
Geocoding Freeform Placenames: An Example of Deciphering the Czech National Immigration Database




Abstract
1. Introduction
- The completeness of the gazetteer, both in names and other data that can resolve ambiguities [7].
- The accuracy of the input placenames—namely the presence of typographical errors, bad or non-conventional formatting, or spelling.
2. Materials and Methods
2.1. Data
- Type of residence permit requested—temporary or permanent. Whereas the former is represented mainly by stays in Czechia on the basis of a long-term visa, long-term residence permit, or (concerning EU citizens) temporary protection status, the latter takes into account chiefly permanent residence permits and international protection statuses (primarily asylum and subsidiary protection). Due to the marginal nature of the latter category in Czechia, the data mainly brings about an overall picture of documented labour and family migration into the country, of both third-country nationals or EU citizens.
- Citizenship, year of birth, and gender.
- Place and country of birth, both in freeform text. This contains the essential information to geocode the record.
- Country of previous residence. This often did not align with the country of birth if the immigrant had moved internationally before coming to Czechia.
- Application decision status: granted, denied, pending, or other. For our analyses, we only filtered out granted applications.
- When the source language does not use the Latin alphabet, the transcription is often flawed:
- Exonyms in Czech, English, and from the source language are frequent. Exonyms are hard to geocode because there is usually no systematic way to derive them from endonyms; they must also be present in the gazetteer. A similar issue is presented by the usage of historical placenames (e.g., Soviet-era city names in Ukraine).
- Typographical errors are present in a significant number of cases.
- The specified country and placename of birth do not match (e.g., the country is given as Czechia but the placename is Moscow).
- Placenames of different hierarchical levels are mixed. This mostly happens in Ukrainian and U.S. placenames, where sometimes a specific placename is used, sometimes just the name of the administrative division (U.S. state or Ukrainian oblast), and sometimes they are used together, in no particular order.
2.2. Methods
2.2.1. Transcription
- The correspondence between the Czech phonetic orthography (which is often used in the input) and the standard Latin orthography of the language of the given country was examined; in the case of countries using non-Latin writing systems, the standard English transcription, which dominates in the gazetteer, was used. In many cases, this produces rather simple non-variant rules transforming strings from one orthography to the other.
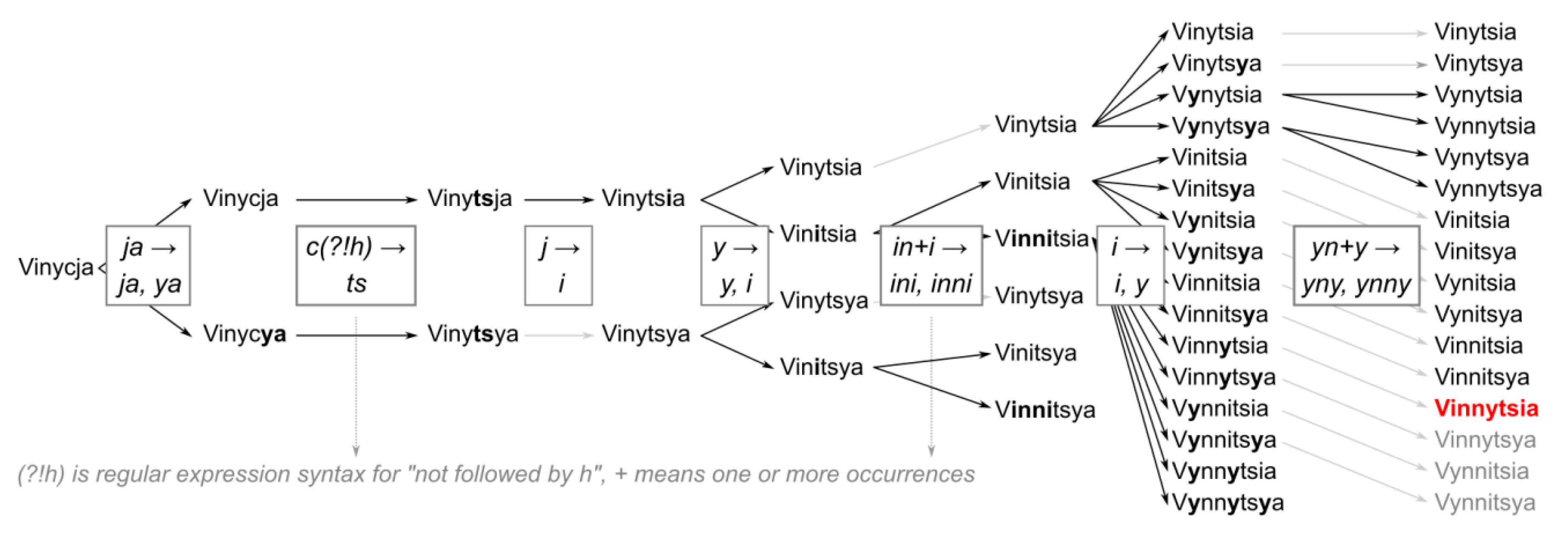
- In the process of developing the geocoding engine on the input data, we devised further empirical rules that improved its accuracy on frequent non-standard transcriptions or typographical errors. This was achieved using a hold-out sample, which was distinct from the validation sample. The sample was repeatedly geocoded using the engine, and its mistakes and unmatched records were manually examined with the help of online web searches to produce new rules. The performance of these rules was tested in the following iterations. An example of a rule devised in this manner is the variant rule transforming between a single and a double ‘N’ in Ukrainian, as shown in Figure 1.
