
Efficient IoT Data Management for Geological Disasters Based on Big Data-Turbocharged Data Lake Architecture





Abstract
:1. Introduction
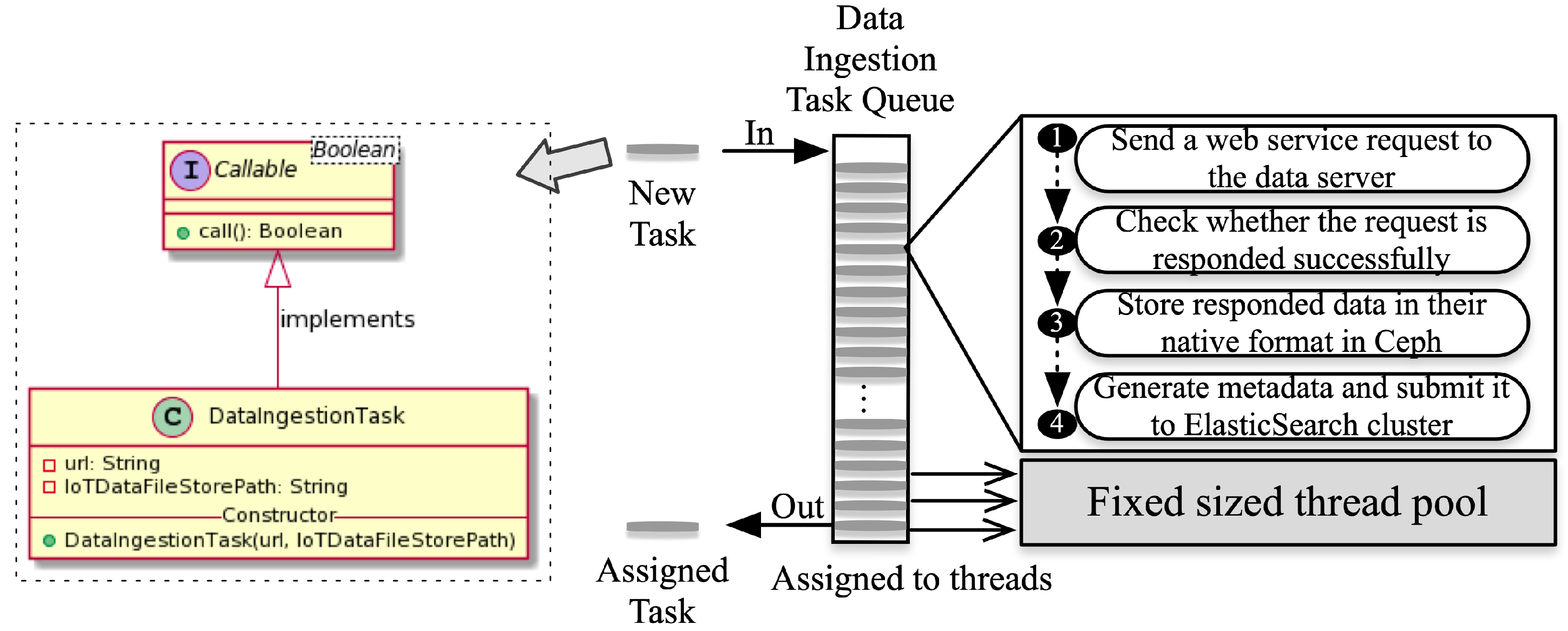
- We propose a multithreading parallel data ingestion method, which adopts a fixed-size thread pool, to enable fast data ingestion from IoT data repositories via web services leveraging the CPU level parallelism.
- We propose scalable, reliable, high-performance storage mechanisms for primarily ingested and processed IoT data in distributed environments, and provide fast IoT data access by building a distributed cache layer with Apache Alluxio.
- We design an ISO standard-based metadata model for both ingested and processed IoT datasets to realize IoT dataset discovery. Additionally, we provide a unified SQL-based interface for efficient IoT data exploration by taking advantage of the excellent processing capability of Apache Spark.
- We implement a prototype system, turbocharged by existing big data technologies, for IoT data management following the data lake architecture and adopt real IoT data repositories provided by the Shenzhen Municipal Government Data Open Platform to evaluate the performance of the proposed system.
