A Safety Monitoring Model for a Faulty Mobile Robot

Abstract
1. Introduction
- Skills Architecture: capable of building highly complex operations by a systematic aggregation of low complexity blocks, using the concept of primitives, skills and tasks.
- Safety Monitoring Model: using a mathematical function to determine the risk using the safety state, which is defined by the fault processes affecting the skill.
- Decision-making Model: which will receive the risk evaluation as an input and classify the situation, and therefore decide the action to take, as an output.
2. State-of-The-Art
2.1. Overview
2.2. Non-Robotic Fields
2.3. Industrial Robots
2.4. Mobile Robots
3. The Safety Monitoring Model for Decision-Making
- Reliability—the probability that there will be no interruptions to the system’s ability to operate during a pre-defined time interval
- Robustness—the amount of noise or perturbations, both internal and external, that the system can sustain without losing functions
- Resilience—the ability of the system to sustain damage, but still be able to recover its function.
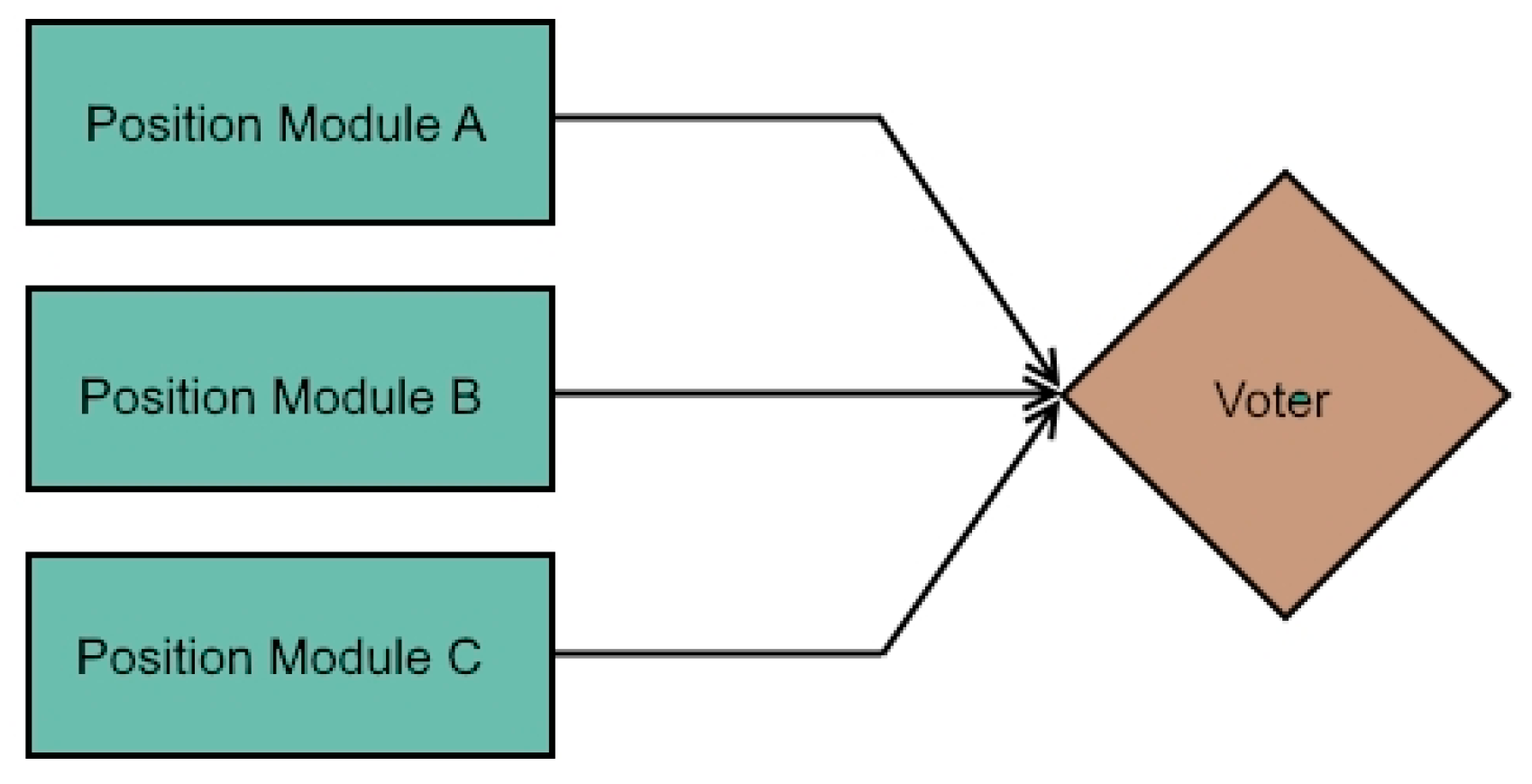
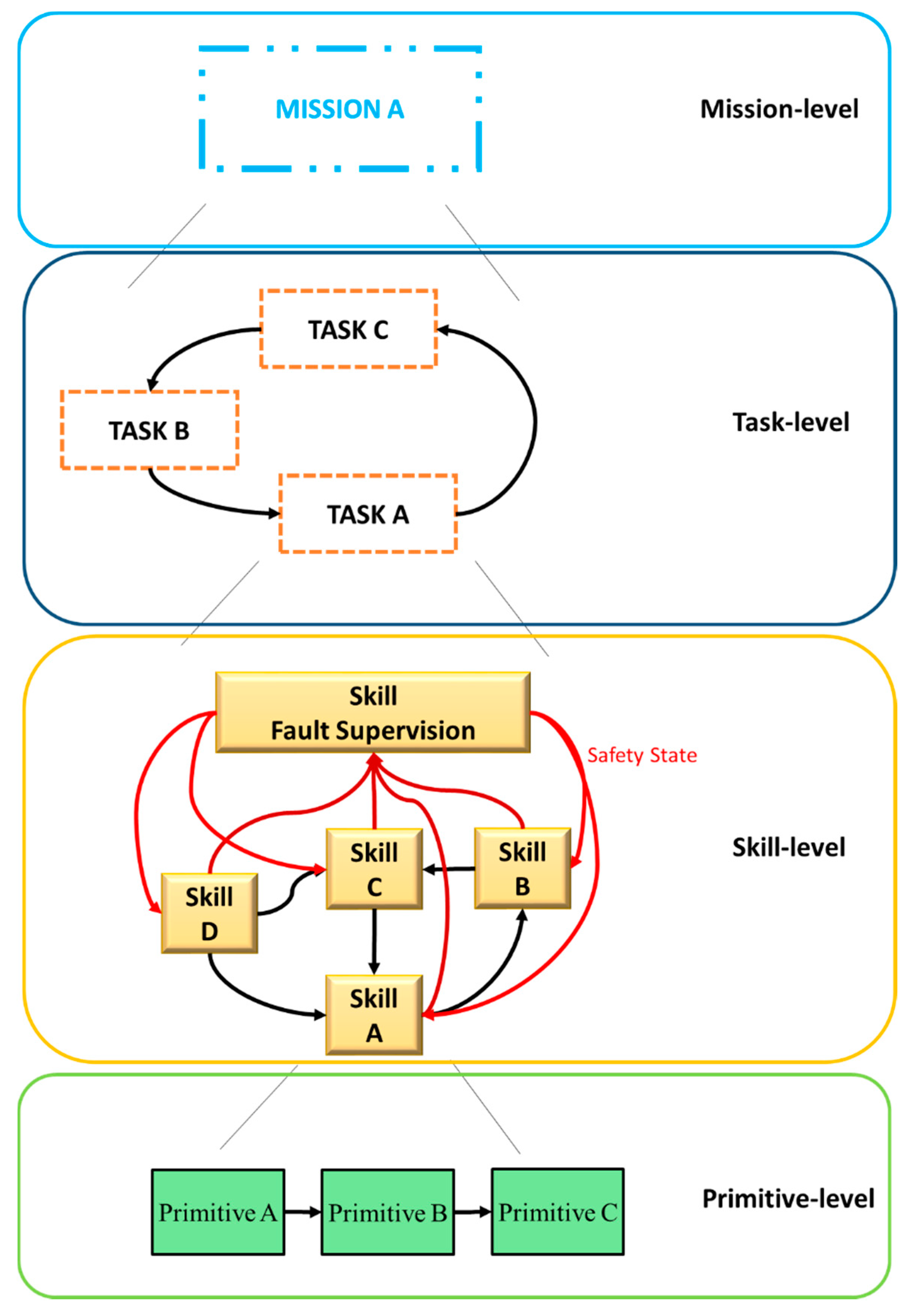
3.1. Skills Architecture
