1. Introduction
In the mining industry, the tracking control of autonomous vehicles presents significant challenges in off-road environments, where complex terra-mechanical interactions can lead to performance degradation. Autonomous driving can be affected by disturbances arising from the unpredictability of the operating environment, including uneven terrain, unpredictable frictional characteristics, and the presence of external aspects, such as airborne particulate matter. Specifically, the mining environment is characterized by complex topographical features on the soil, which reduces the soil’s traction properties, further complicating autonomous vehicle navigation [
1]. These aspects not only impact the vehicle’s ability to maintain stable motion control but also introduce safety risks to both autonomous systems and human operators.
Terrain complexity exacerbates tire stress, particularly through the presence of turns and slopes that induce uneven load distribution, alongside the critical phenomena resulting from wheel–terrain interaction due to debris accumulation on the surface [
2]. In particular, friction loss under these conditions leads to weakened traction forces, which can result in drifting and destabilization, thereby impairing the control of the vehicle [
3]. These challenges can also affect the lifespan of tires [
4], which leads to their necessitating frequent replacements and reduces the availability of the hauling fleet, which in turn impacts overall productivity. Due to the complex wheel–terrain interaction in mining mobile vehicles, there is a critical need to enhance the robustness of motion control systems to counteract terrain disturbances and mitigate the adverse effects of slip phenomena on traction and vehicle dynamics.
Traditional control methods, such as Model Predictive Control (MPC) [
5,
6] and Sliding Mode Control (SMC) [
7,
8], have been used to address such challenges in autonomous vehicle motion control and related dynamics. However, these approaches are inherently dependent on dynamic models of both the robot and its interaction with the environment. This reliance makes them vulnerable to the performance degradation caused by modeling mismatches, which may arise from inaccurate model assumptions or discrepancies between the assumed and actual vehicle dynamics. Such modeling errors can lead to suboptimal control performance, especially in highly dynamic and uncertain environments, such as those found in mining operations. Alternatively, Deep Reinforcement Learning (DRL) techniques offer a promising approach by learning control policies through continuous interaction with the environment, using real-time feedback to adapt to dynamic conditions [
9,
10]. This capability reduces reliance on an exact model, making DRL particularly advantageous in this study, as it enables the controller to operate based on the robot’s real-time dynamics rather than relying on precise and often complex terra-mechanical models. However, limitations in robot sensors during real-time data acquisition often result in partial observability, where the controller is unable to obtain information from a complete representation of the environment, potentially diminishing its effectiveness [
11]. Although DRL-based navigation strategies have shown significant progress in mobile robots, current methods often face limitations in unstructured environments where simplified control structures are not adapted to varying motion conditions or terrain assumptions [
12], highlighting the need for robust and adaptive control schemes capable of learning suitable dynamics under varying system conditions. The use of Recurrent Neural Networks (RNNs) has been studied to address this problem [
11,
13], leveraging historic observations to infer the current environment state. However, to the best of our knowledge, this integration has not been assessed on recent state-of-the-art DRL algorithms.
Work Contributions
The main contributions of this work are as follows:
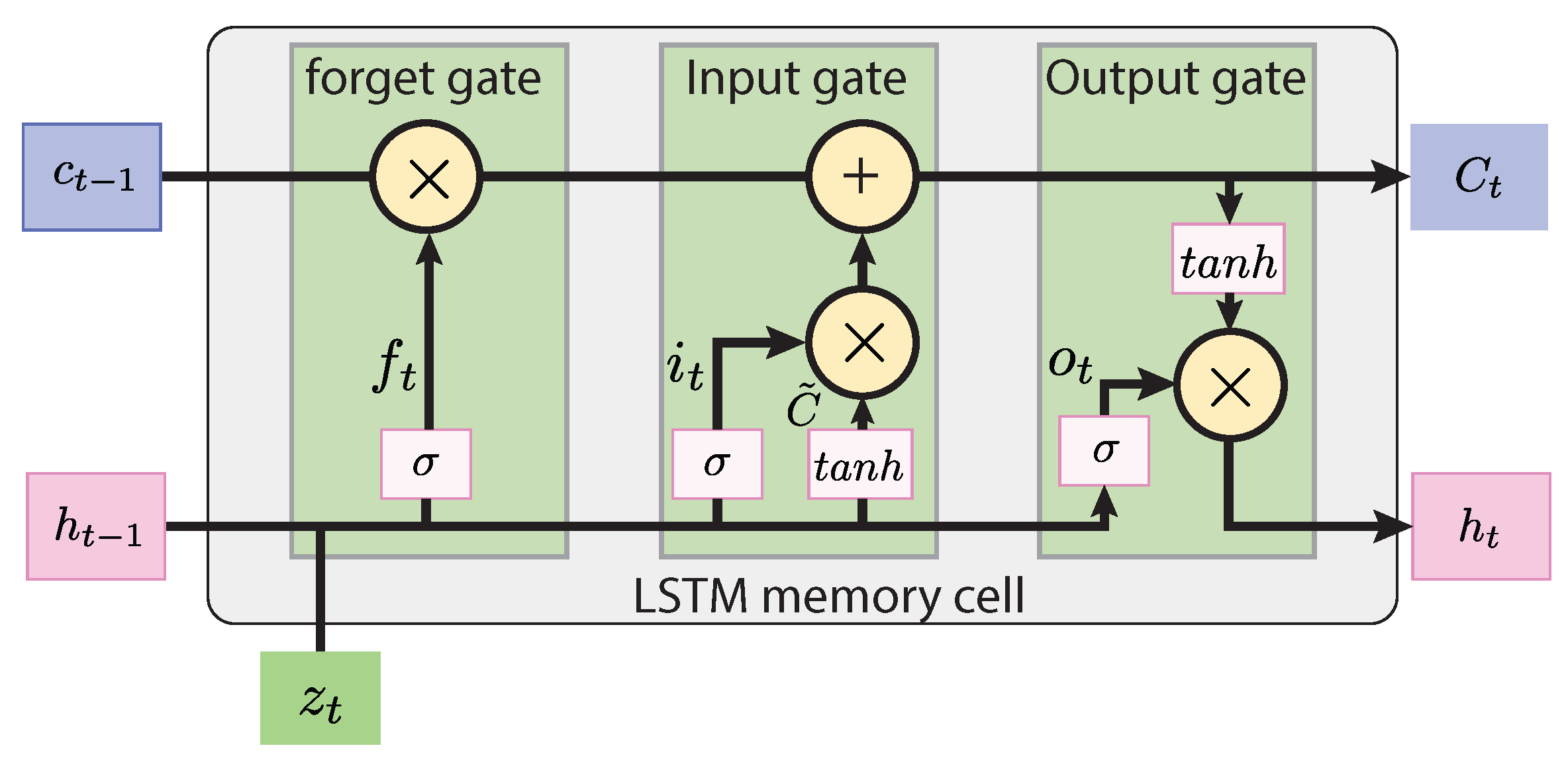
Integration of Long Short-Term Memory (LSTM) networks into DRL-based controllers, enabling control agents to recurrently retain and use temporal dependencies under partial observability of past dynamics. This enhancement improves the agents’ ability to infer unobservable system states caused by sensor limitations and complex terrain interactions, contributing to the generalization of learned policies and greater adaptability under challenging terrain conditions.
A comprehensive evaluation of vanilla-based algorithms under policy gradient-based DRL algorithms that rely on fully observable state representations, such as PPO, DDPG, TD3, and SAC, for trajectory tracking control in skid-steer mobile robots operating under mining terra-mechanical constraints. This study analyzes the stability, adaptability, and effectiveness of the proposed algorithms while ensuring accurate trajectory tracking and regulation despite terrain disturbances and dynamic parameter variations.
