1. Introduction
Visual–Inertial Odometry (VIO) is a widely used navigation solution for robotics, particularly in GPS-denied environments [
1,
2]. Processing IMU and image data, it is able to provide real-time position estimation in previously unknown environments. While LiDAR-based SLAM algorithms generally outperform VIO in terms of accuracy and robustness in structured, feature-rich environments [
3,
4], VIO remains advantageous in scenarios where LiDAR is ineffective, such as large open spaces with few detectable features [
5]. Additionally, VIO is particularly well suited for drones due to the lower weight and occupied space of cameras compared to LiDAR sensors [
6,
7]. It is worth noting that drones are typically equipped with cameras to collect visual information of the environment. Therefore, utilizing these cameras for both perception and localization optimizes onboard resource usage, enhancing overall system efficiency.
Despite its advantages, VIO suffers from inherent limitations, such as drift accumulation over time due to errors in IMU integration and inaccuracies in 3D feature tracking. Furthermore, motion blur during high-speed maneuvers and the presence of featureless environments can severely degrade tracking quality, potentially leading to failures in navigation. A notable example of VIO’s vulnerability occurred with NASA’s Ingenuity helicopter, which operated on Mars as part of the Mars 2020 mission. Ingenuity relied on a VIO system using a downward-facing monocular grayscale camera. On 18th January 2024, its last flight resulted in a crash causing damages in the blades and making the drone unable to fly again. NASA’s subsequent investigation confirmed that the featureless terrain was responsible for the crash [
8]. This incident highlights the importance of enhancing VIO algorithms to ensure robustness in featureless environments. Over the past two decades, several VIO algorithms have been developed to improve localization accuracy and robustness. Non-Linear Factor Recovey (NFR), proposed in [
9], has emerged as one of the most valuable solutions for visual–inertial mapping. This methodology is implemented in the open-source Basalt project (
https://github.com/VladyslavUsenko/basalt, accessed on 22 May 2025). This VIO algorithm achieves state-of-the-art performance on benchmark datasets. Its main novelty lies in leveraging non-linear factors extracted from previous keyframes, which are subsequently used in the global bundle adjustment. In this work, we propose improvements to the Basalt project aimed at increasing its robustness, particularly in high-speed motion scenarios and featureless environments. Our contributions are summarized as follows:
IMU-based Feature Prediction: We introduce a method for predicting feature positions in the next frame using IMU data. Instead of assuming that features remain at the same pixel across consecutive frames, our approach integrates IMU measurements to estimate feature displacement, starting from the last VIO-predicted position. This method improves tracking accuracy during rapid movements. Details are provided in
Section 3.1.
Multi-Camera Extension for Featureless Environments: To mitigate VIO failures in featureless scenarios, we extend Basalt to support a multi-camera setup. By increasing the field of view, this approach significantly reduces the possibility of encountering textureless regions that may lead the algorithm to fail. Implementation details are discussed in
Section 3.2.
Adaptive Threshold for Feature Extraction: Since the multi-camera setup results in a considerable increase in computational complexity, we propose a dynamic feature detection strategy to mitigate the computational load. Specifically, we introduce an adaptive thresholding mechanism that adjusts feature detection parameters. The implementation of this optimization is detailed in
Section 3.3.
Due to its high positional accuracy and efficient CPU usage, the open-source Basalt algorithm has been improved and adapted in two other open-source projects. In [
10], the authors modify Basalt for a monocular setup, introducing a novel method for evaluating the scale factor to locate the feature in the 3D space. The “Basalt for Monado” project (
https://gitlab.freedesktop.org/mateosss/basalt, accessed on 22 May 2025) integrates Basalt with Monado (
https://gitlab.freedesktop.org/monado/monado, accessed on 22 May 2025), enhancing the tracking for XR devices and extending it to support multi-camera setups. However, to the best of our knowledge, no official documentation or published research papers describe this multi-camera implementation. With the goal of improving the robustness of VIO algorithms, several solutions have been proposed in the last decades. In [
11], the authors propose a VIO algorithm based on line features. Their contribution consists of the reduction of the influence of lines upon dynamic objects on system robustness merging the results coming from the semantic segmentation, optical flow, and re-projection error. Then, a weight-based method adjusts the line features matrix in the optimization process. The work in [
12] proposes a methodology to enhance the performances of a VIO algorithm encountering different brightness conditions. The methodology couples a model-based Left Invariant Extended Kalman Filter (LIEKF) with a statistical neural network, both driven by raw inertial measurement. While these approaches mitigate common failures of VIO algorithms, textureless environments continue to pose a significant challenge. Due to its capability to capture images by multiple perspectives, a multi-camera setup remains one of the most effective and widely adopted solutions to detect features in textureless environments.
