
An Approach to Improve the Quality of User-Generated Content of Citizen Science Platforms

Abstract
:1. Introduction
2. Quality of Citizen Science Data and Information
3. Case Study: Information and Data Quality in Citizen Science Platforms
- Inexperienced users or content providers submit information;
- Content can be reviewed by community/moderators;
- Content can be text and multimedia;
- Content is not only freeform text;
- Location and time are part of the information;
- Information can be precise or general.
- Platforms collect different observations;
- Platforms are still collecting observations;
- Platforms provide access to data;
- Platforms have a large quantity of data.
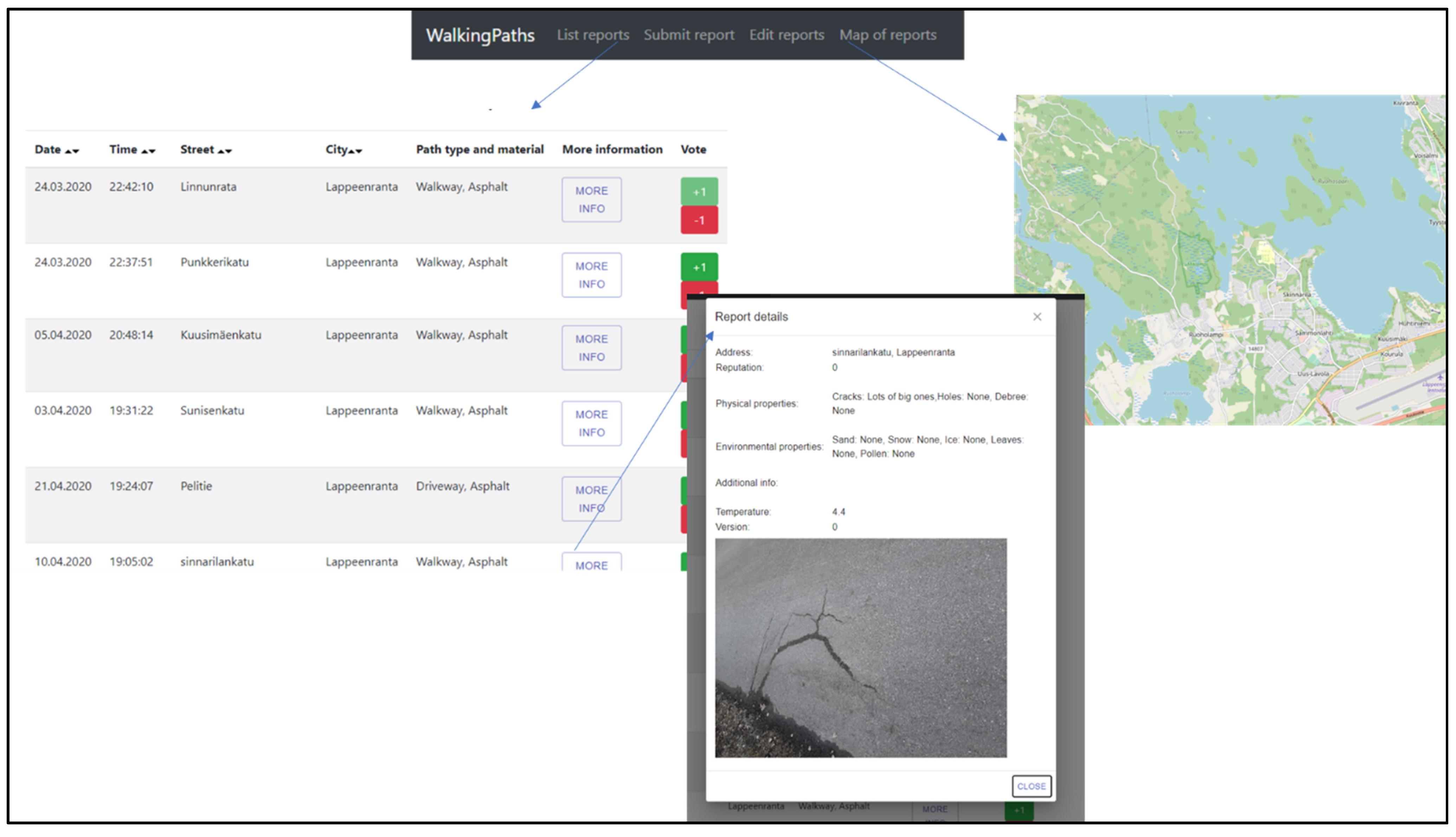
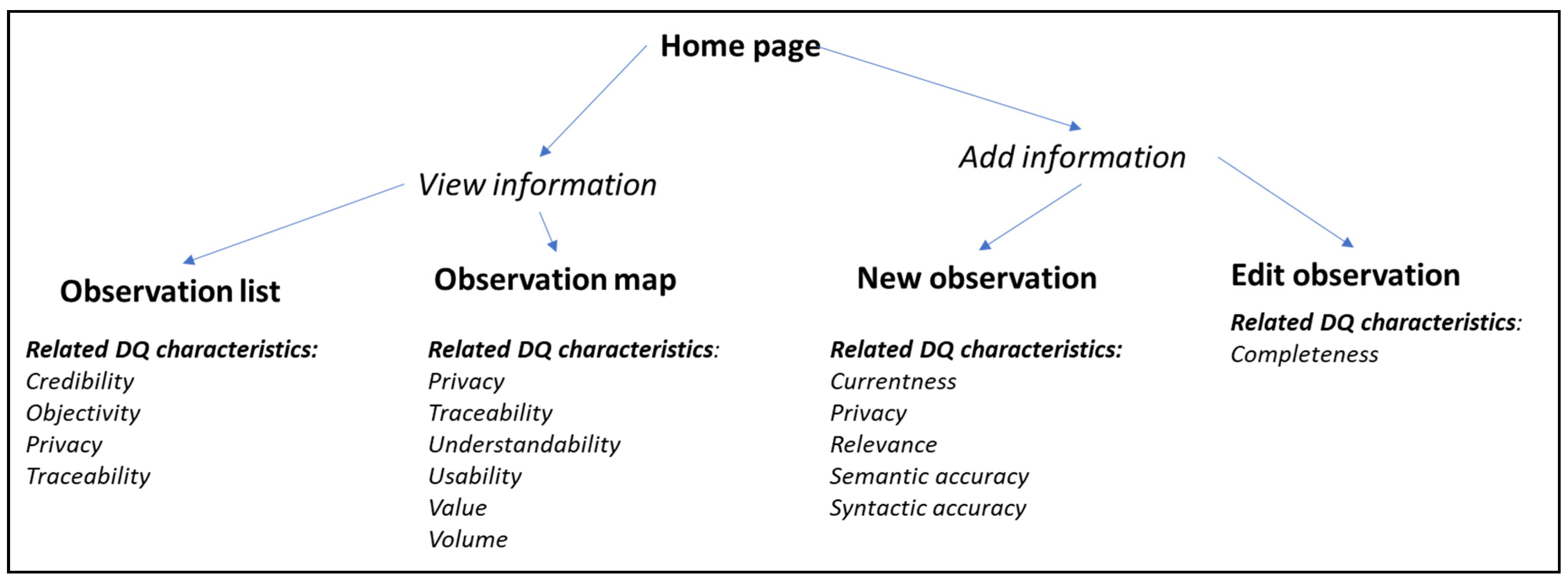
3.1. Information Quality Evaluation through the User Interface
3.2. Data Quality Evaluation
- Syntactic accuracy:
- ⚬
- ALA: Based on the verbatim date attribute and expected syntax of yyyy/MM/dd hh:mm
- ⚬
- Globe at Night: No issues in syntactic accuracy.
