
Trajectory Similarity Analysis with the Weight of Direction and k-Neighborhood for AIS Data



Abstract
:1. Introduction
2. Related Research
3. Methodology
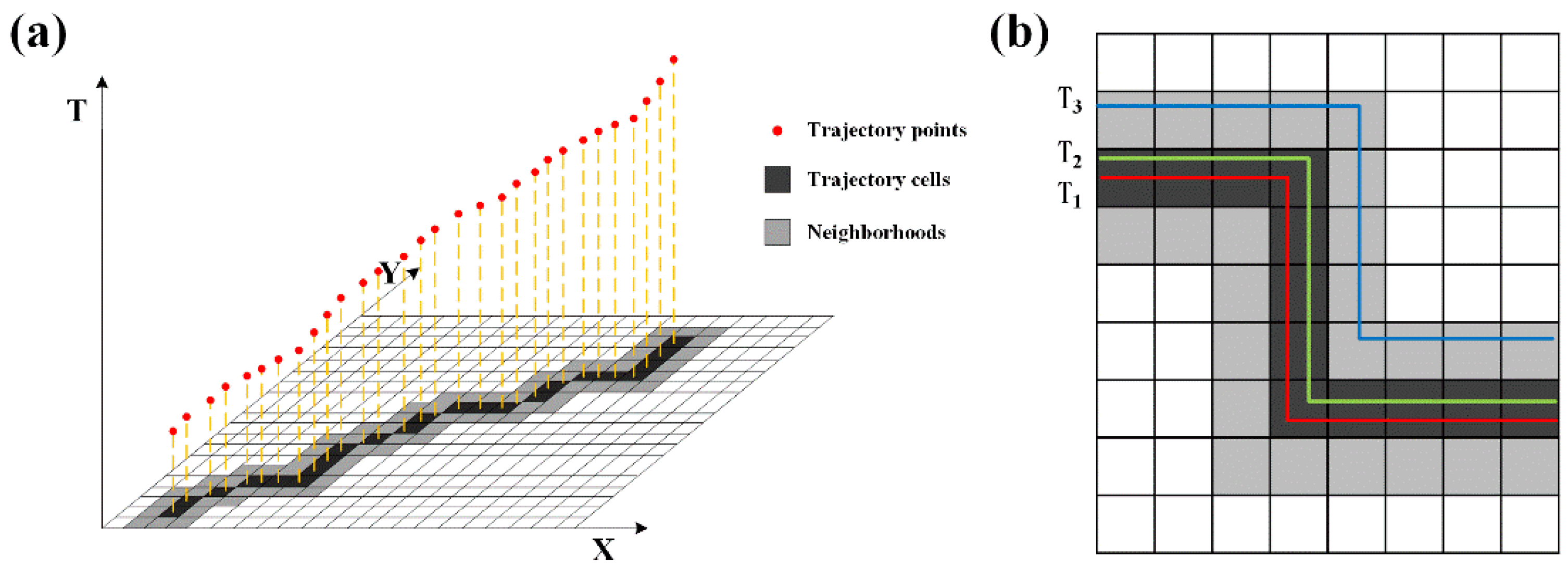
3.1. Overall Idea
- Reconstruct the representative trajectory. Based on the Maritime Mobile Service Identity (MMSI) code, navigation state, and time interval of the trajectory point, we extracted the trajectory segment. The trajectory segment was then mapped to the corresponding grid cells according to its spatial position. The constructed cell sequence was used to calculate the trajectory similarity.
- Quantify the direction and neighborhood of the trajectory. We assigned corresponding weights to various directional relationships for different trajectories on the same grid cell. The directional relationships included three types: same direction, inclined direction, and opposite direction. Meanwhile, different neighborhoods of the central cells were also given corresponding weights according to the degree of proximity to the central cell.
- Calculate similarity between trajectories. The similarity between the trajectories was measured by calculating the number and proportion of overlapping cells between representative trajectories, followed by assigning corresponding weights to the k-neighborhood and motion direction characteristics.