2.2.2. Gazetteer Matching
2.2.3. Result Selection
2.2.4. Comparison
3. Results
3.1. Algorithm
- geocoding precision: the fraction of correct matches out of all of the locations retrieved,
- geocoding recall: the fraction of correct matches out of all of the geocodable locations,
- geocoding F-score: a harmonic mean of geocoding precision and recall, regarded as the primary quality metric,
- nil precision: the fraction of ungeocoded records that truly did not carry location information,
- nil recall: the fraction of records that did not carry location information that were not geocoded (the lower the result, the more this set was “polluted” by false positives),
- completeness: the fraction of records for which a location was retrieved (although this is not in a true sense an accuracy metric, it nevertheless is an important measure of the usefulness of the result).
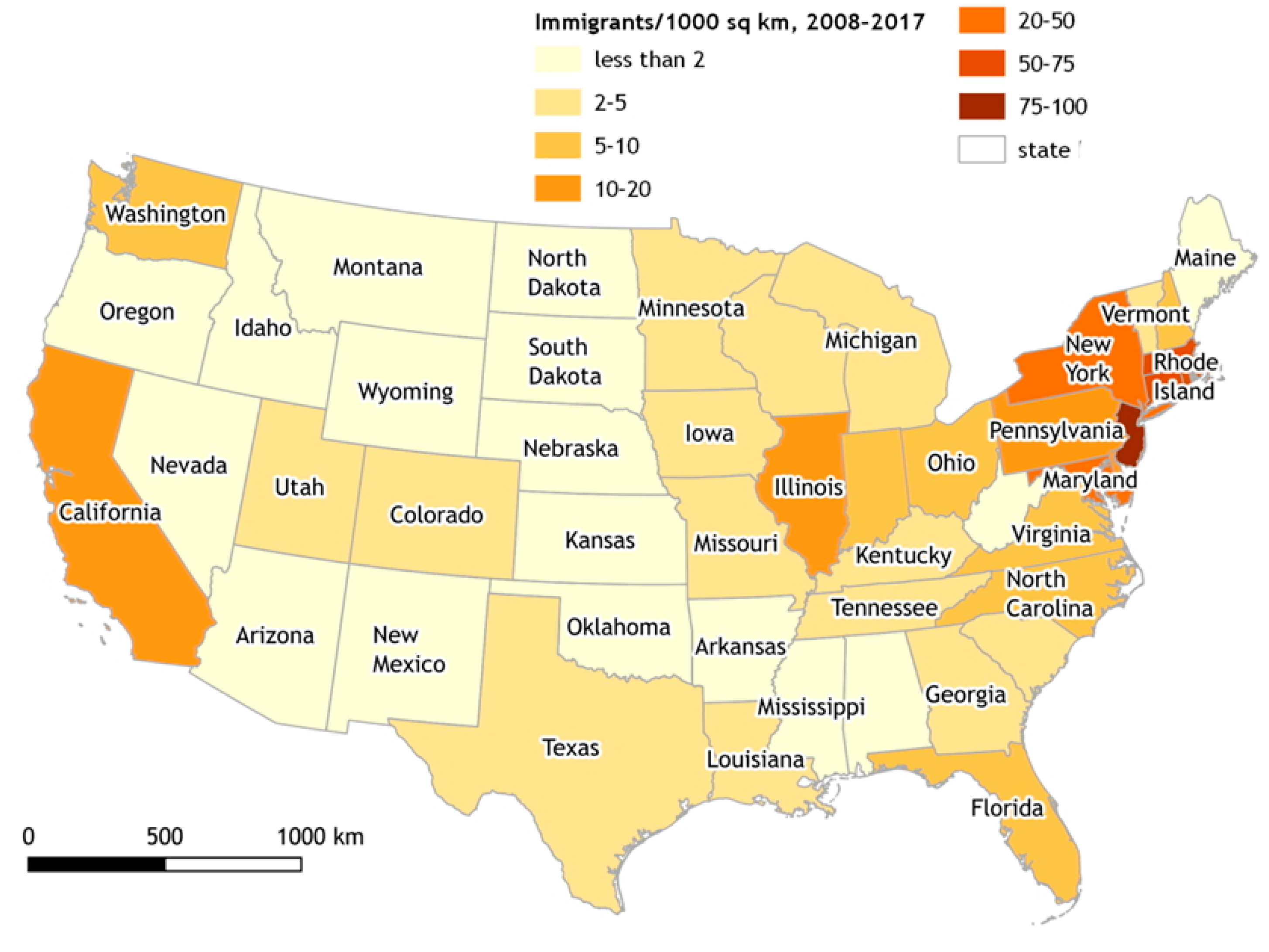
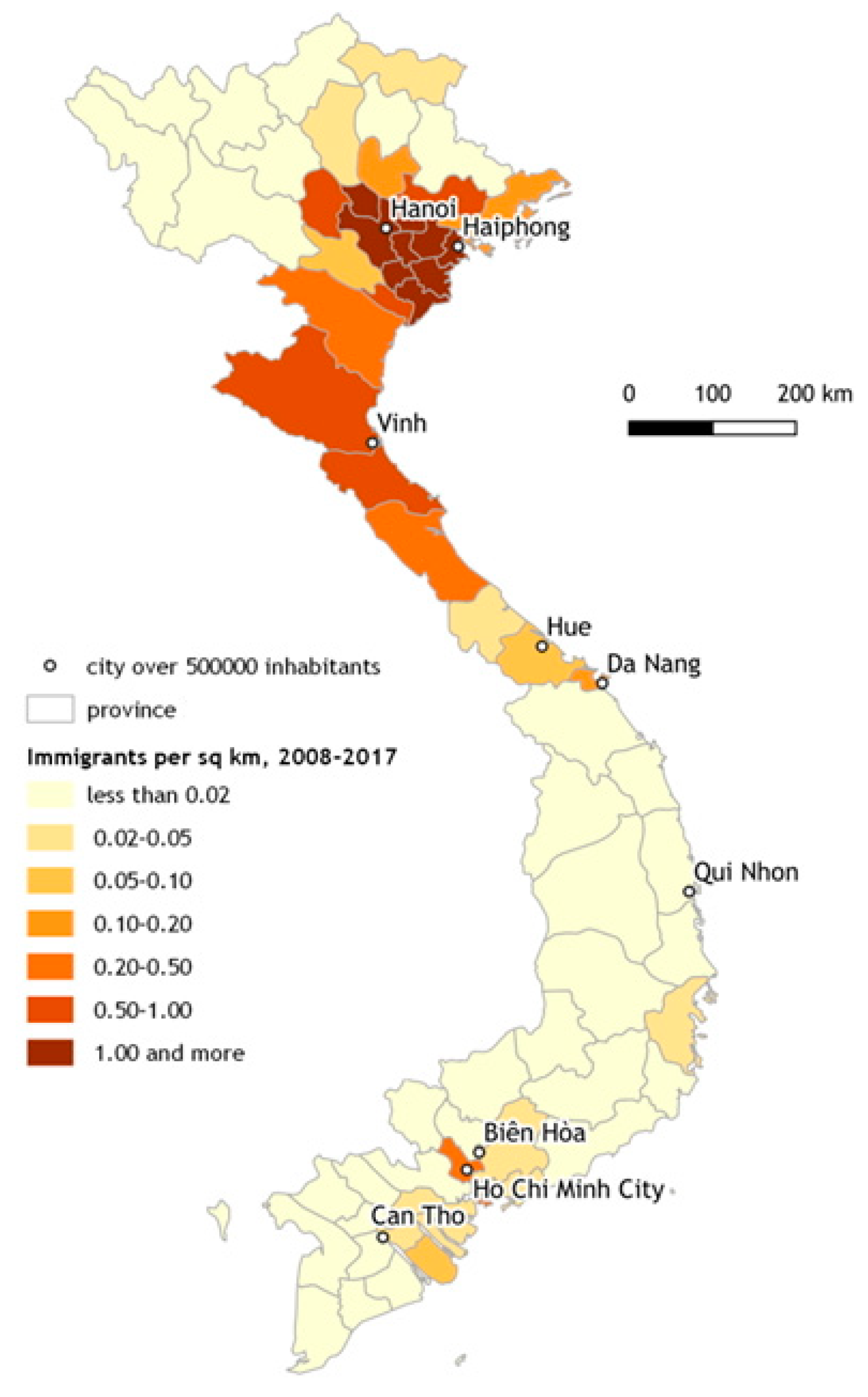
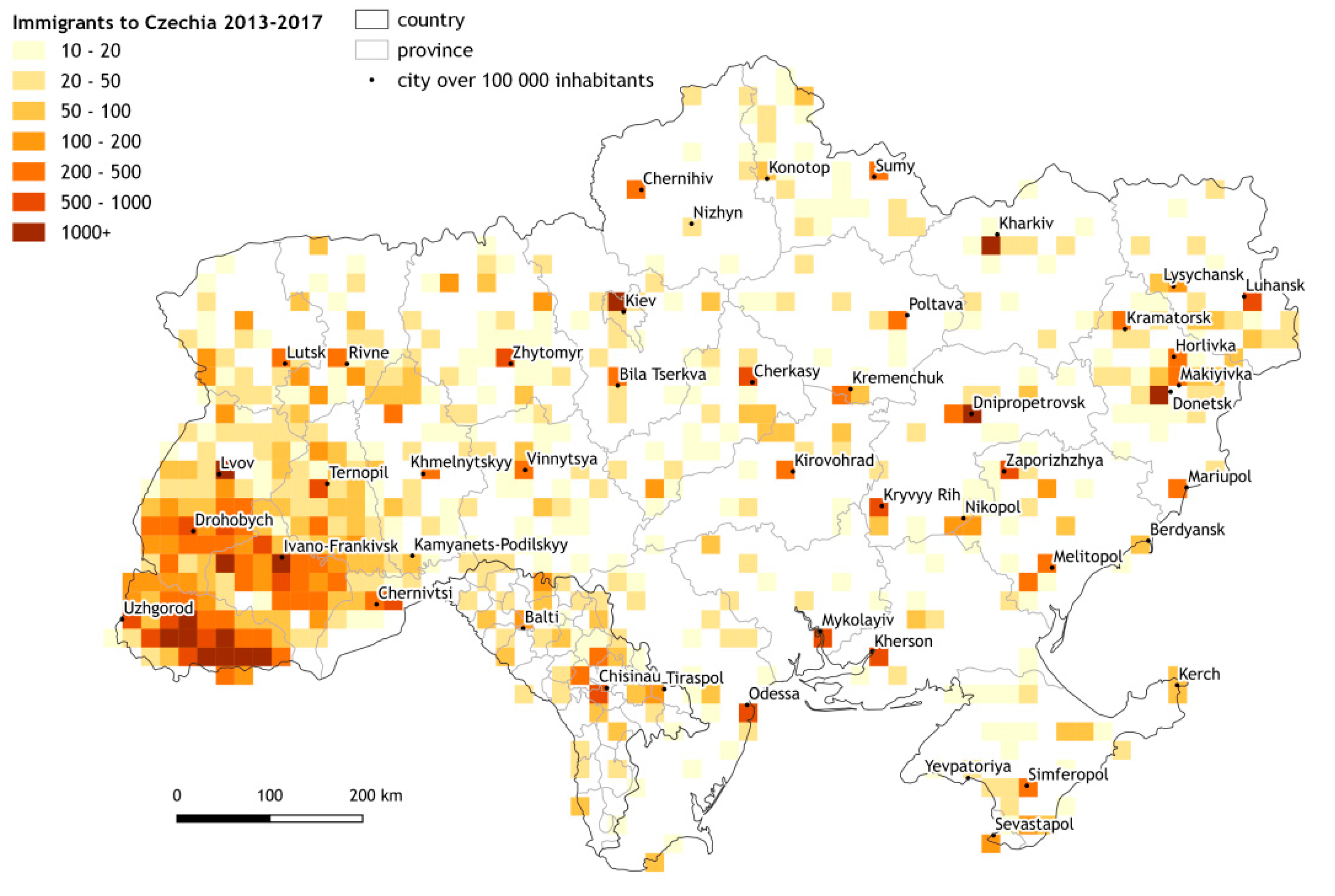
