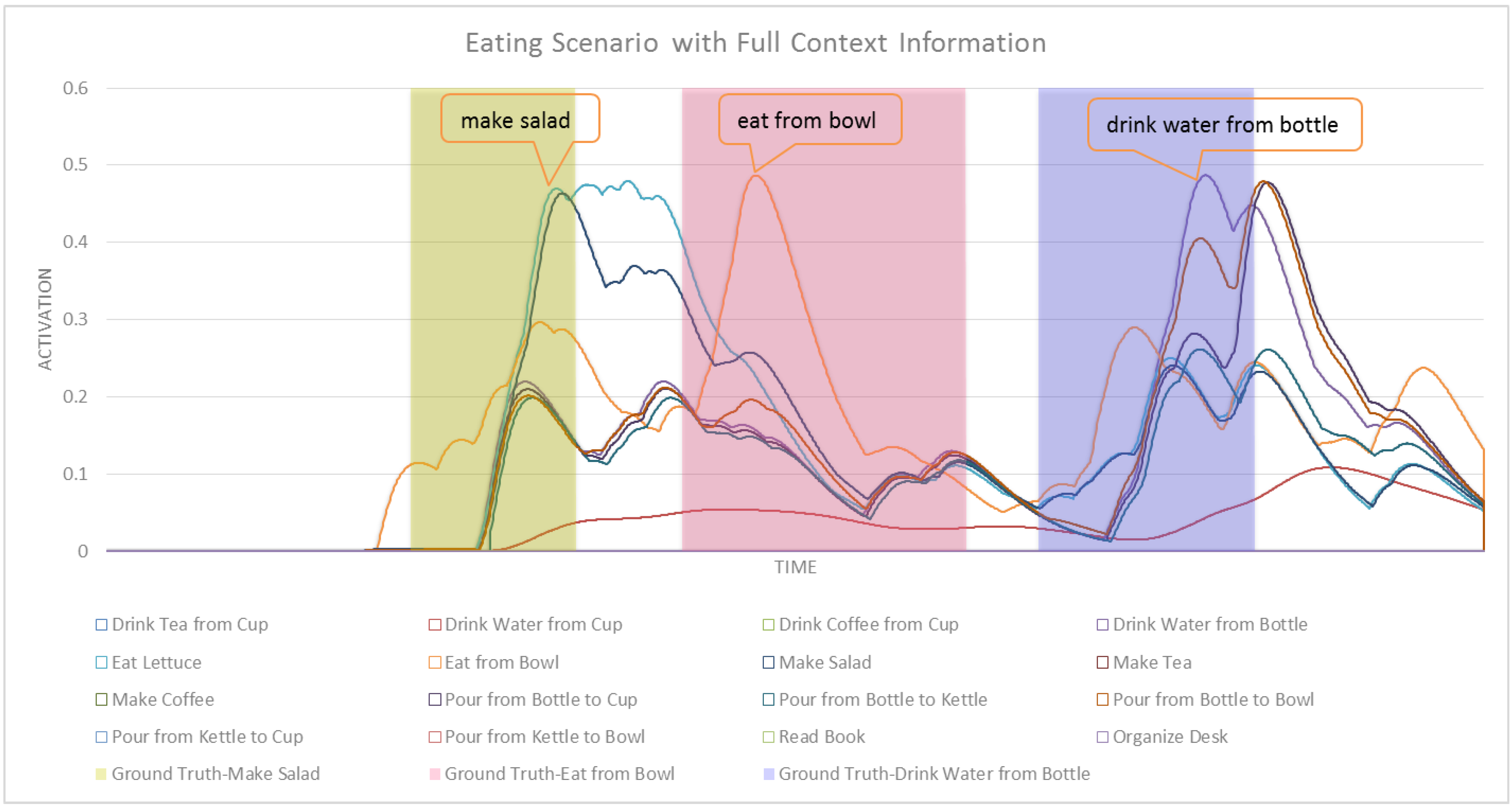
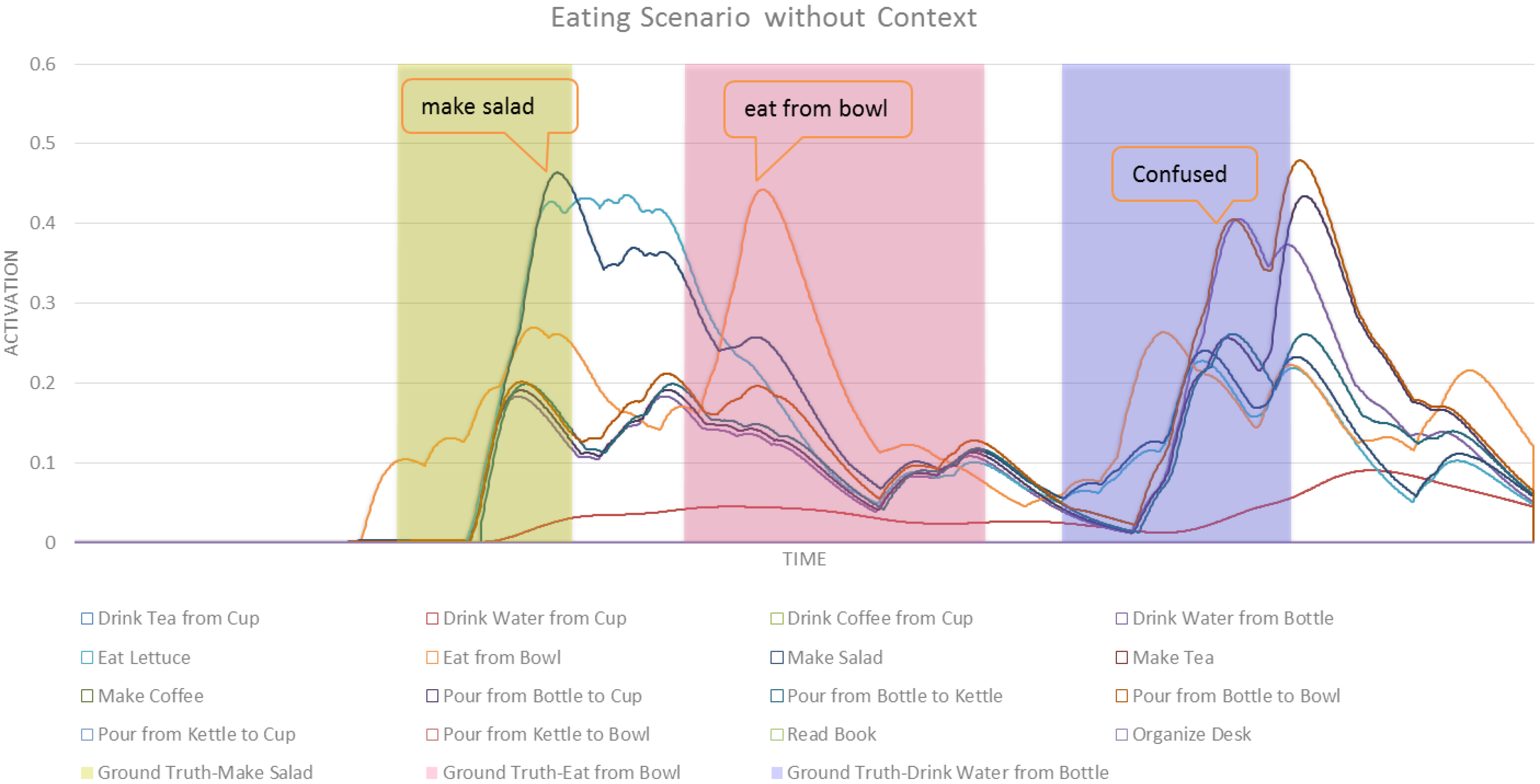
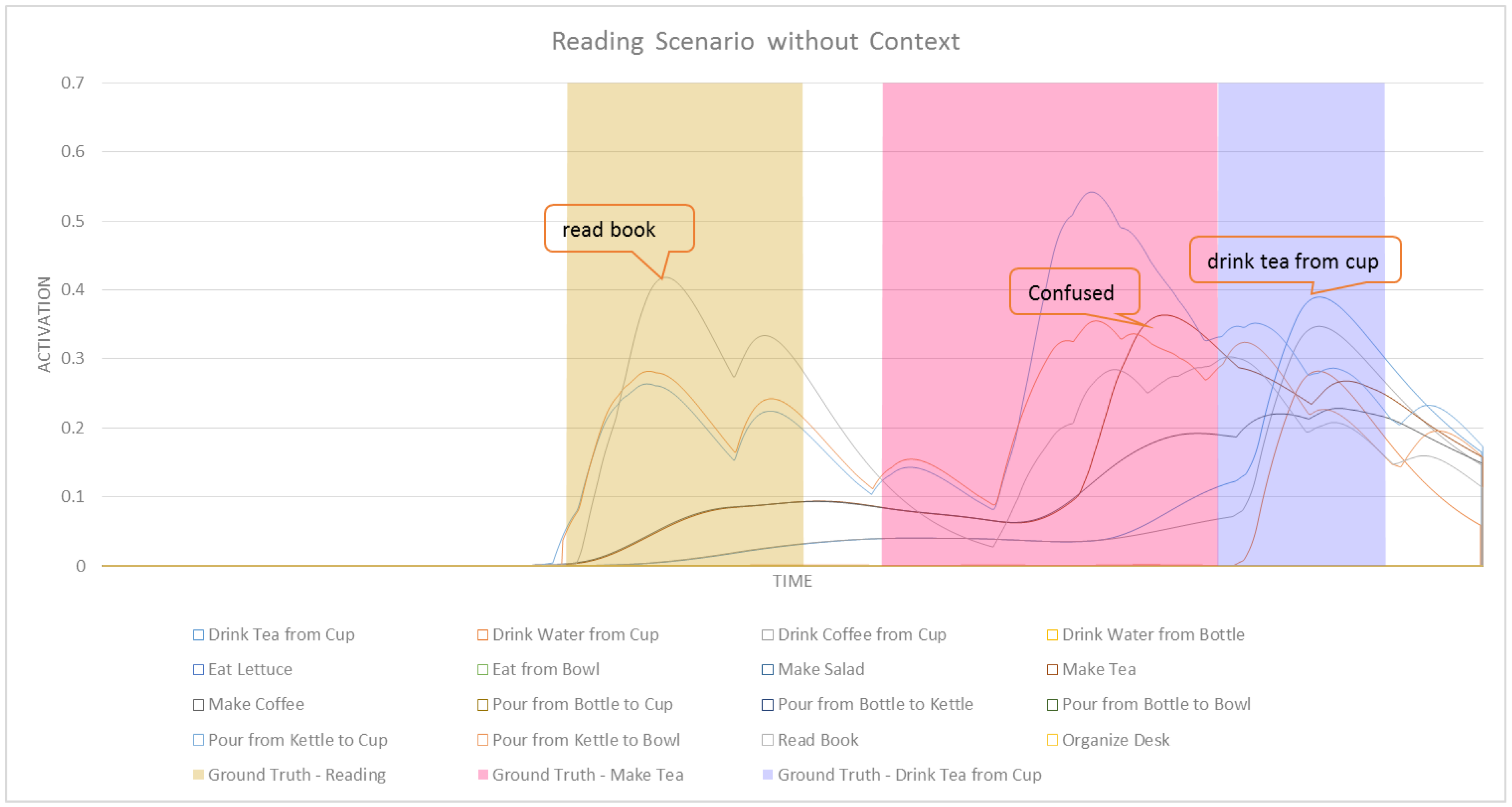
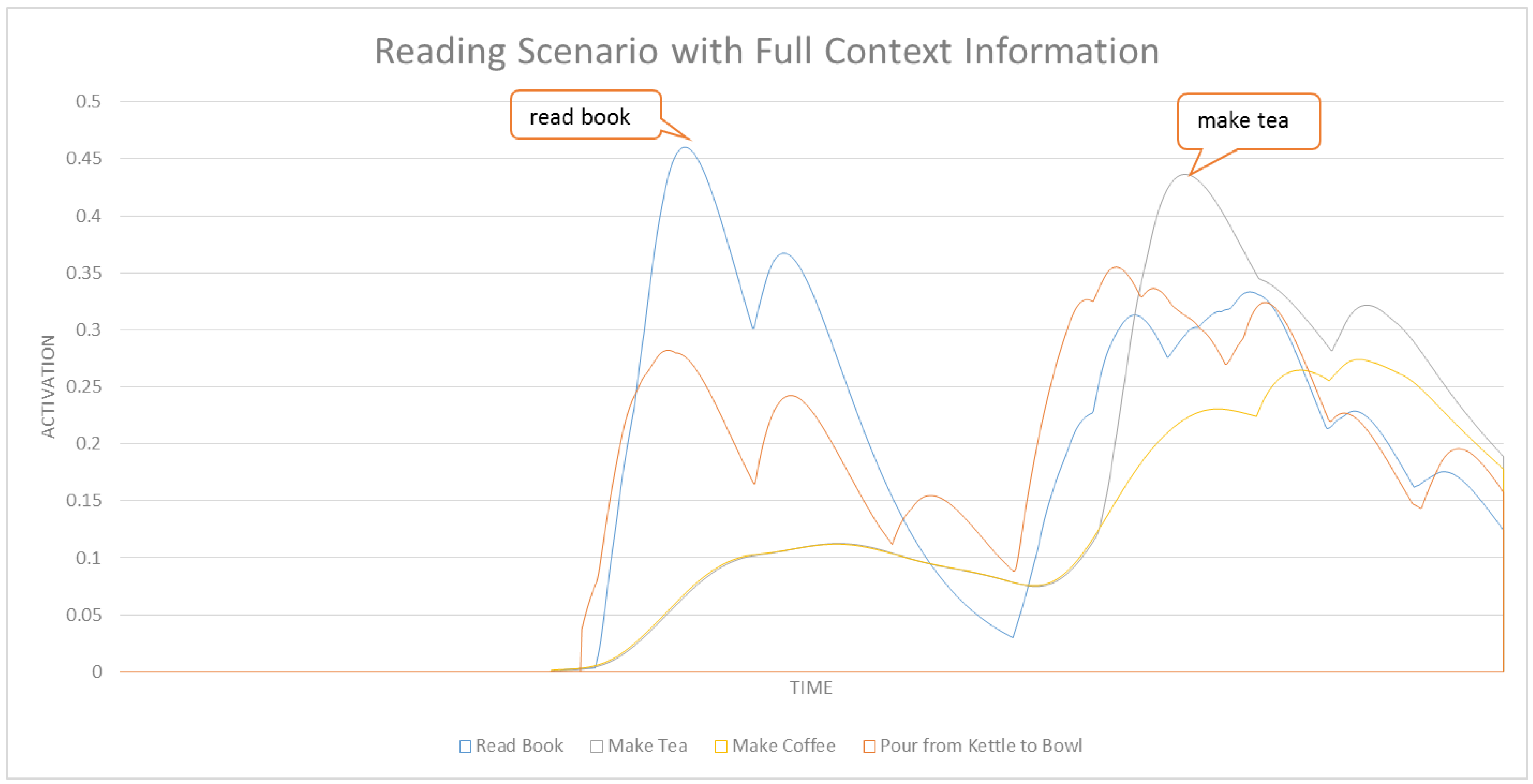
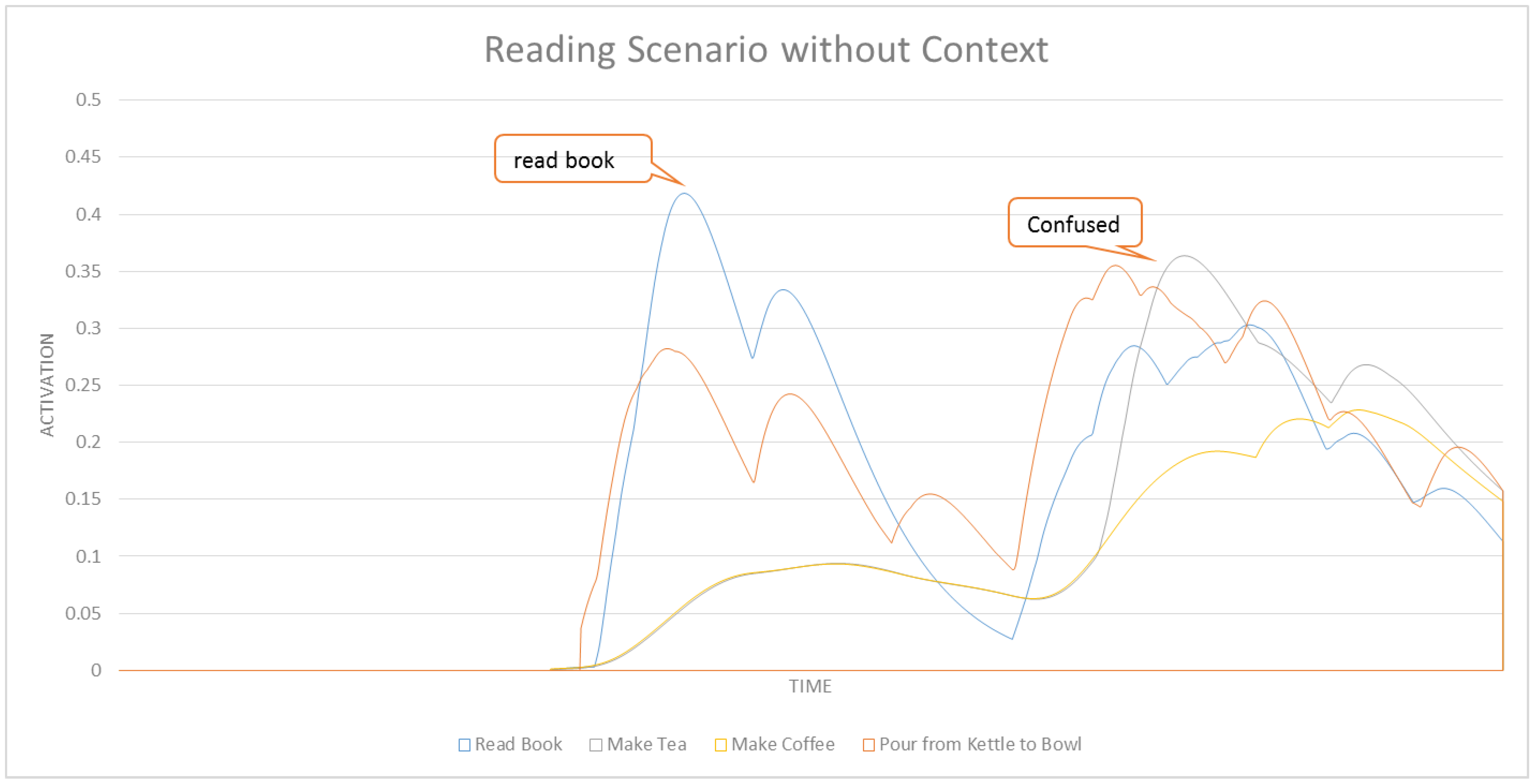
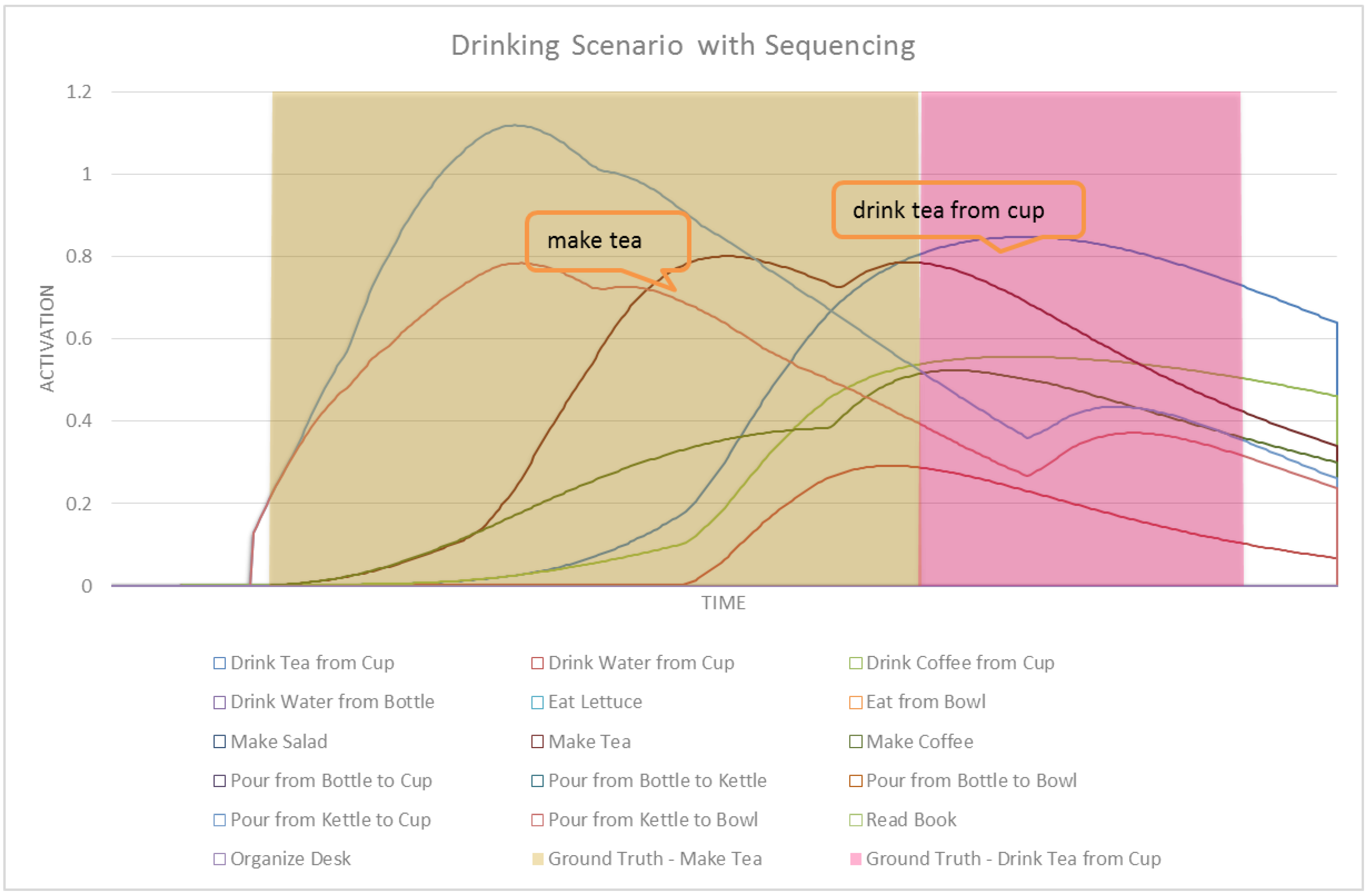
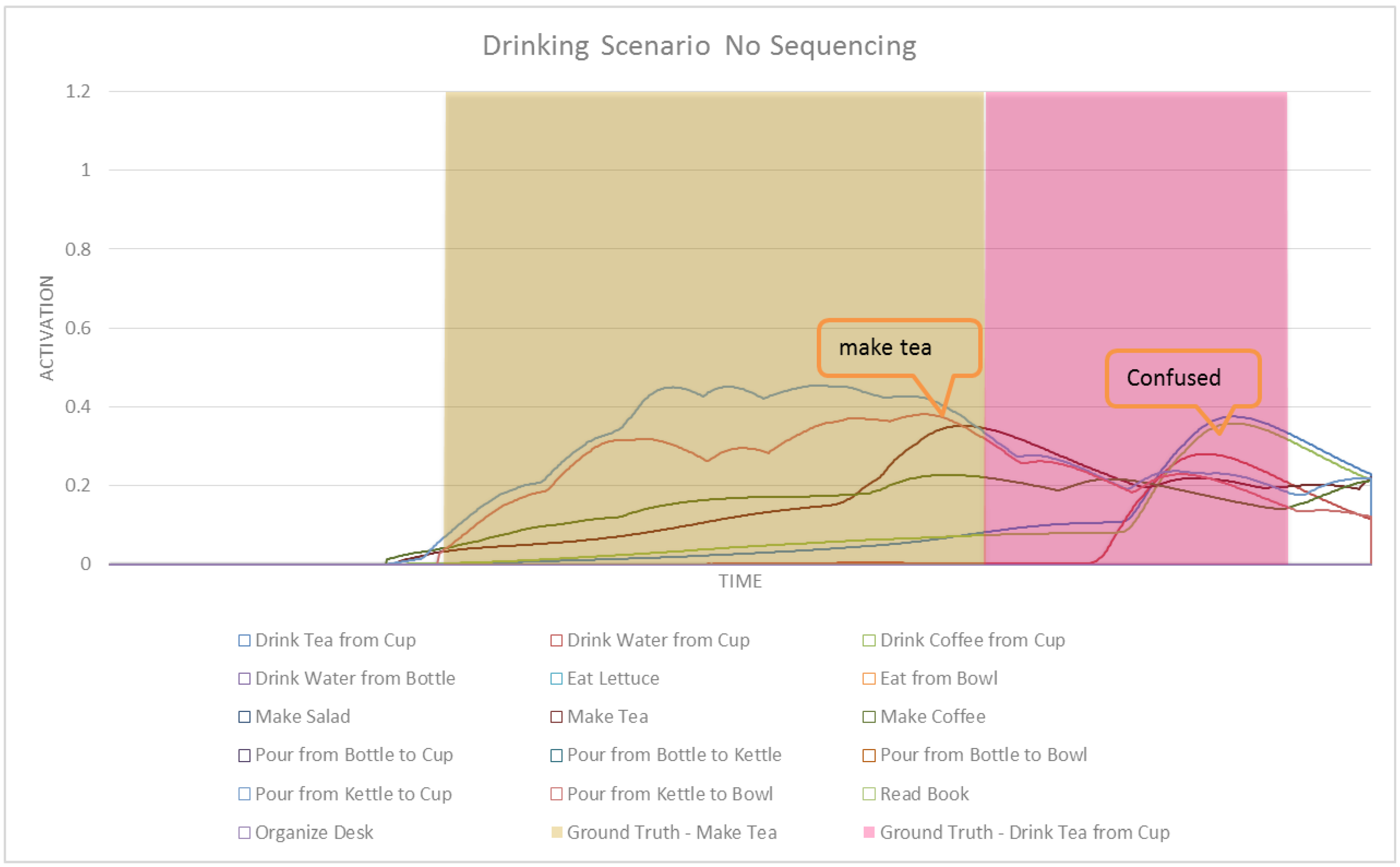
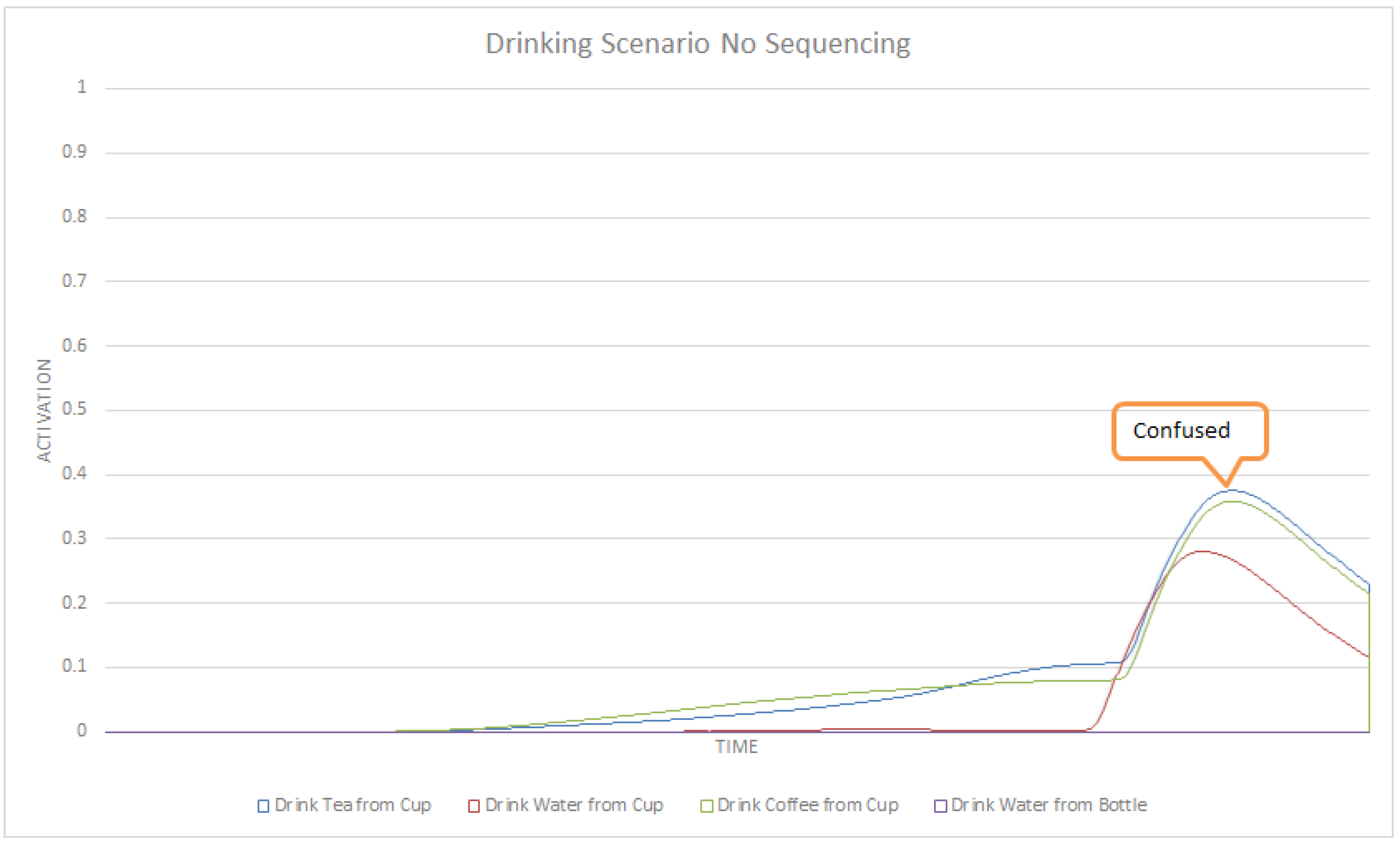
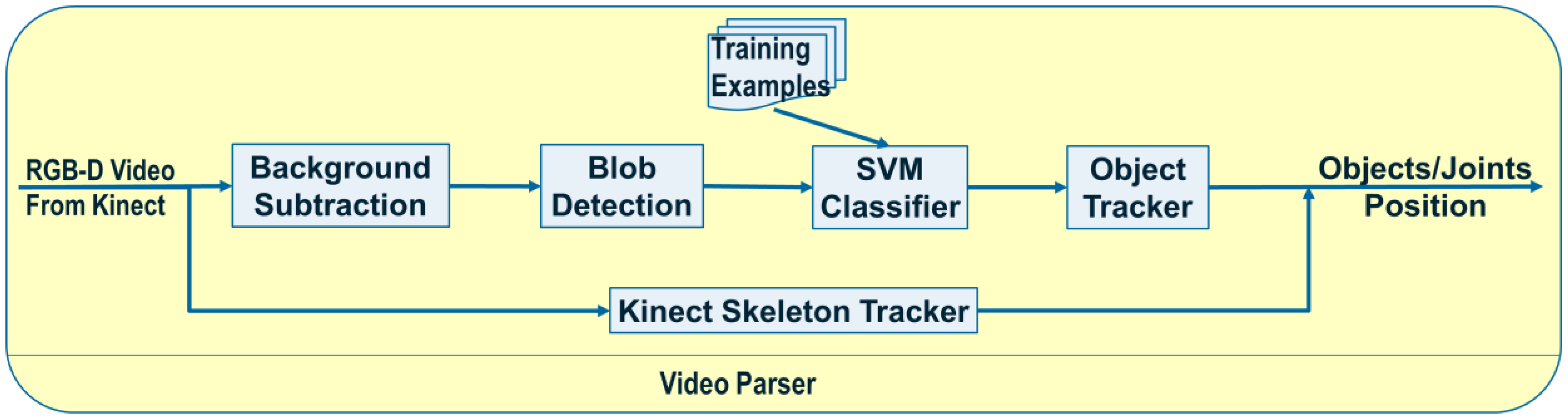
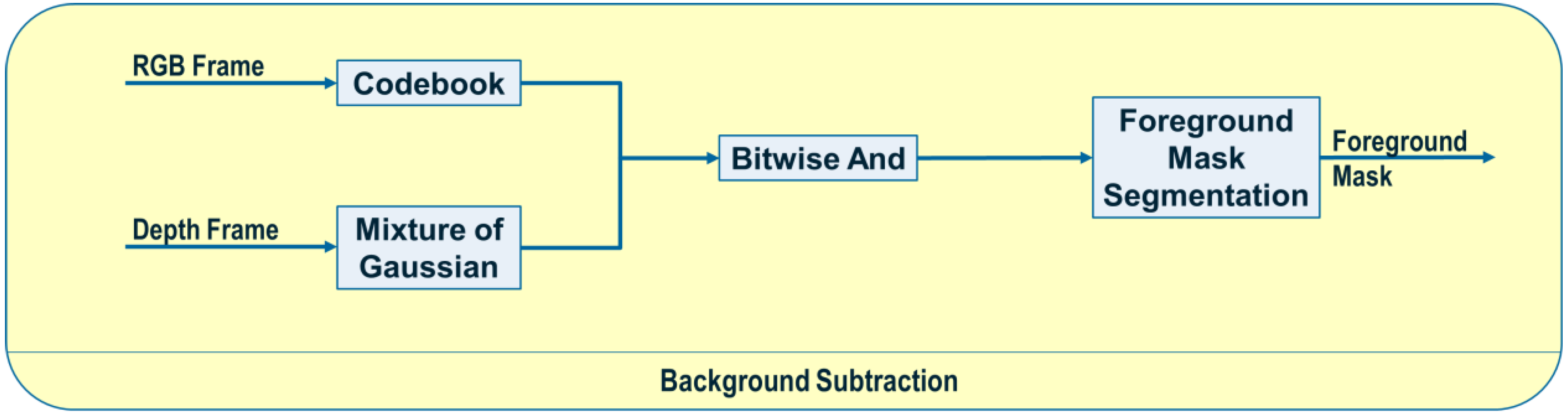
In this section we formally define our ASN-based approach to intent recognition from RGB-D videos. Activation Spreading Networks provide a parallel, distributed and fast search mechanism for intent recognition. Through spreading activation messages to other nodes in the network and accumulating activation by receiving messages from neighbor nodes, we can robustly detect the intention of a subject of interest and the corresponding plan that the subject is following to realize that intention. We can predict a set of future activities of the subject based on the detected plan. These capabilities depend on designing an activation-spreading network that captures the real structure of activities, plans and intentions related to the system. This is the domain knowledge, which (in different forms) is incorporated in every planning system. One of the most widely used forms of representing planning knowledge is Hierarchical Task Networks (HTN) [
42]. The main idea behind HTNs is to store
mini-plans to achieve common goals in a database of reusable methods, and to use them while planning—for fast processing. Theoretical studies [
43] show that HTNs in their unrestricted form are actually more complex than Partial Order Planning (POP) [
5]. Only after enforcing some limitations on the expressivity of HTNs, this form of planning becomes tractable. In the following subsections we formally define ASN and HTN, provide an algorithm to build an ASN from an HTN, and describe an inference algorithm based on ASN for intent recognition.