2. System Design
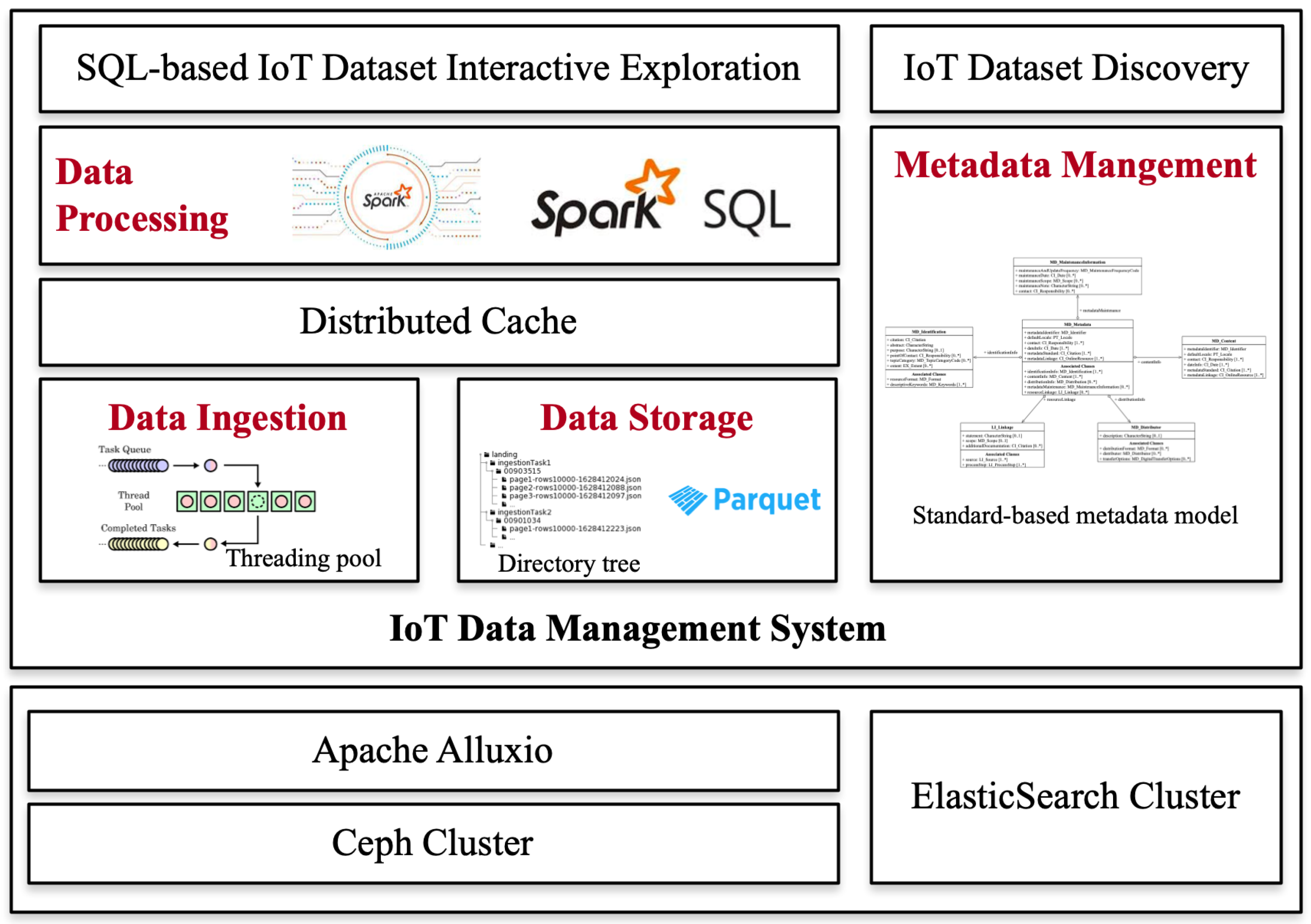
2.1. Overview
2.2. Data Ingestion
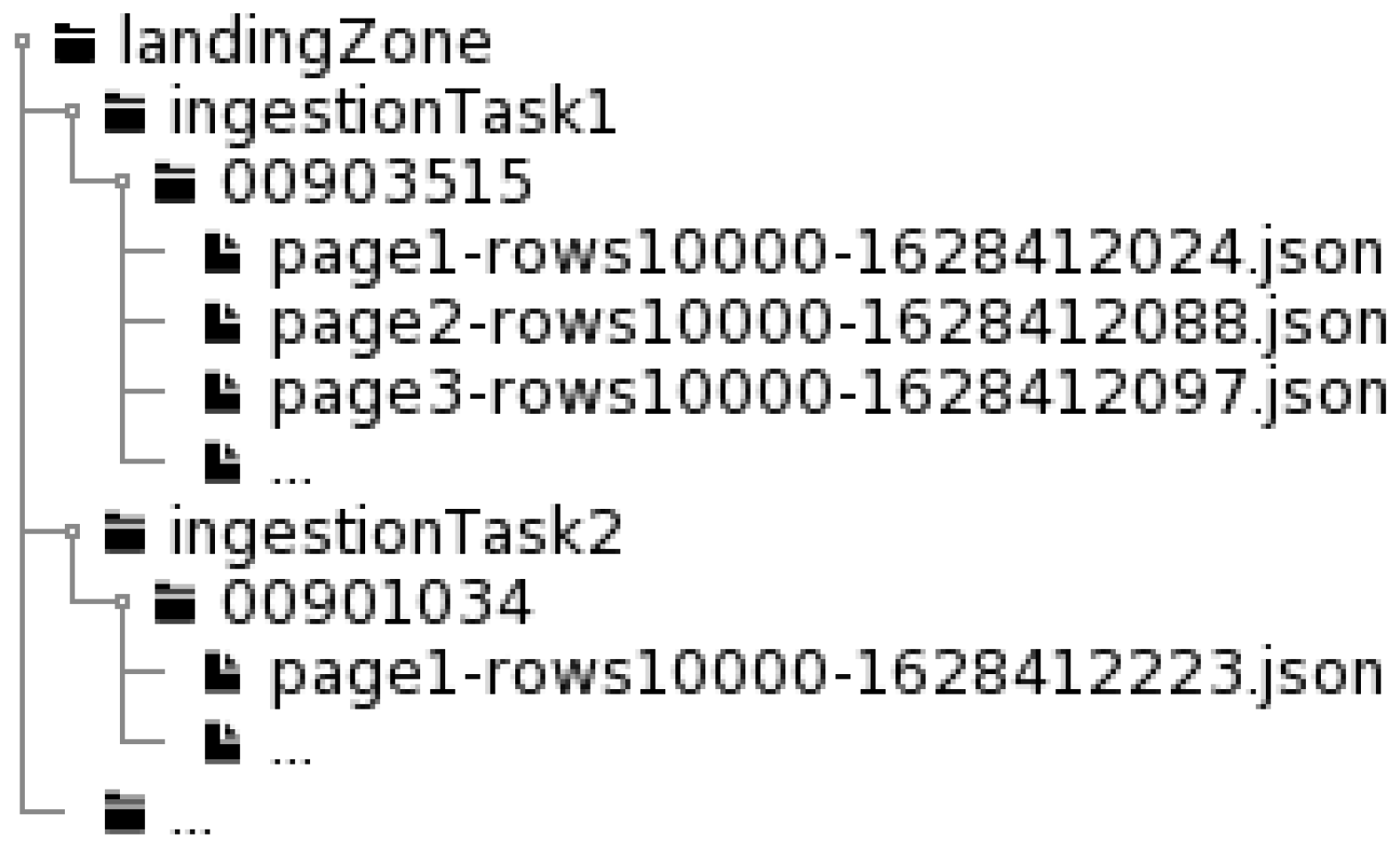
2.3. Data Storage
2.4. Spark SQL-Based Data Processing
| // loading data to generate DataSet object Dataset<Row> dataSet = sqlContext.read() .format(‘‘json’’) .option(‘‘multiline’’, ‘‘true’’) .load(‘‘s3a://geolake/landing/ingestionTask1/00903515/*.json’’) // Create a temporal view for the DataSet dataSet.createOrReplaceTempView(‘‘datasetTV’’); |