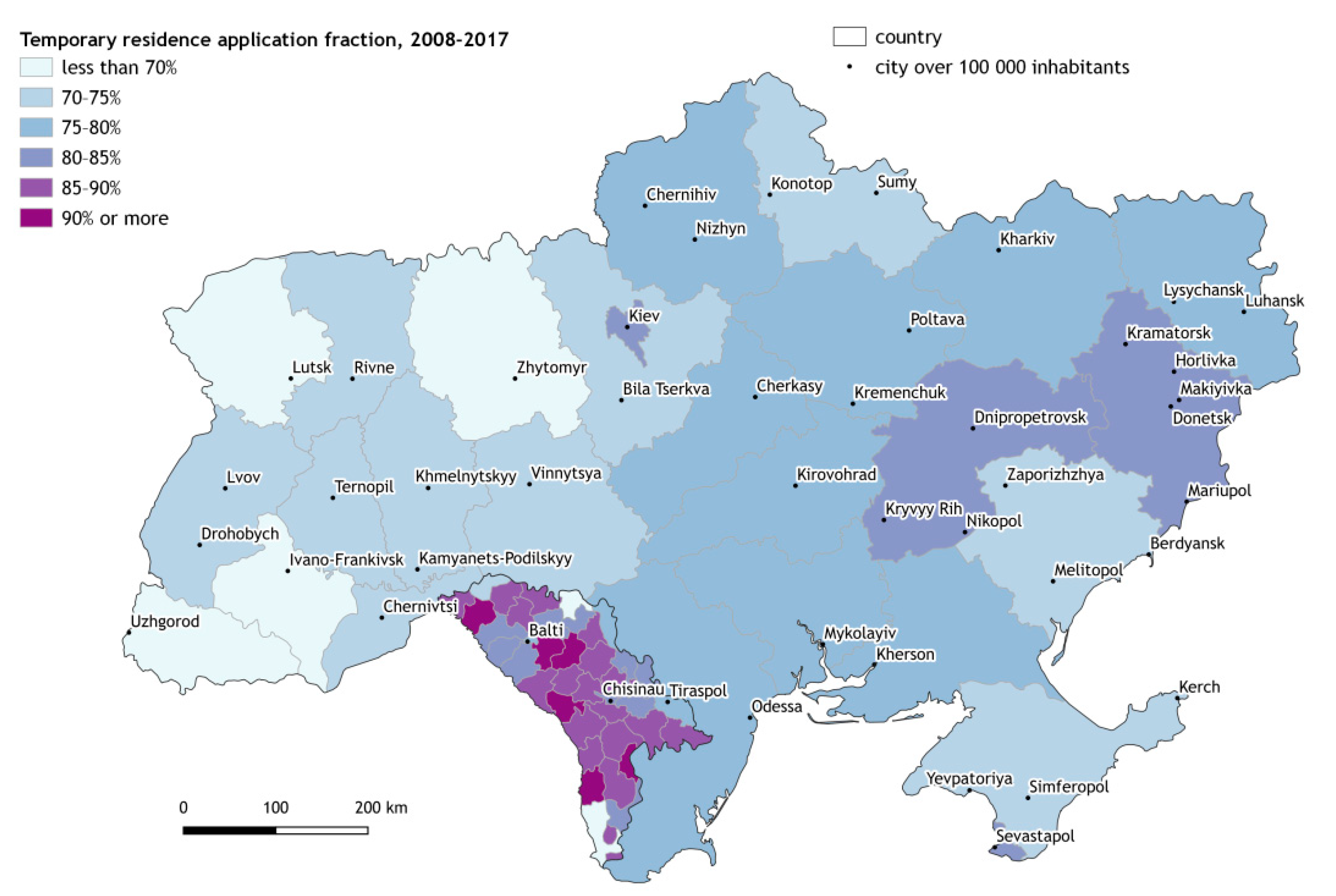
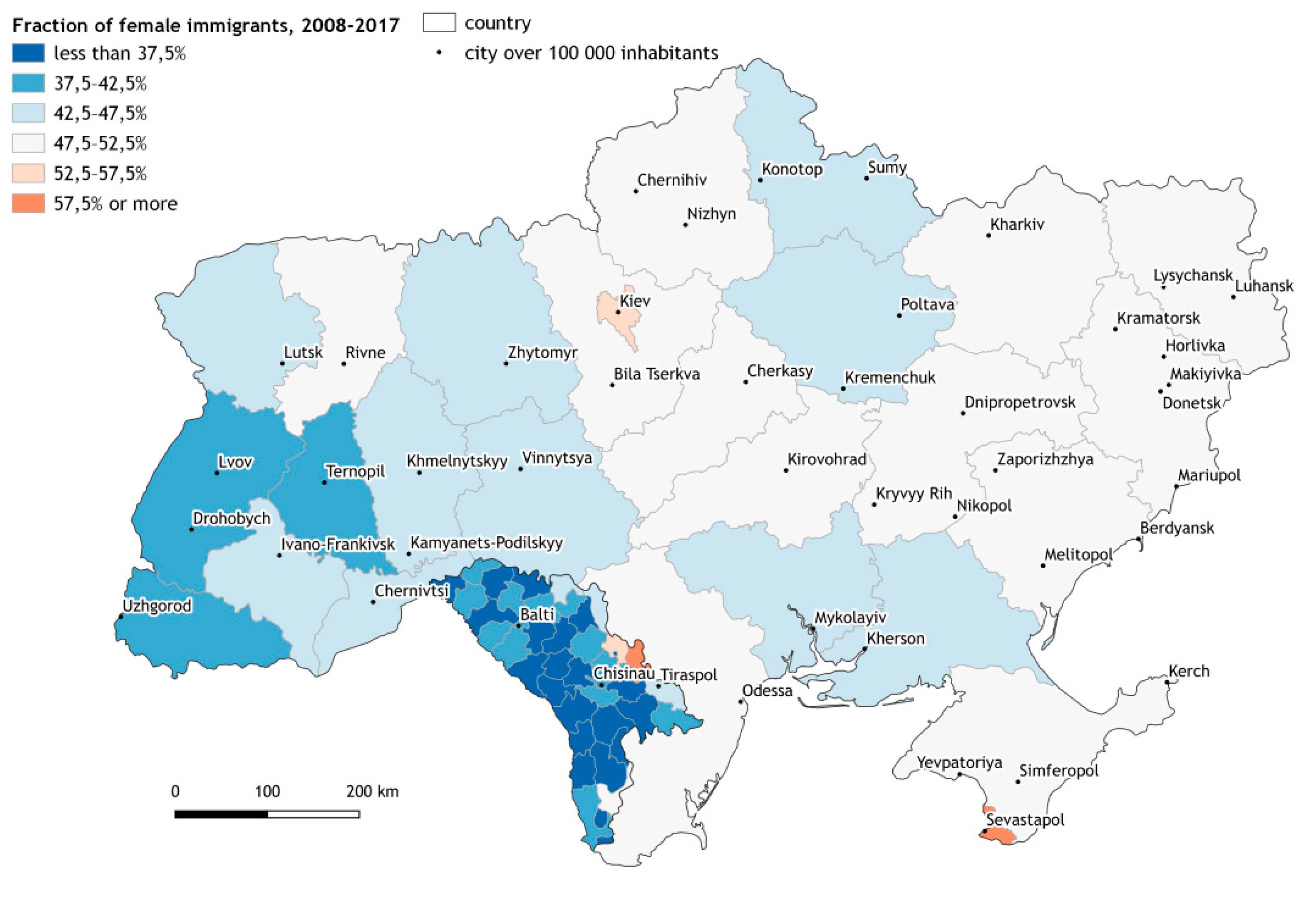
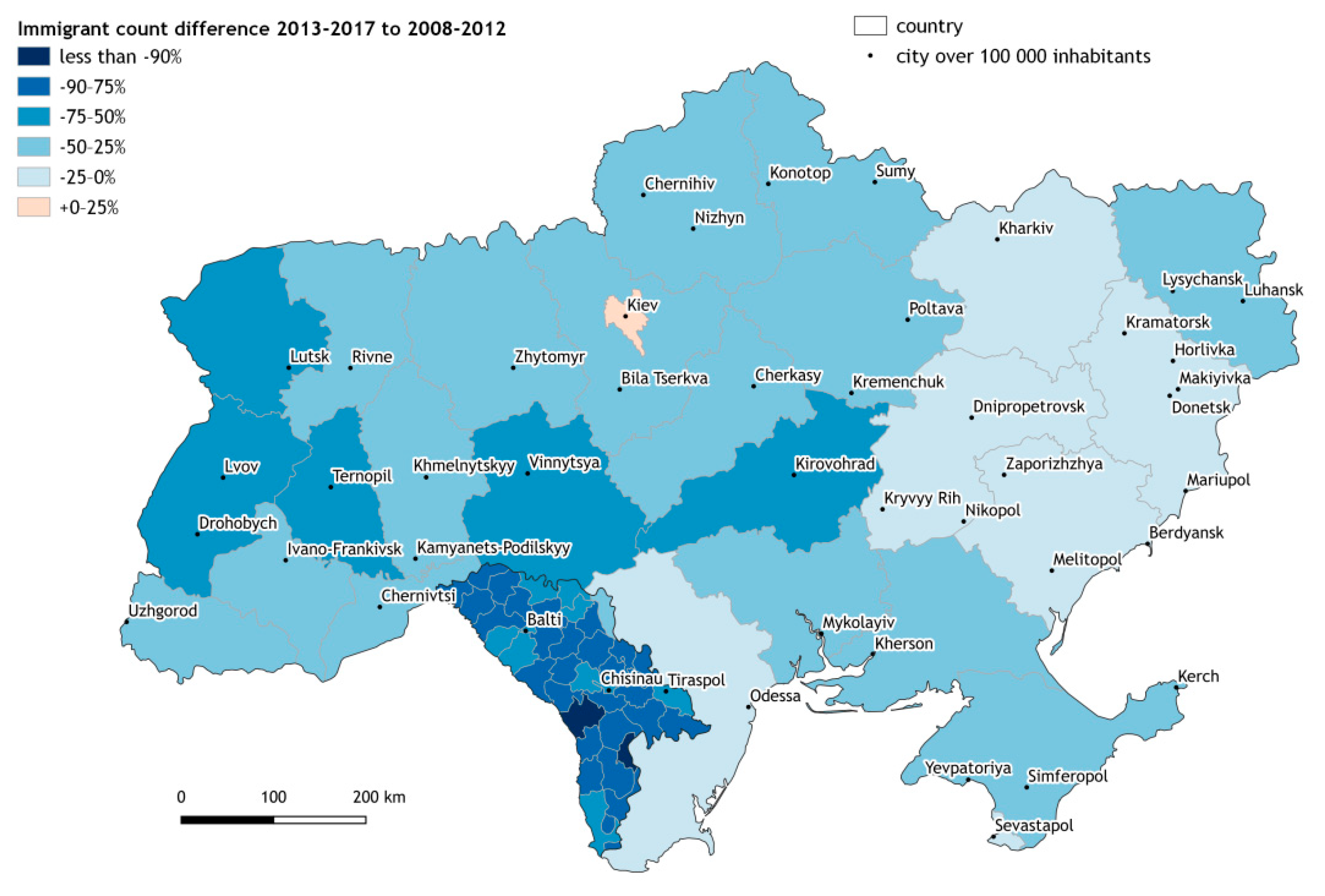
3.2. Analysis of the Immigrants Coming to Czechia
4. Discussion
5. Conclusions
- Why, in terms of migrants’ birthplaces, have the encountered spatial patterns (or the absence thereof) arisen?