3.2. Reconstructing the Representative Trajectory Based on Cell
3.3. Weight of Direction and Neighbor Cell
3.3.1. Weight of Direction
3.3.2. Weight of Neighbor Cells
3.4. Measuring Similarity between Trajectories
4. Performance Evaluation
4.1. Experimental Design
4.1.1. Experimental Dataset
4.1.2. Trajectory Similarity of Different Positional Relationships
4.1.3. Comparisons with Other Similarity Measurement Methods
4.2. Results and Analysis
4.2.1. Results of Different Positional Relationship Experiments
4.2.2. Results of Measurement Comparison Experiments
5. Discussion
5.1. Grid Cell Size Selection Problem
5.2. k Setting Problem
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Metcalfe, K.; Bréheret, N.; Chauvet, E.; Collins, T.; Curran, B.K.; Parnell, R.J.; Turner, R.A.; Witt, M.J.; Godley, B.J. Using satellite AIS to improve our understanding of shipping and fill gaps in ocean observation data to support marine spatial planning. J. Appl. Ecol. 2018, 55, 1834–1845. [Google Scholar] [CrossRef]
- Yan, Z.; Xiao, Y.; Cheng, L.; Chen, S.; Zhou, X.; Ruan, X.; Li, M.C.; He, R.; Ran, B. Analysis of global marine oil trade based on automatic identification system (AIS) data. J. Transp. Geogr. 2020, 83, 102637. [Google Scholar] [CrossRef]
- Cheng, L.; Yan, Z.J.; Xiao, Y.J.; Chen, Y.M.; Zhang, F.L.; Li, M.C. Using big data to track marine oil transportation along the 21st-century maritime silk road. Sci. China Technol. Sci. 2019, 62, 677–686. [Google Scholar] [CrossRef]
- Feng, M.; Shaw, S.L.; Peng, G.; Fang, Z. Time efficiency assessment of ship movements in maritime ports: A case study of two ports based on AIS data. J. Transp. Geogr. 2020, 86, 102741. [Google Scholar] [CrossRef]
- Mou, N.; Ren, H.; Zheng, Y.; Chen, J.; Niu, J.; Yang, T.; Zhang, L.; Liu, F. Traffic Inequality and Relations in Maritime Silk Road: A Network Flow Analysis. ISPRS Int. J. Geo-Inf. 2021, 10, 40. [Google Scholar] [CrossRef]
- Riveiro, M.; Pallotta, G.; Vespe, M. Maritime anomaly detection: A review. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1266. [Google Scholar] [CrossRef] [Green Version]
- Zhao, L.; Shi, G. A trajectory clustering method based on Douglas-Peucker compression and density for marine traffic pattern recognition. Ocean Eng. 2019, 172, 456–467. [Google Scholar] [CrossRef]
- Zhao, L.; Shi, G. Maritime Anomaly Detection using Density-based Clustering and Recurrent Neural Network. J. Navig. 2019, 72, 894–916. [Google Scholar] [CrossRef]
- Chen, R.; Chen, M.; Li, W.; Wang, J.; Yao, X. Mobility Modes Awareness from Trajectories Based on Clustering and a Convolutional Neural Network. ISPRS Int. J. Geo-Inf. 2019, 8, 208. [Google Scholar] [CrossRef] [Green Version]
- Mascaro, S.; Nicholson, A.; Korb, K. Anomaly detection in vessel tracks using Bayesian networks. Int. J. Approx. Reason. 2014, 55, 84–98. [Google Scholar] [CrossRef]
- Ji, Y.; Zhang, J.; Meng, J.; Wang, Y. Point association analysis of vessel target detection with SAR, HFSWR and AIS. Acta Oceanol. Sin. 2014, 33, 73–81. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, G.; Wang, J.; Li, M.; Cheng, L. A GIS-based spatial-temporal autoregressive model for forecasting marine traffic volume of a shipping network. Sci. Program. 2019, 2019, 1–14. [Google Scholar] [CrossRef]
- Alizadeh, D.; Alesheikh, A.; Sharif, M. Vessel Trajectory Prediction Using Historical Automatic Identification System Data. J. Navig. 2021, 74, 156–174. [Google Scholar] [CrossRef]
