors (by specifying the contributor ID, the web link
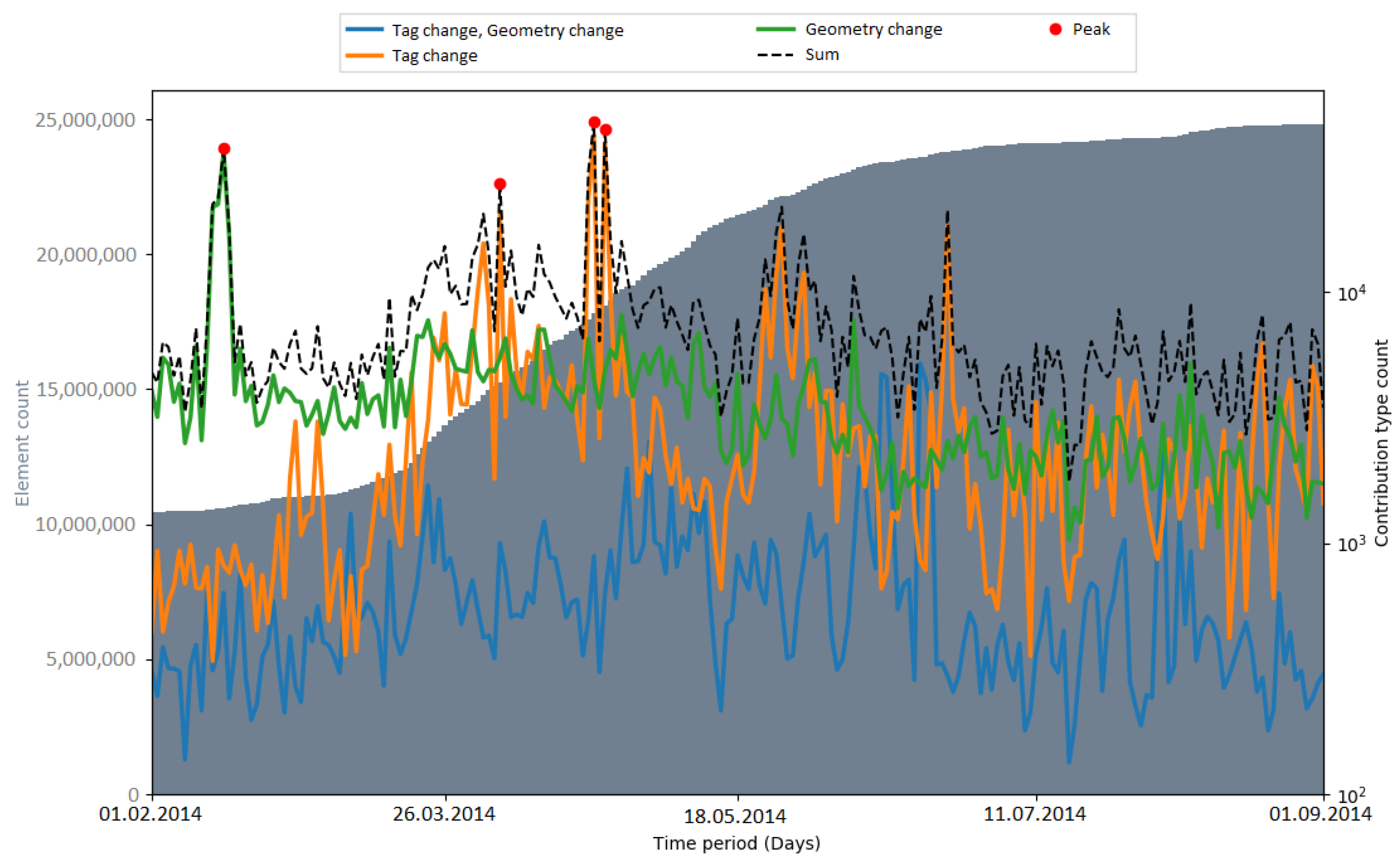
https://www.openstreetmap.org/api/0.6/user/contributorID (accessed on 15 February 2020) provides user details) who were correcting the geometries of the