| Dataset resultDS = sqlContext.sql(‘‘select * from dsTView where OBTID=‘G3558’’’); |
| resultDS.write() .partitionBy(‘‘OBTID’’) .parquet(‘‘s3a://geolake/productionZone/00903515.parquet’’) |
2.5. Metadata Management
3. Experiments
3.1. Settings
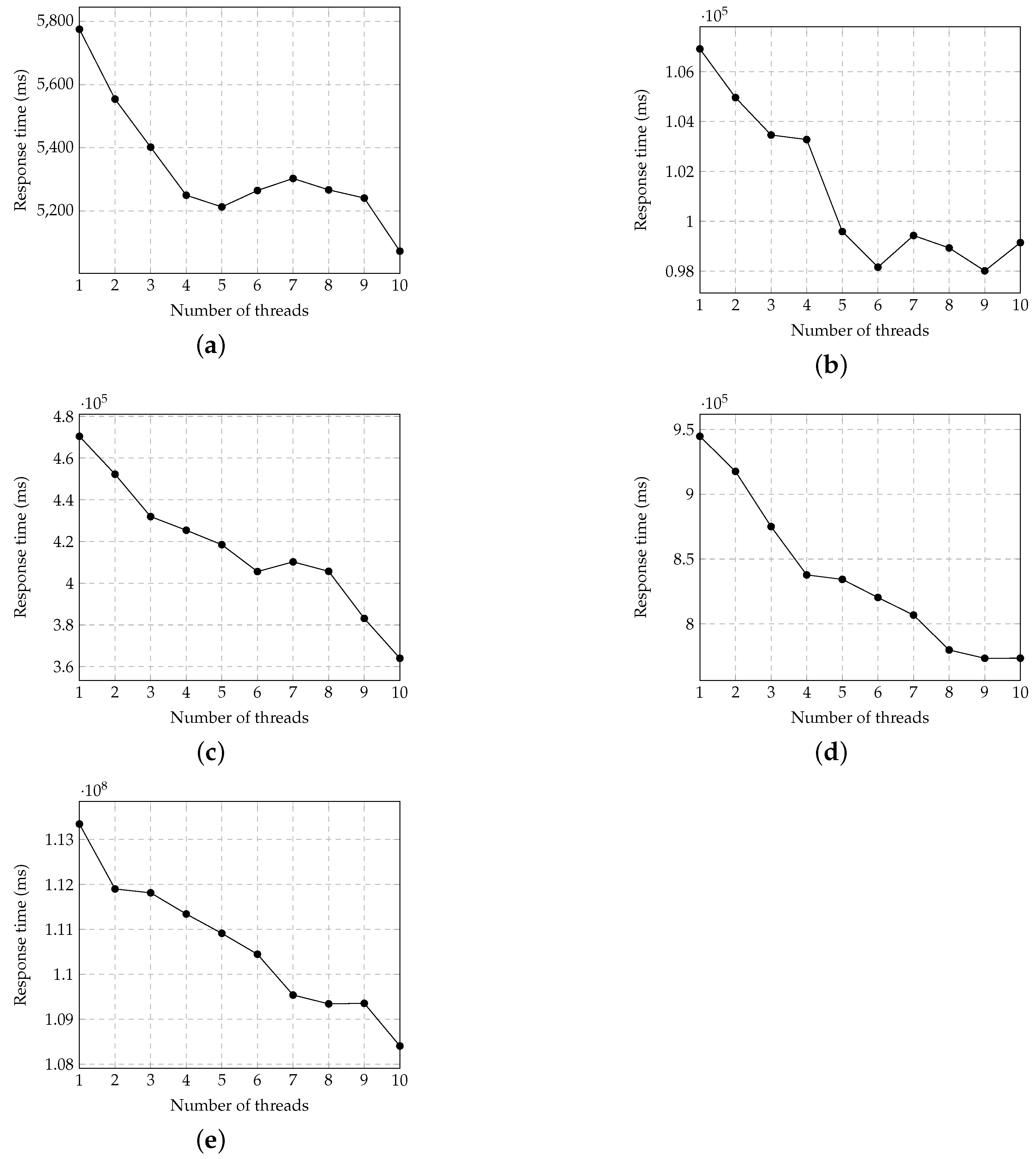
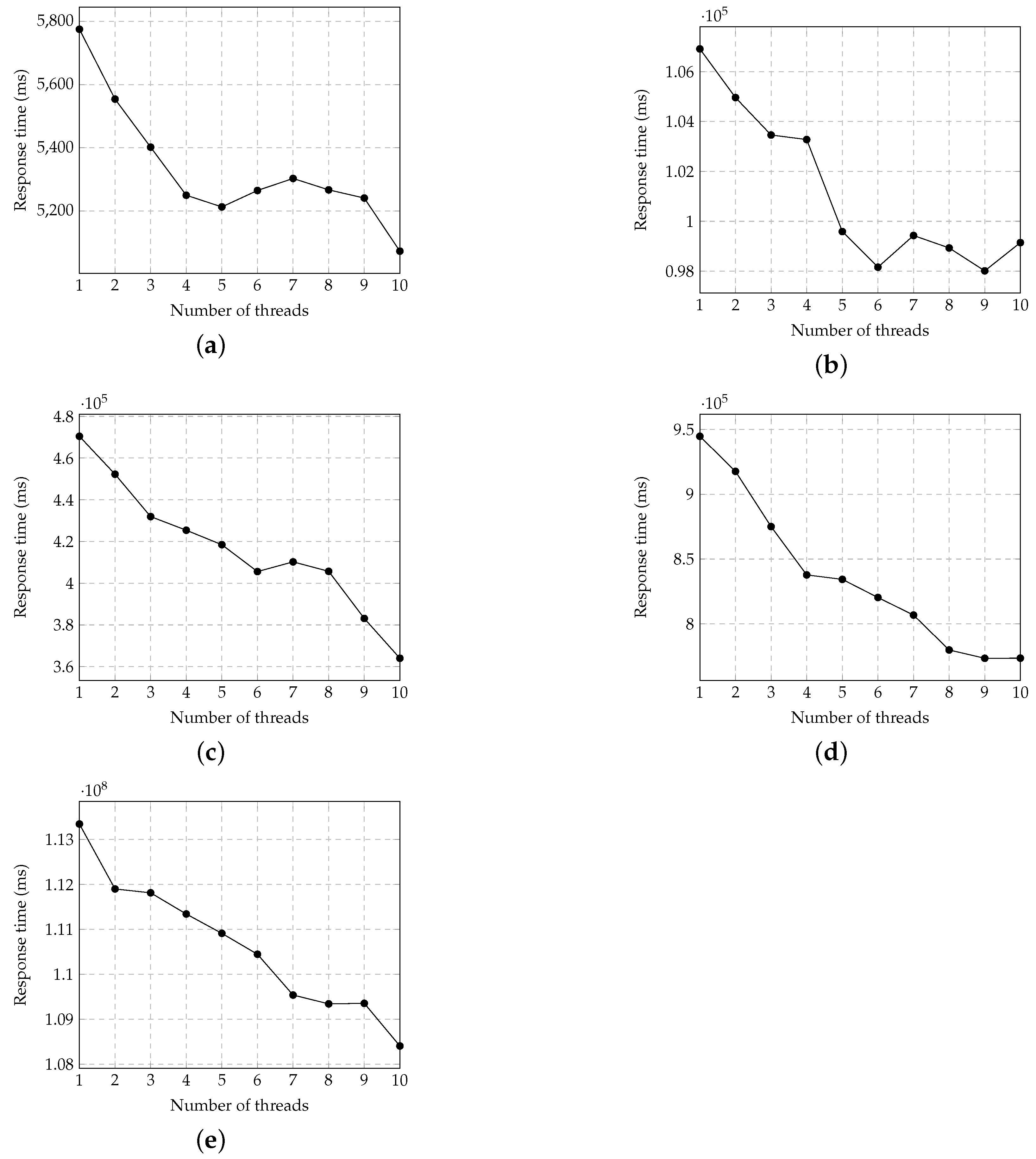
3.2. Evaluation on Multithreading Parallel Data Ingestion Approach
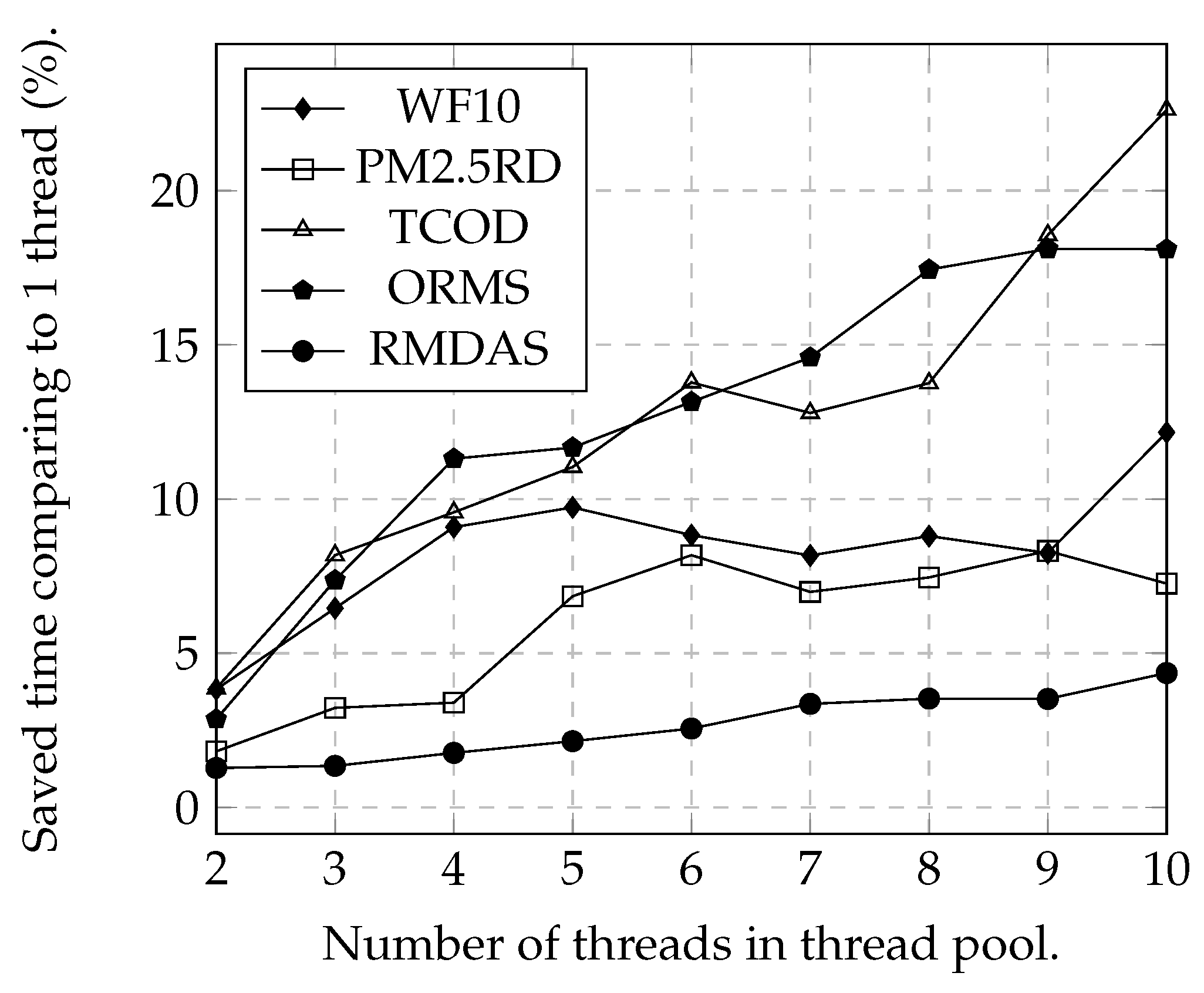
3.2.1. The Impact of the Thread Pool
3.2.2. Varying the Number of Threads
