FumeBot: A Deep Convolutional Neural Network Controlled Robot


Abstract
1. Introduction
2. Neural Network Considerations
2.1. Finding a Deep Neural Network for the Application
2.2. Neural Network Application Solution
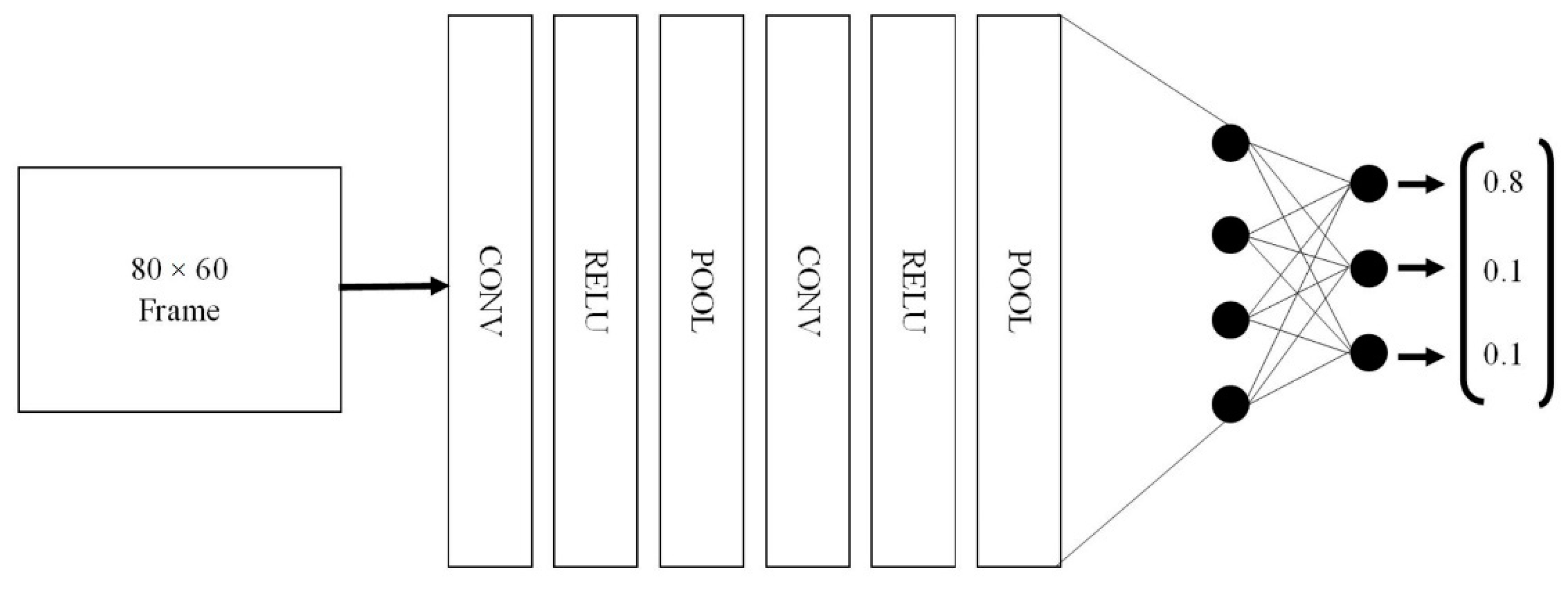
2.3. Setting up the Convolutional Neural Network
- Input Layer—The input layer takes in the RGB or grayscale image in the width, height, and depth format, which is a 3D input and will change according to the image size.
- Convolution Layer—The convolutional layer consists of a set of learnable filters. These filters are spatially small and will only look at a specific region of the image called the receptive field. The filter slides over the image pixels, producing a value that represents whether a certain feature exists in that field. The number of filters is decided by the user with each filter learning to look for a particular feature in the current receptive field. To reduce the number of parameters, a concept called parameter sharing is used whereby the weights used to detect a feature at one location is used at other locations.
- ReLU Layer—The output of the convolution layer is passed through the ReLU layer, which introduces non-linearity into the network, the output of which is a stack of 2D activation maps of where the relevant features are in the image.
- Pooling Layer—The pooling layer is used to reduce the parameter count and can also help with reducing overfitting. The pooling operation is done on each of the individual depth slices separately. For pooling layers, maxpooling is used in which the values that lie in the spatial extent is compared with each other and the maximum value is selected as the pooled value.