imported elements. However, later in the project, far more data were changed—for example, during the 3dShapes import in the Netherlands, there were over three million tag changes in one week (see
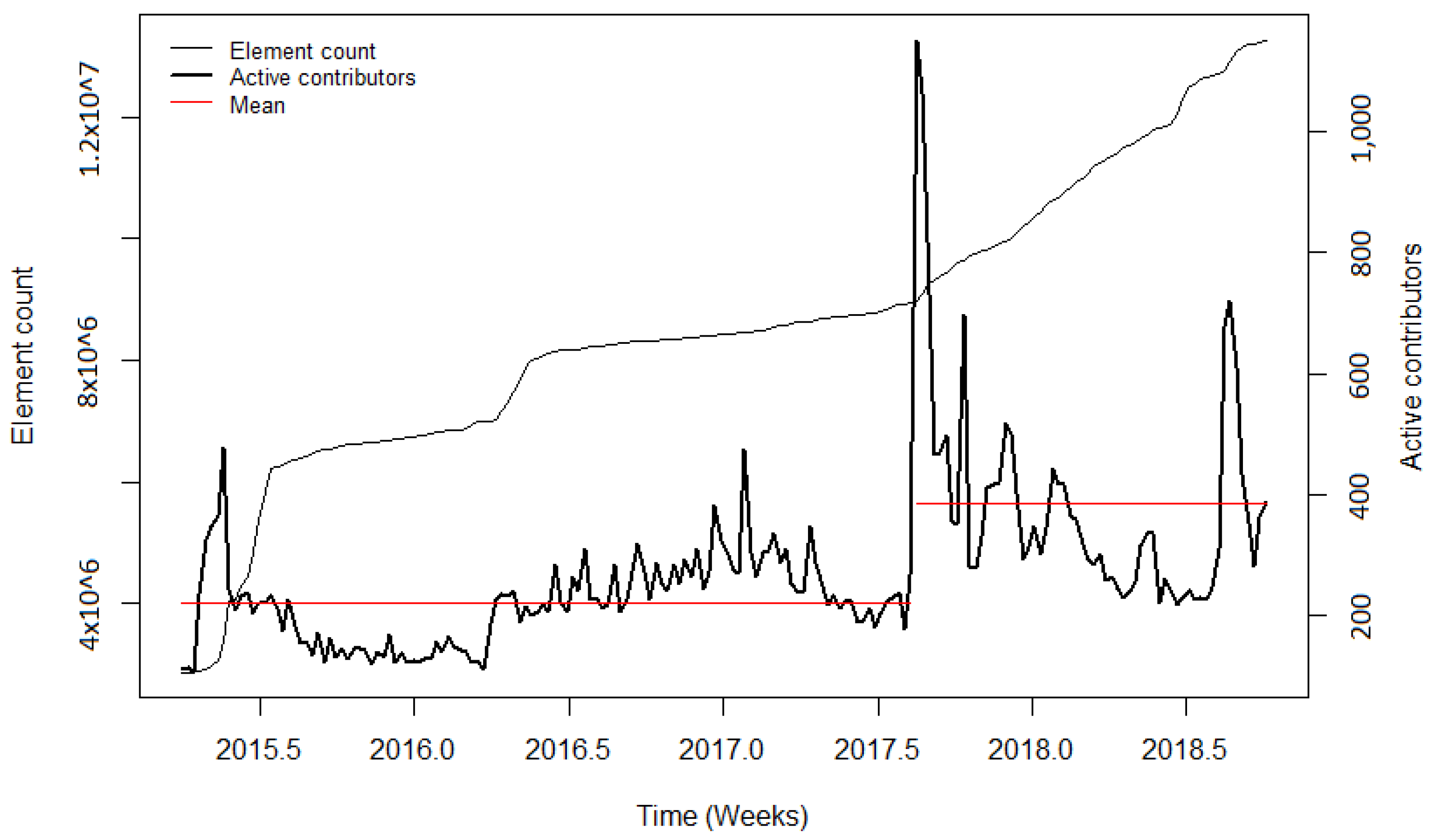