- Primitives as the hardware-specific program blocks. The primitives define the lowest layer of the conceptual model, which is characterized by sensing and actuating capabilities (e.g., data acquisition from sensors and real-time control loops). Each primitive performs a unique operation in the system.
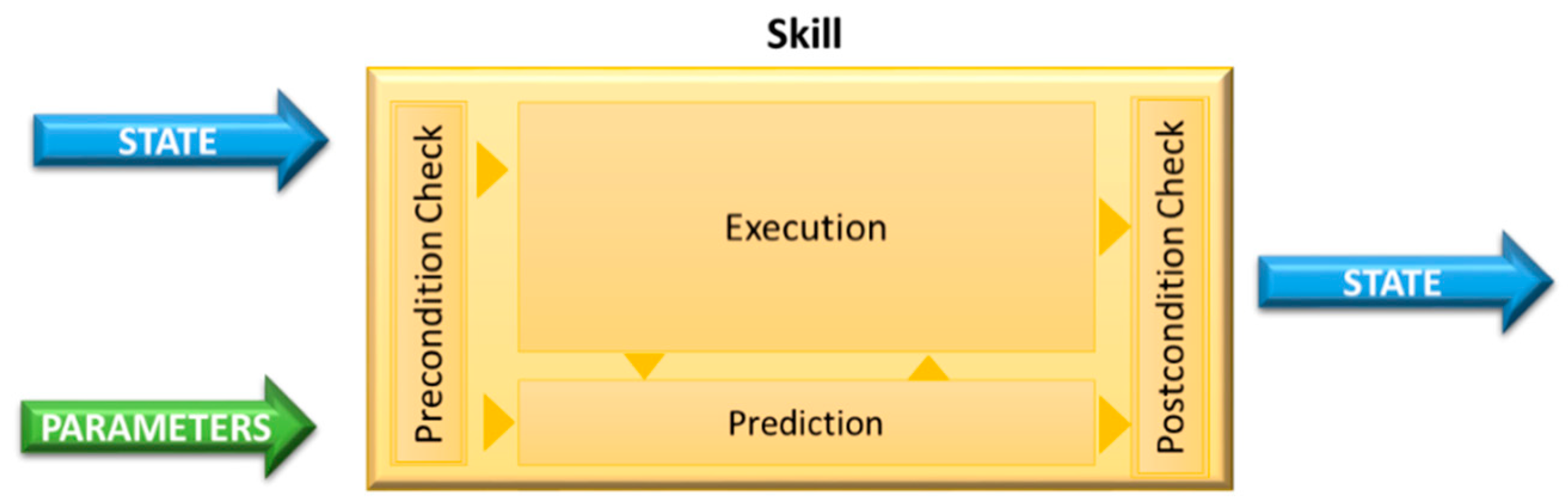
- Skills as intuitive object-centered robot abilities that are self-sustained and can be used for task-level programming. Each skill has input parameters, executing instructions (combinations of primitives: sensing and acting operation sequences) and it is able to verify if the execution of the program was successful (or not).
- Tasks as a set of skills planned to overcome a specific goal. Each task defines the input parameters of skills, accesses state variables of the robot/world, and changes these variables by controlling the execution of a predefined sequence of skills.
- Missions as a sequence of tasks that are executed whenever necessary to achieve specific goals. Each mission captures high-level behavior that should be obtained after the execution of a set of predefined tasks. It defines input parameters and controls the workflow of tasks.