- Fully Connected Layer—This is the last layer of the network and is used to compute the class score for classification. Before this is done, the output from the last convolutional layer is converted to a format that can be given to the fully connected layer. The activation function used in this layer is normally a sigmoid or tanh function, and dropouts are used to reduce overfitting of the network to the data. The final output neurons of this layer are activated using the softmax function, which gives the class probability distribution.
3. Constructing the Deep Convolutional Neural Network Controller
3.1. Hardware Implementation
3.2. Neural Network Architecture
3.3. Training Datasets
- number of layers (convolutional or fully connected layers)
- number of filters at each convolutional layer
- receptive field and stride size
- activation function for the layer
- input and output size of the network
- learning rate
- number of training epochs
- batch size.
3.4. Model Inference
4. Results and Discussion
4.1. Corridor Obstacle Avoidance Test
- If the obstacle was in the middle of the path in the corridor (Figure 4a), the neural network had a hard time navigating around it. Initially the obstacle was successfully avoided, but as the wall became the dominant feature in the image, the resulting course correction caused the robot wheel to collide with the previously avoided obstacle.
- If the obstacles were placed off-center on one side (Figure 4b), then the network found it easier to navigate around because of the extra space available, enabling the network to find a path that avoided the obstacle and wall.
- When obstacles were placed off-center but were placed on opposite sides from the middle (Figure 4c), the neural network navigation avoided the first obstacle, but when the second obstacle came into view, occasionally the network immediate applied a course correction causing the wheel to collide with the first obstacle. On most occasions, however, the robot applied the course correction when the second obstacle was closer and after clearing the first obstacle.
- The robot was able to reorient itself if placed at an angle of 45 degrees to the wall, where the robot predominantly chose the direction that pointed itself to the obstacle course. However, if the robot was placed at 90 degrees to the wall, either a left or right turn was chosen randomly.
- When collecting the training data, in order to make it obvious to the neural network that the obstacles needed to be avoided, the robot was intentionally driven close to the obstacles before navigating around it. This was learned by the network, and as a result, the robot moved toward the obstacle first before trying to avoid them. If the obstacle was moved, the robot began to follow it. Such user biases should not be introduced when collecting the data.
- When allowed to move through the corridor without the presence of any obstacles, the robot was able to travel quite smoothly. The neural network kept the robot in the middle of the corridor. Towards the end of the corridor, the robot tried to turn left because of the presence of the wall at the end.