- ⚬
- BudBurst: Based on the country attribute. The expected syntax is the acronym of a country (US), which means, for example, United States is incorrect.
- ⚬
- iNaturalist: Based on the timezone attribute. The majority of the values are the country locations, and the minority of values are UTC or Eastern Time.
- Semantic accuracy:
- ⚬
- ALA: Sex attribute is inspected to determine whether values are male, female, or unknown.
- ⚬
- Globe at Night: No semantic issues.
- ⚬
- BudBurst: No semantic issues.
- ⚬
- iNaturalist: Timezone is compared to the collection location.
- Credibility:
- ⚬
- ALA: NA
- ⚬
- Globe at Night: NA
- ⚬
- BudBurst: NA
- ⚬
- iNaturalist: NA
- Objectivity:
- ⚬
- ALA: The location similarity is tied to the city/county level.
- ⚬
- Globe at Night: NA
- ⚬
- BudBurst: NA
- ⚬
- iNaturalist: Dataset includes an agreement attribute that reflects how many other users agree on the observation.
- Volume:
- ⚬
- Globe at Night: NA
- ⚬
- BudBurst: NA
- Privacy:
- ⚬
- Globe at Night: No personal information in data.
- ⚬
- BudBurst: No personal information in data.
- Traceability
- ⚬
- Globe at Night: Missing user identification, so traceability is reduced in the calculations.
- ⚬
- BudBurst: Missing user identification, so traceability is reduced in the calculations.