The application of DRL algorithms for autonomous motion control, focusing on tracking reference trajectories in numerical simulations and real-world mining environments subject to external disturbances and uncertainties. The findings provide insights into the role of memory-augmented reinforcement learning for robust motion control in unstructured and high-uncertainty environments, advancing in the enhanced performance of DRL approaches and their applicability for mobile robots in complex mining operations.
In summary, this work aims to develop a robust motion control strategy for the trajectory tracking of autonomous skid-steer robots operating in mining environments by integrating LSTM networks into policy gradient-based DRL methods. The proposed approach addresses the challenges of partial observability arising from vehicle dynamics and terrain-induced slip due to wheel–terrain interaction, enabling adaptive control without dependence on accurate terra-mechanical models.
The remainder of the paper is organized as follows:
Section 2 provides a review of related works on reinforcement learning (RL) techniques applied to trajectory tracking control in autonomous motion.
Section 3 outlines the theoretical background of Deep Reinforcement Learning (DRL), laying the foundation for the proposed methodologies. In
Section 4, the DRL techniques used as the basis for the proposed motion controllers are detailed.
Section 5 presents the vehicle dynamic model and terrain characterization used for training and evaluating the motion controllers.
Section 6 covers the control design and parameter settings implemented in the trajectory tracking controllers.
Section 7 describes the experimental setup and analyzes the results obtained from the experiments. Finally, the paper ends in
Section 8 with concluding remarks on this work.
2. Related Works
Trajectory tracking remains a fundamental challenge in autonomous motion control, with traditional control methods often struggling to address complexities inherent to real-world environments. For instance, approaches such as Model Predictive Control (MPC) [
5], Fuzzy Logic-based control [
14], and Sliding Mode Control [
7] have been extensively applied in trajectory tracking in autonomous motion tasks. However, these methods have been typically designed to be adaptive and have often relied on accurate models of the robot motion dynamics, which can be challenging or even infeasible to obtain in environments in the presence of uncertainties [
15]. In contrast, reinforcement learning (RL) methods currently offer a compelling alternative by learning optimal control policies without necessarily requiring an explicit model formulation of the robot system dynamics. Instead, RL enables an agent to learn motion dynamics through direct interaction with the environment, iteratively refining its policy to maximize reward signals that guide the system toward prescribed trajectory tracking control and regulation objectives. This characteristic makes RL well suited for motion control in complex and uncertain environments, and it has been successfully applied to a wide variety of applications in structured and non-structured environments, including autonomous navigation of aerial [
16,
17,
18] and marine vehicles [
19], industrial process control [
20], and even complex gameplay scenarios [
21]. For instance, the work in [
22] addressed a path tracking problem in autonomous ground vehicles using inverse RL under matched uncertainties. However, the approach assumed idealized system conditions and omitted accounting for external disturbances or environmental variability, which limited its applicability in real-world scenarios. In [
23], a Q-Learning (QL) strategy was used in combination with a PID controller for obstacle avoidance in trajectory tracking tasks for simulated wheeled mobile robots. However, as Q-Learning relies on a tabular estimation of the state–action value function, it does not scale properly according to the continuous state and action spaces, which is often necessary for the effective trajectory tracking control of autonomous vehicles [
21].
To address scalability limitations in Q-Learning and continuous control action constraints, Deep Q-Networks (DQNs) may be used instead by replacing tabular Q-value estimation with neural networks, enabling the handling of high-dimensional continuous state spaces [
21]. Dual Deep Q-Network (DDQN) has been adopted as a variant of the DQN method to enhance stability and reduce overestimation biases in trajectory tracking controllers [
24]. However, both DQN and DDQN inherently rely on discrete action spaces, as they approximate an optimal action value function by selecting actions from a finite set, limiting their ability to execute accurate and smooth control actions. Policy gradient methods address this limitation by directly optimizing a parameterized policy, enabling control in continuous action spaces. Offline learning techniques such as Conservative QL (CQL) [
25] or Bayesian QL (BQL) [
26] were not considered here since our objective focused on interaction-driven policy learning with real-time adaptability rather than leveraging a pre-collected or static dataset obtained from the robot dynamics. Similarly, while model-based RL approaches such as MBPO (Model-Based Policy Optimization) [
27] and PETS (Probabilistic Ensembles with Trajectory Sampling) [
28] have demonstrated data efficiency, they were not used here due to our focus being on model-free methods that avoid potential model bias and complexity in highly uncertain and partially observable environments.
A persistent challenge in autonomous driving arises when sensor limitations prevent the agent from fully observing the system state at any given time [
11,
13]. This issue is especially critical in mining and off-road environments, where observations from range sensors or positioning systems may be intermittent or unreliable due to environmental constraints such as occlusions, dust, or irregular terrain [
29]. Moreover, complex terrain topography and variable soil conditions can constrain traversability and introduce uncertainties in planning and control, resulting from uneven friction conditions and dynamic weather effects on the soil’s physical properties [
16]. For instance, in [
30], RL methods based on convolutional neural networks and value iteration networks were used to address maneuverability tasks. However, the approach was limited to high-level planning under conditions of known terrain maps, with reward structures learned in a fully observable setting. Then, it did not consider partial observability introduced by sensor limitations or dynamic terrain changes, nor did it incorporate low-level control disturbances arising from wheel–terrain interaction.
Deep RL techniques have shown improved robust motion control and navigability on rough terrain [
31,
32]. Among policy gradient methods, Proximal Policy Optimization (PPO) has been applied to motion control tasks [
13], where it has been integrated with Long Short-Term Memory (LSTM) networks in distributed architectures to address partial observability. LSTM networks have been used to process historical state information, which was used exclusively during random initializations of reference states in each learning episode. Such approach enhanced state inference and early exploration, aiding to mitigate the effects of unknown initial conditions on vehicle dynamics [
11,
13].