- When the neural network was placed in an unfamiliar environment, where one of the walls was blue instead of white, the network avoided the obstacle but failed to avoid the blue wall and crashed into it. This points to the fact that the model had not generalized the wall as something to avoid and therefore maybe depended on the grayscale value of the colored wall. This can be caused due to overfitting on the dataset with the white wall as the background.
4.2. Lab Obstacle Avoidance Course
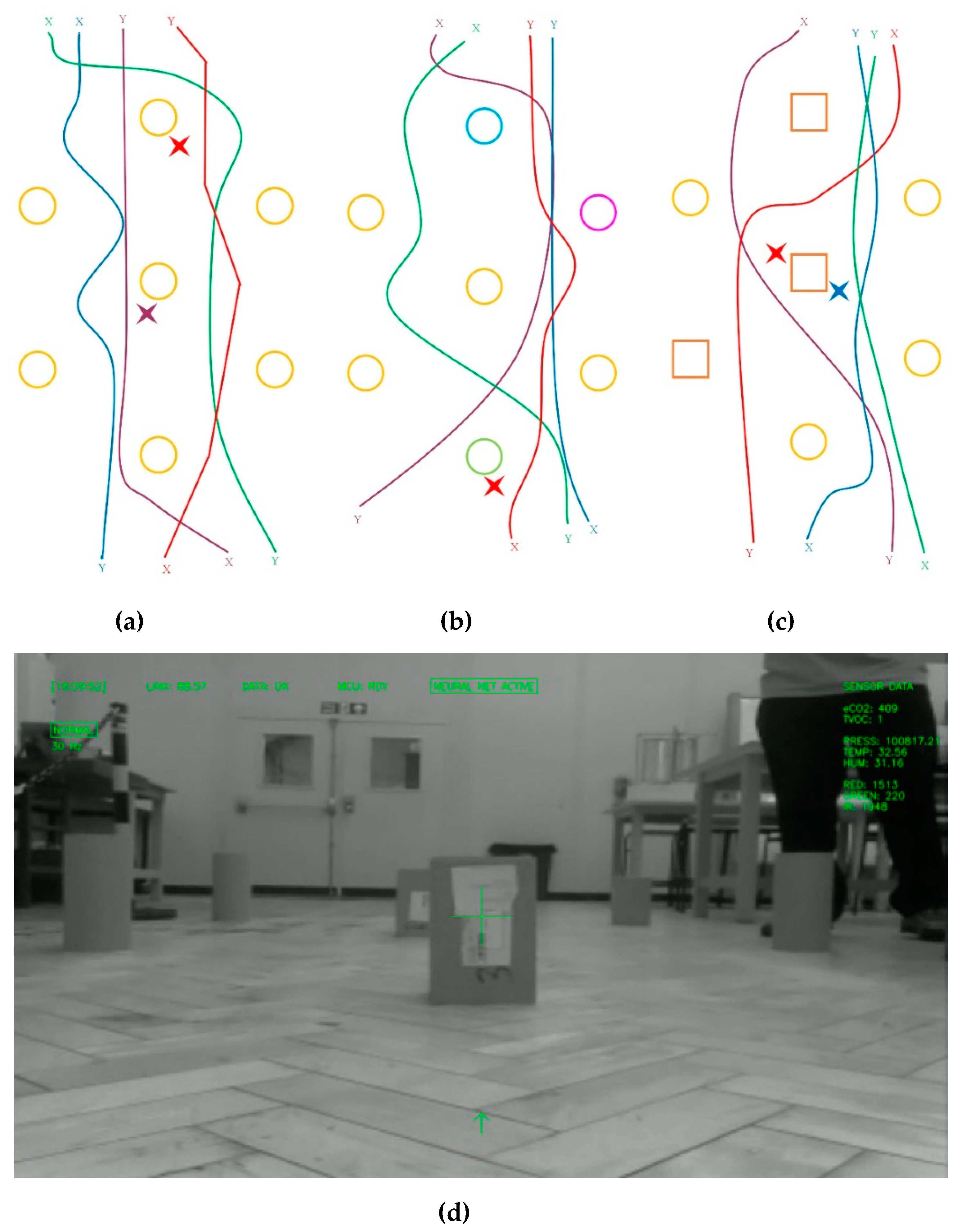
4.2.1. Normal Obstacle Course
- The neural network was able to avoid the obstacles and navigate around the obstacle course, predominantly without collisions. The collisions that did occur happened when the course corrections made by the neural network caused the obstacle to go out of the field of view, resulting in the wheel hitting the obstacle.
- The color obstacle course, in which some of the orange obstacles were replaced with dark and light colors, such as magenta, blue, or green, did not confuse the neural network. When the robot came close to these obstacles, the neural network chose an appropriate directional output to avoid it. As grayscale images were used for inference, this demonstrates that the intensity of obstacles does not matter and the contrast of the object was being recognized.
- The directional control keys were chosen by the robot in such a way as to keep it within the obstacle course without exiting it, even if no clear bounding walls were provided. This demonstrates that the network appeared to use the obstacles as navigational waypoints to keep the robot within the course and was not just simply demonstrating a collision avoidance random walk. To verify this, the distance between the obstacles at the edges were changed or these edge obstacles were removed completely and the robot was still able to exit the course.
- The way in which the direction was chosen for avoiding obstacles appears to be based on which side the obstacle lay from the center of the frame. For example, if the obstacle lay to the left of the frame the “forward-right” (W+D key combination) direction was chosen to avoid the obstacle completely. When driving the robot for creating the training dataset, it was not intentionally driven like this, however, a more systematic set of training data was required to see if this was a significant deduction of the neural network.
- When cylindrical obstacles were replaced by box-shaped obstacles (the surface of which contained stickers as shown in Figure 6d), the neural network still recognized them as obstacles and proceeded to navigate around them. Only on a few occasions did collisions occur with the boxes.
- Although the plots are smooth in Figure 6, in actuality, there was a high level of fluctuation in the way the robot chose the directional control, and as result, the actual trajectory of the robot showed a more pronounced jagged or saw-tooth like pattern. This problem can be associated to the fact that the neural network did not have any memory of the past action or state of the environment.