Figure A9). After a brief investigation of the 3dShapes import, it was found that the large number of tag changes occurred to remove AND tags, and was not related to the 3dShapes import. Consequently, a more detailed analysis is necessary to find out out why exactly changes of many OSM elements are caused.
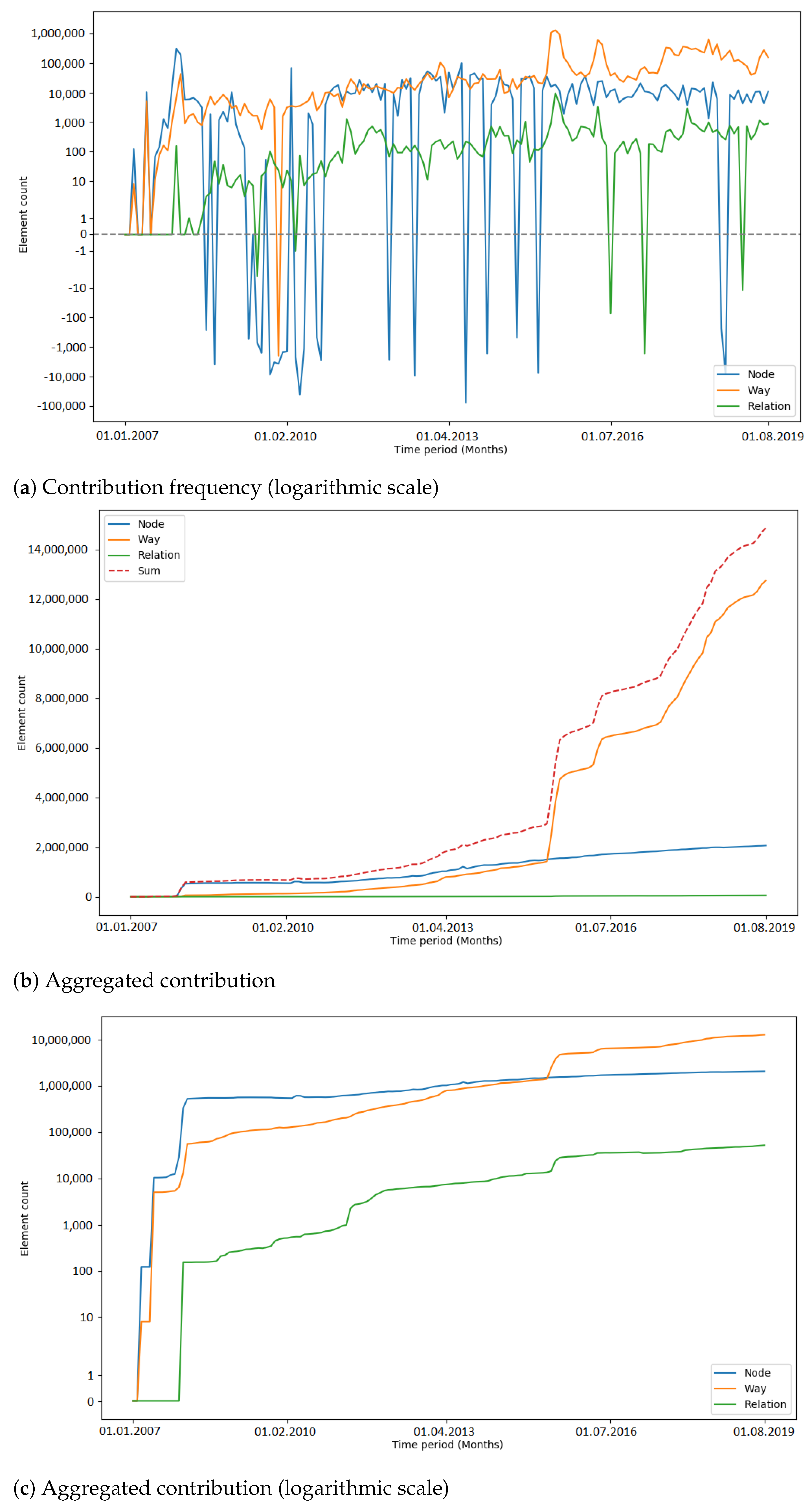
4.1.3. Tags
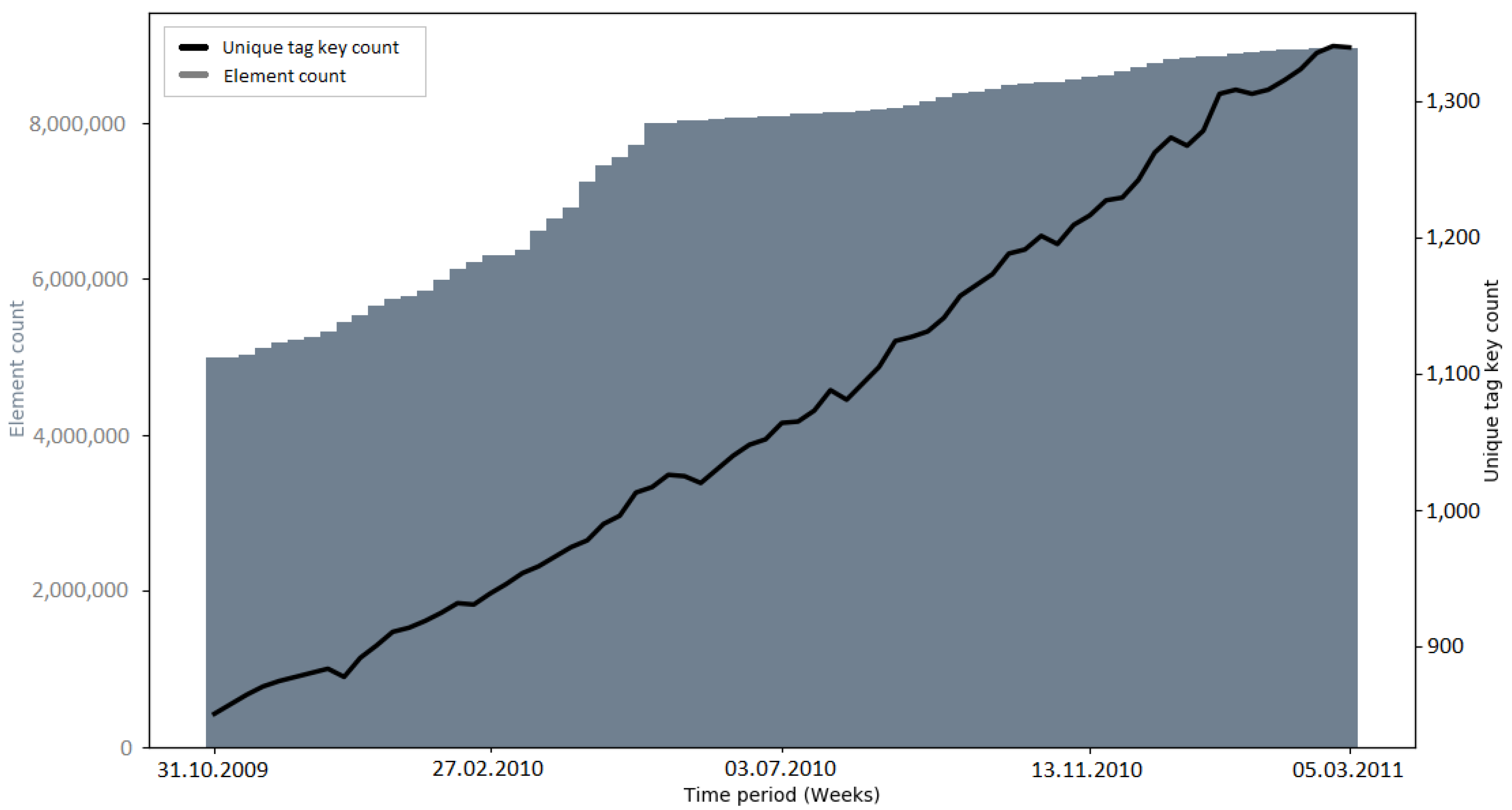
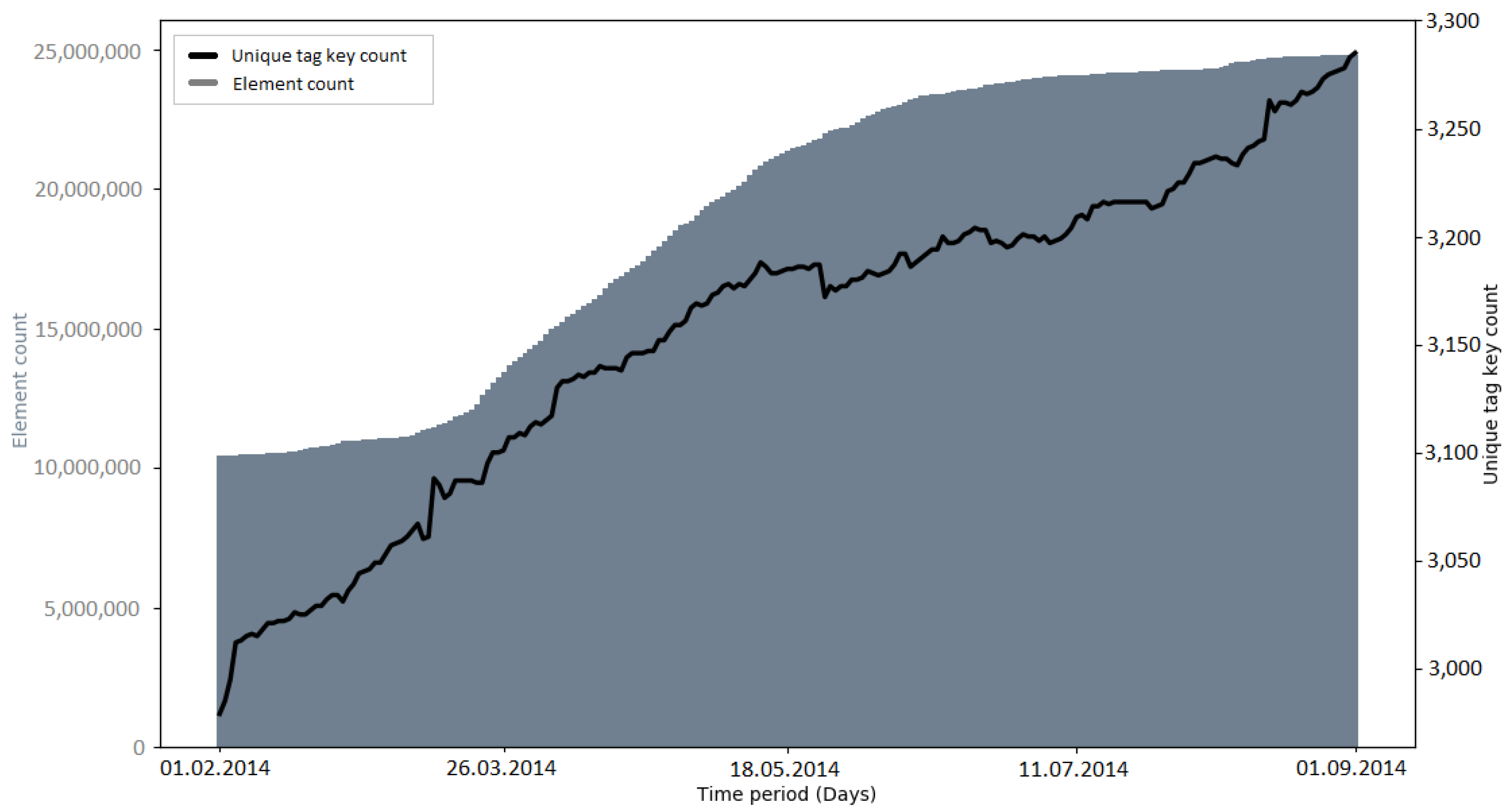
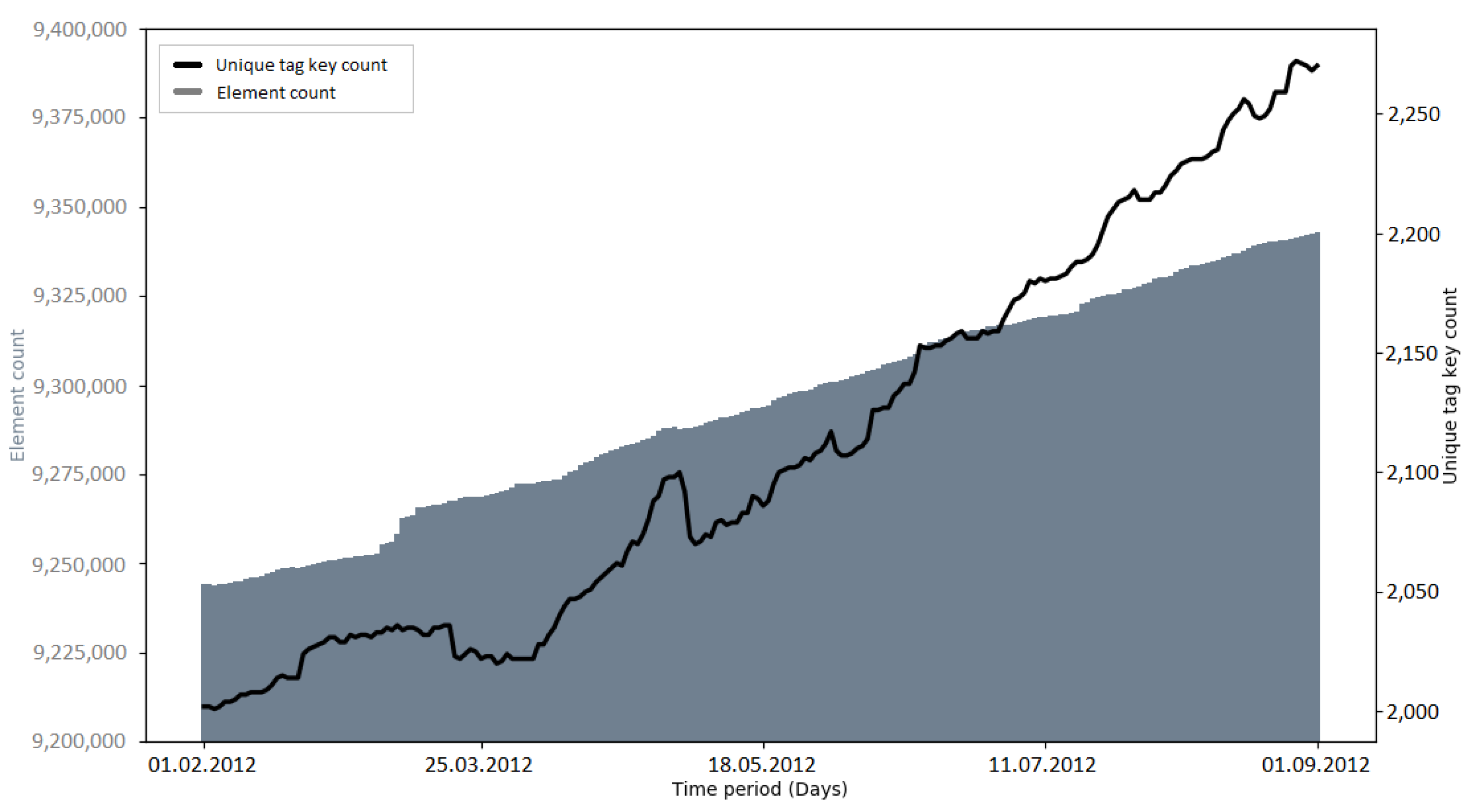
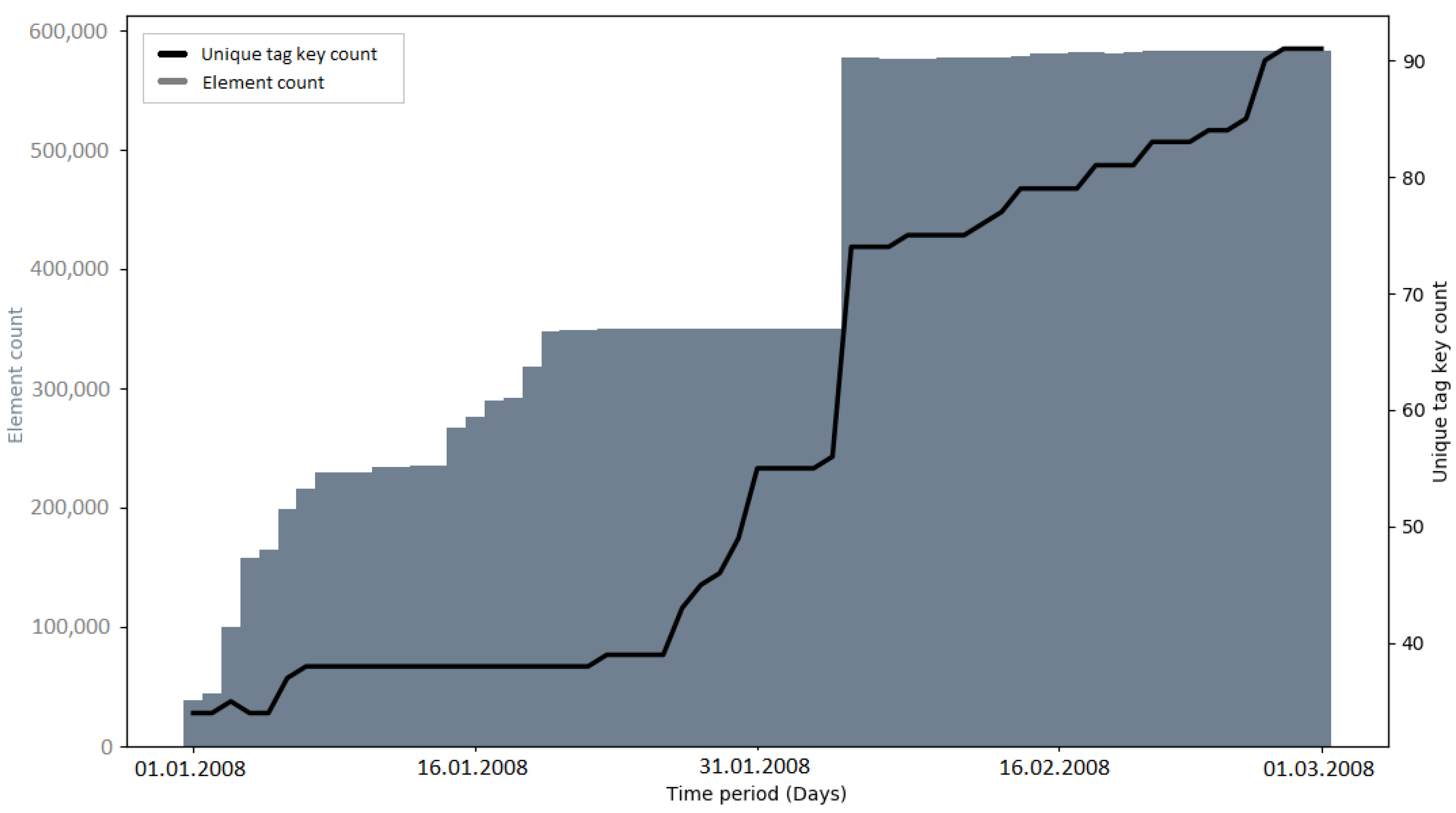