While PPO demonstrated effectiveness in continuous control, the on-policy nature of PPO limits its sample efficiency compared with off-policy approaches, making it less practical in scenarios with restricted data availability. Such concern has encouraged the development of Deep Reinforcement Learning (DRL) techniques that integrate the advantages of policy gradient methods, such as their capability to handle continuous action spaces, with the sample efficiency of off-policy algorithms such as Q-Learning. For instance, Deep Deterministic Policy Gradient (DDPG) strategies optimize deterministic policies by using the deterministic policy gradient approach [
33]. This method uses an off-policy learning paradigm with an actor–critic architecture, enabling more efficient data reuse and improved convergence properties. In [
10,
34], DDPG-based trajectory tracking controllers were designed to enhance motion control in autonomous mobile robots with ground force interactions. Although extensive simulation tests demonstrated the effectiveness of DDPG in handling terrain disturbances, robust control performance was primarily assessed in the presence of external disturbances, while the system’s ability to adapt to dynamic and complex terrain conditions such as slip dynamics or terrain variations was not comprehensively evaluated. For instance, in [
35], the authors developed a one-step RL strategy based on DDGP for simultaneous motion planning and tracking control in a simulated robot under ideal terrain conditions, which restricted the agent’s ability to model temporal dependencies and perform long-horizon multi-step learning. Then, this limitation could reduce control performance in the robot task since it requires sequence learning and complete adaptation over time. Similarly, the work in [
11] proposed an extension of DDPG by integrating Long Short-Term Memory (LSTM) layers into the neural network architecture, improving control performance in partially observable environments. This approach uses a kinematic controller as a reference for two independent PI dynamic controllers for ideal conditions of motion without tractions losses, taking advantage of the LSTM’s ability to retain historical state information and explore control actions. Experimental results demonstrated that the hybrid DDPG-LSTM framework outperformed both conventional PI controllers and standard DDPG under dynamic uncertainty. However, its robustness across diverse trajectory configurations, particularly in scenarios involving sharp turns and terrain disturbances, was not assessed. To address some of DDPG’s limitations, such as value overestimation and training instability, the Twin Delayed DDPG (TD3) algorithm was developed [
36]. In particular, the TD3 method incorporates mechanisms to stabilize learning, such as delayed target network updates and action smoothing [
37]. This algorithm has been successfully applied to trajectory tracking for racing vehicles [
38], particularly for drift control in high-speed racing scenarios. Alongside TD3, the Soft Actor–Critic (SAC) algorithm was introduced in [
39]. SAC trains a stochastic policy in an off-policy manner by optimizing entropy as part of the learning objective. In such work, SAC has been shown to outperform DDPG and DQN in trajectory tracking for racing applications, particularly in drift control, by showcasing its adaptability to unseen environments [
40]. Hybrid methods combining DDPG with deterministic algorithms [
41] or modified SAC variants with heuristic integration [
42] have shown improvements in trajectory smoothness and training efficiency under static or mildly dynamic conditions. Similarly, approaches such as HDRS-based DRL [
43] and improved TD3 algorithms leveraging transfer learning and prioritized experience replay [
44] focus primarily on reducing convergence time and optimizing path planning and control performance in structured environments. However, these methods largely operate under fully observable state assumptions and use feedforward architectures, limiting their ability to model temporally extended dependencies required for robust decision making in scenarios with incomplete state information and complex dynamic interactions. Alternatively to the previously discussed model-free RL algorithms, model-based RL techniques greatly improve sampling efficiency by learning a representation of the model dynamics. For instance, Model-Based Policy Optimization (MBPO) was applied to trajectory tracking in autonomous driving, outperforming SAC while requiring one-order-of-magnitude fewer training episodes [
45]. Nevertheless, their reliance on a learned dynamic model may be unsuitable in mining environments due to a high degree of uncertainty. In particular, unpredictable terrain phenomena such as variable slip conditions, as well as operational hazards such as airborne materials, can degrade sensor reliability, introducing uncertainty into state estimation. These challenges could introduce significant modeling errors, which may lead the agent to exploit inaccuracies in the dynamic model and learn a suboptimal control policy. Moreover, while these RL-based methods have shown promise across various trajectory tracking tasks, selecting the most suitable algorithm for a given problem remains complex. Several factors, such as the agent’s observation space, the tuning of hyperparameters, and the design of the reward function, significantly impact the effectiveness of DRL-based controllers [
46]. Therefore, this work also proposes a comparative study of DRL techniques, specifically for trajectory tracking in mobile robots subject to terra-mechanical constraints, to provide deeper insights into their performance and applicability.
3. Theoretical Background
In this section, the vehicle dynamics for trajectory tracking are formulated within the framework of a Markov Decision Process (MDP). Under this formulation, an agent selects an action
from the action space
based on a policy
, which maps observed system states
to optimal control decisions. The selected action transitions the system to a new state within the state space
and yields a reward
from the reward set
, which quantifies the quality of the chosen action in achieving the trajectory tracking objective. The goal of the proposed RL algorithms is to learn an optimal policy
so that the cumulative discounted reward
is maximized, defined as
where
represents the immediate reward at each time step, and
is the discount factor that determines the relative balance of immediate and future rewards. By optimizing
, the agent learns to make decisions that not only maximize immediate rewards but also improve long-term performance. This optimization process requires balancing the trade-off between exploration, where the agent gathers new information about the environment, and exploitation, where it applies acquired knowledge to maximize rewards. Such a balance is crucial in complex and dynamic environments, where adaptability and continuous learning enable the agent to achieve robust control performance and efficient trajectory tracking.
To quantify the expected cumulative reward associated with specific actions and states, the action–state value function
, commonly referred to as the
Q-function, is used. This function evaluates the long-term reward obtained by taking action
in state
and subsequently following policy
. It is formally defined as follows:
where
represents the control action taken at time step
t,
denotes the environment state at time step
t,
is the state transition probability distribution,
is the discount factor, and
represents the probability of selecting action
under policy
given state
[
47].
5. Environment Characterization: Skid-Steer Mobile Robot
A skid-steer mobile robot (SSMR) is used in this work as part of the environment to assess the proposed DRL approaches for trajectory tracking control. The robot incorporates a differential steering mechanism combined with a pair-driven four-wheel system to distribute the effects of lateral skidding and longitudinal slip experienced by each wheel, as illustrated in
Figure 3. The SSMR model assumes a uniform load distribution across the vehicle to simplify the internal force balance. However, the SSMR is also prone to external forces induced by terrain unevenness, which may disrupt this balance and introduce additional disturbances. As shown in
Figure 3, the SSMR model highlights key force interactions, including longitudinal traction forces
and lateral resistance forces
for each wheel. Unlike ideal unicycle models, this approach adopts the SSMR model presented in [
5,
52] as the environment for training and testing the proposed DRL algorithms. This model offers a more realistic representation of wheel–ground interactions, especially off-road or on uneven terrains commonly found in mining environments, where traction varies dynamically. To account for the nonholonomic restrictions inherent in skid-steer systems, the model explicitly incorporates lateral motion constraints, which are typically neglected in simplified models. This ensures a more accurate representation of the SSMR dynamics, particularly when navigating surfaces with different friction characteristics or when executing turns that may induce lateral skidding. However, model uncertainties still persist in the dynamics associated with the robot model due to the heterogeneous conditions of the navigation terrain. The motion model for the SSMR can be described as follows:
where
x,
y, and
denote the robot’s pose, and
v and
are linear and angular speeds, respectively. Slippage and disturbances in skidding forces are accounted for in the vector
, which characterizes disturbances affecting the robot’s motion, including position, orientation, and speed errors. The vector of model parameters
is derived from the characteristics of the robot chassis, such as mass, inertia, and geometric specifications, obtained from [
5]. Lastly,
and
represent the control actions applied to the SSMR, namely, traction and turning speeds, respectively. The reader is referred to [
5] for further details of the SSMR model.