- What is the role of migration networks in their formation?
- What differences are there for different subnational cultures, ages, and genders?
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fassmann, H. European migration: Historical overview and statistical problems. In Statistics and Reality; Concepts and Measurements of Migration in Europe; Fassmann, H., Reeger, U., Sievers, W., Eds.; University Press: Amsterdam, The Netherlands, 2008; pp. 21–43. [Google Scholar]
- McHugh, K.E. Explaining migration intentions and destination selection. Prof. Geogr. 1984, 36, 315–325. [Google Scholar] [CrossRef]
- The Open Geospatial Consortium (OGC). Reference Model. Version 2.1. 2011. Available online: http://www.opengis.net/doc/orm/2.1 (accessed on 24 January 2021).
- Sanderson, M.; Kohler, J. Analyzing Geographic Queries. In Proceedings of the 27th Annual International ACM SIGIR Con-ference, Sheffield, UK, 25–29 July 2004; pp. 37–39. [Google Scholar]
- Valkanas, G.; Gunopulos, D. Location Extraction from Social Networks with Commodity Software and Online Data. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining Workshops, Brussels, Belgium, 10–13 December 2012; pp. 827–834. [Google Scholar]
- Densham, I.; Reid, J. A geo-coding service encompassing a geo-parsing tool and integrated digital gazetteer service. In Proceedings of the HLT-NAACL 2003 Workshop on Analysis of Geographic References; Association for Computational Linguistics (ACL): Edmonton, AB, Canada, 2003; pp. 79–80. [Google Scholar]
- Huck, J.; Whyatt, D.; Coulton, P. Challenges in geocoding socially-generated data. In Proceedings of the GIS Research UK 20th Annual Conference: Volume 1—Presentations; Whyatt, D., Rowlingson, B., Eds.; Lancaster University: Lancaster, UK, 2012; pp. 39–45. [Google Scholar]
- Derczynski, L.; Maynard, D.; Rizzo, G.; van Erp, M.; Gorrell, G.; Troncy, R.; Petrak, J.; Bontcheva, K. Analysis of named entity recognition and linking for tweets. Inf. Process. Manag. 2015, 51, 32–49. [Google Scholar] [CrossRef]
- Hirschmann, L.; Chinchor, N. MUC-7 coreference task definition. In Proceedings of the MUC-7 Conference, Fairfax, VA, USA, 19 April–1 May 1997. [Google Scholar]
- Rao, D.; McNamee, P.; Dredze, M. Entity linking: Finding extracted entities in a knowledge base. In Multi-Source, Multilingual Information Extraction and Summarization; Springer: Berlin/Heidelberg, Germany, 2013; pp. 93–115. [Google Scholar]
- Amitay, E.; Har’El, N.; Sivan, R.; Soffer, A. Web a where: Geotagging web content. In Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval; ACM: New York, NY, USA, 2004; pp. 273–280. [Google Scholar]
- Ardanuy, M.C.; Sporleder, C. Toponym disambiguation in historical documents using semantic and geographic features. In Proceedings of the 2nd International Conference on Digital Access to Textual Cultural Heritage; Association for Computing Machinery (ACM): New York, NY, USA, 2017; pp. 175–180. [Google Scholar]
- Brando, C.; Frontini, F.; Ganascia, J.-G. Disambiguation of Named Entities in Cultural Heritage Texts Using Linked Data Sets. In Advances in Service-Oriented and Cloud Computing; Metzler, J.B., Ed.; Springer: Cham, Switzerland, 2015; pp. 505–514. [Google Scholar]
- Kim, J.; Vasardani, M.; Winter, S. Similarity matching for integrating spatial information extracted from place descriptions. Int. J. Geogr. Inf. Sci. 2016, 31, 56–80. [Google Scholar] [CrossRef]
- Ardanuy, M.C.; Hosseini, K.; McDonough, K.; Krause, A.; van Strien, D.; Nanni, F. A Deep Learning Approach to Geographical Candidate Selection through Toponym Matching. In Proceedings of the 28th International Conference on Advances in Geographic Information Systems; Association for Computing Machinery (ACM): New York, NY, USA, 2020; pp. 385–388. [Google Scholar]
- Li, H.; Srihari, R.; Niu, C.; Li, W. InfoXtract location normalization: A hybrid approach to geographic references in in-formation extraction. In Proceedings of the HLT-NAACL Workshop on Analysis of Geographic References, Stroudsburg, PA, USA, 10–13 July 2003; pp. 39–44. [Google Scholar]
- Overell, S.; Rüger, S. Using co-occurrence models for placename disambiguation. Int. J. Geogr. Inf. Sci. 2008, 22, 265–287. [Google Scholar] [CrossRef]
- GeoNames. GeoNames. Available online: http://geonames.org/ (accessed on 28 February 2019).