- Tu, E.; Zhang, G.; Rachmawati, L.; Rajabally, E.; Huang, G.B. Exploiting AIS data for intelligent maritime navigation: A comprehensive survey from data to methodology. IEEE Trans. Intell. Transp. Syst. 2018, 19, 1559–1582. [Google Scholar] [CrossRef]
- Zhang, C.; Bin, J.; Wang, W.; Peng, X.; Wang, R.; Halldearn, R.; Liu, Z. AIS data driven general vessel destination prediction: A random forest based approach. Transp. Res. Part C Emerg. Technol. 2020, 118, 102729. [Google Scholar] [CrossRef]
- Pallotta, G.; Vespe, M.; Bryan, K. Vessel Pattern Knowledge Discovery from AIS Data: A Framework for Anomaly Detection and Route Prediction. Entropy 2013, 15, 2218–2245. [Google Scholar] [CrossRef] [Green Version]
- Silveira, P.A.M.; Teixeira, A.P.; Soares, C.G. Use of AIS data to characterise marine traffic patterns and ship collision risk off the coast of Portugal. J. Navig. 2013, 66, 879–898. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Goerlandt, F.; Montewka, J.; Kujala, P. A method for detecting possible near miss ship collisions from AIS data. Ocean Eng. 2015, 107, 60–69. [Google Scholar] [CrossRef]
- Lin, C.; Dong, F.; Le, J.; Wang, G. AIS system and the applications at the harbor traffic management. In Proceedings of the 4th International Conference on Wireless Communications, Networking and Mobile Computing, Dalian, China, 12–14 October 2008; pp. 1–3. [Google Scholar] [CrossRef]
- LU, N.; Liang, M.; Yang, L.; Wang, Y.; Xiong, N.; Liu, R.W. Shape-Based Vessel Trajectory Similarity Computing and Clustering: A Brief Review. In Proceedings of the 2020 5th IEEE International Conference on Big Data Analytics (ICBDA), Xiamen, China, 8–11 May 2020; pp. 186–192. [Google Scholar] [CrossRef]
- Zhang, Y.; Shi, G. Trajectory Similarity Measure Design for Ship Trajectory Clustering. In Proceedings of the 2021 6th IEEE International Conference on Big Data Analytics (ICBDA), Xiamen, China, 5–8 March 2021; pp. 181–187. [Google Scholar] [CrossRef]
- Zhen, R.; Jin, Y.; Hu, Q.; Shao, Z.; Nikitakos, N. Maritime Anomaly Detection within Coastal Waters Based on Vessel Trajectory Clustering and Naïve Bayes Classifier. J. Navig. 2017, 70, 648–670. [Google Scholar] [CrossRef]
- Mao, Y.Z.; Zhong, H.S.; Xiao, X.J.; Li, X.F. A segment-based trajectory similarity measure in the urban transportation systems. Sensors 2017, 17, 524. [Google Scholar] [CrossRef]
- Besse, P.C.; Guillouet, B.; Loubes, J.; Royer, F. Review and Perspective for Distance-Based Clustering of Vehicle Trajectories. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3306–3317. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Li, Z.R.; Meng, J.L.; Zhao, L.P.; Wen, J.X.; Wang, G.L. Extraction method of marine lane boundary from exploiting trajectory big data. J. Comput. Appl. 2019, 39, 105–112. [Google Scholar] [CrossRef]
- Mariescu-Istodor, R.; Fränti, P. Grid-based method for GPS route analysis for retrieval. ACM Trans. Spat. Algorithms Syst. (TSAS) 2017, 3, 1–28. [Google Scholar] [CrossRef]
- Fränti, P.; Mariescu-Istodor, R. Averaging GPS segments competition 2019. Pattern Recognit. 2021, 112, 107730. [Google Scholar] [CrossRef]