- Understandability:
- ⚬
- ALA: Understandability is measured through the locality attribute and mining incomprehensible texts or locations that do not make sense.
- ⚬
- Globe at Night: Sky comment attribute is mined for non-English texts and incomprehensible values.
- ⚬
- BudBurst: Location_title attribute is used to measure understandability by mining incomprehensible texts or locations that do not make sense.
- ⚬
- iNaturalist: Place_guess attribute is mined for invalid words to measure understandability.
4. Integration of Quality Characteristics into the Citizen Science Platform: WalkingPaths
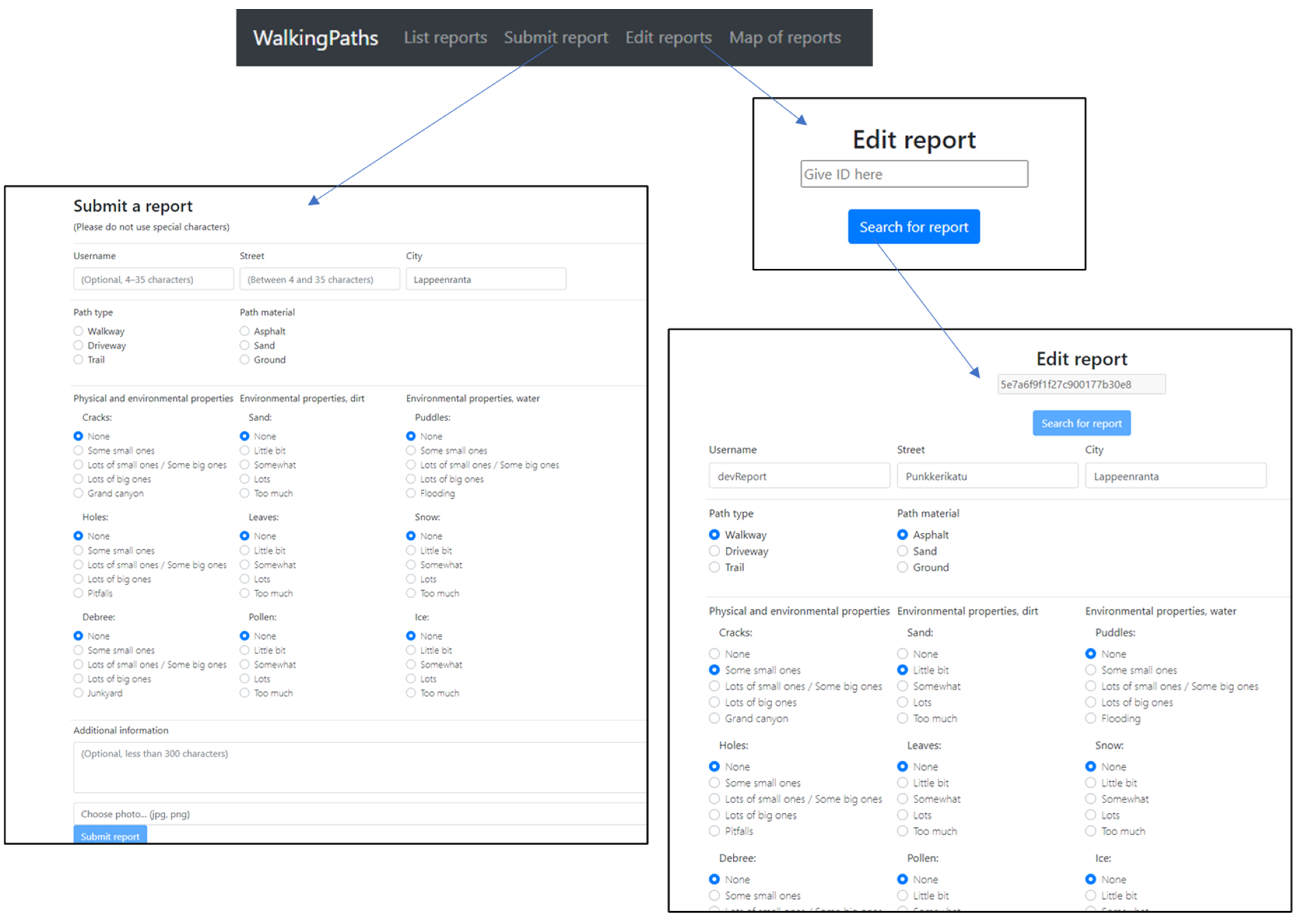
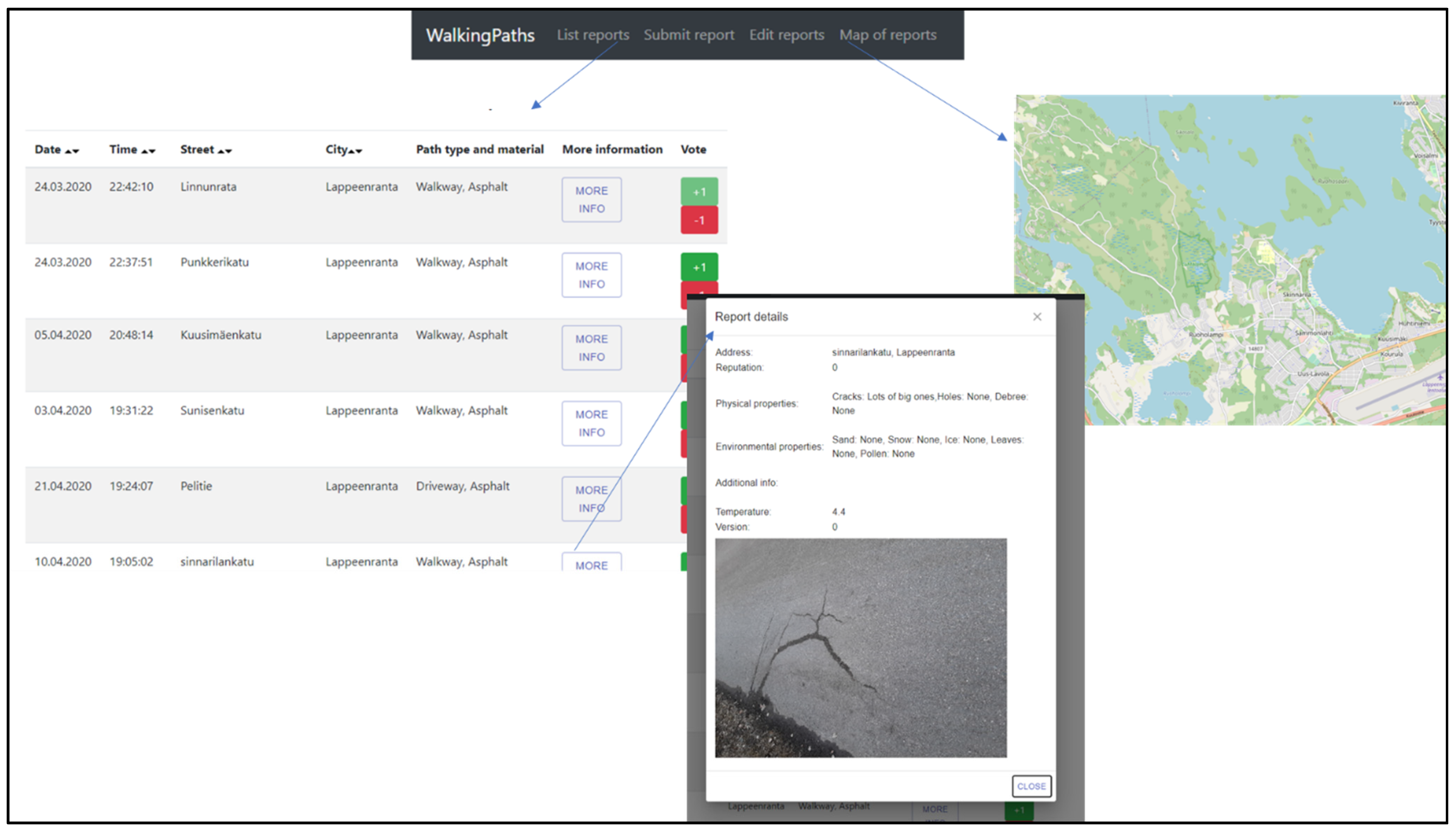
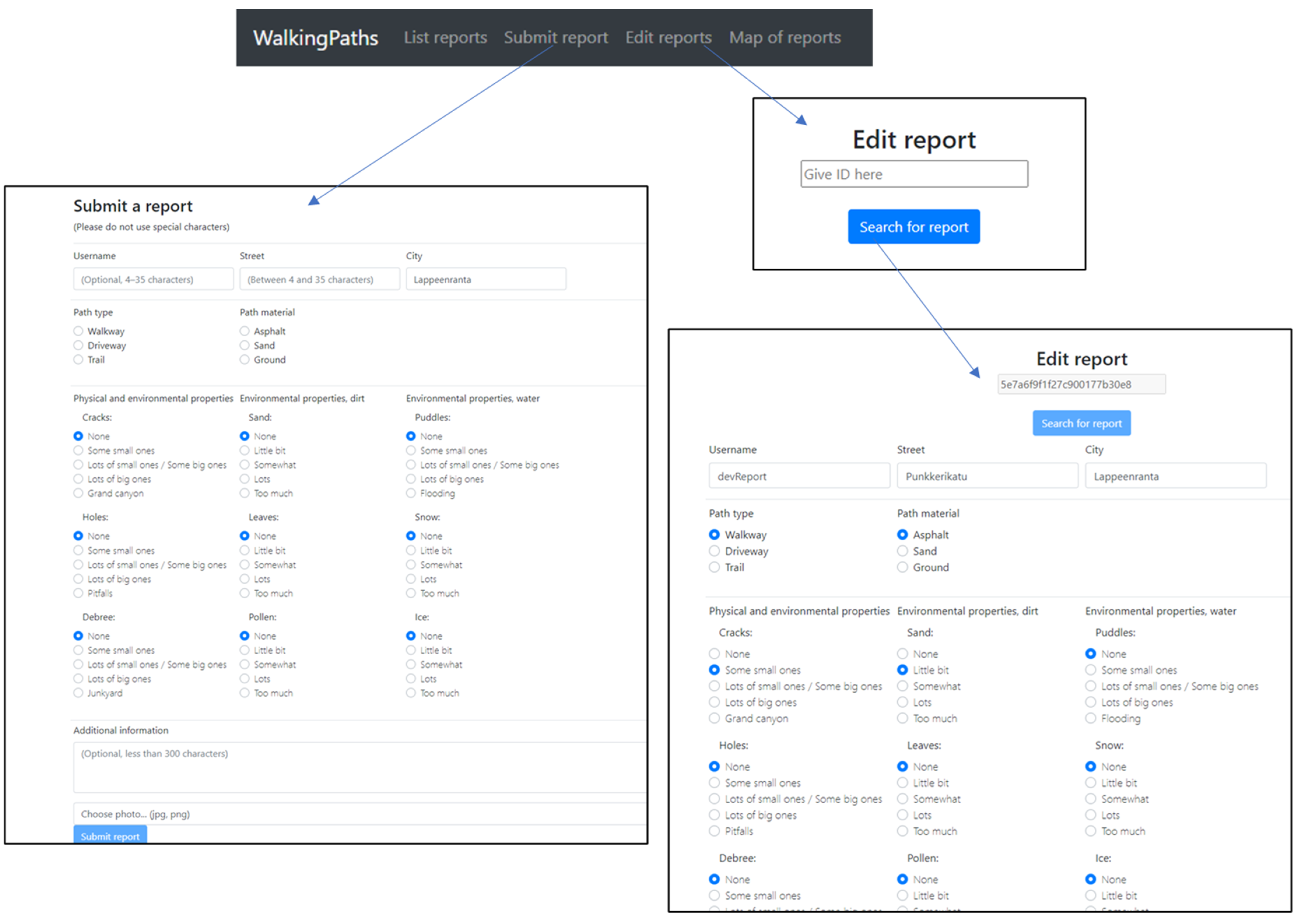
4.1. Platform Design
- Syntactic accuracy: Within the data model, the syntax of each data is defined. Depending on the chosen database, the syntax is automatically enforced or manually enforced via the backend (NoSQL). In this research, the syntax is evaluated using the middleware Mongoose.
- Semantic accuracy: Semantic accuracy rules come from an expected value. When requiring a date, it is expected to receive a valid date. Semantic rules for content come from the database and can be enforced and checked in the backend or user interface.