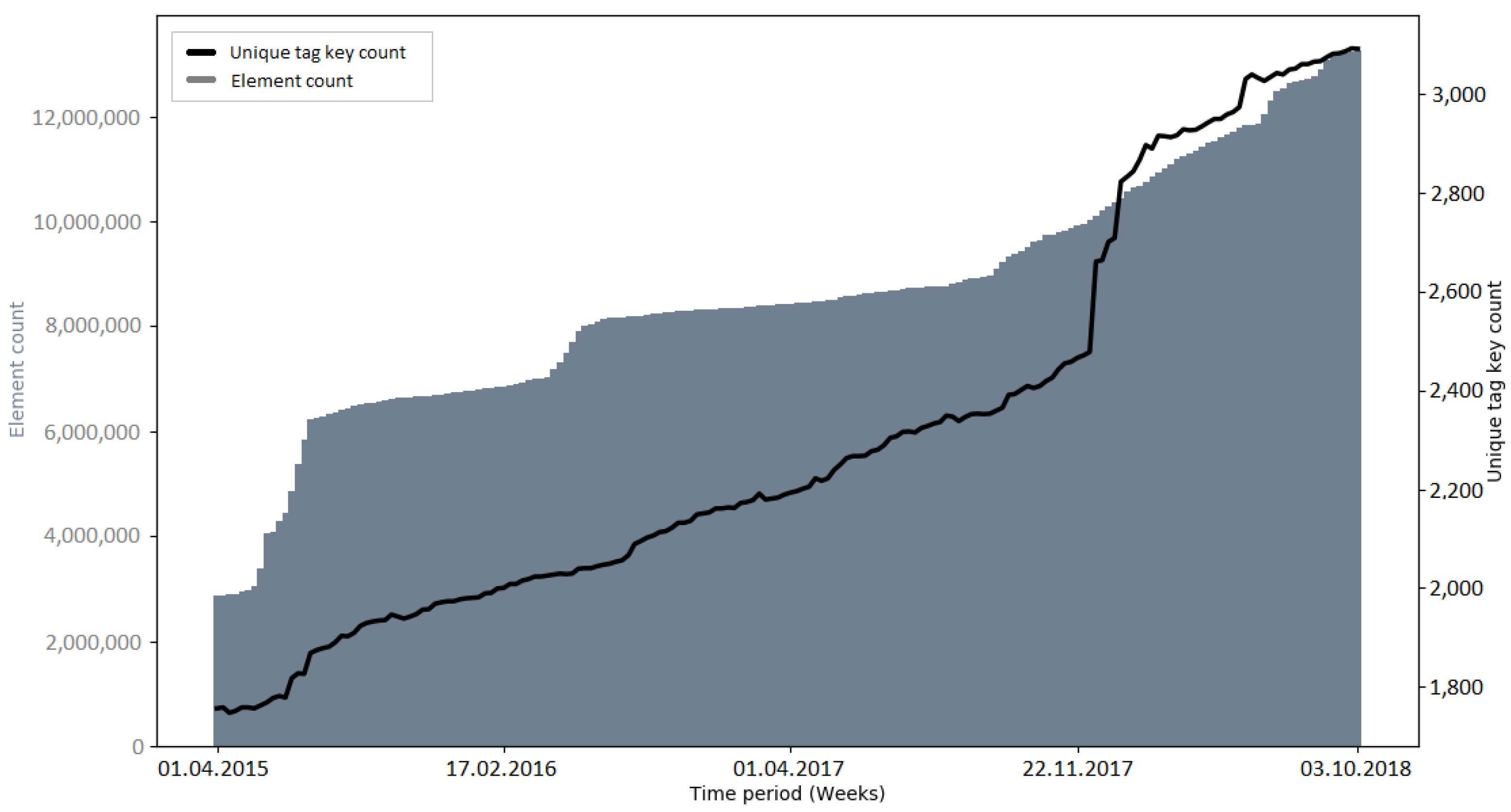
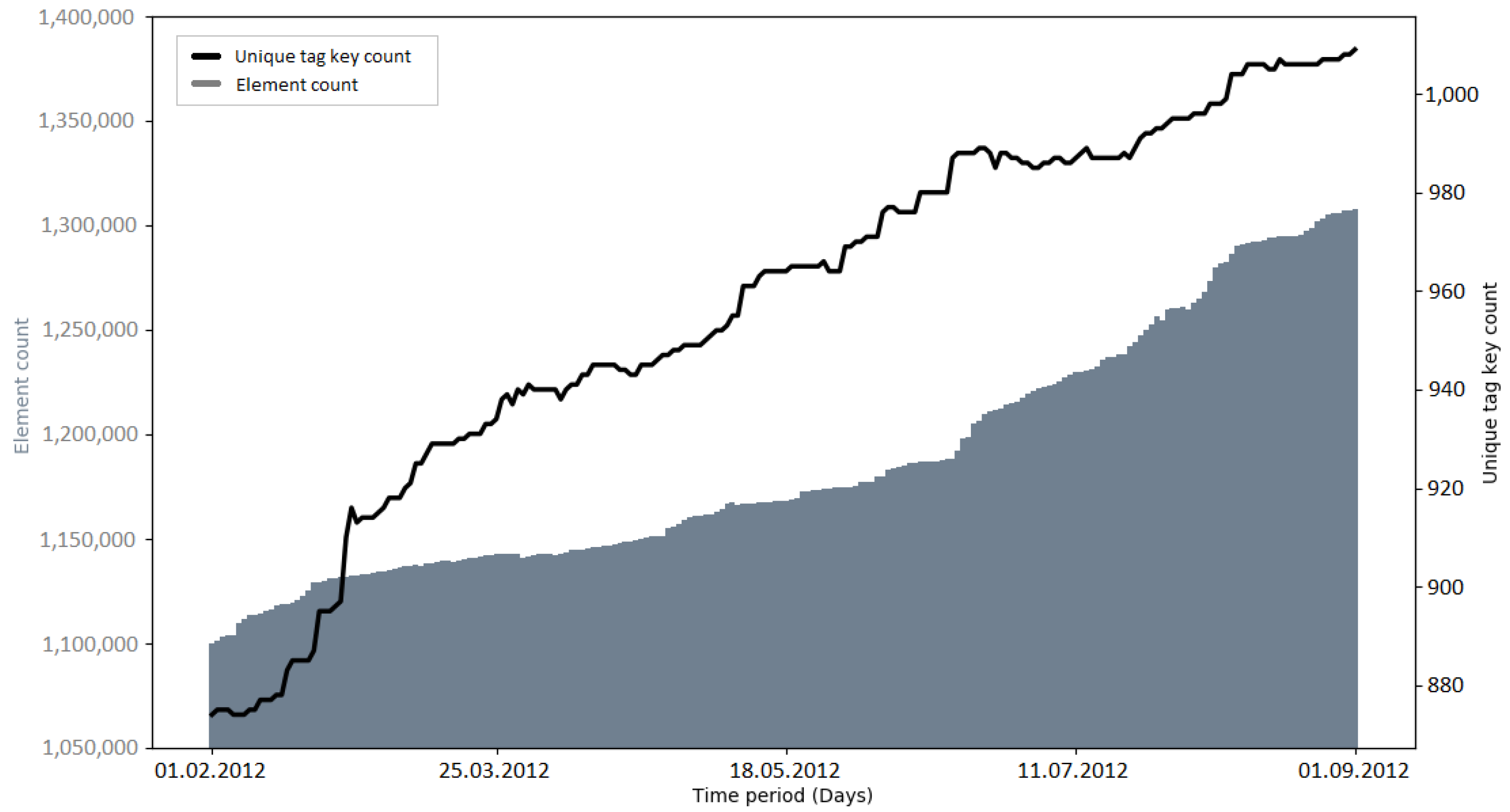
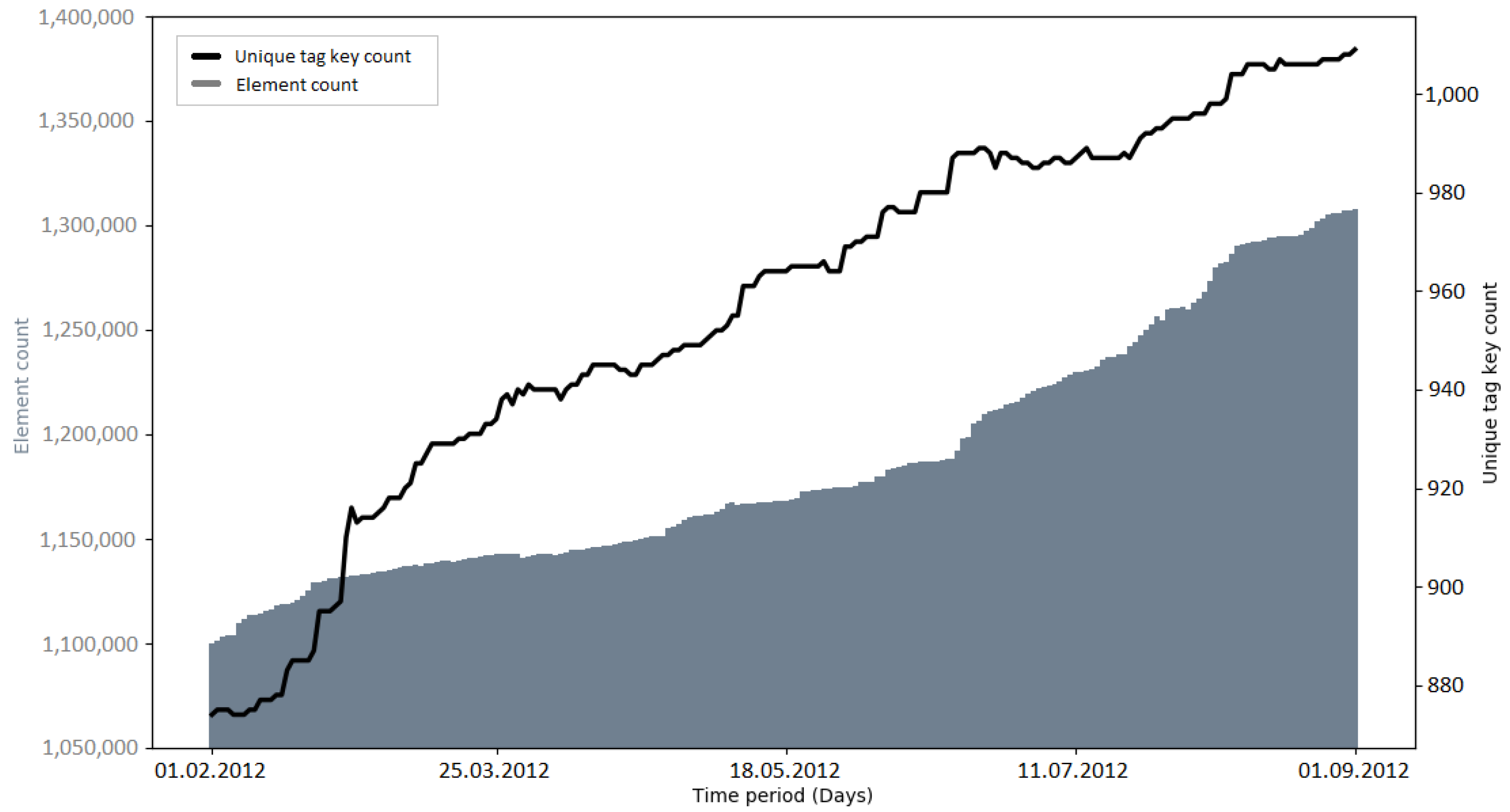
The development of the number of unique tag keys gives insights into the level of detail with which the OSM community is describing the attributes of elements. Since tagging schemes normally develop over time and as a community process, it was interesting to investigate if large data imports have an impact on the progress of these attributes [
19].