- Mattmann, C.A.; Sharan, M. An Automatic Approach for Discovering and Geocoding Locations in Domain-Specific Web Data (Application Paper). In Proceedings of the 2016 IEEE 17th International Conference on Information Reuse and Integration (IRI), Pittsburgh, PA, USA, 28–30 July 2016; pp. 87–93. [Google Scholar]
- Ahlers, D. Assessment of the accuracy of GeoNames gazetteer data. Proc. Python High-Perform. Sci. Comput. 2013, 74–81. [Google Scholar] [CrossRef]
- Ahlers, D. Applying Geographic Information Retrieval. Datenbank-Spektrum 2014, 14, 39–46. [Google Scholar] [CrossRef]
- Chow, T.E.; Dede-Bamfo, N.; Dahal, K.R. Geographic disparity of positional errors and matching rate of residential addresses among geocoding solutions. Ann. GIS 2015, 22, 29–42. [Google Scholar] [CrossRef]
- Liao, Y.; Wang, J. A method for matching Chinese place-name data. In Proceedings of the Geoinformatics 2008 and Joint Conference on GIS and Built Environment: Advanced Spatial Data Models and Analyses; International Society for Optics and Photonics: Washington, DC, USA, 2009; Volume 7146, p. 71461. [Google Scholar]
- Coetzee, S.; Rademeyer, M. Testing the spatial adjacency match of the Intiendo address matching tool for geocoding of ad-dresses with misleading suburb or place names. In Proceedings of the 24th International Cartography Conference, Santiago, Chile, 15–21 November 2009; pp. 10–18. [Google Scholar]
- Lan, T.; Longley, P. Lan Geo-Referencing and Mapping 1901 Census Addresses for England and Wales. ISPRS Int. J. Geo-Inf. 2019, 8, 320. [Google Scholar] [CrossRef]
- Daras, K.; Feng, Z.; Dibben, C. HAG-GIS: A spatial framework for geocoding historical addresses. In Proceedings of the 23rd GIS Research UK Conference, Leeds, UK, 15–17 April 2015; pp. 3–6. [Google Scholar]
- Singh, S.K. Evaluating two freely available geocoding tools for geographical inconsistencies and geocoding errors. Open Geospat. Data Softw. Stand. 2017, 2, 11. [Google Scholar] [CrossRef]
- Arbabi, M.; Fischthal, S.M.; Cheng, V.C.; Bart, E. Algorithms for Arabic name transliteration. IBM J. Res. Dev. 1994, 38, 183–194. [Google Scholar] [CrossRef]
- Cui, Y. A systematic approach to evaluate and validate the spatial accuracy of farmers market locations using multi-geocoding services. Appl. Geogr. 2013, 41, 87–95. [Google Scholar] [CrossRef]
- Ahlers, D.; Boll, S. Adaptive geospatially focused crawling. In Proceedings of the 18th ACM Conference on Information and Knowledge Management–CIKM ’09; ACM: New York, NY, USA, 2009; pp. 445–454. [Google Scholar]
- Karimi, H.A.; Sharker, M.H.; Roongpiboonsopit, D. Geocoding Recommender: An Algorithm to Recommend Optimal Online Geocoding Services for Applications. Trans. GIS 2011, 15, 869–886. [Google Scholar] [CrossRef]
- Ping, D.; Yong, L. Building placename ontology to assist in geographic information retrieval. In Proceedings of the Computer Science Technology and Applications, IFCSTA’09, International Forum, IEEE Computer Society, Washington, DC, USA, 25–27 December 2009; Volume 3, pp. 306–309. [Google Scholar]
- MVČR. Formuláře a Žádosti. Praha: Odbor Azylové a Migrační Politiky, Ministerstvo Vnitra ČR. Available online: http://www.mvcr.cz/clanek/formulare-zadosti.aspx (accessed on 28 December 2019).
- MVČR. Některé Náležitosti Žádosti. Praha: Odbor Azylové a Migrační Politiky, Ministerstvo Vnitra ČR. Available online: https://www.mvcr.cz/clanek/obcane-tretich-zemi-nektere-nalezitosti-zadosti.aspx (accessed on 28 December 2019).
- Foreigners, Total by Citizenship as at 31 December 2017. Directorate of the Alien Police Service, Czech Republic. Available online: https://www.czso.cz/documents/11292/27914491/1712_c01t01.pdf/ff9e9fee-08d3-4bdc-a11b-d0cc1e3ac184?version=1.0 (accessed on 29 January 2021).
- CZSO. Foreigners: Number of Foreigners. Available online: https://www.czso.cz/csu/cizinci/1-ciz_pocet_cizincu (accessed on 28 December 2019).
- Šimbera, J. Python-Based Placename Geocoder for Noisy, Badly Transcripted and Erroneous Data from Migration Geodata-bases. 2018. Available online: http://github.com/simberaj/migration-geocode/ (accessed on 28 December 2019).
- Korotkov, A.; Zakirov, A. Fuzzy Substring Searching with the pg_trgm Extension. Available online: https://dl.acm.org/citation.cfm?id=1463460 (accessed on 15 November 2019).