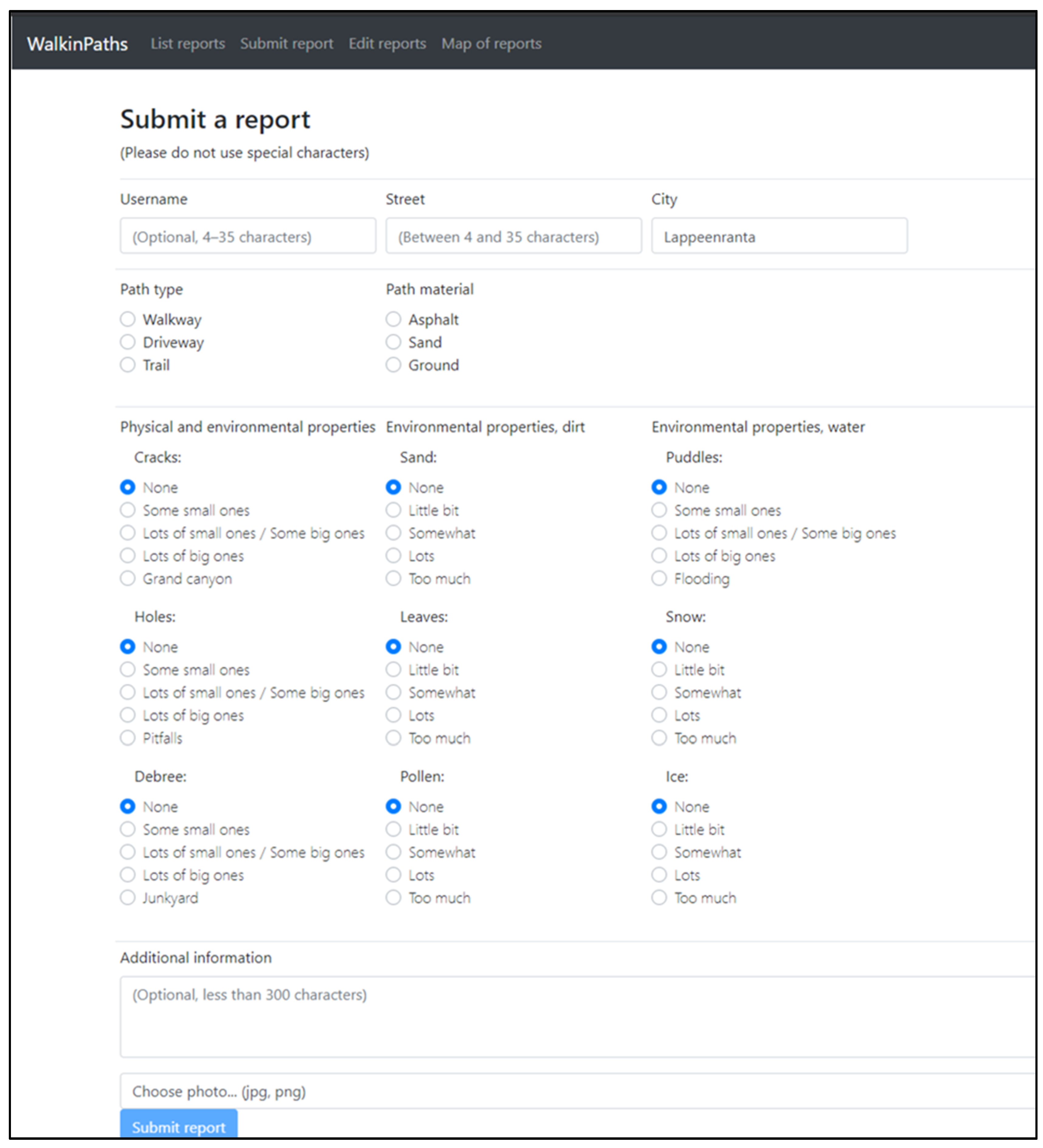
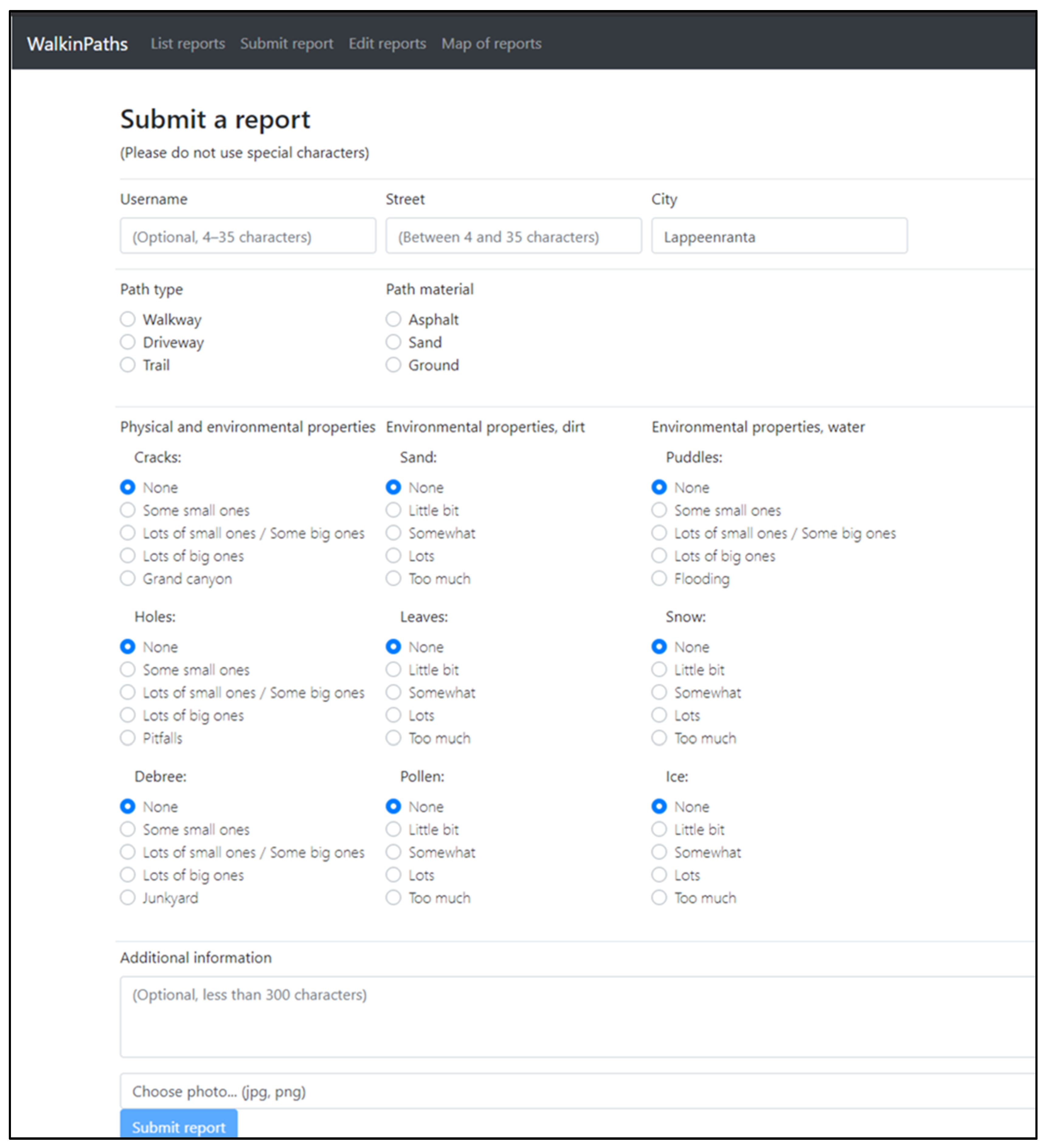
- Syntactic accuracy: Syntactic accuracy during collection can be enforced by making type checks in the user interface and not allowing incorrect or illegal types to be submitted.
- Semantic accuracy: Semantic accuracy can be increased during the collection by giving the content provider a selection field rather than freeform text fields. Another method is to check if the given information in the field matches specific content, such as asking a country and checking whether a given country exists in the list of countries.