- Even when the robot was placed at different starting locations and orientations (but still pointing into the obstacle course), the robot entered the course and completed it successfully.
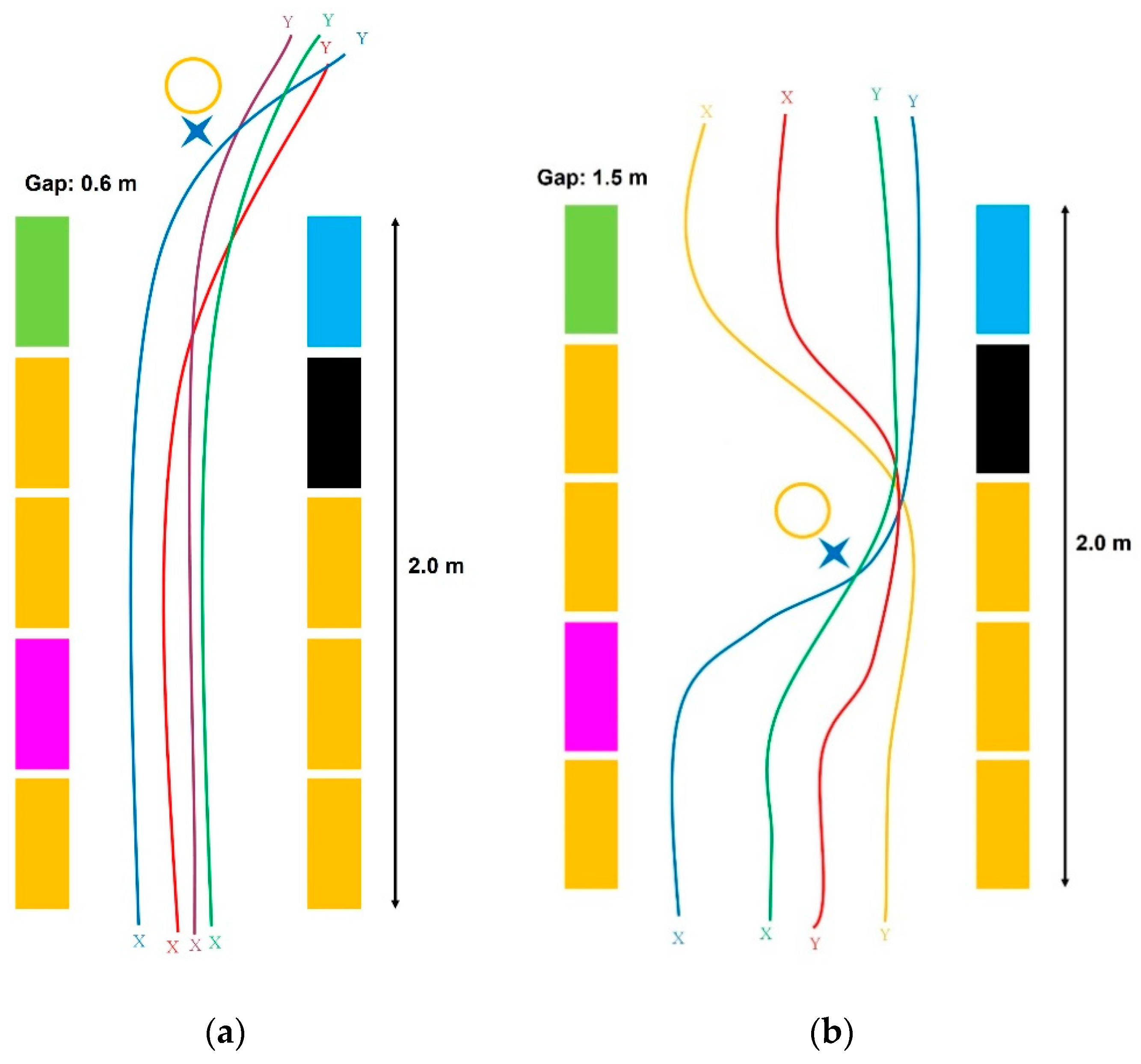
4.2.2. Gate Test
- The neural network was able to clear the gate most of the time provided that the gate was visible in the frame to some degree. When the robot was either placed with half of the gate showing or at an angle with obstacles and the gate in view, the robot successfully cleared the gate. All of these tests were conducted with a starting distance of at least 1.2 m. If the robot was placed too close to the obstacles, namely at a 0.6 m distance, the neural network failed to use the correct directional control keys, even if the gap came partially into view. This issue was attributed to the limited field of view of the camera.