4.1. Preliminaries
We adapt the definition of HTNs from SHOP
2 [
44], which is a well-known HTN planner.
Operator: an operator is a parameterized strips-like atomic action where are variables used in precondition, add and delete lists. Each variable has a set of all possible substitutions or domain .
Task: A task is either a primitive or a compound task where is task symbol along with a list of terms as arguments. If task is primitive then is an operator name and the task arguments are used as the operator parameters.
Method: A method is a possible expansion of the non-primitive task and it is only applicable in situations satisfying the precondition . Intuitively, a method represents a particular way of achieving a given task.
Task Network: a task network is a tuple of the form where is a set of tasks and is a partial order constraint on . If contains only primitive tasks, it is called a primitive task network otherwise it is called non-primitive task network.
Hierarchical Task Network: a hierarchical task network is a set of operators, methods, task networks and tasks. Intuitively, a hierarchical task network is a representation of the planning domain knowledge.
The ultimate goal in HTN planning is to complete a task. Usually the goal task is compound and the planner should choose a suitable method from the set of available methods to break down the goal task into smaller tasks. This recursive procedure continues until all tasks in the network are primitive. HTN planners are equivalent to context-free grammars in their set of possible solutions [
43], but to simplify our intent recognition problem, we restrict the HTN formalism to avoid recursion in the methods. Put differently, we assume that no compound task can be a member of the subtasks of itself. The intention of completing a compound task is the focus of our intent recognition system. From now on, when we mention “detecting a task”, we implicitly mean detecting the intention to complete a task before its completion. Next, we formally define an activation-spreading network.
Activation Spreading Network: An activation spreading network is a directed acyclic graph.
is the set of nodes. Each node has an activation value that is a positive real number.
is the set of sum edges connecting nodes in the graph. Each sum edge has a weight . A sum edge is an edge through which activation messages spread in the network and the receiving node processes it by updating its activation value with a summation.
is the set of max edges connecting nodes in the graph. A max edge is another type of edge through which activation messages spread in the network and the receiving node processes it by updating its activation value with a maximum value selection.
is the internal clock sending periodic signals to all nodes in the graph.
is a firing threshold.
is a decay factor that is a real number between 0 and 1.
A node updates its activation value by multiplying it with the decay factor
on every clock tick. Upon receiving an activation message, a node updates its activation value by summing the activation message multiplied by the edge weight, with its own activation value if the message was received via a sum edge. A node updates its activation value by choosing the maximum activation message on all ingoing max edges. Upon receiving a tick from the clock, a node sends activation messages equal to its activation value on outgoing edges, if its activation value is above
.
Algorithm 1 shows the algorithm of processing activation messages in the ASN. This procedure is called for a node upon receiving an activation message.
Algorithm 2 shows the algorithm of activation spreading in the network. This procedure is called for a node upon receiving a periodic signal from the clock.
| Algorithm 1 Activation message processing algorithm in ASN |
| let v∈V be the node receiving activation message from s |
| let S_max={n|(n,v)∈E_M and n sent message to v in recent clock signal} |
| if S_max≠∅ |
ac(v)=max┬(v'∈S_max ) ![Robotics 04 00284 i001]() ac(v^' ) ac(v^' ) |
| else |
| ac(v)=ac(v)+ac(s)×w((s,v)) |
| Algorithm 2 Activation spreading algorithm in ASN. |
|
let be the node receiving periodic signal from |
|
let |
| if
|
| send activation messages to all nodes in which |
4.2. From Hierarchical Task Network to Activation Spreading Network
We define an activation-spreading network as an acyclic graph to simplify the design by avoiding recurrent ASNs. This is in line with our simplifying assumption about not having recursions in the HTN formalism that we adapted for our work. Each task in HTN can be seen as a potential intention. Tasks in an HTN form a hierarchy according to the definition of methods. Intuitively, this means that intentions can be sub-goals for a higher-level intention. Different methods of the same task describe different ways of achieving the goal. We now describe how to instantiate an ASN from the domain knowledge represented as an HTN.
Algorithm 3 shows the conversion algorithm.
| Algorithm 3 HTN to ASN conversion algorithm |
| for every operator in HTN |
| for every substitution in the domain of |
| add node to the ASN |
| for every compound task in HTN |
| for every substitution of |
| add node to the ASN if not already present |
| for every method and |
| add node to the ASN |
| add a max edge from to |
| for every task in |
| let be a substitution for |
| agreement with |
| if is compound then |
| add if not already present |
| add a sum edge from to with |
| as weight |
| else if is primitive then |
| let be the operator corresponding to |
| add a sum edge from to with |
| as weight |
The conversion algorithm first adds all possible instantiations of operators in the HTN as nodes
in the ASN. These nodes will be the leaves of the hierarchical structure of the obtained ASN. With a similar procedure, we also add new nodes
to the network for each unique instantiation of compound tasks. Each instance of a compound task can be realized in different ways represented by a set of methods. To capture this property of HTNs in our network, we add additional nodes such as
for each method
and connect these nodes to the parent node
with max edges. With this configuration, the activation value of node
would be the maximum activation value among all of its methods. Activation values of nodes in the ASN provide a comparative measure for the likelihood of their corresponding tasks happening in the scene and are used for inference. Sum edges are not a suitable choice for connecting method nodes to task nodes because several methods with low activations should not accumulate a high activation in the task node, since the likelihood of a high-level task happening in the scene is only as high as the maximum likelihood of its methods.
Any method
in our HTN, breaks down a high-level task into lower-level tasks (either compound or primitive). This is captured in our ASN by connecting nodes of lower-level tasks to their parent node corresponding to the method, which in turn is connected to the high-level task. A method should have a higher likelihood if a larger number of its subtasks have higher activation values. For instance, a method with only a single subtask node with activation value greater than zero is less probable than another method with two or more subtasks with the same activation values. This is why we chose to use sum edges to connect subtasks to their parent method. The edge weights are
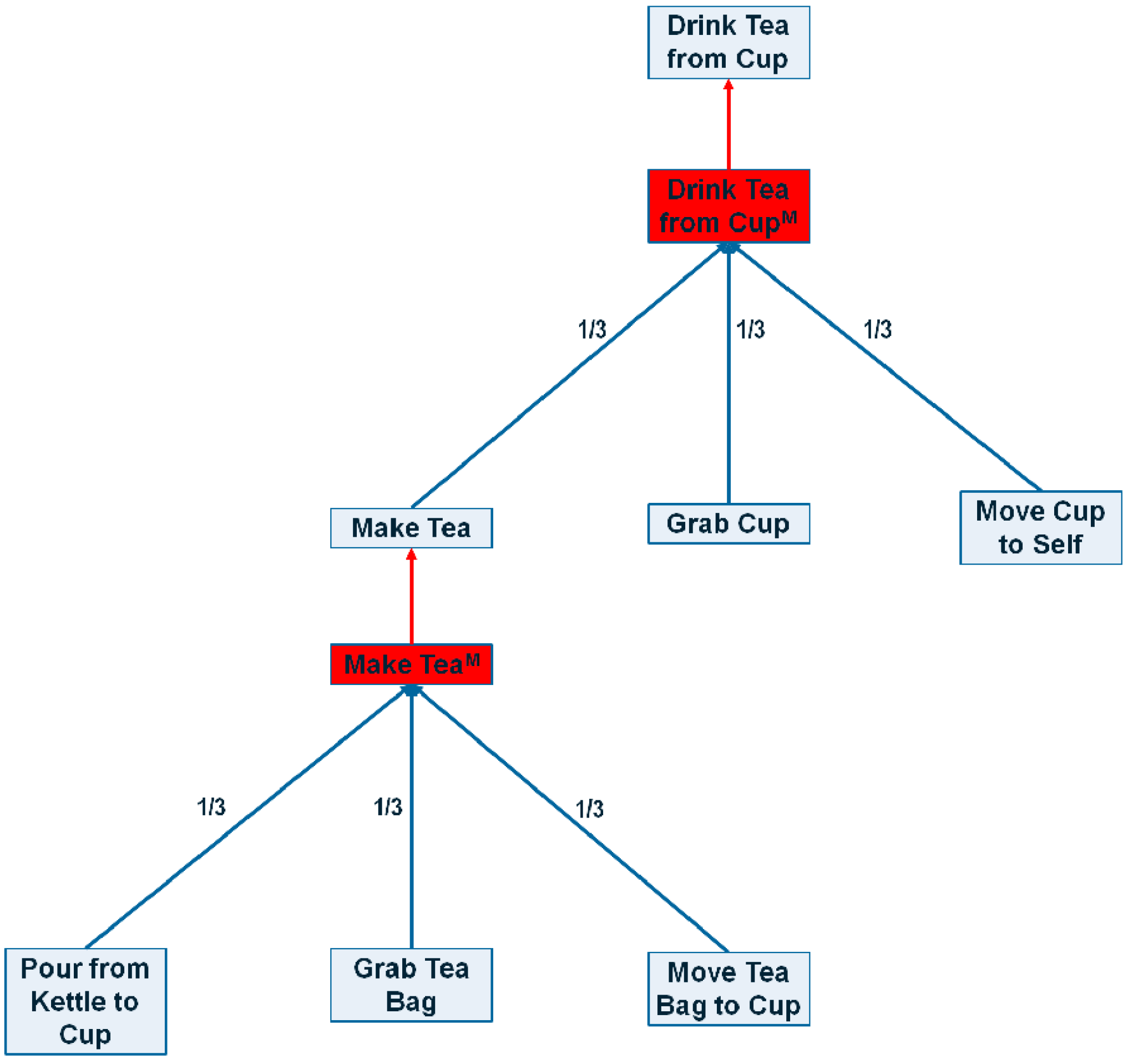
. This is a normalization factor and it makes the activation values in method nodes comparable to each other, regardless of their subtask size. A sample ASN created with this conversion algorithm is shown in
Figure 3. It is important to note that the algorithm in
Algorithm 3 does not use the partial order relation. At this stage, we simply ignore the ordering constraints between tasks and cannot distinguish between methods (perhaps not even for the same high-level task) that have exactly the same subtasks but in different orders. We will extend our ASN approach to handle partial order constraints in
Section 4.5.