- Privacy: Privacy relates to personal information, and it is up to the developers to decide whether or not to collect personal information. The easiest method of increasing privacy is not collecting personal information, especially in a citizen science platform where location is often necessary. Whenever private information is being collected, clear statements should be made on what is collected and how it is used. In addition, the user needs to be offered the opportunity to consent to their personal information being used and be given the option to delete personal information if it has been collected [51,52].
- Completeness: During collection, completeness can be ensured by not allowing content providers to submit incomplete content. There can be a variable degree of completeness.
- Traceability: Traceability requires information regarding when content is submitted and where it comes from. This information is most easily collected from the user interface when a content provider is submitting content. For example, the date and time can be stored, and the location and content provider’s name can be requested if necessary.
- Relevance: Each platform, especially in citizen science projects, has some specific use case for collecting data. For example, content providers can be restricted to providing only information relevant to the topic during the content collection.
- Credibility: Credibility is related to a content provider’s credibility rather than content credibility. Content provider’s credibility can be determined in various ways, but the most common method is reputation models. If the content provider has previously submitted high-quality content, then their credibility score will be higher.
- Currentness: When content is submitted and when the observation has been made can be directly taken from the user interface.
- Completeness: Completeness of given content can be checked after submission, and the provided data can be marked complete/incomplete. If it is possible to edit the content later, this value can then be updated.
- Objectivity: The objectivity of content can be based on various aspects. One aspect is the content provider and what content is submitted. If the content has an image attached, it is easier to determine objectivity. If a reputable content provider submits the content, it is most likely to be objective. Different objectivity values can be directly attached to the data. Objectivity can also be determined using a voting system in the platform.
- Volume: After content is submitted, similar content can be checked and calculated based on the similarity score. For example, content related to the same location area can be grouped to form general information found on its content.
- Value: The value of content can be determined and calculated on various conditions, and this value score can be attached to the data.
- Usability: The usability of data can be determined and calculated on various conditions, and this usability score can be attached to the data.
- Privacy: If personal information has been collected, the extent to which this information is shared with others should be evaluated. It is unnecessary to show personal information in most cases, and thus it should be omitted from the user interface. The option to hide personal information could be added for citizens on the platform.
- Volume: Having multiple similar observations or reports in a platform must be indicated in some form. There is a significant difference between one person making a claim and ten people making the same claim. The volume of content can be presented in different ways, depending on how the content is presented in general.
- Understandability: Information should be presented understandably. For example, a list of observations and reports can be a challenging format for understanding the bigger picture, and it is therefore better to use an alternative method for presenting the information. For example, in most citizen science platforms, there is a map that shows different locations. Another approach is to show statistical analysis of specific pieces of data. Regardless of the methodology, each is implemented in the user interface.
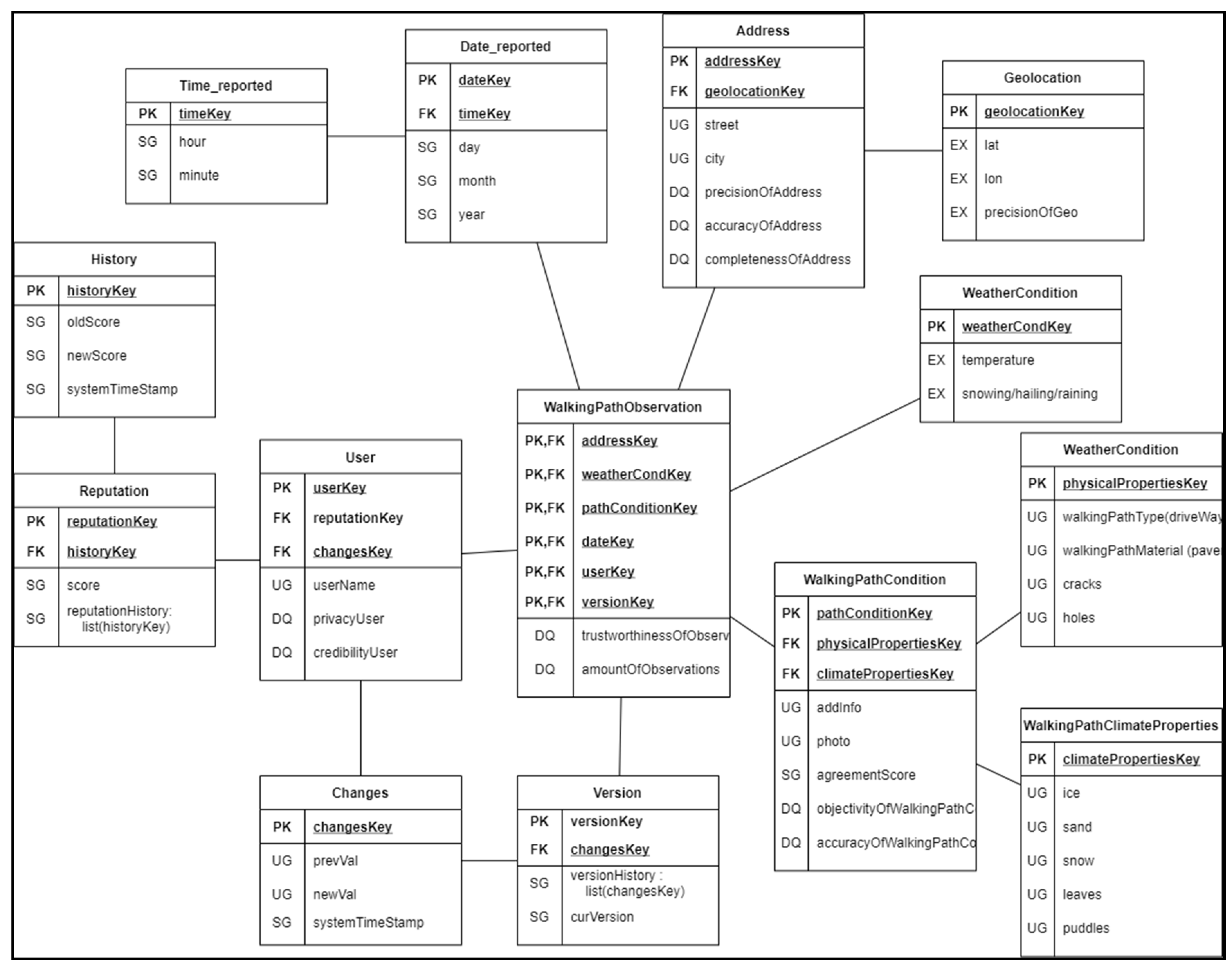
- PK and FK: Indicates the primary and foreign keys.
- SG: The platform generates the attribute.
- UG: The attribute is user-generated, i.e., given by the user.
- EX: The attribute is obtained from external sources.
- DQ: The attribute stores information related to data quality.
- The location precision of a smartphone is inconsistent. The precision varies between smartphone models and, with buildings or trees around the area, the precision decreases. This imprecision may result in placing the actual location on a different street to that which is suggested by the coordinates [54,55,56,57].
- Use of the location requires permission from the user, and not all are willing to give consent.
- Precise location raises privacy concerns [58].
4.2. Evaluation and Analysis
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cornell Lab of Ornithology. eBird. 2021. Available online: https://ebird.org/home (accessed on 9 March 2021).