The approach in [
13] presents an implementation of a multi-camera setup, where two stereo cameras face opposite directions. The authors demonstrate its superiority over state-of-the-art VIO algorithms. However, since the paper was published in 2007, it relies on an Extended Kalman Filter (EKF) for pose estimation rather than modern optimization techniques such as bundle adjustment or Factor Graphs, which are widely used today. In [
14], a generalized multi-camera approach is introduced. The work supports an arbitrary number of cameras in various configurations (overlapping and non-overlapping fields of view). This implementation is based on [
15], one of the first versions of the well-known open-source SLAM algorithm. Similarly, [
16] proposes an alternative multi-camera approach and compares it with [
14], proving its superiority on custom datasets. The paper [
17] presents another multi-camera setup, consisting of a stereo camera with two additional monocular cameras mounted on the sides. To optimize computational efficiency and performance, the authors track features from the stereo camera across the mono cameras, leveraging the shared field of view. Another approach [
18] focuses specifically on configurations where camera fields of view do not overlap. Additionally, the article available at [
19] details an implementation tailored for UAVs. While the proposed method supports an arbitrary number of cameras, the authors provide results only for a dual-camera setup. To the best of our knowledge, no existing research extends Basalt to a multi-camera setup. Moreover, none of the previous works have been explicitly tested on UAVs. A key challenge in deploying multi-camera systems on drones is the computational load. Since UAVs must allocate processing power to other demanding tasks such as image processing and perception algorithms, computationally intensive processes such as VIO algorithms must be optimized to maintain a bounded computational load. Previous studies do not address CPU consumption. The paper [
20] analyzes computational load in a multi-camera setup, comparing the proposed algorithm to ORB-SLAM 3 ([
21]), including CPU usage. However, reported CPU loads are never above 300% for more than two cameras. This makes the algorithm impractical for many onboard computers commonly used in autonomous drones, such as Jetson platforms. In [
22], the authors propose an implementation of a multi-camera setup with non-overlapping images. Even if the paper provides CPU load considerations, the performances are evaluated without tracking features across the cameras. While this approach accomplishes a reduction in the CPU load, it omits the feature triangulation in the current frame, compromising the accuracy of the 3D landmarks’ estimated position. In this paper, we propose improvements to the Basalt algorithm, specifically aimed at enhancing UAV localization. To enable the extension of Basalt to a multi-camera setup while ensuring feasibility on resource-constrained UAV platforms, we introduce a methodology for reducing computational load.
3. Materials and Methods
3.1. IMU-Based Feature Prediction
To track a feature from one frame to another, Basalt employs a frame-to-frame approach. For each camera, the features from the previous frame are tracked by searching for similar patterns in the image using the Lucas–Kanade method. The accuracy of this tracking depends heavily on the initial choice of the feature’s pixel position in the previous frame. Basalt’s original implementation initializes the position of the feature based on its location in the previous frame, assuming that the feature’s position hasn’t changed significantly between frames and that no motion blur has occurred. This assumption works well when the camera motion is slow and the scene remains relatively stable. However, when rapid movements occur, the feature’s position can change drastically between frames, making it challenging to track it accurately. In such cases, the algorithm may fail to track features reliably, which can compromise the accuracy of the estimated trajectory. This is especially problematic in drone applications, where fast movements and rapid changes in orientation are common. In these scenarios, having a method to estimate the feature positions without being constrained by the actual frame-to-frame motion could significantly improve the robustness of the tracking.
To mitigate the impact of the motion blur introduced by rapid movements, we integrate in Basalt a methodology that leverages IMU data to predict the feature positions before a new camera frame is available. The approach begins by estimating the last position of the camera based on the VIO algorithm and then uses the IMU data to predict the camera’s position in the next frame. As soon as the new frame arrives, the relative transformation between the previously estimated camera position and the actual position is calculated. This transformation is then used to estimate the feature positions in the new frame, accounting for the extrinsic calibration parameters of each camera.