7. Experimental Setup and Results
To evaluate the performance of the proposed trajectory tracking controllers, both simulation and experimental trials were conducted by using the SSMR described in
Section 5. The controllers were synthesized by using MATLAB V2024b (MathWorks
®, Natick, MA, USA), leveraging the Reinforcement Learning Toolbox and the Deep Learning Toolbox. The training of the DRL agents was executed on a laptop equipped with an AMD Ryzen 7 4800U processor (AMD
®, Santa Clara, CA, USA), 16 GB of RAM, and an NVIDIA GeForce RTX 3080 Ti graphics card (Nvidia
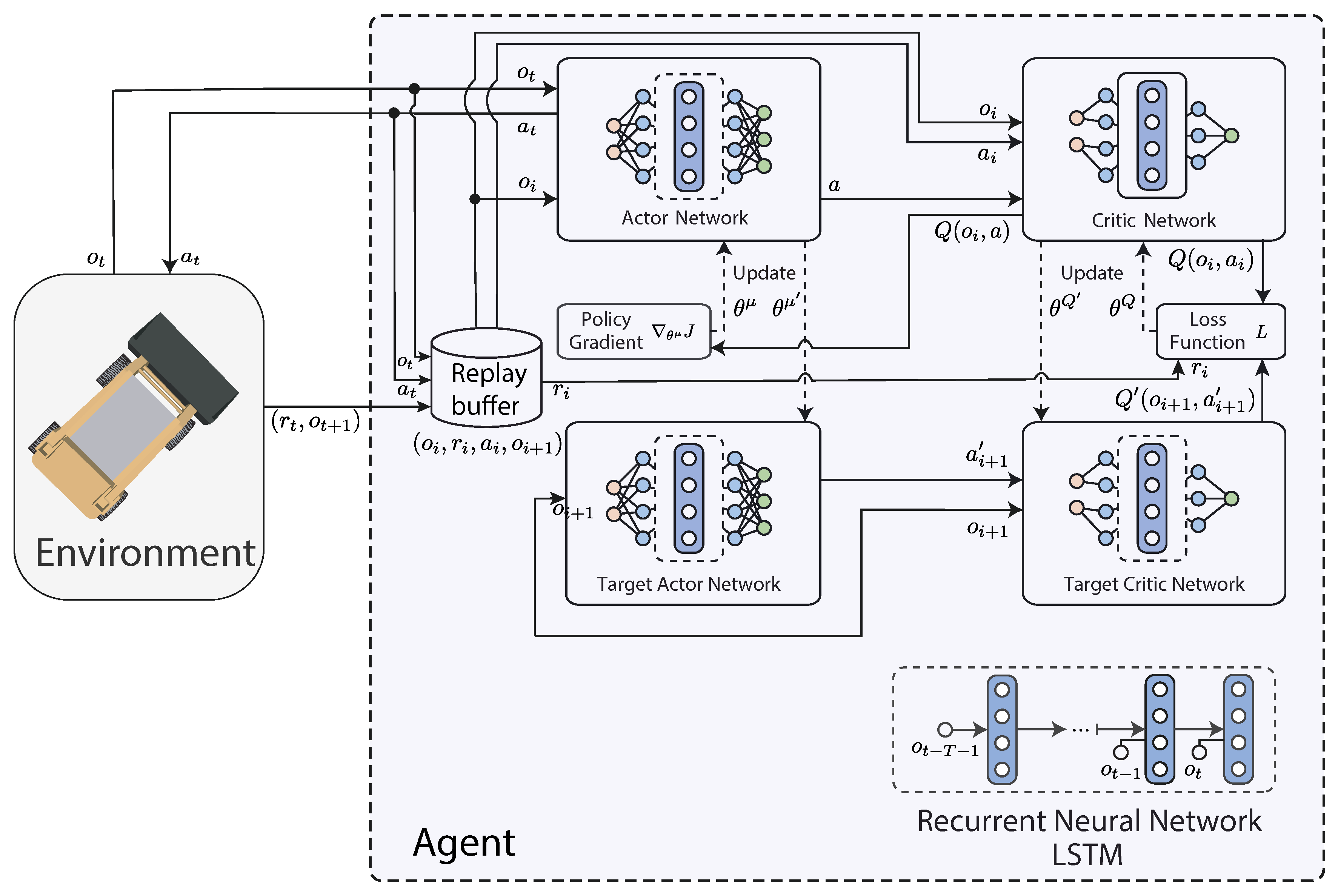
®, Santa Clara, CA, USA) to accelerate computations. Parallel processing was used through the Parallel Computing Toolbox to optimize efficiency by distributing tasks across multiple cores. While the implementation of the DRL algorithms was performed in MATLAB, the training, testing, and validation of the simulated agents were carried out within the Simulink environment (V24.2). The simulation setup featured a custom-built robotic environment in Simulink, which provides real-time feedback on position, orientation, and linear and angular speeds, with data sampled every 0.1 s.
Figure 5 presents the implementation diagram of an agent and the simulation environment.
For experimental validation, field trials were also conducted in a realistic mining environment. Specifically, a geographical model of an underground industrial mine was selected as a testbed [
54]. The dataset was collected from a real-world mining environment within an active pit division, including a complex underground mine with over 4500 km of drifts, located in Chile’s Libertador General Bernardo O’Higgins Region [
55]. The navigation terrain featured irregular surfaces, debris, and surface cavities partially covered by loose soil, generating conditions prone to slip phenomena due to the interaction with vehicle dynamics. Point-cloud maps of narrow tunnels and uneven surfaces with heterogeneous terrain conditions were first acquired by using 3D LiDAR (Riegl®, Horn, Austria), 2D radar (Acumine®, Eveligh, Australia), and stereo cameras (Point Grey Research®, Vancouver, BC, Canada) to define the test environment. The 3D LiDAR scans were manually aligned to estimate the robot pose throughout the traversed tunnels, obtaining a complete projection of the environment, from which a top-view 2D navigation map was extracted [
54]. This top-view map was utilized as a testing environment, and a reference trajectory was generated by connecting pre-planned waypoints that fit on the navigation surface, ensuring alignment with spatial constraints. Only 2D point-cloud data were used to maintain a compact and control-relevant state representation suitable for low-level trajectory tracking under terra-mechanical constraints. The use of full 3D perception was intentionally avoided to reduce the state space dimensionality, minimize the computational burden, and ensure the feasibility of real-time policy deployment. This setup enabled a comprehensive evaluation of the proposed trajectory tracking controllers under realistic mining conditions.
Figure 6 illustrates the tunnel section where the point-cloud dataset was collected, highlighting the segmented navigation map used to assess the performance of the proposed controllers under test.
7.1. Reference Trajectory Setup
To train the DRL-based controllers, two reference trajectories were considered: (i) a lemniscate-shaped trajectory and (ii) a square-shaped trajectory. First, the lemniscate-shaped trajectory was chosen for its ability to provide continuous and smooth turns, with varying angular and linear speeds throughout its path. This trajectory exposes the training agent to changing speeds to provide the agent a wide range of exploration references, which change dynamically over time. It also enables the agent to learn how to drive diverse turning and traction motion profiles. The lemniscate shape is relevant for mining environments as it simulates conditions of curved and narrow tunnels, which are common in underground mines. The continuous nature of the trajectory allows the agent to practice adapting to gradual changes in direction and speed, similar to the maneuvers required in mining tunnels, which often have irregular geometries and non-linear paths. The lemniscate-shaped trajectory is parameterized as follows:
where
a is a scaling factor that defines the reference trajectory’s size and
is the orientation angle for the SSMR, which varies according to a time vector
and frequency
. Additionally, to evaluate the performance of the DRL agents under sharp-turning conditions, a square-shaped trajectory was also employed. The square trajectory, with a side length of
m, was parameterized at a constant speed of 0.6 m/s, leading to a total simulation time of 333 s. This trajectory, characterized by abrupt directional changes at its corners, challenges the agent’s ability to respond to sudden orientation shifts, contrasting and complementing with the smoother transitions of the lemniscate trajectory.
7.2. Hyperparameter Configuration and Tuning
Commonly used hyperparameter configurations from related learning architectures for the control of motion dynamics were first selected [
38,
40]. Subsequently, a broader set of hyperparameters was initialized by using heuristic methods [
10,
11,
13,
34] during the exploration phase, ensuring functionality, bias reduction, and stable consistency of the cumulative rewards. Various parameter values were systematically evaluated to enhance training efficiency while maintaining stability in the learning process. Then, building upon these predefined values, the Whale Optimization Algorithm (WOA) [
56] was applied to fine-tune the hyperparameters. This algorithm, inspired by the bubble-net feeding behavior of humpback whales, optimizes hyperparameters by iteratively refining candidate solutions based on cumulative training rewards [
56]. In this context, each DRL agent is represented as a whale, the optimization objective corresponds to maximizing cumulative rewards, and the agent’s position is defined by the hyperparameter set. Following the approach in [
57], eight PPO agents were trained under the same hardware conditions for ten iterations, resulting in a set of hyperparameters common to DDPG with similar values to the previously described heuristic method. This led to the selection of the final hyperparameter configurations for all the proposed DRL algorithms, which are summarized in
Table 3.