- Lintott, C.; Schawinski, K.; Bamford, S.; Slosar, A.; Land, K.; Thomas, D.; Edmondson, E.; Masters, K.; Nichol, R.C.; Raddick, M.J.; et al. Galaxy Zoo 1: Data release of morphological classifications for nearly 900 000 galaxies. Mon. Not. R. Astron. Soc. 2011, 410, 166–178. [Google Scholar] [CrossRef] [Green Version]
- Waldispühl, J.; Szantner, A.; Knight, R.; Caisse, S.; Pitchford, R. Leveling up citizen science. Nat. Biotechnol. 2020, 38, 1124–1126. [Google Scholar] [CrossRef] [PubMed]
- See, L.; Mooney, P.; Foody, G.; Bastin, L.; Comber, A.; Estima, J.; Fritz, S.; Kerle, N.; Jiang, B.; Laakso, M.; et al. Crowdsourcing, Citizen Science or Volunteered Geographic Information? The Current State of Crowdsourced Geographic Information. ISPRS Int. J. Geo-Inf. 2016, 5, 55. [Google Scholar] [CrossRef]
- Simpson, R.; Page, K.R.; De Roure, D. Zooniverse: Observing the world’s largest citizen science platform. In WWW 2014 Companion, Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; Association for Computing Machinery, Inc: New York, NY, USA, 2014; pp. 1049–1054. [Google Scholar]
- Lukyanenko, R.; Parsons, J.; Wiersma, Y. The IQ of the Crowd: Understanding and Improving Information Quality in Structured User-Generated Content. Inf. Syst. Res. 2014, 25, 669–689. [Google Scholar] [CrossRef]
- Arthur, R.; Boulton, C.A.; Shotton, H.; Williams, H.T.P. Social sensing of floods in the UK. PLoS ONE 2018, 13, e0189327. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Heller, A.; Nielsen, P.S. CITIESData: A smart city data management framework. Knowl. Inf. Syst. 2017, 53, 699–722. [Google Scholar] [CrossRef] [Green Version]
- SciStarter. SciStarter. 2021. Available online: https://scistarter.com/ (accessed on 9 January 2021).
- Lukyanenko, R.; Parsons, J.; Wiersma, Y.F. Emerging problems of data quality in citizen science. Conserv. Biol. 2016, 30, 447–449. [Google Scholar] [CrossRef] [Green Version]
- Nasiri, A.; Abbaspour, R.A.; Chehreghan, A.; Arsanjani, J.J. Improving the Quality of Citizen Contributed Geodata through Their Historical Contributions: The Case of the Road Network in OpenStreetMap. ISPRS Int. J. Geo-Inf. 2018, 7, 253. [Google Scholar] [CrossRef] [Green Version]
- Leibovici, D.G.; Rosser, J.F.; Hodges, C.; Evans, B.; Jackson, M.J.; Higgins, C.I. On Data Quality Assurance and Conflation Entanglement in Crowdsourcing for Environmental Studies. ISPRS Int. J. Geo-Information 2017, 6, 78. [Google Scholar] [CrossRef] [Green Version]
- Sheppard, S.A.; Wiggins, A.; Terveen, L. Capturing quality. In Proceedings of the 17th ACM Conference on Computer Supported Cooperative Work & Social Computing—CSCW ‘14, Baltimore, MD, USA, 15–19 February 2014; Association for Computing Machinery (ACM): New York, NY, USA, 2014; pp. 1234–1245. [Google Scholar]
- Elbroch, M.; Mwampamba, T.H.; Santos, M.J.; Zylberberg, M.; Liebenberg, L.; Minye, J.; Mosser, C.; Reddy, E. The Value, Limitations, and Challenges of Employing Local Experts in Conservation Research. Conserv. Biol. 2011, 25, 1195–1202. [Google Scholar] [CrossRef]
- Haklay, M.; Basiouka, S.; Antoniou, V.; Ather, A. How Many Volunteers Does It Take to Map an Area Well? The Validity of Linus’ Law to Volunteered Geographic Information. Cartogr. J. 2010, 47, 315–322. [Google Scholar] [CrossRef] [Green Version]
- Mitchell, N.; Triska, M.; Liberatore, A.; Ashcroft, L.; Weatherill, R.; Longnecker, N. Benefits and challenges of incorporating citizen science into university education. PLoS ONE 2017, 12, e0186285. [Google Scholar] [CrossRef]
- Bordogna, G.; Carrara, P.; Criscuolo, L.; Pepe, M.; Rampini, A. On predicting and improving the quality of Volunteer Geographic Information projects. Int. J. Digit. Earth 2016, 9, 134–155. [Google Scholar] [CrossRef]
- Medeiros, G.; Holanda, M. Solutions for Data Quality in GIS and VGI: A Systematic Literature Review. Adv. Intell. Syst. Comput. 2019, 930, 645–654. [Google Scholar] [CrossRef]
- Torre, M.; Nakayama, S.; Tolbert, T.J.; Porfiri, M. Producing knowledge by admitting ignorance: Enhancing data quality through an “I don’t know” option in citizen science. PLoS ONE 2019, 14, e0211907. [Google Scholar] [CrossRef]
- Dorn, H.; Törnros, T.; Zipf, A. Quality Evaluation of VGI Using Authoritative Data—A Comparison with Land Use Data in Southern Germany. ISPRS Int. J. Geo-Inf. 2015, 4, 1657–1671. [Google Scholar] [CrossRef]
- Musto, J.; Dahanayake, A. Improving Data Quality, Privacy and Provenance in Citizen Science Applications. Front. Artif. Intell. Appl. 2020, 321, 141–160. [Google Scholar] [CrossRef]
- Bayraktarov, E.; Ehmke, G.; O’Connor, J.; Burns, E.L.; Nguyen, H.A.; McRae, L.; Possingham, H.P.; Lindenmayer, D.B. Do Big Unstructured Biodiversity Data Mean More Knowledge? Front. Ecol. Evol. 2019, 6, 239. [Google Scholar] [CrossRef] [Green Version]
- Sadiq, S.; Indulska, M. Open data: Quality over quantity. Int. J. Inf. Manag. 2017, 37, 150–154. [Google Scholar] [CrossRef]
- Lewandowski, E.; Specht, H. Influence of volunteer and project characteristics on data quality of biological surveys. Conserv. Biol. 2015, 29, 713–723. [Google Scholar] [CrossRef] [PubMed]
- Wang, R.Y.; Strong, D.M. Beyond Accuracy: What Data Quality Means to Data Consumers. J. Manag. Inf. Syst. 1996, 12, 5–33. [Google Scholar] [CrossRef]
- Batini, C.; Scannapieco, M. Data Quality: Concepts, Methodologies and Techniques; Springer: Berlin, Germany, 2006; ISBN 9783540331735. [Google Scholar]
- Redman, T.C. Data Quality for the Information Age; Artech House: Norwood, MA, USA, 1996; ISBN 9780890068830. [Google Scholar]
- Bovee, M.; Srivastava, R.P.; Mak, B. A conceptual framework and belief-function approach to assessing overall information quality. Int. J. Intell. Syst. 2003, 18, 51–74. [Google Scholar] [CrossRef] [Green Version]
- Haug, A.; Arlbjørn, J.S.; Pedersen, A. A classification model of ERP system data quality. Ind. Manag. Data Syst. 2009, 109, 1053–1068. [Google Scholar] [CrossRef]
- Han, J.; Jiang, D.; Ding, Z. Assessing Data Quality Within Available Context. In Data Quality and High-Dimensional Data Analysis Proceedings of the DASFAA 2008 Workshops, New Delhi, India, 19–22 March 2008; World Scientific: Singapore, 2009; pp. 42–59. [Google Scholar]
- Batini, C.; Blaschke, T.; Lang, S.; Albrecht, F.; Abdulmutalib, H.M.; Barsi, Á.; Szabó, G.; Kugler, Z. Data Quality in Remote Sensing. ISPRS Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2009, 42, 447–453. [Google Scholar] [CrossRef] [Green Version]
- Lukyanenko, R.; Parsons, J.; Wiersma, Y.F.; Maddah, M. Expecting the Unexpected: Effects of Data Collection Design Choices on the Quality of Crowdsourced User-Generated Content. MIS Q. 2019, 43, 623–648. [Google Scholar] [CrossRef] [Green Version]
- International Organization for Standardization (ISO). ISO 19157:2013 Geographic Information—Data Quality; ISO: Geneva, Switzerland, 2013. [Google Scholar]
- International Organization for Standardization (ISO). ISO/IEC 25012:2008 Software Engineering—Software Product Quality Requirements and Evaluation (SQuaRE)—Data Quality Model; ISO: Geneva, Switzerland, 2008. [Google Scholar]
- International Organization for Standardization (ISO). ISO/TS 8000:2011 Data Quality; ISO: Geneva, Switzerland, 2011. [Google Scholar]
- Watts, S.; Shankaranarayanan, G.; Even, A. Data quality assessment in context: A cognitive perspective. Decis. Support Syst. 2009, 48, 202–211. [Google Scholar] [CrossRef]
- Davenport, T.H.; Prusak, L. Working Knowledge: How Organizations Manage What They Know; Harvard Business School Press: Boston, MA, USA, 1998. [Google Scholar]
- Batini, C.; Cappiello, C.; Francalanci, C.; Maurino, A. Methodologies for data quality assessment and improvement. ACM Comput. Surv. 2009, 41, 1–52. [Google Scholar] [CrossRef] [Green Version]
- iNaturalist. A Community for Naturalists. 2021. Available online: https://www.inaturalist.org/ (accessed on 29 March 2021).