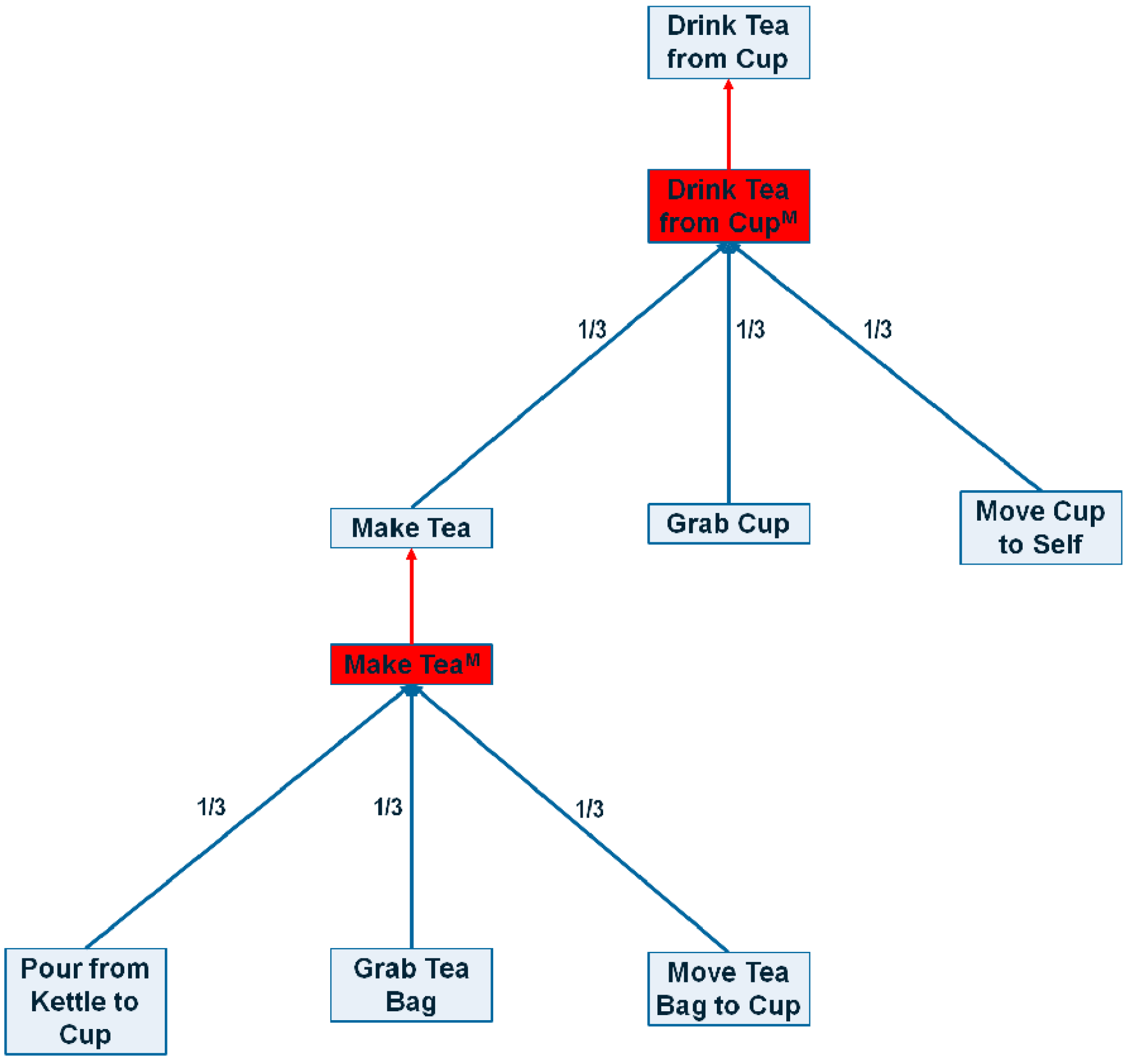
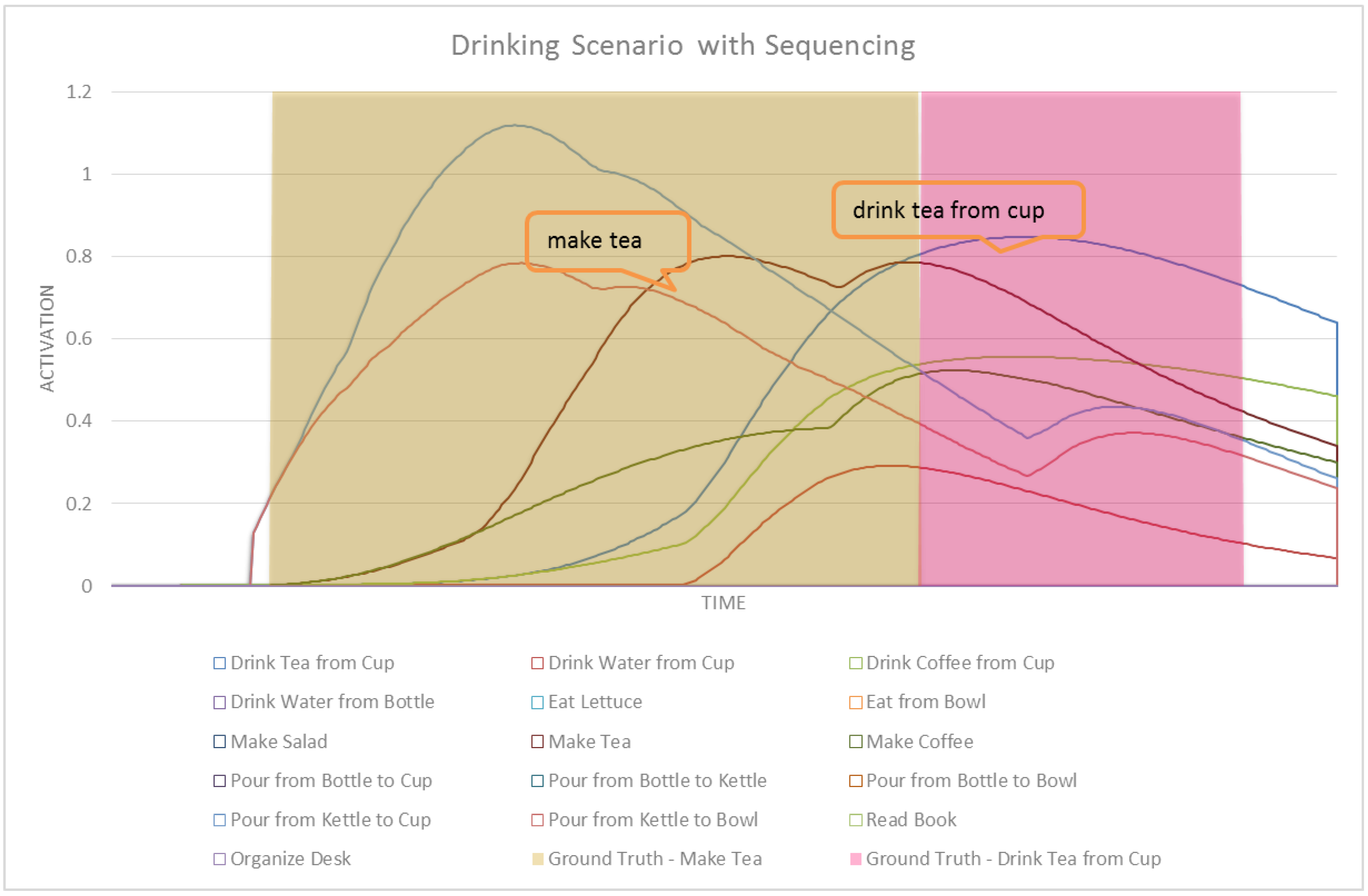
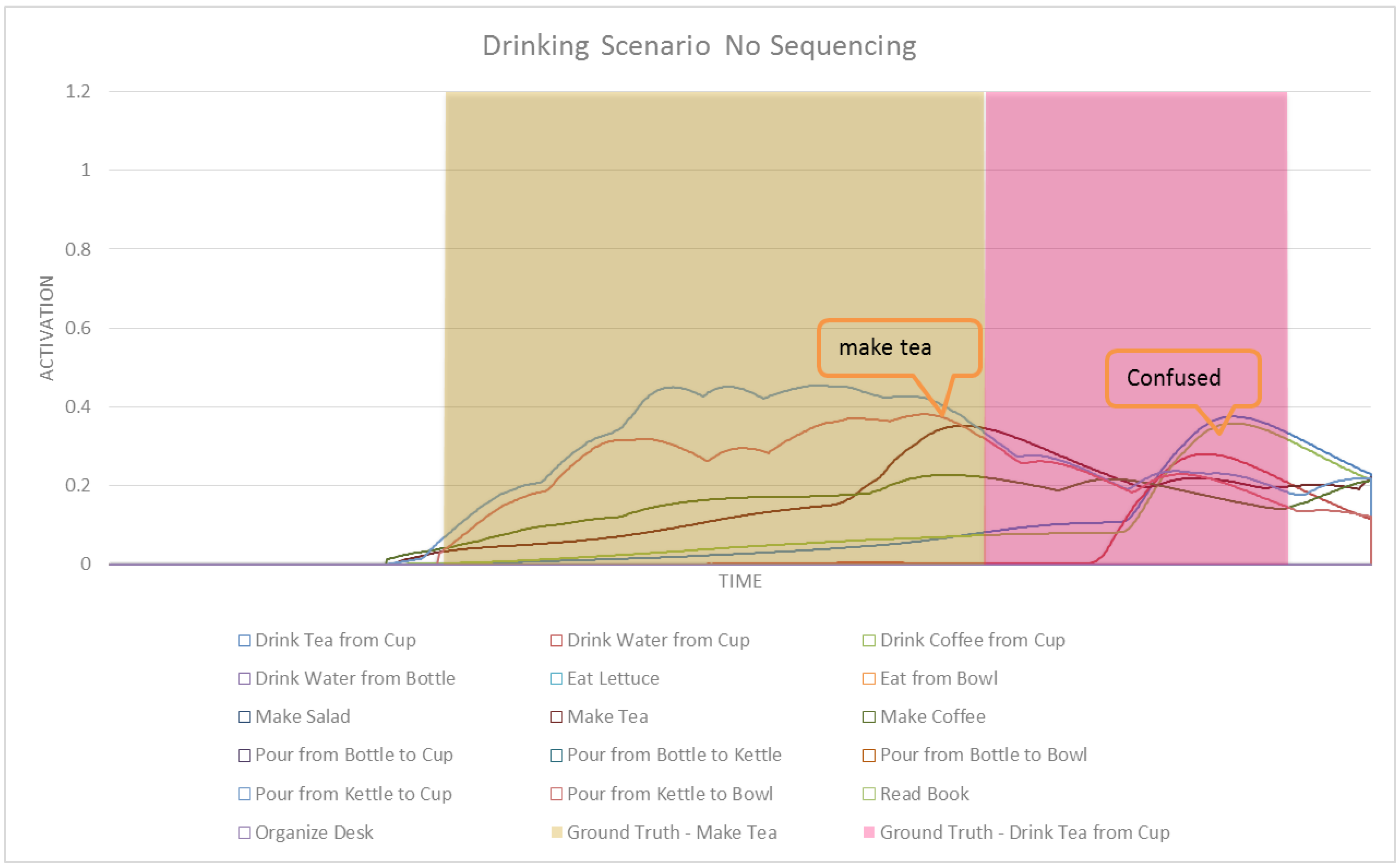
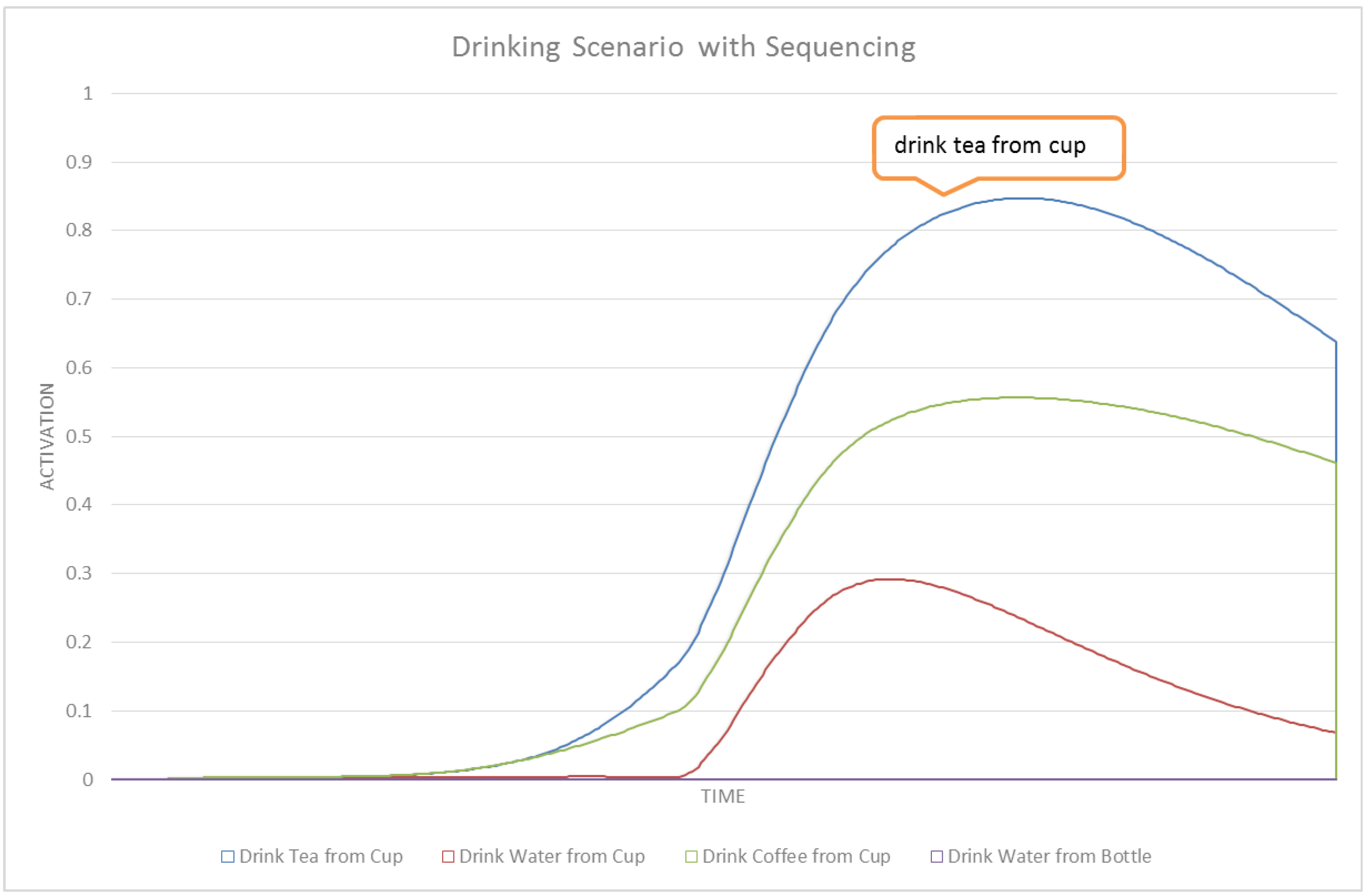
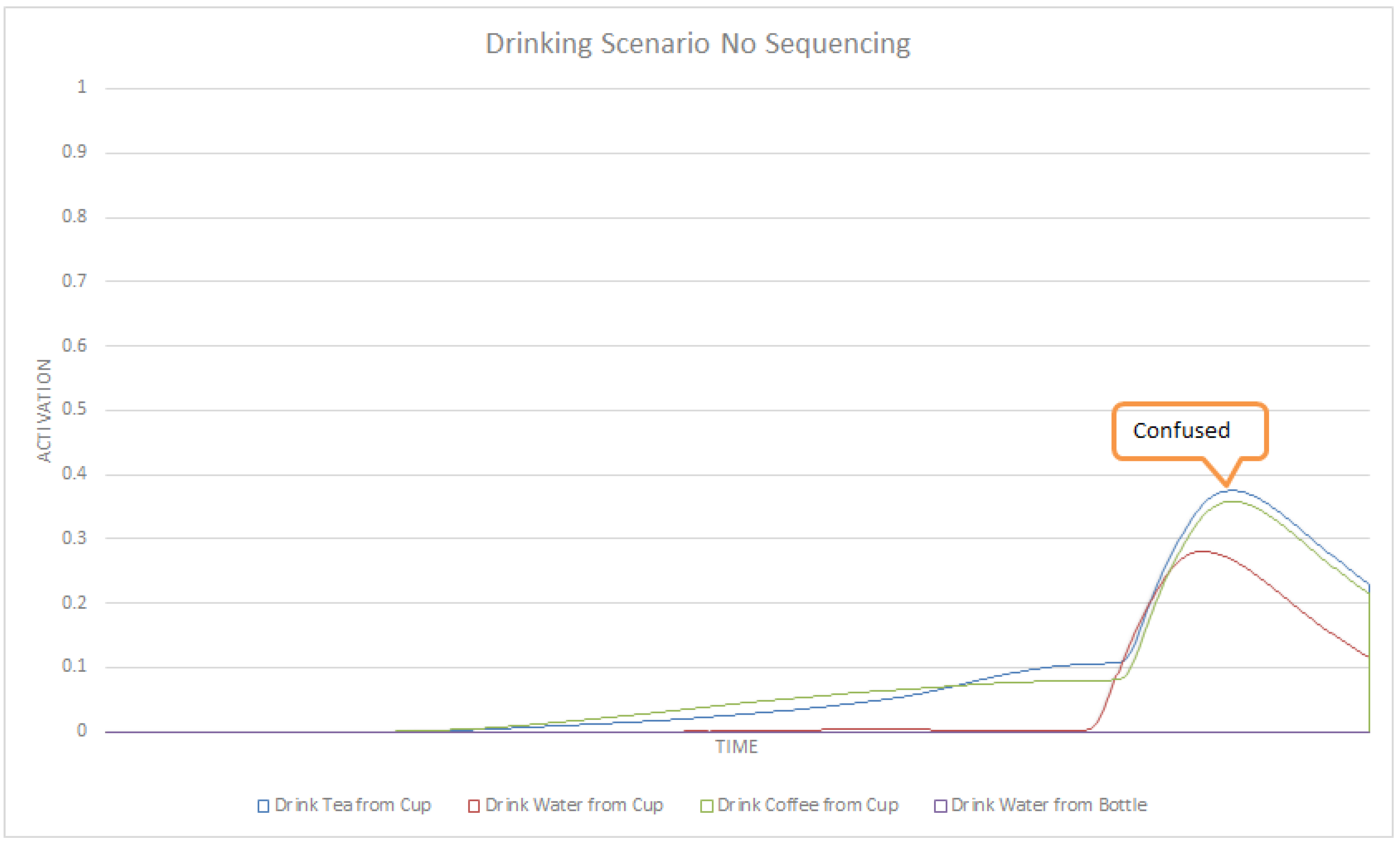
Figure 3.
A sample portion of the ASN generated from an HTN. Red edges are max edges, blue edges represent sum edges and red boxes represents method nodes.
Figure 3.
A sample portion of the ASN generated from an HTN. Red edges are max edges, blue edges represent sum edges and red boxes represents method nodes.
4.3. Intent Recognition in Activation Spreading Networks
As explained in
Section 4.2, the activation values are a comparative measure for selecting the most probable intention based on the observed evidence. The hierarchical structure of tasks in HTN suggests that at any given time, a subject is actively pursuing a set of intentions that are in agreement with each other but are at different levels in the hierarchy. Lower-level tasks that normally correspond to short time span activities that are a part of a larger and longer activity. This hierarchical structure is preserved in the process of converting HTN to ASN in its connected nodes. We use this hierarchical structure and the activation values of the nodes in the network to robustly detect the intention of completing a set of tasks but at different levels in the hierarchy. More precisely, we start the search from the highest-level nodes corresponding to the highest level intentions and choose the one with the largest activation value above a threshold. If none of the nodes have activation values greater than the threshold, then the system detects the