- The obstacles were replaced with color ones to confuse the neural network controller but the results were the same as in the case where all the obstacles were orange. Again, if the robot was placed too close to the obstacles initially, a collision occurred.
- When the obstacles were laid on the ground, the robot managed to pass through the gate. However, on one occasion, the obstacle was seen by the neural network and collision was prevented but the robot veered off to the left and did not pass through the gate. This was probably because the camera had lost sight of the obstacle.
4.2.3. Hallway Test
- The neural network was able to keep the robot between the obstacles on either side even though the colored cylinders were used and this type of environment was not in the dataset. The direction control keys decided by the network still fluctuated, and therefore the actual robot trajectory was jagged and not as smooth as indicated in Figure 8.
- The obstacle placed at the end of the hallway course was added to provide an additional challenge, but as demonstrated, the robot chose to turn right each time. The exact cause for this remains unknown as the initial training dataset was balanced; the rights were almost equal to the lefts and forwards. It is speculated that some other object in the environment was causing the neural network to preferentially deviate to that side.
- With the obstacle in the middle of the hallway, the robot negotiated the course on most occasions, but as previously seen, due to losing sight of the obstacle, collisions between the wheel and the cylinder did occasionally occur.
4.2.4. Human Leg Avoidance
4.3. Memory Model
4.4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Designing Fumebot
Appendix A.1. Chassis


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Minimum | Typical | Maximum |
|---|---|---|---|
| Half axle (l) | - | 166 mm | - |
| Wheel radius (r) | - | 70 mm | - |
| 1 | 0.20 ms−1 | - | 0.30 ms−1 |
| 1 | 45°s−1 | - | 75°s−1 |
| Turn radius (R) 2 | - | 332 mm | - |
| Stepper motor allowed speed 1 | 27 rpm | - | 41 rpm |
| Steps done per command | - | 50 steps | - |
Appendix A.2. Sensors and Communications
- a MAX30105 particle sensor (Mouser Electronics, Mansfield, TX, US) used to detect smoke particles in the atmosphere, a CCS811 metal oxide (MOX) gas sensor (Mouser Electronics, Mansfield, TX, USA) used to detect the presence of equivalent carbon dioxide (eCO2) and total volatile organic compounds (TVOC) in the atmosphere, and a BME280 environmental sensor (Mouser Electronics, Mansfield, TX, USA) used to determine temperature, pressure, and relative humidity readings. The data from the BME280 is also used to compensate the CCS811 sensor. All these sensors are connected to an Arduino and use the I2C (inter-integrated circuit) bus for communication.
- a FLIR Lepton 3 camera (Digi-Key Corporation, Thief River Falls, MN, USA) provides a thermal view of the environment. Communication is via SPI (serial peripheral interface) to the Raspberry Pi at 9 frames per second and a resolution of 160 pixels by 120 pixels. In principle, this camera could be used as the data stream for the neural network; however, in practice, it was found that communication with this device was lost after 5 to 10 min of operation due to the loss of synchronization. It was therefore only used to provide snapshots of the environment rather than a continuous video stream.
- a Raspberry Pi Camera v1.3 (The Pi Hut, Haverhill, UK) provides a visible view of the environment. The camera is connected to the Raspberry Pi using a CSI (camera serial interface) and with a 5 MP resolution at 30 Hz, the video quality is acceptable for this application. Ultimately, this data is processed on a laptop and therefore, to prevent problems with video feed lags, the raw image data was converted to JPEG format before transmission.