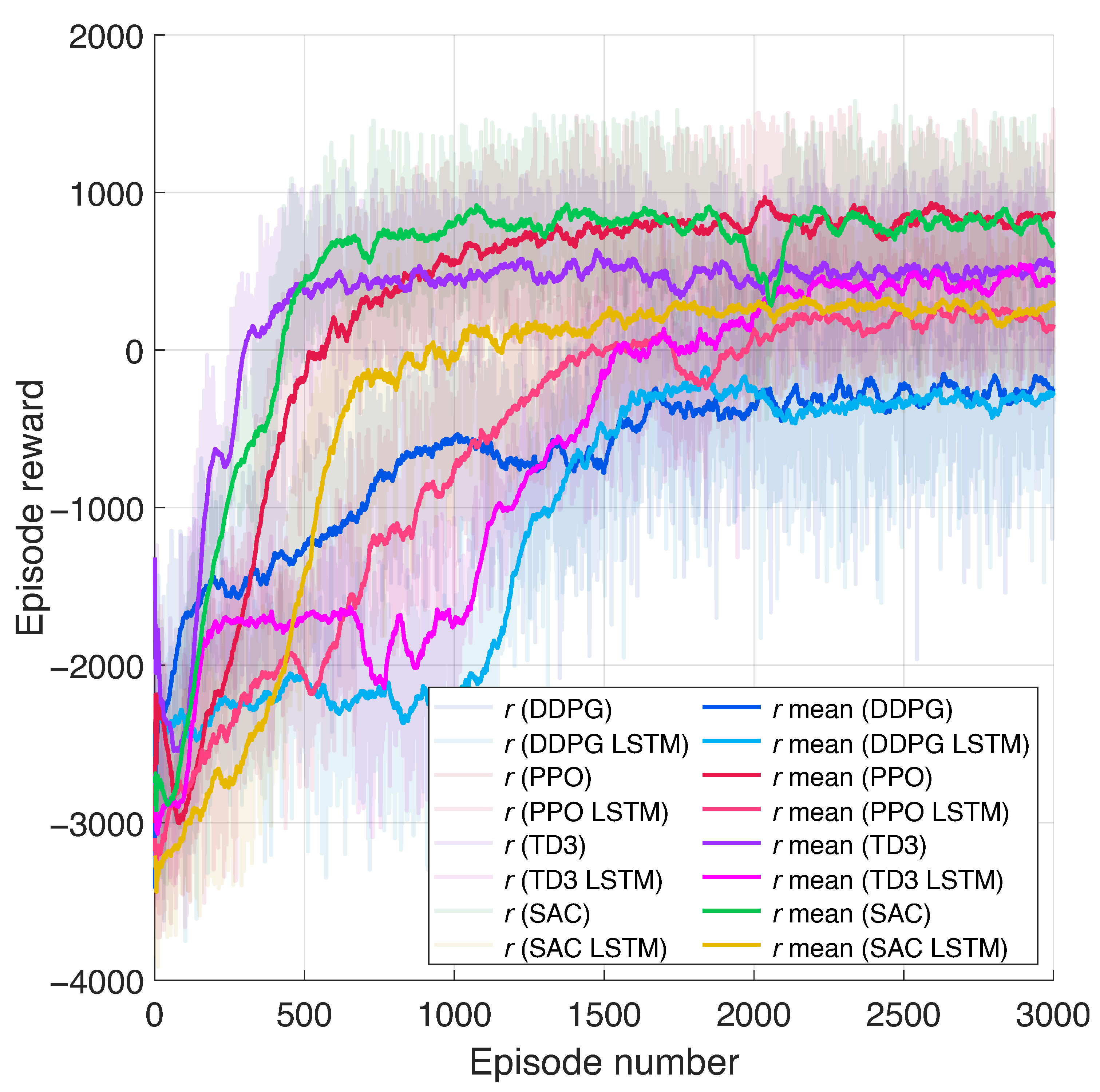
Table 3 also contains the number of episodes under which each algorithm required to approach convergence, as well as the maximum number of training episodes in which the algorithms were expected to stop at final stage. Based on the analysis of the slope of the mean cumulative reward, the TD3 and SAC agents exhibited the fastest policy convergence, as they reached convergence in 806 and 1146 episodes, respectively, which was expected due to their improved sample efficiency and stabilization characteristics. It is worth noting that due to computational constraints and the extensive training times required for hyperparameter tuning, the values used in this study may not represent globally optimal solutions but were selected based on the best trajectory tracking control performance within the given motion constraints.
7.3. Cumulative Reward Analysis
The DRL agents were first trained and evaluated on a lemniscate-shaped trajectory, designed to expose the controllers to a wide range of maneuverability conditions. This trajectory includes continuous turns with both positive and negative angular speeds, as well as straight segments with variable linear speeds, ensuring that the agents learn to adapt to different motion dynamics. The training phase focused exclusively on reference trajectory tracking, without external disturbances in order to isolate here their effects on the learned control policy. To reduce over-fitting and enhance generalization, reference trajectory randomization was applied at the beginning of each training episode. This was achieved by scaling and translating the lemniscate trajectory by a random amount of 25% over the predefined trajectory’s parameters while maintaining kinematic constraints. Additionally, initial condition randomization was implemented to improve the controller’s ability to realign with the reference trajectory. Specifically, an incremental value was added to the initial orientation of the SSMR at the start of each episode, with a randomly assigned sign to alter the direction of the offset. This value was progressively increased to prevent instability of learning, averaging
rads per episode, up to a maximum deviation of
rads over the training procedure.
Figure 7 depicts a comparison of cumulative rewards obtained after training DDPG, PPO, TD3, SAC, and their corresponding LSTM complementary models. The PPO agent achieved comparable convergence rate with respect to TD3 and SAC, which is explained by a grater exploration degree from its stochastic policy and the reduced dimensionality of the observation space that simplifies the optimal policy search space. Conversely, DDPG depicts the slowest mean reward growth compared with TD3, PPO, and SAC, which may be caused by the overestimation of the
Q-function, leading to possible suboptimal local convergence. The LSTM-based approaches required more training episodes to converge on a policy compared with their base models (i.e., DDPG, PPO, TD3, and SAC). Specifically, PPO-LSTM and SAC-LSTM exhibit a lower final mean reward than PPO and SAC, respectively. For PPO-LSTM, the slower convergence could be attributed to the increased dimensionality introduced by historical sequence information, which expands the search space and thus reduces the sample efficiency. In SAC-LSTM, the performance drop may be explained by the increased complexity of entropy temperature optimization, leading to noisier control actions. Similarly, the DDPG-LSTM and TD3-LSTM approaches present comparable mean rewards to their respective base models but at a slower learning rate. The latter is expected, as the recurrent layer introduces additional parameters that require extended training to extract meaningful temporal dependencies from the historical observation sequence.