idle state for the subject. We then continue our search by only considering the children of that node. The highest activation value is chosen at each stage iteratively until we reach the lowest level, containing only operators. To disregard very low activation values, any node with activation below a threshold cannot be chosen even if it has the highest activation. The intent recognition algorithm is presented in
Algorithm 4.
It is important to note that activation values of nodes are only comparable if they are on the same level. Nodes in higher levels usually have smaller activation values, since they only receive activation values from lower-level nodes and edges have weights less than one, which reduces the activation values. This is why we only compare nodes at the same level in each stage of the recognition process. It is also possible that the node with the highest activation value in a lower level conflicts with the node with the highest activation in a higher level. The lower level node might belong to a task that does not contribute to the higher-level task with the largest activation value. To have a coherent recognition of intentions on different levels, at each stage of the process we limit our search space to nodes that are the children of the selected higher-level task.
| Algorithm 4 Intent recognition algorithm in ASN |
| let |
| repeat until |
| let |
| add to the set of recognized intentions if |
|
Since the network is acyclic, an external stimulus (
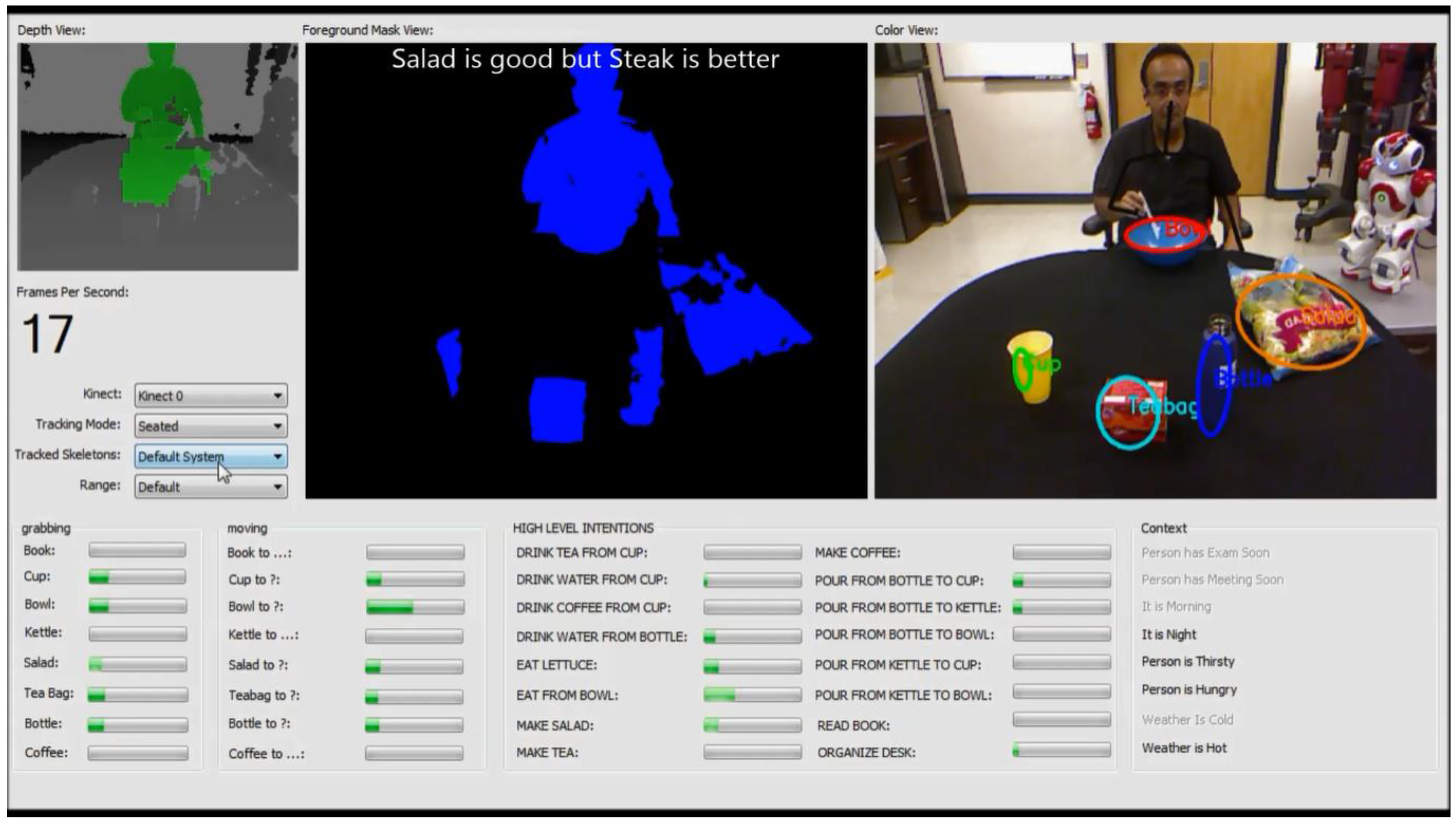
i.e., observation of a low-level activity) starts the activation spreading process in the network. Low-level activities correspond to operator nodes in the network. These nodes are leaves in the network, and they can propagate activation values up in the hierarchy, but no other nodes can send activation messages to them. We use simple formulas to compute the activation values for the operator nodes, based on the features extracted by the video parser. This part of the system will be defined in
Section 5.2.