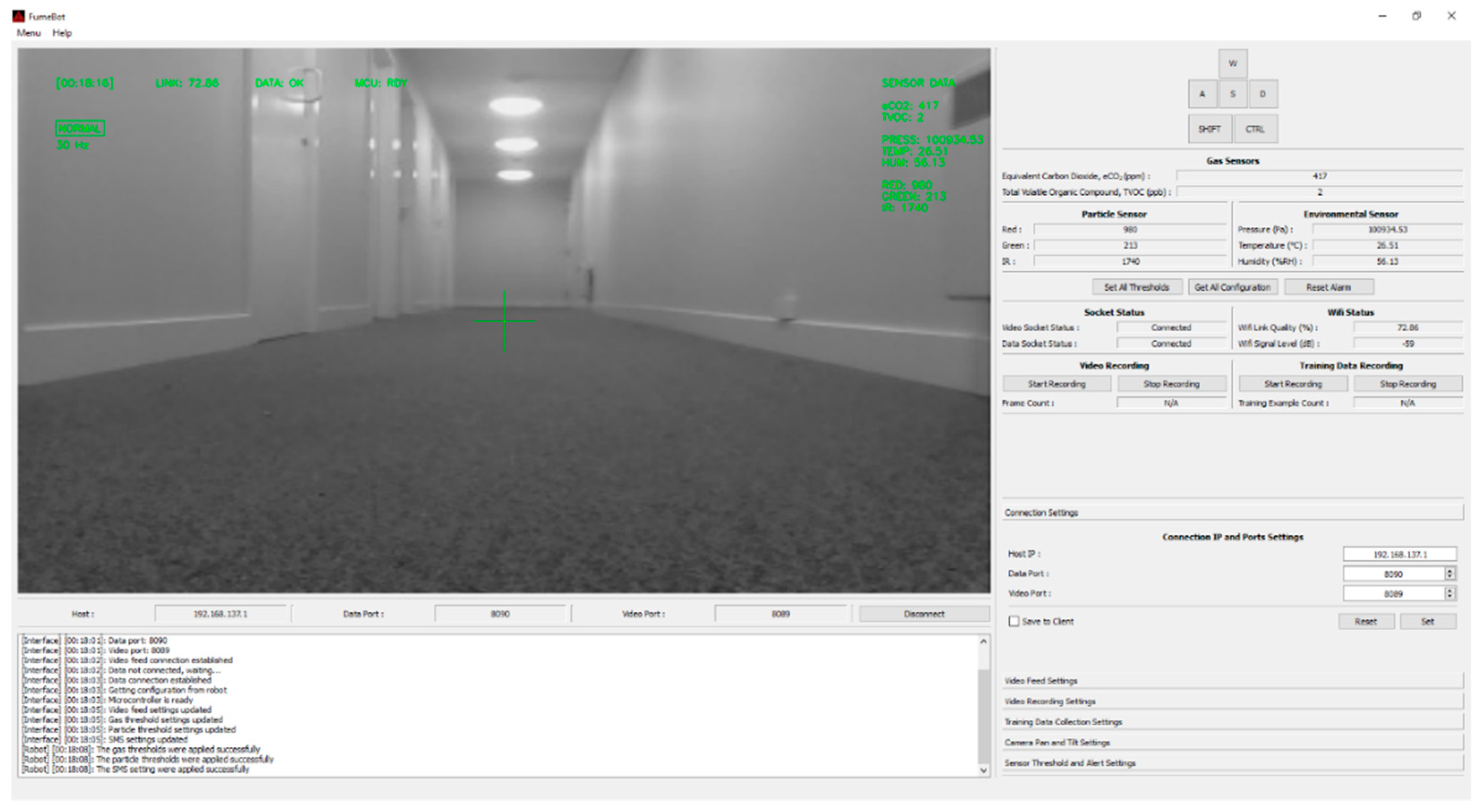
Appendix A.3. Graphical User Interface for FumeBot

- The video display area can be toggled to display the images coming from the optical or thermal camera or a blended image of both. A head-up-display is used to display relevant information directly on top of the video frame to avoid looking away from the video display area. For panning and tilting the camera mount, the mouse is dragged across the video display area while holding down the left mouse button.
- The keyboard is used to control the movement of the robot using the WASD keys while the shift and control keys are used for increasing the speed and braking, respectively.
- The connection settings are used to change the IP address and ports that are used to communicate with the robot. These settings are also saved to the Raspberry Pi.
- The sensors tab contains all the alert thresholds for the gas and particle sensors. The SMS settings for text alerts are also available here.
- The video feed settings tab provides control for image size, frame rate, and color settings. For the capture color, grayscale is preferred as the amount of data that needs to be sent after JPEG compression is considerably less when compared to color frames.