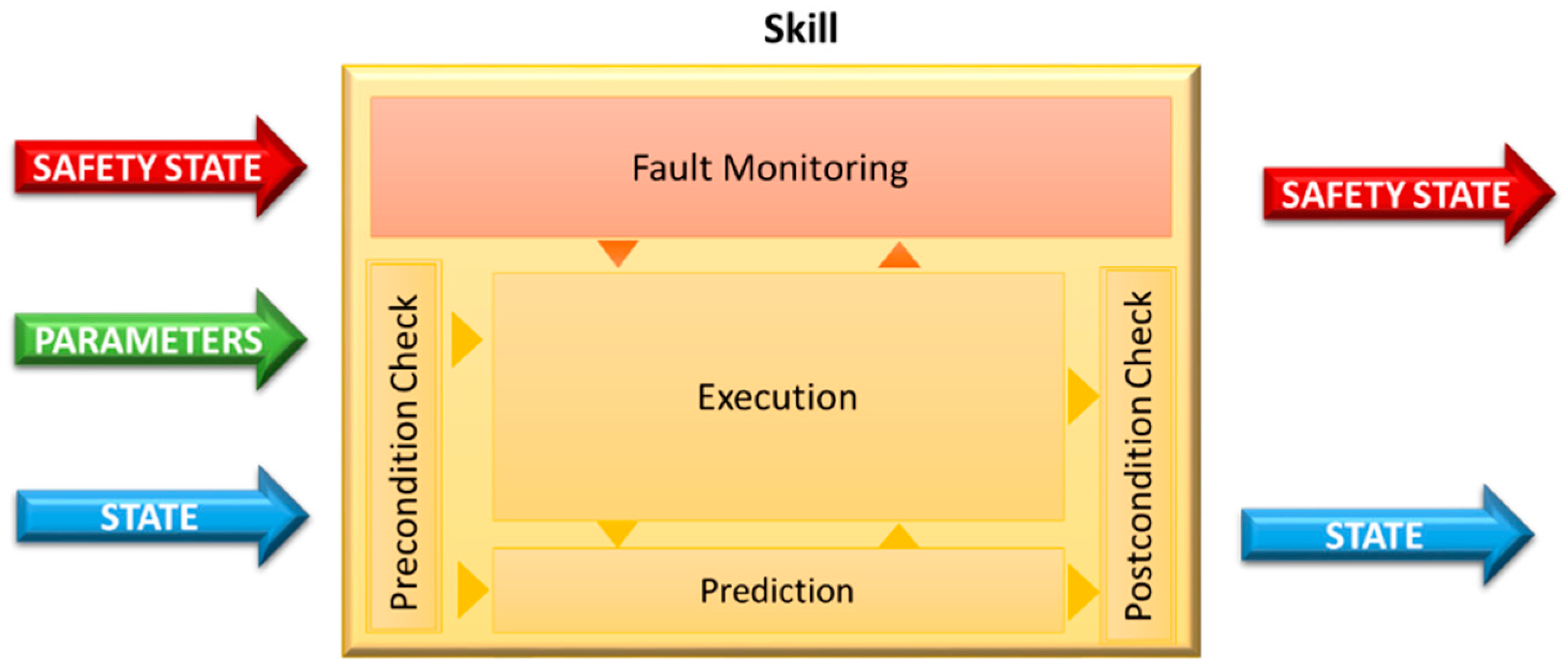
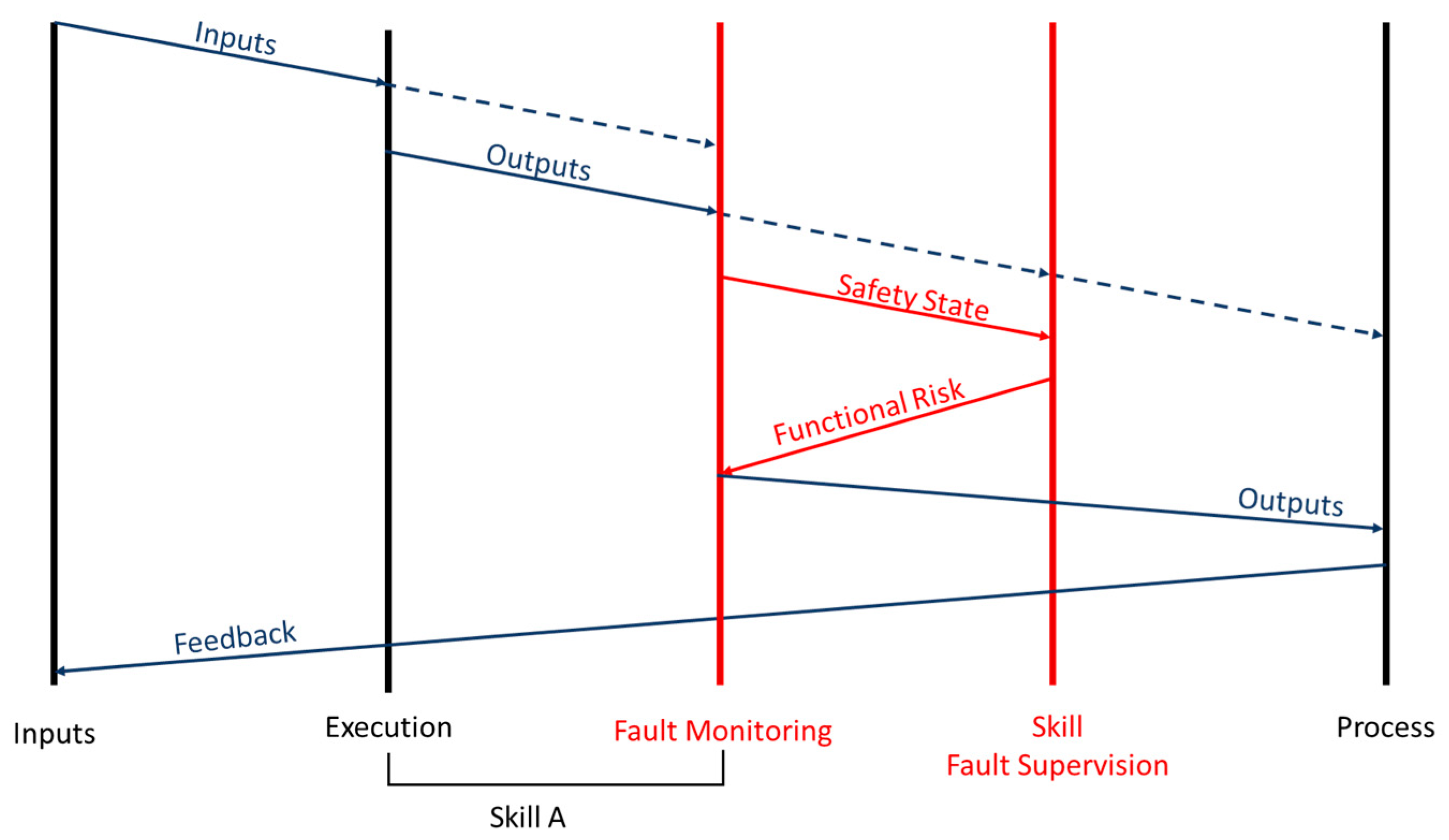
3.2. Safety Monitoring Model for Skills Architecture
- Sensors, which allow to receive input from the scenario
- Actuators, which allow to interact with the scenario
- Decisional layer (primitives, skills, tasks and missions), corresponding to the software module that defines or manages specific behaviors for the mobile robot.
- High (0-level): When no failures were detected and the service can be delivered
- Medium (1-level): When failures were detected. The service can be delivered using the same function mode while adapting sub-objective parameters
- Weak (2-level): When failures were detected. The service can be delivered using an alternative (potentially degraded) sub-objective while remaining at the current autonomy level
- Serious (3-level): When failures were detected. The service cannot be delivered but other component modules can continue the mission with the current autonomy level (there is a reduced risk to hazardous situations)
- Fatal (4-level): When failures were detected. The service cannot be delivered and the mission must stop since there is a high risk to hazardous situations.