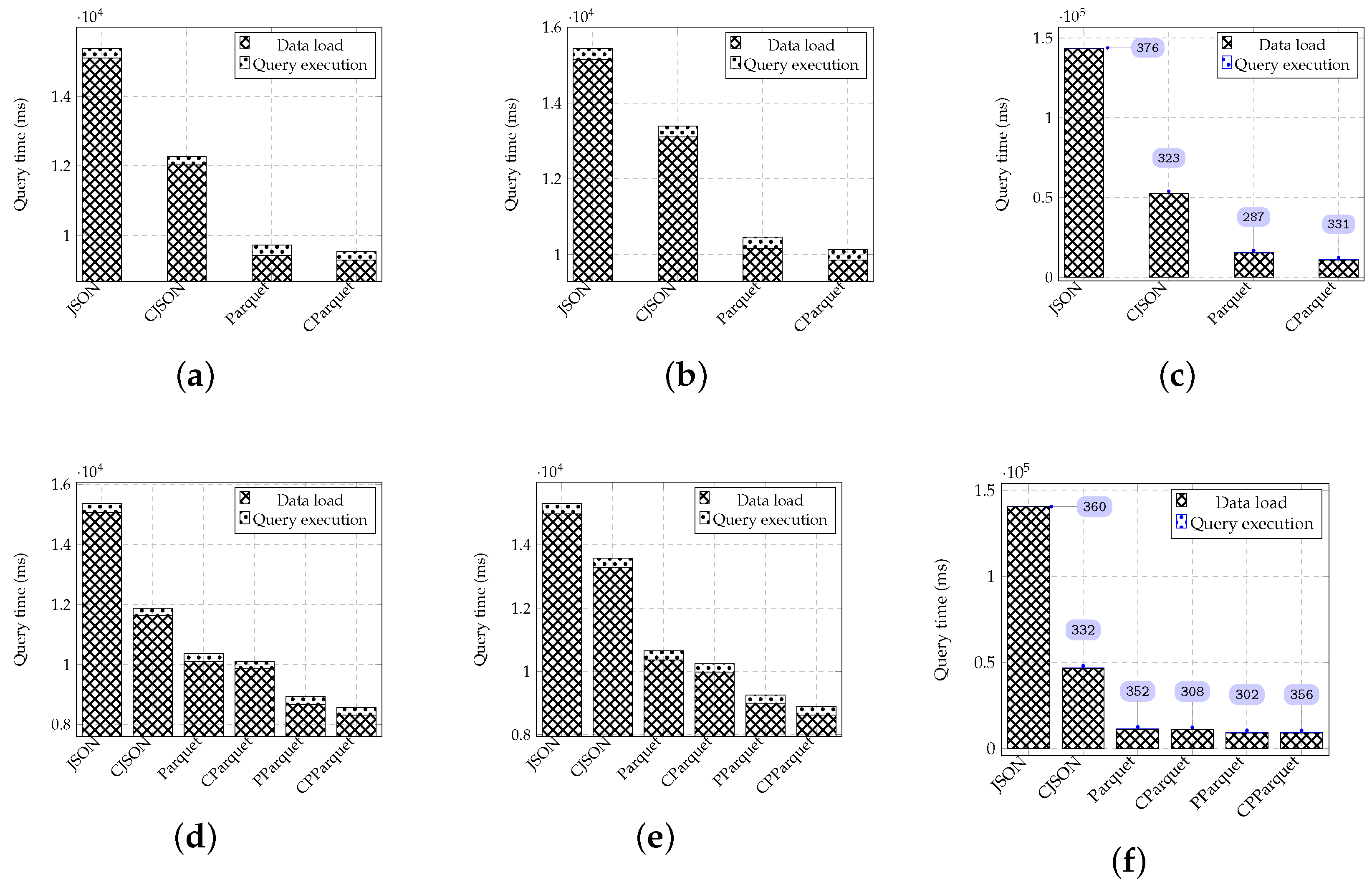
3.3. Evaluation on Parquet-Based IoT Data Storage
3.3.1. Storage Space Consumption
3.3.2. Evaluation of Efficiency on Different Query Scenarios
3.4. Evaluation on Apache Alluxio-Based Caching Strategy
4. Discussion
- The current data ingestion method adopts a thread pool, a CPU-level parallelism technique, and sends a bulk of web services (e.g., HTTP, FTP) to the IoT data server. This method has unsatisfactory performance when the data server limits the number of requests from the same machine. It can be observed from the experimental results that the reduction of IoT data ingestion time is flattened even if the number of threads in the thread pool is increased. To overcome this limitation, in our future works, we will consider first distributing data ingestion tasks to each machine in a cluster. Each machine applies the proposed multithreading parallel data ingestion method to further accelerate the data acquisition process.