- The video recording and training data settings tabs are used to record the video feed frames coming from the robot. The video files are recorded with time stamps so each new recording creates a new file. The training data consists of the image frame coming from the normal optical camera of the robot and the WASD key presses to move the robot. Only the optical camera data is collected because of the issues with the thermal camera, as explained above.
References
- Roomba Robot Models. Available online: https://www.irobot.co.uk/home-robots/vacuuming (accessed on 18 July 2019).
- Dyson 360 Eye robot. Available online: https://www.dyson.co.uk/robot-vacuums/dyson-360-eye-overview.html (accessed on 18 July 2019).
- Bosch Indego. Available online: https://www.bosch-garden.com/gb/en/garden-tools/garden-tools/robotic-lawnmowers-209530.jsp (accessed on 18 July 2019).
- Flymo Robot Lawn Mowers. Available online: https://www.flymo.com/uk/products/robot-lawn-mowers/ (accessed on 18 July 2019).
- Wilson, G.; Pereyda, C.; Raghunath, N.; de la Cruz, G.; Goel, S.; Nesaei, S.; Minor, B.; Schmitter-Edgecombe, M.; Taylor, M.E.; Cook, D.J. Robot-enabled support of daily activities in smart home environments. Cogn. Syst. Res. 2019, 54, 258–272. [Google Scholar] [CrossRef]
- Marek, G.; Peter, S. Design the robot as security system in the home. Procedia Eng. 2014, 96, 126–130. [Google Scholar] [CrossRef][Green Version]
- Song, G.; Yin, K.; Zhou, Y.; Cheng, X. A Surveillance Robot with Hopping Capabilities for Home Security. IEEE Trans. Consum. Electron. 2009, 55, 2034–2039. [Google Scholar] [CrossRef]
- Di Paola, D.; Milella, A.; Cicirelli, G.; Distante, A. An Autonomous Mobile Robotic System for Surveillance of Indoor Environments. Int. J. Adv. Robot. Syst. 2010, 7, 19–26. [Google Scholar] [CrossRef]
- Tseng, C.C.; Lin, C.L.; Shih, B.Y.; Chen, C.Y. SIP-enabled Surveillance Patrol Robot. Robot. Comput. Integr. Manuf. 2013, 29, 394–399. [Google Scholar] [CrossRef]
- Liao, Y.L.; Su, K.L. Multi-robot-based intelligent security system. Artif. Life Robot. 2011, 16, 137–141. [Google Scholar] [CrossRef]
- Ahn, H.S.; Sa, I.K.; Choi, J.Y. PDA-Based Mobile Robot System with Remote Monitoring for Home Environment. IEEE Trans. Consum. Electron. 2009, 55, 1487–1495. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. Comput. Vis. Pattern Recognit. 2015, arXiv:1506.02640. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. Comput. Vis. Pattern Recognit. 2017, arXiv:1703.06870. [Google Scholar]
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamoz, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep Speech: Scaling up end-to-end speech recognition. Comput. Lang. 2014, arXiv:1412.5567. [Google Scholar]
- Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. Sound Mach. Learn. 2016, arXiv:1609.03499. [Google Scholar]
- Fridman, L.; Brown, D.E.; Glazer, M.; Angell, W.; Dodd, S.; Jenik, B.; Terwilliger, J.; Patsekin, A.; Kindelsberger, J.; Ding, L.; et al. MIT Autonomous Vehicle Technology Study: Large-Scale Deep Learning Based Analysis of Driver Behavior and Interaction with Automation. Comput. Soc. 2017, arXiv:1711.06976. [Google Scholar]
- Janglová, D. Neural Networks in Mobile Robot Motion. Int. J. Adv. Robot. Syst. 2004, 1, 15–22. [Google Scholar] [CrossRef]
- Parhi, D.R.; Singh, M.K. Real-time navigational control of mobile robots using an artificial neural network. Proc. Inst. Mech. Eng. Part. C J. 2009, 223, 1713–1725. [Google Scholar] [CrossRef]
- Shamsfakhr, F.; Sadeghibigham, B. A neural network approach to navigation of a mobile robot and obstacle avoidance in dynamic and unknown environments. Turk. J. Electr. Eng. Comput. Sci 2017, 25, 1629–1642. [Google Scholar] [CrossRef]