- Persistence(i) = 1, then the failure “i” is Intermittent (or transient)
- Persistence(i) = 2, then the failure “i” is Permanent
- Very low (=1). There will not be service interruptions
- Low (=2). Service interruptions will happen at a low-frequency or high-confidence in delivering the expected result
- High (=3). Service interruptions will happen at a medium-frequency basis or low-confidence in delivering the expected result
- Relatively high (=4). Service interruptions will happen at a high-frequency basis.
- Redundant (=0), when the service remains available without loss of quality
- Eminent (=1), when the service remains available with loss of quality
- Singular (=2), when the fault removes the system’s ability (the service can no longer be delivered)
- Isolated disturbances (=1). Faults affect only the current component
- External disturbances (=2). Faults propagate to other components and have a global impact.
- Absence of failures (=0), when the normal functioning of the decisional model does not cause harmful consequences
- Minor failures (=2), when the harmful consequences lead to similar costs to the benefits provided by correct service delivery
- Catastrophic failures (= 6), when the harmful consequences lead to costs with orders of magnitude higher than the benefit provided by correct service delivery.
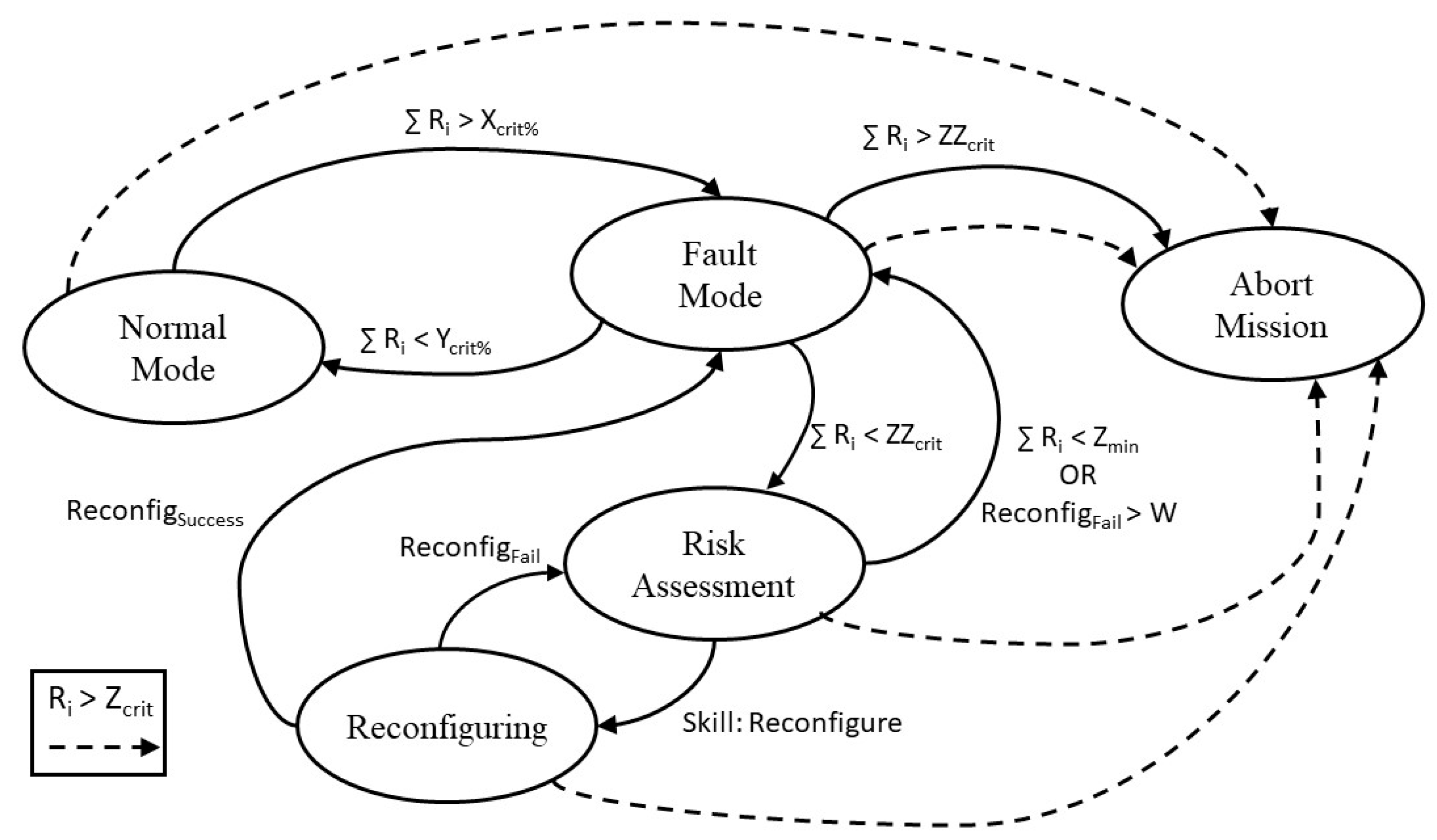
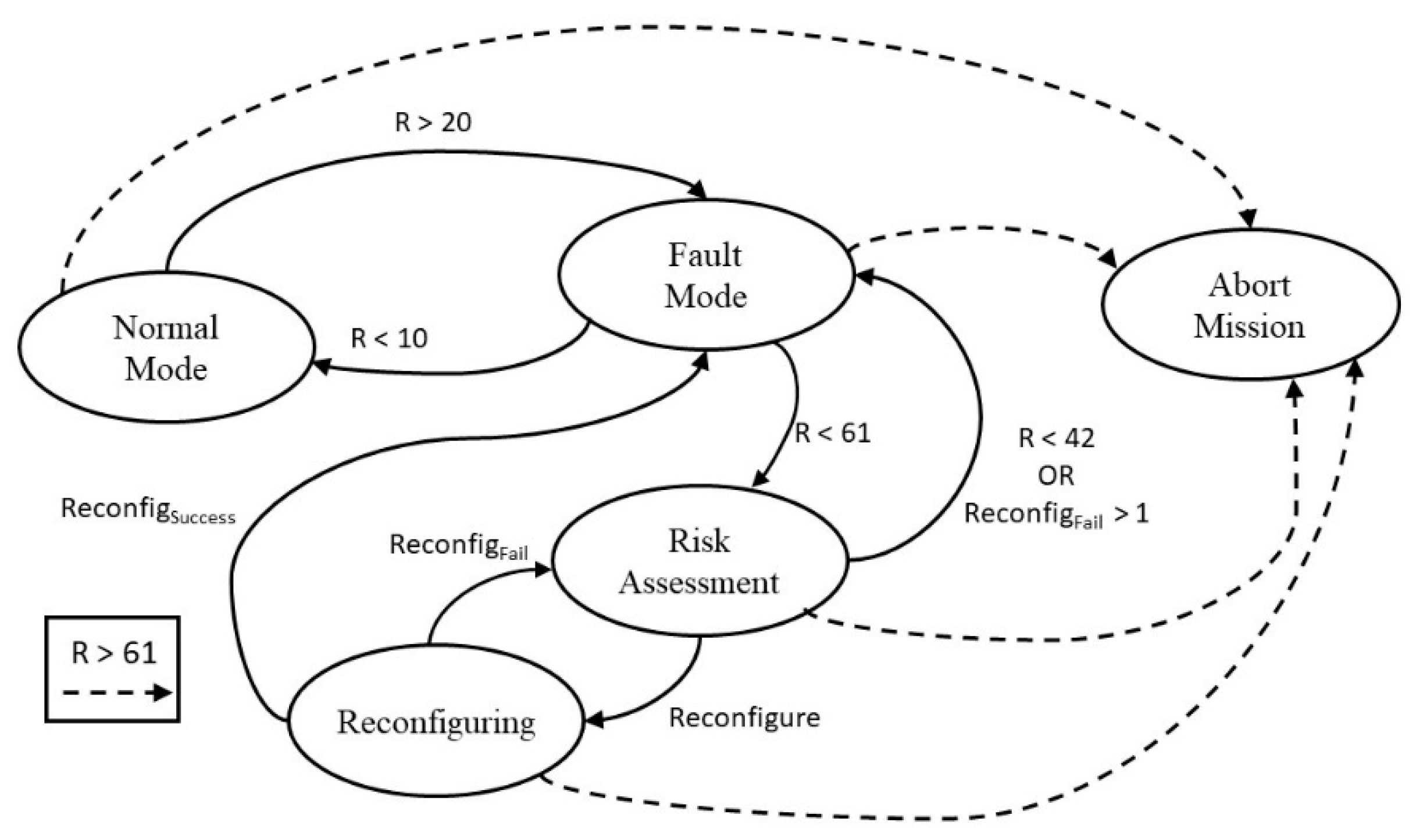
3.3. Decision-Making Model
- Ri—Safety state of skill i
- ∑ Ri—Cumulative safety states of every skill