4.4. Context-Based Intent Recognition
The precondition properties of operators and methods in HTN allow us to choose suitable methods to reduce a task network to a fully formed plan. These preconditions describe a context or situation in which that operator or method is suitable for achieving a goal. Planning approaches usually need to know about preconditions to successfully develop a plan suitable for the current circumstances by choosing suitable methods and operators. Similarly for intent recognition, we also face the problem of choosing the hypothesis that best describes the observed evidence. This suggests that having some information about the actual context of the observed scene can help in intent recognition, by analyzing what method or task is more probable for the subject to undertake, given the known circumstances. Unlike preconditions in planning, which model the required conditions, contextual information for intent recognition in our framework works as a favoring mechanism that makes some tasks more probable, and others less probable.
In order to incorporate contextual information in our intent recognition system, we modify the definition of ASN to include another type of nodes to represent contextual information and two special types of edge to connect contextual information to the relevant task nodes in the network. The formal definition of a contextual ASN (CASN) is as follows:
Contextual Activation Spreading Network: A CASN is an ASN with an additional set of:Context nodes representing different contextual information. A context node has an activation value representing the level of certainty for that context.
Positive context edges connecting nodes in to nodes in .
Negative context edges connecting nodes in to nodes in .
Nodes in
represent contextual information and their activation values represent the level of certainty about that information. It is important to note that the activation values do not represent probabilities and should not be interpreted as such. Nodes in
do not have any ingoing edges of any type and cannot send activation messages to any other nodes. Nodes in
cannot have activation values greater than 1. Nodes in
do not decay by clock ticks. Upon receiving activation messages, the receiving node
would update its activation value by first applying the procedure in
Algorithm 1 and then multiplying the activation value by
.
Algorithm 5 shows the algorithm for processing activation messages in the CASN.
Edges in
and
show the positive and negative effect of contextual information on the tasks. Having additional contextual information about the subject or the environment being observed by the system should not increase or decrease the activation value of any tasks, unless we are observing some activities in the scene. In other words, we should not detect any intentions when no activity is being observed, even if all contextual information is in favor of a particular activity. That is why we chose the above formula to update activation values. If no contextual information is available, then the activation values of nodes in
are zero and the multiplication factor is one. If contextual information in favor of a task is stronger than contextual information against a task, then the multiplication factor would be greater than 1, and it will be less than 1 otherwise. A sample of CASN is shown in
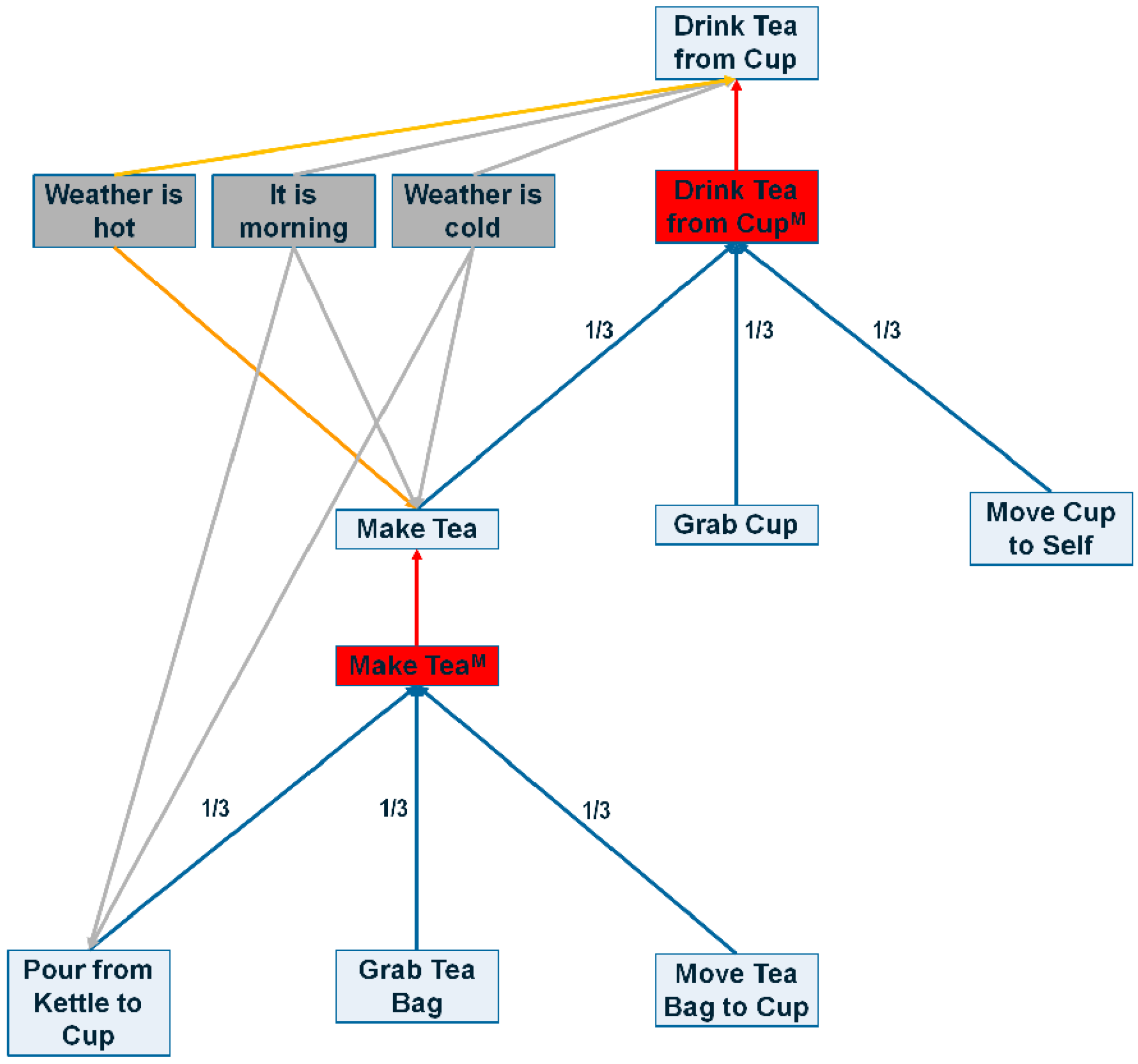
Figure 4.
| Algorithm 5 Activation message processing algorithm in CASN |
| let be the node receiving activation message from |
| let |
| if |
| |
| else |
|
|
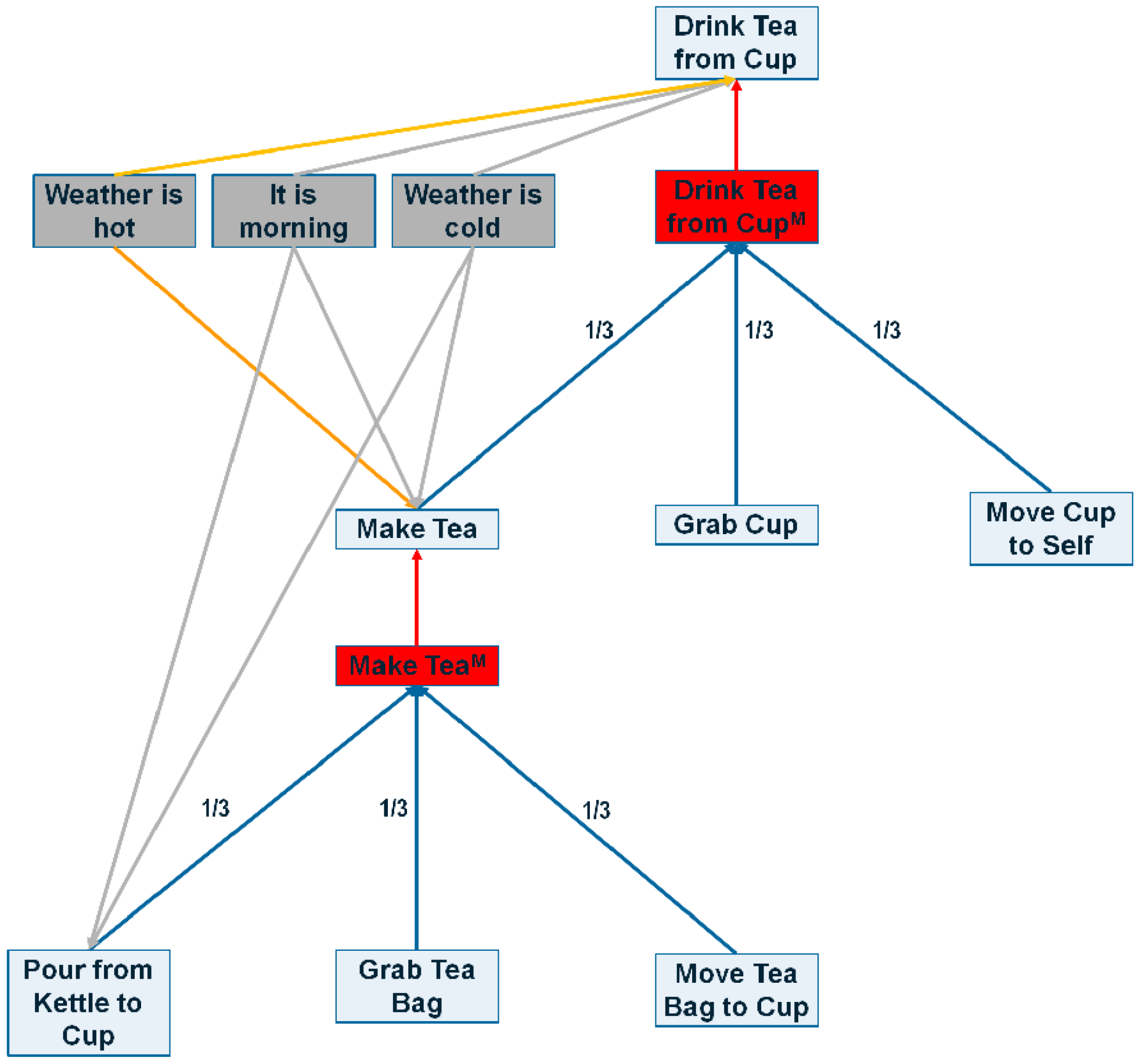
Figure 4.
A sample portion of the CASN. Red edges are max edges, blue edges represent sum edges, grey lines show positive context edges and orange represents negative context edges. Red boxes represents method nodes and grey boxes show context nodes.
Figure 4.
A sample portion of the CASN. Red edges are max edges, blue edges represent sum edges, grey lines show positive context edges and orange represents negative context edges. Red boxes represents method nodes and grey boxes show context nodes.
4.5. Partial-Order Modeling in Activation Spreading Networks
As previously discussed in
Section 4.2, the ASN and CASN cannot model partial-order constraints in the hierarchical task network formalism, and the intent recognition procedure in ASN and CASN cannot distinguish between methods of two different tasks that are only different in their partial-order constraints. We now propose an extension to ASN in order to model partial-order constraints by allowing edges to receive activation messages and defining a special type of edge (ordering edges) to connect nodes to other edges in the network.
Partial-Order Contextual Activation Spreading Network: A Partial-Order Contextual Activation Spreading Network (POCASN) is a CASN with an additional set of:Ordering edges , connecting nodes in to edges in . Every sum edge has an activation value in addition to its weight and can receive activation messages from ordering edges in .
Min edges , connecting nodes in to each other. A min edge is another type of edge in which activation messages spreads in the network and the receiving node processes it by updating its activation value with a minimum value selection.
Upon receiving an activation message from node
, a sum edge
updates its activation value with
. With every clock tick, activation values of all sum edges like
decays according to:
. Upon receiving an activation message, a node updates its activation value by summing the activation message multiplied by the edge weight plus the edge activation value, with its own activation value if the message was received via a sum edge. A node would update its activation value by choosing the minimum activation message on all ingoing min edges.