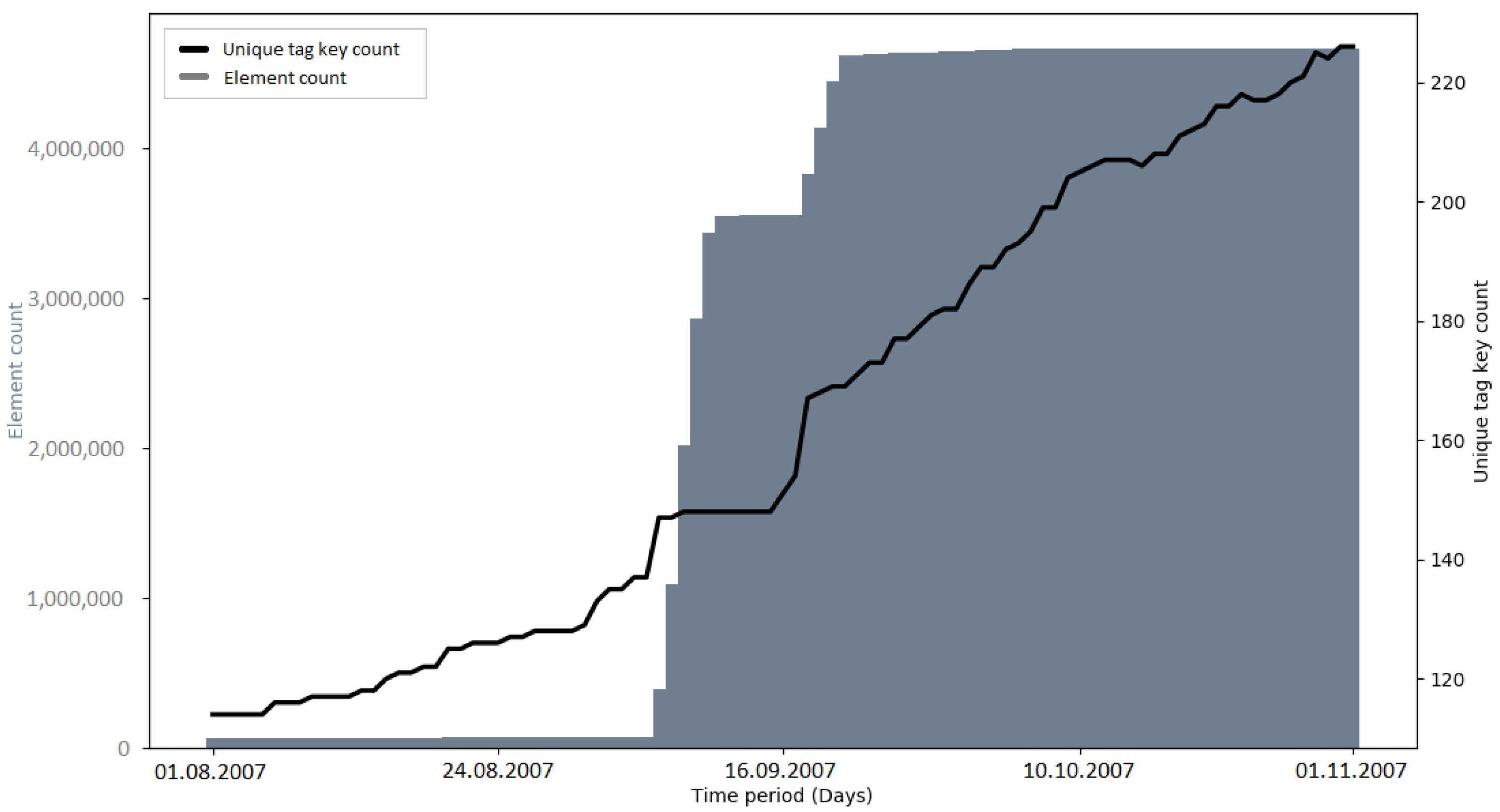
Early imports (e.g., PGS import and AND imports) brought many new tag keys to OSM, because of the external information which was mapped to OSM tags (e.g., “AND_nosr_r” which contains the original AND ID of road sections [
50]). Subsequent imports (e.g., 3dShapes import, BAG import) did not have such a drastic increase of tag keys. This could be explained with the knowledge of the community and lessons learned from the execution of earlier imports (from an external data source, only information that is verifiable should be added as an OSM tag key [
37]). However, there were also cases where the number of tag keys grew significantly without a large data import happening before—for example, towards the end of the observation period of the building import (see
Figure A22) and during the observation period without a large data import in India (see
Figure A23). More research is needed to determine the reasons for these sudden increases.