- The current work lacks an interactive analysis platform for researchers to perform on-demand IoT data processing. In our future works, we will consider combining Jupyter with our proposed data lake-based IoT data management system to provide researchers with the ability to discover IoT datasets archived in either underlying Ceph or a distributed cache, so as to write an IoT data processing code with APIs provided by Apache Spark.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yu, M.; Yang, C.; Li, Y. Big Data in Natural Disaster Management: A Review. Geosciences 2018, 8, 165. [Google Scholar] [CrossRef] [Green Version]
- Zhao, C.; Lu, Z. Remote Sensing of Landslides—A Review. Remote Sens. 2018, 10, 279. [Google Scholar] [CrossRef] [Green Version]
- Akter, S.; Wamba, S.F. Big data and disaster management: A systematic review and agenda for future research. Ann. Oper. Res. 2019, 283, 939–959. [Google Scholar] [CrossRef] [Green Version]
- Khan, A.; Gupta, S.; Gupta, S.K. Multi-hazard disaster studies: Monitoring, detection, recovery, and management, based on emerging technologies and optimal techniques. Int. J. Disaster Risk Reduct. 2020, 47, 101642. [Google Scholar] [CrossRef]
- Mei, G.; Xu, N.; Qin, J.; Wang, B.; Qi, P. A Survey of Internet of Things (IoT) for Geohazard Prevention: Applications, Technologies, and Challenges. IEEE Internet Things J. 2020, 7, 4371–4386. [Google Scholar] [CrossRef]
- Piccialli, F.; Cuomo, S.; Bessis, N.; Yoshimura, Y. Data Science for the Internet of Things. IEEE Internet Things J. 2020, 7, 4342–4346. [Google Scholar] [CrossRef]
- Siow, E.; Tiropanis, T.; Hall, W. Analytics for the Internet of Things: A Survey. ACM Comput. Surv. 2018, 51, 74:1–74:36. [Google Scholar] [CrossRef] [Green Version]
- Maritza, G.Z.A.; Esteban, T.C.; Israel, C.V.; León-Salas, W.D. Synchronization of chaotic artificial neurons and its application to secure image transmission under MQTT for IoT protocol. Nonlinear Dyn. 2021, 104, 4581–4600. [Google Scholar] [CrossRef]
- Li, Z.; Fang, L.; Sun, X.; Peng, W. 5G IoT-based geohazard monitoring and early warning system and its application. EURASIP J. Wirel. Commun. Netw. 2021, 2021, 160. [Google Scholar] [CrossRef]
- Foumelis, M.; Papazachos, C.; Papadimitriou, E.; Karakostas, V.; Ampatzidis, D.; Moschopoulos, G.; Kostoglou, A.; Ilieva, M.; Minos-Minopoulos, D.; Mouratidis, A.; et al. On rapid multidisciplinary response aspects for Samos 2020 M7.0 earthquake. Acta Geophys. 2021, 69, 1–24. [Google Scholar] [CrossRef]
- Ramson, S.R.J.; Leon-Salas, W.D.; Brecheisen, Z.; Foster, E.J.; Johnston, C.T.; Schulze, D.G.; Filley, T.; Rahimi, R.; Soto, M.J.C.V.; Bolivar, J.A.L.; et al. A Self-Powered, Real-Time, LoRaWAN IoT-Based Soil Health Monitoring System. IEEE Internet Things J. 2021, 8, 9278–9293. [Google Scholar] [CrossRef]
- Bansal, M.; Chana, I.; Clarke, S. A Survey on IoT Big Data: Current Status, 13 V’s Challenges, and Future Directions. ACM Comput. Surv. 2021, 53, 131:1–131:59. [Google Scholar] [CrossRef]
- Nikoui, T.S.; Rahmani, A.M.; Balador, A.; Javadi, H.H.S. Internet of Things architecture challenges: A systematic review. Int. J. Commun. Syst. 2021, 34. [Google Scholar] [CrossRef]
- Wang, C.; Huang, X.; Qiao, J.; Jiang, T.; Rui, L.; Zhang, J.; Kang, R.; Feinauer, J.; McGrail, K.A.; Wang, P.; et al. Apache IoTDB: Time-Series Database for Internet of Things. Proc. VLDB Endow. 2020, 13, 2901–2904. [Google Scholar] [CrossRef]
- Ta-Shma, P.; Akbar, A.; Gerson-Golan, G.; Hadash, G.; Carrez, F.; Moessner, K. An Ingestion and Analytics Architecture for IoT Applied to Smart City Use Cases. IEEE Internet Things J. 2018, 5, 765–774. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, Q.H.; Dang, Q.; Pham, C.; Nguyen, T.; Nguyen, H.; Setty, A.; Le, T. Developing an Architecture for IoT Interoperability in Healthcare: A Case Study of Real-time SpO2 Signal Monitoring and Analysis. In Proceedings of the IEEE International Conference on Big Data, Big Data 2020, Atlanta, GA, USA, 10–13 December 2020; Wu, X., Jermaine, C., Xiong, L., Hu, X., Kotevska, O., Lu, S., Xu, W., Aluru, S., Zhai, C., Al-Masri, E., et al., Eds.; IEEE: Piscataway, NJ, USA, 2020; pp. 3394–3403. [Google Scholar] [CrossRef]