- Zcrit—Fatal level threshold for a single skill Ri
- ZZcrit—Mission abort threshold for all skills ∑ Ri
- Zmin—Threshold for all skills. If ∑ Ri is lower, the system reevaluates if the Fault Mode is required
- Xcrit%—Threshold for all skills. If ∑ Ri is higher the system enters Fault Mode
- Ycrit%—Threshold for all skills. If ∑ Ri is lower the system returns to Normal Mode
- ReconfigSuccess—Flag that signals that the system/skill reconfiguration was successful
- ReconfigFail—Flag that signals that the system/skill reconfiguration was unsuccessful
- W—Control of the number of failed reconfigurations. Depends on which skills the Fault Supervision attempts to reconfigure.
- Reconfiguration (general safety state = medium)
- Adaptation (general safety state = weak)
- Autonomy adjustment (general safety state = serious)
- Safety Waiting (general safety state = serious)
- Definitive Stop (general safety state = fatal).
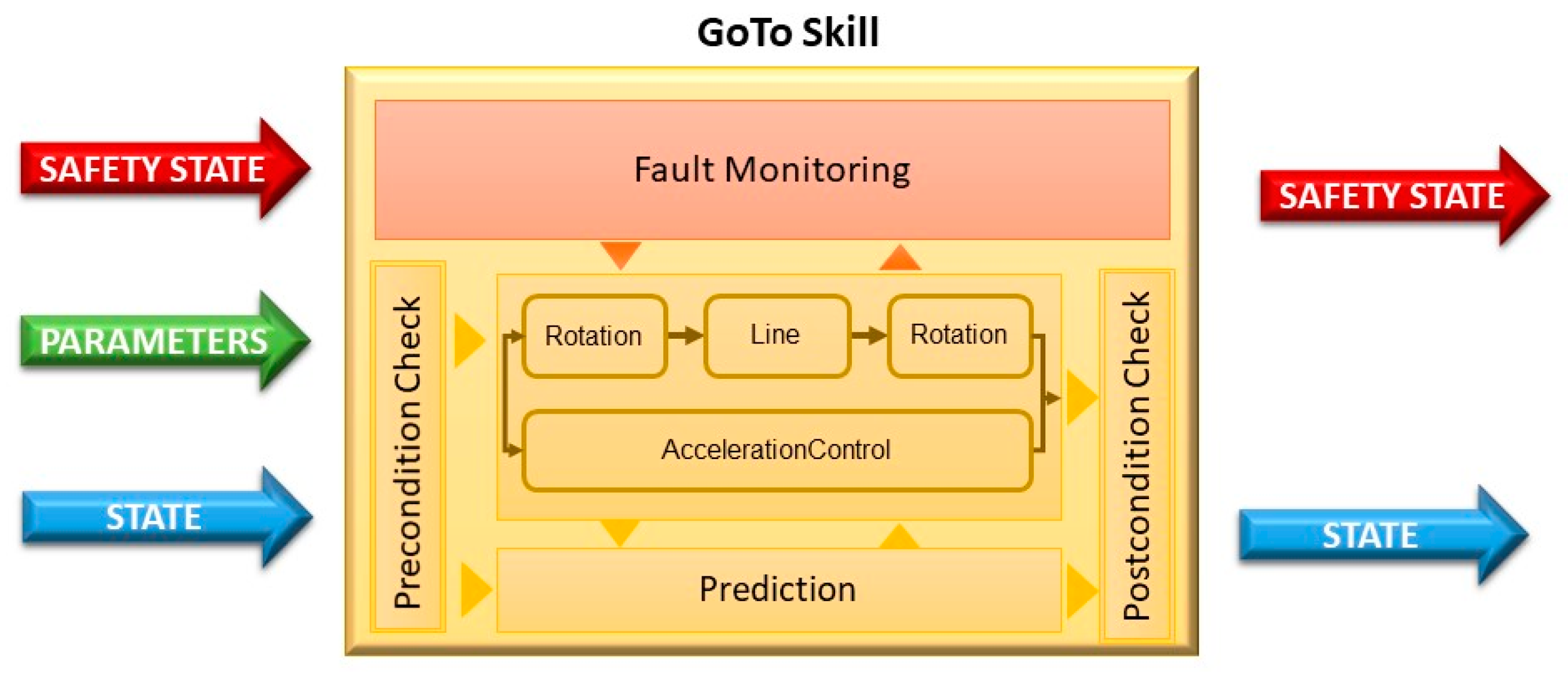
4. Practical Application
- Final Position—given by (x, y, θ), which translates into coordinates x and y, in meters, and by orientation θ, in degrees
- Tolerable Position Error—given by (e, ε), which are small values for the tolerance of coordinate and orientation, respectively, error values that are within an acceptable margin
- Nominal Velocity—named vn, expressed in meters per second, establishes the maximum trajectory speed
- Elapsed Time—(Ρ1, Ρ2) seconds. Used to determine Persistence (used to calculate quality assessment ψ(i)). Will be further explained bellow.