7.4. Tracking Test in Lemniscate-Type Trajectories
This test involved tracking a lemniscate reference trajectory to evaluate the control performance of the proposed agents using DDPG, PPO, TD3, SAC, and their respective LSTM-based approaches. The simulation results of this test are presented in
Figure 8, and the performance metrics in terms of IAE, ISE, ITAE, ITSE, TVu, and cumulative control effort [
58] are shown in
Table 4. As illustrated in
Figure 8, all DRL approaches presented similar trajectory tracking responses, except for PPO-LSTM and SAC-LSTM, under which the orientation and the lateral and longitudinal tracking errors were eventually deviated, as depicted in
Figure 8c–f. Similarly, in
Figure 8c,e, the lateral and longitudinal tracking errors were close to zero for most approaches, including DDPG, DDPG-LSTM, PPO, PPO-LSTM, TD3, and TD3-LSTM. However, among these, PPO was the only agent that achieved lower trajectory tracking errors compared with its LSTM-enhanced counterpart (i.e., PPO-LSTM), which can be attributed to its increased stochasticity relative to the other evaluated approaches. This result also suggests that the PPO agent prioritized minimizing orientation and linear speed errors over positional error, potentially favoring stability in trajectory tracking at the expense of accurate robot position. On the other hand, DDPG-LSTM achieved the lowest positional error across all agents, with reductions of 21% in the IAE and 10% in the ISE compared with TD3, which had the lowest positional error metrics among the base models. Such result in control performance can be attributed to the ability of LSTM-enhanced DDPG to retain past trajectory information, improving position tracking accuracy. In contrast, TD3-LSTM and SAC-LSTM provided only marginal improvements in tracking performance compared with their respective base models. Their IAE metrics showed minor differences, with TD3-LSTM improving by only 1.38% and SAC-LSTM increasing by 5.6% compared with SAC. Additionally, TD3-LSTM exhibited a 4.5% reduction in ISE relative to TD3, whereas SAC-LSTM had a slight 2.2% decrease in ISE compared with SAC.
Table 4 highlights differences in orientation and linear speed errors across the tested agents. For instance, PPO-LSTM exhibits the highest orientation and linear speed errors, with IAE values of 2.175 and 3.393, respectively, which are considerably higher than those of the other agents. In contrast, TD3-LSTM achieves the lowest orientation error, with an IAE of 0.036, while DDPG-LSTM demonstrates the best linear speed tracking performance, obtaining the lowest IAE of 0.065. Examining such error metrics, TD3-LSTM minimizes orientation error in terms of IAE and ITAE, whereas TD3 achieves lower ISE and ITSE values with respect to all test approaches. This behavior is also shown in
Figure 8d, where TD3 maintains near-zero orientation error except for two brief deviations, whereas TD3-LSTM shows a more stable yet slightly less accurate response. Furthermore, the inclusion of LSTM layers in DDPG-LSTM and SAC-LSTM appears to contribute to lower ITAE and ITSE values for position and orientation error compared with their non-LSTM counterparts. A possible explanation for this is that LSTM’s memory mechanism aids to accumulate and mitigate orientation deviations over time, leading to corrective control actions that reduce long-term tracking errors. However, the reduced performance of PPO-LSTM may stem from the interaction between its policy update strategy and the LSTM memory dynamics, potentially leading to error accumulation rather than attenuation. The control effort exerted by each controller is also quantified in
Table 4. Deterministic policy-based controllers exhibited lower control effort, with DDPG and TD3 attaining TVu values of 3.38 and 3.62, respectively. In contrast, stochastic policy-based controllers such as SAC and PPO showed significantly higher control variability, with TVu values of 27.64 and 66.82, respectively, indicating more abrupt control actions. The incorporation of LSTM into the deterministic controllers yielded further reductions in control effort. For instance, DDPG-LSTM and TD3-LSTM reduced TVu by approximately 16% and 20%, respectively, relative to their non-recurrent counterparts. This further supports that LSTM’s memory mechanism contributed to stable corrective actions. However, recurrent stochastic policies exerted a significantly higher control effort, as both PPO-LSTM and SAC-LSTM achieved TVu values of 574.02 and 494.89, respectively, indicating that the inclusion of LSTM may result in increased stochasticity. In general, these results suggest that LSTM layers store and integrate orientation error over time, enabling control actions that achieve lower tracking errors compared with those used by base controllers, as illustrated in the control actions depicted in
Figure 8b.
7.5. Tracking Test in Square-Type Trajectory
This test assessed the control performance of DDPG, PPO, TD3, SAC, and their LSTM-based variants while tracking a square-type reference trajectory. The simulation results are depicted in
Figure 9, whereas performance metrics (IAE, ISE, ITAE, ITSE, and TVu [
58]) are summarized in
Table 5.
Figure 9a depicts a significant error margin while tracking the reference trajectory with DDPG, PPO, TD3, and SAC, whereas the tracked trajectory for the LSTM-based strategies closely approach the reference with minimal positional drift. Except for the baseline DRL approaches, the LSTM-based strategies exhibit minimal lateral, orientation, and speed tracking errors along the trials, as shown in
Figure 9c–f. This reinforces that the proposed LSTM-based agents prioritize maintaining orientation and linear speed accuracy beyond minimizing robot position deviations to effectively track the reference trajectory. Moreover, due to the controller’s limited turning capability, turns are not completed instantaneously, causing the agent to deviate from the trajectory once the turn is executed. Agents improved positional tracking based on the trade-off between positional errors and both linear speed and orientation accuracy. Actually, unlike baseline DRL approaches, the system response with LSTM-based methods can be attributed to the added LSTM layers that noticed and memorized changes for each observed orientation and position tracking error, influencing the learning process with improved rewards for each episode. Then, such rewards prioritized reducing trajectory tracking over orientation errors. For DDPG and DDPG-LSTM, the reduced positional tracking performance and the lack of LSTM improvement on this metric may stem from these agents overestimating the value of states with lower linear speed and orientation error, thereby prioritizing these variables over positional accuracy.
The PPO-LSTM agent demonstrated improved control performance of positional tracking against the other test controllers, achieving the lowest IAE, ISE, ITAE, and ITSE metrics, as shown in
Table 5. Specifically, PPO-LSTM reduced the IAE by 74% compared with PPO, while TD3-LSTM and SAC-LSTM achieved reductions of 21% and 37%, respectively, relative to their non-LSTM counterparts. While DDPG and DDPG-LSTM exhibited similar performance in positional tracking, their tracking errors were higher than those of PPO-LSTM. For the orientation error, PPO-LSTM achieved the lowest IAE (69.34) and ITAE (24,237.61), exhibiting again its effectiveness in maintaining accurate orientation control. Despite each approach presenting a similar orientation error in terms of the ISE, DDPG performed the best among all proposed approaches, obtaining an ISE of around 74.89 and an ITSE of about 1272.98. This suggests that while PPO-LSTM minimized accumulated orientation errors over time, DDPG was more effective in reducing large deviations. In terms of linear speed error, DDPG consistently outperformed all other agents across all metrics, achieving the lowest IAE (0.48), ISE (3.70), ITAE (8.40), and ITSE (40.50). Moreover, the LSTM-enhanced versions of all models introduced higher linear speed errors in the trials, indicating that the added memory component may generate slower adaptation to speed changes. Lastly, regarding the control effort and its variation, DDPG achieved the lowest overall control effort, with a TVu of 5.38, followed closely by TD3 (5.92), suggesting that both deterministic controllers applied smoother control actions. The integration of LSTM slightly increased control effort for DDPG-LSTM (TVu = 6.22) but yielded a marginal reduction for TD3-LSTM (TVu = 5.72) compared with its base model. Conversely, PPO-LSTM and SAC-LSTM exhibited the highest TVu values, reaching 187.30 and 161.03, respectively, indicating high variations in control actions during control execution. These results show that while LSTM integration benefits stochastic policies in terms of tracking accuracy, it also significantly amplifies control action variability, potentially compromising smooth motion. Overall, PPO-LSTM emerged as the best control approach for position and orientation tracking, while DDPG excelled at minimizing linear speed errors and ensuring the smoothest control actions, especially at sharp corners in the square reference trajectory. The results highlight the effectiveness of integrating LSTM for stochastic policy agents, but its impact on deterministic agents led to an increase in errors in linear speed tracking and control action smoothness, suggesting that the added memory component may have hindered rapid adaptation to dynamic changes in the robot.