Relying on IMU data makes the tracking of features more resilient to fast movements, ensuring a more accurate and robust estimation of the trajectory even under challenging conditions such as rapid drone motion. This methodology helps to improve the overall performance of the VIO system, making it more reliable for real-time applications where high-speed motion is common.
As shown in [
23], given the reference system of the camera (C), and an inertial reference system (W), the angular velocity
and the acceleration
of the camera C with respect to the reference system W are
where
is the true angular velocity of the camera estimated by the IMU;
is the gyroscope bias;
is the accelerometer bias;
is the gyroscope noise;
is the accelerometer noise;
is the rotation of the camera frame with respect to the inertial frame;
is the gravity acceleration in the inertial reference system.
The derivative of the rotation of the camera frame with respect to the inertial frame can be evaluated by
where
× is the skew-matrix operator (see
Table 1). Integrating (
3), we obtain the rotation of the camera in the next time step:
where the operator
is the exponential matrix operator (see
Table 1). Integrating two times (
2), we can obtain the position of the camera in the inertial reference system
in the next time step:
where
is the velocity of the camera with respect to the inertial reference system.
Equations (
4) and (
5) can be used to predict the position of the camera in the current frame at
. The transformation matrix
between the camera from the current frame to the previous frame is
where
Now, we unproject each feature to obtain the homogeneous coordinates
and rescale them by the average depth evaluated in the previous step to obtain the 3D position of the feature
:
where
is the average depth of the landmark collected in the previous steps. Note that the feature position refers to the previous time step
. Knowing the 3D position of each feature in the previous time step
, we can predict their 3D position at the current frame
:
Then, we can project the 3D feature in the image plane knowing the intrinsic calibration parameters of the camera to estimate the positions of the features in the current frame.
3.2. Multi-Camera Setup
A multi-camera setup enhances a VIO algorithm in two ways:
It increases the field of view, allowing for the tracking of more features across frames.
It improves the 3D position estimation of landmarks, as more observations of the same landmark are made from different baselines.
To generalize Basalt for a multi-camera setup, we extend the optical flow generation process to accommodate an arbitrary number of cameras. We detail our methodology for tracking features across images when portions of the field of view are shared between multiple cameras, and for extracting new features in the remaining areas of the image. Then, we generalize the landmark selection to be suitable for the multi-camera setup.
3.2.1. Optical Flow Generalization
Optical flow consists of all the features extracted in a single frame, with each feature assigned a unique ID and its coordinates in the image plane.
In its original implementation, Basalt was designed to run on a stereo setup. The optical flow was generated by extracting features from the left image using the FAST algorithm, and then tracking them on the right camera using the Lucas–Kanade method. In the next frame, features from the previous frame were tracked across both images. Basalt’s optical flow is reliable, thanks to pyramid levels, recursive tracking, and point filtering. However, this approach only works with one stereo camera and is unable to handle a multi-camera setup.
In our implementation, we generalize the optical flow generation to support multiple cameras. We account for the possibility that one camera might share part of its field of view with another. In the shared region of the image, we track features from one camera to the other. Then, we extract new features in the remaining part of the image and track them on another camera if its field of view overlaps with that of another camera.