- Keogh, E.J.; Pazzani, M.J. Scaling up dynamic time warping for datamining applications. In Proceedings of the 6th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Boston, MA, USA, 20–23 August 2000; ACM: New York, NY, USA, 2000; pp. 285–289. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Liu, J.; Liu, R.W.; Xiong, N.; Wu, K.; Kim, T.H. A dimensionality reduction-based multi-step clustering method for robust vessel trajectory analysis. Sensors 2017, 17, 1792. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, L.; Shi, G. A Novel Similarity Measure for Clustering Vessel Trajectories Based on Dynamic Time Warping. J. Navig. 2019, 72, 290–306. [Google Scholar] [CrossRef]
- Liu, J.; Li, H.; Yang, Z.; Wu, K.; Liu, Y.; Liu, R.W. Adaptive Douglas-Peucker Algorithm With Automatic Thresholding for AIS-Based Vessel Trajectory Compression. IEEE Access 2019, 7, 150677–150692. [Google Scholar] [CrossRef]
- Lachos, M.; Kollios, G.; Gunopulos, D. Discovering similar multidimensional trajectories. In Proceedings of the l8th International Conference on Data Engineering, San Jose, CA, USA, 26 February–1 March 2002; pp. 673–684. [Google Scholar] [CrossRef]
- Fernandes, C.; Kiwi, M. Repetition-free longest common subsequence of random sequences. Discret. Appl. Math. 2016, 210, 75–87. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Ng, R. On The Marriage of Lp-norms and Edit Distance. In Proceedings of the 30th International Conference on Very Large Data Bases, VLDB, Toronto, ON, Canada, 31 August 2004–3 September 2004; pp. 792–803. [Google Scholar] [CrossRef]
- Chen, L.; Özsu, M.T.; Oria, V. Robust and fast similarity search for moving object trajectories. In Proceedings of the 24th ACM International Conference on Management of Data, Baltimore, MD, USA, 14–16 June 2005; ACM: New York, NY, USA, 2005; pp. 491–502. [Google Scholar] [CrossRef]
- Zhai, W.; Bai, X.; Peng, Z.R.; Gu, C. From edit distance to augmented space-time-weighted edit distance: Detecting and clustering patterns of human activities in Puget Sound region. J. Transp. Geogr. 2019, 78, 41–55. [Google Scholar] [CrossRef]
- Zhu, J.; Hu, B.; Shao, H. Trajectory similarity measure based on multiple movement features. Geomat. Inf. Sci. Wuhan Univ. 2017, 42, 1703–1710. [Google Scholar] [CrossRef]
- Wang, Y.; Qin, K.; Chen, Y.; Zhao, P. Detecting Anomalous Trajectories and Behavior Patterns Using Hierarchical Clustering from Taxi GPS Data. ISPRS Int. J. Geo-Inf. 2018, 7, 25. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Chen, P.; Chen, L.; Mou, J. Ship ais trajectory clustering: An hdbscan-based approach. J. Mar. Sci. Eng. 2021, 9, 566. [Google Scholar] [CrossRef]
- Ma, W.; Wu, Z.; Yang, J.; Li, W. Vessel Motion Pattern Recognition Based on One-Way Distance and Spectral Clustering Algorithm. In Proceedings of the Algorithms and Architectures for Parallel Processing, ICA3PP 2014, Dalian, China, 24–27 August 2014; Springer: Cham, Switzerland; pp. 461–469. [Google Scholar] [CrossRef]
- Lin, B.; Su, J. One way distance: For shape based similarity search of moving object trajectories. GeoInformatica 2008, 12, 117–142. [Google Scholar] [CrossRef]
- Chen, P.; Xu, K.; Li, G.; Wan, J. A Segmented Template Optimization Using the Fréchet Distance. In Proceedings of the 9th International Symposium on Computational Intelligence and Design, Hangzhou, China, 10–11 December 2016; pp. 414–417. [Google Scholar] [CrossRef]
- Shahbaz, K. Applied Similarity Problems Using Fréchet Distance. Doctoral Dissertation, Carleton University, Ottawa, ON, Canada, 2013. [Google Scholar]
- Sharma, K.P.; Pooniaa, R.C.; Sunda, S. Map matching algorithm: Curve simplification for Fréchet distance computing and precise navigation on road network using RTKLIB. Clust. Comput 2018, 22, 13351–13359. [Google Scholar] [CrossRef]