- Madera, C.; Laurent, A. The next information architecture evolution: The data lake wave. In Proceedings of the 8th International Conference on Management of Digital EcoSystems, MEDES 2016, Biarritz, France, 1–4 November 2016; Chbeir, R., Agrawal, R., Biskri, I., Eds.; 2016; pp. 174–180. [Google Scholar] [CrossRef]
- Skluzacek, T.J.; Chard, K.; Foster, I.T. Klimatic: A Virtual Data Lake for Harvesting and Distribution of Geospatial Data. In Proceedings of the 1st Joint International Workshop on Parallel Data Storage and data Intensive Scalable Computing Systems, PDSW-DISCS@SC 2016, Salt Lake, UT, USA, 14 November 2016; pp. 31–36. [Google Scholar] [CrossRef]
- Mehmood, H.; Gilman, E.; Cortés, M.; Kostakos, P.; Byrne, A.; Valta, K.; Tekes, S.; Riekki, J. Implementing Big Data Lake for Heterogeneous Data Sources. In Proceedings of the 35th IEEE International Conference on Data Engineering Workshops, ICDE Workshops 2019, Macao, China, 8–12 April 2019; pp. 37–44. [Google Scholar] [CrossRef] [Green Version]
- Nargesian, F.; Zhu, E.; Miller, R.J.; Pu, K.Q.; Arocena, P.C. Data Lake Management: Challenges and Opportunities. Proc. VLDB Endow. 2019, 12, 1986–1989. [Google Scholar] [CrossRef]
- Cuzzocrea, A. Big Data Lakes: Models, Frameworks, and Techniques. In Proceedings of the IEEE International Conference on Big Data and Smart Computing, BigComp 2021, Jeju Island, Korea, 17–20 January 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Weil, S.A.; Brandt, S.A.; Miller, E.L.; Long, D.D.E.; Maltzahn, C. Ceph: A Scalable, High-Performance Distributed File System. In Proceedings of the 7th Symposium on Operating Systems Design and Implementation (OSDI ’06), Seattle, WA, USA, 6–8 November 2006; Bershad, B.N., Mogul, J.C., Eds.; 2006; pp. 307–320. [Google Scholar]
- Vohra, D. Apache parquet. In Practical Hadoop Ecosystem; Springer: Berlin/Heidelberg, Germany, 2016; pp. 325–335. [Google Scholar]
- Li, H. Alluxio: A Virtual Distributed File System. Ph.D. Thesis, University of California, Berkeley, CA, USA, 2018. [Google Scholar]
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J.; et al. Apache Spark: A unified engine for big data processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
- Jin, H.Y.; Jung, E.; Lee, D. High-performance IoT streaming data prediction system using Spark: A case study of air pollution. Neural Comput. Appl. 2020, 32, 13147–13154. [Google Scholar] [CrossRef]
- Armbrust, M.; Xin, R.S.; Lian, C.; Huai, Y.; Liu, D.; Bradley, J.K.; Meng, X.; Kaftan, T.; Franklin, M.J.; Ghodsi, A.; et al. Spark SQL: Relational Data Processing in Spark. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Melbourne, VIC, Australia, 31 May–4 June 2015; Sellis, T.K., Davidson, S.B., Ives, Z.G., Eds.; 2015; pp. 1383–1394. [Google Scholar] [CrossRef]
- Schiavio, F.; Bonetta, D.; Binder, W. Towards dynamic SQL compilation in Apache Spark. In Proceedings of the Programming’20: 4th International Conference on the Art, Science, and Engineering of Programming, Porto, Portugal, 23–26 March 2020; Aguiar, A., Chiba, S., Boix, E.G., Eds.; 2020; pp. 46–49. [Google Scholar] [CrossRef]
- Zhang, Y.; Ives, Z.G. Juneau: Data Lake Management for Jupyter. Proc. VLDB Endow. 2019, 12, 1902–1905. [Google Scholar] [CrossRef]
- Cheng, Y.; Liu, F.C.; Jing, S.; Xu, W.; Chau, D.H. Building Big Data Processing and Visualization Pipeline through Apache Zeppelin. In Proceedings of the 23–26 Practice and Experience on Advanced Research Computing, PEARC 2018, Pittsburgh, PA, USA, 22–26 July 2018; Sanielevici, S., Ed.; 2018; pp. 57:1–57:7. [Google Scholar] [CrossRef]
- Hai, R.; Geisler, S.; Quix, C. Constance: An Intelligent Data Lake System. In Proceedings of the 2016 International Conference on Management of Data, SIGMOD Conference 2016, San Francisco, CA, USA, 26 June–1 July 2016; Özcan, F., Koutrika, G., Madden, S., Eds.; 2016; pp. 2097–2100. [Google Scholar] [CrossRef]
- Malysiak-Mrozek, B.; Stabla, M.; Mrozek, D. Soft and Declarative Fishing of Information in Big Data Lake. IEEE Trans. Fuzzy Syst. 2018, 26, 2732–2747. [Google Scholar] [CrossRef]
- Brodeur, J.; Coetzee, S.; Danko, D.M.; Garcia, S.; Hjelmager, J. Geographic Information Metadata—An Outlook from the International Standardization Perspective. ISPRS Int. J. Geo-Inf. 2019, 8, 280. [Google Scholar] [CrossRef] [Green Version]