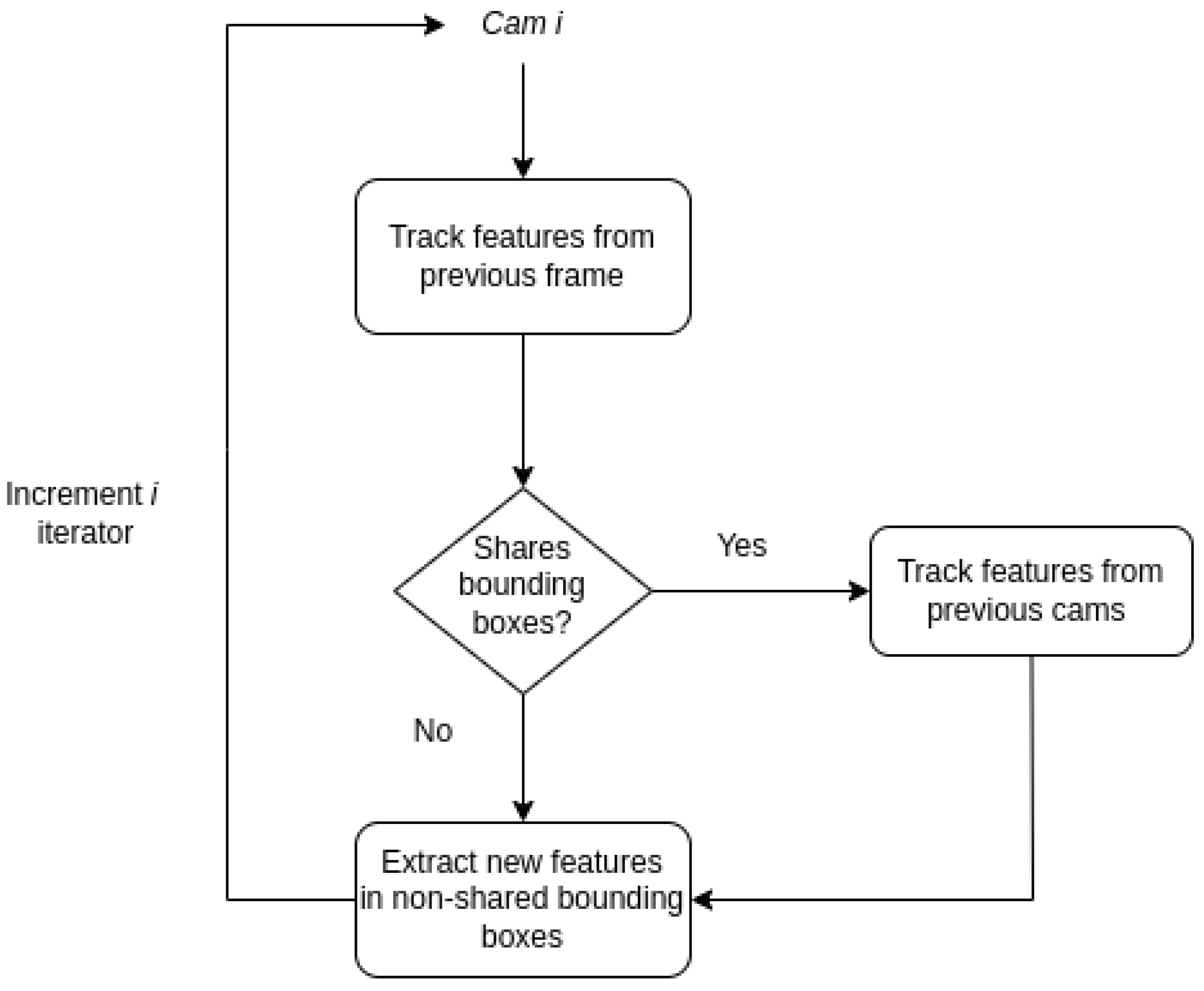
To achieve this generalization, we implement a parent–child structure for camera relationships. In this structure, each of the N cameras may have one parent and from zero to M children cameras. The parent of the camera i specifies the camera j that the camera i shares a part of the field of view with. For the parent of the camera i, a bounding box has to be defined with the shared region of the camera i with camera j. The children of the camera i indicate which cameras share a part of the field of view with i. The shared region of the children with camera i has to be defined for each child.
The process works as follows: First, we extract features from the image captured from camera
i, excluding the bounding box specified by its parent. Then, we track these features across the bounding boxes of each child camera. If a camera has no parent, we extract features from the entire image. This implementation is illustrated by the flow chart in
Figure 1. With this methodology, any multi-camera setup can be accommodated. The relationships between the parent and child cameras, as well as the bounding boxes for the shared fields of view, must be manually provided before running the algorithm. Assuming that the cameras have the same lens, the shared bounding box can be experimentally identified once and remaining consistent over time.