- If task time exceeds a certain measure (/timeout), there is a permanent fault in the skill;
- If the distance error does not reduce in less than Ρ1 seconds, there is an intermittent fault in the primitive Line;
- If the orientation error does not reduce in less than Ρ1 seconds, there is an intermittent fault in the primitive Rotation;
- If the acceleration is greater than the maximum allowed for more than Ρ2 seconds, there is an intermittent fault in the primitive AccelerationControl.
- Because there is not sufficient hardware redundancy in the actuators, if they are the source of the fault, the Availability assessment χ(i) is Singular (=2)
- Line has been deemed such a perfect algorithm to save space, only one implementation exists, although it never fails, Occurrence(Line) = 1
- Rotation has been found to fail to perform in very rare occasions, but there are two different algorithms that can be called at any time, Occurrence(Rotation) = 2
- AccelerationControl is a new feature, i.e., there is a low degree of confidence, and therefore has a medium-frequency of interruption, but to counter it are multiple algorithms that perform this task being compared against each other, Occurrence(AccelerationControl) = 3
- Considering the above descriptions of the primitives’ implementations, if a fault is caused on the software side, the Availability assessment χ(i) of the primitives is different: Availability assessment χ(Line) = 2, Availability assessment χ(Rotation) = 1, Availability assessment χ(3) = 0
- Field tests and expert assessment determined that a fault in the Rotation has a real, but small chance of causing harmful consequences, Severity(Rotation) = 2, but Line and Acceleration Control would have a high risk of catastrophic consequences, Severity(Line) = Severity (AccelerationControl) = 6
- Because it is the only skill installed so far, but also because any mission could be adversely affected by a fault causing a position or orientation error beyond the tolerable margins, any fault to these primitives is considered to propagate, Extent(i) = 2.
- R—Safety state of GoTo skill
- Zcrit—Fatal level threshold. Considering the basic level definition previously presented, 61 is the Fatal level
- Zmin—Since, although there is only one skill, we still want the system to operate with some degree of confidence in its safety, unless reconfiguration is successful, reevaluation of the Fault Mode requires the Safety level to be at least Weak (w < 42)
- Xcrit%—The system enters Fault Mode if the Safety level is Weak (w > 20)
- Ycrit%—The system returns to Normal Mode if the Safety level is well within Medium level margins (w < 11)
- W—Although some reconfiguration might be possible, hardware redundancy is so low that it is considered that it is only possible for the system to reconfigure itself successfully using Software changes, so this value is 1.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, T.; Zhang, W.; Gupta, M.M. An underactuated self-reconfigurable robot and the reconfiguration evolution. Mech. Mach. Theory 2018, 124, 248–258. [Google Scholar] [CrossRef]
- Nevejans, N. European Civil Law Rules in Robotics. In Policy Department C: Citizens’ Rights and Constitutional Affairs; European Parliament: Brussels, Belgium, 2017; p. 34. [Google Scholar]
- Kuestenmacher, A.; Plöger, P.G. Model-Based Fault Diagnosis Techniques for Mobile Robots. IFAC-PapersOnLine 2016, 49, 50–56. [Google Scholar] [CrossRef]
- Koren, I.; Krishna, C.M. Fault-Tolerant Systems; Elsevier Science: San Francisco, CA, USA, 2007; Available online: https://ebookcentral.proquest.com/lib/feup-ebooks/reader.action?docID=294597&query= (accessed on 30 January 2018).
- Guiochet, J.; Machin, M.; Waeselynck, H. Safety-critical advanced robots: A survey. Robot. Auton. Syst. 2017, 94, 43–52. [Google Scholar] [CrossRef]
- European Committee for Standardization. Agreement on Technical Co-Operation Between ISO and CEN (Vienna Agreement) [Internet]. Brussels: CENELEC. 2001, pp. 1–3. Available online: https://www.cencenelec.eu/intcoop/StandardizationOrg/Pages/default.aspx (accessed on 27 March 2018).
- European Committee for Electrotechnical Standardization. Cenelec guide 13—IEC-CENELEC Agreement on Common Planning of New Work and Parallel Voting [Internet]. Brussels: CENELEC. 2016. Available online: https://www.cencenelec.eu/intcoop/StandardizationOrg/Pages/default.aspx (accessed on 27 March 2018).
- MTL Instruments Group. An Introduction to Functional Safety and IEC 61508; MTL Instruments Group: Luton, UK, 2002; Available online: https://www.mtl-inst.com/images/uploads/datasheets/App_Notes/AN9025.pdf (accessed on 27 March 2018).
- Kolek, L.; Ibrahim, M.Y.; Gunawan, I.; Laribi, M.A.; Zegloul, S. Evaluation of control system reliability using combined dynamic fault trees and Markov models. In Proceedings of the 2015 IEEE 13th International Conference on Industrial Informatics (INDIN), Cambridge, UK, 22–24 July 2015; pp. 536–543. Available online: http://ieeexplore.ieee.org/document/7281791/ (accessed on 27 March 2018).