- Kelling, S.; Lagoze, C.; Wong, W.-K.; Yu, J.; Damoulas, T.; Gerbracht, J.; Fink, D.; Gomes, C. E Bird: A human/computer learning network to improve biodiversity conservation and research. AI Mag. 2013, 34, 10–20. [Google Scholar]
- Rajaram, G.; Manjula, K. Exploiting the Potential of VGI Metadata to Develop A Data-Driven Framework for Predicting User’s Proficiency in OpenStreetMap Context. ISPRS Int. J. Geo-Inf. 2019, 8, 492. [Google Scholar] [CrossRef] [Green Version]
- Shanks, G.; Darke, P. Understanding Data Quality in a Data Warehouse. J. Res. Pract. Inf. Technol. 1998, 30, 122–128. [Google Scholar]
- Cai, L.; Zhu, Y. The Challenges of Data Quality and Data Quality Assessment in the Big Data Era. Data Sci. J. 2015, 14, 2. [Google Scholar] [CrossRef]
- Immonen, A.; Pääkkönen, P.; Ovaska, E. Evaluating the Quality of Social Media Data in Big Data Architecture. IEEE Access 2015, 3, 2028–2043. [Google Scholar] [CrossRef]
- Higgins, C.I.; Williams, J.; Leibovici, D.G.; Simonis, I.; Davis, M.J.; Muldoon, C.; Van Genuchten, P.; O’hare, G.; Wiemann, S. Citizen OBservatory WEB (COBWEB): A Generic Infrastructure Platform to Facilitate the Collection of Citizen Science data for Environmental Monitoring. Int. J. Spat. Data Infrastruct. Res. 2016, 11, 20–48. [Google Scholar] [CrossRef]
- Fox, T.L.; Guynes, C.S.; Prybutok, V.R.; Windsor, J. Maintaining Quality in Information Systems. J. Comput. Inf. Syst. 1999, 40, 76–80. [Google Scholar] [CrossRef]
- Fonte, C.C.; Antoniou, V.; Bastin, L.; Estima, J.; Arsanjani, J.J.; Bayas, J.-C.L.; See, L.; Vatseva, R. Assessing VGI Data Quality. In Mapping and the Citizen Sensor; Ubiquity Press: London, UK, 2017; pp. 137–163. ISBN 978-1-911529-16-3. [Google Scholar]
- Atlas of Living Australia. Open access to Australia’s Biodiversity Data. 2021. Available online: http://www.ala.org.au/ (accessed on 17 March 2021).
- Globe at Night. International Citizen-Science Campaign to Raise Public Awareness of the Impact of Light Pollution. 2021. Available online: https://www.globeatnight.org/ (accessed on 27 April 2021).
- Budburst. An Online Database of Plant Observations, a Citizen-Science Project of the Chicago Botanic Garden. Glencoe, Illinois. 2021. Available online: https://budburst.org/ (accessed on 27 April 2021).
- Intersoft Consulting. General Data Protection Regulation (GDPR)—Official Legal Text. 2018. Available online: https://gdpr-info.eu/ (accessed on 7 June 2021).
- California Legislative Information. Bill Text-SB-1121 California Consumer Privacy Act of 2018. 2018. Available online: https://leginfo.legislature.ca.gov/faces/billTextClient.xhtml?bill_id=201720180SB1121 (accessed on 7 June 2021).
- Teorey, T.; Lightstone, S.; Nadeau, T.; Jagadish, H.V. Business Intelligence. In Database Modeling and Design; Elsevier: Amsterdam, The Netherlands, 2011; pp. 189–231. [Google Scholar]
- GPS.gov. GPS Accuracy. 2020. Available online: https://www.gps.gov/systems/gps/performance/accuracy/ (accessed on 19 April 2021).