- Nominatim Geocoding Service: About & Help. Available online: https://nominatim.openstreetmap.org/ui/about.html (accessed on 2 April 2021).
- Geoapify.com geocoding. Available online: https://www.geoapify.com/ (accessed on 1 February 2021).
- Brando, C.; Frontini, F.; Ganascia, J.-G. REDEN: Named Entity Linking in Digital Literary Editions Using Linked Data Sets. Complex Syst. Inf. Model. Q. 2016, 7, 60–80. [Google Scholar] [CrossRef]
- Halemba, A. Not looking through a national lens? Rusyn–Transcarpathians as an anational self-identification in contemporary Ukraine. In Debatten um Polen und Polentum in Geschichte und Gegenwart, Polen: Kultur–Geschichte–Gesellschaft 1; Brückner, A., Ed.; Wallstein Verlag: Göttingen, Germany, 2015; pp. 123–146. [Google Scholar]
- Šimon, M.; Křížková, I.; Klsák, A. Immigrants in large Czech cities 2008–2015: The analysis of changing residential patterns using population grid data. Geografie 2020, 125, 343–374. [Google Scholar] [CrossRef]
- Ignatyeva, E.; Sýkora, L. Strangers among their own: Local interaction, integration, and segregation of Russian immigrants in Prague. Geografie 2019, 124, 341–364. [Google Scholar] [CrossRef]
- Klvaňová, R. The Brother of the Other. Immigration from Belarus, Russia, and Ukraine to the Czech Republic; EDIS Publication Series; Masaryk University, MUNI Press: Brno, Czech Republic, 2017; 167p, Volume 16. [Google Scholar]
- Freidengerová, T. Vietnamci v Česku a ve světě. Migrační a Adaptační Tendence. Praha, Sociologické Nakladatelství (SLON), Prague. 2014, p. 232. Available online: https://sreview.soc.cas.cz/artkey/csr-201604-0001_living-together-in-an-urban-neighbourhood-the-majority-and-vietnamese-immigrants-in-prague-libus.php (accessed on 1 May 2021).
- Angel, A.; Lontou, C.; Pfoser, D.; Efentakis, A. Qualitative geocoding of persistent web pages. In Proceedings of the 16th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems–GIS ’08; ACM: New York, NY, USA, 2008; p. 10. [Google Scholar]
- Drbohlav, D.; Medová, L.; Čermák, Z.; Janská, E.; Čermáková, D.; Dzúrová, D. Migrace a Migranti v Česku. Kdojsme, OdkudPřicházíme, kamJdeme? Sociologické nakladatelství (SLON): Prague, Czech Republic, 2010; p. 184. [Google Scholar]
- McKenzie, G.; Slind, R.T. A user-generated data based approach to enhancing location prediction of financial services in sub-Saharan Africa. Appl. Geogr. 2019, 105, 25–36. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Match in Input | Output Variant(s) | |
|---|---|---|
| i | i | yí |
| ö | ö | ő |
| č | cs | |
| s not before z | s | sz |
| ž | zs | |
| š | s | |
| ď | gy | |
| ť | ty | |
| j | j | ly |
| F-Score | Precision | Recall | Nil Precision | Nil Recall | Completeness | |
|---|---|---|---|---|---|---|
| Full engine | 90.4% | 91.7% | 89.2% | 22.2% | 88.9% | 96.4% |
| Transcription only | 83.8% | 90.9% | 77.7% | 5.2% | 88.9% | 84.7% |
| Fuzzy matching only | 78.4% | 87.2% | 71.2% | 4.2% | 88.9% | 81.0% |
| Both components off | 72.3% | 91.8% | 59.6% | 2.2% | 88.9% | 64.4% |
| Nominatim | 73.4% | 86.3% | 63.8% | 2.6% | 77.8% | 73.2% |
| Geoapify | 64.5% | 74.5% | 56.8% | 2.9% | 77.8% | 75.6% |
| Country | Records | Full Engine F-Score | Nominatim F-Score | Geoapify F-Score |
|---|---|---|---|---|
| Belarus | 23 | 90.5% | 72.2% | 75.7% |
| Czechia | 54 | 91.6% | 70.3% | 72.5% |
| Moldova | 42 | 98.8% | 85.7% | 86.1% |
| Russia | 164 | 97.2% | 77.2% | 71.5% |
| Ukraine | 466 | 88.6% | 64.2% | 42.0% |
| USA | 75 | 68.9% | 83.2% | 85.3% |
| Vietnam | 145 | 96.2% | 85.6% | 91.6% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Šimbera, J.; Drbohlav, D.; Štych, P. Geocoding Freeform Placenames: An Example of Deciphering the Czech National Immigration Database. ISPRS Int. J. Geo-Inf. 2021, 10, 335. https://doi.org/10.3390/ijgi10050335
Šimbera J, Drbohlav D, Štych P. Geocoding Freeform Placenames: An Example of Deciphering the Czech National Immigration Database. ISPRS International Journal of Geo-Information. 2021; 10(5):335. https://doi.org/10.3390/ijgi10050335
Chicago/Turabian StyleŠimbera, Jan, Dušan Drbohlav, and Přemysl Štych. 2021. "Geocoding Freeform Placenames: An Example of Deciphering the Czech National Immigration Database" ISPRS International Journal of Geo-Information 10, no. 5: 335. https://doi.org/10.3390/ijgi10050335
APA StyleŠimbera, J., Drbohlav, D., & Štych, P. (2021). Geocoding Freeform Placenames: An Example of Deciphering the Czech National Immigration Database. ISPRS International Journal of Geo-Information, 10(5), 335. https://doi.org/10.3390/ijgi10050335