7.6. Tracking Test in Mining Environment
This test involves tracking a trajectory composed of pre-planned waypoints, designed to align with maneuverability constraints in a mining environment. The reference trajectory was obtained from the underground mine map presented in
Section 7.1, with trials starting at waypoint A, passing by B, and concluding at waypoint C, as illustrated in
Figure 10. The experimental results of tracking this trajectory within the underground mine are shown in
Figure 10, while quantitative control performance metrics are detailed in
Table 6. Unlike previous tests, it is noticed in all test control approaches that the orientation error in
Figure 10d initially increased at the very beginning of the trials at waypoint A due to changes in the initial pose conditions. However, as the agent began executing turning actions, the orientation error subsequently decreased. This degradation at the start of the trials may be attributed to over-fitting effects, as the trained agents tended to initiate their trajectories with a specific turning action learned during the training phase. This behavior suggests that the models developed a dependency on specific initial conditions, impacting their ability to generalize to initial conditions of new scenarios. Furthermore, during waypoint transitions, particularly at point B, abrupt turning maneuvers exposed significant differences in controller robustness. PPO- and SAC-based agents exhibited high instantaneous control inputs, leading to unstable angular responses and trajectory overshoots. These cases demonstrate limited generalization to tight angular transitions, a critical failure mode for underground navigation. Similarly, turning control actions in DDPG, PPO, PPO-LSTM, SAC, and SAC experienced abrupt compensation while turning at point B in
Figure 10. Beyond the demanding turning actions, the new kinematic conditions for turning were not accurately met. Nonetheless, this issue was mitigated by improving the initial sampling strategy during the agent’s training process.
Table 6 provides a comprehensive comparison of tracking performance across the test DRL controllers. In terms of linear speed error, the lowest IAE was obtained by using the DDPG agent, achieving a value of 1.15, followed closely by SAC with 1.17, while PPO demonstrated slightly higher tracking errors, with an IAE of 1.38. Such results are consistent with the linear speed error trend, where SAC achieved the lowest ISE value (i.e., 52.24), outperforming the other test controllers. This suggests that SAC maintains stable speed control, reducing abrupt changes in the trajectory. Regarding position error metrics, TD3-LSTM achieved the lowest values across multiple metrics, including the IAE (i.e., 80,751.31) and ISE (i.e., 15,543.57), outperforming other LSTM-based models such as SAC-LSTM and DDPG-LSTM (see
Table 6). This performance can be explained by TD3’s ability to mitigate overestimation bias, leading to more stable policy updates, while the LSTM layers enhance temporal information processing, allowing for better adaptation to the dynamic changes in the reference trajectory. Regarding the orientation error, TD3-LSTM also showed improved performance, attaining the lowest IAE (124.92) and ITAE (
) and validating the advantage of memory-based architectures in handling trajectory deviations. In contrast, PPO exhibited the highest orientation error values, with an IAE of 370.88, indicating less stable heading control when navigating the underground mine environment.
In terms of deployment limitations, PPO-LSTM and SAC-LSTM exhibited inconsistent alignment in narrow corridors such as point B, where they occasionally triggered unexpected stops due to unsafe or overly conservative control commands. These issues were not anticipated during the simulation evaluations, underscoring the need to incorporate exteroceptive information into both the learning process and the reward scheme. These results also highlight the need to expose the agents to a broader range of environmental conditions during training, including the adoption of domain randomization strategies to improve policy generalization. Regarding control action smoothness, TD3 demonstrated the lowest variation in linear speed (i.e., 0.30), while TD3-LSTM minimized the variation in angular speed (i.e., 2.26). These results suggest that TD3 and its LSTM-enhanced counterpart generate smoother control actions compared with the other test controllers, reducing oscillations and improving trajectory adherence. TD3-LSTM showed the lowest TVu of 2.57, validating its ability to generate continuous control actions and mitigate oscillatory behavior in the physical actuators of the SSMR. Moreover, the results indicate that TD3-LSTM offers the best overall performance in terms of position and orientation tracking due to its ability to learn more stable policies while incorporating past observations. Conversely, while SAC and DDPG exhibit suitable control performance in linear speed control, they hardly generalize as effectively in position and orientation tracking, particularly in complex environments such as those found in underground mines.
7.7. Robustness Test Under Terrain Disturbances
The proposed controllers were tested for trajectory tracking on lemniscate and square reference trajectories under terrain disturbances to evaluate their robust control performance. The disturbances, unknown for the agents, involved transitioning from flat terrain (where no drifting occurs) to low-friction and uneven terrain, which leads to slip phenomena commonly encountered in mining environments. First, the disturbance conditions occurred across terrain transitions while tracking a lemniscate reference trajectory, specifically at time instants 100.6 [s] and 680.4 [s] of the trials.
Figure 11 presents tracking results for the lemniscate trajectory, highlighting capabilities of tracking error regulation in the tested DRL controllers when rejecting external disturbances (see
Figure 11c,e). At the first disturbance instant, the system response reincorporated each controller to the reference trajectory; thus, the linear speed, orientation, and lateral error reached near-zero values (see
Figure 11d–f). Among the tested controllers, the proposed DDPG and TD3 approaches, along with their LSTM-enhanced variants, exhibited improved disturbance rejection against PPO and SAC, maintaining low tracking errors throughout terrain transition scenarios. In contrast, PPO-LSTM and SAC-LSTM showed increased tracking errors after the disturbance instants and exhibited slower convergence in reducing steady-state errors, leading to residual offsets throughout the trial. This suggests that while PPO combined with LSTM demonstrated adaptability by gradually reducing error offsets over time, its ability to reject disturbances was lower compared with that of the DRL baseline methods, which prioritize policy refinement through continuous value estimation. Moreover, despite all disturbance occurrences, all tested controllers successfully maintained low and close-to-zero orientation and speed errors (see
Figure 11d,f), enabling the SSMR to align with the reference trajectory and recovering the reference speeds. Unlike DDPG-LSTM, TD3-LSTM, and PPO-LSTM, baseline DRL controllers such as PPO and SAC exhibited persistent lateral position errors after each disturbance event, primarily due to unobserved dynamics arising from unmodeled terra-mechanical variations, as shown in
Figure 11e. Such disturbances, omitted during training, may have induced policy prioritization biases, leading the learned DRL controllers to favor orientation and linear speed corrections over accurate lateral position tracking. This highlights the need for a more comprehensive domain randomization strategy that accounts for the inherently random and heterogeneous terrain characteristics, ensuring further exploration across diverse terra-mechanical conditions.
The results of tracking for the square-type trajectory under terrain disturbances are presented in
Figure 12, with disturbances occurring at approximately 12.6 [s] and 12.8 [s]. The agents show robust control performance, maintaining the trajectory orientation, as shown in
Figure 12d, and reference speed, as depicted in
Figure 12f. After the first disturbance, all DRL agents were capable of correcting for the external disturbances, thus showing orientation and linear speed errors close to the origin. However, the positional error was not fully corrected by the PPO agent, where the SSMR aimed to returning to the reference trajectory but maintained large steady-state tracking errors, as shown in
Figure 12c,e. A similar transient response was observed after the second disturbance, where orientation and linear speed errors were again reduced to near-zero values. Longitudinal positional errors were effectively mitigated across all proposed controllers except for the one based on PPO, which initially counteracted disturbances but exhibited a continuous decline in robust control performance. Overall, these results indicate that while LSTM integration enhances trajectory tracking for most DRL agents, PPO demonstrated deficient robustness in the presence of disturbances.