- Merry, K.; Bettinger, P. Smartphone GPS accuracy study in an urban environment. PLoS ONE 2019, 14, e0219890. [Google Scholar] [CrossRef] [Green Version]
- Schaefer, M.; Woodyer, T. Assessing absolute and relative accuracy of recreation-grade and mobile phone GNSS devices: A method for informing device choice. Area 2015, 47, 185–196. [Google Scholar] [CrossRef]
- Tomaštík, J.; Saloň, Š.; Piroh, R. Horizontal accuracy and applicability of smartphone GNSS positioning in forests. Forestry 2016, 90, 187–198. [Google Scholar] [CrossRef] [Green Version]
- De Montjoye, Y.-A.; Hidalgo, C.A.; Verleysen, M.; Blondel, V.D. Unique in the Crowd: The privacy bounds of human mobility. Sci. Rep. 2013, 3, 1376. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lukyanenko, R.; Parsons, J.; Wiersma, Y. Citizen Science 2.0: Data Management Principles to Harness the Power of the Crowd. In DESRIST 2011: Service-Oriented Perspectives in Design Science Research; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6629, pp. 465–473. ISBN 9783642206320. [Google Scholar]
- Wehn, U.; Almomani, A. Incentives and barriers for participation in community-based environmental monitoring and information systems: A critical analysis and integration of the literature. Environ. Sci. Policy 2019, 101, 341–357. [Google Scholar] [CrossRef]
- Hobbs, S.J.; White, P.C.L. Motivations and barriers in relation to community participation in biodiversity recording. J. Nat. Conserv. 2012, 20, 364–373. [Google Scholar] [CrossRef]
- Fonte, C.C.; Bastin, L.; Foody, G.; Kellenberger, T.; Kerle, N.; Mooney, P.; Olteanu-Raimond, A.-M.; See, L. Vgi Quality Control. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2015, 2, 317–324. [Google Scholar] [CrossRef] [Green Version]
- Pang, L.; Li, G.; Yao, X.; Lai, Y. An Incentive Mechanism Based on a Bayesian Game for Spatial Crowdsourcing. IEEE Access 2019, 7, 14340–14352. [Google Scholar] [CrossRef]
- Blatt, A.J. The Benefits and Risks of Volunteered Geographic Information. J. Map Geogr. Libr. 2015, 11, 99–104. [Google Scholar] [CrossRef]
- See, L.; Comber, A.; Salk, C.; Fritz, S.; van der Velde, M.; Perger, C.; Schill, C.; McCallum, I.; Kraxner, F.; Obersteiner, M. Comparing the Quality of Crowdsourced Data Contributed by Expert and Non-Experts. PLoS ONE 2013, 8, e69958. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, J.; Liu, F. Automatic Data Quality Control of Observations in Wireless Sensor Network. IEEE Geosci. Remote. Sens. Lett. 2014, 12, 716–720. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Applicable for Information Quality | Wang and Strong [25] | ISO 25012 [34] | Redman [27] |
|---|---|---|---|
| Yes | believability | credibility | |
| Yes | accuracy | accuracy (syntactic and semantic) | accuracy |
| Yes | objectivity | ||
| Yes | reputation | ||
| Yes | relevancy | appropriateness | |
| Yes | value-added | ||
| Yes | timeliness | currentness | currency |
| Yes | completeness | completeness | completeness |
| Yes | an appropriate amount of data | ||
| Yes | interpretability | interpretability | |
| Yes | ease of understanding | understandability | |
| Yes/No | representational consistency | representation consistency | |
| Yes/No | concise representation | ||
| No | accessibility | accessibility | |
| Yes | access security | confidentiality | |
| No | efficiency | efficient use of memory | |
| No | compliance | ||
| Yes/No | precision | format precision | |
| Yes | traceability | ||
| No | availability | ||
| No | portability | portability | |
| No | recoverability | ||
| No | consistency | consistency | |
| No | ability to represent null values | ||
| No | format flexibility |
| Final List | Definition |
|---|---|
| credibility | The source of information is credible. It does not consider the credibility of the information. |
| accuracy (syntactic and semantic) | Information is syntactically and semantically correct, i.e., of correct type and logical. |
| objectivity | Information is objective and not affected by the source’s opinions or biases. |
| relevancy | Information is relevant for the topic. |
| value | Information is valuable, provides new insights, benefits. |
| currentness | Information is as recent as possible. |
| completeness | Information is complete and not missing important details. |
| volume | Multiple sources provide similar information. |
| understandability | Information is easy to understand. |
| privacy (access security) | Information source’s privacy is protected i.e., personal information of a citizen is protected. |
| traceability | Information origin can be traced to a user, time and location. |
| # | Characteristic | (Data Mining) Technique |
|---|---|---|
| 1 | Syntactic accuracy | Compare values to the expected input and format. Based on the most changing attribute. |
| 2 | Semantic accuracy | Compare values if they are semantically correct based on what is expected. |
| 3 | Completeness | Compare missing values to the total amount of values |
| 4 | Credibility | User reputation if available. |
| 5 | Objectivity | Count how many entities from different sources/content providers have the same information and how many are only from singular content providers/sources. |
| 6 | Volume | Count how many entities from different content providers have relatable information based on selected attributes. Unlike objectivity, the information does not have to be the same, but there must be some similarities, such as location. |
| 7 | Currentness | Given date is later than 31 December 2010. |
| 8 | Privacy | Filter out content providers whose possible real names are given and compare them to the total amount (text mining). |
| 9 | Relevancy | Data comparison to given relevance factor such as the topic. By default, everything is relevant. |
| 10 | Usability | If the content is missing essential attributes (location or time), it is deemed unusable. |
| 11 | Value | Calculation based on other characteristics, (Syntactic + Semantic + Credibility + Relevancy + Usability + Understandability)/6. |
| 12 | Traceability | Count how many entities have a valid time, location, and content provider/source compared to all entities. |
| 13 | Understandability | Text mining of invalid words in specific attributes. |
| Characteristic | ALA | iNaturalist | Globe at Night | Budburst |
|---|---|---|---|---|
| Syntactic accuracy | 0.71 | 0.89 | 1.00 | 0.99 |
| Semantic accuracy | 0.80 | 0.90 | 1.00 | 1.00 |
| Completeness | 0.71 | 0.73 | 0.87 | 0.33 |
| Credibility | NA | NA | NA | NA |
| Objectivity | 0.29 | 0.56 | NA | NA |
| Volume | 0.70 | 0.73 | NA | NA |
| Currentness | 0.44 | 0.99 | 1.00 | 0.80 |
| Privacy | 0.80 | 0.98 | 1.00 | 1.00 |
| Relevancy | 1.00 | 1.00 | 1.00 | 1.00 |
| Usability | 0.96 | 0.83 | 1.00 | 0.87 |
| Value | 0.74 | 0.72 | 0.78 | 0.79 |
| Traceability | 0.91 | 0.90 | 0.86 | 0.70 |
| Understandability | 0.97 | 0.69 | 0.65 | 0.86 |
| Characteristic | WalkingPaths 108 Observations | ALA 14,138 Observations | iNaturalist 39,910 Observations | Globe at Night 29,507 Observations | BudBurst 96,815 Observations |
|---|---|---|---|---|---|
| Syntactic accuracy | 1.00 | 0.71 | 0.89 | 1.00 | 0.99 |
| Semantic accuracy | 0.96 | 0.80 | 0.90 | 1.00 | 1.00 |
| Completeness | 1.00 | 0.71 | 0.73 | 0.87 | 0.33 |
| Credibility | 0.74 | NA | NA | NA | NA |
| Objectivity | 0.54 | 0.29 | 0.56 | NA | NA |
| Volume | 0.36 | 0.70 | 0.73 | NA | NA |
| Currentness | 1.00 | 0.44 | 0.99 | 1.00 | 0.80 |
| Privacy | 1.00 | 0.80 | 0.98 | 1.00 | 1.00 |
| Relevancy | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| Usability | 1.00 | 0.96 | 0.83 | 1.00 | 0.87 |
| Value | 0.95 | 0.74 | 0.72 | 0.78 | 0.79 |
| Traceability | 1.00 | 0.91 | 0.90 | 0.86 | 0.70 |
| Understandability | 1.00 | 0.97 | 0.69 | 0.65 | 0.86 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Musto, J.; Dahanayake, A. An Approach to Improve the Quality of User-Generated Content of Citizen Science Platforms. ISPRS Int. J. Geo-Inf. 2021, 10, 434. https://doi.org/10.3390/ijgi10070434
Musto J, Dahanayake A. An Approach to Improve the Quality of User-Generated Content of Citizen Science Platforms. ISPRS International Journal of Geo-Information. 2021; 10(7):434. https://doi.org/10.3390/ijgi10070434
Chicago/Turabian StyleMusto, Jiri, and Ajantha Dahanayake. 2021. "An Approach to Improve the Quality of User-Generated Content of Citizen Science Platforms" ISPRS International Journal of Geo-Information 10, no. 7: 434. https://doi.org/10.3390/ijgi10070434
APA StyleMusto, J., & Dahanayake, A. (2021). An Approach to Improve the Quality of User-Generated Content of Citizen Science Platforms. ISPRS International Journal of Geo-Information, 10(7), 434. https://doi.org/10.3390/ijgi10070434