Recapitulating, it was found that the number of unique tag keys grew continuously during all of the observed time intervals. Some of the imports (e.g., PGS import, AND imports) introduced a large amount of new tag keys to OSM in a short amount of time. However, this was a logical consequence, given that the metadata of the external data source were mapped to OSM tag keys. Apart from this fact, no specific impact of large data imports on the development of tag keys was discovered. Since large data imports add a lot of information to OSM, it would make sense to look at the semantics of the tag keys in more detail, rather than the quantities. This could be addressed in a study focusing on the semantic changes of OSM tags during or after a large data import.
4.2. Challenges
The OSM community agreed on using conventions and best practices for creating, updating and deleting data [
51]. However, no one has to use them. Anyone can take part in OSM, which results in a heterogeneous data set. Given this heterogeneity, tradeoffs have to be made, for example, if one wants to filter OSM data. Typos in tag keys or tag values could lead to their subsequent exclusion, thereby influencing the final result.
Another challenge was the identification and definition of metrics which were suitable for analysing the impact of large data import, without limiting the scope to a specific import.
The determination of the observation periods for the imports also proved to be challenging. The interval had to be limited, so the analysis would not be influenced by other imports or events. Moreover, the majority amount of data had to be imported within the interval for analysing the impact on OSM.
Due to the heterogeneity of OSM data and the complexity of OSM in general, the interpretation of the results was challenging. In OSM, many aspects happen or can happen independently of each other: for example, data imports and other community events such as mapping marathons. This fact has to be kept in mind during the evaluation of the results.
4.3. Limitations
In this study, only the time period was investigated where approximately 80% of the data were added. Therefore, potential influences and impacts outside the observation periods have not been considered.
For the computation of the contributor activity, all contribution types (i.e., creation, deletion, tag changes and geometry changes) were included to get a general understanding of the number of active users per timestamp. As a consequence, contributors who were deleting data were weighted as much as users who were creating or updating elements.
The changepoint detection was used to compute the most significant changepoint in the observation period. For most of the imports, this approach provided useful results which showed the distinct changes of the contributor activity during or after the import. However, for imports such as the 3dShapes import or the BAG import, the development of the user activity was more complex. During the 3dShapes import, the contributor activity was increasing with the start of the import, and dropped down after most of the data were imported. Then, the contributor activity increased again. A similar pattern could be seen during the BAG import, where the contributor activity increased throughout the conduction of the import but decreased afterwards. By computing only one changepoint, these processes were simplified. Additionally, other OSM events could have influenced the changepoint detection. However, this problem is omnipresent when working with OSM data.
The algorithm for finding peaks in the development of contribution types used a multiple of the mean as the detection criterion. Therefore, other OSM events which happened in the same time period might have been detected as a peak, even though they were maybe not related to the import. Moreover, also peaks that happened before an import but within the observation period were counted. Additionally, more analysis is needed to investigate the peaks in more detail to ensure that the peaks are directly related to the import.
For the import, dedicated user accounts have to be used for importing data into OSM. These accounts were included in the results. Moreover, the differences in the total number of contributors who were involved in the imports (e.g., AND import in India with 18 contributors; AND import in the Netherlands with 108 contributors) have to be considered when evaluating and comparing results.
Furthermore, this study did not distinguish between different types of large imports (e.g., automatically or manually conducted imports, or a combination of both). The quantity of imported data was the only criterion for the selection.
5. Conclusions
This study presented an approach for getting a deeper understanding about the impact of large data imports in OpenStreetMap by investigating large data imports in the Netherlands and India.
The results were manifold. It was found that for most of the large data imports which were analysed, the contributor activity increased during or after the conduction of the import. Looking at the imports in the early stage of OSM, especially the AND imports in 2007 and 2008, one can see that significantly more contributors were active than before. Imports which happened at a later stage did not show such a strong impact. During the BAG import in the Netherlands and the building import in India, the number of contributors increased. However, after most of the data were imported, the contributor activity slightly decreased again. Nonetheless, one can see that during a large data import the number of unique active contributors rose.
The analysis of the contributor engagement pointed out that the majority of users who were involved in an import were import-inspired; i.e., their first contributions happened during an import. Again, this finding supports the argument that with large data imports, more contributors were actively joining the project. However, mappers who were active beforehand were more likely to keep contributing in the time after the import was concluded. Therefore the study showed that already activate mappers were not driven away from the project. This study did not differentiate between dedicated user accounts which were created only for importing data and regular user accounts which need to be considered when reasoning about the findings.
Regarding the contribution patterns and the development of tag keys, no specific impact of large data imports was found in this study. The number of unique tag keys increased as the number of elements increased, given that external information was mapped to OSM tags. More research is needed to understand how the community is changing OSM data after a large data import.
It could not be confirmed that an import has exclusively negative impacts on OSM—not on the contributor activity, nor the contributor engagement nor the contribution patterns—which indicates that the OSM community and the project in general did not suffer from these imports. With more active contributors and a larger community, the actuality of the data is constituted, and therefore, the quality and the applications of the data improve. The worry of the OSM community that data imports drive active contributors away from the project could not be confirmed.
The study considered the impact of large data imports from a data perspective on a small subset of imports that were conducted. For future research, the analysis of different data imports might also incorporate other aspects of OSM—for example, community events or mapping events and how they are related to imports. The investigation of automated processes, e.g., scripts or bots, could lead to better understanding about how large chunks of imported data are changed. Moreover, the phase of OSM in which an import is conducted could be analysed more thoroughly. This might help to understand if an import could be performed to also support the establishment or growth of a community in a specific region. Additionally, in that regard, the effect of the media or the OSM community creating awareness about data donations and respective data imports needs to be investigated. Additionally, the analysis of OSM contributors could be extended, for example, by considering the locations of contributors who are involved in an import process. Emerging spatial patterns could help to understand how local communities are developing during an import. The attributes of imported elements and how they are evolving over time could be analysed with a focus on the semantics of the data.
The findings of this study might support researchers in the field of OSM or VGI or those in the OSM community. Future imports could be discussed more thoroughly to evaluate the possible potentials and benefits. Sustainable plans could be made to keep contributors motivated after a large data import, eventually leading to a more stable community which maintains one of the most prominent VGI projects in the world.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}