Algorithm 6 shows the algorithm of processing activation messages in the POCASN.
The main idea behind POCASN is to allow nodes to strengthen edges that connect subsequent tasks (in the task partial ordering) to the common parent node, by sending activation messages to those edges. If a task receives high activation values (showing a detection of that task), it cannot significantly affect its parent node, unless the preceding task in the partial-order has been detected and strengthened the edge connecting that task to its parent. The procedure of activation spreading in POCASN suppresses spreading of activation among nodes, if the order of observed tasks is not in agreement with the partial order constraints. The edges in
connect task nodes to edges from the subsequent task nodes in the partial order to their common parent. The reason behind defining min edges is to model tasks that have no ordering constraints with respect to each other. For such tasks there is no requirement on their order of execution. However, these tasks can all be the immediate prerequisite of another set of tasks. All the prerequisite tasks should have been detected (have high activation values) to strengthen edges on the subsequent set of tasks. We use min edges to connect all unrelated nodes to an extra node, which, in turn, is connected to the edges of the subsequent set of tasks. This ensures that all prerequisite tasks are detected before expecting to observe the subsequent tasks in the task network. We limit the activation value of edges in
to
, mainly because any activation values more than that would amplify the activation value of the sender node by multiplying it with a number greater than 1, which is not desirable.
We now introduce the algorithm to convert HTN to POCASN by modifying the original conversion algorithm presented in
Algorithm 3. The new conversion algorithm that creates a POCASN from an HTN is shown in
Algorithm 7.
| Algorithm 6 Activation message processing procedure in POCASN |
| let be the node receiving activation message from |
| let |
|
| if |
|
|
|
| else |
|
|
The conversion procedure is similar to the original algorithm in
Algorithm 3 with some modifications. Recall that partial-order constraints in HTN are a part of a task network which itself is the body of a method for accomplishing a compound task. While processing different methods for a compound task, we first need to topologically sort the set of tasks in the method body, according to their partial-order constraints. While processing each task
in the body of a method, we first find a chain containing that particular task to find out all the immediate prerequisite tasks
. Then we add a dummy node to the network for collecting activation values of all tasks in the
via min edges. This dummy node in turn spreads activation to the sum edge from
to the method, in order to model sequencing.
| Algorithm 7 HTN to POCASN conversion algorithm |
| for every operator in HTN |
| for every substitution in the domain of |
| add node to the ASN |
| for every compound task in HTN |
| for every substitution of |
| add node to the ASN if not already present |
| for every method and |
| add node to the ASN |
| add a max edge from to |
|
| for every task in |
| let be a substitution for in |
| agreement with |
|
|
|
|
|
| if is compound then |
| add node if not already present |
| add a sum edge from to with |
| as weight |
|
| else if is primitive then |
| let be the operator corresponding to |
| add a sum edge from to with |
| as weight |
|
Weights of sum edges in POCASN represent a minimum effective value for the edges, since they can receive activation values from ordering edges to make them stronger. Unlike the original ASN in which sum edges would connect task nodes to method nodes in the network with a shared normalization weight of
, in POCASN we need to assign smaller weights to outgoing edges from tasks that come after other tasks in the chain. This is because observing a task that comes after another task in the chain, should not be sufficient for detecting the intention by itself. This observation is only important if we previously detected preceding tasks (high activation values for preceding tasks). Weights of sum edges should be normalized by the size of the subtasks in order for different methods on the same level to have comparable activation values.
was chosen as the weight of sum edge connecting node
to its parent.
is the normalization factor for a method and
is the effect of ordering of task
among other tasks in the network. A sample POCASN is shown in
Figure 5.
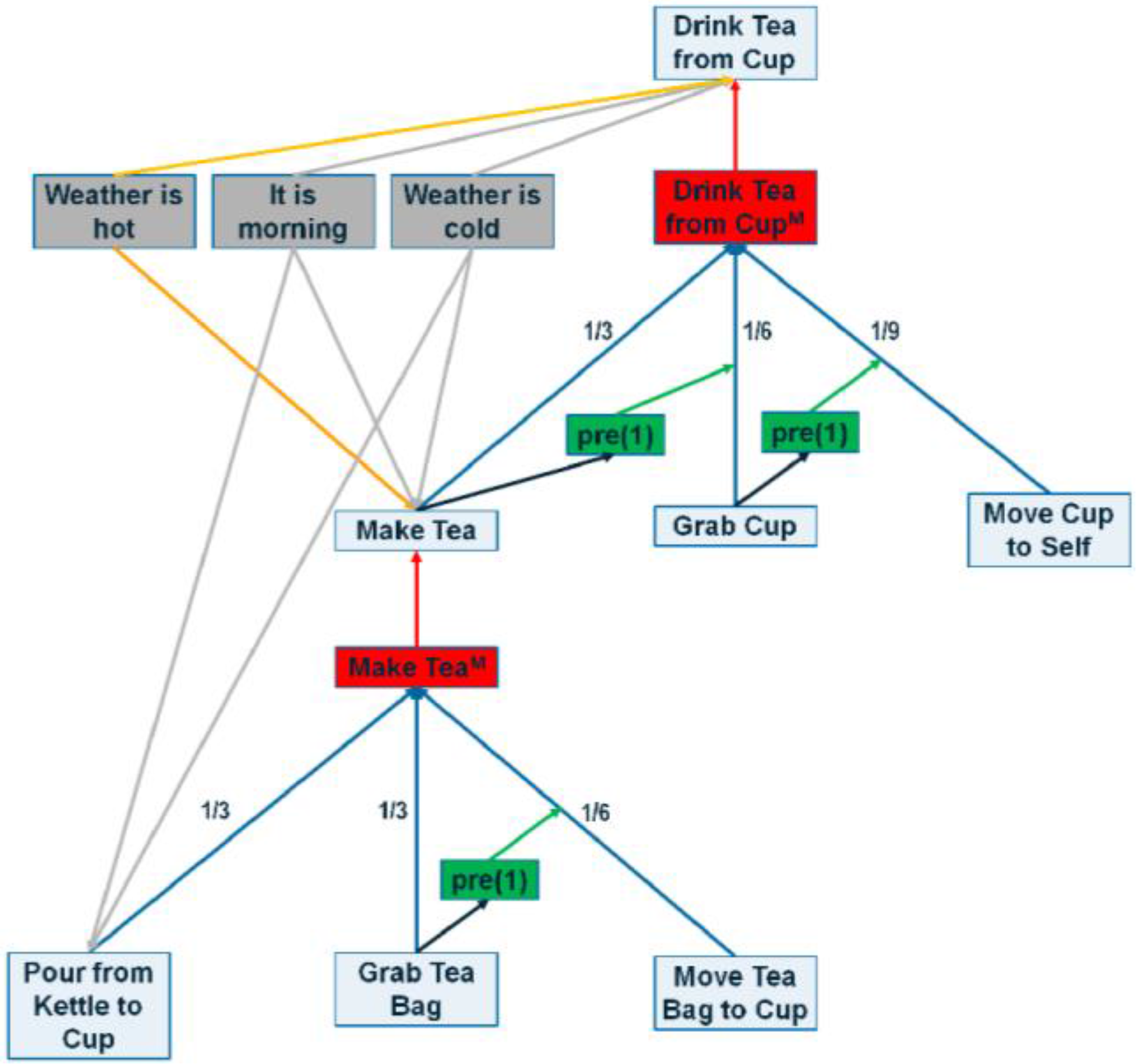
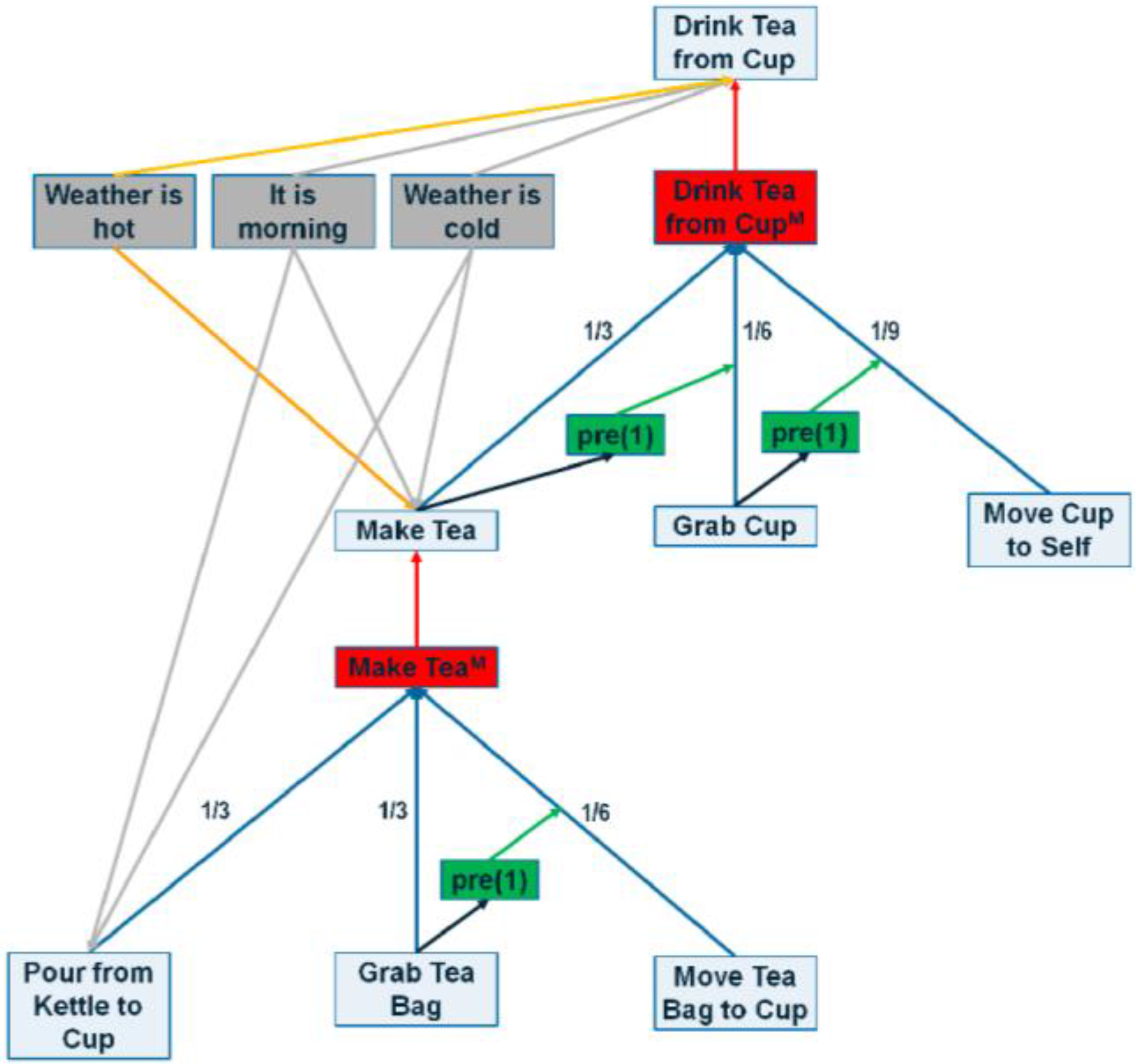
Figure 5.
A sample portion of the POCASN. Red edges are max edges, green lines are ordering edges, black lines are min edges, blue edges represent sum edges, grey lines show positive context edges and orange represents negative context edges. Red boxes represents method nodes, grey boxes show context nodes and green boxes represent dummy nodes used to connect ordering edges to sum edges.
Figure 5.
A sample portion of the POCASN. Red edges are max edges, green lines are ordering edges, black lines are min edges, blue edges represent sum edges, grey lines show positive context edges and orange represents negative context edges. Red boxes represents method nodes, grey boxes show context nodes and green boxes represent dummy nodes used to connect ordering edges to sum edges.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

 ac(v^' )
ac(v^' )