It is worth noting that the training of the DRL controllers was conducted under transitory slip conditions, without incorporating prior physical information about the terrain type, such as grass, pavement, or gravel. Consequently, the learning process did not exploit any terrain classification cues but relied exclusively on observable states, including position, orientation, speed, and their respective tracking errors. Although the experimental validation was limited to a single robot configuration and a particular terrain disturbance scenario, the proposed methodology is not inherently constrained to this setup. The underlying control policy is observation-driven and model-free, allowing for potential transferability to other robotic platforms or unstructured environments exhibiting similar observation–action relationships. Nonetheless, such generalization should be approached under test conditions. Effective transfer would require that key aspects of the wheel–terrain interaction—such as friction and slip dynamics—be implicitly captured within the observation space and appropriately represented during training.
7.8. Test on Robustness Against Model Parameters
To assess the robustness of DRL agents under varying SSMR conditions, the proposed controllers were tested by using a different set of dynamic model parameters for varying robot dynamics. In this test, the parameters
and
were both gradually set to 5% increments, reaching a total variation of 25% from their original values, as defined in the SSMR model in Equation (
10) and detailed in [
3]. Such parameters were selected since they represent direct influence on traction and turning speeds. The results of this test for the maximum parameter variation of 25% on the lemniscate trajectory are presented in
Figure 13. According to
Figure 13a, the proposed DRL controllers successfully led the SSMR along the reference trajectory, maintaining reasonable tracking accuracy. However, lateral and longitudinal tracking errors progressively increased over the trial, indicating that the controllers struggled to generalize to entirely unobserved variations in system dynamics, as such variations were not explicitly included in the training process. While the control performance remained adaptable to moderate parameter variations, the tracking error increase became significant as the parameter variations approached their maximum tested value. In particular, the SSMR deviation from the reference position suggests that the proposed controllers could present potential over-fitting, even when the training process included varying robot dynamics. Comparing all tested DRL controllers, the LSTM-based DRL agents exhibited improved adaptability to dynamic variations by generating control actions that suitably accommodated model parameter changes over time. The integration of historical observations in LSTM-based controllers prevented abrupt policy changes, resulting in smoother and more stable trajectory tracking performance compared with the baseline DRL controllers. On the other hand, in
Figure 13f, the DDPG and TD3 algorithms exhibited the lowest linear speed errors, followed by PPO and SAC, whereas DDPG-LSTM, TD3-LSTM, PPO-LSTM, and SAC-LSTM present higher orientation and linear speed errors with respect to the other controllers. By analyzing
Figure 13d, it can also be observed that deterministic policy agents (i.e., DDPG and TD3) achieved lower orientation errors than their stochastic counterparts (i.e., PPO and SAC). This outcome aligns with the expectation that deterministic controllers can achieve more precise control in environments with parameter stability, whereas stochastic methods may introduce exploration noise that degrades orientation accuracy under dynamic variations. In the case of the on-policy recurrent agent (PPO-LSTM), an improvement in adaptability was observed compared with its base model, PPO. This behavior suggests that the use of the state value function as a critic prevents the over-fitting observed in off-policy recurrent cases. Since the critic network does not receive the agent’s action as an input, it is less likely to overlearn a linear relationship between linear speed error and traction speed control action, preserving adaptability to changing model parameters.
The control performance of the proposed DRL controllers under model parameter variations on a squared-type trajectory is presented in
Figure 14. The turning response of the DRL agents remained qualitatively similar to that observed in trials without parameter variations. However, during cornering maneuvers, the agents exhibited overshoot in the turning response, leading to increased transient responses. The most significant deviations were observed in the SAC-LSTM and PPO-LSTM agents, as well as in PPO, TD3-LSTM, and DDPG-LSTM throughout the final turn of the trajectory.
Figure 14f presents the linear speed error, where the TD3 agent achieved the lowest speed error values, followed by SAC and DDPG, PPO-LSTM, PPO, DDPG-LSTM, TD3-LSTM, and SAC-LSTM. Furthermore, the PPO-LSTM agent improved its positional speed error compared with the baseline PPO agent, as presented in
Figure 14c,e. These results are consistent with the previous robustness test, reinforcing the observation that LSTM-based on-policy agents exhibit improved adaptability to model parameter variations by leveraging historical state information, further confirming the role of the policy architecture in adapting to system dynamics. Deterministic policy agents (DDPG and TD3) maintained better orientation stability than their stochastic counterparts (PPO and SAC), particularly in turns where rapid control adjustments were required. However, recurrent architectures (LSTM-based agents) demonstrated rougher control policies, as they presented increased control effort on turning maneuvers. While recurrent stochastic agents are expected to present a noisier response, as discussed on
Section 7.3, the decrease observed in deterministic agents may be attributed to the over-fitting of the training conditions, as explained by the lemniscate-type trajectory test under model parameter variations. This suggest that LSTM-based agents’ performance on high-precision tasks such as corner turning maneuvers may require further optimization.
8. Conclusions
In this work, Deep Reinforcement Learning (DRL) techniques integrated with Long Short-Term Memory strategies were presented and validated for robust trajectory tracking control of skid-steer mobile robots (SSMRs) operating in mining environments with uncertain terrain conditions. Several DRL algorithms were assessed and compared each other, including Proximal Policy Optimization (PPO), Deep Deterministic Policy Gradient (DDPG), Twin Delayed DDPG (TD3), and Soft Actor–Critic (SAC), alongside their recurrent LSTM-enhanced counterparts, to address partial observability in real-world navigation scenarios. The proposed controllers were trained and tested on various reference trajectories, first in simulation scenarios and subsequently in a field experimental setup of mining environments. In general, performance metrics demonstrated that LSTM-based controllers significantly improved trajectory tracking accuracy, reducing the ISE by 10%, 74%, 21%, and 37% for DDPG-LSTM, PPO-LSTM, TD3-LSTM, and SAC-LSTM, respectively, compared with their non-recurrent counterparts. Furthermore, DDPG-LSTM and TD3-LSTM achieved the lowest orientation errors (in terms of the IAE, ISE and ITAE) and linear speed errors (in terms of the IAE and ITAE), outperforming baseline DRL controllers. These results highlight the effectiveness of integrating LSTM into DRL-based controllers, enabling them to leverage temporal dependencies and infer unobservable states, thereby enhancing robustness against terrain disturbances and model parameter variations. In addition, recurrent architectures improved their non-recurrent counterparts in generalizing to unobserved trajectories, suggesting that incorporating memory mechanisms enhances adaptability to dynamic and unstructured environments. However, further evaluation revealed limitations in the LSTM-based controllers, particularly within on-policy algorithms (PPO-LSTM), where a reduction in adaptability to varying model parameters and terrain disturbances was observed. This finding indicated the potential over-fitting of recurrent networks when subjected to significant model variations, emphasizing the need for improved regularization techniques or hybrid learning strategies to further enhance generalization capabilities. Future work will explore the integration of a more detailed terra-mechanical model with varying friction and slip conditions to enable a more realistic assessment of DRL controllers in adverse terrain scenarios. A formal robust control stability analysis of the proposed trajectory tracking controllers is also required in order to evaluate their practical feasibility for real-world deployment in autonomous mining operations. Furthermore, ongoing work aims to evaluate performance under heterogeneous terrain conditions and varying robot morphologies to assess the robustness and adaptability of the proposed control methodology across diverse operational scenarios.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}