- Isermann, R.; Ballé, P. Trends in the application of model based fault detection and diagnosis of technical processes. Control Eng. Pract. 1997, 5, 709–719. [Google Scholar] [CrossRef]
- Yoshimura, I.; Sato, Y. Safety achieved by the safe failure fraction (SFF) in IEC 61508. IEEE Trans. Reliab. 2008, 57, 662–669. [Google Scholar] [CrossRef]
- Visinsky, M.L.; Cavallaro, J.R.; Walker, I.D. Robotic fault detection and fault tolerance: A survey. Reliab. Eng. Syst. Saf. 1994, 46, 139–158. [Google Scholar] [CrossRef]
- Isermann, R. Mechatronic systems-Innovative products with embedded control. Control Eng. Pract. 2008, 16, 14–29. [Google Scholar] [CrossRef]
- Sghairi, M.; De Bonneval, A.; Crouzet, Y.; Aubert, J.J.; Brot, P. Architecture optimization based on incremental approach for airplane digital distributed flight control system. In Proceedings of the Advances in Electrical and Electronics Engineering—IAENG Special Edition of the World Congress on Engineering and Computer Science 2008, San Francisco, CA, USA, 22–24 October 2008; pp. 13–20. [Google Scholar]
- Stoican, F.; Olaru, S.; Seron, M.M.; De Doná, A. A fault tolerant control scheme based on sensor-actuation channel switching and dwell time. Int. J. Robust. Nonlinear Control 2014, 24, 775–792. Available online: http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=5718146 (accessed on 27 March 2018). [CrossRef]
- Szurman, K.; Miculka, L.; Kotasek, Z. Towards a state synchronization methodology for recovery process after partial reconfiguration of fault tolerant systems. In Proceedings of the 2014 9th International Conference on Computer Engineering & Systems (ICCES), Cairo, Egypt, 22–23 December 2014; pp. 231–236. [Google Scholar]
- Liu, Z.; Zhang, Y.; Yu, X.; Yuan, C. Unmanned surface vehicles: An overview of developments and challenges. Annu. Rev. Control 2016, 41, 71–93. [Google Scholar] [CrossRef]
- Crestani, D.; Godary-Dejean, K.; Lapierre, L. Enhancing fault tolerance of autonomous mobile robots. Robot. Auton. Syst. 2015, 68, 140–155. [Google Scholar] [CrossRef]
- Gonzalez, O.; Shrikumar, H.; Stankovic, J.A.; Ramamritham, K. Adaptive fault tolerance and graceful degradation under dynamic hard real-time scheduling. In Proceedings of the Real-Time Systems Symposium, San Francisco, CA, USA, 2–5 December 1997. [Google Scholar]
- Strollo, E.; Trifiletti, A. A fault-tolerant real-time microcontroller with multiprocessor architecture. In Proceedings of the MIXDES 2016—23rd International Conference Mixed Design of Integrated Circuits and Systems, Lodz, Poland, 23–25 June 2016; pp. 431–436. [Google Scholar]
- Ma, H.J.; Yang, G.H. Simultaneous fault diagnosis for robot manipulators with actuator and sensor faults. Inf. Sci. 2016, 366, 12–30. [Google Scholar] [CrossRef]
- Ranjbaran, M.; Khorasani, K. Fault recovery of an under-actuated quadrotor aerial vehicle. In Proceedings of the 49th IEEE Conference on Decision and Control (CDC), Atlanta, GA, USA, 15–17 December 2010; pp. 4385–4392. [Google Scholar]
- Zhang, M.; Wu, J.; Wang, Y. Simultaneous faults detection and location of thrusters and sensors for autonomous underwater vehicle. In Proceedings of the 2011 Fourth International Conference on Intelligent Computation Technology and Automation, Shenzhen, China, 28–29 March 2011; Volume 1, pp. 504–507. [Google Scholar]
- Zajac, M. Online fault detection of a mobile robot with a parallelized particle filter. Neurocomputing 2014, 126, 151–165. [Google Scholar] [CrossRef]
- Saied, M.; Lussier, B.; Fantoni, I.; Francis, C.; Shraim, H.; Sanahuja, G. Fault diagnosis and fault-tolerant control strategy for rotor failure in an octorotor. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 5266–5271. [Google Scholar]
- Gross, J.N.; Gu, Y.; Rhudy, M.B.; Lassak, K. A Fault-Tolerant Multiple Sensor Fusion Approach Applied to UAV Attitude Estimation. Int. J. Aerosp. Eng. 2016, 2016. [Google Scholar] [CrossRef]
- Bader, K.; Lussier, B.; Schön, W. A fault tolerant architecture for data fusion: A real application of Kalman filters for mobile robot localization. Robot. Auton. Syst. 2017, 88, 11–23. [Google Scholar] [CrossRef]
- Shen, Z.; Ma, Y.; Song, Y. Robust Adaptive Fault-tolerant Control of Mobile Robots with Varying Center of Mass. IEEE Trans. Ind. Electron. 2017, 65, 2419–2428. Available online: http://ieeexplore.ieee.org/document/8012422/ (accessed on 27 March 2018). [CrossRef]