3.2.2. Keyframe Generation
In the original implementation of the algorithm, new landmarks were added, triangulating the unconnected features of the left camera of the stereo setup. When the ratio between the unconnected features of the left camera and the total amount of features tracked in the current frame was below a threshold, the features were triangulated across the previous frame. Then, a new observation was added to the landmark database (see Algorithm 1). Since this approach is only suitable for a stereo camera setup, we propose an implementation to accomplish the landmark database update for a multi-camera setup. For each frame, we evaluate the unconnected points for each camera. For each camera that shares the field of view with another one, we evaluate the ratio between the unconnected and the total amount of features. If at least one of the ratios is below a threshold, we triangulate the unconnected points across the previous frame (see Algorithm 2). In this way, we enable the algorithm to generate keyframes for each camera and not only for the left camera of the original stereo configuration.
| Algorithm 1 Original stereo camera keyframe selection. |
- 1:
Initialize - 2:
Initialize - 3:
for each feature in left camera observations do - 4:
if then - 5:
- 6:
Add observation to landmark database - 7:
Increment - 8:
else - 9:
Add to - 10:
end if - 11:
end for - 12:
Compute ratio: - 13:
ifandthen - 14:
Triangulate unconnected points across the previous frame - 15:
Add new keyframe for left camera - 16:
end if
|
| Algorithm 2 Multi-camera keyframe selection (ours). |
- 1:
Initialize for each camera i - 2:
Initialize for each camera i - 3:
for each camera i do - 4:
for each feature in camera i observations do - 5:
if then - 6:
- 7:
Add observation to landmark database - 8:
Increment - 9:
else - 10:
Add to - 11:
end if - 12:
end for - 13:
end for - 14:
for each camera i sharing FOV with another camera do - 15:
Compute ratio: - 16:
if then - 17:
- 18:
end if - 19:
end for - 20:
ifthen - 21:
for each camera i do - 22:
Triangulate unconnected points across the previous frame - 23:
Add new keyframe for camera i - 24:
end for - 25:
end if
|
3.3. Adaptive Threshold for Feature Selection
While a multi-camera setup is very convenient in terms of position accuracy and localization robustness, it is responsible for a high CPU consumption. Especially for applications involving drones, the CPU that can be dedicated to the localization algorithm has to be constrained to enable the onboard computer to handle many other tasks (path planning, obstacle avoidance, data elaboration). The hightest consumption from a VIO algorithm comes from the optical flow generation. One of the most expensive jobs in terms of CPU consumption is related to the tracking of the features. In many situations, a multi-camera setup may overcome the 400% of CPU consumption because all cameras are tracking a hight number of features. To avoid the multi-camera setup tracking too many features, considerably increasing the computational load, we propose a methodology to reduce the number of the tracked features adaptively.
The Basalt algorithm uses a threshold to extract features from an image with FAST algorithm. The threshold defines the minimum difference between the intensity of the candidate pixel and the surrounding pixels and it is initialized to a fixed value. The OpenCV function CV::Fast evaluates this quantity and it can be use to extract only the features that are above a threshold. If the algorithm was not able to find enough features, the threshold is reduced and new features are extracted. In a multi-camera setup, when a high number of features is tracked from one camera to N cameras, the triangulation process will lead to a good estimate of the 3D position of the feature. This will result in a good quality of position accuracy and high localization robustness. In such a situation, tracking features with the other cameras of the setup might be pointless and would increase the CPU loading considerably without any substantial improvements in position accuracy and robustness. We propose an implementation to adaptively select the feature detection threshold for each camera of the configuration. In our implementation, the threshold is divided by the squared root of a scale factor. The scale factor
is defined as
where
r is the ratio between the amount of features tracked from the camera
i to all its children (cameras that share the field of view with
i) and a fixed value that represents the minimum number of features to have
.
If is less than 0, we take 0 to always have . Therefore, the scale factor is evaluated for the camera i and it will be used to scale the threshold of the camera . If the camera i has tracked a number of features close to , the scale factor of the threshold for the camera will be close to 1 and the algorithm will be able to compensate the lack of the feature for the camera i. The parameter defines the minimum number of features matched from one camera to another to ensure pose estimate robustness. Since the algorithm tends to accumulate drift when less than 2 or 3 features are matched in a single stereo setup, it has been set to 2 in our code.
In scenarios where one camera detects a large number of features, the other camera will prioritize extracting only high-quality features. As a result, some good-quality features may not be tracked by the second camera. Nevertheless, this implementation is designed to reduce drift accumulation when few features are detected by one camera, while also lowering CPU load in texture-rich environments.