- Beheshti, A.; Benatallah, B.; Nouri, R.; Chhieng, V.M.; Xiong, H.; Zhao, X. CoreDB: A Data Lake Service. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, CIKM 2017, Singapore, 6–10 November 2017; Lim, E., Winslett, M., Sanderson, M., Fu, A.W., Sun, J., Culpepper, J.S., Lo, E., Ho, J.C., Donato, D., Agrawal, R., et al., Eds.; 2017; pp. 2451–2454. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hostname and IP Address | Ceph 14.2.20 | Alluxio 2.3.0 | Spark 2.4.0 | ElasticSearch 7.6.0 |
|---|---|---|---|---|
| cslave1 10.3.1.11 | ✓ (monitor) | ✓ | ✓ | |
| cslave2 10.3.1.12 | ✓ (monitor) | ✓ | ✓ | |
| cslave3 10.3.1.13 | ✓ (monitor) | ✓ | ✓ | |
| cslave4 10.3.1.14 | ✓ | ✓ | ✓ | ✓ |
| cslave5 10.3.1.15 | ✓ | ✓ | ✓ | ✓ |
| cslave6 10.3.1.16 | ✓ | ✓ | ✓ | ✓ |
| cmaster 10.3.1.17 | ✓ | ✓ (master node) | ✓ (master node) |
| Dataset Name | Description | No. of Records | No. of Attributes per Record | Data Sources |
|---|---|---|---|---|
| WF101 | The weather forecast for the next ten days. | 61,881 | 18 | 1 |
| PM2.5RD2 | The PM 2.5 real time observation data. | 798,772 | 9 | 2 |
| TCOD3 | The tropical cyclone observation data. | 1,387,324 | 22 | 3 |
| ORMS4 | Observation data of regional meteorological observation station. | 2,738,519 | 10 | 4 |
| RMDAS5 | Real time meteorological monitoring data of automatic station. | 29,069,409 | 53 | 5 |
| Dataset | No. of Records | (ms) | (ms) | Speedup Ratio (%) |
|---|---|---|---|---|
| WF10 | 61,881 | 7074 | 5775 | 22.49 |
| PM2.5RD | 798,772 | 151,625 (>2 min) | 106,906 (>1 min) | 41.83 |
| TCOD | 1,387,324 | 529,038 (>8 min) | 422,860 (>7 min) | 25.11 |
| ORMS | 2,738,519 | 1,648,214 (>27 min) | 944,633 (>15 min) | 74.48 |
| RMDAS | 29,069,409 | 114,884,844 (>31 h 54 min) | 113,344,482 (>31 h 29 min) | 1.36 |
| Dataset | No. of Records | No. of JSON Files | (MB) | (MB) | Effectiveness (%) | (s) |
|---|---|---|---|---|---|---|
| WF10 1 | 61,881 | 7 | 20.74 | 0.97 | 95.32 | 1.954 |
| PM2.5RD 2 | 798,772 | 80 | 119.01 | 29.56 | 75.16 | 2.770 |
| TCOD 3 | 1,387,324 | 139 | 491.68 | 53.46 | 89.13 | 8.889 |
| ORMS 4 | 2,738,519 | 274 | 372.93 | 70.62 | 81.06 | 9.456 |
| RMDAS 5 | 29,069,409 | 2907 | 12,998.43 | 1626.09 | 87.49 | 95.640 |
| Dataset | SQL | / | Description |
|---|---|---|---|
| TCOD | Q1. select * from TCOD where WIND = 20 | 14562/1387324 | ISSUETYPE and WIND refer to the observation site identifier and the forecasting wind speed at the current moment, respectively. |
| Q2. select * from TCOD where ISSUETYPE = ’PGTW’ and WIND = 20 | 9/1387324 | ||
| ORMS | Q3. select * from ORMS where T = 150 | 6615/2738519 | OBTID and T refer to the observation site identifier and the current temperature, respectively. |
| Q4. select * from ORMS where OBTID = ’G3558’ and T = 150 | 128/2738519 | ||
| RMDAS | Q5. select * from RMDAS where U > 90 | 3584510/29069409 | OBTID and U refer to the observation site identifier and relative humidity, respectively. |
| Q6. select * from RMDAS where OBTID = ’G3539’ and U > 90 | 46923/29069409 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Fan, J.; Deng, Z.; Yan, J.; Li, J.; Wang, L. Efficient IoT Data Management for Geological Disasters Based on Big Data-Turbocharged Data Lake Architecture. ISPRS Int. J. Geo-Inf. 2021, 10, 743. https://doi.org/10.3390/ijgi10110743
Huang X, Fan J, Deng Z, Yan J, Li J, Wang L. Efficient IoT Data Management for Geological Disasters Based on Big Data-Turbocharged Data Lake Architecture. ISPRS International Journal of Geo-Information. 2021; 10(11):743. https://doi.org/10.3390/ijgi10110743
Chicago/Turabian StyleHuang, Xiaohui, Junqing Fan, Ze Deng, Jining Yan, Jiabao Li, and Lizhe Wang. 2021. "Efficient IoT Data Management for Geological Disasters Based on Big Data-Turbocharged Data Lake Architecture" ISPRS International Journal of Geo-Information 10, no. 11: 743. https://doi.org/10.3390/ijgi10110743
APA StyleHuang, X., Fan, J., Deng, Z., Yan, J., Li, J., & Wang, L. (2021). Efficient IoT Data Management for Geological Disasters Based on Big Data-Turbocharged Data Lake Architecture. ISPRS International Journal of Geo-Information, 10(11), 743. https://doi.org/10.3390/ijgi10110743