- Pedersen, M.R.; Nalpantidis, L.; Andersen, R.S.; Schou, C.; Bøgh, S.; Krüger, V.; Madsen, O. Robot skills for manufacturing: From concept to industrial deployment. Robot. Comput. Integr. Manuf. 2016, 37, 282–291. [Google Scholar] [CrossRef]
- Cai, M.Y.; Liu, C.J.; Wang, J.W.; Lin, Y.; Van Luttervelt, C.A.; Zhang, W.J. A new safety theory: Concept, methodology, and application. In Proceedings of the 2016 IEEE 11th Conference on Industrial Electronics and Applications (ICIEA), Hefei, China, 5–7 June 2016; pp. 1323–1327. [Google Scholar]
- Zhang, T.; Zhang, W.; Gupta, M. Resilient Robots: Concept, Review, and Future Directions. Robotics 2017, 6, 22. Available online: https://www.mdpi.com/2218-6581/6/4/22 (accessed on 27 March 2018). [CrossRef]
- Zhang, W.J.; Lin, Y.; Sinha, N. On the Function-Behavior-Structure Model for Design. In Proceedings of the Canadian Design Engineering Network Conference, Kaninaskis, AB, Canada, 18–20 July 2005. [Google Scholar]
- Zhang, W.J.; Wang, J.W. Design theory and methodology for enterprise systems. Enterp. Inf. Syst. 2016, 10, 245–248. [Google Scholar] [CrossRef]
- Schou, C.; Andersen, R.S.; Chrysostomou, D.; Bøgh, S.; Madsen, O. Skill-based instruction of collaborative robots in industrial settings. Robot. Comput. Integr. Manuf. 2018, 53, 72–80. [Google Scholar] [CrossRef]
- International Electrotechnical Commission (IEC). IEC 60050-192 International Electrotechnical Vocabulary—Part 192: Dependability; IEC: Geneva, Switzerland, 2015. [Google Scholar]
- Muenchhof, M.; Beck, M.; Isermann, R. Fault tolerant actuators and drives—Structures, fault detection principles and applications. In Proceedings of the 7th IFAC Symposium on Fault Detection, Supervision and Safety of Technical Processes, Barcelona, Spain, 30 June—3 July 2009; Volume 42, pp. 1294–2003. [Google Scholar] [CrossRef]
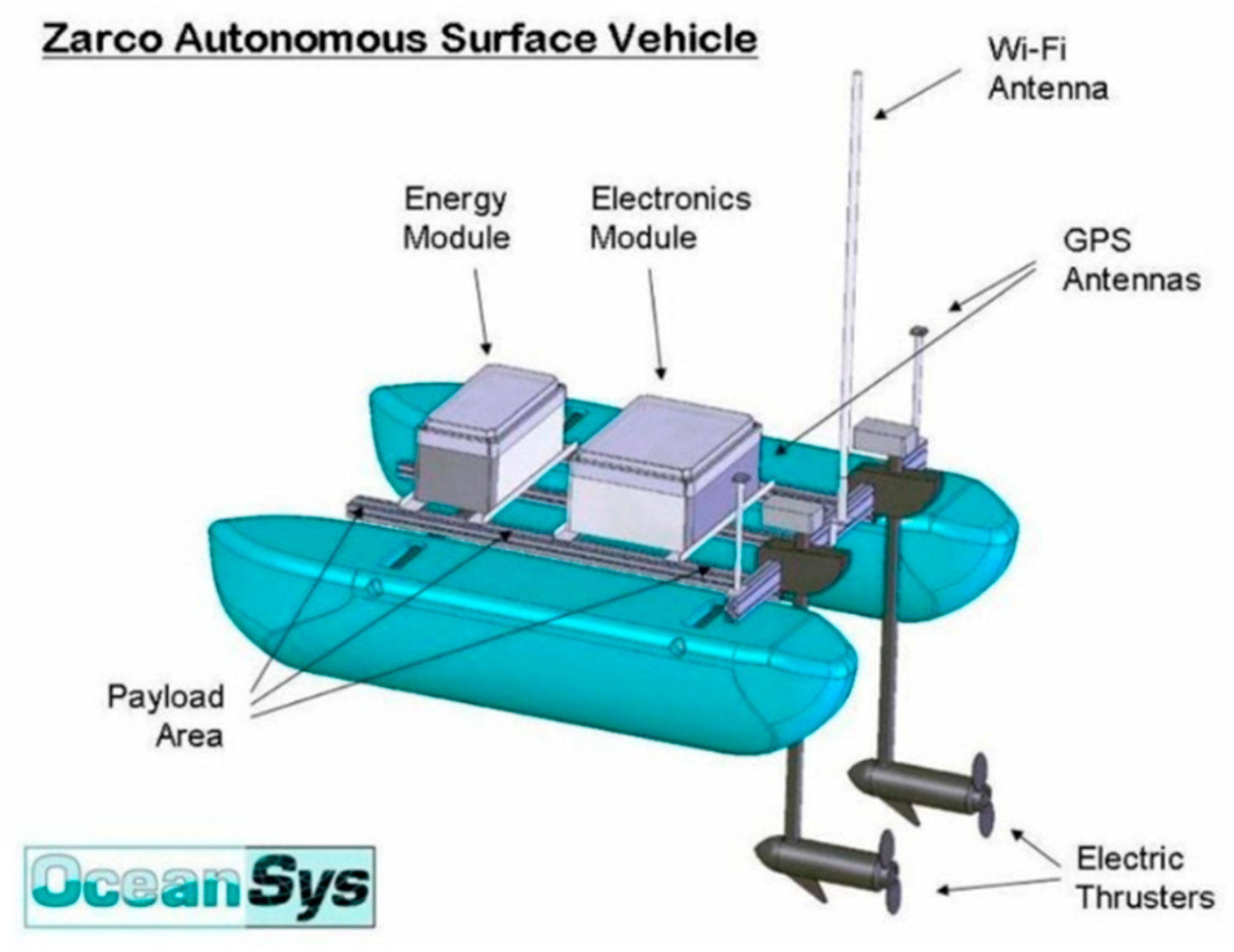
- Cruz, N.; Matos, A.; Cunha, S.; Silva, S. Zarco—An Autonomous Craft for Underwater Surveys. In Proceedings of the 7th Geomatic Week, Barcelona, Spain, 20–23 February 2007. [Google Scholar]
- Cai, M.; Lin, Y.; Han, B.; Liu, C.; Zhang, W. On a simple and efficient approach to probability distribution function aggregation. IEEE Trans. Syst. Man Cybern. Syst. 2017, 47, 2444–2453. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| χ(i) | ψ(i) | Occurrence | Persistence | |||
|---|---|---|---|---|---|---|
| Redundant | Eminent | Singular | ||||
| χ(i) + ψ(i) | 1 | 2 | 3 | 1 | Very Low | Intermittent |
| 2 | 3 | 4 | 2 | Low | Intermittent | |
| 3 | 4 | 5 | 3 | High | Intermittent | |
| 4 | 5 | 6 | 4 | Relatively high | Intermittent | |
| 2 | 3 | 4 | 2 | Very Low | Permanent | |
| 4 | 5 | 6 | 4 | Low | Permanent | |
| 5 | 6 | 7 | 5 | High | Permanent | |
| 8 | 9 | 10 | 8 | Relatively high | Permanent | |
| χ(i) + ψ(i) | Υ(i) | Extent | F. Severity | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||||
| Safety State | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | Isolated | Absence |
| 2 | 4 | 6 | 8 | 10 | 12 | 14 | 16 | 18 | 20 | 2 | Isolated | Minor | |
| 6 | 12 | 18 | 24 | 30 | 36 | 42 | 48 | 54 | 60 | 6 | Isolated | Catastrophic | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | External | Absence | |
| 4 | 8 | 12 | 16 | 20 | 24 | 28 | 32 | 36 | 40 | 4 | External | Minor | |
| 12 | 24 | 36 | 48 | 60 | 72 | 84 | 96 | 108 | 120 | 12 | External | Catastrophic | |
(Severity × Extent) × [Availability + (Persistence × Occurrence)] | Safety State (w) | |
|---|---|---|
| Line | ||
| Rotation | ||
| AccCtrl |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leite, A.; Pinto, A.; Matos, A. A Safety Monitoring Model for a Faulty Mobile Robot. Robotics 2018, 7, 32. https://doi.org/10.3390/robotics7030032
Leite A, Pinto A, Matos A. A Safety Monitoring Model for a Faulty Mobile Robot. Robotics. 2018; 7(3):32. https://doi.org/10.3390/robotics7030032
Chicago/Turabian StyleLeite, André, Andry Pinto, and Aníbal Matos. 2018. "A Safety Monitoring Model for a Faulty Mobile Robot" Robotics 7, no. 3: 32. https://doi.org/10.3390/robotics7030032
APA StyleLeite, A., Pinto, A., & Matos, A. (2018). A Safety Monitoring Model for a Faulty Mobile Robot. Robotics, 7(3), 32. https://doi.org/10.3390/robotics7030032