5. Discussion
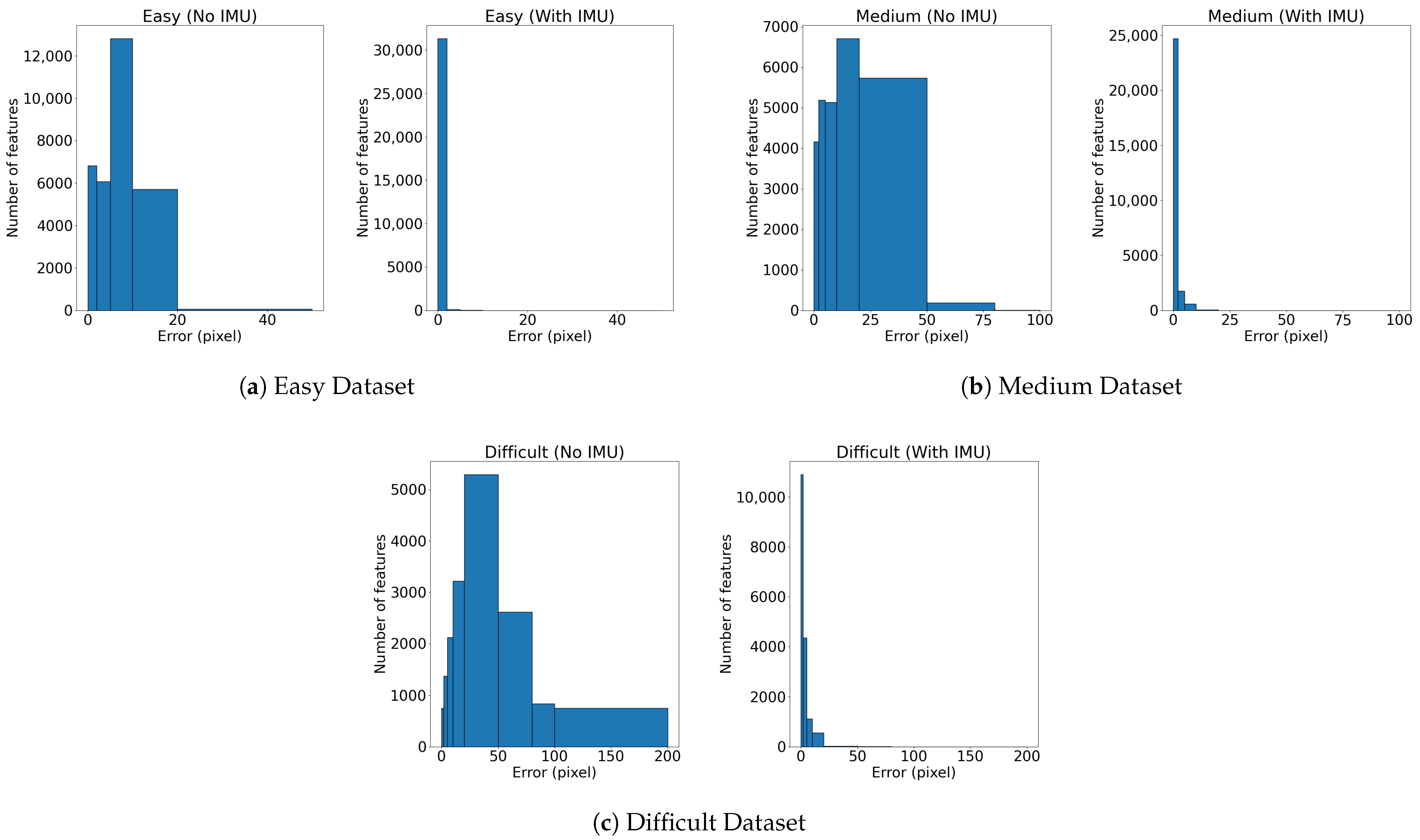
The IMU-based feature prediction significantly enhances feature tracking performance during high-speed maneuvers. Experimental results demonstrate a reduction in the prediction error, leading to more stable tracking of features across consecutive frames. The provided histograms prove the low dispersion of the prediction error when adopting the IMU-based prediction. Considering that the tracking typically fails for errors grater than 30 pixel, in the dataset, more than 3000 features (out of approximately 15,000 features) would be lost without the IMU-based prediction. This highlights the effectiveness of the implementation during aggressive motions.