- Cao, J.; Liang, M.H.; Li, Y.; Chen, J.W.; Li, H.H.; Liu, R.W.; Liu, J.X. PCA-based hierarchical clustering of AIS trajectories with automatic extraction of clusters. In Proceedings of the 2018 IEEE 3rd International Conference on Big Data Analysis (ICBDA), Shanghai, China, 9–12 March 2018; pp. 448–452. [Google Scholar] [CrossRef]
- Roberts, S.A. A shape-based local spatial association measure (LISShA): A case study in maritime anomaly detection. Geogr. Anal. 2019, 51, 403–425. [Google Scholar] [CrossRef]
- Zaman, M.B.; Kobayashi, E.; Wakabayashi, N.; Maimun, A. Risk of navigation for marine traffic in the Malacca Strait using AIS. Procedia Earth Planet. Sci. 2015, 14, 33–40. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Su, H.; Zheng, K.; Sadiq, S.; Zhou, X. An effectiveness study on trajectory similarity measures. In Proceedings of the Twenty-Fourth Australasian Database Conference, Adelaide, Australia, 29 January–1 February 2013; Australian Computer Society: Darlinghurst, Australia; pp. 13–22. [Google Scholar]
- Valsamis, A.; Tserpes, K.; Zissis, D.; Anagnostopoulos, D.; Varvarigou, T. Employing traditional machine learning algorithms for big data streams analysis: The case of object trajectory prediction. J. Syst. Softw. 2017, 127, 249–257. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.K.; Shi, G.Y.; Liu, Z.J.; Zhao, Z.W.; Wu, Z.L. Data-driven based automatic maritime routing from massive AIS trajectories in the face of disparity. Ocean Eng. 2018, 155, 240–250. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter (km) | LCSS | EDR | HC-SIM | WDN-SIM |
|---|---|---|---|---|
| Distance threshold (km) | 2 | 2 | - 1 | - |
| Minimum cell length (km) | - | - | 0.75 | - |
| Cell length (L) (km) | - | - | - | 2 |
| Maximum neighborhood level (k) | - | - | - | 2 |
| Direction | DTW 1 | EDR | LCSS | Fréchet 1 | Hausdorff 1 | OWD 1 | HC-SIM | WDN-SIM |
|---|---|---|---|---|---|---|---|---|
| Same | 1468.933 | 0.593 | 0.652 | 38.764 | 36.379 | 4.580 | 0.785 | 0.479 |
| Perpendicular | 22,980.964 | 0.012 | 0.014 | 142.549 | 97.059 | 51.139 | 0.112 | 0.005 |
| Opposite | 30,262.603 | 0.009 | 0.014 | 197.429 | 36.379 | 4.577 | 0.787 | −0.453 |
| Cell Length (km) | |||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |
| Trajectory point compression rate (%) | 28 | 71 | 76 | 82 | 87 |
| Feature point missing rate (%) | 3 | 10 | 17 | 29 | 38 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nie, P.; Chen, Z.; Xia, N.; Huang, Q.; Li, F. Trajectory Similarity Analysis with the Weight of Direction and k-Neighborhood for AIS Data. ISPRS Int. J. Geo-Inf. 2021, 10, 757. https://doi.org/10.3390/ijgi10110757
Nie P, Chen Z, Xia N, Huang Q, Li F. Trajectory Similarity Analysis with the Weight of Direction and k-Neighborhood for AIS Data. ISPRS International Journal of Geo-Information. 2021; 10(11):757. https://doi.org/10.3390/ijgi10110757
Chicago/Turabian StyleNie, Pin, Zhenjie Chen, Nan Xia, Qiuhao Huang, and Feixue Li. 2021. "Trajectory Similarity Analysis with the Weight of Direction and k-Neighborhood for AIS Data" ISPRS International Journal of Geo-Information 10, no. 11: 757. https://doi.org/10.3390/ijgi10110757
APA StyleNie, P., Chen, Z., Xia, N., Huang, Q., & Li, F. (2021). Trajectory Similarity Analysis with the Weight of Direction and k-Neighborhood for AIS Data. ISPRS International Journal of Geo-Information, 10(11), 757. https://doi.org/10.3390/ijgi10110757