- Chi, K.H.; Lee, M.F.R. Obstacle avoidance in mobile robot using neural network. In Proceedings of the International Conference on Consumer Electronics, Communications and Networks, Xianning, China, 16–18 April 2011; pp. 5082–5085. [Google Scholar]
- Takiguchi, T.; Lee, J.H.; Okamoto, S. Collision avoidance algorithm using deep learning type artificial intelligence for a mobile robot. In Proceedings of the International Multi Conference of Engineers and Computer Scientists, Hong Kong, China, 14–16 March 2018. [Google Scholar]
- Wu, K.; Esfahani, M.A.; Yuan, S.; Wang, H. Learn to Steer through Deep Reinforcement Learning. Sensors 2018, 18, 3650. [Google Scholar] [CrossRef]
- Xie, L.; Wang, S.; Markham, A.; Trigoni, N. Towards Monocular Vision based Obstacle Avoidance through Deep Reinforcement Learning. Robotics 2017, arXiv:1706.09829. [Google Scholar]
- Yang, S.; Konam, S.; Ma, C.; Rosenthal, S.; Veloso, M.; Scherer, S. Obstacle avoidance through deep networks based intermediate perception. Robotics 2017, arXiv:1704.08759. [Google Scholar]
- Singla, A.; Padakandla, S.; Bhatnagar, S. Memory-based deep reinforcement learning for obstacle avoidance in UAV with limited environment knowledge. Robotics 2018, arXiv:1811.03307. [Google Scholar]
- Hwu, T.; Isbell, J.; Oros, N.; Krichmar, J. A self-driving robot using deep convolutional neural networks on neuromorphic hardware. Neural Evol. Comput. 2016, arXiv:1611.01235. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. Neural Evol. Comput. 2012, arXiv:1207.0580. [Google Scholar]
- Bengio, Y. Practical recommendations for Gradient-Based training of deep architectures. Learning 2012, arXiv:1206.5533v2. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- LeCun, Y.; Bottou, L. Efficient BackProp. Neural Networks: Tricks of the Trade; Orr, G.B., Müller, K.R., Eds.; Springer-Verlag: Berlin/Heidelberg, Germany, 1998; pp. 9–50. [Google Scholar]
- CS231n Convolutional Neural Networks for Visual Recognition. Available online: http://cs231n.github.io (accessed on 11 June 2019).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Ha, D.; Schmidhuber, J. World Model. Mach. Learn. 2018, arXiv:1803.10122. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. Mach. Learn. 2014, arXiv:1312.6114. [Google Scholar]
- Graves, A.; Wayne, G.; Danihelka, I. Neural Turing Machines. Neural Evol. Comput. 2014, arXiv:1410.5401. [Google Scholar]
- Siegwart, R.; Nourbakhsh, I.R. Introduction to Autonomous Mobile Robots, 1st ed.; MIT Press: Cambridge, MA, USA, 2004; pp. 51–52. [Google Scholar]









| Model Number | Learning Rate | Epochs | Test Accuracy |
|---|---|---|---|
| 1 | 0.0001 | 12 | 93 |
| 2 | 0.0001 | 15 | 95 |
| 3 | 0.0001 | 20 | 96 |
| 4 | 0.0001 | 40 | 96 |
| Model Number | Learning Rate | Epochs | Accuracy |
|---|---|---|---|
| 1 | 0.0001 | 12 | 95 |
| 2 | 0.0001 | 15 | 95 |
| 3 | 0.0001 | 20 | 96 |
| 4 | 0.0001 | 40 | 97 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thomas, A.; Hedley, J. FumeBot: A Deep Convolutional Neural Network Controlled Robot. Robotics 2019, 8, 62. https://doi.org/10.3390/robotics8030062
Thomas A, Hedley J. FumeBot: A Deep Convolutional Neural Network Controlled Robot. Robotics. 2019; 8(3):62. https://doi.org/10.3390/robotics8030062
Chicago/Turabian StyleThomas, Ajith, and John Hedley. 2019. "FumeBot: A Deep Convolutional Neural Network Controlled Robot" Robotics 8, no. 3: 62. https://doi.org/10.3390/robotics8030062
APA StyleThomas, A., & Hedley, J. (2019). FumeBot: A Deep Convolutional Neural Network Controlled Robot. Robotics, 8(3), 62. https://doi.org/10.3390/robotics8030062