The multi-camera implementation presented in this work supports arbitrary configurations. We evaluated its performance in terms of accuracy and robustness across two different configurations. The multi-camera setup offers improved localization accuracy compared to a traditional stereo configuration in challenging environments. However, determining the optimal camera configuration is not straightforward, as it strongly depends on the specific dataset and the characteristics of the surrounding environment.
For all datasets, Stereo 2 shows RMSE ATE greater than Stereo 1. This is because the estimated position of Stereo 2 relies on the IMU of Stereo 1. Since the relative positions of the cameras of Stereo 2 are further from the IMU than the cameras of Stereo 1, larger errors of the relative transformation are introduced during the calibration process. This explains why, in some cases, the RMSE ATE of a single stereo camera is very close to the multi-camera setup.
Since a multi-camera setup relies on the assumption of rigid motion between the cameras, ensuring this rigidity is essential for the algorithm to work properly. The cameras are supposed to be rigidly mounted on the drone, and no relative movement should occur between them during flight. Even without supporting experimental data, a well-built drone should not experience vibrations that significantly affect the relative positions of the cameras or degrade the accuracy of the position estimate.
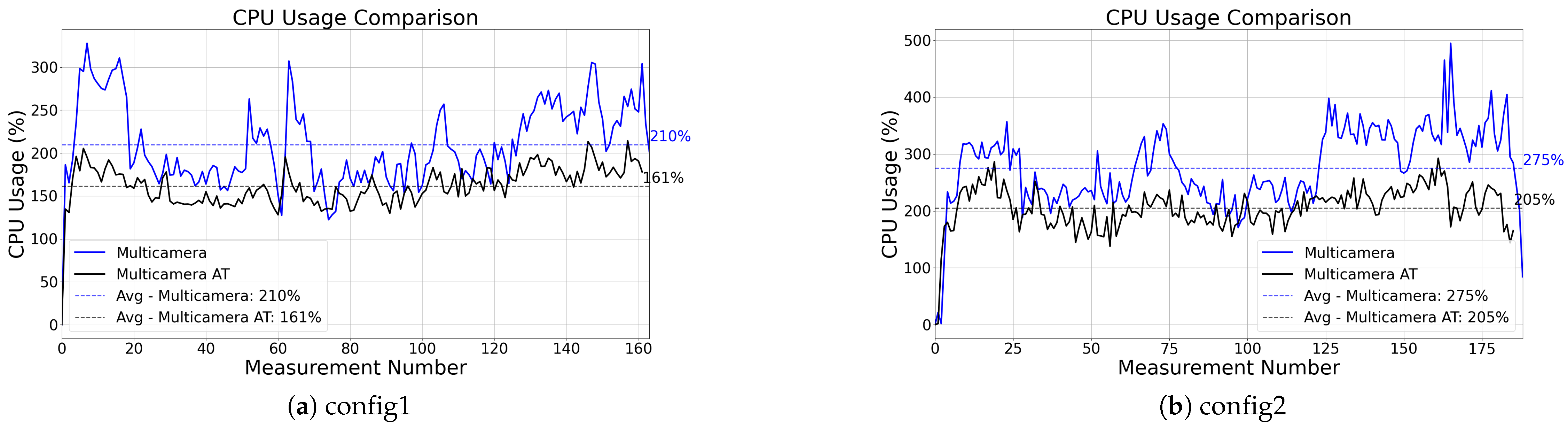
The proposed adaptive threshold methodology contributes to system robustness, reducing the average CPU load by approximately 60%. While the standard multi-camera setup occasionally experiences CPU usage spikes of up to 500%, the integration of adaptive thresholds effectively mitigates these peaks. However, this approach also introduces greater sensitivity to the dataset characteristics, compared to the multi-camera setup.
While the accuracy of the position heavily depends on the quality of the calibration, the multi-camera setup considerably increases the robustness of the localization without being affected by minimal errors in the estimation of the extrinsic calibration parameters. The conducted robustness tests highlight the superior performance of the multi-camera configuration in handling feature-poor environments, while also revealing how quickly the localization accuracy of a stereo setup deteriorates under such challenging conditions.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}